
Abstract
With the increasingly wide spread of COVID-19 pandemic, people’s various behavior activities are influenced more or less all over the world. For example, students in campus have to learn at home or in dormitory so as to avoid the attacks of the virus as much as possible. However, such a location distribution structure of student places a heavy burden on the monitoring and evaluating the sport physique of students in an effective and efficient way. Fortunately, the wide adoption of various mobile computing terminals (e.g., smart watches, mobile phones, etc.) and wireless communication technology makes it possible to know about the daily physique of students in a remote way. However, students’ health physique data are accumulated with time, which raises a challenge of quick data processing and cost-effective data scalability. Moreover, since the students are geographically distributed, we need to integrate their respective health physique data into a central cloud platform for more comprehensive data analysis and mining. However, the above data integration operations often involve student privacy. Motivated by the above two challenges, a mobile computing-aided health physique evaluation solution is brought forth in this paper, which is mainly based on a kind of amplified hashing technique. To prove the evaluation performances of the proposal, extensive experiments are designed to test the algorithm performances in terms of various evaluation metrics.
Similar content being viewed by others


Introduction
Nowadays, COVID-19 virus is spreading worldwide and the people from many countries are undergoing such a big human disaster [1,2,3]. The huge damage of COVID-10 virus towards human health change the way we live significantly. Consequently, the behavior or activities of people are also influenced deeply by the infectivity of the virus [4]. For example, people are apt to wear masks when they go outside for job or shopping or entertainments so as to minimize the probability of inflection. Different from past decades without COVID-19 virus when people are eager to group together for more sharing activities with each other, people nowadays are afraid of going to the places with many population and dense traffic. In one word, COVID-19 significantly shifts the way of our life and will continue to affect the human society in a long term [5,6,7].
As a direct influence brought by COVID-19, students in campus have gradually adopted the studying pattern at home or in dormitory especially in China [8, 9]. Such a location distribution structure of student places a heavy burden on the monitoring and managing the sport physique of students in an effective and efficient way, because education managers or officers cannot ask students at home or in dormitory to take uniform sport physique test [10]. Fortunately, the wide maturity of mobile computing technology and the wide adoption of various mobile terminals (e.g., smart watches, mobile phones, PAD, laptop, etc. [11,12,13]) make it possible to know about the daily physique conditions of students in a remote way. Thus, through collecting and observing the health physique data of students via various mobile terminals, education officers or managers can accurately know the concrete health conditions of students, even the students are not at school.
However, students’ health physique data are often not static, but accumulated with time, which raises a challenge of quick data processing and cost-effective data scalability for health physique analysis tools [14,15,16]. Moreover, since the students are geographically distributed, we need to integrate their respective health physique data into a central cloud platform for more comprehensive data analysis and mining. However, the above data integration operations often involve student privacy [17,18,19,20]; as a result, the privacy leakage risks block the health physique data integration and analysis considerably. Motivated by the above two challenges, a mobile computing-aided health physique evaluation solution is brought forth in this paper, which is mainly based on a kind of amplified hashing technique. At last, to prove the evaluation performances of our proposal, extensive experiments are designed to test the performances of our proposal from multiple evaluation metrics. Summarily, the novelty of the proposal in this research work is three-fold.
-
(1)
The complex problem of amalgamating health physique data from students dispersed across various geographic regions, while also ensuring the protection of their confidential information, is the focus of this study.
-
(2)
Our solution leverages mobile computing to offer a privacy-conscious health physique assessment approach, making use of an amplified hashing technique.
-
(3)
To illustrate the uniqueness and benefits of our approach, we have carried out a series of experiments using a popular dataset. The obtained results indicate that our method surpasses other existing algorithms on several measurement scales.
