
Abstract
The contact list size of modern mobile phone users has increased up to hundreds of contacts, making contact retrieval a relatively difficult task. Various algorithms have been designed to predict the contact that a user will call at a given time. These algorithms use historical call data to make this prediction. However, modern mobile users do not just make calls, but also rely on various communication channels like text messages and calls to maintain their social relations. Despite the prevalence of multiple communication channels, predictive analysis of these channels has not been studied so far. Hence, this study deliberated on proposing a predictive model for dual-channel (text and calls). This study initially investigated the dual-channel communication behaviour of smartphone users by using a mixed approach i.e. subjective and objective data analysis and found many peculiarities. It was observed that the preferred communication channel was different for various contacts, even for a single user. Although the cost-effective texts were found to be more popular over phone calls, a significant proportion of user pairs seemed to prefer calls for most of their communication. A generic predictive framework for the dual-channel environment was proposed based upon these findings. This model predicts the next communication event by modelling temporal information of call and text on a 2D plane. This framework has three variations which not only predict the person who will be contacted at a particular time but also predict the channel of communication (call or text). Finally, the performance of different versions of the algorithm was evaluated using real-world dual-channel data. One version of the predictive model outperformed the other variations with a prediction accuracy over 90 percent, while the other variations also performed well.
Similar content being viewed by others


Introduction
Smartphones allow users to communicate with their social network [1] mostly through verbal, or written communication [2, 3] throughout the day [4, 5] except during resting periods [6]. The volume of this communication may roughly reflect the level of emotional attachment with various social relations [7, 8]. More specifically, if \(f_1,f_2, \ldots , f_n\), is the reverse sorted fractions of communication volume with n contacts of a user; then a large fraction of communication takes place with only a handful of initial contacts in this sequence [9–12]. Note that contacts can also be referred to as alters, in the sociological context. Similarly, the user under observation can be referred to as an ego. These terms will be used more in the rest of the study.
In order to contact a particular person via phone calls or text, people search the desired contact through a repository that now has an average of about 300 contacts [12]. Communication is initiated by searching in a contact list or a call-log. This interaction is sometimes not optimal from a usability point of view as a user sometimes needs to shift between the two available options. For example, a user might start from the call-log only to find that the required alter was not recently contacted and hence might move to contact book to search that alter. Researchers are trying to improve a user’s experience when initiating calls by analysing the calling behaviour of users [13,14,15] and some proposed methods to predict the alter that will be contacted at a given time [ 2, 16,17,18,19,20,21,21]. This prediction is then used to make a short list of alters as a recommendation for the ego with the goal of reducing the effort to find and call a particular alter.
Research gap
Communication on smartphones is not limited only to traditional phone calls as users use text messages extensively. However, a comprehensive literature review revealed that existing studies focus only on predicting calls. Hence, dual-channel i.e. text and calls, usage behaviour and prediction are not considered even though most users prefer text [10] for communication. A dual-channel prediction algorithm will output a short list of 7–10 alters along with the communication channel that an ego is likely to utilize at a given time t. This algorithm can then be used as a subroutine for an adaptive communication initialization interface as shown in Fig. 1.

This is an example of an adaptive interface that will present a small number of alters to the user along with the probable channel. Note here that the same alter can be repeated with a different channel as in case of “Dad” above. At the back-end it needs an algorithm that will analyse the communication history of smartphone users to capture their communication patterns. This interface will facilitate a user by minimizing the need or searching or shifting between different screens
Research questions
Hence, the study explored the following two research questions:
Research question 1
How do users distribute their communication between the two popular communication channels (i.e. calls and text messages) and what factors influence this choice?
Research question 2
Can an alter who will be contacted at a given time t, along with the communication channel (call or text) be predicted? More specifically, given the historical time series communication data of a user,
where \(e_{t_i}\) is a communication event at time instance \(t_i\) with an associated contact and channel (text/call).
If the user shows his/her intention to communicate (say by opening the contact book) at time instance \(t_k\), then what is the possibility to accurately predict both the contact and the channel of communication for the user at \(t_k\)?
Contributions
Data analysis of call and text logs of 111 users was performed on a dataset collected by Bilal et al. [22]. This is a relatively small dataset (31, 515 calls and 135, 474 text messages) of 111 users from an emerging user base for exploring dual-channel communication traits of smartphone users. Big data analytics have been used to explore many aspects of human life; but despite having many capabilities [23], its unstructured and complex nature causes many problems [24]. In contrast, small data is often structured, easy to access, and easy to manage. Hence, small data has been successfully used to solve problems surrounding individuals like impact of communication technologies on relationships [24, 25], communication behaviour of smartphone users [10, 13,14,15], user-centric context aware models for prediction [26], and call prediction [2, 11].
