
Abstract
Background
Adequately conducted systematic reviews with meta-analyses are considered the highest level of evidence and thus directly defines many clinical guidelines. However, the risks of type I and II errors in meta-analyses are substantial. Trial Sequential Analysis is a method for controlling these risks. Erroneous use of the method might lead to research waste or misleading conclusions.
Methods
The current protocol describes a systematic review aimed to identify common and major mistakes and errors in the use of Trial Sequential Analysis by evaluating published systematic reviews and meta-analyses that include this method. We plan to include all studies using Trial Sequential Analysis published from January 2018 to January 2022, an estimated 400 to 600 publications. We will search Medical Literature Analysis and Retrieval System Online and the Cochrane Database of Systematic Reviews, including studies with all types of participants, interventions, and outcomes. Two independent reviewers will screen titles and abstracts, include relevant full text articles, extract data from the studies into a predefined checklist, and evaluate the methodological quality of the study using the AMSTAR 2, assessing the methodological quality of the systematic reviews.
Discussion
This protocol follows the Preferred Reporting Items for Systematic Reviews and Meta-Analysis Protocols (PRISMA-P). The identified mistakes and errors will be published in peer reviewed articles and form the basis of a reviewed guideline for the use of Trial Sequential Analysis. Appropriately controlling for type I and II errors might reduce research waste and improve quality and precision of the evidence that clinical guidelines are based upon.
Similar content being viewed by others

Introduction
Adequately conducted systematic reviews with meta-analyses are considered the highest level of evidence within evidence-based clinical practice [1,2,3]. Despite their place at the top of the hierarchical research pyramid, conventional meta-analyses are still at risks of type I errors (alpha) due to results reaching significance by chance and type II errors (beta) due to results not reaching significance even when an effect exists [1, 4, 5]. The risk of these errors is generally accepted at consensus-based levels (typically 5% for type I and 10% or 20% for type II errors), but may increase beyond those levels due to publication bias, biased trial designs, data heterogeneity, and poorly conducted or inadequately powered meta-analyses with multiple significance testing [1, 4, 5]. The investigated effect of a meta-analysis can reach significance even though the effect might be so small that it is not clinically relevant [6].
Several tools exist for controlling type I and type II errors as described by the Cochrane Handbook [2]. However, little emphasis has been put on mitigating the purely random causes of type I and II errors [7]. As an example, correction for multiplicity issues due to use of several outcomes has historically been under prioritised and underpowered reviews are very common [5, 8,9,10]. Moreover, there is an increased risk of an exaggerated intervention benefit in small trials due to reporting bias or methodological flaws [11]. In a meta-analytic setting, heterogeneity needs to be adequately examined and considered when designing the Trial Sequential Analysis [5, 11,12,13].
Trial Sequential Analysis can be used to estimate the diversity-adjusted required information size (DARIS or the ‘meta-analytic sample size’) in random-effects meta-analysis [14]. Trial Sequential Analysis may establish when firm evidence is reached for an effect of an intervention [12,13,14,15]. Furthermore, Trial Sequential Analysis can establish futility boundaries and thus indicate when conclusion of no effect can be drawn well before reaching the DARIS [12,13,14,15]. If adequate power is not reached by the meta-analysis, DARIS may guide the scaling of future trials [13].
Trial Sequential Analysis can be used to assess imprecision with Grading of Recommendations Assessment, Development and Evaluation (GRADE) [16]. By calculating the DARIS, and compare that with the accrued information, the reviewers can determine if and how to downgrade GRADE for imprecision (see below) [17, 18]. Also, the analysis can supply the reviewers with a trial sequential analysis-adjusted confidence interval to demonstrate a realistic confidence interval [15].
To date, numerous systematic reviews and meta-analyses have used Trial Sequential Analysis since it was first presented at the beginning of this millennium [19]. As with all methods, the Trial Sequential Analysis can be misused and misinterpreted. A rigorous process starting when writing the protocol through to the reporting phase of the results in the review is necessary. Predefined parameters such as alpha level, beta level (and power), relative risk reduction, minimally relevant clinical difference, and heterogeneity can to a large extent affect the results of the analysis and should therefore be enclosed in pre-published or registered protocols prior to searching for literature for the systematic review. Failure to do so might ultimately alter the conclusion of the meta-analysis and thereby directly misguide clinical practice [5, 15, 20].
