
Abstract
In this study, we examined the effects of cognitive task performance on the induction of vection. We hypothesized that, if vection requires attentional resources, performing cognitive tasks requiring attention should inhibit or weaken it. Experiment 1 tested the effects on vection of simultaneously performing a rapid serial visual presentation (RSVP) task. The results revealed that the RSVP task affected the subjective strength of vection. Experiment 2 tested the effects of a multiple-object-tracking (MOT) task on vection. Simultaneous performance of the MOT task decreased the duration and subjective strength of vection. Taken together, these findings suggest that vection induction requires attentional resources.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
A number of early vection studies established that vection is affected by cognitive factors (e.g., Andersen & Braunstein, 1985; Megner & Becker, 1990). For example, Andersen and Braunstein demonstrated that if participants had prior knowledge that the experimental environment could not move, the strength of induced vection was reduced. In addition, Lepecq, Giannopulu, and Baudonniere (1995) reported that the time taken for vection to be induced (latency) could be shortened by informing participants that their seat was able to move according to the optic flow. Palmisano and Chan (2004) manipulated the effect of biasing participants toward the perception of self-motion or object motion by providing different types of information prior to the experiment. The results revealed that object-motion-biased participants experienced weaker vection than did self-motion-biased participants (Palmisano & Chan, 2004). In addition, another study reported that the optic flow elicited by an upright natural scene induced stronger vection than that elicited by an inverted natural scene (Riecke, Schulte-Pelkum, Avraamides, von der Heyde, & Bülthoff, 2006).
These findings indicate that vection is mediated by brain regions engaged in high-level processing. However, the relation between vection and attention is currently unclear, and previous studies have not directly examined the relation between vection and attention. Thus, whether or not attentional resources are required for theinduction of vection remains an open question.
Ehrenfried, Guerraz, Thilo, Yardley, and Gresty (2003) measured body sway while exposing participants to a large field of motion and imposing an attentionally demanding task. Performingthe attentionally demanding task was found to cause a decrease in the standard deviation of body sway. On the basis of these findings, Ehrenfried et al. speculated that, as a result of cognitive task performance, insufficient attentional resources were available to maintain body sway.
If attentional resources are necessary to maintain body sway, they may also be necessary for vection, since vection and body sway are correlated (e.g., Flanagan, May, & Dobie, 2002; Kawakita, Kuno, Miyake, & Watanabe, 2000). Thus, the imposition of attentional load would be expected to weaken vection, because of the attenuation of attentional resources.
Findings regarding the effects of cognitive tasks on vection have not been consistent, however. Kitazaki and Sato (2003) produced a vection stimulus consisting of red dots moving upward and green dots moving downward. They reported that when participants attended to the red or green dots, the unattended dots’ motion was the dominant stimulus component involved in inducing vection. This finding suggests that unattended motion is a stronger vection-inducing factor than is attended motion. Thus, if motion toward a single direction is employed as a vection stimulus, stronger vection would be expected to result from decreasing the amount of attention participants allocated to the motion stimulus. Imposing an attentional task during vection would be expected to cause such a decrease in participants’ attention to the motion. As such, imposing an attentional task would be predicted to increase the strength of vection.
As was described above, imposing an attentional task during vection induction has been previously shown to lead to two possible opposite outcomes—that is, a decrease or an increase in the strength of vection. We sought to determine the causal factors determining which of these outcomes occurs.
In Experiment 1, a rapid serial visual presentation (RSVP) task was performed during the presentation of a motion stimulus. In Experiment 2, a multiple-object-tracking (MOT) task was performed while a motion stimulus was viewed.
In the RSVP task (e.g., Ariga & Yokosawa, 2008; Mitchell, 1979), letters presented in the center of the screen change at a high frequency (i.e., 4 Hz). The participants’ task is to identify or count the number of appearances of a target letter. This task maintains participants’ attention to the letters, which appear in the same position on the screen on each trial. As such, the attention required for this task is not related to spatial or motion perception. The RSVP task is commonly used as a way of reducing the attentional resources available for other cognitive functions. Kikuchi, Sekine, and Nakamura (2001) reported that in a dual-task condition involving shape change detection and RSVP simultaneously, RSVP captured attentional resources and, consequently, decreased change detection performance. Joseph, Chun, and Nakayama (1997) also reported that in dual-task conditions in which an RSVP task and an orientation discrimination task were performed simultaneously, the RSVP task captured attentional resources and impaired orientation discrimination performance. Therefore, we used the dual-task RSVP paradigm as a way of depleting available attentional resources.
