
Abstract
The purpose of this study was to conduct a content analysis of research on technology use for teaching mathematics to students with disabilities. We applied word networks and structural topic modeling of 488 studies published from 1980 to 2021. Results showed that the words “computer” and “computer-assisted instruction” had the highest degree of centrality in the 1980s and 1990s, and “learning disability” was another central word in the 2000s and 2010s. The associated word probability for 15 topics also represented technology use within different instructional practices, tools, and students with either high- or low-incidence disabilities. A piecewise linear regression with knots in 1990, 2000, and 2010 demonstrated decreasing trends for the topics of computer-assisted instruction, software, mathematics achievement, calculators, and testing. Despite some fluctuations in the prevalence in the 1980s, the support for visual materials, learning disabilities, robotics, self-monitoring tools, and word problem-solving instruction topics showed increasing trends, particularly after 1990. Some research topics, including apps and auditory support, have gradually increased in topic proportions since 1980. Topics including fraction instruction, visual-based technology, and instructional sequence have shown increasing prevalence since 2010; this increase was statistically significant for the instructional sequence topic over the past decade.
Similar content being viewed by others

Introduction
Worldwide, the use of technology has rapidly innovated over the last several decades. With the advances in technological tools and systems in society, information has become easily accessible. It is clear that students are now immersed in technology from childhood and exposed to a vast number of technologies. Living in the digital age, in which students and teachers use a range of digital devices in the classroom, technology-mediated education methods have penetrated deeply into the field of education (Jones & Shao, 2011). Students are expected to select and use appropriate mathematical tools when engaging in mathematical activities in classrooms (National Governors Association Center for Best Practices and Council of Chief State School Officers, 2010). Mathematical tools can include any instructional materials and symbols that can be used to assist students in demonstrating their mathematical ideas and solving problems (Koestler et al., 2013). In particular, tools such as technology-incorporated methods can easily accommodate learning environments, optimizing meaningful access to classroom activities (Center for Applied Special Technology, 2018). The implementation of these technological tools in teaching and learning mathematics has been a recommended standard of the National Council of Teachers of Mathematics since 2000 (National Council of Teachers of Mathematics, 2000).
In addition to the proliferation of the use of educational technology in mathematics instruction, increasing attention has been paid to the use of educational technology to achieve diversity, equity, and inclusion in science, technology, engineering, and mathematics (STEM) education. According to the National Center for Education Statistics (2022), 7.2 million students, who comprise 15% of all students enrolled in public schools in the US, have a disability that adversely affects their academic performance and thus, need special education and related services. The use of technology to help students with disabilities has been an important area of research and practice in special education since the Technology-Related Assistance for Individuals with Disabilities Act was passed in 1988 and amended in 1994 (Blackhurst, 2005). One of the major goals of America’s Strategy for STEM Education (Committee on STEM Education, 2018) is to increase diversity, equity, and inclusion in STEM education for at-risk subgroups of students, including those with disabilities. Recently, there have been active movements (e.g., by the National Science Foundation and the Institute of Education Sciences) to advance the inclusion of students with disabilities in STEM education, thereby increasing their opportunities to use technology and eventually broadening their participation and equity in STEM education. Researchers have been disseminating their efforts to improve specifically the mathematical performance of students with disabilities using technology (Aspiranti et al., 2020; Bouck et al., 2020, 2022; García-Redondo et al., 2019; Kagohara et al., 2013; Kellems et al., 2020; Kiru et al., 2018; Nabors et al., 2020; Park et al., 2022; Satsangi et al., 2021a, 2021b; Shin et al., 2021b, 2023b; Xin et al., 2020). However, despite the increasing awareness of the need for diversity, equity, and inclusion in STEM education and the growing volume of research on supporting students who are struggling with mathematics, there is a lack of research on reviewing the topics of extant research in the field to identify the knowledge gap.
Evolution of technology use for teaching mathematics
Starting in the late 1990s, educators implemented virtual manipulatives and technology-based three-dimensional interactive visual models for teaching mathematical concepts and skills (Moyer-Packenham & Bolyard, 2016). Virtual manipulatives were initially developed through Flash or Java Applet programs and were mainly available on computers in the late 1990s. With the introduction of HTML5 web standards, however, virtual manipulatives have become available on mobile devices and have been found to be effective in teaching mathematics to students with disabilities (Bouck et al., 2020, 2022; Satsangi et al., 2021b; Shin et al., 2021b, 2023b).
Since 2010, touch-based tablets and interactive apps have become ubiquitous instructional tools in classrooms, particularly when teaching mathematics to students with disabilities (Pitchford et al., 2018). Both native apps (one-time downloadable apps on information and communication technology [ICT] devices) and web apps (apps accessible with a Wi-Fi connection) have increased the number of learning opportunities and improved students’ mathematical achievements (Aspiranti et al., 2020; Kagohara et al., 2013; Ok & Kim, 2017). Thus, the development and implementation of other types of technology, such as adaptive intelligent tutoring systems (Xin et al., 2020), educational games (García-Redondo et al., 2019), video-based instruction (Park et al., 2019) Satsangi et al. 2021a); augmented reality (Kellems et al., 2020), and virtual reality (Nabors et al., 2020), have increased, becoming important tools in mathematics instruction.
Previous content analysis on educational technology for students with disabilities
Over the past few decades, researchers have been implementing content analysis to deepen the understanding of research topics and trends in educational technology, including for students with disabilities. Specifically, Istenic Starcic and Bagon (2014) reviewed 118 studies on ICT-supported learning for the inclusion of people with special needs in seven educational technology journals (e.g., the British Journal of Educational Technology and Computers and Education) indexed in the Web of Science and published from 1970 to 2011. Applying content analysis, the authors found that more studies were published from 2006 to 2011 (44.7%) than during any other period; they identified the level of inclusion through an analysis of educational context (special schools, mainstream schools, and general support for life), addressing participant characteristics and research design. They further classified ICT interventions into technical interventions in the pedagogical or wider context (e.g., ICT access, teaching and learning methods, development, and testing of ICT solutions).
Adamu and Soykan (2019) also applied a content analysis in identifying trends in articles on the use of technology for people with dyslexia published in the Web of Science database from 2014 to 2019. A total of 46 studies were analyzed to determine the publication year and country, participant groups (e.g., students and adults), research methods (e.g., practical and experimental), teaching methods (e.g., e-learning and mobile-assisted learning), data collecting tools (e.g., quantitative and qualitative), and subject fields (e.g., informational technology and special education). The results revealed that the largest number of studies were published in 2018 and were conducted in the United States. The traditional teaching method had the highest frequency, followed by e-learning and mobile-assisted learning. Regarding the subject fields of the studies, medical and information technology had the highest frequency.
Recent applications of text mining techniques
Recently, beyond reviewing the literature using the traditional approach of content analysis, researchers have applied text mining techniques to further consider nested data structures (tokens nested within words that were nested within a document) when reviewing unstructured text such as large bibliometric datasets. The text mining method enables researchers to examine how the words within each publication are associated, constructing the meaning for each topic. In an effort to display related text information, word networks have been used in the social sciences and been connected with bibliometric reviews (Li & Xiao, 2022; Marín-Marín et al., 2021). Here, networks are considered a collection of the elements and their connected joints, usually displayed as graphs (Newman, 2018). To identify word co-occurrences (pairs of words that occur together within a publication) and analyze topics that have emerged across the published literature over time, researchers have analyzed large bibliographical datasets and implemented machine learning–based text mining approaches (Sharma et al., 2019). Thus, a word co-occurrence network represents a list of words as nodes and edges connecting two co-occurring words (Garg & Kumar, 2018). The application of word co-occurrence using bibliometric data such as abstracts can help educators explore what two words appear in the same publication while comparing the degree of closeness between texts (Kim et al., 2018).
Topic modeling is another text-mining method to explore hidden patterns in unstructured data by automatically organizing a large volume of texts into a set of clusters (Papadimitriou et al., 2000). To analyze trends from large bibliographical datasets of published data, researchers have implemented topic modeling, which is unsupervised machine learning (Grimmer et al., 2022; Sharma et al., 2019). Topic modeling enables people to uncover semantic structures and apply statistical methods. Topic modeling has been widely applied to examine the evolution of topics in certain academic fields, such as education (e.g., Li & Xiao, 2022), science (e.g., Blei & Lafferty, 2007), and human–computer interaction (e.g., Jung & Yoon, 2020). The earliest and most frequently used topic modeling method is latent Dirichlet allocation (Blei et al., 2003), which is based on a three-level (i.e., word, topic, and document) hierarchical Bayesian model in which hidden topics are assigned to explain the observed words in a text corpus of documents. As an extension of the originally suggested latent Dirichlet allocation method and to explain complex topic relationships, researchers have suggested methods to examine changes in topics over time (Wang & McCallum, 2006) and the correlation between topics (Blei & Lafferty, 2007). More recently, the structural topic model (Roberts et al., 2014), which includes covariate information related to the characteristics of documents, was suggested as a more flexible and general model in the social science field. Structural topic modeling can uncover latent topics in texts by assuming each document as a mixture of correlated topics and incorporating document-level external covariates into the prior distribution of topics or words (Bagozzi & Berliner, 2018).
Recently, Chen et al. (2020b) reviewed 40 years of research on educational technology with approximately 4000 articles published in the journal of Computers & Education. Applying structural topic modeling, they detected statistically significant increasing trends in topics such as collaborative learning, e-learning, and social networks and communities. As a follow-up study, Chen et al. (2022) conducted another structural topic modeling on the use of artificial intelligence technologies in education, with more than 4500 publications published from 2000 to 2019. In general, there has been increasing research interest in using artificial intelligence in the educational field. The topics included intelligent tutoring systems for special education, natural language processing for language education, and the application of artificial intelligence engines (e.g., educational robots, affective computing, and recommender systems).
Needs for the current study
Despite several efforts to examine the research trends on educational technology for students with disabilities (e.g., Adamu & Soykan, 2019; Istenic Starcic & Bagon, 2014), previous studies have several limitations when it comes to their methodology. First, the studies did not use various databases when searching the papers; they only included journals indexed in the Web of Science database. Istenic Starcic and Bagon (2014) even analyzed only seven educational technology journals indexed in the Web of Science database.
