
Abstract
The Poisson, geometric and Bernoulli distributions are special cases of a flexible count distribution, namely the Conway-Maxwell-Poisson (CMP) distribution – a two-parameter generalization of the Poisson distribution that can accommodate data over- or under-dispersion. This work further generalizes the ideas of the CMP distribution by considering sums of CMP random variables to establish a flexible class of distributions that encompasses the Poisson, negative binomial, and binomial distributions as special cases. This sum-of-Conway-Maxwell-Poissons (sCMP) class captures the CMP and its special cases, as well as the classical negative binomial and binomial distributions. Through simulated and real data examples, we demonstrate this model’s flexibility, encompassing several classical distributions as well as other count data distributions containing significant data dispersion.
Similar content being viewed by others

Introduction
The Poisson distribution is one of the most popular discrete distributions, serving as a natural, classical distribution to model count data. It is well-known that a random variable Y that is Poisson distributed with rate parameter μ ∗ has a probability mass function (pmf) of the form,
where μ ∗ equals both the mean and variance of the distribution. The relationship between the mean and variance implies a goodness-of-fit index, \(GOF = \frac {Var(Y)}{E(Y)}=1\), i.e. equi-dispersion is established. This constraining assumption, however, does not oftentimes hold true for real data – an issue that has significant implications affecting numerous applications.
Over-dispersion relative to the Poisson distribution (i.e. where the variance is greater than the mean) is a common feature among real data. The most popular distribution to model over-dispersion is the negative binomial distribution; for such a random variable Y with a negative binomial(n,p) distribution, its pmf is
where y denotes the number of failures before the nth success in a series of Bernoulli trials with success probability, 0≤p≤1. The geometric distribution with success probability p is a special case of negative binomial (n,p) where n=1. The mean and variance of this random variable are \(E(Y) = \frac {n(1-p)}{p}\) and \(Var(Y) = \frac {n(1-p)}{p^{2}}\), respectively, thus the goodness-of-fit index for dispersion is
This dispersion index motivates considering the negative binomial distribution as a viable option for addressing data over-dispersion. In fact, this distribution is a popular choice for modeling over-dispersion in various statistical methods (e.g. regression (Hilbe 2008)) and is well studied with statistical computational ability in many softwares (e.g. SAS, R, etc.). The negative binomial distribution, however, is unable to address data under-dispersion, as demonstrated in Eq. (1). This result further illustrates that the Poisson GOF is the boundary case of the negative binomial distribution; the Poisson distribution is known to be the limiting case of the negative binomial distribution where n→∞.
The binomial distribution (while arguably a truncated count distribution) is an under-dispersed count distribution relative to the Poisson model. A binomially distributed random variable Y with b Bernoulli trials and success probability p ∗ has the pmf,
Naturally, the bernoulli (p ∗) distribution is a special case of the binomial distribution where b=1. The associated mean and variance of this random variable equal E(Y)=bp ∗ and Var(Y)=bp ∗(1−p ∗), respectively, thus the goodness-of-fit index for dispersion is GOF=1−p ∗≤1. The Poisson, negative binomial, and binomial distributions are popular, classical tools for modeling count data of a particular (in)finite form. What is most interesting about these distributions is that they each represent sums of other classical distributions, namely the Poisson, geometric, and Bernoulli distributions, respectively. The Poisson, geometric and Bernoulli distributions are themselves special cases of the Conway-Maxwell-Poisson (CMP) distribution – a two-parameter flexible count distribution that generalizes the Poisson distribution to accommodate data over- or under-dispersion. This work introduces and thus considers the sum of CMP random variables to establish the flexible class of distributions that encompass the Poisson, geometric, Bernoulli, negative binomial, binomial, and CMP distributions as special cases.
The paper is outlined as follows. Section 2 acquaints the reader with the CMP distribution in order to motivate and introduce the sum-of-Conway-Maxwell-Poissons (sCMP) class in Section 3, including discussion of the statistical properties associated with this larger class of count distributions. Section 4 addresses parameter estimation and statistical computing procedures. Section 5 illustrates the flexibility of this class of distributions via simulated and real data examples. Finally, Section 6 concludes the manuscript with discussion.
The Conway-Maxwell-Poisson distribution
The CMP distribution is a viable two-parameter count distribution that generalizes the Poisson distribution in light of data dispersion. Conway and Maxwell (1962) derive the distributional form, motivated by considering a queuing system with a flexible state-dependent service rate where ν describes the degree to which the system service rate is affected by the system state. The resulting pmf has the form
for a random variable X, where λ=E(X ν) denotes a generalized form of the Poisson rate parameter, ν≥0 is a dispersion parameter, and \(Z(\lambda, \nu) = \sum _{j=0}^{\infty } \frac {\lambda ^{j}}{(j!)^{\nu }}\) normalizes the distribution such that the distribution satisfies the basic probability axioms. The dispersion parameter, ν, accounts for the amount of data over- or under-dispersion relative to the Poisson distribution: ν=1 implies that data equi-dispersion exists, while ν>(<)1 denotes under- (over-) dispersion relative to the Poisson model. The CMP distribution includes three well-known distributions as special cases: the Poisson(μ ∗=λ) distribution when ν=1, the geometric distribution with success probability p=1−λ when ν=0 and λ<1, and the Bernoulli distribution with success probability \(p_{\ast }=\frac {\lambda }{1+\lambda }\) as ν→∞; see Table 1 for details.
