
Abstract
Feature–reward association elicits value-driven attentional capture (VDAC) regardless of the task relevance of associated features. What are the necessary conditions for feature–reward associations in VDAC? Recent studies claim that VDAC is based on Pavlovian conditioning. In this study, we manipulated the temporal relationships among feature, response, and reward in reward learning to elucidate the necessary components of VDAC. We presented reward-associated features in a variety of locations in a flanker task to form a color–reward association (training phase) and then tested VDAC in a subsequent visual search task (test phase). In Experiment 1, we showed reward-associated features in a task display requiring response selection and observed VDAC, consistent with most previous studies. In Experiment 2, features presented at a fixation display before a task display also induced VDAC. Moreover, in Experiment 3, we reduced the time interval between features and rewards so that features appeared after a task display and we obtained marginally significant VDAC. However, no VDAC was observed when features and rewards were simultaneously presented in a feedback display in Experiments 4 and 5, suggesting that a direct association between feature and reward is not sufficient for VDAC. These results are in favor of the idea that response selection does not mediate feature–reward association in VDAC. Moreover, the evidence suggests that the time interval of feature and reward is flexible with some restriction in the learning of feature–reward association. The present study supports the hypothesis that theories of Pavlovian conditioning can account for feature–reward association in VDAC.
Similar content being viewed by others


When people look for a particular object, they can intentionally attend to it, whereas an irrelevant object unintentionally captures attention if it is physically salient. These top-down (goal-driven) and bottom-up (stimulus-driven) attentional mechanisms have been reported in many previous studies (e.g., Corbetta & Shulman, 2002). Moreover, recent studies have shown that, like these top-down and bottom-up mechanisms, our experiences (e.g., desirable outcomes) also bias the deployment of visual attention (selection history; for reviews, see Awh, Belopolsky, & Theeuwes, 2012; Failing & Theeuwes, in press).
There is substantial evidence regarding the effect of reward on visual selective attention (for reviews, see Anderson, 2013, 2016; Chelazzi, Perlato, Santandrea, & Della Libera, 2013; Failing & Theeuwes, in press; Le Pelley, Mitchell, Beesley, George, & Wills, 2016). For instance, reward shapes attentional orienting to target stimuli in visual search tasks (Hickey, Chelazzi, & Theeuwes, 2010b, 2011). These attentional biases for rewarded stimuli occur from an early stage of visual processing (Hickey, Chelazzi, & Theeuwes, 2010a). Moreover, stimuli previously associated with reward capture attention (value-driven attentional capture [VDAC]; e.g., Anderson, Laurent, & Yantis, 2011a, b). Some VDAC studies contain two experimental phases (i.e., training and test phases; e.g., Anderson et al., 2011a, b). In a training phase, participants learn the association between stimulus features and reward, and VDAC (i.e., the effect of stimulus–reward association on attention) is examined in a subsequent test phase without a reward (e.g., visual search). Value-driven attentional capture is observed when the stimulus–reward association is removed in the test phase (e.g., Anderson et al., 2011a, b) and even 7 to 9 months later without any additional reinforcement (Anderson & Yantis, 2013). In addition, reward associates with a variety of stimulus features, such as color (e.g., Anderson et al., 2011a, b), shape (Wang, Yu, & Zhou, 2013), orientation (Lee & Shomstein, 2014), and category (e.g., Yokoyama, Padmala, & Pessoa, 2015). Moreover, stimulus–reward association in reward learning transfers to different tasks in a test phase (e.g., Anderson, Laurent, & Yantis, 2012; Lee & Shomstein, 2014). Thus, VDAC occurs as a result of associative reward learning, because stimulus features (e.g., color) associated with reward in a training phase originally do not have any particular significance, suggesting that reward experience (i.e., history) biases the deployment of visual selective attention.
Recently, studies have focused on the learning mechanism underlying feature–reward association in VDAC. In the majority of VDAC studies, task-relevant features (e.g., target-defining features) signaled reward outcome during reward learning (e.g., Anderson et al., 2011a, b). In such studies, participants voluntarily attend to or select these features to receive a reward. However, recent studies have also shown that, when reward-associated features are task irrelevant and never appear as a target during reward learning, these features modulate the orienting of visual attention (e.g., Bucker, Belopolsky, & Theeuwes, 2015; Bucker & Theeuwes, 2017a, b; Failing, Nissens, Pearson, Le Pelley, & Theeuwes, 2015; Failing & Theeuwes, 2017; Le Pelley, Pearson, Griffiths, & Beesley, 2015; Mine & Saiki, 2015; Pearson, Donkin, Tran, Most, & Le Pelley, 2015). These findings are interpreted as a consequence of Pavlovian conditioning (e.g., Bucker & Theeuwes, 2017a, b ; Le Pelley et al., 2015). Typically, conditioning has been classified into two types. One is Pavlovian conditioning, which is simply the association between two events or stimuli without operant response selection (stimulus–stimulus association), and the other is instrumental conditioning, which is the formation of an action–outcome (reward) association (response–outcome association). In Pavlovian conditioning, the pairing of a conditioned stimulus (CS; e.g., a tone) and an unconditioned stimulus (US; e.g., food) is repeatedly presented, and then a conditioned response (CR; e.g., salivation) to the CS occurs.
Regarding Pavlovian learning in VDAC, Le Pelley et al. (2015) provided evidence for VDAC where participants did not need to orient their attention to reward-signaling features to perform a task because these features are always task irrelevant (i.e., distractors). During the task, participants’ eye movements were monitored, and the effect of reward on the deployment of visual attention was evaluated. Trials in which participants looked at a reward-associated distractor and consequently did not receive a reward were called omission trials. Results showed that the number of omission trials in the high-reward distractor condition were significantly higher than in the low-reward distractor or no-distractor conditions. These findings indicate that high-reward distractors capture visual attention even when participants do not have any strategic control of attending to reward-signaling distractors (see also Failing et al., 2015), suggesting that feature–reward association in VDAC can be explained by Pavlovian conditioning.
Further evidence for feature–reward association in VDAC explained by Pavlovian conditioning was reported by Bucker and Theeuwes (2017a, b). In their experiments, participants learned a color–reward association via Pavlovian reward learning (training phase). Then, an additional singleton task (test phase) was conducted to examine attentional capture by learned color–reward associations. The main task in Pavlovian reward learning was to respond to fixation changes (45-degree rotation), which were included in 25% of all trials. The reward-signaling color was presented in a peripheral region (Experiment 1) or in a fixated region (Experiment 2) through a Pavlovian reward learning sequence. There were two reward conditions (i.e., high reward and low reward), and these reward values were dependent on stimulus (e.g., circle) color. After the reward-signaling color display, a short fixation display was followed by both visual and auditory reward feedback. Participants were instructed to fixate their vision on a certain point and ignore all peripheral distractors. The color–reward association was temporally and spatially separated from fixation task performance, and the reward-signaling color never appeared at the time of the fixation task that required participants’ responses. After Pavlovian reward learning, participants completed an additional singleton task (Theeuwes, 1992) in the test phase to reveal the effect of learned value on the deployment of attention. In the test phase, trials in the high-reward distractor condition induced performance decline (e.g., in accuracy or reaction time) compared with trials in the low-reward distractor and no-distractor conditions. These results suggest that distractors that signaled high-reward outcome capture attention even when these distractors were not relevant to achieving a task in the training phase. Bucker and Theeuwes concluded that Pavlovian reward learning underlies feature–reward association in VDAC.
