
Abstract
Electrocardiogram (ECG) is conducted to monitor the electrical activity of the heart by presenting small amplitude and duration signals; as a result, hidden information present in ECG data is difficult to determine. However, this concealed information can be used to detect abnormalities. In our study, a fast feature-fusion method of ECG heartbeat classification based on multi-linear subspace learning is proposed. The method consists of four stages. First, baseline and high frequencies are removed to segment heartbeat. Second, as an extension of wavelets, wavelet-packet decomposition is conducted to extract features. With wavelet-packet decomposition, good time and frequency resolutions can be provided simultaneously. Third, decomposed confidences are arranged as a two-way tensor, in which feature fusion is directly implemented with generalized N dimensional ICA (GND-ICA). In this method, co-relationship among different data information is considered, and disadvantages of dimensionality are prevented; this method can also be used to reduce computing compared with linear subspace-learning methods (PCA). Finally, support vector machine (SVM) is considered as a classifier in heartbeat classification. In this study, ECG records are obtained from the MIT-BIT arrhythmia database. Four main heartbeat classes are used to examine the proposed algorithm. Based on the results of five measurements, sensitivity, positive predictivity, accuracy, average accuracy, and t-test, our conclusion is that a GND-ICA-based strategy can be used to provide enhanced ECG heartbeat classification. Furthermore, large redundant features are eliminated, and classification time is reduced.
Similar content being viewed by others
1 Introduction
Cardiovascular diseases (CVDs) are among the most common causes of death worldwide. Although death rate caused by CVDs has decreased in developed countries, death rate has increased rapidly in developing countries. CVD-related socioeconomic burden, as well as risk factors, remains astonishingly high [1]. Behavioral risks (e.g., tobacco smoking, physical inactivity, unhealthy diet, etc.), metabolic risks (e.g., raised blood pressure/sugar/lipids), and other risk factors (e.g., gender, advancing age) increase death rates. For instance, cardiac arrhythmia, which refers to disorders of the electrical conduction system of the heart, may pose a high risk and cause medical emergencies.
Electrocardiogram (ECG), as an adjunct tool in cardiovascular diseases management, is used to non-invasively monitor the electrical activity of the heart [2]. To capture frequent occurrence of arrhythmias, medical practitioners record ECG activity for several hours. Large amounts of data are recorded in computational complexity. Therefore, automated heartbeat classification is essential for diagnostic assistance.
Thus far, simple classifiers, such as linear discriminants [3] and K-nearest neighbor classifier [4], and complex classifiers, including chaotic modeling, spectral coherence analysis, artificial neural networks, and support vector machine, have been extensively applied. Classifier combination is also used in ECG heartbeat classification to improve accuracy [5]. The final decision regarding classifier combination is achieved by considering the decisions of members or aggregating the decisions of one or a few of the members [2].
Feature extraction is one of the most important steps in classification and can capture a certain underlying property of ECG [6]. Various kinds of comprehensive features have been extracted to describe ECG; these features can be divided into three categories, including temporal, morphological, and statistical features [7]. Temporal features are exclusively acquired from time-domain signals and consist of RR- and heartbeat interval features. The hidden complexities of an ECG signal cannot be distinctly interpreted because of subtle changes. More discriminating features can be extracted in a wavelet transform (WT) domain than in a time domain [8]. Morphological and statistical features can be obtained with WT of the ECG signal, which provides good resolution in time and frequency domains [7]. However, WT only displays sufficient frequency resolution at low frequencies but poor frequency resolution at high frequencies. As an extension of WT, wavelet-packet decomposition (WPD) is developed to achieve fine frequency resolution at both low and high frequencies. WPD can also be used to investigate piecewise signal variations.
