
Abstract
The purpose of the paper is to study the proximal split feasibility problems. For solving the problems, we present new self-adaptive algorithms with the regularization technique. By using these algorithms, we give some strong convergence theorems for the proximal split feasibility problems.
Similar content being viewed by others


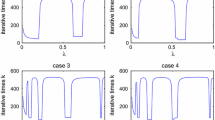
1 Introduction
The split feasibility problem has received much attention due to its applications in signal processing and image reconstruction [1] with particular progress in intensity modulated therapy [2]. Recently, the split feasibility problem (1.3) has been studied extensively by many authors (see, for instance, [3–16]).
Our purpose of the present manuscript is to study the more general case of the proximal split minimization problems by introducing new algorithms with the regularization technique.
In the sequel, we assume that \(H_{1}\) and \(H_{2}\) are two real Hilbert spaces, \(f:H_{1}\to\mathcal{R}\cup\{+\infty\}\) and \(g:H_{2}\to\mathcal {R}\cup\{+\infty\}\) are two proper and lower semi-continuous convex functions and \(A:H_{1}\to H_{2}\) is a bounded linear operator.
Now, we focus on the following minimization problem:
where \(g_{\lambda}\) stands for the Moreau-Yosida approximate of the function g of parameter λ, that is,
Remark 1.1
(1) The problem (1.1) includes the split feasibility problem as a special case. In fact, we choose f and g as the indicator functions of two nonempty closed convex sets \(C\subset H_{1}\) and \(Q\in H_{2}\), that is,
and
Then the problem (1.1) reduces to
which equals
(2) Now, we know that to solve (1.2) is exactly to solve the split feasibility problem of finding \(x^{\ddagger}\) such that
provided \(C\cap A^{-1}(Q)\ne\emptyset\).
In order to solve (1.3), one of key ideas is to use fixed point technique, that is, \(x^{\dagger}\) solves (1.3) if and only if
where \(\gamma>0\) is a constant and \(\operatorname{proj}_{C}\) and \(\operatorname{proj}_{Q}\) stand for the orthogonal projections on the closed convex sets C and Q, respectively.
According to the above fixed point equation, a popular algorithm to solve the split feasibility problems is the CQ method ([4]):
where the step size \(\tau_{n} \in(0, 2/\|A\|^{2})\).
However, the determination of the step size \(\tau_{n}\) depends on the operator norm \(\|A\|\) (or the largest eigenvalue of \(A^{*}A\)) which is in general not an easy work in practice. To overcome the above difficulty, the so-called self-adaptive method which permits step size \(\tau_{n}\) being selected self-adaptively was developed.
Self-adaptive algorithm
([17])
Let \(x_{0}\in H_{1}\) be an initial arbitrarily point. Assume that a sequence \(\{x_{n}\}\) in C has been constructed with \(\nabla{\bar{h}}(x_{n})\ne0\) as follows: Compute \(x_{n+1}\) via the rule
where \(\tau_{n}=\rho_{n}\frac{\bar{h}(x_{n})}{\|\nabla{\bar{h}}(x_{n})\|^{2}}\) with \(0<\rho_{n}<4\) and \(\bar{h}(x)=\frac{1}{2}\|(I-P_{Q})Ax\|^{2}\).
If \(\nabla{\bar{h}}(x_{n})=0\), then \(x_{n+1}=x_{n}\) is a solution of the problem (1.3) and the iterative process stops. Otherwise, we set \(n:=n+1\) and go to the sequence (1.4).
In the present manuscript, our main purpose is to solve the problem (1.1) by using the fixed point technique and the self-adaptive methods. First, by the differentiability of the Yosida approximate \(g_{\lambda}\), we have
where \(\partial f(x^{\dagger})\) denotes the subdifferential of f at \(x^{\dagger}\) and \(\operatorname{prox}_{\lambda g}(x^{\dagger})\) is the proximal mapping of g, that is,
and
Note that the optimality condition of (1.5) is as follows:
which can be rewritten as
which is equivalent to the fixed point equation:
for all \(\mu>0\).
If \(\arg\min f\cap A^{-1}(\arg\min g)\ne\emptyset\), then (1.1) is reduced to the following proximal split feasibility problem.
Find \(x^{\dagger}\) such that
where
and
In the sequel, we use Γ to denote the solution set of the problem (1.8).
Recently, in order to solve the problem (1.8), Moudafi and Thakur [18] presented the following split proximal algorithm with a way of selecting the step sizes such that its implementation does not need any prior information as regards the operator norm.
