
Abstract
Background
The lint percentage of seed cotton is one of the most important parameters for evaluating seed cotton quality and affects its price. The traditional measuring method of lint percentage is labor-intensive and time-consuming; thus, an efficient and accurate measurement method is needed. In recent years, classification-based deep learning and computer vision have shown promise in solving various classification tasks.
Results
In this study, we propose a new approach for detecting the lint percentage using MobileNetV2 and transfer learning. The model is deployed on a lint percentage detection instrument, which can rapidly and accurately determine the lint percentage of seed cotton. We evaluated the performance of the proposed approach using a dataset comprising 66 924 seed cotton images from different regions of China. The results of the experiments showed that the model with transfer learning achieved an average classification accuracy of 98.43%, with an average precision of 94.97%, an average recall of 95.26%, and an average F1-score of 95.20%. Furthermore, the proposed classification model achieved an average accuracy of 97.22% in calculating the lint percentage, showing no significant difference from the performance of experts (independent-sample t-test, t = 0.019, P = 0.860).
Conclusion
This study demonstrated the effectiveness of the MobileNetV2 model and transfer learning in calculating the lint percentage of seed cotton. The proposed approach is a promising alternative to traditional methods, providing a rapid and accurate solution for the industry.
Similar content being viewed by others

Introduction
Cotton is a crucial crop, and its fibers are widely utilized in the manufacture of various textiles. Cotton fibers are long, uniformly coarse, and flexible, making them ideal for the production of textiles for a range of applications, including clothing, bedding, towels, cloth bags, and rope (Cao, 2015). Cotton is also used in the production of pigments and oils as a raw material in the food industry and the pharmaceutical industry. The global annual production of cotton is estimated to be approximately 20 million tons (Chen et al., 2018). Cottonseed, a byproduct of cotton production, holds substantial economic importance and has numerous applications in the agricultural and food industries (Kang et al., 2022; Ma et al., 2022). As a food source, cottonseed is rich in protein, fat, carbohydrates, and minerals, and contains unsaturated fatty acids, which can aid in lowering cholesterol levels and reducing the risk of cardiovascular disease (Kumar et al., 2021; Li et al., 2021). The lint percentage of seed cotton is closely correlated with both cotton yield and quality, with a higher lint percentage serves as a significant indicator of increased yield potential. Consequently, the lint percentage not only impacts the economic viability of cotton production but also plays a pivotal role in the identification and selection of optimal cotton varieties. Prioritizing the cultivation of cotton varieties with elevated lint percentages holds the promise of enhancing yield outcomes and bolstering overall economic returns in cotton farming practices.
Given the significant economic value of both cotton fibre and cottonseed, the assessment of cotton quality is essential for determining its market value, and the lint percentage is one of the important factors in determining the quality and the price of seed cotton. However, the traditional method of measuring lint percentage is complex, time-consuming, and requires four steps: weighing and recording the seed cotton sample, separating lint from the seed cotton sample through a cotton gin, weighing and recording the separated lint, and finally calculating the lint percentage using a professional formula. As the trend towards automation and intelligence in various industries continues, the traditional methods of lint percentage calculation have become increasingly obsolete. Previously, a nondestructive detection method was proposed for automatically obtaining the lint percentage of seed cotton based on optical penetration imaging and machine vision. The test results showed that the average accuracy of this new method for calculating the lint percentage of the H219 and ZHM19 varieties was 96.33% and 95.40%, respectively (Geng et al., 2022). This method offers the advantages of rapid, nondestructive, and intelligent detection. The core algorithm of this method utilizes three features, image grayscale values, perimeter, and area, for the recognition and counting of cottonseeds, enabling the computation of the lint percentage of seed cotton.
