
Abstract
Based on random finite set, the probability hypothesis density (PHD) filter and the cardinalized PHD (CPHD) filter have been proposed for multitarget tracking as they are computational tractable. But the classical PHD and CPHD filter is not applicable when a target generates multiple detections. The general PHD filter was proposed to apply the PHD filter to arbitrary clutter and target measurement process. However, as a filter with better performance than the PHD filter, the CPHD filter for multiple-detection tracking is not proposed except the extended target CPHD filter and the multisensor CPHD filter. In our work, the general CPHD filter, which allows the clutter process and target measurement process to be arbitrary and performs better than the general PHD filter, is proposed. The proposed general CPHD filter is the general form of all kinds of CPHD filters, as well as all kinds of PHD filters and Bernoulli filters. In the simulation, the multiple-detection model of the over-the-horizon radar is used to demonstrate the tracking performance. The simulation results show that the proposed filter improves the accuracy of the state estimates and reduces the variance of the estimated number of targets.
Similar content being viewed by others


1 Introduction
The multitarget tracking (MTT) algorithms to estimate the number and states of targets on the basis of the measurements of the sensors are widely used in military and civil fields such as aerospace target surveillance and visual tracking. Within the framework of finite set statistics (FISST), the random finite set (RFS) [1, 2]-based filters have been proposed for MTT as they are computational tractable. The probability hypothesis density (PHD) filter [3,4,5], which propagates the first moment (PHD) to approximate the multitarget probability density function (PDF), is the first moment approximation of multitarget Bayesian filter. The cardinalized PHD (CPHD) filter [6,7,8,9,10], which propagates the PHD as well as the cardinality distribution, is also a moment approximation of multitarget Bayesian filter. The predicted multitarget process and the clutter process are modeled as Poisson RFS in the PHD filter and modeled as identical, independently distributed cluster (IIDC) RFS in the CPHD filter. As the IIDC RFS is a generalization of the Poisson RFS, the CPHD filter is a generalization of the PHD filter. Compared to the PHD filter, the CPHD filter has the following advantages. First, the CPHD filter produces more stable estimate of the target number. Therefore, the tracking and positioning performance is better than the PHD filter. Second, the classical CPHD filter admits more general clutter processes than the classical PHD filter. Lastly, suppose that the clutter process is IIDC RFS and the target number is no larger than 1, the CPHD filter is not an approximate filter but an accurate single-target filter.
With the development of sensors and the complication of MTT application scenarios, the point target assumption in the ordinary tracking filter is not valid and the multiple-detection assumption is necessary. The multiple-detection assumption, in which one target may generate multiple measurements in a single frame, includes the extended target assumption, the multipath propagation assumption, and multiple sensors assumption. For example, in the extended target scenario, a target can be modeled as a series of point scatterers and produces multiple measurements due to the increased resolution of the sensor. In order to track multiple extended targets, the extended target PHD (ET-PHD) filter [11,12,13,14,15] and the extended target CPHD (ET-CPHD) filter [16, 17] have been researched. However, some multiple-detection scenarios, such as the multipath scenarios, are not as simple as the extended target scenario. In the early warning of missiles, satellites and bombers by the over-the-horizon radar (OTHR) [18], a target may produce multiple measurements as the radar signals are scattered by different ionospheric layers. To track multiple targets under the multiple-detection assumptions, the multiple-detection PHD (MD-PHD) filter [19] has been proposed. However, the CPHD filter under the multiple-detection assumptions has not been proposed except the ET-CPHD filter and the multisensor CPHD filter [20].
In the PHD and CPHD filter, the clutter process is modeled as Poisson and IIDC RFS, respectively. But these two models are unable to describe some complicated clutter process [21, 22]. Particularly when the target is submerged in the clutter background, the distribution of clutter process is more complicated [23]. The general PHD filter [24], which is the underlying theoretical basis for all kinds of PHD filters, allows the clutter process to be arbitrary. But in the PHD filters that have been implemented, such as the ET-PHD filter and the MD-PHD filter, the clutter process is still modeled as Poisson RFS. Only in [25], a PHD filter which assumes a negative binomial distribution for the clutter number has been proposed. Similarly, the clutter process in the ET-CPHD filter is modeled as IIDC RFS. In the previous research, we proposed the implementation of the arbitrary clutter PHD filter [26] and the arbitrary clutter extended target [27] PHD filter. However, the CPHD filter that can be applied to arbitrary clutter has not been proposed.
The general PHD filter proposed in [24] can adapt to arbitrary clutter process and target measurement process. Moreover, it is the underlying theoretical basis for various PHD filters [2]. In [28], a general Bernoulli filter was proposed by us to apply the Bernoulli filter [29, 30] to arbitrary clutter and target measurement process. It is the underlying theoretical basis for various Bernoulli filters. However, the CPHD filter that can be applied to arbitrary clutter and target measurement process has not yet been proposed. The recently proposed Poisson multi-Bernoulli mixture (PMBM) filter [31] has not been generalized to arbitrary clutter and target measurement process.
In our work, we propose a general CPHD filter. The proposed filter allows the clutter process and target measurement process to be arbitrary. Moreover, the proposed general CPHD filter is the general form of all kinds of CPHD filters, PHD filters, and Bernoulli filters. To make the general CPHD filter computationally feasible, we propose a general partitioning algorithm. To illustrate the validity of the general CPHD filter, it is applied to the multiple-detection model of the OTHR. The simulation results show that, compared to the MD-PHD filter, the general CPHD filter improves the accuracy of the state estimates and reduces the variance of the estimated number of targets.
This paper is organized as follows: Sect. 2 briefly introduces the theory of RFS and RFS-based filters. In Sect. 3, the general CPHD filter is proposed and the generality of the filter is proven. Results and discussion of the general CPHD filter are shown in Sect. 4. Section 5 presents conclusions.
2 Background and problem formulation
This section briefly introduces the RFS theory and the RFS-based filters. Ydenotes a RFS, \({\mathbf {y}}\in Y\) denotes a random vector, and Wdenotes a subset of Y. When used to modeled the target state set or the measurement set, the symbol Y is replaced by X or Z.
2.1 Nomenclature, multitarget calculus and important multitarget processes
The functionalf[h], which is widely used in this work, is the function in the variable \(h({\mathbf {y}})\), where \(0\le h({\mathbf {y}})\le 1\). If\(f[h]=\int {f({\mathbf {y}})h({\mathbf {y}})d{\mathbf {y}}}\), f[h] is a linear functional. For a RFS Y, the power functional is defined by \({{h}^{Y}}=\prod \nolimits _{{\mathbf {y}}\in Y}{h({\mathbf {y}})}\) if \(Y=\emptyset\) and \({{h}^{Y}}=1\) otherwise.
If the multitarget PDF is f(Y) , its probability generating functional (PGFL) is defined as
The PDF f(Y) can be expressed by the PGFL G[h] as
In our work, the derivative is Volterra functional derivative, and the integral of RFS is set integral [1].
The cardinality distribution of Yis \(p(n)=\Pr (\left| Y \right| =n)=\int _{\left| Y \right| =n}{f(Y)\delta Y}\), \(\left| Y \right|\) is the number of elements of Y.
If \(0\le y\le 1\) is a scalar, the probability generating function (PGF) of the RFS Y is
Suppose that\({{G}^{(n)}}(y)\) is the nth derivative of the PGF G(y), the cardinality distribution can be calculated as
The PHD \(D({\mathbf {y}})\) can be expressed as the functional derivatives of the PGFL,
Let \(F[h]={{F}_{1}}[h]{{F}_{2}}[h]\) be a product of 2 functionals, for a RFS Y, the product rule can be expressed as
The summation is taken over all subsets of Y.
The permutation coefficient \({{P}_{n,i}}\) is defined by \({{P}_{n,i}}={n!}/{\left( n-i \right) !}\;\) if \(n\ge i\) and \({{P}_{n,i}}=0\) otherwise.
An IIDC RFS Y is one whose objects are independent and identically distributed with the spatial distribution \(s({\mathbf {y}})\) and cardinality distribution p(n). The PGFL and the multitarget PDF are \(G[h]=G(s[h])\) and \(f(Y)=\left| Y \right| !p(\left| Y \right| ){{s}^{Y}}\), where \(G(y)=\sum \nolimits _{n\ge 0}{p(n){{y}^{n}}}\) is the PGF and s[h] denotes a linear functional.
A Poisson RFS Y is an IIDC RFS whose cardinality distribution is Poisson distribution. If the expected number is \(\mu\), the cardinality distribution is \(p(n)={{{e}^{-\mu }}{{\mu }^{n}}}/{n!}\;\), and the PHD is \(D({\mathbf {y}})=\mu s({\mathbf {y}})\). The PGFL and the multitarget PDF can be expressed as \(G[h]={{e}^{D[h-1]}}\) and \(f(Y)={{e}^{-\mu }}{{D}^{Y}}\), where \(D[h-1]\) denotes a linear functional.
