
Abstract
The use of online videos is a common practice today amongst education professionals. Interactive features in videos are constantly evolving and a recent trend is the integration of interactive elements and web content into educational videos. The paper (a) provides a roadmap for using open source tools and open internet resources to develop a learning environment where video content is aggregated with interactive elements, educator content and content coming from the web, (b) describes how these open source tools are used for capturing and storing learner activity data, and, (c) presents findings obtained from analyzing learner activity data gathered in an educational setting during an academic year.
Similar content being viewed by others



Explore related subjects
Find the latest articles, discoveries, and news in related topics.Introduction
Nowadays, educational video distribution over the Internet is a widespread practice. A vast amount of educational videos is offered in either an organized or unorganized manner, by institutions and independent educators in video-sharing sites like Youtube, (2015) and Vimeo, (2015). Furthermore leading institutions deliver educational videos through open courseware initiatives, such as Coursera (2015) and edX (2015), and non-profit educational organizations, such as Khan Academy (2015), have organized large collections of educational videos for a broad range of subjects. Educators typically use video as support material in K-12 and higher education and as a substitute for the physical lecture in distant education settings. Video also plays an important role in the pedagogical method of the “Flipped Classroom” (Bishop and Verleger 2013, Giannakos et al. 2014a).
Video use in education witnessed a significant increase after 2005 and this is depicted in two literature reviews that focus on the topic (Kay 2012, Giannakos 2013). Kay argues that the adoption of high-speed internet connections in homes and schools as well as the appearance of YouTube in 2005 played a main role in this increase. The wide adoption of video use in education as well as the importance of video use in educators’ perceptions is depicted in a survey conducted by Kaltura (2015), a video technology provider. According to this survey (held in April 2015), the rates recorded for various video use cases (e.g. video used in assignments, in classroom, in remote teaching settings or as supplementary course material) have shown significant increase when compared to the rates recorded in a similar survey carried out by Kaltura the year before (i.e. Kaltura 2014).
Together with the increase in the use of educational videos there is also an increase in the interactive features that accompany these videos. The typical interactive features that could exist in an online video are the ones that are facilitated by the interface of most media players. By using the buttons or the progress bar (or playhead) of these media players, the viewers can perform various actions, such as pausing and resuming the video from the same point in the video timeline or performing backward and forward jumps. Videos with this basic level of interactivity, where non-linear viewing is possible, have been proven to have better learning outcomes when compared to videos where the control buttons for stopping, replaying, or changing speed are not present and hence linear viewing is the only option (Schwan and Riempp, 2004).
Besides the basic interactivity features that control the video flow, other forms of interactivity also made their appearance. Video annotation was one of the earliest features. Video annotation refers to the additional notes that learners add to the video at specific points. By adding additional notes to the video content the learners can provide further clarifications, highlight points of interest, raise issues and provide feedback. A number of video annotation tools are reported in literature through the years (Preston et al. 2005, Theodosiou et al. 2009, Risko et al. 2013, Yousef et al. 2015).
Commercial e-learning providers also provided additional means for enhancing the interactivity in video viewing. Some of the features that commercial e-learning packages, such as Adobe Captivate (2015) and Articulate Storyline (2016) provide are the following:
-
quiz questions & other interactive elements: these elements are inserted by the educator and require the learners feedback (or action) in order for the video to proceed
-
table of contents: the educator can organize the video into sections and learners can then navigate directly to these sections through a table of contents
-
“branching”: using this feature the educator can make videos that follow different routes depending on learner actions; for example, a video could jump to a different point in the timeline and show different content depending on learner input (e.g., answer given to a specific question)
Although the tools provided by these commercial e-learning packages are great for introducing interactivity in videos and e-learning content that is created by educators, they do not offer an easy way for an educator to introduce interactivity in educational videos found in video sharing platforms such as YouTube and Vimeo. From the survey conducted by Kaltura (2015), the most widely used source of video in classes is content from free online resources (73 % of 1,200 respondents stated that they used it frequently).
To address the need of adding interactivity to videos found on video sharing sites, a new array of tools such as EDpuzzle, (2015), EduCanon, (2015) and Zaption, (2015) were developed. Zaption, for example, is a platform that allows the educator to choose videos from the web and add content such as basic text and image slides, and interactive elements such as open responses, multiple choice questions, check boxes, drawn responses and numerical responses. The content and elements are added at certain points in the timeline through a drag and drop interface to create a time based interactive video. Discussions can also be accommodated in a video, a feature that is closely related to annotations. Discussions around video content are also the focus of other video based platforms such as Vialogues, (2015) (Agarwala et al. 2012) and Grockit answers, (2015). Learners can submit questions about the video content at any point in the timeline or give responses to other learners’ questions. Popcorn maker was a tool developed by Mozzila and was used to remix web video, audio, images and content coming from internet resources and web services in order to create an educational mash-up. However the project is discontinued from August 2015. On the other hand RaptMedia, (2016) is a commercial tool for creating branching videos.
Although these new tools provide a user-friendly and polished environment for adding interactivity to videos found in the web, they contain only a subset of the possible features that could actually be supported in a video based learning environment.
Furthermore, the majority of these applications are commercial and either are not free (e.g. RaptMedia) or offer only a limited set of features for free and have incremental paid account options for the rest of the features (e.g., Zaption, Educanon). Another drawback is that none of the above tools are open source, meaning that these tools are not open to further development or customization by independent developers.
As far as learning analytics are concerned, some of these tools provide basic level options mainly through visual reports (e.g., eduCanon, Zaption). Analysis of video viewing data is a relatively recent trend and there is a small but increasing body of on-going research that focuses on the topic (e.g. Li et al. 2015a, 2015b, Giannakos et al. 2015, Giannakos et al. 2014b, Kim et al. 2014, Guo et al. 2014, Kleftodimos & Evangelidis 2014a, b, Brooks et al. 2013, Gorissen et al. 2012, De Boer et al. 2011). Thus, it is certainly a plus for a tool to provide more advanced analytics features but most importantly to provide the whole dataset of viewing and activity data that will enable researchers to conduct more elaborate data analysis by applying advanced statistical methods, visualizations and data mining algorithms.
The aim of this paper is to provide alternative solutions that tackle the limitations of the existing video based products that are used for learning and research. This is attempted by providing a roadmap on how to use open source solutions and open internet resources in order to build an interactive video based learning environment that supports learning analytics. Today, the level and types of interactivity are in constant evolution. We anticipate that the steps described in the road map will save significant development time for those who want to follow the trend and incorporate interactive features and learning analytics options into their video based environments.