The main contributions of this study are listed below:
Users in general use text messages more than calls, however interestingly, it was found that some egos seem to prefer phone calls over text messages for a few alters. This was preferred despite the higher cost penalty associated with the calls. Some subjective reasons for this peculiarity in users’ communication behaviour have also been discussed.
Three methods to model time-series data of communication logs on a 2D plane have been proposed. Since there can be multiple ways for this planar modelling, three models to map the communication data on a plane were proposed and evaluated to check which is more suitable. A generic dual-channel prediction algorithm was proposed that can work with any of these three modelling techniques. This framework captures the temporal patterns in dual-channel communication and predicts the alter as well as the channel for an ego. The models were evaluated by comparing their performance.
Organization
The next section provides an overview of related work in this area. Then, the dual-channel behaviour of users will be analysed. After that, three different ways to model time-series data of dual-channel communication will be discussed and a generic dual-channel prediction algorithm will be proposed. Next, the performance of the proposed models is compared. Finally, the study ends with some concluding remarks.
Literature review
This section briefly describes the important background literature about the communication behaviour of smartphone users, and call prediction through call log analysis.
Humans are known to be social and all social relationships (intimate, family, friends, etc.) are created and maintained through communication, which is either face-to-face or through electronic channels. Smartphones play an important role in maintaining these relationships and indeed are the true representative of one’s social network [1]. Like many other activities of life communications of individuals also follow unique and persistent communication patterns known as social signature. Social signature is a distinct and persistent pattern of one’s social behaviour. It is the sequence of fraction of communication \(f_i\) devoted to each alter \(a_i\) of an ego \(<a_1,f_1>,<a_2,f_2>,\cdots ,<a_n,f_n>\) Such that \(f_i \ge f_j\) when \(i<j\). Studies investigated the existence of temporal patterns in human communication behaviour [11] and showed that each individual has a unique and persistent communication pattern that follows daily rhythms [27–29]. Furthermore, these social signatures are present in both calls [9, 11] and text messages [10]. It also seems that these signatures persist over time, despite the major changes in the ego’s social network due to relocation, etc. [10]. Some studies also suggest that personality [30], age, gender [31], and friendship style [32] are some factors which impact an individual’s social signatures.
The existence of patterns in electronic communications motivated researchers to design adaptive interfaces to facilitate faster access to desired contacts. An adaptive interface changes according to changes in the user’s context. These interfaces can potentially reduce the memory load of users, which is one of the most frequently violated heuristic in user interface design [33]. Adaptive interfaces work by first predicting the k most likely alters at a given time and then presenting them to the user. Experimental results show that the adaptive interface offers faster contact retrieval in case of correct prediction and even in the case of prediction failure, there is a delay of 2–3 seconds [2].
Many studies have proposed such adaptive interfaces by exploiting call logs of smartphone users. However, these studies did not mention how long historical logs are required for better prediction. In a recent study, Sarkar et al. [34] resolved the issue of choosing appropriate historical communication logs. They proved that only the most recent communication history (between 2 and 3 weeks) is sufficient to accurately predict the smartphone user’s communication behaviour. They predicted user’s future behaviour using short term data and compared the results with long historical data. They proved that only the most recent data of 2 to 3 weeks is enough to accurately predict a user’s behaviour. Furthermore, Sarker et al. [35] have suggested a context-aware rule learning framework based on machine learning techniques, for effectively learning context-aware rules from smartphone data to develop rule-based adaptive systems.
Call prediction
Various variations of call prediction algorithms using call logs have been proposed with varying effectiveness [16, 18,19,20, 36,37,38]. One of the more established algorithms is proposed by Stefanis et al. [2, 17] which uses recency and frequency of communication as contextual information and achieved a prediction accuracy of 80%. In another recent study, Nasim et al. [11] proposed a machine learning-based algorithm for predicting the next call at a particular time. They achieved an accuracy of 78% for a list of size 5 on the Reality Mining dataset [39]. They also proposed a time clustering-based algorithm, which first extracts the hour and day for all communication events of an ego-alter pair and then identifies various clusters by using the DBSCAN algorithm. It then computes the convex hull (polygon) for each cluster, this polygon indicates a time span in which an ego-alter pair is more likely to communicate. Since humans do not always follow time bounds very strictly, two larger polygons of the same shape were added around the original polygon. These polygons were used to accommodate the possibility of slight variations in the time span. They used an 80 : 20 split to train the algorithm and to test its performance in real-life situations. This algorithm had an accuracy of 40% on the Smartphone dataset [15] and 65% on the Reality Mining dataset [39].
Hence, it can be seen that mining communication data of users for trends and possible applications is a topic that has recently been of interest for many researchers. It has also been noted that these data-based studies are focused on calling data. They generally use smaller data sets as they are doing individual-level analysis. One application of such data analysis is, call prediction as it can improve usability by enabling an adaptive call initialization interface.
