
Abstract
Background
Several studies have tested the reliability of Risk Terrain Modelling (RTM) by focusing on different geographical contexts and types of crime or events. However, to date, there has been no attempt to systematically review the evidence on whether RTM is effective at predicting areas at high risk of events. This paper reviews RTM’s efficacy as a spatial forecasting method.
Methods
We conducted a systematic review and meta-analysis of the RTM literature. We aggregated the available data from a sample of studies that measure predictive accuracy and conducted a proportion meta-analysis on studies with appropriate data.
Results
In total, we found 25 studies meeting the inclusion criteria. The systematic review demonstrated that RTM has been successful in identifying at risk places for acquisitive crimes, violent crimes, child maltreatment, terrorism, drug related crimes and driving while intoxicated (DWI). The proportion meta-analysis indicated that almost half of future cases in the studies analysed were captured in the top ten per cent of risk cells. This typically covers a very small portion of the full study area.
Conclusions
The study demonstrates that RTM is an effective forecasting method that can be applied to identify places at greatest risk of an event and can be a useful tool in guiding targeted responses to crime problems.
Similar content being viewed by others

Background
Research consistently demonstrates crime is spatially concentrated. Urban crimes, such as burglary and robbery, occur most often near common routine activity nodes (Bowers, 2014) and in places known to a large number of people (Davies & Johnson, 2015; Johnson & Bowers, 2010). This has profound implications for policing, as finite resources can be focused on identified micro-level places (Braga et al., 2014; Kennedy et al., 2016). Multiple methods exist to identify crime hotspots using retrospective analyses, including spatial and temporal analysis of crime (STAC) (Block and Block 2004), kernel density estimation (KDE) (Chainey et al., 2008), and nearest neighborhood hierarchical (Nnh) clustering (Levine, 2004). This paper synthesises the evidence base on an alternate approach, risk terrain modelling (RTM) (Caplan & Kennedy, 2010). This method builds upon traditional hotspot techniques by including measures that reflect the study area’s physical and social environment.
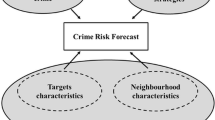
Building on the foundations of environmental criminology, Caplan and Kennedy (2010) developed risk terrain modelling. Whereas competing predictive models rely solely on retrospective analyses, RTM additionally incorporates theoretical foundations in the spatial analysis of crime and identifies the spatial risks determined by the features of a landscape (Caplan et al., 2011a, Caplan et al., 2011b). The combination of multiple criminogenic features at the same place contributes to a risk value that indicates the likelihood of crime occurring in that area and represents that area’s vulnerability to crime (Kennedy et al., 2016). This value can be used to forecast where crime will occur over a period of time.
RTM includes many concepts from crime pattern theory and is capable of measuring Brantingham and Brantingham’s (1993) concepts of crime generators and crime attractors. The RTM process tests a variety of factors that are thought to be geographically related to incidents. It then identifies the features that are potentially correlated with the presence or absence of future event(s) in a particular location. Because RTM includes contextual information relevant to the social and physical environment it can be used to identify areas within a city that have the greatest estimated opportunity and therefore pose the highest level of risk of future incidents. As well as identifying places where events will persist, it can also identify areas where places may emerge or displace, based on relatively stable environmental and contextual risk factors that go beyond incident-based data.
To improve the accessibility of RTM to practitioners, Rutgers University developed software that automates the process: the Risk Terrain Modeling Diagnostics (RTMDx) Utility. This tool evaluates the relative influence and importance of risk factors using a bidirectional stepwise regression process. The variables are examined and the most problematic risk factors are selected, along with their most appropriate spatial influence distance, to build the overall best model. RTMDx allows for two types of model: aggravating (to identify factors that increase risk) and protective (to identify factors that decrease risk).Footnote 1
Spatial influence considers the qualities of features on locations of crimes, i.e., it “describes the way in which features of a landscape affect places throughout the landscape” (Caplan, 2011: 532). Certain places within the spatial influence of criminogenic features may be more vulnerable to crime than those not within this spatial influence and can therefore be considered riskier. Two parameters for spatial influence of each variable can be assessed in RTMDx, based on proximity or density. Spatial influence for proximity is operationalised as the presence of a physical feature within the defined distance from the event. Spatial influence for density is operationalised as a high concentration of a physical feature within the defined distance from the event.
In the software it is also necessary to define the grid cell size for the outputs. Caplan and Kennedy suggest that using the average street length with a cell raster size of half a street length is appropriate to create the cells. Taylor and Harrell (1996) propose that places prone to crime consist of a few streets, and this measure is a realistic area to use for the guidance of future policing measures.
In RTMDx, the testing process begins by building an elastic net penalised regression model assuming a Poisson distribution of events. The process then selects variables that may be potentially useful through cross validation, which are then utilised in a bidirectional step-wise regression process (starting with a null model), to build the optimal model by optimising the Bayesian Information Criteria (BIC). This score is a balance of complexity of the model and fit of the data. The models also include two intercept terms that represent the background rate of events and overdispersion of the event counts. Exponentiated coefficient values are used to produce the relative risk values, which can be interpreted as the weights of the risk factor (Caplan et al., 2013b). These can be used to understand the riskiness of each factor relative to one another.
