
Abstract
In this paper, we explore, extend and simplify the localization of the description ability of the well-established MPEG-7 (Scalable Colour Descriptor (SCD), Colour Layout Descriptor (CLD) and Edge Histogram Descriptor (EHD)) and MPEG-7-like (Color and Edge Directivity Descriptor (CEDD)) global descriptors, which we call the SIMPLE family of descriptors. Sixteen novel descriptors are introduced that utilize four different sampling strategies for the extraction of image patches to be used as points of interest. Designing with focused attention for content-based image retrieval tasks, we investigate, analyse and propose the preferred process for the definition of the parameters involved (point detection, description, codebook sizes and descriptors’ weighting strategies). The experimental results conducted on four different image collections reveal an astonishing boost in the retrieval performance of the proposed descriptors compared to their performance in their original global form. Furthermore, they manage to outperform common SIFT- and SURF-based approaches while they perform comparably, if not better, against recent state-of-the-art methods that base their success on much more complex data manipulation.
Similar content being viewed by others
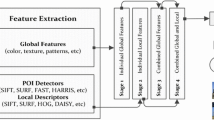

1 Introduction
Extracting a meaningful descriptor from an image is a central problem for a variety of computer vision problems. Depending on the application, a successful vectorization of an image’s depictions can be utilized to solve matching or correspondence problems. However, the design strategy of a description mechanism for problems like classification, object recognition or tracking must be adjusted accordingly. The impact of factors such as the kind of features employed, computational complexity, storing requirements and scalability can vary significantly in different computer vision domains.
In this paper, we are interested in exploring the combination of features that best describe an image with respect to its visual properties and its visual content, specifically focusing on content-based image retrieval (CBIR) tasks. When designing descriptors for CBIR, one must take into account the ever-growing data involved in the process. Image collections are growing exponentially in a variety of domains (medicine, private life, industry, journalism, tourism, etc.), making the need for an effective and yet efficient retrieval system imperative.
However, trying to define what makes a useful and meaningful retrieval for the user remains still unsolved and is most likely not an engineering problem. Different benchmarking datasets try to cover various retrieval scenarios with diverse types of images and different levels of semantics in query to result in relevance interpretation. The complexity of the problem is evident just by thumbing through the great variety of proposed implementations that address the issue [1–8].
Briefly making a historical overview, the first attempts to vectorize image contents proposed by extracting global image features such as colour, texture and shapes that are calculated over the entire image. The foremost advantage of extracting global features is the low cost of the single-feature space computations. Moreover, a global vector representation is a very effective strategy for certain retrieval tasks, for instance, trying to classify natural-scene-depicting images, where a number of blue uniform patches that are part of a lake are equally important as highly textured parts depicting leafage. Annotating an image solely by a global feature vector, however, often leads to a rather generalized outline of its visual information.
As collections and retrieval scenarios became more demanding, global feature methods were overshadowed and often also outperformed by methods that employed local features (LF). Among the most popular points of interest (POI) detectors are corner detectors Harris, Shi-Tomasi and FAST (Features from accelerated segment test) [9–11] and blob detectors Scale-invariant feature transform (SIFT) [12] and Speeded Up Robust Features (SURF) [13], to name a few. Using POIs, the representation of the image is mapped into a high-dimensional local feature space. In applications like Simultaneous Localization and Mapping (visual SLAM [14]), panorama construction, object recognition and tracking, these extracted POIs are used directly to find one-to-one matches between depictions. In CBIR, however, direct usage is impractical even with today’s available computational resources. Typically, hundreds or even thousands of LF are extracted per image. To reduce memory cost and speed up image matching, the features are quantized through some aggregation procedure.
A widely and extensively used approach is the Bag-of-Visual-Words (BOVW) model which originated from the document retrieval field. Because of its simplicity, flexibility, and effectiveness, it has been adopted in various applications such as video classification, 3D shape categorization and image retrieval [15–17]. The BOVW model first constructs a codebook using a clustering algorithm over all detected LF in an image collection. Each cluster represents a visual word while the total number of clusters is typically predefined. Then, an image is represented as a histogram of the visual words, and each bin of the histogram is weighted with a term frequency-inverse document frequency (tf-idf) score or its variants. The aggregation model manages to achieve a vast reduction of the high dimensionality that LF introduce but simultaneously burdens the implementation with a number of free parameters such as predicting the appropriate codebook size and the preferred weighting strategy.
Of course, this type of feature quantization introduces the respective loss of the discriminative ability of the features. Thus, over the years, numerous improvements and alternatives have been proposed. The soft quantization and soft assignment techniques proposed in [18] and [19], respectively, reduce the quantization error of the original BOVW model, paying a price in terms of memory overload and higher searching time. Alternatively, the Fisher vector [20] uses the Gaussian mixture model to train the codebook and quantizes the features by calculating the probability of a feature falling into the Gaussian mixture. Different approaches like Hamming embedding [21] improve the model by generating binary signatures coupling visual words and thus providing additional information to filter false positives. Recently, an alternative to the BOVW model, the Vector of Locally Aggregated Descriptors (VLAD) [22] has gained the community’s attention. Given a codebook, instead of creating a vector of frequencies, the VLAD model creates a vector of differences, as distances, between a feature and the cluster’s centre. VLAD manages to speed up the aggregation step but leads to high-dimensional vector representations per image, which can affect the scalability of a method. Finally, authors in [23] focus on a multilayer deep learning architecture to represent high-level features in an effective compact manner, while [24–26] emphasize the need for domain-adaptive dictionary learning and the benefits of effectively fusing multiple information sources.
Acknowledging the fact that there will probably never be a solution that fits all, we are interested in exploring the benefits of revisiting, reusing and combining strategies proposed from both global feature and local feature approaches, seen under the light and understanding of nowadays knowledge. In this paper, we propose 16 novel local feature descriptors that adapt on the hybrid approach first introduced in [27], named SIMPLE. In its essence, the SIMPLE scheme suggests a framework that localizes the description mechanism of older well-established global descriptors. Originally, the SIMPLE features were a combination of the SURF detector, used to sample textured image patches in multiple scales, and the MPEG-7 (Scalable Colour Descriptor (SCD), Colour Layout Descriptor (CLD) and Edge Histogram Descriptor (EHD)) [28] and the MPEG-7-like (Color and Edge Directivity Descriptor (CEDD)) [29, 30] global descriptors, used for describing the patches. One of the key elements of the scheme is that it allows for indirect combination of texture and colour information, eliminating the need for complicated fusion techniques. Finally, having conducted over 2000 experiments for this work, we put all the obtained data to good use and statistically analyse the impact that the varying BOVW set-ups have on the robustness of the retrieval performance.
2 Related work
The MPEG-7 family of global descriptors has been widely studied and referenced in the literature. The compact and effective representation of images that they provide has introduced a great number of improved techniques that build upon the original standard. Here, we will focus on attempts that propose their utilization combined with additional local information of some kind.
The fusion of various low-level MPEG-7 descriptors is proposed in [31] for content-based image classification. A ‘merging’ fusion combined with a support vector machine (SVM) classifier, a back-propagation fusion with a KNN classifier and a Fuzzy-ART neurofuzzy network strategy are explored, which can be extended in matching the segments of an image with predefined object models. The fusion (baseline fusion and score fusion) of MPEG-7, SIFT and SURF is also explored and evaluated in [32] to address content-based event search. The detailed results conclude that the MPEG-7, SIFT and SURF are broadly comparable and also highly complementary. In [33], a classification-driven similarity matching is presented and evaluated for the biomedical image domain. Various low-level global colour-, edge- and texture-related features are extracted (CLD, EHD, CEDD, FCTH [34]) and utilized along with a visual concept feature [35] extracted using the ‘bag of concepts’ model (that is comprised of local colour and texture patches), thus achieving the generation of feature vectors in different levels of abstraction.
