
Abstract
Background:
The integration of the information encoded in multiparametric MRI images can enhance the performance of machine-learning classifiers. In this study, we investigate whether the combination of structural and functional MRI might improve the performances of a deep learning (DL) model trained to discriminate subjects with Autism Spectrum Disorders (ASD) with respect to typically developing controls (TD).
Material and methods
We analyzed both structural and functional MRI brain scans publicly available within the ABIDE I and II data collections. We considered 1383 male subjects with age between 5 and 40 years, including 680 subjects with ASD and 703 TD from 35 different acquisition sites. We extracted morphometric and functional brain features from MRI scans with the Freesurfer and the CPAC analysis packages, respectively. Then, due to the multisite nature of the dataset, we implemented a data harmonization protocol. The ASD vs. TD classification was carried out with a multiple-input DL model, consisting in a neural network which generates a fixed-length feature representation of the data of each modality (FR-NN), and a Dense Neural Network for classification (C-NN). Specifically, we implemented a joint fusion approach to multiple source data integration. The main advantage of the latter is that the loss is propagated back to the FR-NN during the training, thus creating informative feature representations for each data modality. Then, a C-NN, with a number of layers and neurons per layer to be optimized during the model training, performs the ASD-TD discrimination. The performance was evaluated by computing the Area under the Receiver Operating Characteristic curve within a nested 10-fold cross-validation. The brain features that drive the DL classification were identified by the SHAP explainability framework.
Results
The AUC values of 0.66±0.05 and of 0.76±0.04 were obtained in the ASD vs. TD discrimination when only structural or functional features are considered, respectively. The joint fusion approach led to an AUC of 0.78±0.04. The set of structural and functional connectivity features identified as the most important for the two-class discrimination supports the idea that brain changes tend to occur in individuals with ASD in regions belonging to the Default Mode Network and to the Social Brain.
Conclusions
Our results demonstrate that the multimodal joint fusion approach outperforms the classification results obtained with data acquired by a single MRI modality as it efficiently exploits the complementarity of structural and functional brain information.
Similar content being viewed by others


1 Introduction
Autism spectrum disorders (ASD) are a heterogeneous group of neurodevelopmental disorders characterized by persistent deficits in reciprocal social interaction, communication, and the presence of restricted, repetitive behaviors and interests, which can include sensory processing difficulties [7]. Prevalence data from the most recent investigation conducted by the American Centers for Disease Control and Prevention reported that ASD occurs in about one in every 36 children aged 8 years in U.S. [53].
ASD is currently diagnosed through a multidisciplinary and comprehensive direct evaluation of the individual with suspected ASD, associated with gold-standard behavioral observation [51] and interview [71] performed by clinicians expert in neurodevelopmental disorders [46]. However, methods based on observation of the patient and/or interview with the parents are subjective. Therefore, neuroimaging plays a key role in identifying the neural correlates of this condition. Machine learning (ML) and deep learning (DL) techniques are gaining considerable importance in supporting the diagnosis of ASD on the basis of magnetic resonance imaging (MRI) [44, 57], though these modalities do not have yet a clinical application. The aggregation of large data collections from multiple centers is often used to overcome the problems of appropriate ML training, related to the typical limited size of datasets in this field.
For ASD research, the Autism Brain Imaging Data Exchange (ABIDE) dataset is a public neuroimaging collection that is well characterized at the phenotypic level. Two world-wide multi-site and large-scale collections were released so far, ABIDE I [22] and ABIDE II [23], jointly consisting in more than a thousand cases and as many controls. In spite of the greater sample sizes, analyses based on the ABIDE collections report highly variable classification performances [77]. Moreover, it was pointed out that multi-center MRI data suffer from significant confounding due to batch-related technical variation, called batch effects [26]. In effect, MRI acquisitions made with different scanners and/or with dissimilar acquisition protocols encode confounding information in data which, if not accounted for, may obscure the tiny differences between controls with typical development (TD) and ASD subjects [25].
Several techniques can be employed to mitigate batch effects. During the study design phase, efforts can be made to mitigate batch effects by restricting data collection to a single scanner, manufacturer, field strength, acquisition protocol, or a combination of these criteria. However, this approach may limit the capacity to collect large datasets. Furthermore, even when acquisition conditions and scanner manufacturers are carefully checked, residual differences (resulting from factors such as hardware imperfections, site or operator characteristics, or software or hardware updates) can still introduce batch effects. In the image pre-processing stage, standardizing images through techniques such as gradient distortion correction, bias field correction, and intensity normalization can help to remove batch effects. However, it is important to note that these normalization methods primarily target inter-subject variability. Consequently, they can only mitigate batch effects that overlap with inter-subject variability. In the last few years, a number of advanced strategies, which employ statistical or mathematical concepts, were developed with the aim of removing the batch effect in neuroimaging studies [36]. Fortin et al. developed a harmonization algorithm [29], as an adaptation of the ComBat method developed by Johnson et al. [40] to remove batch effects in genomics data. Even if DL approach has been recently applied on ABIDE dataset [61], at the moment, ComBat appears to be the most used harmonization approach in the field of ASD research to reduce effect size in ABIDE data collections [28, 38, 68, 80]. However, Pomponio et al. [64] have recently presented a modified version of the harmonization protocol, the NeuroHarmonize tool, which is suitable to harmonize pooled dataset in the presence of non-linear age trends. In a recent study published by our group [72], we demonstrated that the implementation of NeuroHarmonize preprocessing [64] in a multi-center analysis conducted on structural MRI (sMRI) data from ABIDE I and II collections results in a significant increase in the ASD vs. TD discrimination performance of ML classifiers.
