
Abstract
Embracing the complexity of biological systems has a greater likelihood to improve prediction of clinical drug response. Here we discuss limitations of a singular focus on genomics, epigenomics, proteomics, transcriptomics, metabolomics, or phenomics—highlighting the strengths and weaknesses of each individual technique. In contrast, ‘systems biology’ is proposed to allow clinicians and scientists to extract benefits from each technique, while limiting associated weaknesses by supplementing with other techniques when appropriate. Perfect predictive modeling is not possible, whereas modeling of intertwined phenomic responses using genomic stratification with metabolomic modifications may greatly improve predictive values for drug therapy. We thus propose a novel-integrated approach to personalized medicine that begins with phenomic data, is stratified by genomics, and ultimately refined by metabolomic pathway data. Whereas perfect prediction of efficacy and safety of drug therapy is not possible, improvements can be achieved by embracing the complexity of the biological system. Starting with phenomics, the combination of linking metabolomics to identify common biologic pathways and then stratifying by genomic architecture, might increase predictive values. This systems biology approach has the potential, in specific subsets of patients, to avoid drug therapy that will be either ineffective or unsafe.
Similar content being viewed by others

Introduction
Recent advances in genomics, epigenomics, transcriptomics, proteomics, metabolomics, and phenomics have allowed identification of certain factors associated with variable drug responses. However, with few exceptions, high-fidelity prediction of drug efficacy and safety on a larger scale has proven elusive. We have experienced many failures with pharmacogenetic attempts to predict success of drug therapy; this is due to insufficient knowledge and oversimplification of experimental approaches, as well as failure to accept that even the simplest traits almost always reflect an intersection of multiple genetic, epigenetic, and environmental factors. Therefore, we make an argument for embracing complexity. Starting with a clinically relevant trait—the individual patient drug response, which we refer to as ‘phenotype’—and then working backward to integrate biological data, is more likely to identify common pathways and inter-individual variability between patient responses. We propose that this integrated-systems biology approach, focused on drug response and adverse drug reactions (ADRs), might be the best way to improve drug efficacy and safety.
Limitations of single biological associations
‘Personalized medicine’ has endured many failures. Clinical phenotype of complex diseases (defined as any biological, physiological, morphological, or behavioral trait) is difficult to predict because most common diseases represent multifactorial traits.
Use of pharmacogenomics in predicting drug efficacy or toxicity is more advanced in oncology than perhaps in any other area of medicine. A high degree of efficacy and toxicity can be predicted for chemotherapeutic agents in cancer, based partially upon patient and tumor genotyping. For example, 5-fluorouracil toxicity is associated with dihydropyrimidine dehydrogenase polymorphisms [1],[2], erlotinib [3] or cetuximab [4] responsiveness is linked to epidermal growth factor receptor polymorphisms, and there are other examples [5]. However, because tumor cells mutate or the patient develops associated co-morbidities (e.g. renal failure, pulmonary hypertension), then efficacy and toxicity remain difficult to predict. Focusing on a single biological association can sometimes efficiently predict drug response within a subset of a large cohort of patients, but rarely, if ever, can we expect to predict drug response in the individual patient [6].
Genotype-phenotype associations
Virtually, all clinical traits are polygenic, raising the number of potential phenotypes factorially; even the simplest genetic predictors lead to a range of phenotypes. This was demonstrated in 1960 when the earliest pharmacogenomic association of polyneuropathy with slow acetylation of isoniazid by N-acetyltransferase-2 (NAT2) was reported [7]. Not all individuals with the slow-acetylator trait develop neuropathy, and there remains a range of serum drug concentrations within each group of NAT2 genotypes. Currently, at least 190 different NAT2 alleles have been identified, and these polymorphisms result in a large range from “no effect”, to slow, to very efficient acetylation [8]. In addition, NAT2 performs AcCoA-dependent O-acetylation of N-hydroxyarylamines and AcCoA-independent N,O-acetylation of N-hydroxy-N-acetylarylamines, which suggests a pleiotropic effect of this polymorphism, likely contributing to variable penetrance of the phenotype [9]. Prediction of the expressed phenotype is more complex than initially appreciated, due to the wide range of downstream modifications and environmental factors that can function to alter expression of the underlying genetic code—leading to the ultimate biological response.
If prediction of success is defined as ‘high positive and high negative predictive value of the test’, then all single biological associations have failed miserably. Strong biological associations can be made in small homogenous cohorts; in larger, more diverse populations, however, these associations are inevitably poor predictors of phenotype.
The literature is replete with examples of small cohort or observational studies, later shown in larger prospective trials to be poorly predictive; CYP2C9 and vitamin K oxidoreductase complex subunit-1 (VKORC1) polymorphism-guided warfarin anticoagulation is foremost among such examples. Several early studies demonstrated benefit to CYPC9 and VKORC1 genotyping for prediction of ‘time in the therapeutic window’ and ‘dose’ of warfarin [9]–[12]. These correlations did not hold up in larger randomized controlled trials [13]–[15].
Genome-wide association studies
Genome-wide association (GWA) studies have demonstrated a strong association between HLA-B*1502 and carbamazepine-associated Stevens-Johnson Syndrome and toxic epidermal necrolysis in Asian [16], but not in European populations [17]. The epigenomic drug vorinostat, a histone deacetylatase inhibitor, was initially found to profoundly decrease lymphoid proliferation in human cell lines [18], but demonstrated only a 30% response rate in a small cohort, prior to US FDA approval for cutaneous T-cell lymphoma [19]. Initial studies had suggested that transcriptomic screening for rejection following cardiac transplantation might be more sensitive than endomyocardial biopsy [20]. In a larger prospective trial, fewer biopsies were necessary in transcriptome-tested patients, although this did not eliminate the need for biopsy and only 6 of 34 rejection episodes were identified by the gene profiling test [21].
Testing for such single biological associations is therefore clinically impractical, due to such poor predictive values. Single biological associations should not be viewed as predictive; failure should be expected because of the extraordinarily large number of steps required to yield a phenotype after drug ingestion [5],[6],[22],[23]. Specifically, the amount of drug absorbed may vary due to intestinal metabolism or disease, unpredictable hepatic blood flow can change the rate that enzymes metabolize the drug, polymorphisms in transporters and metabolic enzymes can lead to variable amounts of drug delivered to the systemic circulation, the drug must be transported to the site-of-action, and the site-of-action itself may be altered by polymorphisms en route to the observed clinical response, and the rate of elimination may be variable due to altered renal clearance [5]. This is further complicated in multifactorial traits, which increase potential phenotypic variability.
