
Abstract
Imaging through diffusers presents a challenging problem with various digital image reconstruction solutions demonstrated to date using computers. Here, we present a computer-free, all-optical image reconstruction method to see through random diffusers at the speed of light. Using deep learning, a set of transmissive diffractive surfaces are trained to all-optically reconstruct images of arbitrary objects that are completely covered by unknown, random phase diffusers. After the training stage, which is a one-time effort, the resulting diffractive surfaces are fabricated and form a passive optical network that is physically positioned between the unknown object and the image plane to all-optically reconstruct the object pattern through an unknown, new phase diffuser. We experimentally demonstrated this concept using coherent THz illumination and all-optically reconstructed objects distorted by unknown, random diffusers, never used during training. Unlike digital methods, all-optical diffractive reconstructions do not require power except for the illumination light. This diffractive solution to see through diffusers can be extended to other wavelengths, and might fuel various applications in biomedical imaging, astronomy, atmospheric sciences, oceanography, security, robotics, autonomous vehicles, among many others.
Similar content being viewed by others


1 Main text
Imaging through scattering and diffusive media has been an important problem for many decades, with numerous solutions reported so far [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19]. In various fields, including e.g., biomedical optics [5, 20], atmospheric physics [6, 21], remote sensing [22, 23], astronomy [24, 25], oceanography [26, 27], security [28, 29] as well as autonomous systems and robotics [30,31,32], the capability to rapidly see through diffusive and scattering media is of utmost importance. In principle, with a prior information of the transmission matrix of a diffuser [16, 33], the distorted images can be recovered using a computer. However, there is no simple solution to accurately obtain the transmission matrix of a diffuser [34]. Furthermore, the transmission matrix will significantly deviate from its measured function if there are changes in the scattering medium [35], partially limiting the utility of such measurements to see through unknown, new diffusers. To overcome some of these challenges, adaptive optics-based methods have been applied in different scenarios [5, 17, 36]. With significant advances in wave-front shaping [37,38,39,40], wide-field real-time imaging through turbid media became possible [8, 41]. These algorithmic methods are implemented digitally using a computer and require guide-stars or known reference objects, which introduce additional complexity to an imaging system. Digital deconvolution using the memory effect [42, 43] with iterative algorithms is another important avenue toward image reconstruction using a computer [9, 44,45,46,47].
Some of the more recent work on imaging through diffusers has also focused on using deep learning methods to digitally recover the images of unknown objects [11, 12, 48, 49]. Deep learning has been re-defining the state-of-the-art across many areas in optics, including optical microscopy [50,51,52,53,54,55], holography [56,57,58,59,60,61], inverse design of optical devices [62,63,64,65,66,67], optical computation and statistical inference [68,69,70,71,72,73,74,75,76,77], among others [78,79,80]. To incorporate deep learning to digitally reconstruct distorted images, neural networks were trained using image pairs composed of diffuser-distorted patterns of objects and their corresponding distortion-free images (target, ground truth). Harvesting the generalization capability of deep neural networks, one can digitally recover an image that was distorted by a new diffuser (never seen in the training phase), by passing the acquired distorted image through a trained neural network using a computer [12].
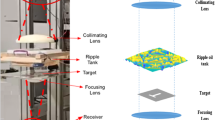
In this paper, we present computer-free and all-optical reconstruction of object images distorted by unknown, randomly-generated phase diffusers, as shown in Fig. 1a. Unlike previous digital approaches that utilized computers to reconstruct an image of the input object behind a diffuser, here we trained a set of diffractive surfaces/layers using deep learning to all-optically reconstruct the image of an unknown object as the diffuser-distorted input optical field diffracts through successive trained layers, i.e., the image reconstruction is processed at the speed of light propagation through the diffractive layers. Each diffractive surface that is trained has tens of thousands of diffractive features (termed as neurons), where the individual phase values of these neurons are adjusted in the training phase through error back-propagation, by minimizing a customized loss function between the ground truth image and the diffracted pattern at the output field-of-view. During this training, many different, randomly-selected phase diffusers, all with the same statistical correlation length, are used to help the generalization of the optical network. After this deep learning-based design of these diffractive layers (which is a one-time effort), they are fabricated to form a physical diffractive network that is positioned between an unknown, new diffuser and the output/image plane. As the input light corresponding to a new, unknown object passes through an unknown diffuser, the scattered light is collected by the trained diffractive network to all-optically reconstruct an image of the object at its output field-of-view, without the need for a computer, any digital computation or an external power source (except for the coherent illumination light).

All-optical imaging through diffusers using diffractive surfaces. a Training and design schematic of a 4-layered diffractive system that can see through unknown/new randomly generated phase diffusers. b Sample images showing the image distortion generated by random diffusers. Top: input images. Second row: free-space propagation (FSP) of the input objects through the diffuser, without the diffractive layers, imaged at the output plane. Third row: the input objects imaged by an aberration-free lens through the diffuser. Fourth row: the outputs of the trained diffractive network. c Schematic of a 4-layered network trained to all-optically reconstruct the input field of view seen through an unknown random diffuser. d The photograph of the 3D printed network shown in c. e Schematic and photograph of the experimental apparatus used for testing the design shown in c using continuous wave coherent THz illumination
We validated the success of this approach using coherent THz illumination, and fabricated our designed diffractive networks with a 3D-printer to demonstrate their capability to see through randomly-generated unknown phase diffusers that were never used in the training phase. We also observed an improved object reconstruction quality using deeper diffractive networks that have additional trainable layers. This all-optical image reconstruction achieved by passive diffractive layers enables to see objects through unknown random diffusers and presents an extremely low power solution compared with existing deep learning-based or iterative image reconstruction methods implemented using computers, only requiring power for the coherent illumination source. Learning-based diffractive models presented here to see through diffusers can also work at other parts of the electromagnetic spectrum, including the visible and far/mid-infrared wavelengths. Although the presented proof-of-concept results considered a thin, random diffuser layer, we believe that this framework and the underlying methods can potentially be extended to see through volumetric diffusers and might bring transformative advances in various fields, where imaging through diffusive media is of utmost importance such as e.g., in biomedical imaging, astronomy, autonomous vehicles, robotics and defense/security applications, among many others.