Self-adaptive split proximal algorithm
For an initialization \(x_{0}\in H_{1}\), assume that a sequence \(\{x_{n}\}\) in H has been constructed and \(\theta(x_{n})\ne\emptyset\) as follows: Compute \(x_{n+1}\) via
for all \(n\ge0\), where the step size \(\mu_{n}=\rho_{n}\frac {h(x_{n})+l(x_{n})}{\theta^{2}(x_{n})}\) in which \(0<\rho_{n}<4\),
and
If \(\theta(x_{n})=0\), then \(x_{n+1}=x_{n}\) is a solution of the problem (1.8) and the iterative process stops. Otherwise, we set \(n:=n+1\) and go to the sequence (1.9).
Consequently, they demonstrated the following weak convergence of the above split proximal algorithm.
Theorem 1.2
Suppose that \(\Gamma\ne\emptyset\). Assume that the parameters satisfy the condition:
for some \(\epsilon>0\) small enough. Then the sequence \(\{x_{n}\}\) generated by (1.9) weakly converges to a solution of the problem (1.8).
Note that Theorem 1.2 has only the weak convergence. So, a natural problem arises:
Could we design a new algorithm such that the strong convergence is obtained?
In this paper, our main purpose is to adapt the algorithm (1.9) by using the regularization means such that the strong convergence is guaranteed.
2 Preliminaries
Let H be a real Hilbert space with the inner product \(\langle\cdot,\cdot\rangle\) and the norm \(\|\cdot\|\), respectively and C be a nonempty closed convex subset of H.
Recall that a mapping \(T:C\to C\) is said to be:
-
(1)
L-Lipschitz if there exists \(L>0\) such that
$$\|Tx-Ty\|\le L\|x-y\| $$for all \(x,y\in C\). If \(L\in(0,1)\), then we call T the L-contraction. If \(L=1\), we call T a nonexpansive mapping.
-
(2)
Firmly nonexpansive if
$$\|Tx-Ty\|^{2}\le\|x-y\|^{2}-\bigl\Vert (I-T)x-(I-T)y\bigr\Vert ^{2} $$for all \(x,y\in C\), where I denotes the identity, which is equivalent to
$$\|Tx-Ty\|^{2}\le\langle Tx-Ty, x-y\rangle $$for all \(x,y\in C\). Also, the mapping \(I-T\) is firmly nonexpansive.
-
(3)
Strongly positive if there exists a constant \(\zeta>0\) such that
$$\langle Tx,x\rangle\ge\zeta\|x\|^{2} $$for all \(x\in C\).
Note that the proximal mapping of g is firmly nonexpansive, namely,
for all \(x,y\in H_{2}\) and it is also the case for the complement \(I-\operatorname{prox}_{\lambda g}\). Thus \(A^{*}(I-\operatorname{prox}_{\lambda g})A\) is cocoercive with coefficient \(\frac{1}{\|A\|^{2}}\), where we recall that a mapping \(B:H_{1}\to H_{1}\) is cocoercive if there exists \(\alpha>0\) such that
for all \(x,y\in H_{1}\). If \(\mu\in (0,\frac{1}{\|A\|^{2}} )\), then \(I-\mu A^{*}(I-\operatorname{prox}_{\lambda g})A\) is nonexpansive.
Let C be a nonempty closed convex subset of H. For all \(x\in H\), there exists a unique nearest point in C, denoted by \(\operatorname{proj}_{C}x\), such that
for all \(y\in C\). The mapping \(\operatorname{proj}_{C}\) is called the metric projection of H onto C. It is well known that \(\operatorname{proj}_{C}\) is a nonexpansive mapping and is characterized by the following property:
for all \(x\in H\) and \(y\in C\).
Now, we introduce two lemmas for our main results in this paper.
Lemma 2.1
([19])
Let \(\{a_{n}\}\) be a sequence of nonnegative real numbers satisfying the following relation:
for all \(n\ge0\), where
-
(a)
\(\{\alpha_{n}\}_{n\in\mathbb{N}}\subset[0,1]\) and \(\sum_{n=1}^{\infty}\alpha_{n}=\infty\);
-
(b)
\(\limsup_{n\to\infty}\sigma_{n}\le0\);
-
(c)
\(\sum_{n=1}^{\infty}\delta_{n}<\infty\).
Then \(\lim_{n\to\infty}a_{n}=0\).
Lemma 2.2
([20])
Let \(\{\gamma_{n}\}\) be a sequence of real numbers such that there exists a subsequence \(\{\gamma_{n_{i}}\}\) of \(\{\gamma_{n}\}\) such that \(\gamma _{n_{i}}<\gamma_{n_{i}+1}\) for all \(i\geq1\). Then there exists a nondecreasing sequence \(\{m_{k}\}\) of positive integers such that \(\lim_{k\to\infty}m_{k}=\infty\) and the following properties are satisfied by all (sufficiently large) positive integers k:
In fact, \(m_{k}\) is the largest number n in the set \(\{1, \ldots, k\}\) such that the condition \(\gamma_{n}<\gamma_{n+1}\) holds.
