
Abstract
Tie strength allows to classify social relationships and identify different types of them. For instance, social relationships can be classified as persistent and similar based respectively on the regularity with which they occur and the similarity among them. On the other hand, rare and somewhat similar relationships are random and cause noise in a social network, thus hiding the actual structure of the network and preventing an accurate analysis of it. In this article, we propose a method to handle social network data that exploits temporal features to improve the detection of communities by existing algorithms. By removing random relationships, we observe that social networks converge to a topology with more pure social relationships and better quality community structures.
Similar content being viewed by others

1 Introduction
Social networks may change their structure due to interactions among their members over time. Such networks, namely Dynamic Social Networks, can be represented by a temporal graph, in which the vertices represent their entities and the edges their interactions, associated with the time when they occurred. In general, the temporal network itself is used as input for specific algorithms that find communities by directly exploring its temporal dimension. Thus, the detection of communities in such networks differs from what is done in a static network, in which the temporal dimension is explicitly expressed (e.g., by weighting the edges) or simply ignored.
Many studies on community detection use static graphs due to the difficulty of considering the temporal dimension [1, 2]. However, most networks are not really static [1, 3], which means that not considering temporal dimension may cause loss of information with respect to the order and proximity of the interactions, i.e., the evolution pattern of the community structure is lost [2]. Therefore, this simplification causes informational noise in the social relations, which can lead to errors in the individuals’ membership in their respective communities. For example, consider a group of people who do not know each other and exchange many emails in a single day, but after that they do not communicate again. Now consider another group of people who exchange many messages regularly over years. Although the relationships between the members of both groups have the same topology when considering a static network, the temporal dimension allows one to differentiate the relationships and, consequently, the community structures involving these groups of people.
In fact, networks formed by aggregating interactions within a dynamic system are subject to a wide variety of noise. This means that an edge, i.e., a relationship, may be randomly established between pairs of vertices representing individuals with a low probability of interaction. This is the case of emails sent to a wrong address or when a contact is just added due to a facility offered by a social media [4]. However, randomness is also related to ephemeral relationships like, for example, casual contacts or coauthorships. On the other hand, considering real communities, a fundamental property shared by different definitionsFootnote 1 is the presence of real social relationships within a community, which are usually sustained over time. Thus, it is of paramount importance to consider the temporal dimension in the identification of true communities that are free from randomness and noise. Moreover, assessing how real a relationship is in a network is very important in order to get a high quality representation of its community structure [4].
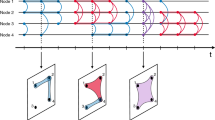
Figure 1 illustrates the role of the temporal dimension in the process of identifying communities. In Fig. 1a, we show the ego-network of researcher F. M. Petters formed from his coauthorship relationships. In this network, a vertex is a researcher and there is an edge between two vertices if they have coauthored a paper in the past. In Fig. 1b, we show the communities detected in this network by the Louvain algorithm [5]. In Fig. 1c, we show the same network after filtering random edges, which are, in this case, edges that are non persistent over years and that connect vertices with no or few neighbors in common. Observe in Fig. 1d that, when the Louvain algorithm is now applied to this network, the revealed community structure is strikingly different from that depicted in Fig. 1b. More important, we show later in this article that this community structure is more representative of the underlying social relationships among the vertices than the one detected without the filtering step.

Example of how noise from random edges may affect the detection of communities in social networks. a A network formed from the scientific collaborations of F. M. Petters from the American Physical Society. The vertices are researchers and there is an edge between two vertices if the respective researchers coauthored a paper in the past. b Communities detected by the Louvain algorithm [5] in the network depicted in a. c The same network after filtering random edges. d Communities detected by the Louvain algorithm in the filtered network, which are strikingly different from the ones depicted in b
In this context, the goal of this work is summarized by three research questions, as follows:
-
1.
How to identify and quantify relationships that cause noise in social networks by using only topological and temporal data from them?
-
2.
What is the effect of noise on the structure of networks from different domains? In other words, does the removal of noise improve the results of state-of-the-art community detection algorithms?
-
3.
How does the noise affect the structure of the communities detected by different algorithms?
To answer such questions, we mined social relationships from temporal networks. Thus, instead of developing new algorithms for detecting communities, we propose a method to favor those that already exist, but that explore minimal properties. Specifically, we propose a process that leverages community detection in static networks by measuring the strength of their ties. To do so, first we measure tie strength based just on topological and temporal data extracted from the social networks, thus allowing us to quantify the noise represented by weak and rare ties, i.e., random relationships. Then, we remove those random relationships from the static (aggregated) networks. The network resulting from this filtering process includes only social relationships, which makes its social structure more apparent, thus allowing us to measure the impact of noise on each network by means of different approaches.
Filtering noise from a network naturally implies an increase in modularityFootnote 2, which is a measure of the quality of a network structure in terms of existing modules (or communities). In a modular network, the connections between vertices are dense within modules (groups or communities) and sparse elsewhere. We show that our proposed method significantly increases the modularity of a network when it is applied together with existing state-of-the-art community detection algorithms.
Despite the absence of an algorithm that solves the problem of community detection [6] in a single manner, we are able to increase the consensus among several of those algorithms, i.e., the communities detected by them become more similar. Also, we show that the filtering step makes the detected communities more similar with their ground truths, when available. Therefore, the main contribution of this article is a social relationship mining process that allows improving the quality of communities detected by existing algorithms.
The rest of this article is organized as follows. Section 2 reviews related work. Next, Section 3 presents the social network models and the datasets used in the experiments, as well the community detection algorithms that we use for evaluating our proposed method. Then, Section 4 describes the proposed method for improving community detection, whereas Section 5 discusses the experimental results. Finally, Section 6 presents our main conclusions and discusses future work.
2 Related work
The goal of this section is to survey existing work related to tie strength (Section 2.1), link assessment (Section 2.2) and community detection (Section 2.3), as well as to present an overview of existing approaches commonly used to evaluate the effectiveness of community detection algorithms (Section 2.4).
2.1 Tie strength
Studies in distinct knowledge areas demonstrate how the strength of ties interferes in the structure of communities. In a seminal work, Granovetter [7] introduces the notion of tie strength in social networks and report how different types of relationship (weak and strong) impact individuals and organizations. The strength of ties aligns with the idea that the strongest links occur during a long period of time among people whose social circles tightly overlap with their own [7], which generally yields a high frequency of interaction [8]. Also, Burt [9] complements that structural factors such as network topology shape tie strength, whereas David et al. [8] present an overview of the theory linking the strength of ties to the formation of communities. Aligned with Granovetter’s studies, they reveal that weak ties serve to combine different cohesive communities composed by stronger ties.