Several studies tested RTM’s reliability by focusing on different geographical contexts and types of crime or events. However, to date, there has been no attempt to systematically review the evidence on whether RTM is effective at predicting areas at high risk of events. This paper reviews RTM’s efficacy as a spatial diagnostic and forecasting method. We conducted a systematic review and meta-analysis of the RTM literature. We answered this by aggregating the available data from a sample of studies that measure predictive accuracy and conducting a proportion meta-analysis on studies with appropriate data. In the following sections, we first discuss the methodology, followed by the synthesized results. We conclude with a discussion of the implications of our findings for future research. Our results reinforce earlier recognitions of RTM as an effective forecasting method.
Methodology
Identifying studies: databases and information sources
Studies were identified using the following search methods:
-
(a)
A keyword search of relevant electronic databases
-
(b)
Forward and backward citation searches of candidate studies.
We searched two electronic databases (Web of Science and ProQuest Central). Full text versions of identified studies were obtained through one of the following means (in order of preference): electronic copies via the university’s e-journals service, electronic copies of studies available from elsewhere on the internet, paper copies, electronic/paper copies requested through the inter-library loan system (which sources most materials from the British Library) and electronic/paper copies requested from the authors themselves.
We used the following inclusion criteria:
-
(a)
The study must have used RTM to identify risk factors for one or more crime types in a defined geographical area
-
(b)
The study must have reported at least one measure of predictive accuracy, e.g. percentage of future events captured in high risk areas, logistic regression, predictive accuracy index, recapture rate index. A predictive tool can be considered accurate when its results are useful for forecasting a large number of future events.
The review considered peer reviewed studies that were published in print or available online from January 2010 to March 2020. We chose to only include peer reviewed studies to avoid the inclusion of non-peer reviewed studies that may have affected the outcome of the meta-analysis. Studies were limited to English because of the language skills existing in the team. The search strategy for the systematic review is based on the Campbell Collaboration method Campbell Collaboration (2017).
Search terms
In order to discover relevant items for the systematic review, a number of search terms were used in the above electronic databases:
-
Risk AND terrain AND model*
-
Risk-terrain AND model*
-
Place-based AND correlate*
-
Place AND based AND correlate*
-
Place-based AND risk AND factor*
-
Spatial AND correlate*
-
Spatial AND risk AND factor*
These search terms resulted in 5067 unique studies (once duplicates were removed) which required screening. The first level of screening involved the review team (Marchment and Gill) examining the title and abstract of those studies returned following our electronic and bibliographic searches.
Next, the studies were read in their entirety in order to rigorously judge whether they should be included in the full systematic review and meta-analysis. Of those studies brought forward to the final phase of the systematic review, backwards and forwards citation searches were performed to pursue further candidate studies. This involved reviewing the titles of each study cited within the initially included study (e.g. backwards) and also the subsequent citations that each candidate study accrued up to and including the end of April 2020 according to Google Scholar (e.g. forwards). The forwards citation search was conducted first. A forward and backward citation search was also conducted on studies found in these initial citation searches and this continued until all lines of inquiry were complete.
In total, we found 25 studies meeting the inclusion criteria (see Table 1). All items and variables measured in these studies were then extracted from the original papers, synthesised and outlined in the below sections.
Proportion meta-analysis
As the results of the studies were typically reported as non-comparative outcomes, a proportion meta-analysis was appropriate, and conducted to estimate the pooled proportion and 95% confidence intervals of cases accurately predicted by RTM in the top 10% of risk cells. When data permitted, proportions of interest were calculated from the relevant numerator and denominator.
Results
Study characteristics
In this section, we discuss the general characteristics of the papers selected for inclusion. More than half of all studies were published since 2017, indicating a rapid growth of knowledge in this area in a relatively short period. This may be due to the availability of the RTMDx software as a free download during this time. The majority of the studies were conducted in the US (n = 14). Other studies were conducted in Italy (n = 3), Colombia (n = 2), Canada (n = 1), Spain (n = 1), Austria (n = 1), Northern Ireland (n = 1), Turkey (n = 1), and Japan (n = 1).
Crime types included burglary, robbery, theft, homicide, assault, gang violence, shootings, terrorism, auto theft, thefts from vehicles, alcohol related traffic crashes, and child maltreatment. In terms of data, this was usually gained from the relevant police department for crime studies.
Evaluation metrics
This section looks at measures of forecasting performance. The most commonly used evaluation metrics were (in the following order): hit rates, predictive accuracy index (PAI), logistic regressions, and incidence rate ratio (IRR). The two main measures used were hit rates and PAI, which are detailed below.