Apparently, the phenomenon of VDAC resembles Pavlovian conditioning. In VDAC, originally neutral features are associated with reward during reward learning and induce attentional capture. According to Pavlovian conditioning, attentional capture by reward in VDAC could be considered as a CR, in that originally neutral features (i.e., the CS) such as color are associated with a reward (i.e., the US) by reward learning, and these features become salient and capture attention. Given that reward is not dependent on task performance (e.g., reaction times or accuracy), people could learn the mere association of features and reward during reward learning, which is similar to Pavlovian conditioning.
Although previous studies support the Pavlovian conditioning hypothesis as a mechanism underlying VDAC, some important issues remain unsettled; thus, it is unknown to what extent this hypothesis can be generalized. The first issue that has been raised in previous studies (Bucker & Theeuwes, 2017a, b) is the role of response selection in VDAC. The difference between Pavlovian and instrumental conditioning mechanisms is whether response selection mediates an association between stimuli. Recently, a few studies directly examined the necessity of motor responses (Bucker & Theeuwes, 2017a, b), in which participants’ response was dissociated from a feature–reward association during reward learning. On the other hand, researchers in most VDAC studies (e.g., Anderson et al., 2011a, b) used a task (e.g., visual search) where response selection was necessary to learn this association. Generally, a conventional reward learning paradigm in VDAC consists of a fixation display, a task display (e.g., visual search), and a feedback display (e.g., Anderson, 2013, 2016). In most previous studies (except for that of Bucker & Theeuwes, 2017a, b), features associated with rewards were always presented with response selection at the time of task display (e.g., Anderson et al., 2011a, b; Le Pelley et al., 2015). Although Pavlovian reward learning revealed by Bucker and Theeuwes (2017a) suggests that features could be directly associated with rewards regardless of response selection, it remains unknown whether the same mere association between features and rewards can be observed in a task with response selection during reward learning. Typically, a feature–reward association in VDAC is not directly associated with response outcomes (e.g., reaction times; Anderson, 2013, 2016) even in a task with motor responses, and the reward is probabilistically manipulated based on features such as target color (e.g., Anderson et al., 2011a, b) or distractor color (e.g., Le Pelley et al., 2015). In many previous studies, participants were not informed about the actual relationship between features and rewards during reward learning (e.g., Anderson et al., 2011a, b), only giving rewards for correct responses. In these situations, participants may recognize that a correct response results in a rewarding outcome and learn this response–reward association, which may be a necessary condition for feature–reward learning to occur, especially in a paradigm with motor responses (e.g., Anderson et al., 2011a, b). As indicated by previous studies (Bucker & Theeuwes, 2017a, b), if a response should not have any role in creating a feature–reward association, the temporal relationship between the feature and response should not matter. In other words, if the mere feature–reward association could be generalized to reward learning where a response selection was given to receive a reward, the same learning effect could be observed regardless of the feature–response temporal relationship.
Another important issue in the Pavlovian hypothesis of VDAC is the temporal relationship between features and rewards. Previous studies have shown that VDAC can be observed as a consequence of a Pavlovian relationship between features and rewards. However, little is known about the properties of the relationship, because in most previous studies on VDAC, the temporal relationship among feature, responses, and rewards was fixed (e.g., Anderson et al., 2011a, b; Le Pelley et al., 2015). Conditioning studies have suggested that the longer the interval of CS (e.g., tone) and US (food) was, the more difficult the formation of CS–US association was (e.g., Molet & Miller, 2014). These findings indicate that the time interval of CS and US modulates the learning of a Pavlovian association. Moreover, some studies and approaches indicate that, in Pavlovian conditioning, it is difficult to form a US–CS association when the stimuli are only contiguous (e.g., Kamin, 1969; Rescorla & Wagner, 1972), suggesting that the temporal precedence of the CS over the US is important for the formation of Pavlovian conditioning (e.g., Rescorla, 1972). This possibility is consistent with findings indicating that it is difficult to form a US–CS association in simultaneous conditioning (e.g., Molet & Miller, 2014), compared to a forward conditioning (Pavlov, 1927). Although, in contrast to previous studies, Bucker and Theeuwes (2017a, b) conducted Pavlovian reward learning, in which feature–reward association separated from a task (response) of participants, the temporal relationship between features and rewards was fixed during the task. Thus, whether the time interval between features and rewards affects the feature–reward association in VDAC remains unclear.
In the present study, we investigated the generalizability of Pavlovian reward learning in VDAC to reveal the underlying mechanisms of the feature–reward association in VDAC. To this end, we manipulated the temporal relationship among features, responses, and rewards to elucidate the characteristics of reward learning in VDAC. In a series of experiments in the present study, we used a task irrelevant VDAC paradigm, in which rewards were associated with task-irrelevant stimuli (e.g., a distractor) during reward learning in a flanker task (Eriksen & Eriksen, 1974), then tested whether VDAC would occur or not in the test phase based on an additional singleton visual search paradigm (Theeuwes, 1992). In Experiment 1, reward-signaling features (i.e., a color of rectangular frame) were presented in a task display. In Experiments 2 and 3, features were presented before (Experiment 2) or after (Experiment 3) the task display. Moreover, features were provided in the feedback display in Experiments 4 and 5.
We expected that if response selection is related to feature–reward association, VDAC would only occur when features are presented in the task display (Experiment 1). Also, we expected that if the time interval between a feature and a reward has some restrictions on an association, we could observe VDAC only in specific situations. Alternatively, if the temporal relationship among features, responses, and rewards is flexible, VDAC would be observed in all experiments.
Experiment 1
Method
Participants
In Experiment 1, 21 undergraduate and graduate students were recruited from Kyoto University, Kyoto, Japan (seven women, mean age 21.5 years, SD = 1.83). All had self-reported normal or corrected-to-normal visual acuity and were screened for color vision (Ishihara, 1917). Written informed consent was obtained from each of them. After the experiment, all participants were given a book coupon worth 1,000 yen for their participation. All experiments were approved by the Institutional Review Board of Kyoto University.