2 Results
2.1 Diffractive network design and experimental set-up
We designed and 3D-fabricated diffractive networks that can all-optically reconstruct object images that are distorted by random phase diffusers under 400 GHz illumination (λ ≈ 0.75 mm). In terms of the optical set-up, custom fabricated phase diffusers (see the Methods section) are individually placed 40 mm (53\(\lambda\)) away from the input object plane. The successive diffractive layers (designed for all-optical reconstruction of the object field-of-view) are placed 2 mm away from the diffuser, with a layer-to-layer distance of 2 mm. The output image plane is positioned 7 mm (9.3 \(\lambda\)) from the last diffractive layer along the optical axis (Fig. 1a). Based on these parameters, characteristic object distortion generated by a randomly selected phase diffuser is reported in Fig. 1b. First, we simulated the free-space propagation (FSP) of a distorted object (i.e., seen through a diffuser) without the presence of the diffractive layers, and got its intensity distribution at the output plane, which is shown in the second row of Fig. 1b. Imaging of the same object through the same diffuser by an aberration-free lens is also shown in the third row of Fig. 1b. These images clearly show the impact of the diffuser at the output plane (through free-space propagation or an imaging lens), which makes it impossible to recognize the object unless further computation or digital reconstruction is applied. As we report here, jointly-trained passive diffractive surfaces can perform this needed computation all-optically, as the scattered light behind an unknown diffuser passes through these layers, forming an image of the object field-of-view at its output plane, as exemplified in the fourth row of Fig. 1b.
A diffractive network generalizes to see through unknown, new diffusers by training its layers with numerous image pairs: diffuser-distorted speckle patterns of various input objects and the corresponding distortion-free object images (target). To make our all-optical diffractive system capable of reconstructing an unknown object’s image that is distorted by new diffusers (i.e., never seen during the training phase), we adopted the strategy of using multiple diffusers to train our diffractive surfaces, following the procedure depicted in Fig. 1a. All of the diffusers that are used in the training and blind testing phases are assumed to have the same correlation length (L~10λ) and are randomly created as thin phase elements (see the Methods section and Fig. 1a). At the beginning of each training epoch, a set of n different phase diffusers are initialized to be used throughout the whole epoch. In each iteration within a given epoch, we randomly selected a batch of B grayscale training images from the MNIST dataset [81] (containing 50,000 handwritten digits for training and 10,000 for testing) and used them, one by one, through the amplitude channel of the input object plane. During each iteration, a total of B×n distorted optical fields were processed by the diffractive network and subsequently measured at the output plane. The corresponding loss value, calculated through a training loss function that blends negative Pearson Correlation Coefficient (PCC) [11] and photon loss (see the Methods section), was then used to calculate the error gradients for updating the phase modulation values of the neurons on the diffractive layers, marking the end of one iteration. An epoch was finished when all the 50,000 training images within the MNIST dataset were exhausted to train the network. After being trained for 100 epochs, the network has seen features from a total of N=100n unique phase diffusers that are randomly generated. As demonstrated in the following subsections, this strategy enabled the generalization of the diffractive network to see and reconstruct unknown objects through novel/new phase diffusers that were never used in the training phase.
2.2 All-optical, computer-free image reconstruction through diffusers
To demonstrate the all-optical image reconstruction performance of a diffractive network, we first trained a 4-layered network using n=20 diffusers in each epoch (Fig. 1c). After being trained for 100 epochs, the resulting network generalized to an imaging system that can see through diffusers at the speed of light, without the need for a computer or a digital reconstruction algorithm. The trained diffractive layers’ phase modulation patterns are reported in Additional file 1: Fig. S1. To shed light on the operation principles of the trained diffractive network, it was initially tested with new hand-written digits (i.e., MNIST test images that were never used in the training phase) distorted by n=20 individual diffusers that were used in the last training epoch (we term these as known diffusers, meaning they were used in the training). The first three rows in Fig. 2a present the successful all-optical reconstruction results corresponding to these new hand-written digits that were distorted by three (K1, K2 and K3) of the last n=20 known diffusers. Next we blindly tested the same trained diffractive network with new phase diffusers that were not used during the training. For this, we randomly generated 20 novel/new diffusers and Fig. 2b shows the all-optical reconstruction results of the same objects (never seen by the network before) distorted by unknown/new diffusers (B1, B2 and B3), which were randomly selected from the 20 new phase diffusers. A comparison between Figs. 2a and b reveals the generalization performance of the trained diffractive network to all-optically reconstruct unknown objects through unknown phase diffusers that were never seen before.

Simulation results of the all-optically reconstructed images of test objects distorted by a known and b new diffusers using the trained diffractive network shown in Fig. 1c. The PCC value of each reconstruction is reported below the corresponding image
In addition to MNIST test images, we further tested the same diffractive network with resolution test targets having different periods (10.8 mm and 12 mm respectively); see Fig. 2, last 2 rows. These types of resolution test targets, composed of periodic lines, were never seen by the diffractive network before (which was trained with only MNIST data), and their successful reconstruction at the network output plane (Fig. 2) further supports the generalization of the diffractive network’s capability to reconstruct any arbitrary object positioned at the input field-of-view, instead of overfitting to a local minimum covering only images from a specific dataset. To quantitatively analyze the generalization performance of trained diffractive networks, in Fig. 3a and b we also report the measured periods corresponding to the all-optically reconstructed images of different resolution test targets that were seen through the last n known diffusers (used in the last training epoch) as well as 20 new, randomly generated diffusers (never used during the training). Despite the use of different training strategies (with n = 1, 10, 15, 20), the results reported in Fig. 3 reveal that all these trained diffractive network models can resolve and accurately quantify the periods of these resolution test targets seen through known as well as new/novel diffusers.

