
Abstract
Implicit contextual cueing refers to a top-down mechanism in which visual search is facilitated by learned contextual features. In the current study we aimed to investigate the mechanism underlying implicit contextual learning using object information as a contextual cue. Therefore, we measured eye movements during an object-based contextual cueing task. We demonstrated that visual search is facilitated by repeated object information and that this reduction in response times is associated with shorter fixation durations. This indicates that by memorizing associations between objects in our environment we can recognize objects faster, thereby facilitating visual search.
Similar content being viewed by others


Introduction
Implicit contextual learning refers to the ability to memorize regularities in our visual environment and use this information on a later occasion to guide attention during a visual search (Chun, 2000; Chun & Jiang, 1998; Van Asselen et al., 2009; Van Asselen & Castelo-Branco, 2009). This type of memory takes advantage of the visual organization of our world, in which a large number of objects are positioned on specific locations (e.g. computer screen on top of a table) or are positioned in close relation to other objects (a computer screen and a keyboard). Interestingly, this kind of top-down knowledge can be memorized without any conscious knowledge, making it an implicit memory process (Chun, 2000; Chun & Jiang, 1998).
To study implicit contextual learning, Chun and Jiang (1998) developed a visual search task in which subjects need to locate a specific target. Unknown to the subjects, half of the trials contain repeated contextual information, usually the spatial configuration of the target and the distractors. Several studies using the contextual cueing paradigm showed that in trials with repeated contextual information, subjects locate the target faster than in the trials without contextual cues (e.g. Chun, 2000; Chun & Jiang, 1998, 1999; Peterson & Kramer, 2001). This difference in response time is called the contextual cueing effect (Chun & Jiang, 1998).
To understand how repeated contextual information can facilitate visual search, Peterson and Kramer (2001) recorded eye movements that were made during a contextual cueing task that contained repeated spatial contextual information. They found that this repeated spatial contextual information does not directly guide attention to the target location, but rather leads to a reduction in the number of fixations that are necessary to locate a target. They suggested that recognition of spatial contextual information is imperfect or that the guiding mechanism to the target location is imprecise. Tseng and Li (2004) also recorded eye movements during a contextual cueing paradigm using repeated spatial context information. They took a closer look at the visual search path that is made to locate the target by calculating the distance between the positions of the different fixations that are made during a search and the target position. It was found that a distinction can be made between an Ineffective and an Effective search phase. During the Ineffective search phase eye movements are not monotonically getting closer to the target, whereas in the Effective search phase each eye movement is approaching the target. When they compared the number of fixations that were made in the repeated and new trials they found a significant reduction in the Ineffective search phase, but not in the Effective search phase (Tseng & Li, 2004). This suggests that once the subjects recognize the spatial configuration they enter the Effective search phase sooner. However, even after recognition more than one fixation is needed to actually locate the target.
More recently, Brockmole and Henderson (2006) recorded eye movements during a contextual cueing task in which real scenes were used, showing that the target was located very quickly (after only 1.8 eye movements). In the end of the experiment they mirrored the scenes to study the effect of a sudden change in the spatial configuration of the scene, while maintaining the scene identity. In this case, eye movements initially moved to the original location of the target, but when subjects failed to find the target on this location they immediately moved their eyes to the mirrored location. Based on these results Brockmole and Henderson (2006) suggested that two recognition processes are involved in contextual cueing. Guiding attention is first dependent on recognition of the scene identity, regardless of the specific arrangement of visual features. When scene recognition fails or is not successful to guide attention, other visual information is recognized, for example local features, local identity, or global orientation information. This suggests that scene identity is particularly important in contextual cueing, although other types of contextual information can be used as well.
Most of the studies on implicit contextual cueing have used spatial information as a contextual cue (e.g., Chun & Jiang, 1998, 2003; Jiang & Chun, 2001; Jiang & Leung, 2005; Jiang, Song, & Rigas, 2005; Olson & Chun, 2002). However, other types of information can be used to facilitate a visual search, such as object, motion (Chun & Jiang, 1999), and temporal information (Olson & Chun, 2001). Chun and Jiang (1999) showed that the covariation of objects that are present in our environment can be learned implicitly and can subsequently be used to guide attention, resulting in faster response times. This type of contextual learning is based on the fact that specific objects are often found in close proximity to each other. That is, in a garage you usually find working tools, tires, and a car, but not books or a television. Thus, a specific set of objects can appear together, although not necessarily in the exact same arrangement, thus lacking spatial information. Learning the association between objects that are often found together can facilitate visual search. However, the mechanism underlying this process is unknown. When objects are used to guide attention, the location of the target is randomly defined, and thus the location of the target is still unknown even after recognizing the set of objects. This suggests that a different guiding mechanism underlies the contextual cueing effect when object information is used than when spatial information is used.