Second, the previous studies analyzed papers published in a short period of time (2014–2019; Adamu & Soykan, 2019) or published about 10 years ago (1970–2011; Istenic Starcic & Bagon, 2014). To include all possible papers, it is necessary to use various databases and expand the publication year period, including both dissertations and journal articles in the analysis.
Third, based on earlier studies by Chen et al. (2020b, 2022) regarding detecting topics and topic trends in educational technology, we extended this comprehensive review by examining the co-occurring words in each decade between 1980 and 2021. As described in the introduction section, there was especially a change and evolution in technology use in almost every decade during this time period. Thus, if we rely on a linear tread across the entire year, it is highly likely that we cannot capture a meaningful decreasing or increasing trend of topic proportions that could happen in a particular time period. Thus, we applied a piecewise model for discontinuity in slope and topic trends.
Finally, neither of the previous studies focused on technology for teaching mathematics to students with disabilities. Istenic Starcic and Bagon (2014) focused on ICT-supported learning for the inclusion of people with disabilities, and Adamu and Soykan (2019) analyzed the use of technology in dyslexia. Considering the importance of using technology to teach mathematics to students with disabilities, it is necessary to review and analyze studies focusing on this topic.
Furthermore, unlike Chen et al. (2020b, 2022), we manually screened all publications using the inclusion criteria (see below in the Methods), following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines (Page et al., 2021).
Research purpose and questions
To fill the gap in the previous research, we have aimed to extend the scope of data collection and analysis of the text corpus while exploring co-occurring words and hidden research topics in the literature on teaching mathematics with technology to students with disabilities. In detecting word co-occurrences and latent topics that have emerged from sizable bibliometric datasets (e.g., abstracts) of several decades of research, semantic machine learning techniques can be beneficial in mitigating human subjective bias and reducing potential measurement errors (Chen et al., 2020a). This text mining approach allowed us to analyze the abstracts of publications from journal articles and dissertations found through an online database. Because the mean topic proportion across the corpus did not show trends in topics over time, we implemented a piecewise linear regression with three knots in 1990, 2000, and 2010 to examine how the research topics evolved in prevalence over time. The current study’s correlation patterns between publication year and topic proportion supported the hypothesis that topical prevalence depends on the document-level covariate, the publication year. The specific research questions (RQ) were as follows:
1. What word pairs are commonly observed in studies on teaching mathematics using technology for students with disabilities in each decade between 1980 and 2021?
2. What research topics emerged from the studies on teaching mathematics using technology for students with disabilities, and what words were highly associated with these topics?
3. How have these research topics evolved in prevalence over time?
Methods
Inclusion criteria
We used four inclusion criteria. First, the focus of the studies had to be on teaching mathematics using technology for students with disabilities in grades K-12. We included studies when the purpose of the study was to provide instructional experiences and perspectives for students with disabilities. Second, we included studies of any type (e.g., experimental, correlational, qualitative, survey), including systematic reviews and meta-analyses. Third, studies were journal articles or dissertations published in English between 1980 and 2021. Unpublished doctoral dissertations were included in the current review to cover the gray literature, reducing publication bias (Paez, 2017). When any dissertations were published as journal articles, we counted these as identical publications and included the latest published articles only to avoid any doubling of publication. Fourth, we included studies when they reported title and publication year with abstract. Considering that the abstract of a publication provides a comprehensive summary of the paper (American Psychological Association, 2020), we used abstracts as the text sources for text mining analysis. Thus, studies without abstracts were excluded. To perform text mining across published studies over the last 42 years, we implemented structural topic modeling and examined trends in the use of technology in mathematics instruction for students with disabilities. Thus, in the initial search, we chose the starting year of 1970. The year 1970 was when the US Congress enacted the Education of the Handicapped Act (P.L. 91–230), a federal law establishing a new Title VI (later known as Part B) for individuals with disabilities, as a way to encourage states to develop educational programs. However, there were only two studies in the 1970s that met the above inclusion criteria (Higgins, 1970; Koller & Mulhern, 1977). Considering the limited number of studies available in the 1970s, we decided to set the starting search year as 1980.
Search strategies and extraction of bibliographic data
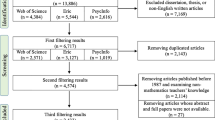
We adapted the PRISMA guidelines for article selection procedures (Page et al., 2021). As shown in Fig. 1, we first conducted an electronic database search of ERIC (n = 3548), Web of Science (n = 1677), Academic Search Complete (n = 1881), Education Source (n = 1657), APA PsycINFO (n = 1515), and MEDLINE (n = 604) for journal articles and dissertations published in English between 1980 and 2021, resulting in a total of 10,882 studies (see Fig. 1 for wildcard search terms used). When the first author exported the above search results as a bibliographic citation file (RIS) through the university library’s EBSCOhost Collection Manager, a total of 1301 duplicates were automatically removed from the online database by default. After exporting references to EndNote (EndNote Team, 2013), the team manually detected 1896 additional duplicates and removed these records from the lists.

Flow diagram of identifying studies. a Search terms: (disab*) AND (math* instruct* OR math* intervent* OR math* teach*) AND (anchored* OR app* OR artificial* OR asynchronous* OR augment* OR blended* OR computer* OR digital* OR e-learning OR game* OR gamificat* OR iPad* OR mobile* OR smart* OR synchronous* OR tablet* OR technolog* OR three-dimensional* OR 3D OR universal design OR universal design for learning OR video* OR virtual* OR web*)
We implemented the following procedure to extract bibliographic data of 7685 studies from EndNote (EndNote Team, 2013) to an Excel spreadsheet: (1) created a new output style that included bibliography records of reference type, author, year, title, keywords, and abstract; (2) removed carriage returns (unwanted paragraphs within each reference) in any field to display each reference in one row; and (3) copied formatted references into an Excel spreadsheet. Out of 7685 studies, we excluded 7197 studies for the following reasons: (a) not published in English (n = 32); (b) not journal articles or dissertations (n = 1603); (c) not focusing on teaching mathematics for students with disabilities in K-12 grades (n = 3169), or not using technology in mathematics instruction (n = 2393). As a result, 488 studies were included in the in-depth text mining.
To calculate inter-rater reliability on whether to include all the extracted studies, the first author reviewed 7685 studies and coded if each study met all four inclusion criteria. The other four co-authors independently double-checked all the metadata. We reached 98% agreement by taking the number of agreements and dividing by the total number of coding items multiplied by 100; after discussing the disagreed items, we reached 100% agreement on the included studies.
Text preprocessing
To make the textual data appropriate for the algorithm, the research team preprocessed the textual data in three steps: (1) constructing a corpus by selecting a text column in the dataset (abstract) and combining texts with document-level variables (publication year); (2) constructing a token object by segmenting complex text into smaller words; and (3) constructing a document–feature matrix that displays the frequencies of features (i.e., tokenized words) for each document. As an initial step, the research team identified and manually extended 146 acronyms (e.g., “WPS” to “word problem-solving” and “VR” to “virtual-representational”). The team applied tokenization by changing texts to lowercase; converting accented characters to the American Standard Code for Information Interchange; splitting hyphens and tags; and removing punctuation marks, symbols, numbers, and separators.
Next, the team created customized dictionary objects that could be processed within the quanteda R package (Benoit et al., 2018). Before constructing dictionary word lists, we detected frequently co-occurring multiwords through the kwic() function, creating a list of multiword expressions (i.e., character vectors) with compound words and synonyms that depended on word order within the dataset. To avoid duplicating the exact words, we sequentially processed two different lists of word patterns with wildcard expressions (233 words list for the first dictionary and 181 words list for the second dictionary) through the dictionary() function.
Then, we removed commonly observed units (tokens) of words or patterns, that is, stop words, that were not distinct across documents. The team processed a predefined stop word lexicon using the English Snowball with a 175 stop words list (Porter, 2001), which is available through the quanteda package (Benoit et al., 2018); this led to 4627 distinct words across 488 publications. As a follow-up analysis, the team created a customized stop words list by calculating the inverse document frequency (idf) of each word. The idf of a term is a metric that shows the degree of distinction of words within documents, which is commonly defined using the following formula: idfi = \(\mathrm{log}\left(\frac{N}{{ {\text{df}}_{\text{i}} }}\right)\), where dfi is the number of documents in the corpus containing word I, and N is the total number of documents in the corpus (Hvitfeldt & Silge, 2021). We manually examined those below 5% in the idf ranking (i.e., 224 words) out of the 4627 unique words and went down the list until we identified distinct words. In this process, 107 of 224 words were eventually included, creating the remaining 117 as the customized stop words list. The lists of the extended acronyms, customized dictionaries, and stop word lists are shared on the online repository (Shin et al., 2023a).
Word network analysis
In constructing and analyzing word networks, the research team identified co-occurring words within each publication regarding the use of technology in mathematics instruction for students with disabilities. To analyze data for each decade, we first filtered data by four different time periods (1980 to 1989, 1990 to 1999, 2000 to 2009, and 2010 to 2021). Then, applying the pairwise_counts() function in the widyr R package (Robinson & Silge, 2022), we counted the number of times each pair of words appeared together within a publication, occurring at least four times (1980s, 1990s, and 2000s) or 14 times (2010 to 2021). Thus, if two words (nodes) co-occurred in one publication, the nodes were connected with a line link (edge). We examined the importance of each individual word through a measure of degree centrality, assuming that influential and important nodes have higher neighbors (degrees) compared to other nodes with fewer degrees (Newman, 2018). To compare degree centrality (C) across networks with different numbers of edges and nodes, we normalized the values to be between zero and one, with one being the central node where all nodes are connected. For the normalized degree centrality calculation, we followed the formula embedded in the igraph (Csárdi & Nepusz, 2006) R package; C (v) = \(\frac{{d}_{v}}{\left|N\right|-1}\), where N is the number of nodes in the network corpus, and dv is the degree of node v. The visualization of the word co-occurrence network was completed through the tidygraph (Pedersen, 2023) and ggraph (Pedersen, 2022) R packages.