A Bernoulli RFS Y is an IIDC RFS that satisfies \(\left| Y \right| \le 1\). If \(\Pr \left( \left| Y \right| =1 \right) =q\), the PGFL and the multitarget PDF can be expressed as \(G[h]=1-q+qs[h]\) and \(f(Y)=\left( 1-q \right) {{\delta }_{\left| Y \right| ,0}}+q{{s}^{Y}}{{\delta }_{\left| Y \right| ,1}}\).
The IIDC RFS needs to be represented by the spatial distribution and cardinality distribution together, while the Poisson RFS, whose cardinality distribution is Poisson distribution, can be represented by the PHD alone. The Bernoulli RFS can be represented by the spatial distribution and the probability of existence. Therefore, the CPHD filter jointly propagates the PHD and cardinality distribution, the PHD filter only propagates the PHD, and the Bernoulli filter propagates the probability of existence and the spatial distribution. The Poisson RFS and Bernoulli RFS are the special case of the IIDC RFS, so the PHD filter and the Bernoulli filter are the special case of the CPHD filter, although they do not jointly propagate the PHD and cardinality distribution.
2.2 General Chain rule
In the framework of FISST, a partition \(\wp\) of a RFS Y is a collection of non-empty disjoint subsets (called cells). The notation \(\wp \angle Y\) denotes all partitions of Y, and the cells are denoted by W. In our work, the symbol \(|\wp |\) denotes the number of cells in \(\wp\). If the set Y is a measurement set, the partition is important when multiple measurements can stem from the same target. But for a measurement set, \(Y=\emptyset\) is possible. In order to characterize the partition of all sets, define the partition \(\wp\) of the empty set as follows. If \(Y=\emptyset\), then the partition is \(\wp =\emptyset\), and \(\left| \wp \right| =0\). When \(\wp =\emptyset\) is used for calculation, \(\prod \nolimits _{W\in \wp }{f(W)}=1\) and \(\sum \nolimits _{W\in \wp }{f(W)}=0\), by convention. As the cardinality \(\left| Y \right|\) increases, the number of all partitions grows very large [32].
The general chain rule (GCR) [24, 33] for functional derivative is
where
The proofs are given in [24]. If \(Y=\emptyset\), \(\left| \wp \right| =0\), and
Thus, the GCR is true for any finite set.
2.3 Measurement processes of RFS-based filters
In this work, the clutter process is denoted by\(\kappa (W)\). The single-target likelihood function \({{M}_{W}}({\mathbf {x}})=f(W|\{{\mathbf {x}}\})\) represents the PDF that the measurement set produced by target \({\mathbf {x}}\) is \(W,W\subseteq Z\).
The clutter process \(\kappa (W)\) is usually modeled as Poisson RFS or IIDC RFS. If modeled by Poisson RFS with spatial distribution \(c({\mathbf {z}})\) and mean number \(\lambda\), \(\kappa (W)={{e}^{-\lambda }}{{\lambda }^{|W|}}{{c}^{W}}\). If modeled by IIDC RFS with spatial distribution \(c({\mathbf {z}})\) and cardinality distribution \({{p}^{\kappa }}(n)\), \(\kappa (W)=\left| W \right| !{{p}^{\kappa }}(\left| W \right| ){{c}^{W}}\).
Within the framework of FISST, common target models include point target, extended target and multiple-detection target. The single-target likelihood function of the point target is
The Kronecker delta \({{\delta }_{i,j}}\) is defined by \({{\delta }_{i,j}}=1\) if \(i=j\) and\({{\delta }_{i,j}}=0\) otherwise. \({{p}_{D}}\left( {\mathbf {x}} \right)\) and \({{\Phi }_{z}}\left( {\mathbf {x}} \right)\) denote the probability of detection and the sensor likelihood function, respectively.
If the measurements number of an extended target is Poisson distributed [34, 35] with an average \(\gamma ({\mathbf {x}})\), the single-target likelihood function is
where \({{p}_{D}}\left( {\mathbf {x}} \right)\) and \({{\Phi }_{z}}\left( {\mathbf {x}} \right)\) denote the probability of detection and the extended target measurement likelihood. In the multiple-detection scenario, assume that there are J possible measurement modes. \(p_{D}^{(j)}\left( \cdot \right)\) and \(f_{k}^{(j)}({\mathbf {z}}|{\mathbf {x}})\) denote the probability of detection and sensor likelihood function of mode \(j(1\le j\le J)\). Then, the single-target likelihood function of the multiple-detection target can be expressed as follows [19]. If \(W\ne \emptyset\),
And if \(W=\emptyset\),
\(\theta\) denotes the association hypotheses \(\left\{ 1,...,P \right\} \rightarrow \left\{ 1,...,\left| W \right| \right\}\) defined in [1, pp.332]. The summation in (12) is taken over all possible \(\theta\). The example of the single-target likelihood function \(f(W|\{{\mathbf {x}}\})\) can be found in [19]. In fact, as discussed in [36], the extended target likelihood function with the binomial cardinality distribution proposed in [30] is only a special case of (12).
2.4 Derivation process of RFS-based filters
In the Bayesian filter, the predictor, which is also called time update, represents the process of obtaining prediction information through the prior information and motion model. The corrector, which is also called measurement update, refers to the process of obtaining posterior information through the prediction information, the measurement model and the current measurement. The purpose of our work is to derive a filter for arbitrary clutter process and target measurement process, so we restrict ourselves to the corrector of the filters. The predictor of various PHD filters can be found in [3]. And the predictor of the CPHD filter can be found in [6]. In our work, the subscript \(k|k-1\) and k|k denote the parameters of the predictor and the corrector. \({{Z}_{k}}\) means the current measurement set, and \(\left| {{Z}_{k}} \right| =m\).
The derivation process of the corrector of the RFS-based filters is as follows.
-
Step 1. Derive the bivariate PGFL F[g, h]
$$\begin{aligned}&F[g,h]=\int {{{h}^{X}}\left( \int {{{g}^{Z}}}{{f}_{k}}(Z|X)\delta Z \right) {{f}_{k|k-1}}(X)\delta X} \\&=\int {{{h}^{X}}{{G}_{k}}[g|X]{{f}_{k|k-1}}(X)\delta X}. \end{aligned}$$(14)where \({{f}_{k}}(Z|X)\) denotes the entire measurement process and \({{G}_{k}}[g|X]=\int {{{g}^{Z}}}{{f}_{k}}(Z|X)\delta Z\) is the PGFL of \({{f}_{k}}(Z|X)\). If all measurements are independent, \({{G}_{k}}[g|X]={{G}^{\kappa }}[g]T{{[g]}^{X}}\), where \(T[g]({\mathbf {x}})=\int {{{g}^{W}}{{M}_{W}}({\mathbf {x}})\delta W}\) and\({{G}^{\kappa }}[g]=\int {{{g}^{W}}\kappa (W)\delta W}\) denote the PGFL of the measurement process \({{M}_{W}}({\mathbf {x}})\) and the clutter process \(\kappa (W)\). Suppose that \(G[h]=\int {{{h}^{X}}{{f}_{k|k-1}}(X)\delta X}\) denotes the predicted PGFL, the joint measurement-target PGFL typically ends up having the form [24]
$$\begin{aligned}&F[g,h]={{G}^{\kappa }}[g]G\left[ hT[g] \right] . \end{aligned}$$(15)This step is the same in the derivation process of various filters.
-
Step 2. Calculate \(\frac{\delta F}{\delta {{Z}_{k}}}[g,h]\).
-
Step 3. Calculate the posterior PGFL\({{G}_{k|k}}[h]\)[1, pp.122].
$$\begin{aligned}&{{G}_{k|k}}[h]={\left( \frac{\delta F}{\delta {{Z}_{k}}}[0,h] \right) }/{\left( \frac{\delta F}{\delta {{Z}_{k}}}[0,1] \right) }\;. \end{aligned}$$(16)Step 4. Calculate the posterior parameters of the filters based on the posterior PGFL. The posterior parameters are the posterior PHD in the PHD filter, the posterior cardinality distribution and PHD in the CPHD filter and the posterior existence probability and PDF in the Bernoulli filter.
The derivation process of the RFS-based filters is summarized as Algorithm 1 in Table 1.
According to the derivation process, the introduction of the RFS-based filters is given in Appendix A.
3 The general CPHD filter
The predictor of the classical CPHD filter can be found in [6] and [7]. The predicted cardinality distribution \({{p}_{k|k-1}}(n)\) and PHD \({{D}_{k|k-1}}({\mathbf {x}})\) are calculated by the prior cardinality distribution \({{p}_{k-1|k-1}}(n)\) and PHD \({{D}_{k-1|k-1}}({\mathbf {x}})\). The predicted cardinality distribution can be expressed as
The predicted PHD can be expressed as
in which
\({{p}_{s}}({\mathbf {x}})\) and \({{f}_{k|k-1}}({\mathbf {x}}|{\mathbf {x}}')\) denote the survival probability and Markov density of the survival target, and \({{b}_{k+1|k}}({\mathbf {x}})\) and \(p_{k+1|k}^{B}(n)\) denote the PHD and cardinality distribution of newborn target. \({{C_{n',i}}}\) represents the binomial coefficient. The predictor of the general CPHD filter is the same as the classical CPHD filter.