To explore an intelligent and more accurate seed cotton lint percentage detection method, this paper delves into a more in-depth nondestructive detection investigation based on optical penetration imaging and visual deep learning algorithms. Deep learning techniques represent a broad category of machine learning methods that have achieved impressive efficacy across a wide range of applications (Wang et al., 2020). These techniques differ from traditional graph-based methods because they eliminate the need for expertise in feature extraction, which is often a labor-intensive and subjective process (Delacre et al., 2017). However, deep learning approaches can automatically extract features for image classification.
Recently, the application of deep learning algorithms in agricultural pest detection and assessment has garnered significant attention from the research community. A deep residual learning algorithm was proposed to identify pest species in crops with a remarkable accuracy of 98.67% (Cheng et al., 2017). An image acquisition system based on fruit posture adjustment equipment was proposed, and the YOLO-v5 algorithm based on deep learning was used to study the real-time recognition of the stem/calyx of apples (Wang et al., 2022). The efficacy of the MobileNetV2 deep learning model in recognizing three termite species was also examined, with results indicated that the model could recognize the species with an accuracy of 94.7%, which was indistinguishable from the accuracy achieved by specialists in the field (Huang et al., 2021). Additionally, a deep learning model to identify and classify foliar plant diseases using images from public datasets and the TensorFlow open source library was proposed, achieving an average classification accuracy of 97% on training datasets and 92% on test data (Elfatimi et al., 2022). The use of the VGG16 model for disease classification of tomato plant leaves was proposed, and an accuracy of 99.17% was achieved (Wagle et al., 2021). In conclusion, these studies demonstrated the potential of deep learning algorithms in agricultural pest detection and assessment, highlighting the importance for further research to improve the accuracy and efficiency of these tools.
In industrial applications, deep learning also plays an important role. A fault diagnosis model for industrial applications that leverages the lightweight convolutional neural network (CNN) MobileNet was proposed. This model can diagnose the health status of rolling bearings in real time and has demonstrated impressive performance, with an accuracy of over 96% for identifying ten different rolling bearing health states (Hu et al., 2022). In another study, an improved model for mechanical fault diagnosis, named the ReLU-CNN model, was proposed. The results of experiments indicated that the proposed model exhibits both good performance and rapid convergence, making it a promising approach for industrial fault diagnosis (Qian et al., 2018). The real-time performance and high accuracy of the proposed models have the potential to significantly impact the maintenance and repair of industrial machinery, ultimately leading to increased productivity.
This study introduces a novel hardware system known as the lint percentage detection system (LPDS), which relies on deploying a MobileNetV2 model trained using transfer learning techniques. LPDS hardware devices help to automate and smarten the lint percentage detection process. This system is designed to be easily adopted.
Materials and methods
This section presents a detailed description of the steps involved in detecting the lint percentage. It is divided into several subsections, including image acquisition, segmentation of cotton seeds, augmentation and preprocessing of the dataset images, description of the proposed model architecture, training of the CNN, classification and performance evaluation, and lint percentage calculation. The steps above are detailed below:
Image acquisition
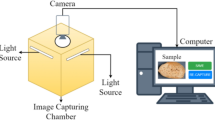
We designed the LPDS hardware, the specific structure of which is shown in Fig. 1a. The device comprises an industrial computer (YanQin0TF-7612 L, i5-4200U, Shenzhen, China), a touch-sensitive LCD screen (with a screen size of 24.5 × 18.5 cm, a resolution of 1 280 × 720 pixels, and a refresh rate of 75 Hz), an LED light source intensity regulator, and an LED light source (measuring 323 mm × 323 mm × 7 mm and providing 24 V/43.2 W of power). The LED light source is fixed on the top lid of the LPDS. The LPDS device is equipped with a black compartment (measuring 50 cm × 54 cm × 84 cm), which houses a built-in camera (Hikvision MV-CE100-30GC, with a sensitivity of 0.8 lx and a resolution of 3 840 × 2 748) and a conditioning board that is used to adjust the position of the camera. The top of the compartment has a recess (measuring 319 mm × 319 mm × 12 mm) to accommodate a piece of clear Plexiglas (measuring 315 mm × 315 mm × 5 mm), which serves as the image acquisition area. The white LED light penetrates the seed cotton samples placed on the Plexiglas to acquire images, as illustrated in Fig. 1b. The depth of the recess is set to 12 mm to avoid stacking seed cotton layers and to improve image quality, given that the thickness of a single cotton seed ranges from 4 to 6 mm. The top lid was closed to firmly press the seed cotton samples against the Plexiglas. This design allows for a reliable and high-quality image acquisition process.

