
Abstract
Applying intelligence algorithms to conceive nanoscale meta-devices becomes a flourishing and extremely active scientific topic over the past few years. Inverse design of functional nanostructures is at the heart of this topic, in which artificial intelligence (AI) furnishes various optimization toolboxes to speed up prototyping of photonic layouts with enhanced performance. In this review, we offer a systemic view on recent advancements in nanophotonic components designed by intelligence algorithms, manifesting a development trend from performance optimizations towards inverse creations of novel designs. To illustrate interplays between two fields, AI and photonics, we take meta-atom spectral manipulation as a case study to introduce algorithm operational principles, and subsequently review their manifold usages among a set of popular meta-elements. As arranged from levels of individual optimized piece to practical system, we discuss algorithm-assisted nanophotonic designs to examine their mutual benefits. We further comment on a set of open questions including reasonable applications of advanced algorithms, expensive data issue, and algorithm benchmarking, etc. Overall, we envision mounting photonic-targeted methodologies to substantially push forward functional artificial meta-devices to profit both fields.
Similar content being viewed by others


Background
With a research focus on light-matter interactions [1, 2], the remarkable progress in nanophotonics has been made over the last two decades, leading to the fruitful innovations such as photonic crystals [3, 4], plasmonic [5, 6], and metamaterials [7]. Owing to their exceptional electromagnetic (EM) features originating from the unique geometric distributions, artificial nanostructures allow the manipulation of light at subwavelength scale and even drive fictional concepts (e.g., invisibility cloaks [8, 9]) into reality. However, the optimal structure design is an iterative and time-consuming process, in which the human-involved trial-and-error strategy combined with the parameter sweep method is usually adopted [10]. A typical workflow initializes from man-guessed or prior verified structural layouts, and subsequently solves Maxwell’s equations or analytical formulas to update photonic geometries [11]. Until optical responses satisfy object demands, these procedures are consistently repeated, taking hours to days for a final output. Apparently, such low design efficiency hinders the rapid growth of nano-optical devices, and the limited human brainpower is characteristically weak in terms of reasoning hyper-dimensional parameter space, that is commonly found in complicated structure-design problems [12].
To tackle these challenges in nanophotonics, using artificial intelligence (AI) techniques to design the sophisticated meta-devices emerges as a promising approach that could assist us to bust the mentioned bottlenecks (e.g., inefficient design process). As the term indicated, AI commonly refers to programmable computer-enabled imitations of human intelligence. In short, the idea of broad AI came firstly, and machine learning (ML, a subfield of AI) blossomed later. The latest stage of deep learning (DL, a subfield of ML) drive today’s AI explosion [13, 14].
The cornerstone of AI techniques lies in varied algorithms, and here we discuss AI as different types of artificial algorithms that could help us to perform nanostructure designs. Up to date, there could be generally classified as two stages of learning algorithms applied for meta-structures designs, identified as traditional optimization techniques [10, 15–17] and latest DL models [12, 18–20], respectively. Historically speaking, traditional optimizations caught public attention in the late 1990s by several initial work on wavelength-scale optical structures [21, 22] (e.g., a fiber-to-waveguide coupler [21]), and hereafter the notable extensions (e.g., a ‘Z’-like photonic crystal waveguide [23] and a Y-shaped splitter [24]) were implemented over the past two decades, enriching the library of nano-device templates (see detailed roadmaps about photonic designs in refs. [20, 25]). In the past couple of years, there is an exponential rise to explore DL potential in artificial photonic structures, as some notable works illustrated in cases of broadband beam-splitters [26], chiral metamaterials [27], optical neural networks [28], and so on. All in all, the growing investigations mentioned here shows that two stages of learning algorithms could enhance optical performance of nanocomponents and, in particular, to inversely design nanostructures on demand.
Here we summarize the latest research on this interdisciplinary topic covering associated publications in the past three years, and we offer a systemically viewpoint on functional meta-components to inspect their optical performances improved by learning algorithms. As shown in Fig. 1, the review is arranged into two units: learning algorithms (highlighted by two gray shadows on the left) and meta-components (shown in the color-coded sector on the right). On the one hand, learning algorithms include traditional optimizations (such as genetic algorithm (GA), particle swarm optimization (PSO), and topological optimization (TO)) together with neural network (NN)-based DL techniques (e.g., multilayer perception (MLP), generative adversarial network (GAN), variational autoencoder (VAE) and double deep Q-learning (DQN)). Note that many works discuss that only neural network-based ML and DL techniques are considered to be AI-related, while other references classify traditional optimizations (e.g., GA) as AI-associated techniques. To clear this point, in this review we employ a more general concept of ‘intelligence algorithms’ to refer to all methods shown in Fig. 1. On the other hand, targeted meta-compenents are listed, namely, meta-lens, meta-grating, beam splitter, on-chip coupler, optical interference unit (OIU), optical diffractive neural network (ONN), etc. To illustrate the interplay of two distinctive study fields, we present the above-mentioned from the individual patterns (e.g., meta-grating) capable of manipulating incident light to the complex devices (e.g., ONN) performing advanced tasks like image processing.

A schematic categorization of intelligence algorithm-aided designs for nanophotonic components. The symbolic brain along with two arrows in the middle signifies that intelligence algorithms could boost optical properties and inversely develop on-demand photonic devices. In this review, the meta-atom spectral tuning (a dashed box) is given as a case study to illustrate two stages of intelligent methods. The splits extended from symbolic brain represent major substances explicitly outlined in the following context. The left gray backgrounds classify these algorithms as traditional optimizers (a light gray sector) and DL-based techniques (a dark gray sector), respectively, while the targeted functional meta-components are highlighted in the rainbow color-coded segment on the right
The Table 1 further generally illustrates modules and their characteristics related to Fig. 1. As an extension of diagram, the table summarizes important concepts and highlights references on meta-atom designs. Also, it works as an outline for subsequent algorithm introductions providing certain guidelines for the choice of appropriate approaches. Due to a lack of open-source database, to reasonably characterize, compare, and benchmark various algorithms performances becomes unrealistic, and thus it is rather difficult to suggest any specific methods to conduct nanostructure designs. In general, parameter-sweeping is a straightforward strategy for the narrow degree of freedom (DoF) space (e.g., < 5 variables), and traditional optimizations could be considered for medium-sized design tasks (e.g., ≈ tens variables). Here, global optimizers (e.g., GA) are recommended for relatively low-dimensional situations, while local optimization method (e.g., TO) is a suitable candidate for high-dimensional problem under high-constrained situations. The training of DL models requires large scale raw data (at least thousands of labels) and demands more computing resources. Hence this is suggested for the much higher DoF, in particular, for inverse design problems.
The review proceeds as follow. Over the second part, we shortly present typical algorithms and then we discuss the progress on the above-mentioned meta-components throughout the third section. After that, the current dilemmas in intelligent designs are summed up, and the future interplays between nanophotonics and AI research are given in the end. Differing from previous literature (see these reviews [10, 12, 15–20, 45–48], tutorials [49–51], and perspectives [52–55]), we deliver an intuitive instruction of GA and MLP algorithms by case studies of spectrum tunings of meta-atoms (see an introduction on meta-atom’s physical properties in ref. [56]), that is a well-known example in the field of nanophotonics. Here we also extended coverage range to include two stages of intelligence algorithms and categorized meta-structure designs for a fairly report on comprehensive advancements of this topic. Additionally, for the reference of newcomers, we summarize available open-source code packages with EM simulators for a quick start in this blooming direction (see Table 2 in appendix). With all these efforts, we hope to provide readers with fundamental knowledge alongside practical toolbox to involve the intensive innovations.
Intelligence algorithms with case study in meta-atom design
Composed of Traditional optimization techniques, Deep learning-based techniques, Reinforcement learning and Open-source packages, this section serves to bridge study fields between AI and meta-structure. How to employ intelligent algorithms to improve nanophotonic properties (e.g., spectral behaviors) is demonstrated through optimizations of meta-atoms. As a fundamental building block, the plasmonic meta-atom commonly refers to the subwavelength artificial particle exhibiting extraordinary optical properties arising from its material and geometries [56]. To distinguish applications varying from specific meta-atoms to general meta-structures, this section concentrates on working principles of design algorithms, whereas functional meta-devices involving more complex geometries will be elaborately presented in the next section. Note that the well-organized nanopatterns (e.g., diffractive optical neural networks [28]) could perform more advanced computation, while isolated simpler meta-atoms fail to fulfill such intricate tasks.
In general, the primary mission of nanostructure designs is to optimize the spatial distribution of candidate types of composite materials (e.g., metallic and/or dielectric), with an aim to best assure the on-demand performances subjected to all needed constraints (e.g., nano-fabrications). In pursuing this goal, two design paradigms (i.e., traditional technique and contemporary DL one) exhibit both pros and cons. A traditional algorithm repetitively updates a structure-related object (defined by a number of variables) to search for target outputs. However, only slight enhancement or even no visible enhancement may be obtained over lengthy optimizations, with no guarantee to approach the optimal geometry.
In contrast, bigdata-driven DL methods could spare immense computational efforts needed for traditional designs. Instead, these state-of-the-art strategies utilize given nanopatterns to train deep neural network (DNN) models in order to fit the input-output relationship of original meta-patterns. Although model trainings could consume a long period of time, the learned neural networks are able to map the geometrical information of functional component to its optical response and vice versa in a second [11]. Note that despite of the mentioned benefits, the network training could be rather timely and expensive due to multiple facts such as computational resources, raw data quality, etc. And it is still believed that the trained networks are unable for structure reasoning beyond the original physical scenarios. Hence, the selection of a proper algorithm should overall consider above-discussed strengths and weaknesses of both design strategies.
Although the instant rush on AI techniques unboxes a multitude of powerful instruments for nanostructure designs, the doubts of the rapid development are also raising recently. First of all, the performance (e.g., design efficiency) of gradient and gradient-less algorithms have not been widely discussed, fairly compared, and solidly examined yet. Secondly, for traditional optimization techniques like GA, the final outputted results may be just iterated layouts with slightly properties enhancement. Especially facing hyper nonlinear design space, TO is assumed to be more efficient compared to GA (see a study in Ref. [51]). At last, several potential factors (e.g., the high cost of nanopattern generations) may fundamentally query the usage of advanced DL models. Critics have argued whether to apply DL model is in doubt under certain scenarios (e.g., high DoF) since the well-established TO could already better cope with such situations. These questions are left open for future studies, and we would like to comment on parts of them in the last section of the review.
Figure 2 explains the relationships between meta-atoms and learning algorithms. Four types of optical particles (circle, square, triangle, and rectangle) are patterned on a substrate and the spectral modification is shown on the right. The meta-atoms, separated by the dashed lines, exhibit distinctive spectral features imposed by their variations in shapes. Aided by learning algorithms, the target spectrum modifications (i.e., to sharpen and/or shift the gaussian lineshape) set solid basis for extended applications like optical filters and color generations. Note that, multiple types of spectral data, including e.g., transmittance, reflectance, absorption, and circular dichroism (CD) could be individually altered or co-optimized. Commonly, the layouts of meta-atoms are processed as pixel-wise image matrices or structural parameter vectors for input/output of learning algorithms. For illustration purpose, we only display necessary variables to define meta-atom geometries (e.g., the length and width of rectangle atoms) and spectral information. Note that, the variables could be further extended to include such as hyper-parameters (e.g., lattice constants) or higher-resolution image matrix. Thereby, the increased variables dramatically improve DoF that may produce high-performance meta-structures, while the parameter expansions also bring a number of problems e.g., longer time of model convergence.

