
Abstract
The computer aided diagnosis (CAD) algorithms are considered crucial during the treatment planning of cerebral aneurysms (CA), where segmentation is the first and foremost step. This paper presents a segmentation algorithm in two-dimensional domain combining a multiresolution and a statistical approach. Precisely, Contourlet transform (CT) extracts the image features, while Hidden Markov Random Field with Expectation Maximization (HMRF-EM) segments the image, based on the spatial contextual constraints. The proposed algorithm is tested on Three-Dimensional Rotational Angiography (3DRA) datasets; the average values of accuracy, DSC, FPR, FNR, specificity, and sensitivity, are found to be 99.64%, 92.44%, 0.09%, 5.81%, 99.84%, and 93.22%, respectively. Both qualitative and quantitative results obtained show the potential of the proposed method.
Similar content being viewed by others
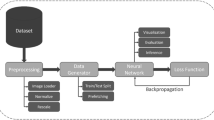


Background
Cerebral aneurysm (CA) is an abnormal inflammation within the brain blood vessels that is commonly detected after the age around forty [1, 2]. The mortality rate of these disease carriers is between 30 and 40%, whereas the morbidity rate ranges between 35 and 60% [3]. Computer Aided Diagnosis (CAD) algorithms, also known as Medical Image Segmentation (MIS) algorithm, have been helpful in reducing the bias, time consumption, increasing the CA detection accuracy, etc. [4]. MIS algorithms support the clinicians in playing a role during decision making in the diagnosis phase by providing a second opinion.
There have been several methods in image segmentation that include both traditional methods and machine-learning/deep-learning methods. It may be noted that the deep learning (DL)-based methods, specifically neural networks for medical image segmentation, have received much attention due to their end-to-end nature and state-of-the-art performance. Deep neural networks (NN) started gaining popularity after their success at ImageNet Large Scale Visual Recognition Challenge 2012 [5]. With the improvement in GPU architectures and the development of dedicated deep learning libraries (e.g., Tensorflow [6] and PyTorch [7]), neural networks have become popular for a wide range of computationally heavy computer vision tasks (e.g., object recognition and segmentation). For image segmentation, a schematic diagram of convolutional neural networks (CNNs) is given in Fig. 1; it comprises a series of convolution and pooling layers to condense the input image into a dense feature representation. The feature representation is utilized to reconstruct the segmentation mask using deconvolution and upsampling layers. During NN training, pre-processed images (e.g., normalized images with contrast enhancement) are fed to the network to generate the segmentation probabilities (forward propagation). A loss function computes the discrepancy between the NNs prediction and the ground truth. Finally, the weights of the network are updated using an optimizer (e.g., Adam [8]) in the back-propagation phase. Altogether, the type preprocessing, architecture, choice of the loss function and optimizer, determines the segmentation accuracy and inference time of the NNs.

Deep learning-based system for image segmentation
Over the years, several CNNs [9,10,11] have been proposed. However, the neural networks face several challenges too. The neural networks are susceptible to variations in data like changes, in contrast, noise, and resolution [12, 13]. In a clinical setting, these variations are expected in the data due to multiple machines with several acquisition parameters that can cause the data distribution to change. One technical limitation for training the neural networks is due to the limited quantity of clinical data, resulting in overfitting (i.e., poor generalizability). Additionally, the training procedure of the neural networks does not provide any convergence guarantees. Other technical challenges include the black-box nature of deep learning-based approaches, which downplays the reliability of the neural networks in clinically sensitive settings. Thus, in this paper, we propose a traditional/conventional algorithm to segment the CA from 3DRA datasets using a multiresolution statistical approach, where the Contourlet Transform (CT), in conjunction with Hidden Markov Random Field, is used to segment 2D images in the Contourlet domain.
Related work
There is rich literature in conventional MIS that includes semi-automatic and automatic [14, 15]. Broadly, the semi-automatic approaches include threshold-based [16], model-based [17], graph-based [18, 19] methods that need human intervention [20], which is tedious, prone to inter and intra-operator variability; these factors certainly affect the segmentation accuracy. Therefore, automatic approaches were introduced. In [16], spatial filtering and dual global thresholding are considered, where three parameters (i.e., two threshold values and filter mask size) are user-defined. Yang et al. present a dot enhancement filter that includes thresholding, and a region growing technique. However, it lacks the inconsistency of the sensitivity, where it ranges between 80 and 95% for CAs larger than 5 millimeters and between 71 and 91% otherwise. Bogunovic et al. [21] present a Geodesic Active Regions (GAR) based algorithm. However, there is the possibility of merging either a vessel with a CA or two vessels together. This partly happens either because of the insufficiency of the imaging resolution and the low blood flow in the small vessels. In [22], a blobness filter and a k-means technique are adapted. The algorithm results in a false positive rate reaching 20.8%. Jerman et al. [23], present a blobness enhancement filter combined with Random Forest Decision (RFD) classifier and a grow-cut technique, where it is assumed that a saccular CA most probably consists of more than 15 voxels. Thus, this assumption reduces the chances to detect small CAs. Suniaga et al. [24], propose a fuzzy logic in a level set framework along with a SVM classifier to segment saccular CAs.