Feature combinations can improve classification results [9]. However, the algorithm of selecting and combining multiple features poses a considerable challenge [3]. In this paper, a novel multi-scale feature-fusion method for ECG heartbeat classification is proposed. In the proposed method, ECG is initially fragmented into separate heartbeats; baseline and noise are further removed from each heartbeat. Features are then extracted by wavelet-packet decomposition, in which features become more distinguishable in a wavelet-packet-transform domain than in a time domain. The fourth-level components of WPD are represented as the features of a heartbeat. All of the features of a heartbeat are arranged into a two-order tensor rather than a long vector; a two-order tensor is further processed by generalized N dimension independent component analysis (GND-ICA) to select and fuse effective components simultaneously. These fused components, as new features of ECG heartbeats, are fed to a support vector machine (SVM) for automated classification. Simulation results from an MIT-BIH arrhythmia database demonstrate high average accuracies of 98, 98.79, 98.87, and 99.43 % of detected normal beats (N), supraventricular ectopic beats (S), ventricular ectopic beats (V), and fusing normal and ventricular ectopic beats (F), respectively. The proposed method is compared with five currently used methods and two conventional fusion methods by using the MIT-BIH database. The proposed method can improve ECG classification results compared with other methods.
2 Methodology
The proposed ECG heartbeat classification method is divided into four parts, namely pre-processing, feature extraction, feature fusion, and classification. Our main contribution is found in the third section, that is, feature fusion, which involves a training stage and a test stage. Each stage is briefly described in Fig. 1.

Flowchart of the proposed method
-
(1)
In the pre-processing stage, baseline and high-frequency noises are initially removed from the original input ECG signals. Heartbeats are then segmented on the detected real R points.
-
(2)
In the feature extraction stage, wavelet-packet decomposition is used to extract WP coefficients as heartbeat features. Fourth-level decompositions are used as features in the following procedure.
-
(3)
In the feature-fusion stage, all of the extracted features of an ECG heartbeat are arranged as a two-way tensor, in which feature-fusion procedure is implemented using a multi-linear subspace-learning method, GND-ICA.
-
(4)
In the classification stage, SVM is directly used as a classifier in final-heartbeat classification.
2.1 Pre-processing
ECG is composed of atrial depolarization (P wave), ventricular depolarization (QRS complex), and ventricular repolarization (T wave). These waves are induced by specific electrical phenomena on the cardiac surface. ECG contains diverse kinds of noises, such as baseline wander, power-line interference, and high-frequency noise. Baseline wander caused by respiration or patient movement can be corrected by subtracting the filtered signal from the original signal with two median filters. These two median filters with widths of 200- and 600-ms are used to remove ORS complexes, P-waves, and T-waves, respectively [10]. After the baseline of ECG is corrected, power-line interference and high-frequency noise are removed using a low-pass filter. Figure 2a, b show a part of the original signal and the signal in which the noise and baseline are removed, respectively.

ECG signals (a) A part of the original signal; b Noise reduction signal
Considering that this study does not contribute to heartbeat detection in ECG, we directly segment the filtered ECG signals by using heartbeat fiducial-point times provided in the MIT-BIH arrhythmia database. Fiducial points (R points) occur instantaneously in the major local extreme of a QRS complex. However, several detected R-point locations are skipped using this provided annotation (Fig. 3a). A time window with a length of 40 samples near the detected R points is utilized to determine real R point locations, where the highest value is found inside the windows (Fig. 3b). Based on the real R points, 99 samples before the R points and 100 samples after the R points are used as the real heartbeat samples, (Fig. 3c).

ECG signal segmentation. a Skipped R-point locations; b Real R-point locations; c Segmented real heartbeat sample
2.2 Feature extraction
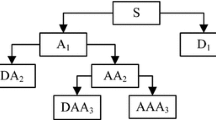
This study mainly investigates the process by which heartbeat features are extracted. Pre-processed ECG heartbeats are utilized in all of the following processing methods. Wavelets provide relevant information to extract features. A multi-resolution representation of non-stationary ECG can be obtained by wavelet analysis, which provides a level-by-level transformation of a signal from a time domain to a frequency domain. In wavelet-packet analysis (WPD) according to wavelet theory, a normalized signal is transmitted through a series of low- and high-pass filters simultaneously [11, 12]; time domain is then transformed into frequency domain in each level. Unlike wavelet transformation, WPD divides the frequency sub-band of a signal with an equal width by using sets of orthonormal basis functions. A signal is split into approximation (A) and detail (D) coefficients; these coefficients are further split into next-level A and D coefficients. Afterward, the process is repeated. Figure 4 illustrates wavelet-packet analysis of level-four decomposition. The top level in Fig. 4 is the time representation of the ECG signal. Time and frequency resolutions are traded off in each level. The bottom level shows the frequency representation of a signal, which decomposes both the approximation and details coefficients.