Shmueli et al. (2005) provide the moments for the CMP distribution via the recursion,
The expected value and variance can alternatively be represented as
where the approximation holds for ν≤1 or λ>10ν (Sellers et al. 2011); see Minka et al. (2003) for details. More generally, the associated moment generating function of X is \(\mathrm {M}_{X}(t) = \frac {Z(\lambda e^{t}, \nu)}{Z(\lambda, \nu)}\), from which the higher moments can be obtained for X.
The CMP distribution satisfies several nice properties. The distribution has an exponential family form with joint sufficient statistics \(\left \{\sum _{i=1}^{n}x_{i},\sum _{i=1}^{n}\log (x_{i}!) \right \}\) for {λ,ν}. Further, the ratio between probabilities of two consecutive values is nonlinear in x, namely,
The linear relation among probabilities of two consecutive values is achieved when ν=1, i.e. given data equi-dispersion associated with the Poisson(λ) model. Meanwhile, for ν=0 and λ<1 (i.e. the geometric distribution with success probability 1−λ), we confirm that the ratio between probabilities of two consecutive values is constant, equaling \(\frac {1}{\lambda }>1\).
The CMP distribution has quickly grown in popularity because of its ability to model count data in a flexible manner. Methodological developments are vast, including works in distribution theory (Sellers 2012; Sellers and Shmueli 2013; Borges et al. 2014), regression analysis (Sellers and Shmueli 2009; 2010; Sellers and Raim 2016), control chart theory (Sellers 2012; Saghir and Lin 2014a; 2014b), stochastic processes (Zhu et al. 2017), and multivariate data analysis (Sellers et al. 2016). The model has further been applied for various data problems including fitting word lengths (Wimmer et al. 1994), modeling online sales (Boatwright et al. 2003; Borle et al. 2006) and customer behavior (Borle et al. 2007), analyzing traffic accident data (Lord et al. 2008), and for use as a disclosure limitation procedure to protect individual privacy (Kadane et al. 2006). See Sellers et al. (2011) for additional overview and discussion.
The sum of Conway-Maxwell-Poissons (sCMP) class of distributions and its statistical properties
The sum of m independent and identically distributed (iid) CMP variables leads to what will be termed a sum of Conway-Maxwell-Poissons (sCMP) (λ,ν,m) class of distributions. Theorem 1 defines the three-parameter structure for some generalized rate parameter (λ), dispersion parameter (ν), and number of underlying CMP random variables (m).
Theorem 1.
The sCMP (λ,ν,m) distribution has the following pmf for a random variable \(Y = \sum \limits _{i=1}^{m} X_{i}\), where \(X_{i} \overset {iid}{\sim }\) CMP (λ,ν):
where \({y \choose x_{1} \cdots x_{m}} = \frac {y!}{x_{1}! \cdots x_{m}!}\) is the multinomial coefficient.
Proof
We prove this result by induction. For m=2, let X i ∼ CMP (λ,ν), i=1,2 and Y=X 1+X 2. Then, the result holds by the transformation technique (see Chapter 2 of Casella and Berger (2002)). Similarly, given that the result is true for m=k−1, we can likewise apply the transformation technique to show that
□
The sCMP(λ,ν,m) class encompasses the Poisson distribution with rate parameter μ ∗=m λ (for ν=1), negative binomial(m,1−λ) distribution (for ν=0 and λ<1), and Binomial(m,p) distribution \(\left (\text {as } \ \nu \rightarrow \infty \ \ \text {with success probability}\ \ p=\frac {\lambda }{\lambda + 1}\right)\) as special cases. Further, for m=1, the sCMP(λ,ν,m=1) is the CMP(λ,ν) distribution. Accordingly, the sCMP class further captures the special case distributions of the CMP model: a geometric distribution with success probability, p=1−λ, when m=1, ν=0, and λ<1; and a Bernoulli distribution with success probability \(p_{\ast \ =\ } \frac {\lambda }{1+\lambda }\) when m=1 and ν→∞.
Figures 1 and 2 display the sCMP class for different values of m=1,2,3,5 and ν=0.5,1,5,30 for λ=2 (Fig. 1) and λ=0.25 (Fig. 2), respectively. Both figures illustrate the right skewness of the distribution, and show that the range of the data decreases as ν increases. Figure 1 more clearly demonstrates how m and ν influence the centrality and shape of the distribution when λ=2. As previously discussed, the special case where ν=1 simplifies the sCMP(λ,ν,m) model to the Poisson(m λ) distribution. This illustrative example thus displays Poisson models with respective means equaling 4, 6, and 10. The increased variation in the respective figures is consistent with the increased shift in the distribution mean; recall that the Poisson mean and variance equal each other. Relative to the Poisson model, we see that (for a given m) increasing ν associates with decreasing variation. Figure 1 displays longer tail distributions relative to the Poisson distribution for ν<1 and shorter tails relative to the Poisson model when ν>1. Meanwhile (for a given ν), increasing m clearly associates with increased shifts in the measures of distributional centrality (i.e. mean, median, and mode).