In the MOT task, participants are required to track target stimuli among distractor stimuli that move at random for a certain period, using their attention only, without eye movements (Pylyshyn & Storm, 1988). In this task, participants have been found to be able to track between four and five targets out of ten moving objects (Pylyshyn & Storm, 1988). Pylyshyn and Storm recorded eye movements while participants performed an MOT task and confirmed that the task could be performed without any corresponding eye movements. Tracking fewer than five targets can be performed with a high level of performance under these conditions (over 80% correct; Yantis, 1992). Thus, visual attention is not restricted to a single area or object. Rather, it can be distributed to multiple objects and places in parallel (Awh & Pashler, 2000). Attention contributes to a certain type of motion perception. Culham, Verstraten, Ashida, and Cavanagh (2000) suggested the existence of a type of motion perception that relies solely on attentional tracking. Thus, the MOT task requires attentional resources that are related to motion perception and spatial perception. A study by He, Cavanagh, and Intriligator (1996) indicated that performance in the MOT task is deeply related to motion perception mechanisms, reporting an asymmetry in MOT performance between the upper and lower visual fields. Kanaya, Maruya, and Sato (2005) further revealed that MOT performance is supported by low-level motion perception mechanisms. Thus, MOT appears to be related to high- and low-level motion processing.
If vection does not require general attentional resources, it would not be expected to differ between control and dual-task experimental conditions in which participants simultaneously perform an RSVP or an MOT task. Vection may even be enhanced under attentionally demanding dual-task conditions. Alternatively, if vection does require general attentional resources, it would be expected to weaken or disappear when RSVP or MOT tasks are performed. Moreover, if vection requires attentional resources that are specific to spatial and motion perception, it would be weakened only in the MOT dual-task condition, but not in the RSVP dual-task condition. In addition, we examined task difficulty to determine whether changing the difficulty of the RSVP and MOT tasks would also alter the strength of vection. The present study was conducted to test these competing hypotheses.
Dual tasks often decrease performance. However, Ho (1998) reported that the perception of luminance-defined motion was not affected by simultaneously performing an RSVP task. Moreover, recent studies have suggested that vection is produced by low-level processing in the brain (Seno, Ito, Sunaga & Nakamura, 2010; Seno & Sato, 2009). Thus, it was not self-evident whether vection would be affected by the performance of dual tasks.
Experiment 1
We tested whether vection would be strengthened or weakened when an RSVP task was performed during vection induction.
Method
Apparatus
Stimulus images (1,024 × 768 pixel resolution at 75-Hz refresh rate) were generated and controlled by a computer (Apple, MB543J/A). Stimuli were presented on a screen using a rear projector (Electrohome Electronics, DRAPAR). The experiment was conducted in a dark chamber.
Stimuli
The stimuli subtended 72° (horizontal) × 57° (vertical) of visual angle at a viewing distance of 90 cm. We presented a luminance-defined grating (0.1 cycle/deg) moving upward or downward and white RSVP letters in a central black blank field (5° × 5°; see Fig. 1) in the middle of the grating. The mean luminance values of the motion gratings and letter stimuli were 25.7 and 36.6 cd/m2, respectively. The Michelson contrast of the luminance grating was 80%. The velocity of the moving grating was approximately 20 °/sec. The duration of stimulus presentation was 20 s. The results of our previous study (Seno, Ito, & Sunaga, 2010) revealed that 20 sof exposure waslong enough to induce vection with our experimental paradigm. The direction (upward or downward) of the motion was randomly switched on every trial. The RSVP letters, including N, P, Q, R, S, X, Y, and Z, were randomly presented at a rate of 4 Hz (Fig. 1). We also included a relatively difficult condition in which the RSVP stimuli refreshed at 8 Hz.

Schematic illustration of a typical rapid serial visual presentation (RSVP) dual-task trial in Experiment 1
Participants
Sixteen adult volunteers participated in both the 4- and 8-Hz conditions. The participants were graduate and undergraduate students (20–27 years of age; 10 males, 6 females). All the participants reported normal vision and no history of vestibular system diseases. All had previously experienced vection, either while participating in other vection experiments or during demonstrations in psychology lectures. None of the participants were aware of the purpose of the experiment.
Procedure
The experiment included two by two conditions that were combinations of an RSVP task anda passive observing (control) condition, presented at 4 or 8 Hz. Ten trials were conducted in each condition. Thus, each participant completed a total of 40 trials. Participants were allowed to take a break between trials. The 4- and 8-Hz conditions were conducted in the separate sessions. All the participants performed the 4-Hz condition first. Participants completed a large number of training sessionsbefore starting the experimental session. Thus, the effect of practice during the experimental sessions was likely to be negligible. Before starting each experimental trial, participants were informed by the experimenter as to whether the trial involved the RSVP task or the passive-viewing condition. Trials from the two conditions were presented in a random order.