We summarize the rest of this paper as follows. Current research outcomes in the field of health evaluation in mobile environment are investigated in Related work section. A concrete example is shown in Motivation section to emphasize the research significance in this paper. Concrete steps of our proposal in introduced in Our solution: \(HPE_{AH}\) section. Extensive simulated experiments are designed in Evaluation section to prove the advantages of our proposal compared with other existing literatures. Conclusions are drawn in Conclusions section where we also discuss the possible research directions in future work.
Related work
Nowadays, people pay more and more attention to the research of some diseases. In this section, we summarize the related literatures in the same field as follows.
In [21, 22], mobile devices are used to collect medical data from patients through various sensors. The main work of this paper is to analyze the medical data collected from sensors on mobile devices and pressure sensors connected to Bitalino devices, so as to complete the test process of Time-Up and Go. In the above process, data are collected from multiple individuals with various diseases in different environments, and then analyzed to estimate the parameters of the Time-Up and Go experiments. In [23], the authors present a system for monitoring and tracking household behavior and health-related data, which includes a system for capturing and accessing the health data of people by a mobile phone-based caregiver, a sensing platform. Furthermore, an activity recognition algorithm is also presented for recording movement of people.
In [24], the application of mobile cloud and healthcare Internet (i.e., IoMT) is being studied intensively, especially in automated diagnosis and health monitoring, because these applications play an important role in modern healthcare systems. In this paper, the authors propose a mobile cloud-based IoMT framework that monitors the progression of neurological disorders through motor coordination tests, while leveraging the computing and storage capabilities of cloud servers to assess severity levels given by established quantitative assessments. In addition, the authors suggest to integrate the proposed system with the data sharing framework in the blockchain network to achieve reliable data exchange between healthcare users. Obesity as a serious public health problem has attracted more and more attention [25]. According to [25], the treatments for obesity include diet and exercise, but more importantly, effective and continuous monitoring of food intake. The authors introduce SapoFitness, a mobile health application for diet detection and assessment. The application allows constant monitoring of the user and can send alerts or messages to monitor the user’s eating plans and physical activity. In [26], the authors present an automated diagnosis solution of soft tissues tumors with the supports of advanced machine learning technology. Through learning the observed medical diagnosis data of patients, the authors can eliminate the negative influence of noisy data and further accurately recognize the possible soft tissues tumors of patients. This way, the diagnosis and recognition speed and accuracy can be improved significantly.
In [27], the authors assert that mobile computing and communication technology is increasingly permeating the domains of health care and public health due to its swift evolution. The core purpose of this paper is to consolidate the advancements that mobile technology has brought to health services. This comprehensive review serves as an invaluable resource for successful implementation of mobile computing technologies in health care and public health, as well as a roadmap for future progress and research in this area. With the quick development of artificial intelligence (AI) technologies in smart world, various AI-based healthcare resolutions are gradually put forward. In [28], the authors propose an online data exception diagnosis solution based on deep learning techniques, so as to provision people better medical services. With the rapid growth of mobile applications in the health sector, there are significant challenges in standards development, adoption, and patient security and privacy [29]. The authors insist that from the development of standards to their use by physicians and patients, there are many competing demands and some effective measures should be taken to ensure the safety of patients. However, this paper also admits that the development of standards presents many challenges, such as the intersection of traditional medical devices and mobile devices, as well as the various standards required in mobile health solutions. In addition, interoperability is also required when developing secure healthcare services besides important patient safety.
As healthcare technology improves, there are more and more medical data to process. The authors in [30] discuss how to develop patient-centered intelligent healthcare application services from the perspective of mobile computing and big data analysis technology. At the same time, it also discusses various healthcare applications, showing the efficient application of mobile computing and big data technology in healthcare. In [31], the authors recognize the importance of privacy protection in health data mining and propose a privacy-aware factorization-based hybrid recommendation method for healthcare services. In concrete, differential privacy technique is recruited in this work to achieve the above goal. In [32, 33], the authors propose a computer-aided medical diagnosis system for the patients healthcare to speed up the disaster diagnosis process.