Then, the corrector of the general CPHD filter is given in this section. Here, the clutter process\(\kappa (W)\) and the single-target likelihood function\({{M}_{W}}({\mathbf {x}})\) are treated as a whole, so the proposed general CPHD filter can adapt to arbitrary clutter and target measurement processes.
3.1 Corrector of the general CPHD filter
The posterior cardinality distribution and PHD are calculated by the predicted cardinality distribution, PHD and the current measurement set. The corrector is derived as follows.
-
Step 1. Derive the PGFL according to (15).
-
Step 2. Calculate \(\frac{\delta F}{\delta {{Z}_{k}}}[g,h]\).
Suppose that the predicted PGFL is \(G[h]=G(s[h])\) with the spatial distribution \(s({\mathbf {x}})\) and cardinality distribution p(n), the functional derivative of \(G\left[ hT[g] \right]\) can be calculated by using the GCR as [24]
$$\begin{aligned}&\frac{\delta }{\delta {{Z}_{k}}}G\left[ hT[g] \right] =\sum \limits _{\wp \angle {{Z}_{k}}}{\frac{{{\partial }^{\left| \wp \right| }}G}{{{\partial }^{W\in \wp }}\left( h\frac{\delta T[g]}{\delta W} \right) }[hT[g]]}\\&\quad =\sum \limits _{\wp \angle {{Z}_{k}}}{{{G}^{\left( \left| \wp \right| \right) }}(s[hT[g]])\prod \limits _{W\in \wp }{s[h\frac{\delta T}{\delta W}[g]]}}. \end{aligned}$$(21)where the symbol \(s[\cdot ]\) denotes a linear functional, and \({{G}^{(i)}}(\cdot )\) denotes the ith derivative of the predicted PGF G(x).
The functional derivative of \(F\left[ g,h \right]\) can be calculated by using the product rule as
$$\begin{aligned}&\frac{\delta }{\delta {{Z}_{k}}}F[g,h]=\sum \limits _{S\subseteq {{Z}_{k}}}{\frac{\delta }{\delta ({{Z}_{k}}-S)}}{{G}^{\kappa }}[g]\frac{\delta }{\delta S}G\left[ hT[g] \right] \\&={{G}^{\kappa }}[g]\sum \limits _{\wp \angle {{Z}_{k}}}{{{G}^{\left( \left| \wp \right| \right) }}(s[hT[g]])\prod \limits _{W\in \wp }{s[h\frac{\delta T}{\delta W}[g]]}} \\&+\sum \limits _{S\subset {{Z}_{k}}}{\frac{\delta }{\delta ({{Z}_{k}}-S)}{{G}^{\kappa }}[g]\sum \limits _{\wp \angle S}{{{G}^{\left( \left| \wp \right| \right) }}(s[hT[g]])\prod \limits _{W\in \wp }{s[h\frac{\delta T}{\delta W}[g]]}}}. \end{aligned}$$(22)Note that
$$\begin{aligned}&\sum \limits _{S\subset Z}{f(Z-S)\sum \limits _{\wp \angle S}{g(\wp )}}=\sum \limits _{S\subseteq Z,S\ne \emptyset }{f(S)\sum \limits _{\wp \angle Z-S}{g(\wp )}}=\sum \limits _{\wp \angle Z}{\sum \limits _{W\in \wp }{f(W)g(\wp -W)}}. \end{aligned}$$(23)and \(\left| {\wp - W} \right|\)= \(\left| \wp \right| - 1\) , thus
$$\begin{aligned}&\sum \limits _{S\subset Z}{\frac{\delta }{\delta (Z-S)}{{G}^{\kappa }}[g]\sum \limits _{\wp \angle S}{{{G}^{\left( \left| \wp \right| \right) }}(s[hT[g]])\prod \limits _{W\in \wp }{s[h\frac{\delta T}{\delta W}[g]]}}}\\&=\sum \limits _{\wp \angle Z}{\sum \limits _{W\in \wp }{\frac{\delta }{\delta W}{{G}^{\kappa }}[g]{{G}^{\left( \left| \wp -W \right| \right) }}(s[hT[g]])\prod \limits _{W'\in \wp -W}{s[h\frac{\delta T}{\delta W'}[g]]}}} \\&=\sum \limits _{\wp \angle Z}{\sum \limits _{W\in \wp }{\frac{\delta }{\delta W}{{G}^{\kappa }}[g]{{G}^{\left( \left| \wp \right| -1 \right) }}(s[hT[g]])\prod \limits _{W'\in \wp -W}{s[h\frac{\delta T}{\delta W'}[g]]}}} . \end{aligned}$$(24)Then, the functional derivative of \(F\left[ g,h \right]\) is
$$\begin{aligned}&\frac{\delta }{\delta {{Z}_{k}}}F[g,h]={{G}^{\kappa }}[g]\sum \limits _{\wp \angle {{Z}_{k}}}{{{G}^{\left( \left| \wp \right| \right) }}(s[hT[g]])\prod \limits _{W\in \wp }{s[h\frac{\delta T}{\delta W}[g]]}}\\&+\sum \limits _{\wp \angle {{Z}_{k}}}{\sum \limits _{W\in \wp }{\frac{\delta }{\delta W}{{G}^{\kappa }}[g]\cdot {{G}^{\left( \left| \wp \right| -1 \right) }}(s[hT[g]])\prod \limits _{W'\in \wp -W}{s[h\frac{\delta T}{\delta W'}[g]]}}}. \end{aligned}$$(25) -
Step 3. Calculate the posterior PGFL \({{G}_{k|k}}[h]\). Assume that\({{\tilde{p}}_{D}}({\mathbf {x}})=1-f(\emptyset |{\mathbf {x}})\) denotes the probability of detection,\({{\tilde{q}}_{D}}({\mathbf {x}})=1-{{\tilde{p}}_{D}}({\mathbf {x}})\) is the probability of missed detection. According to the relationship between the multitarget PDF and the PGFL shown in (1) and (2), \({\delta T[0]}/{\delta W}\;={{M}_{W}}({\mathbf {x}})\), \(T[0]({\mathbf {x}})=f(\emptyset |{\mathbf {x}})={{\tilde{q}}_{D}}({\mathbf {x}})\), \({\delta {{G}^{\kappa }}[0]}/{\delta W}\;=\kappa (W)\), and \({{G}^{\kappa }}[0]=\kappa (\emptyset )\). Substituting \(g=0\) into (25), the numerator of (16) is
$$\begin{aligned}&\frac{\delta }{\delta {{Z}_{k}}}F[0,h]=\kappa (\emptyset )\sum \limits _{\wp \angle {{Z}_{k}}}{{{G}^{\left( \left| \wp \right| \right) }}(s[h{{{\tilde{q}}}_{D}}])\prod \limits _{W\in \wp }{s[h{{M}_{W}}]}}\\&+\sum \limits _{\wp \angle {{Z}_{k}}}{\sum \limits _{W\in \wp }{\kappa (W){{G}^{\left( \left| \wp \right| -1 \right) }}(s[h{{{\tilde{q}}}_{D}}])\prod \limits _{W'\in \wp -W}{s[h{{M}_{W'}}]}}}. \end{aligned}$$(26)Then, substitute \(h=1\) into (26) and define
$$\begin{aligned}&{{\pi }_{\wp }}=\kappa (\emptyset ){{G}^{\left( \left| \wp \right| \right) }}({{\rho }_{k}})\prod \limits _{W\in \wp }{{{\eta }_{W}}}+{{G}^{\left( \left| \wp \right| -1 \right) }}({{\rho }_{k}})\sum \limits _{W\in \wp }{\kappa (W)\prod \limits _{W'\in \wp -W}{{{\eta }_{W'}}}}. \end{aligned}$$(27)The denominator of (16) is
$$\begin{aligned}&\frac{\delta }{\delta {{Z}_{k}}}F[0,1]=\sum \limits _{\wp \angle {{Z}_{k}}}{{{\pi }_{\wp }}}\\&=\sum \limits _{\wp \angle {{Z}_{k}}}{\left( \kappa (\emptyset ){{G}^{\left( \left| \wp \right| \right) }}({{\rho }_{k}})\prod \limits _{W\in \wp }{{{\eta }_{W}}}+\sum \limits _{W\in \wp }{\kappa (W){{G}^{\left( \left| \wp \right| -1 \right) }}({{\rho }_{k}})\prod \limits _{W'\in \wp -W}{{{\eta }_{W'}}}} \right) }. \end{aligned}$$(28)where \({{\eta }_{W}}=s[{{M}_{W}}]\) and \({{\rho }_{k}}=s[{{\tilde{q}}_{D}}]\) are linear functionals.