Apparatus
Participants individually viewed a display on a CRT monitor (Mitsubishi RDF223H) at a distance of 57 cm in a dark room. Stimuli were presented with MATLAB software and Psychtoolbox extensions. Responses were submitted using a keyboard (“z” and “m” keys).
Stimuli and procedure
The experiment consisted of two phases (training and test) and took approximately one hour. Before the experimental trials, participants took part in practice trials.
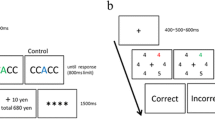
Training phase. Each trial consisted of a fixation display, flanker display, and feedback display with a uniform black background (Fig. 1). In the fixation display, a white fixation cross was presented at the center of the screen (0.5° × 0.5° visual angle). For the flanker task, we selected 20 alphabetical letters (excluding I, J, M, Q, W, and Z) as task stimuli, and these letters were classified into five groups of four letters based on similarity. A target letter was presented in the center of the screen, and two distractor letters were shown on both sides in each trial (1.5° center to center). Moreover, in all flanker displays, a magenta, yellow, or cyan rectangular frame surrounded the letters (12.7° × 6.4° visual angle). In the feedback display, only correct responses were followed by a reward outcome indicating reward points earned in the current trial and the cumulative total amount.
There were high-reward, low-reward, and no-reward conditions indicated by the color of the rectangular frame around the letters. In the high-reward condition, 75% of trials were followed by a high reward (+100 yen), and 25% followed by a low reward (+10 yen). In the low-reward condition, this association of reward probability was reversed; 75% of trials resulted in a low reward, and 25% had a high reward. In the no-reward condition, all trials with correct responses showed four asterisks indicating no reward (i.e., “****”). In incorrect-response or slow-response (more than 800 ms) trials, “Incorrect” appeared on the feedback display. Importantly, this reward schedule was not instructed to participants explicitly. Before the experiments, we told participants that the monetary reward presented in the training phase was imaginary and not related to the actual reward for their participation (i.e., all participants received a book coupon worth 1,000 yen regardless of their performances). Also, we instructed that “in this computer game, please collect as many reward points as possible during reward learning by making a response as quickly and accurately as possible” to our participants.
There were 240 trials comprising five experimental blocks of 48 trials in the training phase. Before each block started, a four-letter group was randomly selected, and response mapping of the target letter was provided on a display for participants (e.g., “A” or “B” target was the “z” key, and “C” or “D” was the “m” key). The objective of the main task was to identify the central letter as quickly as possible using a keyboard response during the flanker display (two-alternative forced choice). All reward conditions (i.e., high-reward, low-reward, and no-reward conditions) had 16 trials in a block, respectively. There were two congruency conditions (i.e., congruent and incongruent conditions). Half of the trials (i.e., eight trials) in each reward conditions included congruent trials (e.g., “AABAA” or “CCDCC”), and the remaining trials were incongruent (e.g., “CCACC” or “DDBDD”). There were no trials in which all the same letters made up a group of letters on congruent trials (e.g., “AAAAA”). These trial conditions were presented in random order.
Each trial followed the same process (see Fig. 1a). A white fixation cross was presented for 400, 500, or 600 ms randomly, and the presentation of the fixation cross was followed by a flanker display for 800 ms. Then, after a black screen for 1,000 ms, a feedback display was shown for 1,500 ms, followed by a black display for 1,000 ms. Participants submitted a response to complete the task in the flanker display. The frame color associated with reward was counterbalanced between participants (Fig. 2).

Sequence of trial events in the training phase (a, b, c, and d). A flanker display was followed by a reward feedback display only in correct trials (e.g., high-reward condition). a Training phase in Experiment 1. Colored frame surrounding the letters in the flanker display was associated with the magnitude of reward. b Training phase in Experiment 2. Colored fixation frame before the flanker display was associated with reward. c Training phase in Experiment 3. The colored fixation frame after the flanker display was associated with reward. d Training phase in Experiment 4. The colored frame presented in the feedback display was associated with reward. Note. 100 yen is nearly equal to $1 as of 2018. (Color figure online)

Sequence of trial events in the test phase. A shape singleton search display was followed by a display showing correct feedback. Participants reported the orientation of the line inside a unique shape target. (Color figure online)
Test phase. Each trial consisted of a fixation display, visual search display, and feedback display (see Fig. 2). A fixation cross was presented at the center of the fixation display (0.5° × 0.5° visual angle). Then, six shapes (i.e., circles or diamonds) surrounding the center fixation cross were shown on three sides of the search display. The middle shapes on each side were presented 4.8° to the left or right of the fixation. Others appeared 4.8° above or below the horizontal center of fixation and 2.4° to the left or right of the vertical center. In each search display trial, six stimuli included a circle (2.5° × 2.5° visual angle) among five diamonds (each at a 2.7° × 2.7° visual angle) or a diamond among five circles. A target was defined as a unique shape (i.e., circle or diamond). The objective of the main task was to respond to the line orientation inside the target stimuli (i.e., vertical or horizontal) using a keyboard (“z” or “m” key). Importantly, one distractor was colored in two-thirds of trials, and this color was previously associated with a reward in the training phase (i.e., high-reward and low-reward color). The reward distractor was never presented at a location adjacent to the target stimuli. In the remaining one-third of trials, all stimuli were colored gray (no-distractor condition). Thus, the color of the no-reward condition during the training phase was excluded in the test phase. In the feedback display, only the messages “Correct” or “Incorrect” were provided.
There were 192 trials comprising four experimental blocks of 48 trials in the test phase. At the beginning, a gray fixation cross was presented for 400 ms, 500 ms, or 600 ms randomly, followed by a visual search display (1,500 ms, the limited time for response). Then, after a black screen (1,000 ms), a feedback display was shown for 1,500 ms, followed by a black display for 1,000 ms. Participants were instructed that color was irrelevant to performing the task, and these colors were never assigned to the target. Based on mapping in the training phase, the color of the distractor was counterbalanced across participants. The type of distractor (circle or diamond) and target orientation (vertical or horizontal) were counterbalanced for each participant. Only correct trials were analyzed, and we excluded the data with reaction times (RTs) more than three standard deviations above or below the mean of their respective conditions.
Results
Table 1 shows average accuracy across all participants in the training and test phases. In the training phase, rewards did not affect performance, consistent with many previous studies (e.g., Anderson et al., 2011a, 2012). We examined statistical differences in RTs in the training phase by conducting a two-way ANOVA with reward (high, low, no reward) and congruency (congruent, incongruent) as the within-subjects factors (see Table 2). There were no main effects of reward, F(2, 40) = 0.89, p = .417, ηp2 = .043, and no significant interactions, F(2, 40) = 0.75, p = .479, ηp2 = .036, but there was a significant main effect of congruency, F(1, 20) = 73.40, p < .001, ηp2 = .786. Mean RTs in the training phase of all experiments are shown in Table 2. This pattern of results was consistent across all experiments in this study (Experiment 4 showed a significant interaction, but post hoc comparisons did not reach statistical significance). Therefore, we did not report the statistical test results for the training phase in subsequent experiments.