In [25], a method on Conditional Random Field (CRF) and gentle Adaboost classifier is proposed that is trained on six datasets and tested on two datasets. However, machine Learning (specifically, Deep Learning (DL)) models need extensive data to capture the underlying distribution for generalization in real-world systems. Additionally, the Blackbox nature of the DL models adds uncertainty to their predictions, thus limiting their use case to a second opinion in a clinical setting [26]. Lu et al. [27] present a method, where multi-scale filtering is used to enhance the vessels suppressing the noise and a mixture model is built to fit the histogram curve of the preprocessed data. Finally, expectation maximization is used for parameter estimation. Kai et al. [28] present a graph-cut based method for aneurysm segmentation. Yu et al. [29] present a geodesic active contour (GAC) and Euler’s elastica model-based method for aneurysm segmentation, where GAC segments the giant aneurysms in high contrast regions and the elastica model estimates the missing boundaries in low contrast regions. Thus, the numerous automatic segmentation algorithms reported so far in the literature have potential limitations that warrant further research on automatic methods. However, the automatic methods are difficult to be controlled, as usually desired by the clinicians during their treatment planning to explore various options. Thus, this paper proposes a semi-automatic algorithm combining Contourlet Transform (CT) and Hidden Markov Random Field with Expectation Maximization (HMRF-EM) to segment CA regardless the CA shape or size.
The rest of this paper is organized as follows: in Sect. "Mathematical background", the foundation and mathematical background for the proposed algorithm are presented. In Sect. "Proposed segmentation algorithm", the proposed algorithm is discussed in detail. In section “Datasets and results”, the objective and subjective evaluation of the proposed work are presented along with the dataset description and the environmental setup for the implementation. Section "Discussion" includes discussion and some future work, whereas the section “Conclusions” concludes the paper.
Mathematical background
Contourlet transform
Multiresolution analysis techniques usually utilize the image features for computer vision. There have been several multiresolution analysis techniques such as Wavelet, Ridgelet, Curvelet, and Contourlet transforms, for medical image segmentation [30,31,32]. We have preferred the Contourlet Transform (CT) in our proposed approach due to its advantages [33]. CT, being an ideal 2D transform in the discrete domain, has other salient features: multiresolution, localization, critical sampling, anisotropy, and multiple directions for different resolutions. In addition, this transformation provides a sparse representation saving a significant amount of memory and offering simple and fast data processing as it requires O(N) operations for an image with N-pixels [31]. These characteristics capture the geometrical smoothness of the 2D contours.
The Pyramidal Directional Filter Bank (PDFB) [34] combines the Laplacian Pyramid (LP) and Directional Filter Bank (DFB) to extract the desirable fine details of CT. LP [35] allows the multiresolution representation of an image to capture point singularities by removing the noise. DFB [36] decomposes an image into multiple directions to capture high-frequency content as smooth contours and directional edges by formulating the captured point singularity into a linear structure.
Briefly, the Contourlet works as follow: First, the image, a0[n], is passed to the LP filter to produce two images as output: a coarse/approximated/low-pass image, a1[n], and a fine/detailed/bandpass image, b1[n]. The latter image (bandpass) is passed to the DFB to produce \(2^{{L_{j} }}\) bandpass directional images, \(c^{{L_{j} }} [n]\). Subsequently, the lowpass image, a1[n], is passed again through LP to repeat the same process until a certain predefined number of decomposition levels, Lj, is reached. Fig. 2 illustrates the CT process to decompose a 512 × 512 image into two levels, where 8 and 4 directions are applied at each level, respectively.

Contourlet transform decomposition process of a 512 × 512 image into 2 levels, where 8 and 4 directions are applied at each level, respectively
CT has the adeptness at capturing geometrical smoothness of 2D contours and anisotropy in the discrete domain. In addition, it has a high degree of directionality as it allows to define different directions for different scales, which is not possible in other multiresolution analysis techniques. These advantages help extract the features from images, which would result consecutively in improved segmentation.

