
Abstract
Identification and characterization of farming systems simplify huge diversity of farm types in complex agro-ecosystems, which is of critical importance for precise technological intervention and informed policy support. Multivariate statistical techniques like Principal Component Analysis (PCA) and Cluster Analysis (CA) may be used for a wide variety of situations associated with farm typology delineation. The present study conducted in coastal saline India demonstratively established the usefulness of such methodology in identification of predominant farm types and their characterization. Data collected from 144 farm households through questionnaire survey could identify four predominant farm types with differential income sources and resource-base. The methodological perspective employed in the study may be used as a decision support tool by extension agencies. On other hand, a differentiated, holistic and broad-based extension intervention with suitable institutional arrangement will be needed to address the need of these identified farm types. This will lead to a reduced transaction cost of the agricultural research and extension systems in diverse ecosystems in India and many similar situations in the developing countries.
Similar content being viewed by others


Background
Adoption of new technologies in agriculture is of central interest to both academicians and policy makers since this is directly related to the efficiency of an agricultural research and extension system (Bozeman [2000]). Higher adoption ensures higher return on investment in research and development and creates a cycle of production-led impact on economy and rural livelihoods. Unfortunately, there are numerous examples of technologies with great potential that have not been accepted by farmers, especially the smallholders of the developing countries. Quite often, these technologies do not fit well into heterogeneous smallholder systems, which need specific technological solutions. Such inherent variability often influences farmers’ response to various technologies that aim at improving farm productivity and natural resource management (Lal et al. [2001]; Emtage and Suh [2005]). Unfortunately, both in agricultural and social sciences, complexity and diversity has been under-perceived and undervalued resulting in their neglect, under-estimation and exclusion from government statistics and policy framework (Chambers et al. [1989]). The archetypal Green Revolution technologies and ‘transfer-of-technology’ paradigm has also historically failed to cater to the needs of these diverse resource-poor agro-ecosystems in the developing countries (Pender and Hazell [2001]). Extension offered blanket recommendation for wide geographical areas and was largely used as a deterministic ‘dart gun’ (Roling [1988]), i.e. ‘take the technology and transfer it to farmers’. The heterogeneity of the farming systems for which different technologies are needed, has been ruefully ignored.
Thus, study of farm typology is of practical interest for precise and effective technological interventions. Farm typology study recognizes that farmers are not a monolithic group and face differential constraints in their farming decisions depending on the resources available to them and their lifestyle (Soule [2001]). Ellis ([1993]) observes that small farmers are always and everywhere typified by internal variations along many lines. Although every farm and farmer is unique in nature, they can be clustered into roughly homogeneous groups. Developing a typology constitutes an essential step in any realistic evaluation of constraints and opportunities that farmers face and helps forwarding appropriate technological solutions, policy interventions (Ganpat and Bekele [2001], Timothy [1994]; Vanclay [2005]), and comprehensive environmental assessment (Andersen et al. [2009]). Moreover, typology studies are of paramount importance for understanding the factors that explain the adoption and/or rejection of new technologies (Kostrowicki [1977]; Mahapatra and Mitchell [2001]).
The heterogeneity of farming systems are created by a host of biophysical (e.g. climate, soil fertility, slope etc.) and socio-economic (e.g. preferences, prices, production objectives etc.) factors (Ojiem et al. [2006]). Researchers have examined factors such as farm resources such as cash and labor (Tittonell et al. [2007]), infrastructure such as agency and markets (Tittonell et al. [2006]), management practices (Tittonell et al. [2005]) and technological level (Gómez-Limón et al. [2007]). Few others have used string of factors together to explain the heterogeneity of farming systems (Ojiem et al. [2006]; Bidogeza et al. [2009]; Guto et al. [2010]; Tittonell et al. [2010]; Rowe et al. [2006]). The selection of factors that define farm typology varies greatly from study to study and may be governed by the purpose of research. For example, farm typologies were used to study appropriate fertilizer application (Tittonell et al. [2006]), resource use efficiency (Zingore [2007]; Tittonell et al. [2007]), water use efficiency (Senthilkumar et al. 2009), or overall classification of farm types (Bidogeza et al. [2009]), IPM (Leeson et al. [1999]) and may sometimes be crop specific in nature (Mwijage et al. [2009]; Reckling [2011]). Most of the farm typology study has focused on socio-economic and agro-ecological factors for classification of farms. Economic factors have been less used, especially in small-scale studies, for classifying farms (USDA, ERS [2000]; Briggeman et al. [2007]; Andersen [2009]). With economic characterization of farms as the objective at hand, the present study assumes that classification of farms based on economic returns from farm enterprises, along with other related non-economic factors, will give more effective insights into the farm type identification.
Indian farmers are heterogeneous in terms of agro-ecology and resource endowments and the transfer of appropriate technology requires careful targeting. This problem is exacerbated in complex-diverse-risk-prone coastal agro-ecosystems of the country covering approximately 10 Mha cultivated area, which is characterized by a host of bio-physical and socio-economic constraints coupled with diversity in livelihoods. At present, agricultural research is based on primarily 15 agro-climatic zones and 127 sub-regions based on comprehensive research review of states (Khanna [1989]). Socio-economic and structural factors are not reflected in such classifications. Economists classify farmers based on landholdings, which is not comprehensive enough for classifying complex farming systems. Indian Council of Agricultural Research (ICAR) used several factors for classification of farming systems, but the bases were more discussion-based with limited statistical applications, perhaps due to functional purpose of the classification (Sanjeev et al. [2010]).
At the micro level, classification of farmers might be of practical use for localized technological solutions and extension support. During the height of farming system research and extension paradigm, conceptualization of recommendation domain wanted to address this issue. A recommendation domain is a group of farmers whose circumstances are similar enough that they are eligible for the same recommendation (Harrington and Trip [1984]). This led to informed decisions in part of technology managers and higher rate of technology integration in smallholder systems. Classification of farming situation by the farmers has also been suggested by some authors (Conroy and Sutherland [2004]; Goswami et al. [2012]). However, these were more project-based and were hardly mainstreamed in the national research and extension systems in the developing countries (Frankenberger et al. [1989]), India being no exception. Participatory research is not mainstreamed in National Agricultural Research System in India and state-owned monolithic extension system is not prepared to deal with the need of small farms in diverse ecosystems (Glendenning et al. [2010]). This leads to poor adoption of technology and large yield gap (Aggarwal et al. [2008]). Extension support and policy intervention also suffers due to lack of informed decision by public extension. Although there has been experimentation with reorganized and decentralized systems of technology assessment and refinement and revitalized public extension systems, development of sound analytical tools for targeting extension has remained undermined till date. A sound methodology for profiling farm typologies will help in rapid transfer of appropriate technology, precise extension support and development of policy environment sensitive to immense diversity of smallholder farms in coastal saline India.