We analyzed trials in the test phase based on conditions during the training phase. Test phase RTs in Experiment 1 are shown in Fig. 3. To evaluate VDAC (i.e., RT difference between high-reward and low-reward conditions), we first conducted a one-way repeated-measures ANOVA with distractor type (high, low, no distractor) as a within-subjects factor. There was a significant main effect of distractor type, F(2, 40) = 14.17, p < .001, ηp2 = .415. To reveal VDAC effects in detail, Shaffer’s post hoc procedure was used for comparisons. There were significant differences between high-reward and no-distractor conditions, t(20) = 7.09, p < .001; high-reward and low-reward conditions, t(20) = 2.22, p = .038; and low-reward and no-distractor conditions, t(20) = 2.61, p = .017. Error rates did not show a significant main effect of reward, F(2, 40) = 1.31, p = .281, ηp2 = .062.

Mean reaction times from the test phase in Experiment 1. Error bars show standard error of the mean (SEM). *p < .05. **p < .01
In Experiment 1, when the reward-associated feature was presented during the task display with response selection, VDAC was observed, with trials including the high-reward distractor showing a significant delay in RT relative to low-reward trials. In Experiment 2, we tested whether a feature–response temporal relationship (i.e., feature–response synchronization) was necessary for the formation of a feature–reward association to elicit VDAC. Also, we examined the effect of feature–reward interval on VDAC to increase the time interval between features and rewards.
Experiment 2
Method
Participants
In Experiment 2, 21 new undergraduate and graduate students were recruited from Kyoto University (six women, mean age 21.5 years, SD = 2.84). All had self-reported normal or corrected-to-normal visual acuity and were screened for color vision (Ishihara, 1917). Written informed consent was obtained from all participants. After the experiment, all participants were given a book coupon worth 1,000 yen for their participation.
Apparatus, stimuli, and procedure
In Experiment 2, the apparatus, design, and procedure were similar to that of Experiment 1. Notably, in Experiment 2, we presented a colored fixation frame in the fixation display for 800 ms, and the magnitude of rewards was dependent on fixation frame color (see Fig. 1b). Therefore, the colored rectangular frame surrounding letters in the flanker display was removed. The test phase was the same as in Experiment 1.
Results
Figure 4 shows test phase RTs. Similar to Experiment 1, an ANOVA with distractor type (high, low, no distractor) as a within-subjects factor revealed a significant main effect of distractor type, F(2, 40) = 13.30, p < .001, ηp2 = .399. Post hoc comparisons using Shaffer’s method revealed a significant difference between the high-reward and no-distractor conditions, t(20) = 5.09, p < .001, and the low-reward and no-distractor conditions, t(20) = 2.81, p = .011. Moreover, the difference between the high- and low-reward conditions was significant, t(20) = 2.30, p = .032. Error rates showed no significant main effect of distractor types, F(2, 40) = 2.35, p = .109, ηp2 = .105.

Mean reaction times from the test phase in Experiment 2. Error bars show standard error of the mean (SEM). *p < .05. **p < .01
In Experiment 2, when reward-associated features preceded response selection and were presented in the fixation display, we found VDAC. Given that the feature presentation was separated from the timing of response selection, the findings indicate that a response is not necessary for feature–reward association in VDAC. Moreover, these results suggest that the relatively long time interval between features and rewards (i.e., about 1,800 ms) is sufficient for developing VDAC. However, it is possible that the relationship between response selection and feature–reward association played a significant role in Experiment 2. The fixation presented before the task display in this study temporally predicted the occurrence of the flanker task stimuli. Therefore, participants might have voluntarily looked at the fixation display and used it as the predictor for the occurrence of the task, resulting in the facilitation of feature–reward associations. If VDAC were to occur regardless of participants’ responses, and the time interval between feature and reward were flexible, then it would be possible to observe VDAC even when reward-associated features are presented after the task display requiring response selection. To test this possibility, in Experiment 3, we decreased the time interval between features and rewards, and showed a colored rectangular frame associated with rewards after the task display.
Experiment 3
Method
In Experiment 3, 21 new undergraduate and graduate students were recruited from Kyoto University (nine women, mean age 18.7 years, SD = 0.96). All had self-reported normal or corrected-to-normal visual acuity and were screened for color vision (Ishihara, 1917). Written informed consent was obtained from each of them. After the experiment, all participants were given course credit for their participation.
Apparatus, stimuli, and procedure
In Experiment 3, the apparatus, design, and procedure were similar to that of Experiment 2 in the training phase. In the training phase, the flanker display was followed by a black screen (200 ms to 1,200 ms randomly). Then, the colored rectangular frame surrounding the white fixation cross was presented in an additional fixation display after responses (see Fig. 1c). As in Experiments 1 and 2, the fixation display with the colored frame lasted for 800 ms. Therefore, the colored rectangular frame was not shown in the fixation display before the task display. The test phase was identical to that of all previous experiments.
Results
Test-phase RTs from Experiment 3 are shown in Fig. 5. An ANOVA with distractor type (high, low, no distractor) as a within-subjects factor revealed a significant main effect of distractor type, F(2, 40) = 11.33, p < .001, ηp2 = .362. Post hoc comparisons using Shaffer’s procedure revealed a marginally significant difference between the high-reward and low-reward conditions, t(20) = 1.96, p = .064. Moreover, differences between the high-reward and no-distractor conditions and the low-reward and no-distractor conditions were significant, t(20) = 3.85, p = .001; t(20) = 3.29, p = .004. Error rates did not show a main effect of distractor types, F(2, 40) = 0.29, p = .749, ηp2 = .014.

Mean reaction times from the test phase in Experiment 3. Error bars show standard error of the mean (SEM). +p < .10. **p < .01
In Experiment 3, we found a marginally significant VDAC when a reward-associated color was presented after response selection. This is not a strong evidence for VDAC, but the same tendency as Experiment 2, which showed a colored frame before the task display requiring response selection, was obtained in Experiment 3. The results of Experiment 3 indicate that the presentation of reward-signaling color may not be limited to the timing of the task display with a response, suggesting that participants’ response is not too much related to a feature–reward association in VDAC. Also, the effect of reward that we observed in Experiment 3 supports the idea that the time interval between feature and reward is flexible because the trial sequence has the short interval between feature and reward (i.e., just before the feedback display) and we found a weak VDAC. There are some possible causes of a relatively weak VDAC in Experiment 3, and we will discuss them in General Discussion. Next, in Experiment 4, we simultaneously presented feature and reward in the feedback display to test whether an association between features and rewards would be solely sufficient for VDAC.