Structural topic modeling
Basic structural topic model
To identify the topics from the 488 studies’ abstracts, we employed structural topic modeling (Roberts et al., 2014). Structural topic modeling allows “topical prevalence” (degree each document is associated with a topic) and “topical content” (associated words in each topic) to be correlated and affected by document-level covariates through a logistic-normal generalized linear model (Roberts et al., 2019, p. 2). However, for the current text mining, we included the document-level covariate (publication year) for the function of topical prevalence only. Document d, d \(\in\){1, …, 488}, is assumed to be a mixture of topics, k \(\in\){1, …, 15}. Each corresponding topic proportion θ denotes the probability that a topic is associated with each publication, and each observed word from a document (wd,n), where n ∈ {1, …, Nd}, denotes that the nth word within a document has a corresponding topic assignment, randomly selected from a multinomial distribution given document-specific distribution over topics, zd,n ~ Multinomial (θd); a word is randomly selected from the corresponding multinomial distribution over terms conditional on the chosen topic, wd,n ~ Multinomial (βd,k,v) (Grimmer et al., 2022; Roberts et al., 2019). A topic was considered a mixture of words selected among the 4510 distinctive terms in the current study. The sums of both topic proportions for a given document and word probabilities for a given topic were restricted to be one (Grimmer et al., 2022; Roberts et al., 2019). The formula for calculating the topic proportion and the document-specific distribution over words is available at https://mshin77.github.io/math-tech-sped.
Evaluating the optimal number of research topics
Before conducting the topic modeling, the team first identified the optimal range of research topics, testing different numbers of topics against four different metrics. Applying a searchK() function in the stm R package (Roberts et al., 2019), we also evaluated multiple goodness-of-fit measures and identified the best fit for the data: (a) held-out likelihood: the log probability of topics assigned in the test set validating topics in the training set; (b) residuals: the difference between the predicted and expected topic predictions; (c) semantic coherence: co-occurrence of words in a topic; and (d) lower bound: the lower bound of the marginal log-likelihood (Rodriguez & Storer, 2020). As shown in Fig. 2, the diagnostic testing depicts the goodness of fit for each number of topics between 5 and 30. A topic number of 15 showed relatively low residuals, high semantic coherence, a maximized lower bound, and a high held-out likelihood.

Model diagnostic by number of topics
Modeling topic prevalence
Before examining the evolution of topics, we calculated Pearson correlations between publication year and topic proportions of all topics to understand the overall trend—whether in a positive or negative direction. Then, considering different trend changes in topic prevalence over time, we estimated the topical prevalence parameter, applying a piecewise linear regression model for each of the 15 topics between 1980 and 2021. Specifically, we specified the intervals of trend changes bounded with three knots in 1990, 2000, and 2010 (Perperoglou et al., 2019).
To achieve continuity of fit in the data over the entire publication period, we restricted the model by adding a dummy coding for the conditions of the three knots and constructed the following piecewise linear regression formula: topic proportion = β0 + β1(year – 1980) + β2(year ≥ 1990)(year – 1990) + β3(year ≥ 2000)(year – 2000) + β4(year ≥ 2010)(year – 2010), where β0 = level (mean topic proportion) in 1980, centered at the year of 1980, β1 = trend (slope) in 1980s, β2 to β4 = trend change, and when year – knot = \(\left\{\begin{array}{l}0, \, {\text{if year}} < {\text{knot}} \\ {\text{year}}-{\text{knot}}, \, {\text{if year}} \ge {\text{knot}}.\end{array}\right.\)
In examining the relationship between the topical prevalence and publication year, the same model of topical prevalence (see above) was passed to an ordinary least squares regression using the estimateEffect() function in the stm R package (Roberts et al., 2019). Then, we extracted the stm effect estimate via the pointestimate() function in the stminsights R package (Schwemmer, 2021) and converted stm objects to a “tidy” format, which is a way of mapping data processed in the R environment through the tidytext R package (Silge & Robinson, 2016). Datasets, R codes, and detailed outputs were posted through an online data repository (Shin et al., 2023a).
Labeling topics and content validity
The research team manually labeled the topics that emerged from structural topic modeling. The first author labeled each topic by reviewing the most frequently observed words and representative publications. Then, four other co-authors in special education technology, mathematics, and computer science reviewed each labeled topic with associated words and publications and shared the recommended labels for each topic. Agreement for labeled topics was 93.33% (the team agreed on 14 out of 15 topics), and the research team reviewed each label and discussed it until a consensus had been reached.
Results
Descriptive summary of included studies
A total of 488 studies were published in English between 1980 and 2021 in teaching mathematics using technology for students with disabilities in K-12 grades; 416 studies (85%) were journal articles, and 71 (15%) were dissertations. The number of publications has increased over the last 42 years. The number of publications by period was 37 for the 1980s, 51 for the 1990s, 70 for the 2000s, 243 for the 2010s, and 87 for years of 2020 and 2021. Between 1980 and 2009, the minimum publication number per year was 1, and the maximum number was 12 per year (median = 5). However, since 2010, there has been a rapid growth in the publication number. In the period 2010–2021, the minimum publication number per year was 11, and the maximum number was 46 (median = 27).
Co-occurring words over time (RQ1)
In 1980 and 1989 (see Fig. 3), a total of 218 pairs co-occurred at least four times (39 nodes and 218 edges) out of 79,090 word pairs (Min = 1, Max = 9, Median = 1) in 37 studies. The word pairs with the highest co-occurrence (n = 9) were “learning disabled” with “program”, “computer” with “learning disabled”, and “computer” with “drill and practice”. A word with the highest level of degree centrality was “computer” (centrality = 0.63), followed by “program”, “drill and practice”, “learning disabled”, “measure”, “level”, “testing”, “achievement”, “microcomputer”, and “computer-assisted instruction (CAI)”.

Co-occurring words (n ≥ 4) among studies published in 1980 to 1989 (39 nodes and 218 edges). CAI: computer-assisted instruction
In 1990 and 1999 (see Fig. 4), the co-occurrence frequency of 174 out of 71,736 word pairs (Min = 1, Max = 8, Median = 1) in 51 studies was greater than or equal to 4 (43 nodes and 174 edges). The word pairs with the highest co-occurrence (n = 8) included two sets: “strategy” with “problem solving” and “word problem” with “problem solving”. The next frequently co-occurring word pairs included “computer” with “program”, “learning disability” with “program”, “computer” with “CAI”, “learning disability” with “CAI”, “learning disability” with “computer”, “learning disability” with “problem solving”, and “word problem” with “strategy” (n = 7). The word with the highest degree of centrality was “CAI” (centrality = 0.43). The following words with relatively high degree centrality included “computer”, “strategy”, “learning disability”, “problem solving”, “word problem”, “program”, “procedure”, “addition”, and “specific”.

Co-occurring words (n ≥ 4) among studies published in 1990 to 1999 (43 nodes and 174 edges). CAI: computer-assisted instruction
In 2000 and 2009 (see Fig. 5), the co-occurrence frequency of 216 out of 132,092 word pairs (Min = 1, Max = 10, Median = 1) in 70 studies was greater than or equal to 4 (52 nodes and 216 edges). The word pair with the highest co-occurrence included “learning disability” with “testing” (n = 10), followed by “learning disability” with “computer” (n = 9), “level” with “testing” (n = 8), and “learning disability” with “problem solving” (n = 7). The word with the highest degree of centrality was “learning disability” (centrality = 0.57), followed by “testing”, “computer”, “level”, “problem solving”, “addition”, “achievement”, “measure”, and “CAI”.

Co-occurring words (n ≥ 4) among studies published in 2000 to 2009 (52 nodes and 216 edges). CAI: computer-assisted instruction; MLD: mathematics learning disability
In 2010 and 2021 (see Fig. 6), the co-occurrence frequency of 206 out of 720,432 word pairs (Min = 1, Max = 27, Median = 1) in 330 studies was greater than or equal to 14 (51 nodes and 206 edges). The word pair with the highest co-occurrence was “functional relation” with “multiple probe” (n = 27), followed by “mathematical” with “practice”, “word problem” with “problem solving”, “MLD” with “learning disability”, and “mathematical” with “solving” (n = 26). The word with the highest degree of centrality was “learning disability” (centrality = 0.48), followed by “mathematical”, “solving”, “practice”, “multiple probe”, “functional relation”, “addition”, “testing”, “intellectual disability”, and “problem solving”.

Co-occurring words (n ≥ 14) among studies published in 2010 to 2021 (51 nodes and 206 edges). MLD: mathematics learning disability; SBI: schema-based instruction
Emerged research topics and associated words (RQ2)
Figure 7 shows the distribution of the probability that a given publication belongs to a given topic across publications. When the topic proportion is close to zero, this means that the particular publication has no association with that specific topic, and when the value is close to one, the target publication covers the topic to a great extent. Out of a total of 7320 topic proportions across the 15 research topics that emerged from the 488 publications, 6646 topic proportions (90.8%) were less than 0.1, and 304 topic proportions (4.2%) were greater than 0.9. Thus, this distinct probability distribution within a topic supports a clear classification for each topic.

Distribution of topic proportions across publications. CAI: computer-assisted instruction; WPS: word problem-solving
Table 1 summarizes the associated terms (word probability per topic), labeled topics (topic proportion per document), and correlations between the topic proportions and the years of publication. The mean topic proportion ranged from .044 to .111 across the 15 labeled topics. Over the past 42 years, the five most frequently discussed topics were CAI (θ = .111), instructional sequence (mean θ = .096), visual-based technology (mean θ = .093), learning disabilities (mean θ = .093), and word problem-solving instruction (mean θ = .077). The other 10 topics investigated in the field included calculators (7.0%), mathematics achievement (6.3%), testing (5.7%), robotics (5.4%), auditory support (5.1%), software (5.0%), support for visual materials (4.8%), apps (4.7%), self-monitoring tools (4.5%), and fraction instruction (4.4%). These topics could be categorized further into instructional practices and assessment, educational technology tools, and disability types. To supplement the characteristics of each topic, we specified the representative study for each topic, that is, the study with the highest topic proportion for each research topic.
Instructional practices and assessment
Six topics (CAI, instructional sequence, word problem-solving instruction, fraction instruction, mathematics achievement, and testing) covered instructional practices and assessment. The CAI research topic has been the most frequently investigated over the past four decades. For example, as a representative study with the highest topic proportion, Nwaizu (1991) showed the effectiveness of teacher-assisted and computer-assisted instructional procedures among students with specific learning disabilities in mathematics. The words highly associated with CAI included “learning disabled”, “strategy”, “addition”, and “procedure”.