3 Main results
Now, we first introduce our self-adaptive algorithm. Let \(H_{1}\) and \(H_{2}\) be two real Hilbert spaces. Let \(f:H_{1}\to\mathcal{R}\cup\{ +\infty\}\) and \(g:H_{2}\to\mathcal{R}\cup\{+\infty\}\) be two proper and lower semi-continuous convex functions and \(A:H_{1}\to H_{2}\) be a bounded linear operator. Let \(\psi:H_{1}\to H_{1}\) be a κ-contraction and \(B:H_{1}\to H_{1}\) be a strongly positive bounded linear operator with coefficient \(\zeta>\kappa\).
Algorithm 3.1
Set
and
for all \(x\in H_{1}\). For an initialization \(x_{0}\in H_{1}\), assume that a sequence \(\{x_{n}\}\) has been constructed in \(H_{1}\) with \(\theta(x_{n})\ne \emptyset\) as follows.
Compute \(x_{n+1}\) via
for all \(n\ge0\), where \(\{\alpha_{n}\}\subset[0,1]\) is a real number sequence and \(\mu_{n}\) is the step size satisfying \(\mu_{n}=\rho_{n}\frac {h(x_{n})+l(x_{n})}{\theta^{2}(x_{n})}\) with \(0<\rho_{n}<4\).
If \(\theta(x_{n})=0\), then \(x_{n}\) is a solution of the problem (1.8) and the iterative process stops. Otherwise, we set \(n:=n+1\) and go to the sequence (3.1).
Theorem 3.2
Suppose that \(\Gamma\ne\emptyset\). Assume the parameters \(\{\alpha_{n}\}\) and \(\{\rho_{n}\}\) satisfy the conditions:
-
(C1)
\(\lim_{n\to\infty}\alpha_{n}=0\);
-
(C2)
\(\sum_{n=0}^{\infty}\alpha_{n}=\infty\);
-
(C3)
\(\epsilon\le\rho_{n}\le\frac{4h(x_{n})}{h(x_{n})+l(x_{n})}-\epsilon\) for some \(\epsilon>0\) small enough.
Then the sequence \(\{x_{n}\}\) generated by (3.1) converges strongly to a point \(z=\operatorname{proj}_{\Gamma}(\psi+I-B)(z)\).
Proof
From (2.1), we deduce that \(z=\operatorname{proj}_{\Gamma}(\psi +I-B)(z)\) implies
for all \(x\in\Gamma\), which has a unique solution. Let \(x^{*}\in\Gamma \). Since minimizers of any function are exactly fixed points of its proximal mappings, we have \(x^{*}=\operatorname{prox}_{\lambda f}x^{*}\) and \(Ax^{*}=\operatorname{prox}_{\lambda g}Ax^{*}\). Since \(\operatorname{prox}_{\lambda f}\) is nonexpansive, by (3.1), we can derive
Thus we have
Since \(\operatorname{prox}_{\lambda g}\) is firmly nonexpansive, we deduce that \(I-\operatorname{prox}_{\lambda g}\) is also firmly nonexpansive. Hence we have
Note that \(\nabla h(x_{n})=A^{*}(I-\operatorname{prox}_{\lambda g})Ax_{n}\) and \(\nabla l(x_{n})=(I-\operatorname{prox}_{\lambda f})x_{n}\). Thus it follows from (3.3) that
By the condition (C3), without loss of generality, we can assume that
for all \(n\ge0\). Thus, from (3.2) and (3.4), we obtain
Hence \(\{x_{n}\}\) is bounded.
Let \(z=P_{\Gamma}(\psi+I-B)z\). From (3.5), we deduce
We consider the following two cases.
Case 1. \(\|x_{n+1}-z\|\le\|x_{n}-z\|\) for all \(n\ge n_{0}\) large enough.