Four-level decomposition using wavelet-packet transform
After wavelet-packet analysis of a heartbeat is conducted, a rich collection of abundant information with arbitrary time-frequency resolution is obtained. This information shows that non-stationary and stationary characteristics of the extracted features are combined.
The four-level decomposition of input ECG signal is provided by WPD, which transfers the time domain to the frequency domain (Fig. 5). With the levels computed from top to bottom, time resolution decreases, whereas frequency resolution increases. After the original signal in the top level is decomposed (Fig. 5a), the data in the next level of nodes (D1) show low-scale and high-frequency properties. Approximations in each level of A1, AA2, AAA3, and AAAA4 nodes appears similar to the original approximations. In our study, a four-level WPD is used to obtain the features of an ECG signal.

WPD of ECG signals. a Original signal; b-f Decomposed ECG signals at A1, D1, AA2, AAA3, and AAAA4 nodes
2.3 Feature fusion
After extracting wavelet coefficients in the fourth-level decomposition of an ECG signal, we aim to fuse all of the features to effectively classify heartbeats. A concept of tensor-based multi-linear subspace-learning method called generalized N dimensional independent component analysis (GND-ICA) is introduced to perform multiple-feature fusion. It can effectively combine and select all of the features extracted from the original signal and considers the interrelationship among different wavelet-packet coefficients. A concept of “tensor” is introduced to arrange all of the features of one heartbeat. A tensor is an N-way array [13], and the order of a tensor is known as mode [14].
In previous studies [15, 16], each mode of a tensor should be defined distinctively. Therefore, the ECG heartbeat can be represented using a two-way tensor \( {X}_i^{tr}\in {R}^{I_1\times {I}_2},i=1,2,\dots, n \) by adjoining the above extracted features. In this tensor, mode-1 is denoted by the number of the bottom level of a full wavelet-packet decomposition (I 1-D), and mode-2 is represented by the number of features (I 2-D). This two-way tensor is presented in Fig. 6. In this manner, the factor inherent to the element of feature vectors and the factor among different features can be disentangled. An optimal de-mixing matrix on each mode is determined by GND-ICA with a series of training tensor samples [17].

ECG heartbeat representation (a) Segmented heartbeat sample; b Features arranged in a two-way tensor
Given a series of training two-way tensors \( {X}_i^{tr}\in {R}^{I_1\times {I}_2},i=1,2,\dots, n \) by learning two de-mixing matrices \( {\mathbf{W}}_z\in {R}^{J_z\times {I}_z},z=1,2\left({J}_z\le {I}_z\right) \) , GND-ICA finds another set of lower-rank core tensor \( {S}_i^{tr}\in {R}^{J_1\times {J}_2},i=1,2,\dots, n \) , that retains as much of the variation of the original data as possible and in which the elements on each mode are as independent as possible:
The optimization problem of GND-ICA is defined to minimize error function, as expressed in the following equation [9, 10, 18]:
where A z , z = 1, 2 is the pseudo-inverse of the de-mixing matrix W z , z = 1, 2.
To effectively represent a heartbeat signal, we fuse all of the features by de-mixing matrices W z , z = 1, 2 in each mode of feature representation \( {X}^{te}\in {R}^{I_1\times {I}_2} \). In this process, the factor inherent to the element of feature vectors and the factor among different features are considered. Thus, we obtain the following expression:
which is used in heartbeat classification.
2.4 Classification
After distinguishing features are extracted from each heartbeat, a classifier is applied to provide the ECG heartbeat classification. In this paper, SVM [19], as an effective tool used to solve numerous classification problems, is used in heartbeat classification.