Construction of lint percentage detection system (LPDS). a Actual device. b The operation diagram of the LPDS device with samples below the white light source. c Transmission images of seed cotton were acquired under white light illumination with a CCD camera
Segmentation of seed cotton image
The raw image of the seed cotton collected by the LPDS is depicted in Fig. 2a. To extract the cotton seeds from the original images, a series of image processing algorithms were applied. The first step involved converting a red-green-blue (RGB) image into a binary image using Otsu thresholding (Otsu, 1979) and reinforcing the edge features of the acquisition area (Fig.2b). By applying this threshold, the area of image acquisition was obtained (Fig. 2c). To prevent loss of features near the edge of the image, each boundary of the image acquisition area was extended outward by 50 pixels (Fig. 2d). In the next step, a dilation operation was applied to expand the area of the cotton seed image (Fig. 2e). This expansion linked some adjacent cotton seeds together and increased the area of extraction, which helped to extract the cotton seed images while avoiding loss of features. Subsequently, using a contour-finding algorithm (Suzuki et al., 1985), all contours of the cotton seed were found (Fig.2f), and a bounding box was applied to frame the cotton seed area using a rectangle as an image mask. Finally, the original image was cropped to acquire all cotton seed areas (Fig. 2g).

Procedure for image segmentation of cotton seeds. a The original full image. b A binary image obtained by the Otsu threshold. c The area of image acquisition was extracted from the original image. d Each boundary of the image acquisition area was extended outward by 50-pixel points. e The cotton seeds near each other were connected, and the area of the cotton seed image was increased by an expansion operation. f All the contours were found by the contour finder function. g The cropped images
Augmentation and preprocessing of the dataset images
To overcome the challenge of acquiring a large quantity of training data, typically required by deep learning techniques, we employed data augmentation techniques to augment the size of our training dataset. By performing augmentation processing on the dataset, we aimed to compensate for the limited quantity of image data and improve the performance of our deep CNN model. The augmentation procedures consisted of ten different combinations: rotation, shear, scaling, adaptive histogram equalization, horizontal flipping, and vertical flipping. The dataset consists of a total of 66 924 seed-cotton images categorized into six categories, which were obtained from 102 original images collected in a real-life scenario. The original images and dataset are available online via the following link: https://pan.baidu.com/s/1NGu7YNuTxhSimywJGMKeJA?pwd=nd3l.
The total dataset was divided into two distinct parts to optimize performance of the deep learning model employed in this study, with 80% of the data designated for training and the remaining 20% reserved for validation. The distribution of images in each dataset and the number of images per category are documented in Table 1. Categories A, B, C, D, E, and F represent the number of cottonseeds in the image of seed cotton as 0, 1, 2, 3, 4, and 5, respectively. Preprocessing, a crucial step in any analysis (Dyrmann et al., 2016), was conducted to standardize the image dimensions of the dataset to the required input size of 224 × 224 × 3 for compatibility with the MobileNetV2 model used. This involved adjusting the image size of all images in the dataset to the specified dimensions, thereby ensuring consistency and efficient operation of the algorithm.
Description of the proposed model architecture
The MobileNetV2 model, developed by the Google development team, is optimized for deployment on mobile and embedded devices (Sandler et al., 2018). The model parameters are presented in Table2. Compared with many other deep CNN models, the MobileNetV2 model has a smaller volume and faster computational speed (Song et al., 2021). The model employs a depthwise separable convolution layer, which is divided into a depthwise convolution layer and a pointwise convolutional layer. The depthwise layer extracts features from the input image, while the pointwise layer merges these features. This design not only reduces the model volume but also decreases computations by approximately one-eighth to one-ninth. The structure of the MobileNetV2 model is depicted in Fig.3, with some modifications made to the fully connected layer, whose output dimension was changed from 1 000 to 6 to match the 6-category division of the dataset.

