
Abstract
Objective
Chronic kidney disease (CKD) patients with coronary artery disease (CAD) in the intensive care unit (ICU) have higher in-hospital mortality and poorer prognosis than patients with either single condition. The objective of this study is to develop a novel model that can predict the in-hospital mortality of that kind of patient in the ICU using machine learning methods.
Methods
Data of CKD patients with CAD were extracted from the Medical Information Mart for Intensive Care IV (MIMIC-IV) database. Boruta algorithm was conducted for the feature selection process. Eight machine learning algorithms, such as logistic regression (LR), random forest (RF), Decision Tree, K-nearest neighbors (KNN), Gradient Boosting Decision Tree Machine (GBDT), Support Vector Machine (SVM), Neural Network (NN), and Extreme Gradient Boosting (XGBoost), were conducted to construct the predictive model for in-hospital mortality and performance was evaluated by average precision (AP) and area under the receiver operating characteristic curve (AUC). Shapley Additive Explanations (SHAP) algorithm was applied to explain the model visually. Moreover, data from the Telehealth Intensive Care Unit Collaborative Research Database (eICU-CRD) were acquired as an external validation set.
Results
3590 and 1657 CKD patients with CAD were acquired from MIMIC-IV and eICU-CRD databases, respectively. A total of 78 variables were selected for the machine learning model development process. Comparatively, GBDT had the highest predictive performance according to the results of AUC (0.946) and AP (0.778). The SHAP method reveals the top 20 factors based on the importance ranking. In addition, GBDT had good predictive value and a certain degree of clinical value in the external validation according to the AUC (0.865), AP (0.672), decision curve analysis, and calibration curve.
Conclusion
Machine learning algorithms, especially GBDT, can be reliable tools for accurately predicting the in-hospital mortality risk for CKD patients with CAD in the ICU. This contributed to providing optimal resource allocation and reducing in-hospital mortality by tailoring precise management and implementation of early interventions.
Similar content being viewed by others


Introduction
In the past few decades, chronic kidney disease (CKD) has become increasingly prevalent among various countries and regions around the world, increasing the enormous financial burden of many countries [1]. A major cause of death among patients with chronic kidney disease is cardiovascular disease [2], and CKD patients with coronary artery disease (CAD) have a poorer prognosis than CKD patients without CAD [3, 4]. Moreover, the risk factors of patients with CKD combined with CAD are much different from those with only CAD [5]. Some studies demonstrated that atherosclerosis is the leading cause of death in advanced CKD patients with CAD, especially end-stage renal disease (ESRD) patients [6]. In addition, the pathogenesis of CKD patients with CAD has not been clearly elucidated [7]. Thus, the present indicators and prediction models perform poorly in predicting clinical outcomes for CKD patients with CAD.
Machine learning (ML) is a cutting-edge technology with the rapid development of artificial intelligence [8]. Compared to the traditional statistical method, ML has better clinical predictive accuracy and performance with faster processing speed [9]. With the development of the online public standard database, such as the Medical Information Mart for Intensive Care IV (MIMIC-IV), ML has increasingly penetrated the medical analysis field [10]. However, a few ML algorithms focused on the mortality prediction of CKD patients with CAD.
The purpose of our study is to (1) construct novel predictive models based on the various machine learning algorithm for in-hospital mortality of patients with CAD and CKD in intensive care units (ICU); (2) select an ML model with the best predictive performance and clinical value; and (3) validate these ML models via external set from the Telehealth Intensive Care Unit Collaborative Research Database (eICU-CRD) database.
Methods
Data sources
Data from the MIMIC-IV database were used in this study to establish predictive models for patients with CKD and CAD [11]. MIMIC-IV was a free, online accessible public database containing more than 50,000 ICU admissions from 2008 to 2019 in Beth Israel Deaconess Medical Center (Boston, Massachusetts). Data from eICU-CRD were used as an external validation cohort [12]. Over 200,000 ICU admissions from 208 hospitals across the country were compiled in the eICU-CRD, which was a publicly available multicenter database. The MIMIC-IV and the eICU-CRD database included the following information: demographics, vital signs, laboratory results, and diagnosis of International Classification of Diseases and Ninth Revision (ICD-9) codes. One author (ASY) obtained the certification to access these databases and extracted variables needed in the study (certification number: 39674606). Patients in these databases were unidentified with their health information, so individual patient consent was not required.
