
Abstract
An extension of the baseline non-intrusive load monitoring approach for energy disaggregation using temporal contextual information is presented in this paper. In detail, the proposed approach uses a two-stage disaggregation methodology with appliance-specific temporal contextual information in order to capture time-varying power consumption patterns in low-frequency datasets. The proposed methodology was evaluated using datasets of different sampling frequency, number and type of appliances. When employing appliance-specific temporal contextual information, an improvement of 1.5% up to 7.3% was observed. With the two-stage disaggregation architecture and using appliance-specific temporal contextual information, the overall energy disaggregation accuracy was further improved across all evaluated datasets with the maximum observed improvement, in terms of absolute increase of accuracy, being equal to 6.8%, thus resulting in a maximum total energy disaggregation accuracy improvement equal to 10.0%.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.1 Introduction
In the last decades, rising energy consumption needs within residential and industrial environments have become a crucial issue with nowadays consumer households accounting for approximately 40% of the total worldwide consumed energy [1, 2]. With the development of information and communication technologies (ICT) and the increasing usage of electrical appliances and automation of tasks, the electric power needs will grow further and the number of electrical appliances per household will significantly increase within the next 20 years [1, 2]. Despite the expected increase in total energy consumption, studies estimate that 20% of households’ consumed energy could be saved by changing consumers’ behaviour and improving the existing poor operational strategies [3, 4]. Furthermore, the establishment of smart grids and demand management as well as the fluctuation of power generation due to an increasing percentage of renewable energies are enhancing the issue of increasing energy needs [5, 6]. These changes in energy demand and generation are challenging for network operators and power generation facilities, since power needs are becoming less stable and unpredictable while rising at the same time [7, 8]. To address those challenges, accurate and fine-grained monitoring of electrical energy consumption within residential environments is needed [2, 9] as well as proper demand management [10]. However, nowadays, energy monitoring is mostly done via an aggregated measure of energy consumption in the form of monthly bills and therefore does not address the above-mentioned issues.
To measure energy consumption, smart meters are used. A smart meter, also referred to as a smart plug, is a device used to measure electrical power/energy consumption with resolution in the order of seconds to minutes. Smart meters measure the voltage drop over the device/circuit and the current flowing through the device/circuit with an arbitrary sampling frequency fs, which usually varies from 1/60 Hz to 30 kHz [11]. Higher sampling frequencies are usually preferred, since they contain more detailed information about the energy consumption; however, they increase linearly the amount of acquired data and exponentially the cost of hardware [12]. With the sampling rate in the order of seconds, data handling for several months/years becomes feasible and hardware costs are relatively low. However, with the ability to provide real-time information through smart metering and determining detailed household energy consumption, consumer privacy concerns are arising and energy data protection becomes prominent [7, 13]. To address these issues, energy monitoring must be carried out cost-effectively and under the consideration of privacy concerns.
According to [14], the largest improvements in terms of energy savings can be made when monitoring energy consumption on a device level to detect faulty device operation and inefficient or suboptimal operational strategies. To measure energy consumption on a device level, energy has to be measured either for each device separately using one sensor per device or the aggregated energy (combined energy of several devices measured at one central point, e.g. the power inlet of a household) has to be disaggregated into a device level using computational algorithms. When only using one sensor to disaggregate the total consumed energy and extract energy consumption on the appliance level, the task is referred to as non-intrusive load monitoring (NILM) as introduced in [15]. NILM formulates the energy disaggregation problem as a single-channel source separation problem, where the smart meter is the only input channel measuring the total power consumption, and the goal is to find the inverse of the aggregation function to calculate consumption per device. Comparing with intrusive load monitoring (ILM), NILM has the advantage of requiring less hardware (ILM uses one smart meter per device) as well as meets consumers’ acceptability with respect to privacy conserving [7, 13].
In general, NILM assumes that there is a single observation (smart meter measurements) and multiple unknowns (electrical devices) making the disaggregation problem highly under-determined and difficult to solve without any further constraints. Therefore, several approaches for disaggregation have been proposed, which can be briefly split into methods with and without source separation (SS). Approaches without SS are based on the decomposition of the aggregated signal to a sequence of feature vectors, which will be classified to device labels by a machine learning (ML) algorithm (e.g. artificial neural networks (ANN) [16], decision trees (DT) [17], hidden Markov models (HMM) [18], K-nearest neighbours (KNN) [19], support vector machines (SVM) [20]), or by a pre-defined set of rules and thresholds [21, 22]. Furthermore, recent research in deep learning and big data has led to a significant increase of use of data-driven approaches using large-scale datasets (e.g. AMPd [23]). Approaches based on convolutional neural networks (CNNs) [24,25,26], recurrent neural networks (RNNs) [27, 28] and long short-time memories (LSTMs) [27, 29] have been proposed in the literature, while denoising autoencoders (dAEs) [30] and gate recurrent units (GRUs) [26] have also been used. Approaches with SS are based on single-channel source separation algorithms (e.g. non-negative matrix factorization [31], sparse component analysis [32]) to extract the consumption of each device from the aggregated signal by using additional constraints (e.g. sparseness or sum-to-one [33]) during the optimization procedure. The features extracted from the aggregated signal in approaches with and without SS strongly depend on the sampling frequency, with either macroscopic (for low sampling frequency) or microscopic (for high sampling frequency) features being extracted. Macroscopic features are mainly active and reactive power, while statistical values from the active or reactive power (e.g. mean, median, variance or energy) can be estimated as well [34]. Microscopic features can be current harmonics or transient energy [21, 35] and require high-sampling frequency to be calculated (1 kHz and above).