Macro-economic perspective on this systematic problem leads us to the examination of efficiency in agricultural research and extension system. Ruttan and Hayami ([1984]) cites the shortcomings of ‘induced innovation’ model (Hayami and Ruttan [1981]) that considers factor prices and user demand to induce the development of appropriate technology and the widely cited ‘diffusion of innovations’ theory (Rogers [1962], [1995]) that assumes diffusion to have taken place in an institutional vacuum. Unlike the neoclassical theory in economics, New Institutional Economics recognized the importance of institutions in explaining uneven performance of economies (North [1997]) and suggested that this type of analysis can lead to the necessary institutional developments vis-à-vis technical developments generated by R&D systems (Kydd [2002]). Within the extension science literature, responses could be traced in the form of Agricultural Knowledge and Information System (AKIS) concept (Engel [1995]) that sees agricultural innovation as a function of multi-stakeholder process. Roling ([1988]) departed from Rogers’ theory towards a precise technological targeting and drew on the marketing research tradition (Kotler [1986]) for the same.
Increasing focus on the role of institutions in differential economic growth has now added new dimension to the study of technology transfer and appropriate technology (Hall and Yoganand [2004]; Radulovic [2005]). New Institutional Economics (NIE) that makes explicit considerations of institutional arrangement and institutional environment (North [1997]; Williamson [1990]), are now frequently drawn on in the literature on efficient extension mechanisms (that reduces transaction cost and enhances economic efficiency) (Birner and Anderson [2007]; Kherallah and Kirsten [2002]). However, the application of NIE was mostly focused on the budgetary constraints and institutional evolution, markets, and institutional development (Pal et al. [2003]). Methodology for identification of farm types for precise technological intervention and policy support, if mainstreamed, may be beneficial to the institutional arrangement that reduces transaction cost in smallholder agricultural production by providing appropriate technology to the smallholders rapidly. This is even more important in the regime of open economy where smallholders will have to be served with less transaction cost for long-term economic and environmental sustainability.
The present study was undertaken to identify the predominant farm types in coastal agro-ecosystem of India and to characterize them by some important socio-economic indicators. The article demonstrates the methodology of farm typology study when farming systems are heterogeneous and in need of appropriate technology for agricultural sustainability.
Methods
Area of the study
West Bengal is an eastern state of India and one of the major players in agricultural production. It has a high population density (976 per sq km) and varied farming systems. Agriculture is the mainstay of rural livelihoods and nearly 90% of the cultivators are small and marginal farmers jointly holding 84% of the State’s agricultural lands. Another 3 million landless families have earned the right to cultivate and grow crops on their own land after enactment of Operation Barga system (land reform movement) by the State Government (GoWB [2005]). The high population density has resulted in unabated fragmentation of cultivable land and insufficient farm size to sustain livelihoods. Moreover, increase in the price of agricultural inputs, uncertain price of perishable agricultural produce, inadequate market infrastructure, distress sale of produce by small and marginal farmers are some of the problems that pose serious challenges to sustainability of farm sector in the state. The socio-economic condition of the farming community is declining in the absence of appropriate technical, social, financial and market interventions (NABCOM [2009]).
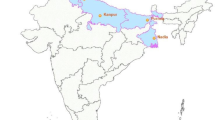
Based on climate, soil and physiography, there are six agro-climatic Zones for West Bengal. Among these, South 24 Parganas district comes under Coastal Saline Zone (Figure 1) (Gajbhiye and Mandal [2008]), one of the biggest Zones with high cropping intensity (143%) i.e. the ratio of gross and net cultivated area in percentage terms, and covering part or whole of 6 districts of West Bengal. Climate is tropical moist sub-humid with 1796.2 mm rainfall, and wide range of air temperature (maximum 35.0°C, minimum 15.6°C). Rice is the main crop grown over different land terrains and seasons. Aus (spring paddy), sesame and green gram in pre-kharif (early wet season), jute and aman rice in kharif (wet season) and wheat, different oilseeds and pulses, and potato in rabi (winter season) are important crops. South 24 Parganas (22°32′N to 22.53°N & 88°20′E to 88.33°E) has an area of 8165.05 km2 with population of 81,53,176 (sixth highest in India), of which 74.39% stay in rural areas. Percentage of households below the poverty line is 37.21, much higher than the state and country average (26% and 29%). The district is one of the poor districts of West Bengal having large number of resource poor farmers. Natural resource is fragile and highly prone to degradation.

Study locations in South 24 Parganas district of West Bengal, India (shown by red circles).
Joynagar II, Baruipur, Basanti and Gosaba, the sampled Community Development Blocks, are distributed across the middle and eastern part of the district (Figure 1). Percentage of cropped and irrigated area of the district was 393.47 thousand ha and 98.31 thousand ha in 2006-07. Net cropped area of the district is 3,72,290 hectares, decreasing slowly due to the conversion of agricultural land for other purposes. Production of food grain, pulse and oilseed, vegetables and fruits has registered a growth in recent years (GoWB [2005]).
The district is characterized by complex, diverse and risk-prone ecosystem, which is perturbed by extreme climatic events, water logging in low lands for considerable part of the year and soil salinity in winter and summer months resulting in dearth of appropriate technology for the district. Population density has risen rapidly over the last decade, with 819 people per km2 arable land (2011 Census) and at a growth rate of 18.05% between 2001 and 2011 (GoWB [2005]). Sustainable use of natural resources in the face of high population density and ecosystem fragility is critically important for the region. Overexploitation of natural resources is overwhelming in this district. Farming has diversified greatly over recent years (Ghosh and Kuri [2005]) and technological intervention with appropriate technology has become critically challenging to the extension system. That is why classification of farming systems is a pragmatic starting point for facilitating appropriate technology in this region.
Samplinga
Following the guidelines of Indian Agricultural Statistical Research Institute, data collection was organized using a multi-stage random sample survey method (Sukhatme et al. [1984]). Four blocks (namely Joynagar II, Baruipur, Basanti and Gosaba) were randomly selected from 29 blocks of South 24 Parganas district. Then, three villages from each of the block and 12 farmers from each of the village were selected randomly. Care was taken that four farmers each were selected from marginal-small (2.50-7.50 bigha), medium (7.50-12.00 bigha) and large (>12.00 bigha) categories (1 bigha = 0.13 ha). A quick survey of these 144 households was conducted with a focus on socio-economic information and income of the farms from different farm enterprises. This data was used for identification of predominant farm types for the region. After the identification of predominant farm types, half of the members from each of the identified farm types were selected randomly and were interviewed in details for eliciting additional socio-economic and farm management related information (to be used for characterization). Thus, a total of 72 farmers were interviewed in details for characterization of farm types. This helped us to avoid detailed and time-consuming interviewing with all 144 respondents.
Data
Instead of conducting a conventional way of identifying and characterizing farming system based on the source of the highest gross income received (from crops, vegetables, fruits and orchard, livestock, dairy, fishery, and poultry), the study employed multivariate statistics for identification of farm types and their characterization. Data were collected in two phases as mentioned in Sampling section.
Based on an extensive literature survey (Dixon et al. [2001]; Fliegel et al. [1968]; Mohammad [1978]; Singh et al. [1993]), initial case explorations in the field and expert counsel, a structured interview schedule was developed for the study. Apart from socio-economic parameters of the households, farm size, infrastructural facilities, information on cost of cultivation and yield of different crops, and price received by the farmers were included in the data collection instrument. The draft interview schedule was then pre-tested on 20 non-sampled respondents to incorporate necessary modifications. Description and measurement of some of the variables used in the study is given in Table 1.