Starting with phenomics
Phenomics, defined as the unbiased study of a large number of expressed traits across a population, is the logical starting point for biological association studies. Traditional biological experiments, such as GWA studies, begin with the investigator selecting a phenotype and then attempting to associate biological differences within a population. Significant resources have been devoted to characterize the individual patient’s whole genome, epigenome, transcriptome, proteome, metabolome, as well as gut microbiome. This approach has been robust; GWA studies have identified more than 4,000 polymorphisms linked to more than 500 clinical traits [24]. Unfortunately, it remains possible that identified single-nucleotide variants (SNVs) are not the causative factor but rather are associated with some additional metabolic factor that is polygenic. This effect-modification phenomenon has been recognized for decades in epidemiologic studies [25].
Ultimately, the unequivocal phenotype is what patients and clinicians wish to predict. Therefore, studies should shift focus away from these single biological associations that are only statistically associated with a phenotype when studying a large cohort, to an approach that characterizes the biologic system starting with phenotypic variables. Initiating analysis from a wide number of characterized traits [termed phenome-wide association (PheWA) studies] allows the investigator to see the intertwined biological processes leading all the way back to genetic associations.
Phenomics captures pleiotropic associations (genes associated with several traits) that are often overlooked [26]. Examples include HLA8.1 association with both myasthenia gravis and thymus hyperplasia [27] (and likely other autoimmune diseases), as well as lipid-gene associations with plasma glucose and insulin resistance [28]. Whereas two traits may both be associated with the same SNV, this association does not provide unequivocal information about the relationship between the traits.
Some traits may be the direct result of SNVs while others are secondarily associated, thereby confounding the relationship. The aldehyde dehydrogenase-2 (ALDH2) Glu504Lys polymorphism is a classic example of this phenomenon; this amino-acid change is associated with a disulfiram-like reaction in Asians [29], one of the strongest genotype-phenotype associations. This polymorphism can also be associated with alcohol intolerance, but this is not the causal phenotype of the ALDH2 polymorphism. Instead, a decrease in ALDH2-dependent metabolism is the associated phenotype, and decreased tolerance is likely due to the unpleasant disulfiram-like reaction rather than an inability to develop alcohol tolerance [30]. The clinically-relevant phenotype of alcohol intolerance may be modified by co-linearity with other metabolism enzyme gene polymorphisms such as CYP2E1[31],[32], with genotypic factors dictating body mass index [33], and/or with addictive behaviors [34].
Examination of a wide range of phenotypes can identify which pathways are causal, and which are secondary effects. Specialized analysis techniques for PheWA studies must be utilized because phenomic data structure varies significantly, comprising binary as well as continuous variables when compared with other large datasets such as GWA studies [35],[36]. At present, we are not aware of any phenomics studies that have been applied to drug therapy, although we predict this will happen soon. Detailed electronic medical record (EMR) data will allow for large-scale phenomic studies, when paired with GWA studies or other biological databases [37].
Phenomics demands a systems biology approach. Phenotypes must be associated with biological pathways, which in turn reflect genomic architecture. For example, a systems biology approach, starting with the trait ‘sepsis survival’, has identified new metabolic pathways characterizing survival [38]. This breakthrough gives us a more comprehensive understanding of the metabolite markers of survival as well as numerous genetic contributors, thereby permitting identification of biomarkers and potential therapeutic targets. Lack of a full understanding of all involved biological pathways can lead to false prioritization of phenotypes. For example, for years, the ‘cataplexy’ phenotype in rodents was targeted for the development of neuropsychiatric drugs. Unfortunately, this narrow focus appears to have led to the development of more drugs that produce extrapyramidal symptoms than provide antipsychotic efficacy [39].
Adding metabolomics to your arsenal
Metabolomics is the study of small molecules in biologic fluids or tissues. This methodology has been used to discover metabolites that act as diagnostic tools for a growing number of medical conditions. For example, metabolite profiles from human tissue, urine and plasma accurately predicted differentiated benign prostate hypertrophy from clinically-localized prostate cancer and metastatic disease [40]. In this case, complex and overlapping clinical phenotypes are tightly correlated with specific changes in metabolite homeostasis, which could then be further segregated into precise, distinguishable disease states. A similar scenario has been seen for metabolomic studies of ovarian cancer progression [41]. Moreover, urinary and serum biomarkers may also serve as a non-invasive and rapid means of identifying and monitoring phenotype-metabotype relationships during the onset and progression of disease [42],[43]. Performed in an unbiased manner, addition of metabolomics to systems biology has provided insight into gene networks, resultant metabolic changes, and genotype-phenotype relationships [44]. These studies highlight the need for unbiased metabolomics to link phenomic data with genomic data.
Metabolomics: linking genomics with phenomics
Small molecules identified by metabolomics represent the substrates, intermediates, and products of all biochemical pathways. Consequently, this technique represents an integrated snapshot-in-time of all upstream biologic processes, ultimately leading to a clinical phenotype. Therefore, the metabolome may be the closest biological representation of a clinical trait. Indeed, metabolomics has identified possible biomarkers for cardiac [45], kidney [46], liver [47], and gastrointestinal [48] diseases, as well as many other pathophysiological conditions.
Metabolomics profiling is incredibly sensitive and can detect femtomolar to attomolar changes in metabolite concentrations [49]. Anything from small dietary changes, increased physical activity, elevated stress, or even seasonal variables can significantly alter the composition of metabolomic profiles. This profound sensitivity has obvious advantages: small metabolomic changes can account for complex physiological changes. However, because of increased sensitivity, specificity may be sacrificed, thus decreasing the predictive value of the test.