Study population and data extraction
All patients diagnosed with CAD and CKD were included in this study. Patients who stayed in ICU for less than 6 h, less than 18 years old, without baseline creatinine results, and with missing data > 30% were excluded. Only the first admission was taken into account if a patient had multiple admissions. Baseline creatinine was defined as the creatinine level in the patient's first blood test after hospital admission. Data of demographic information, lab results, hourly vital signs, comorbidities, medications (including aspirin, clopidogrel, ticagrelor, statin, beta-blocker, NOAC, and warfarin), operative procedures, ICU stay details, and in-hospital mortality were extracted from MIMIC-IV and eICU-CRD database using pgAdmin PostgreSQL tools (version 1.22.1).
Data preprocessing and feature selection
Variables with > 30% missing values were dropped, and multiple imputations were conducted for other vacant data. Multivariate Imputation by Chained Equations (MICE) was performed and returned an object containing five complete datasets. Then, statistical models such as linear regression or generalized linear model were applied to each complete dataset in turn for interpolation modeling. The pool function consolidates these individual analysis results into a group. The complete dataset is finally returned based on the standard errors and P-values of the model. MIMIC-IV and eICU (external validation data) databases were imputed separately using the fully conditional specification to avoid data leakage via the “mice” package in R [13].
Feature selection was a crucial process of reducing the number of features in a massive dataset according to the importance of the study variables. The Boruta algorithm was a wrapper method for feature selection built around the Random Forest Classifier algorithm. During the model construction, Boruta created a copy of the original dataset features as Shadow Features and compared the Z-score between the actual features and shadow features calculated via Random Forest Classifier in each iteration. If the Z-score of an actual feature was higher than the maximum Z-score of shadow features, this feature was considered pivotal and kept; otherwise, it was dropped [14].
Statistical analysis
Patients were divided into two groups according to whether they survived to discharge. Categorical variables were summarized as numbers with percentages and compared by Fisher’s exact probability method (or Chi-square tests). The Wilcoxon rank sum test was used to test continuous variables that were expressed as the median with interquartile ranges.
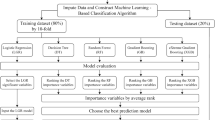
Eight machine learning models, including logistic regression (LR), random forest (RF), Decision Tree, K-nearest neighbors (KNN), Gradient Boosting Decision Tree Machine (GBDT), Support Vector Machine (SVM), Neural Network (NN), and Extreme Gradient Boosting (XGBoost), were established to develop the predictive models. 70% of the patients from MIMIC-IV were randomly extracted as the training set, while the remaining 30% was utilized for internal validation. Tenfold cross-validation was performed in each model to prevent overfitting to acquire average accuracy. The performance of each model was evaluated by the area under the receiver operating characteristic (ROC) curve (AUC) and average precision (AP) from precision/recall (P-R) curves in the validation set. Further, the model with the best performance was picked up to recognize the risk factors most related to in-hospital deaths interpreted by Shapley Additive Explanations (SHAP) method. The SHAP value visually exhibited each feature's importance and contribution to in-hospital mortality. In addition, data from eICU-CRD were used as external validation to assess the prediction model's performance. Decision curve analysis (DCA), AUC, and calibration curves were conducted to evaluate the clinical application and the consistency of the predictive probabilities.
All statistical analyses, machine learning algorithms, and SHAP were implemented via Python (version 3.9.12). The Boruta algorithms were conducted by R (version 4.1.3, Austria). A P-value lower than 0.05 (two-sided) was regarded as statistically significant.