Objective
In this review, we aim to systematically evaluate the use of Trial Sequential Analysis in published systematic reviews and meta-analyses. Specifically, we seek to evaluate how the authors prepared and conducted their Trial Sequential Analysis, and interpreted their results in the assessment of imprecision in the obtained meta-analytic results. We want to identify the most common major mistakes and errors in order to publish these in peer reviewed journals and update recommendations for a more proper use of the Trial Sequential Analysis programme in future systematic reviews [21]. The Trial Sequential Analysis programme is freely accessible from www.ctu.dk/tsa in a java-format and compatible with RevMan 5.0 [15, 20, 22].
Methods
Criteria for considering studies for this quality assessment study
As this is a methodological review examining the use of Trial Sequential Analysis in systematic reviews or in meta-analyses, there are only a few criteria for considering eligible reviews. This protocol adheres to the reporting guidelines PRISMA-P (Supplemental material) [23].
Types of studies
This review will include peer reviewed publications of systematic reviews with meta-analyses or of meta-analysis of randomised clinical trials that have included a Trial Sequential Analysis and analysed at least two randomised clinical trials. A meta-analysis is a statistical approach for combining data, while a systematic review is a detailed, organised, and transparent method of gathering, appraising and synthesising data to answer a well-defined question [2]. The included studies must at least include two randomised clinical trials in at least one meta-analysis and Trial Sequential Analysis. Only studies published from January 2018 to January 2022 will be included. For practical reasons, only articles in English will be included in the study. We expect that we will identify 400 to 600 relevant publications.
Types of participants
We accept all participants of any race, sex, or age with any disease or condition for this review.
Types of interventions
We accept all types of intervention for this review.
Types of outcomes
All dichotomous or continuous outcomes are accepted for this review if they are analysed using both meta-analysis and Trial Sequential Analysis.
Search strategy
The following databases will be sought:
-
Medical Literature Analysis and Retrieval System Online (MEDLINE)
-
The Cochrane Database of Systematic Reviews (CDSR)
Keywords used in the search strategy:
-
Trial Sequential Analysis OR TSA
-
Systematic Review OR Meta-analysis
The preliminary search strategy can be found in Supplemental material.
Selection of studies
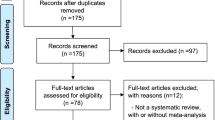
Two authors (CGR and MHO) will independently screen the title and abstract using the web-based application Covidence (www.covidence.org, Melbourne, Australia) [24]. All relevant full-text articles will be retrieved and screened for eligibility, and reasons for exclusion will be recorded. Any discrepancy will be resolved through discussion. If an agreement is not reached, a third author (CG) will resolve the disagreement. Trial selection will be shown through a flow chart following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement (Supplemental material).
Methodological quality of the systematic reviews and meta-analyses
Two authors will independently evaluate the methodological quality in all included systematic reviews and meta-analyses using the AMSTAR 2 - Assessing the Methodological Quality of Systematic Reviews [25]. The assessment of the methodological quality of the studies will be used to evaluate whether improper use of Trial Sequential Analysis is related to other methodological flaws. Each of the 16 items will be rated, and a final rating of the overall confidence in the results of each study will be given on a scale of confidence as high, moderate, low, or critically low [25]. Any discrepancy will be resolved through discussion. If an agreement is not reached, a third author (CG) will resolve the disagreement.
Extraction of data
Two independent authors will extract data from each included study. After extraction, all data will be compared, consensus will be reached, or a third author will be consulted to resolve disagreement.
General information (review characteristics) on each study will be extracted (author, year, medical field, intervention characteristics). For data concerning the conduct of the systematic reviews we will extract data related to the PRISMA statement on transparent reporting of systematic reviews such as comparator used, description of outcomes, number of included trials in the analyses, GRADE, methods for grading imprecision etc. [26]. For the specificities on the use and conduct of Trial Sequential Analysis we will extract data regarding the parameters used in the chosen analysis such as information on how the analysis was conducted (fixed- or random-effects, relative risk or odds ratio, etc.), and to what degree adjustments of alpha-level, and power were used. Also, details about the relative risk reduction and minimally relevant difference and how these were conceived are extracted. We will mainly report on the primary outcomes of the systematic reviews prioritising to include both dichotomous and continuous outcomes if possible. Specific data regarding the Trial Sequential Analysis will be extracted systematically through a predefined checklist made in REDCap (Research Electronic Data Capture, University of Kansas, United States) hosted at Rigshospitalet [27,28,29].