The visual representation of the MobileNetV2 model
Training of the convolutional neural network
In this study, two MobileNetV2 models were utilized to calculate the percentage of lint in seed cotton. The two models were almost identical, differing only in the training approach applied. One MobileNetV2 model was trained using the transfer learning technique, which involves fine-tuning the parameters of a network that has been pretrained on a large dataset (Martineau et al., 2018). The other model was trained without transfer learning. The MobileNetV2 model trained with transfer learning was initialized with weights obtained from a network pretrained on the ImageNet dataset (Deng et al., 2009), which comprises 1.4 million images and 1 000 classes of web images. Both models were trained with 64 samples per batch, an initial learning rate of 0.01, a momentum factor of 0.9, and a total of 600 iterations. The initial learning rate was gradually reduced by a factor of 5 after every 100 training iterations, and the model weights were saved every 5 iterations until the end of the training process. The accuracy rate and loss rate were recorded at each session to monitor the performance of the models.
Classification and performance evaluation
A test dataset was utilized to evaluate the performance of the deep learning models for the classification task, and four evaluation metrics were employed: accuracy rate, precision rate, recall rate, and F1-score. These metrics provide insight into the ability of the models to accurately classify the data. The equations of these metrics are as follows:
The results of the classification task were also represented through confusion matrices, which depicted the correct or incorrect classifications of objects. In the matrices, the diagonal elements in the matrices represented the correctly classified objects, while the off-diagonal elements represented the incorrectly classified objects. The classification performance was further evaluated by computing true positives (TPs), true negatives (TNs), false positives (FPs), and false negatives (FNs). These four parameters have been widely used in machine learning to assess the performance of classification models and provide insights into their behavior. The meanings of these four parameters are as follows (Sathyanarayana et al., 2016):
-
True Positive (TP): positive samples that were correctly labeled by the classifier,
-
True Negative (TN): negative samples that were correctly labeled by the classifier,
-
False Positive (FP): negative samples that were incorrectly labeled as positive,
-
False Negative (FN): positive samples that were incorrectly labeled negative.
According to the evaluation metrics discussed above, a comprehensive evaluation of the experimental results was carried out. Given that the dataset was composed of six classes, the size of the confusion matrix utilized in this study was 6 × 6.
Lint percentage calculation
In the cotton industry, the lint percentage of seed cotton (LPOSC) is calculated by the following formula:
where M represents the mass of the seed cotton sample and m represents the mass of the cotton seed in the seed cotton sample. In traditional methods, m is obtained by initially separating the seed cotton into cotton seed and lint using a cotton gin, and then weighing the cotton seed. In this research, the value of m can be obtained using the following equation:
where N represents the total number of cotton seeds in the seed sample, which was obtained by the trained MobileNetV2 model, and mavg represents the average weight of a single cotton seed. Thus, Eq. (5) can be expressed as Eq. (7):
In this study, the cotton varieties GB819 and X1907 were selected as the research objects.
We randomly sampled the GB819 cotton variety and performed measurements and statistics.The statistical results showed that the total number of cotton seeds in the sample (N) was 2 036, and the average weight of a single cotton seed (mavg) was approximately 0.090 128 g. Similarly, for the X19075 variety, N was 2 129, and mavg was approximately 0.100 563 g. In calculating the LPOSC, the mavg for each cotton variety was compiled into the computing system as known data. The computing system could choose to call or not call mavg, depending on the specific application. The total seed cotton mass (M) was obtained by a weighing sensor, which was automatically passed through the LPOSC computing system.