Generalization of diffractive networks that were trained with MNIST image data to reconstruct the images of different resolution test targets, seen through a known and b new randomly generated diffusers. Despite the fact that such resolution test targets or similar line-based objects were never seen by the networks during their training, their periods are successfully resolved at the output plane of the diffractive networks
After these numerical analyses of all-optical image reconstruction under different conditions, next we experimentally verified its performance and fabricated the designed diffractive layers using a 3D printer (Fig. 1d); we also fabricated diffusers K1-K3 and B1-B3 as well as 5 test objects (3 hand-written digits and 2 resolution test targets). The test objects were further coated using aluminum foil to provide binary transmittance. For each hand-written digit, a 42×42 mm field-of-view at the output plane was imaged by scanning a 0.5×0.25 mm detector with a step size of 1 mm in each direction (see Fig. 1e). The experimental results are shown in Fig. 4a and b, clearly demonstrating the success of the all-optical network’s capability to see through unknown diffusers. For comparison, we also report the intensity distribution generated by a lens-based imaging system as well as free-space propagation (without the diffractive layers) of an input object with the presence of the diffuser K1 (see Additional file 1: Fig. S2); a similar comparison is also provided in Fig. 1b. These comparisons clearly highlight the success of the all-optical image reconstruction achieved by the diffractive network despite the presence of significant image distortion caused by the unknown diffuser and free-space propagation.

Experimental results of the all-optically reconstructed images of test objects distorted by a known and b new diffusers using the trained diffractive network shown in Fig. 1c. The PCC value of each measured image is reported in black. c The measured periods of the resolution test targets imaged through known and unknown diffusers are labeled in red
We also imaged resolution test targets using the same experimental setup at the output plane of the diffractive network (see Fig. 4c). From the all-optically reconstructed output images of the diffractive network, we measured the periods of the resolution test targets imaged through known and (new/novel) diffusers as 10.851±0.121 mm (11.233±0.531 mm) and 12.269±0.431 mm (12.225 ± 0.245 mm), corresponding to the fabricated resolution test targets with periods of 10.8 mm and 12 mm, respectively. These experimental results further demonstrate the generalization capability of the trained diffractive network to all-optically reconstruct/image unknown objects through unknown diffusers, which were never used during the training phase; moreover, we should emphasize that this fabricated diffractive network design was only trained with MNIST image data, without seeing grating-like periodic structures.
Several factors affect the experimental performance of our system. First, the incident THz wave is not completely uniform at the input object plane due to the practical limitations of the THz source that we used, deviating from our assumption of plane wave incidence. Second, potential fabrication imperfections and the mechanical misalignments between successive diffractive layers as they are assembled together might have also partially degraded our experimental results, compared with the numerical test results. Finally, since the random diffuser layer strongly diffracts light, our experiments might also suffer from reduced signal-to-noise ratio at the detector.
2.3 Performance of all-optical image reconstruction as a function of the number of independent diffusers used in the training
An important training parameter to be further examined is the number of diffusers (n) used in each epoch of the training. To shed more light on the impact of this parameter, we compared the all-optical reconstruction performance of four different diffractive networks trained with n=1, n=10, n=15 and n=20, while keeping all the other parameters the same. To further quantify the image reconstruction performance of these trained diffractive networks, we adopted the Pearson Correlation Coefficient (PCC) [82] as a figure of merit, defined as:
where \(O\) is the output image of the diffractive network and \(G\) is object image to be reconstructed, i.e., the ground truth. Using this metric, we calculated the mean PCC value for the all-optical reconstruction of 10,000 MNIST test objects (never used in the training) distorted by the same diffusers. Stated differently, after being trained for 100 epochs, all the finalized networks (n = 1, 10, 15, 20) were compared to each other by calculating the average PCC values over unknown MNIST test objects distorted by each one of the 100n known diffusers as well as each one of the 20 new/novel randomly generated diffusers (see Fig. 5). This figure should not be confused with learning curves typically used to monitor the ongoing training of a neural network model; in fact, the results in Fig. 5 report the all-optical reconstruction fidelity/quality achieved for unknown test objects after the training is complete. From top to bottom, the four panels in Fig. 5a present the comparison of the diffractive networks trained with n =1, n =10, n=15 and n=20, respectively, while the inserts in last three panels show the same plot zoomed into the last 50 diffusers. An increased PCC value can be clearly observed corresponding to testing of unknown objects through the last n diffusers used in the final epoch of the training. Furthermore, we observe that the trained diffractive models treat all the diffusers used in the previous epochs (1–99) on average the same (dashed lines in Fig. 5a), while the diffusers used in the last epoch (100) are still part of the “memory” of the network as it shows better all-optical reconstruction of unknown test objects through any one of the last n diffusers used in the training. Interestingly, due to the small learning rate used at the end of the training phase (~3\(\times\)10–4, see the Methods section for details), the diffractive network trained with n=1 maintained a fading memory of the last 10 known diffusers. However, this memory did not provide an additional benefit for generalizing to new, unknown diffusers.

Memory of diffractive networks. a After being trained for 100 epochs, all the finalized networks (n = 1, 10, 15 and 20) were compared by calculating the average PCC values over unknown objects distorted by all the known diffusers (solid line). Dashed line: the average PCC value over unknown objects distorted by diffusers indexed as 1–99n. Inserts: the same plot zoomed into the last 50 diffusers. b PCC values of each finalized network tested with images distorted by 10n diffusers used in last 10 epochs in training (n = 1, 10, 15 and 20, respectively) and 20 new random diffusers (never seen before). The error bars reflect the standard deviation over different diffusers
Another important observation is that the all-optical reconstruction performance of these trained networks to image unknown test objects through new diffusers is on par with the reconstruction of test objects seen through the diffusers used in epochs 1 through 99 (see Fig. 5b). These results, along with Figs. 2, 3 and 4, clearly show that these trained diffractive networks have successfully generalized to reconstruct unknown test objects through new random diffusers, never seen before. Figure 5 further illustrates that the training strategies that used n=10, n=15 and n=20 perform very similar to each other and are significantly superior to using n=1 during the training, as the latter yields relatively inferior generalization and poorer all-optical reconstruction results for unknown new diffusers, as also confirmed in Figs. 6a, b.