In our study, LIBSVM package is used. For fair comparison, the optimum parameters of the kernel function (radial basis function) are assigned to SVM for each signal representation [20].
3 Experimental results
The MIT-BIH arrhythmia database is utilized in our study [21, 22]. Approximately 109,000 heartbeats contained in 48 ECG recordings can be achieved for approximately 30 min in each recording. MIT-BIT heartbeat types are classified into five main classes according to the standards recommended by the Association for the Advancement of Medical Instrumentation. Heartbeats belonging to class N and originating from the sinus node are normal and bundle-branch-block beat types. Supraventricular ectopic beats and ventricular ectopic beats belong to classes S and V, respectively. Fused normal and ventricular ectopic beats belong to class F. The unknown heartbeats, including paced beats, are classified in class Q. The ECG signals of the MIT-BIH arrhythmia database are sampled at 360Hz, and 200 sampling points are used for signal representation.
All of the experiments are conducted using a standard PC (Intel (R) Core (TM) i7-4770 CPU @ 3.40GHz), and the learning phase to obtain the transformation matrix is carried out in Matlab 2013 [23]. The performance of the proposed feature-fusion method is evaluated using all of the heartbeat segments found in the MIT-BIT database. In this study, random subsampling is conducted to train and evaluate classifiers. Data are randomly selected from the whole database ten times; the number of each class is shown in Table 1. The schematic of average heartbeats in each class of training heartbeats is shown in Fig. 7.

Schematic of average heartbeats for (a) Class N; (b) Class S; (c) Class V; (d) Class F
WPD was computed in each of the ECG heartbeat by using discrete approximation of the Meyer wavelet, which is considered as the most efficient decomposition of feature extraction [24]. All of the decomposition coefficients in the fourth level are used as features, with 16 sets of vectors and 107 components. The performance of the multi-linear subspace-learning method GND-ICA and the linear subspace-learning method PCA of heartbeat classification is described in terms of sensitivity, positive predictivity, accuracy, and average accuracy.
3.1 Evaluation criterion
Four classes, namely, N, S, V, and F, are used in the experiments. We assume that i, j ∈ {N, S, V, F}, C i,j is the number of heartbeats of class i classified as j. If ∀ i ≠ j, then C i,j is an incorrectly classified heartbeat, whereas C i,i is a correctly classified heartbeat [7]. We define B j = ∑∀ j C i,j as the total number of examples originally belonging to class i; A j = ∑∀ i C i,j as the total number of examples labeled as class j; and C total = ∑∀ i ∀ j C i,j . We denote TP i = C i,i as the true positives of I, TN i = C total − B i − A i + C i,i as the true negatives of I, FP i = A i − C i,i as the false positives of I, and FN i = B i − C i,i as the true negatives of i. The accuracy (AC i ) of i is the proportion of the total number of correct predictions defined as follows:
The sensitivity (Sens i ) of i refers to the ability of the method to correctly identify the heartbeat with the corresponding class.
The positive predictive value (PPV i ) of i is a proportion used to determine the probability that the result actually belongs to a particular class if the result is positive:
The average accuracy (MAC total ) is defined as Eq. 22 corresponding to the average classification rate of all classes:
3.2 Classification performance of different features
After WPD, PCA, and GND-ICA are conducted, the features are fed to SVM for automated classification [25]. The average classification rates of the methods except WPD vary with the dimension of reduced features. Figure 8 shows the average accuracy in each experiment by using PCA components and GND-ICA components, respectively. In this study, the original dimension of WPD features (107 × 16 = 1712) reduced into 10, 12, 14, 16, 18, and 20 dimensions is investigated. We observe that GND-ICA can improve the average accuracy, although the dimension is reduced to ten. In addition, the highest-average accuracy is obtained by GND-ICA with 16 dimensions. Therefore, GND-ICA not only reduces high dimension of original concatenation features but also improves classification results.

