
Abstract
In the case of manufactured products, there are situations where some components of a product are produced over a period of time by collecting items from different vendors, using different raw materials, machines, and manpower. The physical characteristics and the reliabilities of such components may be different, but sometimes it is difficult to distinguish them clearly. In such situations, mixtures of distributions are often used in the analysis of reliability data for these components. Here a twofold Weibull–Weibull mixture model is applied to analyze product reliability data that consist of both failure and censored lifetimes. The Expectation–Maximization (EM) algorithm is used to find the maximum likelihood estimates of the model parameters. As a case study, it analyses an Aircraft component (Windshield) failure data and various characteristics of the mixture model, such as the reliability function, B10 life, mean time to failure, etc., are estimated to assess the reliability of the component. Simulation studies are performed to investigate the properties and uses of the proposed method.
Similar content being viewed by others


Background
Reliability of a product is defined by the probability that the product will perform well it is intended function for a specified time period or usage limit under normal operating condition (Meeker and Escobar 1998; Blischke and Murthy 2000). Because of rapid advances in manufacturing technology, customers expect to purchase products that will be highly sophisticated, reliable and safe. In recent years many manufacturers are collecting and analyzing field failure data to enhance the reliability of their products and to improve goodwill and customer satisfaction (Blischke et al. 2011).
The paper analyses an Aircraft component (Windshield of a particular model) failure data that contain both failure and censored times. The same data are analyzed by Murthy et al. (2004) and Ruhi (2015). Murthy et al. (2004) have fitted a twofold Weibull mixture model for the data and estimated the parameters of the model by applying a graphical method based on Weibull probability paper (WPP) plot. The graphical method has been used widely to estimate the parameters of the Weibull mixture model. The bulk of the existing literature deals with the well-separated subpopulations cases and uses various approximations for plotting and the characterizations of the asymptotes. As mentioned in Murthy et al. (2004), there are two serious drawbacks in the graphical method. These are as follows:
-
The graphical method yields very crude estimates unless applied repeated iteration and evaluated by vision. As such, they can be used as starting points for more sophisticated statistical methods.
-
They do not provide any statistical confidence limits for the estimated parameters.
To overcome these drawbacks, here we apply the Expectation–Maximization (EM) algorithm to find the maximum likelihood estimates of the twofold Weibull mixture model and investigate the performance of the proposed method over the method of Murthy et al. (2004). The performance of the method will be evaluated by numerical simulation studies.
The outline of the paper is as follows. “Mixture models” describes the assumed mixture model. “Maximum-likelihood estimation of model parameters” explains the parameter estimation method. “Case study: analysis of aircraft Windshield failure” data presents a case study based on aircraft Windshield failure data. “Simulation study” presents a simulation study to investigate the performance of the method and “Conclusion” concludes the paper. Finally Appendix provides R codes that used in the paper for estimating the parameters of the model.
Mixture models
Various types of statistical models have been applied extensively in the analysis of failure data for manufactured products. However, there are situations where some components of a product are produced over a period of time by collecting items from different vendors, using different raw materials, machines, and manpower. In such situations, mixtures of distributions are often used in the analysis of reliability data as the physical characteristics and the reliabilities of such components may be different and difficult to distinguish easily and clearly.
The cumulative distribution function (cdf), probability density function (pdf) and hazard function (hf) of a general K-fold mixture model involving K subpopulations have presented in Murthy et al. (2004) and Blischke et al. (2011). The cumulative distribution function (cdf) of a general K-fold mixture model can be written as
where F j (t) is the cdf of the j-th sub-population, p j is the mixing probability of the j-th sub-population, p j > 0 and \(\sum\nolimits_{j = 1}^{K} {p_{j} = 1}\). The probability density function (pdf) is given by
where f j (t) is the pdf associated with F j (t). The hazard function h(t) is
where h j (t) is associated with subpopulation j, and
where \(\sum\nolimits_{j = 1}^{K} {w_{j} (t) = 1}\) with
From (3), we see that the failure rate for the model is a weighted mean of the failure rate for the subpopulations with the weights varying with t, t ≥ 0.
Special case: twofold Weibull mixture model
The cdf of the twofold mixture model (putting K = 2 in (1)) for the random variable T is given by
If F 1(t) follows Weibull (α 1, β 1) and F 2(t) follows Weibull (α 2, β 2) distributions, the cdf for twofold Weibull–Weibull mixture model from Eq. (6) becomes
The corresponding probability density function (pdf) is
The reliability function is
And the hazard function is
Other two-fold mixture models can be derived by using different cdfs from different lifetime distributions, similarly. In the remainder of the paper we apply this twofold Weibull mixture model to analyze the data set.