Comparison of diffractive network output images under different conditions. a Output images corresponding to the same input test object imaged through diffractive networks trained with n=1, n=10, n=15 and n=20. Second column: imaged through a known diffuser; third column: imaged through a new diffuser; fourth column: imaged without a diffuser. b The PCC values corresponding to the networks trained with n = 1, 10, 15 and 20 over input test objects distorted by known diffusers, new diffusers, as well as imaged without a diffuser. The error bars reflect the standard deviation over different diffusers
To shed more light on the operation principles of our designed diffractive networks, we also tested the same networks to image distortion-free objects, and therefore removed the random phase diffuser in Fig. 1a while keeping all the other components at their corresponding locations; see Figs. 6a and b for the resulting images and the PCC values corresponding to the same networks trained with n=1, n=10, n=15 and n=20. The fourth column in Fig. 6a visually illustrates the diffracted images formed at the output field-of-view of each network, without a diffuser present, demonstrating that the networks indeed converged to a general purpose imager. In other words, the diffractive network converged to an imager design with built-in resilience against distortions created by random, unknown phase diffusers, as also confirmed by the increased PCC values reported in Fig. 6b for the cases without a diffuser.
It is also worth noting that, the diffractive network trained with n=1 diffuser per epoch had an easier time to overfit to the last diffuser used during the training phase, and therefore it scored higher when imaging through this last known diffuser (Fig. 6b). This is a result of overfitting, which is also evident from its poorer generalization performance under new diffusers as compared to the training strategies that used n=10, n=15 and n=20 diffusers per epoch (see Fig. 6b).
2.4 Deeper diffractive networks improve all-optical image reconstruction fidelity
We also analyzed the impact of deeper diffractive networks that are composed of a larger number of trainable diffractive surfaces on their all-optical reconstruction and generalization performance to see through diffusers. Figure 7 compares the average PCC values for the all-optical reconstruction of unknown test objects using diffractive networks that are designed with different number of diffractive layers. Our results reveal that, with additional trainable diffractive layers, the average PCC values calculated with test images distorted by both known and new random diffusers increase, demonstrating a depth advantage for all-optical image reconstruction.

Additional trainable diffractive surfaces improve the all-optical image reconstruction of objects seen through unknown random diffusers. The error bars reflect the standard deviation over different diffusers
3 Discussion
As demonstrated in our numerical and experimental results, a diffractive network trained with MNIST dataset can all-optically reconstruct unknown resolution test targets through new random diffusers, both of which were not included in the training dataset; these results confirm that the trained diffractive networks do not perform dataset-specific reconstruction, but serve as a general-purpose imager that can reconstruct objects through unknown diffusers. The same conclusion is further supported by the fact that once the diffuser is eliminated from the same set-up, the trained diffractive networks still provide a correct image of the sample at their output, in fact with improved reconstruction fidelity (see Fig. 6). Further investigation of the phase patterns of the designed diffractive layers sheds more light on the imaging capability of the diffractive network: the combination of an array of small phase islands and the rapidly changing phase variations surrounding these islands work together in order to collectively image the input objects through unknown, random phase diffusers (see Additional file 1: Figs. S3 and S4). Moreover, the generalization of the diffractive network’s imaging capability to different types of objects that were not included in the training phase is also emphasized in Additional file 1: Fig. S4.
To further demonstrate the generalization of the all-optical image reconstructions achieved by trained diffractive networks, Additional file 1: Fig. S5 reports the reconstruction of unknown test objects that were seen through a new diffuser, which had a smaller correlation length (~5λ) compared to the training diffusers (~10λ); stated differently, not only the randomly generated test diffuser was not used as part of the training, but also it included much finer phase distortions compared to the diffusers used in the training. The results presented in Additional file 1: Fig. S5 reveal that, despite a reduction in image contrast, the test objects can still be faithfully reconstructed at the output of the same diffractive network designs using a new diffuser with a smaller correlation length, further deviating from the training phase.
All the results presented in this paper are based on optically thin phase diffusers, which is a standard assumption commonly used in various related studies [5, 11, 83,84,85]. As a result of this assumption, our results ignore multiple scattering within a volumetric diffuser. Future work will include training diffractive networks that can generalize over volumetric diffusers that distort both the phase and amplitude profiles of the scattered fields at the input plane of a diffractive network. In reality, our experiments already include 3D-printed diffusers that present both phase and amplitude distortions due to the absorption of the THz beam as it passes through different thicknesses of individual features of a fabricated diffuser. Considering the fact that the training of the diffractive networks only included random phase diffusers, the success of our experimental results with 3D-printed diffusers indicate the robustness of this framework to more complex diffuser structures not included in the training.
4 Conclusions
We presented an all-optical diffractive network-based computational imaging platform to see through random diffusers at the speed of light, without any digital image reconstruction or a computer. Extensions of this work to all-optically reconstruct object information passing through volumetric diffusers might form the basis of a new generation of imaging systems that can see through e.g., tissue scattering, clouds, fog, etc. at the speed of light, without the need for any digital computation. Hybrid systems that utilize diffractive networks as a front-end of a jointly-trained electronic neural network (back-end) [74] is another exciting future research direction that will make use of the presented framework to see through more complicated, dynamic scatters. Application of the presented framework and the underlying methodology to design broadband diffractive networks [66, 67, 76] is another exciting future research direction that can be used to reconstruct multi-color images distorted by unknown, random diffusers or other aberration sources. Finally, our results and presented method can be extended to other parts of the electromagnetic spectrum including e.g., visible/infrared wavelengths, and will open up various new applications in biomedical imaging, astronomy, astrophysics, atmospheric sciences, security, robotics, and many others.
5 Methods
5.1 Terahertz continuous wave scanning system
The schematic diagram of the experimental setup is given in Fig. 1e. Incident wave was generated through a WR2.2 modular amplifier/multiplier chain (AMC), and output pattern was detected with a Mixer/AMC, both from Virginia Diode Inc. (VDI). A 10 dBm sinusoidal signal at 11.111 GHz (fRF1) was sent to the source as RF input signal and multiplied 36 times to generate continuous-wave (CW) radiation at 0.4 THz, and another 10 dBm sinusoidal signal at 11.083 GHz (fRF2) was sent to the detector as a local oscillator for mixing, so that the down-converted signal was at 1 GHz. A horn antenna compatible with WR 2.2 modular AMC was used. We electrically modulated the source with a 1 kHz square wave. The source was put far enough from the input object so that the incident beam can be approximated as a plane wave. A customized reflector is added to the horn antenna to further suppress the reflection noise. The resulting diffraction pattern at the output plane of the network was scanned by a single-pixel detector placed on an XY positioning stage. This stage was built by placing two linear motorized stages (Thorlabs NRT100) vertically to allow precise control of the position of the detector. The output IF signal of the detector was sent to two low-noise amplifiers (Mini-Circuits ZRL-1150-LN +) to amplify the signal by 80 dBm and a 1 GHz (±10 MHz) bandpass filter (KL Electronics 3C40-1000/T10-O/O) to get rid of the noise coming from unwanted frequency bands. The amplified signal passed through a tunable attenuator (HP 8495B) and a low-noise power detector (Mini-Circuits ZX47-60), then the output voltage was read by a lock-in amplifier (Stanford Research SR830). The modulation signal was used as the reference signal for the lock-in amplifier. We performed calibration for each measurement by tuning the attenuation and recorded the lock-in amplifier readings. The raw data were converted to linear scale according to the calibration.