Several NILM approaches with and without SS have been proposed in the literature. In these approaches, one- or multi-state electrical devices have been modelled by finite-state machines, i.e. with steady energy consumption behaviour per operational state [15]. In contrast to one/multi-state devices, there is no established approach in detecting appliances with continuous power consumption or with non-linear behaviour and highly varying power signature [36, 37]. Researchers have addressed this issue by using high-frequency features or wavelets to detect transient device behaviour, which however have the drawback of higher cost in hardware and increased computational power needed [12, 37, 38]. Therefore, most approaches use disaggregation algorithms with sampling rates in the order of seconds to minutes, in addition to temporal information (e.g. factorial hidden Markov models (FHMM) [18, 39]) to identify appliances with varying power consumption [12, 40]. Furthermore, special filtering techniques (e.g. Kalman filters [41]) with time-varying coefficients and probabilistic approaches using appliance grouping [42] have been proposed to address the issue of modelling devices with continuous or non-linear characteristics.
In this paper, we propose the integration of temporal contextual information for each electrical appliance in the form of concatenation of adjacent feature vectors within a device-dependent time window to improve device detection performance in NILM. The remainder of this paper is organized as follows: in Section 2, the proposed NILM approach using temporal contextual information per device is presented. In Section 3, the experimental set-up is described, and in Section 4, the evaluation results are presented. Finally, the paper is concluded in Section 5.
2 Methods
NILM energy disaggregation can be formulated as the task of determining the power consumption on a device level based on the measurements of one sensor, within the time window (frame or epoch). Specifically, for a set of M − 1 known devices each consuming power pm with 1 ≤ m ≤ M, the aggregated power Pagg measured by the sensor will be:
where pg = pM is a ‘ghost’ power consumption usually consumed by one or more unknown devices. In NILM, the goal is to find estimations \( \hat{P}=\Big\{{\hat{p}}_m \), \( {\hat{p}}_g \)} of the power consumption of each device m using an estimation method f−1 with minimal estimation error and \( {\hat{p}}_M={\hat{p}}_g \), i.e.:
2.1 Baseline NILM architecture
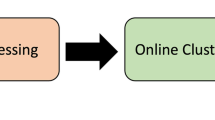
As a baseline NILM approach, we consider a data-driven energy disaggregation methodology without the use of SS techniques, adopted in several publications found in the literature [39, 43,44,45,46]. The baseline NILM consists of pre-processing of the aggregated signal Pagg, then decomposition of the sequence of frames to a sequence of feature vectors followed by processing from a classification/regression algorithm using pre-trained appliances’ models to determine device operation as shown in Fig. 1.

Baseline NILM approach
During the pre-processing step, filtering and/or down-sampling is performed, and then the signal is frame blocked. Framing can be done either with constant or with variable frame length [35, 47]. In the state-based baseline NILM approach, in order to estimate the device consumption on a state level, a regression algorithm instead of a classification algorithm is used [48, 49], while classification is used in event-based approaches to detect devices’ on/off states [39, 45, 46].
2.2 Proposed NILM architecture
The proposed methodology uses a two-stage disaggregation scheme, with the first stage performing power consumption estimation for each device by extending the baseline NILM architecture to using temporal contextual information (TCI) and the second stage fusing the estimation results of each device using a regression model. The block diagram of the proposed two-stage NILM architecture using TCI is illustrated in Fig. 2.

Block diagram of the NILM architecture using device-dependent temporal contextual information (TCI)
Similarly to the baseline NILM, the aggregated power consumption signal Pagg is initially pre-processed, and a feature vector vt, vt ∈ ℝL is extracted for every frame ht, with 1 ≤ t ≤ T, where T is the total number of frames. During stage 1, the feature vectors are expanded to Cm using their N adjacent ones, thus creating a temporal contextual window w of length equal to w = 2N + 1 concatenated frames, i.e.:
where TCIm is the temporal contextual information expansion function for the m-th device and \( {C}_{m_t} \) is the expansion for the m-th device and the t-th frame. The TCI expansion is performed separately for each device m using its optimal temporal contextual information \( {w}_{\mathrm{opt}}=\left\{{w}_{\mathrm{opt}}^m\right\} \), with wopt being calculated offline on a bootstrap training dataset. The expanded feature vector Cm of each device m is then processed by a regression model f(), and the output of stage 1, \( {\hat{p}}_m^{\prime } \), is an initial estimation of the power consumption of each device:
The power consumption estimations, \( {\hat{P}}^{\prime}\in {\mathbb{R}}^M \) of the M devices from stage 1, are used together with the feature vector, vt, in order to calculate enhanced estimations of the power consumptions of the M devices. In detail, in the second stage M regression, models are receiving as input the power consumption estimates \( {\hat{P}}^{\prime } \) from stage 1 and the initial feature vector vt. The use of the device estimates \( {\hat{P}}^{\prime } \) allows the second-stage regression model estimators to model power consumption correlations between different devices. In both stages 1 and 2, the regression models of the M devices operate in parallel and separately for each device. The proposed methodology combines the integration of temporal contextual information with the device-specific operation of each of the M appliances, thus capturing temporal information individually for each appliance and learning it by the regression model.
3 Experimental set-up
The proposed two-stage NILM architecture with the device-dependent temporal contextual information presented in Section 2 was evaluated using a number of publicly available datasets and a deep learning algorithm for regression. The datasets and parameters set for deep learning regression are presented below.
3.1 Databases
Three different publicly available databases were used, namely the ECO [50], the REDD [51], and the iAWE [52] database. The ECO and REDD databases consist of different datasets with each of them containing power consumption recordings from different houses, while iAWE database consists of recordings from one house. The evaluated datasets are tabulated in Table 1 with the number of appliances denoted in column ‘#App’. In the same column, the number of appliances in brackets is the number of appliances after excluding devices with power consumption below 25 W (italic entries), which were added to the power of the ‘ghost device’, similarly to the experimental set-up followed in [53, 54]. The next three columns in Table 1 are tabulating the sampling period Ts, the duration T and the appliance types of each evaluated dataset.