Authors in [36] present a grid-based framework for image retrieval where the images are partitioned into blocks. Localized feature representations employing the MPEG-7, HS and the HSV colour histogram descriptor [28] are extracted and achieve better results compared to global techniques. In [37], authors index a collection of images combining local and global features. The method extracts SURF local features and five MPEG-7 descriptors (CS, CL, SC, HT, EH) as global features. Each image is associated with six text fields, one corresponding to the bag of features obtained from the SURF descriptor and five surrogate text representations, one for each MPEG-7 descriptor. These segments form the basic units on which search is performed. Finally, authors in [38] use cluster correlograms to combine MPEG-7 descriptors with spatial information, for image categorization. They employ fixed partitioning and salient point schemes to extract image patches and use four MPEG-7 descriptors to represent them. Similar patterns are aggregated into a cluster codebook. A correlogram is then constructed from the spatial relations between visual keyword indices in an image, in order to obtain high-level information about the relational context. Four 2D signatures (one for each MPEG-7 descriptor) are assigned per image, which leads to a feature dimension of 4m 2, where m is the number of clusters used in the clustering algorithm.
Overall, the most commonly followed strategy to combine global and local information usually relies on some late fusion method that severely slows down the retrieval process. Fixed partitioning of images and region-based image segmentation are also presented, but when applied, they not only add a new level of complexity but also tend to suffer in domain-specific tasks, where background information and foreground are not easily dissociated. Our proposed implementation of localized MPEG-7 descriptors is designed around the fact that CBIR tasks employ a large number of images for indexing and retrieval. Thus, efficiency, low complexity and compactness of the final representation are of great importance.
3 Extending the SIMPLE family of descriptors
The SIMPLE family of descriptors proposed in [27] is a combination of the SURF local-points detector and three of the global MPEG-7 descriptors along with the MPEG-7-like global CEDD descriptor to produce new local features specifically designed for CBIR. The SURF detector is employed to locate and extract salient image patches, whose size is determined as a squared area (s×s) according to the scale (S) that the points were detected in. The method proceeds by applying the aforementioned global descriptors on the detected patches, as if they were stand-alone images. This results in four different kinds of local features that were tested for CBIR using the BOVW model. In this paper, we are interested not only in exploring different combinations of detectors and descriptors, but also in analysing the results so as to gain a deeper understanding of the preferred attributes to incorporate in a CBIR scheme, according to the application’s and the user’s requirements.
3.1 The image datasets
The employed dataset is one of the most important factors when building a CBIR system. Even the most successful implementations reported cannot guarantee high performance for any kind of datasets. In an effort to draw useful conclusions concerning the preferred type of point detection and description mechanisms in a generalized manner and simultaneously minimize the case that good achieved performances might have to do with specificities of the database, we decided to employ four diverse kinds of datasets.
The UKBench image database [39] consists of 10,200 images, separated in 2250 groups of four images each. Each group includes images of a single object placed in the centre of the image, captured from different viewpoints and lighting conditions. This dataset represents a much requested retrieval scenario in real-life applications for industrial and commercial purposes. The collection presents high in-class variability, and the information concerning localized aspects of the images’ content is of great importance. Thus, local features are reported to perform better in this collection than global descriptors do.
The UCIDimage collection [40] consists of 1338 images on a variety of topics including natural scenes and man-made objects, both indoors and outdoors. All the UCID images were subjected to manual relevance assessments against 262 selected images. UCID includes several query images where the ground truth consists of images with a similar visual concept to the query image, without necessarily the co-occurrence of the same objects. In contrast to the UKBench dataset, the visual content of the images that form this database favours the performance of the global descriptors [41].
The INRIA Holidays dataset [21] consists of 1491 photos, depicting a variety of natural and man-made scenes, captured mainly during personal holidays. The challenges that a retrieval system has to deal with are rotations, viewpoint and illumination changes, blurring, etc. The Holidays dataset is accompanied by a ground truth for 500 queries along with the images that represent the same scene for each one of them.
Finally, the Zurich Building Database (ZuBuD) [42] consists of two separate parts. Two hundred one buildings were captured from five different viewpoints each, forming a dataset of 1005 images of Zurich’s city building. The queries’ part contains 115 additional images of lower resolution, depicting some of the buildings of the main dataset captured from a different viewpoint and sometimes under different weather conditions. For each query, only the images that represent the same building are considered relevant.
For readability purposes, we focus and provide analytic experimental results on the first two datasets (UKBench and UCID) and proceed with the presentation and comments for the rest of the employed collections in a more condensed form.
3.2 Detecting points of interest
Four different points-of-interest detection mechanisms were explored in this paper. In all cases, the objective is to extract square image regions, hereinafter referred to as image patches. During the detection stage, we are only interested in locating the position (x, y) of the centres of the image patches and deciding their size. Their description will be handled in a subsequent step, utilizing descriptors formerly used in global feature techniques.
-
First, we employed the SURF detector. The SURF detector uses the determinant of the Hessian to detect both the location and the scale of blob-like structures. The Hessian matrix is approximated, using a set of box-type filters. The scale space is analysed by upscaling the filter size rather than iteratively reducing the image size. Independently of their size, these approximate second-order Gaussian derivatives are evaluated using integral images, significantly speeding up the whole process. The responses are stored in a blob response map, and local maxima are detected and refined using quadratic interpolation.
-
The second detector we employed was the SIFT detector. The key points are searched in a scale space by applying the difference of the Gaussian function and locating the maxima and the minima to a series of re-sampled and smoothed images. We define our image patches’ size (s×s) according to the scale (S) they were detected.
The first two detectors both focus and locate blob-like structures in images. This means that the obtained patches will contain interesting achromatic information. Even if we do not proceed and describe this achromatic information, but instead focus on the colour information contained in the patches, we still achieve to indirectly combine texture and colour information. We are describing colour information with textural attention, i.e. apply a colour descriptor on image regions where something interesting is happening texture-wise. We used the SIFT and SURF emguCV detector implementations, following the default parameter initializations.
However, CBIR tasks are not always oriented towards object recognition and direct matching. Some applications request retrieval results to be similar in a more conceptual fashion. Image regions that may not carry textural information should still be vectorized. For instance, blue, uniform patches of images depicting the sky or sea could boost the retrieval performance of a system that is ranking landscape images to a provided query. Thus, inspired by the principle that global feature CBIR systems are designed around, we implemented and tested two more detectors: a uniform, random, multiscale image patch generator and a random patch extractor where the selection of the centres (x, y) of the patches follow the Gaussian distribution.
-
The Random patch generator, as its name implies, randomly selects x and y positions in the images to mark square regions of pixels. The probability of the selection, both for x and y, follows the uniform distribution (for a visual, kindly refer to Fig. 1, third column). The sizes of the regions were decided as follows: the smallest patch size (hereinafter referred to as reference patch, RP) was set to 40×40 pixels, so as to be aligned with the highest patch size limitation, which is introduced by the CEDD descriptor (kindly refer to the next section). From there, we employ a scaling factor (sf) to produce larger patches of sizes RP∗sf×RP∗sf pixels. More details about the sf and the total number of patches in this implementation can be found in the ‘Experimental set-ups’ section.
Fig. 1 
Sampling distributions of the four employed methods: the first two rows are example images taken from UCID, and the third row shows the accumulative distribution over all images on UCID
-
The GaussRandom patch generator operates as the Random generator presented above, only this time, the probability of the selection of an x and the selection of a y follows two separate univariate Gaussian distributions with the mean values set at the centre of the x and y range, respectively. This means that the x,y centres are more densely sampled in the centre of the image and become gradually sparser as we move to the outer parts of the image (for a visual, kindly refer to Fig. 1, fourth column). The standard deviation (σ) is automatically adapting to the image dimensions of each dataset so that a 2σ standard deviation includes 95.5 % of the samples, while a 3σ covers 99.7 %. If for instance the image has a 400×600 resolution, the first Gaussian will have a mean value\(~=\frac {400}{2}\) and a \(\sigma =\frac {400}{6}\), while respectively the second Gaussian has a mean value\(~=\frac {600}{2}\) and a \(\sigma =\frac {600}{6}\).
