
Abstract
Background
In solid-predominantly invasive lung adenocarcinoma (SPILAC), occult lymph node metastasis (OLNM) is pivotal for determining treatment strategies. This study seeks to develop and validate a fusion model combining radiomics and deep learning to predict OLNM preoperatively in SPILAC patients across multiple centers.
Methods
In this study, 1325 cT1a-bN0M0 SPILAC patients from six hospitals were retrospectively analyzed and divided into pathological nodal positive (pN+) and negative (pN-) groups. Three predictive models for OLNM were developed: a radiomics model employing decision trees and support vector machines; a deep learning model using ResNet-18, ResNet-34, ResNet-50, DenseNet-121, and Swin Transformer, initialized randomly or pre-trained on large-scale medical data; and a fusion model integrating both approaches using addition and concatenation techniques. The model performance was evaluated by the area under the receiver operating characteristic (ROC) curve (AUC).
Results
All patients were assigned to four groups: training set (n = 470), internal validation set (n = 202), and independent test set 1 (n = 227) and 2 (n = 426). Among the 1325 patients, 478 (36%) had OLNM (pN+). The fusion model, combining radiomics with pre-trained ResNet-18 features via concatenation, outperformed others with an average AUC (aAUC) of 0.754 across validation and test sets, compared to aAUCs of 0.715 for the radiomics model and 0.676 for the deep learning model.
Conclusion
The radiomics-deep learning fusion model showed promising ability to generalize in predicting OLNM from CT scans, potentially aiding personalized treatment for SPILAC patients across multiple centers.
Similar content being viewed by others

Background
Lung cancer remains the leading cause of cancer-related mortality globally [1]. Surgical resection is currently recognized as the primary treatment option for early-stage cases. In invasive lung adenocarcinoma, the solid predominant subtype serves as a substantial prognostic factor for both mortality and recurrence in patients undergoing resection. Additionally, it exhibits a strong correlation with a higher incidence of lymph node involvement [2,3,4]. Computed tomography (CT) scanning and positron emission tomography (PET)/CT scanning are the main non-invasive techniques for pre-surgical lymph node metastasis diagnosis. Yet, patients often progress from a clinical N0 (cN0) diagnosis to a pathological N1 (pN1) or N2 (pN2) stage after surgery, a condition termed occult lymph node metastasis (OLNM) [5].
The accurate preoperative identification of OLNM in solid-predominantly invasive lung adenocarcinoma (SPILAC), particularly for tumors with a solid component diameter of 2 cm or smaller, has emerged as a key focus and challenge for radiologists and thoracic surgeons. On the one hand, the OLNM status can assist in stratifying patients and providing therapeutic decision-making. High-risk patients may benefit from lobectomy and radical lymph node dissection, leading to improved survival, while low-risk patients may opt for less invasive procedures, such as sublobectomy or wedge resection, to enhance their quality of life [6, 7]. On the other hand, the interpretation of lymph node short-axis diameter on CT has been shown to be unreliable in diagnosing lymph node metastasis [8]. A meta-analysis revealed that PET/CT assessment for OLNM in non-small cell lung cancer patients can result in false positives due to inflammation and granuloma [9]. Additionally, the high cost associated with PET/CT poses a significant challenge to its broad clinical implementation [10, 11].
Recent studies [12, 13] have utilized CT-based radiomics for lymph node metastasis prediction. Radiomics features possess interpretability but are limited to extracting information solely from the tumor region, neglecting the relationship with surrounding tissues. Deep learning, particularly convolutional neural networks (CNNs) [14] and Transformers [15], has shown great potential in automatically capturing representative information from the entire image. A few works [16, 17] developed deep learning methods to predict lymph node metastasis for lung cancer. However, these studies had limited sample sizes or failed to account for lymph node characteristics. Furthermore, these models, developed and validated in single-center studies, faced challenges in broader clinical applications. Diverging from these approaches, our study: (1) amassed a substantial, multi-center dataset of SPILAC patients, emphasizing clinical generalizability; (2) integrated radiomics and deep learning, enhancing the predictive model’s performance; (3) explored various model architectures, data initialization methods, and feature fusion techniques to bolster generalization capabilities.
Thus, the purpose of this study was to develop and validate a radiomics-deep learning fusion model for OLNM prediction in SPILAC patients across multiple centers.