Results
Baseline characteristics
A total of 3590 CKD patients with CAD from MIMIC-IV and 1657 CKD patients with CAD from eICU-CRD were included in this study cohort according to the inclusion and exclusion criteria. Figure 1 exhibits the screening process. In the MIMIC-IV database, 536 of 3590 (14.9%) CKD patients with CAD died during hospitalization, while 3054 participants survived. The differences in baseline characteristics are summarized in Tables 1, 2. Patients who died during the hospitalization have higher serum creatinine and troponin level and higher myocardial infarction, heart failure, and arrhythmia risks (P < 0.001).

Flowchart of patient selection from MIMIC-IV and eICU-CRD database. MIMIC Medical Information Mort for Intensive Care, eICU-CRD Telehealth Intensive Care Unit Collaborative Research Database
Feature selection
According to the Boruta algorithm analysis, 76 of 124 variables most closely associated with in-hospital mortality were selected (Fig. 2). Based on the Z-values, the top twenty variables are the history of cardiac arrest, sequential organ failure assessment (SOFA) score, the maximum values of aspartate aminotransferase (AST) and phosphate, the average values of spo2, white blood cell (WBC), AST, systolic blood pressure (sbp), sodium and platelet, and the minimum values of oxyhemoglobin saturation (spo2), SBP, heart rate, WBC, AST, glucose, phosphate, partial thromboplastin time (PTT), and mean blood pressure (mbp). Although the Z-values for acute coronary syndromes and diabetes were lower than the maximum Z-value of shadow feature, they were included in the analyses based on clinical experience. Therefore, a total of 78 variables were selected for the machine learning model development process.

Feature selection analyzed by Boruta algorithm. The horizontal axis is the name of each variable, and the vertical axis is the Z-value of each variable. The box plot shows the Z-value of each variable in the model calculation. The green boxes represent the 76 important variables, the yellow represents tentative attributes, and the red represents unimportant variables. los_icu length of stay in intensive care unit, scr serum creatinine, eGFR estimated glomerular filtration rate, CKD chronic kidney disease, ACS acute coronary syndrome, HT hypertension, PCI percutaneous coronary intervention, CABG coronary artery bypass grafting, NOAC Non-vitamin K Antagonist Oral Anticoagulant, CRRT continuous renal replacement therapy, max maximum, min minimum, WBC white blood cell, RBC red blood cell, ALT alanine aminotransferase, AST aspartate aminotransferase, ALP alkaline phosphatase, BUN blood urea nitrogen, INR International Normalized Ratio, PT prothrombin time, PTT partial thromboplastin time, SOFA sequential organ failure assessment, sbp systolic blood pressure, dbp diastolic blood pressure, mbp mean blood pressure, HR heart rate, spo2 oxyhemoglobin saturation
Machine learning model development and comparisons
Eight machine learning models were generated to predict the in-hospital mortality in CKD patients with CAD. Among the eight models, GBDT had the best predictive value of in-hospital death, with AUC = 0.946 and AP = 0.778. Figure 3 exhibited the discrimination performance of these machine learning models via ROC and P-R curves after ten cross-fold-validation in the test set. The SVM (AUC = 0.937), XGBOOST (AUC = 0.939), and GBDT had superior performance in the predictive ability for in-hospital death of CKD patients with CAD compared to the traditional logistic regression model. A set of detailed performance metrics for various machine learning models is presented in Table 2.

Discrimination performance of eight machine learning models. A ROC of eight machine learning models. B P-R curves of eight machine learning models. The GBDT algorism exhibited the best performance both in ROC and P-R curves. ROC Receiver Operating Characteristic, P-R curve precision/recall curve, SVM support vector machine, GBDT Gradient Boosting Decision Tree Machine, KNN k-nearest neighbors, NN neural network, XGBoost Extreme Gradient Boosting, AUC area under the curve
Visualization by SHAP
The SHAP algorithm was conducted to visually exhibit each factor's importance to the hospital mortality predicted by the GBDT model. Figure 4A shows the feature importance plot, including 20 significant variables most correlated to in-hospital death in descending order. The age factor had the most potent predictive power, followed by the minimum value of spo2 and warfarin. Figure 4B presents whether that feature is high (in red) or low (in blue) for that observation according to the SHAP value. The utilization of warfarin has a negative impact on in-hospital mortality.