The experimenter instructed participants to keep a corresponding button pressed (one button for upward, one for downward motion) while they perceived vection. In the RSVP task condition, participants were instructed to simultaneouslycount the number of appearances of the letter X. The following instructions were given: “Please press the corresponding button while you are perceiving upward or downward self-motion. If this becomes difficult to report, or if the perception of self-motion disappears, please release the button.” We took care to avoid any suggestion of our hypothesis, because previous studies had shown that vection can be modulated by instructions that induce cognitive biases (e.g., Lepecq et al., 1995; Palmisano & Chan, 2004). Participants were instructed to fixate on the letters at the center of the screen. In the passive condition, participants did not perform the RSVP task but were instructed only to report vection. The instruction “please fixate on the letters but do not count the number of appearances of any letter” was given.
Participants practiced pressing the buttons before the experiment began. Each trial began with a screen that was blank except for a red fixation point (presented for 1 s). The RSVP letters and a grating then appeared for 20 s after the fixation point had vanished. The letter X appeared between one and nine times (with the number of appearances selected at random) duringeach trial. After each trial, participants verbally reported the number of appearances of the letter X (Fig. 1). The subjective strength of vection was measured using the magnitude estimation method after each stimulus presentation. The possible range of estimated values was between 0 (no vection) and 100 (very strong vection). This method was similar to that used by Seno et al. (Seno, Ito, & Sunaga, 2010; Seno, Ito, Sunaga & Nakamura, 2010).
After the trials, we calculated the latency and duration of vection for each trial from the button data. In previous studies of vection, three measurements (latency, duration, and magnitude value) have been found to be valid for assessing vection strength. These three measurements have a long history of study and have become standard in vection research (Andersen & Braunstein, 1985; Nakamura & Shimojo, 1999, 2000; Palmisano, Burke, & Allison, 2003; Palmisano & Chan, 2004; Palmisano, Gillam, & Blackburn, 2000; Seno, Ito, & Sunaga, 2009; Seno, Ito, & Sunaga, 2010; Seno, Ito, Sunaga & Nakamura, 2010).
On each trial, the fixation point appeared, followed by the RSVP letters and the motion gratings, moving either upward or downward. The RSVP letters were refreshed at a rate of 4 or 8 Hz. On RSVP trials, participants counted the number of appearances of the letter X. Finally, the participants’ verbal responses were presented at the center of the screen by the experimenter
Results and discussion
All the participants exhibited a high level of performance in the 4-Hz RSVP task. The average percentage of correct responses was 84.16%. In the 8-Hz condition, however, the performance on the RSVP task was drastically reduced, as compared with that in the 4-Hz condition, with an average percentage of correct responses ofonly 7.81% (Fig. 2a). This result indicates that the RSVP task at 8 Hz was extremely difficult, as intended.

Results in Experiment 1. a Percentage of correct responses in the rapid serial visual presentation (RSVP) task. b Average latency of vection in the RSVP task and passive condition in Experiment 1. The error bars indicate standard errors. c Average duration of vection in the RSVP task and passive condition in Experiment 1. d Average magnitude of vection in the RSVP task and passive condition in Experiment 1. e Time-averaged vection strengthacquired from an additional experiment. We calculated these values by treatingresponses from the weak, moderate, and strong vection keys as the values 1, 2, and 3, respectively
In the debriefing session, all the participants reported that the letters were perceived in front of the grating, and no difference in depth between the passive and RSVP conditions was reported. This excludes the possibility that the perceived depth of the letters influenced the main findings.
First, we describe the results regarding vection latency. As is shown in Fig. 2b, the latency appeared to differ between the RSVP and passive conditions only when the temporal frequency was 8 Hz. We compared vection results using a two-way analysis of variance (ANOVA) withtemporal frequency of letters and presence of attentional load as the two factors. The ANOVA revealed no significant main effect of temporal frequency of RSVP (4 or 8 Hz), F(1, 15) = 0.00, p > .05. The main effect of presence of the attentional load (RSVP or passive), F(1, 15) = 3.07, p > .05, and the interaction, F(1, 15) = 3.11, p > .05, did not reach statistical significance. No participant exhibited a latency exceeding20 s (i.e., an absence of vection), indicating that all the participants experienced vection. Thus a 20-s exposure period was considered to be valid as the duration of stimulus presentation for obtaining latency and duration values.