A prespecified extraction checklist containing items about the methodology of Trial Sequential Analysis will be prepared prior to the literature search. By using the Trial Sequential Analysis manual [30] and randomly selecting 10 systematic reviews, including meta-analysis and Trial Sequential Analysis, the most common and important steps in the analysis has been selected by the review group and synthesised into the extraction checklist. The extraction checklist contains four main categories (identification, content of the pre-registred protocol, content of the systematic review, and results), each of which has relevant questions depending on the type of outcome (dichotomous or continuous) used in the review. For more information on the extraction checklist, see Supplemental material.
Assessment of Trial Sequential Analysis results for downgrading for imprecision
We will assess the way authors of systematic reviews or meta-analyses have used Trial Sequential Analysis for downgrading for imprecision in GRADE [16, 17] or by other methods. The GRADE approach for downgrading imprecision recommends evaluating the naïve 95% confidence interval and calculating the optimal information size [16, 31]. Thus, the approach does not emphasise the possibility to adjust alpha and beta-level, a priori decide a relative risk reduction or minimally relevant difference, and take into account heterogeneity in the analysis. We will compare the downgrading for imprecision in the included studies with the following method: imprecision in GRADE is downgraded by two levels if the accrued number of participants is below 50% of the DARIS, and one level if between 50 and 100% of DARIS. We will not expect downgrading if the cumulative Z-curve crosses the monitoring boundaries for benefit, harm, or futility, or if DARIS is reached. This method for assessing imprecision has been described and used in previous systematic reviews [32, 33]. We will examine if this methodology has an impact on how the level of imprecision is assessed and on the outcome of the systematic review or meta-analysis.
Data analysis
The most common mistakes will be ranked according to their prevalence and comparisons of the AMSTAR 2 score in groups of studies will be made. The consequences of the most common errors and mistakes found in the literature when using Trial Sequential Analysis will be explained by examples and suggestions on how to correct these. Finally, a guideline for future reviewers will be created from the identified mistakes and errors.
Mistakes and errors will be categorised as related to the protocol, methodology, presentation of the results, and the interpretation. Each mistake and error will, furthermore, be classified as major or minor. Major mistakes or errors are those with the potential to cause a wrong conclusion. This classification will be based on a consensus by the investigators.
Statistical considerations
The number of major or minor mistakes and errors per article will be presented as median and interquartile range. The AMSTAR 2 overall rating of confidence will be used to classify systematic reviews as high, moderate, low, or critically low confidence. Systematic reviews without any major mistakes will be compared to those with any major mistake using Wilcoxon-signed rank test or Fisher’s exact test for dichotomous outcomes.
The mistakes and errors will be presented as frequencies, with a 95% confidence interval calculated using 1-sample proportions test without continuity correction. The AMSTAR 2 score for the manuscripts where the specific mistake and error was present will be presented as a covariate. We will combine these mistakes and errors based on our recommendations, as errors referring to both protocol and presentation of results might be handled by one recommendation. Both the specified and aggregated frequency will be presented in a table related to the recommendation.
Discussion
This review aims to assess the use of Trial Sequential Analysis in the current body of systematic reviews and meta-analyses. Trial Sequential Analysis offers important pieces of information [4, 14, 34] and provides more stringent planning of how to calculate the DARIS and interpret the imprecision in GRADE [15, 17, 18, 20, 22, 33,34,35] than present recommendations regarding the calculation of optimal information size and assessment of imprecision in GRADE [16]. However, the method is currently not a mandatory part of Cochrane Reviews. Arguments put forward against the use is that authors of systematic reviews and meta-analysis rarely has the power to start or stop a trial being conducted and that conclusions of meta-analyses should not be driven by statistical testing [36, 37].
Since the introduction of Trial Sequential Analysis in 2005 [19], an increasing number of authors have used the Trial Sequential Analysis to control the risk of type I and II errors and thus improve the quality of evidence and the recommendations. However, strict systematic approaches to this analysis are important as it can be misused for a ‘cherry-picking’ approach. Therefore, this systematic review of the methodology of current systematic reviews and meta-analyses is important for understanding and conceptualising the use of Trial Sequential Analysis. As mistakes and errors in the use of the Trial Sequential Analysis are likely to be found, these will be used to establish a guideline for future reviewers.