The paper also presents the educational settings in which the learning environment is used and findings from analysing learner activity data. The analysis is carried out with the aid of graphical representations and statistical methods. The aim of the data analysis is to (a) obtain insights on how the learners used educational videos and the available interactive features within the environment, throughout an academic year, and, (b) to investigate if educational video viewing has better learning outcomes when accompanied by other activities such as written assignments and quizzes, that are related to the video content. Other factors that may affect performance are also investigated (i.e. viewing time).
More specifically, in section “Developing a video based learning environment using open source tools and open internet resources”, we describe how open source technologies and open internet resources are used to create a learning environment where interactive elements, user content and web content are aggregated with educational videos in order to transform the video viewing process into a more interactive experience. In section “Video learning analytics”, we describe a module for gathering and storing viewing activity data for data analysis and data mining purposes. Details of the educational settings together with findings obtained from analyzing learner activity data are presented in section “The educational settings and findings”. The paper concludes in section “Discussion and conclusions” with a short discussion on the contribution, limitations and future directions of the study.
Developing a video based learning environment using open source tools and open internet resources
After conducting research in order to spot open source technologies that can be used to develop time based interactive videos we recorded two available options, namely, the Mozilla Popcorn Framework (2015) (used in Popcorn Maker and Grockit answers) and open source HTML 5 players such as MediaElement.js, (2015) and Flowplayer, (2015).
To build the application that we have used in educational settings, we used MediaElement.js, an HTML5 player that can be used for videos hosted on a web server or act as wrapper for videos hosted in YouTube and Vimeo. By using the API of MediaElement (or similarly the API of the other mentioned tools), actions can be initiated when specific time points (or intervals) are reached in the video timeline or when certain video events occur (e.g., pause, resume, start and end of video, volume change). A typical action is the retrieval (or storage) of content from (or to) a database and this is the basis for building time based interactive videos.
The basic components of the application are the “Administrator” and “Viewer” modules. The “Administrator Module” is where various elements are defined by the educator at various time intervals or points. The elements can then be previewed by executing the video and are finally stored in the database if the result satisfies the educator. If the result is not satisfying the elements can be deleted. The interface of the “Administrator Module” is kept very simple.
In Fig. 1, we can see a picture of this module where multiple choice questions are set and previewed, before they are stored in the database. If answers are not defined then an open response answer is expected.

Snapshot of the Administrator Module. Associating quiz questions with time points (or intervals) in the video
The other module is the “Viewer Module”. This is used by learners and in this module the elements are retrieved from the database and presented to the learner at the specified time intervals (or time points) during video execution.
Javascript (and Jquery) is used in the front-end of both modules. More specifically, it is used to track video time and video events and for handling input coming from the educator (e.g., insertion of multiple choice questions) as well as the learner (e.g., submission of answers). At the back-end, for storing and retrieving content from the database, PHP and MySQL are used.
The mechanism for defining and storing elements to the database and retrieving these elements when learners view the educational video is depicted in Fig. 2.

Storing and retrieving elements to and from the database at various time points (or time intervals) and events
The features that are present in the developed learning environment are the following:
-
a)
Questions that appear at various points in the timeline.
In-video quizzes are a relatively new feature that can be found in educational videos including educational videos found in Coursera and edX. In-video quizzes are even the focus of some recent research (Cummins et al. 2015). Quiz question elements can be defined and stored in the database by the educator. These are then retrieved when the learners view the video (in the Viewer Module). The quiz questions appear when the player head reaches specified time points and the video pauses at these points. Feedback can be provided to the learner after the answer is given, but in our setting this feature was not present, since the in-video quizzes were part of an assignment. So far we have implemented multiple choice and open response questions.
-
b)
Sections and the Table of Contents
Very often it is useful to logically (rather than physically) segment an educational video into sections, where each section covers a particular subtopic. Then, a pause can be initiated at the end of each section in order to give the learner the opportunity to reflect on the video material or, alternatively, video quizzes can be placed at the end of sections to test the learners’ acquired knowledge. The learner can also be provided with a table of contents, a feature that allows him/her to access the video sections at will. This feature aids learner navigation by providing better control over the learning process and is particularly useful for long videos. As a result, the linearity of traditional video is eliminated. The table of contents enables efficient random content access in video, and past research supports that random content access in video increases learner engagement and satisfaction (Zhang 2005, Zhang et al. 2006).
Furthermore, the breakdown of multimedia in logical segments is supported in the literature as a way to make multimedia learning more effective and is referred to as the “segmenting principle”. According to Mayer (2005) the segmenting principle is that people learn more deeply when a multimedia message is presented in learner-paced segments rather than as a continuous unit.
In Fig. 3, we can see an instance of the environment where a video is accompanied with a table of contents to aid navigation, and an area where quiz questions appear.
Fig. 3 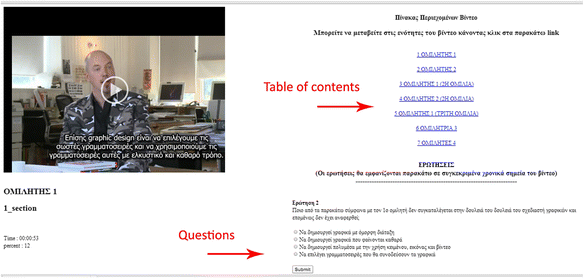
A snapshot of the learning environment where an educational video is used to support the course “Graphic Design”
-
c)
Subtitles
There is a vast range of educational videos on YouTube or Vimeo but these videos are mostly in English. In order to make them usable in countries where English is not the native language, the educator can carry out the subtitling process by associating subtitles with specified time intervals. Then, during learner viewing these subtitles are fetched from the database and shown in a text box underneath the video.
-
d)
Content aggregation
Another feature is the integration of web content to educational videos. More specifically, web content coming from web pages and web services can appear next to the video. Using the Administrator Module the educator defines the web pages that will appear when the player is within certain time intervals. The web pages will appear next to the video either as links (and the learner will have to follow the links) or as embedded web pages in an iframe. For example a Google forms questionnaire can appear at certain time points to test learner knowledge, a Google map can show up presenting an exact location mentioned in the video, or a wiki page can appear presenting relevant content in text form. Another useful option is the synchronization of an educational video with content coming from web services. This is achieved with the parallel use of the MediaElement API and other web services APIs. For example, in the developed learning environment, video content can be synchronized with slides from Slideshare, (2015) (Fig 4.)