To summarize, the CT takes a 2D image, a0[n], as an input and decomposes it into a lowpass sub-band, aj[n], and several bandpass directional sub-bands, \(c^{{L_{j} }} [n]\), which are called as the Contourlet coefficients. This process can be expressed by:
where is the LP basis function for scale decomposition composed of the lowpass filter, gk[n], and the scaling function, φj,k(t); and ρ(L) is the DFB basis function for directional decomposition composed of orthogonal filter, dk[n], and the directional function, ϕj,n(t). The parameters j, k, d, and n, used in Eqs. (1) and (2), are number of levels/scales, number of directions for each level, dimensionality (in our case, it is 2 since we are working in 2D domain), and a scale parameter along the frequency axis, respectively. The overall decomposition process of the CT is provided in Algorithm 1.
The number of the decomposition levels is experimentally selected since it depends on the image size and the amount of the details to be highlighted. For the number of directions, it is recommended to gradually increase them by 2k.
Hidden Markov random field model
HMRF model is a statistical approach in the stochastic domain that provides prior knowledge helping simplify the MIS task.
HMRF model segments the medical images based on the spatial correlation between the neighboring pixels. Some important notions about this model are:
-
Random field: The random variables are the intensity levels in an image. In HMRF model, two random fields exist:
-
Hidden random field: X = (x1, x2,.., xN)l/xi ∈ L, i ∈ S is a random field in a finite state space, L, and indexed by a set, S, with respect to a neighboring system of size, N.
The state of this field X is unobservable/hidden and every xi is independent of all other xj. The objective of this assumption is to classify each pixel independently [37].
-
Observable random field: Y = {y = (y1, y2,.., yN)l/yi ∈ D, i ∈ S} is a random field in a finite space, D, and indexed by a set, S, with respect to a neighboring system of size, N.
This random field, Y , is observable and it can only be defined with respect to X, where yi follows a conditional probability distribution given any configuration of \(x_i=l: p({y_i}\parallel {l})= \{ {f}(y_{i};{\theta}_l),\,\, {\forall}l \in L \}\), where θl is the set of the involved parameters.
-
-
Parameters: The set of involved parameters, θl, are unknown. Therefore, a model fitting is adopted to estimate them. In our context, the parameters are mainly the mean, µ, and the standard deviation, σ.
-
Conditional independence: The two random fields, (X, Y), are conditionally independent.
-
Neighborhood system: It is a way to define the surrounding pixels for a specific pixel [38].
-
Clique: It is a subset of pixels, where every pair of distinct pixels are neighbors. A value is assigned to each clique, c, to define the clique potential Vc(x), where the sum of all these values results in the energy function, U (x), that we aim to minimize.
$$U\left( x \right) = \mathop \sum \limits_{c \in C} {V_{c } \left( x \right)} $$(3)
To know θl, EM algorithm is preferred. The HMRF-EM framework [39] incorporates the EM algorithm in association with HMRF model to estimate the parameters and segment using iterative updates. The framework starts by initializing both: the segmentation and parameters (means, µ, and standard deviations, σ). Then, iteratively, it goes through the Expectation Step (E-Step) and Maximization Step (M-Step) to update these parameters and the initial segmentation until no further development is observed.
The E-Step updates the segmentation by assigning to each pixel an estimated class label, xˆ, from a set of labels, L. The assignment is done based on the MAP criterion, which tries to minimize the posterior energy using the current parameters estimate, during the energy maximization the conditional posterior probability distribution, P (Y l/X), gets maximized. Eq. (4) illustrates the energy calculation:
where U (x) is the energy function as illustrated in Eq. (3) and U (yl/x) is the likelihood energy illustrated below in Eq. (5).
While the M-Step updates the parameters based on the ML criterion, which tries to maximize the expected likelihood found in the E-Step. The parameters µ and σ are calculated using the Eqs. (6) and (7), respectively.

This framework works well for small data dimensions; its main advantages are easy to implement, provides an accurate segmentation, and it is less sensitive to noise compared to other segmentation techniques since it well considers contextual information [40].
Modifications to conventional k-means clustering
This is well-known that k-means is a clustering technique maximizing the similarity of intra-class and minimizing the similarity of inter-class; it is computationally fast. In our method, we initialize k automatically based on the image entropy, a statistical measure of randomness that can be used to characterize the texture of the gray-scale image [41]. It is expressed in Eq. (8):
where X is a vector of all intensities of an image and n is the number of pixels.