Hit rates capture the percentage of events occurring in defined risk areas (e.g. high to very high risk cells) in a post study time period. Our review found 27 different hit rate measures (see Table 2). Results varied from 23 to 85%, with an average of 43.6%. Given the relatively small geographic spaces identified as high or very high risk within these studies (see below), this result confirms RTM’s predictive capabilities. However, given the variance between studies, further research should investigate the reasons for the differences between high performance and lower performance studies.
Hit rates have limitations, as they do not take into account the size of the area where crimes are predicted to occur, necessitating the need for the PAI as a comparable metric. PAI standardizes predictions by the size of the geographic area determined to be problematic, defined by the percent of crime divided by the percent of the area forecasted to be a hotspot (Chainey et al., 2008). Higher PAI values indicate better performance, or more accurate predictions. Greater prediction accuracy reflects a higher hit rate over a small geographic area. Our review identified 13 different PAI values ranging from 1.71 (auto theft; Kocher & Leitner, 2015) to 41.04 (robbery; Drawve, 2016) (see Table 3). The median PAI value was 7.42. Although the average across these studies is 12.98, it is highly skewed by five high performing RTM’s reported in three separate analyses.
Crime types
Acquisitive crimes
8 studies applied RTM to acquisitive crimes. 3 studies generated PAI values for five crime types. PAI values ranged from 1.71 (auto theft; Kocher & Leitner, 2015) to 18.46 (robbery, Kocher & Leitner, 2015). The other three PAI values were closer to the lower end of the range and included 1.87 (vehicle theft; Ohyama & Amemiya, 2018), 3.61 (robbery; Caplan et al., 2020) and 4.46 (burglary, Kocher & Leitner, 2015). Hit rate values ranged from 25% (burglary; Kocher & Leitner, 2015) to 53.4% (burglary; Dugato et al., 2018).
Caplan et al., (2020) examined robberies in Brooklyn, New York, using RTM. The average hit rate for one month was 8.41, meaning an average of 8.41% of robberies were predicted in the high-risk cells. The average PAI value for RTM across all months was 3.61. Anyinam (2015) examined robberies in New Haven, Connecticut. In the test period, 39% of robberies occurred in high or very high-risk cells, which made up only 6.09% of the city. Dugato (2013) looked at robberies in Milan, Italy, between 2007 and 2010. 36% of the robberies committed during the test period occurred in 6.8% of the riskiest areas identified using RTM. 43% of events occurred within high or very high-risk cells (the top 10% of total cells).
Dugato et al., (2018) also examined residential burglaries in Milan, Italy. Burglaries that occurred in 2014 were used to evaluate the effectiveness of the final risk map. More than half (53.37%) occurred in areas defined as high or very high risk. Yerxa (2013) analysed burglary in a city in the Pacific Northwest using RTM. The odds ratio from their logistic regression suggested that with every increased unit of risk, the likelihood of a residential burglary increased by approximately 59%.
Kocher and Leitner (2015) used RTM to look at several crime types in Salzburg Austria, including burglary, robbery and auto theft. Their RTMs correctly predicted 25% of burglaries, and 43.5% of robberies. The PAI value for robberies was 18.46. In contrast, the predictions for burglaries and auto thefts performed rather poorly, with PAI values of 4.46 and 1.71, respectively.
Ohyama and Amemiya (2018) examined thefts from vehicles in Fukuoka, Japan. They found that 40.9% of thefts from vehicles occurred in high or very high-risk cells. The PAI was 1.87. Giménez-Santana et al., (2018a, 2018b) used RTM to look at theft in Bogotá, Colombia. The top 10% of cells with the highest risk predicted 40% of all theft incidents occurring during 2013 in the city.
Violent crimes
Twelve studies identified risk factors for violent crimes using RTM. 2 studies generated PAI values for 3 crime types. They were 3.53 (homicide; Giménez-Santana et al., 2018a, 2018b), 3.56 (assault; Giménez-Santana et al., 2018a, 2018b) and 19.246 (gun crime; Drawve et al., 2016). Hit rates ranged from 18% (homicide; Giménez-Santana et al., 2018a, 2018b) to 85% (mafia homicide; Dugato et al., 2017).
Anyinam (2015) showed that 41% of non-fatal shootings and 57% of murders occurred in areas deemed to be high or very high-risk, which made up only 6.09% of the study area (the city of New Haven).
Caplan et al., (2011a, 2011b) studied shootings in Irvington, New Jersey using RTM. They used two six-month periods to test the predictive validity of the risk terrains. The odds ratios for period 2 suggested that for every increased unit of risk, the likelihood of a shooting significantly increased by at least 56%. The odds ratio for period 1 suggested a shooting likelihood of 69%.
Caplan (2011) found that 42% of all shooting incidents occurred in the top 10 percent of the highest risk places during their post study period of the calendar year 2007. The logistic regression suggested that for every increased unit of risk, the likelihood of a shooting more than doubled.