SHAP analysis result. A Bar charts that rank the importance of the top 20 significant variables most correlated to in-hospital death in GBDT model. B Impact of each feature on the in-hospital mortality in GBDT model by SHAP values. GBDT Gradient Boosting Decision Tree Machine, SHAP Shapley Additive Explanations, spo2 oxyhemoglobin saturation, HR heart rate, WBC white blood cell, CABG coronary artery bypass grafting, SOFA sequential organ failure assessment, sbp systolic blood pressure, BUN blood urea nitrogen, PTT partial thromboplastin time, ALT alanine aminotransferase, AST aspartate aminotransferase, PT prothrombin time
Subgroup analysis
Subgroup analyses were conducted stratifying by ACS and dialysis condition. Age was no longer the most potent predictive factor in ACS and non-ACS patients and warfarin dropped out of the top 20 significant variables in ACS patients. SOFA score had the most potent predictive value in dialysis patients followed by glucose level. Interestingly, phosphate level was one of the top 20 influencing factors in non-dialysis patients, but its predictive value in dialysis patients was limited (Additional file 1: Fig. S1, Additional file 2: Fig. S2).
External validation
A total of 1657 CKD patients with CAD were extracted from the eICU-CRD database as an external validation dataset to verify the predictive accuracy of the selected GBDT model. Additional file 3: Table S1 exhibits the baseline characteristics of these patients. A total of 211 (12.7%) patients died during hospitalization. Taken together, GBDT had good predictive values (AUC = 0.865, AP = 0.672), while the clinical value was limited in the validation cohort based on the result of DCA and calibration curve (Fig. 5).

External validation for the GBDT model in the eICU-CRD dataset. A DCA curve of the GBDT model in external validation. B calibration curve of the GBDT model in external validation. C ROC of the GBDT model in external validation. D P-R curves of the GBDT models in external validation. DCA showed the GBDT model had some net benefit compared with the “treat-none” or “treat-all” strategies with a certain degree of clinical utility. The AUC (0.865) and AP (0.672) results demonstrated the GBDT model had good predictive values in external validation. DCA decision curve analysis, ROC Receiver Operating Characteristic, P-R curve precision/recall curve, GBDT Gradient Boosting Decision Tree Machine, eICU-CRD Telehealth Intensive Care Unit Collaborative Research Database
Discussion
Patients with CKD and CAD became more and more popular in recent decades. And mortality in patients suffering from these two conditions is twice as compared to patients with CAD alone [4]. Despite the increased incidence and incredibly lethal, their patients were excluded from most clinical trials due to the disease complexity and treatment conflicts. To date, factors associated with the prognosis in CKD patients with CAD were not clear and current risk stratification tools could not be applied to these patients. With the development of artificial intelligence, accurate prediction of these complex conditions could be achieved using machine learning methods.
MIMIC-IV and eICU-CRD were large-scale and high-quality databases performed in many crucial pieces of research in recent years. In this retrospective study, CKD patients with CAD admitted to ICU were extracted from MIMIC-IV to develop predictive models for in-hospital mortality via various ML algorithms. The GBDT model outperformed the predictive performance of seven other ML algorithms, including LR, RF, Decision Tree, KNN, SVM, NN, and XGBoost, according to the features selected by the Boruta algorithm. Next, the SHAP method was conducted to explain GBDT visually, ensuring clinical interpretability and facilitating the utilization of the prediction model. The performance and clinical application value of GBDT were also validated by an external set from the eICU-CRD database. This is the first prediction method especially for CKD patients with CAD to evaluate the in-hospital mortality with precise efficiency in two large cohorts, which means good generalization to extend to clinical practice.