Multi-modal machine learning is a subfield of ML that aims to develop and train models that can exploit different types of data and combine them in order to improve prediction performance [2]. Indeed, combining data from multiple modalities allows to extract more comprehensive and complementary information, resulting in better performing models compared to using a single data modality [37, 81, 83]. In particular, the joint fusion approach employs a neural network model to extract feature representations from each modality, which are then combined and used as inputs to another model. The fusion model’s prediction loss is back propagated to the feature extracting models to enhance the learned feature representations.
In the research field of neurogenerative disorders, fusion strategies were frequently employed in the diagnosis and prediction of Alzheimer’s disease. Neither imaging or clinical data alone are sufficient for accurately diagnosing Alzheimer’s disease in clinical practice. However, leveraging DL fusion techniques has consistently shown improvements in diagnostic performance [65, 75, 78]. Some studies reported good results in applying DL models using functional and structural MRI images demonstrating that a DL framework for multi-modality data fusion outperforms single-modality DL [1, 5, 67]. In this work, we developed a multi-modal joint fusion DL model, which combines structural and functional MRI to distinguish between ASD and TD subjects. Although DL models are highly efficient and accurate, their complexity makes the rationale behind their decisions unclear, thus limiting their use in clinical applications such as disease diagnosis. To address this issue in recent years, different algorithms were proposed to explain which features contribute the most to the classification results. In this work we implemented the SHapley Additive exPlanations (SHAP) [52], which utilizes optimal Shapley values derived from game theory, in order to pointing out the most important feature involved in the identification of ASD subjects.
2 Materials and methods
2.1 Participants and data description
We analyzed the T1-weighted sMRI and resting-state fMRI (rs-fMRI) data of the ABIDE I [22] and ABIDE II [23] publicly available collections. Since \(97\%\) of the subjects were under the age of 40 years, we limited our study to subjects aged 5 to 40 years only, similarly to other studies in the field [33, 42]. Moreover, we restricted our analysis to male subjects, due to both the limited representation of female subjects in the ABIDE collection (less than 20% of subjects, spread over different sites and a wide age-range), and the sex differences in functional brain connectivity, characterized by predominant underconnectivity in ASD males as compared to TD males and extensive overconnectivity in ASD females as compared to TD females [6]. Since our goal is to propose a classification strategy dealing with both structural and functional information, we excluded subjects with missing multimodal MRI data after using the preprocessing pipelines. Thus, we obtained a final sample of 1383 subjects (680 ASD and 703 TD) from 35 sites. A summary of the sample sizes of the ABIDE I and II cohorts included in this study and of the participants’ average age is reported in Table 1. To allow the reproducibility of the analysis, the identification numbers (IDs) of the participants selected in the final sample are reported in Additional file 1.
2.2 Image processing and feature extraction
2.2.1 Structural MRI scan
As in our previous work [72], the sMRI scans were processed with Freesurfer [27] version 6.0 with the recon-all pipeline.Footnote 1This procedure includes cortical surface modelling, spherical coordinate transformation, non-linear curvature registration, automated volumetric segmentation and cortical reconstruction. Among the outputs generated by the Freesurfer processing pipeline, the following brain features were selected: the global measures and the subcortical features available in the file aseg.stats and the cortical features available in the bilateral files aparc.stats. In this way, a total number of 221 brain morphometric features were obtained. These brain descriptive characteristics can be grouped into:Footnote 2
-
9 global quantities: left (L) and right (R) mean thickness, L and R cortex volumes, L and R cerebral white matter volume, cerebrospinal fluid volume, total gray volumes and the volume of segmented brain without ventricles;
-
26 volumes of sub-cortical structures and corpus callosum;
-
186 measures, including the volume, the mean and standard deviation of the thickness of 62 structures (31 per hemisphere) from the Desikan-Killiany-Tourville Atlas [45]: 14 in the temporal lobe, 20 in the frontal lobe, 10 in the parietal lobe, 8 in the occipital lobe and 10 in the cingulate cortex.
2.2.2 Resting-state fMRI scan
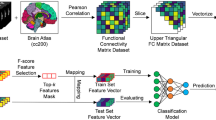
The rs-fMRI scans selected from ABIDE I and ABIDE II cohorts were processed with the Configurable Pipeline for the Analysis of Connectomes (C-PAC) [20], that includes motion correction, slice timing correction, band-pass filtering, spatial smoothing and registration. The Harvard-Oxford (HO) atlas was used to extract time series from brain regions, obtaining 110 timeseries for each subject. Seven regions were eliminated because they were not associated with any time series in a significant number of patients. In order to maximize the population of the dataset, the region was removed instead of discarding the patient’s exam. Thus, we obtained 103 timeseries for each subject. The Pearson correlation was calculated between the timeseries of pairs of regions to derive a functional connectivity (FC) matrix. The correlation values were normalized according to Fisher transformation [16] in order to make them approximately normally-distributed. Moreover, the correlation values were multiplied by \(\sqrt{(N-3)}\) (where N is the number of timepoints) to have a unitary standard deviation. From the symmetric FC matrix, we used \(N(N - 1)/2\) non-redundant values as features, obtaining 5253 connectivity features for each subject.
2.3 Harmonization
Due to the multisite nature of the dataset, we separately harmonized the Freesurfer structural features and the functional connectivity measures using the publicly available Python package NeuroHarmonize,Footnote 3 which is the state-of-the-art tool for multi-site neuroimaging analysis developed by Pomponio et al. [64]. We estimated the NeuroHarmonize model parameters on the entire cohort of control subjects, by specifying the age as a covariate, whose effect is to be preserved during the harmonization process. Finally, we applied the estimated model on the entire sample of subjects with ASD and TD controls.