With the above summarization of existing literatures, we can conclude that existing approaches often fall short in the health physique evaluation issue in campus in a time-efficient and privacy-free way. Inspired by the above observation, we propose a mobile computing-aided health physique evaluation solution based on amplified hashing.
Motivation
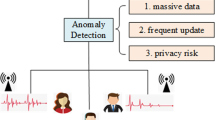
To better describe the research significance and value of this paper, we present a real-world example in Fig. 1 to show the challenges of existing research work. In the exampled scenario, mobile computing is used to monitor the health conditions of students in campus. In concrete, various mobile terminals (e.g., phone, laptop, smart watch and PAD) are responsible for collecting the sport physique signals or data of students and transmitting them to nearby edge servers for pre-processing. Afterwards, the health data are sent to a central cloud platform for uniform integration, processing and mining. This edge-cloud collaboration structure not only lessens the massive load on the cloud platform - as there is no need to transfer all health data to it - but also introduces two additional challenges. Firstly, the health data of various students are sent to and processed by distinct edge services, necessitating rapid consolidation of scattered health data. Secondly, in this integration process between the edge and the cloud, there’s a potential risk of students’ privacy being exposed to malevolent individuals. The above two challenges significantly interfere with the normal health data integration and evaluation. To tackle this issue, a mobile computing-aided health physique evaluation solution based on amplified hashing is put forward in this paper. We will elaborate the details of our proposal in the next section.

Mobile computing-aided health physique analysis in Edge-Cloud collaboration
Our solution: \(HPE_{AH}\)
Next, we introduce a new health physique evaluation solution based on amplified hashing, named \(HPE_{AH}\). In summary, \(HPE_{AH}\) can be divided into the following three steps: (1) according to the distributed health data of students collected by mobile terminals, student indexes are created based on amplified hashing; (2) students are clustered based on their respective indexes; (3) students’ health physique conditions are predicted and evaluated according to the students in the same clusters.
Step 1: Calculate student indexes.
We can track and gather health physique signals of students (such as blood pressure, heart rate, sleep duration, breathing rate, etc.) via various mobile devices. Consequently, each student’s health signals can be embodied by a multi-dimensional vector. As a result, all students along with their corresponding health signals can be portrayed in the form of a matrix. Concretely, we use the matrix Q in (1) to model the health signals of students. In (1), \(stu_1\),...,\(stu_m\) represent a set of students in campus; \(ph_1\),...,\(ph_n\) denote the physique dimensions such as sleeping hours and breathing frequency. In matrix Q, each row delegates the physique conditions of a student, eg., \(stu_i\)(\(s_{i,1}\),...,\(s_{i,n}\)), and each column delegates all students health condition on a certain physique dimension; eg., \(ph_j\)(\(s_{1,j}\),...,\(s_{n,j}\)). More intuitively, each student stui is corresponding to an n-dimensional vector (\(s_{i,1}\),...,\(s_{i,n}\)). Since vector(\(s_{i,1}\),...,\(s_{i,n}\)) often contains private information of student \(stu_i\), we cannot use it directly in the following health physique evaluation process of students due to privacy disclosure concern.
Therefore, we need to transform the sensitive vector \(stu_i\)(\(s_{i,1}\),...,\(s_{i,n}\)) into a less-sensitive expression. Concretely, amplified hashing is adopted here to achieve the above goal. More formally, we first produce an n-dimensional vector T(\(t_1\),...,\(t_n\)) as presented in (2). Here, each dimension in vector T is assigned a random value belonging to [-1, 1] as formalized in (2). The purpose of vector T is to provide a mapping function for transforming the sensitive vector \(stu_i\)(\(s_{i,1}\),...,\(s_{i,n}\)) into a less-sensitive vector \(STU_i\)(\(S_{1}\),...,\(S_{k}\))(\(k\le n\)). The concrete mapping process is formalized in (3)-(5). Here, the multiplication operation in Eq. (3) is used to convert an n-dimensional vector \(STU_i\) into a concrete value \({\wedge }stu_i\). Furthermore, we use Eq. (4) to convert the concrete value \({\wedge }stu_i\) into a Boolean value S. The above conversion is intended to reduce the time complexity of the subsequent clustering in step 2, as the complexity of the Boolean operations is relatively low. As can be seen from Eqs. (3)-(4), the conversion from \(stu_i\) to \({\wedge }stu_i\) and the conversion from \({\wedge }stu_i\) to S both drop some valuable information.
