
Abstract
Target recognition and tracking is a hot research in image and video processing and is widely used in motion analysis, behavior recognition, and so on. In this paper, we studied target recognition and tracking in a series of images, and our approach is based on the multiple-instance learning technique. Firstly, we present a general target tracking framework. Within the proposed framework, we use image frames to generate positive and negative samples to train a classifier and use the classifier to differentiate target from its background. We use a set of weak classifiers to construct a strong classifier. The experiments show that the proposed approach has better precision and recall on two public datasets than related works.
Similar content being viewed by others


1 Introduction
Target recognition and tracking is applied in many fields, such as motion analysis [1] and behavior recognition [2]. However, occlusion, similar background, lighting, surface, and etc. pose great challenges for target recognition and tracking, which will make target shift or even tracking fail [3]. Appearance model-based tracking algorithms [4,5] represent targets with scale-invariant feature transformation or histogram of oriented gradient, but these features cannot reflect the basis of targets, and mismatches usually appear in the process of tracking. Moreover, complex appearance models lead to very high computation.
The combination of appearance model and traditional machine learning techniques consumes target tracking as a binary classification problem [6,7], and this method can utilize background information effectively and thus can improve the effectiveness of tracking. However, as there are not enough training data to the classification model, the recognition ability of target is very low and thus misclassification usually occurs. Deep learning is a hot research in image and visual processing. According to construct deep non-linear network model [8,9], the essential features of images can be learned with the constructed model, and then, the classification accuracy is improved.
Flock of tracker [10] combines local trackers with global motion model and can handle the problem of occlusion and local changes of non-rigid targets. Cell flock of tracker [11] tracks targets with the selected optimal local tracker and thus can handle the problem of target shifting and is more robust in target tracking.
Multiple-instance learning is first proposed by Dietterich et al. [12], and it is the fourth machine learning technique besides supervised learning, unsupervised learning, and reinforcement learning. Zhang et al. [13] propose to embed multiple-instance learning into the AnyBoost algorithm framework and construct the MILBoost classifier for target detection. Babenko et al. [14] use multiple-instance learning for target tracking, which gets a good tracking effectiveness, so multiple-instance learning becomes a hot research in target tracking. Zeisl et al. [15] apply the semi-supervised multiple-instance learning for target tracking, in which the target and background of the first frame is assumed to be tagged sample, and targets of the subsequent frames are assumed untagged samples. When the first frame comes, the tagged sample and untagged samples, which are tracked correctly, are priors for the following frame, and this improves the stability of target tracking [16]. In addition, Babenko et al. [17] has analyzed the visual tracking with online multiple-instance learning, but they aim to track the predefined target, and our method can recognize any target from its background.
However, the original multiple-instance learning has the weaknesses of low classification effectiveness and real-time ability. In order to handle these weaknesses, we propose a new weak classifier, which assigns different positive samples, different weights and assigns, different weak classifiers, and different weights. In addition, we propose a strong classifier to improve the accuracy and real-time ability of target tracking.
The rest of the paper is organized as follows. In Section 2, we present our proposed target tracking algorithm based on multiple-instance learning. Experiments and conclusion are given in Sections 3and4, respectively.
2 Multiple-instance learning target tracking algorithm
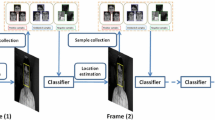
The flowchart of a tracking system is in Fig. 1, where we use all previous frames as training data to train a classifier and use this classifier to classify thet + 1-th frame; once thet + 1-th frame is classified, we add it into the training data for future prediction. The classifier evolves as time goes on.