Depending on the visualization technique SHAP, our study identified several crucial variables related to the in-hospital mortality of patients with CKD and CAD in the ICU. This study identified a factor strongly associated with the in-hospital mortality observed in our study which was serum phosphate. Previous studies have shown that elevated serum inorganic phosphorous (P) is tightly associated with cardiac death in CKD patients [15]. A national study illustrated that hyperphosphatemia could lead to a predisposition to metastatic calcification and the development and progression of secondary hyperparathyroidism, which may contribute to the abundant morbidity and mortality of patients with ESRD [16]. Another research with a 2-year follow-up also identified strong relationships between hyperphosphatemia and cardiac causes of death in hemodialysis patients [17]. Moreover, a cross-sectional study showed elevated serum levels of P were significantly related to calcified coronary atherosclerotic plaque detected by cardiac computed tomography, even in patients with normal kidney function [18]. The previous studies exhibited the significance of P in prognosis in CKD patients. In our study, we focused on CKD patients with CAD and showed that serum P was a strong predictor of in-hospital mortality. Therefore, phosphate is a promising therapeutic target to improve the clinical outcome in CKD patients with CAD. Both dietary and pharmacological therapeutic strategies should be used to reduce of serum phosphate levels to prevent hyperphosphatemia in CKD patients with CAD.
Whether Coronary Artery Bypass Grafting (CABG) or PCI is the better approach for revascularization of CAD in CKD patients was still controversial. Several observational studies reported CABG was associated with lower mortality than PCI in CKD patients [19,20,21]. But the Coronary REvascularization Demonstrating Outcome Study in Kyoto PCI/CABG Registry Cohort-2 study showed the risk of all-cause death was similar between PCI and CABG in ESRD patients requiring dialysis [22], which was consistence with the result of ISCHEMIA-CKD research [3]. Another meta-analysis also pointed out that patients with stage 3–5 CKD who underwent either approach to revascularization did not experience significant differences in mortality. However, CABG significantly reduced the myocardial infarction risks and required fewer additional revascularization procedures [23]. Different results in these studies might be attributed to different study participants, some focused on advanced CKD patients, while others focused on ESRD patients. Our study included patients with all staged CKD, ML visible results showed that both PCI and CABG were beneficial to the prognosis of CKD patients with CAD, and CABG was a more critical feature than PCI to the in-hospital mortality in those patients in ICU.
A growing number of machine learning applications in cardiovascular medicine have been made possible by the development of artificial intelligence [24, 25]. Using machine learning, it has been possible to predict death risk among CAD patients more accurately than before. Motwani et al. constructed a boosted ensemble algorithm combining clinical and coronary computed tomographic angiography (CCTA) to predict 5-year all-cause mortality with higher AUC (0.79) than clinical or CCTA metrics alone [26]. Silva et al. established a prognostic model using health conditions, including age and maximal exercise capacity, to precisely predict the mortality of CAD patients via the survival tree (ST) algorithm (C-index 0.729) [27]. In addition, Pezel and colleagues developed multiple fractional polynomial algorithm ML models, including 31,752 consecutive patients, to predict 10-year death [28]. This ML model also has a higher prognostic value than traditional clinical or Cardiac Magnetic Resonance scores (AUC 0.76). However, the mechanism of CKD combined with CAD is more complex and harder to explain than the mechanism of CAD alone [4]. For example, statin lipid-lowering therapy is still contradictory in improving the prognosis of patients with ESRD and CAD [29]. Predictions based on the traditional model cannot be made with reasonable accuracy and comprehensiveness for patients suffering from such complex diseases [5, 30]. For this reason, machine learning is of great significance.
The GBDT algorithm, also known as the multiple additive regression trees, has more accurate predictive ability and sophisticated algorithms than the LR, decision tree, and random forest algorithms [31]. It has many nonlinear transformations and solid, expressive ability, and does not require complex feature engineering and transformation [32]. The XGBoost model, a modified GBDT algorithm, could cope efficiently and flexibly with missing data and combines weak predictors to produce accurate predictions [33]. The no free lunch theorem (NFL) illustrates that the expected performance of each learning algorithm is the same if all possible problems are considered, which means there is no single, universal best machine learning algorithm for every situation [34]. Among eight ML models, the GBDT model performed the best clinical predictive value in in-hospital mortality risks in this kind of patient.