To minimize the negative influence brought by the information loss, we repeat the conversions in Eqs. (2)-(4) multiple times and obtain \(S_1,...,S_k\). Thus, we get a new vector \(STU_i\)(\(S_1,...,S_k\))(\(k<n\)) in (5). Here, the constraint condition (\(k<n\)) means that we successfully decrease the n dimensions of \(stu_i\)(\(s_{i,1}\),...,\(s_{i,n}\)) to the k new dimensions of \(STU_i\)(\(S_1,...,S_k\)). Moreover, vector \(STU_i\)(\(S_1,...,S_k\)) is a Boolean vector that contains less privacy; therefore, the conversion from \(stu_i\)(\(s_{i,1}\),...,\(s_{i,n}\)) to \(STU_i\)(\(S_1,...,S_k\)) can also secure the sensitive information of students. From a certain point of view, \(STU_i\)(\(S_1,...,S_k\)) can be taken as the index for \(stu_i\)(\(s_{i,1}\),...,\(s_{i,n}\)). Therefore, we will use \(STU_i\)(\(S_1,...,S_k\)), instead of \(stu_i\)(\(s_{i,1}\),...,\(s_{i,n}\)), to take part in the subsequent calculations in Step 2 and Step 3.
Concrete details of Step 1 are clarified in Algorithm 1.

Algorithm 1
Step 2: Index-based student clustering.
In Step 1, we assign an index \(STU_i\)(\(S_1,...,S_k\)) to each student \(stu_i\)(\(1\le i \le m\)). Then all students as well as their respective indexes form a table IT as presented in Table 1. Next, we use the student index table to achieve the clustering purpose. However, Table 1 only provides an index value for each student, which is often not enough. Therefore, we construct K index tables \(IT_i\),...,\(IT_K\) as presented in Table 2.
Next, we use the K student index tables in Table 2 to cluster the m students \(stu_1\),..., \(stu_m\) into different groups. The clustering process is based on amplified hashing. In concrete, let us consider two students for illustration of clustering, ie., \(stu_1\) and \(stu_2\). According to (5), the indexes for \(stu_1\) and \(stu_2\) are represented by \(STU_1\) = (\(S_{1,1}\),..., \(S_{1,k}\)) and \(STU_2\) =(\(S_{2,1}\),..., \(S_{2,k}\)), respectively. Thus, we initially evaluate the similarity between \(stu_1\) and \(stu_2\) based on the judgment condition in (6). More intuitively, for \(stu_1\) and \(stu_2\) they will be similar, ie., s(\(stu_1\),\(stu_2\)) = 1 if their mapping values over any dimension of (\(S_1\),...,\(S_k\)) are equal.
Nonetheless, the similarity assessment condition expressed in Eq. (6) is somewhat lax. This may result in identifying students as similar who are, in reality, not closely alike. To address this concern, we utilize the K index tables listed in Table 2 to tighten the similarity evaluation criteria. Consequently, we arrive at an updated similarity evaluation condition, formalized in Eq. (7). More intuitively, if there exists an x(1 \(\le\) x \(\le\) k) satisfying \(s_{1,x} = s_{2,x}\) in all index tables \(IT_{1}\),...,\(IT_{K}\), then we can conclude that the two students \(stu_1\) and \(stu_2\) are similar. This way, we can cluster the m students \(stu_1\),..., \(stu_m\) into different groups based on the student similarity, i.e., the students whose similarity is equal to 1 belonging to an identical cluster.
Concrete details of Step 2 are clarified in Algorithm 2.