5.2 Random diffuser design
A random diffuser is modeled as a pure phase mask, whose transmittance \({t}_{D}\left(x,y\right)\) is defined using the refractive index difference between air and diffuser material \((\Delta n\approx 0.74)\) and a random height map \(D\left(x,y\right)\) at the diffuser plane, i.e.,
where \(j=\sqrt{-1}\) and \(\lambda =0.75\) mm. The random height map \(D\left(x,y\right)\) is further defined as [11]
where \(W\left(x,y\right)\) follows normal distribution with a mean \(\mu\) and a standard deviation \({\sigma }_{0}\), i.e.
\(K\left(\sigma \right)\) is the zero mean Gaussian smoothing kernel with standard deviation of \(\sigma\). ‘\(*\)’ denotes the 2D convolution operation. In this work, we chose \(\mu =25\lambda\), \({\sigma }_{0}=8\lambda\) and \(\sigma =4\lambda\) to randomly generate the training and testing diffusers, mimicking glass-based diffusers used in the visible part of the spectrum. For this choice of diffuser parameters, we further calculated the mean correlation length (\(L\)) using a phase-autocorrelation function \({R}_{d}\left(x,y\right)\) that is defined as [86]
Based on 2000 randomly generated diffusers with the above described parameters and their corresponding phase-autocorrelation functions, we determined the average correlation length as \(\sim 10\lambda\). Different from these diffusers, for Additional file 1: Fig. S5, we used \(\sigma =2\lambda\) to randomly generate phase diffusers with an average correlation length of \(L=\sim 5\lambda\).
The difference between two randomly-generated diffusers are quantified by the average pixel-wise absolute phase difference, i.e., \(\Delta \phi =\overline{{\left|\left({\phi }_{1}-\overline{{\phi }_{1}}\right)-\left({\phi }_{2}-\overline{{\phi }_{2}}\right)\right|}}\), where \({\phi }_{1}\) and \({\phi }_{2}\) represent the 2D phase distributions of two diffusers, and \(\overline{{\phi }_{1}}\) and \(\overline{{\phi }_{2}}\) are the mean phase values of each. When we randomly generate new phase diffusers, it can be regarded as a novel/unique diffuser when \(\Delta \phi\)>π/2 compared to all the existing diffusers randomly created before that point.
5.3 Forward propagation model
A random phase diffuser defined in Eq. (2) positioned at \({z}_{0}\) provides a phase distortion \({t}_{D}\left(x,y\right)\). Assuming that a plane wave is incident at an amplitude-encoded image \(h\left(x,y,z=0\right)\) positioned at \(z=0\), we modeled the disturbed image as:
where,
is the propagation kernel following the Rayleigh-Sommerfeld equation [71] with \(r=\sqrt{{x}^{2}+{y}^{2}+{z}^{2}}\). The distorted image is further used as the input field to the subsequent diffractive system. The transmission of layer \(m\) (located at \({z=z}_{m}\)) of a diffractive system provides a field transmittance:
Being modulated by each layer, the optical field \({u}_{m}(x,y,{z}_{m})\) right after the mth diffractive layer positioned at \(z={z}_{m}\) can be formulated as
where \(\Delta {z}_{m}\) is the axial distance between two successive diffractive layers, which was selected as 2.7\(\lambda\) in this paper. After being modulated by all the \(M\) diffractive layers, the light field is further propagated by an axial distance of \(\Delta {z}_{d}=9.3\lambda\) onto the output plane, and its intensity is calculated as the output of the network, i.e.,
5.4 Network training
The diffractive neural networks used in this work were designed for λ≈0.75 mm coherent illumination and contain 240×240 pixels on each layer providing phase-only modulation on the incident light field, with a pixel size (pitch) of 0.3 mm. During the training, each hand-written digit of the MNIST training dataset is first upscaled from 28×28 pixels to 160×160 pixels using bilinear interpolation, then padded with zeros to cover 240×240 pixels. B=4 different randomly selected MNIST images form a training batch. Each input object \({h}_{b}(x,y)\) in a batch is numerically duplicated n times and individually disturbed by a set of n randomly selected diffusers. These distorted fields are separately forward propagated through the diffractive network. At the output plane, we get n different intensity patterns: \({o}_{b1},{o}_{b2}\dots {o}_{bn}\). All \(B\times n\) output patterns are collected to calculate the loss function:
In Eq. (11) \(P\left({o}_{bi}, {h}_{b}\right)\) denotes the PCC between the output and its ground truth image \({h}_{b}\), calculated based on Eq. (1). Furthermore, \(E\left({o}_{bi}, {h}_{b}\right)\) denotes an object-specific energy efficiency-related penalty term, defined as:
In Eq. (12) \(\widehat{{h}_{b}}\) is a binary mask indicating the transmittance area on the input object, defined as:
where \(\alpha\) and \(\beta\) are hyper-parameters that are optimized to be 1 and 0.5 respectively.
The resulting loss value (error) is then back-propagated and the pixel phase modulation values are updated using the Adam optimizer [87] with a decaying learning rate of \(Lr={0.99}^{Ite}\times {10}^{-3}\), where \(Ite\) denotes the current iteration number. Our models were trained using Python (v3.7.3) and TensorFlow (v1.13.0, Google Inc.) for 100 epochs with a GeForce GTX 1080 Ti graphical processing unit (GPU, Nvidia Inc.), an Intel® Core™ i9-7900X central processing unit (CPU, Intel Inc.) and 64 GB of RAM. Training of a typical diffractive network model takes ~24 h to complete with 100 epochs and n=20 diffusers per epoch. The phase profile of each diffractive layer was then converted into the height map and corresponding.stl file was generated using MATLAB, and subsequently 3D printed using Form 3 3D printer (Formlabs Inc., MA, USA).