Thus, substituting (26) and (28) into (16), the posterior PGFL \({{G}_{k|k}}[h]\) is
$$\begin{aligned}&{{G}_{k|k}}[h]=\frac{\left\{ \begin{matrix} \kappa (\emptyset )\sum \limits _{\wp \angle {{Z}_{k}}}{{{G}^{\left( \left| \wp \right| \right) }}(s[h{{{\tilde{q}}}_{D}}])\prod \limits _{W\in \wp }{s[h{{M}_{W}}]}}+ \\ \sum \limits _{\wp \angle {{Z}_{k}}}{\sum \limits _{W\in \wp }{\kappa (W){{G}^{\left( \left| \wp \right| -1 \right) }}(s[h{{{\tilde{q}}}_{D}}])\prod \limits _{W'\in \wp -W}{s[h{{M}_{W'}}]}}} \\ \end{matrix} \right\} }{\sum \limits _{\wp \angle {{Z}_{k}}}{{{\pi }_{\wp }}}}. \end{aligned}$$(29) -
Step 4. Calculate the posterior cardinality distribution \({{p}_{k|k}}(n)\) and PHD \({{D}_{k|k}}({\mathbf {x}})\).
Theorem 1
The posterior cardinality distribution \({{p}_{k|k}}(n)\) and the PHD \({{D}_{k|k}}({\mathbf {x}})\) are
where
\({{N}_{k|k-1}}=\sum {n{{p}_{k|k-1}}(n)}\) denotes the predicted expected number.
The derivation process of the general CPHD filter is summarized as Algorithm 2 in Table 2.
The proofs are given in Appendix B.
3.2 Generality of the general CPHD filter
In this section, we will prove the general CPHD filter is the general form of all kinds of CPHD filters, PHD filters and Bernoulli filters, as shown in Fig. 1.

Generality of the general CPHD filter
3.2.1 Reduce to CPHD filter
Theorem 2
If the target is point target shown in (10), and the clutter process is IIDC process with cardinality distribution \({{p}^{\kappa }}(m)\) and spatial distribution \(c({\mathbf {z}})\), the equations of the posterior cardinality distribution in (26) are reduced to
The equations of the pseudo-likelihood in (32) are reduced to
where
where \({{\sigma }_{i}}({{Z}_{k}})=\sum \limits _{W\subset {{Z}_{k}},\left| W \right| =i}{\left( \prod \limits _{{\mathbf {z}}\in W}{\frac{\tau ({\mathbf {z}})}{c({\mathbf {z}})}} \right) }\), and \(\tau ({\mathbf {z}})=s[{{p}_{D}}{{\Phi }_{{\mathbf {z}}}}]\) denotes linear functionals.
Thus, the proposed general CPHD filter is a generalized classical CPHD filter, and it can reduce to the classical CPHD filter. The proofs are given in Appendix C.1.
The general CPHD filter reduces to the ET-CPHD filter if \({{M}_{W}}({\mathbf {x}})\) is defined as shown in (11). Furthermore, as the definition of the partition of the empty set, \({{Z}_{k}}=\emptyset\) and \({{Z}_{k}}\ne \emptyset\) do not need to be studied separately as in the ET-CPHD filter in [17]. Until now, the study for multiple-detection CPHD filter has not appeared. Our filter reduces to the multiple-detection CPHD filter, if the single-target likelihood function \({{M}_{W}}({\mathbf {x}})\) is defined as shown in (12) and (13).
3.2.2 Reduce to the general PHD filter
Theorem 3
Suppose that the predicted target process of the general CPHD filter is simplified to Poisson RFS, the pseudo-likelihood of the general CPHD filter in (32) is equal to the pseudo-likelihood of the general PHD filter in (58). Thus, the proposed filter reduces to the general PHD filter [24]. The proofs are given in Appendix C.2.
As discussed in Sect. 2.2, the PHD filter is the special case of the CPHD filter although the PHD filter only propagates the PHD. This is because the spatial distribution and the cardinality distribution can be expressed by the PHD if the predicted target process of the general CPHD filter is simplified to Poisson RFS.
3.2.3 Reduce to the Bernoulli filter
Theorem 4
When the number of targets does not exceed 1, the corrector in (30) and (31) can be recalculated as
The proofs are given in Appendix C.3.
When the number of targets does not exceed 1, \({{p}_{k|k-1}}(0)+{{p}_{k|k-1}}(1)=1\). Define the predicted probability of existence \({{\omega }_{k|k-1}}={{p}_{k|k-1}}(1)\) and the posterior probability of existence \({{\omega }_{k|k}}={{p}_{k|k}}(1)\), then \({{p}_{k|k-1}}(0)=1-{{\omega }_{k|k-1}}\). Thus,
In fact, this is the general Bernoulli filter proposed by us in [28]. \(s({\mathbf {x}})\) and \({{s}_{k|k}}({\mathbf {x}})\) denote the predicted and the posterior spatial distribution. Thus, when the number of targets does not exceed 1, the general CPHD filter reduces to the general Bernoulli filter.
As discussed in 2.2, though the CPHD filter jointly propagates the PHD and the cardinality distribution while the Bernoulli filter jointly propagates the spatial distribution and the probability of existence, the Bernoulli filter is the special case of the CPHD filter. This is because the probability of existence can be derived from the cardinality distribution.
3.3 Measurement set partitioning
As discussed in Sect. 2.3, the number of partitions grows very large as the measurement number increases [32]. The corrector of the general CPHD filter includes a combinatorial sum of all partitions. Thus, some effective partitioning algorithm must be developed to make the general CPHD filter computationally practicable.
3.3.1 Analysis of partitioning
Some special issues of the general PHD filters are implemented effectively by some approximation, such as the ET-PHD filter and the MD-PHD filter. As discussed in [36], the distance partitioning [12],[14] proposed for the ET-PHD filter or the generalized distance (GD) partitioning [36] proposed for the MD-PHD filter are not useful because the clutter process is not modeled by Poisson RFS and cannot be denoted by the Log-clutter density \({{\kappa }_{W}}\).
Both \({{\pi }_{\wp }}\) and \({{\psi }_{\wp }}\) contain two items, which are calculated by the partition \(\wp\) of the measurement set. In the item containing \(\prod \limits _{W\in \wp }{{{\eta }_{W}}}\), all cells W are treated as target cells and used to calculate \({{\eta }_{W}}\). In the item containing \(\sum \limits _{W\in \wp }{\kappa (W)\prod \limits _{W'\in \wp -W}{{{\eta }_{W'}}}}\), one cell is treated as clutter cell and the other cells are treated as target cells. Therefore, the partition, which makes great contribution to the posterior PHD, consists of at most one clutter cell. Similarly, in (30), the calculation of the posterior cardinality distribution consists of 2 items, too. The first item is \({{p}^{\kappa }}(0){{\zeta }_{\wp }}(n),\) and the second item is \(\sum \limits _{W\in \wp }{\kappa (W){{\zeta }_{\wp -W}}(n)}\). In the first item, whenever \(n<\left| \wp \right|\), \({{\zeta }_{\wp }}(n)=0\). In the second item, whenever \(n<\left| \wp \right| -1\), \({{\zeta }_{\wp -W}}(n)=0\). Therefore, the partition, which makes great contribution to the posterior cardinality distribution, consists of at most one clutter cell. Therefore, the informative partitions for the general CPHD filter consist of several target cells and at most one clutter cell.
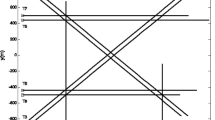
As an illustration shown in Fig. 2, the measurement set is generated by two targets. Figure 2b shows the partition generated by the distance partitioning or the GD partitioning. The partition for the general CPHD filter is illustrated in Fig. 2c. With Fig. 2b, we can obtain Fig. 2c by combining all the individual clutter cells into 1 cell.

Partitioning illustration. a Measurement set. b A partition generated by the distance partitioning or the GD partitioning. c Partition should be used in the general CPHD filter. The clutter measurements are merged to a single cell
3.3.2 General partitioning algorithm
Here, a general partitioning algorithm is proposed for the general CPHD filter. The partitions generated by the general partitioning algorithm are referred as general partitions. In [36], a multiple-detection distance is defined in the GD partitioning algorithm. Although the GD partitioning algorithm cannot be directly applied to the general CPHD filter, the multidetection distance is useful in this work.
3.3.2.1 The potential target measurement
In the partition in Fig. 2b, the measurements generated by the same target are in the same cell, and each clutter measurement becomes a cell by itself. Thus, when a target generates only one measurement, it is an individual cell. In the general PHD filter implemented effectively with the Poisson clutter process, the cell can be treated as a target cell, so the target will not be lost. However, in the general CPHD filter, the informative partitions consist of at most one clutter cell. When a target generates only one measurement, it is an individual cell which is represented in the same way as a clutter measurement. Thus, the cell may be treated as a clutter cell, so the target will be loss. To avoid the missing of the target with only one measurement, the potential target (PT) measurement is defined as follows.