Algorithm 2
Step 3: Student health physique prediction and evaluation based on clusters.
In Step 2, all the similar students have been grouped into multiple clusters. Here, we assume that there are Y clusters: \(C_1\),..,\(C_Y\). Next, we introduce how to evaluate or predict the health physique of a certain student \(stu_i\)(1\(\le\) i \(\le m\)) based on the derived Y clusters. More formally, we can predict the health condition of student \(stu_i\) in terms of physique dimension \(ph_i\)(1\(\le\) j \(\le n\)). ie., \(s_{i,j}\) according to (8). Here, we assume that student \(stu_i\) belongs to cluster \(C_y\)(1\(\le\) y \(\le\) Y) and \(\vert C_y \vert\) . This way, we can predict the health physique of student \(stu_i\) based on their friends’ health physique conditions. Since the above prediction process do not involve the original student health physique data that are sensitive, the prediction approach \(HPE_{AH}\) proposed in this paper can protect user privacy well. Moreover, as Eqs. (2)-(8) shows, the time complexity of \(HPE_{AH}\) is rather small. Therefore, \(HPE_{AH}\) can achieve the prediction goal in a time-efficient way.
Concrete details of Step 3 are clarified in Algorithm 3.

Algorithm 3
Here, we would like to highlight the fact that the \(HPE_{AH}\) method differs from the normal hash in two main ways. (a) The hash function is defined as shown in Eq. (2). (b) Multiple index tables are defined to improve the conditions for similarity evaluation as shown in Table 2. The above two aspects are not present in the normal hash.
Evaluation
The evaluation in this research work is made through simulation based on WS-DREAM dataset which records a total of 339*5825 entries regarding the monitored performance data of 339 users over 5825 items. In this section, for simulation purpose, we use this dataset to represent the sport physique data of 339 students over 5825 health physique metrics. For comparative purposes, we juxtapose our HPEAH method with two pre-existing ones: P-UIPCC [34] (an approach where a random value is added to the original data to obscure the true data in the original space, thereby safeguarding user privacy), and PPICF [35] (a technique where original data are partitioned into several fragments and stored by different stakeholders. This strategy ensures that even if a portion of the data is unfortunately disclosed, malicious users can’t accurately capture the entirety of the real data). The comparison metrics include MAE and time cost. Each set of experiments are run 100 times to overcome the negative influence incurred by data randomness and network running environment. In each experiment, following parameters are involved: m (size of student set), n (number of physique dimensions), k (dimension volume of vector \(STU_i\) in (5)) and K (number of index tables shown in Table 2). Concrete experiment results are presented as follows.
Time cost comparison
The physique evaluation accuracy of the proposed \(HPE_{AH}\) approach is measured and compared with other ones. Here, the related parameters are briefly introduced as follows: m = {100, 150, 200, 250, 30}, n = {1000, 2000, 3000, 4000, 5000}, k = 10, K = 10. Experimental results are shown in Fig. 2. We explain the concrete performances of different approaches in terms of MAE. As the experiment results in Fig. 2(a) indicate, the consumed time of both P-UIPCC and PPICF approaches is both relatively high since additional calculation operations are necessary in these two approaches: random confusion operations in P-UIPCC and division operations in PPICF. These additional operations bring more computational cost. On the contrary, the consumed time of HPEAH is relatively low because the index table creation phase in Step 1 is often available in an offline way and the rest operations in Step 2 and Step 3 can be executed in an online way whose time complexity is O(1). Another observation from Fig. 2(a) is that the consumed time of P-UIPCC and PPICF approaches both increases with the rising of parameter m; this is because all m students are necessary to take part in the computation task. Similar results could be observed from Fig. 2(b) where the horizontal axis denotes the number of physique dimensions. The low time complexity in the figure also shows the advantages of our proposal in outputting a quick health physique evaluation result.