Experiment 4
Method
Participants
In Experiment 4, 22 new undergraduate and graduate students were recruited from Kyoto University (12 women, mean age 21.5 years, SD = 1.71). All had self-reported normal or corrected-to-normal visual acuity and were screened for color vision (Ishihara, 1917). Written informed consent was obtained from each of them. After the experiment, all participants were given a book coupon worth 1,000 yen for their participation. Data from one participant were excluded from the analysis because accuracy was very low (training phase, 51.3%; test phase, 34.9%). The remaining data were from 21 participants (11 women, mean age 21.5 years, SD = 1.70).
Apparatus, stimuli, and procedure
In Experiment 4, the apparatus, design, and procedure were identical to that of Experiment 3, with some exceptions. In the training phase, the colored rectangular frame (9.5° × 5.1° visual angle) surrounding the amount of reward points earned in the present trial (e.g., “+100 yen”) was presented in the feedback display, and this color was associated with reward (see Fig. 1d). Therefore, the additional fixation display with the colored rectangular frame after the task display was removed. The test phase was the same as all previous experiments.
Results
Test-phase RTs from Experiment 4 are shown in Fig. 6. As in Experiment 3, we conducted a one-way repeated-measures ANOVA with distractor type (high, low, no distractor) as a within-subjects factor and observed a significant main effect of distractor type, F(2, 40) = 7.98, p = .001, ηp2 = .285. Post hoc comparisons using Shaffer’s procedure were conducted to analyze main effects in detail. There were significant differences between high-reward and no-distractor conditions, as well as between low-reward and no-distractor conditions, t(20) = 3.68, p = .001; t(20) = 3.25, p = .004. However, there was no significant difference between high-reward and low-reward conditions, t(20) = 0.55, p = .586. Error rates did not show significant differences among distractor types, F(2, 40) = 1.30, p = .283, ηp2 = .061.

Mean reaction times from the test phase in Experiment 4. Error bars show standard error of the mean (SEM).**p < .01
In Experiment 4, we presented reward-associated stimulus features (i.e., a colored rectangular frame) in the feedback display, and VDAC was not observed in that RTs in the high-reward condition were not significantly different from those in the low-reward condition. However, a previous study (Sali, Anderson, & Yantis, 2014) showed that contingency is necessary for VDAC, the findings of Experiment 4 indicate that a direct association between features and rewards alone is not sufficient for VDAC. Based on Pavlovian conditioning, it is hard to form a US–CS association in simultaneous conditioning (e.g., Molet & Miller, 2014). Experiment 4’s results suggest that the precedence of features over rewards is necessary.
However, there are some possibilities regarding no VDAC in Experiment 4. One possibility is that it is difficult for observers to obtain information about reward-associated color in the feedback display. When reward-signaling features appear in the task display (Experiment 1), they might be easily recognized because participants engage the task in this display. Also, in Experiments 2 and 3, in which features appeared before or after the task display, reward-signaling features were physically salient and might have captured attention in a bottom-up method (Theeuwes, 1991, 1992). On the other hand, although only the feature that signaled reward outcome had a salient color in the feedback display in Experiment 4, as in these experiments, these features might not capture attention because the feedback display has a lot of information, such as the earnings in the current trial, the cumulative total amount, and reward-signaling feature, resulting in no VDAC.
In Experiment 5, we made the feedback display simpler (i.e., less information) and tested again the possibility of VDAC occurring when features and rewards are simultaneously presented in the feedback display. To this end, in the feedback display, we only presented the earning for the current trial surrounding the reward-signaling feature (i.e., a colored rectangular frame) at the center of the display. Additionally, we focused on the reward conditions and removed the no-reward condition, which was never used in the test phase. Therefore, we only used the high-reward and low-reward conditions in the training phase.
Experiment 5
Method
Participants
In Experiment 4, 25 new undergraduate and graduate students of Kyoto University were recruited (12 women, mean age 21.6 years, SD = 3.93). All had self-reported normal or corrected-to-normal visual acuity. Before the experiment, they were screened for color vision (Ishihara, 1917). Written informed consent was obtained from each of them. At the end of the experiment, all participants were given a book coupon worth 1,000 yen for their participation. Data from one participant were excluded from the analysis because accuracy was low (i.e., 2.5 SDs below the group mean). The remaining data were from 24 participants (11 women, mean age 21.7 years, SD = 3.97).
Apparatus
In Experiment 5, the apparatus was identical to that of Experiment 4.
Stimuli and procedure
The stimuli and procedure were similar to all previous experiments, with few changes.
Training phase. In the training phase, we used 12 alphabetical letters as task stimuli. Unlike Experiment 4, the cumulative total amount (i.e., “total XX yen”) was removed in the feedback display and only the reward points earned in the current trial (i.e., “+100” or “+10”) were presented at the center of the display, which were surrounded by the rectangular frame (12° × 6° visual angle). Also, we removed the no-reward condition so that the frame was magenta or yellow in color for the reward conditions (i.e. high-reward and low-reward). In the high-reward condition, 83% of trials were followed by a high reward (“+100”), and 17% were followed by a low reward (“+10”). In the low-reward condition, this association of reward probability was reversed; 83% of the trials resulted in a low reward, and 17% had a high reward. The color-reward association was counterbalanced across participants.
There were 192 trials comprising six experimental blocks of 32 trials in the training phase. The time course changed slightly from the previous experiments as follows: a flanker display (800 ms or until response) was followed by a black screen (750 ms), a feedback display (1,000 ms), and a black display (750 ms). Between blocks, we presented the cumulative total amount of reward points, accuracy, and response time of the previous block.
Test phase. In the visual search display, six shapes (i.e., circles or diamonds; 2.7° × 2.7° visual angle) were presented on an imaginary circle (diameter 12°). There were 288 trials comprising four experimental blocks of 72 trials in the test phase. Unlike all previous experiments, the feedback display was shown for 750 ms, followed by a black display for 750 ms.
Results
Figure 7 shows test-phase RTs from Experiment 5. As in Experiment 4, we ran a one-way repeated-measures ANOVA with distractor type (high, low, no distractor) as a within-subjects factor and observed a significant main effect of distractor type, F(2, 46) = 9.23, p < .001, ηp2 = .286. Post hoc comparisons using Shaffer’s procedure showed significant differences between high-reward and no-distractor conditions, as well as between low-reward and no-distractor conditions, t(23) = 3.44, p = .002; t(20) = 4.88, p < .001. As in Experiment 4, there was no significant difference between high-reward and low-reward conditions, t(23) = 0.09, p = .931. Error rates did not show significant differences among distractor types, F(2, 46) = 1.91, p = .160, ηp2 = .077.