Methods
Patients and images
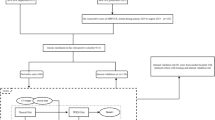
This multi-center retrospective study was approved by the institutional review boards of the six hospitals (Additional file 1: Appendix A), and the requirement for obtaining informed consent from the patients was waived. A total of 1325 patients with cT1a-bN0M0 SPILAC who were admitted for treatment between August 2011 and August 2022 were selected. Figure 1 presents the inclusion and exclusion criteria for patient screening in this study. The training and internal validation sets from hospitals 1–4 were generated by randomly splitting patients with pN+ and pN- cases in a 7:3 ratio, respectively. To select pN- patients, a 1:1 matching ratio based on gender, age, density, and nodular location was employed with pN+ patients in the training and internal validation sets. As for the two independent test sets, all eligible patients in hospitals 5–6 with pN+ and pN- cases were included.

Flowchart illustrating the process of patient enrollment and the criteria for inclusion and exclusion in the dataset. CTR = consolidation-to-tumor ratio, GGO = ground-glass opacity, pN + = pathological nodal positive, pN- = pathological nodal negative
Preoperative consecutive thin-slice CT images of 1325 patients were obtained from the picture archiving and communication system (PACS). Among the 1325 CT images, 899 images were non-enhanced, while the remaining 426 images were contrast-enhanced. A total of 70 mL of contrast agent was intravenously injected with bolus at a flow rate of 3.5–4 mL/s. The contrast-enhanced scans were acquired at 30–35 s. The CT imaging protocols were detailed in Additional file 1: Appendix A.
Image preprocessing
Thin-slice CT images (slice thickness ≤ 2 mm) of all patients were imported into the uAI Research Portal (uRP, Shanghai United Imaging Intelligence, Co., Ltd, China) in DICOM format for initial automatic tumor region segmentation. In the absence of knowledge regarding the pathological results, an experienced radiologist manually corrected the tumor masks slice-by-slice on the axial images obtained from the non-enhanced or contrast-enhanced phase in fixed lung window (window level: -600 HU, window width: 2000 HU), generating the three-dimensional volumes of interest (VOIs). Both the images and the masks were isotropically resampled to a voxel size of 1 × 1 × 1 mm3 using bilinear interpolation and nearest neighbor interpolation, respectively, for resolution normalization. The VOIs corresponding to the tumor regions served as the inputs for the radiomic model. Subsequently, we selected images of size 96 × 96 × 96 voxels containing the entire tumor regions by padding and cropping, which served as inputs to the deep learning model.
Radiomics model development
The workflow for the development of the radiomics model includes (a) Feature extraction: A total of 1364 radiomics features were extracted from the delineated three-dimensional VOIs based on uRP. (b) Feature selection: Ten most important radiomics features were selected using a decision tree. (c) Model development: A radiomics-based model for predicting OLNM was constructed using the support vector machine. For detailed information on the radiomics approach, please refer to Additional file 1: Appendix B.
Deep learning model development
To investigate the impact of model architecture and data initialization strategies on the performance of OLNM prediction in SPILAC across multiple centers, five common neural networks, namely ResNet-18 [18], ResNet-34 [18], ResNet-50 [18], DenseNet-121 [19], and Swin Transformer [20], were employed to build classification models separately. Beyond training from scratch, both ResNet and Swin Transformer models could be pre-trained on extensive medical datasets and subsequently fine-tuned on our specific dataset, aligning with the paradigm of transfer learning. The ResNet was pre-trained through segmentation tasks on the 3DSeg-8 dataset [21], which includes CT/magnetic resonance (MR) images of 1638 cases from different organs/tissues. The Swin Transformer was pre-trained on a set of 5050 CT cases derived from various organs. The pre-training was accomplished through three proxy tasks of self-supervised learning: masked volume inpainting, contrastive learning, and rotation prediction [22]. We developed a total of nine deep learning models. By feeding the output of each neural network into a global average pooling layer, we were able to obtain deep learning features.
Radiomics-deep learning fusion model development
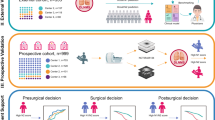
The architecture of radiomics-deep learning fusion model was depicted as detailed in Fig. 2. To explore whether feature fusion techniques help to enhance the performance of the classification model, we introduced four methods of feature fusion. Radiomics features and deep learning features were fused either by addition or concatenation. The overall training objective incorporated cross-entropy loss \({\mathcal{L}}_{ce}\) to evaluate classification errors, along with contrastive learning loss \({\mathcal{L}}_{cl}\) [23] to enhance the domain invariance of semantic features from pN+ and pN- cases across different centers. To mitigate overfitting, we also trained a momentum model following [24]. This model, which evolves continuously, shares initial parameters with the base model. The parameters of the momentum model are updated via the exponential moving average (EMA).