Consumed time comparison
MAE comparison
Next, we compare the evaluation accuracy between different approaches. Here, we adopt the same parameters as those in Fig. 2, i.e., m = {100, 150, 200, 250, 300}, n = {1000, 2000, 3000, 4000, 5000}, k = 10, K = 10. Concrete execution results are presented in Fig. 3. From Fig. 3(a), we can observe that MAE of \(HPE_{AH}\) is the smallest among all the three approaches. Here, we analyse the reasons for this as follows. Although the two compared approaches can secure user privacy, different data confusion strategies are adopted to achieve the goal of privacy protection, which reduces the availability of data to a certain extent; therefore, the MAE of these two approaches is relatively high. On the contrary, \(HPE_{AH}\) utilizes hash technique to protect user privacy without confusing the original data for evaluation decision; as a result, the data availability is relatively high and the MAE is relatively low. In one word, the evaluation accuracy of \(HPE_{AH}\) is higher than the other two competitive approaches. Similar results could be observed from Fig. 3(b), where the horizontal axis denotes the number of physique dimensions. In Fig. 3(b), the accuracy of \(HPE_{AH}\) still outperforms the other competitive approaches.

Evaluation accuracy comparison
MAE of \(HPE_{AH}\)
Next, we observe the evaluation accuracy of our \(HPE_{AH}\) with respect to different parameters. Here, the parameters are set as follows: m = 300, n = 5000. Concrete results are presented in Figs. 4 and 5. Concretely, in Fig. 4 (k = 10, K is varied from 1 to 5), the MAE of \(HPE_{AH}\) generally declines with the growth of parameter K. We analyze the reason as follows. As K increases from 1 to 5, more hash tables are used in Eq. (7), which indicates that the condition for assessing whether two students belong to an identical cluster is relatively high. Thus, all students belonging to the same cluster are indeed close to each other. In this situation, the evaluation accuracy is guarantee and the MAE drops accordingly.

Evaluation accuracy of our solution w.r.t. K

Evaluation accuracy of our solution w.r.t. k
On the contrary, different variation tendency of MAE of\(HPE_{AH}\) is presented in Fig. 5 where K = 5 and k is varied from 4 to 12. We can see from Fig. 5 that the MAE of \(HPE_{AH}\) generally increases with the growth of parameter k. We analyze the reason as follows: when k increases from 4 to 12, more hash functions are used in Eqs. (6), which indicate a relatively lower condition to evaluate whether two students are belonging to an identical cluster; as a result, all the students belonging to the same cluster are not very close to each other. In this situation, the evaluation accuracy is decreased and the MAE rises accordingly.
Conclusions
The widespread impact of the COVID-19 pandemic has limited people’s range of activities. Consequently, students on campuses are required to pursue their studies at home or in dormitories to minimize the risk of virus exposure. This dispersed learning environment places a significant strain on the effective and efficient monitoring and management of students’ physical health. However, the broad utilization of various mobile computing devices and wireless communication technologies has made remote monitoring of students’ daily health possible. However, students’ health physique data are often big enough and sensitive, which makes the integration of distributed student health data challenging. Motivated by the above two challenges, a mobile computing-aided health physique evaluation solution is brought forth in this paper, which is mainly based on a kind of amplified hashing technique. Extensive experiments are designed to prove the performances of our proposal compared to other competitive approaches.