sCMP Probability Mass Functions. Collection of probability mass function figures for sCMP(λ=2,ν,m) distributions with varying values for ν=0.5,1,5,30 and m=1,2,3,5

sCMP Probability Mass Functions. Collection of probability mass function figures for sCMP(λ=0.25,ν,m) distributions with varying values for ν=0.5,1,5,30 and m=1,2,3,5
The ratio between probabilities of two consecutive values is
where the ratio of sums drops out in the special case where m=1 (i.e. one CMP(λ,ν) random variable); clearly, this produces the special case shown in Eq. (6). For the special case where ν=1, \(\gamma _{Y,y} = \frac {y}{m\lambda }\), which is the linear form property of the Poisson random variable with parameter m λ (i.e. the distribution of the sum of m Poisson random variables). Meanwhile, for ν=0, \(\gamma _{Y,y} = \frac {y}{\lambda (m+y-1)}\), namely the form associated with a negative binomial distribution (i.e. the sum of m geometric random variables). Equation (8) implies that the sCMP model has a mode at 0 when γ Y,y >1, i.e. \(\lambda < y^{\nu } \cdot \frac {\sum _{\stackrel {a_{1},\ldots,a_{m} = 0} {a_{1} + \ldots + a_{m} = y-1} }^{y-1} {y-1 \choose a_{1}, \cdots, a_{m}}^{\nu } }{\sum _{\stackrel {b_{1},\ldots,b_{m} = 0} {b_{1} + \ldots + b_{m} = y} }^{y} {y \choose b_{1}, \cdots, b_{m}}^{\nu }}\). In particular, \(\gamma _{Y,1} = \frac {P(Y = 0)}{P(Y = 1)}= \frac {1}{m\lambda }\), thus sCMP(λ,ν,m) models where \(\lambda < \frac {1}{m}\) have a mode at 0. Figure 2 displays the sCMP(λ=0.25,ν,m) distributions for ν=0.5,1,5,30 and m=1,2,3,5. Given that \(\lambda = 0.25 = \frac {1}{4}\), we expect sCMP distributions where m<4 to have the mode at 0. This is illustrated accordingly in Fig. 2; sCMP(λ=0.25,ν,m) distributions for m=2,3 and any ν≥0 have the mode at 0, while the sCMP(λ=0.25,ν,m=5) distribution has the mode at 1 for all ν≥0.
The moment-generating function M Y (t), probability generating function Π Y (t), and characteristic function ϕ Y (t) of a sCMP(λ,ν,m) random variable Y are given, respectively, as
The moment generating function technique can be used to show that, given the same parameters λ and ν, the sum of independent sCMP distributions is invariant under addition (i.e. the sum of sCMP random variables has a sCMP distribution). For two independent random variables, Y 1∼ sCMP (λ,ν,m 1) and Y 2∼ sCMP (λ,ν,m 2),
which is the mgf of a sCMP (λ,ν,m 1+m 2) distribution, therefore Y 1+Y 2 has a sCMP (λ,ν,m 1+m 2) distribution. This result is logically sound because Y 1 and Y 2 respectively represent the sum of m 1 and m 2 iid CMP (λ,ν) random variables; thus, Y 1+Y 2 defines the sum of m 1+m 2 iid CMP random variables, which precisely has a sCMP(λ,ν,m 1+m 2) distribution. This distinction is key between the CMP distribution and the larger sCMP class – the CMP distribution does not have the invariance property under addition.
3.1 Moments of the distribution
One can differentiate Eq. (9) to obtain the moments of the sCMP model, with the help of the following relation.
Theorem 2.
For a normalizing function of the form, Z(λ e t,ν), where Z(·,·) is as defined following Eq. (2), the kth (k=1,2,3,…) derivative is
Proof
This proof is straightforward, given the differentiation formula for exponential functions. □
This result proves helpful in showing that the sCMP(λ,ν,m) has mean E(Y)=mE(X) and variance V(Y)=mV(X), where E(X) and V(X) (provided in Eqs. (4)-(5), respectively) are the mean and variance of a CMP(λ,ν) random variable X.
3.2 Introducing the generalized Conway-Maxwell-Binomial (gCMB) distribution
Conditioning a CMP random variable on a sum of two independent CMP random variables produces a random variable whose distribution is Conway-Maxwell-Binomial (CMB) (Kadane 2016) (alternatively termed as “Conway-Maxwell-Poisson-Binomial” in Shmueli et al. (2005) and Borges et al. (2014)). The CMB random variable X has the pmf,
for \(r \in \mathcal {Z}^{+}\), p∈(0,1), and \(\nu \in \mathcal {R}\) such that ν=1 produces the usual binomial(r,p) distribution, ν>1 corresponds to data under-dispersion relative to a binomial distribution while ν<1 corresponds to data over-dispersion relative to the binomial(r,p) model. Extreme distribution cases hold where, for ν→∞, the pmf is concentrated at the point, rp and, for ν→−∞, it is concentrated at 0 or r (Borges et al. 2014).