Average classification rates of tensor-based and conventional methods
Average accuracies (Fig. 8) are obtained with the optimum parameter gamma in the radial basis function of SVM. For example, numerous possible values in SVM of GND_ICA_16 are tested, and MAC total is plotted with respect to different gamma values (Fig. 9). The highest-average accuracy is provided at gamma = 0.7, and the corresponding average accuracy is 97.54 % (Fig. 9).

Number of average accuracy with respect to corresponding gamma values in GND-ICA
3.3 Classification Evaluation with Different Criteria
Considering that the average accuracy is changed according to dimension reduction, we select the highest-classification rate to compare our results.
Table 2 displays the complete classification description obtained by applying conventional feature-fusion methods or tensor-based feature-fusion methods in the form of confusion matrices. Performance detail per beat is provided by these matrices. Considering that the average accuracy is changed according to dimension reduction, we obtain all of the results from the best experimental set with 16 dimensions to achieve unity and compare the results. Table 3 shows the results obtained using the different methods on the basis of the introduced evaluation criteria. In conventional methods, all of the features should be concatenated as a vector (107 × 16 = 1712) and then projected into a PCA subspace. In the tensor-based method, all of the features should be arranged as a two-way tensor (size of 107 × 16), and directly processed by GND-ICA.
Differences between proposed method and conventional methods should be quantified. A t-test is a statistical test that can be used to determine if two sets of groups are significantly different from each other. A p value is a parameter of t-test used to assess significant difference. In general, a p value equal to or less than 0.05 is regarded as a significant difference and less than 0.01 is considered a highly significant difference. In addition, smaller p value corresponds to greater significant difference between two groups. Table 4 shows the p value obtained from algorithm-labeled class (GND-ICA) and conventional-labeled classes (WPD, PCA). After the difference between GND-ICA and WPD is evaluated, a highly significant difference is found between S and V. After the difference between GND-ICA and PCA is evaluated, a highly significant difference is found between S and V; likewise, a significant difference is observed in N. Therefore, highly significant differences are observed between GND-ICA and WPD and between GND-ICA and PCA. This result indicates that the average accuracy of the proposed method is only less than 2 % higher than that of WPD or PCA. However, highly significant differences can be achieved in ECG heartbeats classification.
3.4 Computational efficiency
Computational efficiency is investigated using the computing time of the transformation matrix of the methods with 16 dimensions. In the multi-linear subspace-learning methods, tensor mode 1 is reduced to 16-D, and mode 2 is reduced to 1-D. In all of the training heartbeats, GND-ICA requires 9.73 s to calculate the transformation matrices. This time is considerably shorter than 19.59 s, which is required by PCA.
3.5 Comparison with state-of-the-art methods
The MIT-BIH arrhythmia database is the standard database used in current methods to evaluate performance. Therefore, a comprehensive summary of ECG heartbeat classifications is provided using this database (Table 5). In [26], temporal features (pre-RR-interval, post-RR-intervals, average RR-intervals, and local average RR-interval), and morphological features (ST-based, WT-based, and combinations) are extracted, and five classes (N, S, V, F, Q) are classified using a multilayer perceptron neural network classifier with an average accuracy of 97.5 %. Wavelet-transformed ECG waves with timing information are the feature of the two classes (normal and premature ventricular contractions) in [27]. The method achieves 95.16 % accuracy with neural network as a classifier. Hermite transform coefficients and the time interval between two neighboring R-peaks are used in [28] as features and input to the block-based neural networks for heartbeats classification, and the average accuracy is 96.6 %. Morphological-wavelet transform features reduced by PCA and temporal features are extracted in [29] at 95.58 % accuracy. A classifier is composed of feed-forward and fully connected artificial neural networks, which are improved by a multidimensional particle swarm optimization technique. Five types of heartbeats are classified in [30] using bispectrum features further reduced by PCA for dimension reduction. An average accuracy of 93.47 % is achieved using a least-square-support vector machine with a radial basis function.