In practice, simple metrics based on these ideas, such as frequency of interaction [8] and number of mutual friends [10], are commonly used to measure tie strength. Nevertheless, depending on the context, other factors can be considered when modelling tie strength [11–15]. Adamic et al. [14] consider information such as membership of mailing lists and use of common phrases on personal Web pages to measure the similarity between users (or tie strength). Brandão et al. [15] measure the strength of coauthorship ties based on topological properties of academic networks. Gilbert and Karahalios [11] propose a tie strength metric based on specific information extracted from Facebook, such as the number of days since the last communication and the number of words exchanged in Wall posts. Finally, Marsden et al. [12] use socioeconomic and demographic data to validate the quality of a measure of tie strength by different aspects. Although these authors use a prediction model, they show that the temporal aspect influences tie strength measurement.
Other factors have been considered to model tie strength [11–13]. However, the attributes required to apply a model are not always present on all vertices or edges of a network. This occurs, for example, because a network with sensitive or covert information cannot use all ties for this purpose [10]. These attributes may also be applicable in a limited way, for example, to networks of a specific domain. Besides, the high-dimensionality transforms excessively rich information into data that are algorithmically infeasible to collect, extract and use. Despite different dimensions and tie strength models, in practice, the simple ones have been commonly used to measure tie strength, such as frequency of interaction [11] and number of mutual friends [10].
In addition, the strength of a particular link may vary over time. Thus, considering the temporal aspect in the study of social interactions is important because it reveals properties and patterns that cannot be perceived when the information is aggregated. In fact, Holme and Saramäki [16] show how the temporal aspect can be represented in static graphs and demonstrate the implications of this mapping. Moreover, Vaz de Melo et al. [17] address the classification of relations based on temporal properties in mobility networks. Furthermore, Kossinets and Watts [18] consider the time dimension to make an empirical analysis of a social network built from e-mail exchanged among students, teachers and college staff. Such a study clarifies the importance of the temporal dimension to identify and distinguish factors that lead to the emergence, evolution and strength of relationships.
2.2 Link assessment
Usually, real social networks contain noise, i.e., links that do not reflect a real relationship. Such noisy links (especially, false-positives) change the real structure of a network and prevent its accurate analysis [4]. In this context, link assessment is the process of identifying noisy and non-noisy links by automatically inferring real world connections in a network [14]. In addition, this process provides potential applications in various situations, such as discovering, labeling and characterizing communities [4]. For example, Shi et al. [10] examine the effect of removing all non-transitive ties from two real social network datasets. Likewise, Ouyang and Jiang [19] filter out diverse networks to improve accuracy in predicting links. Moreover, Spitz et al. [20] use distinct metrics to assess links and identify random interactions over static biological networks. Differently, Klymko et al. [21] propose an approach that consists in adding the weight dimension based on the number of triangles of static and directed networks. This approach generates an undirected network that can be used by community detection algorithms that take advantage of weighted edges.
In general, current works that propose a method to remove noise to improve the quality of communities detected by existing techniques face the following limitations:
-
(i)
rely on a single definition of community structure, which means finding the partitions of its vertices by maximizing modularity;
-
(ii)
consider static graphs as input or output;
-
(iii)
apply only to few and small networks.
In addition, such works evaluate the improvement in the community structures by using a small set of community detection algorithms. Hence, a biased interpretation of the results is likely to occur.
To the best of our knowledge, the work of Wen et al. [22] is the one closest to ours. In this case, the authors use a distinct concept of noise, which is based on the presence of “violators”, i.e., vertices that are characterized by the largest degree. Therefore, they do not filter any noise caused by edges connecting “non-violator vertices”. Furthermore, they use only the concept of modularity to evaluate the effectiveness of their filter in communities that have been detected in two static networks by two distinct algorithms. Thus, their results are evaluated by using a single metric. In addition, their analysis does not present an interpretation of the removal criterion.
2.3 Community detection
In complex networks, a community can be seen as a group of densely interconnected vertices that are sparsely connected with the rest of the network [23–25, 77]. This is not the only existing definition of community. For instance, Wang and Hopcroft [26] characterize communities as a set of entities that, in addition to being more connected than expectedFootnote 3, they can also be well connected to the rest of the network. Moreover, Abrahao et al. [77] and Fortunato [75] demonstrate that the structure of a community is difficult to define, quantify and extract because there is no universally accepted definition of this concept.
There are many approaches for detecting communities in networks [5, 24, 27, 28, 77, 79]. Abrahao et al. [77] and Xie et al. [29] present a comprehensive analysis of the properties of communities detected by several algorithms. They show that the detected communities and their properties vary consistently across algorithms. In these two works and in many others on community extraction, only the static relationships are analyzed [30]. However, real social networks can have other types of relationship (such as strong or weak) and multiple layers [31, 32]. For instance, time-varying networks are multilayer and describe a wide variety of systems whose entities and interactions evolve over time. Some works address the temporal aspect in mobile Wi-Fi networks [17], in which the vertices represent users and the edges access points over time. Likewise, other works address scientific collaboration networks, where vertices represent researchers and edges model their temporally aggregated coauthorship interactions [33, 34].
Nevertheless, some community detection algorithms have been applied over temporal networks [35–41], which represent snapshots as a sequence of static graphs. In this case, the usual approaches detect communities in each snapshot independently [41] or iteratively [40]. Other algorithms consider the temporal aspect to identify dynamic communities by globally detecting them in all snapshots [37, 38]. Unfortunately, community detection approaches that exploit temporal aspects still comprise a very small part of current work when compared to those based on static networks.
2.4 Evaluation
Different approaches can be used to evaluate the performance of community detection algorithms. In fact, depending on the task, some approaches may be more appropriate than others. For instance, Almeida et al. [42, 43] show that some popular evaluation metrics, such as modularity and conductance, turned out to be biased when applied to large communities. They also claim that there is not a “best” metric for graph cluster evaluation and show that an evaluation approach based on the optimization of a single metric is not enough. This reveals the importance of using different metrics that complement each other, making it easier to interpret and validate the measurements.
Probably the most used metric to evaluate community detection algorithms is modularity. Such a metric has been largely used to compare the quality of community detection algorithms in different networks [3, 28, 44–49, 75, 78, 79]. In addition, many community detection algorithms use modularity as a metric to be maximized in the detection process [27, 50–52]. However, the interpretation of modularity should be done carefully, since its resolution limit is determined by the community size [53].
Conductance [54] is another widely used metric to evaluate the quality of the communities found by community detection algorithms. Given a graph G(V,E) and a cut S over G, conductance measures the quality of S or, more specifically, how well S separates G. In doing so, sets of vertices, i.e., communities, with small conductance values are those that are densely linked inside and sparsely linked outside and, therefore, are considered good quality communities. Based on conductance, Leskovec et al. [55] defined the Network Community Profile (NCP) that allows one to get the best possible cluster of k vertices and estimate the community structure in large real-world networks.