Spectral tuning for meta-atoms. The dark blue and orange arrows with texts represent the close interplays among three parts of the schematics, namely, meta-atoms (left, as input), learning algorithms (middle) and spectra (right, as output). Left: four typical geometric shapes of meta-atoms situated on a substrate. Middle: the traditional optimizer (e.g., GA) versus deep learning model (e.g., MLP of deep neural network). Right: spectrum modifications from the original line-shape in blue towards the target response in red. Note that the layout of mete-atoms could be represented as image matrices (see Fig. 3) or physical parameter vectors (see Figs. 4 & 5) for the further treatment in the learning algorithms

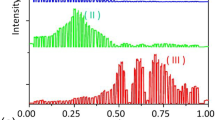
GA for meta-atoms spectral modifications. (a) The working flowchart of GA. Here the spatial distribution of meta-atom in a unit cell is processed as a binary matrix (referred as an individual X) for the evaluation of a fitness function F(X). (b) GA-based prominent enhancement of broadband absorbances arising from gold nanoparticles. Left: the optimization process with the best value (red diamonds) and averaged value (green diamonds) of fitness scores \(\bar {A}\). After 25 generations the best value approaches 0.792, being equal to a spectral (from 350 to 800 nm) averaged absorption of 79.2%. Right: two best structure arrangements (upper) with their spectral behaviors (lower) at initial (red framed) and ultimate (black framed) generations, respectively. Figure reproduced with permission: (b) Ref. [29], Copyright 2020 ACS

A neural network (NN) for meta-atoms. (a) A simple structure of NN with an input of X, an output of Y and two hidden layers of X(l−1) and X(l), respectively. (b) A magnified view of one artificial neuron layer to perform nonlinear transformation from layer X(l−1) to layer X(l). (c) The set-up and training process of NN-based model for meta-atoms. The procedures are composed of four labeled steps, starting from raw data generation, model training and validation, model test, to new applications

A mutual directional MLP (a type of DNN) model based upon H-shaped gold meta-atoms. (a) The establishment procedures. The alphabet labels (i.e., A to D) reveal the four phases of constructions, from creation of initial population, spectral computations, model training, to performance evaluations. (b) An inversely drafted meta-atom to fit on-demand sensing usage. The targeted organic molecule dichloromethane, requiring varied spectral polarization responses (e.g., blue for vertical polarization and red for horizontal direction), is depicted in the inside graph on the left spectra. Top: the meta-atom structure with a detailed table of all relative parameters. Bottom: spectral distributions by vertical and horizontal polarized incident light. In each set of transmissions, the spectra exhibit the excellent lineshapes agreement among demanded response (solid lines), DL predictions (dots), and numerical simulations (dashed lines). Figures reproduced with permission: (a) and (b) Ref. [11], Copyright 2018 Nature Publishing Group
In the middle of diagram 3, the widely covered intelligence algorithms-associated techniques are presented as traditional optimizer and deep learning, respectively, where the electromagnetic simulators (highlighted in the light green) take charge for cost functions and DL-model data preparations. As AI techniques burst, amounts of algorithms have been proposed and applied spanning past several decades. Within the scope of nanophotonics, here we spotlight two typical approaches (i.e., GA in Fig. 3 and MLP in Figs. 4 & 5) as corresponding representatives, and other algorithms (i.e., TO, VAE, and GAN) would be generally narrated as well. Two specific approaches have been consistently reported in broad designs of meta-structures, and we explain key steps packed with easy-to-understand schematics. Principally, GA is a metaheuristic global optimizer widely reported in property optimizations, and MLP is a learning model capable of inversely nanostructure designs. Due to the review interest, more problems occurred over algorithm usages could be looked up in these documents [57–59]. Note that, GA and MLP may fail to reach the optimal designs of functional meta-structures and thus maybe not best fit for certain occasions. Especially taken high DoF into account, alternative effective methodologies (e.g., TO) could be particularly considered. Detailed step-by-step tutorials of TO can be obtained from here [51, 60, 61].
Traditional optimization techniques
Within this section, we firstly provide a detailed establishment process of genetic algorithm and then present two additional approaches (i.e., PSO and TO). In brief, usually with a starting point of well-established solutions, traditional optimization algorithms define an objective function or a figure of merit (FoM) to tailor the form of nanostructures in an iterative process. Note that computational costs of objective functions are closely related to the model complexity, applied constraints and design degrees of freedom. For a proper choice of global or local optimizers, these references [10, 15, 62] can be examined in depth.
Genetic algorithm
Genetic algorithm is a gradient-free optimization method mimicking natural concept of selection and genetics [15]. A typical operational diagram of the GA is set out in Fig. 3 (a).
The first step is to create initial populations containing underlying physics of meta-atoms. Here the meta-atom is firstly recorded as a binary N ×N pixel-wise image and additionally represented by a N ×N dimensional matrix (defined as an individual of X with unity of 1 and void of 0). To illustrate, the transmission spectrum T (as a function of individual X) of the meta-atoms is computed by EM simulators. Hence the fitness function F can be evaluated as the mean square error (MSE) between calculated value T(X) and target spectral intensity G. i.e., F=MSE(T(X),G).
After the fitness assessment, GA repeats steps of selection, crossover and mutation until the termination criteria are fulfilled. In principle, the GA picks up these ‘elite’ individuals (e.g., higher fitness scores) to construct the next generation by operators of crossover and mutation. Note that the mutation procedure is likely to maintain the population diversity and prevent premature convergence. The algorithm can be ended once the fitness scores reach an appropriate threshold (e.g., the MSE is less than the demanded value) and/or the finite iterations run out.
Figure 3 (b) shows a GA methodology for broadband absorption optimization of a single meta-atom [29]. Organized in a fixed lattice, a gold nanodisk was placed on a gold substrate coated with a SiO2 middle-layer. The unit cell pitch, the disk height alongside diameter, and the thickness of middle-layer were those participating variables. In the reference [29], the fitness function was defined as \(F= 1-\bar {A}\), with \(\bar {A}\) being the averaged absorption between spectral range of 350nm and 800nm. An increasing trend of \(\bar {A}\) was clearly observed for both best and average value of absorption, and the best value of \(\bar {A}\) (red diamonds) reached a plateau after about twenty generations. Two illustrative meta-atom shapes (upper panel) together with their absorptances (lower panel) at a generation of 0 and 25 denoted prominent value enhancements from about 60% (red dashed line) to around 80% (black dashed line). In addition, the authors surveyed how to apply GA to enlarge the color coverage and to generate structural colors by increasing the pitch size and adding more meta-atoms in one cell [29].
So far, various studies on spectral regulations by GA have been conducted among cases of all-dielectric magnetic nanoantennas [30], infrared binary-pattern absorbers [31], reconfigurable meta-atoms [32] and strong circular dichroism of chiral patterns [33], etc. These works substantially extend the usage of GAs for meta-atoms modifications and pave the way for further investigations in GA-assisted photonic structure design.
In spite of above-mentioned work, further critics question the efficiency of GA dealing with large-scale design variables. Firstly, GA requires a set of solutions. It is unfriendly for brand-new usages since the prior verified layouts are exceptionally rare. Secondly, over numerous function evaluations, GA is computationally expensive and time-consuming. The high cost also denotes that GA-embedded parameters (e.g., mutation rate) need huge efforts to be finely tuned. Last but not least, as we previously discussed, there is no guarantee to identify global maxima. In extreme situation, the final outputs maybe merely the updated patterns, which lack substantial property enhancement. Hereby, alternative approaches (e.g., TO) are more advisable for high DoF circumstance.
Particle swarm optimization
Inspired by the animal social behaviors akin to bird flocking and fish schooling, PSO is an evolutionary computation method which is strongly linked to GA and evolutionary programming [63, 64]. A standard working flow of PSO starts from a set of randomly distributed particles. Until the system converges (or a certain termination criterion is satisfied), these particles keep searching for better positions by remembering and sharing their best location achieved so far [15]. An example of PSO is the study showcased by Forestiere [34] to optimize an array of 55×55 plasmonic nanospheres with the goal of creating field enhancement across the 400-900 nm spectral range. The process of binary PSO was eventually stopped after 100 iterations, upgrading the maximum field improvements to a value of 35.9 (at 500 nm). While the associated values for periodic particles and single particle both approximated to 6, being almost 6 times smaller than the PSO-amended arrays. This behavior comparison implies PSO as an effective method for more general layout-development problems within functional nanostructures.
Topology optimization
TO is often taken as an inverse design technique [49] expansively studied in engineering fields within fine mechanics, aerospace, and building architectures, etc. By combining with gradient and/or non-gradient algorithms, it is a highly efficient tool to address large-scale structure design problems with potentially up to millions of DoF [17]. From the functionality’s aspects (i.e., forward prediction and inverse design), a main difference compared to the undermentioned DL-models is that TO cannot perform the forward prediction functionality (i.e., to directly project nano-structural optical properties with no need of any simulators). However, TO exhibits enormous advantages and high working efficiency especially dealing with freeform nanophotonics under high DoF situations (potentially billions of DoF [35]). For instance, a metalens-based study reveals that the computational cost by TO-identified local optimum structure required merely ≈1.0% in comparison to counterparts via GA calculations [51].
Overall, with an initial guess, TO seeks to maximize the geometry-associated related FoM (Φ) over a series of iterations. Assuming that the distribution of meta-atom is reasonably arranged to obtain high transmission T at wavelengths of λ, the FoM could be defined as \(\underset {\epsilon }{\max }\: \Phi (T(\lambda), \epsilon)\), where ε denotes design variables (e.g., material distributions) within the assigned field [65]. Commonly utilizing the adjoint variables method, the gradients of the FoM Φ provide a guide for iteratively modifying these design variables ε in order to search for a local minimum (or maximum) of FoM [10]. Note that the last outputs may be significantly influenced by the initial guess if the FoM value fails to be dramatically improved. For step-by-step tutorials on TO, we would suggest these materials [35, 51, 60, 66, 67] for in-depth examinations.
Recently TO for design and optimization of nanophotonic components becomes a soaring trend. Up to date, there exist a large number of reports to investigate TO applications in nanophotonics due to its significant benefits discussed above. Confined to meta-atoms, a good illustration of TO for the meta-atom adjustments could be found in Christiansen work [35], where TO-modified metallic resonators showed over two order’s improvement in surface-enhanced Raman scattering (SERS) efficiency compared to a parameter-optimized bowtie antenna. Here the physical model was numerically simulated in COMSOL Multiphysics and the TO problem was executed by a built-in algorithm titled Globally Convergent Method of Moving Asymptotes.
Deep learning-based techniques
As arranged in a consequence of ‘multilayer perceptron’, ‘autoencoder and variational autoencoder’ and ‘generative adversarial network’, this section focuses on DL models to examine how the advanced algorithms could inversely generate functional nanopatterns on demand. At first, we would like to introduce fundamentals on neural network learning model as illustrated in Fig. 4. The diagram of (a) shows a simple NN consisted of an input layer (‘X’, green circles on the right), an output layer (‘Y’, green circles on the left) and two hidden layers (X(l−1)& X(l), dark blue circles in the middle). In principle, the neural network could perform a nonlinear transformation from the input X to the output Y. Given training data, deep learning is used to learn network parameters (e.g., weights (indicated by connected black strips) and biases) that characterize the transformation. Specifically in lower panel of Fig. 4b, the artificial neuron layer transforms its input X(l−1) to the output X(l) by X(l)=f(X(l−1)W(l−1)), where f is the nonlinear activation function (e.g., sigmoid) and W(l−1) is the transformation matrix of weights. For optical component designs, the transformation from input to output is an also a function of a given meta-structure S so that the output could be interpreted as a function of X(l)=f(X(l−1)W(l−1)|S).
A general training procedure of NN for meta-atom spectral tuning is provided in Fig. 4 (c), where four numbered steps start from raw data, training and validation, model test, to new applications. At beginning, raw data are prepared including nanostructure geometry (represented by an image matrix or a parameter vector) and its spectral distribution (calculated by simulators). The obtained labels would be further divided into three groups for training, validation, and test usages, respectively. Secondly, a NN model with initial parameters of weights W is established and thus learning procedure is conducted so as to obtain an optimal matrix W. Here, a common loss function L(W) is defined as L(W)=MSE(f(Ytraining)−Yground_truth), where f(Ytraining) and \(Y_{ground\_truth}\) denote current model outputs and original value, respectively. To search for the minimum value of loss function, the gradient stochastic descent (\(\frac {\partial L}{\partial W}\)) is usually adopted. Here, an ideal lineshape of L(W) (presented as a dark green line in second frame of Fig. 4 c) gradually declines as training epochs, reaching a minimum value where the model converges. Furthermore, the learned model should be examined by the validation data in order to give an unbiased estimate of NN performance (see the ideal light green line). After the first two steps, the trained NN will be finally checked using test data. Once it passes the task, the NN could be utilized as a highly efficient tool for new structure designs.
Multilayer perceptron
As illustrated by an exemplary case [11] shown in Fig. 5 (a), the bi-directional multilayer perceptron model [19] (originally discussed as DNN model) was composed of two sub-networks, namely, a spectrum-predicting-network (SPN) and a geometry-predicting-network (GPN), respectively. The former could anticipate the nanoparticle’s spectrum without any assistance of simulators, and the latter was assumed to execute inverse design functionality (i.e., outputting the nanostructure geometry given the input spectrum). The construction of such a bidirectional model typically goes as follows:
(A) Building physical models of meta-atoms. This step is aimed to set physics behind light-nanostructure interactions under diverse experiments. Each experiment encompassed, but not limited to, a plasmonic meta-atom with parameterized geometry, the environmental permittivity and the incident light field. Here various H-shaped gold antennas (see a sketch in Fig. 5 (b)) could be described by eight values: three continuous parameters (L0,L1 and rotation angle ϕ) and five binary ones (leg 1 to leg 5). Some randomly generated populations are presented within the inner box of step A. Alternatively, these meta-atoms could be taken as pixel-wise images for more general treatments (see the illustration in Fig. 3 (a)).