Analogously, conditioning a sCMP variable on the sum of two independent sCMP variables produces a generalized form of the CMB distribution; we denote this as the gCMB distribution. Letting S=Y 1+Y 2 where Y 1∼ sCMP (λ 1,ν,m 1) and Y 2∼ sCMP (λ 2,ν,m 2) are independent, and given S=s,
where
is a normalizing constant and \(p = \frac {\lambda _{1}}{\lambda _{1} + \lambda _{2}}\). Thus, the conditional probability of a sCMP(λ 1,ν,m 1) random variable given the value of a sum of sCMP random variables as described above is
This generalized CMB distribution [denoted as gCMB(p,ν,s,m 1,m 2)] contains several special cases. When m 1=m 2=1, the gCMB distribution reduces to the CMB (s,p,ν) distribution. For ν=1, the probability reduces to
i.e. given data equi-dispersion, we have a binomial distribution with s trials and \(p^{*} = \frac {{m_{1}}p}{{m_{1}}p + {m_{2}}(1-p)} = \frac {{m_{1}}\lambda _{1}}{{m_{1}}\lambda _{1} + {m_{2}}\lambda _{2}}\) success probability. In particular, for m 1=m 2=1 and ν=1, the gCMB distribution reduces to the Bin (s,p) = Bin\(\left (s, \frac {\lambda _{1}}{\lambda _{1}+\lambda _{2}}\right)\) distribution. For the special case where λ 1=λ 2=λ, Eq. (12) reduces to the following for y 1=0,…,s:
i.e. a gCMB(1/2, ν,s,m 1,m 2) distribution. In particular, this implies that
The probability generating function for the gCMB distribution is
where
Parameter estimation and statistical computing
Because m is a natural number, we consider a series of sCMP estimations for a given m, from which we can determine an optimal sCMP(λ,ν,m) model. Given m, estimates for λ and ν are obtained via maximum likelihood estimation (MLE), where we consider the log-likelihood,
for a random sample Y 1,…,Y N , where P(Y i =y i ∣λ,ν,m), i=1,…,N is defined in Eq. (7). Given the complex nature of the log-likelihood function and the corresponding score equations, as well as the constrained parameter space for λ>0 and ν≥0, maximum likelihood estimates are determined via the nlminb function in R (R Core Team 2017) which is used to identify the parameters that minimize the negated log-likelihood function (thus determining the MLE values). Meanwhile, parameter robustness is quantified through the corresponding standard errors for the stated estimates obtained via the information matrix,
where P(Y=y) is defined in Eq. (7). The information matrix is computed (via the hessian function in the numDeriv package (Gilbert and Varadhan 2016) in R (R Core Team 2017)) and inverted, and the square root of the resulting diagonal elements contain the standard errors of the parameter estimates.
Optimal sCMP(λ,ν,m) models are determined by comparing potential conditional sCMP models where m is assumed known and identifying the conditional model with the largest log-likelihood value. Section 5 illustrates this procedure via simulated and real data examples.
Statistical computing for the Poisson and negative binomial distributions are conducted in R (R Core Team 2017) via the function, fitdistr, contained in the MASS package (Venables and Ripley 2002). This package uses an alternative parametrization for the negative binomial model, namely θ=n and \(\mu =\frac {n(1-p)}{p}\), hence we can backsolve for \(p=\frac {\theta }{\mu +\theta }\). Estimates for θ and μ are reported in the discussions provided in Section 5.
Examples
5.1 Simulation study
The sCMP distribution is a generalizable distribution that encompasses five classical distributions: the Bernoulli, binomial, Poisson, geometric, and negative binomial distributions; more broadly, for a general m, the sCMP distribution captures the binomial, Poisson, and negative binomial distributions. To demonstrate this general flexibility, data samples of size 100 were generated from a binomial(b=3, p ∗=0.667), Poisson(μ ∗=6), and negative binomial(n=3, p=0.333) distribution, respectively. To assess model performance, we compare model estimation via the sCMP distribution (assuming m=1,2,3,4) with estimations assuming a Poisson and negative binomial distribution, respectively; the CMP distribution is the sCMP(m=1) case. Table 2 provides the parameter estimates and standard errors associated with the various models considered for model comparisons via the log-likelihood (log(L)), Akaike and Bayes Information Criterions (AIC and BIC), respectively.
For model comparison via AIC, Burnham and Anderson (2002) suggest considering Δ i =AIC i −AIC min, where AIC min is the minimum of the model AIC values being compared, thus infering that the best model has Δ=0 and the other models have Δ>0. Model comparisons are thus determined via these difference measures in that “models having Δ i ≤2 have substantial support (evidence), those in which 4≤Δ i ≤7 have considerably less support, and models having Δ i >10 have essentially no support" in comparison with the best model; see p. 70-71 of Burnham and Anderson (2002). We will apply this approach for model comparison accordingly, and can analogously apply this method using BIC.
The sCMP class of distributions appears to offer a consistent ability to properly model all of the simulated classical data structures. What is interesting to see is the distribution’s resulting parameter estimations as m increases. For the binomial example (i.e. the case of extreme under-dispersion), we see that λ decreases and ν increases for m≤3. While that pattern does not continue for m=4, we see that the log-likelihood value is maximized (and the AIC and BIC values minimized) with the sCMP(m=3) case. We see that the sCMP(\(\hat {\lambda } = 2.0000\), \(\hat {\nu } = 33.6942\), m=3) distribution is the best model, when compared with the other considered distributions. In fact, all other models produce a difference Δ that associates with considerably less support to essentially no support.
The binomial case can be viewed as the summation of three Bernoulli trials, thus we expect the corresponding sCMP estimates to be \(\hat {\lambda } \approx 2\) and \(\hat {\nu } \ge 30\); recall that the special CMP case that corresponds with a Bernoulli distribution occurs when ν→∞ with probability \(\frac {\lambda }{1+\lambda }\), where empirical evidence shows that dispersion parameter estimation is sufficiently achieved when \(\hat {\nu } \approx 30\) or more (see Sellers et al. (2016) and Sellers and Raim (2016) for examples). In fact, for the simulated Binomial dataset, we obtain \(\hat {\lambda } = 2.0000\), \(\hat {\nu } = 33.6942\); the obtained estimate for ν implies extreme under-dispersion, thus we have sufficient evidence implying that the estimates approximate a Bernoulli distribution with success probability, \(\hat {p}_{\ast } = \frac {2.0000}{1 + 2.0000} = 0.6667\). The sCMP(m=3) distribution best models the binomial data, producing the largest log-likelihood (log(L)=−116.2486), and the smallest AIC and BIC (236.4972 and 241.7075, respectively). In comparison, the Poisson and negative binomial models produce comparable log-likelihoods (both that are considerably less than those from the sCMP class) because they are unable to effectively model the under-dispersion present in this dataset. The large negative binomial parameter (\(\hat {\theta } = 276.5396\)) shows that the model is converging to a Poisson model (i.e. towards data equi-dispersion) to estimate this data. While the CMP model is able to recognize the dataset as being under-dispersed (\(\hat {\nu } = 3.3931 > 1\)), the form of the distribution still limits the amount of model flexibility it can address.