The strengths of this protocol are that it is pre-published and detailed prior to conducting the systematic search. As the purpose of the review is to explore the current practice of using Trial Sequential Analysis, the use of a standardised extraction template is difficult to produce as mistakes and errors comes in a variety of ways that are not always predictable. Furthermore, the extent of the work will require several persons to extract data from protocols, articles, and supplemental data from the publications. This may compromise the internal validity of the extraction. To account for this, weekly meetings are held for consensus, and all investigators are encouraged to extract in different pairs throughout the process.
Trial Sequential Analysis has been accepted as a supplementary analysis in the Cochrane Hepato-Biliary Group systematic reviews (https://hbg.cochrane.org/information-authors) and as stated in the Cochrane Handbook for Systematic Reviews of Interventions: “…trial sequential analysis may, however, be used in the context of a prospectively planned series of randomized trials” [38].
The results from this review will be used in the development of a comprehensive and more intuitive guideline including a standard operating procedure for conducting Trial Sequential Analysis. It is our intention that such a guideline will help future reviewers avoid these errors and mistakes. Furthermore, as the Trial Sequential Analysis software is currently being updated, the results can be incorporated in the steps when conducting the analysis to avoid mistakes.
Stage of the review at the time of the submission
At the time of submitting this protocol, ten randomly selected systematic reviews with meta-analysis and Trial Sequential Analysis were used to test and improve the extraction checklist. Minor changes to the extraction checklist can occur during the first stage of data extraction. A preliminary search was done on the 9th of July, 2021 and the final search will be conducted after the submission of this protocol.
Availability of data and materials
Not applicable.
Abbreviations
- AMSTAR 2:
-
Assessing the methodological quality of systematic reviews 2
- D2 :
-
Diversity
- DARIS:
-
Diversity-adjusted required information size
- GRADE:
-
Grading of Recommendations Assessment, Development and Evaluation
- Pc:
-
Proportion of participants with the outcome in the control group
- RRR:
-
Relative risk reduction
References
Garattini S, Jakobsen JC, Wetterslev J, Bertelé V, Banzi R, Rath A, et al. Evidence-based clinical practice: Overview of threats to the validity of evidence and how to minimise them. Eur J Intern Med. 2016;32:13–21. https://doi.org/10.1016/j.ejim.2016.03.020.
Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA (editors). Cochrane Handbook for Systematic Reviews of Interventions version 6.3. Updated February 2022. Cochrane; 2022. Available from http://www.training.cochrane.org/handbook.
Ioannidis JPA. The mass production of redundant, misleading, and conflicted systematic reviews and meta-analyses. Milbank Q. 2016;94:485–514. https://doi.org/10.1111/1468-0009.12210.
Brok J, Thorlund K, Gluud C, Wetterslev J. Trial sequential analysis reveals insufficient information size and potentially false positive results in many meta-analyses. J Clin Epidemiol. 2008;61:763–9. https://doi.org/10.1016/j.jclinepi.2007.10.007.
Jakobsen JC, Wetterslev J, Winkel P, Lange T, Gluud C. Thresholds for statistical and clinical significance in systematic reviews with meta-analytic methods. BMC Med Res Methodol. 2014;14:120.
Shrier I, Christensen R, Juhl C, Beyene J. Meta-analysis on continuous outcomes in minimal important difference units: an application with appropriate variance calculations. J Clin Epidemiol. 2016;80:57–67. https://doi.org/10.1016/j.jclinepi.2016.07.012.
Roberts I, Ker K, Edwards P, Beecher D, Manno D, Sydenham E. The knowledge system underpinning healthcare is not fit for purpose and must change. BMJ. 2015;350:h2463. https://doi.org/10.1136/bmj.h2463.
Bender R, Bunce C, Clarke M, Gates S, Lange S, Pace NL, et al. Attention should be given to multiplicity issues in systematic reviews. J Clin Epidemiol. 2008;61:857–65. https://doi.org/10.1016/j.jclinepi.2008.03.004.
Turner RM, Bird SM, Higgins JPT. The impact of study size on meta-analyses: Examination of underpowered studies in Cochrane reviews. PLOS ONE. 2013;8:e59202. https://doi.org/10.1371/journal.pone.0059202.
Imberger G, Vejlby AD, Hansen SB, Møller AM, Wetterslev J. Statistical multiplicity in systematic reviews of anaesthesia interventions: a quantification and comparison between Cochrane and non-Cochrane reviews. PLOS ONE. 2011;6:e28422. https://doi.org/10.1371/JOURNAL.PONE.0028422.