Caplan et al., (2013a, 2013b) studied violent crime incidents in Irvington, New Jersey. They found that for every unit increase of a 100 ft × 100 ft cell’s risk value, the likelihood of a violent crime occurring there during the 6-month test period increased by 92%. 45% of all violent crimes in 2008 happened at places with risk values of 3 or more, which comprised 10% of the study area.
As well as burglary, robbery and auto theft, Kocher and Leitner (2015) examined assault in Salzburg Austria, 2013. The PAI value for spring was 31 and the PAI for summer was 23.
Kennedy et al., (2016) identified risk factors for aggravated assault in Chicago using RTM. The IRR from the negative binomial regression suggested that the aggravated assault count increased 2% (IRR = 1.02) for every unit increase of risk.
Giménez-Santana et al., (2018a, 2018b) looked at violent crime in Bogotá, Colombia using RTM. The top 10% cells with the highest risk for homicide incidents witnessed 32% of all homicide events. For assault, 20% of all events that occurred during 2013 were located in the top 5% cells posing the highest risk.
Valasik (2018) used RTM to study gang homicides in Los Angeles, California. 8% of gang homicides committed in 2012 occurred in very high risk cells, while about 42% of gang homicides took place in medium risk cells. The remaining half occurred in low risk cells.
Valasik et al., (2019) used RTM to forecast homicide in Baton Rouge, Louisiana. Very high risk cells were significantly more likely (23 × higher) to experience a homicide when compared to low risk cells. The incidence rate ratio for very high risk cells was 22.9.
Drawve (2016) found that the odds of a gun crime occurring in an area identified as having very high risk experienced over 55 times the odds of gun crime relative to areas with a spatial risk value of zero (odds ratio = 55.05). The PAI prediction value for the RTM was 19.246. The RRI for the RTM was 1.18.
Kennedy et al., (2011) found that the top 40% of high-risk cells in the risk terrain map correctly predicted the locations of 84% of the shootings during the next period.
RTM has also been applied to the study of organised crime related homicide. Dugato et al., (2017) examined both attempted and completed mafia homicides committed by the Camorra in Naples, Italy, during 2012 (data obtained from Italian government). 85% of the mafia homicides committed in 2012 were located within cells at high or very high risk. The regression suggested that the few cells with very high or high risk had a significantly higher probability of experiencing a mafia homicide in comparison with those categorized as being at very low risk. The incidence rate ratio for very high risk cells was 47.99 and for high risk was 37.92.
Drug related crime
Two studies have used RTM to study drug related crimes. Escudero and Ramírez (2018) looked at the locations of illicit drugs sale points in Bogotá, Colombia. The approximate accuracy for high and very high risk was 64%. Onat et al., (2018) looked at illicit drug activities in the Durham Region in Ontario, Canada. They found that nearly 85% of all places with illicit drugs arrests in 2012 and 2013 overlapped with places they had identified as high-risk places of 2011 and 2012, respectively.
Child maltreatment
One study, Daley (2016), looked at maltreatment of children, who were either physically, sexually, or psychologically abused, neglected, or abandoned in Fort Worth, Texas. They used data from the year 2013, obtained from the Department of Family and Protective Services (DFPS) and Fort Worth Police Department (FWP). In the following year, 2014, 52% of all cases of child maltreatment were accurately predicted in the 10% of highest risk cells determined by the RTM. Further, almost all observed incidents were located in cells that were predicted to have an elevated risk. The highest risk stratum (10% of the study area) included 52% of all future cases; the second risk stratum (20% of the study area) contained over 80%; and the third risk stratum (30% of the study area) predicted over 90% of 2014 cases. Only 133 of the 5391 or 2% of all instances occurred in areas that were not identified as having an elevated risk.
Driving while intoxicated
Giménez-Santana et al., (2018a, 2018b) used RTM to identify correlates of alcohol-related traffic crashes in the Spanish province of Cádiz. RTM was able to predict 41% of all alcohol related crashes that occurred in places identified as posing a higher risk for future traffic accidents. The PAI value was 9.1.
Terrorism
Two studies have used RTM to examine predictive accuracy for terrorist events. Both had promising results, with hit rates of 43% (Onat & Gul, 2018) and 50% (Marchment et al., (2019). Onat and Gul (2018) used RTM to identify correlates of terrorist incidents in Turkey, using data acquired from Istanbul Police Department between 2008 and 2012. More than 43% of all places with terrorist incidents in the second period overlapped with the top 10% highest risk-places of the first period. Logistic regression results suggested that for every increased unit of risk, the likelihood of a violent terrorist incident happening at a particular place increased by 2.2%. Marchment et al., (2019) used RTM to identify correlates of dissident Republican incidents in Belfast, Northern Ireland. They compared two incident types, bombings and bomb hoaxes. Logistic regression or other methods of testing predictive accuracy were not possible due to the size of data. During the post-study period, 28 bombings occurred. Seven bombings occurred in the cells that were inferred as being at very high risk. Seven occurred in high risk cells. 2 bombings occurred in medium risk cells and 12 bombings occurred in areas deemed to be at low risk. Eight hoaxes occurred post-2013. Four occurred in medium risk areas, two in high risk areas and two in very high-risk areas. No hoaxes occurred in areas deemed to be at low risk.