Fig. 4 
Synchronizing video content with slides from Slideshare in the “Administrator Module”


The web content called at specific time points can also be created by the educator using various applications. For example in order to incorporate more exercise activities we have used Hot Potatoes (2016), a software that creates various educational exercises such as “fill in the blanks”, “cross word puzzle”, “matching” and “jumbled sentence” exercises. Hot Potatoes software is not open source but the web pages created with the use of the software can be incorporated into a video based learning environment and called at specific time points. User responses can also be stored in a local database after making modifications to the web page scripts. In Fig. 5 we can see a snapshot of the environment where video content is accompanied by exercises (e.g. fill in blanks) created by Hot Potatoes.

Incorporating into the video based learning environment webpages with activities created using Hot Potatoes
Furthermore, using the same mechanism, where various elements are stored and retrieved from the database at specific time points, other features can be facilitated, such as learner video annotation and discussions. Practically, by using the API of HTML 5 video players, and the mechanism for associating actions (such as retrieving database content) with specific time points or time intervals, the number of features that can be supported in a video based environment are really up to the creator’s judgment and imagination. At the moment we are experimenting with time based discussions, the incorporation of collaborative activities and the incorporation of web based applications into the video based environment. These are applications that are typically used in learning and which can be used within the video based learning environment to accompany related videos.
At the moment, for a course entitled “Image and Video Editing Principles” we have incorporated Pixlr, (2016), an image editing online software, into our video based environment (Kleftodimos and Evangelidis 2016). The students in this particular setting after following a login procedure are prompted to watch a video explaining image editing techniques using Pixlr. During video execution exercise links appear at various time points together with a short description of the exercise. If these links are followed, the Pixlr environment is opened on a separate browser tab together with the necessary image files for the exercise. Once an image editing exercise is completed by the student and the “save” menu item is selected, the output is stored on the environment web server. The students are able to see their files and replace them if they are not happy with the result. Pixlr API is used for the communication between the server and the Pixlr application. In this way students watch the related video and perform the given exercises from within their environment account.
Furthermore, collaborative activities can also be incorporated in the video based environment. For example an online collaborative quiz can be incorporated into the environment and performed by a group of learners who are watching a related video. Learners would have to agree on a quiz answer for the answer to be recorded. The effectiveness of in-class collaborative quizzes in performance and student satisfaction has been researched in past papers (Yokomoto and Ware, 1997, Slusser and Erickson, 2006) and it can also be investigated if their presence is effective in an online video based environment. Other collaborative activities such collaborative writing (answers to questions, short essays etc.) can also be facilitated. Students can be asked to write a text in groups at the end of a relevant video segment. At the moment we are experimenting with Etherpad, (2015), a collaborative word processing web application that supports group synchronous and asynchronous collaborative writing. Students can be split up into groups and answer questions collaboratively when these appear at various points in the timeline. Etherpad supports multiple pads and different pads can be created at group level and question level. Etherpad contains also a chat application for communication amongst the authors. In Fig. 6, we can see a snapshot where a question appears at a specified time point and then a collaborative writing activity takes place in order to answer the question. The text that each user contributes is highlighted by different colour.

Incorporating collaborative writing activities in a video based learning environment. Experimenting with Etherpad
The options for integrating web content and web activities into the video based environment are many and its really up to the creator to adopt the features that are useful for learning. Although the usefulness of some interactive video features are supported by the literature, such as segmenting a video into portions that reflect different concepts (Mayer 2005) and providing a table of contents for random access to these portions (Zhang 2005, Zhang et al. 2006), it is still a research question what features and activities actually assist video learning. It can be argued that some of the described features may cause frustration and slowdown the learning process instead of assisting it. However, video based environments built by following the ideas presented in this paper can be used to accommodate a broad range of interactive features, conduct experiments and answer research questions regarding these features and their effectiveness in learning.
Video learning analytics
In the heart of the learning environment lies a module with the task of collecting and storing learner viewing activity for data analysis and data mining purposes. The module consists of a program that tracks and stores video events that are triggered by learner actions and changes in the video state. A database with a suitable schema is used for storing all the relevant information.
Learners are required to perform a login procedure to be able to view the videos. All the activity data stored is then associated to the current learner id and is not anonymous. It is also possible to associate the collected data to IP addresses rather than user ids if ethical issues are raised.
In the application database, viewing data is stored in three tables, Sessions, Session_videos, and Session_events. The database schema is an extended version of the schema presented in our former research (Kleftodimos and Evangelidis 2013). A session starts on learner login and at that point an entry is stored in table Sessions. Videos started within a session are associated with the specific session and stored in the table Session_videos. Similarly, events triggered during video execution are associated with the particular video and stored in table Session_events. Date and time are stored for all the database entries. The same database schema can also be used to accommodate viewing activity data if a different technology is used (e.g., Flowplayer, Adobe Captivate). The tracking program however will need to be specific to the technology used and its underlying API function calls.
The events that are specific to the MediaElement API and are used in the module for tracking learner activity are listed in Table 1.
A set of properties can be retrieved when these events occur such as the video time, the current date and time, etc. The full list of properties and events is provided in the MediaElement webpage.
The database also contains tables to accommodate administrator-educator and learner input (e.g., questions defined by the educator, answers given by learners, subtitles, web content - urls and embedded code - and topic sections, again, defined by the educator).
Another feature that plays role in analytics is sections. As already mentioned, sections defined by the educator reflect different conceptual topics. Sections can also play the role of marker points in the video. When a section is entered while viewing the video sequentially or after a jump, an entry is stored in the database together with the current date and time. Another way of splitting the video is through equal time intervals (rather than different conceptual topics). In this case the markers are inserted in equal time intervals. The time interval is again set by the educator and stored in a general parameters database table.
The insertion of cue markers that initiate events (section enter event), which are then stored in the database together with other events (e.g., pause, resume), can give us a good estimate of the video portions viewed and provide us with a dataset of viewing behaviors that can be used for data analysis and data mining purposes.
Currently, in the developed application we use both markers for topic sections and markers for time intervals. Although this causes more database accesses (and scalability problems are possible), we concluded that this option is necessary for MediaElement in order get more accurate approximations for the segments viewed by learners. By storing all these events, we obtain a very rich database of learner viewing activity. The acquired data can then be processed and analyzed by using a variety of open source packages, such as R (R Development Core Team, 2008) and Weka (Hall et al. 2009). At the moment the environment does not incorporate data analysis and visualization modules but once research confirms the usefulness of certain data analysis tasks the incorporation can take place.
The educational settings and findings
The developed learning environment is used at the Department of Digital Media and Communication of the Technological Education Institute of Western Macedonia, Greece. The application was first used in the autumn semester of the academic year 2014–2015 to support the theoretical part of the first semester courses “Introduction to new Technologies in Communication” (5 videos from YouTube) and “Image and Video Editing Principles” (1 video, Fig. 7).