Data were collected during May-June 2012 through personal interview method from 144 sampled households for quick survey in the first phase followed by a detailed survey on 72 respondents in the second phase. The dataset was prepared and analyzed using SPSS 17 (SPSS Version 17, SPSS Inc., Chicago, Illinois) and XLSTAT 2012 software (Version 2012, Addinsoft, Inc., Brooklyn, NY, USA).
Statistical analysis
Both univariate descriptive statistics and multivariate statistical techniques were employed for the analysis of data. Multivariate statistical techniques have been widely used for farm typology and characterization study (Kobrich et al. [2003]; Andersen et al. [2009]; Guto et al. [2010]). These statistical techniques allow us creating farm typologies, particularly when an in-depth database is available. The combination of principal component analysis for necessary reduction of the number of variables followed by cluster analysis to identify typical farm households was used. Similar examples may be drawn from Gebauer ([1987]) in Germany that employs cluster analysis; Jolly ([1988]) in Senegal that employs canonical-discriminant analysis for identification of recommendation domains; Orr and Jere ([1999]) in Malawi employing cluster analysis followed by profiling through discriminant analysis; Hardiman et al. ([1990]) in China using cluster analysis; Köbrich et al. ([2003]) in Chile and Pakistan and Usai et al. ([2006]) in Sardinia, both using principal component analysis and successive cluster analysis.
For the present study, farm household typologies were identified by using two sequential multivariate statistical techniques: principal component analysis (PCA) and cluster analysis (CA) (Ding and He [2004]). PCA condenses the information from the interdependent variables to a smaller set of factors (Jolliffe [2002]; Abdi [2007]). We used both socio-economic variables and income from different crop enterprises in the PCA. Since the impact of off-farm income on technology adoption is well-reported, the present study also used off-farm income as a factor for classification (Savadogo et al. [1998]; Nehring et al. [2005]; Fernandez-Cornejo et al. [2005]).
Factors were identified using orthogonal rotation (varimax method as in Kaiser [1970]; Gorsuch [1983]) so that a smaller number of highly-correlated variables might be put under each factor and interpretation becomes easier (Field [2005]). In accordance with Kaiser’s criterion, all factors exceeding an eigenvalue of one were retained (Kaiser [1970]). Kaiser’s criterion is accurate when the number of variables is less than 30 (Field [2005]), which was the case for our data set.
The sampled farms were clustered based on the five principal components identified by PCA. Cluster analysis is a collective term covering a wide variety of techniques for defining natural groups or clusters in data sets (Anderberg [1973]). These groups are relatively homogeneous within themselves and heterogeneous between each other based on a defined set of variables. In a word, it is the art of finding groups in data (Kaufman and Rousseeuw [1990]). Entities within a certain group or cluster are expected to be very similar to each other, and entities belonging to different classes are expected to be dissimilar (Bidogeza et al. [2009]).
To determine the number of clusters two steps were followed for clustering – the hierarchical method and K-means clustering method. For hierarchical clustering, Euclidian distance and Ward’s computation method was considered. The number of clusters retained from Ward’s method (four in our study) was used as starting values in the K-means method. Accordingly, the number of clusters that seemed most realistic and meaningful was chosen for the final solution.
In addition to CA, a one-way analysis of variance test was performed. The test allowed us to identify the differences in variance between clusters in terms of PC scores (Field [2005]). Thus, the variables that explained the largest differences between clusters could be identified.
Results and discussion
Description of the farming systems
Four major types of farms, based on the source from which maximum gross income was earned by the farmers, were identified. These were – rice-based farming system (34 households), vegetable-based farming system (70 households), fishery-based farming system (10 households) and farming system based on off-farm income (20 households). The farm size wise distribution of these farm types in four study Blocks has been reported in Figure 2.

Farmer category wise sub-farming systems in four study blocks of South 24 Parganas district.
A general observation revealed that large proportion of farmers followed rice-based farming systems, perhaps to grow rice for self-consumption and not for sale. On the other hand, medium farmers followed vegetable-based farming systems and marginal-small farmers relied on off-farm income sources. This might be due to the pressing need for income from their small holdings. Medium farmers could allocate enough land for vegetables after growing rice for subsistence purposes. However, vegetable-based farming systems were found across farm sizes, perhaps for their high economic return. Chili, tomato, brinjal, ladies finger, and cole crops were common in this part of the state (Basu et al. [2009]; Halder and Das [2012]). Fishery-based farming systems were found among medium and large farmers only, who could afford to spare land for water bodies, in case of dug pond, and invest in commercial fishery. Spatially, most of the vegetable-based systems were found in Joynagar-II Block followed by Baruipur Block. In Basanti and Gosaba Block, all types of farm were found. A considerable proportion of these farms earned large off-farm income.
Had we used the conventional method for identifying farm types, i.e. classification based on farm size or income sources of the farm, the diversity of farming systems would have been grossly underestimated. For example, it is difficult to understand the importance of fishery (only 10 households) and animal husbandry (only four households, not featured in Figure 2) in different farming systems if we go by the numbers in Table 2 only.
In all the four study blocks, a large number of sub-farming systems were found. These sub-farming systems were determined by unique combination of farm enterprises (Table 2). The label of enterprises in a given sub-system was given according to their contributions to the gross farm income. For example, ‘Rice + Jute + Vegetables’ sub-system denoted that Rice contributed highest to the farm income, followed by Jute and Vegetables. Number of sub-farming systems in Joynagar-II, Baruipur, Basanti and Gosaba Blocks were 18, 16, 16 and 18 respectively. This huge diversity in sub-farming systems (68 in no.) was inherent to the farms of this region and they ideally required specific extension interventions. However, in practice, it was difficult to address the needs of all these 68 sub-farming systems.
Since these sub-systems are huge in number and farm size or enterprise-based classification is oversimplification of farm heterogeneity, we followed an alternative methodology for identification of farm types and their characterization by employing a combination of PCA and CA with the derived principal components. The results of these multivariate analyses are described below.
The principal component analysis
Table 3 shows rotated factor (Varimax) matrix of independent variables with factor loadings for each variable. The communality column shows the total amount of variance of each variable retained in the factors. For the interpretation of the PCs, variables with high factor loadings and high communality were considered from the rotated factor matrix (Harris [2001]). In total, 17 variables were included in PCA, of which 5 principal components with eigenvalues greater than 1 were retained for further analysis. These five PCs explained 73.46% of total variability in the dataset. A closer look at each column of Table 3 helps us to define each component according to the strongly associated variables. The first component explains 27.78% variance and is correlated with the land holding, owned land, land fragment and income from rice crop. Thus the component represents land entitlement and income from rice crop. Principal component 2, 3, 4 and 5 explain 15.87%, 11.02%, 9.59% and 8.20% variance respectively. That means the first two factors have more importance in explaining the variance in dataset than the other three factors combined. PC 2 is correlated with crop diversification index and income from pulse, oilseed, fruits and plantation, representing crop and income diversification. PC 3 is correlated with income from poultry, fishery and family size, embodying the income from poultry and fishery enterprises driven by family labor. PC 4 represents off-farm income and PC 5, correlated with income from goatery and cattle, represents livestock enterprises. Thus the five principal components could be names as ‘land ownership and income from staple food’ (PC 1), ‘farm diversification’ (PC 2), ‘income from poultry and fishery’ (PC 3), ‘off-farm income’ (PC 4), and ‘income from livestock’ (PC 5).