2.4 Neural network architecture: a joint fusion approach
We developed a multi-modal DL classification model that integrates both structural and functional information. The fusion of different data modalities can be performed at different stages of the classification process. There are three main fusion strategies: early fusion, joint fusion, and late fusion, as discussed in Huang et al. [37] and Acosta et al. [2]. Early fusion is the simplest approach where input modalities or features are concatenated before training a single model. Instead, the joint fusion is a more advanced technique that combines and co-learns representations of different modalities during the training process. In contrast, late fusion involves training separate models for each modality and then combining their output probabilities.

Multimodal DL model with joint fusion approach. The model contains a feature-reduction neural network (FR-NN) and a classification neural network (C-NN). The main advantage of this strategy is that the loss is propagated back to the FR-NN during the training (black arrows). The solid blue and cyan circles represent a starting feature set, while the shaded circles represent the fixed-length feature vectors extracted from all modalities
In this study, the ASD vs. TD classification was carried out with a DL model, consisting in a feature dimensionality reduction neural network (FR-NN) which generates a fixed-length feature representation of the data for each modality. The two vectors are then merged and passed through a classification neural network (C-NN). Specifically, we implemented the joint fusion approach [37], whose main advantage is that the loss is propagated back to the FR-NN during the training, thus creating informative feature representations for each data modality. The C-NN, with several layers and neurons per layer, is optimized during the model training and performs the ASD-TD discrimination. In Fig. 1 a simplified scheme of our model was shown. Moreover, in order to evaluate the improvement of using a multimodal joint fusion model, we also implemented models based on single data modality. Only structural or connectivity features were considered using similar NN to perform the classification. We implemented the DL model using Keras [18], a Python DL API that uses Tensorflow as backend. The model was trained using Stochastic Gradient Descent (SGD) optimizer with a learning rate of 0.001 and a momentum of 0.9 and a ReLU as the activation function. During training we minimised the binary cross entropy between the model’s predictions and the true labels for ASD and TD subjects. The model was trained for 150 epochs, moreover standard DL techniques were adopted to reduce overfitting. In particular, we used:
-
batch normalisation [39], a technique which normalises the outputs of each layer for each batch of data, thus accelerating the rate of training and acting as a regularizer, reducing the internal covariate shift;
-
dropout [76] which works by randomly dropping units and their connections during training. Dropout was set to 0.5 and 0.2;
-
L1 regularisation which adds a penalty to the loss function and, hence, it shrinks the less important features’ coefficients, allowing for a better feature selection. The L1 regularisation hyperparameter was 0.01.
We implemented a feature scaling function (the Scikit-learn RobustScaler), that consists in the subtraction of the median and the scaling with respect to the interquartile range (IQR). The model has been trained according to a nested \(10-\)fold cross-validation scheme preserving the matching proportions of diagnosis (ASD/TD). The training of the model was performed in the inner CV loop. The performances were evaluated in the outer CV loop by computing the Area under the Receiver Operating Characteristic (ROC) curve (AUC) and accuracy. The metrics were computed within each fold; then, results across the test folds were used to calculate the mean and the standard deviation of accuracy and AUC.
2.5 Explainability: identify important features
In order to identify the most significant features able to discriminate between ASD and TD, the explainable method SHAP [52], based on Shapley values computation, was adopted. SHAP is a local model-agnostic approach, since it uses only the input and the output of a classifier. The explanation of each feature is quantified in Shapley values (\(\Phi\)) and the importance of each feature in the DL model can be calculated by averaging the absolute values of the Shapley values for all instances as:
where N is the number of instances in the dataset. We implemented the Gradient SHAP method, offered by the Python package SHAPFootnote 4; this method uses the gradients of the model output with respect to input features to approximate Shapely values. Because we implemented a multimodal model using different inputs with different dimensionality, it was necessary to make comparable the SHAP values, by rescaling them in the same numerical range. Therefore, we performed a normalization with respect to the total sum of SHAP values and with respect to different number of input features (N\(_{s,f}\)). The normalized values were calculated as follows:
The SHAP method was applied on the inner CV loop. To increase the robustness of results, the Shapely values were calculated using 100 different fold and the importance score were obtained as the average of the scores from 100 folds.
As the most important features, we selected the scores above the 99th percentile of importance features selected by SHAP. Moreover, the effect size of ASD vs. TD group difference was quantified using Cohen’s d coefficient. It consists in the standardized difference between two mean values \(\mu\) defined as (\(\mu _{\textrm{ASD}}\)-\(\mu _{\textrm{TD}}\))/SD\(_{\text {pooled}}\), where SD\(_{\text {pooled}}\) is the weighted average of the standard deviations of the two groups [19].
3 Results
3.1 Model performances
The model was trained to distinguish subjects with ASD from TD according to a nested 10-fold cross-validation scheme. The classification performance was estimated both on the single data modality model (structural NN and functional NN) and on the multimodal joint fusion model in order to evaluate the improvement in discrimination capability. Figure 2 shows the ROC curves obtained by averaging the ROC curves computed on each of the 10 folds of the cross validation. The mean AUC values and the standard deviations are reported. The performance in the ASD vs. TD discrimination is reported in term of AUC and accuracy in Table 2.

ROC curves obtained for the ASD vs. TD classification within 10-fold cross-validation scheme for the three different approaches: a structural DL model, a functional DL model and joint fusion DL model
From the Table 2, it can be noticed an improvement of the performance using a multi-modality with joint fusion approach model, which outperforms the model based on functional features only (\(p<0.001\)). The superior performance is due to its ability to extract relationships among features from different modalities. Moreover, if we consider the single data modality, we can conclude that the functional model significantly outperforms the structural one, as known in the literature.