The appliances’ type categorization is based on their operation as described in [55, 56], i.e. one-state devices have only on/off status (e.g. resistive lamps, kettles, or fridges without significant power spikes), multi-state devices have several discrete power consumption states (e.g. washing machines including different washing cycles), non-linear loads (e.g. electronics) and devices with continuous power consumption signature, which are controlled by power electronics (e.g. air condition) and usually have an exponential decay pattern. In all appliance types, a peak might appear at the beginning of their signature, e.g. in refrigerators. Characteristic examples of the power consumption signatures of each of the four appliance types are illustrated in Fig. 3. The ECO-3 and REDD-5 datasets were excluded as ECO-3 contains only the aggregated signal and not the power consumptions per device; thus, there is no ground truth to evaluate NILM approaches [50], and REDD-5 has significantly short-monitoring duration [57]. Regarding the size of the evaluated data, the whole REDD database was used (ignoring the gaps in the measurements as in [58]), while 1 week of data was chosen for the ECO and iAWE databases to have similar amounts of training samples as in the REDD dataset. In detail, the week from 5 July until 11 July 2012 was selected from the ECO database while the week from 8 June until 14 June was selected for the iAWE database, respectively. These particular weeks were selected in order as many as possible devices to appear in the aggregated signal, and since in previous papers using the ECO and iAWE databases [44, 50], the time interval used has not been reported.

Different appliance signatures for the four appliance types: (a) one-state without significant peak (lamp), (b) one-state appliance with significant peak (refrigerator), (c) non-linear appliance (laptop) and (d) continuous appliance with decay (air conditioning)
In Table 2, the appliances from each dataset are categorized according to the four different appliance types mentioned above. The categorization is done with respect to the electrical properties of the appliances and their corresponding power consumption signatures. In addition, the percentage of the total energy per appliance type in each dataset is given. The ID number of appliances (columns ‘App’) corresponds to the appliances of each dataset as denoted in Table 2.
As can be seen in Tables 1 and 2, the number of appliances as well as the appliance type in the evaluated datasets is varying. In particular, the number of appliances varies from 6 (ECO-1) to 18 (REDD-3) while the number of appliance types varies from 2 (REDD-2) to 4 (REDD-4/6); thus, the 11 evaluated datasets include different device combinations and characteristics, which are representative of modern households. Common in all datasets is their relatively low sampling period (1–3 s) and the consideration of active power samplings only, resulting to computational simplicity and runtime advantages [59]. Furthermore, all three databases were recorded within the last decade meaning that the households used were equipped with recent device technology [50, 51].
In our experimental set-up, the real aggregated signal (which includes ghost power from unknown devices) was used to evaluate the performance of the proposed NILM methodology, thus making the experimental set-up identical to real-life conditions. Specifically, the input aggregated power consumption signal we used was the originally measured by the smart meter (one sensor only) during data acquisition (similarly to [60]) and not an artificially generated aggregated signal created by adding the power consumption signals from a manually selected closed set of devices (synthesized data), as in [29, 61,62,63], which was criticized in [64] for not corresponding to real-world conditions.
3.2 Pre-processing and feature extraction
During pre-processing, the aggregated signal was frame blocked in frames of ten samples with overlap between successive frames equal to 50% (i.e. five samples). For every frame, a feature vector consisting of the mean, root mean square, standard deviation and peak to root mean square value was calculated, similarly to [65], resulting to feature vectors of dimensionality equal to four. In detail, the mean value is used as the most general information about the energy consumption in each frame, while the root mean square value is used as a filtered version of the mean value smoothing outliers and small changes (noise) in the power consumption signal [65]. Moreover, the standard deviation is used in order to capture sudden changes of the power signal within a frame, i.e. changes of device states, while the peak to root mean square value is selected to capture the maximum change in power normalized to the root mean square value of the frame in order to have a quantitative measure of change in power within each frame [65]. In order to consider temporal contextual information, expanded feature vectors were extracted by concatenating to each feature vector, the N preceding and the N succeeding vectors as described in Section 2.
For the regression models of stage 1, feed-forward deep neural networks (DNNs) were used. In detail, the DNN consisted of 3 hidden layers with 32 sigmoid nodes per layer. The number of layers and nodes was empirically selected after evaluation on a bootstrap training subset with artificially generated aggregated data (removed ghost power) as shown in Table 3. A ‘one vs. all’ regression approach was followed; thus, the output layer consisted of one regression node only predicting the power of the m-th appliance. In order to avoid overlap between training and test data, each of the evaluated datasets was equally split into two subsets, one for training the DNN models and one for evaluating the proposed architecture.
4 Results and discussion
The architecture presented in Section 2 was evaluated according to the experimental set-up described in Section 3. The performance was evaluated in terms of estimation accuracy (EACC), as proposed in [51], taking into account the estimated power \( {\hat{p}}_m \) where T is the number of disaggregated frames and M is the number of disaggregated devices including the ghost power, i.e.:
For evaluating the estimation accuracy on the device level, Eq. 5 was modified and the summation over M appliances was eliminated resulting in Eq. 6
The NILM architecture with temporal contextual information (TCI) was tested for a set of temporal contextual windows of different length. The experimental results of the TCI architecture (i.e. the output of stage 1 in Fig. 2) for different temporal contextual window lengths w, with the same w for all devices and 1 ≤ N ≤ 6, are shown in Table 4. The best performing length of the temporal contextual window w for each of the evaluated datasets is indicated in italics. In the first column (w = 1), the performance without TCI is given. In the last column (wopt), the estimation accuracy EACC when using the optimal temporal contextual window separately for each device is shown.