(B) Obtaining spectral information of meta-atoms. For such H-like meta-atoms, the calculations of broad-band spectra require well-established EM simulators to conduct full-wave numerical simulations. In particular, this stage could be extremely time-consuming for a large-scale data (at least several thousand spectra). For the choices of EM simulators and DL model training approaches, we will discuss the potential solutions and sum up available open-sourced ones in appendix.
(C) Training DL models using the dataset prepared by the simulator. Overall, the MLP was based on fully connected NNs, with one sub-model GPN being made of three fully connected layers and another sub-model SPN employing eight connected layers. The input of GPN was composed three groups of data: two vectors of 43 samples (two polarizations spectra) and a vector of 25 parameters (material’s properties). While the output of eight neurons in GPN encoded the predicted geometry. For the SPN, the input layer received the eight output parameters from GPN, additionally with the materials’ properties and a flag (indicating the polarization). And the output layer of SPN was constituted by 43 neurons representing wavelength data points.
It was proposed to train both GPN and SPN simultaneously, so that two sub-models could co-adapt to each other. The complete dataset generated from previous two steps was categorized into three parts: 80% for model training, 5% for validation, and 15% for model testing. By a gradient descent optimization algorithm (i.e., Adadelta), the networks were trained to minimize the MSE between the predicted spectra and geometry to their ground truths. The process took around two hours and terminated at about 3000 epochs with a final MSE of 0.16.
(D) Meta-atom design using the trained model. The authors employed the model to design a gold plasmonic structure targeted for the organic molecule dichloromethane. For this type of molecule, the required transmissions should vary with incident polarizations (e.g., vertical and horizontal directions). The guessed plasmonic structure and an elaborate configuration table are displayed at bottom of Fig. 5 (b). The spectral evidence exhibited a fine data match among desired response, DL-estimated value and numerical simulated results, indicating the strong capability of neural network model to address various targeted resonances. Up to date, deep neural network models have been substantially explored for chiral metamaterials [27, 36, 37], accurate silicon color design [38], plasmonic spectral sensors [39], etc. These groundworks allow the on-demand design of optical responses of nanostructures and enable metasurface-like structures for considerable utilization.
Autoencoder and variational autoencoder
Autoencoder (AE) is often regarded as an unsupervised learning neural network constituted of an encoder and a decoder [12]. Basically, the encoder compresses the input data as ‘code’ (alternatively referred as latent variables or latent representations), and the decoder maps the ‘code’ to reconstruct data that imitates original inputs. An applied case of AE for meta-atom design can be examined in Hemmatyar’s research [40], in which Fano-type resonant HfO2 nanopillars (prime variables: height h, diameter d, and a square-lattice with periodicity p) were adjusted to generate a largescale high-quality reflective color gamut. Here the AE transforms data in the input space of dimensionality to a lower dimensional latent space of dimensionality, reducing space dimensionality of the prepared reflectance data. And the output from AE was further fed into a pseudo-encoder to extract the importance of each design parameter (h, d, or p).
Variational autoencoder (VAE) is a productive DL scheme with autoencoder-like architecture, while the mathematical basis of VAEs owns loose connections with classical AEs [68]. In fact, as a major kind of generative models, VAEs provide a probabilistic manner to describe an observation in latent space. A breakthrough using VAE for meta-atoms is carried out by Ma et al. [41], who introduced a probabilistic graphic model by encoding metamaterial geographies and optical response (in total > 20000 data of reflectance and CD spectra) into a 20-dimentional latent space. The network was able to answer both the forward and inverse problems simultaneously, and the clear separation of three shape groups (cross, split ring, and h-shape meta-atoms) could be discovered in a visualization of the latent space.
Generative adversarial network
Composed of a generator and a discriminator, the GAN is a recently developed unsupervised DL framework [12]. The generator is trained to produce more plausible images, while the discriminator learns to distinguish the generated fake graphs or real ones. As an outcoming, a well-trained GAN could yield numerous images resembling true data in a second. For a very first demonstration, Liu et al. [42] applied a modified GAN to inversely outline gold meta-atom geometries with targeted optical responses ranging from 500 nm to 1800 nm. Consisted of three parts (namely a simulator, a generator, and a critic), the network (trained by 6500 sets data) granted generations of arbitrary patterns of periodical structures. To solve the instability problem of GANs, So et al. [43] inquired a conditional deep convolutional generative adversarial network (cDCGAN) to devise nanophotonic antennae, where the 500 nm × 500 nm physical domain was represented as a 64 × 64 pixel binary image (resulting in a 2 64×64 DoF). The spectral mean absolute error of 12 test samples between a network-generated geometry and original one was only 0.0322, reflecting that the cDCGAN could archetype proper nanostructures with the desired reflection spectra.
Reinforcement learning
Reinforcement learning (RL) is the one of three machine learning paradigms and its self-learning mechanism is to teach AI agents how to behave in an uncertain environment [12]. To achieve a goal (e.g., the expected benefits are sought maximized), the agent interacts with the environment and gets either rewards or penalties for every action. By this trial-and-error way, the agent obtains the so-called strategy policy and further applies it to determine the next movement. A remarkable benefit of RLs lies in the low amount requirements of training dataset since the agent could search the parameter environment independently, which is of vast interest for meta-elements devising. However, unlike other types of DL methods, the RL-assisted optical structure designs are less reported by far, among which the deep Q-learning network (DQN) manifests as an exemplary model. The DQN-related articles probe its usages from color generations [44], ultra-broadband perfect absorbers [69] (moth-eye structures) to highly efficient metasurface holograms [70]. For more detailed illustrations on RL, we would like to draw readers’ attention to corresponding references.
Open-source packages
The high entry threshold and expensive learning costs of computer sciences are unfriendly to many newcomers from the optics community, particularly considering the broad knowledge gap between nanophotonic and artificial intelligence. Therefore, we summarize parts of available open-source code packages to help those longing for a rapid start (see the attached Table 2 in appendix). To employ these ready-to-use tools, more detailed tutorials (e.g., Ref. [19]) could be consulted and online self-learning platforms (such as Coursera) are also recommended for practical coding.
Functional meta-components and devices
In this section, we will state the current trend in intelligent designs for application-oriented optical components and practical devices. We roughly categorize these meta-structures into subgroups of meta-lens, meta-gratings, beam splitters, on-chip couplers, optical interference units, optical diffractive neural networks, and other applications (see Fig. 6 to Fig. 12). In each division, we are intended to arrange the traditional optimization algorithms firstly and then introduce the advanced DL schemes. Here we discuss the mutual benefits between AI and nanophotonics. On the one hand, as versatile tools, intelligence algorithms could evidently improve design efficiency of photonic system. On the other hand, well-arranged photonics systems can be employed as optical hardware to accelerate AI-related tasks (e.g., object classifier empowered by ONN). After all, the intensive interplay of two field could generate novel photonic designs that are designed by AI and potentially used for AI.

(a) A ultra-high NA (=1.512 in oil immersion) meta-lens optimized by multiple traditional algorithms. Top: the FoM evolution with an inserted meta-lens diagram. Bottom: the measured beam spot showing a full width at half maximum (FWHM) of 207 nm. (b) A linearization approach to design large area metasurfaces. Top: the linearization strategy by slicing the desired phase profile into wavelength-scale sections, and then using TO to model individual piece. Bottom: simulated and experimental intensity distributions of a high NA (=0.8) meta-lens. (c) A multi-layer phase-change-material (GST41T1) meta-lens for the tunable foci and NA. Left: the physical design and model domain of meta-lens along with focused beam profiles (blue: n=3.2, red: n=4.6+0.01i). Right: the sketch of a ten-layer meta-lens structure. (d) A directly designed (by adjoint optimization techniques) meta-lens focuses two different wavelengths (780 and 915 nm) into separated positions (distance ≈ 20 μm). Left: the working mechanism of bi-layer meta-lens composed of dissimilar interacting block-based meta-atoms (magnified in the right red box). Right: the intensity profile confirming the remarkable agreement between the ideal performance (dashed lines) and the experimental data (solid lines). Figures reproduced with permission: (a) Ref. [71], Copyright 2018 ACS; (b) Ref. [72], Copyright 2019 Nature Publishing Group; (c) Ref. [73], Copyright 2020 OSA;(d) Ref. [74], Copyright 2020 OSA
Meta-lens
Capable of manipulating the phase distribution, meta-lens is increasingly applied in the practical applications [75]. Here we highlight some recent advances in Fig. 6. As illustrated in (a), Liang et al. [71] exploited a hybrid optimization algorithm (combining differential evolution, GA, PSO, and adaptive simulated annealing) to shape high-performance c-Si nanobricks-based meta-lenses. The fused algorithm gradually converged after 43946 iterations, reaching a final FoM of 0.93. The high numerical aperture (NA with a value of 1.48) meta-lens (oil immersion) exhibited a 207 nm full width at half maximum (FWHM) of a beam spot with an operational efficiency of 48%, representing one of highest NA of any metalens by that time. Other types of traditional algorithms such as GA and binary search techniques are also demonstrated in, e.g., Pancharatnam-Berry type metalens [76] as well as multi-level diffractive lenses [77–79], respectively.
To fully modify large area meta-lens requires numerous computation power, and thus a set of approximate approaches are developed in order to decrease the calculation complexity. For instance, Phan et al. [72] proposed to approximate desired phase profile by a series of linear segments and further formed an aperiodic Fourier modal method for large-scale metasurface lenses. Figure 6 (b) displays a linearization-approach-designed meta-lens achieving an NA of 0.8, where the experimental evidence coincided well with simulations, both showing concentrated beam waists of about 340 nm.
Another brand of widely employed algorithms for large-area meta-lens is topological optimizations [80]. As depicted in Fig. 6 (c), Christiansen et al. investigated a group of tunable multilayer meta-lens [73]. By switching the refractive index (n = 3.2 or 4.6+0.01i) of stacked phase change materials (GST41T1), the focused beam profile exported from the ten-layer meta-lens could be altered accordingly. More TO-designed meta-lens can be checked in the references [17, 81, 82]. In addition, the general adjoint-based optimizations [83, 84] have been reported by Mansouree et al. [74] for designing a double-wavelength nano-post meta-lens as shown in Fig. 6 (d). Here the inter-post and inter-layer coupling were comprehensively taken into consideration. The systemically designed dual- λ meta-lens showed the near-diffraction-limited focusing ability and the intensity distributions captured two split spots with dimensions of 1.33 μm (wavelength: 780 nm) and 1.54 μm (wavelength: 915 nm), respectively.
Moreover, there is increasing attention on the DL-assisted meta-lens design [84]. A specific example can be found from the Pestourie’s report [85], where they presented an active-learning algorithm to reduce at least one order of magnitude of the training time for the surrogate model. The demonstrated ten-layer meta-structure (with 100 unit-cells of period 400 nm) could converge light at three wavelengths (405 nm, 540 nm, and 810 nm) into three different focal spots, respectively. This surrogate evaluation is believed to be further exploited to exceptionally accelerate large-scale engineering optimization.
Meta-grating
The meta-grating [90] could deflect incident light into desired diffraction order, bending light propagating direction at will. Among the traditional optimizations, evolutionary strategies [91] and TO [72] are two representative algorithms for meta-grating designs. The former can be found in Afar-Zanjani studies [92], where an adaptive GA was adopted for a leaky-wave-antenna type meta-grating, and the latter is illustrated in Fig. 7 (a). In this example, David Sell et al. [86] applied an adjoint-based TO for high efficiency silicon gratings under a physical configuration that a meta-grating deflected normal incident light into an refraction angle of 75°. The efficiency plot showed its value gradually exceeded 80% after 300 iterations and corresponding experimental statistics of a fabricated grating (see a SEM image in Fig. 7 (a)) characterized its working efficiency over 80%. Subsequently, more reports investigated several types of DL models [93, 94] (such as generative networks [95, 96]) to generate high-performance meta-gratings. An example of GAN network is presented in Fig. 7 (b), where the GAN learned geometric features from a set of meta-grating images and thus was able to yield equal-quality layouts [87]. After additional topology optimizations, these ‘fake’ structures were fed back into the neural network for retraining and GAN refinement. In this manner, GAN could be employed to facilitate the production of near-optimal device at a desired deflection angle and wavelength.