The flowchart of tracking system
2.1 Selection of positive and negative samples
During the process of traditional target tracking, the target is usually one candidate object. When the target changes a lot or is occluded, the tracking frame shifts easily. Taking the limit of single candidate target, we consider multiple candidate targets. Here, we consider the target as positive sample and consider the background as negative samples. The samples including both positive and negative samples are denoted as X. Let the location of a sample bel t at timet, then the category of sample isy ∈ {0, 1}, wherey = 1, ifXis the target, andy = 0, if X is the background.Let the location of the target be\( {l}_{t-1}^{*} \)at timet − 1, then the sample set that is waited for classification at timet is
where l(X) is the location of sample X and s is the searching radius.
In order to acquire the location \( {l}_t^{*} \) of the target at time t, compute the probability p(y = 1) that all samples X is a positive sample. Let the probability that the target occurs in a cycle region with radiussbe uniform, then we have
Then, the new location of the target is
When the new location is calculated out, we need to select new positive and negative samples to update the classifier. While selecting the positive samples, the positive sample set X +contains N samples, which is a cycle with \( {l}_t^{*} \) as its center, radius α, that is
The negative sample set X −contains L samples, which is a cirque with \( {l}_t^{*} \) as its center, radius from β to γ, that is
2.2 Training a classifier
While training the classifier, we use the selected positive and negative sample set, X + and X −, and then, the probability that a sample is a positive sample is as follows [14]:
where\( \tan h(z)=\frac{e^{H(X)}-{e}^{-H(X)}}{e^{H(X)}+{e}^{-H(X)}} \), H(X) is a strong classifier of the samples and consists of K weak classifiers.
The definition of H(X) is in the following equation:
where h k (X) is the kth weak classifier and λ k is its weight. The weak classifiers are selected according to their classification ability. If a weak classifier is good at classification, then we give it a big weight; otherwise, we give it a small weight. Let \( {\lambda}_k={e}^{\frac{1-k}{K}} \), then the weak classifier is selected from the set of weak classifier set Φ, where Φ = {h 1, …, h M } and M > K. The weak classifier set is generated with the following method: let\( {h}_k= \log \left(\frac{p\left(y=1\Big|{f}_k(X)\right)}{p\left(y=0\Big|{f}_k(X)\right)}\right) \), where f k (X) is the Haar-like feature [18]; let p(y = 0) = p(y = 1), then, with the Bayes rule, we can have\( {h}_k= \log \left(\frac{p\left({f}_k(X)\Big|y=1\right)}{p\left({f}_k(X)\Big|y=0\right)}\right) \), where p(f k (X)|y = 1) and p(f k (X)|y = 0) conform to the Gaussian distribution [19], that is
where μ 1, σ 1, μ 0, and σ 0 are expectations and variances of the two Gaussian distributions.
During the training of the classifier, we use the gradient descent method, and the iterations of μ i and σ i are as follows:
where i = 0, 1, η is the learning coefficient.
2.3 Selecting weak classifiers
As we can see from Eq. 7, target tracking needs to use a set Φ of K weak classifiers, and then, the rule for the selection of weak classifiers is to assure an optimal strong classifier [20]. Babenko et al. [14] propose to ascertain weak classifier h by maximizing the log-likelihood function with both positive and negative sample sets, that is
whereL(H) is computed as follows:
where \( p\left(y=1\Big|{X}^{+}\right)={\displaystyle {\sum}_{j=1}^{N-1}{w}_jp\left(y=1\Big|{X}_{1j}\right)} \). As there exists similarity between positive sample and negative sample, we define the similar coefficient as follows:
where c is the normalization constant.
With the same reason, we can have
In Eq. 15, the similarities between negative samples are small, so we let w be constant.
Computing h with Eq. 12consumes a lot of computing resources, so we use a more efficient approach. Unwrapping L(H k − 1 + λ k h) with the first-order Taylor formula, we have
where\( <{\lambda}_kh,\mathit{\nabla}L(H)>=\frac{\lambda_k}{N+L}{\displaystyle {\sum}_{j=0}^{N+L-1}h\left({x}_{ij}\right)}\mathit{\nabla}L(H)\left({X}_{ij}\right) \).
where y i = i and i = 0, 1.
L(H k − 1) is already known, so in order to compute the maximum of L(H k − 1 + λ k h), we only need to compute the maximum of\( <{\lambda}_kh,\mathit{\nabla}L(H)>\Big|{}_{H={H}_{k-1}} \); then, the Eq. 12 can be rewrote as follows:
In the MIL algorithm proposed by Babenko et al. [14], it needs to maximize Eq. 13, and this would compute additional M probabilities belonging positive or negative set for each sample, so the computing complexity is very high. In this paper, we propose an algorithm for computing \( H(X)={\displaystyle {\sum}_{k=1}^K{\lambda}_k{h}_k(X)} \), and the algorithm is in algorithm 1. According to the first frame of a video, we find the target to be tracked and generate positive and negative sample set {X +, X −}, where X + = {X 1j , y 1 = 1, j = 0, 1, …, N − 1}, andX − = {X 0j , y 0 = 1, j = N, 1, …, N + L − 1}. Next, according to Eqs. 8 and 9, we compute p(f(X 1j )|y = 1) and p(f(X 0j )|y = 0) and then compute h k for k from 1 to M to generate weak classifier set Φ = {h 1, …, h M }.