By only measuring response times, we know that contextual information is learned and visual search is facilitated. However, we do not know what mechanism is responsible for this learning effect. To have a better understanding of this underlying mechanism, we can measure eye movements that are made during a visual search. One hypothesis is that recognition of a set of objects activates a specific memory trace (template), thereby facilitating recognition of objects. Subsequently, if recognition of the objects is facilitated, the fixation of the objects should be shorter. Alternatively, if facilitation of visual search is due to attentional guidance, the actual visual search path would be different, resulting in fewer fixations or shorter saccade amplitudes. In the current study we aim to study how object information, in the absence of information conveyed by spatial configuration, can facilitate a visual search by recording eye movements during an object based contextual cueing task.
Methods
Participants
Fifteen healthy young adults (nine female, six male) with a mean age of 24.4 years and an average education of 15.3 years participated in this study. They were all right handed and had normal or corrected to normal visual acuity.
Apparatus and stimuli
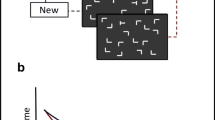
Stimuli were presented with the Presentation software (Neurobehavioral Systems) on a computer screen. Seventy-two black, abstract line drawings were created. These drawings included 12 targets and 60 distractors (see Fig. 1). All targets were different, as well as the distractors. The distractors were closed abstract line drawings, whereas the targets had a small opening. For each target, two options were created, one in which the opening was to the left side and one in which the opening was on the right side. Stimulus sizes were about 2.2 degrees, and the distance between the subjects’ eyes and the computer screen was 52 cm. The size of the computer screen was 38 × 30.2 cm, which corresponds to 41.6 × 33.6º visual angle. To define the positions of the stimuli, a 12 by 12 grade was used, of which the most extreme positions were displayed within an area of 29.3º by 29.1º. The distance between the object was minimally 2.7º. Eye movements were recorded during the contextual cueing experiment with an iViewX High-speed Eye-Tracker (SMI), using the dominant eye. Each trial started with a fixation cross in the center of the computer screen. A trial would start when subjects foveated the fixation cross for 500 ms.

Example of a few repeated and new displays used during the object contextual cueing task
Procedure
During each trial ten distractor stimuli and one target stimulus were presented simultaneously. Subjects were instructed to locate the target stimulus as quickly as possible and indicate whether the opening of the target was on the left or the right side. It is important to note that the side of the opening was randomly defined for both new and repeated trials to prevent subjects from learning fixed stimulus-response associations. The total experiment consisted of 24 blocks of 12 trials each, resulting in a total of 288 trials. Each block included six trials in which the set of objects was repeated during the experiment (repeated trials). In this case, the same distractors were consistently presented together with a specific target stimulus. For the remaining six trials the set of objects was randomly combined with each other and with the target from block to block (new trials) to guarantee that throughout the experiment the target was presented with different distractors. It is important to note that the positions of the objects and the direction of the opening of the target were randomly defined for both the repeated and new trials. This indicates that only the covariation of object presence could serve as a contextual cue, and not the spatial configuration. The objects that were presented in the repeated and new trials were chosen from two different sets of 30 distractor and 6 target objects. This implies that the objects in the repeated and new trials were repeated the same number of times. This is important, because otherwise a possible facilitation effect could be due to mere familiarization with the objects, and not due to learning of the contextual information. To familiarize the subjects with the task, 18 practice trials using randomly defined sets of objects were given at the beginning of the experiment.
Recognition memory task
To make sure that participants were not consciously aware of the repetitions and verify whether the learning that took place was really implicit, the following questions were asked after performing the contextual cueing paradigm: (1) Did you notice anything during the experiment? (2) ‘Did you notice that some of the sets of objects were repeated? (3) Did you try to remember the repeated sets of objects? Additionally, a recognition memory task was performed, in which the sets of objects that were repeated during the experiment were presented among new sets of objects. For each subject the number of repeated trials was randomly defined (average 6.7). Please note that a fully random approach may lead to a small deviation in the mean number of trials per set per subject. Subjects were asked to indicate whether they thought a specific set of objects was repeated during the contextual cueing experiment or not.