(a) Topological optimizations for a 75° deflection meta-grating. Left: a plot of absolute efficiency of a meta-grating (see interior graphs at different stages) over 350 iterations. The sharp dips are induced by the applied geometric modifications in order to remove the teeny features that are too difficult to fabricate. Middle: a scanning electron microscope (SEM) image of meta-grating operated at 1050 nm. Right: the measured efficiencies. (b) An illustration of GAN (formed with a generator and a discriminator) for meta-grating generation. The well-trained generator produces grating images at the desired angle and wavelength, while the discriminator helps to instruct the generator to create high-performance devices. (c) A fused framework (see the diagram) of a compositional pattern-producing network and a cooperative coevolution algorithm for metaatom-based deflective gratings. The bottom panel showcases the SEM image of a manufactured eight atoms (alighted in the top frame) with simulated E y field profile (right). (d) A liquid crystal (LC) based tunable meta-grating for high switching efficiencies and wide angular deflection (±72°). Top: the inverse design and global optimization area. Bottom: the diffraction efficiencies of an optimized triple-grating. The data expresses -1 order diffraction efficiency of 62% (red line) for voltage-on state and +1 order efficiency of 76% (teal line) in the voltage-off status. Figures reproduced with permission: (a) Ref. [86], Copyright 2017 ACS; (b) Ref. [87], Copyright 2019 ACS; (c) Ref. [88], Copyright 2020 Wiely;(d) Ref. [89], Copyright 2020 ACS
Recently growing attention has focused on the hybrid tactics to customize meta-gratings [97], e.g., to combine NN with conventional optimizers. Besides the above-noted contributions [87], another seminal work of Liu et al. [88] proposed a fusion scheme connecting compositional pattern-producing network and a cooperative coevolution to tailor molecule-resembled meta-surfaces (see the algorithm diagram in Fig. 7 (c)). The simulated electric field of E y component emerging from the metasurface confirmed the accurate phase gradient as demanded. Furthermore, for a systemically design of tunable meta-gratings depicted in Fig. 7 (d), Chuang [89] developed a combination framework comprised of the adjoint-based local-optimization with a global-optimization search (i.e., PSO). Here, the liquid crystal (LC) was aligned perpendicular to TE-mode electric fields once the voltage turned on, while the LC became parallel to TE-mode on the condition of voltage-off, thereby maximizing the effective refractive-index change of the LC. The optimal device exhibited a broad deflection angle span (from 12° to 144°) and a high switching efficiency (> 80%), both being 6 times improvements to the state-of-the-art reports.
On-chip waveguide-based coupler
The vertical couplers tend to deliver the light from the optical fibers to planar waveguide/chips/photonic circuits. For the purpose of elevating coupling efficiencies, Su et al. [102] proposed a two-stage gradient-based optimization algorithm for 1D uniform grating couplers, suppressing the insertion loss of a blazed-grating-based coupler below 0.2 dB. Thereafter, the broadband (> 100 nm) grating couplers devised by the gradient-based strategy achieved 3 dB bandwidths while maintaining central coupling efficiencies ranging from -3.0 dB to -5.4 dB [103]. A recent work on TO was undertaken by Dory et al. [98] who demonstrated several types of diamond-based vertical couplers. The efficiency plot of a representative structure is presented in Fig. 8 (a) with an eventual value stabilized at about 25%. The footprint of such a compact coupler was only 1.0 × 1.0 μm2 (see the SEM image). Together with other nanophotonic interfaces, the inverse-designed diamond platforms represent a critical advancement toward integrated diamond quantum optical circuits.

(a) An inverse-designed diamond vertical coupler with a plot of coupling efficiency. The insets indicate the coupler geographies at three phases. (b) A vertical polarization-insensitive grating coupler developed by an ANN model. Top: the operational configurations. The variables for ANN model are pictured as fiber angle, polarization, grating pitch, the duty cycle, and the fill factor (FF), respectively. Bottom: transmissions of an ANN-created grating coupler. The blue (TM0) and red (TE0) lines cross at 1.596 μm, resulting in the same amplitude of 0.31, thereby identifying the working wavelength for the requested polarization-insensitive coupler. (c) A ML methodology outlined for vertical grating couplers. The basic procedures contain steps of initial sparse collection of good designs, dimensionality reduction of machine learning and exhaustive mapping of the sub-space stages. (d) Cavity couplers reformed by TO for on-chip nonlinear optical devices. Left: an overall model illustrating functioning principle. The well-arranged black region acts as a coupler for energy exchange between a multimode cavity and a waveguide. Right: three developed couplers (featuring in red-dashed boxes) for second harmonic generation (SHG), sum-frequency generation (SFG), and frequency combs, respectively. In each framed area, black region is made of GaP, while the white part is assumed to be vacuum. Figures reproduced with permission: (a) Ref. [98], Copyright 2019 Nature Publishing Group; (b) Ref. [99], Copyright 2018 IEEE; (c) Ref. [100], Copyright 2019 Nature Publishing Group; (d) Ref. [101], Copyright 2018 OSA
Regarding DL schemes, Gostimirovic et al. [99] discussed on how to use ANN to accelerate preparations of polarization-insensitive grating couplers (see the geometrical configuration in Fig. 8 (b)). Here the training of ANN model terminated when the validation error reached a value of 6.8%. The optimal operating wavelength for polarization-insensitive coupler was characterized at 1.596 μm, where two transmittance lines (represented as TM0 and TE0 polarized incident light) intersected, obtaining an identical amplitude of 0.31. The performance comparison between ANN and FDTD simulations proved that the former was 1830 times faster than the latter while the accuracy was slightly lower (with a 93.2% accuracy). In addition, to quest the overall design potential of vertical grating couplers, Melati et al. [100] demonstrated a ML-based methodology as described in Fig. 8 (c). Following by the procedures of design collection, dimensionality reduction and exhaustive mapping, this pattern recognition method could increase coupler-to-fiber efficiencies > 0.74 at 1550 nm. By dimensionality reduction technique, the ML methodology was expected to navigate and comprehend a wide range of high-dimensional design spaces.
Besides the above-mentioned, optimizations on other types of on-chip couplers have been reported in several studies [104]. For instance, Jin et al. [101] utilized a gradient adjoint-variable TO approach to intuitively fashion waveguide-cavity couplers served for nonlinear frequency conversion as well as frequency comb generation. The total (or near total) critical coupling between multi-mode ring resonators and waveguides was achieved at all relevant wavelengths (up to six widely separated wavelengths spanning the 560-1500 nm domain), and the ultimate structure distributions are portrayed in Fig. 8 (d).
Beam spiltter
Planar beam splitter (or routers [107, 108]) has been intensively discussed in these publications [25] and here we select recent highlights in this field. Among these advancements, some pioneering breakthroughs were accomplished by Jelena group. For instance, Piggott et al. [26] employed an inverse design algorithm combined the so-called objective first method and the steepest descent approach to formulate the smallest dielectric wavelength splitter at that time (a footprint of 2.8 × 2.8 μm2, see a fabricated SEM image in Fig. 9 (a)). The entire discussion on this gradient-based adjoint photonic optimization could be examined in the relevant documents [109, 110]. A consequential work by Hughes et al. [105] extended the adjoint method to devise nonlinear beam switch by introducing Kerr nonlinearity (induced by the chalcogenide glass, see Fig. 9 (b)). The light was guided to either the right port (linear regime with low power) or the bottom port (nonlinear regime with high power) depending on the refractive index shift imposed by beam intensities. As for DL approach, Tahersima et al. [106] developed a deep residual network model for designs of highly efficient (maximum value > 90%) power splitter (see Fig. 9 (c)). The DNN was trained with nearly 20000 simulation data and could project the nanostructured geometry (i.e., to arrange positions of 20 × 20 etch holes) in a fraction of second. This approach paves the way for speedy design of integrated photonic components with complex layouts.

(a) A TO-modified 1 × 2 beam splitter. Left: an SEM image (size: 2.8 × 2.8 μm2). Right: the measured transmissions. The S-parameters exhibit low insertion losses down to -1.8 dB and -2.4 dB in the 1300 nm and 1550 nm bands, respectively, and the crosstalk is suppressed < -11 dB throughout both bands. (b) An adjoint method-derived beam switch displaying different E-field distributions induced by the Kerr nonlinearity. Left: the light passes to the right port in case of a low power of 10 −9 W/ μm. Right: the light goes to the downward gate with a high input power of 0.057 W/ μm. (c) A DNN-based framework for fast prototyping of 1 × 2 power splitters. Left: the spatial configuration of a close-packed splitter (footprint: 2.6 × 2.6 μm2). The exported intensity division is given by T1:T2, and effective manipulations of arbitrary ratios count on manipulating binary positional sequence of 20 × 20 etch holes (white circles). Middle: the established DNN model for forward and inverse modeling of nanophotonic devices. Right: targeted transmision spectra of the beam splitter. Figures reproduced with permission: (a) Ref. [26], Copyright 2015 Nature Publishing Group; (b) Ref. [105], Copyright 2018 ACS; (c) Ref. [106], Copyright 2019 Nature Publishing Group
Optical interference unit
Lately, there is a rising attention towards utilizing optical computing [55, 111–113] to carry out specific machine learning tasks, thanks to the inherent advantages of nano-optics like parallel computation, low power consumption and propagating at the speed of light. Among the proposed optical hardware schemes, the so-named artificial intelligence interference [52] may offer opportunities to establish photonic systems for visual computing applications. In the next two subsections, we would brief optical interference-based neural network [52] and diffractive neural networks [114], respectively, with priorities given to network elements and the training methods.
A pioneering work (Fig. 10 (a)) by Shen et al. [115] experimentally demonstrated ONNs using a cascaded array of programmable Mach-Zehnder interferometers (MZIs) and further showed its utility for vowel identifications. Overall, the preprocessed signals (e.g., vowels of ‘ABCD’) were encoded in optical pulse and transported through the main body of ONN, that is, photonic integrated circuits (i.e., built-in n-layer architecture in the sketch of Fig. 10 (a)). As the key component of an ONN, optical interference units (OIUs), relying on MZI-like structures (containing a phase shifter, directional couplers, followed by another phase shifter) can implement any real-valued optical matrix multiplication. The voice-recognition matrixes showed that the electrical and optical hardware were both good at classifying vowels ‘A’ and ‘B’, while the computer surpassed ONN in terms of ‘C’ and ‘D’. After that, intensive studies have profoundly explored interference-like photonic processors [52]. In fact, the implementations of ONNs depend upon the models simulated in electrical computers due to a lack of efficient training protocols for these optical networks [116]. Hence, for in situ tutoring of an optical neural network, Hughes et al. [116] employed adjoint variable methods to derive the photonic analogue of the backpropagation algorithm. As an example, they numerically demonstrated the instruction of a network (consisting of two 3 × 3 unitary OIUs) to form an XOR gate (see the sketch of neural networks in Fig. 10 (b)), where the MSE between predictions and targets slowly declined to a sufficient small value. The property comparisons of before and after training proved that the ONN had successfully learned the XOR function with projections (blue circles) coinciding well with the targets (black crosses) in the post-training diagram.

(a) Optical interference unit (OIU) as a key component for optical neural network (ONN). A general ONN architecture was consisted of optical inputs (‘X’), internal multiple layers, and optical outputs (‘Y’). For a single internal layer (see a zoomed-in graph of ‘layer i’), it can be decomposed into OIUs (for matrix multiplications) joined with nonlinearity units (as the nonlinear activation). (b) An ONN-based XOR gate trained by the situ backpropagation and adjoint method. Top: the neural network containing inputs of X0, two layers of 3 × 3 OIUs (two rectangles), z2 activations (two red blocks) and outputs of XL. Bottom: XOR gate properties before and after learning. The circles represent target function, and the crosses mean the true output of network. (c) A sketch of the optical scattering unit (OSU) to execute matrix multiplications. Right: training MSE errors (right corner: the targeted matrix P). Bottom: E-field distributions at wavelengths of 1.55, 1.56, 1.57, and 1.58 μm, respectively. Each sub-image corresponds to one column of the matrix P. (d) An OIU-like nanophotonic medium to execute image detection. Top: the mini-batch stochastic gradient descent-based training process. All gradients information is calculated by adjoint state method in one step. Bottom: the media appearance and field distributions at iteration of 1, 33, and 66, respectively. The disordered media patterns (denoted by multiple inclusions embedded in a rectangle host material) progressively evolves upgrading the classification accuracy from 10.1% to 77.3%. Figures reproduced with permission: (a) Ref. [115], Copyright 2017 Nature Publishing Group; (b) Ref. [116], Copyright 2018 OSA; (c) Ref. [117], Copyright 2020 Elsevier; (d) Ref. [118], Copyright 2019 OSA
Besides OIUs, a sequence of functional computing elements [119–122] have been proposed and thus occupied as fundamentals to set up ONNs. For example, as displayed in Fig. 10 (c), Qu et al. [117] introduced a novel integrated ONN framework based on optical scattering units (OSUs). In principle, resting on multimode interferences, OSUs could directly manipulate light intensity to run arbitrary matrix multiplications (see the sketch on the top panel of Fig. 10 (c)). In order to realize a high-precision multiplication matrix, the relative permittivity distribution of a specific 4 × 4 OSU was optimized by an adjoint-based training process (i.e., Adam optimizer), minimizing the eventual MSE < 10−4 (the working performances are presented in Fig. 10 (c)).