The cluster analysis
The first five factors from the principal component analysis were used for hierarchical clustering using Euclidean Distance as distance measure and Ward’s technique as agglomerative clustering. The agglomeration schedule, resulting from this analysis, illustrated the sequence of analysis and produced coefficients. The objective of generating such schedule is to arrive at an appropriate number of clusters that best fit the data set. A check of the agglomeration schedule and Scree Diagram suggested that the number of clusters should be four. It was then checked that the number of retained clusters is realistic with respect to the field observation in order to be accepted as a meaningful classification. Thus, four clusters were found to be appropriate, as these seemed to be most representative of farm households within the study blocks. The k-means clustering method was employed with 4 numbers of clusters. The analysis produced final cluster centres (Table 4), and distribution of farms within a cluster among study blocks (Table 5) and size of farms (Table 6).
Final cluster centers interpret what is typical for a particular cluster. Cluster 1 is characterized by relatively higher income from poultry and fishery enterprises, has large holdings, and earns high from rice crop. Cluster 2 is characterized by higher diversification of farm income and Cluster 3 is characterized by smaller farms with higher off-farm income. Cluster 4 represents farms with higher income from livestock and other diverse sources such as rice, vegetables, poultry and fishery (Table 4). In all clusters, the contribution of several important crops and off-farm income could be observed.
Figures 3 & 4 (A, B) represents the observations and variables simultaneously in the two dimensional space. The individual farms have been labeled with study blocks (Figure 3A & B) and size category of farms (Figure 4A & B). The A series (3A & 4A) depicts the distribution of observations in a space defined by two principal components, after varimax rotation. The B series (3B & 4B) depicts the same along with the initial variables plotted in the form of vectors. Farms clustered (circled) together represent a farm type. A visual check suggests one group at the right and lower quadrant of the figure (Figure 3A), another clustered at the left lower quadrant, which is closer to the axis. The third one is also located at the left lower quadrant, but away from vertical axis. The scattered farms of upper right and left quadrants form the fourth group. A check of these Figures (3 & 4) in combination with Tables 5 and 6 helps us to understand this clustering better.

Distinct cluster of farms delineated by PCA axis and labeled by study blocks. A. Principal component analysis observations plot diagram of farming systems based on PCA of variables after varimax rotation. The numbers 1-4 on the plane indicate the community development blocks namely Joynagar II - 1, Baruipur - 2, Basanti - 3 and Gosaba - 4. The distance between the positions of the farms approximates the dissimilarity of their variables measured by Euclidean distance. Four circles/ovals represent four farm types. B. Ordination bi-plot diagram of farming system characterization based on PCA of variables. The numbers 1-4 on the plane indicate the community development blocks namely Joynagar II - 1, Baruipur - 2, Basanti - 3 and Gosaba - 4. Red dots represent variables used in PCA. The distance between the positions of the farms approximates the dissimilarity of their variables measured by Euclidean distance. Samples close to the origin have average values of a particular variable in a study sample.

Distinct cluster of farms delineated by PCA axis and labeled by size category of farms. A. Principal component analysis observations plot diagram of farming systems based on PCA of variables after varimax rotation. The numbers 1-3 on the plane indicate the different farm sizes – Marginal-Small - 1, Medium – 2, and Large - 3. The distance between the positions of the farms approximates the dissimilarity of their variables measured by Euclidean distance. Four circles/ovals represent four farm types. B. Ordination bi-plot diagram of farming system characterization based on PCA of variables. The numbers 1-3 on the plane indicate the different farm sizes – Marginal-Small - 1, Medium – 2, and Large - 3. Red dots represent variables used in PCA. The distance between the positions of the farms approximates the dissimilarity of their variables measured by Euclidean distance. Samples close to the origin have average values of a particular variable in a study sample.
Noticeably, type of farms is not specific to a study block. The labels ‘1’ , ‘2’ , ‘3’ and ‘4’ are scattered throughout the plot. However, in some places similar labels are clustered signifying similar farms within a Block. The findings from Figure 4A are even more interesting. Small and marginal farms labeled as ‘1’ are clustered together signifying their similarity in terms of a host of factors. Large farms labeled as ‘2’ are also found closely clustered. Instead, medium farms are scattered throughout the plot representing higher instrinsic variability of medium farms. The nearness of blue dots (individual farms) to the red dots (initial variables) shows the characteristics of those farms in terms of the variables (represented by red dots). A close look of both 3A and 4A provides better understanding of farm classification in the study areas.
It is observed that all the Cluster 1 farms (100%) are situated in Baruipur Bock (Table 5). Cluster 2 farms are predominant in Joynagar II (36.00%) and Gosaba (32.00%), Cluster 3 farms are distributed across the four study blocks and Cluster 4 farms are predominant (57.14%) in Joynagar II Block. The data suggest that Joynagar II Block is predominated by diversified farms, Baruipur and Basanti Blocks by smaller farms with higher off-farm income and Gosaba Block with diversified and smaller farms with off-farm income. The distribution of clusters across the study blocks differed significantly (Likelihood ratio sig. value = .00) indicating heterogeneous nature of farm types in these blocks.
From Table 6, it may be observed that marginal-small farms are mostly Cluster 3 farms (91.67%), i.e. smaller farms with higher off-farm income. Medium farms are Cluster 2 (56.52%) and Cluster 3 (30.43%) farms i.e. diversified farms and small farms with higher off-farm income. Noticeably, large farms are distributed across all clusters, perhaps due to their higher flexibility in allocation of land resources among different crops/enterprises. Alternatively, Cluster 1 farms are mostly (75.00%) large farms, Cluster II farms are largely Medium (56.52%) and Large (41.67%) farms, Cluster 3 farms are mostly Marginal-small farms (82.86%) and Cluster 4 farms are Large farms (71.43%). The distribution of clusters across the farm size differed significantly (Likelihood ratio sig. value = .00) indicating heterogeneous nature of farm types across farm sizes.
In some parts of West Bengal including South 24 Parganas district, departure from traditional cropping pattern has been a trend for the last one and half decades (Goswami [2007]; Bhattacharyya [2008]) for enhancing income from fragmented land resources, which are challenged by abiotic stresses (e.g. salinity). The number of smallholders has in fact increased in West Bengal (De [2003]) and there is evidence of increased crop diversity on fragmented lands in the state (De [2002]; Bagchi et al. [2012]). In many places, farmers have changed land shapes to grow vegetables in low lands (Basu et al. [2009]). Introduction of farm-ponds and land-shaping has also resulted in high cropping and income diversity among small farmers (Bahu and Mishra [2001]). Off-farm income has also become a burgeoning reality of rural India especially for the smallholders and this has often become the largest source of rural farm income. This also contributes to the investment in farming activity and asset creation (Mehta [2009]).