We employed this type of sampling driven by the fact that, usually, the main theme of the image or the dominant objects, both in queries and collections, is the centred depictions.

3.3 The global descriptors employed to be localized
Four different global descriptors from the literature were selected to be localized. Three of them originate from the MPEG-7 family of global descriptors (SCD, CLD and EHD) [28], and the fourth global descriptor (CEDD) originally presented in [29] is an MPEG-7-like descriptor, in the sense that its implementation principles are strongly inspired by the MPEG-7 standard.
We proceed focusing on the specific attributes of each method that differentiate the experimental set-ups and will allow us to get some insight into what type of descriptors are best suited for CBIR, under different circumstances. All the selected descriptors were preferred because they are well established, widely accepted, easy to implement and, most importantly, represent the images’ features in a compact and quantized manner. Since we are particularly interested in evaluating local features for CBIR, it is intuitive that compactness of the vectors and quantized local feature representations are imperative.
Image collections can vary from a few thousands to millions of images. Thus, the more compact the descriptor, the more likely it is for the retrieval system to be able to manage great amounts of data on limited computational resources. Furthermore, the scope of an image retrieval-oriented local descriptor is to provide small vector distances for visually similar patches. Approaches in the literature, however, utilize local features that were originally developed for different tasks. The goal of a local feature intended, for instance, Simultaneous Localization and Mapping (SLAM) or panorama construction, is to describe each point of interest as uniquely and detailed as possible so as to achieve a one-to-one matching of points in different images. Retrieval systems that employ such local features are often forced to fail due to many possible matching candidates whose vector distance is not apparent.
On the other hand, quantizing features means that image properties (like detected colours or edges) are categorized in a preset number of explicitly defined possible variations. When employing such features to describe the image, we get a more abstract image signature. This abstract representation allows for faster and safer comparisons of similarities between images. Especially in CBIR tasks, where the objective is not to find the one and only similar image but a set of k top correctly retrieved results, this discrete domain of features minimizes classification errors [43].
Taking into account that colour is a very important element for image retrieval tasks [3, 29, 38, 41], we begin our description of the detected patches employing two MPEG-7 colour descriptors.
-
The Scalable Colour Descriptor (SCD) [28] is essentially a colour histogram in a fixed HSV colour space, achieved through a uniform quantization of the space. A total of 256 coefficients is used to represent the descriptor. Since it is a histogram, it is rotation and transformation invariant. Moreover, due to the quantization of the colour space, SCD presents good tolerance to change of lighting conditions and hue variations.
-
The Colour Layout Descriptor (CLD) [28] represents the spatial distribution of the colour in images. In order to incorporate the spatial relationship, each image patch needs to be divided into 8×8 discrete blocks. Any image patches too small for this type of division are ignored in our implementation, as if they were never detected. This descriptor quantizes the space domain, allowing some slight shifts and rotations to be flattened and also presents good tolerance to changes in lighting conditions and hue variations because it represents each block by calculating the dominant colour, thus indirectly quantizing the colour space as well.
Next, we employ an edge descriptor and a descriptor that combines both texture and colour information so as to widen the spectrum of tested approaches and gain a generalized outlook on local features and their retrieval effectiveness.
-
The Edge Histogram Descriptor (EHD) [28] represents the spatial distribution of five types of edges in the image. A given image patch is subdivided into 4×4 sub-image patches, and a local edge histogram is computed. Again, in our implementation, any image patch that is too small to undergo such a division is ignored as though never detected. This descriptor quantizes the edge information into five broadly grouped edge types that vary with intervals of 45°, resulting in features that present commensurate rotation invariance.
-
The Color and Edge Directivity Descriptor (CEDD) [29] utilizes both colour and edge information in a compact, quantized manner. The original CEDD implementation demands a division of the image patch into 40×40 blocks of at least 2×2 pixels each. However, the latest version of CEDD1 adapts to the description of smaller sized images and according to the image’s size in question, and defines a minimum of 20×20 block division of at least 2×2 pixels each. For the edge information extraction, it adopts the five filters presented in the MPEG-7 EHD descriptor along with an additional non-Edge filter and it introduces a heuristic pentagon diagram to classify each block into one or more edge types. The colour information is represented by a 24-bin colour histogram where each bin corresponds to a preset colour. This descriptor, just as the EHD, presents rotation invariance of 45°, and due to the quantized colour space that it uses, it presents also tolerance to change in lighting conditions and hue variations.
4 Utilizing the SIMPLE local features in a CBIR system
By combining the four different detection mechanisms and localizing the description ability of the four global descriptors presented in the previous section, we produced four sets of local features using the SURF detector (SIMPLE srf-SCD, srf-CLD, srf-EHD, srf-CEDD), the SIFT detector (SIMLE sft-SCD, sft-CLD, sft-EHD, sft-CEDD), the Random detector (SIMPLE rnd-SCD, rnd-CLD, rnd-EHD, rndŰCEDD) and the Gaussian Random detector (SIMPLE gaussRnd-SCD, gaussRnd-CLD, gaussRnd-EHD, gaussRnd-CEDD). In order to test them in CBIR tasks, we employed the Bag-of-Visual-Words (BOVW) model to calculate vector image representations and went on calculating eight weighted equivalents of those vectors by applying an equal number of weighting schemes.
Please note that we deliberately chose to employ the simplest form of the model and not any of the improvements that have been recently proposed in the literature because our goal is to calculate the performance of the local features and their ability to capture the images’ contents. The proposed local features can be employed for CBIR using any other retrieval system framework, but this exceeds the scope of this paper.
4.1 The Bag-of-Visual-Words model
The BOVW model uses an unsorted set of discrete visual words (VW) to represent the contents of an image. It is directly inspired by the Bag-of-Words (BOW) model, which was first introduced for text classification. In our implementation, when all SIMPLE local features have been detected in a collection of images, we randomly select a sample to be clustered via the k-means classifier into a preset number of clusters (visual words) so as to form the codebook. Each image from the collection is then represented by a histogram of the frequencies of the visual words that it contains. When a query is set to the system, its features are also extracted and matched to the VWs of the codebook and the VW histogram is calculated. This is the simplest form of the BOVW model.
4.2 The weighting schemes
We incorporate the common textual term weighting schemes in the BOVW model. The first weighting factor is the raw term frequency (tf t,d ) where a weight is assigned to every term (t) in the codebook according to the number of occurrences in a document (d). A second factor for assigning weights is the document frequency (df t ). This time, df t is defined as the number of documents that contain the term t. Many times, the inverse document frequency idf t = log(N/df t ) of a collection is used to determine weights, where N is the total number of documents in the collection. In our case, ‘term’ equals ‘visual word’, and ‘document’ equals ‘image’. Last, a normalization can be performed to quantify the similarity between two documents in terms of the cosine similarity of their vector representation.
The System for the Mechanical Analysis and Retrieval of Text (SMART) notation is a compact way to describe combinations of weighting schemes in the form of (d.d.d). The first letter denotes the tf weighting method, the second letter denotes the df weighting method, and the third letter specifies the normalization used. Table 1 presents the SMART notation for several tf.idf variants. For more details concerning the weighting scheme adoption, kindly refer to [41].
In our implementation, after generating the VW histogram for every image (collection and query) through the BOVW model, the vectors are recalculated using the eight weighting schemes (kindly refer to Table 1).