\({\hat{n}}=\underset{n}{\mathop {\max }}\,{{p}_{k|k-1}}(n)\) denotes the predicted number of targets. If \(p_{D}^{(p)}\left( \cdot \right)\) is the target detection probability of mode p, the expected number of measurements from one target is \(\sum \nolimits _{p=1:P}{p_{D}^{(p)}}\). The expected number of measurements from targets can be expressed as \({\hat{m}}=ceil\left( {\hat{n}}\cdot \sum \nolimits _{p=1:P}{p_{D}^{(p)}} \right)\), where \({\text {ceil}}\left( x \right)\) denotes the minimum integer no less than x.
Suppose that \(f_{k}^{(p)}({\mathbf {z}}|{\mathbf {x}})\) is the sensor likelihood function of mode \(p(1\le p\le P)\). For each measurement \({{{\mathbf {z}}}_{i}}\), define a coefficient that can reflect the likelihood that the measurement comes from target as follows.
If the number of measurements in the measurement set is \({{M}_{k}}\), we can obtain a sequence \(\Gamma =\left\{ {{\gamma }_{i}} \right\} _{i=1}^{{{M}_{k}}}\). If \({{{\mathbf {z}}}_{i}}\) is generated by a target, the value of \({{\gamma }_{i}}\) is more likely to be large. If \({{\gamma }_{i}}\) is one of the largest \({\hat{m}}\) values in the sequence \(\Gamma\), the measurement \({{{\mathbf {z}}}_{i}}\) is called PT measurement. Here, \({\hat{m}}\) is the expected number of measurements from targets.
3.3.2.2 Obtain the general original partition
In \({{Z}_{k}}=\left\{ {{{\mathbf {z}}}_{i}} \right\} _{i=1}^{{{M}_{k}}}\), a credibility coefficient is defined as
Then, the multiple-detection distance is defined as
Here, \(d({{{\mathbf {z}}}_{i}},{{{\mathbf {z}}}_{j}})\) is used to judge whether 2 measurements come from the same target. Then, with the cutoff value \({{\delta }_{u}}\), one can obtain the original partition \({{\wp }_{o}}=\left\{ {{O}_{d}} \right\} _{d=1}^{D}\) of measurement set as in [36]. The partitions used for the general CPHD filter in this work are all obtained on the basis of this original partition.
In the original partition, if a cell consists of multiple measurements or a PT measurement, it is a target cell and should be reserved. And if a cell consists of one measurement which is not a PT measurement, it should be merged into the clutter cell C. So the general original partition can be expressed as \({{\wp }_{c}}=\left( \bigcup \nolimits _{d=1:{\hat{D}}}{{{O}_{d}}} \right) \bigcup C\). \({\hat{D}}\) means the number of the target cells (including the cells with multiple measurements and the cells with a PT measurement). Here, the target cells and the clutter cell are notated by different symbols, as they are distinguished successfully.
As an illustration, the process of obtaining the general original partition from a measurement set is shown in Fig. 3. \({{{\mathbf {z}}}_{1}}\), \({{{\mathbf {z}}}_{2}}\) and \({{{\mathbf {z}}}_{3}}\) are generated by target 1. \({{{\mathbf {z}}}_{4}}\) and \({{{\mathbf {z}}}_{5}}\) are generated by target 2. \({{{\mathbf {z}}}_{6}}\) is generated by target 3. \({{{\mathbf {z}}}_{7}}\), \({{{\mathbf {z}}}_{8}}\) and \({{{\mathbf {z}}}_{9}}\) are clutter measurements. In the original partition, \({{{\mathbf {z}}}_{6}}\), \({{{\mathbf {z}}}_{7}}\), \({{{\mathbf {z}}}_{8}}\) and \({{{\mathbf {z}}}_{9}}\) are individual cells. In order to show that the measurements are divided into a cell, we put the measurements together in the second layer. The location of the measurements does not change from the first to the second layer in fact. While \({{{\mathbf {z}}}_{6}}\) is a PT measurement, it should be reserved. So \({{{\mathbf {z}}}_{7}}\), \({{{\mathbf {z}}}_{8}}\) and\({{{\mathbf {z}}}_{9}}\) should be merged into the clutter cell C in the general original partition.

General original partition illustration
3.3.2.3 Obtain the general partitions
With the general original partition \({{\wp }_{c}}\), the general partitions can be obtained. At first, calculate all partitions of each target cell in the general original partition \({{\wp }_{c}}=\left( \bigcup \nolimits _{d=1:{\hat{D}}}{{{O}_{d}}} \right) \bigcup C\). A target cell \({{O}_{d}}\) of \({{\wp }_{c}}\) can be treated as a small measurement cell, and thus, it can be partitioned into cells and get a series of partitions. Then, for every target cell of \({{\wp }_{c}}\), choose one of its partitions to constitute the target cells of the partition. The clutter cell does not change. The general partition consists of the clutter cell and the target cells. As an illustration, if \({{\tilde{\wp }}^{(d)}}\) is a partition of \({{O}_{d}}\), a general partition is
This is the first type of partition. Merging all the individual cells in the first type of partition into the clutter cell, we can get the second type of partition. In the first type of partition, merging all the individual cells which are not the PT measurement into the clutter cell, we can get the third type of partition.
As an illustration, the general original partition and the 3 types of partition are shown in Fig. 4. In the general original partition, there are 3 target cells \(\left\{ {{O}_{d}} \right\} _{d=1}^{3}\) and a clutter cell C.

General partitioning algorithm illustration. a General original partition, b The 1st type of partition, c The 2nd type of partition, d The 3rd type of partition
In Fig. 4b, \(\left\{ {{W}_{1}},{{W}_{2}} \right\}\) is a partition of \({{O}_{1}}\), \(\left\{ {{W}_{3}} \right\}\) is a partition of \({{O}_{2}}\), \(\left\{ {{W}_{4}} \right\}\) is a partition of \({{O}_{3}}\), and \({{W}_{C}}=C\). So a first type of partition is \(\wp =\left\{ {{W}_{1}},{{W}_{2}} \right\} \bigcup \left\{ {{W}_{3}} \right\} \bigcup \left\{ {{W}_{4}} \right\} \bigcup {{W}_{C}}\).
\({{W}_{2}}\) and \({{W}_{4}}\) are the individual cells. So a second type of partition can be expressed as \(\wp =\left\{ {{W}_{1}} \right\} \bigcup \left\{ {{W}_{3}} \right\} \bigcup {{W}_{C}}\), in which \({{W}_{C}}=C\bigcup {{W}_{2}}\bigcup {{W}_{4}}\), as shown in Fig. 4c.
As \({{{\mathbf {z}}}_{6}}\) is a PT measurement but \({{{\mathbf {z}}}_{3}}\) is not, a third type of partition can be expressed as \(\wp =\left\{ {{W}_{1}} \right\} \bigcup \left\{ {{W}_{3}} \right\} \bigcup \left\{ {{W}_{4}} \right\} \bigcup {{W}_{C}}\), in which \({{W}_{C}}=C\bigcup {{W}_{2}},\) as shown in Fig. 4d.
The general partitioning algorithm is summarized as Algorithm 3 in Table 3.
3.3.3 Computational complexity analysis
The number of partitions of the measurement set Z is given by the Bell number \({{B}_{\left| Z \right| }}\) that obeys the following recursive equation.
\({{C}_{m,i}}\) is the binomial coefficient, and \({{B}_{0}}={{B}_{1}}=1\) is the initial value for recursion. Table 4 shows the relationship between the number of measurements and the partitions number. It can be seen that as the number of measurements in Z increases, the partitions number increases rapidly, which causes it difficult to sum all the partitions.
In our work, the number of the first type of partitions generated by the general partitioning algorithm is the product of the partitions number of every target cell in \({{\wp }_{c}}\). In the measurement set shown in Fig. 4, the number of partitions of \({{O}_{1}}\) , \({{O}_{2}}\) and \({{O}_{3}}\) is 5, 2 and 1, respectively. Thus, the number of the first type of partitions is 10. The number of the second and third type of partitions is less than the number of the first type of partitions. Then, the number of partitions of our general partitioning algorithm is less than 30. As shown in Table 1, the number of all partitions of the set with 9 measurements is 21147. Therefore, the partitions number is reduced significantly.
It must be pointed out that the partition number of the general partitioning algorithm is related to the measurement set. As the uncertainty of the target measurement process, the number is not fixed. But in general, the number of partitions in this work is considerably smaller than the number of all partitions.