In some cases, large metabolic changes are able to maintain stability of a clinical trait; these findings can identify potential areas of metabolic decompensation. For instance, elevated lactate is a marker of impaired gluconeogenesis, as are increased concentrations of other gluconeogenic substrates, such as pyruvate and alanine, which are preferentially metabolized to lactate [50],[51]. Mildly elevated levels of these metabolites are not clinically significant, but instead represent compensated buffer activity. If further stress is placed on the system, lactic acid itself can overwhelm the buffered system and lead to decompensated metabolic acidosis with high mortality [52]. Metabolic changes, such as lactic acidosis, can be the result of numerous upstream responses; post-exposure monitoring may predict severe disease processes and ADRs prior to phenotypic manifestation.
Therefore, the metabolome may be viewed as an overly sensitive tool with insight into adaptive physiology [53]. This sensitivity can serve to identify a wider range of genomic polymorphisms that contribute to expressed phenotypes, even if only under specific circumstances. Unbiased metabolomics has identified novel pathways in hypertension that include microbiome associations and sex steroid mediators previously not appreciated to contribute to the hypertensive phenotype [54]. Metabolomics identified the mechanism of anti-retroviral drug interaction mediated by the CYP3A4 enzyme through newly recognized enzymatic functions [55]. These mechanisms have implications for choosing drug therapy in HIV patients. The presence of five amino acids was correlated with the development of diabetes as well as an insulin-resistant phenotype in a cohort of initially normoglycemic patients followed for 12 years [56]. Similar findings identified new pathways in insulin resistance identified by the oral glucose tolerance test [57]. Metabolomics was able to predict poor response to insulin; thus, metabolomics has potential to predicting development of disease and therapeutic success [58]. Metabolomics can be a powerful tool to elucidate complex mechanisms of drug-modified clinical traits [59].
Genomic architecture
Despite the claim that pharmacogenetics has ‘at best, a marginal benefit’ [60], genetics represents a constant in any biological system on which we can build models and stratify expected phenotypes. As noted above, limitations of GWA studies must be recognized, but stratification of clinical traits can be accomplished with a systems biology approach. Pharmacogenetics may allow stratification of starting doses for drugs and identification of patients who are unlikely to respond at the recommended prescribed dose or who are at risk for serious ADRs.
Elucidation of such ‘extreme discordant phenotypes’ (EDPs) [61] is useful to physicians because EDP methodology can lead to decreased healthcare expense and lower patient morbidity. Seventy-four percent of all physician office visits involve drug therapy. In 2008, prescriptions accounted for $234.1 billion in patient costs [62]. Forty-eight percent of people in the USA take at least one prescription; more than 76% of people 60 years and older take two or more [62]–[64]. Despite the remarkable number of prescribed drugs, many of these medications are ineffective. For instance, hypertension is the most common chronic disease in the USA, yet 64% of patients receiving antihypertensive therapy fail to achieve blood pressure control [65]. Another factor beyond the scope of this review is the issue of ‘non-compliance’: the patient failing to adhere to his prescribed drug regimen. Non-compliance can easily be misinterpreted by the investigator as drug failure, thereby leading to increased ‘noise’ in any study of genotype-phenotype associations [6]. This confounder can be addressed by metabolomic screening to confirm drug ingestion [66].
If patients can be stratified with an EDP approach and clinical phenotypes modeled using sensitive metabolomics, it may be possible to reduce the number of office visits for ineffective therapy or ADRs. However, virtually, all clinical traits are multifactorial, with each haplotype contributing only a small fraction (0.1%–0.0001%) to the ultimate phenotype. For example, in a GWA study of almost 184,000 subjects, 180 loci associated with ‘height’ as the trait were identified; however, these loci together contributed only approximately 10% to variation in the phenotype [67]. This underscores the need to account for downstream modifying factors, and to assess the individual as a sum of his phenotypic parts.
Another major problem in all genotype-phenotype association studies is that our present-day methods can capture only additive genetic variance, which probably accounts for 70%–80% of heritability for any multifactorial trait. The remaining 20%–30% represents non-additive genetic variance. At this time, we have no methodology for finding this ‘missing heritability’ [cf.[68],[69] for further details].
Triangulating phenomics with genomics and metabolomics
Combining metabolomic and GWA databases has resulted in identification of new biological pathways in cardiovascular, kidney disorders, type-2 diabetes, cancer, gout, venous thromboembolism, and Crohn’s disease [70]. Phenomics has not yet been overlaid upon these analyses. Thus, important pleiotropic clinical traits with common biological pathways remain to be discovered.
By viewing each phenotype as a node within a systems biology model, linked by metabolic pathways and dictated by genetic architecture, we can more fully understand the relationship between biological processes that result in variable clinical traits. Proof of this concept has been demonstrated in the KORA F4 cohort that identified several SNVs associated with type-2 diabetes by way of metabolomics association studies [71]. Preliminary metabolomic studies have also proved useful in helping to differentiate phenotypically heterogeneous disorders, such as Parkinson’s disease (PD). PD can present as either slowly or rapidly progressive forms, which can be distinguished early by comparing metabolite profiles. Identified metabolites might subsequently be used to shed light on the underlying metabolic abnormalities and pathway perturbations driving phenotypic variation [72]. Only by embracing the complexity of the biological system can we improve predictive accuracy.
Combining transcriptomics and metabolomics
Other methodologies will undoubtedly need to be integrated. For instance, transcriptome analysis using RNA sequencing (RNA-seq) can be used to quantitatively identify global changes in gene expression in tissues and serum. Integration of transcriptomics and metabolomics data allows accurate identification of genes and enzymatic pathways driving downstream alterations in metabolite distribution, production, and degradation. These data can provide profound insight into a given phenotype by positioning biochemical compounds within metabolic pathways as substrates, intermediates or products. In addition, compensatory mechanisms can be identified during pathway analysis and help explain the absence of an expected phenotype. Integration of transcriptomics-metabolomics data provides a means to track how metabolic pathways change, in response to disease and/or therapy, and then directly tie those alterations with phenotypic outcomes.
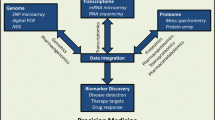
Multilayer systems biology is still an emerging field, but initial studies using combined transcriptomics and metabolomics data look promising with regard to identifying phenotype-genotype-metabotype relationships (Figure 1), including those observed during pancreatic cancer progression, melanoma response to chemotherapy, as well as others [73]–[77].

