
Abstract
Polygenic scores (PGS) can be used for risk stratification by quantifying individuals’ genetic predisposition to disease, and many potentially clinically useful applications have been proposed. Here, we review the latest potential benefits of PGS in the clinic and challenges to implementation. PGS could augment risk stratification through combined use with traditional risk factors (demographics, disease-specific risk factors, family history, etc.), to support diagnostic pathways, to predict groups with therapeutic benefits, and to increase the efficiency of clinical trials. However, there exist challenges to maximizing the clinical utility of PGS, including FAIR (Findable, Accessible, Interoperable, and Reusable) use and standardized sharing of the genomic data needed to develop and recalculate PGS, the equitable performance of PGS across populations and ancestries, the generation of robust and reproducible PGS calculations, and the responsible communication and interpretation of results. We outline how these challenges may be overcome analytically and with more diverse data as well as highlight sustained community efforts to achieve equitable, impactful, and responsible use of PGS in healthcare.
Similar content being viewed by others

Introduction
Genome-wide association studies (GWAS) have linked genetic loci across the genome with many hundreds of diseases and quantitative traits [1, 2], and found that many of these complex traits have a polygenic architecture, where phenotypic variance is accounted for by many genetic variants of small effect. GWAS information, either individual-level or summary statistics, can be leveraged to estimate an individual’s genetic predisposition for a given phenotype [3,4,5,6,7,8,9]. This genetic predisposition is typically represented as a score and is referred to as a polygenic score (PGS), polygenic risk score (PRS) or genetic/genomic risk score (GRS). PGS are based on cost-effective technology (e.g. genome-wide genotyping array or sequencing) which, since it is measuring the germline genome, only needs to be performed once in an individual’s lifetime. Further, PGS for hundreds of diseases and/or clinically relevant traits can be calculated from one genome-wide array or sequence.
For many clinical use cases, PGS are being evaluated around the world to determine what clinical utility they may have. For example, Genomics PLC and GP practices in the North of England are piloting PGS as part of an integrated risk tool for cardiovascular risk assessment [10]. The PGS-augmented CanRisk tool [11] for breast and ovarian cancer is being evaluated as part of the PERSPECTIVE I&I study [12], and additional trials of PGS-augmented integrated risk tools (IRTs) for breast cancer are in progress, including WISDOM [13] and MyPEBS [14]. The GPPAD, PLEDGE and CASCADE trials are evaluating PGS for use in autoantibody screening of type 1 diabetes [15]. In the USA, multiple studies are ongoing for how returning genetically-informed risk information using PGS for multiple diseases impacts outcomes in individuals of diverse ancestries, such as the Genomic Medicine at Veterans Affairs (GenoVA) [16] and electronic MEdical Records and GEnomics (eMERGE) studies [17]. Large-scale biobanks and infrastructures are also accelerating the speed of development and translation for PGS (e.g. UK Biobank), and the next generation of genomic cohorts are well-placed to widen both the scale, demographic diversity and power of PGS (e.g. All of Us Program [18] and Our Future Health [19]).
The translation and clinical implementation of new tools is challenging, and this has been particularly the case for PGS. The technologies on which PGS depend, genotyping arrays and sequencing, are largely yet to make their way into routine healthcare. Genotyping arrays have seen slow clinical adoption while whole genome sequencing has had several major applications for the genomic surveillance of microbial pathogens [20], cancer genomics [21] and diagnosis of rare developmental disorders [22]. The breadth of potential clinical applications for PGS combined with other risk factors is extensive, yet there are common challenges. Here, we review the potential benefits and challenges facing the implementation of polygenic scores in clinical practice. In doing so, we highlight a series of important findings which may guide future clinical research in evaluating the utility of PGS.
Potential benefits of polygenic scores
Disease risk prediction alongside other risk factors
PGS have the potential for clinical utility as they measure aspects of disease risk that are independent of or precede traditional risk factors [6] recent studies have expanded the evidence in this area. Genetic predisposition to disease can be partially captured by family history; however, family history is a composite variable that captures both shared environment and genetic similarity that is often incomplete and poorly captured [23]. As such, PGS has been shown to add information beyond family history in phenotype prediction for a child based on the average of their parents (mid-parent) for traits like height [24, 25] and risk of common diseases [24, 26]. Family history may also correlate with the presence of familial forms of disease caused by rare pathogenic variants, and most genetic tests implemented in current clinical practice assess a variant’s occurrence in familial and sporadic disease cases. However, there is significant heritability outside of rare variants which is quantified by the common genetic variants comprising PGS, which can predict sporadic cases of polygenic disease [27]. As such, PGS has been shown to add additional risk stratification in individuals with high genetic risk for diseases including type 1 diabetes [28] and BRCA1/2 carriers [29, 30].