5 Experimental set-ups
5.1 Sampling parameters
The SIFT detector produces on average 1000 patches of interest per image on the UKBench collection, 1400 on the UCID collection, 1000 on Holidays and 1600 on ZuBuD. Respectively, SURF detects on average 600 patches on the UKBench, 800 on the UCID collection, 650 on Holidays and 1850 on ZuBuD, per image. However, the usability of the patches is determined by their size due to the limitation that the description methods introduce. The percentage of unusable patches cannot be foreseen since it depends on the image collections involved. Through our tests, we found that statistically about 20 % of SIFT points and about 10 % of SURF points are unusable for our implementations.
Another interesting observation made through our tests concerning the SIFT and SURF point detectors has to do with their distribution on the images. Since they are both blob detectors, the total number and the centres’ coordinates of the points vary significantly depending on the depiction. Uniform areas of the images are disregarded completely from these detectors. Thus, we had images with less than 100 points and others with more than 4000.
In the second and third columns of Fig. 1, we present scatter plots of the x,y centres for SIFT and SURF. The first two rows are example images from the UCID collection, while in the third row, the results report the accumulative points over the whole collection. In the first example (Eiffel tower), even though 1513 points are detected, almost no information will be considered from the upper half of the image (sky). This is a significant loss since the depicted landmark, being an outdoor location, is in most cases captured with this blue background. The loss of useful information is even more dramatic in our second example (a person running on the beach). Using the SIFT and the SURF points, we gain almost no information about the surroundings (brown uniform sand, green sea and blue sky).
Finally, when plotting the points detected over the whole collection, we see that spatially every possible x,y was picked as a point centre. What is more interesting is the distribution of those coordinates. In this multi-theme collection2, the x and y variables present no particular distribution pattern when examined per image, but when collectively studied, they clearly follow a Gaussian-like distribution.
The aforementioned findings and detected drawbacks inspired the two proposed random patch generators. As discussed earlier in the ‘Detecting points of interest’ section, this type of sampling allows us to utilize information from parts that would be disregarded from blob detectors. Furthermore, the constant number of samples per image (i) produces final vector representations that do not need normalization in order to be compared via a distance measure and (ii) can be pre-defined so as to be manageable depending on the available resources and the scale of the application.
For the two random sampling strategies, in order to maintain the order of magnitude suggested both from SIFT and SURF for the employed collections, we set the number of extracted patches to be a total of 600 per image (i.e. 150 samples per scale). Taking into account the highest size limitation introduced by CEDD, we define the minimum patch size to consist of 40×40 pixels. This will ensure that all image patches will be usable for description by all four of our employed description methods. Next, we scale the minimum/reference patch size by a scaling factor (sf) to produce different patch sizes. The upper patch size limit is related to the employed images. We did not want to produce image patches that would be greater than one third of the smallest image dimension. Thus, the greatest sf used was sf=3 resulting in 120×120 pixel image patches. Having an upper and a lower size limit allowed us to decide on further scaling factors for in-between patch sizes. The sf for both Rnd and GaussRnd generators were 1, 1.6, 2.3 and 3, and the respective patch sizes were 40×40, 64×64, 92×92 and 120×120.
5.2 BOVW parameters
Taking into consideration limitations in computational resources and desired efficiency, we set our four different codebook sizes to consist of 32, 128, 512 and 2048 VWs, respectively. The codebooks are generated by forwarding a random 10 % sample of the extracted features to a k-means classifier. We weight the histograms of VWs with eight weighting schemes and conduct the similarity search between query and dataset using the Euclidean distance measure.
5.3 Querying mode
For the evaluation of the features’ retrieval effectiveness, we employ four different image collections (UKBench, UCID, Holidays, ZuBuD) that vary both in theme and relevance interpretation so as to minimize the probability of good performances occurring due to collection specificities. Concerning the querying mode, for the UKBench collection, the first 250 images of the first 250 groups were used as queries. The ground truth consists of the four images belonging to the same group as the query. For the UCID collection, the first 262 images were used as queries. By design, all the UCID images were subjected to manual relevance assessments against 262 selected images, creating 693 ground truth image sets for performance evaluation. For the Holidays and the ZuBuD collections, we also followed the default querying mode, using the 500 and 115 query images that accompany the datasets, respectively.
5.4 Baseline formation and evaluation metrics
In order to ensure fair and direct comparison, we reimplemented and tested under the same retrieval set-ups five well-established local feature descriptors from the literature (SURF, SIFT, opponent-SIFT [5], ORB [44] and BRISK [45]3), and since our method is a combination of local POI detectors and global feature descriptors, we also conducted experiments for seven global descriptors (using the img(Rummager) [46] application and their default settings), including of course the original MPEG-7 SCD, CLD and EHD.4 To evaluate the systems’ performance, we calculate the mean average precision (MAP, max at 1) and the average normalized modified retrieval rank (ANMRR, max at 0). For the UKBench and the UCID collections, we also provide the precision-at-position (P@k, with k=4 for UKBench and k=10 for UCID, max at 1) [47] evaluations.
In each experiment, we assumed as baseline the best performance that can be obtained employing a non-SIMPLE descriptor of those we re-implemented. However, in order to allow the readers to compare and get a better perspective of the achieved performances, we also include state-of-the-art methods from the recent literature that propose improvements on various different aspects of a retrieval system.
6 Experimental results
In total, we performed 16SIMPLE×4Codebooks×8WS×4Collections=2048 experiments for the evaluation of the proposed local features. In this section, we will provide the evaluation of the retrieval performances of the proposed SIMPLE descriptors and discuss the impact of the weighting schemes. Please note that the experimental results will be focused on the first two datasets (UKBench and UCID) for readability reasons. A more condense presentation of the results is followed for the Holidays and ZuBuD collections. The experimental results and the drawn conclusions are in line for all four employed datasets.
We prepared separate tables of results for the tested non-SIMPLE and SIMPLE descriptors. Table 2 presents the performances evaluated using MAP of seven global feature (GF) and five local feature (LF) descriptors from the literature tested using four codebooks (2048, 512, 128, 32) all re-implemented and tested in the same retrieval system for fair comparison with the SIMPLE descriptors. The respective performance evaluations by P@4, P@10 and ANMRR can be found in [27].
Tested on the UKBench collection, the best performing non-SIMPLE descriptor with a MAP score of 0.8159 was the SURF LF descriptor with a codebook size of 512 VWs. This will be considered the ‘baseline’ UKBench result for further reference. On the UCID image collection, CEDD, a global descriptor (as expected, due to the nature of the depictions in this dataset), with a MAP score of 0.6748, will be the baseline performance for comparison with our SIMPLE descriptors.
Tables 3 and 4 summarize the experimental results of all 16 proposed SIMPLE descriptors on the UKBench and the UCID datasets, respectively. The tables consist of four sub-tables for the facilitation of the reader. Every sub-table shows the performance evaluations by MAP, P@k and ANMRR per detector used, for all four descriptors, in all four codebook sizes. The weighting scheme (WS) reported in the tables was the highest performance among the eight WS.
Results on UKBench. Overall, 10 out of the 16 proposed SIMPLE descriptors managed to surpass the baseline experiment in this collection. In all cases, the best performing combination involved the SCD description method. When detecting patches using the SIFT detector, and due to the percentage of non-usable patches, only SIMPLE sft-SCD (which uses a descriptor that does not introduce minimum patch size limitations) manages to present a performance improvement compared to the baseline. However, compared to their global equivalences, SIMPLE CEDD, SCD and CLD descriptors perform vastly better. A degradation in performance is reported for SIMPLE sft-EHD. This leads to the assumption that employing a detection mechanism that searches for interesting texture patches of one type, and then describes them with texture descriptors of another type, is an abortive attempt.
SIMPLE descriptors that employ the SURF detector perform significantly better than SIFT. SIMPLE srf-SCD and srf-CEDD 512, in particular, achieve an almost perfect retrieval score for all evaluation metrics. Please note that compared to their global equivalences, SIMPLE srf-(CEDD, SCD, CLD) perform comparably - if not better - even with a tiny codebook size of 32 VWs. SIMPLE msrf-EHD showed better results than the SIFT-based implementation but still did not manage to surpass the EHD-global performance, corroborating the aforementioned assumption concerning texture-based descriptors on texture-based detectors.