Comparisons to other methods and integrated approaches
This section discusses the papers identified in the search that examined the accuracy of RTM in comparison to other approaches or used RTM in combination with other spatial analyses.
Ohyama and Amemiya (2018) compared five methods (RTM, KDE, ProMap, SEPP and ST-GAM) and concluded that RTM yielded the best results. The hit rate and PAI for RTM were almost twice as high as those for KDE, ProMap, and SEPP. 40.9% of thefts from vehicles occurred in high or very high risk cells, with a PAI of 1.87. Both hit rate (40.9%) and PAI (1.87) were the highest for RTM.
Marchment (2019)Footnote 2 compared RTM to KDE in her study of dissident Republican activity in Northern Ireland. For KDE, only three bombings (out of 28) occurred in high or very high-density areas during the test period of two years. However, most hoaxes occurred in high or medium density areas. For RTM, 50% of bombings and 50% of bomb hoaxes occurred in high or very high risk. Seeing as only a small proportion of the city was deemed to be at the high or very high levels of risk, this is impressive. However, some caution should be taken in interpreting these results due to the small amount of data used, and a large proportion (43%) of bombings did occur in low risk cells.
Daley (2016) found the highest risk stratum of their RTM (10% of the study area) included 52% of all future cases, which was almost 10% more than the hotspot model, which included 43% of cases. The second risk stratum (20% of the study area) contained over 80% of cases, compared with 66% for the hotspot model, and the third risk stratum (30% of the study area) predicted over 90% of 2014 cases, compared with 81% for the hotspot model.
However, KDE outperformed RTM in Dugato’s (2013) study of robberies in Milan. The hot spots for each method were identified using 6.8% of the cells with the highest level of risk value for RTM and density value for KDE. Although KDE was more accurate, RTM was more reliable and its predictive power remained more stable over time. This was measured using the Recapture Rate Index (RRI), which measure of the reliability of the forecasting power over time. Drawve (2016) compared RTM to Spatial and Temporal Analysis of Crime, KDE, nearest neighbour hierarchical. He also found that KDE was the most accurate, but it had the second lowest average reliability value/ RTM was the most reliable and precise, with the highest RRI, as well as having the second highest PAI. These results suggest that although RTM may be less likely to forecast rapid changes in the short term, it can produce consistent results in the long term.
Giménez-Santana et al., (2018a, 2018b) compared RTM and KDE for alcohol related vehicle incidents. They found PAI values of 3.3 for KDE, 9.1 for RTM, and 13.3 for all places where high vulnerability (spatial risk values) and exposure (recent incidences) to past crashes intersected. These results indicate that RTM as a solo method was overall more accurate in predicting the location of future driving while intoxicated (DWI) crash accidents when compared to KDE.
Giménez-Santana et al., (2018a, 2018b) found that using a joint utility approach predicted 19% of all theft incidents in Bogotá. Their RTM for assault resulted in PAI values of 3.57 for high-risk places, compared to 4.76 for hotspots, and 5.85 for all places where high vulnerability and exposure to past crime intersected. The combined effect of high-risk places and exposure to past crime events increased the overall accuracy for predicting future assault incidents by 23%. For homicides, the PAI values were 3.53 for high-risk places, 6.43 for hotspots, and 6.47 for locations where high-risk places overlapped with crime hotspots. Garnier et al., (2018) found that a combined model of event-dependence and environmental influences (RTM) performed significantly better than RTM only in their study of robberies in Newark. The RTM only model also performed better than the event dependence only model.
Drawve et al., (2019) found that their RTM and KDE had very similar predictive accuracy to one another. They also used RTM and KDE jointly, restricting high-risk (vulnerability) and hot spots (exposure) places to where they overlapped. The predictive accuracy doubled using this joint utility approach when compared to each technique on its own.
Caplan et al.’s (2020) RTM outperformed KDE in terms of prediction accuracy, but only slightly. In 7 of the 11 months, RTM produced a higher PAI value than KDE. KDE resulted in a higher PAI value in 4 of the 11 months. The average PAI value for RTM across all months was 3.61 (SD = 1.16), and the average PAI value for KDE across all months was 3.11 (SD = 0.69). However, the results of an independent samples t-test suggest that the differences were not statistically significant. PAI values were highest when employing an approach that identified locations that could be considered as both hotspots using KDE, and risky using RTM. This integrated approach produced the highest PAI values in 8 of the 11 time periods. The average PAI value for the integrated approach across monthly periods was 7.18 (SD = 6.06), twice as high as KDE or RTM alone.