For the instructional sequence topic, Park (2019) implemented intervention packages with a sequenced combination of instructional methods, such as a virtual-representational-abstract instructional sequence with fading support or overlearning, to promote the maintenance skills of basic operations among students with disabilities. In the current topic modeling, words such as “maintenance”, “framework”, “virtual-representational-abstract”, and “evidence-based practice” were associated with the instructional sequence topic.
For the word problem-solving instruction topic, Schaefer Whitby (2009) showed the highest topic proportion; this study focused on the effects of a modified learning strategy (“Solve It!”) when solving multiple-step mathematical word problems among middle school students with high-functioning autism or Asperger’s syndrome. The highest associated words, such as “problem solving”, “schema-based instruction”, and “video”, supported the findings of previous syntheses and meta-analyses that schema-based instruction (Peltier et al., 2018), and video-based instruction (Kim & Xin, 2022) have been used for teaching word problems to students with disabilities.
In mathematics, fraction instruction has emerged as a distinctive research topic (Bouck et al., 2017). Other than “fractions”, the highly associated words, including “accuracy”, “solving”, “enhanced anchored instruction”, “instructional sequence”, and “virtual abstract”, show that studies have utilized various instructional practices when teaching fractions to students with disabilities.
Researchers have also focused on topics such as mathematics achievement in examining the relationships between education technology and mathematics achievement (McLeod, 2011) and testing in evaluating a computerized test battery for the diagnosis of learning disabilities (Billard et al., 2021). Of the highly associated words, “blended learning” for mathematics achievement and “computerized” for testing demonstrated the features of the measures and evaluations discussed within the included studies (Billard et al., 2021; Stewart, 2007).
Educational technology tools
Eight topics (visual-based technology, calculators, software, apps, self-monitoring tools, robotics, auditory support, and support for visual materials) covered the implementation of various educational technology tools for improving students’ mathematical performance. For the visual-based technology topic, representative studies with high topic proportions focused on technologies such as augmented reality, virtual reality, and virtual manipulatives. Miundy et al. (2019) examined the experiences of students with dyscalculia using augmented reality–based assistive digital technology. Altun and Kahveci (2019) evaluated the effects of virtual reality–based teaching material on geometry-related problem solving for students with learning disabilities. Prabavathy and Sivaranjani (2020) investigated the effects of virtual manipulatives on promoting basic arithmetic skills for students with developmental dyscalculia.
Regarding highly associated words, “accommodation”, “testing”, and “graphing calculator” demonstrated the purpose of calculators (Towers, 2018). For the consideration of software, words including “geometry”, “number”, and “computer” showed the targeted mathematics domain (Emprin & Petitfour, 2021). For the primary features of apps, “app” and “online” depicted the learning environment (Remata & Lomibao, 2021). Studies focusing on self-monitoring tools have addressed the usage of technology in expanding “access” to mathematics learning, such as using “digital text” (Bouck et al., 2013). These educational technology tools were found to be beneficial for teaching basic mathematics to primary school students with disabilities (Pitchford et al., 2018) and for improving the accuracy of mathematics homework (Falkenberg, 2010).
Furthermore, the research topic robotics highlighted the adapted and alternative function of a tool. Highly associated words, such as “robot”, “communication”, and “speech generating”, indicated the role of robotics in teaching mathematics to students with disabilities. A representative study by Adams and Cook (2014) also validated that robots have been used for the benefit of speech-generating functions in “hands-on” mathematics activities. Topics such as auditory support and support for visual materials were often investigated for students with visual impairments. The highly associated words for these topics were matched with representative studies: an interactive sonification of images in serious games as auditory support (Radecki et al., 2020) and textual materials (words, math expressions) describing visual images as support for visual materials (Emerson & Anderson, 2018).
Disability types
From the current topic modeling, only one topic (learning disabilities) was specifically related to disability type. Namely, the learning disabilities topic emerged as a separate research topic across the corpus. This topic covered words such as “problem solving”, “game”, “mathematics learning disability”, “strategy”, “problem”, and “digital”. These highly associated words can also be corroborated by the representative study conducted by Huscroft-D’Angelo et al. (2014), who investigated the impacts of a digital writing tool on improving students’ mathematical reasoning.
Topic evolution over time (RQ3)
To some extent, the degree of association between topic proportions and publications varied over time. Namely, the cases in which each publication was closely associated with a certain topic have shifted over time. This pattern of evolution of different topical prevalences over time demonstrates the effects of publication year as a document-level covariate. Figure 8 depicts the change in topic proportion per year during the four segmented periods of the 1980s, 1990s, 2000s, and 2010s, along with the more recent years of 2020 and 2021. Increasing or decreasing trends at the three knots (years 1990, 2000, and 2010) in the piecewise linear regression graph demonstrated the evolution of research interests and fluctuation in the publication numbers for a given topic. Table 2 summarizes the results of the piecewise linear regressions for each topic.

Piecewise linear trend of topic proportion for each topic. CAI: computer-assisted instruction; WPS: word problem-solving. The slopes of piecewise linear regressions are displayed above or below the line
Generally decreasing trends
Although there were fluctuations in the slopes, there were decreasing trends for CAI, software, mathematics achievement, calculators, and testing topics. Table 1 shows the negative associations between topic proportions and publication year for these topics. In 1980, the topics of CAI and software showed average topic proportions (0.270 and 0.206, ps < .01, respectively) that were statistically significantly different from 0. Although not statistically significant, in 1980, the average topic proportion of the mathematics achievement topic (0.146, p = .07) was also relatively higher than the remaining topics. In the 1980s and 2000s, the trends of topic proportion for the software topic were reduced by .017 and .018, respectively, compared with those of each previous decade (ps > .05). Although there was a slight annual increase in the topic proportion (a .017 increase) in the 1980s, the slope for the CAI topic showed a decreasing trend since 1990; in particular, compared with the 1980s, the trend was decreased by .048 in the 1990s, which was statistically significant (p < .05). Furthermore, even though there was a statistically significant increase in the trend for the mathematics achievement topic in the 2000s compared with that of the 1990s by .024 (p < .05), after 2010, this again reduced by .012 (p = .08). There was also a slightly increasing topic proportion trend in the 2000s compared with the previous decade of .012 (p = .29) for the calculator topic; however, the topic proportions in other periods were largely decreasing trends. Regarding the testing topic, the topic proportion was estimated to increase annually by .007 in the 1980s (p = .47); yet in the following decades, the topic proportions followed generally decreasing trends.
Generally increasing trends
Although there were almost no existing publications in 1980, apps, auditory support, fraction instruction, visual-based technology, and instructional sequence have shown increasing trends since 1980. Table 1 depicts the positive associations between these topics and publication year. Specifically, regarding apps and auditory support topics, topic proportions increased by .005 and .009 (ps > 0.05), respectively, in the 1980s. Starting in 1990, there was no noticeable change for these topics; comparable topic proportions were maintained throughout the remaining decades for the apps and auditory support topics. Furthermore, the topic trends of fraction instruction, visual-based technology, and instructional sequence showed similar patterns. Despite a slight fluctuation before 2010 for the instructional sequence topic (trend increase by 0.009 in the 1990s and decrease by 0.014 in the 2000s compared with each previous decade), there was a statistically significant increase in the topic trend after 2010 by .024 (p < .01); thus, the average topic proportion was expected to increase by .018 during the years between 2010 and 2021. Both the topics of fraction instruction and visual-based technology showed limited topic proportions until the year 2010; there was .002 or less annual increase in the topic proportions. After 2010, there were relatively large trend changes: by .010 for visual-based technology and .007 for fraction instruction. Although these topic evolutions were not statistically significant, even after 2010, the increasing trends of these last topics demonstrated the latest technology being used in teaching mathematics to students with disabilities.
The topic proportions for the support for visual materials, learning disabilities, robotics, self-monitoring tools, and word problem-solving instruction topics showed increasing trends, particularly after 1990. Although statistically not significant, the average topic proportions of these topics increased after 1990. The topic proportion trends increased by .018 for the robotics and .013 for the learning disabilities topics in the 1990s, yet these were slightly reduced again in the 2000s (ps > .05). Regarding the topics of support for visual materials and self-monitoring tools, these topics also showed slightly increasing trends in the 1990s by .009 and .012, respectively, compared with those in the 1980s, and these increasing patterns persisted throughout the 2000s. Then, the trends for these topics declined after 2010. In the case of the word problem-solving instruction topic, after the initial decreasing trend in the 1980s, the topic trends increased slightly throughout the following decades; the trend change in the 1990s (.002) was relatively higher than in the other periods.
Discussion
We conducted a content analysis via word networks and structural topic modeling exercise targeting studies on teaching mathematics using technology for students with disabilities. We examined 488 journal articles or dissertations published from 1980 to 2021. Our purpose was to identify co-occurring words and research topics investigated over the past 42 years. Using document–topic and topic–word distributions, we investigated the highly associated words for each topic and the topic evolution over time. By aggregating the results at the journal or dissertation level, we found that publications covered topics of different degrees both during a specific period and over time.
Co-occurring words over time
Applying word networks, we sought to identify co-occurring words for journal articles and dissertations on teaching mathematics using technology for students with disabilities and to examine the empirical evidence for centrality among the co-occurring words. The central word of “computer” in the 1980s and its co-occurring words such as “CAI”, “microcomputer”, and “software” demonstrated the features of the computer in this earlier time in the education field. The word networks in this period validated the emergence and early efforts in the development of microcomputers and computer software focusing on number facts, such as “multiplication facts” and “addition”, for students with learning disabilities (Kelly et al., 1986; Palmer et al., 1985).
Unlike in the 1980s, “word problem” appeared to frequently co-occur with “CAI”, which had the highest degree centrality. This result highlighted the publication regarding the development of CAI that targeted teaching word problem-solving through strategic and procedural training in the earlier periods (Jaspers, 1991). Another noticeable word was “strategy”, which connected words such as “word problem”, “problem solving”, and “procedure”. These word networks showed the emphasis on instructional strategies and procedures in teaching word problems for students with disabilities in 1990s’ publications (Swanson, 1999).