Many diseases have multiple biological, environmental or lifestyle risk predictors that are combined into risk prediction models. These conventional risk predictors frequently include age, sex, body mass index (BMI), smoking behaviour, family disease history and established clinical assays [31]. However, many models have disease-specific predictors. Various studies have found that, when treated the same as other risk factors, PGS contributes independent information that improves the accuracy of these risk prediction models [6], and studies continue to show that PGS modestly improve risk prediction when combined into an IRT for diseases of major public health burden, including coronary heart disease [32, 33], stroke [34, 35], type 2 diabetes [36, 37], and breast cancer [38]. Improvements in risk prediction have frequently been shown in terms of classification accuracy (e.g. ‘high’, ‘intermediate’ or ‘low’ risk groups which correspond to different clinical recommendations), leading to the conclusion that PGS only modestly improves risk stratification. However, it is important to highlight that prima facie small changes in overall classification accuracy can translate into meaningful benefits at scale. For example, Sun et al. [32] showed that adding PGS of coronary artery disease (CAD) and ischaemic stroke [39, 40] to conventional risk factors resulted in increases in classification accuracy of 1–2% (ΔC-index); however, the addition of PGS improved continuous net reclassification for 10% of incident cardiovascular disease cases and 12% of non-cases, yielding an additional 72 prevented cases per 100,000 adults, per 10 years.
The Sun et al. study carefully evaluated PGS in the context of baseline risks which mirrored demographics in primary care (i.e., correcting for the healthy participant bias in UK Biobank); however, despite being integral to the clinical utility of risk prediction, baseline risk is frequently forgotten in PGS studies. Baseline risk can be critical for apparently modest predictors like PGS, especially in groups with otherwise high baseline risk (Table 1, Fig. 1).

Baseline risk can substantially change the utility of a polygenic score. A Effect size (odds ratio) of PGS for an example disease in the populations of European (EUR) and African (AFR) ancestry. B Prevalence of disease risk across PGS percentiles. The bolded line indicates a high-risk threshold that impacts treatment decisions (here 10%, similar to most clinical guidelines [53]). Dashed lines indicate the average disease risk in each ancestry group. Data presented are simulated [54] to match observed effect sizes for PGS for CAD [52] and assuming that the African population has a two-fold higher disease risk than the European ancestry population (here with a baseline risk of 4%) similar to the observed difference in cardiovascular disease incidence between ethnicities [55]
Age is the strongest risk factor for most common diseases and contributes to the baseline risk profile along with the accumulation of other risk factors. As such, analyses show that PGS is a stronger predictor of disease incidence earlier in the life course [33, 35, 56, 57], which motivates measuring genetics earlier in life for targeted prevention and screening before the accumulation of risk factors and environmental exposures. While age affects genetic relative risk for many common diseases as captured by PGS [57], a recent study of prostate cancer illustrates the utility of PGS for absolute risk-stratification despite age-related attenuation of relative risk [58]. Taken together, there is now a strong evidence base across many diseases that PGS captures disease risk information that is independent of other risk factors and improves integrated risk calculators.
Assessing the clinical utility of polygenic scores
The utility of a PGS ultimately depends on its predictive ability and the clinical scenario in which it is applied [59]. Here we highlight examples of clinical scenarios where a PGS has been proposed to have the potential for utility.
Risk stratification
For many diseases, PGS may be useful for risk stratification as they tend to be more informative earlier in life, and those of different genetic predispositions will be predicted to become high risk at different ages. As is the case with other risk factors, disease prevalence may affect the performance of a PGS — for example, for a disease with a prevalence of 1% (e.g. schizophrenia), the top 10% of a current PGS would only identify 3% of patients [60, 61]. However, PGS can still be useful for risk stratification in high-risk groups of low-prevalence diseases (e.g.T1D [28, 62]), or used in combination with other risk factors to define a higher-than-average risk population in which to screen. Thus, PGS may be useful for changing the age and/or frequency at which people are screened for cardiovascular risk factors, common cancers (e.g. breast, prostate, colorectal), and other conditions (e.g. dementias). The benefits of using PGS to optimize cancer screening have been shown to be cost-effective [63, 64], but more evidence is needed and multiple trials assessing outcomes and feasibility are ongoing (WISDOM [13], MY-PEBS [14], BARCODE [65]). Similar analyses of PGS in cardiometabolic diseases also indicate clinical benefits and cost-effectiveness [66]. While cost-effectiveness studies of PGS are still emerging, few assess multiple disease use cases and thereby do not account for the fact that a single array/sequence could marginally improve risk stratification for multiple diseases simultaneously.