Design of the study. A Overall framework of the radiomics-deep learning fusion model for the prediction of OLNM in SPILAC. The w/o stands for with/without. \({\mathcal{L}}_{ce}\) and \({\mathcal{L}}_{cl}\) represent the cross-entropy loss function and the contrastive learning loss function, respectively. B Comparison of different feature fusion techniques. * denotes the mapping of radiomics features to the same dimension as the deep learning features through the fully connected layer. \({w}_{1}\) and \({w}_{2}\) represent the learnable weight parameters
In the training process, we employed a batch size of 12. Optimization was executed using the Adam optimizer, with an initial learning rate of 10–4. The training persisted for a total of 100 epochs, with cosine decay applied to the learning rate starting from the fifth epoch. Our compiling platform was based on the Python library (version 3.7.16) and Pytorch library (version 1.10.0) with CUDA (version 10.2) for GPU (NVIDIA Tesla V100, nvidia corporation, Santa Clara, California, USA) acceleration on a Linux operating system (Ubuntu 16.04 long-term support of a 64-bit server, 40 CPUs, and 503 GB of memory). Our codes are publicly available at https://github.com/paradisetww/OLNM_Prediction.
Statistical analysis
Statistical analysis was conducted using R software (version 4.0.2). The clinical characteristics across the training, internal validation, and two independent test sets were analyzed using the \({\chi }^{2}\)-test for categorical variables and the Kruskal-Wallis H-test for continuous variables to assess distribution differences. The area under the receiver operating characteristic (ROC) curve (AUC), accuracy, sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) were used to evaluate the performance of all models in predicting OLNM of SPILAC patients. The comparison between the ROC curves of different models was conducted using DeLong’s test. A p-value of less than 0.05 indicated statistical significance.
Results
Patient clinical characteristics
Our study comprised a total of 1325 SPILAC patients. This included 478 pN+ cases and 847 pN- cases. Patient clinical characteristics -- gender, age, nodule maximum diameter, density, and location relative to lung structures -- are detailed in Table 1. Solid nodules show a CTR of 1, while part-solid nodules have a CTR between 0.5 and 1. Comparisons across the training, internal validation, and two independent test sets showed significant inter-cohort differences.
Model performance evaluation
The accuracy, sensitivity, specificity, PPV, NPV, and AUC of the nine radiomics-deep learning fusion models using concatenation based on ResNet-18, pre-trained ResNet-18, ResNet-34, pre-trained ResNet-34, ResNet-50, pre-trained ResNet-50, DenseNet-121, Swin Transformer, and pre-trained Swin Transformer, on the internal validation set, independent test set 1, and independent test set 2 are shown in Table 2 and Fig. 3. The average AUC (aAUC) of the three datasets trained with ResNet-18, pre-trained ResNet-18, ResNet-34, pre-trained ResNet-34, ResNet-50, pre-trained ResNet-50, DenseNet-121, Swin Transformer, and pre-trained Swin Transformer were 0.746 ± 0.018, 0.754 ± 0.018, 0.710 ± 0.019, 0.746 ± 0.018, 0.722 ± 0.019, 0.733 ± 0.018, 0.674 ± 0.020, 0.742 ± 0.018, 0.737 ± 0.018, respectively. The radiomics-deep learning fusion model trained with pre-trained ResNet-18 obtained the highest aAUC (0.754 ± 0.018), whereas the models trained with ResNet-34 (0.710 ± 0.019) and DenseNet-121 (0.674 ± 0.020) performed the worst. On the internal validation set, there was no significant difference discerned in the AUC of the fusion model, combining radiomics and deep learning, trained with a pre-trained ResNet-18 when compared to other models. However, a distinct performance improvement was noted on the independent test set 1, where the AUC of the radiomics-deep learning fusion model trained with the pre-trained ResNet-18 significantly exceeded those of the models trained with ResNet-34, ResNet-50, pre-trained ResNet-50, DenseNet-121, and Swin Transformer. The respective p-values were 0.009, 0.038, 0.022, 0.019, and 0.044, illustrating statistical significance. Similarly, on the independent test set 2, the AUC of the radiomics-deep learning fusion model trained with the pre-trained ResNet-18 demonstrated significantly higher performance than the models trained with ResNet-50 (p = 0.028) and DenseNet-121 (p < 0.001).