In the 2000s and 2010s, the word “learning disability” showed the highest centrality. Although “learning disabled” and “handicapped” appeared in studies published in the 1990s, researchers started using person-first language around 2000 (e.g., students with learning disabilities instead of learning-disabled students), as well as applying videos, multimedia (Bottge et al., 2007), and calculators (Steele, 2007) in mathematics instruction and testing. In the 2010s, “solving” also showed a relatively high between centrality within the network, co-occurring with several other words, such as “virtual manipulatives”, “schema-based instruction (SBI)”, “single case”, and “middle school”. This indicates that, since the 2010s, publications on the use of virtual manipulatives have also included problem solving as their essential instructional component (Shin & Bryant, 2017). Furthermore, “intellectual disability” was also observed to co-occur with “problem solving”, which was connected to “SBI” and “middle school”. This indicates that SBI was frequently implemented when teaching mathematical problem solving to students with intellectual disabilities (Root et al., 2019). Additional words, such as “functional relation”, “multiple probe”, and “addition”, were connected to “middle school” and “intellectual disability” to indicate patterns of frequently observed research designs (i.e., single-case experimental designs) of mathematical domains (i.e., addition) for secondary school students (Bouck et al., 2021).
Emerged research topics and associated words
Beginning with a relatively smaller number of publications in the 1980s, there has been exponential growth in the number of studies on teaching mathematics using technology for students with disabilities. In particular, the findings showed that researchers have largely focused on topics related to instructional practices and assessment. The high-probability words for each topic validated the instructional components and features used in each mathematics instruction. For example, associated words such as “learning disabled”, “strategy”, “addition”, and “procedure” applied for the CAI topic were aligned with the instructional design features of CAI, as analyzed by Ok et al. (2020), for teaching mathematical operations. Furthermore, other sets of high-probability words, such as “virtual-representational-abstract” and “evidence-based practice” for the instructional sequence topic, demonstrated the increased research focus on graduated instructional frameworks as evidence-based practices for teaching mathematics to students with disabilities (Jaspers et al., 2017). The highly associated words, such as “evidence-based practice” and “explicit instruction”, indicated that the instructional sequence was implemented based on the essential elements of explicit instruction (Bouck et al., 2020; Shin et al., 2021b).
Furthermore, the relatively high mean topic proportion for the fraction instruction and word problem-solving instruction topics also shows increasing interest in fractions and word problem-solving as primary concerns among students with disabilities. Because these two mathematics topics have consistently been a building block for successful mathematics in elementary and secondary mathematics (National Center for Education Statistics, 2019), it is assumed that researchers have been trying to investigate how to tackle these mathematical difficulties. Furthermore, since the release of the National Mathematics Advisory Panel’s report (2008) on highlighting the importance of teaching fractions as being a critical foundation of algebra and emphasizing students’ conceptual knowledge for understanding and solving mathematical word problems across topics, there have been an increasing number of intervention and review studies (Ennis & Losinki, 2019; Morano et al., 2020; Shin et al., 2021a).
Researchers have also focused on examining the roles and effects of various educational technology tools. As noticed among studies on visual-based technology topics, a growing number of researchers have applied virtual manipulatives, augmented reality, and virtual reality when teaching mathematics to students with learning disabilities (Altun & Kahveci, 2019; Prabavathy & Sivaranjani, 2020). In recent reviews and syntheses, researchers (Carreon et al., 2022; Nabors et al., 2020) have shown the positive outcomes and effectiveness of applying these technology tools for academic and behavioral aspects.
Although the overall research interest was low for the topics of apps, self-monitoring tools, robotics, auditory support, and support for visual materials compared with other research topics, these research topics should be noted. The associated word probabilities (e.g., “blind”, “visually impaired”, “speech generating”, and “digital text”) for these topics represented studies related to the support of students with low-incidence disabilities, such as visual impairment, blindness, and hearing impairment (Individuals with Disabilities Education Act, 2004; U.S. Department of Education, 2022). With a growing emphasis on promoting diversity, equity, and inclusion through technology in education, educational technology should consider a range of universal instructional supports for all learners and highly specialized assistive technology, such as text-to-speech, text/screen reader programs, and augmentative and alternative communication devices, for those who need specially designed functions (Kaczorowski et al., 2022).
Topic evolution over time
In the current study, we found either generally decreasing or increasing topic trends. In particular, the topic trends addressed in the publications reflected the development and evolution of technology. For example, in the early 1980s, research topics such as CAI, software, mathematics achievement, calculators, and testing received attention, demonstrating relatively higher topic proportions or increasing trends, and these trends decreased over time. This research trend could be influenced by the emergence and rise of the personal computer and CD-ROM in the 1980s (Amankwah-Amoah, 2016). In the 1990s, the development of multimedia software was expanded through videodisc anchors (e.g., The Adventures of Jasper Woodbury) in mathematics instruction (Barron & Kantor, 1993). With the development of computers and software, these technologies were implemented in education research for students with disabilities at these times.
Although there were almost no available publications in 1980, research topics such as apps, auditory support, fraction instruction, visual-based technology, and instructional sequence have received attention since then. In particular, the increasing attention to auditory support and apps demonstrated the rise of ICT-supported learning for students with disabilities since 1990 (Istenic Starcic & Bagon, 2014). These findings have also highlighted the emergence of research applying technology-mediated instruction as enhanced anchored instruction (Bottge et al., 2018) and virtual manipulatives with a gradual systematic approach (e.g., virtual-representational-abstract instructional sequence; Bouck et al., 2017) or cognitive strategies within interactive computer application (Shin & Bryant, 2017) since 2010. Furthermore, although the words highly associated with the visual-based technology topic only included terms related to “virtual manipulatives” and “app”, the review of representative studies with the highest topic proportions also showed an increasing focus on augmented reality (Miundy et al., 2019) and virtual reality (Altun & Kahveci, 2019) over the past decade. Furthermore, driven by COVID-19 in 2020 and 2021, researchers have shown the increased application of online learning using these existing visual-based technologies in mathematics instruction (Bouck et al., 2022; Cox et al., 2021; Shin et al., 2023b; Tsuei, 2017).
Research topics such as support for visual materials, learning disabilities, robotics, self-monitoring tools, and word problem-solving instruction received increasing attention after 1990. These findings have indicated the increasing development of adaptive tools such as speech-generating robots (Adams & Cook, 2014) and audiovisual aids in digital texts (Bouck et al., 2013) during this time period. The learning disabilities topic was found to be the only disability type-related topic that emerged from the entire corpus. The increasing topic trend of learning disabilities over time shows a relatively higher degree of research focus on issues covering the identification and intervention of students with learning disabilities in teaching mathematics (Kiru et al., 2018; Lämsä et al., 2018; Ok et al., 2020) than others. Although other disability types did not appear as a distinctive research topic, words associated with the word problem-solving instruction topic also demonstrated that there was growing attention targeting students with intellectual disabilities, here incorporating video-based instruction (Saunders et al., 2018) and schema-based instruction (Root, 2016).
Limitations and future research
The current study has several limitations. First, to examine the topics and trends in research on teaching mathematics through technology to students with disabilities, we explored journal articles and dissertations published in English between 1980 and 2021. Although we followed PRISMA guidelines (Page et al., 2021) and thoroughly screened publications from various online databases (e.g., ERIC, Web of Science, APA PsycINFO, and MEDLINE), we did not include some other types of publications, such as documents from social media (e.g., news and blogs) or gray literature (e.g., conference proceedings and unpublished works). These selection procedures could have limited the generalization of our findings by not capturing issues across domains beyond the academic field. Thus, future research should examine how the currently proposed topics and trends differ according to publication sources.
Second, although we applied several essential wildcard search terms (see Fig. 1) for the set of disabilities, mathematics, and technology, we did not include many other terms in the current database search. For example, the application of advanced technology in education was not fully considered through search terms, such as “flipped”, “online”, “mixed reality”, “machine learning”, and “deep neural network”. Furthermore, the aim of the current study was to review studies on the use of technology in teaching mathematics, but we excluded the emphasis on learning mathematics. Thus, in future research, a more extended search with comprehensive sets of the use of technology and mathematics learning should be included.
Third, in an effort to construct data-driven text preprocessing, the researchers developed user-defined dictionary objects and a customized stop words list that could be processed through the quanteda R package (Benoit et al., 2018). Although we took multiple and sequenced steps to develop customized dictionary objects (e.g., identifying frequently used multiword expressions) and the stop words list (e.g., removing commonly observed terms or patterns that are not distinct across documents), these lists could still be biased. Thus, in future research, the customized dictionary and stop words lists should be validated by external reviewers in multiple sectors, including linguistics, special education, technology, and mathematics.
Fourth, in the current study, we analyzed only the abstracts of the publications. Although an abstract is a comprehensive summary of a study (American Psychological Association, 2020), possibly it does not include all the key text contents in view of the publishers’ word limit guidelines. Additionally, dissertation abstracts usually include longer and more detailed summaries than journal article abstracts. These unequal word counts across documents could affect topic proportion and discovery. Thus, in future studies, researchers could extend the current study by analyzing keywords or even entire documents. Furthermore, word network analysis can be extended through the application of cluster-based topic modeling (ClusTop; Mu et al., 2022). Significantly, researchers can apply a word network graph with word embedding techniques or edge weights, depending on word embedding. This will enable researchers to systematically capture topical meaning in texts based on the network analysis’s community detection algorithms to automatically find the optimal number of subjects.
Finally, in the current structural topic model, only document-level covariates were considered when analyzing the associations between covariates (i.e., publication year) and topical prevalence. However, it is possible that topic-level covariates, such as types of studies that have been conducted (e.g., experimental and survey), types of instructional practices (e.g., fraction instructions and word problem-solving instructions), and educational technology tools (e.g., apps and calculators), which cover the categories of each topic label, could be of higher level affecting the topical prevalence across the corpus. Therefore, in future research, a structural topic model that considers covariates of topic and document levels should be investigated.