Illustration of an integrated systems biology approach to improve drug therapy. Using phenomics to fully characterize clinical traits associated with drug therapy. When combined with metabolomics, common biological pathways can be identified, providing insight into mechanisms of efficacy and safety. When phenomic data associated with genomics data are also combined, pleiotropic associations can be further identified and contribute to our understanding of underlying biological pathways. Other techniques, such as RNA-seq, can be integrated to add depth to the pathway data and supplement our understanding of genomic expression.
Technically, the biggest bottleneck confronting the utilization of extremely large combined datasets is the difficulty in analysis and processing bioinformatics. In other words, there can be drawbacks to adding too much data. We will likely experience an ‘hourglass effect’ as we integrate more variables into predictive models. Initially, more data may improve such a model. As too many factors become integrated into the model, overfitting becomes problematic and the model becomes inherently unstable, sacrificing predictive accuracy. This phenomenon has been well documented in climate modeling. This argues for simplification of the model variables at points distant from the phenotypic outcome, as well as elimination of factors that contribute only marginally. New software systems, such as GenAMAP have been developed specifically for this purpose. GenAMAP allows for integration of genomics, transcriptomics, and phenomics data accounting for differences in dataset structure when one uses multivariate structured association-mapping algorithms [78].
A clinical example
Ideally, the approach starts with phenomics, then is stratified by genetic associations, and finally, further refined with metabolomic associations. This will require following thousands of patients with full characterization of biological samples and clinical outcomes for every commonly prescribed drug. For example, if we consider hydrocodone efficacy and safety phenotypes, we can build a model based on genetics/genomics and metabolomics factors. Consider patients given 10 mg of hydrocodone with careful characterization of phenotypic clinical responses and ADRs (Figure 2). Adding RNA-seq transcriptomic data from serum may allow determination of human opioid mu-1 receptor expression (OPRM1), which would differentiate chronic users from naïve users. Metabolomic analysis in pre- and post-drug-challenged patients may identify factors associated with efficacy, ADR phenotypes, and genetic architecture known to be associated with hydrocodone variability in response. Clinical responses can be stratified by genetic factors such as CYP2D6 polymorphisms, principle metabolic pathways for hydrocodone activation associated with active drug levels [79], the multi-drug resistance transporter-1 (MDR1; official name ABCB1) that transports many opioid drugs [80], and OPRM1, in which 118A/A homozygous patients exhibit a correlation with hydrocodone pain relief [81]. Again, metabolomics associations may provide markers of these polymorphisms and identify the pertinent pathways involved, as well as new previously unrecognized pathways that might serve to identify additional associations.

A clinical example of the proposed integrated method for predicting drug response. (1) Patients are given 10 mg of hydrocodone. (2) Clinical phenotypes are captured fully and completely. These may include (among others) development of ADRs, chronicity of treatment, ethnic differences, and demographic factors. (3) Association studies may contribute to characterization of the clinical phenotypes (e.g. RNA-sequencing may help distinguish chronicity of treatment). (4) The drug response is categorized into phenotypically pertinent groups. (5) Relevant biological pathways are identified and linked by individual metabolomic markers. (6) Stratification of drug response is refined by accounting for biological pathway polymorphisms and controlled for phenotypic variables captured in #2 above. (7) The final stepwise model is built, allowing for a high, although not perfect, receiver operating characteristic (ROC).
Ultimately, this stratification of data can be distilled into an integrated model using programs that raise the receiver operator characteristic (ROC) curve for determining rate of efficacy and risk of ADRs. Some clinical factors may contribute to the ultimate drug-response phenotype, to varying degrees between patients. For instance, stomach acidity may affect drug dissolution; this complex trait (among other factors) can be influenced by inter-individual gene expression, concomitant drug therapy, and even the time of the day. Consequently, it should be obvious that specific factors may contribute significantly to the ultimate phenotype in some patients, provide only a minor contribution in others, and only contribute under certain circumstances (e.g. suppression of stomach acid with a proton pump inhibitor), in a third group. Because many of these complex relationships are present in each drug-patient interaction, a perfect predictive model will never be possible.
Conclusions
Whereas perfect prediction of efficacy and safety of drug therapy is not possible, improvements can be achieved by embracing the complexity of the biological system. Starting with phenomics, linking metabolomics to identify common biologic pathways, and stratifying by genomic architecture—this combination can increase predictive values. We believe that this systems biology approach has the potential to eliminate drug therapy that will either be ineffective or unsafe, in specific subsets of patients.
References
Ciaparrone M, Quirino M, Schinzari G, Zannoni G, Corsi DC, Vecchio FM, Cassano A, La Torre G, Barone C: Predictive role of thymidylate synthase, dihydropyrimidine dehydrogenase and thymidine phosphorylase expression in colorectal cancer patients receiving adjuvant 5-fluorouracil. Oncology. 2006, 70: 366-377. 10.1159/000098110.
Lee A, Ezzeldin H, Fourie J, Diasio R: Dihydropyrimidine dehydrogenase deficiency: impact of pharmacogenetics on 5-fluorouracil therapy. Clin Adv Hematol Oncol. 2004, 2: 527-532.
Gaughan EM, Costa DB: Genotype-driven therapies for non-small cell lung cancer: focus on EGFR, KRAS and ALK gene abnormalities. Ther Adv Med Oncol. 2011, 3: 113-125. 10.1177/1758834010397569.
Cappuzzo F, Finocchiaro G, Rossi E, Janne PA, Carnaghi C, Calandri C, Bencardino K, Ligorio C, Ciardiello F, Pressiani T, Destro A, Roncalli M, Crino L, Franklin WA, Santoro A, Varella-Garcia M: EGFR FISH assay predicts for response to cetuximab in chemotherapy refractory colorectal cancer patients. Ann Oncol. 2008, 19: 717-723. 10.1093/annonc/mdm492.
Monte AA, Heard KJ, Vasiliou V: Prediction of drug response and safety in clinical practice. J Med Toxicol. 2012, 8: 43-51. 10.1007/s13181-011-0198-7.
Nebert DW, Zhang G, Vesell ES: From human genetics and genomics to pharmacogenetics and pharmacogenomics: past lessons, future directions. Drug Metab Rev. 2008, 40: 187-224. 10.1080/03602530801952864.