For the Poisson example, we see that all of the considered models perform comparably well. While the best model is naturally Poisson, this is true moreso because the distribution only requires estimating one parameter. All of the models considered produced log-likelihoods equalling approximately − 228, thus the associated difference measures imply that the other models (in particular, the sCMP class of distributions) show substantial support for model consideration. The negative binomial estimates (\(\hat {\theta }=239.7812\) and \(\hat {\mu }=6.1100\)) demonstrate the convergence of the negative binomial distribution to the Poisson model as θ→∞ in order to address the limiting case of analyzing equi-dispersed data.
Because the simulation reflects a Poisson(6) dataset, we expect to obtain sCMP parameter estimates \(\hat {\lambda }\approx 6/m\) and \(\hat {\nu }\approx 1\) for all m=1,2,3,4. The obtained estimates for λ and ν are consistently larger than their projected values where \(\hat {\nu }\) increases slightly with m. The corresponding parameter standard errors, however, suggest that none of these estimates is statistically significantly different from their hypothesized values.
For the negative binomial example, we see that the sCMP class of distributions again performs well in estimating the form of the simulated dataset. The true parameter values associated with the negative binomial model imply that \(\mu =\frac {n(1-p)}{p} = 6\) and θ=3. The negative binomial distribution(\(\hat {\theta }=3.5599\), \(\hat {\mu }=5.3001\)) is the best model among the distributions considered (AIC = 521.4971), however, the sCMP class of distributions performs more optimally as m increases (among those values for m considered). Larger values for m were not considered here because the sCMP models for m=3,4 produce approximately equal log-likelihood values, thus likewise producing comparable AIC and BIC values; this makes sense because the negative binomial estimate is \(3< \hat {\theta }=3.5599 <4\). Meanwhile, even for the sCMP models where m=1,2, the difference in AIC when compared with the best model still implies that these models show considerable support.
With the sCMP class of distributions, we see that \(\hat {\nu }\) decreases as m increases. Interestingly here, because we know the data are simulated from a negative binomial(n=3,p=0.333) distribution, we expect the sCMP(m=3) distribution to produce estimates \(\hat {\lambda } = 0.667\) and ν≈0. In fact, the observed estimates (\(\hat {\lambda }=0.6709\) and \(\hat {\nu }=0.0392\)) are within one standard error of the projected estimates. The CMP (i.e. the sCMP(m=1)) model does reasonably well, as evidenced by the resulting log-likelihood and AIC values ( −260.3649 and 524.7298, respectively); the CMP estimated dispersion parameter, \(\hat {\nu } = 0.3150\), indicates recognized over-dispersion in the dataset. The Poisson model is the worst performer (with log(L) = −288.0710) because of its constraining equi-dispersion requirement.
5.2 Under-dispersed real data example: word count
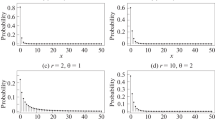
Bailey (1990) studies the frequency of articles in 10-word samples from Macaulay’s “Essay on Milton”, counting the number of occurrences of articles ‘the’, ‘a’, and ‘an’ as a means to infer the author’s style. The provided dataset contains 100 observations where the number of occurrences of these articles in the 10-word samples range from 0 to 3; see Fig. 3.

We consider the Poisson, negative binomial, and sCMP(m) models where m=1,2,3,4 to describe the data distribution; Bailey (1990) previously considered a binomial model to describe the data. Table 3 provides the sCMP parameter estimates and standard errors (in parentheses), along with the log-likelihood, AIC, and BIC values for model comparison. The sCMP(m=2) model is the optimal choice, producing a log-likelihood equaling −117.327, and AIC and BIC equaling 238.6546 and 243.8649, respectively. Because this dataset is under-dispersed (with a sample mean and sample variance equaling 1.05 and 0.654, respectively), all models considered from the sCMP family outperform the Poisson and negative binomial models. The Poisson model produces an estimated sample mean and standard error, 1.0500 (0.1025), with log-likelihood − 123.2741. The negative binomial model meanwhile produces estimates (\(\hat {\theta } = 269.9607\) (702.1046), \(\hat {\mu }=1.0500\) (0.1027), log(L)=−123.3487) comparable to the Poisson. Because the data are under-dispersed, the negative binomial model can only perform as well as the Poisson model. As demonstrated, the estimated size parameter is large and the estimated mean equals that from the Poisson model.