Results and discussion
Model training and testing were conducted by using the Windows 10 operating system (CPU Intel Core i5 10600KF, 64 GB RAM, NVIDIA GeForce RTX 3060TI) with Python 3.9.9, PyTorch 1.10.2, Torchvision 0.11.3, and CUDA 11.4. We used an adaptive moment (Kingma et al., 2014), estimation as the optimizer, and categorical cross-entropy (De Boer et al., 2005) served as the loss function for training classifiers.
The six image categories of the seed cotton in the dataset used for training the network are depicted in Fig. 4. The entire dataset was segmented into six sub-datasets based on the number of cotton seeds present in each image. Specifically, category A corresponds to images containing 0 cotton seeds, category B corresponds to images containing 1 cotton seed, category C corresponds to images containing 2 cotton seeds, category D corresponds to images containing 3 cotton seeds, category E corresponds to images containing 4 cotton seeds, and category F corresponds to images containing 5 cotton seeds. To ensure the accuracy of the model classification, the seed cotton images in the dataset were meticulously reviewed multiple times to confirm their correctness and to prevent potential decreases in model performance resulting from incorrectly classified samples.

Six category images of the seed cotton in the dataset used for training the network
The performance curves of the seed cotton image classification based on MobileNetV2, both without transfer learning and with transfer learning, are displayed in Figs. 5 and 6. As the number of training epochs increases, the training accuracy of both models increases, while the loss function curve decreases downward in a symmetrical manner during training. The relatively small gap between the training and validation curves indicates that the models exhibit strong generalizability and are proficient in providing accurate predictions for previously unseen seed cotton images. After 600 training iterations, the MobileNetV2 model without transfer learning achieved an average accuracy of 97.01% with a loss value of 0.493 0. The MobileNetV2 model with transfer learning outperformed its counterpart, with an average accuracy of 98.30% and a lower loss value of 0.394 2.

Performance of seed cotton image classification based on MobileNetV2 without transfer learning

Performance of seed cotton image classification based on MobileNetV2 with transfer learning
The utilization of a confusion matrix is deemed an essential method for evaluating the performance of CNN models in image classification (Pan et al., 2020). The confusion matrix provides a clear understanding of the accuracy and mode of confusion during the predictions made by the model. In the matrix, the rows represent the actual categorization of the seed cotton images, while the columns represent the predicted categorization of the seed cotton images. As illustrated in Fig.7, the results of the seed cotton image classification are presented, where the categories are labeled A, B, C, D, E, and F, and the scale on the right represents the number of seed cotton images.

Confusion matrix for the MobileNetV2 models. a MobileNetV2 model training without transfer learning. b MobileNetV2 model training with transfer learning
Table 3 presents a binary representation of the 6 × 6 confusion matrix depicted in Fig. 7. It is important to note that the number of test images for each category is not equal, leading to unequal values for FNs, FPs, TNs, and TPs for each category.
The results of the seed cotton image classification task utilizing the two MobileNetV2 models are presented in Fig. 8. It is evident that the two MobileNetV2 models displayed a robust ability to differentiate between the various seed cotton image categories, as evidenced by the successful predictions during the testing phase. However, in some cases, similar images from categories A and B were misclassified, as shown in Fig. 7a. This misclassification occurred due to the similarities between the two categories, resulting in a miscalibration in the MobileNetV2 model without transfer learning.

Visualization results of the seed cotton dataset for an input size of 224 × 224 × 3. a MobileNetV2 model training without transfer learning. b MobileNetV2 model training with transfer learning
The presentation of image features is important for the analysis of seed cotton images. MobileNet uses the k-nearest neighbor (kNN) algorithm, which uses the semantic information represented in the logits to compare the images in the dataset and unknown samples as the classifier (Ong et al., 2021); Howard et al., 2017)). To ensure an accurate representation of seed cotton morphological features, a controlled environment was established to develop the model. Stringent measures were taken to standardize the lighting intensity and sample camera distance, thereby minimizing potential sources of error.