Proposed segmentation algorithm
The proposed CA segmentation algorithm is illustrated in Fig. 3. The algorithm starts by feeding a series of 2D images, of a certain patient, in the Digital Imaging and Communications in Medicine (DICOM) format. The selection of the Region of Interest (ROI) from the entire cerebral vasculature is done manually. Subsequently, the following steps are performed on each 2D image.

Flowchart of the proposed segmentation
During the first step, CT is applied to extract features from the input image by decomposing it into 6 pyramidal levels and different number of directions for each level, where the number of the directional decomposition at each pyramidal level (from coarse to fine) are: 22, 22, 42, 42, 82, and 82 [31, 42]. As discussed earlier, CT consists of two main filters, LP and DFB. A ladder filter, known as PKVA filter [43], is selected for the first filter. The PKVA filter is effective to localize edge direction as it reduces the inter-direction mutual information [31]. As for the second filter, 9 − 7 bi-orthogonal Daubechies filter [44] is selected; this filter significantly reduces all the inter-scale, inter-location, and inter-direction mutual information of the Contourlet [31]. After the decomposition by CT, the lowpass subband image, aj[n], is used to perform the rest of the steps.
To apply the second step (HMRF-EM) of the segmentation algorithm, two prior steps need to be performed. First, an initial segmentation is generated using the k-means method, which is known with its under-estimation to complement the HMRF-EM framework [30]. In addition, a Canny edge filter [45] is applied to highlight the image edges. After that, the HMRF-EM algorithm iterates between the E-Step and M-Step to enhance the initial segmentation constrained by the Canny edge detector.
The HMRF-EM method starts after getting the initial segmentation, xˆ(0), and initial parameters, θ(0), obtained by the k-means clustering, the constrained image, cej[n], obtained by the Canny edge operator, and the lowpass subband image, aj[n], obtained by the Contourlet decomposition. During this step, the algorithm iterates between the steps E and M to refine the initial segmented image, constrained by the Canny segmented image, resulting in the final segmented 2D image by minimizing the posterior energy function as explained in section "Hidden Markov random field model".
As the last step, Inverse Contourlet Transform (ICT) is applied to reconstruct the image. Here, the lowpass subband image, aj[n], which represents the coarsest Contourlet coefficients, is replaced by the final segmented image, \({\widehat{\mathcal{x}}}^{(\mathrm{MAP}\_itr)}\) The ICT is achieved using the same filters as in the decomposition stage, where the 9 − 7 and PKVA filters are used for the LP and DFB, respectively.

After completing these two phases, the reconstruction of all the segmented 2D images is performed to get the final segmented 3D volume of the ROI. The pseudocode for the overall proposed CA segmentation algorithm is presented in Algorithm 3.
Datasets and results
Datasets
The aneurysms obtained from the respective 3DRA scanner (Siemens machine) were small (≤ 3 millimeters) and with decent contrast. This contrast is obtained by subtracting two images: the first image is acquired by injecting a contrast agent through a catheter into one of the vessels that leads to the brain vessels, while the second one is obtained before injecting this agent. Six 3D RA datasets are provided by Hamad Medical Cooperation (HMC) to validate the proposed segmentation; each dataset consists of 385 2D slices of size 512 × 512 each. In addition, the corresponding ground truth datasets were obtained from the same hospital that were prepared by three neuro-experts.
Results
We have two scenarios: 1-to segment the region of interest, and 2-the entire input volumetric data. in scenario 1, we manually, select the slices to get the ROI and it is, on average, 86 slices and they are continuous, whereas in scenario 2, we feed all the slices as input to the algorithm. Both the quantitative and qualitative results are obtained by comparing the segmented volumes with the respective ground truth volume, as elaborated in section "Objective evaluation" and "Subjective evaluation", respectively. Figs. 4, 5, 6, and 7 depict each dataset before and after applying the segmentation. To test, if the results are statistically significant, we set the significance level, α = 0.05 and we obtained the p-values smaller than 0.05, indicating that these segmentation results correctly identified the brain aneurysm.

Three slices from dataset 1 a before segmentation b after segmentation c original ROI d segmented ROI

Three slices from dataset 2 a before segmentation b after segmentation c original ROI d segmented ROI

Three slices from dataset 3 a before segmentation b after segmentation c original ROI d segmented ROI

Three slices from dataset 4 a before segmentation b after segmentation c original ROI d segmented ROI
Registration
We have also considered image registration in our work to enable the comparison between the segmented volume and the corresponding ground truth.