Figure 3 provides the empirical and estimated distributions for this data based on the various considered models, including the estimated binomial frequencies provided in Bailey (1990). This figure confirms the results provided in Table 3, namely that the sCMP(m=2) best represents the shape of the observed distribution for the number of occurrences of an article in 10-word samples from Macaulay’s ‘Essay on Milton’. In particular, we see the small estimated sCMP(m=2) frequency associated with more than 3 articles; recall that the observed number of articles is zero. Meanwhile, the number of occurrences as determined via the Poisson and negative binomial are visibly over- or under-estimated, including a sizable estimated frequency associated with more than 3 articles. The estimated frequencies determined by the binomial distribution, while better than those from the Poisson and negative binomial models, still deviate considerably in comparison to the sCMP class. Finally, while Table 3 shows that the sCMP(m=3) distribution performs comparably well, we nonetheless determine the sCMP(\(\hat {\lambda }=0.9120, \hat {\nu }=3.7750, m=2\)) model to be the best choice to estimate the observed distribution, based on the resulting estimated frequencies shown in Fig. 3.
5.3 Over-dispersed real data example: fetal lamb movement
Guttorp (1995) provides data on the number of movements by a fetal lamb observed by ultrasound and counted in successive 5-second intervals. The dataset contains 225 observations ranging in value from 0 to 7, and are over-dispersed with dispersion index \(\widehat {\text {Var}(Y)}/\widehat {E(Y)}= 0.693/0.382 = 1.8119\); summary information regarding the distribution is provided in Table 4(a). Assuming no knowledge of the data dispersion type, we consider various count data model parameter estimations to describe this real data distribution: Poisson, negative binomial, and sCMP at various levels of m=1,2,3,4. Table 5 provides the resulting estimation output (including the corresponding log-likelihood, AIC, and BIC) associated with the various distributions considered to model the original 5-second movement data summarized in Table 4(a).
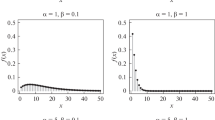
The sCMP class consistently recognizes this real count distribution to be extremely over-dispersed (\(\hat {\nu }=0.000\) and λ<1), implying that the sCMP class interprets the data as being represented as sums of size m from geometrically distributed data with some success probability, \(1-\hat {\lambda }\). In fact, the estimates for λ decrease as m increases yet the corresponding log-likelihood value decreases, thus providing a sense of the contour of the larger log-likelihood space that is determined by λ,ν, and m. Because m is a natural number, we find that the optimal sCMP(m) class for modeling the 5-second fetal lamb dataset occurs for m=1, i.e. the CMP distribution with \(\hat {\lambda }=0.277\) and \(\hat {\nu }=0.000\). Continuing with this logic, however, we recognize then that one should thus consider the special case of a geometric (i.e. the CMP distribution where ν=0) distribution with approximate success probability, \(\hat {p}=1 - 0.277 = 0.723\)). Indeed, estimating the observed count distribution via a geometric model produces the estimated success probability, \(\hat {p}=0.723\) (with standard error, 0.025). While this estimation procedure determines a geometric model to be the best model within the sCMP class, the negative binomial distribution is another viable model, as determined by Burnham and Anderson (2002); see Table 5.
Figure 4 provides a comparison of the empirical versus estimated count distributions associated with the different models. While the negative binomial best fits the observed count distribution, we see that the geometric (\(\hat {p}=0.723\)) (i.e. the sCMP(m=1)/CMP model with \(\hat {\lambda }=0.277\) and \(\hat {\nu }=0.000\)) model likewise performs reasonably. More generally, as m increases, the sCMP class appears to underestimate the number of zeroes and overestimate the number of ones. The estimated frequencies for counts greater than or equal to two, however, appear comparable for all distributions.

To further illustrate the utility of the sCMP family, we consider a condensed representation of the Guttorp (1995) data by summing successive triples of data, thus representing fetal lamb data observed by ultrasound and counted in successive 15-second intervals. Table 4(b) provides the resulting summary information – 75 observations now range in value from 0 to 12, where the dispersion index is now 3.694/1.147 = 3.221, maintaining apparent data over-dispersion. Again, assuming no knowledge regarding the type of the data dispersion, we consider the Poisson, negative binomial, and sCMP distributions at m=1,2,3,4 and estimate the corresponding model parameters via maximum likelihood estimation. Table 6 provides the resulting estimation output (including the corresponding log-likelihood, AIC, and BIC) associated with the various distributions considered to model the 15-second movement data summarized in Table 4(b).
Table 6 again displays an interesting trend with respect to the sCMP class estimators. Again, the estimations for λ decrease as m increases, while the dispersion parameter consistently estimates to be \(\hat {\nu } = 0\) (indicating consideration of an appropriate negative binomial model structure). Further, as m increases, the corresponding log-likelihood associated with each of the models decreases. Hence, the optimal sCMP model is again the CMP model (i.e. sCMP when m=1). Meanwhile, the CMP model with estimated dispersion parameter, \(\hat {\nu }=0\), again suggests to consider a geometric model with success probability \(1-\hat {\lambda } = 0.466\). In fact, the estimated success probability for the geometric model is \(\hat {p}=0.466 \ (0.039)\). The negative binomial model slightly outperforms the CMP model, although both models perform comparably well, based on their respective AIC values (Burnham and Anderson 2002). The slight outperformance in the negative binomial model relative to the CMP/geometric model (based on log-likelihood comparisons) stems from the negative binomial estimation procedure’s allowance for real θ, thus obtaining a more precise estimation of the data over-dispersion. However, because we recognize that this special case of the sCMP class where m=1 and ν=0 corresponds to a geometric model, the geometric model is deemed better than the negative binomial model, given the reduction in the number of estimated parameters and thus the reduced AIC and BIC (224.441 and 226.759 for the geometric model, versus 225.819 and 230.454 for the negative binomial model); see Table 6.