Another variant demonstration of OIUs can be found from Khoram paper [118], where an OIU-like media (namely nanophotonic neural medium, NNM) accomplished computer vision tasks such as image recognition of handwritten digits. The input wave recorded the image (20 × 20 pixels) as the intensity distribution and the optical energy yielded from NNM concentrated to corresponding locations according to the image’s label. The iterative training cycle (using mini-batch stochastic gradient descent) is displayed in Fig. 10 (d) with an illustrative classifier for an image of number ‘8’ showing a final identification accuracy of 77.3%. In addition, the recognition accuracy could be even more improved to 84% by extending NNM from the flat structure to three-dimensional medium.
Optical diffractive neural network
As discussed, optical diffractive neural network could execute various ML tasks as well [28, 126]. An exploratory milestone of diffractive neural networks is displayed in Fig. 11 (a), in which Lin et al. [28] developed an all-optical diffractive deep neural network (D2NN) comprised of multiple passive cascaded layers patterned with complex-valued transmission (or reflection) coefficients. The parameters embedded in diffractive layers were iteratively tuned throughout the error backpropagation learning process. As a result, the classification accuracy of optical D2NN reached 93.39% (seven layers) for digits dataset (Modified National Institute of Standards and Technology, MNIST) and 86.60% (ten layers) for fashion products images (Fashion-MNIST class 5), respectively. In follow-up studies, a set of groups continued to improve the system performance of D2NN by several meanings [127–130]. For acceleration of D2NN training speed, Zhou et al. [123] conducted the backpropagation algorithm for in situ training of both linear and nonlinear optical networks. As a sketch illustrated in Fig. 11 (b), the vital instruction procedures involved forward propagation, error calculation, backward propagation, and gradient update. This optical learning architecture achieved a high accuracy on the specific tasks (e.g., object classification and matrix-vector multiplication) close to in silico training on an electronic computer.

(a) Schematics of optical diffractive deep neural networks (D2NN). Multiple diffractive layers can work as a classifier (left for handwritten digits and fashion products) and an imager (right) (b) Error back-propagation algorithms for in situ optical training of diffractive ONNs. During each iteration, layer coefficients are constantly upgraded by four-step procedures marked as a sequence of forward propagation, error calculation, backward propagation, and gradient update. (c) A diagram of Fourier-space diffractive neural network (F-D2NN) worked for salient objective detection. The F-D2NN is implemented by placing a D2NN and optical nonlinearity (introduced from ferroelectric thin films SBN:60) at the Fourier plane. (d) Optical logic operations allowed by a diffractive neural network. Top: the layout of diffractive neural network including an input, hidden layers, and an output. Metasurface-based hidden layers could directionally scatter specially coded incident light into one of two regions (red labels of ‘1’ and ‘0’) at the output layer. Bottom: experimental intensity distributions at the output layer for NOT, OR and AND logic operations, respectively. Figures reproduced with permission: (a) Ref. [28], Copyright 2018 AAAS; (b) Ref. [123], Copyright 2020 OSA; (c) Ref. [124], Copyright 2019 APS; (d) Ref. [125], Copyright 2020 Nature Publishing Group

(a) ANN-assisted designs of vectorial field for the optical holography. Left: a floating display of a 3D kangaroo image. The vectorial hologram incorporates a phase hologram and a 2D vector field. Right: an amplified view stressing an arbitrary 3D vectorial field originated from the ANN model. (b) TO-developed microstructured fibers for third-harmonic generation. Left: a general sketch depicting fiber geometries. Right: dispersion relations (solid line) and radiative lifetimes Q (dashed line) verses propagation constant k. The graph indicates that the optimized kopt achieves frequency matching condition and leads to a large nonlinearity. Top corner: fiber cross-sections at power density of ω1 (red frame) and ω3 (blue frame), respectively. (c) ANN-aided optical information retrieval from digit-encoded nanostructures. Left: a sketch of an individual geometry storing a 9-bit (e.g., ‘101000001’) data. The digits are encoded in tagged (labels of ‘i’ to ‘ix’) silicon blocks (entity: ‘1’; vacuum: ‘0’) and the added L-shaped sidewall allows to distinguish symmetric arrangements in case of polarized excitations. Right: selected examples illustrating ANN training data (lower panel) produced from a numerical expansion of the experimental spectra (upper panel). The legend of ‘X’ and ‘Y’ denotes the applied light polarizations, i.e., X for vertical direction and Y for horizontal orientation. Figures reproduced with permission: (a) Ref. [136], Copyright 2020 AAAS; (b) Ref. [137], Copyright 2018 OSA; (c) Ref. [138], Copyright 2019 Nature Publishing Group
Furthermore, there exist several studies on Fourier space image processing by optical neural network [124, 131]. For instance, Yan et al. [124] set up a Fourier space D2NN by placing an optical nonlinear activation function (introduced by ferroelectric thin films) in an 2f system (see Fig. 11 (c)). The Fourier D2NN exhibited a classification accuracy of 97.0% based on MNIST database and the hybrid D2NN (diffractive layers embedded in both Fourier space and real space) further lifted the accuracy to 98.1%.
Wider NN-like diffractive optics has been analyzed in bibliographies of diffraction grating based neural network [132], neuromorphic metasurface [133], azimuthal multiplexing 3D diffractive neural network[134], and vortex beams possessing [135], etc. In particular, a noted work [125] of the NN-enabled logic gates is conceptually illustrated in Fig. 11 (d). Here, the incident wave was firstly spatially encrypted by a specific logic operator at the input layer and the composite meta-surfaces (built on gradient descent training) directionally scattered the encoded light into corresponding designated regions (marked as numbers of ‘0’ and ‘1’). The experimental demonstration of three basic logic operations (i.e., NOT, OR, and AND) exhibited an intensity contrast ratio over 9.6 dB (at a work frequency of 17 GHz), suggesting a strong functional reliability of three gates. Applying extra training on metasurfaces, all seven logic operations (additionally NOR, XNOR, NAND and XOR) were numerically demonstrated via the same optical diffractive neural network.
Other applications
AI-algorithm-aided design methodologies are fast becoming fundamental toolboxes to develop high-quality photonic structures. To date, the soaring number of nanoscale applications [139–141] have been appreciably benefited from the artificial intelligence such as photonic crystals [142], Fano resonators [143], photon extractors [144], topological insulators [145], and particle accelerators [146], etc. in addition to the aforesaid meta-devices. Since it is impractical to cover every aspect, here we would additionally provide three more demonstrations in Fig. 12, listed as holography, nonlinear optical fibers, and optical information storage. Note that, even though they are slightly off the review focus, three cases here show tightly connections between AI and nanophotonic, and further indicate there are plenty room that we can explore.
Optical holography permits the fully restoring and reconstruction amplitude and phase information of object targets [147]. In a recent work by Ren et al. [136], the authors made use of multilayer perceptron ANNs to inversely create a floating-displayed holography (see the schematic in Fig. 12 (a)). The trained ANN could instantly output a 2D vector field used for the generation of any desired 3D vectorial field targets, enlarging holographic viewing angle up to 94° with the diffraction efficiency of 78%.
The optical fibers have been intensively studied for more than half a century and so far, still typify as a major scientific field within the photonics community. Recently, Sitawarin et al. [137] applied topological and shape optimization to simulate chalcogenide/polyethersulfone heterostructure fibers to boost third-harmonic generation at desired wavelength. As can be seen from Fig. 12 (b), the phase-matching condition was satisfied at kopt=1.4×2π/λ, improving nonlinear overlap factor almost 4 orders of magnitude larger than standard plain fibers.
Recording information in the scattering spectra of plasmonic nanostructures is perceived as a potential approach for high-density information storage. While a major problem lies in robust information retrieval in which dissimilar nanostructure geometries may lead to indistinguishable optical responses. To address this issue, Wiecha et al. [138] experimentally demonstrated ANN-aided quasi-error-free readout spectral message of silicon nano-patterns loaded up to 9 bits data (in Fig. 12 (c)), contributing to a digit-storage capacity of around 40% higher than that of a Blu-ray disk.
Perspective and conclusion
Overall, this review contributes to the emerging role of AI learning algorithms in the context of functional meta-devices, and spotlights the exponential growth in this cross-disciplinary topic over past three years. The intelligent algorithms, classified as traditional optimization methods and latest DL models, generate productive design approaches for high DoF meta-structures, extending the toolkits for reliable photonic devices and liberating us from the heavy workloads over development routines. In addition, the immense innovations of AI may shed new insights into understandings of light-matter interactions, and hereby help us to further explore the fundamental optics studies.
Despite of the explosive progress achieved so far, the studies of the nanophotonic intelligent designs are still limited in terms of, e.g., design object scopes (wavelength-scale optimizations and independent physical fields) and DL dataset issue (small volume of raw data and distributions). Here we would like to comment on current difficulties with possible solutions, and discuss future meta-element applications (photonic computation scheme) in short.
For the majority of meta-devices covered in this review, the dimensional scope of target objects concentrate on the wavelength scale. The large-magnitude and high DoF structures are commonly decomposed into periodical arrays, thereby optimized to enhance the performance of individuals with advanced algorithms. And the separately improved elements would additionally be ‘stitched’ together [17, 72]. Obviously when confronting the practical devices such as achromatic meta-lens [75], the nanoscale ‘misalignment’ may lead to the degeneration of overall functionalities. Therefore, the efficient optimizers (such as topological optimizations [49, 60, 61, 148]) for systemic and large scale designs [62, 149] should be given higher priorities. Recent attempts on TO studies [150, 151] make promising progress to expedite photonic devices from nanoscale elements toward feasible applications.
A second limitation within object scopes lies in the solo EM simulator. Nowadays, nanophotonics turns to be a much general scientific area and several reports on meta-components optimizations are expanded to multi-physical backgrounds, e.g., acoustic metamaterials [152] and thermal emitters [153]. Under such multi-physics scenes, merely EM simulator can not offer comprehensive information. Consequently, it is advised to cooperate with multiphysics simulation platforms that encompass diverse solvers, in which we can access software modules by the interfaces and fulfil optimization tasks on demand.
Data is always crucial for deep learnings. The high-quality and sufficient information leads to high performance DL models, while a poor data representation is likely to reduce qualities even for most performant algorithms. However, to acquire massive dataset is expensive and sometimes unrealistic regarding the economic and labor costs. To release data generation pressures, generative models (e.g., GANs and VAE) should be much welcomed, since they require a relatively small amount of labels to produce equal-quality dataset. Moreover, other advanced AI techniques such as transfer learning and RL models could be particularly considered. For instance, Qu et al. established a DNN architecture with transfer learning ability that can significantly improve the performance of physical problems albeit that the original data sets only included 500 examples [154]. To some extent, these approaches could elucidate behavior of nanophotonic structures [155], enable exploration on design feasibility [100] and potentially discover the underlying physical rules. [156, 157].
Another problem of tackling dataset is how to reasonably collect and coordinate them. On the one hand, many algorithms and nanostructure layouts remain unshared so far. On the other hand, there is a lack of appropriate and reliable platforms, which could properly maintain and effectively distribute meta-element dataset. Apart from some professional sites (e.g., Github) and open platforms (e.g., Metanet[158]), here we would like to call for more neutral databases to share design templates as well as source codes for extra usage like benchmarking algorithm performances.
In addition to the previous issue of data generations and collections, couples of more debates are ongoing centered around the usages of varied algorithms. In comparison to the long-established approaches (e.g., TO), there exist uncertainties that may further hinder the DL applications. First of all, the comprehensive evaluations of traditional techniques and DL models for meta-structure designs are growing in importance, especially considering key aspects such as cost-performance ratio. The comparative studies could offer feasible guidance on appropriate selections for various meta-structures. Secondly, AI-designed meta-structures ought to be crucially examined particularly including experimental evidence. The emerging meta-components serves for practical applications all along. Without explicit and solid verification, all designs are empty talks. Lastly, the open questions like performance limits of nanostructures, underlying physics, etc. remain unexplored yet. We should pay more efforts towards fundamental mechanism that cannot be directly answered by DL models. In total, the above-mentioned queries are merely the tip of the iceberg, and these would be critically investigated in future studies.