A snapshot of the learning environment where an educational video is used to support the course “Image and Video Editing Principles”
The environment was then used in the spring semester of the same academic year (i.e. 2015) to support the second semester course “Graphic Design” for both the theoretical part (1 video from YouTube, Fig. 3) and the laboratory part (10 videos for learning the vector graphics software Inkscape, (2015)).
Part of the syllabus was covered by the videos. The features activated in the application for the courses were the following: (a) Table of contents, for the videos supporting the theoretical part of the courses “Image and Video Editing Principles” and “Graphic Design” (b) Subtitles, for some of the videos supporting the course “Introduction to new Technologies in Communication”, and, (c) Questions, (in-video quizzes with multiple choice and open response questions) for the theoretical part of the course “Graphic Design”. The data recording module was activated for all the lessons mentioned above (theoretical and laboratory). For the courses “Image and Video editing Principles” and “Graphic Design” we have defined sections that reflect different subtopics (e.g. interviews by different professionals or information about the different stages in the video production process), and the titles of these sections were provided as links in the table of contents. For the rest of the videos sections were not defined and a table of contents was not provided. This was done in order to observe the learners viewing behaviour in the presence and absence of this interactive feature. However, the videos were split in equal time intervals for data analysis purposes. For the rest of the section we will concentrate only on the two videos for which we have defined sections that reflect different subtopics, and provided the learner with a table of contents. As already mentioned, these two videos were used for the theoretical part of the courses “Image and Video Editing Principles” or “IVEP”, and ‘Graphics Design” or “GD”.
Results from case study 1
During the autumn semester of the academic year 2014–2015 students attending the course “IVEP” were given a video to watch as part of the syllabus. The video length was about 30 min and it contained information about the promotional video creation process as well as the professionals involved in this process (script writer, director, video editing specialist, etc.). The video also contained interviews with such professionals. The video had been produced by a student with a professional experience in the field as part of his thesis.
Students were given an optional assignment that was related to the video. The assignment consisted of two parts, a questionnaire (20 %) that was delivered through Google Forms and a written assignment (80 %) that consisted of several open-ended questions. The assignment counted 15 % towards the overall mark.
The assignment questions were of low cognitive complexity. According to the Blooms Revised taxonomy (Krathwohl 2002) there are six levels of cognitive complexity: remember, understand, apply, analyze, evaluate and create. The questions that were present in the assignment did not go beyond the second level which means that students had to only to remember and understand content exhibited in the video in order to answer the questions.
The assignment was not incorporated in the video environment but was distributed through the institutional learning management system. The video content was also included in the exam syllabus and students were notified that some questions in the exam would be related to the video content. The period for the assignment completion was about 20 days and the period between the deadline of the assignment and the final exam was about 24 days.
Sections were defined for the video and the headers of these sections appeared as a table of contents next to the video (Fig. 7). The video consisted of 14 sections that reflected different subtopics. The learners were able to use the table of contents to navigate directly to the specified sections. They were also able to use the typical player buttons (i.e., pause, play, mute sound, etc.)
In Fig. 8, we see some temporal aspects of the learner viewing behaviour. Figure 8a represents the views in the time interval from the time that the video was delivered to the students and the assignment was set, until the exam.

Views and actions during a semester period. (a) Views, (b) Views, pauses and clicks in the table of contents
In Fig. 8a, we can clearly see two peaks, one before the assignment and another before the exam. We can also see that there are views in the period before the peak related to the assignment but almost no views in the period between the assignment deadline and the peak related to the exam. In Fig. 8b, one can also see in a relative scale the views but also the number of pauses as well as the clicks in the table of contents. From this graph one can clearly see that the table of contents received more clicks during the assignment period.
Another aspect that we focused on is the section transition matrix. This is a table depicting the number of transitions (or jumps) from section to section. Transition matrices can be obtained through various ways. We used (a) TraMiner, (2016), a sequence analysis package within R and its seqtrate function, to obtain a table of transitions, and, (b) the Heatmap2 function of R to obtain a graphical heatmap representation of the transitions. In this investigation, we excluded transitions from one section to itself (e.g., section 1 to section 1) that typically occur via a pause/resume action within a section.
The most typical transition that can be encountered in a transition matrix is the transition from one section to the section that succeeds it (e.g., section 1 to section 2). In a video that is viewed linearly without dropouts or backward jumps, the number of transitions from one section to the next would remain constant. However this is rarely the case and because of these two factors transitions amongst sections can either decrease or increase.
In Fig. 9, we see two heatmap graphs depicting section transitions, one from the period before the assignment (pre-assignment period) and the other from the period after the assignment and before the exam (post-assignment period).

Section Transition Matrices for course “IVEP”
In these heatmap graphs the lines correspond to the start sections, the columns to the destination sections, and, the numerical values are the number of transitions from the start sections to the destination sections.
Figure 9a reveals that besides the typical transitions from one section to the next (e.g., 90 transitions from section 1 to section 2), there are also transitions to other sections that stand out. Among these transitions, the ones to the previous sections are the ones that stand out clearly meaning that learners performed backward jumps probably because they wanted to view a video segment again before answering an assignment question.
When comparing the two images of Fig. 9, we observe that the second transition matrix (Fig. 9b) is less ‘turbulent’ than the first one (Fig. 9a), meaning that learners viewed videos in a more linear fashion in the period close to the exam. Another conclusion is that although the table of contents was used more in the pre-assignment period (Fig. 8b), students used it mainly to navigate to a previous section rather than make arbitrary jumps. The majority of the questions in the assignment followed the sequential order of the sections (e.g., a question related to section 2 was followed by a question related to section 3). However, there were exceptions to the rule and some of these (but not all) can be distinguished in the graph. For example, there are 23 transitions from section 2 to 4 and 15 transitions from section 11 to 13. Both of these cases reflect exceptions in the sequence of questions.
Lastly, in Fig. 9 we observe that although the pre-assignment period and the post- assignment period were almost equal (post-assignment period was by 4 days longer) the number of views were more in the pre-assignment period (124 vs. 61) and also more interactive. Thus, it seems like the assignment caused more engagement with the video material and this will be investigated further in a following subsection.
Results from case study 2
During the spring semester of the academic year 2014–2015 students attending the course “GD” were given a video from YouTube where five professionals are talking about Graphic Design (Fig. 3). The video length was about 7 min. A video related assignment was again set and students were notified that the video would be part of the exam syllabus.