Pedagogical and research implications
Three primary pedagogical and research implications were obtained from the current findings. The co-occurring word pairs that appeared within publications in each decade between 1980 and 2021 represented the usage and pattern changes of words in each time period. Although the use of computers through CAI was the most frequently researched topic in the 1980s and 1990s, especially for students with learning disabilities, we observed an exponential increase in research on mobile-friendly and online learning. Although disability types other than learning disabilities did not emerge as a distinctive research topic, the associated words probably supported the use of visual-based technology and videos for teaching word problems and basic mathematics to students with intellectual disabilities and autism spectrum disorder. These results indicate the need for research on students with other types of disabilities, particularly low-incidence disabilities. Future researchers can utilize educational technology applications, such as self-monitoring tools, robotics, auditory support, and support for visual materials, in their mathematics instruction for students with disabilities and validate the efficacy and roles of the interventions.
The results indicate that educators, researchers, and policymakers could use text-mining techniques to identify the essential features of instructional practices and tools. The associated words for each topic can be considered key components in designing technology-mediated mathematics curricula for students with disabilities. However, these data cannot suggest how effective each of the technologies is in improving the performance of students with disabilities in mathematics. Thus, in future studies, systematic reviews and meta-analyses are needed to synthesize the findings across studies, analyze deeper engagement with the issues unearthed in each study, and investigate how the inclusion of each component differs according to the student variables (e.g., grade and disability) and the field of study variables (e.g., technology). The public datasets and codes found in the current study will help future researchers replicate the suggested methodology, encouraging open and continuous communications in broadening the pathways for underrepresented groups of students in STEM and across disciplines.
Finally, the current study indicates research trends that align with the development of educational technology within the infrastructure of the industry. Specifically, accessible technology tools (e.g., speech-generating tools) are more frequently used in studies that target only students with visual or hearing impairments (Adams & Cook, 2014). However, in more recent years, researchers who teach students with other disabilities (i.e., learning disabilities, intellectual disabilities, and autism spectrum disorders) have applied virtual manipulatives, augmented reality, and virtual reality in their mathematics instructions (Bouck et al., 2022; Carreon et al., 2022; Nabors et al., 2020). In contrast to the findings of Chen et al. (2022), in the current study, the intelligent tutoring system did not emerge as a distinctive research topic. These findings indicate a lack of research on implementing other innovative approaches, including, but not limited to, the use of artificial intelligence or machine learning in mathematics instruction. In future research, partners across academia, industry, and other organizations need to collaboratively communicate to design, develop, and implement technology-mediated mathematics interventions that could extend learning access and promote the performance of students with disabilities in mathematics so that all learners can eventually succeed in their postsecondary education, careers, and independent living.
Conclusion
Observing the discussed research topics and their evolution over the past 42 years can provide educators with a comprehensive understanding of the changes in research focus regarding the use of technology in teaching mathematics to students with disabilities. Because of the explosion of new sources and publications, a traditional content analysis through the manual coding of each document might appear to be consuming excessive time and effort. Text mining approaches, such as word networks and topic modeling, could prove effective in extracting meaningful categories and themes from large datasets, such as biblical datasets. By applying the suggested methods, researchers and policymakers can efficiently understand the key patterns addressed in published documents.
Availability of data and materials
The data and materials used and analyzed for the manuscript are publicly available at https://mshin77.github.io/math-tech-sped.
Abbreviations
- AR:
-
Augmented reality
- CAI:
-
Computer-assisted instruction
- EAI:
-
Enhanced anchored instruction
- EBP:
-
Evidence-based practice
- FXS:
-
Fragile X syndrome
- HTML:
-
HyperText Markup Language
- ICT:
-
Information and communication technology
- idf:
-
Inverse document frequency
- MLD:
-
Mathematics learning disability
- PRISMA:
-
Preferred Reporting Items for Systematic Reviews and Meta-Analyses
- SBI:
-
Schema-based instruction
- STEM:
-
Science, technology, engineering, and mathematics
- VR:
-
Virtual reality
- VRA:
-
Virtual-representational-abstract
- WPS:
-
Word problem-solving
References
Adams, K., & Cook, A. (2014). Access to hands-on mathematics measurement activities using robots controlled via speech generating devices: Three case studies. Disability and Rehabilitation: Assistive Technology, 9(4), 286–298. https://doi.org/10.3109/17483107.2013.825928
Adamu, I., & Soykan, E. (2019). Content analyses on the use of technology in dyslexia: The articles in the web of science data base. International Online Journal of Education and Teaching, 6(4), 789–797.
Altun, H., & Kahveci, G. (2019). The effectiveness of virtual reality-based teaching material on geometry related problem solving in students with learning disabilities. Necatibey Faculty of Education Electronic Journal of Science and Mathematics Education, 13(1), 460–482. https://doi.org/10.17522/balikesirnef.562047
Amankwah-Amoah, J. (2016). Competing technologies, competing forces: The rise and fall of the floppy disk, 1971–2010. Technological Forecasting and Social Change, 107, 121–129. https://doi.org/10.1016/j.techfore.2016.03.019
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). https://doi.org/10.1037/0000165-000
Aspiranti, K. B., Larwin, K. H., & Schade, B. P. (2020). iPads/tablets and students with autism: A meta-analysis of academic effects. Assistive Technology, 32(1), 23–30. https://doi.org/10.1080/10400435.2018.1463575
Bagozzi, B. E., & Berliner, D. (2018). The politics of scrutiny in human rights monitoring: Evidence from structural topic models of US State Department human rights reports. Political Science Research and Methods, 6(4), 661–677. https://doi.org/10.1017/psrm.2016.44
Barron, B., & Kantor, R. J. (1993). Tools to enhance math education: The Jasper series. Communications of the ACM, 36(5), 52–54. https://doi.org/10.1145/155049.155060
Benoit, K., Watanabe, K., Wang, H., Nulty, P., Obeng, A., Müller, S., & Matsuo, A. (2018). quanteda: An R package for the quantitative analysis of textual data. Journal of Open Source Software, 3(30), 774. https://doi.org/10.21105/joss.00774
Billard, C., Jung, C., Munnich, A., Gassama, S., Touzin, M., Mirassou, A., & Willig, T. N. (2021). External validation of BMT-i computerized test battery for diagnosis of learning disabilities. Frontiers in Pediatrics, 9, 733713. https://doi.org/10.3389/fped.2021.733713
Blackhurst, A. E. (2005). Historical perspectives about technology applications for people with disabilities. In D. Edyburn, K., Higgins, & R. Boone (Eds.), Handbook of special education technology research and practice (pp. 1–27). Knowledge by Design.
Blei, D. M., & Lafferty, J. D. (2007). A correlated topic model of science. The Annals of Applied Statistics, 1(1), 17–35. https://doi.org/10.1214/07-AOAS114
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of Machine Learning Research, 3, 993–1022.
Bottge, B. A., Cohen, A. S., & Choi, H. J. (2018). Comparisons of mathematics intervention effects in resource and inclusive classrooms. Exceptional Children, 84(2), 197–212. https://doi.org/10.1177/0014402917736854
Bottge, B. A., Rueda, E., Serlin, R. C., Hung, Y.-H., & Kwon, J. M. (2007). Shrinking achievement differences with anchored math problems: Challenges and possibilities. The Journal of Special Education, 41(1), 31–49. https://doi.org/10.1177/00224669070410010301
Bouck, E. C., Long, H., & Park, J. (2021). Using a virtual number line and corrective feedback to teach addition of integers to middle school students with developmental disabilities. Journal of Developmental and Physical Disabilities, 33(1), 99–116. https://doi.org/10.1007/s10882-020-09735-z
Bouck, E. C., Mathews, L. A., & Peltier, C. (2020). Virtual manipulatives: A tool to support access and achievement with middle school students with disabilities. Journal of Special Education Technology, 35(1), 51–59. https://doi.org/10.1177/0162643419882422
Bouck, E. C., Meyer, N. K., Joshi, G. S., & Schleppenbach, D. (2013). Accessing algebra via MathSpeak™: Understanding the potential and pitfalls for students with visual impairments. Journal of Special Education Technology, 28(1), 49–63. https://doi.org/10.1177/016264341302800105
Bouck, E. C., Myers, J. A., & Witzel, B. S. (2022). Teaching math online to secondary students with learning disabilities: Moving beyond the pandemic. TEACHING Exceptional Children. https://doi.org/10.1177/00400599221092136
Bouck, E. C., Park, J., Sprick, J., Shurr, J., Bassette, L., & Whorley, A. (2017). Using the virtual-abstract instructional sequence to teach addition of fractions. Research in Developmental Disabilities, 70, 163–174. https://doi.org/10.1016/j.ridd.2017.09.002
Carreon, A., Smith, S. J., Mosher, M., Rao, K., & Rowland, A. (2022). A review of virtual reality intervention research for students with disabilities in K–12 settings. Journal of Special Education Technology, 37(1), 82–99. https://doi.org/10.1177/0162643420962011
Center for Applied Special Technology. (2018). Universal design for learning guidelines (Graphic organizer version 2.2). Center for Applied Special Technology.
Chen, Z., Zhang, R., Xu, T., Yang, Y., Wang, J., & Feng, T. (2020a). Emotional attitudes towards procrastination in people: A large-scale sentiment-focused crawling analysis. Computers in Human Behavior, 110, 106391. https://doi.org/10.1016/j.chb.2020.106391
Chen, X., Zou, D., Cheng, G., & Xie, H. (2020b). Detecting latent topics and trends in educational technologies over four decades using structural topic modeling: A retrospective of all volumes of Computers & Education. Computers & Education, 151, 103855. https://doi.org/10.1016/j.compedu.2020.103855
Chen, X., Zou, D., Xie, H., Cheng, G., & Liu, C. (2022). Two decades of artificial intelligence in education. Educational Technology & Society, 25(1), 28–47.
Committee on STEM Education. (2018). Charting a course for success: America’s strategy for STEM education. National Science & Technology Council. https://www.whitehouse.gov/wp-content/uploads/2018/12/STEM-Education-Strategic-Plan-2018.pdf
Cox, S. K., Root, J. R., & Gilley, D. (2021). Let’s see that again: Using instructional videos to support asynchronous mathematical problem solving instruction for students with autism spectrum disorder. Journal of Special Education Technology, 36(2), 97–104. https://doi.org/10.1177/0162643421996327
Csárdi, G., & Nepusz, T. (2006). The igraph software package for complex network research. InterJournal, Complex Systems, 1695. https://igraph.org
Emerson, R. W., & Anderson, D. L. (2018). Using description to convey mathematics content in visual images to students who are visually impaired. Journal of Visual Impairment & Blindness, 112(2), 157–168. https://doi.org/10.1177/0145482X1811200204
Emprin, F., & Petitfour, É. (2021). Using a simulator to help students with dyspraxia learn geometry. Digital Experiences in Mathematics Education, 7(1), 99–121. https://doi.org/10.1007/s40751-020-00077-1
EndNote Team. (2013). EndNote (Version EndNote 20) [Computer software]. Clarivate.