The performance of the proposed classification system was evaluated using four widely recognized metrics: accuracy, precision, recall, and F1-score (Assi et al., 2010). The evaluation results are presented in Table4. Both proposed models demonstrated satisfactory performance, with the MobileNetV2 model without transfer learning achieving a mean accuracy, precision, recall, and F1-score of 97.92%, 93.98%, 93.83%, and 93.88%, respectively. However, the MobileNetV2 model incorporating transfer learning demonstrated significantly improved results, with a mean accuracy, precision, recall, and F1-score of 98.43%, 94.97%, 95.26%, and 95.20%, respectively.
The receiver operating characteristic (ROC) curves of the two proposed models are depicted in Fig. 9, where the horizontal axis represents the true positive rate (TPR) and the vertical axis represents the false positive rate (FPR). The results show a high TPR and a low FPR, indicating that the proposed models exhibit strong image recognition abilities for seed cotton images. Furthermore, a comparison of the ROC curves reveals that the model incorporating transfer learning exhibits improved classification performance, as demonstrated by a larger area under the curve compared with the model without transfer learning. This suggests that the MobileNetV2 model trained with transfer learning technique has superior classification capability.

ROC curves for different approaches. a ROC curve for MobileNetV2 without transfer learning. b ROC curve for MobileNetV2 with transfer learning
In this study, the MobileNetV2 model incorporating transfer learning techniques was deployed on an LPDS device for LPOSC calculations. A test group consisting of twenty groups, each of the cotton varieties GB819 and X19075, was used to assess the model’s reliability. To further evaluate the dependability of the model, the same 40 groups of seed cotton samples were subjected to lint percentage determination with the assistance and guidance of professionals from the Fiber Inspection Bureau in Henan Province. The results of the LPOSC calculations performed by the proposed model are presented in Table 5, while the results obtained by the LPOSC detection institution are provided in Table 6.
Figure 10 shows the accuracy of the MobileNetV2 model in determining the lint percentage for the 40 groups of samples. Upon deployment of the MobileNetV2 model on an industrial computer, the model achieved an accuracy of 97.22%. Although the model performance was slightly inferior to human detection, an independent sample t-test (t = 0.019, P = 0.860) revealed no statistically significant differences in accuracy between the two methods. These results indicate that the proposed method performs comparably to human detection in determining the lint percentage.

The accuracy of the results calculated with the MobileNetV2 model
Conclusion
In this study, we explored the use of white light as a transmitted light source for seed cotton image analysis. Furthermore, a nondestructive detection system to determine the lint percentage of seed cotton was developed, using the MobileNetV2 architecture and transfer learning techniques. The system was trained on seed cotton images and evaluated using various metrics, such as accuracy and F1-score. The results of the experiments indicated that the optimal classifier achieved an accuracy of 98.43% and an F1-score of 95.20%. Furthermore, the deployment of the proposed model to an industrial computer for lint percentage calculation resulted in an accuracy of 97.22%.
In conclusion, based on the white light penetrating imaging, we introduced a novel method for detecting the lint percentage utilizing MobileNetV2 and transfer learning techniques. To the best of our knowledge, limited research exists on the nondestructive detection of the percentage of seed cotton lint. Therefore, this study provides a new feasible approach to fill this gap, and the results show that this method holds potential for enhancing automation and intelligence in the cotton industry.
Availability of data and materials
The data presented in this study are available on request from the corresponding author.
References
Assi SA, Tanaka T, Rabbitts TH, et al. PCRPi: Presaging critical residues in protein interfaces, a new computational tool to chart hot spots in protein interfaces. Nucleic Acids Res. 2010;38(6):e86. https://doi.org/10.1093/nar/gkp1158.
Cao XF. Whole genome sequencing of cotton-a new chapter in cotton genomics. Sci China Life Sci. 2015;58(5):515–6. https://doi.org/10.1007/s11427-015-4862-z.