4 Conclusions and discussion
ECG heartbeat classification is one of the most significant research fields in computer-aided diagnosis. A study of a feature-fusion method based on a multi-learning subspace-learning algorithm called GND-ICA for ECG heartbeat classification is proposed. The commonly used MIT-BIH arrhythmia database is employed in all of our experiments. ECG signals are segmented after baseline; high-frequency noise is removed and fiducial points are detected. Four groups labeled in the MIT-BIH arrhythmia database are selected and used in our classification study. These labeled ECG heartbeats include normal beats (N), supraventricular ectopic beats (S), ventricular ectopic beats (V), and fused normal and ventricular ectopic beats (F). Wavelet-packet decomposition, as a technique used to analyze the relationship between time and frequency information is also performed to extract features. Wavelet-packet coefficients extracted in the fourth level, which is composed of approximations and details, are used for further feature fusion. A total of 16 sets of coefficients with a size of 107 represent one ECG heartbeat simultaneously. In contrast to linear subspace-learning methods (PCA) in which all of the features should be transformed as a vector, multi-linear subspace-learning method (GND-ICA) can be used to process input data in a tensor form. Thus, 16 sets of coefficients features are further fused with GND-ICA by arranging them as a two-way tensor; in this technique, the factor inherent in the element of feature vectors and the factor among different features are considered. With SVM, the fused features are used to discriminate four different types of heartbeats. Five common evaluation criteria, including sensitivity, positive predictivity, accuracy, average accuracy, and t-test, are used to investigate classification performance. Based on the classification results, our conclusion is that performance of GND-ICA-based feature fusion is more distinguished than that of the linear subspace-learning method PCA. Furthermore, the computing time of the transformation matrices of GND-ICA is considerably shorter than that of conventional PCA. Thus, GND-ICA not only improves the classification time but also eliminates numerous redundant features, prevents the drawbacks of dimensionality.
References
S Mendis, P Puska, B Norrving, Global Atlas on cardiovascular disease prevention and control. World Health Organization, ISBN: 978 92 4 156437 3, 1-168 (2011).
M Javadi, R Ebrahimpour, A Sajedin, S Faridi, S Zakernejad, Improving ECG classification accuracy using an ensemble of neural network modules. PLoS one 6(10), e24386 (2011). doi:10.1371/journal.pone.0024386
M Llamedo, JP Martinez, Heartbeat classifier using feature selection driven by database generalization criteria. IEEE Trans. Biomed. Eng. 58(3), 616–625 (2011)
I Jekova, G Bortolan, I Christov, Assessment and comparison of different methods for heartbeat classification. Med. Eng. Phys. 30(2), 248–257 (2008)
LI Kuncheva, Combining pattern classifiers: methods and algorithms. John Wiley & Sons, ISBN: 978-0-471-21078-8, 1-376 (2004).
Y Kutlu, D Kuntalp, Feature extraction for ECG heartbeats using higher order statistics of WPD coefficients. Comput. Methods Programs Biomed. 105(3), 257–267 (2012)
T Mar, S Zaunseder, JP Martinez, M Llamedo, R Poll, Optimization of ECG classification by means of feature selection. IEEE Trans. Biomed. Eng. 58(8), 2168–2177 (2011)
RJ Martis, UR Acharya, CM Lim, ECG beat classification using PCA, LDA ICA and discrete wavelet transform. Biomed. Signal Process. Control 8(5), 437–448 (2013)
DN Ai, GF Duan, XH Han, YW Chen, Generalized N-dimensional independent component analysis and its application to multiple feature selection and fusion for image classification. Neurocomputing 103, 186–197 (2013)
P de Chazal, M O'Dwyer, RB Reilly, Automatic classification of heartbeats using ECG morphology and heartbeat interval features. IEEE Trans. Biomed. Eng. 51(7), 1196–1206 (2004)