Gap in literature
A comprehensive literature review revealed a quite few studies on call prediction. Table 1 summarises these studies. It can be clearly seen that existing literature only focused on predicting the alter for a single channel. In this study, such prediction is referred to as single-channel prediction. However, communication on mobile phones is not limited to phone calls only, instant-messaging is also very popular to support social interactions [40]. For example, one of the most used channels is text messages via SMS [10]. Yet surprisingly, no study has so far investigated alter prediction for the more realistic dual-channel environment. Note that in the dual-channel environment, both the alter and the channel need to be predicted.
Data cleaning
This study analysed the text and call data of 116 users collected by Bilal et al. [22, 41] in December 2016, from a local university in Pakistan. The participants aged between 17 and 36 years, including 63 males and 53 females. Most of the participants were undergraduate while the remaining 10 were graduate students and 3 Ph.D. scholars. The dataset originally had 47, 558 calls and 3, 68, 116 text messages.
Like any data-based analysis, it is important to clean the data to avoid the risk of getting misleading results. For this purpose, a total of \(0.055\%\) communication records have been removed because they were inconsistentFootnote 1. To maintain the integrity of results, the data has further been filtered which resulted in 111 users in the end. The data was cleaned in the following steps:
- 1
Android phones store up to 500 call records while there is no limit on the history of text messages, hence, there was a need to extract text and call data of the same time duration for each ego. This was done by noting the minimum and maximum timestamps in calling data for each ego-alter pair and then extracting the text history for the same duration. The resulting mean duration for all the ego-alter pairs came out to be 13.5 days (s.d 12.4 days).
- 2
Next, all the ego-alter pairs with less than 15 communication events have been excluded to ensure that only important pairs with non-negligible communication shall be considered. This resulted in a total of 2, 173 ego-alter pairs. This threshold has been selected after computing the communication percentage of all egos with the alters having less than 15 communication events. Fig. 2 shows a birds-eye view of the data by comparing the communication percentages with two groups of alters i.e. those with less than 15 communication events and those with more than 15 events. More specifically the communication percentage with the alters having less than 15 events was 21%, which is relatively low.
- 3
Finally, the ego-alter pairs without any outgoing communication events have been filtered to exclude unsolicited alters such as marketing companies, etc.
At the end of this data cleaning process, the dataset left with 1, 968 ego-alter pairs; with the mean number of 16 calls (s.d 30.5) and 68.8 texts (s.d 186.2) for these pairs. The main statistics of the cleaned dataset are summarized in Table 2.

The communication percentages with two groups of alters; first group contains alters having < 15 communication events and the second group has alters with the number of communication events \(\ge \) 15
Exploratory data analysis
This section presents the initial exploratory data analysis, which revealed that text messages were a more common communication channel. It was observed that on average \(81\%\) communication took place via text messaging while only \(19\%\) through calls. Earlier studies also observed the popularity of text messages [10, 22] and one possible reason is its cost-effectiveness [22]. A slightly counter intuitive trend in the data is discussed below.
Categorization of alters
One would expect that a user would use text more frequently for all alters. However, surprisingly, it was observed that the number of alters contacted through text, were more than those contacted through calls. More specifically, the mean number of alters who were contacted through text was 14.3 (s.d 10.4), while the mean number of call alters was 12.5 (s.d 7.4). This was unlike the results of Heydari et al. [10] whose European dataset had more call alters than text alters. Interestingly, it was found that users call and text to different sets of people. As the mean Jaccard similarity coefficient came out to be 2.7 for call and text alters of an ego.
The data analysis showed that \(27.6\%\) ego-alter pairs preferred phone calls for \(80\%\) (or more) of their total communication. These pairs are referred to frequently-called alters(FCA), whereas the rest are called infrequently-called alters(IFCA). The reasons behind this trend were unclear, hence, an interview based study [42] of 21 participants was conducted. This was done to explore the subjective reasons behind this trend from the users’ point of view. In the first step, the study analysed the dual-channel data of all participants, especially focusing on the (FCA). In the second step, an interview sessionFootnote 2 with each participant to ask them about the reason for using calls more for specific alters. From the participants’ replies, it was observed that some alters were uncomfortable with text messages and preferred calls due to eyesight problems, busy schedules, and the need for frequent discussions, etc.
The analysis of the dual-channel communication behaviour of smartphone users on special days could reveal interesting patterns. These days could include weekends, major holidays like Christmas, and Eid, but the data did not contain any special days except weekends. It was noted that users communicated more on weekends in both groups. Similarly, users communicated mostly between 12 p.m. and 5 p.m. every day. Interestingly, the users in the FCA group communicated with the same alters on weekends and weekdays. Whereas, the users in the IFCA group were found to have a few different alters during both.