The video was segmented into 7 sections reflecting different issues covered by the professionals. A table of contents was again provided for quick access to the sections contents. However, this time quizzes were incorporated into the video environment and next to the relevant video (in-video quizzes). Quiz questions appeared at the end of each section (multiple choice and open ended). The quiz questions were part of an optional assignment and the assignment counted 10 % towards the overall mark. The pre-assignment period was 23 days and the post assignment period was 41 days. Learners had only one go at each question. Once the question was answered by a learner, the answer was stored in the database and the question would no longer appear in the video for the particular learner. The video could be watched as many times as the learners wished and only the unanswered questions would appear on each video viewing. Questions were again of low cognitive complexity and simply required from students to remember and understand video content.
Graphs similar to the ones depicted in Fig. 8, concerning the views in time and also the pauses and the table of contents clicks were also obtained for this course. The patterns were similar as in Fig. 8 as far as the views and the pauses are concerned. However, the clicks in the table of contents were much less, probably because the length of the particular video was shorter and learners thought it would suffice to navigate just by using the time slide bar (play head). Moreover, the heatmaps for the pre-assignment and the post-assignment period (Fig. 10) were also similar to the ones obtained for the “IVEP” course and, somehow, this was an unexpected observation. The observation was unexpected because almost all questions that concerned a particular section appeared before the end of the section and, therefore, there was no obvious reason for jumping back to a previous section.

Section Transition Matrices for course “GD”
We tried to obtain an answer to this unexpected behaviour by observing the learner viewing patterns.
In our setting there were 2 questions associated with section 1, 2 questions with section 2, 1 with section 3, 3 with section 4, 1 with section 6, and, 1 with section 7. Questions appeared at the end of the sections and the video paused so that the learners could give their answer. After giving their answer (or by passing the question) the video would continue in the same section for one or two seconds and then advance to the next section. For example, towards the end of section 1 (S1), learners were expected to answer the two questions associated with the particular section. After these questions, S1 played again for one or two seconds and then the video advanced to section 2 (S2). Thus the viewing pattern up to section 2 would be “S1-A1-A1-S1-S2” where A1 is an abbreviation for the answers given by learners to the questions associated with section 1.
Following this logic the viewing pattern that we expected to be dominant in viewings of this particular video would have the following form “S1-A1-A1-S1-S2-A2-A2-S2-S3-A3-S3-S4-A4-A4-A4-S4-S5-S6-A6-S6-S7-A7-S7” where “S” stands for ‘section” and “A” for answer. We soon realized that a small error was occurring in the video and the second question that was associated with section 2 was appearing at the first second of section 3 (rather than before it). So the expected viewing pattern after taking this abnormality into account would be “S1-A1-A1-S1-S2-A2-S2-S3-A2-A3-S3-S4-A4-A4-A4-S4-S5-S6-A6-S6-S7-A7-S7”. However, out of the 84 viewings that took place before the assignment, only three viewings followed this exact state pattern. Some sequences were short (videos viewed partially) and some were long (with many jumps from state to state). The maximum sequence length was 54.
From a careful observation of the state sequences it was obvious that the backward jumps occurred mainly due to 3 reasons:
-
(a)
Learners hesitated to submit their answers as soon as the questions appeared but rather preferred to skip the question and continue viewing for a very short period by advancing to the next section. After staying in the next section for a short time they came back to the previous section to submit their answer. The reason for this hesitation is not fully understood.
-
(b)
Learners encountered a question and went back in video time to review content but without using the table of contents. By using the time progress bar instead they landed to the previous section. This behaviour explained the large number of visits that were recorded from section 4 to section 3. When learners encountered the first question of section 4 they had to track the content which contained the answer. This content was located at the very beginning of the section and when students tried to reach it by using the progress bar, they landed in section 3 instead.
-
(c)
Learners returned to the video after answering all questions possibly to search for unanswered questions. These viewings are not linear and they contain a number of jumps to previous sections where these jumps probably occur because learners wanted to be certain that they had not left anything unanswered.
From the views we observed that many learners did not submit all the answers on their first viewing but rather submitted answers in two or more viewings. We also identified a strategy where some students viewed the whole video and the related questions one or more times without submitting any answers, and at some subsequent point in time they accessed the video again to give their answers.
The sessions after the assignment were less turbulent as it was observed in the first semester course with only a small number of jumps. Thus, again, besides the fact that the pre-assignment period was much shorter than the post-assignment period, there were more viewings in the pre-assignment period and these viewings were also more interactive.
Investigating associations between video related activities, viewing time and learner performance
Taking into account that the designated assignments caused more viewings and more interactivity within the viewings (in terms of jumps from section to section), we wanted to test whether the completion of the assignments had also an effect on learning.
For both courses the number of students that enrolled for the courses was larger than the number of students that accessed the videos and these were mostly students that attended the lectures. The study that follows focuses only on the students that viewed the related video lessons at least once and participated in the exam.
For both courses besides the overall exam mark, the student marks on the questions associated to the video were recorded and only these marks were used in the study conducted. These marks will be referred to as “Video Exam marks” or “VE marks”. In the investigation conducted, we tried to spot any differences in the VE marks between students that completed the assignments and those who did not. This test was carried out for the two courses separately since the video characteristics (e.g. video length) and the assignment activities were not the same for each course.
An independent sample t-test was conducted for the students of the course “IVEP” in order to check for differences in the final VE mark, between the students that participated in the assignment and those who did not. The sample of students was divided into two groups. The first group was comprised of 30 students who completed the assignment and the second group consisted of 27 students who did not complete the assignment. Findings from the t-test indicate that significant differences (p < 0.05) exist in the mean scores of the two groups (t = 3.289, p = 0.002). Students who completed the assignment received higher VE marks (M = 6.63 out of 10) than those who did not complete the assignment (M = 4.09 out of 10).
For the course “GD” in order to test whether there were differences in the VE marks obtained by students who completed the assignment (31 students) and those who did not (20 students) we carried out a Mann–Whitney U test. A t-test was not used for this course since the VE marks did not follow a normal distribution for the two groups and the two groups were not of equal size (nor nearly equal size). The test showed that VE marks for students that performed the in-video quizzes successfully (mean rank = 31.58) were statistically significantly higher than for the students who did not complete the assignment (mean rank = 17.35), U = 137, z = −3.59, p = .000 (p < 0,05).
According to the ICAP framework (Chi and Wylie, 2014), there are four different levels of cognitive engagement while learning and there are differences in the learning outcomes depending on the engagement involved. The ICAP hypothesis predicts that as students become more engaged with the learning materials, from passive to active and then to constructive and interactive, their learning will increase.