Risk stratification based on IRTs that include PGS may also be used to guide treatment decisions, including pharmacological interventions. Multiple studies have shown the potential benefit of adding PGS to cardiovascular disease calculators and that combined models identify significant numbers of additional future cases surpassing risk thresholds to receive statins, the most common risk-reducing medication for atherosclerotic disease [32, 67]. Indeed, benefit estimation may need to take into account the potential for effect modification of polygenic risk on treatment effectiveness as multiple studies have shown that individuals at high polygenic risk of CAD may benefit disproportionately from the use of statins or PCSK9 inhibitors in terms of relative and absolute risk reductions (see below) [66, 68,69,70].
Behaviour change in humans is frequently difficult to achieve and the impact of phenotypic or genetic risk score information is no exception [71]. While more follow-up will ultimately determine whether changes in behaviour are persistent and corresponding disease events reduced, recent large-scale studies suggest IRTs including PGS may motivate positive changes to modifiable risk factors. Results from the GeneRISK in Finland study showed that after 1.5 years of interacting with an online CVD risk communication tool integrating PGS, 42.6% of 7342 participants at high risk had made positive health behavioural changes, including weight loss, quitting smoking or becoming a member of online health coaching services [72]. This is to be contrasted with other studies such as INFORM which have assessed, in a randomized trial, whether provision of genetic or phenotypic risk scores cause positive behaviour changes [73]. Exemplifying the difficulty of affecting human behavioural change, the INFORM trial found no significant effects for either genetic or phenotypic scores. Importantly, the studies did not find anxiety and depression in response to PGS information to be common.
CanRisk is a web tool for the Breast and Ovarian Analysis of Disease Incidence and Carrier Estimation Algorithm (BOADICEA), which combines PGS with conventional risk factors like age, family history, mammographic density and known pathogenic variants [74,75,76]. CanRisk is CE marked and is an early implementation of PGS for clinical use. When only using questionnaire-based risk factors and mammographic density, BOADICEA identifies 9.2% of women with moderate to high-risk [74]. The 313-SNP PGS [74] for breast cancer alone identifies 10% and when the PGS is added to BOADICEA, the integrated model identifies 13% of women in moderate to high-risk [74, 76]. The CanRisk model is amenable to updates using other PGS [77] and estimates from CanRisk can be used to guide screening and choices of risk-reducing interventions, including surgical procedures (e.g. UK’s NICE guidelines [78]).
Diagnosis
In some diseases, patients with severe and early onset disease undergo genome analysis to identify a putative genetic cause. Currently, gene panel testing is the most common type of testing, with exome and whole-genome sequencing being increasingly applied to challenging cases to improve diagnostic yield [79, 80]. For example, of 60 patients from a preventative genomics clinic (both self-referred and referred by cardiologists) [81], two had a monogenic variant for familial hypercholesterolemia (i.e. classified as high monogenic risk), but 19 had a PGS in the top quintile. Lu et al. [82] showed that PGS can discriminate high familial monogenic risks for breast cancer, bowel cancer, heart disease, type 2 diabetes and Alzheimer's disease [82]. Their study demonstrated that PGS may be able to prioritize patients for subsequent diagnostic sequencing, which may increase cost-effectiveness. While rare pathogenic variants are clearly disease-causing, the majority of common disease cases will not have one of these variants, and a polygenic aetiology (e.g. presence of a ‘high’ PGS) will be more likely [83]. Of course, scores integrating the full spectrum of allele frequencies will likely be optimal [84] and the development of methodologies to construct PGS that include rare variants is an active area of research [85,86,87]. There are also clinical scenarios where PGS might be useful for differentiating between possible diagnoses, e.g. discriminating type 1 diabetes from type 2 diabetes [88] or MODY [62]. For ankylosing spondylitis (AS) and individuals who present with back pain, a PGS had the highest classification accuracy, compared to MRI scans or HLA-B risk allele status, to distinguish AS cases and non-AS ([89]). PGS in autoimmune diseases frequently exhibit higher classification accuracies than other diseases (e.g. AUROC > 0.9 [28]), likely due to high heritability and the combination of large effect-size HLA variants, illustrating their potential utility for improving screening pathways.
Use in clinical trials and for understanding treatment benefits
As outlined by Fahed et al. [90], PGS also have potential uses for assessing the benefits of pharmacological therapies. Clinical trials can be large in scale and expensive to run in order to accumulate the numbers of outcomes to measure an effect; thus, to achieve this, trials often enrol individuals at high risk of the outcome. Fahed et al. showed how using a PGS might reduce trial sample size by focusing on individuals at high polygenic risk to increase the outcome rate. A PGS-guided trial strategy might be especially useful for preventative interventions in high-risk individuals before disease onset (e.g. before cognitive impairment in dementias or Alzheimer’s disease [91, 92]) or in those individuals who are susceptible to T1D [28]. Notably, PGS-based enrichment of trials may result in more efficient trials but they would require participants to be genotyped prior to enrolment. Emerging population-scale platforms (such as Our Future Health in the UK) may enable such PGS-guided trials.