The next section first describes three different planar modelling techniques and then presents a generic algorithm that can predict both the alter and the channel.
Temporal clustering of channels and dual-channel prediction
This study focuses on dual-channel prediction using time-series data. Machine learning methods are well known for prediction tasks by employing classification algorithms. However, these models have an inherent assumption that data is independently and identically distributed. This means that the observations should not depend upon each other and come from the same generative distribution. Hence, several studies argued against using time series data for obtaining predictions by using machine learning algorithms and some have termed it as a complex problem [43]. The primary reason for this premise is based on the fact that time series data is chronologically developed, where a forthcoming instance of the dataset has some level of dependency with the previous instance. Thus the training and cross-validation performed for the performance evaluation of a classification algorithm do not stand valid. There are various proposed methods in the literature that try to mitigate this issue. However, applying standard machine learning models to time series data is still a challenging problem.
Due to these limitations, this study proposed a prediction algorithm for the dual-channel environment that is not based on a machine learning algorithm. This study proposes to map the communication data on planar surface using one of three alternative models. These models will be used to design a dual-channel prediction algorithm; which is discussed in detail below.
Planar modelling of communication events
This section discusses the proposed algorithm for the dual-channel prediction that is a generalized version of an algorithm for single-channel prediction by Nasim et. al [11]. The previous study showed that calls between an ego-alter pair contain patterns induced by sociological constraints called socio-temporal patterns. The argument was proved using several techniques, one of themFootnote 3 argued that calls when mapped to a plane, with the day of the week on the y-axis and the hour of the day on the x-axis, generally lie in small high-density areas. Motivated by these findings, it was conjectured that similar socio-temporal patterns can also be found in the dual-channel communication environment. However, it was noted that there can be other alternatives to the planar models besides the one proposed in [11]. The three planar modelling techniques for dual-channel communication are described below.
Planar model: This method was proposed for single-channel prediction [11], this study generalized it for dual-channel prediction. Here, the days of the week are presented as a number ranging from 0 to 6 on the y-axis and the hours of the day are mapped on the x-axis. The rationale behind taking the time and day of the communication event as a contextual cue for predicting future communication is that people normally communicate with each other at a particular time and day of the week. Fig. 3a shows the communication records modelled this way. One can clearly see two different clusters of communication events in different concentrated regions with respect to the time and day of the week.
Radial-hours model: In this model, each communication event is mapped to one of the 24 concentric circles representing each of the 24 h and the angle is determined by the number of minutes elapsed since midnight on that day. The angle is calculated by the following formula: \(\theta = {(W - 1)+(M/60)}* 2\pi /7\). Here, W refers to the day of the week, and M represents the number of minutes that have elapsed since midnight 00 : 00 on that particular day. Hence, a communication event on Sunday at 00 : 00 o’clock is mapped to \(0^0\), an event on Monday 00 : 00 is mapped to \(51.4^0\) and so on. An example of this modelling technique is shown in Fig. 3b.
Radial-days models: In this model, the days are represented by 7 circles such that the inner and outermost circles represent Sunday and Saturday respectively. The time of a communication event is mapped to an angle \(\theta \) between \(0^0\) and \(360^0\) by the following formula: \(\theta = (M/T) *360 \). Here, M represents the number of minutes that have passed since 12 : 00AM on that day and T refers to the total minutes in a day i.e. 1440. An example of this modelling technique is shown in Fig. 3c.
The data of each ego-alter pair have been modelled using the above-mentioned techniques and obtained various clusters for each ego-alter pair. Note that, a cluster with only text events is referred to as a text cluster, while the cluster with only calling data is known as a call cluster. Finally, a hybrid cluster contains both call and text events. Since the primary aim of this study is to predict the communication channel for future communication, hence, a modelling technique with fewer hybrid clusters would probably show better results. The percentages of these clusters were calculated for both FCA and IFCA groups defined in the last section. The results shown in Table 3 indicated that radial-hours performed better as there were \(14.9\%\) hybrid clusters for the FCA group and \(22.1\%\) for the IFCA group.

Three alternative modelling techniques represent the dual-channel communication data of a particular ego-alter pair. Note that, circles \(\varvec{\circ }\) represent text messages and cross symbols \(\varvec{\times }\) represent calling events
Prediction algorithm
This section presents the flow of the dual-channel prediction algorithm which takes call and text logs of smartphone users as input. It then extracts the time and day of communication events to capture the communication patterns of smartphone users. The algorithm generates a list of alters that are likely to be contacted at a particular time along with the preferred channel.