In this process, one of the images is defined as the target (or the subject), which we wish to apply a transformation, while the other image is defined as the reference (or the source). In our case, the target image is the segmented ROI volume, while the reference image is the ground truth ROI volume. The target image is transformed by means of the selected mapping functions to align it with the reference image [46]. We have selected an affine transformation; Fig. 8c illustrates the coordinate systems of the segmented volume and the ground truth data before and after registration.

Co-ordinate system of dataset 1 before and after registration. The right column is related to the ground truth data. The left column is related to the original segmented ROI volume
Objective evaluation
Six performance metrics are used to measure the proposed segmentation quantitatively: Dice Similarity Index (DSI), sensitivity, specificity, accuracy, False Positive Ratio (FPR), and False Negative Ratio (FNR). The value of these metrics’ ranges between 0 and 1. Table 1 provides the definition and the formula of each metric.
Two measures, True Positive (TP) and True Negative (TN), in Table 1 indicate a correct segmentation, while False Positive (FP) and False Negative (FN) indicate an incorrect segmentation. Fig. 9 depicts the meaning of each measure more clearly.

Four measures used in performance metrics
The values of these performance metrics are presented in Table 2 against each dataset.
Subjective evaluation
Each segmentation has been assessed visually by five observers (neurologists). The score, ranging between 0 and 5, is assigned by each observer, where 5 means that the ground truth volume almost completely matches with segmented one and 0 means that the two volumes do not match. Table 3 presents the observations.
Discussion
Both the qualitative and quantitative results are promising when tested on these 3DRA datasets. In the quantitative evaluation, the average values of accuracy, DSC, FPR, FNR, specificity, and sensitivity, are 99.64%, 92.44%, 0.09%, 5.81%, 99.84%, and 93.22%, respectively; an average of 4.14 over 5 is obtained in the qualitative evaluation.
It may be observed in Tables 2 and 3 that the last dataset has the worst results as compared to the remaining datasets in both the quantitative and qualitative evaluation. This may be since the provided ground truth data does not involve the complete brain vessels tree and only a delineated ROI is provided, where some surrounding vessels are excluded. The same may be observed from Fig. 10.

Dataset 4 a Segmented volume from the original DICOM dataset b Ground truth volume delineated by the experts
The computational time to segment a CA volume is considerably fast. Table 4 reports the running time of the proposed segmentation algorithm for the ROI in seconds (sec) and the whole volume of a subject in minutes (min). Even though the results are acceptable, the computational time can further be reduced by using Field-Programmable Gate Array (FPGAs) or Graphics Processing Unit (GPUs).
We have also compared the performance of the proposed method with some similar methods that have been published recently. The results are provided in Table 5. The results show that the performance of the proposed method is better than the others.
Additionally, we have compared (in Table 6) the proposed method with some popular DL-based methods, including Voxel-Morph (VM) [49], LT-Net [50], and Symmetric Normalization (SyN) [51]. We have selected these methods because they have been regularly preferred by the research fraternity for comparison purpose. Among these, Voxel-Morph is probably the most famous methods in recent years. The results show that the proposed method fairly performs as compared to the DL-based methods although the margin is not very significant. Furthermore, we have also compared the computational complexity involved in table 7.
Conclusions
Sub-Arachnoid Hemorrhage (SAH), caused by a ruptured CA, is a serious condition associated with high rates of morbidity and mortality. Therefore, detecting and diagnosing CAs at an early stage is imperative. In this paper, a semi-automatic CA segmentation method is proposed using Contourlet transform, as a multiresolution technique, and the hidden Markov random field model with expectation maximization, as a statistical technique. Promising results have been obtained when tested on 3DRA datasets. In future, we intend to increase the number of datasets to validate its robustness and reduce the computational time further so that the method can be considered for real clinical practice. Furthermore, this algorithm can be extended to test on other human organs such that liver vessels.
Availability of data and materials
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study. If you do not wish to publicly share your data, please write: Please contact author for data requests.
References
Higashida RT. What you should know about cerebral aneurysms. Pamphlet. American Heart Association Cardiovascular Council. 2003.
Nikravanshalmani A, Karamimohammdi M, Dehmeshki J. Segmentation and separation of cerebral aneurysms: a multi-phase approach. In: Image and signal processing and analysis (ISPA), 2013 8th international symposium on. 2013. pp. 505–510. https://doi.org/10.1109/ISPA.2013.6703793. IEEE.
Li Q, Li H. A novel algorithm based on contourlet transform for medical image segmentation. In: Bioinformatics and biomedical engineering (iCBBE), 2010 4th international conference on. 2010. pp. 1–3. https://doi.org/10.1109/ICBBE.2010.5515202. IEEE.