The ROC curves of nine radiomics-deep learning fusion models using concatenation on the internal validation set, independent test set 1, and independent test set 2. The numbers in parenthesis represent the AUC metrics
To further investigate the impact of feature fusion techniques on classification performance, we evaluated six models grounded in radiomics, deep learning, and radiomics-deep learning fusion across three datasets: the internal validation set, independent test set 1, and independent test set 2, as shown in Table 3 and Fig. 4. The aAUC for the three datasets, trained with radiomics, deep learning, and radiomics-deep learning fusion utilizing addition*, learnable addition*, concatenation*, or simple concatenation, were 0.715 ± 0.019, 0.676 ± 0.021, 0.736 ± 0.018, 0.740 ± 0.017, 0.737 ± 0.018, and 0.754 ± 0.018, respectively. Here, the asterisk(*) denotes that radiomics features were mapped to the same dimensional space as the deep learning features prior to the feature fusion process. Radiomics leveraged a support vector machine model, whereas deep learning implemented a pre-trained ResNet-18 model. The model achieving the highest aAUC was the radiomics-deep learning fusion model using concatenation (0.754 ± 0.018), while those trained solely with radiomics (0.715 ± 0.019) and deep learning (0.676 ± 0.021) exhibited the least effective performance. Within the internal validation set, the AUC of the radiomics-deep learning fusion model employing concatenation was significantly greater than that of the model trained exclusively with deep learning (p = 0.027). Within the independent test set 1, the AUC of the radiomics-deep learning fusion model using concatenation significantly outperformed those of the models trained with radiomics and the radiomics-deep learning fusion utilizing addition*, learnable addition*, and concatenation*, with respective p-values of 0.001, 0.002, 0.002, and 0.012. Similarly, within the independent test set 2, the AUC of the radiomics-deep learning fusion model using concatenation was significantly superior to that of the model trained solely with deep learning (p < 0.001).

Performance of six models based on radiomics, deep learning, and radiomics-deep learning fusion. Radiomics employed the support vector machine model, while deep learning utilized the pre-trained ResNet-18 model. Addition*, learnable addition*, concatenation*, and concatenation indicate different feature fusion techniques. * represents that before feature fusion, the radiomics features were mapped to the same dimension as the deep learning features
Discussion
In this study, our primary investigation focused on the efficacy of various factors--model architectures, data initialization strategies, and feature fusion techniques--in enhancing the generalizability to predict OLNM in SPILAC across multiple centers. The experimental outcomes indicated that the integration of the ResNet-18 network architecture, the pre-training strategy, and the concatenation-based fusion technique of radiomics-deep learning features yielded the highest predictive performance (aAUC: 0.754 ± 0.018). In contrast, the models trained from scratch using ResNet-34 or DenseNet121 within a concatenation-based radiomics-deep learning fusion framework, or the models trained separately using radiomics or deep learning, demonstrated inferior performance, with aAUCs of 0.710 ± 0.019, 0.674 ± 0.020, 0.715 ± 0.019, and 0.676 ± 0.021, respectively. These results would be discussed from three perspectives: (1) When compared to other model architectures based on CNN or Transformer, the ResNet-18 outperformed, thanks to its shallower network depth and relatively simplistic structure, which effectively minimized model overfitting. (2) As opposed to training from scratch, employing a pre-training strategy on a large-scale medical dataset followed by fine-tuning on a self-built dataset significantly and universally augmented the model’s generalizability on the independent test set 1 and independent test set 2 obtained from other centers. This improvement can be attributed to the model’s ability to learn diverse and useful feature representations from large-scale medical data, which can be transferred efficaciously to the downstream OLNM prediction task. (3) Radiomics methods provide interpretability, but their scope is limited to the VOIs. Conversely, deep learning methods possess the ability to automatically learn and prioritize task-relevant critical regions. However, the interpretability of deep learning models remains constrained. Compared to models trained separately using radiomics and deep learning, or other radiomics-deep learning feature fusion models, the concatenation-based fusion technique of radiomics-deep learning features effectively combined the strengths of both radiomics and deep learning, thereby achieving superior performance.