Retrospective genetic analyses of clinical trials for multiple cardiovascular disease treatments have also shown that treatment benefit may be greatest for those at high polygenic risk, including the FOURIER trial [69], Odyssey Outcomes trial [70] and statin therapy [68, 93, 94]. This is consistent with observational data, where PGS but not clinical risk factors were shown to stratified populations most likely to benefit from treatment (59% vs. 33% relative risk reduction for incident myocardial infarction in the highest and lowest genetic risk groups respectively) [68]. Targeting treatments to those most likely to benefit would be advantageous [95], particularly for treatments that are costly. While high profile studies have been performed in cardiovascular disease, PGS have been shown to have potential to predict treatment responses to other conditions, including migraine [96], type 2 diabetes [97] and psychiatric disorders [98] like schizophrenia [99], and depression [100]. Overall, PGS could prove useful for designing more efficient trials as well as for identifying those most likely to benefit from specific treatments.
Analytic challenges for translation of polygenic scores
PGS are moving toward clinical implementation in many scenarios. As such multiple consortia of researchers and clinicians have put forward guidance on the use and interpretation of PGS, these include a statement from the Polygenic Risk Score Task Force of the International Common Disease Alliance (ICDA) [9], and the American College of Medical Genetics and Genomics (ACMG) [101]. In this section, we highlight key analytic challenges, possible solutions, and linkages across translational efforts.
Developing, calculating, and applying PGS is a data-intensive endeavour, and should strive to be Findable, Accessible, Interoperable and Reusable (FAIR, [102]) in order to maximize PGS reproducibility and utility as research and potentially clinical tools. PGS are typically constructed using coefficients from GWAS, and as such it is critical that the GWAS summary statistics are openly shared and reusable by other researchers. Sharing data via a recognized repository, such as the GWAS Catalog [2], where data is stably accessioned and made available in a standard format facilitates the linking of PGS to source data. High-quality study and variant-level metadata in GWAS summary statistics (e.g. imputation INFO scores, allele frequencies, and per-variant sample sizes) are required for accurate PGS development and input to many methods [103]. As many fields are underreported in shared GWAS summary statistics (e.g. allele frequency), submitters are encouraged to format and openly share these data according to recently established community standards [104]. The information necessary to reproduce PGS (e.g. the variants and weights) should also be shared, thereby enabling independent evaluations in new cohorts and comparison to newly developed PGS. To facilitate the open sharing of PGS, Lambert et al. [105] developed PGS Catalog (https://www.pgscatalog.org/). Currently, the PGS Catalog has catalogued ~ 4000 scores predicting ~ 600 different complex traits and/or diseases from ~ 500 publications (Fig. 2). Alongside the PGS Catalog, the Polygenic Risk Score Reporting Standards (PRS-RS) [106] have outlined key performance metrics and considerations for PGS analyses as reporting has been highly heterogenous. Both GWAS and PGS should be shared with clear and unambiguous license terms (ideally CC0 or, if necessary, CC-BY-NC) to ensure reusability for the widest range of research and clinical applications.

Summary of publicly available PGS. A Top 25 traits/diseases which have the greatest number of PGS in the PGS Catalog. B Distribution of total sample size (sum) used to develop each PGS (either as a GWAS or in score development). C Ancestry composition of sample sets used for PGS development and evaluation for each PGS. All evaluation samples were aggregated to define the final label. Data was extracted on December 7, 2023, with a total of 3900 PGS with catalogued IDs for 619 traits from 507 publications
Although biased by the availability of PGS that have been added to the PGS Catalog (see inclusion criteria https://www.pgscatalog.org/about/inclusioncriteria), European ancestries still comprise the plurality of PGS training and prediction samples, followed training samples combining data from multiple ancestry groups and then a much smaller number of Asian ancestry studies (Fig. 2C), highlighting that ancestral diversity is a problem for PGS, consistent with other systematic reports [107]. This lack of ethnic, ancestral and demographic diversity is observed in many epidemiological and clinical studies, including the vast majority of the GWAS which underpin the training of PGS.
Improving the transferability of polygenic scores across ancestries
A key challenge for the utility of PGS is to ensure they make equitable predictions for all groups; however, many PGS have weaker predictive performance between populations defined by their genetic ancestry [108] and within some sub-groups of a single ancestry group [109]. This issue, which is common to other biomarkers and risk models, is often called the transferability (or portability) gap and, in this case, refers to the relative predictive ability of a PGS in samples that are external to the PGS development populations. It should be noted that some attenuation of predictive performance (e.g., effect size, accuracy, R2) is expected and can be based on differences between the training cohort and that being evaluated (e.g., demographic differences, social determinants of health, case ascertainment/phenotyping), which is why external validation is a critical step in any risk model evaluation [106, 110]. It is also well-documented that the attenuation in PGS predictive ability is proportional to the genetic distance from the training population [111, 112]. Over 95% of recent GWAS study participants have been of European ancestry [107, 113]. Several recent reviews [5, 114,115,116] have also acknowledged the transferability issue of PGS.