In particular cases, it is possible to evaluate the quality of the detected communities by comparing them with a ground truth [56]. In this case, Danon [57], Dongen [58] and Rand [59] propose, respectively, the metrics Normalized Mutual Information, Split Join Distance and Rand Index to verify the similarity between the detected communities and a given ground truth. The Normalized Mutual Information is a similarity metric from information theory that is based on the mutual dependence between the entropy associated to an identified community and that of a ground truth. The Split Join Distance measures the overlaps between sets of two partitions. Finally, the Rand Index allows one to measure the ratio of the number of agreements and the number of disagreements between two partitions.
In this work, we propose a new method to filter random relationships that cause noisy and evaluate the improvements obtained by applying it to the task of community detection. In addition, we use some of the most common metrics in the literature, such as modularity and conductance, to compare the quality of the communities detected before and after the application of our method. Notice that these two metrics allow a diversification of the evaluation approaches and avoid bias [43]. Moreover, the quality of the detected communities is also evaluated by means of the three aforementioned metrics that compare the similarity of the detected communities with their ground truths. Thus, our proposed method is exposed to a robust evaluation process that reveals the amount of improvement that has been achieved by the communities detected in the filtered networks. Therefore, our work differs from existing ones by not only detecting communities [5, 27, 49, 77, 78], but also by investigating how mining social relationships influence the quality (evaluated by distinct approaches) of the results provided by such algorithms.
3 Materials and methods
Vertices in real-world networks are usually organized in communities. In turn, such communities tend to persist over time and their detection is one of the most popular and relevant tasks in network science [60, 61, 75]. Thus, numerous techniques and tools are available for this task, mainly for static social networks. Conversely, in this work we leverage temporal properties of social networks to improve the quality of communities detected by traditional methods. The general idea behind our proposed method is to remove from a network the set of interactions that cause noise in the structure of the communities. Then, the resulting network is mapped to a static graph, allowing one to evaluate the quality of the process by comparing its results with those obtained without using the social relationship mining process.
3.1 Our model and the networks used
The community detection problem can be summarized in the following way. Given a non-directed graph G = (V,E), where V={v1,...,vn} is the set of vertices and E= {e1,...,em} is the set of edges representing the interactions between two vertices, the community detection problem consists of finding the set of non-overlapping communities C={c1,c2,...,ck} in which each vertex vi is associated with a community ci∈C.
Considering a dynamic scenario, in which vertices interact with each other over time, it is possible to construct temporal graphs from interaction windows. More specifically, each temporal graph Gκ=(Vκ,Eκ) in G represents the aggregation of interactions in discrete periods of time κ. Thus, for a given value of κ, Vκ includes all vertices that interacted in the κth period of time. The edges in the set Eκ represent the interactions between pairs of vertex (vi,vj) that occurred during the time period κ
Here, we apply this temporal graph model to real social networks of scientific collaborations in the period 2000-2016, built from APS, DBLP and PubMed datasetsFootnote 4 [15], university campus mobility networks from Dartmouth College and USC [17], and an e-mail network derived from communications among Enron’s employees from 1999 to 2003Footnote 5. Table 1 presents a general characterization of these networks. In the collaboration social networks, vertices represent researchers and there is an edge between two researchers if they have coauthored a paper together. In the mobility networks, vertices represent members of a university community (e.g., students or faculty members) and there is an edge between two individuals if they have been both connected to a given Wi-Fi access point at the same time. Finally, in the e-mail network, vertices are employees from Enron and there is an edge between them if they have exchanged e-mails.
3.2 Community detection algorithms
Based on the state-of-the-art in community detection, we selected the algorithms listed in Table 2. Our goal is to evaluate the performance of these algorithms before and after our proposed filtering method is applied. These algorithms are briefly described nextFootnote 6.
Edge Betweenness. This algorithm discovers communities in networks by partitioning vertices into densely connected subgroups [79]. It is based on the iterative removal of network edges according to their betweenness value, which is recalculated after each removal. In short, the edge betweenness is a measure of the centrality of an edge in a network that is based on the number of shortest paths that pass through that given edge. The strategy is to first remove the most central edges, which are the few ones that join the largest communities.
Greedy Optimization of Modularity. This algorithm is based on the maximization of the modularity and uses a greedy approach [27]. In a first step, it identifies a hierarchical structure of communities. Then, a partition on the hierarchy is done in order to globally maximize modularity.
Infomap. This algorithm discovers communities by applying the Random Walk technique to map the flow of information through a network. Infomap aggregates in a community a group of vertices through which information flows quickly and easily among them [62].
Label Propagation. It is a stochastic algorithm for community detection based on the propagation of labels between vertices. Each vertice is randomly initialized with a label. Then, the vertices have their labels iteratively replaced by the one that most of its neighbors have. In this way, densely connected groups form a consensus on their labels indicating that they participate in the same community [28].
Leading Eigenvector. This algorithm separates the vertices into communities considering the eigenvector of the modularity matrix of the graph [63, 78]. The modularity matrix plays a role in community detection similar to what is done by using a Laplacian matrix in the partitioning of a graph. Different signs of the elements in the eigenvector determine distinct communities or, on the contrary, that there is no underlying community structure.
Louvain Modularity. This is a greedy algorithm for modularity optimization that works in two steps to build a hierarchical structure of communities. First, it clusters the neighboring vertices into “small” communities in order to optimize modularity locally. Then, it constructs the hierarchical structure by aggregating each cluster of vertices in a vertice of a new graph [5, 77].
Walktrap. This is an agglomerative algorithm to compute the community structure of a network based on a similarity metric among vertices. This metric is also based on random walks, which naturally captures the community structure of a network, and can be efficiently computed [64].
All experiments were replicated because of the variability associated with runtime and the estimations of values obtained by non-deterministic algorithms. In particular, due to their complexity, two community detection algorithms, Edge Betweenness (EB) and Walktrap (WT), could not have their replications recorded or did not finish within a time limit, as shown in Fig. 2. Because of that, these two algorithms are not considered in our experiments described in Section 5.

Number of executions for each algorithm on each network instance. Note that more intense colors indicate a higher number of executions, and vice-versa
3.3 Community detection evaluation
The evaluation of the community detection algorithms was performed as follows. Initially, from the sequence of interactions among the entities, we constructed an aggregated static graph. Then, we executed each algorithm on this graph and evaluated the quality of the detected communities using three different evaluation strategies (modularity, conductance and ground truth). After that, we used our proposed filtering strategy to remove random interactions from the sequence of interactions and constructed another aggregated static graph from themFootnote 7. Finally, we executed and evaluated again all algorithms over this new filtered graph.