Wong, K.-P.: Medical image segmentation: methods and applications in functional imaging. In: Handbook of Biomedical Image Analysis, pp. 111–182. Boston: Springer; 2005. https://doi.org/10.1007/0-306-48606-7_3
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, Berg AC, Fei-Fei L. ImageNet large scale visual recognition challenge. Int J Comput Vision. 2015;115(3):211–52. https://doi.org/10.1007/s11263-015-0816-y.
Abadi M, Barham P, Chen J, Chen Z, Davis A, Dean J, Devin M, Ghemawat S, Irving G, Isard M, Kudlur M, Levenberg J, Monga R, Moore S, Murray DG, Steiner B, Tucker P, Vasudevan V, Warden P, Wicke M, Yu Y, Zheng X. Tensorflow: a system for large-scale machine learning. In: Proceedings of the 12th USENIX conference on operating systems design and implementation. OSDI’16. USA: USENIX Association;2016. pp. 265–283.
Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z, Gimelshein N, Antiga L, Desmaison A, Kopf A, Yang E, DeVito Z, Raison M, Tejani A, Chilamkurthy S, Steiner B, Fang L, Bai J, Chintala S. PyTorch: An imperative style high-performance deep learning library. Red Hook: Curran Associates Inc.; 2019.
Kingma DP, Ba J. Adam: a method for stochastic optimization. arXiv. 2014. https://doi.org/10.48550/ARXIV.1412.6980.
Khan MZ, Gajendran MK, Lee Y, Khan MA. Deep neural architectures for medical image semantic segmentation: review. IEEE Access. 2021;9:83002–24. https://doi.org/10.1109/ACCESS.2021.3086530.
Siddique N, Paheding S, Elkin CP, Devabhaktuni V. U-net and its variants for medical image segmentation: a review of theory and applications. IEEE Access. 2021;9:82031–57. https://doi.org/10.1109/ACCESS.2021.3086020.
Torres-Velazquez M, Chen W-J, Li X, McMillan AB. Application and construction of deep learning networks in medical imaging. IEEE Trans Radiat Plasma Med Sci. 2021;5(2):137–59. https://doi.org/10.1109/TRPMS.2020.3030611.
Thambawita V, Strmke I, Hicks SA, Halvorsen P, Parasa S, Riegler MA. Impact of image resolution on deep learning performance in endoscopy image classification: an experimental study using a large dataset of endoscopic images. Diagnostics. 2021. https://doi.org/10.3390/diagnostics11122183.
Orlando N, Gyacskov I, Gillies DJ, Guo F, Romagnoli C, D’Souza D, Cool DW, Hoover DA, Fenster A. Effect of dataset size, image quality, and image type on deep learning-based automatic prostate segmentation in 3d ultrasound. Phys Med Biol. 2022;67(7):074002. https://doi.org/10.1088/1361-6560/ac5a93.
Dakua SP. Performance divergence with data discrepancy: a review. Artif Intell Rev. 2013;40(4):429–55. https://doi.org/10.1007/s10462-011-9289-8.
Dakua SP, Sahambi JS. Detection of left ventricular myocardial contours from ischemic cardiac mr images. IETE J Res. 2011;57(4):372–84. https://doi.org/10.4103/0377-2063.86338.
Mitra J, Chandra A. Detection of cerebral aneurysm by performing thresholding-spatial filtering-thresholding operations on digital subtraction angiogram. Adv Comput Inf Technol. 2013. https://doi.org/10.1007/978-3-642-31552-7_93.
Dakua SP, Abinahed J, Zakaria A, Balakrishnan S, Younes G, Navkar N, Al-Ansari A, Zhai X, Bensaali F, Amira A. Moving object tracking in clinical scenarios: application to cardiac surgery and cerebral aneurysm clipping. Int J Comput Assist Radiol Surg. 2019;14(12):2165–76. https://doi.org/10.1007/s11548-019-02030-z.
Dakua SP, Sahambi JS. Weighting function in random walk based left ventricle segmentation. In: 2011 18th IEEE international conference on image processing. 2011. pp. 2133–2136. https://doi.org/10.1109/ICIP.2011.6116031.
Dakua SP, Sahambi JS. Automatic left ventricular contour extraction from cardiac magnetic resonance images using cantilever beam and random walk approach. Cardiovasc Eng. 2010;10(1):30–43. https://doi.org/10.1007/s10558-009-9091-2.