We describe the results regarding vection duration below. As is shown in Fig. 2c, the duration appeared to be different between the RSVP task and passive conditions only when the temporal frequency was 8 Hz. We compared vection results using a two-way ANOVA with temporal frequency of letters and presence of attentional load as the two factors. There was no significant main effect of temporal frequency of RSVP, F(1, 15) = 1.42, p > .05. There was no significant main effect of presence of attentional load, F(1, 15) = 2.96, p > .05, and no significant interaction, F(1, 15) = 1.35, p > .05.
Finally, we describe the results regarding vection magnitude. As is shown in Fig. 2d, the magnitude values appeared to differ between the RSVP task and the passive conditions in both the 4- and 8-Hz conditions. We compared vection results using a two-way ANOVA with temporal frequency of letters and presence of attentional load as the two factors. There was nosignificant main effect of temporal frequency of RSVP, F(1, 15) = 3.14, p > .05, butthe main effectof presence of attentional load was significant, F(1, 15) = 91.70, p < .01. The interaction between these two factors was also significant, F(1, 15) = 14.77, p < .01.
Thus, subjective vection strength differed substantially between the RSVP task and passive conditions. The effect sizes (Cohen’s d) between the two conditions in the 8-Hz condition were 0.43, 0.64, and 1.45 for latency, duration, and magnitude, respectively. Thus, the results revealed strong effects of task type on the magnitude of vection and small and medium effects on the latency and duration, respectively. The effect sizes in the 4-Hz condition, however, were 0.05, 0.04, and 1.03 for latency, duration, and magnitude, respectively. Thus, we found a strong effect of task type on the magnitude of vection but no effect on latency or duration.
It is possible that the observed magnitude of vection was affected by memory, because the time at which magnitude values were reported and the time at which participants actually perceived vection were temporally separated. To examine the possible effect of memory or temporal factors, we conducted additional testing. Participants were instructed to report vection strength atthree levels (weak, moderate, and strong), in real time while they perceived vection (no key was pressed if they did not perceive vection). Eleven participants who took part in Experiment 1 participated in this experiment. Participants reported current vection strength using three different keys corresponding to weak, moderate, and strong vection (we refer to this method as the real-time magnitude estimation method). In this paradigm, the possible effects of mediation by memory are excluded. We employed a temporal frequency of 8 Hz for the RSVP stimuli.
We calculated vection strength by treatingthe responses from the weak, moderate, and strong vection keys as three numerical values, 1, 2, and 3, respectively. For example, if the strongkey was pressed for 20 s, the calculated time-averaged vection strength would be 3. If no key was pressed, this value would be 0. The results are shown in Fig. 2e. The vertical bar indicates the time-averaged vection strength. The time-averaged vection strength in the RSVP task condition was approximately 0.4. Since the average reported vection duration (the period during which any key was pressed) in the RSVP task condition was 8 s for a stimulus duration of 20 s, the value of 0.4 for the time-averaged vection strength indicated that the weak key (valued “1”) was pressed through almost the entire vection-reported duration. In the passive condition, this value increased to approximately 0.7. This indicates that stronger vection was obtained in the passive condition than in the RSVP task condition. The average vection duration for this condition was 10 s. Thus, participants typically pressed the moderate or strong button. There was a significant difference between the two conditions, t(15) = 6.02, p < .01. This result was similar to the results of the magnitude estimation in the main experiment, indicating that the effect of mediation by memory was negligible.
The results suggest that increased attentional load weakened the strength of perceived vection. This notion is in accord with our previous finding that increased attention to motion increased vection strength (Seno et al., 2009).
Experiment 2
Experiment 2 examined the relation between performance in a motion-related attentional task and vection, by employing an MOT task. If vection requires attention that is specific to motion and spatial perception, itwould be expected to be weaker during the simultaneous performance of the MOT task, as compared with during the performance of the RSVP task. That is, the effect of the secondary task would be greater for the MOT than for the RSVP task.
Method
Apparatus
The experimental apparatus was the same as that in Experiment 1.
Stimuli
We used an eight-disc and a three-disc condition as a difficult and an easy MOT task condition, respectively. In the eight-disc condition, the stimuli subtended 57° (horizontal) × 57° (vertical) ofvisual angle at a viewing distance of 90 cm. A luminance-defined grating (0.1 cycle/deg) moving upward or downward was presented, and eight red discs (with a radius of 2°) were presented on the grating (see Fig. 3c). The eight discs moved in eight different directions, and their vectors were randomly selected on each trial. The velocity of the grating and discs were approximately 20 and 3 °/s, respectively. A white border (1°) surrounded the grating. The duration of stimulus presentation was 20 s. The directions of the motion of the grating were randomly switched on each trial. The mean luminance of the motion stimulus and the discs was 14.32 and 2.13 cd/m2, respectively. A fixation point (1° × 1°) was presented at the center of the screen.