As can be seen in Table 4, the use of TCI improves energy disaggregation performance when compared with the baseline NILM system (w = 1) across all evaluated datasets. In the case of using a temporal contextual window of the same length for all devices, i.e. w = 3 up to w = 13, the best performing set-up varies from w = 5 to w = 11. In general, the datasets with optimal w in low lengths (w ≤ 5) mostly have one/multi-state types of devices, while datasets with higher optimal TCI lengths (w ≥ 9) are dominated by devices of non-linear/continuous type. The NILM performance using TCI is further improved when the optimal temporal contextual window length per device is used (wopt). Specifically, the use of an optimized w value for each device instead of a flat value for all devices improves the performance from 0.5 (REDD-4) up to 2.2% (ECO-2/REDD-1), in terms of absolute improvement. The use of device-dependent TCI was found to improve the performance across all evaluated datasets and especially in the datasets with approximately equal energy consumption distribution of the appliances types, like datasets ECO-2 and REDD-1.
Next, we evaluated the performance of the two-stage methodology presented in Section 2. The evaluation results of the proposed NILM architecture are shown in Table 5. For the purpose of direct comparison of the two-stage architecture with the TCI approach (stage 1), the same training and test subset division was used in all evaluated datasets. The best achieved performance of the TCI approach for each of the evaluated datasets shown in Table 4 is repeated in Table 5 as well.
As can be seen in Table 5, the proposed two-stage methodology outperforms the TCI NILM architecture (stage 1) in all evaluated datasets. In detail, the highest performance improvement (when considering temporal contextual window of the same length for all devices) in terms of EACC values was observed in the REDD-3 dataset (+ 5.2% for w = 5) followed by the REDD-2/ECO-5 dataset (+ 3.0%, for w = 5), while the lowest improvement was found in the REDD-6 dataset (+ 0.1%, for w = 3), when compared with the TCI NILM. Moreover, the best energy disaggregation performance for 10 out of 11 datasets was observed for temporal contextual window lengths between 3 ≤ w ≤ 11 with the majority of the datasets having an optimal temporal contextual window length between 5 ≤ w ≤ 9. In the case of the ECO database (with only 6–9 appliances per dataset), the two-stage NILM methodology offered an improvement of 0.5–3.0% in terms of EACC, while the REDD database (with 10–18 appliances per dataset) offered an improvement of 0.1–5.2%. When considering the optimal temporal contextual window length per device (column ‘wopt’ in Table 5), the energy disaggregation improvement offered by the two-stage NILM architecture is even higher. In particular, the highest performance improvement was observed in ECO-2 and ECO-4 datasets (+ 5.2% and + 3.0%, respectively), while the lowest improvement was observed in ECO-5 dataset (+ 0.1%), when compared with the TCI NILM. When compared with the baseline NILM, the highest performance improvement is + 10.0% (iAWE) and the lowest one is + 2.0% (ECO-6).
To further compare the results with the NILM methods proposed in the literature, the very recent work of [66] was used, which includes a summary of NILM performances for the REDD database for different set-ups. Approaches using the most popular experimental set-up using houses 1, 2, 3, 4, and 6 with all devices and measuring performance using the EACC metric were considered. Moreover, the results from [66] were extended by including recently published results [67, 68] on the same experimental set-up. It is worth mentioning that although the same data and the same accuracy metric was used, direct comparison is not assured as data splits or pre-processing might vary between the compared approaches (such information is not provided in most papers found in the bibliography). The results are tabulated in Table 6.
As can be seen in Table 6, the proposed fusion methodology outperforms all other reported approaches on the REDD-1/2/3/4/6 dataset set-up. In detail, the proposed approach outperforms the Powerlets approach [67] by 4.3%, while it performs 1.7% better than supervised GSP proposed in [68]. However, it must be noted that the approach in [68] uses a reduced number of appliances and thus cannot be directly compared with the other NILM approaches.
Analysis of the proposed two-stage NILM methodology on a device level was performed. In Table 7, the energy disaggregation improvement in terms of absolute increase of device estimation accuracy (\( {E}_{\mathrm{ACC}}^i \)) and the corresponding optimal temporal contextual window length per device, respectively are presented. The first column in Table 7 denotes the type of each appliance as defined in Tables 1 and 2.
As can be seen in Table 7, appliances belonging to type A (i.e. single- or multi-state appliances with their power consumption signature not varying in time, like air exhaust, disposal, electric heat, iron, lamp) are not significantly benefiting by the two-stage NILM methodology with temporal contextual information since the energy disaggregation improvement for type A devices ranges between 0.0 and 3.4% with an average improvement of 1.6%. Type B appliances (i.e. devices without strong temporal behaviour but with significant peak power at the beginning of their power signature, like dishwasher, freezer, fridge, washer-dryer) were found to benefit from the proposed methodology with the energy disaggregation improvement for type B appliances ranging between 0.4 and 17.8% with an average improvement of 8.6%. In the case of non-linear appliances (appliances type C, e.g. electronic devices, entertainment, laptops), the power signature is usually strongly varying with time and the temporal contextual information can capture well their dynamic characteristics, with the energy disaggregation improvement for type C appliances ranging between 0.2 and 12.7% with an average improvement of 3.8%. As regards continuous devices (appliances type D, like air-conditioner and water motor), their power signature appears in the form of an exponential rise or decay including significant power peaks at the onset of their signature. Due to their slowly but strongly time-varying behaviour, their amplitude variation can be captured by temporal contextual information and misclassification with multi-state appliances of the similar consumption amplitude levels can be reduced, with the energy disaggregation improvement for type D devices ranging between 1.4 and 44.7% with an average improvement of 28.6%. The effect of the two-stage temporal contextual information NILM methodology proposed in Section 2 on each of the four appliance types is summarized in Table 8.