Proportion meta-analysis of predictive accuracy
Next, we performed a proportion meta-analysis on studies where the relevant data were available. Studies were excluded when the data was not reported in a format to calculate a proportion (e.g., a numerator and denominator were not reported, or the only outcome measure was an odds ratio) leaving 16 studies. This was appropriate to carry out a proportion meta-analysis. An I2 test for heterogeneity indicated considerable inconsistency (I2 > 99%). This statistic describes the percentage of variation that is due to heterogeneity rather than chance. Heterogeneity was to be expected considering the different crime types and settings across the included studies. Therefore, a random effects model was used in order to minimize the effect of heterogeneity among studies. As a random effects model was used it was appropriate for each study to be weighted by the inverse of its variance (including both the within studies variance plus the between studies variance). A forest plot was constructed showing the individual study results and weights (demonstrating the influence of each study on the weighted average) of the individual studies, together with 95% CIs.
Figure 1 presents the meta-analytical proportion of cases accurately predicted by RTM in the top 10% of risk cells was 44.7%, 95% CI = [38.26, 51.1]. The proportions ranged from 22.5 to 85.1%.

Pooled proportion of cases accurately predicted by RTM in the top 10% of risk cells. Each box represents the estimate of the proportion within a study and its area is proportional to the weight of the study. The horizontal solid lines represent 95% confidence intervals
Discussion
To our knowledge, this is the first study that has systematically summarised the available evidence for the predictive accuracy of RTM. We used a systematic literature review and proportion meta-analysis approach to estimate the proportion of future cases accurately predicted by high risk cells. This study has demonstrated that RTM is an effective spatial diagnostic and forecasting method that can be applied to identify places at greatest risk of an event and can be a useful tool in guiding targeted responses to crime problems. RTM reliably identifies problematic features that exacerbate the likelihood of future crimes in a given geographic area. The detection of these areas helps prioritise efficient police patrols and other preventative and deterrent measures. In this way, RTM guides efficient resource allocation. It not only identifies potential hot-spots, but provides a reasoning for why they are ‘hot’ in the first place. Importantly RTM, can also predict where crime may displace to, based on relatively stable environmental and contextual risk factors that go beyond incident-based data. RTM can also be applied to a variety of crime types and has been shown to be an effective forecasting method for a range of acquisitive crimes, violent crimes, terrorist incidents, child maltreatment, traffic incidents, drug related crime and organised crime. The systematic review demonstrated that RTM has been successful in identifying at risk places for acquisitive crimes, violent crimes, child maltreatment, terrorism, drug related crimes and DWI. The proportion meta-analysis indicated that almost half of future cases in the studies analysed were captured in the top ten per cent of risk cells. This typically covers a very small portion of the full study area.
RTM as an overall approach is relatively simple and user-friendly, and the associated RTMDx software provides an opportunity for practitioners to readily utilize the approach with minimal resources and time spent on learning new processes. This means that it is within the reach of many operational crime analysts in practical law enforcement settings. Police often try to predict where future crime will occur by looking at past crime locations, and then determine the allocation of resources accordingly. These retrospective analyses, such as KDE, cannot consider the influence of underlying social and physical factors. The additional characteristics determined by RTM allow for more accurate predictions of future crime locations and can improve the allocation of police resources to designated areas with higher predicted levels of criminal activity. As it is possible to identify the correlates of the criminal events, due to the diagnostic focus on the risk factors, targeted countermeasures can be designed (Caplan & Kennedy, 2016). Further, crime doesn’t have to be included as a risk factor to create an RTM and can indicate risky areas based on crime generators and attractors.
A key limitation of RTM is that it does not address temporal variations in crime locations (over the course of day, duration of a week, over different seasons, etc.) Another limitation of RTM in general is that it may identify areas as being risky where crime may never emerge. It cannot be assumed that because a location is high in risk according to identified risk factors, that crime will always ensue—there can be numerous areas identified as risky, but no crime may actually occur in these defined risky areas. This is an avenue for future research. There is also a need to evaluate interventions put in place that are based on areas that have been identified using RTM as risky.
The findings from this systematic review reiterate Van Patten et al., (2009), Kennedy et al., (2011), and Caplan, Kennedy, and Piza (2013) who assert that RTM and KDE should be used jointly. This review suggests that the predictive strength of RTM, and in turn the practical utility of the method, may be enhanced when it is considered in conjunction with other spatial analysis techniques, such as KDE. Hotspots tend to change over time, so whilst the presence of previous crime can be a reasonable predictor of future crimes, it cannot forecast the spatial distribution of where crime might emerge. It is important to consider both the spatial distribution of past crime and to identify correlates of events to most accurately forecast where future crime incidents are likely to occur.
Whilst the synthesised results do point towards RTM's impressive predictive capabilities, some care should be taken in interpretation, as with all crime and place research. First, there is a great deal of variance across a limited number of studies. Further investigation is warranted to understand the study-level features which might contribute toward greater model performance. For the meta-analysis, only 16 studies had the data reported in a format to calculate a proportion, meaning the results of 9 studies were not included. The heterogeneity associated with the meta-analysis estimates was very high, indicating that the summary estimates must be interpreted with caution. RTM has been applied to a wide number of crime types and the spatial features examined vary from study to study. Further research is needed for each to enable subgroup meta-analyses for the different crime types.