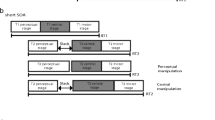
Schematic illustration of a trial in Experiment 2 (corresponding details are provided in the text)
In the three-disc condition, the MOT task was much easier than in the eight-disc condition. The size of the discs was 4°in visual angle (twice the size of that used in the difficult condition), and the movement of the discs was slower (1 °/s) than that in the eight-disc condition.
Participants
The same 16 participants from Experiment 1 took part in this experiment. None of the participants were aware of the purpose of the experiment.
Procedure
The experiment included two by two conditions, which were combinations of an MOT task condition and a passive-viewing condition, with eight-disc and three-disc conditions. Ten trials were conducted under each condition, so each participant underwent a total of 40 trials. Participants were able to take a break between trials. The eight-disc and three-disc conditions were tested in separate sessions. All participants first performed the eight-disc condition. Before starting the experimental session, participants completed a large number of training sessions. Thus, the effect of practice during the experimental sessions was considered to be negligible. Trials in the twoconditions (i.e., MOT task and passive conditions) were presented in a random order. We asked the participants to keep a corresponding button pressed (one for upward, one for downward motion) while they perceived vection, and to simultaneously track either fouror two specific discsin the eight-and three-disc MOT conditions, respectively. Before each trial, the experimenter informed participants whether the trial involved the passive or MOT task condition. In the passive condition, the instruction “please do not track any disc and fixate on the fixation point” was given, and participants were instructed to only report vection. In the MOT task condition, the instruction was “please track four (or two) targets as long as possible without moving your eyes, instead, while fixating on the fixation point” under the eight-disc (or three-disc) MOT task condition. Before presenting the motion of the grating, a fixation point appeared alone (Fig. 3a). Next, eight (or three) discs appeared, and four (or two) of them blinked for 1 s to indicate that they were the designated targetsunder the eight-disc (or three-disc) MOT task condition. (Fig. 3b). The participants tracked these four (or two) discs by fixing their attention toward them (Fig. 3c). After the grating disappeared, the eight (or three) discs remained on display (Fig. 3d), and participants were required to identify the four (or two) tracked discs, using a computer mouse (Fig. 3d). No feedback was given to the participants as to whether their responses were correct. In addition, we determined the subjective strength of vection using the same method as in Experiment 1. Participants were trained to complete the MOT task while fixating on the center of the screen. The criterion for success on the eight-disc MOT task was that participants tracked more than two discs correctly, because, on average, two correct discs would be expected to be chosen by chance when four discs out of eight are selected under the eight-disc MOT task condition. In the three-disc MOT task condition, participants had to track only two discs out of three. Thus, there was only one distractor.
Results and discussion
The average number of correctly tracked objects (MOT score) was 2.48 across all participants in the eight-disc MOT task condition. This value was significantly greater than 2 (the level expected by chance; p < .05) but was smaller than 4, the typical value reported in previous MOT experiments (e.g., Pylyshyn & Storm, 1988; Yantis, 1992). This relatively low score may have been due to participants’ performance of the MOT task while simultaneously reporting vection. That is, it is possible that reporting vection required attentional resources, reducing the resources available for performing the MOT task. A wider visual field and the existence of motion in the background may have also contributed to the lower score.
Performance in the MOT task was markedly better in the three-disc condition than in the eight-disc condition, with the percentage of correct responses reaching 100% for all participants. This result confirmed that the difficulty between the three-disc and eight-disc conditions of the MOT task was manipulated as we intended.
As is shown in Fig. 4a, the latency of vection appeared to differ between the MOT task and passive condition in both the eight-disc and three-disc conditions, but to a greater extent in the eight-disc condition. We compared vection results using a two-way ANOVA (with number of discs and presence of attentional load as the two factors). The ANOVA revealed a significant main effect of number of discs, F(1, 15) = 4.56, p < .05. In addition, we found a significant main effect of presence of attentional load, F(1, 15) = 43.21, p < .01. There was no significant interaction, F(1, 15) = 2.62, p > .05.