As can be seen in Table 8, the energy disaggregation performance in type D devices improves by almost 30%, followed by type B benefiting by almost 10%. Also, the average optimal temporal contextual window length for appliance types D and B is w = 9.00 and w = 7.38, respectively. For the case of non-linear appliances (type C), the performance improvement is almost 4%; however, the average optimal window length is greater than the one of type B, which is most probably owed to the longer duration of patterns as well as the non-repetitive micropatterns within non-linear appliances. Furthermore, the two-stage architecture improves the detection of continuous or non-linear appliances as they can be highly related to the daily routine of the users/consumers or even be related/dependent to each other as for example, in the case of TV and entertainment appliances which are usually interconnected. For such devices, with inter-device dependencies or daily routine patterns, the a priori knowledge of the power consumption of other devices they operate together with or devices with similar daily routine (i.e. usually operating or not operating simultaneously) can be beneficial for the estimation of their power consumption. Such devices can benefit from the fusion stage of the proposed architecture in which estimates of the power consumption of the other appliances (calculated from the first stage) are used as input. Except this, detection of devices with power spikes, i.e. peaks that appear during the switching on of electrical motors, e.g. in fridges or freezers, was found to benefit from the fusion stage of the proposed methodology, since the presence of a power spike within a frame affects the distribution of energy among the set of devices to be disaggregated which is implicitly expressed by the power consumption estimates of each device detector computed at the first stage of the proposed architecture. The power signature for each appliance type was illustrated in Fig. 3.
5 Conclusion
A two-stage methodology for energy disaggregation using temporal contextual information was presented. The methodology extends the baseline non-intrusive load monitoring (NILM) approach by employing a two-stage disaggregation and using a temporal expansion of the feature vectors within a time window of variable length. The proposed methodology was evaluated using the real-aggregated signal as measured by the smart meter across various datasets of different sampling frequency, number, and types of appliances, demonstrating improvement of performance across all datasets. The maximum improvement in terms of absolute increase of accuracy was equal to 10.0% when using appliance-driven temporal contextual information lengths and two-stage disaggregation. In detail, the most significant improvements were observed for devices with power peaks and exponential decay power consumption signatures such as refrigerators and air conditions. Moreover, improvements in energy disaggregation performance were observed for appliances with strong time-varying power signatures like electronic devices, e.g. stereos, laptops or entertainment electronics. With the use of the fusion stage inter-device dependencies or daily routine patterns can be modelled and power spikes can be found, thus resulting in further improvement of the disaggregation accuracy.
Availability of data and materials
The utilized datasets are available online and free to download under common creative licence (ECO [50] (10.5905/ethz-1007-35), REDD (http://redd.csail.mit.edu/) [51] and iAWE [52] (https://iawe.github.io/)).
Abbreviations
- ANN:
-
Artificial neural network
- CNN:
-
Convolutional neural network
- dAE:
-
Denoising autoencoders
- DNN:
-
Deep neural network
- DT:
-
Decision trees
- FHMM:
-
Factorial hidden Markov model
- GRU:
-
Gate recurrent units
- HMM:
-
Hidden Markov model
- ICT:
-
Information and communication technologies
- ILM:
-
Intrusive load monitoring
- KNN:
-
K-nearest -Neighbours
- LSTM:
-
Long short-time memory
- NILM:
-
Non-intrusive load monitoring
- RNN:
-
Recurrent neural network
- SS:
-
Source separation
- SVM:
-
Support vector machines
- TCI:
-
Temporal contextual information
References
L. Pérez-Lombard, J. Ortiz, C. Pout, A review on buildings energy consumption information. Energy and Buildings. 40, 394–398 (2008). https://doi.org/10.1016/j.enbuild.2007.03.007
Mostafavi S, Cox RW. An unsupervised approach in learning load patterns for non-intrusive load monitoring. In: Fortino G, editor. [Piscataway, NJ]: IEEE; 2017. p. 631–636. doi:10.1109/ICNSC.2017.8000164 .
Ogwumike C, Short M, Denai M. Near-optimal scheduling of residential smart home appliances using heuristic approach. In: Piscataway, NJ: IEEE; 2015. p. 3128–3133. doi:https://doi.org/10.1109/ICIT.2015.7125560.
J. Froehlich, E. Larson, S. Gupta, G. Cohn, M. Reynolds, S. Patel, Disaggregated end-use energy sensing for the smart grid. IEEE Pervasive Computing. 10, 28–39 (2011). https://doi.org/10.1109/MPRV.2010.74
Chis A, Rajasekharan J, Lunden J, Koivunen V. Demand response for renewable energy integration and load balancing in smart grid communities. In: 2016 24th European Signal Processing Conference (EUSIPCO); Budapest, Hungary. Piscataway, NJ: IEEE; 2016. p. 1423–1427. doi:https://doi.org/10.1109/EUSIPCO.2016.7760483.
L.R.M. Silva, C.A. Duque, P.F. Ribeiro, Smart signal processing for an evolving electric grid. EURASIP J. Adv. Signal Process. 2015, 210 (2015). https://doi.org/10.1186/s13634-015-0229-7
Li Z, Oechtering TJ, Skoglund M. Privacy-preserving energy flow control in smart grids. In: Piscataway, NJ and Piscataway, NJ: IEEE; 2016. p. 2194–2198. doi:https://doi.org/10.1109/ICASSP.2016.7472066.