Second, as the studies included in this paper were selected carefully from peer-reviewed journals, there might be a risk of publication bias. Studies that fail to demonstrate impressive or meaningful results may be less likely to get published and therefore fall out of our rigorous search strategy. The field of psychology is undergoing an open science revolution on the back of similar concerns regarding replicability and other associated endemic problems. Criminology, and therefore RTM, will not be immune to such problems. A greater cultural emphasis on behaviours such as pre-registration of analyses, provision of data and code would go some way toward mitigating these problems. Third, RTM is still an emerging method. Whilst 25 studies appears a lot, and certainly sufficiently large for a systematic review, the truth also remains that these 25 studies have looked at 12 different crime types. A lot more research is needed before we can get specific about which crime types, and contexts (e.g. urban vs. rural), RTM works best in. Additionally, our focus was on RTM’s predictive accuracy and forecasting capabilities. RTM’s function goes beyond prediction and includes diagnostic approaches to understanding crime occurrence in a given location. Future systematic reviews and meta-analyses might seek to synthesise this neighbouring evidence base.
Notes
See Hefner, J. (2013). Statistics of the RTMDx Utility. In J. Caplan, L. Kennedy, and E. Piza, Risk Terrain Modeling Diagnostics Utility User Manual (Version 1.0). Newark, NJ: Rutgers Center on Public Security.
This information regarding KDE was taken from Marchment’s doctoral thesis, which uses the same data as Marchment et al., (2019).
References
Anyinam, C. (2015). Using risk terrain modeling technique to identify places with the greatest risk for violent crimes in new haven. Crime Mapping and Analysis News.
Block, R., & Block, C. R. (2004). Spatial and temporal analysis of crime (STAC). In N. Levine (Ed.), CrimeStat III: A spatial statistics program for the analysis of crime incident locations. Houston: Ned Levine & Associates. Washington, DC: The National Institute of Justice.
Bowers, K. (2014). Risky facilities: Crime radiators or crime absorbers? A comparison of internal and external levels of theft. Journal of Quantitative Criminology, 30(3), 389–414.
Braga, A. A., Papachristos, A. V., & Hureau, D. M. (2014). The effects of hot spots policing on crime: An updated systematic review and meta-analysis. Justice Quarterly, 31(4), 633–663.
Brantingham, P. L., & Brantingham, P. J. (1993). Environment, routine and situation: Toward a pattern theory of crime. Advances in Criminological Theory, 5(2), 259–294.
Campbell Collaboration. (2017). Campbell systematic reviews: Policies and guidelines.
Caplan, J. M. (2011). Mapping the spatial influence of crime correlates: A comparison of operationalization schemes and implications for crime analysis and criminal justice practice. Cityscape., 13, 57–83.
Caplan, J. M., & Kennedy, L. W. (2010). Risk terrain modeling manual. Rutgers Center on Public Security.
Caplan, J. M. & Kennedy, L. W. (2013). Risk Terrain Modeling Diagnostics Utility (Version 1.0). Rutgers Center on Public Security, Newark, NJ.
Caplan, J. M., & Kennedy, L. W. (2016). Risk terrain modeling: Crime prediction and risk reduction. Oakland: University of California Press.
Caplan, J. M., Kennedy, L. W., & Miller, J. (2011). Risk terrain modeling: Brokering criminological theory and GIS methods for crime forecasting. Justice Quarterly, 28(2), 360–381.
Caplan, J. M., Kennedy, L. W., & Piza, E. L. (2013a). Joint utility of event-dependent and environmental crime analysis techniques for violent crime forecasting. Crime & Delinquency, 59(2), 243–270.
Caplan, J. M., Kennedy, L. W., & Piza, E. L. (2013b). Risk Terrain Modeling Diagnostics Utility User Manual. Rutgers Center on Public Security.
Caplan, J. M., Kennedy, L. W., Piza, E. L., & Barnum, J. D. (2020). Using vulnerability and exposure to improve robbery prediction and target area selection. Applied Spatial Analysis and Policy, 13(1), 113–136.
Chainey, S., Tompson, L., & Uhlig, S. (2008). The utility of hotspot mapping for predicting spatial patterns of crime. Security Journal, 21(1–2), 4–28.
Daley, D., Bachmann, M., Bachmann, B. A., Pedigo, C., Bui, M. T., & Coffman, J. (2016). Risk terrain modeling predicts child maltreatment. Child Abuse & Neglect, 62, 29–38.
Davies, T., & Johnson, S. D. (2015). Examining the relationship between road structure and burglary risk via quantitative network analysis. Journal of Quantitative Criminology, 31(3), 481–507.
Drawve, G. (2016). A metric comparison of predictive hot spot techniques and RTM. Justice Quarterly, 33(3), 369–397.
Drawve, G., Thomas, S. A., & Walker, J. T. (2016). Bringing the physical environment back into neighborhood research: The utility of RTM for developing an aggregate neighborhood risk of crime measure. Journal of Criminal Justice, 44, 21–29.