5.5 Quantification of the reconstructed resolution test target period
For an amplitude-encoded, binary resolution test target (with a period of \(p\)) the transmission function can be written as:
The diffractive network forms the reconstructed image \(o(x,y)\) of the resolution test target at the output field-of-view, over an area of X×Y mm2. To quantify/measure the period of the reconstructed test targets, the intensity was first averaged along the y axis, yielding a 1D intensity profile:
Subsequently we fit a curve \(F(x)\) to \(l(x)\) by solving:
where
The measured/resolved period \((\widehat{p})\) at the output image plane is then calculated as:
5.6 Image contrast enhancement
For the purpose of better image visualization, we digitally enhanced the contrast of each experimental measurement using a built-in MATLAB function (imadjust), which by-default saturates the top 1% and the bottom 1% of the pixel values and maps the resulting image to a dynamic range between 0 and 1. The same default image enhancement is also applied to the results shown in Figs. 1b, c, 4 and Additional file 1: Figs. S2 and S5. All quantitative data analyses, including PCC calculations and resolution test target period quantification results, are based on raw data, i.e., did not utilize image contrast enhancement.
5.7 Lens-based imaging system simulation
We numerically implemented a lens-based imaging system to evaluate the impact of a given random diffuser on the output image; see e.g., Fig. 1b and Additional file 1: Fig. S2. A Fresnel lens was designed to have a focal length \((f)\) of 145.6 λ and a pupil diameter of 104 λ [88]. The transmission profile of the lens \({t}_{L}\) was formulated as:
where \(\Delta x\) and \(\Delta y\) denote the distance from the center of the lens in lateral coordinates. \(A\left(\Delta x,\Delta y\right)\) is the pupil function, i.e.,
The lens was placed 2\(f\) (291.2\(\lambda\)) away from the input object. The input object light was first propagated axially for \({z}_{0}=53\lambda\) to the random diffuser plane using the angular spectrum method. The distorted field through the diffuser was then propagated to the lens plane, and after passing through the lens the resulting complex field was propagated to the image plane (2\(f\) behind the lens), also using the angular spectrum method. The intensity profile at the image plane was calculated as the resulting image, seen through an aberration-free lens, distorted by a random phase diffuser.
Availability of data and materials
All the data and methods needed to evaluate the conclusions of this work are present in the main text and the Additional file 1. Additional data can be requested from the corresponding author. The deep learning models and codes in this work used standard libraries and scripts that are publicly available in TensorFlow.
References
Eckart, A. & Genzel, R. Stellar proper motions in the central 0.1 pc of the Galaxy. Monthly Notices of the Royal Astronomical Society 284, 576–598 (1997).
M. Solan et al., Towards a greater understanding of pattern, scale and process in marine benthic systems: a picture is worth a thousand worms. J. Exp. Mar. Biol. Ecol. 285–286, 313–338 (2003)
Tan, R. T. Visibility in bad weather from a single image. in 2008 IEEE Conference on Computer Vision and Pattern Recognition 1–8 (2008). https://doi.org/10.1109/CVPR.2008.4587643.
V. Ntziachristos, Going deeper than microscopy: the optical imaging frontier in biology. Nat. Methods 7, 603–614 (2010)
N. Ji, D.E. Milkie, E. Betzig, Adaptive optics via pupil segmentation for high-resolution imaging in biological tissues. Nat. Methods 7, 141–147 (2010)
K. He, J. Sun, X. Tang, Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 33, 2341–2353 (2011)
J. Bertolotti et al., Non-invasive imaging through opaque scattering layers. Nature 491, 232–234 (2012)
A.P. Mosk, A. Lagendijk, G. Lerosey, M. Fink, Controlling waves in space and time for imaging and focusing in complex media. Nat. Photonics 6, 283–292 (2012)
O. Katz, P. Heidmann, M. Fink, S. Gigan, Non-invasive single-shot imaging through scattering layers and around corners via speckle correlations. Nature Photon 8, 784–790 (2014)
S.-C. Huang, B.-H. Chen, Y.-J. Cheng, An Efficient Visibility Enhancement Algorithm for Road Scenes Captured by Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 15, 2321–2332 (2014)
S. Li, M. Deng, J. Lee, A. Sinha, G. Barbastathis, Imaging through glass diffusers using densely connected convolutional networks. Optica, OPTICA 5, 803–813 (2018)
Y. Li, Y. Xue, L. Tian, Deep speckle correlation: a deep learning approach toward scalable imaging through scattering media. Optica 5, 1181 (2018)
D.B. Lindell, G. Wetzstein, Three-dimensional imaging through scattering media based on confocal diffuse tomography. Nat Commun 11, 4517 (2020)
J.W. Goodman, W.H. Huntley, D.W. Jackson, M. Lehmann, Wavefront-reconstruction imaging through random media. Appl. Phys. Lett. 8, 311–313 (1966)
H. Kogelnik, K.S. Pennington, Holographic Imaging Through a Random Medium. J. Opt. Soc. Am. 58, 273 (1968)
S. Popoff, G. Lerosey, M. Fink, A.C. Boccara, S. Gigan, Image transmission through an opaque material. Nat Commun 1, 81 (2010)
J. Li et al., Conjugate adaptive optics in widefield microscopy with an extended-source wavefront sensor. Optica 2, 682 (2015)
E. Edrei, G. Scarcelli, Optical imaging through dynamic turbid media using the Fourier-domain shower-curtain effect. Optica 3, 71 (2016)
X. Li, J.A. Greenberg, M.E. Gehm, Single-shot multispectral imaging through a thin scatterer. Optica, OPTICA 6, 864–871 (2019)
M. Jang et al., Relation between speckle decorrelation and optical phase conjugation (OPC)-based turbidity suppression through dynamic scattering media: a study on in vivo mouse skin. Biomed. Opt. Express 6, 72 (2015)
S.G. Narasimhan, S.K. Nayar, Contrast restoration of weather degraded images. IEEE Trans. Pattern Anal. Mach. Intell. 25, 713–724 (2003)
E.A. Bucher, Computer Simulation of Light Pulse Propagation for Communication Through Thick Clouds. Appl. Opt. 12, 2391 (1973)
A. Lopez, E. Nezry, R. Touzi, H. Laur, Structure detection and statistical adaptive speckle filtering in SAR images. Int. J. Remote Sens. 14, 1735–1758 (1993)
Lohmann, A. W., Weigelt, G. & Wirnitzer, B. Speckle masking in astronomy: triple correlation theory and applications. Appl. Opt., AO 22, 4028–4037 (1983).