L. Alfieri, Some advanced parametric methods for assessing waveform distortion in a smart grid with renewable generation. EURASIP J. Adv. Signal Process. 2015, 41 (2015). https://doi.org/10.1186/s13634-015-0195-0
J.A. Cortés, A. Sanz, P. Estopiñán, J.I. García, Analysis of narrowband power line communication channels for advanced metering infrastructure. EURASIP J. Adv. Signal Process. 2015, 18 (2015). https://doi.org/10.1186/s13634-015-0211-4
J. Xu, M. van der Schaar, Incentive-compatible demand-side management for smart grids based on review strategies. EURASIP J. Adv. Signal Process. 2015, 34 (2015). https://doi.org/10.1186/s13634-015-0235-9
Gao J, Kara EC, Giri S, Berges M. A feasibility study of automated plug-load identification from high-frequency measurements. In: Piscataway, NJ and Piscataway, NJ: IEEE; 2015. p. 220–224. doi:https://doi.org/10.1109/GlobalSIP.2015.7418189.
G.C. Koutitas, L. Tassiulas, Low cost disaggregation of smart meter sensor data. IEEE Sensors Journal. 16, 1665–1673 (2016). https://doi.org/10.1109/JSEN.2015.2501422
K. Buchanan, N. Banks, I. Preston, R. Russo, The British public’s perception of the UK smart metering initiative: threats and opportunities. Energy Policy. 91, 87–97 (2016). https://doi.org/10.1016/j.enpol.2016.01.003
S. Katipamula, M. Brambley, Review article: methods for fault detection, diagnostics, and prognostics for building systems--a review, part II. HVAC&R Research. 11, 169–187 (2005). https://doi.org/10.1080/10789669.2005.10391133
G.W. Hart, Nonintrusive appliance load monitoring. Proceedings of the IEEE. 80, 1870–1891 (1992). https://doi.org/10.1109/5.192069
Y.-H. Lin, M.-S. Tsai, An advanced home energy management system facilitated by nonintrusive load monitoring with automated multiobjective power scheduling. IEEE Transactions on Smart Grid. 6, 1839–1851 (2015). https://doi.org/10.1109/TSG.2015.2388492
Bilski P, Winiecki W. Generalized algorithm for the non-intrusive identification of electrical appliances in the household. In: 2017 9th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS); Bucharest, Romania. Piscataway, NJ: IEEE; 2017. p. 730–735. doi:https://doi.org/10.1109/IDAACS.2017.8095186.
Zoha A, Gluhak A, Nati M, Imran MA. Low-power appliance monitoring using factorial hidden Markov models. In: Palaniswami M, editor. Piscataway, NJ and Piscataway, NJ: IEEE; 2013. p. 527–532. doi:https://doi.org/10.1109/ISSNIP.2013.6529845.
Kim Y, Kong S, Ko R, Joo S-K. Electrical event identification technique for monitoring home appliance load using load signatures. In: 2014 IEEE International Conference on Consumer Electronics (ICCE); Las Vegas, NV, USA. Piscataway, NJ: IEEE; 2014. p. 296–297. doi:https://doi.org/10.1109/ICCE.2014.6776012.
T. Hassan, F. Javed, N. Arshad, An empirical investigation of V-I trajectory based load signatures for non-intrusive load monitoring. IEEE Transactions on Smart Grid. 5, 870–878 (2014). https://doi.org/10.1109/TSG.2013.2271282
Bilski P, Winiecki W. The rule-based method for the non-intrusive electrical appliances identification. In: 2015 IEEE 8th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS); Warsaw, Poland. Piscataway, NJ: IEEE; 2015. p. 220–225. doi:https://doi.org/10.1109/IDAACS.2015.7340732.
Zhou Y, Zhai Q, Li X, Yang Y. A method for recognizing electrical appliances based on active load demand in a house/office environment. In: [Piscataway, NJ] and [Piscataway, NJ]: IEEE; 2017. p. 3584–3589. doi:10.1109/CAC.2017.8243403 .
S. Makonin, F. Popowich, L. Bartram, B. Gill, I.V. Bajic, editors. AMPds: a public dataset for load disaggregation and eco-feedback research; 2013.
Q. Wu, F. Wang, Concatenate convolutional neural networks for non-intrusive load monitoring across complex background. Energies. 12, 1572 (2019). https://doi.org/10.3390/en12081572
Barsim KS, Yang B. On the feasibility of generic deep disaggregation for single-load extraction; 2018/02/05.
Murray D, Stankovic L, Stankovic V, Lulic S, Sladojevic S. Transferability of neural network approaches for low-rate energy disaggregation. In: ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); Brighton, United Kingdom: IEEE; 2019. p. 8330–8334. doi:https://doi.org/10.1109/ICASSP.2019.8682486.
He W, Chai Y. An empirical study on energy disaggregation via deep learning. In: 2016 2nd International Conference on Artificial Intelligence and Industrial Engineering (AIIE 2016); Beijing, China. Paris, France: Atlantis Press; 2016. doi:https://doi.org/10.2991/aiie-16.2016.77.
İ. ÇAVDAR, V. FARYAD, New design of a supervised energy disaggregation model based on the deep neural network for a smart grid. Energies. 12, 1217 (2019). https://doi.org/10.3390/en12071217
Mauch L, Yang B. A new approach for supervised power disaggregation by using a deep recurrent LSTM network. In: Piscataway, NJ and Piscataway, NJ: IEEE; 2015. p. 63–67. doi:https://doi.org/10.1109/GlobalSIP.2015.7418157.