Results in Experiment 2. a Average latencyof vection in the MOT and passive conditions in Experiment 2. b Average duration of vection in the MOT and passive conditions in Experiment 2. c Average magnitude of vection in the MOT and passive conditions in Experiment 2. d Time-averaged vection strengthacquired from an additional experiment. We calculated these values by treatingresponses in the weak, moderate, and strong vection keys as the values 1, 2, and 3, respectively
As is shown in Fig. 4b, the duration of vection appeared to differ between the MOT task and passive conditions, in both the eight-disc and three-disc conditions, with a greater difference in the eight-disc condition. We compared vection using a two-way ANOVA with the number of the discs and presence of attentional load as the two factors. The ANOVA revealed significant main effects of number of discs, F(1, 15) = 5.52, p < .05, and presence of attentional load, F(1, 15) = 44.10, p < .01. In addition, there was a significant interaction between the two factors, F(1, 15) = 6.43, p < .05.
As is shown in Fig. 4c, the magnitude of vection appeared to differ between the MOT task and passive conditions in both the eight-disc and three-disc conditions, with a greater difference in the eight-disc condition. We compared vection results using a two-way ANOVA (with number of discs and presence of attentional load as the two factors). We found significant main effects of number of discs, F(1, 15) = 5.22, p < .05, and presence of attentional load, F(1, 15) = 126.97, p < .01. There was a significant interaction, F(1, 15) = 4.05, p < .05.
The effect sizes (Cohen’s d) of the difference between the MOT task and passive conditions in the eight-disc condition were 1.13, 1.02, and 1.84 for latency, duration, and magnitude, respectively. Effect sizes in the three-disc condition were 0.92, 0.49, and 1.60 for latency, duration, and magnitude, respectively. Thus, the results revealed a strong effect on vection of attentional load in the MOT task. The effects we observed on all three indicators suggest that task difficulty appeared to enhance the difference in vection strength between the MOT task and the passive conditions.
We also considered the possibility that the observed effects in this experiment were mediated by memory. Anadditional experiment was conducted using the eight-disc MOT task. All 16 participants who took part in Experiments 1 and 2 participated in this additional experiment. The obtained time-averaged vection strength is shown in Fig. 4d. The time-averaged vection strength in the MOT condition was approximately 0.4. The average duration in this condition was 8 s. This value (0.4) indicates that participants in the MOT condition experienced 8 s of weak vection, as described in Experiment 1. In the passive condition, this value increased to approximately 1.1. The average duration for this condition was 9 s. Thus, participants were found to press the moderate or strong button. These results indicate that stronger vection was obtained in the passive condition than in the MOT condition. There was a significant difference between the two conditions, t(15) = 5.86, p < .01. This result corresponds closely to the magnitude values in the main experiment, indicating that the effect of mediation by memory was negligible.
Thomas and Seiffert (2010) reported that self-motion decreased the performance of MOT. This indicates that performing MOT and processing self-motion information share some resources for visual processing. Considered together with our results, it is likely that vection and visually cognitive tasks share the same attentional resources.
General discussion
In Experiment 1, we used an RSVP task to capture attentional resources, reducing the amount of resources available for the processing underlying vection. We found that, during performance of the RSVP task, vection was weakened, particularly in terms of its magnitude. In Experiment 2, an MOT task was used as a way of capturing motion-specific or spatiallyspecific attentional resources. We found that vection was weakened in terms of its latency, duration, and magnitude. Taken together, these findings suggest that vection requires attentional resources, particularly those related to motion and spatial perception. This finding is in accord with the results of a previous study conducted in our laboratory (Seno et al., 2009).
Difficulty in response
It could be argued that the present results do not reflect the effect of attentional load on vection directly but, rather, the effect of attentional load on participants’ responses in the task. That is, it is possible that increased attentional load does not affect the perception of vection per se but, rather, leads to an increase in difficulty at the response level. For example, if response difficulty is increased, the onset and cessation of vection may be less accurately reported (by pressing or releasing the button, respectively). If this was the case, it might be expected that the button would be pressed and released fewer times in the RSVP and MOT conditions than in the passive conditions. Thus, we calculated the number of the buttonpresses and releases on each trial. In Experiment 1, under the passive condition, there were 1.23 presses, whereas in the 4-Hz RSVP condition, there were 1.43 presses. In the 8-disc condition in Experiment 2, there were 1.45 and 1.56 presses for the passive and MOT conditions, respectively. These values are not significantly different, excluding the possibility that our results were caused by an effect of changes in response difficulty.
As was noted above, we conducted additional experiments employing the real-time magnitude estimation method and showed that participants pressed the moderate or strong key under passive conditions, while they almost exclusively pressed the weak key under the RSVP or MOT task conditions. These results also demonstrated that the results observed here were caused not by response difficulty, but by perceived vection strength itself.