Evans DA, Manley KA, Mc KV: Genetic control of isoniazid metabolism in man. Br Med J. 1960, 2: 485-491. 10.1136/bmj.2.5197.485.
McDonagh EM, Boukouvala S, Aklillu E, Hein DW, Altman RB, Klein TE: PharmGKB summary: very important pharmacogene information for N-acetyltransferase 2. Pharmacogenet Genomics. 2014, 24: 409-425.
Anderson JL, Horne BD, Stevens SM, Grove AS, Barton S, Nicholas ZP, Kahn SF, May HT, Samuelson KM, Muhlestein JB, Carlquist JF: Randomized trial of genotype-guided versus standard warfarin dosing in patients initiating oral anticoagulation. Circulation. 2007, 116: 2563-2570. 10.1161/CIRCULATIONAHA.107.737312.
Burmester JK, Berg RL, Yale SH, Rottscheit CM, Glurich IE, Schmelzer JR, Caldwell MD: A randomized controlled trial of genotype-based Coumadin initiation. Genet Med. 2011, 13: 509-518. 10.1097/GIM.0b013e31820ad77d.
Caraco Y, Blotnick S, Muszkat M: CYP2C9 genotype-guided warfarin prescribing enhances the efficacy and safety of anticoagulation: a prospective randomized controlled study. Clin Pharmacol Ther. 2008, 83: 460-470. 10.1038/sj.clpt.6100316.
Wang M, Lang X, Cui S, Fei K, Zou L, Cao J, Wang L, Zhang S, Wu X, Wang Y, Ji Q: Clinical application of pharmacogenetic-based warfarin-dosing algorithm in patients of Han nationality after rheumatic valve replacement: a randomized and controlled trial. Int J Med Sci. 2012, 9: 472-479. 10.7150/ijms.4637.
Kimmel SE, French B, Kasner SE, Johnson JA, Anderson JL, Gage BF, Rosenberg YD, Eby CS, Madigan RA, McBane RB, Abdel-Rahman SZ, Stevens SM, Yale S, Mohler ER, Fang MC, Shah V, Horenstein RB, Limdi NA, Muldowney JA, Gujral J, Delafontaine P, Desnick RJ, Ortel TL, Billett HH, Pendleton RC, Geller NL, Halperin JL, Goldhaber SZ, Caldwell MD, Califf RM, et al: A pharmacogenetic versus a clinical algorithm for warfarin dosing. N Engl J Med. 2013, 369: 2283-2293. 10.1056/NEJMoa1310669.
Pirmohamed M, Burnside G, Eriksson N, Jorgensen AL, Toh CH, Nicholson T, Kesteven P, Christersson C, Wahlstrom B, Stafberg C, Zhang JE, Leathart JB, Kohnke H, Maitland-van der Zee AH, Williamson PR, Daly AK, Avery P, Kamali F, Wadelius M: A randomized trial of genotype-guided dosing of warfarin. N Engl J Med. 2013, 369: 2294-2303. 10.1056/NEJMoa1311386.
Verhoef TI, Ragia G, de Boer A, Barallon R, Kolovou G, Kolovou V, Konstantinides S, Le Cessie S, Maltezos E, van der Meer FJ, Redekop WK, Remkes M, Rosendaal FR, van Schie RM, Tavridou A, Tziakas D, Wadelius M, Manolopoulos VG, Maitland-van der Zee AH: A randomized trial of genotype-guided dosing of acenocoumarol and phenprocoumon. N Engl J Med. 2013, 369: 2304-2312. 10.1056/NEJMoa1311388.
Chung WH, Hung SI, Hong HS, Hsih MS, Yang LC, Ho HC, Wu JY, Chen YT: Medical genetics: a marker for Stevens-Johnson syndrome. Nature. 2004, 428: 486-10.1038/428486a.
McCormack M, Alfirevic A, Bourgeois S, Farrell JJ, Kasperaviciute D, Carrington M, Sills GJ, Marson T, Jia X, de Bakker PI, Chinthapalli K, Molokhia M, Johnson MR, O’Connor GD, Chaila E, Alhusaini S, Shianna KV, Radtke RA, Heinzen EL, Walley N, Pandolfo M, Pichler W, Park BK, Depondt C, Sisodiya SM, Goldstein DB, Deloukas P, Delanty N, Cavalleri GL, Pirmohamed M: HLA-A*3101 and carbamazepine-induced hypersensitivity reactions in Europeans. N Engl J Med. 2011, 364: 1134-1143. 10.1056/NEJMoa1013297.
Sakajiri S, Kumagai T, Kawamata N, Saitoh T, Said JW, Koeffler HP: Histone deacetylase inhibitors profoundly decrease proliferation of human lymphoid cancer cell lines. Exp Hematol. 2005, 33: 53-61. 10.1016/j.exphem.2004.09.008.
Mann BS, Johnson JR, He K, Sridhara R, Abraham S, Booth BP, Verbois L, Morse DE, Jee JM, Pope S, Harapanhalli RS, Dagher R, Farrell A, Justice R, Pazdur R: Vorinostat for treatment of cutaneous manifestations of advanced primary cutaneous T-cell lymphoma. Clin Cancer Res. 2007, 13: 2318-2322. 10.1158/1078-0432.CCR-06-2672.
Horwitz PA, Tsai EJ, Putt ME, Gilmore JM, Lepore JJ, Parmacek MS, Kao AC, Desai SS, Goldberg LR, Brozena SC, Jessup ML, Epstein JA, Cappola TP: Detection of cardiac allograft rejection and response to immunosuppressive therapy with peripheral blood gene expression. Circulation. 2004, 110: 3815-3821. 10.1161/01.CIR.0000150539.72783.BF.
Pham MX, Teuteberg JJ, Kfoury AG, Starling RC, Deng MC, Cappola TP, Kao A, Anderson AS, Cotts WG, Ewald GA, Baran DA, Bogaev RC, Elashoff B, Baron H, Yee J, Valantine HA: Gene-expression profiling for rejection surveillance after cardiac transplantation. N Engl J Med. 2010, 362: 1890-1900. 10.1056/NEJMoa0912965.