Boxplot of the top 40 importance features selected by SHAP. The functional labels are defined by the Harvard-Oxford cortical and subcortical atlases [48]
3.2 Relevant brain features in the ASD vs. TD discrimination problem
The most important features in the ASD vs. TD discrimination problem were identified using Shapely values. The top 40 important features selected by SHAP are reported in Fig. 3. A list of the features whose importance scores exceeded the 99\(^{th}\) percentile are reported in Table 3. In addition to the specification of the feature name, the table reports the sign of the Cohen’s d, thus indicating whether a feature mean is larger/smaller (\(+/-\)) in the sample of subjects with ASD with respect to TD controls. It can be noticed that the features identified as important in the ASD vs. TD discrimination problem were mainly from functional MRI data. A visual representation of the relevant features is shown in Fig. 4, which allows an immediate identification of the set of significant functional connections. We found out a long-range inter-hemispheric hypo-connectivity and an intra-hemispheric hyper-connectivity in ASD subjects with respect to TDs.

The most important features (see Table 3) in the ASD vs. TD discrimination are highlighted. Significant functional connections are reported in left box. The over-connectivity (in red) and under-connectivity (in blue) patterns are shown. In right box the brain regions whose features were identified as relevant are highlighted
4 Discussion
We developed a multi-modality DL model with a joint fusion approach that uses the combination of structural and functional MRI data to discriminate subjects with ASD with respect to TDs. This DL model outperforms those based on each single modality. Several works demonstrated that better performance can be achieved by combining the results from structural and functional MRI data.
The work by Dekhil et al. [21] proposes a computer-aided diagnosis system that integrates features from sMRI and fMRI to predict autism diagnoses. They utilized traditional ML models, in particular, a local classifier (K-nearest neighbors) and a global classifier (Random Forest). The system was tested on 18 datasets from the ABIDE consortium, and the results demonstrated high accuracy (\(0.75-1.00\) on sMRI and \(0.79-1.00\) on fMRI data). However, the reported performances are specific to individual modalities and sites, lacking a comprehensive evaluation of the performance of the algorithm on combined data.
In their study, Aghdam et al. [5] utilized a deep belief network (DBN) to classify ASD subjects using both rs-fMRI and sMRI data. The study included participants aged 5 to 10 years from the ABIDE I and ABIDE II datasets. By combining rs-fMRI, gray matter, and white matter (WM) data, the study achieved an accuracy of 0.65, demonstrating that there were significant correlations between rs-fMRI and sMRI in diagnosing ASD. However, they employed an early fusion approach by combining the multi-modal features prior to the classification process. Despite a direct comparison between their work and ours cannot be done because of the different choice made in the selection of paticipants’ age range, we obtained substantially higher performances (an accuracy of \(0.85\pm 0.12\)) which may be attributable to the use of a joint fusion approach instead of an early fusion one.
Rakic et al. [67] propose a network consisting of autoencoders and multilayer perceptrons for the classification of ASD. The model was tested on both rs-fMRI and sMRI data from the ABIDE I dataset, both separately and in combination. They implemented both an early and a late fusion strategy, where connectivity and structural feature vectors were concatenated prior to classification (early approach) or classified separately and then the obtained label were fused (late approach). The best result was obtained using the late fusion approach, achieving a mean accuracy of 0.85, using an ensemble of 5 functional and 5 structural data classification models. This result is consistent with the performance obtained by our joint fusion model. However, late approach may potentially obscure valuable information that could be extracted from the interaction between modalities.
In their study, Abbas et al. [1] implemented a 3D model, which is completely different from ours and strongly more demanding from the computational point of view. The authors stated that they had implemented a subject partitioning criterion in the training, validation and test sets aimed at balancing the contribution of the different sites and diagnostic groups to each set. This approach to data partitioning may account for the fact that the ASD vs control classification performance they achieved is sensibly higher (AUC of 92.35) than ours.
Niu et al. [60] developed a multichannel deep attention neural network (DANN) model using functional neuroimaging data and personal characteristic data (e.g. sex, handedness, full-scale intelligence quotient) from ABIDE dataset. They achieved an accuracy of \(0.73\pm 0.02\) in classifying subjects with ASD with respect to TDs. The results by Niu et al. [60] suggest that integrating additional data modalities can facilitate the utilization of ML in the context of computer-aided diagnosis of ASD. This work employed a joint fusion approach, however, the authors did not incorporate structural information. In our study, we obtained an improvement of the performance combining sMRI and rs-fMRI data.
To the best of our knowledge, our work is the first study to utilize a joint fusion approach on harmonized sMRI and rs-fMRI data, involving data from all 35 ABIDE sites. However, the diagnostic performance might be further improved by incorporating phenotype information. Additionally, we introduced the SHAP analysis within the framework of the multimodal model. This approach allows us to explore both the relative relevance and the interplay between structural and functional information in the ASD vs control DL discrimination task.