To examine the authenticity of the cluster analysis, a one-way analysis of variance for each principal component (equality of group means) was performed with the four clusters (Table 7). The more distinct a PC value is among groups, the lower is the p-value. Judging from the p-values, all the factors namely ‘land ownership and income from rice crop’ , ‘income from poultry and fishery’ , ‘off-farm income’ and ‘income from livestock’ found to be significant in differentiating the clusters (p = 0.00 for all factors). However, factor 2 characterized by ‘farm diversification’ was not significantly differing across identified clusters, although the p value was not far from significant (p = 0.09).
Characterization of identified farm types
Table 8 helps us to understand the characteristics of the clusters in terms of background variables and economic performance indicators of the farming systems.
Cluster I accounts for 5.63% of farm households. The cluster is comprised of households having large land holding, large family size (representing joint extended families), relatively higher family education, and relatively higher crop diversification (Col. 1, Table 8). The households both lease out and lease in land, land are highly fragmented and situated at a high distance from the dwellings. In terms of economic performance indicators, this cluster is characterized by relatively high system gross return, higher cost of cultivation and system net return and relatively higher cost-benefit ratio. These households, on an average, secured high income from rice crop, poultry and vegetables followed by fruits and fishery. They depended wholly on agriculture with no off-farm income. These farms may be supported for technically sound intensification of agriculture with assured input and advisory services. Since these groups pursue a capital intensive diversified farming, access to credit is important for them. The farmers may be assisted in commercial production techniques with provision for building requisite capacity in farm and non-farm based entrepreneurship (Folmer et al. [2010]). Export-oriented crops may be tried with these farmers with suitable incentive (Singh [2002]). Since these farms are capital and management intensive, they are prone to become environmentally unsustainable in the long run. An environmental monitoring mechanism is needed to be in place in addition to an incentivized system in favour of sustainable farming (Dhiman and Thambi [2009]).
Cluster II comprised of 35.21% of the farm households. The cluster members had relatively smaller land, smaller family size, relatively poor family education, and high crop diversification (Col 2, Table 8). These farms lease-in land and their fragmented lands are relatively nearer to their settlement. This cluster is characterized by low system gross return, low cost of cultivation, moderate system net return, but relatively better cost-benefit ratio. These households secured large proportion of income from vegetables, fishery, livestock and rice crop and may be grouped as diversified farms. These farms are management intensive, presumably supported by human labor, and pursue diversification in enterprises. Integrated farming with livestock and fishery will help in higher food and livelihood security without undermining farm resources (Prein [2002]). This will require specialized extension support with a farming system approach, and institutional convergence for sound planning (Nabi [2008]). Cash crops may be promoted for enhancing farm income with assured provision for credit and insurance (Fafchamps [1992]). On account of the large proportion of such farms, collectivization might be a viable strategy for their market integration (Hazell [2005]).
Cluster III comprises of 49.30% of the sampled farms. This cluster is characterized by small land holding, relatively poor family education, smaller family size and relatively low crop diversification (Col. 3, Table 8). These farms have started shifting to off-farm income to offset low income from farming. In terms of economic performance, this cluster is characterized by low system gross return, low cost of cultivation or low investment in farming, poor net return from farming, but higher benefit-cost ratio (since they invest less). The farm households earn most of their income from rice crop, vegetables and from off-farm sources. These are typical subsistence farms that have started to shift from traditional farming to non-farming vocations, often in the form of seasonal migration. Maintaining food security is a key policy goal for these farms, which may be achieved through sustainable and risk-averting cultivation of food grains (e.g. climate resilient agriculture) coupled with assured coverage under public distribution system for food grains (Thomas [2006]). This might be supplemented with a comprehensive capacity building programme on non-farm enterprises, since these people are poor in human resources and exploited in the labor markets in nearer towns (Deb et al. [2002]). Collectivization of small enterprises may follow this capacity building programme for their market integration.
Cluster IV comprises of 9.86% of the farm households. The cluster members had relatively larger land holding (owner cultivator), relatively larger family size, moderate family education, and moderate crop diversification (Col. 4, Table 8). They do not lease-in land, i.e. these farms represent owner cultivator who lease-out land occasionally. Land is highly fragmented. These households secure high income from rice crop, vegetables, and fishery and are characterized by high system gross return, high cost of cultivation, high system net return and relatively low benefit-cost ratio. The cluster members had little off-farm income. These farms are capital intensive, developed to meet growing food demand in the nearest town markets. Unlike Cluster I, these farms earn higher income from vegetables and fishery. These may be supported for intensive farming with improved technology. Since they specialize is in food grain and vegetables, assured marketing support and crop insurance are critical for these farms. Due to their available family labors, sustainable agriculture and agro-based enterprises also seem to be promising propositions (Bhattacharjee and Saravanan [2012]).
This farm typology classification offers clear advantages over classifications based on farm size or agro-ecological characteristics. The farm types delineated are manageable in number and represent both socio-economic, resource ownership and management orientation of the farms. Farm size-based classifications undermine the huge diversity among size classes and agro-ecological classification and ignore socio-economic realities of the farms. At the same time, the farm classes are based on sound statistical procedures instead of size-based classifications and, hence, more acceptable to policymakers.
The four farm types differed among themselves in terms of all studied parameters including a string of background variables, income sources and economic indicators, showing the efficiency of the classification methodology employed. The farm types, however, did not differ in terms of education index and cost-benefit ratio. Increasing dependence on costly external inputs has perhaps rendered an increase in cost of cultivation, relative to system net return, irrespective of farm types. Education was not an important means to classify farms, as access and control over natural resource was more important in differentiating farm types.
Conclusions and implications
The implications of the study may be illustrated in practical and academic terms. While the practical focus is on institutional arrangement and policy interventions, the academic focus has been on methodological insights gained and its possible upscaling.
The methodological implication and scope for modification and upscaling
The study departs from conventional methodology of economic characterization of predominant farming systems (classification based on land holding or discussion with stakeholders with little statistical rigor) in terms of at least two dimensions. First, it uses multivariate statistics for identification of farm types, and second, it uses a string of economic and non-economic variables for such classification. This methodology has reduced the time of data collection significantly, as quick survey was employed for farm type identification and only half of the households were interviewed in detail for their economic characterization. In-depth and comprehensive classification of farms was possible resulting in a manageable number of farm types (four) that could be taken up for appropriate policy and technological intervention.
The methodology employed in this study can be modified under different situations of farm typology study. The variables used for PCA may be different, based on the nature of agro-ecosystem, nature of agriculture practiced, objective of classification (nutrient management, irrigation intervention, credit support) etc. Variables may also vary when the focus of farm characterization is different from economic characterization only (e.g. these may be energy efficiency, ecological sustainability). The implication would also reflect in the development of data collection instruments to be used in quick and detailed survey. The process of variable selection may involve stakeholder participation, thus promoting popular participation in the study. The multivariate approach (algorithm) followed for the farm type delineation may also be used for the development of software or web-based decision support system. Separate modules in the software may be incorporated with flexible set of indicators under each of them. This may be used by research and extension agencies after rigorous multi-locational field testing.