Monte AA, Vasiliou V, Heard KJ: Omics screening for pharmaceutical efficacy and safety in clinical practice.J Pharmacogenomics Pharmacoproteomics 2012, S5.,
Nebert DW, Jorge-Nebert L, Vesell ES: Pharmacogenomics and “individualized drug therapy”: high expectations and disappointing achievements. Am J Pharmacogenomics. 2003, 3: 361-370. 10.2165/00129785-200303060-00002.
A catalog of published genome wide association studies. [], [http://www.genome.gov/page.cfm?pageid=26525384&clearquery=1#result_table]
Davis CE: The effect of regression to the mean in epidemiologic and clinical studies. Am J Epidemiol. 1976, 104: 493-498.
Wagner GP, Kenney-Hunt JP, Pavlicev M, Peck JR, Waxman D, Cheverud JM: Pleiotropic scaling of gene effects and the ‘cost of complexity’. Nature. 2008, 452: 470-472. 10.1038/nature06756.
Vandiedonck C, Beaurain G, Giraud M, Hue-Beauvais C, Eymard B, Tranchant C, Gajdos P, Dausset J, Garchon HJ: Pleiotropic effects of the 8.1 HLA haplotype in patients with autoimmune myasthenia gravis and thymus hyperplasia. Proc Natl Acad Sci U S A. 2004, 101: 15464-15469. 10.1073/pnas.0406756101.
Li N, van der Sijde MR, Study LC, Bakker SJ, Dullaart RP, van der Harst P, Gansevoort RT, Elbers CC, Wijmenga C, Snieder H, Hofker MH, Fu J: Pleiotropic effects of lipid genes on plasma glucose, HbA1c and HOMA-IR levels.Diabetes 2014. Epub ahead of print.,
Jones GL, Teng YS: A chemical and enzymological account of the multiple forms of human liver aldehyde dehydrogenase. Implications for ethnic differences in alcohol metabolism. Biochim Biophys Acta. 1983, 745: 162-174. 10.1016/0167-4838(83)90045-6.
Newlin DB: The skin-flushing response: autonomic, self-report, and conditioned responses to repeated administrations of alcohol in Asian men. J Abnorm Psychol. 1989, 98: 421-425. 10.1037/0021-843X.98.4.421.
Howard LA, Ahluwalia JS, Lin SK, Sellers EM, Tyndale RF: CYP2E1*1D regulatory polymorphism: association with alcohol and nicotine dependence. Pharmacogenetics. 2003, 13: 321-328. 10.1097/00008571-200306000-00003.
Tang K, Li X, Xing Q, Li W, Feng G, He L, Qin S: Genetic polymorphism analysis of cytochrome P4502E1 (CYP2E1) in Chinese Han populations from four different geographic areas of Mainland China. Genomics. 2010, 95: 224-229. 10.1016/j.ygeno.2010.01.005.
Brondani LA, Assmann TS, de Souza BM, Boucas AP, Canani LH, Crispim D: Meta-analysis reveals the association of common variants in the uncoupling protein (UCP) 1-3 genes with body mass index variability. PLoS One. 2014, 9: e96411-10.1371/journal.pone.0096411.
Ehlers CL, Gizer IR: Evidence for a genetic component for substance dependence in Native Americans. Am J Psychiatry. 2013, 170: 154-164. 10.1176/appi.ajp.2012.12010113.
Carroll RJ, Bastarache L, Denny JC: R PheWAS: data analysis and plotting tools for phenome-wide association studies in the R environment. Bioinformatics. 2014, 30: 2375-2376. 10.1093/bioinformatics/btu197.
Neuraz A, Chouchana L, Malamut G, Le Beller C, Roche D, Beaune P, Degoulet P, Burgun A, Loriot MA, Avillach P: Phenome-wide association studies on a quantitative trait: application to TPMT enzyme activity and thiopurine therapy in pharmacogenomics. PLoS Comput Biol. 2013, 9: e1003405-10.1371/journal.pcbi.1003405.
Denny JC, Bastarache L, Ritchie MD, Carroll RJ, Zink R, Mosley JD, Field JR, Pulley JM, Ramirez AH, Bowton E, Basford MA, Carrell DS, Peissig PL, Kho AN, Pacheco JA, Rasmussen LV, Crosslin DR, Crane PK, Pathak J, Bielinski SJ, Pendergrass SA, Xu H, Hindorff LA, Li R, Manolio TA, Chute CG, Chisholm RL, Larson EB, Jarvik GP, Brilliant MH, et al: Systematic comparison of phenome-wide association study of electronic medical record data and genome-wide association study data. Nat Biotechnol. 2013, 31: 1102-1110. 10.1038/nbt.2749.
Langley RJ, Tsalik EL, van Velkinburgh JC, Glickman SW, Rice BJ, Wang C, Chen B, Carin L, Suarez A, Mohney RP, Freeman DH, Wang M, You J, Wulff J, Thompson JW, Moseley MA, Reisinger S, Edmonds BT, Grinnell B, Nelson DR, Dinwiddie DL, Miller NA, Saunders CJ, Soden SS, Rogers AJ, Gazourian L, Fredenburgh LE, Massaro AF, Baron RM, Choi AM, et al: An integrated clinico-metabolomic model improves prediction of death in sepsis. Sci Transl Med. 2013, 5: 95-113.
Bilder RM, Sabb FW, Cannon TD, London ED, Jentsch JD, Parker DS, Poldrack RA, Evans C, Freimer NB: Phenomics: the systematic study of phenotypes on a genome-wide scale. Neuroscience. 2009, 164: 30-42. 10.1016/j.neuroscience.2009.01.027.
Sreekumar A, Poisson LM, Rajendiran TM, Khan AP, Cao Q, Yu J, Laxman B, Mehra R, Lonigro RJ, Li Y, Nyati MK, Ahsan A, Kalyana-Sundaram S, Han B, Cao X, Byun J, Omenn GS, Ghosh D, Pennathur S, Alexander DC, Berger A, Shuster JR, Wei JT, Varambally S, Beecher C, Chinnaiyan AM: Metabolomic profiles delineate potential role for sarcosine in prostate cancer progression. Nature. 2009, 457: 910-914. 10.1038/nature07762.