In addition, we made an informal observation regarding this possible artifact, while participants completed a buttonpress task for motion direction discrimination. The stimulus was a motion grating, which moved rightward or leftward (randomly selected) for 20 s. Three naïve participants reported the direction of motion they perceived while performing RSVP and MOT tasks that were the same as those used in Experiments 1 and 2. The buttonpress response data indicated that there were no significant differences between the dual-task and passive conditions. That is, buttonpresses were performed with the same accuracy in the two conditions, and there was no increased time lag for buttonpresses in the dual-task condition.
The possibility of mediation by memory
The values of magnitude of vection observed in Experiments 1 and 2 could have been mediated by memory, because the time at which participants reported the estimated values and the time at which they perceived vection were temporally separated. We used the real-time magnitude estimation method to address this issue. The pattern in the results was similar between the two methods, indicating that the main findings of Experiments 1 and 2 were not mediated by memory. Thus, mediation by memory does not appear to have been a serious confound in this study.
With regard to working memory, we conducted an informal observation, wherein vection was measured for 4 participants while they were listening to music or, more actively, humming. Thus, the participants reported vection under a dual-task condition—that is, reporting vection and humming. Humming may seem to be performed without visual attention. However, at least, some songs must have been loaded ontoworking memory, and some attentional resource must have been consumed to control the voice as a “report.” Under these conditions, vection was never found to have weakened. Thus, we believe that MOT and RSVP weakened measured vection not by the nature of dual tasks, but by the consumption of attentional resources that are shared by both visual processes. Humming may not consume the resources. We think that our results arise from the dual tasks in the visual process, and not in reporting or in the level of working memory.
The possibility of an effect of knowledge of the experimental conditions
It was easy for participants to speculate that the passive and dual-task phases constituted different experimental conditions. However, the effect of such speculation alone cannot account for the pattern of results. Even if participants knew that there were two important experimental conditions, it was not clear in which condition they would be expected respond as if vection was stronger. If there was a cognitive bias related to knowledge of the two conditions, the direction of that bias would thus be expected to occur in opposite directions for different participants (i.e., stronger vection in the dual-task condition for some and stronger vection in the passive condition for others). We were careful not to give any suggestion that stronger vection would be expected in the without-task condition. The results were consistent over more than 16 participants (no participant did not obey this tendency), indicating that the stronger vection observed in the passive condition was not an experimental artifact.
In addition, we conducted a thought experiment. Twenty participants who did not participate in the main experiments speculated on the vection strength. All of them had an experience of vection and understood the MOT and RSVP tasks. We asked them the following question:“The vection strength under a condition where an MOT or RSVP task is imposed would be: (a) strengthened, (b) weakened, or (c) unchanged.” The results indicate that six chose “strengthened,” nine chose “weakened,” and the remaining five chose “unchanged.” Thus, we think that our results cannot be explained by naïve participants’ speculation on our design of the experiment.
Attention or awareness?
Our results may be explained by a lack of awareness of the vection stimuli leading to a weakening of vection, because the MOT and RSVP tasks could be thought of as depriving awareness to the motion stimuli. We were unable to separate the effects of attention and awareness in this study, so the possibility that a change in awareness, rather than attention, affected our results cannot be excluded. To separate these two possibilities, future studies should examine the effects on vection of a task that depletes awareness directly (e.g., a vigilance task).
Conclusion
Previous studies have shown that vection is affected by cognitive factors (Andersen & Braunstein, 1985; Lepecq et al., 1995; Megner & Becker, 1990; Palmisano & Chan, 2004; Riecke et al., 2006). The present results supported this notion, revealing that the simultaneous performance of attentionally demanding tasks impairs the induction of vection. The study of vection from the perspective of attention provides a novel approach for studying the phenomenon. The present results suggest that vection is modulated by cognitive factors and requires attentional resources, particularly those related to motion and space perception.
References
Andersen, G. J., & Braunstein, M. L. (1985). Induced self-motion in central vision. Journal of Experimental Psychology, 11, 122–132.
Ariga, A., & Yokosawa, K. (2008). Attentional awakening: Gradual modulation of temporal attention in rapid serial visual presentation. Psychological Science, 72, 192–202.
Awh, E., & Pashler, H. (2000). Evidence for split attentional foci. Journal of Experimental Psychology. Human Perception and Performance, 26, 834–846.
Culham, J. C., Verstraten, F. A., Ashida, H., & Cavanagh, P. (2000). Independent aftereffects of attention and motion. Neuron, 28, 607–615.
Ehrenfried, T., Guerraz, M., Thilo, V., Yardley, L., & Gresty, M. (2003). Posture and mental task performance when viewing a moving visual field. Cognitive Brain Research, 17, 140–153.