Maximum-likelihood estimation of model parameters
If the data contain the failure/censored random variable t i and failure/censored indicator δ i , (if the ith observation is failure then δ i = 1 and if it is censored then δ i = 1) for \(i = 1, 2, \cdots n\), the likelihood function under random censoring scheme for the data is given by
where, θ is the parameter vector for the assumed model. Taking log on both sides of Eq. (11), we get,
In the case of twofold Weibull mixture model with θ = {β 1, α 1, β 2, α 2, p}, the log-likelihood function (12) becomes
The maximum likelihood estimates of the parameters are obtained by taking the partial derivatives of (13) with respect to β 1, α 1, β 2, α 2 and p and setting to zero. The maximum likelihood estimating equations obtained from (13) do not give closed form solutions for the parameters θ = {β 1, α 1, β 2, α 2, p}. Therefore, it requires a numerical iterative procedure for finding the MLEs of the parameters.
Estimation of mixing proportions using EM Algorithm
The Expectation–Maximization (EM) algorithm is an efficient iterative procedure to compute the Maximum Likelihood Estimates (MLEs) of the parameters of the distribution in the presence of missing or hidden data (Dempster et al. 1977; McLachlan and Krishnan 2008). Bordes and Chauveau (2012) discussed several iterative methods based on EM and stochastic EM methodology to estimate parametric or semi parametric mixture models for randomly right censored lifetime data, conditioned that they are identifiable. Here we discuss the EM algorithm for finding the MLEs of the parameters of a general K-fold mixture model with parameters \(\Theta = (p_{ 1} , \cdots , p_{K} , \theta_{ 1} , \cdots , \theta_{K} )\), where p j is mixing parameters and θ j is the parameters for the density function f j , \(j = 1, 2, \ldots , K\). Let \(y = \left( {t_{ 1} , \ldots , t_{n} } \right)^{\prime }\) denotes the observed random sample obtained from the mixture density. Let us introduce the unobservable or missing data vectors \(z = \left( {z_{ 1}^{\prime } , \ldots , z_{n}^{\prime } } \right)^{\prime }\) , where z i is a K-dimensional vector of zero–one indicator variables and where z ij is one or zero according to whethert i arose or did not arise from the j-th component of the mixture \((i = 1, 2, \ldots , n; \;j = 1, 2, \ldots , K)\). The EM algorithm handles the unobservable data to the problem by working with the current conditional expectation of the complete-data log likelihood given the observed data. Let us define the complete-data vector x as \(x = \left( {y^{\prime } , z^{\prime } } \right)^{\prime } .\)
Each iteration of the EM algorithm consists of two steps. The Expectation or E-step computes the conditional expectation of the complete-data log-likelihood for Θ given observed data, which at the (m + 1)th iteration can be expressed as
As (14) is linear in the unobservable data z ij , the E-step (on the (m + 1)th iteration) simply requires the calculation of the current conditional expectation of Z ij given the observed data y, where Z ij is the random variable corresponding to z ij . Now
Here z (m) ij are the posterior probabilities which can be expressed using the Bayes’s theorem as
The evaluation of this expectation is called the E-step of the algorithm. The second step (the Maximization or M-step) maximizes (14) with respect to the parameters to obtain new parameter estimations Θ(m+1). To maximize (14), we can maximize the term containing p j and the term containing θ j independently since they are not related. To find the expression for p j , we introduce the Lagrange multiplier λ with the constraint \(\sum\nolimits_{j = 1}^{K} {p_{j} = 1}\). Under this constraint, taking the derivative of (14) with respect to p j and setting equal to zero, we get
Summing both sizes over j and using \(\sum\limits_{j = 1}^{m} {z_{ij}^{(m)} = 1}\); we get that λ = −n resulting in
See, Bucar et al. (2004) for more details.
For some distributions, it is possible to get closed-form analytical expressions for θ j . However, in the case of Weibull distributions with θ j = (α j , β j ), \(j = 1,{ 2}, \ldots ,K\), we have to apply numerical procedures to find MLEs of the parameters. Here we apply the survreg function with weight (weight > 0) given in the survival package of the R-program. The algorithm proceeds by using the newly derived parameters as the guess for the next iteration. The E- and M-steps are iterated until the algorithm converges.
Finally, the EM algorithm for estimating the parameters of a K-fold Weibull mixture distribution can be summarized in a step-by-step procedure as follows:
-
Step 1 Begin with initial guesses of p (0) j , α (0) j and β (0) j for \(j = 1, 2, \ldots , K\)
-
Step 2 Using the initial values of p (0) j , α (0) j and β (0) j , at m-th iteration calculate the conditional expectation of z ij , i.e., z (m) ij using (15).
-
Step 3 At them-th iteration, find the MLEs of p (m+1) j , α (m+1 j and β (m+1) j as follows:
-
(a)
Find the MLE for p (m+1) j , using (17).
-
(b)
Estimate α (m+1) j , and β (m+1) j using survreg function.