4.1 Considerations of important features
Overall, our results revealed that individuals with ASD have poorer FC in brain regions spanning long, interhemispheric distances compared to TD controls, whereas FC seems to be increased in local, intrahemispheric circuits. This pattern has been firstly identified by Belmonte and colleagues [11] and confirmed by several subsequent independent investigations [8, 35, 41, 43, 56]. Among the most involved circuits, the weaker connection between pivotal hubs of the Default Mode Network (DMN) [66] including right middle temporal gyrus and left angular gyrus, right and left middle temporal gyrus, right and left posterior cingulate gyrus greatly contributed to distinguishing ASD participants from TD peers. Crucially, DMN is implicated in social cognition [55], theory of mind [17], emotional processing [15], self-evaluation [32], autobiographical memory ([59], and its disruption has been consistently described in subjects with ASD [9, 10, 24, 34, 79, 82]. Indeed, under-functional connectivity in regions of the DMN might contribute to the social-cognitive impairments associated with ASD. In addition, other brain regions that constitute the DMN, such as the superior frontal gyrus, the posterior cingulate gyrus, the superior temporal gyrus, the middle temporal gyrus, and the angular gyrus are part of the weaker connections we detected in individuals with ASD. Moreover, we observed atypical functional activation of areas belonging to the social brain, a network specialized in processing social cues and encoding human social behaviors [3, 14, 30], which includes the inferior frontal gyrus, the anterior cingulate cortex (subcallosal region), the superior temporal cortex, the temporal poles, and the fusiform gyrus. In line with our findings, previous investigations detected altered neural substrates in social brain [31, 62], which in turn may underlie abnormal processing of social cues, a hallmark of ASD.
It is also important to note a degree of overlap between the structural and functional findings of the current study: indeed, the left superior temporal gyrus (a crucial structure implicated in language and social cognition frequently impaired in ASD subjects [12, 13, 47]) is both increased in thickness and altered as far as FC is concerned in ASD individuals compared with control participants. This result support the notion that brain changes in ASD, even if subtle and diffuse, converge into specific, close localized areas of structural and functional alterations [58, 63, 69].
In our study, the classical case–control approach was implemented. However, it is crucial to acknowledge the limitations and challenges associated with this approach. Despite its widespread use, the classical approach did not take into account the intrinsic heterogeneity of ASD [50], presuming that the group mean is representative of the entire population. This assumption may not be valid for heterogeneous populations like ASD [54]. Recognizing the limitations of the classical approach, recent investigations tried to address the heterogeneity within ASD by exploring its biological underpinnings including neuroanatomical measures, with predominantly inconsistent results [4, 49, 85]. Moreover, a novel method for dealing with the neurobiological heterogeneity associated with ASD, and more broadly neurodevelopmental disorders, is normative modeling [70]. This method utilizes the trajectory of the typical developing brain across relevant variables to predict brain measures for each individual, highlighting deviations from the typical pattern for each individual. Normative modeling has been applied in previous investigations involving ASD individuals, revealing widespread patterns of deviations [73, 74, 84]. Given these considerations, it is evident that one of the most significant challenges in current ASD research is addressing and reducing the high heterogeneity at the neurobiological level in order to pave the way for more individualized treatment strategies for ASD individuals.
5 Conclusions
In conclusion, our findings indicate that the DL-based joint fusion approach outperforms single modality DL models, as it can effectively exploit the complementary information encoded in each acquisition modality. The improvement in AUC demonstrated that sMRI and rs-fMRI images contain complementary information related to the ASD diagnosis. Furthermore, our work suggests that multi-modality DL models are promising tools for identifying potential neuroimaging biomarkers of neurodevelopmental disorders.
Availability of data and materials
In this study the public dataset ABIDE was used. To allow the reproducibility of the analysis, the identification numbers (IDs) of the participants selected in the final sample are reported in Supplementary Materials.
Notes
The extensive list of analyzed brain features can be found in the supplementary materials.
Abbreviations
- ABIDE:
-
Autism brain imaging data exchange
- ASD:
-
Autism spectrum disorders
- AUC:
-
Area under the curve
- C-NN:
-
Classification neural network
- C-PAC:
-
Configurable pipeline for the analysis of connectomes
- DL:
-
Deep learning
- FR-NN:
-
Feature reduction neural network
- HO:
-
Harvard-Oxford
- IQR:
-
Interquartile range
- ML:
-
Machine learning
- MRI:
-
Magnetic resonance imaging
- ROC:
-
Receiver operating characteristic
- rs-fMRI:
-
Resting-State fMRI
- SDG:
-
Stochastic gradient descent
- SHAP:
-
SHapley additive exPlanations
- sMRI:
-
Structural MRI
- TD:
-
Typical development
References
Abbas SQ, Chi L, Chen YPP (2023) Deepmnf: Deep multimodal neuroimaging framework for diagnosing autism spectrum disorder. Artif Intell Med 136:102475