Mean reaction times from the test phase in Experiment 5. Error bars show standard error of the mean (SEM). **p < .01
In Experiment 5, we replicated findings with no VDAC as in Experiment 4 when we presented reward-associated stimulus features in the feedback display. In Experiment 5, unlike Experiment 4, the feedback display only had the reward points received for the current trial surrounding a colored frame associated with the reward. Although participants might have easily obtained information about features that signaled a reward, relative to Experiment 4, in which the feedback display contained a lot of information, we could not find VDAC. These results indicate that the simultaneous presentation of features and rewards is not sufficient for VDAC, consistent with the findings in simultaneous conditioning (e.g., Molet & Miller, 2014).
General discussion
This study tested the hypothesis of Pavlovian conditioning in VDAC by manipulating the temporal relationship among features, responses, and reward, based on two questions. The first question regards the role of response selection in VDAC. In Experiment 1, color was bound to a rectangular frame surrounding flanker letters in the task display with response selection, and we observed significant VDAC in a subsequent visual search task. Importantly, a significant or marginally significant VDAC was also observed when we presented features without synchronizing with participant’s overt responses in Experiments 2 and 3, where reward-associated features were presented before or after the task display (i.e., fixation display), respectively. These VDAC results suggest that response selection did not mediate feature–reward association in VDAC because features associated with rewards were not synchronized with participant’ overt responses in these experiments, although the results in Experiment 3 would not lead us to the strong conclusion on the presence of VDAC. We found that, at least from the results of Experiment 2, the presentation of reward-associated features is not limited to the timing of the task display with a response. The second question regards whether the temporal relationship between features and rewards affect the formation of feature–reward association in VDAC. As in Experiment 1, we also obtained a significant VDAC when features were shown before the task display in Experiment 2 (i.e., long interval: 1,800 ms). Moreover, when features appeared in the period between the task and the reward in Experiment 3 (i.e., short interval), a marginally significant VDAC was observed. These findings suggest that the temporal relationship between reward-signaling features and rewards is not limited to specific time intervals. However, when features and rewards were synchronized in the feedback display after the task display in Experiments 4 and 5, VDAC disappeared, suggesting that the simple association between features and rewards is not sufficient for VDAC. These findings indicate that the time interval between features and rewards is flexible, but the temporal precedence of feature to reward is necessary for the formation of the feature–reward association in VDAC. Taken together, the evidence is in favor of the hypothesis that Pavlovian conditioning can explain the mechanism underlying VDAC.
Previous studies’ (e.g., Bucker & Theeuwes, 2017a, b; Le Pelley et al., 2015) findings on the Pavlovian hypothesis indicate that instrumental behavior (e.g., response selection) does not mediate the formation of feature–reward association. Most previous studies investigating the effect of reward on visual attention, however, presented reward-signaling stimuli at the task display with response selection (e.g., Anderson et al., 2011a, b; Le Pelley et al., 2015). In those studies, it was unclear whether this direct temporal association between features and responses is necessary or not. Importantly, unlike previous studies (e.g., Anderson et al., 2011a, b; Le Pelley et al., 2015), reward-signaling features did not appear in the task display in this study (Experiments 2, 3, 4, and 5). Even in these situations, we observed the effect of VDAC (Experiment 2) or a tendency of VDAC (Experiment 3), suggesting that the time separation of features and responses is sufficient for VDAC. Our findings generalize the Pavlovian hypothesis of VDAC reported by previous studies even when participants required response selection to achieve a task during reward learning.
In previous studies that support the Pavlovian hypothesis, the temporal relationship between features and rewards was fixed during reward learning (e.g., Anderson et al., 2011a, b; Bucker & Theeuwes, 2017; Le Pelley et al., 2015), thus little is known about the properties of Pavlovian learning in VDAC. Even in Bucker and Theeuwes’s study (2017), in which the authors used Pavlovian reward learning, and in which the feature–reward association was temporally and spatially separated from participants’ responses, rewards were always preceded by reward-signaling features with fixed time intervals. Regarding a CS–US association, studies on Pavlovian conditioning have demonstrated the importance of temporal precedence of the CS over the US (e.g., Kamin, 1969; Rescorla, 1972; Rescorla & Wagner, 1972) and showed that the time interval of CS–US affects the formation of a Pavlovian relationship (e.g., Molet & Miller, 2014). It is a viable hypothesis that the same characteristic of this temporal relationship is responsible for VDAC, and empirical testing of this hypothesis is important for our understanding of VDAC. Our results showed that VDAC occurs regardless of the time interval between features and rewards (Experiments 1, 2, and 3), although only a marginal effect was observed in Experiment 3. One possible reason for the marginal VDAC in Experiment 3 is that given an overall reduction in RTs (i.e., ceiling effect), relative to all other experiments, the relatively weak VDAC in Experiment 3 may reflect a ceiling effect. Importantly, however, when features synchronized with appearance of a reward (Experiments 4 and 5), we could not detect the effect, suggesting a restriction for feature–reward association in VDAC. These findings are consistent with evidence of Pavlovian reward learning as shown in previous studies (e.g., Bucker & Theeuwes, 2017a, b; Le Pelley et al., 2015) and highlight the mechanism of the temporal relationship between reward-signaling features and reward outcomes.
Note that it is hard to claim no VDAC in Experiments 4 and 5 where features appeared in the feedback display, because our discussion was mostly based on null hypothesis testing. To confirm the effect of VDAC (a difference in RTs between the high-reward and low-reward conditions), especially in Experiments 4 and 5, we calculated a Bayes factor using JASP (Version 0.8.4; JASP Team, 2017 ). A Bayes factor was computed for quantification of the likelihood that the null hypothesis was supported. We conducted a Bayesian repeated-measures ANOVA on the difference in RTs among distractor types (high, low, no distractor) of the test phase, and then post hoc comparisons were performed to compute a Bayes factor for each pair of the distractor type. Table 3 shows Bayes factors across all experiments in the test phase. Importantly, in Experiment 4, we obtained a Base factor of 3.83 in the comparison between the high-reward and low-reward conditions, suggesting that the data in Experiment 4 is in favor of the null hypothesis, comparing to the alternative hypothesis. This indicates that it was more than three times more likely that there was no difference in RTs between the high-reward and low-reward conditions. Moreover, a Bayes factor was 4.64 in Experiment 5, suggesting the null hypothesis (there was no difference in RTs between the high-reward and low-reward conditions) was more than four times more likely to explain the data compared to the alternative hypothesis (there was a difference in RTs between the high- and low-reward conditions). From these results, we believe that the preceding of reward-signaling features over reward outcome is the necessary component of VDAC.