Multiple studies have shown that more diverse and multi-ancestry GWAS can improve the predictive power and transferability of PGS, likely because the effect sizes of the true causal variants are shared across ancestry groups [117]. For example, a recent study of blood lipid levels showed that PGS constructed using multi-ancestry GWAS outperforms those constructed using single-ancestry matched data [118]. A larger analysis of 14 disease endpoints results from the Global Biobank Meta-analysis Initiative (GBMI) also concluded that using multi-ancestry GWAS improved the accuracy of PGS for all ancestries, although a significant amount of heterogeneity in accuracy exists across ancestries [119], and many other PGS based on multi-ancestry GWAS can be validated in diverse populations [46, 120, 121]. However, multiple studies constructing and evaluating PGS in African populations have come to the opposite conclusion that ancestry-matched PGS is most optimal for the prediction [25, 115, 122, 123]. One reason for this could be that not all traits are perfectly genetically correlated across ancestry groups [124], with notable examples for psychiatric disorders [125, 126].
More transferrable PGS can also be developed by using improved statistical methods (see [4] for a recent comprehensive review of PGS development methodologies). The major advancements used to close the transferability gap are primarily based on ensembling and leveraging multi-ancestry and multi-trait data and incorporating functional information to identify more likely causal variants. Ensembling-based methods are based on the idea that incorporating multiple sets of GWAS data from either multiple ancestries or multiple diseases/risk factors can create a better set of variants and weights for PGS calculation. One such approach is PRS-CSx [127], an extension of the population PRS-CS continuous shrinkage (CS) models that can be shared across ancestries. Another example of ensembling is CT-SLEB [128] which integrates clumping and thresholding, empirical Bayes and super learning to process multi-ancestry GWAS data into a single PGS. More complex methods that calculate and normalize PGS based on variants in local ancestry blocks are also being developed [129]; however, the complexity of software implementation will be a challenge as they also require sharing of reference panels for chromosome painting.
As causal variants are similar across ancestries [117, 130], it is possible that PGS based on these causal variants may yield more similar prediction performances. Causal variants are expected to have relevant biological functions, thus such information can be used as biological priors to better select variants and then train better weights [131]. Multiple methods using biological information/annotation have been shown to improve the transferability across ancestries, including LDpred-funct [132], PolyPred + [133] and BayesRC [134]. Simpler methods exist to use relevant annotations for variant selection and use GWAS effect sizes [135]. Since integrating GWAS summaries from multi-ancestries and leveraging SNP annotation both improve the transferability of PGS, combined approaches such as X-Wing [136] and PolyPred + [133] may significantly improve PGS accuracy in non-European populations [136].
The differences in PGS accuracy that can be observed between genetically defined populations can be related to differences in effect sizes, LD patterns and allele frequency patterns, but they can also be due to correlations with other factors. For example, the accuracy of PGS within African populations was found to be low but highly variable between different ethnic groups of Sub-Saharan Africa [137], which may be due to the correlation between ancestry groups and social determinants of healthcare, selection and the differential impacts of genetics in different environments [5, 109, 138].
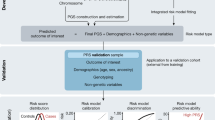
Reliable and reproducible PGS: assays and computational pipelines required for implementation and interpretation
PGS development results in a set of variants and weights that can be used to estimate genetic predisposition; however, other steps are necessary to measure PGS in individuals and return an interpretable test result [59]. Typically PGS have been developed in cohorts of genotyped individuals using a limited set of directly measured variants on a genotyping array, which has been imputed to higher genome coverage using reference panels [139]. Recent studies have shown that the choice of imputation panel and strategy can affect PGS accuracy [140], and the choice of genotyping array can be particularly important for underrepresented populations [141]. Ideally, the clinical use of PGS should combine common and rare variants [139], even if the improvements to risk-stratification at the population level may be limited [142]. However, as rare variants are difficult to impute accurately [143], they are usually excluded from PGS development and/or calculation [139]. A potential solution is to use whole genome sequencing; however, the cost of whole genome sequencing still inhibits large-scale implementation. An alternative is low-coverage sequencing (< 1 × coverage) coupled to genotype imputation, which is more scalable and improves the accuracy of PGS calculation as compared to genotyping arrays [144,145,146].