Chen Y, Navarro L, Wang Y, Courbebaisse G. Segmentation of the thrombus of giant intracranial aneurysms from ct angiography scans with lattice boltzmann method. Med Image Anal. 2014;18(1):1–8. https://doi.org/10.1016/j.media.2013.08.003.
Bogunovic H, Pozo JM, Villa-Uriol MC, Majoie CB, van den Berg R, Gratama van Andel HA, Macho JM, Blasco J, San Roman L, Frangi AF. Automated segmentation of cerebral vasculature with aneurysms in 3dra and tof-mra using geodesic active regions: an evaluation study. Med Phys. 2011;38(1):210–22. https://doi.org/10.1118/1.3515749.
Hentschke CM, Beuing O, Nickl R, Tonnies KD. Automatic cerebral aneurysm detection in multimodal angiographic images. In: Nuclear science symposium and medical imaging conference (NSS/MIC), 2011 IEEE, pp. 3116–3120 (2011). https://doi.org/10.1109/NSSMIC.2011.6152566. IEEE.
Jerman T, Pernus F, Likar B, Spiclin Z. Computer-aided detection and quantification of intracranial aneurysms. In: International conference on medical image computing and computer-assisted intervention. Cham: Springer; 2015 pp. 3–10. https://doi.org/10.1007/978-3-319-24571-3_1.
Suniaga S, Werner R, Kemmling A, Groth M, Fiehler J, Forkert ND. Computer-aided detection of aneurysms in 3d time-of-flight mra datasets. In: International workshop on machine learning in medical imaging. Berlin, Heidelberg: Springer; 2012. pp. 63–69. https://doi.org/10.1007/978-3-642-35428-18.
Zhang H, Jiao Y, Zhang Y, Shimada K. Automated segmentation of cerebral aneurysms based on conditional random field and gentle adaboost. Mesh Process Med Image Anal. 2012;2012:59–69. https://doi.org/10.1007/978-3-642-33463-47.
Su J, Vargas DV, Sakurai K. One pixel attack for fooling deep neural networks. IEEE Trans Evol Comput. 2019;23(5):828–41. https://doi.org/10.1109/TEVC.2019.2890858.
Lu P, Xia J, Li Z, Xiong J, Yang J, Zhou S, Wang L, Chen M, Wang C. A vessel segmentation method for multi-modality angiographic images based on multi-scale filtering and statistical models. BioMed Eng. 2016;15(1):120. https://doi.org/10.1186/s12938-016-0241-7.
Lawonn K, Meuschke M, Wickenhfer R, Preim B, Hildebrandt K. A geometric optimization approach for the detection and segmentation of multiple aneurysms. Comput Graphics Forum. 2019;38(3):413–25. https://doi.org/10.1111/cgf.13699.10.1111/cgf.13699.
Chen Y, Courbebaisse G, Yu J, Lu D, Ge F. A method for giant aneurysm segmentation using euler aos elastica. Biomed Signal Process Control. 2020;62:102111. https://doi.org/10.1016/j.bspc.2020.102111.
AlZubi S, Islam N, Abbod M. Multiresolution analysis using wavelet, ridgelet, and curvelet transforms for medical image segmentation. J Biomed Imag. 2011;2011:4. https://doi.org/10.1155/2011/136034.
Po D-Y, Do MN. Directional multiscale modeling of images using the contourlet transform. IEEE Trans Image Process. 2006;15(6):1610–20. https://doi.org/10.1109/TIP.2006.873450.
Moayedi F, Azimifar Z, Boostani R, Katebi S. Contourlet-based mammography mass classification using the svm family. Comput Biol Med. 2010;40(4):373–83. https://doi.org/10.1016/j.compbiomed.2009.12.006.
Do MN, Vetterli M. 4-contourlets. Stud Comput Math. 2003;10:83–105. https://doi.org/10.1016/S1570-579X(03)80032-0.
Do MN, Vetterli M (2001) Pyramidal directional filter banks and curvelets. In: Proceedings 2001 international conference on image processing. 2001. vol. 3, pp. 158–161. https://doi.org/10.1109/ICIP.2001.958075. IEEE.
Burt P, Adelson E. The laplacian pyramid as a compact image code. IEEE Trans Commun. 1983;31(4):532–40. https://doi.org/10.1109/TCOM.1983.1095851.
Bamberger RH, Smith MJ. A filter bank for the directional decomposition of images: theory and design. IEEE Trans Signal Process. 1992;40(4):882–93. https://doi.org/10.1109/78.127960.
Marroquin JL, Santana EA, Botello S. Hidden markov measure field models for image segmentation. IEEE Trans Pattern Anal Mach Intell. 2003;25(11):1380–7. https://doi.org/10.1109/TPAMI.2003.1240112.