The advantages of this study were that it was the first study focusing on the in-hospital mortality for CKD patients with CAD in ICU based on a public database and constructed an ML model to predict it with external validation. Some limitations must be acknowledged. First, MIMIC-IV was a single-center database; most white patients may lead to racial bias and limit the applicability to other populations. However, external validation was applied using data from a multicenter database, eICU-CRD. Second, the deviation of missing data was inevitable because the data were extracted from the open public database. We performed fully conditional specification (FCS) implemented by the MICE algorithm to multiply and impute the missing data. Third, the selection bias was inevitable because this was a retrospective and observative study. Data were extracted from two different databases as internal and external sets, and further multicenter and large-scale clinical research was still needed. Nevertheless, the constructed ML model still may contribute to clinicians improving the prognosis and treating CKD patients with CAD at high risk in ICU timely. Collecting clinical data on ICU patients have been difficult due to the impact of the CoronaVirusDisease2019 outbreak. Public databases have helped tide clinical workers over worldwide. But more prospective multicenter clinical studies should also be established for further research.
Conclusions
In conclusion, machine learning algorithms can be reliable tools for accurately predicting the in-hospital mortality risk for CKD patients with CAD in the ICU. GBDT technology had the best predictive performance, which may provide optimal resource allocation and reduce in-hospital mortality by tailoring precise management and implementing early interventions.
Availability of data and materials
The data supporting this study’s findings are available from the Medical Information Mart for Intensive Care IV (MIMIC-IV), but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are, however, available from the author Shuoyan An (anshuoyan@126.com) upon reasonable request and with permission of MIMIC.
Abbreviations
- CKD:
-
Chronic kidney disease
- CAD:
-
Coronary artery disease
- MIMIC-IV:
-
Medical Information Mart for Intensive Care IV
- LR:
-
Logistic regression
- RF:
-
Random forest
- GBDT:
-
Gradient Boosting Decision Tree Machine
- KNN:
-
K-nearest neighbors
- SVM:
-
Support Vector Machine
- NN:
-
Neural Network
- XGBoost:
-
Extreme Gradient Boosting
- AP:
-
Average precision
- AUC:
-
Area under the receiver operating characteristic curve
- SHAP:
-
Shapley Additive Explanations
- eICU-CRD:
-
Telehealth Intensive Care Unit Collaborative Research Database
- ESRD:
-
End-stage renal disease
- ML:
-
Machine learning
- ICD-9:
-
International Classification of Diseases and Ninth Revision
- ICU:
-
Intensive care unit
- AP:
-
Average precision
- P-R curves:
-
Precision/recall curves
- DCA:
-
Decision curve analysis
- CCTA:
-
Coronary computed tomographic angiography
- NFL:
-
No free lunch theorem
- FCS:
-
Fully conditional specification
- los_icu:
-
Length of stay in intensive care unit
- scr:
-
Serum creatinine
- eGFR:
-
Estimated glomerular filtration rate
- ACS:
-
Acute coronary syndrome
- HT:
-
Hypertension
- PCI:
-
Percutaneous coronary intervention
- CABG:
-
Coronary artery bypass grafting
- NOAC:
-
Non-vitamin K Antagonist Oral Anticoagulant
- CRRT:
-
Continuous renal replacement therapy
- max:
-
Maximum
- min:
-
Minimum
- WBC:
-
White blood cell
- RBC:
-
Red blood cell
- ALT:
-
Alanine aminotransferase
- AST:
-
Aspartate aminotransferase
- ALP:
-
Alkaline phosphatase
- BUN:
-
Blood urea nitrogen
- INR:
-
International Normalized Ratio
- PT:
-
Prothrombin time
- PTT:
-
Partial thromboplastin time
- SOFA:
-
Sequential organ failure assessment
- sbp:
-
Systolic blood pressure
- dbp:
-
Diastolic blood pressure
- mbp:
-
Mean blood pressure
- HR:
-
Heart rate
- spo2:
-
Oxyhemoglobin saturation
References
Ruiz-Ortega M, et al. Targeting the progression of chronic kidney disease. Nat Rev Nephrol. 2020;16(5):269–88.