The levels in the ICAP framework are the following:
-
Passive - simply receiving information, as in watching an educational video in a linear fashion
-
Active -receiving information but at the same time doing something with the material, such as manipulating the material by carrying out motoric actions (e.g., pausing, rewinding) as well as answering quiz questions that are related to video content.
-
Constructive -generating some information beyond the information presented in the educational material (video content in our case).
-
Interactive -when students engage with each other through dialogue or collaborative activities.
Since the assignment questions that were related to the video did not require from the students to generate new information we can say that the level of cognitive engagement did not go beyond the “active” level. Thus we can say that in the described settings active engagement proved to be better than passive.
But what actually causes this better performance in the particular settings? Is it the higher level of cognitive engagement that is associated with the video related assignments or does it also have to do with the higher level of behavioural engagement, such as the higher number of video visits or the larger amount of time spend on video viewing, that could also be associated with these assignments?
To answer the last question we will first investigate if there is an association between the time spend on video viewing and the learner “VE marks”, and if this is the case then we will investigate if the students that completed the assignments actually spend more time on video viewing.
In the past, we have also used videos for supporting lab classes where various software programs were taught. The topics were taught in class and video was used as support material. Assignments that contributed to the final mark were also set. An analysis on video activity data was carried out and results were presented in previous papers (Kleftodimos and G. Evangelidis, 2014a, b). For those courses we did not observe any linear correlations (using the Pearson test) between the final marks and indicators such as the total number of video views, the total time spend on viewing the videos (video engagement), or the percentage of the videos covered by the student. Through questionnaires it became clear that a number of students who performed well did not rely much on videos since they grasped most of the necessary knowledge from class. However, the settings described in this paper are different in the sense that the video related knowledge had to come entirely from viewing the videos, and this could be a factor that affects the relation between engagement and performance.
In order to investigate whether there is an association between learner engagement and performance we first calculate the overall time spend on video viewing for all the students in the sample. We will be referring to this time as the “Overall Viewing time” or “OV time”. “OV time” may also include breaks (time between a pause and a resume) and when these breaks are long this time interval can be considered as off task time. In order to exclude time that was not on task the threshold of 30 min was used. Any pause time exceeding 30 min was subtracted from the “OV time”.
To find out whether “OV time” is correlated to the final VE marks a correlation test was conducted using Pearson’s correlation coefficient.
Regarding students that attended the course “IVEP” (57 students), results indicate that there is a significant (p = 0,000) positive correlation between the time spent by students viewing the video and their final VE mark (r = 0.481). The significant correlation found could be regarded as moderate (0.30 < r < 0,50).
In a similar vein, for the course “GD” (51 students), a statistically significant (p = 0.000, p < 0,05) strong positive correlation was found between the “OV time” and the final VE mark (r = 0.512).
From the two statistical tests we can conclude that for the particular educational settings where the educational video is the only source of knowledge for answering the video related exam questions, there is a positive association between “OV time” and the final VE mark.
Once we found that the learner performance is related to the learner engagement with the video content we can now also investigate if the students that completed the video related assignments actually spend more time on viewing the videos.
As it is depicted in Figs. 8, 9 and 10 of the previous section, the video visits coming from the whole sample of learners were higher and also more interactive in terms of backward jumps during the pre-assignment periods.
The assignments also seem to have caused higher levels of “OV time” for students that engaged with them. This is concluded after comparing the average “OV time” from students of the sample that completed the assignment in the pre-assignment period, with the average “OV time” of all students that accessed the videos in the post-assignment period.
As it was logically expected, for both courses all students that completed the assignment had at least one access in the pre-assignment period. The average and median “OV times” are given in Table 2.
What one can notice from the values in Table 2 is that the average “OV time” in the pre-assignment period (for students that completed the assignment) is considerably higher than in the post-assignment period (for all students) for both courses, and we can thus assume that the higher engagement with the video content is a result of the designated video related assignments. Another observation is that the “OV time” in both the pre-assignment period and post-assignment period exceed significantly the video durations.
To summarize, viewing a video and performing a related assignment is a more active way of learning when compared to passive video viewing and requires a higher level of cognitive engagement. Students who followed this way of learning performed better in the video related exam questions. The better results are also a product of the higher amount of time spend on video viewing by students who performed the assignment.
Discussion and conclusions
Today the levels and types of interactivity in video based learning environments are constantly evolving. Interactive features can be used for various reasons such as testing the learners knowledge at specific time points (e.g. in-video quizzes), making learner navigation more efficient (e.g. table of contents), and making video viewing a richer experience by aggregating video content with content from the open web and content that is generated by the educator.
A number of video based tools have recently appeared (e.g. Zaption, Educanon, Raptmedia, Grockit Answers) and these tools support a different set of interactive features. While only few of these tools offer their platforms for free (e.g. Grockit Answers), the majority of these tools are commercial and either are not free (e.g. RaptMedia) or provide only a limited set of features for free and incremental account options for the rest (e.g. Zaption, Educanon). Moreover none of these tools are open source (or expose any implementation details) which means that researchers and e-learning developers cannot rely on them for customization and further development.
To overcome these limitations this paper presents a roadmap on how open source tools and open web resources can be used for facilitating a broad range of interactive features into a video based learning environment. By doing this the paper aims at:
-
a)
Saving valuable resources in terms of time and money, for researchers, IT staff, and educators (with the technical knowledge) who wish to enhance educational videos with interactive features. Such a road map can be particularly valuable in cases where resources are limited as this is the case with many educational establishments today.
-
b)
Providing stakeholders with ideas on the possible interactive features that could be incorporated in a video based environment. While some of the features mentioned in the paper are also supported by other environments (e.g. in-video quizzes) there are also a number of features that are unique to this research effort. For example in the described environment video content can be aggregated with content coming from the open web (e.g. Google Maps, Slideshare slides) and with activities created by the educator using the software Hot Potatoes as well as collaborative writing activities facilitated by Etherpad. By introducing these features we aim at making the video learning process a richer experience by mixing video content with related web resources and by providing more ways to test the student knowledge besides the typical in-video quizzes.