Acosta JN, Falcone GJ, Rajpurkar P et al (2022) Multimodal biomedical ai. Nat Med 28:1773–1784. https://doi.org/10.1038/s41591-022-01981-2
Adolphs R (2009) The social brain: neural basis of social knowledge. Ann Rev Psychol 60:693–716
Aglinskas A, Hartshorne JK, Anzellotti S (2022) Contrastive machine learning reveals the structure of neuroanatomical variation within autism. Science 376(6597):1070–1074
Akhavan Aghdam M, Sharifi A, Pedram MM (2018) Combination of rs-fmri and smri data to discriminate autism spectrum disorders in young children using deep belief network. J Digital Imag 31:895–903
Alaerts K, Swinnen SP, Wenderoth N (2016) Sex differences in autism: a resting-state fmri investigation of functional brain connectivity in males and females. Soc Cognit Affect Neurosci 11(6):1002–1016
American Psychiatric Association (2013) Diagnostic and statistical manual of mental disorders: DSM-5, 5th edn. Autor, Washington, DC
Anderson JS, Druzgal TJ, Froehlich A et al (2011) Decreased interhemispheric functional connectivity in autism. Cereb Cortex 21(5):1134–1146
Anderson JS, Nielsen JA, Froehlich AL et al (2011) Functional connectivity magnetic resonance imaging classification of autism. Brain 134(12):3742–3754
Assaf M, Jagannathan K, Calhoun VD et al (2010) Abnormal functional connectivity of default mode sub-networks in autism spectrum disorder patients. Neuroimage 53(1):247–256
Belmonte MK, Allen G, Beckel-Mitchener A et al (2004) Autism and abnormal development of brain connectivity. J Neurosci 24(42):9228–9231
Xa Bi, Zhao J, Xu Q et al (2018) Abnormal functional connectivity of resting state network detection based on linear ica analysis in autism spectrum disorder. Front Physiol 9:475
Bigler ED, Mortensen S, Neeley ES et al (2007) Superior temporal gyrus, language function, and autism. Devel Neuropsychol 31(2):217–238
Brothers L (1990) The social brain: a project for integrating primate behavior and neuropsychology in a new domain. Conc Neurosci 1:27–51
Broyd SJ, Demanuele C, Debener S et al (2009) Default-mode brain dysfunction in mental disorders: a systematic review. Neurosci Biobehav Rev 33(3):279–296
Chen H, Nomi JS, Uddin LQ et al (2017) Intrinsic functional connectivity variance and state-specific under-connectivity in autism. Human Brain Mapping 38(11):5740–5755
Chen L, Chen Y, Zheng H et al (2021) Changes in the topological organization of the default mode network in autism spectrum disorder. Brain Imag Behav 15:1058–1067
Chollet F et al (2015) Keras. https://github.com/fchollet/keras
Cohen J (1988) Statistical Power Analysis for the Behavioral Sciences, 2nd edn. Routledge; Taylor and Francis.
Craddock C, Sikka S, Cheung B et al (2013) Towards automated analysis of connectomes: The configurable pipeline for the analysis of connectomes (c-pac). Front Neuroinform 42:10–3389
Dekhil O, Ali M, Haweel R et al (2020) A comprehensive framework for differentiating autism spectrum disorder from neurotypicals by fusing structural mri and resting state functional mri. Semin Pediat Neurol 34:100805
Di Martino A, Yan CG, Li Q et al (2014) The autism brain imaging data exchange: towards a large-scale evaluation of the intrinsic brain architecture in autism. Mol Psych 19:659–667. https://doi.org/10.1038/mp.2013.78
Di Martino A, O’Connor D, Chen B et al (2017) Enhancing studies of the connectome in autism using the autism brain imaging data exchange ii. Scient Data 4:170010. https://doi.org/10.1038/sdata.2017.10
Feng Y, Kang X, Wang H et al (2023) The relationships between dynamic resting-state networks and social behavior in autism spectrum disorder revealed by fuzzy entropy-based temporal variability analysis of large-scale network. Cerebral Cortex 33(3):764–776
Ferrari E, Bosco P, Calderoni S et al (2020) Dealing with confounders and outliers in classification medical studies: The autism spectrum disorders case study. Artif Intell Med 108:101926. https://doi.org/10.1016/j.artmed.2020.101926
Ferrari E, Retico A, Bacciu D (2020) Measuring the effects of confounders in medical supervised classification problems: the confounding index (ci). Artif Intell Med 103:101804. https://doi.org/10.1016/j.artmed.2020.101804
Fischl B (2012) Freesurfer. NeuroImage 62:774–781. https://doi.org/10.1016/j.neuroimage.2012.01.021
Floris DL, Filho JOA, Lai MC et al (2021) Towards robust and replicable sex differences in the intrinsic brain function of autism. Mol Autism. https://doi.org/10.1186/s13229-021-00415-z
Fortin JP, Parker D, Tunç B et al (2017) Harmonization of multi-site diffusion tensor imaging data. NeuroImage 161:149–170. https://doi.org/10.1016/j.neuroimage.2017.08.047
Frith U, Frith C (2010) The social brain: allowing humans to boldly go where no other species has been. Philos Trans Royal Soci B Biol Sci 365(1537):165–176
Gotts SJ, Simmons WK, Milbury LA et al (2012) Fractionation of social brain circuits in autism spectrum disorders. Brain 135(9):2711–2725
Gusnard DA, Akbudak E, Shulman GL et al (2001) Medial prefrontal cortex and self-referential mental activity: relation to a default mode of brain function. Proc Natl Acad Sci 98(7):4259–4264
Haar S, Berman S, Behrmann M et al (2016) Anatomical abnormalities in autism? Cereb Cortex. https://doi.org/10.1093/cercor/bhu242
von dem Hagen EA, Stoyanova RS, Baron-Cohen S et al (2013) Reduced functional connectivity within and between ‘social’resting state networks in autism spectrum conditions. Soc Cognit Affect Neurosci 8(6):694–701
Heinsfeld AS, Franco AR, Craddock RC et al (2018) Identification of autism spectrum disorder using deep learning and the abide dataset. NeuroImage Clin 17:16–23
Hu F, Chen AA, Horng H et al (2023) Image harmonization: a review of statistical and deep learning methods for removing batch effects and evaluation metrics for effective harmonization. NeuroImage. https://doi.org/10.1016/j.neuroimage.2023.120125