Roggemann, M. C., Welsh, B. M. & Hunt, B. R. Imaging Through Turbulence. (CRC Press, 1996).
J.S. Jaffe, K.D. Moore, J. Mclean, M.R. Strand, Underwater optical imaging: Status and prospects. Oceanography 14, 64–66 (2001)
Schettini, R. & Corchs, S. Underwater Image Processing: State of the Art of Restoration and Image Enhancement Methods. EURASIP Journal on Advances in Signal Processing 2010, (2010).
Z. Jia et al., A two-step approach to see-through bad weather for surveillance video quality enhancement. Mach. Vis. Appl. 23, 1059–1082 (2012)
Tarel, J.-P. & Hautière, N. Fast visibility restoration from a single color or gray level image. in 2009 IEEE 12th International Conference on Computer Vision 2201–2208 (2009). https://doi.org/10.1109/ICCV.2009.5459251.
M. Johnson-Roberson et al., High-Resolution Underwater Robotic Vision-Based Mapping and Three-Dimensional Reconstruction for Archaeology. Journal of Field Robotics 34, 625–643 (2017)
Hao, Z., You, S., Li, Y., Li, K. & Lu, F. Learning From Synthetic Photorealistic Raindrop for Single Image Raindrop Removal. in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops 0–0 (2019).
Majer, F., Yan, Z., Broughton, G., Ruichek, Y. & Krajník, T. Learning to see through haze: Radar-based Human Detection for Adverse Weather Conditions. in 2019 European Conference on Mobile Robots (ECMR) 1–7 (2019). doi:https://doi.org/10.1109/ECMR.2019.8870954.
Popoff, S. M. et al. Measuring the Transmission Matrix in Optics: An Approach to the Study and Control of Light Propagation in Disordered Media. Physical Review Letters 104, (2010).
Goodman, J. W. Speckle Phenomena in Optics: Theory and Applications. (Roberts and Company Publishers, 2007).
D.B. Conkey, A.M. Caravaca-Aguirre, R. Piestun, High-speed scattering medium characterization with application to focusing light through turbid media. Opt. Express 20, 1733 (2012)
Wang, K. et al. Direct wavefront sensing for high-resolution in vivo imaging in scattering tissue. Nature Communications 6, (2015).
I.M. Vellekoop, A.P. Mosk, Focusing coherent light through opaque strongly scattering media. Opt. Lett. 32, 2309 (2007)
I.M. Vellekoop, A. Lagendijk, A.P. Mosk, Exploiting disorder for perfect focusing. Nat. Photonics 4, 320–322 (2010)
R. Horstmeyer, H. Ruan, C. Yang, Guidestar-assisted wavefront-shaping methods for focusing light into biological tissue. Nat. Photonics 9, 563–571 (2015)
M. Nixon et al., Real-time wavefront shaping through scattering media by all-optical feedback. Nat. Photonics 7, 919–924 (2013)
O. Katz, E. Small, Y. Silberberg, Looking around corners and through thin turbid layers in real time with scattered incoherent light. Nat. Photonics 6, 549–553 (2012)
S. Feng, C. Kane, P.A. Lee, A.D. Stone, Correlations and Fluctuations of Coherent Wave Transmission through Disordered Media. Phys. Rev. Lett. 61, 834–837 (1988)
I. Freund, M. Rosenbluh, S. Feng, Memory Effects in Propagation of Optical Waves through Disordered Media. Phys. Rev. Lett. 61, 2328–2331 (1988)
Edrei, E. & Scarcelli, G. Memory-effect based deconvolution microscopy for super-resolution imaging through scattering media. Scientific Reports 6, (2016).
W. Yang, G. Li, G. Situ, Imaging through scattering media with the auxiliary of a known reference object. Sci. Rep. 8, 9614 (2018)
He, H., Guan, Y. & Zhou, J. Image restoration through thin turbid layers by correlation with a known object. Opt. Express, OE 21, 12539–12545 (2013).
X. Wang et al., Prior-information-free single-shot scattering imaging beyond the memory effect. Opt. Lett. 44, 1423 (2019)
Yang, M. et al. Deep hybrid scattering image learning. J. Phys. D: Appl. Phys. 52, 115105 (2019).
Lyu, M., Wang, H., Li, G., Zheng, S. & Situ, G. Learning-based lensless imaging through optically thick scattering media. AP 1, 036002 (2019).
Y. Rivenson et al., Deep learning microscopy. Optica, OPTICA 4, 1437–1443 (2017)
Y. Rivenson et al., Deep Learning Enhanced Mobile-Phone Microscopy. ACS Photonics (2018). https://doi.org/10.1021/acsphotonics.8b00146
E. Nehme, L.E. Weiss, T. Michaeli, Y. Shechtman, Deep-STORM: super-resolution single-molecule microscopy by deep learning. Optica, OPTICA 5, 458–464 (2018)
H. Wang et al., Deep learning enables cross-modality super-resolution in fluorescence microscopy. Nat. Methods 16, 103–110 (2019)
Y. Rivenson et al., Virtual histological staining of unlabelled tissue-autofluorescence images via deep learning. Nat Biomed Eng 3, 466–477 (2019)
Y. Wu et al., Three-dimensional virtual refocusing of fluorescence microscopy images using deep learning. Nat. Methods 16, 1323–1331 (2019)
Y. Wu et al., Extended depth-of-field in holographic imaging using deep-learning-based autofocusing and phase recovery. Optica 5, 704 (2018)
Wu, Y. et al. Bright-field holography: cross-modality deep learning enables snapshot 3D imaging with bright-field contrast using a single hologram. Light: Science & Applications 8, 1–7 (2019).