Availability of data and materials
Abbreviations
- \(HPE_{AH}\) :
-
Health Physique Evaluation based on Amplified Hashing
References
Zhou Y, Varzaneh M (2022) Efficient and scalable patients clustering based on medical big data in cloud platform. J Cloud Comput 11. https://doi.org/10.1186/s13677-022-00324-3
Kumari R, Kumar S, Poonia RC, Singh V, Raja L, Bhatnagar V, Agarwal P (2021) Analysis and predictions of spread, recovery, and death caused by covid-19 in india. Big Data Min Analytics 4(2):65–75
Xie Y, Zhang K, Kou H, Jafar Mokarram M (2022) Private anomaly detection of student health conditions based on wearable sensors in mobile cloud computing. J Cloud Comput 38. https://doi.org/10.1186/s13677-022-00300-x
Pang J, Huang Y, Xie Z, Li J, Cai Z (2021) Collaborative city digital twin for the covid-19 pandemic: A federated learning solution. Tsinghua Sci Technol 26(5):759–771
Singh KK, Singh A (2021) Diagnosis of covid-19 from chest x-ray images using wavelets-based depthwise convolution network. Big Data Min Analytics 4(2):84–93
Xu X, Tian H, Zhang X, Qi L, He Q, Dou W (2022) Discov: distributed covid-19 detection on x-ray images with edge-cloud collaboration. IEEE Trans Serv Comput 15(3):1206–1219
Huang Q, Zhou Y, Tao L, Yu W, Zhang Y, Huo L, He Z (2021) A chan-vese model based on the markov chain for unsupervised medical image segmentation. Tsinghua Sci Technol 26(6):833–844
Agarwal A, Sharma S, Kumar V, Kaur M (2021) Effect of e-learning on public health and environment during covid-19 lockdown. Big Data Min Analytics 4(2):104–115
Liu Y, Song Z, Xu X, Rafique W, Zhang X, Shen J, Khosravi MR, Qi L (2022) Bidirectional gru networks-based next poi category prediction for healthcare. Int J Intell Syst 37(7):4020–4040
Gupta VK, Gupta A, Kumar D, Sardana A (2021) Prediction of covid-19 confirmed, death, and cured cases in india using random forest model. Big Data Min Analytics 4(2):116–123
Zhou X, Li Y, Liang W (2020) Cnn-rnn based intelligent recommendation for online medical pre-diagnosis support. IEEE/ACM Trans Comput Biol Bioinforma 18(3):912–921
Qi L, Lin W, Zhang X, Dou W, Xu X, Chen J (2022) A correlation graph based approach for personalized and compatible web apis recommendation in mobile app development. IEEE Trans Knowl Data Eng. https://doi.org/10.1109/TKDE.2022.3168611
Zhou X, Liang W, Kevin I, Wang K, Yang LT (2020) Deep correlation mining based on hierarchical hybrid networks for heterogeneous big data recommendations. IEEE Trans Comput Soc Syst 8(1):171–178
Tian Y, Zheng R, Liang Z, Li S, Wu FX, Li M (2021) A data-driven clustering recommendation method for single-cell rna-sequencing data. Tsinghua Sci Technol 26(5):772–789
Bouras MA, Farha F, Ning H (2020) Convergence of computing, communication, and caching in internet of things. Intell Converged Netw 1(1):18–36
Qi L, Hu C, Zhang X, Khosravi MR, Sharma S, Pang S, Wang T (2020) Privacy-aware data fusion and prediction with spatial-temporal context for smart city industrial environment. IEEE Trans Ind Inform 17(6):4159–4167
Catlett C, Beckman P, Ferrier N, Nusbaum H, Papka ME, Berman MG, Sankaran R (2020) Measuring cities with software-defined sensors. J Social Comput 1(1):14–27
Zheng X, Zhang L, Li K, Zeng X (2021) Efficient publication of distributed and overlapping graph data under differential privacy. Tsinghua Sci Technol 27(2):235–243
Hartpence B, Kwasinski A (2021) Cnn and mlp neural network ensembles for packet classification and adversary defense. Intell Converged Netw 2(1):66–82
Qi L, Yang Y, Zhou X, Rafique W, Ma J (2021) Fast anomaly identification based on multiaspect data streams for intelligent intrusion detection toward secure industry 4.0. IEEE Trans Ind Inform 18(9):6503–6511