The non-invasive preoperative prediction of OLNM status plays a critical role in the treatment decision-making process for patients suffering from SPILAC. However, the robustness and practicality of most existing radiomics or deep learning models for lymph node metastasis prediction were debatable, as they were typically constructed based on limited or single-center datasets [16, 17]. Our research differed in that we collected an extensive array of CT images from six different hospitals, utilizing multiple scan devices and a variety of image reconstruction parameters. The broad distribution of this dataset has enabled us to conduct a comprehensive investigation into the impacts of model architectures, data initialization strategies, and feature fusion techniques on the challenging task of predicting OLNM, bringing our work into closer alignment with real-world clinical scenarios.
Our study does present several limitations. First, despite the comprehensive inclusion of a significant number of multi-center SPILAC patients for OLNM prediction, our study possessed an inherent bias, owing to its retrospective design. Going forward, a prospective exploration would be valuable to mitigate this bias. Second, we have not yet assessed the actual benefits of non-invasive preoperative OLNM prediction for patients with SPILAC. This important area merits further investigation in the future.
Conclusions
The integration of the ResNet-18 network architecture, the pre-training strategy, and the concatenation-based fusion technique of radiomics-deep learning features have the potential to enhance the generalizability of predicting OLNM based on preoperative CT images in SPILAC across multiple centers.
Availability of data and materials
The data and materials used or analyzed during the study are available upon reasonable request through the corresponding authors.
Abbreviations
- AUC:
-
Area under the curve
- CNN:
-
Convolutional neural network
- CT:
-
Computed tomography
- CTR:
-
Consolidation-to-tumor ratio
- EMA:
-
Exponential moving average
- GGO:
-
Ground-glass opacity
- MR:
-
Magnetic resonance
- NPV:
-
Negative predictive value
- OLNM:
-
Occult lymph node metastasis
- PACS:
-
Picture archiving and communication system
- PET:
-
Positron emission tomography
- pN-:
-
Pathological nodal negative
- pN+:
-
Pathological nodal positive
- PPV:
-
Positive predictive value
- ROC:
-
Receiver operating characteristic
- SPILAC:
-
Solid-predominantly invasive lung adenocarcinoma
- VOI:
-
Volume of interest
References
Siegel RL, Miller KD, Wagle NS, Jemal A. Cancer statistics, 2023. CA Cancer J Clin. 2023;73:17–48.
Hung J-J, Jeng W-J, Chou T-Y, Hsu W-H, Wu K-J, Huang B-S, et al. Prognostic value of the new International Association for the Study of Lung Cancer/American Thoracic Society/European Respiratory Society lung adenocarcinoma classification on death and recurrence in completely resected stage I lung adenocarcinoma. Ann Surg. 2013;258:1079–86.
Hung J-J, Yeh Y-C, Jeng W-J, Wu K-J, Huang B-S, Wu Y-C, et al. Predictive value of the international association for the study of lung cancer/American Thoracic Society/European Respiratory Society classification of lung adenocarcinoma in tumor recurrence and patient survival. J Clin Oncol. 2014;32:2357–64.
Hung J-J, Yeh Y-C, Jeng W-J, Wu Y-C, Chou T-Y, Hsu W-H. Factors predicting occult lymph node metastasis in completely resected lung adenocarcinoma of 3 cm or smaller. Eur J Cardiothorac Surg. 2016;50:329–36.
Moon Y, Kim KS, Lee KY, Sung SW, Kim YK, Park JK. Clinicopathologic factors associated with occult lymph node metastasis in patients with clinically diagnosed N0 lung adenocarcinoma. Ann Thorac Surg. 2016;101:1928–35.
Nakamura K, Saji H, Nakajima R, Okada M, Asamura H, Shibata T, et al. A phase III randomized trial of lobectomy versus limited resection for small-sized peripheral non-small cell lung cancer (JCOG0802/WJOG4607L). Jpn J Clin Oncol. 2010;40:271–4.
Postmus PE, Kerr KM, Oudkerk M, Senan S, Waller DA, Vansteenkiste J, et al. Early and locally advanced non-small-cell lung cancer (NSCLC): ESMO Clinical Practice Guidelines for diagnosis, treatment and follow-up. Ann Oncol. 2017;28:iv1–21.