As far as learning analytics are concerned some commercial interactive video environments provide basic reports using graphs and a dataset with certain aspects of the activity data (e.g. viewing time, number of jumps, completed questions). However to the best of our knowledge these tools do not provide the whole viewing and activity data (click level video interactions, segments viewed etc.). This data is however necessary in order to proceed to more elaborate data analysis. In the presented roadmap detailed information is given on how HTML 5 players and their event driven capabilities are used in order to collect a detailed dataset of viewing activity. This dataset can then be analyzed using data analysis, datamining (e.g. Kleftodimos & Evangelidis 2016, 2014b) and visualization techniques. The analysis can take place in order to understand learner viewing behaviors with respect to various parameters, such as the integrated elements (e.g., quiz questions, table of contents), the type of videos used (e.g., instructional videos, documentaries, lectures), and, the educational settings and learning scenarios in which the video learning activities take place. Some findings obtained from such analysis were presented in this paper mainly using visualizations and statistical methods. Visualizations have been used before in literature for spotting points of interest and drop out (e.g. Giannakos et al. 2015, Kim et al. 2014). However, in this paper we present a “transition matrix heatmap” visualization that can depict sections of interest (logical or time defined sections) but also the transitions from section to section that occur during video viewing (with forward and backward jumps).
One limitation of our study is that although we were able to incorporate many different features in our environment not all of these were used in classroom settings and in our analytics research. In this investigation only two features were used, the “table of contents” and the “in-video quizzes”. More work can be done to examine how learners interact with other features and if these features affect the learner viewing behaviour and performance.
Another limitation is that this study was carried out under specific settings. The videos were used in first year courses in a Communication Department where most of the incoming students have a theoretical focus and not much exposure to information and communication technologies. The videos where used as part of an assignment and were included in the examination syllabus. The videos covered a specific topic and no other source of information was provided. Therefore, the results of the analysis are connected to the motives and educational background of the specific students as well as to the other factors of the educational settings. Thus more work will have to be done in different settings in order to be able to generalize the results.
As future work we intend to use more features within learning scenarios and include these features into our learning analytics research in order to understand learners’ viewing behaviour and interactions with respect to these features. The impact that these features may have on the learning process could also be investigated. Another goal would be to integrate into the environment visualizations and functions produced by known data analysis packages (e.g. R and Weka) that prove to be useful in analysing video activity data.
Availability of data and materials
The source code for many of the modules described in this paper is hosted in GitHub and any further work will also be accommodated in this space.
Project name: IVB (An interactive video builder that supports learning analytics)
Project home page: https://github.com/kleftodimos/IVB-An-interactive-video-builder-that-supports-learning-analytics
Operating system(s): Platform independent
Programming language: PHP scripting language
Other requirements: Apache webserver, MySQL database, MediaElement opensource HTML 5 video player.
Abbreviations
- GD:
-
Graphic Design
- IVEP:
-
Image and Video Editing Principles
- OV time:
-
Overall Viewing time
- VE marks:
-
Video Exam marks
References
Adobe Captivate, http://www.adobe.com/products/captivate.html. (Accessed Nov 2015)
M. Agarwala, I.H. Hsiao, H.S. Chae, G. Natriello, Vialogues: videos and dialogues based social learning environment, Proceedings of the 2012 IEEE 12th International Conference on Advanced Learning Technologies (IEEE, 2012), pp. 629–633
Articulate Storyline, https://en-uk.articulate.com/products/storyline-why.php. (Accessed June 2016)
J.L. Bishop, M.A. Verleger, The flipped classroom: A survey of the research (ASEE National Conference Proceedings, Atlanta, GA, 2013)
C. Brooks, C. Thompson, J. Greer. Visualizing lecture capture usage: A learning analytics case study. Proceedings of the LAK 2013 Workshop on Analytics on Video-based Learning (WAVe), (2013), pp. 9-14
M.T. Chi, R. Wylie, The ICAP framework: Linking cognitive engagement to active learning outcomes. Educational Psychologist 49(4), 219–243 (2014)
Coursera (2015), https://www.coursera.org/. (Accessed Nov 2015)
S. Cummins, A. Beresford, A. Rice, Investigating Engagement with In-Video Quiz Questions in a Programming Course. IEEE Transactions on Learning Technologies PP, 99 (2015)
J. De Boer, P.A. Kommers, B. De Brock, Using learning styles and viewing styles in streaming video. Computers & Education 56(3), 727–735 (2011)
EDpuzzle, http://edpuzzle.com. (Accessed Nov 2015)
EduCanon (now called Playposit), http://www.educanon.com or https://www.playposit.com/. (Accessed Nov 2015)
edX, https://www.edx.org/. (Accessed Nov 2015)
Etherpad, http://etherpad.org/. (Accessed Nov 2015)
Flowplayer, http://flowplayer.org. (Accessed Nov 2015)
M.N. Giannakos, Exploring the video‐based learning research: A review of the literature. British Journal of Educational Technology 44(6), E191–E195 (2013). doi:10.1111/bjet.12070
M. N. Giannakos, K. Chorianopoulos, N. Chrisochoides. Collecting and making sense of video learning analytics, in Frontiers in Education Conference (FIE), 2014 IEEE (IEEE, 2014b), pp. 1–7. doi:10.1109/FIE.2014.7044485
M. N. Giannakos, J. Krogstie, N. Chrisochoides. Reviewing the flipped classroom research: reflections for computer science education, in Proceedings of the Computer Science Education Research Conference (ACM, 2014a), pp. 23–29
M.N. Giannakos, K. Chorianopoulos, N. Chrisochoides, Making sense of video analytics: Lessons learned from clickstream interactions, attitudes, and learning outcome in a video-assisted course. The International Review of Research in Open and Distributed Learning 16, 1 (2015)
P. Gorissen, J. Van Bruggen, W. Jochems, Usage reporting on recorded lectures using educational data mining. International Journal of Learning Technology 7(1), 23–40 (2012)
Grockit answers, http://grockit.com/answers. (Accessed Nov 2015)
P. J. Guo, J. Kim, R. Rubin. How video production affects student engagement: An empirical study of mooc videos, in Proceedings of the first ACM conference on Learning@ scale conference (ACM, (2014), pp. 41–50. doi:10.1145/2556325.2566239
M. Hall, E. Frank, G. Holmes, B. Pfahringer, P. Reutemann, I.H. Witten, The WEKA data mining software: an update. ACM SIGKDD explorations newsletter 11(1), 10–18 (2009)
Hot Potatoes, https://hotpot.uvic.ca/. (Accessed Apr 2016)
Inkscape, https://inkscape.org/en/. (Accessed Nov 2015)
Kaltura, State of Video in Education Report, 2014. http://site.kaltura.com/Education_Survey.html
Kaltura, State of Video in Education Report, 2015. http://site.kaltura.com/Kaltura_Survey_State_of_Video_in_Education_2015.html
R.H. Kay, Exploring the use of video podcasts in education: A comprehensive review of the literature. Computers in Human Behavior 28(3), 820–831 (2012)
Khan Academy (2015) https://www.khanacademy.org. (Accessed Nov 2015)
J. Kim, P. J. Guo, D. T. Seaton, P. Mitros, K. Z. Gajos, R. C. Miller. Understanding in-video dropouts and interaction peaks inonline lecture videos, in Proceedings of the first ACM conference on Learning@ scale conference (ACM, 2014), pp. 31–40
A. Kleftodimos, G. Evangelidis, An interactive video-based learning environment that supports learning analytics for teaching ‘Image Editing’, 2016. International Workshop on Smart Environments and Analytics in Video-Based Learning (SE@VBL), organized in conjunction with the 6th Conference on Learning Analytics & Knowledge
A. Kleftodimos, G. Evangelidis, An Interactive Video-Based Learning Environment Supporting Learning Analytics: Insights Obtained from Analyzing Learner Activity Data. Proceedings of the 2nd International Conference on Smart Learning Environments, ICSLE 2015, in State-of-the-Art and Future Directions of Smart Learning, Lecture Notes in Educational Technology, pp. 471–481, Springer 2015.