Algorithm 1 shows the predictive model which works with any of the three modelling techniques presented earlier. Note that the state of the art algorithm [2, 17] for 1 channel (call only) prediction is also very intuitional as it weights each alter based on just the recency and frequency of the alter. Given the input and a modelling technique, it models the communication events in the training set for each ego-alter pair. For each ego-alter pair, it first finds different clusters of communication events. This algorithm works by first getting the time and day information for each communication event for each ego-alter pair. It then models this data using one of the 3 modelling techniques. After that DBSCAN is applied to form clusters of communication events. In the end, it checks the event type (call or text) in each cluster and accordingly assigns a probability to the alter and the channel at the current time t. Note that DBSCAN is an algorithm for clusteringFootnote 4. The algorithm then computes a convex hull \(P_0\) around each of these clusters, which shows the likelihood of an ego-alter pair to communicate in a particular timespan. Note that, small polygons indicate temporal regularity among ego-alter pairs, i.e. specific time and day of the week when they usually communicate [11].
Next, it identifies the event typesFootnote 5 in each cluster. It then checks the position of time t of test point with respect to the cluster. Finally, it assigns each ego-alter pair, a probability score according to the following scheme:

- 1
Call or text cluster: An alter is assigned a probability of \(100\%\), if the test point lies inside the polygon \(P_0\); otherwise, it is assigned a score of \(0\%\). The predicted channel will be the same as the type of the cluster.
- 2
Hybrid clusters: If a cluster contains both types of events then it computes the percentage for both channels. The channel with a percentage greater or equal to event percentage\(\alpha \), will be predicted. Note that, \(\alpha \) represents various percentages of event types in each cluster. Otherwise, the algorithm is unable to predict with confidence the channel of communication and this is considered as a prediction failure.
Using recency: Some ego-alter pairs occasionally communicate with each other and do not exhibit temporal regularity in their communication behaviour [11]. The communication of such pairs is often bursty. There can be various reasons for this bursty communication such as arranging meetings, booking appointments, or event management, etc. Since the assumption of this prediction framework is temporal regularity which may not capture such bursty pairs. Hence, information about recent events can further improve prediction accuracy for such pairs [17]. Therefore, a variation of the algorithm named as With-Recency is proposed to improve its performance. In this version, the alter of the most recent communication event is added in the prediction list along with the channel used for that communication.
Performance
This section first describes the evaluation procedure of the dual-channel prediction and then provides a comparison of the performance of the three proposed modelling techniques and their various variations.
Evaluation procedure
The dual-channel logs of 111 users were used to evaluate the proposed predictive model. The evaluation of the proposed algorithm for dual-channel prediction was performed by adopting the evaluation mechanism of the different but related problem of call prediction [36, 2, 11, 17]. These studies suggested that a communication prediction algorithm should predict a list of 5–10 alters rather than a single alter. The reason for this suggestion is that this number of alters can be easily displayed on a typical smartphone. Hence, the proposed model outputs a prediction list of eight alters along with the possible communication channel.
Cross validation was employed for evaluation by implementing the proposed algorithm in R. Dual-channel logs were separated into training and test sets, such that the latest 20% of the data was used as the test set while the rest of 80% was considered as the training set. Fig. 4, shows the distribution of dual-channel logs of a user into test and training sets. The evaluation method was designed to simulate the communication initialization process of a real user. The communication event \(C_t\) in the test set was picked and its time t was noted, as shown in Fig. 4. It was assumed that this is the time when the user indicated his/her intention to start a communication; say by opening the adaptive interface as shown in Fig. 1. Algorithm 1 is then applied with time t and the training set as input. The algorithm computes the probability of communicating with each alter and returns the top eight alters as a prediction list. Next, the prediction list is checked to find whether the prediction was a success or a failure. A prediction is successful if the intended alter and the communication channel both matches the intent of the user (ego), otherwise it is considered a failure. Various combinations of correct and incorrect alter and channel predictions are shown in Table 4. It can be clearly seen that this prediction is more difficult as compared to simple call prediction. After each prediction, the \(C_t\) was removed from the test set and added to the training set. The process was repeated until the test set is exhausted. Finally, the average accuracy for each variation of the algorithm was computed by the following formula:
Note that this is the first study that proposes prediction for the dual-channel environment i.e. for both the calls and text messages. Existing studies have been proposed for single-channel environment i.e. only for calls. While this study predicts both the alter and the channel, therefore, it is not possible to provide a comparison with any existing technique. Moreover, studies on the related but different problem of call prediction, also use similar evaluation as mentioned earlier.

Dual-channel prediction mechanism. Note that \(C_1, C_2,\ldots ,C_n\) present the communication events in the training set, whereas, \(C_t, C_{t+1},\ldots ,C_{t_n}\) denotes the events in the test set. The communication events are organised in ascending order of time from left to right, as the most recent data was used in test set to simulate the real world communication environment in the evaluation procedure
Performance comparison of three models
The performance of all variations of the predictive model was evaluated. Recall that there are 3 planar models and two variations i.e. Simple and With-Recency. Further, different values of the parameter event percentage\(\alpha \) were used. Specifically, the following values for \(\alpha \) have been considered: \(60\%\), \(65\%\), \(70\%\), \(75\%\), and \(80\%\).