Analyses of eye movements
We used the Begaze software of SMI to define the fixations and saccades. Since a high-speed eye tracking system was used (250 Hz), we used saccade detection as the primary event. Subsequently, Matlab was used to analyze the oculomotor correlates. We eliminated saccades outside the screen and those trials in which more saccades were made than an individually based cutoff score. The latter means that trials were excluded if the total number of saccades in a trial were made in less then 5% of the trials. Subsequently, three oculomotor parameters were defined: (1) the mean fixation duration to distractor stimuli; (2) the average number of fixations that were made during a search; (3) the mean saccade amplitude in degrees. These oculomotor parameters were defined for the repeated and new trials separately.
Results
Response times
To define the contextual cueing effect as was proposed by Chun and Jiang (1998), we calculated the difference in response times between the trials with repeated and new contextual information. Therefore, the 24 blocks of trials were averaged into four epochs (each epoch containing six blocks). For statistical analyses, trials in which an incorrect response was made (on average 1.5 %) or in which the response took more than 2 SD above the average response time (calculated for each subject separately) were excluded (on average 3.9%).
A 2 × 4 repeated measures analysis was performed with within-subject variables Condition (repeated and new trials) and Epoch (1-4). These results indicated that object identity can indeed facilitate visual search as was shown by the faster response times in the repeated trials [F(1, 14) = 23.4, p < 0.01]. An interaction effect was found for Condition and Epoch [F(3, 42) = 4.4, p < 0.01], indicating that learning took place during the experiment. Subsequently, we performed a paired t-test for each epoch separately. A significant difference was found between the repeated and new trials for the second [t(14) = 6.0, p < 0.001], third [t(14) = 2.6, p < 0.05] and fourth Epoch [t (14) = 2.9, p < 0.05], but not for the first Epoch [t(14) = 1.2]. We feel that this convincingly shows that the contextual learning effect was not present during the initial part of the experiment, but was consistently found during the rest of the experiment. Average response times for the repeated and new trials are shown in Fig. 2.

Average response times (ms) including standard errors, for the repeated and new trials separately, as a function of Epoch (1-4)
Eye movements
Paired samples t-tests were performed for the three oculomotor parameters, using a Bonferroni correction. Fixation duration to the distractors was significantly larger in the new trials than in the repeated trials [t(14) = 3.1, p < 0.01]. This indicates that subjects needed less time to recognize the objects. To define whether learning took place during the experiment, we performed repeated measures analyses, including Epoch (1-4) and Condition (repeated and new trials) as within-subject variables. We found a significant difference in fixation duration between repeated and new trials [F(1, 14) = 9.6, p < 0.01]. However, no interaction effect was found between Epoch and Condition. As can be seen in Fig. 3, the difference between repeated and new trials already appears in the first Epoch. When we looked at the individual blocks of the first Epoch, it was clear that no difference between repeated and new trials was found (fixation duration for both repeated and new trials was 164 ms).

Average fixation durations to distractor objects (ms) for the repeated and new trials separately; (a) as a function of Epoch (1-4); (b) as a function of Block (first six blocks of experiment)
No difference was found between the difference in number of fixations [t(14) = 2.3] that were needed to locate the target or the saccade amplitude [t(14) = 0.9]. Eye movement data are presented in Table 1.
Recognition memory task
To define whether subjects had explicit knowledge about the repeated contextual information, we first asked them three questions. None of the subjects indicated spontaneously that they had noticed the repetitions (question 1). When they were explicitly asked whether they had noticed any repetitions, two subjects indicated that they had (question 2). However, none of these subjects tried to memorize the repeated contextual information (question 3). For the recognition memory task the total number of correctly identified trials (7.0) was compared to the average number of repeated trials (6.7). A one-tailed t-test demonstrated no significant effect, indicating that subjects were performing on chance level [t(14) = 0.5]. Therefore, we can assume that participants did not have any explicit knowledge of the repeated context information.
Discussion
The aim of this study was to disentangle the mechanism underlying object-based contextual cueing by measuring eye movements. The visual search task that was used included trials with a set of random objects (new trials) and trials with a set of associated objects (repeated trials). We found that response times were significantly faster in the Repeated trials than in the New trials, indicating that subjects were able to memorize the sets of objects and could use this information to facilitate visual search. This finding replicates a previous study of Chun and Jiang (1999), who used a similar contextual cueing task based on the covariation between objects. To investigate the mechanism underlying object-based contextual cueing we measured eye movements during our contextual cueing task. Subsequently, we calculated various oculomotor parameters and compared the difference between repeated and new trials. Interestingly, we found that the fixation durations to the distractors were shorter in the repeated trials than in the new trials. This suggests that object recognition is faster by memorizing sets of objects, thereby facilitating visual search.