Another challenge in PGS calculation is that scores are often on different scales (different mean and variance), and different genetic ancestry groups can have shifted PGS distributions that do not reflect differences in the disease prevalence [147]. Thus the main way to convert a PGS into an interpretable individual measure is to represent it as a relative risk of where an individual sits in a population distribution. In a cohort of genetically similar individuals, one can simply normalize the PGS for the mean and standard deviation of the population of interest or use percentiles; however, this becomes challenging for diverse ancestries and/or admixed individuals. One way to calculate an individual’s PGS is to use a population reference panel (e.g. 1000 Genomes Project) and report an individual's relative PGS with respect to the most similar population in the panel. Recent methods have been proposed that do not rely on reference population labels as they use the associations of PCA loadings to PGS values to decorrelate PGS distributions from genetic ancestry. Initially, these methods only corrected for different mean distributions in PGS distributions [148], which has been implemented for PGS reporting in the GenoVA Study [16]. However, differences in the variance of PGS distributions between populations can also be corrected by regressing the variance of the new PGS distribution with the PCs [149] — this was used to report PGS information within the eMERGE study’s genome-informed risk assessment (GIRA) report [17]. All three methods of normalizing PGS (using empirical distributions, or using PCA loadings to centre the mean and equalize variance) result in a relative risk to a population average and can be reported as is for interpretation (e.g. polygenic risk reports) or as a predictor in risk tools. Overall considerations for how to report a PGS depend on choices of genotyping assay, imputation, and how a PGS is calculated/adjusted, and these all have implications for how it is regulated and reported [59, 106].
Ensuring the responsible use, communication and interpretation of PGS
Polygenic risk ultimately has to be communicated to many different stakeholders, including patients (and/or consumers of commercial genetic testing) and clinicians if they are to be used in the clinic. Understanding of PGS among these groups may be low, so effective PGS reports and communication [150] are critical [114, 151] — some examples of reports being used to communicate PGS results already exist [17, 152]. Notably, it is important that PGS reports/results do not convey genetic determinism (that genetics predictions are fait accompli) or exceptionalism (that genetic predisposition is more important than other risk factors). However, information about how the estimate was developed is just as important as the risk estimate itself, e.g. the population(s) used to develop and train the score is critical for interpreting whether the risk estimate is applicable to the individual at hand [101]. Adherence to reporting standards and key metadata requirements describing how the PGS was developed and evaluated can achieve this goal [106, 153], as different studies often report PGS metrics with different statistics and covariate adjustments that make comparisons difficult. During the reporting of PGS/IRT development, it is important to describe participant inclusion, as the labels we use to describe populations can be imprecise or comprise outdated language that can cause harm and misinterpretation (see NASEM review [154]). Consistent with what many have advised, the NASEM report recommended that we should not use race as a proxy for human genetic variation nor as part of PGS, and one should carefully consider any labels applied when grouping individuals. This is especially important as most PGS studies compare effect sizes and accuracies across groups, usually labelled according to their continental ancestries which individuals might not identify with. The use of continental ancestry descriptors also causes problems as researchers do not always consider the genetic diversity within these populations, and examples of fine-scale genetic structure impacting PGS calculation exist [155,156,157]). Methods used to calculate PGS as a relative risk often also rely on matching individuals to a reference population/label; however, promising improvements to normalize PGS using continuous measures of genetic ancestry derived from reference panels are outlined above [148, 149], and can avoid the use of labels that can differ from how a person identifies [158].
Consistent with the views of the vast majority of the PGS research community, the ACMG’s statement advocates against using PGS as a standalone test, as a negative result is not conclusive, and a positive result does not always mean the carrier is at high immediate risk. As we have highlighted above, except in some diseases such as autoimmunity (e.g., [159]) or Alzheimer’s disease (e.g., [160]), PGS are frequently modest standalone predictors of disease risk — their main advantage is that they capture risk information that is not being measured already using genetic testing or traditional risk factor models. The ACMG also outline that PGS should be combined with genetic testing for rarer pathogenic variants or those causing monogenic disease, as well as combining PGS with other clinical measurements to understand a patient's current health status and the examples of PGS utility we summarized in this review mainly implement PGS alongside currently implemented risk estimation and rarely in isolation. Both the ICDA and ACMG statements also outline a shared goal of making sure that PGS are used equitably and that methodological development and data collection should be advanced to ensure PGS work optimally in all individuals regardless of their genetic ancestry. This also includes making sure that PGS is not used in any situations that might cause harm or otherwise be unethical. A significant gap in the literature exists to define what is best practice when an individual engages a healthcare practitioner with PGS results which they have obtained from a third-party provider (commercial or otherwise). Anecdotal reports indicate this is no longer a rare event. While not the focus of this review, parallel statements have been released calling for an end to the use of PGS for embryo selection [161,162,163] or for unscientific claims about racial/ethnic group differences.