F.C.C. Garcia, C.M.C. Creayla, E.Q.B. Macabebe, Development of an intelligent system for smart home energy disaggregation using stacked denoising autoencoders. Procedia Computer Science. 105, 248–255 (2017). https://doi.org/10.1016/j.procs.2017.01.218
A. Rahimpour, H. Qi, D. Fugate, T. Kuruganti, Non-intrusive energy disaggregation using non-negative matrix factorization with sum-to-k constraint. IEEE Transactions on Power Systems. 32, 4430–4441 (2017). https://doi.org/10.1109/TPWRS.2017.2660246
Makonin S, Bajic IV, Popowich F. Efficient sparse matrix processing for nonintrusive load monitoring (NILM). Makonin 2014 EfficientSM.
Pathak N, Roy N, Biswas A. Iterative signal separation assisted energy disaggregation. In: Piscataway, NJ: IEEE; 2015. p. 1–8. doi:https://doi.org/10.1109/IGCC.2015.7393701.
Gisler C, Ridi A, Zufferey D, Khaled OA, Hennebert J. Appliance consumption signature database and recognition test protocols. In: Piscataway, NJ: IEEE; 2013. p. 336–341. doi:https://doi.org/10.1109/WoSSPA.2013.6602387.
Meziane MN, Abed-Meraim K. Modeling and estimation of transient current signals. In: 2015 23rd European Signal Processing Conference (EUSIPCO); Nice. [Piscataway, New Jersey]; 2015. p. 1960–1964. doi:10.1109/EUSIPCO.2015.7362726.
Zhu Y, Lu S. Load profile disaggregation by blind source separation: a wavelets-assisted independent component analysis approach. In: Piscataway, NJ and Piscataway, NJ: IEEE; 2014. p. 1–5. doi:https://doi.org/10.1109/PESGM.2014.6938947.
H.-H. Chang, K.-L. Lian, Y.-C. Su, W.-J. Lee, Power-spectrum-based wavelet transform for nonintrusive demand monitoring and load identification. IEEE Transactions on Industry Applications. 50, 2081–2089 (2014). https://doi.org/10.1109/TIA.2013.2283318
H.-H. Chang, Non-intrusive demand monitoring and load identification for energy management systems based on transient feature analyses. Energies. 5, 4569–4589 (2012). https://doi.org/10.3390/en5114569
Y. Li, Z. Peng, J. Huang, Z. Zhang, J.H. Son, Energy disaggregation via hierarchical factorial HMM (2014)
W. Wichakool, Z. Remscrim, U.A. Orji, S.B. Leeb, Smart metering of variable power loads. IEEE Transactions on Smart Grid. 6, 189–198 (2015). https://doi.org/10.1109/TSG.2014.2352648
S.R. Shaw, C.R. Laughman, A Kalman-filter spectral envelope preprocessor. IEEE Transactions on Instrumentation and Measurement. 56, 2010–2017 (2007). https://doi.org/10.1109/TIM.2007.904475
Y. Liu, G. Geng, S. Gao, W. Xu, Non-intrusive energy use monitoring for a group of electrical appliances. IEEE Transactions on Smart Grid. 9, 3801–3810 (2018). https://doi.org/10.1109/TSG.2016.2643700
A. Cominola, M. Giuliani, D. Piga, A. Castelletti, A.E. Rizzoli, A hybrid signature-based iterative disaggregation algorithm for non-intrusive load monitoring. Applied Energy. 185, 331–344 (2017). https://doi.org/10.1016/j.apenergy.2016.10.040
van Cutsem O, Lilis G, Kayal M. Automatic multi-state load profile identification with application to energy disaggregation. In: [Piscataway, NJ] and [Piscataway, NJ]: IEEE; 2017. p. 1–8. doi:10.1109/ETFA.2017.8247684 .
A. Marchiori, D. Hakkarinen, Q. Han, L. Earle, Circuit-level load monitoring for household energy management. IEEE Pervasive Computing. 10, 40–48 (2011). https://doi.org/10.1109/MPRV.2010.72
M. Figueiredo, A. de Almeida, B. Ribeiro, Home electrical signal disaggregation for non-intrusive load monitoring (NILM) systems. Neurocomputing. 96, 66–73 (2012). https://doi.org/10.1016/j.neucom.2011.10.037
Jin Y, Tebekaemi E, Berges M, Soibelman L. Robust adaptive event detection in non-intrusive load monitoring for energy aware smart facilities. In: Staff I, editor. [Place of publication not identified]: IEEE; 2011. p. 4340–4343. doi:10.1109/ICASSP.2011.5947314 .
Kaselimi M, Doulamis N, Doulamis A, Voulodimos A, Protopapadakis E. Bayesian-optimized bidirectional LSTM regression model for non-intrusive load monitoring. In: ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); Brighton, United Kingdom: IEEE; 2019. p. 2747–2751. doi:https://doi.org/10.1109/ICASSP.2019.8683110.
P. Vrablecová, A. Bou Ezzeddine, V. Rozinajová, S. Šárik, A.K. Sangaiah, Smart grid load forecasting using online support vector regression. Computers & Electrical Engineering. 65, 102–117 (2018). https://doi.org/10.1016/j.compeleceng.2017.07.006
Beckel C, Kleiminger W, Cicchetti R, Staake T, Santini S. The ECO data set and the performance of non-intrusive load monitoring algorithms. In: Srivastava M, editor. New York: ACM; 2014. p. 80–89. doi:https://doi.org/10.1145/2674061.2674064.
Kolter JZ, Johnson MJ, editors. REDD: a public data set for energy disaggregation research; 2011.
Batra N, Gulati M, Singh A, Srivastava MB. It’s different. In: Unknown, editor. the 5th ACM Workshop; Roma, Italy. New York, NY: ACM; 2013. p. 1–8. doi:https://doi.org/10.1145/2528282.2528293.