4 Results and discussion
4.1 Setup

Transmitter–receiver–target model in OTHR
The OTHR is an early warning tool for missiles, satellites and strategic bombers. The transmitter–receiver–target model in OTHR [18] shown in Fig. 5 is used to obtain the single-target multiple-detection measurement likelihood function. The parameters acquired by the OTHR include the slant range Rg, the rate of change of slant range fd and the apparent azimuth Az. The measurement vector \({\mathbf {z}}={{[Rg,fd,Az]}^{T}}\) can be expressed as
where
\(\rho\) is the range, b is the bearing, and \(\dot{\rho }\) is the range rate.
The sensor likelihood functions of various modes can be calculated by using different \({{h}_{r}}\) and \({{h}_{t}}\). The values of \({{h}_{r}}\) and \({{h}_{t}}\) can be selected from \({{h}_{E}}=100km\) and \({{h}_{F}}=220km\). So the number of the measurement modes is\(P=4\)(mode EE in which \({{h}_{r}}={{h}_{t}}={{h}_{E}}\), mode EF in which \({{h}_{r}}={{h}_{E}}\) and \({{h}_{t}}={{h}_{F}}\), mode FE in which \({{h}_{r}}={{h}_{F}}\) and \({{h}_{t}}={{h}_{E}}\), mode FF in which \({{h}_{r}}={{h}_{t}}={{h}_{F}}\)). The detection probabilities are heuristically selected as \(p_{D}^{(EE)}=p_{D}^{(FF)}=0.4\) and \(p_{D}^{(EF)}=p_{D}^{(FE)}=0.5\), respectively. We assume that the measurement noise of various modes obeys the same distribution. In the surveillance area of OTHR, the interval of possible values of Rg is \([700,1200]km\), the interval of possible values of fd is \([-0.4,-0.1]km/s\), and the interval of possible values of Az is \([\pi /8,3\pi /8]rad\). The distance from the receiver to the transmitter is \(d=100km\).
The state transition model [37] is
where \({{x}_{k}}={{[{{x}_{k}},{{\dot{x}}_{k}},{{y}_{k}},{{\dot{y}}_{k}}]}^{T}}\) is the vector of target state.
\({{w}_{k-1}}={{\left[ {{w}_{x,k-1}},{{w}_{y,k-1}} \right] }^{T}}\) means the noise components with standard deviations \({{\sigma }_{x}}={{\sigma }_{y}}=1m/{{s}^{2}}\). \(\otimes\) denotes the Kronecker product, and \({{I}_{2}}\) denotes a \(2\times 2\) identity matrix. \(T=20s\) represents the time interval between two frames. The simulations last for 50 scans. Two different dynamic scenarios are simulated, as shown in Table 5 and Fig. 6.

Ground truth. (a) 2 targets, (b) 3 targets
The clutter process \(\kappa (Z)\) is modeled by an IIDC RFS, with the cardinality distribution as follows.
where \(\alpha >0\) and \(\beta >0\). This cardinality distribution is a negative binomial distribution [25, 38]. The mean of clutter number is \(\lambda {=\alpha }/{\beta }\;\). The clutter measurements are uniformly distributed in the surveillance area of OTHR.
The proposed general CPHD filter is approximated by particle filter (PF) implementation [4], in which the initial particles are uniformly distributed and the particles for new born target are distributed based on the measurements [39]. The particles number for new born target and each survival target is 2000. The cutoff value of the general partitioning algorithm is selected as \({{\delta }_{u}}=0.999\).
4.2 Simulation results
The general CPHD filter allows the clutter process and target measurement process to be arbitrary. In order to show that the proposed filter can achieve better tracking performance than the other CPHD filters under the multiple-detection assumption, the classical CPHD filter, in which the targets are assumed to be point targets, is selected as a comparison algorithm. At the same time, to show that the proposed filter can achieve better tracking performance than the other multiple-detection filters, the MD-PHD filter, in which the clutter process is assumed to be Poisson, is selected as a comparison algorithm. The reason why we choose the MD-PHD filter is that the only implemented PHD filter with negative binomial clutter for the multiple-detection tracking is the arbitrary clutter ET-PHD filter, and the arbitrary clutter PHD filter that can apply to more complex multiple-detection tracking such as the multipath tracking has not yet been implemented.
Then, the tracking performance of the general CPHD filter and the comparison algorithm is simulated. The standard deviation of the measurement noise of Rg, fd and Az are \(5km\), \(0.005km/s\) and \(0.003rad\), respectively. The parameters of the clutter process cardinality distribution are \(\alpha =0.25\) and \(\beta =0.05\). In the classical CPHD filter for comparison, the targets are assumed to be point target whose measurement mode is mode EE of the OTHR, in which \({{h}_{r}}={{h}_{t}}={{h}_{E}}\). The clutter process of the classical CPHD filter is the same as the general CPHD filter. In the MD-PHD filter for comparison, the mean of the amount of clutter is \(\lambda {=\alpha }/{\beta }\;=5\), which is consistent with the average number of clutters used by the general CPHD filter. The measurement mode of the MD-PHD filter is the same as the general CPHD filter. The results in this section are obtained from 500 independent simulations.
The tracking performance is evaluated by using the optimal subpattern assignment (OSPA) metric [40] between the estimated state and true state. The OSPA metric jointly captures differences in target states and cardinality between the estimated state and true state [40]. Let X ,Y denote RFS, \({\mathbf {x}}\in X\), \({\mathbf {y}}\in Y\) denote the random vector, \(\left| X \right| =m\), \(\left| Y \right| =n\) and \({{d}^{(c)}}({\mathbf {x}},{\mathbf {y}})=\min (c,\left\| {\mathbf {x}}-{\mathbf {y}} \right\| )\). If \(m\le n\), the OSPA metric between X and Y is defined as follows.
where \(p\ge 1\), \(c>0\) and \({{\prod }_{k}}\) denote the permutation set on \(\left\{ 1,2,...,k \right\}\). If \(m>n\), \({\bar{d}}_{p}^{(c)}(X,Y)={\bar{d}}_{p}^{(c)}(Y,X)\). If \(m=n=0\), \({\bar{d}}_{p}^{(c)}(X,Y)=0\). For full details, see [40].
The average estimated cardinality and the standard deviation of the general CPHD filter and the comparison algorithm along with the true number are shown in Fig. 7 (scenario 1 with two targets) and Fig. 8 (scenario 2 with three targets). The simulation results shown in both scenario 1 and scenario 2 can reach the same conclusion. The average estimated cardinality of the classical CPHD filter is significantly greater than the true target number. This is because the targets are assumed to be point targets in the classical CPHD filter, and the generated multiple measurements in a single frame may be treated as multiple targets. The average estimated cardinality of the MD-PHD filter is slightly higher than the correct number of targets present, while the simulation results demonstrate that the estimate of the number from the general CPHD filter in our work accurately converges to the correct number of targets present, although it takes longer to converge to the new number of targets than the MD-PHD filter when targets disappear. Moreover, the standard deviation of the estimated cardinality, which is used to measure the estimated error of the target number in each independent simulation, is much smaller in the general CPHD filter than in the MD-PHD filter. There are two reasons. The first reason is that the general CPHD filter produces more stable estimates than the MD-PHD filter, because the predicted PGFL is modeled as IIDC RFS. The second reason is that the clutter process is well modeled in the general CPHD filter but not well modeled in the MD-PHD filter.

Average of cardinality for scenario 1

Average of cardinality for scenario 2
Figure 9 shows the average of the OSPA metric [40] with the parameters \(p=2\), \(c=15km\). Since the average estimated cardinality deviates too much from the true target number, the OSPA metric of the classical CPHD filter becomes meaningless, and we only study the OSPA metric of the general CPHD filter and the MD-PHD filter here. The peaks of the OSPA metric in the figure correspond to the appearance and disappearance of targets, respectively. According to Fig. 9, in both scenario 1 and scenario 2, the OSPA metric of the general CPHD filter is smaller than that of the MD-PHD filter. The reason is the same as in the mean and standard deviation of the estimated cardinality. Thus, we can conclude that the tracking performance the general CPHD filter is better than that of the MD-PHD filter.

OSPA metric of the general CPHD filter and the MD-PHD filter
Then, we simulate the tracking performance for scenario 1 with various parameters. Figure 10a shows the tracking performance of the general CPHD filter with different measurement noise variances. The standard deviation \(\sigma\) of the measurement noise of the slant range Rg is 5 km, 10 km and 15 km, respectively. Figure 10b shows the tracking performance of the general CPHD filter with different clutter numbers. The parameters of the negative binomial distribution of the clutter process are \(\alpha = 0.25\), \(\alpha = 0.5\) and \(\alpha = 0.75,\) respectively. As \(\lambda = {\alpha }/{\beta }\;\), the average clutter number of the general CPHD filter is 5, 10 and 15, respectively. As shown in Fig. 10a, the OSPA metric increases as the standard deviation of the measurement noise of the slant range Rg increases. As shown in Fig. 10b, the OSPA metric increases as the number of clutter increases. It is easy to understand that as the tracking performance deteriorates, the measurement noise increases or the clutter number increases.