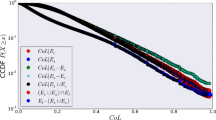
Figure 5 shows the performance of all variations of the algorithm for frequently-called alters group. Here, it can be seen that the With-Recency version of all three models outperformed the Simple version with an accuracy greater than 93%. A possible reason for the better performance of the With-Recency model is that some ego-alter pairs do not exhibit temporal regularity in their communications and only occasionally communicate with each other. This occasional communication behaviour could only be captured by adding recent a communication event that improves prediction accuracy for such pairs [17].
Figure 6 shows the prediction performance of all variations of the proposed algorithm for infrequently-called alters group. Here, again the With-Recency version of all three models outperformed the other Simple version with an accuracy of about 90%.

This figure shows the accuracy of predicting dual-channel communication for frequently-called alters against different values of event percentage\(\alpha \). Here, one can clearly see that the With-Recency version of three models outperformed the Simple versions with an accuracy of 93%

This figure shows the accuracy of predicting dual-channel communication for infrequently-called alters against different values of event percentage\(\alpha \). Here, we can clearly see that the With-Recency version of three models i.e. Planar With-Recency, Radial Hours With-Recency, and Radial Days With-Recency outperformed the Simple versions with more than 90% accuracy
Prediction accuracy and impact of various parameters
This section discusses various parameters and their effect on the prediction accuracy of the proposed predictive model. The dual-channel prediction algorithm takes a number of parameters including: dual-channel (call/text) communication logs, three modelling techniques (Planar, Radial Hours, and Radial Days), two model variations (Simple and With-Recency), and event percentage\(\alpha \), which represents various percentages of event types in each cluster. The following values of \(\alpha \) were used: 60%, 65%, 70%, 75%, and 80%. Some of these parameters are fixed such as the dual-channel logs, and cannot be varied to see their impact on the performance of the algorithm. However, the other parameters were varied and summarized results are discussed below. The impact of varying different parameters could be easily seen in Figs. 5 and 6.
Modelling techniques: Three modelling techniques do not impact prediction accuracy significantly.
Adding recent event: Adding the recent event improves the performance of all three models. Figs. 5 and 6 show that the With-Recency variation of all three models outperformed the Simple version with an accuracy of \(93\%\) and 90% for FCA and IFCA groups respectively.
Event percentage (\(\varvec{\alpha }\)): Various values of \(\alpha \) have also been tested, but they did not significantly affect the prediction accuracy of any model and their variations.
Hence, it is obvious that the most important parameter that impacts the prediction accuracy of the proposed model is recency, i.e. the addition of the alter of the most recent communication along with the used channel in the top k list. Table 5 shows the average accuracy of all model variations for the above-stated values of \(\alpha \).
Conclusion
Mobile phone users can use a lot of channels for communication with their alters. Two of the most popular channels of communication are calls and text. This study explores the dual-channel communication behaviour of smartphone users from a developing country. Note that previous studies explored users’ patterns for making calls and proposed algorithms for prediction of the next call, while this study extends it to the dual-channel environment.
The preliminary data analysis of 111 users revealed some interesting trends in the dual-channel environment. For example, text messages were a more popular communication channel capturing \(81\%\) communication and some ego-alters pairs communicated exclusively through text. Moreover, there are only 2 to 3 common contacts between the set of contacts to whom calls are made and the set of contacts to whom texts were sent. Further, the study found that some ego-alter pairs prefer phone calls for their communications (equal to or more than 80%). These alters are known as frequently-called altersFCA while the rest are called infrequently-called altersIFCA.
After the dual-channel behaviour of smartphone users, the study proposes the first algorithm for dual-channel prediction. This algorithm output a short list of contacts along with a channel and can be used to assist a user to initiate a communication event with an alter. This study proposes different variations of the algorithm for predicting the next communication event and the likely channel for that event. All variations of the prediction algorithm were evaluated using cross validation by dividing the data set into a training set and a test set. The evaluation showed that one can attain an accuracy of more than \(90\%\).
This study opens the doors for several research directions. For example, an obvious extension is to extend this work to predict more than two channels. However, this might not be possible due to security and privacy restrictions on smartphones. Another research direction is to implement this algorithm as a smartphone app and conduct a field study to assess its usefulness in real life scenarios. For example, it is generally desired that smartphone applications do not drain a phone’s battery, and hence such a field study will reveal the power consumption requirements of this algorithm.
Availability of data and materials
The datasets used during the current study are available from the corresponding author on reasonable request.