Regardless of object scopes and dataset issue, the AI learning algorithms certainly reduce design effects to develop photonic elements. Among the reviewed photonic-elements, one of key application could be anticipated in optical computing. Apart from the aforementioned optical hardware (e.g., OIU and D2NN), numerous efforts including schemes of photonic neuromorphic computing [112, 159–162], optical analog computing [111, 120, 163], photonic integrated circuits [115, 164, 165], and programmable meta-surface [166–168] have been persistently forged to drive progressive innovations of photonic computing to real-world usages, such as image processing [169] and equation solvers [170]. These proposed full-optical or electric-optics coprocessor [171] could be developed as faster, energy-efficient, and more powerful computation tools [122, 172] to prompt the AI community as well.
In conclusion, we summarize the AI-assisted designs of meta-components and -system from the simple to the complex. We believe that further strengthening the connection between nanophotonics and intelligence algorithms will be of great importance to promote the upcoming breakthroughs in both fields. We warmly welcome the advent of intelligence designed photonic systems that are destined to revolutionize our digital society and remarkably benefit this information era.
Appendix
Open-source packages
Inverse design approaches have reshaped the landscape of nanophotonic structures and here goes to the summary of open-source code packages for inversely designed meta-devices illustrated in the main content. Note that, a variety of solutions have been developed and maintained by individual research groups worldwide. Unfortunately, only finite proportions could be presented here due to the limited space. To execute these lines, we strongly endorse powerful CPU, GPU resources and adequate RAM capacity to diminish time spent on date preparations and model trainings. Besides the attached, there exist well-organized online platforms (e.g., Metanet) collecting and distributing codes together with deduced structure geometries. We would like to recommend readers to consult the relevant documents and websites for more information.
The design and optimization of meta-structures require intensive computational efforts due to the heavily dependency on the simulator. These EM solvers are constructed based on various numerical methods like finite-element method (FEM) and finite-difference time-domain (FDTD) or alternatively using an analytic or a semi-analytic model (e.g., rigorous coupled wave analysis (RCWA)). Here, we recap part of well-founded interpreters into appendix Table 2 (see the content below the dashed line). Except for these listed, another type of highly suggested EM simulators is commercial products including, without limitation, COMSOL Multiphysics, Lumerical, CST Studio, and JCMwave, etc. The numerical software could imitate true 3D/2D physical scenarios to obtain multi-dimensional optical properties, providing accessible application interface for customized programming.
Availability of data and materials
Data sharing is not applicable to this article as no datasets were generated or analysed during the current study.
Abbreviations
- AI:
-
Artificial intelligence
- ANN:
-
Artificial neural network
- AE:
-
Autoencoder
- CD:
-
Circular dichroism
- cDCGAN:
-
Conditional deep convolutional generative adversarial network
- DL:
-
Deep learning
- DNN:
-
Deep neural network
- DQN:
-
Deep Q learning network
- DoF:
-
Design degree of freedom
- D2NN:
-
Diffractive deep neural network
- EM:
-
Electromagnetic
- FoM:
-
Figure of merit
- FF:
-
Fill factor
- FDTD:
-
Finite-difference time-domain
- FEM:
-
Finite-element method F-D2NN: Fourier-space diffractive neural network
- FWHM:
-
Full width at half maximum
- GAN:
-
Generative adversarial network
- GA:
-
Genetic algorithm
- GPN:
-
Geometry prediction network
- LC:
-
Liquid crystal
- ML:
-
Machine learning
- MZI:
-
Mach–Zehnder interferometer
- MSE:
-
Mean square root
- MNIST:
-
Modified National Institute of Standards and Technology
- MLP:
-
Multilayer perception
- NNM:
-
Nanophotonic neural medium
- NN:
-
Neural network
- NA:
-
Numerical aperture
- N.A.:
-
Not applicable
- OF:
-
Objective function
- OIU:
-
Optical interference unit
- ONN:
-
Optical neural network
- OSU:
-
Optical scattering unit
- PSO:
-
Particle swarm optimization
- RL:
-
Reinforcement learning
- RCWA:
-
Rigorous coupled wave analysis
- SEM:
-
Scanning electron microscopy
- SHG:
-
Second harmonic generation
- SPN:
-
Spectrum predicting network
- SFG:
-
Sum-frequency generation
- SERS:
-
Surface enhanced Raman scattering
- TO:
-
Topological optimization
- VAE:
-
Variational autoencoder
References
Novotny L, Hecht B. Principles of Nano-optics. Cambridge: Cambridge University Press; 2012.
Maier SA. Plasmonics: Fundamentals and Applications. Berlin: Springer; 2007.
Lin S-y, Fleming J, Hetherington D, Smith B, Biswas R, Ho K, Sigalas M, Zubrzycki W, Kurtz S, Bur J. A three-dimensional photonic crystal operating at infrared wavelengths. Nature. 1998; 394(6690):251–53.
Russell P. Photonic crystal fibers. Science. 2003; 299(5605):358–62.
Maier SA, Brongersma ML, Kik PG, Meltzer S, Requicha AA, Atwater HA. Plasmonics - a route to nanoscale optical devices. Adv Mater. 2001; 13(19):1501–05.
Barnes WL, Dereux A, Ebbesen TW. Surface plasmon subwavelength optics. Nature. 2003; 424(6950):824–30.
Smith DR, Padilla WJ, Vier D, Nemat-Nasser SC, Schultz S. Composite medium with simultaneously negative permeability and permittivity. Phys Rev Lett. 2000; 84(18):4184.
Yan M, Ruan Z, Qiu M. Scattering characteristics of simplified cylindrical invisibility cloaks. Opt Express. 2007; 15(26):17772–82.
Zhang B, Luo Y, Liu X, Barbastathis G. Macroscopic invisibility cloak for visible light. Phys Rev Lett. 2011; 106(3):033901.
Campbell SD, Sell D, Jenkins RP, Whiting EB, Fan JA, Werner DH. Review of numerical optimization techniques for meta-device design. Opt Mater Express. 2019; 9(4):1842–63.
Malkiel I, Mrejen M, Nagler A, Arieli U, Wolf L, Suchowski H. Plasmonic nanostructure design and characterization via deep learning. Light: Sci Appl. 2018; 7(1):1–8.
So S, Badloe T, Noh J, Rho J, Bravo-Abad J. Deep learning enabled inverse design in nanophotonics. Nanophotonics. 2020; 9(5):1041–57.
Russell S, Norvig P. Artificial Intelligence: a Modern Approach, 4th Ed. Hoboken: Pearson Education, Inc.; 2020.
corporation N. Difference Between AI, Machine Learning, and Deep Learning. 2021. https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/. Accessed 28 June 2021.
Elsawy MM, Lanteri S, Duvigneau R, Fan JA, Genevet P. Numerical optimization methods for metasurfaces. Laser Photon Rev. 2020; 14(10):1900445.
Rho J, Fan JA. Freeform metasurface design based on topology optimization. MRS Bull. 2020; 45(3):196–201.
Lin Z, Liu V, Pestourie R, Johnson SG. Topology optimization of freeform large-area metasurfaces. Opt Express. 2019; 27(11):15765–75.
Zhang Q, Yu H, Barbiero M, Wang B, Gu M. Artificial neural networks enabled by nanophotonics. Light: Sci Appl. 2019; 8(1):1–14.
Ma W, Liu Z, Kudyshev ZA, Boltasseva A, Cai W, Liu Y. Deep learning for the design of photonic structures. Nat Photon. 2021; 15(2):77–90.
Jiang J, Chen M, Fan JA. Deep neural networks for the evaluation and design of photonic devices. Nat Rev Mater. 2020:1–22.
Offrein BJ, Bona G-L, Germann R, Massarek I, Erni D, et al. A very short planar silica spot-size converter using a nonperiodic segmented waveguide. J Lightwave Technol. 1998; 16(9):1680.
Dobson DC, Cox SJ. Maximizing band gaps in two-dimensional photonic crystals. SIAM J Appl Math. 1999; 59(6):2108–20.
Borel PI, Harpøth A, Frandsen LH, Kristensen M, Shi P, Jensen JS, Sigmund O. Topology optimization and fabrication of photonic crystal structures. Opt Express. 2004; 12(9):1996–2001.
Lalau-Keraly CM, Bhargava S, Miller OD, Yablonovitch E. Adjoint shape optimization applied to electromagnetic design. Opt Express. 2013; 21(18):21693–701.
Molesky S, Lin Z, Piggott AY, Jin W, Vucković J, Rodriguez AW. Inverse design in nanophotonics. Nat Photonics. 2018; 12(11):659–70.
Piggott AY, Lu J, Lagoudakis KG, Petykiewicz J, Babinec TM, Vučković J. Inverse design and demonstration of a compact and broadband on-chip wavelength demultiplexer. Nat Photonics. 2015; 9(6):374–77.
Ma W, Cheng F, Liu Y. Deep-learning-enabled on-demand design of chiral metamaterials. ACS Nano. 2018; 12(6):6326–34.
Lin X, Rivenson Y, Yardimci NT, Veli M, Luo Y, Jarrahi M, Ozcan A. All-optical machine learning using diffractive deep neural networks. Science. 2018; 361(6406):1004–08.
Liu C, Maier SA, Li G. Genetic-algorithm-aided meta-atom multiplication for improved absorption and coloration in nanophotonics. ACS Photonics. 2020; 7(7):1716–22.
Bonod N, Bidault S, Burr GW, Mivelle M. Evolutionary optimization of all-dielectric magnetic nanoantennas. Adv Opt Mater. 2019; 7(10):1900121.
Li Z, Stan L, Czaplewski DA, Yang X, Gao J. Broadband infrared binary-pattern metasurface absorbers with micro-genetic algorithm optimization. Opt Lett. 2019; 44(1):114–17.
Pogrebnyakov AV, Bossard JA, Turpin JP, Musgraves JD, Shin HJ, Rivero-Baleine C, Podraza N, Richardson KA, Werner DH, Mayer TS. Reconfigurable near-ir metasurface based on ge 2 sb 2 te 5 phase-change material. Opt Mater Express. 2018; 8(8):2264–75.
Li Z, Rosenmann D, Czaplewski DA, Yang X, Gao J. Strong circular dichroism in chiral plasmonic metasurfaces optimized by micro-genetic algorithm. Opt Express. 2019; 27(20):28313–23.
Forestiere C, Donelli M, Walsh GF, Zeni E, Miano G, Dal Negro L. Particle-swarm optimization of broadband nanoplasmonic arrays. Opt Lett. 2010; 35(2):133–35.
Christiansen RE, Michon J, Benzaouia M, Sigmund O, Johnson SG. Inverse design of nanoparticles for enhanced raman scattering. Opt Express. 2020; 28(4):4444–62.
Li Y, Xu Y, Jiang M, Li B, Han T, Chi C, Lin F, Shen B, Zhu X, Lai L, et al. Self-learning perfect optical chirality via a deep neural network. Phys Rev Lett. 2019; 123(21):213902.
Tao Z, You J, Zhang J, Zheng X, Liu H, Jiang T. Optical circular dichroism engineering in chiral metamaterials utilizing a deep learning network. Opt Lett. 2020; 45(6):1403–06.
Gao L, Li X, Liu D, Wang L, Yu Z. A bidirectional deep neural network for accurate silicon color design. Adv Mater. 2019; 31(51):1905467.
Li X, Shu J, Gu W, Gao L. Deep neural network for plasmonic sensor modeling. Opt Mater Express. 2019; 9(9):3857–62.
Hemmatyar O, Abdollahramezani S, Kiarashinejad Y, Zandehshahvar M, Adibi A. Full color generation with fano-type resonant hfo 2 nanopillars designed by a deep-learning approach. Nanoscale. 2019; 11(44):21266–74.
Ma W, Cheng F, Xu Y, Wen Q, Liu Y. Probabilistic representation and inverse design of metamaterials based on a deep generative model with semi-supervised learning strategy. Adv Mater. 2019; 31(35):1901111.
Liu Z, Zhu D, Rodrigues SP, Lee K-T, Cai W. Generative model for the inverse design of metasurfaces. Nano Lett. 2018; 18(10):6570–76.
So S, Rho J. Designing nanophotonic structures using conditional deep convolutional generative adversarial networks. Nanophotonics. 2019; 8(7):1255–61.
Sajedian I, Badloe T, Rho J. Optimisation of colour generation from dielectric nanostructures using reinforcement learning. Opt Express. 2019; 27(4):5874–83.
Yao K, Unni R, Zheng Y. Intelligent nanophotonics: merging photonics and artificial intelligence at the nanoscale. Nanophotonics. 2019; 8(3):339–66.
Liu Z, Zhu D, Raju L, Cai W. Tackling Photonic Inverse Design with Machine Learning. Adv Sci. 2021; 8(5):2002923.
Xu Y, Zhang X, Fu Y, Liu Y. Interfacing photonics with artificial intelligence: an innovative design strategy for photonic structures and devices based on artificial neural networks. Photon Res. 2021; 9(4):135–52.