OSPA metric with various parameters. a Various range variances, b Various clutter numbers
Lastly, the tracking performance of the general CPHD filter and the MD-PHD filter for different parameters is shown in Fig. 11. The standard deviation \(\sigma\) of the measurement noise of the slant range Rg is 10 km and 15 km, respectively. The comparison of tracking performance when the standard deviation is 5 km can be found in Fig. 9. The simulation results show that as the standard deviation of the measurement noise increases, the gap between the OSPA metric of the general CPHD filter and the MD-PHD filter becomes larger and larger, which shows that the general CPHD filter has a greater advantage in tracking performance. This is because the PHD filters will react much more sensitively to the change of the measurement noises than the CPHD filters.

OSPA metric of the general CPHD filter and the MD-PHD filter for different range variances
When the target number is large, the computational complexity of the proposed filter increases significantly. This is because the filters for multiple-detection tracking include a combinatorial sum of all partitions. For extended target tracking filter, the partitioning algorithms can significantly reduce the computational complexity, while for multiple-detection tracking filter, the partitioning algorithms are difficult to reduce the computational complexity significantly. But compared to the MD-PHD filter in [19] which can only track 2 targets, and the MD-PHD filter in [36] which can track 3 targets, the general CPHD filter with the general partitioning algorithm mentioned in this work has the ability to track at least 3 targets stably. This shows that the partitioning algorithm proposed in this paper can reduce the computational complexity of the general CPHD filter and make the filter computationally tractable. Though it can only track a small number of targets by using the partitioning algorithm, the general CPHD filter proposed in this work is of great significance.
5 Conclusion and future work
In this work, the general CPHD filter is proposed. This filter is the general form of all kinds of CPHD filters, as well as all kinds of PHD filters and Bernoulli filters. Then, a general partitioning algorithm is proposed to make the proposed filter computationally feasible. The simulation results show that, compared to the MD-PHD filter, the general CPHD filter reduces the variance of the estimated number of targets and improves the accuracy of the state estimates. A venue for further research is the multisensor version of the general CPHD filter.
Availability of data and materils
Not applicable.
Abbreviations
- CPHD:
-
Cardinalized probability hypothesis density
- ET-CPHD:
-
Extended target cardinalized probability hypothesis density
- ET-PHD:
-
Extended target probability hypothesis density
- FISST:
-
Finite set statistics
- GCR:
-
General chain rule
- IIDC:
-
Identical, independently distributed cluster
- MD-PHD:
-
Multiple-detection probability hypothesis density
- MTT:
-
Multitarget tracking
- OSPA:
-
Optimal subpattern assignment
- OTHR:
-
Over-the-horizon radar
- PDF:
-
Probability density function
- PGFL:
-
Probability generating functional
- PHD:
-
Probability hypothesis density
- RFS:
-
Random finite set
References
R. Mahler, Advance in Statistical Multisource-Multitarget Information Fusion (Artech House, Norwood, 2014)
R. Mahler, Statistical Multisource-Multitarget Information Fusion (Artech House, Norwood, 2007)
R. Mahler, Multitarget Bayes filtering via first-order multitarget moments. IEEE Trans. Aerosp. Electron. Syst. 39(4), 1152–1178 (2003)
B.N. Vo, S. Singh, A. Doucet, Sequential Monte Carlo methods for multi-target filtering with random finite sets. IEEE Trans. Aerosp. Electron. Syst. 41(4), 1224–1245 (2005)
B.N. Vo, W.K. Ma, The Gaussian Mixture probability hypothesis density filter. IEEE Trans. Signal Process. 54(11), 4091–4104 (2006)
R. Mahler, PHD filters of higher order in target number. IEEE Trans. Aerosp. Electron. Syst. 43(4), 1523–1543 (2007)
B.T. Vo, B.N. Vo, A. Cantoni, Analytic implementations of the cardinalized probability hypothesis density filter. IEEE Trans. Signal Process. 55(7), 3553–3567 (2007)
F.E. Delo, S. Maskell, A CPHD approximation based on a discrete-gamma cardinality model. IEEE Trans. Signal Process. 67(2), 336–350 (2018)
P. Jing, J. Zou, Y. Duan, S. Xu, Z. Chen, Generalized CPHD filter modeling spawning targets. Signal Process. 128, 48–56 (2016)
D.S. Bryant, E.D. Delande, S. Gehly, J.E.E. Houssineau, D.E. Clark, B.A. Jones, The CPHD filter with target spawning. IEEE Trans. Signal Process. 65(5), 1324–1338 (2017)
R. Mahler, PHD filters for nonstandard targets, I: Extended targets, in 12th International Conference on Information Fusion. (Seattle, WA, USA, 2009), pp. 15–921
K. Granström, C. Lundquist, O. Orguner, Extended target tracking using a Gaussian-mixture PHD filter. IEEE Trans. Aerosp. Electron. Syst. 48(4), 3268–3286 (2012)
K. Granström, U. Orguner, R. Mahler, C. Lundquist, Corrections on: Extended target tracking using a Gaussian-mixture PHD Filter. IEEE Trans. Aerosp. Electron. Syst. 53(2), 1055–1058 (2017)
K. Granström, U. Orguner, A PHD filter for tracking multiple extended targets using random matrices. IEEE Trans. Signal Process. 60(11), 5657–5671 (2012)
Y. Li, H. Xiao, Z. Song, R. Hu, H. Fan, A new multiple extended target tracking algorithm using PHD filter. Signal Process. 93, 3578–3588 (2013)
U. Orguner, C. Lundquist, K. Granström, Extended target tracking with a cardinalized probability hypothesis density filter, in 14th International Conference on Information Fusion, (IL, USA, Chicago, 2011), pp.65–72
C. Lundquist, K. Granström, U. Orguner, An extended target CPHD filter and a gamma Gaussian inverse Wishart implementation. IEEE J. Select. Topics Signal Process. 7(3), 472–483 (2013)
G.W. Pulford, R.J. Evans, A multipath data association tracker for over-the-horizon radar. IEEE Trans. Aerosp. Electron. Syst. 34(4), 1165–1183 (1998)
X. Tang, X. Chen, M. McDonald, R. Mahler, R. Tharmarasa, T. Kirubarajan, A multiple-detection probability hypothesis density filter. IEEE Trans. Signal Process. 63(8), 2007–2019 (2015)
S. Nannuru, M. Coates, M. Rabbat, S. Blouin, General solution and approximate implementation of the multisensor multitarget CPHD filter, in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4055–4059 (2015)
C. Cao, Y. Zhao, X. Pang, B. Xu, Z. Suo, Sequential Monte Carlo Cardinalized probability hypothesized density filter based on Track-Before-Detect for fluctuating targets in heavy-tailed clutter. Signal Process. 169, 107367 (2020)
B. Yang, J. Wang, C. Yuan, J. Thiyagalingam, T. Kirubarajan, Multi-object Bayesian filters with amplitude information in clutter background. Signal Process. 152, 22–34 (2018)
Z. Lu, W. Hu, Y. Liu, T. Kirubarajan, Seamless group target tracking using random finite sets. Signal Process. 176, 107683 (2020)
D. Clark, R. Mahler, Generalized PHD filters via a general chain rule, in 15th International Conference on Information Fusion, pp. 157–164, Singapore (2012)
I. Schlangen, E. Delande, J. Houssineau, D.E. Clark, A PHD filter with negative binomial clutter, in 2016 19th International Conference on Information Fusion (FUSION), pp. 658–665 (2016)
X. Shen, L. Zhang, M. Hu, Arbitrary clutter PHD filter and its implementation. 2020 15th IEEE Int. Conf. Signal Process. (ICSP) 1, 20–25 (2020)
X. Shen, L. Zhang, M. Hu, S. Xiao, H. Tao, Arbitrary clutter extended target probability hypothesis density filter. IET Radar Sonar Navig. 15(5), 510–522 (2021)
X. Shen, Z. Song, H. Fan, Q. Fu, General Bernoulli filter for arbitrary clutter and target measurement processes. IEEE Signal Process. Lett. 25(10), 1525–1529 (2018)
B.T. Vo, C.M. See, N. Ma, W.T. Ng, Multi-sensor joint detection and tracking with the Bernoulli filter. IEEE Trans. Aerosp. Electron. Syst. 48(2), 1385–1402 (2012)
B. Ristic, B.T. Vo, B.N. Vo, A. Farina, A tutorial on Bernoulli filters: Theory, implementation and applications. IEEE Trans. Signal Process. 61(13), 3406–3430 (2013)
A.F. García-Fernández, S. Maskell, Continuous-discrete multiple target filtering: PMBM, PHD and CPHD filter implementations. IEEE Trans. Signal Process. 68, 1300–1314 (2020)
J.B. Hamzeh Torabi, S.M. Mirhosseini, On the number of partitions of sets and natural numbers. Appl. Math. Sci. 3(33), 1635–1646 (2009)
D.E. Clark, J. Houssineau, Faà di Bruno’s formula and spatial cluster modelling. Sp. Stat. 6, 109–117 (2013)
K. Gilholm, D. Salmond, Spatial distribution model for tracking extended objects. IEE Proc. Radar Sonar Navig. 152(5), 364–371 (2005)
K. Gilholm, S. Godsill, S. Maskell, D. Salmond, Poisson models for extended target and group tracking. Proc. Signal Data Process Small Targets 5913, 230–241 (2005)
X. Shen, Z. Song, H. Fan, Q. Fu, Generalised distance partitioning for multiple-detection tracking filter based on random finite set. IET Radar Sonar Navig. 12(2), 260–267 (2018)
X.R. Li, V.P. Jilkov, Survey of maneuvering target tracking. Part I. Dynamic models. IEEE Trans. Aerosp. Electron. Syst. 39(4), 1333–1364 (2003)
I. Schlangen, E.D. Delande, J. Houssineau, D.E. Clark, A second-order PHD filter with mean and variance in target number. IEEE Trans. Signal Process. 66(1), 48–63 (2018)
B. Ristic, D. Clark, B.-N. Vo, B.-T. Vo, Adaptive target birth intensity for PHD and CPHD filters. IEEE Trans. Aerosp. Electron. Syst. 48(2), 1656–1668 (2012)
D. Schuhmacher, B.T. Vo, B. Ngu, A consistent metric for performance evaluation of multi-object filters. IEEE Trans. Signal Process. 56(8), 3447–3457 (2008)
Acknowledgements
The authors thank the reviewers for their comments.