-
(a)
-
Step 4 Repeat Steps 2 and 3 until the algorithm converges with a desired accuracy.
The applications of the EM algorithm are broad because of its flexibility in analyzing incomplete or missing data. In any fields, when it is difficult to maximize the complicated likelihood function, various extensions and modifications of the EM algorithm have been proposed to simplify the computations, e.g., see Wei and Tanner (1990), Meng and Rubin (1993) and Liu and Rubin (1994). More detailed theory and applications of the EM algorithm can be found in McLachlan and Krishnan (2008).
Case study: analysis of aircraft Windshield failure data
In this section, as a case study, we analyze a set of aircraft Windshield failure data. We apply twofold Weibull mixture model for the failure data and estimate various characteristics of the Windshield, such as the reliability function, B10 life, mean time to failure, etc. to assess the reliability of the Windshield.
Aircraft Windshield failure data
Data on failure and censored times for a particular model of Windshield given in Table 1 are taken from Murthy et al. (2004), originally given in Blischke and Murthy (2000). The data consist of 88 failure times and 65 censored times out of 153 observations. Here censored time (or service time) means that the Windshields have not failed at the time of observation. The unit for measurement of time is 1000 h.
Nonparametric estimate of reliability function
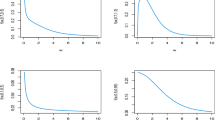
Figure 1 is the reliability (or survival) plot for the component. The plot appears to be reasonable; it shows the estimated MTTF is 3.03549 thousand hours or approximately 127 days. The nonparametric estimate of median lifetime is 2964 h, indicates that 50 % of the Windshield fails at 2964 h. The nonparametric estimate of cdf, known as empirical distribution function (edf) is one minus the estimated reliability function.

Nonparametric reliability plots
Parametric estimate of reliability function
Murthy et al. (2004) assumed the twofold Weibull mixture model for this data set and estimated the model parameters based on Weibull Probability Plots (WPP) method. In this article we apply the EM algorithm, discussed in “Estimation of mixing proportions using EM algorithm”, to find the maximum likelihood estimates of the parameters θ = {β 1, α 1, β 2, α 2, p} for the twofold Weibull mixture model and investigate the performance of the proposed method over the method of Murthy et al. (2004). A comparison between the estimates of the parameters obtained by two different methods is given in Table 2.
We have estimated the cdfs and reliability functions of twofold Weibull mixture model based on both non-parametric (by Kaplan–Meier method) and parametric (by EM Algorithm) approaches. The cdf and reliability function are also estimated by using the WPP plot method [estimates are taken from Murthy et al. (2004)]. Figures 2 and 3 compare the estimated reliability functions and cdfs, respectively to find out the best approach for the data set.

Comparison of reliability functions

Comparison of cdfs
From Fig. 2, we observe that the reliability function obtained by the EM algorithm method is much closer to the Kaplan–Meier estimate than that of the reliability function estimated by the WPP plot method. The plots of cdfs shown in Fig. 3 conclude the same. These indicate that the method of estimation with the EM algorithm procedure is better than the WPP plot procedure.
The estimates of adjusted Anderson–Darling (AD) test statistic based on WPP method and EM algorithm method are 412.5845 and 410.2851, respectively. This again indicates that the EM algorithm method provides better fit for the data set than the WPP method.
Reliability Characteristics of Windshield Data
Some of the reliability related important characteristics such as mean time to failure (MTTF), B10 lifetime, B50 (median) lifetime of the Windshield obtained by two methods are displayed in Table 3.
Table 3 indicates that the estimates of MTTF obtained from maximum likelihood method via the EM algorithm and from WPP plot method are 3.0525 (thousand hours) and 5.5782 (thousand hours), respectively. Estimate of MTTF obtained by EM algorithm is very close to the nonparametric estimate of MTTF (3.03549 thousand hours) given in Fig. 1. The WPP method overestimates the MTTF in this case. From the estimates of B10-lifetime and B50-lifetime, we may conclude according to EM algorithm method that, 10 % of the total components fail approximately at 1524 h and 50 % fail at 3004 h.
Simulation study
In this section, we use computer simulation to evaluate the performance of the method numerically. Numerically generated twofold mixture data are used to develop the twofold Weibull mixture model and to find the ML estimates of model parameters under right censored data. Using simulated data, the ML estimates of the model parameters, the sample means (SMs) and the mean squared errors (MSEs) of estimates are computed. Simulation programming codes are written using statistical software package R.
Steps of simulation study
Here we describe the step-by-step algorithm for simulation of twofold Weibull mixture model and estimation of model parameters via the EM algorithm.