What factors affect the formation of associations between features and rewards? One possibility is the effect of attention on the formation of feature–reward associations attending to features associated with rewards may be necessary for VDAC. In previous studies (e.g., Bucker & Theeuwes, 2017a; Le Pelley et al., 2015) and in the current study, participants did not need to attend to reward-associated features to achieve tasks. However, features used in these studies were physically salient, and bottom-up attentional capture for those stimuli might have occurred (Theeuwes, 1992). Given such a situation, the attentional capture observed in these studies may not be completely value driven, although the RT difference between the high-reward and low-reward conditions cannot be explained by physical salience alone. Based on these findings, some recent studies argue that associative reward learning would modulate the likelihood of attentional capture by the physically salient stimuli that signal rewards, which is called value-modulated attentional capture (VMAC, e.g., Le Pelley et al., 2016; Pearson et al., 2015).
More recently, studies have shown that the effect of reward learning can be observed even when reward-signaling features are task-irrelevant and not physically salient (Bucker & Theeuwes, 2017b; Failing & Theeuwes, 2017). Failing and Theeuwes (2017) investigated the boundaries learning about stimuli that signaled reward outcomes in detail. In their series of experiments, a nonsalient task-irrelevant feature (e.g., the color of a distractor) signaled reward outcome. Importantly, these reward-signaling features caused attentional capture only when the authors told participants (or participants realized) about the association between features and rewards, and the authors could not obtain the same effect when participants did not know about the association. From these findings, the authors argued that initial attentional prioritization of the reward-associated features triggers the learning between features and rewards and leads to developing reward-based attentional capture (see also Bucker & Theeuwes, 2017b). Also, regarding the role of attention on learning, a previous study on VSL indicated that attention is necessary to learn associations (Turk-Browne, Jungé, & Scholl, 2005). These studies suggest that the physical salience of reward-signaling features is unnecessary to form feature–reward association in VDAC, but some attentional processes could be related to the associations.
The results of Experiment 3 in this study showed the relatively weak VDAC. Regarding this finding, we assumed the possibility that when we presented reward-signaling color before the task display (e.g., Experiment 2), participants might have looked at the color to predict the occurrence of the task, and these manipulations might cause the facilitation of feature–reward association. Our results in Experiment 3 would partly support these possibilities and suggest that participants might tend to release their attention from the display, resulting in a weaker VDAC. However, the relationship between attentional control and VDAC was not sufficiently revealed in this study and awaits further investigation.
Moreover, regarding an explicit knowledge of feature–reward association, most previous studies and this study did not tell participants about the feature–reward association (e.g., Anderson et al., 2011a, b). After the experiment, we asked participants whether they realized the manipulation of a color–reward association during reward learning, and we noticed that most people could not report the clear association. The proportion of explicit awareness of feature–reward association was not much different across experiments, suggesting that it may be hard for us to interpret the results in this study based on the explicit knowledge of feature–reward association.
In Experiments 4 and 5, we presented reward-signaling features in the feedback display and could not observe VDAC. The possible reason why VDAC did not occur may be explained by a blocking effect (e.g., Kamin, 1969). The feedback display in Experiments 4 and 5 was redundant because it had two predictors regarding rewards: one is a reward-signaling feature (i.e., colored rectangular frame), another is the reward itself. In this situation, participants may look at reward outcomes and ignore features. This might cause no association between features and rewards because participants first learn reward, then learning about reward-signaling features may be blocked. Given that the blocking effects is characteristic of Pavlovian conditioning, the present findings still support the Pavlovian hypothesis even if they reflect the blocking effect. However, the experiments in this study were not designed to examine the blocking effect and/or difference between this effect and the original blocking paradigm; thus, the clarification of the more detailed mechanism on Pavlovian learning in VDAC is beyond the scope of the current study.
In this study, we revealed important aspects of the Pavlovian hypothesis for VDAC that have not been examined in previous studies (e.g., Bucker & Theeuwes, 2017a; Le Pelley et al., 2015). This study had some limitations. Although, in Experiments 2 and 3, response selection was unrelated to feature–reward associations in VDAC, participants needed to respond to target stimuli to perform a task. Importantly, Bucker and Theeuwes (2017a, b) used Pavlovian reward learning for attentional capture by learned value, and separated feature–reward associations from responses in task achievement. Compared to previous VDAC studies, Bucker and Theeuwes’s experimental design paralleled Pavlovian conditioning more closely. However, even in their studies, participants had to respond to (or detect) a target (i.e., fixation change) during reward learning, unlike in pure Pavlovian conditioning.
Note that manipulation of response selection and attention might be more difficult than it appears. For example, in the go/no-go task, whereas responses as actions (e.g., key press) were unnecessary in no-go trials, it would not strictly mean there is a lack of responses, in that participants would have to identify the stimuli and decide their action (response inhibition). Although visual perceptual learning studies have often used the passive viewing paradigm (e.g., Seitz, Kim, & Watanabe, 2009), maintaining participants’ motivation at a level similar to their motivation levels while performing a task can be difficult. Observing no VDAC effect using a passive viewing task would not alone constitute strong evidence against Pavlovian conditioning. Resolving these issues is beyond the scope of this study, and future studies are necessary.
Conclusion
In this study, we investigated the temporal relationships among features, responses, and rewards of feature–reward associations to increase the understanding of Pavlovian reward learning in VDAC. We showed that the temporal relationship between features and responses is less sensitive to the formation of feature–reward associations, as reported in previous studies, suggesting that the feature presentation at the timing of the task display is not the necessary components of VDAC. On the other hand, the temporal relationship between feature and reward affects feature–reward associations, such that features precede reward outcomes in VDAC. These characteristics of feature–reward associations could be persuasive evidence of Pavlovian reward learning in VDAC.
References
Anderson, B. A. (2013). A value-driven mechanism of attentional selection. Journal of Vision, 13(3), 1–16.
Anderson, B. A. (2016). The attention habit: How reward learning shapes attentional selection. Annals of the New York Academy of Sciences, 1369(1), 24–39. doi:https://doi.org/10.1111/nyas.12957
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011a). Learned value magnifies salience-based attentional capture. PLOS ONE, 6, e27926. doi:https://doi.org/10.1371/journal.pone.0027926
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011b). Value-driven attentional capture. Proceedings of the National Academy of Sciences of the United States of America, 108, 10367–10371. doi:https://doi.org/10.1073/pnas.1104047108
Anderson, B. A., Laurent, P. A., & Yantis, S. (2012). Generalization of value-based attentional priority. Visual Cognition, 20, 647–658. doi:https://doi.org/10.1080/13506285.2012.679711
Anderson, B. A., & Yantis, S. (2013). Persistence of value-driven attentional capture. Journal of Experimental Psychology: Human Perception and Performance, 39, 6–9. doi:https://doi.org/10.1037/a0030860
Awh, E., Belopolsky, A. V., & Theeuwes, J. (2012). Top-down versus bottom-up attentional control: A failed theoretical dichotomy. Trends in Cognitive Sciences, 16, 437–443.