Wiecha PR, Arbouet A, Girard C, Muskens OL. Deep learning in nano-photonics: inverse design and beyond. Photon Res. 2021; 9(5):182–200.
Christiansen RE, Sigmund O. A tutorial for inverse design in photonics by topology optimization. arXiv preprint arXiv:2008.11816. 2020.
Ma L, Li J, Liu Z, Zhang Y, Zhang N, Zheng S, Lu C. Intelligent algorithms: new avenues for designing nanophotonic devices. Chin Opt Lett. 2021; 19(1):011301.
Christiansen RE, Sigmund O. Compact 200 line matlab code for inverse design in photonics by topology optimization: tutorial. J Opt Soc Am B. 2021; 38(2):510–20.
Wetzstein G, Ozcan A, Gigan S, Fan S, Englund D, Soljačić M, Denz C, Miller DA, Psaltis D. Inference in artificial intelligence with deep optics and photonics. Nature. 2020; 588(7836):39–47.
Zhou J, Huang B, Yan Z, Bünzli J-CG. Emerging role of machine learning in light-matter interaction. Light: Sci Appl. 2019; 8(1):1–7.
Brown KA, Brittman S, Maccaferri N, Jariwala D, Celano U. Machine learning in nanoscience: Big data at small scales. Nano Lett. 2019; 20(1):2–10.
Shastri BJ, Tait AN, de Lima TF, Pernice WH, Bhaskaran H, Wright CD, Prucnal PR. Photonics for artificial intelligence and neuromorphic computing. Nat Photon. 2021; 15(2):102–14.
Meinzer N, Barnes WL, Hooper IR. Plasmonic meta-atoms and metasurfaces. Nat Photon. 2014; 8(12):889.
Weile DS, Michielssen E. Genetic algorithm optimization applied to electromagnetics: A review. IEEE Trans Antennas Propag. 1997; 45(3):343–53.
LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015; 521(7553):436–44.
Goodfellow I, Bengio Y, Courville A, Bengio Y. Deep Learning vol. 1: MIT press Cambridge; 2016.
Bendsoe MP, Sigmund O. Topology Optimization: Theory, Methods, and Applications. Berlin: Springer; 2013.
Jensen JS, Sigmund O. Topology optimization for nano-photonics. Laser Photonics Rev. 2011; 5(2):308–21.
Schneider P-I, Garcia Santiago X, Soltwisch V, Hammerschmidt M, Burger S, Rockstuhl C. Benchmarking five global optimization approaches for nano-optical shape optimization and parameter reconstruction. ACS Photonics. 2019; 6(11):2726–33.
Kennedy J, Eberhart R. Particle swarm optimization. In: Proceedings of ICNN’95-international Conference on Neural Networks, vol. 4. IEEE: 1995. p. 1942–48.
Shi Y, et al. Particle swarm optimization: developments, applications and resources. In: Proceedings of the 2001 Congress on Evolutionary Computation (IEEE Cat. No. 01TH8546), vol. 1. IEEE: 2001. p. 81–86.
Christiansen RE, Sigmund O. Inverse design in photonics by topology optimization: tutorial. J Opt Soc Am B. 2021; 38(2):496–509.
Sigmund O. A 99 line topology optimization code written in matlab. Struct Multidiscip Optim. 2001; 21(2):120–27.
Ferrari F, Sigmund O. A new generation 99 line matlab code for compliance topology optimization and its extension to 3d. Struct Multidiscip Optim. 2020; 62(4):2211–28.
Doersch C. Tutorial on variational autoencoders. arXiv preprint arXiv:1606.05908. 2016.
Badloe T, Kim I, Rho J. Biomimetic ultra-broadband perfect absorbers optimised with reinforcement learning. Phys Chem Chem Phys. 2020; 22(4):2337–42.
Sajedian I, Lee H, Rho J. Double-deep q-learning to increase the efficiency of metasurface holograms. Sci Rep. 2019; 9(1):1–8.
Liang H, Lin Q, Xie X, Sun Q, Wang Y, Zhou L, Liu L, Yu X, Zhou J, Krauss TF, et al. Ultrahigh numerical aperture metalens at visible wavelengths. Nano Lett. 2018; 18(7):4460–66.
Phan T, Sell D, Wang EW, Doshay S, Edee K, Yang J, Fan JA. High-efficiency, large-area, topology-optimized metasurfaces. Light: Sci Appl. 2019; 8(1):1–9.
Christiansen RE, Lin Z, Roques-Carmes C, Salamin Y, Kooi SE, Joannopoulos JD, Soljačić M, Johnson SG. Fullwave maxwell inverse design of axisymmetric, tunable, and multi-scale multi-wavelength metalenses. Opt Express. 2020; 28(23):33854–68.
Mansouree M, Kwon H, Arbabi E, McClung A, Faraon A, Arbabi A. Multifunctional 2.5 d metastructures enabled by adjoint optimization. Optica. 2020; 7(1):77–84.
Zou X, Zheng G, Yuan Q, Zang W, Chen R, Li T, Li L, Wang S, Wang Z, Zhu S. Imaging based on metalenses. PhotoniX. 2020; 1(1):1–24.
Fan Y, Xu Y, Qiu M, Jin W, Zhang L, Lam EY, Tsai DP, Lei D. Phase-controlled metasurface design via optimized genetic algorithm. Nanophotonics. 2020; 9(12):3931–9.
Meem M, Banerji S, Pies C, Oberbiermann T, Majumder A, Sensale-Rodriguez B, Menon R. Large-area, high-numerical-aperture multi-level diffractive lens via inverse design. Optica. 2020; 7(3):252–53.
Banerji S, Meem M, Majumder A, Sensale-Rodriguez B, Menon R. Imaging over an unlimited bandwidth with a single diffractive surface. arXiv preprint arXiv:1907.06251. 2019.
Banerji S, Meem M, Majumder A, Sensale-Rodriguez B, Menon R. Extreme-depth-of-focus imaging with a flat lens. Optica. 2020; 7(3):214–17.
Chung H, Miller OD. High-na achromatic metalenses by inverse design. Opt Express. 2020; 28(5):6945–65.
Lin Z, Johnson SG. Overlapping domains for topology optimization of large-area metasurfaces. Opt Express. 2019; 27(22):32445–53.
Lin Z, Johnson SG. Topology-optimized nanostructures for high-na lensing optics. In: 2020 International Applied Computational Electromagnetics Society Symposium (ACES). IEEE: 2020. p. 1–2.
Bayati E, Pestourie R, Colburn S, Lin Z, Johnson SG, Majumdar A. Inverse designed metalenses with extended depth of focus. ACS Photon. 2020; 7(4):873–78.
Mansouree M, McClung A, Samudrala S, Arbabi A. Large-scale parametrized metasurface design using adjoint optimization. ACS Photon. 2021; 8(2):455–63.
Pestourie R, Mroueh Y, Nguyen TV, Das P, Johnson SG. Active learning of deep surrogates for pdes: Application to metasurface design. npj Comput Mater. 2020; 6(1):1–7.
Sell D, Yang J, Doshay S, Yang R, Fan JA. Large-angle, multifunctional metagratings based on freeform multimode geometries. Nano Lett. 2017; 17(6):3752–57.
Jiang J, Sell D, Hoyer S, Hickey J, Yang J, Fan JA. Free-form diffractive metagrating design based on generative adversarial networks. ACS Nano. 2019; 13(8):8872–78.
Liu Z, Zhu D, Lee K-T, Kim AS, Raju L, Cai W. Compounding meta-atoms into metamolecules with hybrid artificial intelligence techniques. Adv Mater. 2020; 32(6):1904790.
Chung H, Miller OD. Tunable metasurface inverse design for 80% switching efficiencies and 144 angular deflection. ACS Photon. 2020; 7(8):2236–43.
Khorasaninejad M, Capasso F. Broadband multifunctional efficient meta-gratings based on dielectric waveguide phase shifters. Nano Lett. 2015; 15(10):6709–15.
Elsawy MM, Lanteri S, Duvigneau R, Brière G, Mohamed MS, Genevet P. Global optimization of metasurface designs using statistical learning methods. Sci Rep. 2019; 9(1):1–15.
Jafar-Zanjani S, Inampudi S, Mosallaei H. Adaptive genetic algorithm for optical metasurfaces design. Sci Rep. 2018; 8(1):1–16.
Inampudi S, Mosallaei H. Neural network based design of metagratings. Appl Phys Lett. 2018; 112(24):241102.
Jiang J, Fan JA. Global optimization of dielectric metasurfaces using a physics-driven neural network. Nano Lett. 2019; 19(8):5366–72.
Wen F, Jiang J, Fan JA. Robust freeform metasurface design based on progressively growing generative networks. ACS Photon. 2020; 7(8):2098–104.
Jiang J, Fan JA. Simulator-based training of generative neural networks for the inverse design of metasurfaces. Nanophotonics. 2020; 9(5):1059–69.
Chen M, Jiang J, Fan JA. Design space reparameterization enforces hard geometric constraints in inverse-designed nanophotonic devices. ACS Photon. 2020; 7(11):3141–51.
Dory C, Vercruysse D, Yang KY, Sapra NV, Rugar AE, Sun S, Lukin DM, Piggott AY, Zhang JL, Radulaski M, et al.Inverse-designed diamond photonics. Nat Commun. 2019; 10(1):1–7.
Gostimirovic D, Winnie NY. An open-source artificial neural network model for polarization-insensitive silicon-on-insulator subwavelength grating couplers. IEEE J Sel Top Quantum Electron. 2018; 25(3):1–5.
Melati D, Grinberg Y, Dezfouli MK, Janz S, Cheben P, Schmid JH, Sánchez-Postigo A, Xu D-X. Mapping the global design space of nanophotonic components using machine learning pattern recognition. Nat Commun. 2019; 10(1):1–9.
Jin W, Molesky S, Lin Z, Fu K-MC, Rodriguez AW. Inverse design of compact multimode cavity couplers. Opt Express. 2018; 26(20):26713–21.
Su L, Trivedi R, Sapra NV, Piggott AY, Vercruysse D, Vučković J. Fully-automated optimization of grating couplers. Opt Express. 2018; 26(4):4023–34.
Sapra NV, Vercruysse D, Su L, Yang KY, Skarda J, Piggott AY, Vučković J. Inverse design and demonstration of broadband grating couplers. IEEE J Sel Top Quantum Electron. 2019; 25(3):1–7.
Jin W, Li W, Orenstein M, Fan S. Inverse design of lightweight broadband reflector for relativistic lightsail propulsion. ACS Photon. 2020; 7(9):2350–55.
Hughes TW, Minkov M, Williamson IA, Fan S. Adjoint method and inverse design for nonlinear nanophotonic devices. ACS Photon. 2018; 5(12):4781–87.
Tahersima MH, Kojima K, Koike-Akino T, Jha D, Wang B, Lin C, Parsons K. Deep neural network inverse design of integrated photonic power splitters. Sci Rep. 2019; 9(1):1–9.
Liu Z, Liu X, Xiao Z, Lu C, Wang H-Q, Wu Y, Hu X, Liu Y-C, Zhang H, Zhang X. Integrated nanophotonic wavelength router based on an intelligent algorithm. Optica. 2019; 6(10):1367–73.
Lu C, Liu Z, Wu Y, Xiao Z, Yu D, Zhang H, Wang C, Hu X, Liu Y-C, Liu X, et al. Nanophotonic polarization routers based on an intelligent algorithm. Adv Opt Mater. 2020; 8(10):1902018.
Su L, Vercruysse D, Skarda J, Sapra NV, Petykiewicz JA, Vučković J. Nanophotonic inverse design with spins: Software architecture and practical considerations. Appl Phys Rev. 2020; 7(1):011407.
Piggott AY, Petykiewicz J, Su L, Vučković J. Fabrication-constrained nanophotonic inverse design. Sci Rep. 2017; 7(1):1–7.
Zangeneh-Nejad F, Sounas DL, Alù A, Fleury R. Analogue computing with metamaterials. Nat Rev Mater. 2020:1–19.
Marković D, Mizrahi A, Querlioz D, Grollier J. Physics for neuromorphic computing. Nat Rev Phys. 2020; 2(9):499–510.
Xu R, Lv P, Xu F, Shi Y. A survey of approaches for implementing optical neural networks. Opt Laser Technol. 2021; 136:106787.
Liu J, Wu Q, Sui X, Chen Q, Gu G, Wang L, Li S. Research progress in optical neural networks: theory, applications and developments. PhotoniX. 2021; 2(1):1–39.