Chen S, Tong H, Cattani C. Markov models for image labeling. Math Problems Eng. 2011. https://doi.org/10.1155/2012/814356.
Zhang Y, Brady M, Smith S. Segmentation of brain mr images through a hidden markov random field model and the expectation-maximization algorithm. IEEE Trans Med Imaging. 2001;20(1):45–57. https://doi.org/10.1109/42.906424.
Yazdani S, Yusof R, Karimian A, Pashna M, Hematian A. Image segmentation methods and applications in mri brain images. IETE Tech Rev. 2015;32(6):413–27. https://doi.org/10.1080/02564602.2015.1027307.
Liang J, Zhao X, Li D, Cao F, Dang C. Determining the number of clusters using information entropy for mixed data. Pattern Recogn. 2012;45(6):2251–65. https://doi.org/10.1016/j.patcog.2011.12.017.BrainDecoding.
Hiremath P, Akkasaligar PT, Badiger S. Speckle reducing contourlet transform for medical ultrasound images. Int J Compt Inf Engg. 2010;4(4):284–91.
Phoong S-M, Kim CW, Vaidyanathan P, Ansari R. A new class of two-channel biorthogonal filter banks and wavelet bases. IEEE Trans Signal Process. 1995;43(3):649–65. https://doi.org/10.1109/78.370620.
Cohen A, Daubechies I. Non-separable bidimensional. Revista Matematica Iberoamericana. 1993. https://doi.org/10.4171/RMI/133.
Gonzalez RC, Wood RE. Digital image processing, 2nd Edtn. Prentice-Hall; 2002.
Zitova B, Flusser J. Image registration methods: a survey. Image Vis Comput. 2003;21(11):977–1000. https://doi.org/10.1016/S0262-8856(03)00137-9.
Dakua SP, Abinahed J, Al-Ansari A. A pca-based approach for brain aneurysm segmentation. Multidimens Syst Signal Processng. 2016. https://doi.org/10.1007/s11045-016-0464-6.
Rai A, Brotman R, Hobbs G, Boo S. Semi-automated cerebral aneurysm segmentation and geometric analysis for web sizing utilizing a cloud-based computational platform. Interv Neuroradiol. 2021;27(6):828–36. https://doi.org/10.1177/15910199211009111.
Balakrishnan G, Zhao A, Sabuncu MR, Guttag J, Dalca AV. Voxelmorph: a learning framework for deformable medical image registration. IEEE Trans Med Imag. 2019;38(8):1788–800. https://doi.org/10.1109/TMI.2019.2897538.
Wang S, Cao S, Wei D, Wang R, Ma K, Wang L, Meng D, Zheng Y. Lt-net: Label transfer by learning reversible voxel-wise correspondence for one-shot medical image segmentation. In: 2020 IEEE/CVF conference on computer vision and pattern recognition (CVPR). (2020). pp. 9159–9168. https://doi.org/10.1109/CVPR42600.2020.00918.
Avants BB, Epstein CL, Grossman M, Gee JC. Symmetric diffeomorphic image registration with cross-correlation: evaluating automated labeling of elderly and neurodegenerative brain. Med Image Anal. 2008;12(1):26–41. https://doi.org/10.1016/j.media.2007.06.004.
Ansari MY, Yang Y, Meher PK, Dakua SP. Dense-psp-unet: a neural network for fast inference liver ultrasound segmentation. Comput Biol Med. 2022. https://doi.org/10.1016/j.compbiomed.2022.106478.
Acknowledgements
Not applicable
Funding
This publication was made possible by NPRP-11S-1219-170106 from the Qatar National Research Fund (a member of Qatar Foundation). The findings herein reflect the work and are solely the responsibility of the authors.
Author information
Authors and Affiliations
Contributions
AA and SPD have conceptualized the study and participated in design of the study, data analysis, while YR has participated in manuscript preparation, literature search, data analysis, and manuscript review.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The research protocol was approved by the ethical committee in Institutional Review Board of Hamad Medical Corporation on 25 October 2018. Informed written consent was obtained from each patient. The QNRF NPRP 5-792-2-328 and the IRB reference number is: 11/11234.
Consent for publication
Not applicable
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Regaya, Y., Amira, A. & Dakua, S.P. Towards developing a segmentation method for cerebral aneurysm using a statistical multiresolution approach. Egypt J Neurosurg 38, 33 (2023). https://doi.org/10.1186/s41984-023-00213-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s41984-023-00213-0