Huang SC, Pareek A, Seyyedi S et al (2020) Fusion of medical imaging and electronic health records using deep learning: a systematic review and implementation guidelines. npj Digit Med. https://doi.org/10.1038/s41746-020-00341-z
Ingalhalikar M, Shinde S, Karmarkar A et al (2021) Functional connectivity-based prediction of autism on site harmonized abide dataset. IEEE Trans Biomed Eng 68(12):3628–3637. https://doi.org/10.1109/TBME.2021.3080259
Ioffe S, Szegedy C (2015) Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: Bach F, Blei D (eds) Proceedings of the 32nd International Conference on Machine Learning, Proceedings of Machine Learning Research, vol 37. PMLR, Lille, France, pp 448–456, https://proceedings.mlr.press/v37/ioffe15.html
Johnson WE, Li C, Rabinovic A (2006) Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostatistics 8(1):118–127. https://doi.org/10.1093/biostatistics/kxj037
Just MA, Keller TA, Malave VL et al (2012) Autism as a neural systems disorder: a theory of frontal-posterior underconnectivity. Neurosci Biobehav Rev 36(4):1292–1313
Katuwal GJ, Baum SA, Cahill ND et al (2016) Divide and conquer: Sub-grouping of asd improves asd detection based on brain morphometry. PLoS ONE 11(4):1–24. https://doi.org/10.1371/journal.pone.0153331
Keown CL, Shih P, Nair A et al (2013) Local functional overconnectivity in posterior brain regions is associated with symptom severity in autism spectrum disorders. Cell Rep 5(3):567–572
Khodatars M, Shoeibi A, Sadeghi D et al (2021) Deep learning for neuroimaging-based diagnosis and rehabilitation of autism spectrum disorder: A review. Comput Biol Med. https://doi.org/10.1016/j.compbiomed.2021.104949
Klein A, Tourville J (2012) 101 labeled brain images and a consistent human cortical labeling protocol. Front Neurosci. https://doi.org/10.3389/fnins.2012.00171
Le Couteur A, Haden G, Hammal D et al (2008) Diagnosing autism spectrum disorders in pre-school children using two standardised assessment instruments: the adi-r and the ados. J Autism Devel Disord 38:362–372
Lee Y, By Park, James O et al (2017) Autism spectrum disorder related functional connectivity changes in the language network in children, adolescents and adults. Front Human Neurosci 11:418
Lin CS, Ku HL, Chao HT et al (2014) Neural network of body representation differs between transsexuals and cissexuals. PLoS ONE 9(1):1–10. https://doi.org/10.1371/journal.pone.0085914
Liu G, Shi L, Qiu J et al (2022) Two neuroanatomical subtypes of males with autism spectrum disorder revealed using semi-supervised machine learning. Mol Autism 13(1):1–14
Lombardo MV, Lai MC, Baron-Cohen S (2019) Big data approaches to decomposing heterogeneity across the autism spectrum. Mol Psych 24(10):1435–1450
Lord C, Rutter M, DiLavore P et al (2012) Edition (ados-2) manual (part i). Modules 1–4 (Autism Diagnostic Observation Schedule, Second)
Lundberg SM, Lee SI (2017) A unified approach to interpreting model predictions. In: Guyon I, Luxburg UV, Bengio S et al (eds) Advances in Neural Information Processing Systems 30. Inc; New york, Curran Associates, pp 4765–4774
Maenner MJ, Warren Z, Williams AR et al (2023) Prevalence and characteristics of autism spectrum disorder among children aged 8 years-autism and developmental disabilities monitoring network, 11 sites, united states, 2020. MMWR Surveill Summ 72(2):1
Marquand AF, Rezek I, Buitelaar J et al (2016) Understanding heterogeneity in clinical cohorts using normative models: beyond case-control studies. Biol Psych 80(7):552–561
Mars RB, Neubert FX, Noonan MP et al (2012) On the relationship between the “default mode network’’ and the “social brain’’. Front Human Neurosci 6:189
Maximo JO, Keown CL, Nair A et al (2013) Approaches to local connectivity in autism using resting state functional connectivity mri. Front Human Neurosci 7:605
Moridian P, Ghassemi N, Jafari M et al (2022) Automatic autism spectrum disorder detection using artificial intelligence methods with mri neuroimaging: A review. Front Mol Neurosci. https://doi.org/10.3389/fnmol.2022.999605
Mueller S, Keeser D, Samson AC et al (2013) Convergent findings of altered functional and structural brain connectivity in individuals with high functioning autism: a multimodal mri study. PloS ONE 8(6):e67329
Nielsen JA, Zielinski BA, Fletcher PT et al (2014) Abnormal lateralization of functional connectivity between language and default mode regions in autism. Mol Autism 5(1):1–11
Niu K, Guo J, Pan Y et al (2020) Multichannel deep attention neural networks for the classification of autism spectrum disorder using neuroimaging and personal characteristic data. Complexity 2020:1–9
Okamoto N, Akama H (2021) Extended invariant information clustering is effective for leave-one-site-out cross-validation in resting state functional connectivity modeling. Front Neuroinform. https://doi.org/10.3389/fninf.2021.709179
Patriquin MA, DeRamus T, Libero LE et al (2016) Neuroanatomical and neurofunctional markers of social cognition in autism spectrum disorder. Human Brain Mapping 37(11):3957–3978
Pereira AM, Campos BM, Coan AC et al (2018) Differences in cortical structure and functional mri connectivity in high functioning autism. Front Neurol 9:539
Pomponio R, Erus G, Habes M et al (2020) Harmonization of large mri datasets for the analysis of brain imaging patterns throughout the lifespan. NeuroImage 208:116450. https://doi.org/10.1016/j.neuroimage.2019.116450
Qiu S, Chang GH, Panagia M et al (2018) Fusion of deep learning models of mri scans, mini-mental state examination, and logical memory test enhances diagnosis of mild cognitive impairment. Alzheimer’s Demen Diagn Assess Dis Monit 10:737–749