In addition, we analyzed the results of the communities obtained from a graph constructed by a null filtering model, which randomly removes edges from the original network until it reaches the size of the filtered network. Given a complete graph G with n vertices and m edges, and the number k of edges to be removed in the stochastic filtering, each edge mi is removed from the graph with the probability p until to achieve k edges. At the end, all disconnected vertices are removed from G. The resulting graph Ga is then used to compare the results achieved by our proposed method with those of the stochastic edge removal method.
Regarding the evaluation strategies, the modularity metric chosen is the most used to evaluate community detection algorithms [75]. Furthermore, such a metric is used as the objective function for the community detection problem by most algorithms [5, 24, 27, 28]. To better understand the structure of the communities found by the algorithms, we also used the conductance metric, which is a widely-adopted notion of community quality [26, 55, 56]. The conductance measures the quality of the cut between a set of vertices and the rest of the network as the proportion of the number of edges outside the community (inter-cluster conductance) and the number of edges inside the community (intra-cluster conductance) [26, 43].
Another approach to evaluate improvements in the quality of the detected communities is to compare them with existing network ground truths [6]. According to Yang and Leskovec [54], a ground truth is built upon particular features of the application domain (e.g., department affiliation), which makes it possible to divide its entities into specific groups. However, obtaining a ground truth to evaluate the quality of community detection algorithms is not an easy task, because it is necessary to have data that describes the natural topology of the communities in order to make sense to compare them with the results provided by such algorithms. Furthermore, there is not a consensus whether the evaluation with a ground truth is adequate for real datasets or only for synthetic ones, exactly because of the difficulty to build a ground truth for those datasets. Thus, we were able to build a ground truth only for the APS dataset, since it was possible to explicitly assign a specific research area to each journal. Notice that DBLP and PubMed do not provide any explicit information on the research area of their publication venues. For the other datasets, we did not find a way to build a ground truth that could be compared with the results of the algorithms.
Given a graph G, a ground truth P(G) and a set of identified communities C(G), similarity metrics applied to communities are able to estimate the similarity between C(G) and P(G). Thus, we selected three metrics commonly used to measure the similarity between C(G) and P(G) [56], which are described next.
Normalized Mutual Information. This metric is based on a confusion matrix, in which the rows correspond to the ground truth and the columns correspond to the detected communities [57, 65]. It is defined as follows:
where H is the entropy function, and X and Y are random variables associated to an identified community and the ground truth, respectively. It ranges from 0 to 1 (when the compared communities are identical).
Split Join Distance. This metric is the sum of the projection distance between partitions A and B, being defined, according to Dongen [58], as:
where |a∩b| denotes the number of common members (overlap) between any subset a∈A and b∈B [56].
Rand Index. This metric measures the similarity between two network clusters and has been largely used to evaluate how similar a detected community is regarding a ground truth [26, 64, 66, 67]. For this, the number of pairs of vertices correctly classified (true positives and true negatives) in both clusters is divided by the total number of pairs [59]. It gives a result between 0 and 1, where 0 indicates that the two clusters do not agree on any pair of points and 1 indicates that they are exactly the same [56].
In scientific collaboration networks, communities are usually identified by the venues in which the researchers predominantly publish. Thus, in order to identify such venues, we extracted the journal identifiers of the published articles from the APS network. Next, we labeled the researchers based on the predominant journal in their list of publications. Note that the predominant journal is the one in which a researcher publishes most frequently. In order to exemplify an evaluation carried out by using a ground truth, we present here an analysis for the APS collaboration network. The ground truth for such a network is briefly characterized in Table 3. We recall that the ground truth evaluation was made only for such a network, due to the difficulty to generate a ground truth for the other five datasets (PubMed, DBLP, Darthmouth, USC and Enron).
Figure 3a shows the layout of the APS network, where the color of each vertice identifies a specific journal. Moreover, note that the network seems to be splitted into two large partitions when we consider a superficial view of the APS network ground truth. However, Fig. 3b, which shows two distinct zoomed portions of the graph in Fig. 3a, reveals that vertices from different real communities are not in the same moduleFootnote 8 as observed through the network when compared to the modules in Fig. 3c. This characteristic is due to the diversity of areas in which Physics researchers publish. Moreover, this leads to a low similarity between the static topology of the network and the area in which each researcher predominantly publishes. The apparent dissimilarity is confirmed by the low values of most similarity measures when comparing the detected communities and the APS network ground truth (GT), as shown by Fig. 4. The modularity values and the expressive discrepancy among the number of detected communities shown in Table 4 (second and third lines, respectively) also reinforce the difference between the topological communities and the real ones shown in Fig. 3c.

Structural layout of the APS Physics network (Force Atlas): a ground truth of the identified communities (the top 10 largest communities correspond to 100% of the vertices); b the embedded subgraphs of the ground truth; c the communities detected by the Louvain algorithm [5] (top 10 largest communities correspond to 98% of the vertices)

APS Physics network ground truth (GT) compared to the detected communities
Despite the lack of similarity between the detected communities and the ground truth in the APS network, we shall see in Section 5 that noise removal provides a significant improvement in the quality of the detected communities. This improvement can be measured and further analyzed by comparing the similarity levels found in the initial characterization with those from the filtered network.
4 Mining social relationships
In this section, we detail the process proposed for mining social relationships from existing networks. The main idea behind this process is to remove from a network the noise caused by the presence of random interactions. Thus, our main aim is to reduce errors when associating vertices to communities. More formally, we consider a scenario composed of a set of n entities V={v1,v2,…,vn} and an ordered sequence of m interactions E={e1,e2,…em} (e.g., e-mail exchanges) among the entities of V. The kth interaction in E is a tuple ek=(τ,vi,vj), where τ is the time the interaction occurred, and vi and vj are the entities that interacted with each other. The usual approach to detect communities in such a scenario is to construct an aggregated graph from the interactions in E and use this graph as input to any community detection algorithm. Our hypothesis is that if we are able to identify pairs of vertices vi and vj that are occasionally relate (or are very unlikely to interact in the future), we can remove all interactions between them before constructing the aggregate graph, thus improving the quality of the detected communities.
Figure 5 details the main steps that summarize our social relationship mining process, which are: (i) characterization of the strength of the relationships from the stream of interactions, (ii) removal of the random relationships and (iii) reconstruction of the static graph that will be used as input to a community detection algorithm. It is important to note that some techniques for tie strength characterization from a sequence of interactions may produce different results when the filtered sequence of interactions is used as input for a second time. Because of that, after step (iii), step (i) may be performed again using the filtered graph S as input. This cycle stops when step (ii) does not remove any more relationship. Thus, when there are no more random relationships, we obtain a static graph that is composed of only social relationships. Our other hypothesis is that such a static graph allows for more representative communities to be detected by community detection algorithms.