In this case, \(\lim_{n\to\infty}\|x_{n}-z\|\) exists and is finite, and hence
This together with (3.6) implies that
Since \(\rho_{n} (\frac{4h(x_{n})}{h(x_{n})+l(x_{n})}-\rho_{n} )\ge\epsilon ^{2}\) by the condition (C3), we have
Noting that \(\theta^{2}(x_{n})=\|\nabla h(x_{n})\|^{2}+\|\nabla l(x_{n})\|^{2}\) is bounded, we deduce immediately that
Therefore, we have
Next, we prove that
Since \(\{x_{n}\}\) is bounded, there exists a subsequence \(\{x_{n_{i}}\}\) of \(\{x_{n}\}\) such that \(x_{n_{i}}\rightharpoonup z^{\dagger}\) and
By the lower semi-continuity of h, we have
So, we have
that is, \(Az^{\dagger}\) is a fixed point of the proximal mapping of g or, equivalently, \(0 \in\partial g(Az^{\dagger})\). In other words, \(Az^{\dagger}\) is a minimizer of g.
Similarly, from the lower semi-continuity of l, we have
Therefore, we have
that is, \(z^{\dagger}\) is a fixed point of the proximal mapping of f or, equivalently, \(0 \in\partial f(z^{\dagger})\). In other words, \(z^{\dagger}\) is a minimizer of f. Hence \(z^{\dagger}\in\Gamma\). Therefore, we have
By (3.4), we have
Thus it follows from (3.1) that
Thus it follows that
From Lemma 2.1, (3.8) and (3.9) we deduce that \(x_{n}\to z\).
Case 2. There exists a subsequence \(\{\|x_{n_{j}}-z\|\}\) of \(\{\| x_{n}-z\|\}\) such that
for all \(j\ge1\). By Lemma 2.2, there exists a strictly increasing sequence \(\{m_{k}\}\) of positive integers such that \(\lim_{k\to\infty}m_{k}=+\infty\) and the following properties are satisfied: for all \(k\in\mathbb{N}\),
Consequently, we have
and so
By a similar argument to Case 1, we can prove that
and
where \(\sigma_{m_{k}}=2\langle\psi(z)-Bz,x_{m_{k}+1}-z\rangle\). In particular, we have
Then we have
Thus it follows from (3.10) and (3.11) that
which implies that \(x_{n}\to z\). This completes the proof. □
Algorithm 3.3
For an initialization \(x_{0}\in H_{1}\). Assume that a sequence \(\{x_{n}\}\) has been constructed as follows: Set
and
for all \(n\in\mathbb{N}\).
If \(\theta(x_{n})\ne\emptyset\), then compute \(x_{n+1}\) via
for all \(n\ge0\), where \(\{\alpha_{n}\}_{n\in\mathbb{N}}\subset[0,1]\) is a real number sequence and \(\mu_{n}\) is the step size satisfying
with \(0<\rho_{n}<4\).
If \(\theta(x_{n})=0\), then \(x_{n}\) is a solution of the problem (1.8) and the iterative process stops. Otherwise, we set \(n:=n+1\) and go to (3.12).
From Theorem 3.2, we have the following corollary.
Corollary 3.4
Suppose that \(\Gamma\ne\emptyset\). Assume the parameters \(\{\alpha_{n}\}\) and \(\{\rho_{n}\}\) satisfy the conditions:
-
(C1)
\(\lim_{n\to\infty}\alpha_{n}=0\);
-
(C2)
\(\sum_{n=0}^{\infty}\alpha_{n}=\infty\);
-
(C3)
\(\epsilon\le\rho_{n}\le\frac{4h(x_{n})}{h(x_{n})+l(x_{n})}-\epsilon\) for some \(\epsilon>0\) small enough.
Then the sequence \(\{x_{n}\}\) generated by (3.12) converges strongly to a point \(z=\operatorname{proj}_{\Gamma}(\psi)(z)\).
Algorithm 3.5
For an initialization \(x_{0}\in H_{1}\). Assume that a sequence \(\{x_{n}\}\) has been constructed as follows: Set
and
for all \(n\in\mathbb{N}\).
If \(\theta(x_{n})\ne\emptyset\), then compute \(x_{n+1}\) via
for all \(n\ge0\), where \(\{\alpha_{n}\}_{n\in\mathbb{N}}\subset[0,1]\) is a real number sequence and \(\mu_{n}\) is the step size satisfying
with \(0<\rho_{n}<4\).
If \(\theta(x_{n})=0\), then \(x_{n}\) is a solution of the problem (1.8) and the iterative process stops. Otherwise, we set \(n:=n+1\) and go to (3.13).
Corollary 3.6
Suppose that \(\Gamma\ne\emptyset\). Assume the parameters \(\{\alpha_{n}\}\) and \(\{\rho_{n}\}\) satisfy the following conditions:
-
(C1)
\(\lim_{n\to\infty}\alpha_{n}=0\);
-
(C2)
\(\sum_{n=0}^{\infty}\alpha_{n}=\infty\);
-
(C3)
\(\epsilon\le\rho_{n}\le\frac{4h(x_{n})}{h(x_{n})+l(x_{n})}-\epsilon\) for some \(\epsilon>0\) small enough.