Impressive results were obtained employing the Rnd and GaussRnd patch generators. As reported in Table 3, we scored comparable performances to the SIMPLE SURF-based descriptors and, in many cases, even outperformed those results with both generators. However, the last two implementations (Rnd and GaussRnd) are additionally much more efficient and light-weighted, since they strip the respective computational overhead that the detectors (SIFT and SURF) introduce. An increase in the performance of the SIMPLE rnd/gaussRnd-EHD descriptor is achieved. For the first time, we managed to outperform the global-EHD score on the respective collection.
Results on UCID. On the UCID collection, 11 out of the 16 proposed SIMPLE descriptors outperform the baseline non-SIMPLE descriptor.
In all cases, CEDD is involved in the best performing SIMPLE combinations, except when employing SIFT. Again, when SIFT is involved, the high percentage of non-usable patch sizes leads to low performance scores for descriptors that introduce size limitations (CEDD has the highest limitation of minimum 40×40 pixel patches).
SURF-based, Rnd-based and GaussRnd-based sample strategies perform similarly, for all respective codebook sizes, when combined with CEDD, SCD or CLD. We would like to underline that in this collection, SIMPLE rnd/gaussRnd-EHD performances not only present an impressive increase, but also actually surpass the second-best non-SIMPLE descriptor (kindly refer to Table 2). This allows us to assume that the efficient SIMPLE rnd/gaussRnd-EHD descriptors would prove to be competitive choices for similar datasets, where no colour information is available.
Tables 5 and 6 present in a ranked manner, the % improvement of the metrics MAP, P@k and ANMRR that the proposed SIMPLE descriptors attained against the respective baseline non-SIMPLE descriptor. In order to keep the tables concise, we only included the top 10 SIMPLE descriptors that best the baseline results in both collections. On UKBench, 27 descriptors with varying codebooks surpassed the baseline MAP score of 0.8159. Nine of them managed to improve MAP by more than 12 %, P@4 by more than 15 % and ANMRR by an impressive more than 53 %. On UCID, 28 SIMPLE descriptors achieved a higher MAP evaluation compared to the respective baseline (CEDD global). The top six SIMPLE descriptors improved MAP by more than 15 %, P@10 by more than 13 % and ANMRR by more than 32 %.
Overall, the light-weighted and efficient combinations of rnd and gaussRnd detectors with SCD, CEDD and CLD descriptors dominated the top results for both collections. Concerning the random-patches techniques, please note that every time we tested a descriptor for a given codebook size, newly extracted random patches were generated. In other words, for the presented results in Tables 3 and 4 under ‘Rnd (600 samples)’, we generated 600 random patches 16 times. The same applies for the GaussRnd experiments as well. This strategy was chosen deliberately in order to test the robustness of the random-based implementations. However, we went on and further tested the robustness of these methods by repeating the SIMPLE rnd-SCD and gaussRnd-SCD experiment multiple times (five). The calculated standard deviations of the obtained MAP scores can be found in Table 7.
Studying the experimental results (Tables 3 and 4) and focusing on the two random sampling techniques, we can see that introducing the Gaussian distribution for the localization of the patches allows for better performances in almost all combinations, which is more evident as the codebook sizes shrink. Moreover, the results in Table 7 suggest that the gaussRnd generator is a more robust approach, especially when employing small codebook sizes. On a last note, we would like to comment that as for any detection method, the robustness of both rnd and gaussRnd generators is subject to the employed images. However, when employing the UKBench collection, where the images are background clutter-free centred depictions of objects, the gaussRnd generator which samples for patches more densely in image centres presents higher robustness compared to the rnd generator, whose standard deviation doubles as we move to smaller codebook sizes.
Finally, we experimented with lower numbers of generated samples for our SIMPLE descriptors that employ the rnd or gaussRnd patch generators. We tested for 300 samples and 100 samples for combinations of rnd and gaussRnd with CEDD, SCD and CLD of 512 VW codebooks, in both collections, evaluated by MAP. The experimental results that can be found in Table 8 show that even with half the samples, the performances are directly comparable to those achieved when extracting 600 samples for the respective descriptors and codebook. What is more interesting is that satisfying MAP evaluations are reported with as little as 100 image patches per image. However, we need to underline that these are early results that need to be extended for more combinations, codebook sizes and types of collections, in order to draw conclusive statements about appropriate sampling rates.
Wrapping up the results on the first two collections and in order to provide a wider perspective on the achieved retrieval performances, we collected some of the best reported MAP scores for those collections. For the UKBench, our best performing descriptor SIMPLE gaussRnd-SCD scored a 0.9254 MAP evaluation. Further methods from the literature implemented and tested under the same querying mode are SURF 16-VLAD with a MAP = 0.668 and SIFT 64-VLAD MAP = 0.804 [48], while some of the best reported methods on this collection are [19] with a MAP = 0.8780, [49] with a MAP = 0.9070 and [50] with MAP = 0.9170.
In UCID, the best performing SIMPLE descriptor (gaussRnd-CEDD) achieves a MAP score of 0.7955. SURF 64-VLAD has reportedly a MAP = 0.6441 score, SIFT 64-VLAD a MAP = 0.6933 [48] and Local- SIFT Global Search achieves a MAP = 0.625 evaluation [1].
Results on Holidays and ZuBud. Tables 9 and 10 present the experimental results of the SIMPLE descriptors and results from methods from the literature on the two collections, respectively. The Holidays collection consists of images with diverse depictions of scenery, landmarks, objects, etc. and presents rotation, viewpoint and illumination challenges. We could roughly say that it is a collection with characteristics that land in between those previously discussed datasets (UKBench and UCID). Again, the proposed descriptors achieve a great increase of the retrieval performance compared to the performances of the original methods they emerged from (Table 10: re-implemented). Furthermore, employing the random sampling strategies yield results that are directly comparable and often outperform some of the much more sophisticated and complex methods from recent literature (Table 10: reported in literature).
Finally, the ZuBuD collection which is depicting urban scenery uses query images of smaller resolution, forcing descriptors that are not scale invariant to fail by default. Thus, the former global descriptors gain significantly when localized through the SIMPLE scheme. Furthermore, in this collection due to the specifics of the depictions (buildings photographed up-close), the two POI detectors, SURF and SIFT, locate a much higher number of POIs compared to the other collections. However, even when dealing with images that present these repetitive patterns while also querying with smaller images, the random samplers preserve their robustness, which is now verified for all four collections.
6.1 Analysing the weighting schemes’ impact
When an image is processed by the BOVW model, a histogram of the VWs that it contains becomes its vector representation. This vector is weighted and normalized by the tf, df and normalization variants of the weighting schemes (WS).
The tf variant refers to the number of occurrences of a given VW in an image. Since the histogram calculated by BOVW is exactly that (i.e. VW frequencies in the image), when employing n.∗.∗ weighting schemes, we do not alter the weighting factor based on tf. On the other hand, when employing l.∗.∗ weighting schemes, we suggest that relevance does not increase proportionally with VW frequency. It is a well known fact in information retrieval that a document with tf=10 occurrences of a term is more relevant than a document with tf=1 occurrence of the same term, but not ten times more relevant.
The df variant refers to the number of images in a collection that contain a given VW. When employing ∗.n.∗ schemes, we do not alter the vectors based on df. When using ∗.t.∗ schemes, we suggest that when a VW is found in many images in the collection, then the VW is rather general and hence is given a smaller weighting factor.
For the normalization of the vectors, ∗.∗.n refers to ‘no normalization’ while ∗.∗.c schemes normalize the descriptors using cosine similarity so that all image vectors turn into unit vectors.