Overview of the social relationship mining process that results in a filtered static graph S for the community detection task. Source (adapted): Leão et al. [81]

Algorithm 1 summarizes the main steps of our process for mining social relationships, which takes as input a sequence of interactions. At each iteration of the algorithm, relationships are classified (line 4), resulting in a simple graph with labeled edges Gc=(Vc,Ec,ℓ). An edge (vi,vj) is labeled as random or social. Note that the function filter (line 5) builds two edge-induced subgraphs from Gc: S=(VS,ES) and R=(VR,ER), where S is the filtered network and R is the residual network. Each edge-induced subgraph includes a subset of the edges of the graph Gc, which contains the vertices of VS that are in their endpoints. Then, the convergence check is performed (line 6) and, if there are still random-labeled edges to be removed, the function convert constructs the temporal graph Ti+1 from Ti (line 9).
For the purpose of this work, we use the RECAST classifier [17] to identify random and social interactions. RECAST classifies relationships (edges in a graph) by assigning a label to each pair of vertices in the graph. Topological and temporal aspects are considered to measure the strength of the edges and then determine which label will be assigned to each relation. Table 5 details each label and their characteristics. For instance, a relationship receives a label “Friend” if the pair of individuals in such a relation have many common friends and regularly interact over time.
RECAST is based on sociological studies that revealed that the topology in which pairs (vi,vj) of individuals are involved suggests the strength of the relation between them [7]. In this work, this kind of strength is calculated by the neighborhood overlap metric (NO), also known as the Jaccard Index [68]. Equation 3 shows how this metric is calculated. As we can see, NO is calculated by dividing the number of neighbors (Ni and Nj, respectively) that are common to pairs of vertices (vi,vj) by the total number of neighbors of both vertices [8].
In addition, the persistence P of the relationships can be used to measure tie strength. Such a metric represents the regularity of the interactions between pairs of vertices vi and vj [17]. This regularity is given by the sum of the time intervals in which at least one interaction occurs as given by Eq. 4, in which εκ represents the set of interactions that have occurred over the time interval κ.
Finally, RECAST has a single parameter, namely p_rand, which assumes values between 0 and 1. This parameter determines the probability of an edge being classified as social by chance, i.e., it is associated with the error rate of the classifier. If p_rand=1, then all relationships are classified as social. Thus, smaller values for p_rand generally lead to more relationships classified as random, which, in turn, may lead to denser communities when this relationships are removed from the aggregated static graph. Figure 6 shows the impact of p_rand in the modularity metric. The value of this parameter, which maximizes the community structure, varies in different networks. Thus, the calibration of this parameter is necessary in order to consider as an objective function another quality metric besides modularity or the amount of removed noise.

Value of p_rand due to the modularity of the communities in each network
5 Experimental results
This section presents the communities obtained by applying the selected algorithms in the six social networks. Note that we show the results for the original social networks and also for the filtered ones, i.e., those generated after the complete removal of random relationships. For a given metric, the ratio between its value in the filtered network and its value in the noisy network represents the percentage of change with respect to this metric. Table 6 shows the percentage of changes for different topological metrics in each network considered, which indicates how much noise has interfered in the characterization of the social networks.
By analyzing each social network separately in Fig. 7, it is possible to distinguish them by the total amount of random relationships. Mobility and communication networks are those with the highest proportion of random relationships. In addition, most of their relationships are classified as random (see column ER in Table 6). As a consequence, vertices that have all their relations classified as random are disconnected from the network because they do not correspond to members of any community. This means that the individuals represented by these disconnected vertices do not socially participate in any community [69].

Relationship classes at the end of each convergence iteration of the social relationship mining process
Figure 7 also shows that, for most of the networks, the random relationships were removed with few iterations (five or less), except in the case of the USC network that required 10 iterations. The maximum degree of the social networks was also affected in the inverse proportion to the amount of noise removed. Also, the degree of the hubs was reduced more than the degree of the other vertices in the network.
Another topological property that became more explicit in the networks after noise removal was the tendency to form groups, as measured by the cluster coefficient. As shown in Table 6, the global clustering coefficient CC has not changed or increased, even for networks that became sparse after noise removalFootnote 9.
Also, after the removal of random relationships at each iteration of the social relationship mining process, there was a significant increase in the modularity of the communities detected in each network by all algorithms, except the Leading Eigenvector, as shown in Fig. 8. Furthermore, it should be noticed that the structure of the random-edge induced subgraph R (formed only by random edges) of the network Gc is weakly modular when compared to the structure of the original network as a whole.

Modularity of the communities in the original network, in the network generated by the stochastic process of edge removal (null model) and in the network filtered until the last iteration of the social relationship mining process
The structures of the filtered network S and of the residual network R are exemplified by the Dartmouth network in Fig. 9d. The Dartmouth network had originally a high tendency to form modules and gained in modularity in just one iteration of the random relationship removal step. Although the gain in modularity after one iteration of the social relationship mining process is of only 2%, visually the modules are more clearly identified in Fig. 9. Moreover, the communities detected by the Louvain algorithm in the original network C(Got) (Fig. 9a) are not exactly the same in the filtered network C(S) (Fig. 9e).

Set of vertices (V), edges (E* represents relationships) and communities (C), and the modularity measure (M) of the Dartmouth network in different steps that compose an iteration of the social relationship mining process: a original network; b communities detected by the Louvain algorithm; c edges classified by RECAST; d noise only (random-edge induced subgraph R); e only the social relationships of the network (social-edge induced subgraph S). The colors of the vertices represent the communities they belong to and the colors of the edges represent the corresponding relationship classes
Looking at the filtered network S (Fig. 9e), it is possible to identify the emergence of new communities, being most of them isolated, i.e., they correspond to disconnected subgraphs. In other cases, a group of vertices was detected as a community due to the presence of noise. After being filtered, some of these groups had all their edges removed because they were identified as random and, consequently, their vertices are now disconnected, forming what is called random communities. Random communities are most notable in the Enron, Dartmouth and USC networks, which are also the ones with the highest proportion of random relationships (see Table 6). Due to the removal of these communities, the structure of such networks has undergone more significant changes.
Table 7 shows, for each algorithm and each dataset, the number of detected communities before and after noise removal. As we can see, for all networks, except the Enron, there has been an increase in this number after noise removal. More important, this number is more similar to each other for most datasets. In other words, the standard deviation for all networks but one (Dartmouth) is much smaller after noise removal.
In addition to the reduction in the number of vertices (Table 6), the increase in the number of new communities has resulted in a reduction in their average size. This observation is also confirmed by the characterization of the best community size scale over a range of possibilities obtained by the Network Community Profile (NCP) [55] as presented in Fig. 10. The conductance metric has a tendency to give better scores for groupings with a smaller number of groups (since more groups are likely to have more cut edges) [43, 56]. Even with the increase in the number of communities, an improvement in the conductance is obtained after filtering random relations. Different gains in improvement have been verified in all networks and can be observed in the APS network example presented in Fig. 10. It can also be observed that the ideal community size that optimizes the conductance is smaller in the filtered network and is, therefore, more similar to real communities [55]. This also reinforces the perception that the community structure at a more granular level best represents the structure of a non-noise network.