Flanagan, M. B., May, J. G., & Dobie, T. G. (2002). Optokinetic nystagmus, vection, and motion sickness. Aviation Space and Environmental Medicine, 73, 1067–1073.
He, S., Cavanagh, P., & Intriligator, J. (1996). Attentional resolution and the locus of awareness. Nature, 383, 334–338.
Ho, C. E. (1998). Letter recognition reveals pathways of second-order and third-order motion. Proceedings of the National Academy of Sciences, 6, 400–404.
Joseph, J. S., Chun, M. M., & Nakayama, K. (1997). Attentional requirements in a preattentive feature. Nature, 387, 805–807.
Kanaya, H., Maruya, K., & Sato, T. (2005). The contribution of low-level motion systems in multiple object tracking. Journal of Vision, 5, 144.
Kawakita, T., Kuno, S., Miyake, Y., & Watanabe, S. (2000). Body sway induced by depth linear vection in reference to central and peripheral visual field. The Japanese Journal of Physiology, 50, 315–321.
Kikuchi, T., Sekine, M., & Nakamura, M. (2001). Functional visual field in a rapid serial visual presentation task. Japanese Psychological Research, 443, 1–12.
Kitazaki, M., & Sato, T. (2003). Attentional modulation of self-motion perception. Perception, 32, 475–484.
Lepecq, J. K., Giannopulu, I., & Baudonniere, P. M. (1995). Cognitive effects on visually induced body motion in children. Perception, 24, 435–449.
Megner, T., & Becker, W. (1990). Perception of horizontal self-rotation: Multisensory and cognitive aspects. In R. Warren & A. H. Wertheim (Eds.), Perception & control ofself-motion (pp. 219–264). Hillsdale: Erlbaum.
Mitchell, D. C. (1979). The locus of experimental effects in the rapid serial visual presentation (RSVP) task. Perception & Psychophysics, 25, 143–149.
Nakamura, S., & Shimojo, S. (1999). Critical role of foreground stimuli in perceiving visually induced self-motion (vection). Perception, 28, 893–902.
Nakamura, S., & Shimojo, S. (2000). A slowly moving foreground can capture an observer's self-motion—a report of a new motion illusion: Inverted vection. Vision Research, 40, 2915–2923.
Palmisano, S., Burke, D., & Allison, R. S. (2003). Coherent perspective jitter induces visual illusions of self-motion. Perception, 32, 97–110.
Palmisano, S., & Chan, A. Y. (2004). Jitter and size effects on vection are immune to experimental instructions and demands. Perception, 33, 987–1000.
Palmisano, S., Gillam, B. J., & Blackburn, S. G. (2000). Global-perspective jitter improves vection in central vision. Perception, 29, 57–67.
Pylyshyn, Z. W., & Storm, R. W. (1988). Tracking multiple independent targets: Evidence for a parallel tracking mechanism. Spatial Vision, 3, 179–197.
Riecke, B. E., Schulte-Pelkum, J., Avraamides, M. N., von der Heyde, M., & Bülthoff, H. H. (2006). Cognitive factors can influence self-motion perception (vection) in virtual reality. ACM Transactions on Applied Perception, 3, 194–216.
Seno, T., Ito, H., & Sunaga, S. (2009). The object and background hypothesis for vection. Vision Research, 49, 2973–2982.
Seno, T., Ito, H., & Sunaga, S. (2010). Vection aftereffect from expanding/contracting stimuli. Seeing & Perceiving, 23, 273–294.
Seno, T., Ito, H., Sunaga, S., & Nakamura, S. (2010). Temporonasal motion projected on the nasal retina underlies expansion–contraction asymmetry in vection. Vision Research, 50, 1131–1139.
Seno, T., & Sato, T. (2009). Positional and directional preponderances in vection. Experimental Brain Research, 192, 221–229.
Thomas, L. E., & Seiffert, A. E. (2010). Self-motion impairs multiple-object tracking. Cognition, 117, 80–86.
Yantis, S. (1992). Multielement visual tracking: Attention and perceptual organization. Cognitive Psychology, 24, 295–340.
Acknowledgments
This study was partly supported by grants-in-aid for scientific research (20300048, 19103003, and 21830081) provided by the Ministry of Education, Culture, Sports, Science and Technology, Japan, and a grant provided by the Nissan Science Foundation.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Seno, T., Ito, H. & Sunaga, S. Attentional load inhibits vection. Atten Percept Psychophys 73, 1467–1476 (2011). https://doi.org/10.3758/s13414-011-0129-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-011-0129-3