Kjaergard LL, Villumsen J, Gluud C. Reported methodologic quality and discrepancies between large and small randomized trials in meta-analyses. Ann Intern Med. 2001;135:982–9. https://doi.org/10.7326/0003-4819-135-11-200112040-00010.
Wetterslev J, Thorlund K, Brok J, Gluud C. Estimating required information size by quantifying diversity in random-effects model meta-analyses. BMC Med Res Methodol. 2009;9:86. https://doi.org/10.1186/1471-2288-9-86.
Claire R, Gluud C, Berlin I, Coleman T, Leonardi-Bee J. Using Trial Sequential Analysis for estimating the sample sizes of further trials: example using smoking cessation intervention. BMC Med Res Methodol. 2020;20:284. https://doi.org/10.1186/s12874-020-01169-7.
Wetterslev J, Thorlund K, Brok J, Gluud C. Trial sequential analysis may establish when firm evidence is reached in cumulative meta-analysis. J Clin Epidemiol. 2008;61:64–75. https://doi.org/10.1016/j.jclinepi.2007.03.013.
Wetterslev J, Jakobsen JC, Gluud C. Trial Sequential Analysis in systematic reviews with meta-analysis. BMC Med Res Methodol. 2017;17:1–18. https://doi.org/10.1186/s12874-017-0315-7.
Guyatt GH, Oxman AD, Kunz R, Brozek J, Alonso-Coello P, Rind D, et al. GRADE guidelines 6. Rating the quality of evidence–imprecision. J Clin Epidemiol. 2011;64:1283–93. https://doi.org/10.1016/j.jclinepi.2011.01.012.
Castellini G, Bruschettini M, Gianola S, Gluud C, Moja L. Assessing imprecision in Cochrane systematic reviews: A comparison of GRADE and Trial Sequential Analysis. Syst Rev. 2018;7:110. https://doi.org/10.1186/s13643-018-0770-1.
Gartlehner G, Nussbaumer-Streit B, Wagner G, Patel S, Swinson-Evans T, Dobrescu A, et al. Increased risks for random errors are common in outcomes graded as high certainty of evidence. J Clin Epidemiol. 2019;106:50–9. https://doi.org/10.1016/j.jclinepi.2018.10.009.
Thorlund K, Wetterslev J, Brok J, Gluud C. Trial sequential analyses of six meta-analyses considering heterogeneity and trial weight. In: Corroboree. Abstracts of the 13th Cochrane Colloquium; 2005 22-26 Oct; Melbourne, Australia. 2005. https://abstracts.cochrane.org/2005-melbourne/trial-sequential-analyses-six-meta-analyses-considering-heterogeneity-and-trial.
Thorlund K, Devereaux PJ, Wetterslev J, Guyatt G, Ioannidis JPA, Thabane L, et al. Can trial sequential monitoring boundaries reduce spurious inferences from meta-analyses? Int J Epidemiol. 2009;38:276–86. https://doi.org/10.1093/ije/dyn179.
Copenhagen Trial Unit, Centre for Clinical Intervention Research. TSA Trial Sequential Analysis. 0.9.5.10 Beta. [Computer program]. Copenhagen Trial Unit, Centre for Clinical Intervention Research 2022. https://www.ctu.dk/tsa/downloads/. Accessed 26 Apr 2022.
Brok J, Thorlund K, Wetterslev J, Gluud C. Apparently conclusive meta-analyses may be inconclusive–Trial sequential analysis adjustment of random error risk due to repetitive testing of accumulating data in apparently conclusive neonatal meta-analyses. Int J Epidemiol. 2009;38:287–98. https://doi.org/10.1093/ije/dyn188.
Moher D, Shamseer L, Clarke M, Ghersi D, Liberatî A, Petticrew M, et al. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement. Syst Rev. 2015;4(1):1. https://doi.org/10.1186/2046-4053-4-1.
Covidence systematic review software. Veritas Health Innovation, Melbourne, Australia. https://www.covidence.org. Accessed 3 Jun 2021.
Shea BJ, Reeves BC, Wells G, Thuku M, Hamel C, Moran J, et al. AMSTAR 2: a critical appraisal tool for systematic reviews that include randomised or non-randomised studies of healthcare interventions, or both. BMJ. 2017;358:4008. https://doi.org/10.1136/bmj.j4008.
Moher D, Liberati A, Tetzlaff J, Altman DG; PRISMA Group. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLOS MED. 2009;6:e1000097. https://doi.org/10.1371/journal.pmed.1000097.