Raichle ME, MacLeod AM, Snyder AZ et al (2001) A default mode of brain function. Proc Natl Acad Sci 98(2):676–682
Rakić M, Cabezas M, Kushibar K et al (2020) Improving the detection of autism spectrum disorder by combining structural and functional mri information. NeuroImage Clin 25:102181
Reardon AM, Li K, Hu XP (2021) Improving between-group effect size for multi-site functional connectivity data via site-wise de-meaning. Front Comput Neurosci. https://doi.org/10.3389/fncom.2021.762781
Rudie JD, Brown J, Beck-Pancer D et al (2013) Altered functional and structural brain network organization in autism. NeuroImage Clin 2:79–94
Rutherford S, Kia SM, Wolfers T et al (2022) The normative modeling framework for computational psychiatry. Nat Prot 17(7):1711–1734
Rutter M, Le Couteur A, Lord C et al (2003) Autism diagnostic interview-revised. Los Angeles CA Western Psychol Serv 29(2003):30
Saponaro S, Giuliano A, Bellotti R et al (2022) Multi-site harmonization of mri data uncovers machine-learning discrimination capability in barely separable populations: An example from the abide dataset. NeuroImage Clin 35:103082. https://doi.org/10.1016/j.nicl.2022.103082
Segal A, Parkes L, Aquino K et al (2023) Regional, circuit and network heterogeneity of brain abnormalities in psychiatric disorders. Nat Neurosci 26(9):1613–1629
Shan X, Uddin LQ, Xiao J et al (2022) Mapping the heterogeneous brain structural phenotype of autism spectrum disorder using the normative model. Biol Psych 91(11):967–976
Spasov SE, Passamonti L, Duggento A et al (2018) A multi-modal convolutional neural network framework for the prediction of alzheimer’s disease. In: 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, pp 1271–1274
Srivastava N, Hinton G, Krizhevsky A et al (2014) Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research 15(56):1929–1958
Vargason T, Grivas G, Hollowood-Jones KL et al (2020) Towards a multivariate biomarker-based diagnosis of autism spectrum disorder: Review and discussion of recent advancements. Semin Pediat Neurol 34:100803. https://doi.org/10.1016/j.spen.2020.100803
Venugopalan J, Tong L, Hassanzadeh HR et al (2021) Multimodal deep learning models for early detection of alzheimer’s disease stage. Scient Rep 11(1):3254
Weng SJ, Wiggins JL, Peltier SJ et al (2010) Alterations of resting state functional connectivity in the default network in adolescents with autism spectrum disorders. Brain Res 1313:202–214
Xie Y, Xu Z, Xia M et al (2022) Alterations in connectome dynamics in autism spectrum disorder: A harmonized mega- and meta-analysis study using the autism brain imaging data exchange dataset. Biol Psych 91(11):945–955. https://doi.org/10.1016/j.biopsych.2021.12.004
Yala A, Lehman C, Schuster T et al (2019) A deep learning mammography-based model for improved breast cancer risk prediction. Radiology 292(1):60–66
Yerys BE, Gordon EM, Abrams DN et al (2015) Default mode network segregation and social deficits in autism spectrum disorder: Evidence from non-medicated children. NeuroImage Clin 9:223–232
Yoo Y, Tang LY, Li DK et al (2019) Deep learning of brain lesion patterns and user-defined clinical and mri features for predicting conversion to multiple sclerosis from clinically isolated syndrome. Comp Meth Biomech Biomed Eng Imag Visualiz 7(3):250–259
Zabihi M, Floris DL, Kia SM et al (2020) Fractionating autism based on neuroanatomical normative modeling. Transl Psych 10(1):384
Zhang J, Fang S, Yao Y et al (2023) Parsing the heterogeneity of brain-symptom associations in autism spectrum disorder via random forest with homogeneous canonical correlation. J Affect Disord 335:36–43
Funding
Research partly supported by: Artificial Intelligence in Medicine (next_AIM, https://www.pi.infn.it/aim) project, funded by INFN-CSN5; FAIR-AIM project funded by Tuscany Government (POR FSE 2014–2020); PNRR - M4C2 - Partenariato Esteso “FAIR - Future Artificial Intelligence Research” - Spoke 8, and PNRR - M4C2 - Centro Nazionale “ICSC - Centro Nazionale di Ricerca in High Performance Computing, Big Data and Quantum Computing” - Spoke 8, funded by the European Commission under the NextGeneration EU programme; the Italian Ministry of Health Grant RC and 5\(\times\) 1000 Health Research; AIMS2-Trials, http://aims-2-trials.eu.
Author information
Authors and Affiliations
Contributions
SS: Performed data analysis, interpreted the data, and drafted the manuscript. FL: Participated in the study design and supported the creation of DL model. GS: Generated functional connectivity measures. FM: Contributed to the manuscript preparation and revision. PO: Defined functional connectivity analysis pipeline. Revised the manuscript. AG: Revised the current literature and drafted portions of the manuscript. SC: Provided a clinical interpretation of the important features and contributed to the writing. AR: Conceived the study, participated in its design, and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors have no competing interests or other interests that might be perceived to influence the results and/or discussion reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
Sheet list of features: List of analyzed brain structural features. Sheet IDs of the participants: List of ID subjects per site selected in the final sample of the study.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Saponaro, S., Lizzi, F., Serra, G. et al. Deep learning based joint fusion approach to exploit anatomical and functional brain information in autism spectrum disorders. Brain Inf. 11, 2 (2024). https://doi.org/10.1186/s40708-023-00217-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40708-023-00217-4