Lai AC, et al. A personalized approach to chronic kidney disease and cardiovascular disease: JACC review topic of the week. J Am Coll Cardiol. 2021;77(11):1470–9.
Bangalore S, et al. Management of coronary disease in patients with advanced kidney disease. N Engl J Med. 2020;382(17):1608–18.
Sarnak MJ, et al. Chronic kidney disease and coronary artery disease: JACC state-of-the-art review. J Am Coll Cardiol. 2019;74(14):1823–38.
Hakeem A, Bhatti S, Chang SM. Screening and risk stratification of coronary artery disease in end-stage renal disease. JACC Cardiovasc Imaging. 2014;7(7):715–28.
Murthy VL, et al. Coronary vascular dysfunction and prognosis in patients with chronic kidney disease. JACC Cardiovasc Imaging. 2012;5(10):1025–34.
Washam JB, et al. Pharmacotherapy in chronic kidney disease patients presenting with acute coronary syndrome: a scientific statement from the American Heart Association. Circulation. 2015;131(12):1123–49.
Deo RC. Machine learning in medicine. Circulation. 2015;132(20):1920–30.
Lee A, et al. Machine learning has arrived! Ophthalmology. 2017;124(12):1726–8.
Wiens J, et al. Do no harm: a roadmap for responsible machine learning for health care. Nat Med. 2019;25(9):1337–40.
Johnson A et al. Mimic-iv. PhysioNet. Available online at: https://physionet.org/content/mimiciv/1.0/. (Accessed 23 Aug 2021), 2020.
Pollard TJ, et al. The eICU Collaborative Research Database, a freely available multi-center database for critical care research. Sci data. 2018;5(1):1–13.
Blazek K, et al. A practical guide to multiple imputation of missing data in nephrology. Kidney Int. 2021;99(1):68–74.
Degenhardt F, Seifert S, Szymczak S. Evaluation of variable selection methods for random forests and omics data sets. Brief Bioinform. 2019;20(2):492–503.
Stevens LA, et al. Calcium, phosphate, and parathyroid hormone levels in combination and as a function of dialysis duration predict mortality: evidence for the complexity of the association between mineral metabolism and outcomes. J Am Soc Nephrol. 2004;15(3):770–9.
Block GA, et al. Association of serum phosphorus and calcium x phosphate product with mortality risk in chronic hemodialysis patients: a national study. Am J Kidney Dis. 1998;31(4):607–17.
Ganesh SK, et al. Association of elevated serum PO(4), Ca x PO(4) product, and parathyroid hormone with cardiac mortality risk in chronic hemodialysis patients. J Am Soc Nephrol. 2001;12(10):2131–8.
Shin S, et al. Impact of serum calcium and phosphate on coronary atherosclerosis detected by cardiac computed tomography. Eur Heart J. 2012;33(22):2873–81.
Chertow GM, et al. Survival after acute myocardial infarction in patients with end-stage renal disease: results from the cooperative cardiovascular project. Am J Kidney Dis. 2000;35(6):1044–51.
Reddan DN, et al. Chronic kidney disease, mortality, and treatment strategies among patients with clinically significant coronary artery disease. J Am Soc Nephrol. 2003;14(9):2373–80.
Chang TI, et al. Multivessel coronary artery bypass grafting versus percutaneous coronary intervention in ESRD. J Am Soc Nephrol. 2012;23(12):2042–9.
Marui A, et al. Percutaneous coronary intervention versus coronary artery bypass grafting in patients with end-stage renal disease requiring dialysis (5-year outcomes of the CREDO-Kyoto PCI/CABG Registry Cohort-2). Am J Cardiol. 2014;114(4):555–61.