Conductance in the APS network for different community sizes
Notice that the conductance and modularity metrics have some structural bias towards giving better results for a smaller number of clusters [43]. Thus, the best results for both metrics occur in a context opposite to what leads to bias because there is an increase in the number of communities after the network is filtered. Moreover, to evaluate the improvements in the quality of the detected communities, we also use three similarity metrics to compare the clusters [56]. Such a comparison was made between the communities of the original network C(Got), the communities of the filtered network C(S) and the ground truth P(G).
The APS network originally presents a high overlap of researchers from distinct areas (Table 3), low modularity of their real communities, and low similarity between these communities and the detected ones. Despite this, significant improvements have been achieved in all of these aspects after the APS network was filtered. Table 8 presents the percentage of gain for all the metrics. This gain is positive for most of the community detection algorithms, i.e., the detected communities have approximated to the real ones after the network has been filtered. Thus, even considering only the APS network, the comparison with the ground truth revealed that our social relationship mining process is able to provide very effective results.
Besides providing a gain of similarity between the network and the ground truth, our social relationship mining process also allows the convergence of the community structure, as shown in Fig. 11. This convergence indicates how much randomness affects a consensus among the diversity of community structure definitions. By removing the noise, we were able to increase the consensus among the algorithms on which communities should be detected. Likewise, such communities have become more similar to the ground truth based on distinct similarity metrics.

Similarity (upper value) between each detected community and its ground truth. The gain after the application of the social relationship mining process is shown below of each similarity value. For the Normalized Mutual Information and the Rand Index metrics a positive gain means increase in similarity. A reduction in the values obtained by the Split Join metric expresses an improvement in the similarity between the detected communities and their ground truths
Finally, the results for the modularity and conductance metrics in all datasets reveal improvements for the detected communities when random relationships were removed. Regarding the lack of similarity between the detected communities and the APS ground truth, we notice that this was already expected due to the large difference between such communities and those derived from specific metadata (e.g., the researchers’ areas of interest), as explained by Hric et al. [70].
6 Conclusions and future work
The main contribution of this article is the proposal of a method for removing noise from temporal social networks. This method is based on the classification of random relationships and the construction of a static graph composed only of social relationships. To evaluate our method, we applied it to six real temporal networks from three different domains (scientific collaboration, communication and mobility), and then assessed the quality of their resulting structures.
In order to answer our first research question (“How to identify and quantify relationships that cause noise in social networks by using only topological and temporal data from them?”), we note that our method relies on the Granovetter’s “strength of the ties” principle to classify relations as social or random, which means that a relationship is said to be social when the number of common neighbors associated to its pair of vertices is high or these vertices interact regularly. On the other hand, a relationship is classified as random when its both vertices connect to few common neighbors or interact very rarely.
The application of our method converged by removing noise from all six social networks considered in our experiments. Furthermore, regarding the second and third research questions (“What is the effect of noise on the structure of networks from different domains?” and “How does the noise affect the structure of the communities detected by different algorithms?”), our results revealed improvements in the communities detected by the state-of-the-art algorithms when compared with those obtained without using our method. In addition, we have experimentally showed that the amount of noise in social networks negatively affects the task of community detection, as this contributes to errors in the structure of the detected communities.
Specifically, after applying our noisy removal method, the results revealed the following: (i) most of the community detection algorithms have been able to found more communities, which indicates that noise may be responsible for wrongly attracting vertices to a community; (ii) a gain in modularity and conductance for all considered algorithms; and (iii) a significant improvement in the quality of the detected communities as showed by the ground truth evaluation in the APS network.
Although our method was applied only to temporal networks and makes use of topological properties to classify tie strength, it can also be used with other kinds of predictive variables in this task. Ideally, for the purposes of this work, tie strength should be modeled by social relation properties assessed by sociological studies, representing characteristics available in the field of the application. In tie strength evaluation, even though different quality metrics can be considered, it is necessary to interpret the results and compare them with ground truths to understand the effectiveness and limitations of this model. Therefore, the continuity of this work involves the application of our method using different alternatives to measure the strength of ties.
Thus, as future work we plan to better interpret the topological changes occurred in the social networks considering their respective fields of application. For example, vertices that have had their relationship classified as random can be analyzed qualitatively in order to explain the properties that are associated or correlated with randomness and other classes of relationship.
In addition, we intend to validate our method by adopting other approaches for community detection and considering additional algorithms such as those that explore temporal aspects or identify overlapping communities [76]. Future work also includes the use of new strategies proposed by Leão [71] for evaluating filtered networks. Among these strategies are the use of synthetic data and the comparison with other methods for network filtering.
Notes
According to Wang and Hopcroft [26], a community is a densely connected subset of a network in which the probability that there is an edge between two randomly selected vertices is above the average.
APS (http://www.aps.org/): collaboration network of the American Physical Society; PubMed (https://www.ncbi.nlm.nih.gov/pubmed): collaboration network from MEDLINE articles; DBLP (http://dblp.org/): collaboration network from DBLP computer science conferences.
Enron email dataset: https://www.cs.cmu.edu/~./enron
Some algorithms did not run within a reasonable time on the largest datasets. Thus, the combinations of these algorithms and datasets are not considered in our analysis.
Datasets and source code available at http://cnet.jcloud.net.br/
In this context, a module is a community that is characterized by high modularity.
Real networks are usually sparse with the number of edges increasing linearly with the number of vertices [80]
References
Holme P. Modern temporal network theory: a colloquium. Eur Phys J B. 2015; 88(9):234.
Greene D, Doyle D, Cunningham P. Tracking the Evolution of Communities in Dynamic Social Networks. In: Proceedings of the International Conference on Advances in Social Networks Analysis and Mining, 2010. Washington DC: IEEE: 2010. p. 176–183.
Orke RG, Maillard P, Schumm A, Staudt C, Wagner D, Görke R, Maillard P, Schumm A, Staudt C, Wagner D. Dynamic graph clustering combining modularity and smoothness. J Exp Algorithmics. 2013; 18(1):1.
Abufouda M, Zweig KA. Are We Really Friends?: Link Assessment in Social Networks Using Multiple Associated Interaction Networks. In: Proceedings of the 24th International Conference on World Wide Web, Companion Volume. New York: ACM: 2015. p. 771–6.
Blondel VD, Guillaume JL, Lambiotte R, Lefebvre E. Fast unfolding of communities in large networks. J Stat Mech Theory Exp. 2008; 2008(10):P10008.