MY Gokhale, DK Khanduja, Time domain signal analysis using wavelet packet decomposition approach. Int. J. Commun. Network Syst. Sci. 3(3), 321–329 (2010)
I Khalil, F Sufi, Real-time ECG data transmission with wavelet packet decomposition over wireless networks, International Conference on Intelligent Sensors. Sens. Networks Inf. Process. , E-ISBN 978-1-4244-2957-8, 267–272 (2008)
TG Kolda, BW Bader, Tensor decompositions and applications. SIAM Rev. 51(3), 455–500 (2009)
L de Lathauwer, B de Moor, J Vandewalle, On the best rank-1 and rank-(R1, R2, …, Rn) approximation of higher order tensors. SIAM J. Matrix Anal. Appl. 21(4), 1324–1342 (2000)
S Yan, D Xu, Q Yang, H Zhang et al., Multilinear discriminant analysis for face recognition. IEEE Trans. Image Process. 16(1), 212–220 (2007)
R Xu, YW Chen, Generalized N-dimensional principal component analysis (GND-PCA) and its application on construction of statistical appearance models for medical volumes with fewer samples. Neurocomputing 72(10), 2276–2287 (2009)
XH Han, YW Chen, X Ruan, Multilinear supervised neighborhood embedding of a local descriptor tensor for scene/object recognition. IEEE Trans. Image Process. 21(3), 1314–1326 (2012)
AJ Bell, TJ Sejnowski, An information-maximization approach to blind separation and blind deconvolution. Neural Comput. 7(6), 1129–1159 (1995)
BM Asl, SK Setarehdan, M Mohebbi, Support vector machine-based arrhythmia classification using reduced features of heart rate variability signal. Artif. Intell. Med. 44(1), 51–64 (2008)
RE Fan, PH Chen, CJ Lin, Working set selection using second order information for training SVM. J. Mach. Learn. Res. 6, 1889–1918 (2005)
GB Moody, RG Mark, The impact of the MIT-BIH arrhythmia database. IEEE Eng. Med. Biol. Mag. 20(3), 45–50 (2011)
AL Goldberger, LAN Amaral, L Glass, JM Hausdorff, PC Ivanov, RG Mark, JE Mietus, GB Moody, CK Peng, HE Stanley, Physiobank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals. Circulation 101(23), e215–e220 (2000)
B Mali, S Zulj, R Magjarevic, D Miklavcic, T Jarm, Matlab-based tool for ECG and HRV analysis. Biomed. Signal Process. Control 10, 108–116 (2014)
RJ Martis, UR Acharya, AK Ray, C Chakraborty, Application of higher order cumulants to ECG signals for the cardiac health diagnosis, Engineering in Medicine and Biology Society, EMBC, 2011 Annual International Conference of the IEEE, August 30 2011-September 3 2011, 1697–1700 (2011)
RO Duda, PE Hart, DG Stork, Pattern classification, 2nd edn. (John Wiley & Sons, New York, 2001)
MK Das, S Ari, ECG beats classification using mixture of features. Int. Scholarly Res. Not. 2014, Article ID 178436, 12 pages (2014)
OT Inan, L Giovangrandi, GTA Kovacs, Robust neural-network-based classification of premature ventricular contractions using wavelet transform and timing interval features. IEEE Trans. Biomed. Eng. 53(12), 2507–2515 (2006)
W Jiang, SG Kong, Block-based neural networks for personalized ECG signal classification. IEEE Trans. Neural Networks 18(6), 1750–1761 (2007)
T Ince, S Kiranyaz, M Gabbouj, A generic and robust system for automated patient-specific classification of ECG signals. IEEE Trans. Biomed. Eng. 56(5), 1415–1426 (2009)
RJ Martis, UR Acharya, KM Mandana, AK Ray, C Chakraborty, Cardiac decision making using higher order spectra. Biomed. Signal Process. Control 8(2), 193–203 (2013)
Acknowledgements
This work was supported by the National Basic Research Program of China (2013CB328806), the Key Projects in the National Science & Technology Pillar Program (2012BAI02B01), China Postdoctoral Science Foundation funded project (2014M560050).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit https://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ai, D., Yang, J., Wang, Z. et al. Fast multi-scale feature fusion for ECG heartbeat classification. EURASIP J. Adv. Signal Process. 2015, 46 (2015). https://doi.org/10.1186/s13634-015-0231-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-015-0231-0