Dugato, M. (2013). Assessing the validity of risk terrain modeling in a European city: Preventing robberies in the city of Milan.
Dugato, M., Calderoni, F., & Berlusconi, G. (2017). Forecasting organized crime homicides: risk terrain modeling of camorra violence in Naples, Italy. Journal of Interpersonal Violence, 0886260517712275.
Dugato, M., Favarin, S., & Bosisio, A. (2018). Isolating target and neighbourhood vulnerabilities in crime forecasting. European Journal on Criminal Policy and Research, 24(4), 393–415.
Escudero, J. A., & Ramírez, B. (2018). Risk terrain modeling for monitoring illicit drugs markets across Bogota, Colombia. Crime Science, 7(1), 3.
Garnier, S., Caplan, J. M., & Kennedy, L. W. (2018). Predicting dynamical crime distribution from environmental and social influences. Frontiers in Applied Mathematics and Statistics, 4, 13.
Giménez-Santana, A., Medina-Sarmiento, J. E., & Miró-Llinares, F. (2018a). Risk terrain modeling for road safety: Identifying crash-related environmental factors in the province of Cádiz, Spain. European Journal on Criminal Policy and Research, 24(4), 451–467.
Giménez-Santana, A., Caplan, J. M., & Drawve, G. (2018b). Risk terrain modeling and socio-economic stratification: Identifying risky places for violent crime victimization in Bogotá, Colombia. European Journal on Criminal Policy and Research, 24(4), 417–431.
Hefner, J. (2013). Statistics of the RTMDx Utility. In J. Caplan, L. Kennedy, and E. Piza, Risk Terrain Modeling Diagnostics Utility User Manual (Version 1.0). Newark, NJ: Rutgers Center on Public Security.
Johnson, S. D., & Bowers, K. J. (2010). Permeability and burglary risk: Are cul-de-sacs safer? Journal of Quantitative Criminology, 26(1), 89–111.
Kennedy, L. W., Caplan, J. M., & Piza, E. (2011). Risk clusters, hotspots, and spatial intelligence: Risk terrain modeling as an algorithm for police resource allocation strategies. Journal of Quantitative Criminology, 27(3), 339–362.
Kennedy, L. W., Caplan, J. M., Piza, E. L., & Buccine-Schraeder, H. (2016). Vulnerability and exposure to crime: Applying risk terrain modeling to the study of assault in Chicago. Applied Spatial Analysis and Policy, 9(4), 529–548.
Kocher, M., & Leitner, M. (2015). Forecasting of crime events applying risk terrain modeling. GI_Forum, Journal of Geographic Information.
Levine, N. (2004). CrimeStat III: a spatial statistics program for the analysis of crime incident locations (version 3.0). Houston (TX): Ned Levine & Associates/Washington, DC: National Institute of Justice.
Marchment, Z., Gill, P., & Morrison, J. (2019). Risk Factors for Violent Dissident Republican Incidents in Belfast: A Comparison of Bombings and Bomb Hoaxes. Journal of Quantitative Criminology, 1–20.
Ohyama, T., & Amemiya, M. (2018). Applying crime prediction techniques to Japan: A comparison between risk terrain modeling and other methods. European Journal on Criminal Policy and Research, 24(4), 469–487.
Onat, I., & Gul, Z. (2018). Terrorism risk forecasting by ideology. European Journal on Criminal Policy and Research, 24(4), 433–449.
Onat, I., Akca, D., & Bastug, M. F. (2018). Risk Terrains of Illicit Drug Activities in Durham Region, Ontario. Canadian Journal of Criminology and Criminal Justice, 60(4), 537–565.
Taylor, R. B., & Harrell, A. (1996). Physical environment and crime. US Department of Justice, Office of Justice Programs. Washington, DC: The National Institute of Justice.
Valasik, M. (2018). Gang violence predictability: Using risk terrain modeling to study gang homicides and gang assaults in East Los Angeles. Journal of Criminal Justice, 58, 10–21.
Valasik, M., Brault, E. E., & Martinez, S. M. (2019). Forecasting homicide in the red stick: Risk terrain modeling and the spatial influence of urban blight on lethal violence in Baton Rouge, Louisiana. Social Science Research, 80, 186–201.
Van Patten, I. T., McKeldin-Coner, J., & Cox, D. (2009). A microspatial analysis of robbery: Prospective hot spotting in a small city. Crime Mapping, 1, 7–32.
Yerxa, M. (2013). Evaluating the temporal parameters of risk terrain modeling with residential burglary. Crime Mapping: A Journal of Research and Practice, 5(1), 7–38.
Funding
This work was funded by Newark Public Safety Collaborative.
Author information
Authors and Affiliations
Contributions
Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Marchment, Z., Gill, P. Systematic review and meta-analysis of risk terrain modelling (RTM) as a spatial forecasting method. Crime Sci 10, 12 (2021). https://doi.org/10.1186/s40163-021-00149-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40163-021-00149-6