Peel L, Larremore DB, Clauset A. The ground truth about metadata and community detection in networks. Sci Adv. 2017;3(5).
Granovetter MS. The Strength of Weak Ties. Am J Sociol. 1973; 78(6):1360.
David E, Jon K, Easley D, Kleinberg J. Networks, Crowds, and Markets: Reasoning About a Highly Connected World. New York: Cambridge University Press; 2010.
Burt RS. Structural Holes the social structure of competition. Explor Econ Sociol. 1992; 65:103.
Shi X, Adamic LA, Strauss MJ. Networks of strong ties. Physica A: Stat Mech Appl. 2007; 378(1):33.
Gilbert E, Karahalios K. Predicting Tie Strength with Social Media. In: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. New York: ACM: 2009. p. 211–220.
Marsden PV, Campbell KE. Measuring Tie Strength. Soc Forces. 1984; 63(2):482.
Huang H, Dong Y, Tang J, Yang H, Chawla NV, Fu X. Will Triadic Closure Strengthen Ties in Social Networks?. ACM Trans Knowl Discov Data. 2018; 12(3):30:1.
Adamic LA, Adar E. Friends and neighbors on the Web. Soc Netw. 2003; 25(3):211.
Brandão MA, Moro MM. The strength of co-authorship ties through different topological properties. J Braz Comput Soc. 2017; 23(1):5.
Holme P, Saramäki J. Temporal networks. Phys Rep. 2012; 519(3):97.
Vaz de Melo POS, Viana AC, Fiore M, Jaffrès-Runser K, Mouël FL, Loureiro AAF, Addepalli L, Guangshuo C. RECAST: Telling Apart Social and Random Relationships in Dynamic Networks. Perform Eval. 2015; 87:19.
Kossinets G, Watts DJ. Empirical Analysis of an Evolving Social Network. Science. 2006; 311(5757):88.
Ouyang B, Jiang L, Teng Z. A Noise-Filtering Method for Link Prediction in Complex Networks. PLoS ONE. 2016; 11(1):1.
Spitz A, Gimmler A, Stoeck T, Zweig KA, Horvát EÁ. Assessing Low-Intensity Relationships in Complex Networks. PLoS ONE. 2016; 11(4):e0152536.
Klymko C, Gleich DF, Kolda TG. Using Triangles to Improve Community Detection in Directed Networks. CoRR. 2014; abs/1404.5874.
Wen H, Leicht EA, D’Souza RM. Improving community detection in networks by targeted node removal. Phys Rev E. 2011; 83:016114.
Brandão MA, Moro MM. Social professional networks: A survey and taxonomy. Comput Commun. 2017; 100:20.
Newman MEJ. Detecting community structure in networks. Eur Phys J B. 2004; 38(2):321.
Aktunc R, Toroslu IH, Ozer M, Davulcu H. A Dynamic Modularity Based Community Detection Algorithm for Large-scale Networks: DSLM. Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. 2015; 70 article 066111:1177–83.
Wang L, Hopcroft J. Community Structure in Large Complex Networks. In: International Conference on Theory and Applications of Models of Computation. Berlin: Springer: 2010. p. 455–466.
Clauset A, Newman MEJ, Moore C. Finding community structure in very large networks. Phys Rev E. 2004; 70:066111.
Raghavan UN, Albert R, Kumara S. Near linear time algorithm to detect community structures in large-scale networks. Phys Rev E. 2007; 76(3):1.
Xie J, Kelley S, Szymanski BK. Overlapping Community Detection in Networks : The State-of-the-Art and Comparative Study. ACM Comput Surv. 2013; 45(4):43.
Leskovec J, Kleinberg J, Faloutsos C. Graph Evolution : Densification and Shrinking Diameters. ACM Trans Knowl Discov Data. 2007; 1(1):2.
Kawadia V, Sreenivasan S. Sequential detection of temporal communities by estrangement confinement. Sci Rep. 2012; 2:794.
Bassett DS, Porter MA, Wymbs NF, Grafton ST, Carlson JM, Mucha PJ. Robust detection of dynamic community structure in networks. Chaos. 2013; 23(1):2.
Alves BL, Benevenuto F, Laender AHF. The Role of Research Leaders on the Evolution of Scientific Communities. In: Proceedings of the 22nd International Conference on World Wide Web, Companion Volume. New York: ACM: 2013. p. 649–656.
Barabâsi AL, Jeong H, Néda Z, Ravasz E, Schubert A, Vicsek T. Evolution of the social network of scientific collaborations. Physica A Stat Mech Appl. 2002; 311(3):590.
Bazzi M, Porter MA, Williams S, McDonald M, Fenn DJ, Howison SD. Community Detection in Temporal Multilayer Networks, with an Application to Correlation Networks. Multiscale Model Simul. 2016; 14(1):1.
Jiao P, Wang W, Jin D. Constrained Common Cluster Based Model for Community Detection in Temporal and Multiplex Networks. Neurocomput. 2018; 275(C):768.
Liu F, Choi D, Xie L, Roeder K. Global spectral clustering in dynamic networks. Proc Natl Acad Sci. 2018.
Mucha PJ, Richardson T, Macon K, Porter MA, Onnela JP. Community Structure in Time-Dependent, Multiscale, and Multiplex Networks. Science. 2010; 328(5980):876.
Peixoto TP, Rosvall M. Modelling sequences and temporal networks with dynamic community structures. Nat Commun. 2017; 8(1):582.
Lancichinetti A, Fortunato S, Kertész J. Detecting the overlapping and hierarchical community structure in complex networks. New J Phys. 2009; 11(3):033015.
Palla G, Barabási AL, Vicsek T. Quantifying social group evolution. Nature. 2007; 446(7136):664.
Almeida H, Guedes D, Meira W, Zaki M. Is there a best quality metric for graph clusters?. Mach Learn Knowl Disc Databases. 2011:44–59.
Almeida H, Neto DG, Meira Jr W, Zaki MJ. Towards a Better Quality Metric for Graph Cluster Evaluation. J Inf Data Manag. 2012; 3(3):378.
Lambiotte R, Delvenne JC, Barahona M. Laplacian dynamics and multiscale modular structure in networks. 2008. arXiv preprint arXiv:0812.1770.
Radicchi F, Castellano C, Cecconi F, Loreto V, Parisi D, Fisica D. Defining and identifying communities in networks. Proc Natl Acad Sci U S A. 2004; 101(9):2658.
Sah P, Singh LO, Clauset A, Bansal S. Exploring community structure in biological networks with random graphs. BMC Bioinformatics. 2014; 15(1):220.
Šubelj L, Bajec M. Unfolding communities in large complex networks: Combining defensive and offensive label propagation for core extraction. Phys Rev E. 2011; 83(3):036103.