Denkert C, Budczies J, Kind T, Weichert W, Tablack P, Sehouli J, Niesporek S, Konsgen D, Dietel M, Fiehn O: Mass spectrometry-based metabolic profiling reveals different metabolite patterns in invasive ovarian carcinomas and ovarian borderline tumors. Cancer Res. 2006, 66: 10795-10804. 10.1158/0008-5472.CAN-06-0755.
Manna SK, Tanaka N, Krausz KW, Haznadar M, Xue X, Matsubara T, Bowman ED, Fearon ER, Harris CC, Shah YM, Gonzalez FJ: Biomarkers of coordinate metabolic reprogramming in colorectal tumors in mice and humans. Gastroenterology. 2014, 146: 1313-1324. 10.1053/j.gastro.2014.01.017.
Mathe EA, Patterson AD, Haznadar M, Manna SK, Krausz KW, Bowman ED, Shields PG, Idle JR, Smith PB, Anami K, Kazandjian DG, Hatzakis E, Gonzalez FJ, Harris CC: Noninvasive urinary metabolomic profiling identifies diagnostic and prognostic markers in lung cancer. Cancer Res. 2014, 74: 3259-3270. 10.1158/0008-5472.CAN-14-0109.
Widmann P, Reverter A, Fortes MR, Weikard R, Suhre K, Hammon H, Albrecht E, Kuehn C: A systems biology approach using metabolomic data reveals genes and pathways interacting to modulate divergent growth in cattle. BMC Genomics. 2013, 14: 798-10.1186/1471-2164-14-798.
Rhee EP, Gerszten RE: Metabolomics and cardiovascular biomarker discovery. Clin Chem. 2012, 58: 139-147. 10.1373/clinchem.2011.169573.
Weiss RH, Kim K: Metabolomics in the study of kidney diseases. Nat Rev Nephrol. 2012, 8: 22-33. 10.1038/nrneph.2011.152.
Chen S, Kong H, Lu X, Li Y, Yin P, Zeng Z, Xu G: Pseudotargeted metabolomics method and its application in serum biomarker discovery for hepatocellular carcinoma based on ultra high-performance liquid chromatography/triple quadrupole mass spectrometry. Anal Chem. 2013, 85: 8326-8333. 10.1021/ac4016787.
Kim JH, Yamaori S, Tanabe T, Johnson CH, Krausz KW, Kato S, Gonzalez FJ: Implication of intestinal VDR deficiency in inflammatory bowel disease. Biochim Biophys Acta. 1830, 2013: 2118-2128.
Veenstra TD: Metabolomics: the final frontier?. Genome Med. 2012, 4: 40-10.1186/gm339.
Bailey CJ, Turner RC: Metformin. N Engl J Med. 1996, 334: 574-579. 10.1056/NEJM199602293340906.
Sirtori CR, Pasik C: Re-evaluation of a biguanide, metformin: mechanism of action and tolerability. Pharmacol Res. 1994, 30: 187-228. 10.1016/1043-6618(94)80104-5.
Seidowsky A, Nseir S, Houdret N, Fourrier F: Metformin-associated lactic acidosis: a prognostic and therapeutic study. Crit Care Med. 2009, 37: 2191-2196. 10.1097/CCM.0b013e3181a02490.
Johnson CH, Gonzalez FJ: Challenges and opportunities of metabolomics. J Cell Physiol. 2012, 227: 2975-2981. 10.1002/jcp.24002.
Zheng Y, Yu B, Alexander D, Mosley TH, Heiss G, Nettleton JA, Boerwinkle E: Metabolomics and incident hypertension among blacks: the atherosclerosis risk in communities study. Hypertension. 2013, 62: 398-403. 10.1161/HYPERTENSIONAHA.113.01166.
Li F, Wang L, Guo GL, Ma X: Metabolism-mediated drug interactions associated with ritonavir-boosted tipranavir in mice. Drug Metab Dispos. 2010, 38: 871-878. 10.1124/dmd.109.030817.
Wang TJ, Larson MG, Vasan RS, Cheng S, Rhee EP, McCabe E, Lewis GD, Fox CS, Jacques PF, Fernandez C, O’Donnell CJ, Carr SA, Mootha VK, Florez JC, Souza A, Melander O, Clish CB, Gerszten RE: Metabolite profiles and the risk of developing diabetes. Nat Med. 2011, 17: 448-453. 10.1038/nm.2307.
Ho JE, Larson MG, Vasan RS, Ghorbani A, Cheng S, Rhee EP, Florez JC, Clish CB, Gerszten RE, Wang TJ: Metabolite profiles during oral glucose challenge. Diabetes. 2013, 62: 2689-2698. 10.2337/db12-0754.
Bain JR, Muehlbauer MJ: Metabolomics reveals unexpected responses to oral glucose. Diabetes. 2013, 62: 2651-2653. 10.2337/db13-0605.
Johnson CH, Patterson AD, Idle JR, Gonzalez FJ: Xenobiotic metabolomics: major impact on the metabolome. Annu Rev Pharmacol Toxicol. 2012, 52: 37-56. 10.1146/annurev-pharmtox-010611-134748.
Furie B: Do pharmacogenetics have a role in the dosing of vitamin K antagonists?. N Engl J Med. 2013, 369: 2345-2346. 10.1056/NEJMe1313682.
Nebert DW: Extreme discordant phenotype methodology: an intuitive approach to clinical pharmacogenetics. Eur J Pharmacol. 2000, 410: 107-120. 10.1016/S0014-2999(00)00809-8.
Gu Q, Dillon CF, Burt VL: Prescription drug use continues to increase: U.S. prescription drug data for 2007-2008.NCHS Data Brief 2010:1-8.,
Kaufman DW, Kelly JP, Rosenberg L, Anderson TE, Mitchell AA: Recent patterns of medication use in the ambulatory adult population of the United States: the Slone survey. JAMA. 2002, 287: 337-344. 10.1001/jama.287.3.337.
Tinetti ME, Bogardus ST, Agostini JV: Potential pitfalls of disease-specific guidelines for patients with multiple conditions. N Engl J Med. 2004, 351: 2870-2874. 10.1056/NEJMsb042458.
Cutler JA, Sorlie PD, Wolz M, Thom T, Fields LE, Roccella EJ: Trends in hypertension prevalence, awareness, treatment, and control rates in United States adults between 1988-1994 and 1999-2004. Hypertension. 2008, 52: 818-827. 10.1161/HYPERTENSIONAHA.108.113357.