For the purposes of this paper, Figs. 2 and 3 present the behaviour of the eight WS of the best performing descriptor per collection (UKBench, UCID), combined with all four detectors, for the four different codebooks5.

Weighting schemes’ MAP scores on UKBench. SIMPLE SCD descriptor with all four detector for a codebook 2048, b codebook 512, c codebook 128 and d codebook 32

Weighting schemes’ MAP scores on UCID. SIMPLE CEDD descriptor with all four detector for a codebook 2048, b codebook 512, c codebook 128 and d code book 32
Beginning the analysis with the tf variant, we have observed that for smaller codebooks, the term ‘l’ (log-weighted term frequency) behaves better. Small codebooks involve high term frequencies, making the use of the log frequency weight necessary. In larger codebooks, the use of the log frequency weight does not affect the results significantly. In Figs. 2a and 3a, where a large codebook is employed, l.t.c scores comparable to n.t.c, l.n.c comparable to n.n.c, and so on. On the other hand, as the codebooks get smaller in graphs c and d, weighting schemes that use the ‘l’ term perform significantly better.
Regarding the df, for small codebooks due to the fact that there is a limited number of VW available for indexing, most VWs are found in multiple images. Thus, employing the ‘t’ term, many VWs are falsely credited with the same significance value and we notice a degradation in performance (in both collections, graph d shows that l.n.c performs better than l.t.c, the same for l.t.n and l.n.n, etc.). As the codebooks get larger, the df does not seem to significantly alter the performances.
Finally, normalizing each vector by the cosine similarity so that all image vectors turn into unit vectors seems to add to the performance of methods with large codebook sizes. This is justified by the fact that the use of larger codebooks produces descriptors with greater length than smaller codebooks. Thus, the benefits of the normalization are more evident as the sizes grow.
Overall, the behaviour of the weighting schemes seems to be collection independent. Methods that utilize large codebooks can benefit by weighting the produced descriptors with an l.*.c weighting scheme or even an *.*.c scheme so as to reduce computational cost with a small discount performance-wise. On the other hand, for small codebooks, an l.n.* weighting scheme will result in the best performance.
6.2 Large-scale experiments
The common practice [19, 21, 39, 51, 52] to evaluate large-scale image retrieval performance is to employ a large image database as distractors included in the retrieval database. This is a strategy that allows the evaluation of the scalability of a method overcoming the fact that there is not a publicly available large dataset with an assigned ground truth for CBIR. The evaluation of a method is based on the retrieved ranked list of images per query compared to the initial collection’s ground truth. This means that retrieved images that are part of the distractors are considered false results. The theme of the images used as distractors, their resolution and possible artifacts caused by their encoding can bias the evaluation.
With that being said, we populate the UKbench, UCID, Holidays, and ZuBuD datasets with a random fraction of 100,000 images (distractors) of the MIR Flickr 1M dataset [53]. The MIR Flickr dataset was chosen because it has relevant depictions to three out of our four initial collections (UCID, Holidays and to some degree with UKBench), it has the same encoding (JPG) with half our collections (UKBench and Holidays) and a resolution of the same order of magnitude with three of our datasets (only Holidays has a significantly higher resolution).
We test and evaluate the best performing descriptors (CEDD and SCD) with all extractor combinations (SIFT, SURF, Rnd, GaussRnd) in all four datasets. The codebooks were re-generated after randomly forwarding a 10 % sample of extracted features from the combined collections (UKBench+MIRFlickr, UCID+MIRFlickr, etc) to the k-means classifier. This strategy ensures a more fair and realistic set-up, so as not to favour the description of images belonging to the initial collections.
Table 11 summarizes the experimental results per dataset. Overall, the proposed descriptors present robust retrieval performances.
The average loss in performance for the UKBench, Holidays and ZuBuD collections is only 3.8, 5.8 and 7.1 % respectively, while even when challenged with distractors, the calculated performances in many cases exceed the baseline (non-SIMPLE) descriptors without distractors. A higher loss is reported for the UCID collection with an average 10.3 % degradation. However again, the absolute performances in the large-scale experiments match or even exceed the performances of the baselines without distractors.
In order to test how the scalability of the proposed localized descriptors compares to that of the methods they originated from, we performed the large-scale scenarios for the original CEDD and SCD methods. CEDD reported a loss of 6.95 % in UKBench, 15.64 % in Holidays, 8.18 % in ZuBuD and 20.96 % in UCID. For the SCD descriptor, the losses were 12.32, 15.03, 14.70 and 24.12 %, respectively.
It is evident through the results that the retrieval accuracy of the proposed methods as the datasets scale-up not only remains sufficiently high in absolute numbers but, more importantly, also significantly outperforms the scalability of the original methods, validating the overall robustness and reliability of the scheme.
7 Discussion and future work
Through our experimental results, we verified that the proposed scheme for localizing the discrimination ability of the compact MPEG-7 and MPEG-7-like global descriptors is an effective strategy for CBIR. A significant boost of their retrieval performance is reported not only compared to their original global form, but moreover, the proposed local features tested in the most straightforward retrieval model perform comparably and even outperform some of the most recently proposed retrieval models that base their success in much more complex data manipulations.
Regarding the sampling strategies, we explored two different directions: first, we employed two POI detectors from the literature (SIFT and SURF) that search for salient textural information in an image, in multiple scales, and then we introduced two different generators that randomly extract multiscale random image patches. Through the experimental results, we observed that detection mechanisms based on texture saliency are successful when combined with descriptors that vectorize colour information, since they achieve colour description of POIs with textural attention. However, depending on the employed description method, this strategy can potentially suffer if the extracted patches are too small to be treated by the descriptors.
The success of the random generators, on the other hand, is most likely associated with the fact that in CBIR, we are not always interested in one-to-one matching of points between images. We examined this allegation by employing four different image collections which vary both in depiction and in relevance association. In many cases, the useful information is not constrained at textured image parts. Searching exclusively for salient texture parts limits the retrieval effectiveness. Additionally, it was found that even though the distribution of POIs from blob detectors follows no particular pattern when seen per image, over a large number of images, the overall distribution has a Gaussian-like behaviour. The random sampling strategies furthermore allow us to have much better control over the number of patches and their sizes, are light-weighted and can be adjusted depending on the available computational resources. Even though the tests conducted are preliminary at this stage, sampling with as little as 100 samples per image performs promisingly enough to be further examined. The number of extracted patches can affect vastly the overall usability of a method. Extracting a high number of patches per image (for instance, following a dense sampling strategy) could make a method more robust but demands extensive use of memory and storing resources, making it impractical for large-scale retrieval scenarios.
Regarding the description parameters that should be selected for CBIR tasks, and although they are heavily subject to the images involved, we confirmed that quantized, compact representations of image features allow for better retrieval performances. The abstract representation allows for faster and safer comparisons of similarities between images because the discrete domain of features minimizes classification errors. Moreover, due to the massive amount of data that is usually involved in CBIR, compact descriptions are imperative when computational resources are limited.
Finally, weighting the descriptors with eight different weighting schemes and analysing their impact gave us useful insight into the relationship of codebook sizes and local features. Having employed four very different kinds of image collections, four description methods and four different codebook sizes ranging from a tiny 32 VW codebook up to a much wider 2048 VW codebook, the experimental results suggest that the preferred weighting scheme strategy is collection and feature-type independent and should be selected based on the size of the codebook. Another interesting direction worth exploring left for future work is testing the impact on the retrieval performance of different distance metrics. This type of investigation demands an in-depth study of multiple parameters such as the chosen representation (feature generation), the distribution of the data, the representation’s dimensionality and the detected variance per dimension.