Notes
Inconsistent records had either too few records or major parts of the time series of communication events were missing.
Each interview session lasted between 8 and 15 minutes.
Covered in-depth in the section on related work.
DBSCAN is a density-based clustering algorithm that groups the points in dense areas. It needs two parameters: \(\varepsilon \) (eps \(=3\)), which specifies the radius of a neighbourhood with respect to a point, and the minimum number of points (minPts \(=3\)) required to form a cluster.
Event type specifies whether the communication event is a phone call or text.
Abbreviations
- FCA::
-
Frequently-called alters
- IFCA::
-
Infrequently-called alters
References
Kardos P, Unoka Z, Pléh C, Soltész P (2018) Your mobile phone indeed means your social network: priming mobile phone activates relationship related concepts. Comput Hum Behav 88:84–88
Plessas A, Stefanis V, Komninos A, Garofalakis J (2017) Field evaluation of context aware adaptive interfaces for efficient mobile contact retrieval. Pervasive Mobile Comput 35:51–64
LaRue EM, Mitchell AM, Terhorst L, Karimi HA (2010) Assessing mobile phone communication utility preferences in a social support network. Telematics Inform 27(4):363–369
Dwyer RJ, Kushlev K, Dunn EW (2018) Smartphone use undermines enjoyment of face-to-face social interactions. J Exp Soc Psychol 78:233–239
Böhmer M, Hecht B, Schöning J, Krüger A, Bauer G (2011) Falling asleep with angry birds, facebook and kindle: a large scale study on mobile application usage. In: Proceedings of the 13th International Conference on Human Computer Interaction with Mobile Devices and Services, ACM, 47-56 September 2011
Monsivais D, Bhattacharya K, Ghosh A, Dunbar RI, Kaski K (2017) Seasonal and geographical impact on human resting periods. Sci Rep 7(1):10717
Dunbar R (2018) The anatomy of friendship. Trends Cognitive Sci 22(1):32–51
Mac Carron P, Kaski K, Dunbar R (2016) Calling dunbar’s numbers. Soc Netw 47:151–155
Saramäki J, Leicht EA, López E, Roberts SG, Reed-Tsochas F, Dunbar RI (2014) Persistence of social signatures in human communication. Proc Natl Acad Sci USA 111(3):942–947
Heydari S, Roberts SG, Dunbar RI, Saramäki J (2018) Multichannel social signatures and persistent features of ego networks. Appl Netw Sci 3(1):8
Nasim M, Rextin A, Hayat S, Khan N, Malik MM (2017) Data analysis and call prediction on dyadic data from an understudied population. Pervasive Mobile Comput 41:166–178
Bentley FR, Chen YY (2015) The composition and use of modern mobile phonebooks. In: Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems. CHI ’15, 2749-2758. ACM, New York, NY, USA, April 2015
Jiang ZQ, Xie WJ, Li MX, Podobnik B, Zhou WX, (2013) Stanley HE. (2013) Calling patterns in human communication dynamics. Proc Natl Acad Sci USA 110(5):1600–1605
Kim H, Zang H, Ma X (2013) Analyzing and modeling temporal patterns of human contacts in cellular networks. In: 22nd International Conference On Computer Communication and Networks (ICCCN), IEEE, 1–7 August 2013
Nasim M, Rextin A, Khan N, Malik MM (2016) Understanding call logs of smartphone users for making future calls. In: Proceedings of the 18th International Conference on Human-Computer Interaction with Mobile Devices and Services. MobileHCI ’16, 483-490. ACM, New York, NY, USA, September 2016
Barzaiq OO, Lok SW (2011) Adapting the mobile phone for task efficiency: the case of predicting outgoing calls using frequency and regularity of historical calls. Pers Ubiquitous Comput 15(8):857–870
Stefanis V, Plessas A, Komninos A, Garofalakis J (2014) Frequency and recency context for the management and retrieval of personal information on mobile devices. Pervasive Mobile Comput 15:100–112
Phithakkitnukoon S, Dantu R, Claxton R, Eagle N (2011) Behavior-based adaptive call predictor. ACM Transact Auton Adapt Syst 6(3):21
Phithakkitnukoon S, Dantu R (2007) Predicting calls new service for an intelligent phone. In: (eds) Real-Time Mobile Multimedia Services. MMNS 2007. Lecture Notes in Computer Science, Springer, Berlin, Heidelberg p. 4787
Haddad MR, Baazaoui H, Ziou D, Ghezala HB (2014) A predictive model for recurrent consumption behavior: an application on phone calls. Knowl Based Systems 64:32–43
Nasim M, Rextin A, Khan N, Malik MM (2015) On temporal regularity in social interactions: Predicting mobile phone calls. arXiv preprint arXiv:1512.08061