-
Step 1 We consider a set of true value for the 5 parameters θ = {β 1, α 1, β 2, α 2, p} of twofold Weibull mixture model. Under this set of parameter, we generate n = n 1 + n 2 samples from the twofold Weibull mixture model using the software R-Language (version-3.2.2). A desired percent (10, 20 and 30 %) of the largest generated sample out of 200, are considered as the right censored observations and remaining are assumed as failed lifetime.
-
Step 2 Based on the generated right censored data, we estimate the parameters via the EM algorithm assuming that the mixing sub-populations are unknown. The methodology is discussed in “Estimation of mixing proportions using EM algorithm”.
-
Step 3 The above Steps 1 and 2 are repeated 1000 times under two Cases:
-
Case (i) for a variety percent of censored observations (10, 20 and 30 %) and
-
Case (ii) for different sample sizes (n = 200, 400 and 600).
We compute the sample means (SMs) and mean squared errors (MSEs) of the estimates for the both Cases (i) and (ii).
-
Steps 4 Summarize and discuss the simulation results based on 1000 repetition.
Simulation output analysis
The simulation results are shown in Tables 4 and 5.
Tables 4 and 5 present the summary results of the simulations based on 1000 repetitions under the given true values. In these tables, the first column shows the parameters of the model and second column shows the true values of the parameters. Tables 4 and 5 give the sample means of the MLEs of parameters obtained by the EM algorithm. For all of the sets, the sample means of the estimated parameters are close to the corresponding true values of the parameters. If the percent of censored observations decrease (i.e., if number of failures increase), the sample means of the MLEs become more closers to the true values for all most all sets, as expected. Similarly, the sample means of the MLEs become more closers to the true values for increasing sample sizes.
The mean squared errors (MSEs) of the MLEs of parameters for different percent of censored observations and for different sample sizes are given in Tables 6 and 7, respectively. The MSEs decrease for decreasing of the percent of censored observations (i.e., for increasing the number of failures). Also the MSEs decrease for increasing of the sample sizes. These comparisons indicate that the proposed method of estimation is applicable for analyzing mixture model for censored data.
Conclusion
There are situations where variations in product reliability can be occurred across different component vendors. In such situations, mixture of distributions can model the variability resulting from parts being bought from K different suppliers with F k (t) denoting the failure distribution for parts obtained from supplier k, \(k = 1,{ 2}, \ldots ,K\). This paper has applied a twofold Weibull mixture model for analyzing product reliability data with failure and censored observations. It has proposed the Expectation–Maximization (EM) algorithm to find the maximum likelihood estimates of the parameters of mixture model and compared this method with a method based on Weibull Probability Paper plots. An aircraft component (Windshield) failure data is analyzed as an example and investigated that the performance of the proposed method of estimation is impressive. The results would be useful for managerial implications in assessing and predicting the reliability of the component more accurately.
The mixture model considered here is the twofold Weibull mixture model. The proposed method is easily extendable for other mixture models also. A scope of the future research with other mixture models and with various types of censored data would be interesting.
References
Blischke WR, Murthy DNP (2000) Reliability modelling, prediction, and optimization. Wiley, New York
Blischke WR, Karim MR, Murthy DNP (2011) Warranty data collection and analysis. Springer Verlag, London
Bordes L, Chauveau D (2012). EM and stochastic EM algorithms for reliability mixture models under random censoring, Hal-VousConsultezL’Archive
Bucar T, Nagode M, Fajdiga M (2004) Reliability approximation using finite Weibull mixture distributions. Reliab Eng Syst Saf 84:241–251
Dempster AP, Laird NM, Rubin DB (1977) Maximum likelihood from incomplete data via the EM algorithm (with discussion). J R Stat Soc B 39:1–38
Liu C, Rubin DB (1994) The ECME algorithm: a simple extension of EM and ECM with faster monotone convergence. Biometrika 81:633–648
McLachlan GJ, Krishnan T (2008) The EM algorithm and extensions, 2nd edn. Wiley, New York
Meeker WQ, Escobar LA (1998) Statistical methods for reliability data. Wiley, New York
Meng X-L, Rubin D (1993) Maximum likelihood estimation via the ECM algorithm: a general framework. Biometrika 80:267–278
Murthy DNP, Xie M, Jiang R (2004) Weibull model. Wiley, New York
Ruhi S (2015) Application of mixture models for analyzing reliability data: a case study. Open Access Libr J 2:e1815
Wei GCG, Tanner MA (1990) A Monte Carlo implementation of the EM algorithm and the poor man’s data augmentation algorithms. J Am Stat Assoc 85:699–704
Authors’ contributions
The authors with the consultation of each other have carried out this work and drafted the manuscript together. All authors have read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
R codes for estimating parameters of Weibull–Weibull mixture model via the EM algorithm 
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ruhi, S., Sarker, S. & Karim, M.R. Mixture models for analyzing product reliability data: a case study. SpringerPlus 4, 634 (2015). https://doi.org/10.1186/s40064-015-1420-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40064-015-1420-x