Proposed institutional environment for technology transfer
The results from the analysis suggested four major farm types in the study areas – (i) capital-intensive large diversified farms with high economic efficiency, (ii) management-intensive, medium, diversified farms with moderate economic efficiency, (iii) small, subsistence farms with high off-farm income and high economic efficiency, and (iv) large diversified owner-cultivated farms with relatively lower economic efficiency. Smaller farms have inclined towards non-farm income more than the medium and large farms. On the other hand, medium and large farms have diversified more than smaller farms with a departure from grain-based systems to vegetable-based farming systems. This asks for a holistic farm planning and extension intervention than confining efforts to technology transfer alone. India, along with a large number of countries having agrarian society, has entered the open economy regime and need to establish economic efficiency for their smallholder system (Birner et al. [2009]). The extension system must precisely target agricultural inputs, advisory services, credit access and critical information for identified farm. The selection of beneficiaries for many public extension programs may also be guided by such farm typology.
To respond to the need of such comprehensive farm types, institutional innovation (development and/or convergence) often becomes necessary. In India, a nationwide revitalized extension system has just started functioning. It explicitly encourages such convergence in planning and execution of technology transfer programs. Linkage with existing donor supported and Ministry funded efforts might also lead to improved institutional environment. India is now experiencing a handful of flagship rural development programs that builds on constitutional provisions for basic services to its citizens and development of rural institutions (mostly in the form of rural collectives), and these may be efficiently tapped for effective transfer of agricultural technologies.
Extrapolation of the study outcome
The study does not necessarily claim to extrapolate the identified farm types to larger context. But, since the study locations are representative of coastal saline zone of India, this may be generalized for at least 10 Mha of cultivable lands with nearly 900 million people operating under this system. However, it is the methodology that is subject to generalization for even larger regions. India has almost 200 districts under complex agro-ecological systems covering a population of nearly 400 million. Integration of the methodology in the formal policy or in the form of web-based decision support tool may reach these people effectively. Need not to say, the same may be explored anywhere in the world using flexible and participatory indicator selection and their subsequent validation.
Endnote
aLogistic support during sampling and data collection was received from All India Coordinated Research Project on Integrated Farming System and academic research programme of Ramakrishna Mission Vivekananda University.
References
Abdi H: Discriminant Correspondence Analysis. In Encyclopedia of Measurement and Statistics. Edited by: Salkind NJ. Sage, Thousand Oaks, CA; 2007.
Aggarwal PK, Hebbar KB, Venugopalan MV, Rani S, Bala A, Biswal A, Wani SP: Quantification of yield gaps in rainfed rice, wheat, cotton and mustard in india. ICRISAT, Hyderabad; 2008.
Anderberg MR: Cluster Analysis for Applications. Academic, New York; 1973.
Andersen E: Regional Typologies Of Farming Systems Contexts, seamless Integrated Project, Eu 6th Framework Programme. 2009.
Andersen E, Elbersen B, Godeschalk F, Verhoog D: Farm management indicators and farm typologies as a basis for assessments in a changing policy environment. J Env Manage 2009, 82: 353–362.
Bagchi BD, Roy SB, Jaim WMH, Hossain M: Diversity, spatial distribution, and the process of adoption of improved rice varieties in West Bengal. In Adoption and diffusion of modern rice varieties in Bangladesh and eastern India. Edited by: Hossain M, Jaim WMH, Paris TR, Hardy B. IRRI, Philippines; 2012:31–44.
Bahu RR, Mishra P: Farm ponds in Coastal Saline Zone of West Bengal: a techno-economic feasibility study. J Agric Eng 2001, 38: 17–22.
Basu D, Banerjee S, Goswami R: Vegetable cultivation on ail (bund): a successful farmer-led technology transfer. Acta Hort 2009, 809: 155–160.
Bhattacharyya R: Crop Diversification: A Search For An Alternative Income Of The Farmers In The State Of West Bengal In India. 2008.
Bhattacharjee S, Saravanan R: Poverty In Natural Prosperity: Can Agriculture Bring The Renaissance In North-East India? In Saving Humanity Saving Humanity, Swami Vivekananda Perspective. Vivekanand Swadhyay Mandal. Edited by: Kashyap SK, Pathak A, Papnai G. GBPUAT, Pantnagar, India; 2012:260–274.
Bidogeza JC, Berentsen PBM, de Graaff J, Lansink AGJMO: A typology of farm households for the Umutara Province in Rwanda. Food Sec 2009, 1: 321–335.
Birner R, Anderson JR: How To Make Agricultural Extension Demand-Driven? The case of india’s agricultural extension. International Food Policy Research Institute, Washington DC; 2007.
Birner R, Davis K, Pender J, Nkonya E, Anandajayasekeram P, Ekboir J, Mbabu A, Spielman D, Horna D, Benin S, Kisamba-Mugerwa W: From best practice to best fit: a framework for designing and analyzing pluralistic agricultural advisory services worldwide. J Agric Edn Ext 2009, 15: 341–355.
Bozeman B: Technology transfer and public policy: a review of research and theory. Res Policy 2000, 29: 627–655.
Briggeman BC, Gray AW, Morehart MJ, Baker TG, Wilson CA: A new U.S. farm household typology: Implications for agricultural policy. Rev Agric Econ 2007, 29: 765–782.
Chambers R, Pacey A, Thrupp LA: Farmer First: Farmer Innovation And Agricultural Research. Intermediate Technology Publications, London; 1989.
Conroy C, Sutherland A: Participatory technology development with resource-poor farmers: maximising impact through the use of recommendation domains. ODI, London; 2004.
De UK: Economics Of Crop Diversification. Akansha Pub, House, New Delhi; 2002.
De UK: Diversification of crop in West Bengal: a spatio-temporal analysis. Artha Vijnana 2003, 42: 170–182.
Deb UK, Rao GN, Rao YM, Slater R: Diversification And Livelihood Options: A Study Of Two Villages In Andhra Pradesh, India. Department for International Development (DFID), United Kingdom; 2002.
Dhiman SC, Thambi DS: Ground water management in coastal areas. Bhu-Jal 2009, 24: 69–73.
Ding C, He X: K-Means Clustering Via Principal Component Analysis. Proceedings Of The Twenty-First International Conference On Machine Learning ᅟ, Banff, Canada; 2004. . Available via [http://ranger.uta.edu/~chqding/papers/KmeansPCA1.pdf]
Dixon J, Gulliver A, Gibbon D: Farming Systems and Poverty: Improving Farmers’ Livelihoods In A Changing World. FAO, Rome; 2001.
Ellis F: Peasant Economics: Farm Households and Agrarian Development. Cambridge University Press, Cambridge; 1993.
Emtage N, Suh J: Variations in socioeconomic characteristics, farming assets and livelihood systems of Leyte rural households. Ann Trop Res 2005, 27: 35–54.
Engel PGH: Facilitating Innovation: An Action-Oriented Approach and Participatory Methodology To Improve Innovative Social Practice In Agriculture. Wageningen Agricultural University, Dissertation; 1995.
Fafchamps M: Cash crop production, food price volatility, and rural market integration in the third world. Am J Agric Econ 1992, 74: 90–99.