Ennis, R. P., & Losinski, M. (2019). Interventions to improve fraction skills for students with disabilities: A meta-analysis. Exceptional Children, 85(3), 367–386. https://doi.org/10.1177/0014402918817504
Falkenberg, C. A. (2010). The effects of self-monitoring on homework completion and accuracy rates of students with disabilities in an inclusive general education classroom (Publication No. 3447782) [Doctoral dissertation, Florida International University]. ProQuest Dissertations and Theses Global.
García-Redondo, P., García, T., Areces, D., Núñez, J. C., & Rodríguez, C. (2019). Serious games and their effect improving attention in students with learning disabilities. International Journal of Environmental Research and Public Health, 16(14), 2480. https://doi.org/10.3390/ijerph16142480
Garg, M., & Kumar, M. (2018). The structure of word co-occurrence network for microblogs. Physica a: Statistical Mechanics and Its Applications, 512, 698–720. https://doi.org/10.1016/j.physa.2018.08.002
Grimmer, J., Roberts, M. E., & Stewart, B. M. (2022). Text as data: A new framework for machine learning and the social sciences. Princeton University Press.
Higgins, C. (1970). Mathematics for handicapped-programming concepts. Focus on Exceptional Children, 2(4), 8–10.
Huscroft-D’Angelo, J., Higgins, K., & Crawford, L. (2014). Communicating mathematical ideas in a digital writing environment: The impacts on mathematical reasoning for students with and without learning disabilities. Social Welfare Interdisciplinary Approach, 4(2), 68–84.
Hvitfeldt, E., & Silge, J. (2021). Supervised machine learning for text analysis in R. Chapman and Hall/CRC. https://doi.org/10.1201/9781003093459
Individuals With Disabilities Education Act, 20 U.S.C. § 1400 (2004).
Istenic Starcic, A., & Bagon, S. (2014). ICT-supported learning for inclusion of people with special needs: Review of seven educational technology journals, 1970–2011. British Journal of Educational Technology, 45(2), 202–230. https://doi.org/10.1111/bjet.12086
Jaspers, K. E., McCleary, D. F., McCleary, L. N., & Skinner, C. H. (2017). Evidence-based interventions for math disabilities in children and adolescents. In L. A. Theodore (Ed.), Handbook of evidence-based interventions for children and adolescents (pp. 99–110). Springer Publishing Company.
Jaspers, M. W. M. (1991). Prototypes of computer-assisted instruction for arithmetic word-problem solving [Doctoral dissertation, University of Nijmegen].
Jones, C., & Shao, B. (2011). The net generation and digital natives: implications for higher education. Higher Education Academy.
Jung, S., & Yoon, W. C. (2020). An alternative topic model based on Common Interest Authors for topic evolution analysis. Journal of Informetrics, 14(3), 101040. https://doi.org/10.1016/j.joi.2020.101040
Kaczorowski, T., McMahon, D., Gardiner-Walsh, S., & Hollingshead, A. (2022). Designing an inclusive future: Including diversity and equity with innovations in special education technology. TEACHING Exceptional Children. https://doi.org/10.1177/00400599221090506
Kagohara, D. M., van der Meer, L., Ramdoss, S., O’Reilly, M. F., Lancioni, G. E., Davis, T. N., Rispoli, M., Lang, R., Marschik, P. B., Sutherland, D., Green, V. A., & Sigafoos, J. (2013). Using iPods® and iPads® in teaching programs for individuals with developmental disabilities: A systematic review. Research in Developmental Disabilities, 34(1), 147–156. https://doi.org/10.1016/j.ridd.2012.07.027
Kellems, R. O., Eichelberger, C., Cacciatore, G., Jensen, M., Frazier, B., Simons, K., & Zaru, M. (2020). Using video-based instruction via augmented reality to teach mathematics to middle school students with learning disabilities. Journal of Learning Disabilities, 53(4), 277–291. https://doi.org/10.1177/0022219420906452
Kelly, B., Carnine, D., Gersten, R., & Grossen, B. (1986). The effectiveness of videodisc instruction in teaching fractions to learning-disabled and remedial high school students. Journal of Special Education Technology, 8(2), 5–17. https://doi.org/10.1177/016264348600800202
Kim, S. J., & Xin, Y. P. (2022). A synthesis of computer-assisted mathematical word problem-solving instruction for students with learning disabilities or difficulties. Learning Disabilities: A Contemporary Journal, 20(1), 1–19.
Kim, Y., Jang, S. N., & Lee, J. L. (2018). Co-occurrence network analysis of keywords in geriatric frailty. Journal of Korean Academy of Community Health Nursing, 29(4), 429–439. https://doi.org/10.12799/jkachn.2018.29.4.429
Kiru, E. W., Doabler, C. T., Sorrells, A. M., & Cooc, N. A. (2018). A synthesis of technology-mediated mathematics interventions for students with or at risk for mathematics learning disabilities. Journal of Special Education Technology, 33(2), 111–123. https://doi.org/10.1177/0162643417745835
Koestler, C., Felton-Koestler, M. D., Bieda, K., & Otten, S. (2013). Connecting the NCTM process standards and the CCSSM practices. National Council of Teachers of Mathematics.
Koller, E. Z., & Mulhern, T. J. (1977). Use of pocket calculator to train arithmetic skills with trainable adolescents. Journal for Special Educators of the Mentally Retarded, 13(2), 309–319.
Lämsä, J., Hämäläinen, R., Aro, M., Koskimaa, R., & Äyrämö, S. M. (2018). Games for enhancing basic reading and maths skills: A systematic review of educational game design in supporting learning by people with learning disabilities. British Journal of Educational Technology, 49(4), 596–607. https://doi.org/10.1111/bjet.12639
Li, Y., & Xiao, Y. (2022). Authorship and topic trends in STEM education research. International Journal of STEM Education, 9, 62. https://doi.org/10.1186/s40594-022-00378-4
Marín-Marín, J. A., Moreno-Guerrero, A. J., Dúo-Terrón, P., & López-Belmonte, J. (2021). STEAM in education: a bibliometric analysis of performance and co-words in Web of Science. International Journal of STEM Education, 8, 41. https://doi.org/10.1186/s40594-021-00296-x
McLeod, K. G. (2011). An investigation of the relationships between educational technology and mathematics achievement of students with learning disabilities (Publication No. 3455448) [Doctoral dissertation, The University of Southern Mississippi]. ProQuest Dissertations and Theses Global.
Miundy, K., Zaman, H. B., Nordin, A., & Ng, K. H. (2019). Screening test on dyscalculia learners to develop a suitable augmented reality (AR) assistive learning application. Malaysian Journal of Computer Science. https://doi.org/10.22452/mjcs.sp2019no1.7
Morano, S., Flores, M. M., Hinton, V., & Meyer, J. (2020). A comparison of concrete-representational-abstract and concrete-representational-abstract-integrated fraction interventions for students with disabilities. Exceptionality, 28(2), 77–91. https://doi.org/10.1080/09362835.2020.1727328
Moyer-Packenham, P. S., & Bolyard, J. J. (2016). Revisiting the definition of a virtual manipulative. In P. S. Moyer-Packenham (Ed.), International perspectives on teaching and learning mathematics with virtual manipulatives (pp. 3–23). Springer.
Mu, W., Lim, K. H., Liu, J., Karunasekera, S., Falzon, L., & Harwood, A. (2022). A clustering-based topic model using word networks and word embeddings. Journal of Big Data, 9(1), 1–38. https://doi.org/10.1186/s40537-022-00585-4
Nabors, L., Monnin, J., & Jimenez, S. (2020). A scoping review of studies on virtual reality for individuals with intellectual disabilities. Advances in Neurodevelopmental Disorders, 4, 344–356. https://doi.org/10.1007/s41252-020-00177-4
National Center for Education Statistics. (2019). NAEP report card: 2019 NAEP mathematics assessment. National Center for Education Statistics. https://www.nationsreportcard.gov/highlights/mathematics/2019
National Center for Education Statistics. (2022). Students with disabilities. Condition of education. National Center for Education Statistics. https://nces.ed.gov/programs/coe/indicator/cgg
National Council of Teachers of Mathematics. (2000). Principles and standards for school mathematics. National Council of Teachers of Mathematics.
National Governors Association Center for Best Practices and Council of Chief State School Officers. (2010). Common core state standards for mathematics. http://www.corestandards.org/Math
National Mathematics Advisory Panel. (2008). Foundations for success The final report of the National Mathematics Advisory Panel. National Mathematics Advisory Panel.
Newman, M. (2018). Networks. Oxford University Press.
Nwaizu, P. C. I. (1991). Using teacher-assisted and computer-assisted instruction to teach multiplication skills to youths with specific learning disabilities (Publication No. 9103959) [Doctoral dissertation, University of New Orleans]. ProQuest Dissertations and Theses Global.