Shen Y, Harris NC, Skirlo S, Prabhu M, Baehr-Jones T, Hochberg M, Sun X, Zhao S, Larochelle H, Englund D, et al.Deep learning with coherent nanophotonic circuits. Nat Photon. 2017; 11(7):441.
Hughes TW, Minkov M, Shi Y, Fan S. Training of photonic neural networks through in situ backpropagation and gradient measurement. Optica. 2018; 5(7):864–71.
Qu Y, Zhu H, Shen Y, Zhang J, Tao C, Ghosh P, Qiu M. Inverse design of an integrated-nanophotonics optical neural network. Sci Bull. 2020; 65(14):1177–83.
Khoram E, Chen A, Liu D, Ying L, Wang Q, Yuan M, Yu Z. Nanophotonic media for artificial neural inference. Photon Res. 2019; 7(8):823–27.
Harris NC, Carolan J, Bunandar D, Prabhu M, Hochberg M, Baehr-Jones T, Fanto ML, Smith AM, Tison CC, Alsing PM, et al.Linear programmable nanophotonic processors. Optica. 2018; 5(12):1623–31.
Estakhri NM, Edwards B, Engheta N. Inverse-designed metastructures that solve equations. Science. 2019; 363(6433):1333–38.
Hamerly R, Bernstein L, Sludds A, Soljačić M, Englund D. Large-scale optical neural networks based on photoelectric multiplication. Phys Rev X. 2019; 9(2):021032.
Miscuglio M, Sorger VJ. Photonic tensor cores for machine learning. Appl Phys Rev. 2020; 7(3):031404.
Zhou T, Fang L, Yan T, Wu J, Li Y, Fan J, Wu H, Lin X, Dai Q. In situ optical backpropagation training of diffractive optical neural networks. Photon Res. 2020; 8(6):940–53.
Yan T, Wu J, Zhou T, Xie H, Xu F, Fan J, Fang L, Lin X, Dai Q. Fourier-space diffractive deep neural network. Phys Rev Lett. 2019; 123(2):023901.
Qian C, Lin X, Lin X, Xu J, Sun Y, Li E, Zhang B, Chen H. Performing optical logic operations by a diffractive neural network. Light: Sci Appl. 2020; 9(1):1–7.
Sui X, Wu Q, Liu J, Chen Q, Gu G. A review of optical neural networks. IEEE Access. 2020; 8:70773–83.
Li J, Mengu D, Luo Y, Rivenson Y, Ozcan A. Class-specific differential detection in diffractive optical neural networks improves inference accuracy. Adv Photon. 2019; 1(4):046001.
Luo Y, Mengu D, Yardimci NT, Rivenson Y, Veli M, Jarrahi M, Ozcan A. Design of task-specific optical systems using broadband diffractive neural networks. Light: Sci Appl. 2019; 8(1):1–14.
Dou H, Deng Y, Yan T, Wu H, Lin X, Dai Q. Residual d 2 nn: training diffractive deep neural networks via learnable light shortcuts. Opt Lett. 2020; 45(10):2688–91.
Rahman MSS, Li J, Mengu D, Rivenson Y, Ozcan A. Ensemble learning of diffractive optical networks. Light: Sci Appl. 2021; 10(1):1–13.
Muminov B, Vuong LT. Fourier optical preprocessing in lieu of deep learning. Optica. 2020; 7(9):1079–88.
Lu L, Zhu L, Zhang Q, Zhu B, Yao Q, Yu M, Niu H, Dong M, Zhong G, Zeng Z. Miniaturized diffraction grating design and processing for deep neural network. IEEE Photon Technol Lett. 2019; 31(24):1952–55.
Wu Z, Zhou M, Khoram E, Liu B, Yu Z. Neuromorphic metasurface. Photon Res. 2020; 8(1):46–50.
Wang H, Piestun R. Azimuthal multiplexing 3d diffractive optics. Sci Rep. 2020; 10(1):1–9.
Huang Z, Wang P, Liu J, Xiong W, He Y, Xiao J, Ye H, Li Y, Chen S, Fan D. All-optical signal processing of vortex beams with diffractive deep neural networks. Phys Rev Appl. 2021; 15(1):014037.
Ren H, Shao W, Li Y, Salim F, Gu M. Three-dimensional vectorial holography based on machine learning inverse design. Sci Adv. 2020; 6(16):4261.
Sitawarin C, Jin W, Lin Z, Rodriguez AW. Inverse-designed photonic fibers and metasurfaces for nonlinear frequency conversion. Photon Res. 2018; 6(5):82–89.
Wiecha PR, Lecestre A, Mallet N, Larrieu G. Pushing the limits of optical information storage using deep learning. Nat Nanotechnol. 2019; 14(3):237–44.
Li L, Shuang Y, Ma Q, Li H, Zhao H, Wei M, Liu C, Hao C, Qiu C-W, Cui TJ. Intelligent metasurface imager and recognizer. Light: Sci Appl. 2019; 8(1):1–9.
Piggott AY, Ma EY, Su L, Ahn GH, Sapra NV, Vercruysse D, Netherton AM, Khope AS, Bowers JE, Vuckovic J. Inverse-designed photonics for semiconductor foundries. ACS Photon. 2020; 7(3):569–75.
Xie Z, Lei T, Qiu H, Zhang Z, Wang H, Yuan X. Broadband on-chip photonic spin hall element via inverse design. Photon Res. 2020; 8(2):121–26.
Minkov M, Williamson IA, Andreani LC, Gerace D, Lou B, Song AY, Hughes TW, Fan S. Inverse design of photonic crystals through automatic differentiation. ACS Photon. 2020; 7(7):1729–41.
Yang KY, Skarda J, Cotrufo M, Dutt A, Ahn GH, Sawaby M, Vercruysse D, Arbabian A, Fan S, Alù A, et al.Inverse-designed non-reciprocal pulse router for chip-based lidar. Nat Photon. 2020; 14(6):369–74.
Chakravarthi S, Chao P, Pederson C, Molesky S, Ivanov A, Hestroffer K, Hatami F, Rodriguez AW, Fu K-MC. Inverse-designed photon extractors for optically addressable defect qubits. Optica. 2020; 7(12):1805–11.
Christiansen RE, Wang F, Sigmund O. Topological insulators by topology optimization. Phys Rev Lett. 2019; 122(23):234502.
Sapra NV, Yang KY, Vercruysse D, Leedle KJ, Black DS, England RJ, Su L, Trivedi R, Miao Y, Solgaard O, et al.On-chip integrated laser-driven particle accelerator. Science. 2020; 367(6473):79–83.
Zhao R, Huang L, Wang Y. Recent advances in multi-dimensional metasurfaces holographic technologies. PhotoniX. 2020; 1(1):1–24.
Liu J, Ma Y. A survey of manufacturing oriented topology optimization methods. Adv Eng Softw. 2016; 100:161–75.
Zhan A, Gibson R, Whitehead J, Smith E, Hendrickson JR, Majumdar A. Controlling three-dimensional optical fields via inverse mie scattering. Sci Adv. 2019; 5(10):4769.
Augenstein Y, Rockstuhl C. Inverse design of nanophotonic devices with structural integrity. ACS Photon. 2020; 7(8):2190–96.
Lin Z, Roques-Carmes C, Christiansen RE, Soljačić M, Johnson SG. Computational inverse design for ultra-compact single-piece metalenses free of chromatic and angular aberration. Appl Phys Lett. 2021; 118(4):041104.
Zheng B, Yang J, Liang B, Cheng J-c. Inverse design of acoustic metamaterials based on machine learning using a gauss–bayesian model. J Appl Phys. 2020; 128(13):134902.
Kudyshev ZA, Kildishev AV, Shalaev VM, Boltasseva A. Machine-learning-assisted metasurface design for high-efficiency thermal emitter optimization. Appl Phys Rev. 2020; 7(2):021407.
Qu Y, Jing L, Shen Y, Qiu M, Soljacic M. Migrating knowledge between physical scenarios based on artificial neural networks. ACS Photon. 2019; 6(5):1168–74.
Yeung C, Tsai J-M, King B, Kawagoe Y, Ho D, Knight MW, Raman AP. Elucidating the behavior of nanophotonic structures through explainable machine learning algorithms. ACS Photon. 2020; 7(8):2309–18.
Kiarashinejad Y, Zandehshahvar M, Abdollahramezani S, Hemmatyar O, Pourabolghasem R, Adibi A. Knowledge discovery in nanophotonics using geometric deep learning. Adv Intell Syst. 2020; 2(2):1900132.
Wiecha PR, Arbouet A, Girard C, Muskens OL. Deep learning in nano-photonics: inverse design and beyond. arXiv preprint arXiv:2011.12603. 2020.
Jiang J, Lupoiu R, Wang EW, Sell D, Hugonin JP, Lalanne P, Fan JA. Metanet: a new paradigm for data sharing in photonics research. Opt Express. 2020; 28(9):13670–81.
Goi E, Zhang Q, Chen X, Luan H, Gu M. Perspective on photonic memristive neuromorphic computing. PhotoniX. 2020; 1(1):1–26.
Lugnan A, Katumba A, Laporte F, Freiberger M, Sackesyn S, Ma C, Gooskens E, Dambre J, Bienstman P. Photonic neuromorphic information processing and reservoir computing. APL Photon. 2020; 5(2):020901.
Ballarini D, Gianfrate A, Panico R, Opala A, Ghosh S, Dominici L, Ardizzone V, De Giorgi M, Lerario G, Gigli G, et al. Polaritonic neuromorphic computing outperforms linear classifiers. Nano Lett. 2020; 20(5):3506–12.
de Lima TF, Tait AN, Mehrabian A, Nahmias MA, Huang C, Peng H-T, Marquez BA, Miscuglio M, El-Ghazawi T, Sorger VJ, et al.Primer on silicon neuromorphic photonic processors: architecture and compiler. Nanophotonics. 2020; 9(13):4055–73.
Abdollahramezani S, Hemmatyar O, Adibi A. Meta-optics for spatial optical analog computing. Nanophotonics. 2020; 9(13):4075–95.
Norman JC, Jung D, Wan Y, Bowers JE. Perspective: The future of quantum dot photonic integrated circuits. APL Photon. 2018; 3(3):030901.
Peng H-T, Nahmias MA, De Lima TF, Tait AN, Shastri BJ. Neuromorphic photonic integrated circuits. IEEE J Sel Top Quantum Electron. 2018; 24(6):1–15.
Zhang XG, Jiang WX, Jiang HL, Wang Q, Tian HW, Bai L, Luo ZJ, Sun S, Luo Y, Qiu C-W, et al.An optically driven digital metasurface for programming electromagnetic functions. Nat Electron. 2020; 3(3):165–71.
Tsilipakos O, Tasolamprou AC, Pitilakis A, Liu F, Wang X, Mirmoosa MS, Tzarouchis DC, Abadal S, Taghvaee H, Liaskos C, et al.Toward intelligent metasurfaces: The progress from globally tunable metasurfaces to software-defined metasurfaces with an embedded network of controllers. Adv Opt Mater. 2020; 8(17):2000783.
Ma Q, Cui TJ. Information metamaterials: bridging the physical world and digital world. PhotoniX. 2020; 1(1):1–32.
Xu X, Tan M, Corcoran B, Wu J, Boes A, Nguyen TG, Chu ST, Little BE, Hicks DG, Morandotti R, et al.11 tops photonic convolutional accelerator for optical neural networks. Nature. 2021; 589(7840):44–51.
Camacho M, Edwards B, Engheta N. A single inverse-designed photonic structure that performs parallel computing. arXiv preprint arXiv:2009.01187. 2020.
Zhou T, Lin X, Wu J, Chen Y, Xie H, Li Y, Fan J, Wu H, Fang L, Dai Q. Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit. Nat Photon. 2021:1–7.
Zuo Y, Li B, Zhao Y, Jiang Y, Chen Y-C, Chen P, Jo G-B, Liu J, Du S. All-optical neural network with nonlinear activation functions. Optica. 2019; 6(9):1132–37.
Acknowledgements
The authors gratefully acknowledge support from the National Natural Science Foundation of China (No. 62005224, 61927820) and the National Key Research and Development Program of China (2017YFA0205700). N.W. specially thanks for Dr. Tim Jiangbo Zhao for his proofreading of the manuscript.
Funding
National Natural Science Foundation of China (No. 62005224,61927820), National Key Research and Development Program of China (2017YFA0205700)
Author information
Authors and Affiliations
Contributions
NW and MQ conceived the idea. NW prepared the manuscript. WY, YQ, SM, SL, and MQ revised the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare that they have no competing interests
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, N., Yan, W., Qu, Y. et al. Intelligent designs in nanophotonics: from optimization towards inverse creation. PhotoniX 2, 22 (2021). https://doi.org/10.1186/s43074-021-00044-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s43074-021-00044-y