Harris PA, Taylor R, Thielke R, Payne J, Gonzalez N, Conde JG. Research electronic data capture (REDCap)— a metadata-driven methodology and workflow process for providing translational research informatics support. J Biomed Inform. 2009;42(2):377–81. https://doi.org/10.1016/j.jbi.2008.08.010.
Harris PA, Taylor R, Thielke R, Payne J, Gonzalez N, Conde JG. Research electronic data capture (REDCap)-A metadata-driven methodology and workflow process for providing translational research informatics support. J Biomed Inform. 2009;42:377–81.
Harris PA, Taylor R, Minor BL, Elliott V, Fernandez M, O’Neal L, et al. The REDCap consortium: Building an international community of software platform partners. J Biomed Inform. 2019;95:103208.
Thorlund K, Engstrøm J, Wetterslev J, Brok J, Imberger G, Gluud C. User manual for Trial Sequential Analysis (TSA) [pdf]. 2nd ed. Copenhagen: Copenhagen Trial Unit, Centre for Clinical Intervention Research, 2017: pp 1–119. www.ctu.dk/tsa/files/tsa_manual.pdf.
Schünemann H, Brożek J, Guyatt G, Oxman A (editors). GRADE handbook for grading quality of evidence and strength of recommendations. Updated October 2013. The GRADE Working Group; 2013. Available from http://www.guidelinedevelopment.org/handbook. Accessed 27 Apr 2022.
Juul S, Nielsen EE, Feinberg J, Siddiqui F, Jørgensen CK, Barot E, et al. Interventions for treatment of COVID-19: a living systematic review with meta-analyses and trial sequential analyses (The LIVING Project). PLOS MED. 2020;17(9):e1003293. https://doi.org/10.1371/journal.pmed.1003293.
Korang SK, Juul S, Nielsen EE, Feinberg J, Siddiqui F, Ong G, et al. Vaccines to prevent COVID-19: a protocol for a living systematic review with network meta-analysis including individual patient data (The LIVING VACCINE Project). Syst Rev. 2020;9:262. https://doi.org/10.1186/s13643-020-01516-1.
Bangalore S, Wetterslev J, Pranesh S, Sawhney S, Gluud C, Messerli FH. Perioperative β blockers in patients having non-cardiac surgery: a meta-analysis. Lancet. 2008;372:1962–76. https://doi.org/10.1016/S0140-6736(08)61560-3.
Nielsen N, Friberg H, Gluud C, Herlitz J, Wetterslev J. Hypothermia after cardiac arrest should be further evaluated-A systematic review of randomised trials with meta-analysis and trial sequential analysis. Int J Cardiol. 2011;151:333–41. https://doi.org/10.1016/j.ijcard.2010.06.008.
Cochrane Scientific Committee. Trial Sequential Analysis or sequential meta-analysis. 2017. https://methods.cochrane.org/sites/default/files/public/uploads/2017_1_18_may_scientific_committee_agenda_docs.pdf. Accessed 15 May 2021.
Cochrane Scientific Comittee. Should Cochrane apply error-adjustment methods when conducting repeated meta-analyses? 2018. https://methods.cochrane.org/sites/default/files/public/uploads/tsa_expert_panel_guidance_and_recommendation_final.pdf. Accessed 15 May 2021.
Thomas J, Askie LM, Berlin JA, Elliott JH, Ghersi D, Simmonds M, et al. Chapter 22: Prospective approaches to accumulating evidence. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA (editors). Cochrane Handbook for Systematic Reviews of Interventions version 6.3. Updated February 2022. Cochrane; 2022. Available from http://www.training.cochrane.org/handbook.
Acknowledgements
We would like to thank Information specialist Sarah Louise Klingenberg at The Cochrane Hepato-Biliary Group, Copenhagen for help in developing the search strategy.
Funding
No external funding was received for this study.
Author information
Authors and Affiliations
Contributions
CGR, MHO, JBM, and CG are responsible for the conception and design of the study. CGR is the guarantor of the protocol and drafted the manuscript, and all authors approved the final version of the manuscript.
Corresponding author
Ethics declarations
Ethics and approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors’ declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1.
Supplemental information can be found in supplemental material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Riberholt, C.G., Olsen, M.H., Milan, J.B. et al. Major mistakes and errors in the use of Trial Sequential Analysis in systematic reviews or meta-analyses – protocol for a systematic review. Syst Rev 11, 114 (2022). https://doi.org/10.1186/s13643-022-01987-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13643-022-01987-4