Ok, M. W., Bryant, D. P., & Bryant, B. R. (2020). Effects of computer-assisted instruction on the mathematics performance of students with learning disabilities: A synthesis of the research. Exceptionality, 28(1), 30–44. https://doi.org/10.1080/09362835.2019.1579723
Ok, M. W., & Kim, W. (2017). Use of iPads and iPods for academic performance and engagement of preK–12 students with disabilities: A research synthesis. Exceptionality, 25(1), 54–75. https://doi.org/10.1080/09362835.2016.1196446
Paez, A. (2017). Gray literature: An important resource in systematic reviews. Journal of Evidence-Based Medicine, 10(3), 233–240. https://doi.org/10.1111/jebm.12266
Page, M. J., McKenzie, J. E., Bossuyt, P. M., Boutron, I., Hoffmann, T. C., Mulrow, C. D., Shamseer, L., Tetzlaff, J. M., & Moher, D. (2021). Updating guidance for reporting systematic reviews: Development of the PRISMA 2020 statement. Journal of Clinical Epidemiology, 134, 103–112. https://doi.org/10.1016/j.jclinepi.2021.02.003
Palmer, J. T., Hendel, A., & Dempsey, B. (1985). The micro-computer and the learning disabled a useful tool. Journal of Reading, Writing and Learning Disabilities, 1(2), 117–125. https://doi.org/10.1080/0748763850010204
Papadimitriou, C. H., Raghavan, P., Tamaki, H., & Vempala, S. (2000). Latent semantic indexing: A probabilistic analysis. Journal of Computer and System Sciences, 61(2), 217–235. https://doi.org/10.1006/jcss.2000.1711
Park, J. (2019). Supporting maintenance in mathematics using the virtual-representational-abstract instructional sequence intervention package (Publication No. 13882021) [Doctoral dissertation, Michigan State University]. ProQuest Dissertations and Theses Global.
Park, J., Bouck, E., & Duenas, A. (2019). The effect of video modeling and video prompting interventions on individuals with intellectual disability: A systematic literature review. Journal of Special Education Technology, 34(1), 3–16. https://doi.org/10.1177/0162643418780464
Park, J., Bryant, D. P., & Shin, M. (2022). Effects of interventions using virtual manipulatives for students with learning disabilities: A synthesis of single-case research. Journal of Learning Disabilities, 55(4), 325–337. https://doi.org/10.1177/00222194211006336
Pedersen, T. (2022). ggraph: An implementation of grammar of graphics for graphs and networks (R package version 2.1.0). https://CRAN.R-project.org/package=ggraph
Pedersen, T. (2023). tidygraph: A tidy API for graph manipulation (R package version 1.2.3). https://CRAN.R-project.org/package=tidygraph
Peltier, C. J., Vannest, K. J., & Marbach, J. J. (2018). A meta-analysis of schema instruction implemented in single-case experimental designs. The Journal of Special Education, 52(2), 89–100. https://doi.org/10.1177/0022466918763173
Perperoglou, A., Sauerbrei, W., Abrahamowicz, M., & Schmid, M. (2019). A review of spline function procedures in R. BMC Medical Research Methodology, 19(1), 1–16. https://doi.org/10.1186/s12874-019-0666-3
Pitchford, N. J., Kamchedzera, E., Hubber, P. J., & Chigeda, A. L. (2018). Interactive apps promote learning of basic mathematics in children with special educational needs and disabilities. Frontiers in Psychology, 9, 262. https://doi.org/10.3389/fpsyg.2018.00262
Porter, M. F. (2001). Snowball: A language for stemming algorithms. https://snowballstem.org
Prabavathy, M., & Sivaranjani, R. (2020). Effects of virtual manipulative in enhancing basic arithmetic for students with developmental dyscalculia. Journal of Emerging Technologies and Innovative Research, 7(6), 19–26.
Radecki, A., Bujacz, M., Skulimowski, P., & Strumiłło, P. (2020). Interactive sonification of images in serious games as an education aid for visually impaired children. British Journal of Educational Technology, 51(2), 473–497. https://doi.org/10.1111/bjet.12852
Remata, H. R., & Lomibao, L. S. (2021). Attention deficit hyperactivity disorder (ADHD)-specific learning disorder (SLD) in mathematics learner’s response towards synchronous online class. American Journal of Educational Research, 9(7), 426–430. https://doi.org/10.12691/education-9-7-5
Roberts, M. E., Stewart, B. M., & Tingley, D. (2014). stm: R Package for structural topic models. Harvard University.
Roberts, M. E., Stewart, B. M., & Tingley, D. (2019). stm: An R package for structural topic models. Journal of Statistical Software, 91(2), 1–40. https://doi.org/10.18637/jss.v091.i02
Robinson, D., & Silge, J. (2022). widyr: Widen, process, then re-tidy data (R package version 0.1.5). https://CRAN.R-project.org/package=widyr
Rodriguez, M. Y., & Storer, H. (2020). A computational social science perspective on qualitative data exploration: Using topic models for the descriptive analysis of social media data. Journal of Technology in Human Services, 38(1), 54–86. https://doi.org/10.1080/15228835.2019.1616350
Root, J. R. (2016). Effects of modified schema-based instruction on real-world algebra problem solving of students with autism spectrum disorder and moderate intellectual disability (Publication No. 10111877) [Doctoral dissertation, The University of North Carolina at Charlotte]. ProQuest Dissertations and Theses Global.
Root, J. R., Cox, S. K., & Gonzalez, S. (2019). Using modified schema-based instruction with technology-based supports to teach data analysis. Research and Practice for Persons with Severe Disabilities, 44(1), 53–68. https://doi.org/10.1177/154079691983391
Satsangi, R., Billman, R. H., Raines, A. R., & Macedonia, A. M. (2021a). Studying the impact of video modeling for algebra instruction for students with learning disabilities. The Journal of Special Education, 55(2), 67–78. https://doi.org/10.1177/0022466920937467
Satsangi, R., Raines, A. R., & Fraze, K. (2021b). Virtual manipulatives for teaching algebra: A research-to-practice guide for secondary students with a learning disability. Learning Disabilities: A Multidisciplinary Journal, 26(1), 46–58. https://doi.org/10.18666/LDMJ-2021-V26-I1-10349
Saunders, A. F., Spooner, F., & Ley Davis, L. (2018). Using video prompting to teach mathematical problem solving of real-world video-simulation problems. Remedial and Special Education, 39(1), 53–64. https://doi.org/10.1177/0741932517717042
Schaefer Whitby, P. J. (2009). The effects of a modified learning strategy on the multiple step mathematical word problem solving ability of middle school students with high-functioning autism or Asperger’s syndrome (Publication No. 3383694) [Doctoral dissertation, University of Central Florida]. ProQuest Dissertations and Theses Global.
Schwemmer, C. (2021). stminsights: A ‘Shiny’ application for inspecting structural topic models (R package version 0.4.1). https://CRAN.R-project.org/package=stminsights
Sharma, D., Kumar, B., & Chand, S. (2019). A trend analysis of machine learning research with topic models and Mann–Kendall test. International Journal of Intelligent Systems and Applications, 11(2), 70–82. https://doi.org/10.5815/ijisa.2019.02.08
Shin, M., & Bryant, D. P. (2017). Improving the fraction word problem solving of students with mathematics learning disabilities: Interactive computer application. Remedial and Special Education, 38(2), 76–86. https://doi.org/10.1177/0741932516669052
Shin, M., Bryant, D. P., Powell, S. R., Jung, P.-G., Ok, M. W., & Hou, F. (2021a). A meta-analysis of single-case research on word-problem instruction for students with learning disabilities. Remedial and Special Education, 42(6), 398–411. https://doi.org/10.1177/0741932520964918
Shin, M., Ok, M. W., Choo, S., Hossain, G., Bryant, D. P., & Kang, E. (2023a). A content analysis of research on technology use for teaching mathematics to students with disabilities: Word networks and topic modeling [Data files and scripts]. Center for Open Science. https://doi.org/10.17605/OSF.IO/8CNYW
Shin, M., Park, J., Grimes, R., & Bryant, D. P. (2021b). Effects of using virtual manipulatives for students with disabilities: Three-level multilevel modeling for single-case data. Exceptional Children, 87(4), 418–437. https://doi.org/10.1177/00144029211007150
Shin, M., Simmons, M., Meador, A., Goode, F. J., Deal, A., & Jackson, T. (2023b). Mathematics instruction for students with learning disabilities: Applied examples using virtual manipulatives. Intervention in School and Clinic, 58(3), 198–204. https://doi.org/10.1177/10534512221081268
Silge, J., & Robinson, D. (2016). tidytext: Text mining and analysis using tidy data principles in R. Journal of Open Source Software, 1(3), 37. https://doi.org/10.21105/joss.00037
Steele, M. M. (2007). Teaching calculator skills to elementary students who have learning problems. Preventing School Failure: Alternative Education for Children and Youth, 52(1), 59–62. https://doi.org/10.3200/PSFL.52.1.59-64
Stewart, K. B. (2007). Blending assessment with instruction program (BAIP): Impact of an online standards-based curriculum on 8th grade students’ math achievement (Publication No. 3274526) [Doctoral dissertation, University of Kansas]. ProQuest Dissertations and Theses Global.
Swanson, H. L. (1999). Interventions for students with learning disabilities: A meta-analysis of treatment outcomes. Guilford Press.
Towers, D. (2018). Effects of the graphing calculator on students with and without disabilities (Publication No. 10831620) [Doctoral dissertation, St. John's University]. ProQuest Dissertations and Theses Global.
Tsuei, M. (2017). Learning behaviours of low-achieving children’s mathematics learning in using of helping tools in a synchronous peer-tutoring system. Interactive Learning Environments, 25(2), 147–161. https://doi.org/10.1080/10494820.2016.1276078
U.S. Department of Education. (2022). 43rd annual report to congress on the implementation of the Individuals with Disabilities Education Act, 2021. U.S. Department of Education, Office of Special Education and Rehabilitative Services, Office of Special Education Programs. https://sites.ed.gov/idea/files/43rd-arc-for-idea.pdf
Wang, X., & McCallum, A. (2006). Topics over time: A non-Markov continuous-time model of topical trends. Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 424–433). ACM.
Xin, Y. P., Park, J. Y., Tzur, R., & Si, L. (2020). The impact of a conceptual model-based mathematics computer tutor on multiplicative reasoning and problem-solving of students with learning disabilities. The Journal of Mathematical Behavior, 58, 100762. https://doi.org/10.1016/j.jmathb.2020.100762
Acknowledgements
Not applicable.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
MS conceptualized the study, coded and analyzed the data, and wrote the manuscript. MO, SC, GH, DB, and EK helped with data coding, wrote the manuscript, and reviewed manuscript drafts. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shin, M., Ok, M.W., Choo, S. et al. A content analysis of research on technology use for teaching mathematics to students with disabilities: word networks and topic modeling. IJ STEM Ed 10, 23 (2023). https://doi.org/10.1186/s40594-023-00414-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40594-023-00414-x