Charytan DM, et al. Reduced risk of myocardial infarct and revascularization following coronary artery bypass grafting compared with percutaneous coronary intervention in patients with chronic kidney disease. Kidney Int. 2016;90(2):411–21.
Rim TH, et al. Deep-learning-based cardiovascular risk stratification using coronary artery calcium scores predicted from retinal photographs. Lancet Digit Health. 2021;3(5):e306–16.
Lin A, et al. Deep learning-enabled coronary CT angiography for plaque and stenosis quantification and cardiac risk prediction: an international multicentre study. Lancet Digit Health. 2022;4(4):e256–65.
Motwani M, et al. Machine learning for prediction of all-cause mortality in patients with suspected coronary artery disease: a 5-year multicentre prospective registry analysis. Eur Heart J. 2017;38(7):500–7.
de Souza ESCG, et al. Prediction of mortality in coronary artery disease: role of machine learning and maximal exercise capacity. Mayo Clin Proc. 2022;97(8):1472–82.
Pezel T et al. Machine-learning score using stress CMR for death prediction in patients with suspected or known CAD. JACC Cardiovasc Imaging, 2022.
Wanner C, Tonelli M, M. Kidney Disease: Improving Global Outcomes Lipid Guideline Development Work Group. KDIGO Clinical Practice Guideline for Lipid Management in CKD: summary of recommendation statements and clinical approach to the patient. Kidney Int. 2014;85(6):1303–9.
Fukuta H, et al. Prognostic value of nonlinear heart rate dynamics in hemodialysis patients with coronary artery disease. Kidney Int. 2003;64(2):641–8.
Zhou ZH, Feng J. Deep forest. Natl Sci Rev. 2019;6(1):74–86.
Zhang Z, Jung C. GBDT-MO: gradient-boosted decision trees for multiple outputs. IEEE Trans Neural Netw Learn Syst. 2021;32(7):3156–67.
Hou N, et al. Predicting 30-days mortality for MIMIC-III patients with sepsis-3: a machine learning approach using XGboost. J Transl Med. 2020;18(1):462.
Wolpert D. The lack of a priori distinctions between learning algorithms. Neural Comput. 1996;8:1341.
Acknowledgements
The authors acknowledge all participants in the MIMC IV research team for survey design and data collection.
Funding
This work was supported by the National High Level Hospital Clinical Research Funding (2022-NHLHCRF-YSPY-01), the National Natural Science Foundation of China (No. 82270352), the Capital’s Founds for Health Improvement and Research (No. 2022-1-4062), Chinese Society of Cardiology's Foundation (No. CSCF2021B02) and the National Key Clinical Specialty Construction Project (2020-QTL-009).
Author information
Authors and Affiliations
Contributions
JZ, ZY, and SA contributed to the study design. ZY, SA, and YG contributed to data collection, manuscript writing, data processing, and figure mapping. EX, XZ, and ZG contributed to the data proofreading. YL and NS contributed to formal analysis and writing—original draft preparation; ZY and JR contributed to review and to edit. All the authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1: Fig. S1
Subgroup analysis showed via SHAP plot stratified by ACS. A: Impact of each feature on the in-hospital mortality in non-ACS patients; B: Impact of each feature on the in-hospital mortality in ACS patients.
Additional file 2: Fig. S2
Subgroup analysis showed via SHAP plot stratified by dialysis. A: Impact of each feature on the in-hospital mortality in non-dialysis patients; B: Impact of each feature on the in-hospital mortality in dialysis patients.
Additional file 3: Table S1
Baseline characteristics of CKD patients with CAD in the external validation set (eICU-CRD).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Ye, Z., An, S., Gao, Y. et al. The prediction of in-hospital mortality in chronic kidney disease patients with coronary artery disease using machine learning models. Eur J Med Res 28, 33 (2023). https://doi.org/10.1186/s40001-023-00995-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40001-023-00995-x