Monte AA, Heard KJ, Hoppe JA, Vasiliou V, Gonzalez FJ: The accuracy of self-reported drug ingestion histories in emergency department patients.J Clin Pharmacol 2014. Epub ahead of print.,
Lango Allen H, Estrada K, Lettre G, Berndt SI, Weedon MN, Rivadeneira F, Willer CJ, Jackson AU, Vedantam S, Raychaudhuri S, Ferreira T, Wood AR, Weyant RJ, Segre AV, Speliotes EK, Wheeler E, Soranzo N, Park JH, Yang J, Gudbjartsson D, Heard-Costa NL, Randall JC, Qi L, Vernon Smith A, Magi R, Pastinen T, Liang L, Heid IM, Luan J, Thorleifsson G, et al: Hundreds of variants clustered in genomic loci and biological pathways affect human height. Nature. 2010, 467: 832-838. 10.1038/nature09410.
Lander ES: Initial impact of the sequencing of the human genome. Nature. 2011, 470: 187-197. 10.1038/nature09792.
Nebert DW, Zhang G, Vesell ES: Genetic risk prediction: individualized variability in susceptibility to toxicants. Annu Rev Pharmacol Toxicol. 2013, 53: 355-375. 10.1146/annurev-pharmtox-011112-140241.
Suhre K, Shin SY, Petersen AK, Mohney RP, Meredith D, Wagele B, Altmaier E, Deloukas P, Erdmann J, Grundberg E, Hammond CJ, de Angelis MH, Kastenmuller G, Kottgen A, Kronenberg F, Mangino M, Meisinger C, Meitinger T, Mewes HW, Milburn MV, Prehn C, Raffler J, Ried JS, Romisch-Margl W, Samani NJ, Small KS, Wichmann HE, Zhai G, Illig T, Spector TD, et al: Human metabolic individuality in biomedical and pharmaceutical research. Nature. 2011, 477: 54-60. 10.1038/nature10354.
Illig T, Gieger C, Zhai G, Romisch-Margl W, Wang-Sattler R, Prehn C, Altmaier E, Kastenmuller G, Kato BS, Mewes HW, Meitinger T, de Angelis MH, Kronenberg F, Soranzo N, Wichmann HE, Spector TD, Adamski J, Suhre K: A genome-wide perspective of genetic variation in human metabolism. Nat Genet. 2010, 42: 137-141. 10.1038/ng.507.
Roede JR, Uppal K, Park Y, Lee K, Tran V, Walker D, Strobel FH, Rhodes SL, Ritz B, Jones DP: Serum metabolomics of slow vs. rapid motor progression Parkinson’s disease: a pilot study. PLoS One. 2013, 8: e77629-10.1371/journal.pone.0077629.
Jun HJ, Lee JH, Kim J, Jia Y, Kim KH, Hwang KY, Yun EJ, Do KR, Lee SJ: Linalool is a PPARalpha ligand that reduces plasma TG levels and rewires the hepatic transcriptome and plasma metabolome. J Lipid Res. 2014, 55: 1098-1110. 10.1194/jlr.M045807.
Morvan D, Demidem A: Metabolomics and transcriptomics demonstrate severe oxidative stress in both localized chemotherapy-treated and bystander tumors. Biochim Biophys Acta. 1840, 2014: 1092-1104.
Mukherjee K, Edgett BA, Burrows HW, Castro C, Griffin JL, Schwertani AG, Gurd BJ, Funk CD: Whole blood transcriptomics and urinary metabolomics to define adaptive biochemical pathways of high-intensity exercise in 50-60 year old masters athletes. PLoS One. 2014, 9: e92031-10.1371/journal.pone.0092031.
Zhang G, He P, Tan H, Budhu A, Gaedcke J, Ghadimi BM, Ried T, Yfantis HG, Lee DH, Maitra A, Hanna N, Alexander HR, Hussain SP: Integration of metabolomics and transcriptomics revealed a fatty acid network exerting growth inhibitory effects in human pancreatic cancer. Clin Cancer Res. 2013, 19: 4983-4993. 10.1158/1078-0432.CCR-13-0209.
Zhang Y, Deng Y, Zhao Y, Ren H: Using combined bio-omics methods to evaluate the complicated toxic effects of mixed chemical wastewater and its treated effluent. J Hazard Mater. 2014, 272: 52-58. 10.1016/j.jhazmat.2014.02.041.
Xing EP, Curtis RE, Schoenherr G, Lee S, Yin J, Puniyani K, Wu W, Kinnaird P: GWAS in a box: statistical and visual analytics of structured associations via GenAMap. PLoS One. 2014, 9: e97524-10.1371/journal.pone.0097524.
Jannetto PJ, Bratanow NC: Utilization of pharmacogenomics and therapeutic drug monitoring for opioid pain management. Pharmacogenomics. 2009, 10: 1157-1167. 10.2217/pgs.09.64.
Lotsch J, Skarke C, Liefhold J, Geisslinger G: Genetic predictors of the clinical response to opioid analgesics: clinical utility and future perspectives. Clin Pharmacokinet. 2004, 43: 983-1013. 10.2165/00003088-200443140-00003.
Boswell MV, Stauble ME, Loyd GE, Langman L, Ramey-Hartung B, Baumgartner RN, Tucker WW, Jortani SA: The role of hydromorphone and OPRM1 in postoperative pain relief with hydrocodone. Pain Physician. 2013, 16: E227-E235.
Acknowledgements
This work was supported in part by the National Institutes of Health Grants K23 GM110516 (A.A.M), P30 ES06096 (D.W.N.), R24 AA022057 and R01 EY14390 (V.V). Dr. Monte is supported by the Emergency Medicine Foundation Research Training Grant.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
All authors contributed knowledge and expertise in the writing of this review. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

{kind=link}
{kind=link}
Cite this article
Monte, A.A., Brocker, C., Nebert, D.W. et al. Improved drug therapy: triangulating phenomics with genomics and metabolomics. Hum Genomics 8, 16 (2014). https://doi.org/10.1186/s40246-014-0016-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40246-014-0016-9