Ponciano V, Pires IM, Ribeiro FR, Villasana MV, Crisóstomo R, Canavarro Teixeira M, Zdravevski E (2020) Mobile computing technologies for health and mobility assessment: research design and results of the timed up and go test in older adults. Sensors 20(12):3481
Wu X, Qi L, Xu X, Yu S, Dou W, Zhang X (2022) Crowdsourcing-based multi-device communication cooperation for mobile high-quality video enhancement. In: Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining. ACM, New York, pp 1140–1148
Hayes GR, Patterson DJ, Singh M, Gravem D, Rich J, Cooper D (2011) Supporting the transition from hospital to home for premature infants using integrated mobile computing and sensor support. Pers Ubiquit Comput 15:871–885
Nguyen DC, Nguyen KD, Pathirana PN (2019) A mobile cloud based iomt framework for automated health assessment and management. In: 2019 41st annual international conference of the IEEE engineering in medicine and biology society (EMBC). IEEE, San Francisco, pp 6517–6520
Lopes IM, Silva BM, Rodrigues JJ, Lloret J, Proença ML (2011) A mobile health monitoring solution for weight control. In: 2011 International Conference on Wireless Communications and Signal Processing (WCSP). IEEE, San Francisco, pp 1–5
Tekouabou SCK, Hartini S, Rustam Z, Silkan H, Agoujil S et al (2021) Improvement in automated diagnosis of soft tissues tumors using machine learning. Big Data Min Analytics 4(1):33–46
Free C, Phillips G, Felix L, Galli L, Patel V, Edwards P (2010) The effectiveness of m-health technologies for improving health and health services: a systematic review protocol. BMC Res Notes 3(1):1–7
Zhou X, Xu X, Liang W, Zeng Z, Yan Z (2021) Deep-learning-enhanced multitarget detection for end-edge-cloud surveillance in smart iot. IEEE Internet Things J 8(16):12588–12596
Williams PA, McCauley VB (2013) A rapidly moving target: Conformance with e-health standards for mobile computing. 2nd Australian eHealth Informatics and Security Conference. https://doi.org/10.4225/75/57981c3131b41
Ma X, Wang Z, Zhou S, Wen H, Zhang Y (2018) Intelligent healthcare systems assisted by data analytics and mobile computing. In: 2018 14th International Wireless Communications & Mobile Computing Conference (IWCMC). IEEE, San Francisco, pp 1317–1322
Meng S, Fan S, Li Q, Wang X, Zhang J, Xu X, Qi L, Bhuiyan MZA (2022) Privacy-aware factorization-based hybrid recommendation method for healthcare services. IEEE Trans Ind Inform 18(8):5637–5647
Liu G, Wei Y, Xie Y, Li J, Qiao L, Jj Yang (2021) A computer-aided system for ocular myasthenia gravis diagnosis. Tsinghua Sci Technol 26(5):749–758
Wu X, Khosravi MR, Qi L, Ji G, Dou W, Xu X (2020) Locally private frequency estimation of physical symptoms for infectious disease analysis in internet of medical things. Comput Commun 162:139–151
Zhu J, He P, Zheng Z, Lyu MR (2015) A privacy-preserving QoS prediction framework for web service recommendation. In: IEEE International Conference on Web Services, pp. 241–248
Li D, Chen C, Lv Q, Shang L, Zhao Y, Lu T, Gu N (2016) An algorithm for efficient privacy-preserving item-based collaborative filtering. Future Gener. Comput Syst 55;311–320
Acknowledgements
We would like to thank the provider of the WS-DREAM dataset.
Funding
Not available
Author information
Authors and Affiliations
Contributions
Yu Xie: writing, idea; Qiyun Zhang: motivation and model; Khosro Rezaee: idea and English writing; Yanwei Xu: model and experiments.
Authors’ information
Not available.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not available.
Consent for publication
The authors all agree on the publication of the paper if accepted.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xie, Y., Zhang, Q., Rezaee, K. et al. Mobile computing-enabled health physique evaluation in campus based on amplified hashing. J Cloud Comp 12, 102 (2023). https://doi.org/10.1186/s13677-023-00476-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13677-023-00476-w