3 Experiments
3.1 Experimental setup
In the experiments, we use iCoseg [21] and MSRC [22], the two public datasets. The iCoseg dataset consists a series of related images for each object. For example, an athlete moves on a horizontal bar. The MSRC dataset monitors an environment in a forest. In this dataset, a panda occurs and disappears in the camera. We test target recognition and tracking in these two scenes.
The baseline algorithms are MIL [14], OAB [23], and SBT [6]. The MIL algorithm is a classical multiple-instance learning approach for target tracking. The OAB algorithm is a boosting approach for target classification in image series. The SBT algorithm is a semi-supervised machine learning approach, and it uses massive untagged data to improve the accuracy of classification.
3.2 Experimental results
While evaluating the performance of the proposed algorithm, we use precision and recall two metrics. Here, we use “Jumping” to represent a woman moving on a horizontal bar and ‘panda’ to represent a panda appearing in a camera.
Firstly, we compare the precision of the four algorithms on both two datasets, and the result is in Fig. 2. As we can see from the figure, the OAB and SBT algorithms have better precisions in Jumping than they are in the panda dataset. Moreover, the MIL algorithm has better precision in the panda dataset than it is in the Jumping dataset. The above observation concludes that different tracking algorithms would have different precision in different scenes. However, as we use multiple-instance learning while classifying target from its background, it has the best precision in both of the two dataset.

Comparison of precision
Secondly, we compare the recall of the four algorithms on both of the two datasets, and the result is in Fig. 3. As we can see from the figure, the OAB and SBT algorithms have lower recalls in Jumping than they are in the panda dataset. Moreover, the MIL algorithm has better recall in the Jumping dataset than it is in the panda dataset. The above observation also concludes that different tracking algorithms would have different recalls in different scenes. However, as we use multiple-instance learning while classifying target from its background, it has the best recall in both of the two dataset.

Comparison of recall
Next, we illustrate the target recognition results on these two scenes, and the results are in Fig. 4. The images in the first line capture the panda. Whenever the panda sits down, walks, or crosses a river, it can be easily recognized. Even some part of the panda is not in the images, the panda can also be recognized. The images in the second line illustrate the recognition of a woman while she is moving on a horizontal bar. In this scene, the backgrounds in the images are almost the same, and the woman does different actions. This situation is much easier than the last one, and classification accuracy can be assured. In this dataset, even though some parts of the woman are occluded, the woman can also be recognized clearly.

Illustration of target recognition results in image series
Finally, we compare the performances of executing time and memory usage of the algorithms on the two datasets. Figure 5 illustrates the executing time comparison, and from the figure, we can see that our proposed algorithm consumes the least executing time under both datasets, the OAB algorithm is the second least, and the other two algorithms take longer executing time. While comparing SBT and MIL, the MIL algorithm takes the longest executing time under the jumping dataset and the SBT algorithm takes the longest executing time under the panda dataset. Figure 6 illustrates the memory usage comparison of the algorithms under both datasets. From this figure, we can see that our proposed algorithm consumes the least memory usage while recognizing and tracking targets under the two datasets and the OAB algorithm consumes the second least memory on both datasets. In addition, for SBT and MIL algorithms, SBT needs more memory than MIL under the jumping dataset and MIL needs more memory than SBT under the panda dataset.