A. Kleftodimos, G. Evangelidis, Exploring student viewing behaviors in online educational videos. In Advanced Learning Technologies (ICALT), 2014 IEEE 14th International Conference, 2014a, pp. 367–369. doi:10.1109/ICALT.2014.109. IEEE
A. Kleftodimos, G. Evangelidis. A framework for recording, monitoring and analyzing learner behavior while watching and interacting with online educational videos, in Advanced Learning Technologies (ICALT), 2013 IEEE 13th International Conference on (IEEE, 2013), pp. 20–22. doi:10.1109/ICALT.2013.10
A. Kleftodimos, G. Evangelidis, Using metrics and cluster analysis for analyzing learner video viewing behaviours in educational videos. In Computer Systems and Applications (AICCSA), 2014 IEEE/ACS 11th International Conference on, 2014b, pp. 280–287. doi:10.1109/AICCSA.2014.7073210. IEEE
D.R. Krathwohl, A revision of Bloom’s taxonomy: An overview. Theory into practice 41(4), 212–218 (2002)
N. Li, L. Kidzinski, P. Jermann, P. Dillenbourg. How Do In-video Interactions Reflect Perceived Video Difficulty?, in Proceedings of the European MOOCs Stakeholder Summit 2015 (No. EPFL-CONF-207968), (2015b, PAU Education), pp. 112–121. doi EPFL-CONF-207968
N. Li, Ł. Kidziński, P. Jermann, P. Dillenbourg. MOOC Video Interaction Patterns: What Do They Tell Us?, in Design for Teaching and Learning in a Networked World (2015a, Springer International Publishing), pp. 197–210
R.E. Mayer, Principles for managing essential processing in multimedia learning: Segmenting, pretraining, and modality principles. The Cambridge handbook of multimedia learning, 2005, pp. 169–182
MediaElement.js, Html 5 video player, http://mediaelementjs.com. (Accessed Nov 2015)
Pixlr, https://pixlr.com/. (Accessed May 2016)
Popcorn Framework http://popcornjs.org/. (Accessed Nov 2015)
M. Preston, G. Campbell, H. Ginsburg, P. Sommer, F. Moretti, Developing new tools for video analysis and communication to promote critical thinking, in EdMedia: World Conference on Educational Media and Technology, vol. 1, 2005, pp. 4357–4364
R Development Core Team, R: A language and environment for statistical computing (R Foundation for Statistical Computing, Vienna, Austria, 2008). http://www.R-project.org. ISBN 3-900051-07-0 (Accessed Nov 2015)
RaptMedia, http://www.raptmedia.com/. (Accessed Apr 2016)
E.F. Risko, T. Foulsham, S. Dawson, A. Kingstone, The collaborative lecture annotation system (CLAS): A new TOOL for distributed learning. IEEE Transactions on Learning Technologies, 6(1), 4–13 (2013)
S. Schwan, R. Riempp, The cognitive benefits of interactive videos: Learning to tie nautical knots. Learning and Instruction 14(3), 293–305 (2004)
Slideshare, http://www.slideshare.net. (Accessed Nov 2015)
S.R. Slusser, R.J. Erickson, Group quizzes: an extension of the collaborative learning process. Teaching Sociology 34(3), 249–262 (2006)
Z. Theodosiou, A. Kounoudes, N. Tsapatsoulis, M. Milis. Mulvat: A video annotation tool based on xml-dictionaries and shot clustering, in Artificial Neural Networks–ICANN 2009 (2009, Springer Berlin Heidelberg), pp. 913–922. doi:10.1007/978-3-642-04277-5_92
TraMiner, http://traminer.unige.ch/. (Accessed June 2016)
Vialogues, http://vialogues.com. (Accessed Nov 2015)
Vimeo, http://www.vimeo.com. (Accessed Nov 2015)
C.F. Yokomoto, R. Ware, Variations of the group quiz that promote collaborative learning. In Frontiers in Education Conference, 1997. 27th Annual Conference. Teaching and Learning in an Era of Change. Proceedings. 1, 552–557 (1997). IEEE
A.M.F. Yousef, M.A. Chatti, N. Danoyan, H. Thüs, U. Schroeder, Video-Mapper: A Video Annotation Tool to Support Collaborative Learning in MOOCs. Proceedings of the Third European MOOCs Stakeholders Summit EMOOCs, 2015, pp. 131–140
Youtube, http://www.youtube.com. (Accessed Nov 2015)
Zaption, http://www.zaption.com. (Accessed Nov 2015)
D. Zhang, Interactive multimedia-based e-learning: A study of effectiveness. The American Journal of Distance Education 19(3), 149–162 (2005). doi:10.1207/s15389286ajde1903_3
D. Zhang, L. Zhou, R.O. Briggs, J.F. Nunamaker, Instructional video in e-learning: Assessing the impact of interactive video on learning effectiveness. Information & management 43(1), 15–27 (2006)
Acknowledgments
This paper is an extended version of the paper “An Interactive Video-Based Learning Environment Supporting Learning Analytics: Insights Obtained from Analyzing Learner Activity Data” presented in the Workshop: Smart Environments and Analytics on Video-Based Learning, 2nd International Conference on Smart Learning Environments, ICSLE 2015, (Kleftodimos & Evangelidis 2015).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
Both authors read and approved the final manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Kleftodimos, A., Evangelidis, G. Using open source technologies and open internet resources for building an interactive video based learning environment that supports learning analytics. Smart Learn. Environ. 3, 9 (2016). https://doi.org/10.1186/s40561-016-0032-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40561-016-0032-4