Fernandez-Cornejo J, Hendricks C, Mishra A: Technology adoption and off-farm household income: the case of herbicide-tolerant soybeans. J Agric Appl Econ 2005, 37: 549–63.
Field A: Discovering Statistics Using Spss For Windows. Sage, London; 2005.
Fliegel F, Kivlin JE, Sekon GS: A cross-national comparison of farmers’ perceptions of innovations as related to adoption behavior. Rural Sociol 1968, 33: 437–449.
Folmer H, Dutta S, Oud H: Determinants of rural industrial entrepreneurship of farmers in West Bengal: a structural equations approach. Int Region Sc Rev 2010, 33(4):367–396.
Frankenberger TR, Dewalt BR, McArthur HJ, Hudgens RE, Mitawa G, Rerkasem K, Finan T, Butler Flora C, Young N: Identification of results of farming systems research and extension activities: a synthesis. FSRE Newsl 1989, 1: 8–10.
Gajbhiye KS, Mandal C: Agro–Ecological Zones, Their Soil Resource and Cropping Systems. 2008.
Ganpat W, Bekele I: Looking For The Trees In The Forest: Farm Typology As A Useful Tool In Defining Targets For Extension.In Proceedings of the 17th Annual Conference of the Association for International Agricultural and Extension Education Edited by: Lindner JR. ᅟ, Baton Rouge, Louisiana; 2001. . Available via [http://agris.fao.org/agris-search/search.do?f=2002/TT/TT02001.xml;TT2002001006]
Gebauer RH: Socio-economic classification of farm household - conceptual, methodical and empirical considerations. Eur Rev Agric Econ 1987, 14: 261–283.
Ghosh BK, Kuri PK: Changes in cropping pattern in West Bengal during 1970–71 to 2000–2001. IASSI Quart 2005, 24: 39–56.
Glendenning CJ, Babu S, Asenso-Okyere K: Review Of Agricultural Extension In India. Are Farmers Information Needs Being Met?. IFPRI, Washington DC; 2010.
Gómez-Limón JA, Berbel J, Arriaza M: MCDM Farm System Analysis For Public Management Of Irrigated Agriculture. In Handbook On Operations Research In Natural Resources In International Series In Operations Research And Management Science. Edited by: Weintraub A, Bjorndal T, Epstein R, Romero YC. Páginas, Kluwer, New York; 2007:93–114.
Gorsuch RL: Factor Analysis. Erlbaum, Hillsdale, NJ; 1983.
Goswami R: Understanding Farmer-To-Farmer Communication Within The Sustainable Rural Livelihood Framework. Dissertation, Bidhan Chandra Krishi Viswavidyalaya; 2007.
Goswami R, Biswas MS, Basu D: Validation of participatory farming situation identification: a case of rainfed rice cultivation in selected area of West Bengal, India. Ind J Tradition Knowl 2012, 11: 471–479.
Go WB: District Statistical Handbook. Bureau of Applied Economics & Statistics, Government of West Bengal, India; 2005.
Guto SN, Pypers P, Vanlauwe B, de Ridder N, Giller KE: Socio-ecological niches for minimum tillage and crop-residue retention in continuous maize cropping systems in smallholder farms of Central Kenya. Agron J 2010, 104: 188–198.
Halder JC, Das P: Present status and futuristic view of horticulture in West Bengal. Geo-Analyst 2012, 2(1):ᅟ. . Available via [http://gswb.in/wp-content/uploads/2012/08/v2n1jully2012_1.pdf]
Hall AJ, Yoganand B: New Institutional Arrangements In Agricultural Research And Development In Africa: Concepts And Case Studies. In Innovations In Innovation: Reflections On Partnership, Institutions And Learning. Edited by: Hall AJ, Sulaiman RV, Raina RS, Shambu Prasad C, Naik GC, Clark NG. International Crops Research Institute for the Semi-Arid Tropics/National Centre for Agricultural Economics and Policy Research, Andhra Pradesh/New Delhi; 2004:105–134.
Hardiman RT, Lacey R, Yang MY: Use of cluster analysis for identification and classification of farming systems in Qingyang County, Central North China. Agric Syst 1990, 33: 115–125.
Harrington LH, Tripp R: Recommendation domains: a framework for on-farm research. CIMMYT Economics Working Paper 02/84. Series: CIMMYT Economics Working Paper, CIMMYT, Mexico; 1984.
Harris RJ: A Primer Of Multivariate Statistics. Academic, New York; 2001.
Hayami Y, Ruttan VW: Agricultural Development: An International Perspective. Johns Hopkins University Press, Baltimore, USA; 1981.
Hazell PB: Is there a future for small farms? Agric Econ 2005, 32: 93–101.
Jolliffe IT: Principal Component Analysis. Springer Verlag, New York; 2002.
Jolly CM: The use of action variables in determining recommendation domains: senegalese farmers for research and. Agric Admin Ext 1988, 30: 253–267.
Kaiser HF: A second generation Little-Jiffy. Psychomelrika 1970, 35: 401–415.
Kaufman L, Rousseeuw PJ: Finding groups in data: an introduction to cluster analysis. Wiley, New York; 1990.
Khanna SS: The Agro-Climatic Approach. In Survey of Indian Agriculture. The Hindu, Madras, India; 1989:28–35.
Kherallah M, Kirsten JF: The New Institutional Economics: applications for agricultural policy research in developing countries. Agrekon 2002, 41: 111–134.
Kobrich C, Rehman T, Khan M: Typification of farming systems for constructing representative farm models: two illustrations of the application of multi-variate analyses in Chile and Pakistan. Agric Syst 2003, 76: 141–157.
Kostrowicki J: Agricultural typology concept and method. Agric Syst 1977, 2: 33–45.
Kotler P: Principles of Marketing. Prentice-Hall, Englewood Cliffs, NJ; 1986.
Kydd J: Agriculture And Rural Livelihoods: Is Globalisation Opening Or Blocking Paths Out Of Rural Poverty?. Overseas Development Institute (ODI), London, UK; 2002.
Lal P, Lim-Applegate H, Scoccimarro M: The adaptive decision making process as a tool for integrated natural resource management: focus, attitudes and approach. Conserv Ecol 2001, 5: 11.
Leeson JY, Sheard JW, Thomas AG: Multivariate classification of farming systems for use in integrated pest management studies. Can J Plant Sci 1999, 79: 647–654.
Mahapatra AK, Mitchell CP: Classifying tree planters and non planters in a subsistence farming system using a discriminant analytical approach. Agroforest Syst 2001, 52: 41–52.
Malik DP, Singh IJ: Crop diversification – an economic analysis. Ind J Agric Res 2002, 36: 61–64.
Mehta R: Rural Livelihood Diversification and Its Measurement Issues: Focus India. Wye City Group on Statistics On Rural Development And Agriculture Household Income, Second Meeting, at FAO HQ, Italy, Rome, 11–12 June 2009. 2009.
Mohammad A: Situation Of Agriculture, Food, And Nutrition In Rural India. Concept, New Delhi; 1978.
Mwijage NA, de Ridder N, Baijukya F, Pacini C, Giller EK: Exploring the variability among smallholder farms in the banana-based farming systems in Bukoba district, Northwest Tanzania. Afr J Agric Res 2009, 4: 1410–1426.