Comparison of executing time

Comparison of memory
4 Conclusions
In this paper, we studied target recognition and tracking in a series of images, and our approach is based on the multiple-instance learning technique. In the target tracking framework, we use image frames to generate positive and negative samples to train a classifier, and use the classifier to differentiate target from its background. We use a set of weak classifiers to construct a strong classifier. The experiments show that the proposed approach has better precision and recall on two public datasets than related works.
References
L Chen, H Wei, J Ferryman, A survey of human motion analysis using depth imagery. Pattern Recogn Lett 34(15), 1995–2006 (2013)
OP Popoola, K Wang, Video-based abnormal human behavior recognition—a review. IEEE Trans Syst Man Cybern Part C Appl Rev 42(6), 865–878 (2012)
A Milan, K Schindler, S Roth, Challenges of ground truth evaluation of multi-target tracking, in IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2013, pp. 735–742
X Jia, H Lu, MH Yang, Visual tracking via adaptive structural local sparse appearance model, in IEEE Conference on Computer vision and pattern recognition (CVPR), 2012, pp. 1822–1829
S Zhang, H Yao, X Sun et al., Robust visual tracking using an effective appearance model based on sparse coding. ACM Trans Intell Syst Technol 3(3), 43 (2012)
H Grabner, C Leistner, H Bischof, Semi-supervised on-line boosting for robust tracking, in Computer Vision–ECCV(Springer, Berlin Heidelberg, 2008), pp. 234–247
Z Kalal, J Matas, K Mikolajczyk, Pn learning: bootstrapping binary classifiers by structural constraints, in 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2010, pp. 49–56
M Denil, L Bazzani, H Larochelle et al., Learning where to attend with deep architectures for image tracking. Neural Comput24(8), 2151–2184 (2012)
S Zhang, H Yao, X Sun et al., Sparse coding based visual tracking: review and experimental comparison. Pattern Recogn 46(7), 1772–1788 (2013)
V Tomas, M Jiri, Robustifying the flock of trackers(Proceedings of Computer Vision Winter Workshop, Graz, Austria, 2011), pp. 91–97
ME Maresca, A Petrosino, Clustering local motion estimates for robust and efficient object tracking. in Computer Vision-ECCV 2014 Workshops. Springer International Publishing, 2014, pp. 244–253
TG Dietterich, RH Lathrop, T Lozano-Pérez, Solving the multiple instance problem with axis-parallel rectangles. Artif Intell 89(1), 31–71 (1997)
C Zhang, JC Platt, PA Viola, Multiple instance boosting for object detection, inAdvances in neural information processing systems, 2005, pp. 1417–1424
B Babenko, MH Yang, S Belongie, Robust object tracking with online multiple instance learning. IEEE Trans Pattern Anal Mach Intell33(8), 1619–1632 (2011)
B Zeisl, C Leistner, A Saffari et al., On-line semi-supervised multiple-instance boosting, in2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2010, pp. 1879–1879
Z Wang, S Yoon, S Xie J et al., Visual tracking with semi-supervised online weighted multiple instance learning. Vis. Comput. 2015, pp. 1–14.
B Babenko, MH Yang, S Belongie, Visual tracking with online multiple instance learning, inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009, pp. 983–990
R Lienhart, J Maydt, An extended set of haar-like features for rapid object detection, inInternational Conference on Image Processing, 2002. 1: I-900-I-903 vol. 1
J Gao, H Ling, W Hu et al., Transfer learning based visual tracking with gaussian processes regression. in Computer Vision–ECCV 2014. Springer International Publishing, 2014, pp. 188–203
B Ma, J Shen, Y Liu et al., Visual tracking using strong classifier and structural local sparse descriptors. IEEE Trans Multimedia17(10), 1818–1828 (2015)
D Batra, A Kowdle, D Parikh et al., Icoseg: interactive co-segmentation with intelligent scribble guidance, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2010, pp. 3169–3176
JC Rubio, J Serrat, A López et al., Unsupervised co-segmentation through region matching, in IEEE International Conference on Computer Vision and Pattern Recognition, 2012, pp. 749–756
H Grabner, M Grabner, H Bischof, Real-time tracking via on-line boosting, in British Machine Vision Conference, 2006, pp. 47–56
Acknowledgements
This work was financially supported by the Science and Technology Research Program for the Education Department of Hubei province of China (Q20156002).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The author declares no competing interests.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Qin, J. Research of multiple-instance learning for target recognition and tracking. J Embedded Systems 2016, 4 (2016). https://doi.org/10.1186/s13639-016-0027-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13639-016-0027-9