Chen TT, Zeng R, Guo WX, et al. Detection of stress in cotton (Gossypium hirsutum L.) caused by aphids using Leaf Level Hyperspectral measurements. Sensors. 2018;18(9):13. https://doi.org/10.3390/s18092798.
Cheng X, Zhang YH, Chen YQ, et al. Pest identification via deep residual learning in complex background. Comput Electron Agr. 2017;141:351–6. https://doi.org/10.1016/j.compag.2017.08.005.
De Boer PT, Kroese DP, Mannor S, et al. A tutorial on the cross-entropy method. Ann Oper Res. 2005;134(1):19–67. https://doi.org/10.1007/s10479-005-5724-z.
Delacre M, Lakens D, Leys C. Why psychologists should by default Use Welch’s t-test instead of Student’s t-test. Int Rev Soc Psychol. 2017;30(1):92–101. https://doi.org/10.5334/irsp.82.
Deng J, Dong W, Socher R, et al. ImageNet: A large-scale hierarchical image database. 2009 IEEE Conference on Computer Vision and Pattern Recognition (CCVPR). Miami, USA; 2009. p. 248–55. https://doi.org/10.1109/CVPR.2009.5206848.
Dyrmann M, Karstoft H, Midtiby HS. Plant species classification using deep convolutional neural network. Biosyst Eng. 2016;151:72–80. https://doi.org/10.1016/j.biosystemseng.2016.08.024.
Elfatimi E, Eryigit R, Elfatimi L. Beans Leaf diseases classification using MobileNet models. IEEE Access. 2022;10:9471–82. https://doi.org/10.1109/ACCESS.2022.3142817.
Geng LJ, Ji ZK, Yan PJ, et al. A new method for lint percentage non-destructive detection based on optical penetration imaging. Emir J Food Agr. 2022;34(5):411–21. https://doi.org/10.9755/ejfa.2022.v34.i5.2854.
Howard AG, Zhu M, Chen B, et al. Mobilenets: efficient convolutional neural networks for mobile vision applications. arXiv. 2017. https://doi.org/10.48550/arXiv.1704.04861.
Hu BB, Tang JH, Wu JM, et al. An attention efficient net-based strategy for bearing fault diagnosis under strong noise. Sensors. 2022;22(17):19. https://doi.org/10.3390/s22176570.
Huang JH, Liu YT, Ni HC, et al. Termite Pest Identification Method based on deep convolution neural networks. J Econ Entomol. 2021;114(6):2452–9. https://doi.org/10.1093/jee/toab162.
Kang XY, Huang CP, Zhang LF, et al. Downscaling solar-induced chlorophyll fluorescence for field-scale cotton yield estimation by a two-step convolutional neural network. Comput Electron Agr. 2022;201:17. https://doi.org/10.1016/j.compag.2022.107260.
Kingma DP, Ba J, Adam. A method for stochastic optimization. arXiv. 2014. https://doi.org/10.48550/arXiv.1412.6980.
Kumar M, Tomar M, Punia S, et al. Cottonseed: a sustainable contributor to global protein requirements. Trends Food Scie Technol. 2021;111:100–13. https://doi.org/10.1016/j.tifs.2021.02.058.
Li C, Su B, Zhao T, et al. Feasibility study on the use of near-infrared spectroscopy for rapid and nondestructive determination of gossypol content in intact cottonseeds. J Cotton Res. 2021;4(1):13. https://doi.org/10.1186/s42397-021-00088-2.
Ma L, Chen Y, Xu S, et al. Metabolic profile analysis based on GC-TOF/MS and HPLC reveals the negative correlation between catechins and fatty acids in the cottonseed of Gossypium hirsutum. J Cotton Res. 2022;5(1):17. https://doi.org/10.1186/s42397-022-00122-x.
Martineau M, Raveaux R, Chatelain C, et al. Effective training of convolutional neural networks for insect image recognition. 19th International Conference on Advanced Concepts for Intelligent Vision Systems (ACIVS). Poitiers, France; 2018. https://doi.org/10.1007/978-3-030-01449-0_36.