Figure 5 provides a comparison of the empirical versus estimated count distributions for the different models associated with the 15-second fetal lamb data. Here, we can see that the geometric(\(\hat {p}=0.466\)) distribution (i.e. the sCMP(m=1)/CMP model where \(\hat {\lambda }=0.534, \hat {\nu }=0.000\)) best estimates the observed count distribution, given that the geometric model requires only one parameter. Meanwhile, the negative binomial distribution performs comparably well to the geometric/CMP(\(\hat {\nu }=0\)). This makes sense, given the relationship between the geometric and negative binomial distributions. The estimated geometric and negative binomial distributions are so close because the negative binomial size estimate, \(\hat {\theta }=0.767\), is close to one, while the corresponding probability estimate, \(\hat {p}=0.401\), is close to that from the geometric model (\(\hat {p}= 0.466\)).

Notice that sCMP(m=3) parameter estimates associated with the 15-second fetal lamb data equal the sCMP(m=1)/CMP parameter estimates for the 5-second fetal lamb example. This result is logically sound, given the means by which the sCMP distribution is derived; conducting estimations over an interval that is three times its original period is akin to “summing" the three CMP random variables to consider the sCMP model.
This example demonstrates the suitability of the sCMP class to serve as an exploratory tool for count data modeling. For over-dispersed data examples, the negative binomial distribution is generally expected to be a good model to describe the distribution. The sCMP class of distributions contains the negative binomial (and geometric) distribution as a special case; accordingly, it is not necessarily expected for the sCMP distribution to outperform simpler distributions but rather to demonstrate that the sCMP distribution offers insights regarding model considerations. Indeed, applying the sCMP model to these over-dispersed examples motivated consideration of the geometric distribution, which turned out to be an optimal model. Accordingly, while one may not consider the geometric distribution to be a viable model a priori, the sCMP showed why the geometric model is viable.
Discussion
The sum-of-Conway-Maxwell-Poissons (sCMP) class of distributions is a flexible construct for modeling count data that captures several well-known distributions as special cases: the Poisson, negative binomial, binomial, geometric, Bernoulli, and Conway-Maxwell-Poisson (CMP). Just as the CMP distribution bridges the gap between the Poisson, geometric, and Bernoulli distributions through the addition of a dispersion parameter, the sCMP distribution sums over m CMP random variables, producing an encompassing distributional form that has an even greater containment of numerous count distributions.
The provided examples illustrate the flexibility of the sCMP class for handling over- or under-dispersed data. These examples, however, consider only the marginal distribution through unconditional means and variances (and hence unconditional dispersion), thus the true significance of the sCMP class is subdued. In actuality, it is not necessarily straightforward to determine if observed dispersion is true or “apparent". In a regression setting, for example, dispersion is measured via conditional means and variances, and exploratory data analysis may not detect the true complexity of the data (Sellers and Shmueli 2013). Under such circumstances, the sCMP class can aid with detecting dispersion when a more sophisticated approach is required.
As noted in the over-dispersed data example, we are limited in our ability to estimate m because it is a natural number. We opt for this formulation as it holds true to the form that generalizes the construction of the three special case models (negative binomial, Poisson, and binomial) as sums of their respective special case distributions associated with the CMP distribution (namely, the geometric, Poisson, and Bernoulli models). For example, the negative binomial pmf is often described as the probability of observing y failures before the nth success in a series of Bernoulli trials, or as a sum of n geometric random variables. Yet, the negative binomial distribution can alternatively be derived via a Poisson-gamma mixture, in which case the parameter n is a real number. As Hilbe (2008) notes, “there is no compelling mathematical reason to limit this parameter to integers." (page 82). Future work considers broadening the sCMP formulation to likewise allow for real-valued m and any associated implications from such a definition.
While we estimate the standard errors of the parameter estimates via the approximate information matrix as described in Section 4, the sampling distributions associated with λ and ν are known to possess skewness (Sellers and Shmueli 2013). Thus, an alternative approach is non-parametric bootstrapping. To compute parameter estimates and associated variation in this manner, one can (for example) randomly draw 1000 samples with replacement from the data using the boot package (Canty and Ripley 2015) in R (R Core Team 2017).
Change history
16 October 2017
A correction to this article has been published.
References
Bailey, BJR: A model for function word counts. J. R. Stat. Soc. Ser. C. 39(1), 107–114 (1990).
Boatwright, P, Borle, S, Kadane, JB: A model of the joint distribution of purchase quantity and timing. J. Am. Stat. Assoc. 98, 564–572 (2003).
Borges, P, Rodrigues, J, Balakrishnan, N, Bazán, J: A COM-Poisson type generalization of the binomial distribution and its properties and applications. Stat. Probab. Lett. 87, 158–166 (2014).
Borle, S, Boatwright, P, Kadane, JB: The timing of bid placement and extent of multiple bidding: An empirical investigation using ebay online auctions. Stat. Sci. 21(2), 194–205 (2006).
Borle, S, Dholakia, U, Singh, S, Westbrook, R: The impact of survey participation on subsequent behavior: An empirical investigation. Mark. Sci. 26(5), 711–726 (2007).
Burnham, KP, Anderson, DR: Model Selection and Multimodel Inference. Springer, New York (2002).
Canty, A, Ripley, B: Boot: Bootstrap Functions. 1.3-15 edn (2015). http://cran.r-project.org/web/packages/boot/index.html.