Then the sequence \(\{x_{n}\}\) generated by (3.13) converges strongly to a point \(z=\operatorname{proj}_{\Gamma}(0)\), which is the minimum norm element in Γ.
Remark 3.7
Where the bounded linear operator A is the identity operator, the problem (1.8) is nothing else than the problem of finding a common minimizer of f and g and (3.1) reduces to the following relaxed split proximal algorithm:
for all \(n\ge0\).
References
Combettes, PL, Wajs, VR: Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 4, 1168-1200 (2005)
Censor, Y, Elfving, T: A multiprojection algorithm using Bregman projections in a product space. Numer. Algorithms 8, 221-239 (1994)
Byrne, C: Iterative oblique projection onto convex subsets and the split feasibility problem. Inverse Probl. 18, 441-453 (2002)
Xu, HK: Iterative methods for the split feasibility problem in infinite-dimensional Hilbert spaces. Inverse Probl. 26, 105018 (2010)
Byrne, C: A unified treatment of some iterative algorithms in signal processing and image reconstruction. Inverse Probl. 20, 103-120 (2004)
Zhao, J, Yang, Q: Several solution methods for the split feasibility problem. Inverse Probl. 21, 1791-1799 (2005)
Dang, Y, Gao, Y: The strong convergence of a KM-CQ-like algorithm for a split feasibility problem. Inverse Probl. 27, 015007 (2011)
Wang, F, Xu, HK: Approximating curve and strong convergence of the CQ algorithm for the split feasibility problem. J. Inequal. Appl. 2010, Article ID 102085 (2010)
Yao, Y, Wu, J, Liou, Y-C: Regularized methods for the split feasibility problem. Abstr. Appl. Anal. 2012, Article ID 140679 (2012)
Yang, Q, Zhao, J: Several solution methods for the split feasibility problem. Inverse Probl. 21, 1791-1799 (2005)
Ceng, LC, Ansari, QH, Yao, JC: An extragradient method for split feasibility and fixed point problems. Comput. Math. Appl. 64, 633-642 (2012)
Chang, SS, Kim, JK, Cho, YJ, Sim, J: Weak and strong convergence theorems of solutions to split feasibility problem for nonspreading type mapping in Hilbert spaces. Fixed Point Theory Appl. 2014, 11 (2014)
Yang, L, Chang, SS, Cho, YJ, Kim, JK: Multiple-set split feasibility problems for total asymptotically strict pseudocontractions mappings. Fixed Point Theory Appl. 2011, 77 (2011)
Yao, Y, Agarwal, RP, Postolache, M, Liou, YC: Algorithms with strong convergence for the split common solution of the feasibility problem and fixed point problem. Fixed Point Theory Appl. 2014, 183 (2014)
Dong, QL, Yao, Y, He, S: Weak convergence theorems of the modified relaxed projection algorithms for the split feasibility problem in Hilbert spaces. Optim. Lett. 8, 1031-1046 (2014)
Yao, Y, Postolache, M, Liou, YC: Strong convergence of a self-adaptive method for the split feasibility problem. Fixed Point Theory Appl. 2013, 201 (2013)
Lopez, G, Martin-Marquez, V, Wang, F, Xu, HK: Solving the split feasibility problem without prior knowledge of matrix norms. Inverse Probl. 28, 085004 (2012)
Moudafi, A, Thakur, BS: Solving proximal split feasibility problems without prior knowledge of operator norms. Optim. Lett. 8, 2099-2110 (2014)
Xu, HK: Iterative algorithms for nonlinear operators. J. Lond. Math. Soc. 66, 240-256 (2002)
Mainge, PE: Strong convergence of projected subgradient methods for nonsmooth and non-strictly convex minimization. Set-Valued Anal. 16, 899-912 (2008)
Acknowledgements
This project was funded by the Deanship of Scientific Research (DSR), King Abdulaziz University, under grant no. (18-130-36-HiCi). The authors, therefore, acknowledge with thanks DSR technical and financial support. Zhangsong Yao was supported by the Scientific Research Project of Nanjing Xiaozhuang University (2015NXY46). Yeol Je Cho was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT and future Planning (2014R1A2A2A01002100).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interest.
Authors’ contributions
All authors read and approved the final manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Yao, Y., Yao, Z., Abdou, A.A. et al. Self-adaptive algorithms for proximal split feasibility problems and strong convergence analysis. Fixed Point Theory Appl 2015, 205 (2015). https://doi.org/10.1186/s13663-015-0462-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13663-015-0462-7