T. Liu et al., Deep learning-based super-resolution in coherent imaging systems. Sci. Rep. 9, 1–13 (2019)
Liu, T. et al. Deep learning-based color holographic microscopy. Journal of Biophotonics 12, e201900107 (2019).
G. Barbastathis, A. Ozcan, G. Situ, On the use of deep learning for computational imaging. Optica, OPTICA 6, 921–943 (2019)
Wang, F. et al. Phase imaging with an untrained neural network. Light: Science & Applications 9, 77 (2020).
Malkiel, I. et al. Plasmonic nanostructure design and characterization via Deep Learning. Light: Science & Applications 7, (2018).
D. Liu, Y. Tan, E. Khoram, Z. Yu, Training Deep Neural Networks for the Inverse Design of Nanophotonic Structures. ACS Photonics 5, 1365–1369 (2018)
Peurifoy, J. et al. Nanophotonic particle simulation and inverse design using artificial neural networks. Science Advances 4, eaar4206 (2018).
W. Ma, F. Cheng, Y. Liu, Deep-Learning-Enabled On-Demand Design of Chiral Metamaterials. ACS Nano 12, 6326–6334 (2018)
Luo, Y. et al. Design of task-specific optical systems using broadband diffractive neural networks. Light: Science & Applications 8, 1–14 (2019).
M. Veli et al., Terahertz pulse shaping using diffractive surfaces. Nat. Commun. 12, 37 (2021)
D. Psaltis, D. Brady, X.G. Gu, S. Lin, Holography in artificial neural networks. Nature 343, 325–330 (1990)
Y. Shen et al., Deep learning with coherent nanophotonic circuits. Nat. Photonics 11, 441–446 (2017)
Chang, J., Sitzmann, V., Dun, X., Heidrich, W. & Wetzstein, G. Hybrid optical-electronic convolutional neural networks with optimized diffractive optics for image classification. Scientific Reports 8, (2018).
X. Lin et al., All-optical machine learning using diffractive deep neural networks. Science 361, 1004 (2018)
N.M. Estakhri, B. Edwards, N. Engheta, Inverse-designed metastructures that solve equations. Science 363, 1333–1338 (2019)
J. Li, D. Mengu, Y. Luo, Y. Rivenson, A. Ozcan, Class-specific differential detection in diffractive optical neural networks improves inference accuracy. Adv. Photon. 1, 1 (2019)
D. Mengu, Y. Luo, Y. Rivenson, A. Ozcan, Analysis of Diffractive Optical Neural Networks and Their Integration With Electronic Neural Networks. IEEE J. Sel. Top. Quantum Electron. 26, 1–14 (2020)
Mengu, D. et al. Misalignment resilient diffractive optical networks. Nanophotonics 0, (2020).
Li, J. et al. Spectrally encoded single-pixel machine vision using diffractive networks. Science Advances 7, eabd7690 (2021).
O. Kulce, D. Mengu, Y. Rivenson, A. Ozcan, All-optical information-processing capacity of diffractive surfaces. Light Sci Appl 10, 25 (2021)
B. Rahmani, D. Loterie, G. Konstantinou, D. Psaltis, C. Moser, Multimode optical fiber transmission with a deep learning network. Light Sci Appl 7, 1–11 (2018)
Bai, B. et al. Pathological crystal imaging with single-shot computational polarized light microscopy. Journal of Biophotonics 13, e201960036 (2020).
T. Liu et al., Deep Learning-Based Holographic Polarization Microscopy. ACS Photonics 7, 3023–3034 (2020)
LeCun, Y. et al. Handwritten Digit Recognition with a Back-Propagation Network. in Advances in Neural Information Processing Systems 2 (ed. Touretzky, D. S.) 396–404 (Morgan-Kaufmann, 1990).
Benesty, J., Chen, J., Huang, Y. & Cohen, I. Pearson Correlation Coefficient. in Noise Reduction in Speech Processing vol. 2 1–4 (Springer Berlin Heidelberg, 2009).
Wu, T., Dong, J., Shao, X. & Gigan, S. Imaging through a thin scattering layer and jointly retrieving the point-spread-function using phase-diversity. Opt. Express, OE 25, 27182–27194 (2017).
X. Xu et al., Imaging of objects through a thin scattering layer using a spectrally and spatially separated reference. Opt. Express 26, 15073 (2018)
Hofer, M., Soeller, C., Brasselet, S. & Bertolotti, J. Wide field fluorescence epi-microscopy behind a scattering medium enabled by speckle correlations. Opt. Express, OE 26, 9866–9881 (2018).
S. Lowenthal, D. Joyeux, Speckle Removal by a Slowly Moving Diffuser Associated with a Motionless Diffuser. J. Opt. Soc. Am. 61, 847 (1971)
Kingma, D. P. & Ba, J. Adam: A Method for Stochastic Optimization. arXiv:1412.6980. [cs] (2014).
Rahman, M. S. S., Li, J., Mengu, D., Rivenson, Y. & Ozcan, A. Ensemble learning of diffractive optical networks. Light: Science & Applications 10, 14 (2021).
Acknowledgements
The authors acknowledge the assistance of Derek Tseng (UCLA) on 3D printing.
Funding
The authors acknowledge the U.S. National Science Foundation and Fujikura.
Author information
Authors and Affiliations
Contributions
YL and EC performed the design and fabrication of the diffractive systems, and YL, YZ and JL performed the experimental testing. YR provided assistance with the design and experimental testing of the diffractive models. All the authors participated in the analysis and discussion of the results, as well as writing of the manuscript. AO and MJ supervised the project. AO initiated the concept and the research project. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Supplementary Information
Additional file 1:
Figure S1: Phase patterns of the transmissive layers corresponding to the diffractive network that was trained using n = 20 diffusers at each epoch. Figure S2: Numerical and experimental results showing the image distortion generated by a random phase diffuser. Figure S3: Overlap map of phase islands on successive diffractive layers. Figure S4: Comparison of diffractive network output images under different levels of pruning. Figure S5: Imaging through random joysttdiffusers with different correlation lengths (L).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Luo, Y., Zhao, Y., Li, J. et al. Computational imaging without a computer: seeing through random diffusers at the speed of light. eLight 2, 4 (2022). https://doi.org/10.1186/s43593-022-00012-4
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1186/s43593-022-00012-4