Currently, we are expanding the SIMPLE family by varying the aggregation model and the description methods. More specifically, we employ the VLAD model as a BOVW alternative and test four different global descriptors that are evaluated based on their length, content and type of attributes their description is based upon. Early results confirm that global descriptors that are compact and quantized and carry colour information are successfully localized through the SIMPLE scheme while the introduction of VLAD, although not outperforming the respective BOVW implementations, achieves directly comparable performances with tiny codebooks of 16 or 64 clusters, eliminating simultaneously the need of applied weighting schemes.
8 Conclusions
In this paper, we explored, extended and simplified the SIMPLE family of local feature descriptors. We combined four sampling strategies, with four global feature descriptors, in a BOVW architecture and evaluated the produced descriptor in four diverse, popular image collections so as to (i) minimize the case that good achieved performances might have to do with specificities of the database and (ii) allow the comparison of the proposed method to many others from the literature that might have been left out in this work.
The primary scope of this study was to investigate how the parameters of a CBIR system (points-of-interest detection, description mechanisms, codebook sizes and weighting strategies) can best be selected to serve specifically for the needs of retrieval tasks. We built our design strategy keeping in mind the usability of the proposed descriptors in terms of scalability, compactness, efficiency and effectiveness and were rewarded with a set of very promising local feature descriptors that hit the mark on all of them.
We strongly encourage the incorporation of these light-weighted local features into different retrieval systems, the experimentation with collections varying in domain, relevance assumption or scale and overall the expansion of the SIMPLE family, and thus, we provide open source implementations in C#, Java and MATLAB (http://tinyurl.com/SIMPLE-Descriptor). Furthermore, all descriptors are part of the LIRE library [48] and can be used under the GNU GPL license.
9 Endnotes
1 The latest version of CEDD can be found in http://tinyurl.com/CEDD-Descriptor.
2 The results are in line for UKBench and Holidays, while for the ZuBuD dataset, the accumulative distribution presents less of a curve but rather a more flat distribution.
3 Local feature descriptors were tested using the recently proposed GRIRe [54] open source framework and the respective OpenCV implementation of the descriptors.
4 The MPEG-7 descriptors availiable on img(Rummager) follow the implementation found in the LIRE [48] open source library.
5 Resources in the form of spreadsheets presenting all results are available upon request.
References
R Datta, D Joshi, J Li, JZ Wang, Image retrieval: ideas, influences, and trends of the new age. ACM Comput. Surv. 40(2), 5:1-5:60 (2008).
T Deselaers, D Keysers, H Ney, Features for image retrieval: an experimental comparison. Inf. Retr. 11(2), 77–107 (2008). http://dx.doi.org/10.1007/s10791-007-9039-3.
OAB Penatti, R da Silva Torres, in SIBGRAPI. Color descriptors for web image retrieval: a comparative study, (2008), pp. 163–170. http://dx.doi.org/10.1109/SIBGRAPI.2008.20.
J Annesley, J Orwell, J-P Renno, in Visual Surveillance and Performance Evaluation of Tracking and Surveillance, 2005. 2nd Joint IEEE International Workshop on. Evaluation of MPEG7 color descriptors for visual surveillance retrieval (IEEE, 2005), pp. 105–112.
KEA van de Sande, T Gevers, CGM Snoek, Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 32(9), 1582–1596 (2010). http://doi.ieeecomputersociety.org/10.1109/TPAMI.2009.154.
S Loncaric, A survey of shape analysis techniques. Pattern Recognit. 31(8), 983–1001 (1998). http://dx.doi.org/10.1016/S0031-2023(97)00122-2.
D Zhang, G Lu, Review of shape representation and description techniques. Pattern Recognit. 37(1), 1–19 (2004).
P Howarth, SM Rüger, in CIVR. Evaluation of texture features for content-based image retrieval (Springer, 2004), pp. 326–334. http://dx.doi.org/10.1007/978-3-540-27814-6_40.
CG Harris, J Pike, 3D positional integration from image sequences. Image Vis. Comput. 6(2), 87–90 (1988).
J Shi, C Tomasi, in Computer Vision and Pattern Recognition, 1994. Proceedings CVPR’94., 1994 IEEE Computer Society Conference on. Good features to track (IEEE, 1994), pp. 593–600.
E Rosten, T Drummond, in ECCV (1). Machine learning for high-speed corner detection, (2006), pp. 430–443. http://dx.doi.org/10.1007/11744023_34.
DG Lowe, Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 60(2), 91–110 (2004). http://dx.doi.org/10.1023/B:VISI.0000029664.99615.94.
H Bay, T Tuytelaars, LJV Gool, in ECCV (1). SURF: Speeded up robust features (Springer, 2006), pp. 404–417. http://dx.doi.org/10.1007/11744023_32.
D Scaramuzza, M Achtelik, L Doitsidis, F Fraundorfer, EB Kosmatopoulos, A Martinelli, MW Achtelik, M Chli, SA Chatzichristofis, L Kneip, D Gurdan, L Heng, GH Lee, S Lynen, M Pollefeys, A Renzaglia, R Siegwart, JC Stumpf, P Tanskanen, C Troiani, S Weiss, L Meier, Vision-controlled micro flying robots: from system design to autonomous navigation and mapping in GPS-denied environments. IEEE Robot. Automat. Mag. 21(3), 26–40 (2014). [Online]. Available http://dx.doi.org/10.1109/MRA.2014.2322295.
OG Cula, KJ Dana, in CVPR (1). Compact representation of bidirectional texture functions (IEEE, 2001), pp. 1041–1047. http://doi.ieeecomputersociety.org/10.1109/CVPR.2001.990645.
X Li, A Godil, Investigating the bag-of-words method for 3D shape retrieval. EURASIP J. Adv. Signal Process. 2010(5) (2010).
Y Chen, X Li, A Dick, R Hill, Ranking consistency for image matching and object retrieval. Pattern Recognit. 47(3), 1349–1360 (2014).
J Philbin, O Chum, M Isard, J Sivic, A Zisserman, in Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on. Lost in quantization: improving particular object retrieval in large scale image databases (IEEE, 2008), pp. 1–8.
H Jégou, M Douze, C Schmid, Improving bag-of-features for large scale image search. Int. J. Comput. Vis. 87(3), 316–336 (2010).
F Perronnin, J Sánchez, T Mensink, in Computer Vision–ECCV 2010. Improving the Fisher kernel for large-scale image classification (Springer, 2010), pp. 143–156.
H Jegou, M Douze, C Schmid, in Computer Vision–ECCV 2008. Hamming embedding and weak geometric consistency for large scale image search (Springer, 2008), pp. 304–317.
H Jégou, M Douze, C Schmid, P Pérez, in Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. Aggregating local descriptors into a compact image representation (IEEE, 2010), pp. 3304–3311.
L Shao, D Wu, X Li, Learning deep and wide: a spectral method for learning deep networks. Neural Netw. Learn. Syst. IEEE Trans. 25(12), 2303–2308 (2014).
F Zhu, L Shao, Weakly-supervised cross-domain dictionary learning for visual recognition. Int. J. Comput. Vis. 109(1-2), 42–59 (2014).
L Liu, M Yu, L Shao, Multiview alignment hashing for efficient image search. Image Process. IEEE Trans. 24(3), 956–966 (2015).
L Shao, L Liu, X Li, Feature learning for image classification via multiobjective genetic programming. Neural Netw. Learn. Syst. IEEE Trans. 25(7), 1359–1371 (2014).
C Iakovidou, N Anagnostopoulos, A Kapoutsis, Y Boutalis, S Chatzichristofis, in Content-Based Multimedia Indexing (CBMI), 2014 12th International Workshop. Searching images with MPEG-7 (and MPEG-7-like) powered localized descriptors: the simple answer to effective content based image retrieval (IEEE, 2014), pp. 1–6. http://dx.doi.org/10.1109/CBMI.2014.6849821.
BS Manjunath, J-R Ohm, VV Vasudevan, A Yamada, Color and texture descriptors. Circ. Syst. Video Technol. IEEE Trans. 11(6), 703–715 (2001).