Wang M, Wang C, Yu JX, Zhang J. Community detection in social networks: an in-depth benchmarking study with a procedure-oriented framework. Proc VLDB Endowment. 2015; 8(10):998.
Yang Z, Algesheimer R, Tessone CJ. A Comparative Analysis of Community Detection Algorithms on Artificial Networks. Sci Rep. 2016; 6(8):30750.
Barber MJ, Clark JW. Detecting network communities by propagating labels under constraints. Phys Rev E. 2009; 80:026129.
Liu X, Murata T. Advanced modularity-specialized label propagation algorithm for detecting communities in networks. Physica A Stat Mech Appl. 2010; 389(7):1493.
Schuetz P, Caflisch A. Efficient modularity optimization by multistep greedy algorithm and vertex mover refinement. Phys Rev E. 2008; 77(4):046112.
Fortunato S, Barthélemy M. Resolution limit in community detection. Proc Natl Acad Sci. 2007; 104(1):36.
Yang J, Leskovec J. Defining and evaluating network communities based on ground-truth. Knowl Inf Syst. 2015; 42(1):181.
Leskovec J, Lang KJ, Mahoney MW. Statistical Properties of Community Structure in Large Social and Information Networks. In: Proceedings of the 17th International Conference on World Wide Web. New York: ACM: 2008. p. 695–704.
Zaki MJ, Meira Jr. W. Data Mining and Analysis: Fundamental Concepts and Algorithms. New York: Cambridge University Press; 2014.
Danon L, Díaz-Guilera A, Duch J, Arenas A. Comparing community structure identification. J Stat Mech Theory Exp. 2005; 2005(09):P09008.
Dongen SV. Performance criteria for graph clustering and Markov cluster experiments. Tech. rep. Amsterdam: National Research Institute for Mathematics and Computer Science in the Netherlands; 2000.
Rand WM. Objective Criteria for the Evaluation of Clustering Methods. J Am Stat Assoc. 1971; 66(336):846.
Kivelä M, Arenas A, Barthelemy M, Gleeson JP, Moreno Y, Porter MA. Multilayer networks. J Complex Netw. 2014; 2(3):203.
He J, Chen D. A fast algorithm for community detection in temporal network. Physica A Stat Mech Appl. 2015; 429(Supplement C):87.
Rosvall M, Bergstrom CT. Multilevel Compression of Random Walks on Networks Reveals Hierarchical Organization in Large Integrated Systems. PLoS ONE. 2011; 6(4):1.
Newman MEJ. Finding community structure in networks using the eigenvectors of matrices. Phys Rev E. 2006; 74:036104.
Pons P, Latapy M. Computing Communities in Large Networks Using Random Walks. Berlin: Springer; 2005, pp. 284–293.
Fortunato S, Hric D. Community detection in networks: A user guide. Phys Rep. 2016; 659:1.
Shiokawa H, Fujiwara Y, Onizuka M. SCAN++: Efficient Algorithm for Finding Clusters, Hubs and Outliers on Large-scale Graphs. Proc VLDB Endowment. 2015; 8(11):1178.
Pons P, Latapy M. Post-processing hierarchical community structures: Quality improvements and multi-scale view. Theor Comput Sci. 2011; 412(8):892.
Papadimitriou P, Dasdan A, Garcia-Molina H. Web graph similarity for anomaly detection. J Internet Serv Appl. 2010; 1(1):19.
Leão JC, Brandão MA, Vaz de Melo POS, Laender AHF. Mineração de Perfis Sociais em Redes Temporais. In: Anais do XXXII Simpósio Brasileiro de Bancos de Dados - Short Papers. Uberlândia: 2017. p. 264–269.
Hric D, Darst RK, Fortunato S. Community detection in networks: Structural communities versus ground truth. Phys Rev E Stat Nonlin Soft Matter Phys. 2014; 90(6):62805.
Leão JC. Uma Abordagem para Detecção de Comunidades a partir de Sequências de Interações Sociais. Dissertação de Mestrado, UFMG; 2018.
Henderson T, Kotz D, Abyzov I. The Changing Usage of a Mature Campus-wide Wireless Network. In: Proceedings of the 10th Annual International Conference on Mobile Computing and Networking. New York: ACM: 2004. p. 187–201. MobiCom ’04.
Hsu W, Helmy A. IMPACT: Investigation of Mobile-user Patterns Across University Campuses using WLAN Trace Analysis. CoRR. 2005; abs/cs/0508009.
Rossetti G, Cazabet R. Community Discovery in Dynamic Networks: a Survey. CoRR. 2017; abs/1707.03186.
Fortunato S. Community detection in graphs. Phys Rep. 2010; 486(3-5):75.
Palla G, Derenyi I, Farkas I, Vicsek T. Uncovering the overlapping community structure of complex networks in nature and society. Nature. 2005; 435(7043):814.
Abrahao B, Soundarajan S, Hopcroft J, Kleinberg R. On the Separability of Structural Classes of Communities. In: Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM: 2012. p. 624–632.
Newman ME. Modularity and community structure in networks. Proc Natl Acad Sci. 2006; 103(23):8577.
Newman MEJ, Girvan M. Finding and evaluating community structure in networks. Phys Rev E. 2004; 69(2):26113.
Barabási AL. Linked: How Everything Is Connected to Everything Else and What It Means for Business, Science, and Everyday Life. New York: Basic Books; 2014.
Leão JC, Brandão MA, Vaz de Melo POS, Laender AHF. Classificação de Relações Sociais para Melhorar a Detecção de Comunidades. In: Proceedings of the VI Brazilian Workshop on Social Network Analysis and Mining. São Paulo: 2017. p. 647–657.
Acknowledgments
Work supported by project MASWeb (FAPEMIG/PRONEX grant APQ-01400-14) and by the authors’ individual grants from CNPq and FAPEMIG. Particularly, the first author would like to thank the Federal Institute of Northern Minas Gerais for granting him a scholarship under its Employee Qualification Program.
Funding
The research was partially supported by research projects funded by CNPq and FAPEMIG, and by the authors’ individual grants from CNPq, FAPEMIG and IFNMG.
Author information
Authors and Affiliations
Contributions
JL, PO and AL designed the experiments. JL executed the experiments. JL, PO, AL and MB reviewed the results and contributed to the writing. All authors reviewed the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional information
Availability of data and materials
The datasets used and analyzed during the current study have also been used elsewhere: [15] (APS, PubMed, DBLP), [72] (Dartmouth), [73] (USC) and [30, 74] (Enron). The generated datasets are available from the corresponding author on reasonable request in the http://cnet.jcloud.net.br repository.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License(http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Leão, J., Brandão, M., Vaz de Melo, P. et al. Who is really in my social circle?. J Internet Serv Appl 9, 20 (2018). https://doi.org/10.1186/s13174-018-0091-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13174-018-0091-6