Bilal A, Rextin A, Kakakhel A, Nasim M (2017) Roman-txt: forms and functions of roman urdu texting. In: Proceedings of the 19th International Conference on Human-Computer Interaction with Mobile Devices and Services, 15, ACM, September 2017
Wang Y, Kung L, Byrd TA (2018) Big data analytics: understanding its capabilities and potential benefits for healthcare organizations. Technolo Forecast Soc Change 126:3–13
Goodman-Deane J, Mieczakowski A, Johnson D, Goldhaber T, Clarkson PJ (2016) The impact of communication technologies on life and relationship satisfaction. Comput Hum Behav 57:219–229
Hampton AJ, Rawlings J, Treger S, Sprecher S (2018) Channels of computer-mediated communication and satisfaction in long-distance relationships. Interpers Inte J Pers Relatsh 11(2):171–187
Sarker IH, Colman A, Han J, Khan AI, Abushark YB, Salah K (2019) BehavDT: A behavioral decision tree learning to build user-centric context-aware predictive model. Mobile Netw Appl. https://doi.org/10.1007/s11036-019-01443-z
Aledavood T, López E, Roberts SGB, Reed-Tsochas F, Moro E, Dunbar RIM, Saramäki J (2015) Daily rhythms in mobile telephone communication. PloS ONE 10(9):e0138098
Aledavood T, López E, Roberts SGB, Reed-Tsochas F, Moro E, Dunbar RIM, Saramäki J (2016) Channel-Specific Daily Patterns in Mobile Phone Communication. In: Battiston S, De Pellegrini F, Caldarelli G, Merelli E (eds) Proceedings ECCS Springer Proceedings in Complexity. Springer, Cham, pp 209–218
Aledavood T, Lehmann S, Saramäki J (2015) Digital daily cycles of individuals. Front Phys 3:73
Centellegher S, López E, Saramäki J, Lepri B (2017) Personality traits and ego-network dynamics. PloS ONE 12(3):e0173110
Bhattacharya K, Ghosh A, Monsivais D, Dunbar RI, Kaski K (2016) Sex differences in social focus across the life cycle in humans. R Soc open Sci 3(4):160097
Roberts SBG, Dunbar RIM (2015) Managing relationship decay. Hum Nat 26(4):426–450
Salman HM, Ahmad WFW, Sulaiman S (2018) Usability evaluation of the smartphone user interface in supporting elderly users from experts’ perspective. IEEE Access 6:22578–22591
Sarker IH, Colman A, Han J (2019) Recencyminer: mining recency-based personalized behavior from contextual smartphone data. J Big Data 6(1):49
Sarker IH (2019) Context-aware rule learning from smartphone data: survey, challenges and future directions. J Big Data 6(1):95
Mehk F, Rextin A, Hayat S (2019) Exploiting contextual information to improve call prediction. PloS ONE. https://doi.org/10.1371/journal.pone.0223780
Kang S (2018) Outgoing call recommendation using neural network. Soft Comput 22(5):1569–1576
Lee S, Seo J, Lee G (2010) An adaptive speed-call list algorithm and its evaluation with esm. In: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’10, 2019-2022, April 2010
Eagle N, Pentland AS (2006) Reality mining: sensing complex social systems. Pers Ubiquitous Comput 10(4):255–268
Sun Z, Lin CH, Wu M, Zhou J, Luo L (2018) A tale of two communication tools: discussion-forum and mobile instant-messaging apps in collaborative learning. Br J Educ Technol 49(2):248–261
Bilal A, Rextin A, Kakakhel A, Nasim M (2018) Analyzing emergent users’ text messages data and exploring its benefits. IEEE Access 7:2870–2879
Scissors LE, Gergle D (2013) Back and forth, back and forth: Channel switching in romantic couple conflict. In: Proceedings of the 2013 Conference on Computer Supported Cooperative Work, ACM, 237-248, February 2013
Bontempi G, Taieb SB, Borgne YA (2012) Machine learning strategies for time series forecasting. In:(eds) Business Intelligence. eBISS 2012. Lecture Notes in Business Information Processing, vol 138. Springer, Berlin
Acknowledgements
The work has been partially supported by the Cyber Security Research Centre Limited whose activities are partially funded by the Australian Government’s Cooperative Research Centres Programme.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
SH wrote the initial manuscript and was responsible for all simulations in this study, including data cleaning, programming and execution. AR and MN were responsible for supervision of the project which included conceiving and designing algorithm at broad level and editing and revision of manuscript. AI gave input on the the design of algorithm and its evaluation . All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hayat, S., Rextin, A., Idris, A. et al. Text and phone calls: user behaviour and dual-channel communication prediction. Hum. Cent. Comput. Inf. Sci. 10, 11 (2020). https://doi.org/10.1186/s13673-020-00217-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13673-020-00217-x