Funding
This research was funded by the National Natural Science Foundation of China (Grant No. 61901489).
Author information
Authors and Affiliations
Contributions
XS is the first author and the corresponding author of this paper. His main contributions include the basic idea, mathematical analysis, derivation, simulations and writing. ZS is the second author, and his contribution is conceptualization, reviewing and editing. HF is the third author, and his contribution is conceptualization and supervision. QF is the fourth author, and his contribution is investigation. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A. Derivation of RFS-based filters
The PHD filter, which models the predicted PGFL as Poisson RFS, only propagates the PHD to approximate the multitarget PDF. If the predicted PHD is \({{D}_{k|k-1}}({\mathbf {x}})\) and the predicted PGFL is \(G[h]={{e}^{{{D}_{k|k-1}}[h-1]}}\), \(G\left[ hT[g] \right] ={{e}^{{{D}_{k|k-1}}[hT[g]-1]}}\). Suppose that \({{N}_{k|k-1}}\) is the integral of \({{D}_{k|k-1}}({\mathbf {x}})\), the bivariate PGFL F[g, h] in (15) can be calculated as
Thus, it is easy to calculate \(\frac{\delta F}{\delta {{Z}_{k}}}[g,h]\) with the GCR as shown in [24]. Then in step 4 of the derivation process, the posterior PHD is
where \({{\tau }_{W}}={{D}_{k|k-1}}[{{M}_{W}}]\), \({{\kappa }_{W}}=\frac{\delta \log {{G}^{\kappa }}}{\delta W}[0]\) denotes the Log-clutter density, and
\({{G}^{\kappa }}[g]\) is the PGFL of the clutter process. If \(\kappa (W)\) is a Poisson RFS with PGFL \({{G}^{\kappa }}[g]={{e}^{\lambda c[g-1]}}\), the Log-clutter density is
Thus, whenever \(\left| W \right| >1\), \({{\kappa }_{W}}=0\). As discussed in [27], the general PHD filter reduces to different PHD filters by using different likelihood functions in Sect. 2.4.
The Bernoulli filter, which models the predicted PGFL as Bernoulli RFS, propagates the probability of existence as well as the spatial distribution to express the PDF. If the PGFL of the predicted target process is \(G[h]=1-q+qs[h]\), as the functional derivatives of G[h] are easy to be calculated, it is easy to calculate \(\frac{\delta F}{\delta {{Z}_{k}}}[g,h]\) with the product rule. On basis of the functional derivatives, we proposed the general Bernoulli filter [28], which is the theoretical basis for various Bernoulli filters.
The CPHD filter, which models the predicted PGFL as IIDC RFS, jointly propagates the cardinality distribution and the PHD to approximate the multitarget PDF. In this case, the derivation of \(\frac{\delta F}{\delta {{Z}_{k}}}[g,h]\) is more complicated. Only with the IIDC clutter process, the researchers proposed the point target CPHD filters and ET-CPHD filters.
Appendix B. Derivation of theorem 1 (The corrector of the general CPHD filter)
If \(0\le x\le 1\) is a scalar, the posterior PGF \({{G}_{k|k}}(x)\) can be calculated as
Substituting \(h=x\) into (26), the numerator of (61) is
Here, \(h=x\) indicate that \(h({\mathbf {x}})\) is the constant functional over the state space with value x. If \({{\vartheta }_{\wp }}(x)={{x}^{\left| \wp \right| }}{{G}^{\left( \left| \wp \right| \right) }}(x{{\rho }_{k}})\prod \nolimits _{W\in \wp }{{{\eta }_{W}}}\), the PGF \({{G}_{k|k}}(x)\) is
The nth derivative of the PGF is
Note that
According to the relationship between the PGF and the cardinality distribution shown in (4), \({{G}^{\left( n \right) }}(0)=n!{{p}_{k|k-1}}(n)\) and \(G_{k|k}^{(n)}(0)=n!{{p}_{k|k}}(n)\), the posterior cardinality distribution \({{p}_{k|k}}(n)\) can be expressed as (30).
The posterior PHD\({{D}_{k|k}}({\mathbf {x}})\) can be calculated as
Derive the functional derivative of \(\frac{\delta }{\delta {{Z}_{k}}}F[0,h]\) with respect to \({\mathbf {x}}\) and substitute \(h=1\) into the derivative,
So the posterior PHD \({{D}_{k|k}}({\mathbf {x}})\) is
Rewrite \({{D}_{k|k}}({\mathbf {x}})\) as (31), as \({{D}_{k|k-1}}({\mathbf {x}})={{N}_{k|k-1}}s({\mathbf {x}})\), the pseudo-likelihood \({{L}_{{{Z}_{k}}}}({\mathbf {x}})\) can be expressed as (32). And the derivation of the general CPHD filter is finished.
Appendix C. Derivation of the generality of the general CPHD filter
1.1 C.1. Derivation of theorem 2
If the target is point target, whenever \(\left| W \right| >1\), \({{M}_{W}}({\mathbf {x}})=0\) and \({{\eta }_{W}}=0\).
When \(W=\left\{ {\mathbf {z}} \right\}\), \({{M}_{\left\{ {\mathbf {z}} \right\} }}({\mathbf {x}})={{p}_{D}}({\mathbf {x}}){{\Phi }_{{\mathbf {z}}}}({\mathbf {x}})\) and \({{\eta }_{\left\{ {\mathbf {z}} \right\} }}=\tau ({\mathbf {z}})\). Suppose that the clutter process is modeled by an IIDC RFS,
Here, the summation over all partitions reduces to the summation over all subsets. Similarly,
\({{p}_{k|k}}(n)\) in (30) is reduced to (35). Thus, the general CPHD filter proposed in our work reduces to the classical CPHD filter. Note that
Therefore,
Thus, the pseudo-likelihood in (31) is reduced to (36).
1.2 C.2. Derivation of theorem 3
Suppose that the predicted target process of the general CPHD filter is simplified to Poisson RFS, the predicted PGF is simplified to \(G(x)={{e}^{D[x-1]}}={{e}^{(x-1){{N}_{k|k-1}}}}\). Thus, \({{\tau }_{W}}={{N}_{k|k-1}}{{\eta }_{W}}\) and \({{G}^{\left( \left| \wp \right| \right) }}({{\rho }_{k}})=N_{k|k-1}^{\left| \wp \right| }G({{\rho }_{k}})\). Then, \({{\pi }_{\wp }}\) is simplified to
and \({{\psi }_{\wp }}={{N}_{k|k-1}}{{\pi }_{\wp }}.\) So the pseudo-likelihood shown in (32) is reduced to
Then, define a functional H[g] that satisfy \({\delta H[0]}/{\delta W}\;={{\tau }_{W}},\)
On the other hand,
Then,
Thus,
Note that
Thus, using the weight \({{\omega }_{\wp }}\) defined in (59),
Therefore, the pseudo-likelihood \({{L}_{{{Z}_{k}}}}({\mathbf {x}})\) in (32), which is reduced to (76), is the same as that in (58).
1.3 C.3. Derivation of theorem 4
When the maximum number of targets is 1, whenever \(n>1\), \({{p}_{k|k-1}}(n)=0\). Thus,
So (30) can be recalculated as (39). Similarly,
Thus,
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shen, X., Song, Z., Fan, H. et al. A general cardinalized probability hypothesis density filter. EURASIP J. Adv. Signal Process. 2022, 94 (2022). https://doi.org/10.1186/s13634-022-00924-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-022-00924-w