H. Wang, W. Yang, An iterative load disaggregation approach based on appliance consumption pattern. Applied Sciences. 8, 542 (2018). https://doi.org/10.3390/app8040542
S.M. Tabatabaei, S. Dick, W. Xu, Toward non-intrusive load monitoring via multi-label classification. IEEE Transactions on Smart Grid. 8, 26–40 (2017). https://doi.org/10.1109/TSG.2016.2584581
S.R. Shaw, S.B. Leeb, L.K. Norford, R.W. Cox, Nonintrusive load monitoring and diagnostics in power systems. IEEE Transactions on Instrumentation and Measurement. 57, 1445–1454 (2008). https://doi.org/10.1109/TIM.2008.917179
A. Zoha, A. Gluhak, M.A. Imran, S. Rajasegarar, Non-intrusive load monitoring approaches for disaggregated energy sensing: a survey. Sensors (Basel, Switzerland) 12, 16838–16866 (2012). https://doi.org/10.3390/s121216838
M. Gaur, A. Majumdar, Disaggregating transform learning for non-intrusive load monitoring. IEEE Access. 6, 46256–46265 (2018). https://doi.org/10.1109/ACCESS.2018.2850707
Batra N, Kelly J, Parson O, Dutta H, Knottenbelt W, Rogers A, et al. NILMTK. In: Crowcroft J, Penty R, Le Boudex J-Y, Shenoy P, editors. New York, New York, USA: ACM Press; 2014. p. 265–276. doi:https://doi.org/10.1145/2602044.2602051.
Welikala S, Dinesh C, Ekanayake MPB, Godaliyadda RI, Ekanayake J. A real-time non-intrusive load monitoring system. In: [Piscataway, NJ]: IEEE; 2016. p. 850–855. doi:10.1109/ICIINFS.2016.8263057 .
S. Makonin, F. Popowich, I.V. Bajic, B. Gill, L. Bartram, Exploiting HMM sparsity to perform online real-time nonintrusive load monitoring. IEEE Transactions on Smart Grid. 7, 2575–2585 (2016). https://doi.org/10.1109/TSG.2015.2494592
K. Chen, Q. Wang, Z. He, K. Chen, J. Hu, J. He, Convolutional sequence to sequence non-intrusive load monitoring (2018)
D. Piga, A. Cominola, M. Giuliani, A. Castelletti, A.E. Rizzoli, Sparse optimization for automated energy end use disaggregation. IEEE Transactions on Control Systems Technology. 24, 1044–1051 (2016). https://doi.org/10.1109/TCST.2015.2476777
D. Egarter, V.P. Bhuvana, W. Elmenreich, PALDi: online load disaggregation via particle filtering. IEEE Transactions on Instrumentation and Measurement. 64, 467–477 (2015). https://doi.org/10.1109/TIM.2014.2344373
L. Pereira, N. Nunes, Performance evaluation in non-intrusive load monitoring: datasets, metrics, and tools-a review. Wiley Interdisciplinary Reviews: data mining and knowledge discovery. 8, e1265 (2018). https://doi.org/10.1002/widm.1265
K. Basu, V. Debusschere, S. Bacha, U. Maulik, S. Bondyopadhyay, Nonintrusive load monitoring: a temporal multilabel classification approach. IEEE Trans. Ind. Inf. 11, 262–270 (2015). https://doi.org/10.1109/TII.2014.2361288
S. Welikala, C. Dinesh, M.P.B. Ekanayake, R.I. Godaliyadda, J. Ekanayake, Incorporating appliance usage patterns for non-intrusive load monitoring and load forecasting. IEEE Transactions on Smart Grid. 10, 448–461 (2019). https://doi.org/10.1109/TSG.2017.2743760
Elhamifar E, Sastry S. Energy disaggregation via learning ‘powerlets’ and sparse coding. In: Proceeding AAAI’15 Proceedings of the Twenty-Ninth AAAI Conference on Artificial. Pages 629-635.
B. Zhao, K. He, L. Stankovic, V. Stankovic, Improving event-based non-intrusive load monitoring using graph signal processing. IEEE Access. 6, 53944–53959 (2018). https://doi.org/10.1109/ACCESS.2018.2871343
J. Zico Kolter, Siddarth Batra, Andrew Ng, editor. Energy disaggregation via discriminative sparse coding; 2010.
V. Stankovic, J. Liao, L. Stankovic, A graph-based signal processing approach for low-rate energy disaggregation. In: 2014 IEEE Symposium on Computational Intelligence for Engineering Solutions (CIES), Orlando, FL. 2014. p. 81–87. https://doi.org/10.1109/CIES.2014.7011835.
S. Singh, A. Majumdar, Deep sparse coding for non-intrusive load monitoring. IEEE Transactions on Smart Grid. 1 (2017). https://doi.org/10.1109/TSG.2017.2666220
Acknowledgements
This work was partially supported by the UA Doctoral Training Alliance (https://www.unialliance.ac.uk/) for Energy in the UK.
Funding
This work was partially funded by the UA Doctoral Training Alliance (https://www.unialliance.ac.uk/) for Energy in the UK.
Author information
Authors and Affiliations
Contributions
PAS and IM developed the methodology. PAS carried out the simulations. All authors prepared, read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable
Consent for publication
Not applicable
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Schirmer, P.A., Mporas, I. & Sheikh-Akbari, A. Robust energy disaggregation using appliance-specific temporal contextual information. EURASIP J. Adv. Signal Process. 2020, 3 (2020). https://doi.org/10.1186/s13634-020-0664-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-020-0664-y