Conclusions and future directions
The evidence for the clinical utility of PGS is continuously developing, but PGS are already used in some risk tools implemented in clinical practice, and select preventative genomics clinics. In the near-term, it is likely that the continued deployment of PGS in clinics will rely on extending conventional risk models into integrated risk tools enhanced by PGS (e.g. CanRisk [11]). Despite their manifold potential benefits, PGS have inherent risks and limitations, similar to other risk factors, such as variable portability across genetic ancestry groups. While improvements to PGS development methods can partially overcome these limitations, the only genuine solution is to increase the representation of diverse samples in the GWAS [122]. The open sharing of this genomic data and the developed PGS should be openly shared according to FAIR principles [102] and established reporting guidelines [106] to maximize equitable translation of these results. There is also additional work to be done to develop best practices for calculating individuals' PGS, both in genotyping assay and/or imputation choices and how to calculate and report a person’s risk. As with many tools already utilized for disease risk prediction (e.g. QRISK [10]), there is an absence or paucity of randomized trial evidence as to their clinical benefit and there are various reasons for this, e.g. the vast number of PGS, clinical use cases, number of patients needed and corresponding scarce resources [164]. Alongside efforts to conduct pragmatic trials of PGS, large-scale validation together with rigorous clinical and population health modelling should continue. Health economic modelling and feasibility studies will also inform decisions of whether PGS implementation should proceed in any particular use case. Following from these requirements is the need to communicate how the full PGS development, evaluation and calculation has been performed so that ensures it is understandable to physicians and patients. Importantly, significant community efforts should be invested to ensure the responsible use of PGS to counter genetic determinism and exceptionalism.
While analytic solutions (including methods development and modelling of baseline risk) are being developed, the lack of diverse genomic data continues to be an important limitation. While it will take substantial time to recruit participants from historically underrepresented groups and to generate genomic data, the most effective strategy at the moment is to leverage multi-biobank resources, e.g. the Global Biobank Meta-analysis Initiative [119, 165]. Many wealthy countries like the USA and UK are recruiting and delivering the next phase of larger and more diverse biobanks (e.g. the All of US Program [18] and Our Future Health [19]). However, continued efforts should ensure that the benefits of PGS are not only available to those in wealthy countries and capacity building and ethical partnerships for data collection and analysis in underrepresented groups, particularly low-middle income countries, should be promoted [166,167,168,169,170]. Statistical methods, tools and resources also should be improved to facilitate analysis of genetic ancestry on a continuum, particularly so that admixed individuals are not excluded from studies [154, 171]. The standardization of GWAS/PGS results reporting, responsible use and communication will require a concerted effort from academic, industry and government bodies. Overall, through community efforts towards common goals, it is clear that continued progress in PGS is being made and that it could benefit human health. There is now a substantive need for further translational studies, including pragmatic trials, to provide empirical evidence as to PGS utility in specific clinical scenarios.
Availability of data and materials
The summary data used from the Polygenic Score Catalog [105] is publicly available at https://www.pgscatalog.org/.
Abbreviations
- ACMG:
-
American College of Medical Genetics and Genomics
- AS:
-
Ankylosing spondylitis
- AUROC:
-
Area under the ROC (receiver operating characteristic) curve
- BMI:
-
Body mass index
- BOADICEA:
-
Breast and Ovarian Analysis of Disease Incidence and Carrier Estimation Algorithm
- CAD:
-
Coronary artery disease
- eMERGE:
-
Electronic MEdical Records and GEnomics study
- FAIR:
-
Findable, Accessible, Interoperable, and Reusable
- GBMI:
-
Global Biobank Meta-analysis Initiative
- GenoVA:
-
Genomic Medicine at Veterans Affairs study
- GIRA:
-
Genome-informed risk assessment
- GRS:
-
Genetic/genomic risk score
- GWAS:
-
Genome-wide association
- ICDA:
-
International Common Disease Alliance
- IRT:
-
Integrated risk tools
- NASEM:
-
National Academies of Sciences, Engineering, and Medicine
- PGS:
-
Polygenic score
- PRS:
-
Polygenic risk score
- T1D:
-
Type 1 diabetes
References
Abdellaoui A, Yengo L, Verweij KJ, Visscher PM. 15 years of GWAS discovery: realizing the promise. Am J Hum Genet. 2023;110:179.
Sollis E, Mosaku A, Abid A, Buniello A, Cerezo M, Gil L, Groza T, Güneş O, Hall P, Hayhurst J. The NHGRI-EBI GWAS Catalog: knowledgebase and deposition resource. Nucleic Acids Res. 2023;51:D977–85.