SA Chatzichristofis, YS Boutalis, in ICVS. CEDD: color and edge directivity descriptor: a compact descriptor for image indexing and retrieval, (2008), pp. 312–322. http://dx.doi.org/10.1007/978-3-540-79547-6_30.
SA Chatzichristofis, YS Boutalis, Compact Composite Descriptors for Content Based Image Retrieval: Basics, Concepts, Tools (VDM Verlag Dr. Muller, 2011).
E Spyrou, HL Borgne, TP Mailis, E Cooke, YS Avrithis, NE O’Connor, in ICANN (2). Fusing MPEG-7 visual descriptors for image classification, (2005), pp. 847–852. http://dx.doi.org/10.1007/11550907_134.
AR Doherty, CO Conaire, M Blighe, AF Smeaton, NE O’Connor, in Multimedia Information Retrieval. Combining image descriptors to effectively retrieve events from visual lifelogs (ACM, 2008), pp. 10–17. http://doi.acm.org/10.1145/1460096.1460100.
MM Rahman, S Antani, GR Thoma, in Multimedia Information Retrieval. A classification-driven similarity matching framework for retrieval of biomedical images (ACM, 2010), pp. 147–154. http://doi.acm.org/10.1145/1743384.1743413.
SA Chatzichristofis, YS Boutalis, in WIAMIS. FCTH: fuzzy color and texture histogram - a low level feature for accurate image retrieval (IEEE, 2008), pp. 191–196. http://doi.ieeecomputersociety.org/10.1109/WIAMIS.2008.24.
MM Rahman, S Antani, GR Thoma, in CBMS. A medical image retrieval framework in correlation enhanced visual concept feature space (IEEE, 2009), pp. 1–4. http://dx.doi.org/10.1109/CBMS.2009.5255392.
CK Dagli, TS Huang, in ICPR (2). A framework for grid-based image retrieval (IEEE, 2004), pp. 1021–1024. http://doi.ieeecomputersociety.org/10.1109/ICPR.2004.1334433.
G Amato, P Bolettieri, F Falchi, C Gennaro, F Rabitti, in CBMI. Combininglocal and global visual feature similarity using a text search engine (IEEE, 2011), pp. 49–54. http://dx.doi.org/10.1109/CBMI.2011.5972519.
A Abdullah, RC Veltkamp, MA Wiering, Fixed partitioning and salient points with MPEG-7 cluster correlograms for image categorization. Pattern Recognit. 43(3), 650–662 (2010).
D Nistér, H Stewénius, in CVPR (2). Scalable recognition with a vocabulary tree (IEEE, 2006), pp. 2161–2168. http://doi.ieeecomputersociety.org/10.1109/CVPR.2006.264.
G Schaefer, M Stich, in Storage and Retrieval Methods and Applications for Multimedia. UCID: an uncompressed color image database (SPIE, 2004), pp. 472–480. http://dx.doi.org/10.1117/12.525375.
SA Chatzichristofis, C Iakovidou, YS Boutalis, O Marques, Co.vi.wo.: color visual words based on non-predefined size codebooks. IEEE T. Cybernet. 43(1), 192–205 (2013).
H Shao, T Svoboda, L Van Gool, in Computer Vision Lab, Swiss Federal Institute of Technology, Switzerland, Tech. Rep, 260. ZuBuD-Zurich buildings database for image based recognition, (2003).
G Zajić, N Kojić, V Radosavljević, M Rudinac, S Rudinac, N Reljin, I Reljin, B Reljin, Accelerating of image retrieval in CBIR system with relevance feedback. EURASIP J. Adv Signal Process. 2007(1), 62678 (2007).
E Rublee, V Rabaud, K Konolige, GR Bradski, in ICCV. ORB: an efficient alternative to sift or surf (IEEE, 2011), pp. 2564–2571. http://dx.doi.org/10.1109/ICCV.2011.6126544.
S Leutenegger, M Chli, R Siegwart, in ICCV. BRISK: binary robust invariant scalable keypoints (IEEE, 2011), pp. 2548–2555. http://dx.doi.org/10.1109/ICCV.2011.6126542.
SA Chatzichristofis, YS Boutalis, M Lux, in SISAP. Img(rummager): an interactive content based image retrieval system (IEEE, 2009), pp. 151–153. http://doi.ieeecomputersociety.org/10.1109/SISAP.2009.16.
SA Chatzichristofis, C Iakovidou, YS Boutalis, E Angelopoulou, Mean Normalized Retrieval Order (MNRO): a new content-based image retrieval performance measure. Multimedia Tools Appl, 1–32 (2012).
M Lux, SA Chatzichristofis, in ACM Multimedia. LIRe: Lucene Image Retrieval: an extensible Java CBIR library (ACM, 2008), pp. 1085–1088. http://doi.acm.org/10.1145/1459359.1459577.
H Jégou, M Douze, C Schmid, in Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. On the burstiness of visual elements (IEEE, 2009), pp. 1169–1176.
X Wang, M Yang, T Cour, S Zhu, K Yu, TX Han, in Computer Vision (ICCV), 2011 IEEE International Conference on. Contextual weighting for vocabulary tree based image retrieval (IEEE, 2011), pp. 209–216.
L Zheng, S Wang, Q Tian, Coupled binary embedding for large-scale image retrieval. IEEE Trans. Image Process. 23(8), 3368–3380 (2014).
S Zhang, Q Huang, G Hua, S Jiang, W Gao, Q Tian, in Proceedings of the International Conference on Multimedia. Building contextual visual vocabulary for large-scale image applications (ACM, 2010), pp. 501–510.
MJ Huiskes, B Thomee, MS Lew, in Proceedings of the international conference on Multimedia information retrieval. New trends and ideas in visual concept detection: the MIR flickr retrieval evaluation initiative (ACM, 2010), pp. 527–536. http://dx.doi.org/10.1145/1743384.1743475.
LT Tsochatzidis, C Iakovidou, SA Chatzichristofis, YS Boutalis, in ACM Multimedia. Golden retriever: a Java based open source image retrieval engine (ACM, 2013), pp. 847–850. http://doi.acm.org/10.1145/2502081.2502227.
SA Chatzichristofis, YS Boutalis, Content based radiology image retrieval using a fuzzy rule based scalable composite descriptor. Multimedia Tools Appl. 46(2-3), 493–519 (2010). http://dx.doi.org/10.1007/s11042-009-0349-x.
H Tamura, S Mori, T Yamawaki, Textural features corresponding to visual perception. Syst. Man Cybernet. IEEE Trans. 8(6), 460–473 (1978).
S Zhang, M Yang, X Wang, Y Lin, Q Tian, in Computer Vision (ICCV), 2013 IEEE International Conference on. Semantic-aware co-indexing for image retrieval (IEEE, 2013), pp. 1673–1680.
M Jain, H Jégou, P Gros, in Proceedings of the 19th ACM International Conference on Multimedia. Asymmetric hamming embedding: taking the best of our bits for large scale image search (ACM, 2011), pp. 1441–1444.
Acknowledgements
This work was supported by Lakeside Labs GmbH, Klagenfurt, Austria, and funding from the European Regional Development Fund and the Carinthian Economic Promotion Fund (KWF) under grant KWF-20214/25557/37319. This research has been also co-financed by the European Union (European Social Fund-ESF) and Greek national funds through the Operational Program ‘Education and Lifelong Learning’ of the National Strategic Reference Framework (NSRF)- Research Funding Program: Heracleitus II. Investing in knowledge society through the European Social Fund.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Iakovidou, C., Anagnostopoulos, N., Kapoutsis, A. et al. Localizing global descriptors for content-based image retrieval. EURASIP J. Adv. Signal Process. 2015, 80 (2015). https://doi.org/10.1186/s13634-015-0262-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-015-0262-6