NABCOM (2009) State Agricultural Plan of Government of West Bengal. NABARD Consultancy Service Private Limited. Kolkata, India. Available via http://rkvy.nic.in/sap/wb/wb.pdf. Accessed 9 May 2013
Nabi R: Constraints to the adoption of rice-fish farming by smallholders in Bangladesh: a farming systems analysis. Aquacult Econ Manage 2008, 12: 145–153.
Nehring R, Fernandez-Cornejo J, Banker D: Off-farm labour and the structure of U.S. Agriculture: the case of Corn/Soybean farms. Appl Econ 2005, 10: 633–650.
North DC: Prologue In The Frontiers Of New Institutional Economics. In The Frontiers of The New Institutional Economics. Edited by: Drobak JN, Nye VCJ. Academic, New York; 1997.
Ojiem J, Ridder N, Vanlauwe B, Giller KE: Socio-ecological niche: a conceptual framework for integration of legumes in smallholder farming systems. Int J Agric Sust 2006, 4: 79–93.
Orr A, Jere P: Identifying smallholder target groups for IPM in southern Malawi. Int JPest Manage 1999, 45: 179–187.
Pal S, Mruthyunjaya J, Joshi PK, Saxena R: Institutional change in Indian agriculture. National Centre for Agricultural Economics and Policy Research. Indian Council of Agricultural Research, New Delhi; 2003.
Pender J, Hazell P: Promoting Sustainable Development In Less-Favored Areas, IFPRI Policy Brief, Focus 4. IFPRI, New York; 2001.
Prein M: Integration of aquaculture into crop–animal systems in Asia. Agric Syst 2002, 71: 127–146.
Radulovic V: Are new institutional economics enough? Promoting photovoltaics in India’s agricultural sector. En Policy 2005, 33: 1883–1899.
Reckling M: Characterisation of Bean Farming System Across Farm Types in Northern and Eastern Rwanda.: Identification Of Potential Niches For Legume Technologies. Dissertation, Wageningen University, The Netherlands; 2011.
Rogers EM: Diffusion of Innovations. The Free Press, New York; 1962.
Rogers EM: Diffusion of innovation. The Free Press, New York; 1995.
Roling N: Extension Science: Information Systems In Agricultural Development. Cambridge University Press, Cambridge; 1988.
Rowe EC, van Wijk MT, de Ridder N, Giller KE: Nutrient allocation strategies across a simplified heterogeneous African smallholder farm. Agric Ecosyst Environ 2006, 116: 60–71.
Ruttan VW, Hayami Y: Toward a theory of induced institutional innovation. J Dev Stud 1984, 20: 203–223.
Sanjeev MV, Venkatasubramanian V, Singha AK: Farming Dystems Of North East India: Research And Development Strategies for KVKs. Zonal Project Directorate, Zone – III. Indian Council of Agricultural Research, Umiam, Meghalaya, India; 2010.
Savadogo K, Reardon T, Pietola K: Adoption of improved land-use technologies to increase food security in Burkina Faso: relating animal traction, productivity, and nonfarm income. Agric Syst 1998, 58: 441–464.
Senthilkumar K, Bindraban PS, de Boer W, de Ridder N, Thiyagarajan TM, Giller KE: Characterising rice-based farming systems to identify opportunities for adopting water efficient cultivation methods in Tamil Nadu, India. Agric Water Manage 2009, 96: 1851–1860.
Singh S: Contracting out solutions: political economy of contract farming in Indian Punjab. World Dev 2002, 30: 1621–1638.
Singh AK, Singh S, Venkatasubramanian V: Relationship between farmers. Socio- personal traits and adoption of dairy innovations. Charion 1993, 22: 84–87.
Soule MJ: Soil management and the farm typology: do small family farms manage soil and nutrient resources differently than large family farms? Agric Resour Econ Rev 2001, 30: 179–188.
Sukhatme PV, Sukhatme BV, Sukhatme S, Asok C: Theory Of Sample Surveys With Applications. ISAS, IASRI, New Delhi; 1984.
Thomas HC (ed) (2006) Trade Reforms And Food Security: Country Case Studies And Synthesis. Food and Agriculture Organisation of UN, Rome
Timothy WO: Identifying target groups for livestock improvement research: the classification of sedentary livestock producers in western Niger. Agric Syst 1994, 46: 227–237.
Tittonell P, Vanlauwe B, Leffelaar PA, Shepherd KD, Giller KE: Exploring diversity in soil fertility management of smallholder farms in western Kenya. II. Within-farm variability in resource allocation, nutrient flows and soil fertility status. Agric Ecosyst Environ 2005, 110: 166–184.
Tittonell P, Leffelaar PA, Vanlauwe B, van Wijk MT, Giller KE: Exploring diversity of crop and soil management within smallholder African farms: a dynamic model for simulation of N balances and use efficiencies at field scale. Agric Syst 2006, 91: 71–101.
Tittonell P, Vanlauwe B, de Ridder N, Giller KE: Heterogeneity of crop productivity and resource use efficiency within smallholder Kenyan farms: soil fertility gradients or management intensity gradients. Agric Syst 2007, 94: 376–390.
Tittonell P, Muriukid A, Shepherde KD, Mugendif D, Kaizzig KC, Okeyoa J, Verchote L, Coee R, Vanlauwea B: The diversity of rural livelihoods and their influence on soil fertility in agricultural systems of East Africa – A typology of smallholder farms. Agric Syst 2010, 103: 83–97.
Usai MG, Casu S, Molle G, Decandia M, Ligios S, Carta A: Using cluster analysis to characterize the goat farming system in Sardinia. Livest Sci 2006, 104: 63–76.
USDA, ERS (2000) ERS Farm Typology For A Diverse Agricultural Sector, Agriculture Information Bulletin Number 759. USDA, US. Accessed via http://ageconsearch.umn.edu/bitstream/33657/1/ai000759.pdf. Accessed 12 August 2012
Vanclay JK: Using a typology of tree-growers to guide forestry extension. Ann Trop Res 2005, 27: 97–103.
Williamson OE: A comparison of alternative approaches to economic organization. J InstTheor Econ 1990, 146: 61–71.
Zingore S, Murwiraa HK, Delvea RJ, Gillerb KE: Soil type, management history and current resource allocation: Three dimensions regulating variability in crop productivity on African smallholder farms. Field Crops Res 2007, 101(3):296–305.
Acknowledgement
Logistic supports received from the All India Coordinated Research Project on Integrated Farming System and Academic Research Programme of Ramakrishna Mission Vivekananda University is duly acknowledged. Authors are also thankful to all the farmers who assisted and participated in the survey.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
RG designed research, analysed and interpreted data and prepared the manuscript, SC conceptualized and designed the research work, and BP collected data and drafted the manuscript with RG. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0), which permits use, duplication, adaptation, distribution, and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cite this article
Goswami, R., Chatterjee, S. & Prasad, B. Farm types and their economic characterization in complex agro-ecosystems for informed extension intervention: study from coastal West Bengal, India. Agric Econ 2, 5 (2014). https://doi.org/10.1186/s40100-014-0005-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40100-014-0005-2