Prabhakar B, Shende P, Augustine S. Current trends and emerging diagnostic techniques for lung cancer. Biomed Pharmacother. 2018;106:1586–99.
Pak K, Park S, Cheon GJ, Kang KW, Kim I-J, Lee DS, et al. Update on nodal staging in non-small cell lung cancer with integrated positron emission tomography/computed tomography: a meta-analysis. Ann Nucl Med. 2015;29:409–19.
Seol HY, Kim YS, Kim S-J. Predictive value of 18F-fluorodeoxyglucose positron emission tomography or positron emission tomography/computed tomography for assessment of occult lymph node metastasis in non-small cell lung cancer. Oncology. 2021;99:96–104.
Kandathil A, Kay FU, Butt YM, Wachsmann JW, Subramaniam RM. Role of FDG PET/CT in the eighth edition of TNM staging of non-small cell lung cancer. Radiographics. 2018;38:2134–49.
He L, Huang Y, Yan L, Zheng J, Liang C, Liu Z. Radiomics-based predictive risk score: a scoring system for preoperatively predicting risk of lymph node metastasis in patients with resectable non-small cell lung cancer. Chin J Cancer Res. 2019;31:641–52.
Cong M, Feng H, Ren J-L, Xu Q, Cong L, Hou Z, et al. Development of a predictive radiomics model for lymph node metastases in pre-surgical CT-based stage IA non-small cell lung cancer. Lung Cancer. 2020;139:73–9.
Gu J, Wang Z, Kuen J, Ma L, Shahroudy A, Shuai B, et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018;77:354–77.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017. p. 6000–6010.
Wang Y-W, Chen C-J, Huang H-C, Wang T-C, Chen H-M, Shih J-Y, et al. Dual energy CT image prediction on primary tumor of lung cancer for nodal metastasis using deep learning. Comput Med Imaging Graph. 2021;91:101935.
Ma X, Xia L, Chen J, Wan W, Zhou W. Development and validation of a deep learning signature for predicting lymph node metastasis in lung adenocarcinoma: comparison with radiomics signature and clinical-semantic model. Eur Radiol. 2023;33:1949–62.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2016. p. 770–778.
Huang G, Liu Z, Maaten L van der, Weinberger KQ. Densely connected convolutional networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2017. p. 4700–4708.
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, et al. Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF international conference on computer vision. 2021. p. 10012–10022.
Chen S, Ma K, Zheng Y. Med3d: transfer learning for 3d medical image analysis. arXiv preprint arXiv. 2019:1904.00625.
Tang Y, Yang D, Li W, Roth HR, Landman B, Xu D, et al. Self-supervised pre-training of swin transformers for 3d medical image analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022. p. 20730–20740.
Wang Z, Liu Q, Dou Q. Contrastive cross-site learning with redesigned net for COVID-19 CT classification. IEEE J Biomed Health Inform. 2020;24:2806–13.
He K, Fan H, Wu Y, Xie S, Girshick R. Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020. p. 9729–9738.
Acknowledgements
We would like to express our gratitude to all the collaborating hospitals for their contribution to the data collection process.
Funding
This work was supported by the National Natural Science Foundation of China (No.62172101), the Clinical Research Plan of SHDC (No.SHDC2020CR3080B), and the Science and Technology Commission of Shanghai Municipality (No.22511106003).
Author information
Authors and Affiliations
Contributions
Weiwei Tian conceived and designed the study, conducted data collection, analysis, and interpretation, and drafted the manuscript. Qinqin Yan contributed to the conception and design of the study and performed data collection, statistical analysis, and manuscript editing. Xinyu Huang contributed to the conception and design of the study, conducted data analysis, and revised the manuscript. Rui Feng, Fei Shan, Daoying Geng, and Zhiyong Zhang contributed to the study’s design and coordination and participated in the manuscript revision. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
This retrospective study was approved by the Ethics Committee of each hospital, and the requirement to obtain informed consent from patients was waived.
Consent for publication
All authors have read the manuscript and have agreed to its publication in Cancer Imaging.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1: Appendix A.
CT imaging protocols. Appendix B. Radiomics model development.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Tian, W., Yan, Q., Huang, X. et al. Predicting occult lymph node metastasis in solid-predominantly invasive lung adenocarcinoma across multiple centers using radiomics-deep learning fusion model. Cancer Imaging 24, 8 (2024). https://doi.org/10.1186/s40644-024-00654-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40644-024-00654-2