Casella, G, Berger, RL: Statistical Inference, Second Edition. Duxbury, Pacific Grove (2002).
Conway, RW, Maxwell, WL: A queuing model with state dependent service rates. J. Ind. Eng. 12, 132–136 (1962).
Gilbert, P, Varadhan, R: NumDeriv: Accurate Numerical Derivatives. 2016.8-1 edn (2016). https://cran.r-project.org/web/packages/numDeriv/index.html.
Guttorp, P: Stochastic Modeling of Scientific Data. Chapman & Hall/CRC, Boca Raton (1995).
Hilbe, JM: Negative Binomial Regression. Cambridge University Press, United Kingdom (2008).
Kadane, JB, Krishnan, R, Shmueli, G: A data disclosure policy for count data based on the COM-Poisson distribution. Manag. Sci. 52(10), 1610–1617 (2006).
Kadane, JB: Sums of possibly associated Bernoulli variables: The Conway-Maxwell-Binomial distribution. Bayesian Anal. 11(2), 403–420 (2016).
Lord, D, Guikema, SD, Geedipally, SR: Application of the Conway-Maxwell-Poisson generalized linear model for analyzing motor vehicle crashes. Accid. Anal. Prev. 40(3), 1123–1134 (2008).
Minka, TP, Shmueli, G, Kadane, JB, Borle, S, Boatwright, P: Computing with the COM-Poisson distribution. Technical Report 776, Dept. of Statistics, Carnegie Mellon University (2003). http://www.stat.cmu.edu/tr/tr776/tr776.pdf.
R Core Team: R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna (2017). https://www.R-project.org/.
Saghir, A, Lin, Z: Cumulative sum charts for monitoring the COM-Poisson processes. Comput. Ind. Eng. 68, 65–77 (2014).
Saghir, A, Lin, Z: A flexible and generalized exponentially weighted moving average control chart for count data. Qual. Reliab. Eng. Int. 30(8), 1427–1443 (2014).
Sellers, KF, Shmueli, G, Borle, S: The COM-Poisson model for count data: a survey of methods and applications. Appl. Stoch. Model. Bus. Ind. 28, 104–116 (2011).
Sellers, K: A distribution describing differences in count data containing common dispersion levels. Adv. Appl. Stat. Sci. 7(3), 35–46 (2012).
Sellers, KF, Shmueli, G: A regression model for count data with observation-level dispersion. In: Booth, JG (ed.) Proceedings of the 24th International Workshop on Statistical Modelling, pp. 337–344. Cornell University Press, Ithaca (2009).
Sellers, KF, Shmueli, G: Data dispersion: Now you see it... now you don’t. Commun. Stat. Theory Methods. 42, 1–14 (2013).
Sellers, KF: A generalized statistical control chart for over- or under-dispersed data. Qual. Reliab. Eng. Int. 28(1), 59–65 (2012).
Sellers, KF, Raim, A: A flexible zero-inflated model to address data dispersion. Comput. Stat. Data Anal. 99, 68–80 (2016).
Sellers, KF, Shmueli, G: A flexible regression model for count data. Ann. Appl. Stat. 4(2), 943–961 (2010).
Sellers, KF, Morris, DS, Balakrishnan, N: Bivariate Conway-Maxwell-Poisson distribution: Formulation, properties, and inference. J. Multivar. Anal. 150, 152–168 (2016).
Shmueli, G, Minka, TP, Kadane, JB, Borle, S, Boatwright, P: A useful distribution for fitting discrete data: revival of the Conway-Maxwell-Poisson distribution. Appl. Stat. 54, 127–142 (2005).
Venables, WN, Ripley, BD: Modern Applied Statistics with S. 4th edn. Springer, New York (2002).
Wimmer, G, Köhler, R, Frotjahn, R, Altmann, G: Towards a theory of word length distribution. J. Quant. Linguist. 1(1), 98–106 (1994).
Zhu, L, Sellers, KF, Morris, DS, Shmuéli, G: Bridging the gap: A generalized stochastic process for count data. Am. Stat. 71(1), 71–80 (2017).
Acknowledgements
Support for Kimberly Sellers was provided in part by the American Statistical Association (ASA)/National Science Foundation (NSF)/Census Research Program, U. S. Census Bureau Contract #YA1323-14-SE-0122. Support for Andrew W. Swift was provided by a grant from the Simons Foundation (#359536). Support for Kimberly S. Weems was provided in part by the NSF grant #1700235. The authors thank the reviewers and Drs. Darcy S. Morris (U.S. Census Bureau) and Derek Young (University of Kentucky) for helpful comments regarding the manuscript.
Author information
Authors and Affiliations
Contributions
KFS conceived the study. KFS, AS, and KSW contributed to statistical methods and computational development, and analyses. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional information
The original version of this article was revised: following publication the authors reported that the typesetters had misinterpreted some of the edits included in their proof corrections, namely instances of “sp” to denote that an extra space was required.
A correction to this article is available online at https://doi.org/10.1186/s40488-017-0078-z.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Sellers, K.F., Swift, A.W. & Weems, K.S. A flexible distribution class for count data. J Stat Distrib App 4, 22 (2017). https://doi.org/10.1186/s40488-017-0077-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40488-017-0077-0
Keywords
- Conway-Maxwell-Poisson (CMP)
- Negative binomial
- Poisson
- Binomial
- Geometric
- Bernoulli
- Over-dispersion
- Under-dispersion