Bucker, B., Belopolsky, A.V. & Theeuwes, J. (2015). Distractors that signal reward attract the eyes. Visual Cognition, 23, 1–24.
Bucker, B. & Theeuwes, J. (2017a). Pavlovian reward learning underlies value driven attentional capture. Attention, Perception, & Psychophysics. 79, 415–428. doi:https://doi.org/10.3758/s13414-016-1241-1
Bucker, B., & Theeuwes, J. (2017b). Stimulus-driven and goal-driven effects on Pavlovian associative reward learning. Visual Cognition, 26, 131-148. https://doi.org/10.1080/13506285.2017.1399948
Chelazzi, L., Perlato, A., Santandrea, E., & Della Libera, C. (2013). Rewards teach visual selective attention. Vision Research, 85, 58–72.
Corbetta, M., & Shulman, G. L. (2002). Control of goal-directed and stimulus-driven attention in the brain. Nature Reviews Neuroscience, 3, 201–215. doi:https://doi.org/10.1038/nrn755.
Eriksen, B. A., & Eriksen, C. W. (1974). Effects of noise letters upon identification of a target letter in a non-search task. Perception and Psychophysics, 16, 143–149.
Failing, M., Nissens, T., Pearson, D., Le Pelley, M., & Theeuwes, J. (2015). Oculomotor capture by stimuli that signal the availability of reward. Journal of Neurophysiology, 114, 2316−2327. doi:https://doi.org/10.1152/jn.00441.2015
Failing, M., & Theeuwes, J. (2017). Don’t let it distract you: How information about the availability of reward affects attentional selection. Attention, Perception, & Psychophysics, 79, 2275–2298. doi:https://doi.org/10.3758/s13414-017-1376-8.
Failing, M., & Theeuwes, J. (in press). Selection history: How reward modulates selectivity of visual attention. Psychonomic Bulletin & Review. doi:https://doi.org/10.3758/s13423-017-1380-y
Hickey, C., Chelazzi, L., & Theeuwes, J. (2010a). Reward changes salience in human vision via the anterior cingulate. The Journal of Neuroscience, 30, 11096–11103. doi:https://doi.org/10.1523/JNEUROSCI.1026-10.2010
Hickey, C., Chelazzi, L., & Theeuwes, J. (2010b). Reward guides vision when it’s your thing: Trait reward-seeking in reward-mediated visual priming. PLOS ONE, 5, e14087. doi:https://doi.org/10.1371/journal.pone.0014087
Hickey, C., Chelazzi, L., & Theeuwes, J. (2011). Reward has a residual impact on target selection in visual search, but not on the suppression of distractors. Visual Cognition, 19, 117–128.
Ishihara, S. (1917). Tests for color-blindness. Tokyo: Hongo Harukicho.
JASP Team (2017). JASP (Version 0.8.4) [Computer software] Retrieved from https://jasp-stats.org/
Kamin, L. J. (1969). Predictability, surprise, attention and conditioning. In B. A. Campbell & R. M. Church (Eds.), Punishment and aversive behavior (279–296). New York: Appleton-Century-Crofts.
Le Pelley, M. E., Mitchell, C. J., Beesley, T., George, D. N., & Wills, A. J. (2016). Attention and associative learning in humans: An integrative review. Psychonomic Bulletin & Review, 142(10), 1111–1140.
Le Pelley, M. E., Pearson, D., Griffiths, O., & Beesley, T. (2015). When goals conflict with values: Counterproductive attentional and oculomotor capture by reward-related stimuli. Journal of Experimental Psychology: General, 144, 158–171.
Lee, J., & Shomstein, S. (2014). Reward-based transfer from bottom-up to top-down search task. Psychological Science, 25, 466–475. doi:https://doi.org/10.1177/0956797613509284
Mine, C., & Saiki, J. (2015). Task-irrelevant stimulus-reward association induces value-driven attentional capture. Attention, Perception, & Psychophysics, 77, 1896–1907. doi:https://doi.org/10.3758/s13414-015-0894-5
Molet M., & Miller, R. R. (2014). Timing: An attribute of associative learning. Behavioural Processes, 101, 4–14. doi:https://doi.org/10.1016/j.beproc.2013.05.015
Pavlov, I. P. (1927). Conditioned reflexes. London: Oxford University Press.
Pearson, D., Donkin, C., Tran, S. C., Most, S. B., & Le Pelley, M. E. (2015). Cognitive control and counterproductive oculomotor capture by reward-related stimuli. Visual Cognition, 23, 41–66.
Rescorla, R. A. (1972). Informational variables in Pavlovian conditioning. In G. H. Bower (Ed.), The psychology of learning and motivation (Vol. 6, pp. l–46). New York: Academic Press.
Rescorla, R. A., & Wagner, A. R. (1972). A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. In A. H. Black & W. F. Prokasy (Eds.), Classical Conditioning II (pp. 64–99). New York: Appleton-Century-Crofts.
Sali, A. W., Anderson, B. A., & Yantis, S. (2014). The role of reward prediction in the control of attention. Journal of Experimental Psychology: Human Perception and Performance, 40, 1654–1664. doi:https://doi.org/10.1037/a0037267
Seitz, A., Kim, D., & Watanabe, T. (2009). Rewards evoke learning of unconsciously processed visual stimuli in adult humans. Neuron, 61, 700–707. doi:https://doi.org/10.1016/j.neuron.2009.01.016
Theeuwes, J. (1991). Cross-dimensional perceptual selectivity. Perception & Psychophysics, 50, 184–193.
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51, 599–606.
Turk-Browne, N. B., Jungé, J., & Scholl, B. J. (2005). The automaticity of visual statistical learning. Journal of Experimental Psychology: General, 134, 552–564.
Wang, L., Yu, H., & Zhou, X. (2013). Interaction between value and perceptual salience in value-driven attentional capture. Journal of Vision, 13, 1–13. doi:https://doi.org/10.1167/13.3.5
Yokoyama, T., Padmala, S., & Pessoa, L. (2015). Reward learning and negative emotion during rapid attentional competition. Frontiers in Psychology, 6, 269. doi:https://doi.org/10.3389/fpsyg.2015.00269
Acknowledgments
We would like to thank Berno Bucker for valuable feedback on earlier draft of the manuscript. We also thank three anonymous reviewers for their helpful comments and suggestions. This research was supported by Grants 16H01727 and 16J04500 from the Grants-in-Aid for Scientific Research (KAKENHI) program of the Japan Society for the Promotion of Science.
Author information
Authors and Affiliations
Corresponding authors
Rights and permissions
About this article

Cite this article
Mine, C., Saiki, J. Pavlovian reward learning elicits attentional capture by reward-associated stimuli. Atten Percept Psychophys 80, 1083–1095 (2018). https://doi.org/10.3758/s13414-018-1502-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-018-1502-2