No significant effect was found for other oculomotor parameters, such as the number of fixations and the saccade amplitude. This suggests that the actual visual path (i.e., number of saccades and the search slope) is not affected by learning object associations when spatial configuration cues are absent. It should be noted that a marginally significant effect was still found between the number of fixations made in the repeated and new trials. However, the effect of repeated context information on the number of fixations is much larger when the visual search path is modulated by spatial information (Peterson & Kramer, 2001; Tseng & Li, 2004). That is, in the latter studies a significant difference was found between repeated and new trials for the number of fixations, but not for fixation duration. When naturalistic scenes were repeated during a visual search task, a reduction in the number of saccades was also found (Brockmole & Henderson, 2006; Brockmole & Võ, 2010). Together, this suggests that learning different types of contextual information can modulate visual search through distinct mechanisms.
In all, the current study resolves an important issue in object contextual cueing by showing that repeated objects can facilitate visual search through direct modulation of object identification, as was reflected by the shorter fixation durations, indicating faster processing.
References
Brockmole, J. R., & Henderson, J. M. (2006). Recognition and attention guidance during contextual cueing in real-world scenes: Evidence from eye movements. The Quarterly Journal of Experimental Psychology, 59(7), 1177–1187.
Brockmole, J. R., & Võ, M. L. (2010). Semantic memory for contextual regularities within and across scene categories: Evidence from eye movements. Attention, Perception & Psychophysics, 72(7), 1803–1813.
Chun, M. M. (2000). Contextual cueing of visual attention. Trends in Cognitive Sciences, 4, 170–177.
Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psyhology, 36, 28–71.
Chun, M. M., & Jiang, Y. (1999). Top-down attentional guidance based on implicit learning of visual covariation. Psychological Science, 10(4), 360–365.
Chun, M. M., & Jiang, Y. (2003). Implicit, long-term spatial contextual memory. Journal of Experimental Psychology. Learning, Memory, and Cognition, 29, 224–234.
Jiang, Y., & Chun, M. M. (2001). Selective attention modulates implicit learning. The Quarterly Journal of Experimental Psychology, 54A, 1105–1124.
Jiang, Y., & Leung, A. W. (2005). Implicit learning of ignored visual context. Psychonomic Buletin & Review, 12, 100–106.
Jiang, Y., Song, J. H., & Rigas, A. (2005). High-capacity spatial contextual memory. Psychonomic Bulletin & Review, 12, 524–529.
Olson, I. R., & Chun, M. M. (2001). Temporal contextual cuing of visual attention. Journal of Experimental Psychology. Learning, Memory, and Cognition, 27(5), 1299–1313.
Olson, I. R., & Chun, M. M. (2002). Perceptual constraints on implicit learning of spatial context. Visual cognition, 9(3), 273–302.
Peterson, M. S., & Kramer, A. F. (2001). Attentional guidance of the eyes by contextual information and abrupt onsets. Perception & Psychophysics, 63, 1239–1249.
Tseng, Y. C., & Li, C. S. (2004). Oculomotor correlates of context-guided learning in visual search. Perception & Psychophysics, 66, 1363–1378.
Van Asselen, M., Almeida, I., André, R., Januário, C., Freire Gonçalves, A., & Castelo-Branco, M. (2009). The role of the basal ganglia in implicit contextual learning: A study of Parkinson’s disease. Neuropsychologia, 47, 1269–1273.
Van Asselen, M., & Castelo-Branco, M. (2009). Long-term implicit memory for peripherally perceived contextual information. Perception & Psychophysics, 71(1), 76–81.
Acknowledgments
This research was supported by a grant from the BIAL Foundation (no. 73/06) and the Portuguese Foundation for Science and Technology/FEDER/COMPETE (project PTDC/PSI-PCO/108208/2008 and PTDC/PSI/67381/2006).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
van Asselen, M., Sampaio, J., Pina, A. et al. Object based implicit contextual learning: a study of eye movements. Atten Percept Psychophys 73, 297–302 (2011). https://doi.org/10.3758/s13414-010-0047-9
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-010-0047-9