Ong SQ, Ahmad H, Nair G, et al. Implementation of a deep learning model for automated classification of Aedes aegypti (Linnaeus) and Aedes albopictus (Skuse) in real time. Sci Rep. 2021;11:9908. https://doi.org/10.1038/s41598-021-89365-3.
Otsu N. A threshold selection method from gray-level histograms. IEEE Trans Syst Man Cybern. 1979;9(1):62–6. https://doi.org/10.1109/TSMC.1979.4310076.
Pan H, Pang Z, Wang Y, et al. A new image recognition and classification method combining Transfer Learning Algorithm and MobileNet model for welding defects. 2020;8:119951–60. https://doi.org/10.1109/ACCESS.2020.3005450.
Qian WW, Li SM, Wang JR, et al. An intelligent fault diagnosis framework for raw vibration signals: adaptive overlapping convolutional neural network. Mea Sci Technol. 2018;29(9):13. https://doi.org/10.1088/1361-6501/aad101.
Sandler M, Howard A, Zhu M, et al. MobileNetV2: inverted residuals and linear bottlenecks. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CCVPR). Salt Lake City, UT, USA; 2018. p. 4510–20. https://doi.org/10.1109/CVPR.2018.00474.
Sathyanarayana A, Joty S, Fernandez-Luque L, et al. Correction of: sleep quality prediction from wearable data using deep learning. Jmir Mhealth Uhealth. 2016;4(4):e130. https://doi.org/10.2196/mhealth.6953.
Song BF, Sunny S, Li SB, et al. Mobile-based oral cancer classification for point-of-care screening. J Biomed Opt. 2021;26(6):10. https://doi.org/10.1117/1.Jbo.26.6.065003.
Suzuki S, be K. Topological structural analysis of digitized binary images by border following. CVGIP. 1985;30(1):32–46. https://doi.org/10.1016/0734-189X(85)90016-7.
Wagle SA, Harikrishnan RA. Deep learning-based approach in classification and validation of tomato leaf disease. Trait Signal. 2021;38(3):699–709. https://doi.org/10.18280/ts.380317.
Wang HN, Liu N, Zhang YY, et al. Deep reinforcement learning: a survey. Front Inf Technol Electron Eng. 2020;21(12):1726–44. https://doi.org/10.1631/fitee.1900533.
Wang Z, Jin L, Wang S, Xu H. Apple stem/calyx real-time recognition using YOLO-v5 algorithm for fruit automatic loading system. Postharvest Biol Tec. 2022;185:111808. https://doi.org/10.1016/j.postharvbio.2021.111808.
Acknowledgements
Not applicable.
Funding
This research was funded by the National Natural Science Foundation of China (Grant number: 11904327, 61905223, and 62073299), Training Plan of Young Backbone Teachers in Universities of Henan Province (2023GGJS087), Henan Provincial Science and Technology Research Project (222102110279, 222102210085, and 242102210157), the Project of Central Plains Science and Technology Innovation Leading Talents (224200510026).
Author information
Authors and Affiliations
Contributions
Conceptualization, Geng LJ and Ji ZK; methodology, Geng LJ, Yan PJ, and Zhang RL; software, Ji ZK, Song CY, Yan PJ, and Zhang ZF; validation, Song CY, Song SF, and Jiang LY; investigation, Ji ZK, and Zhai YS; data curation, Yan PJ and Ji ZK; writing—original draft preparation, Geng LJ and Ji ZK; writing—review and editing, Yan PJ, Geng LJ, and Yang K; project administration, Geng LJ; funding acquisition, Geng LJ and Jiang LY. All authors have read and agreed to the final version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no conflict of interest.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Geng, L., Yan, P., Ji, Z. et al. A novel nondestructive detection approach for seed cotton lint percentage using deep learning. J Cotton Res 7, 16 (2024). https://doi.org/10.1186/s42397-024-00178-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s42397-024-00178-x