Wray NR, Lin T, Austin J, McGrath JJ, Hickie IB, Murray GK, Visscher PM. From basic science to clinical application of polygenic risk scores: a primer. JAMA Psychiat. 2021;78:101–9.
Ma Y, Zhou X. Genetic prediction of complex traits with polygenic scores: a statistical review. Trends Genet. 2021;37:995–1011.
Wang Y, Tsuo K, Kanai M, Neale BM, Martin AR. Challenges and opportunities for developing more generalizable polygenic risk scores. Annu Rev Biomed Data Sci. 2022;5:293–320.
Lambert SA, Abraham G, Inouye M. Towards clinical utility of polygenic risk scores. Hum Mol Genet. 2019;28:R133–42.
Lewis CM, Vassos E. Polygenic risk scores: from research tools to clinical instruments. Genome Med. 2020;12:1–11.
Kullo IJ, Lewis CM, Inouye M, Martin AR, Ripatti S, Chatterjee N. Polygenic scores in biomedical research. Nat Rev Genet. 2022;23:524–32.
Adeyemo A, Balaconis MK, Darnes DR, Fatumo S, Granados Moreno P, Hodonsky CJ, Inouye M, Kanai M, Kato K, Knoppers BM, et al. Responsible use of polygenic risk scores in the clinic: potential benefits, risks and gaps. Nat Med. 2021;27:1876–84.
Fuat A, Adlen E, Monane M, Coll R, Groves S, Little E, Wild J, Kamali FJ, Soni Y, Haining S. A polygenic risk score added to a QRISK2 cardiovascular risk calculator demonstrated robust clinical acceptance in the primary care setting. Circulation. 2022;146:A10947–A10947.
Carver T, Hartley S, Lee A, Cunningham AP, Archer S, de Babb Villiers C, Roberts J, Ruston R, Walter FM, Tischkowitz M. CanRisk Tool—A web interface for the prediction of breast and ovarian cancer risk and the likelihood of carrying genetic pathogenic variants. Cancer Epidemiol Biomarkers Prev. 2021;30:469–73.
Knoppers BM, Bernier A, Granados Moreno P, Pashayan N. Of screening, stratification, and scores. J Pers Med. 2021;11:736.
Esserman LJ. The WISDOM Study: breaking the deadlock in the breast cancer screening debate. NPJ breast cancer. 2017;3:34.
Roux A, Cholerton R, Sicsic J, Moumjid N, French DP, Giorgi Rossi P, Balleyguier C, Guindy M, Gilbert FJ, Burrion J-B. Study protocol comparing the ethical, psychological and socio-economic impact of personalised breast cancer screening to that of standard screening in the “My Personal Breast Screening”(MyPeBS) randomised clinical trial. BMC Cancer. 2022;22:1–13.
Sims EK, Besser RE, Dayan C, Geno Rasmussen C, Greenbaum C, Griffin KJ, Hagopian W, Knip M, Long AE, Martin F. Screening for type 1 diabetes in the general population: a status report and perspective. Diabetes. 2022;71:610–23.
Hao L, Kraft P, Berriz GF, Hynes ED, Koch C, Kumar KV, Parpattedar SS, Steeves M, Yu W, Antwi AA. Development of a clinical polygenic risk score assay and reporting workflow. Nat Med. 2022;28:1006–13.
Linder JE, Allworth A, Bland ST, Caraballo PJ, Chisholm RL, Clayton EW, Crosslin DR, Dikilitas O, DiVietro A, Esplin ED. Returning integrated genomic risk and clinical recommendations: The eMERGE study. Genet Med. 2023;25:100006.
Investigators A. The “All of Us” research program. New Engl J Med. 2019;381:668–76.
Our Future Health Protocol version 4.0 [https://ourfuturehealth.org.uk/our-research-mission/].
Smith D, Bashton M. An integrated national scale SARS-CoV-2 genomic surveillance network. The Lancet Microbe. 2020;3:E99–100.
Lakeman IM, Rodríguez-Girondo MD, Lee A, Celosse N, Braspenning ME, van Engelen K, van de Beek I, van der Hout AH, García EBG, Mensenkamp AR. Clinical applicability of the polygenic risk score for breast cancer risk prediction in familial cases. J Med Genet. 2023;60:327–36.
Trotman J, Armstrong R, Firth H, Trayers C, Watkins J, Allinson K, Jacques TS, Nicholson JC, Burke GA. The NHS England 100,000 genomes project: feasibility and utility of centralised genome sequencing for children with cancer. Br J Cancer. 2022;127:137–44.
Dineen M, Sidaway-Lee K, Pereira Gray D, Evans PH. Family history recording in UK general practice: the lIFeLONG study. Fam Pract. 2022;39:610–5.
Lu T, Forgetta V, Wu H, Perry JR, Ong KK, Greenwood CM, Timpson NJ, Manousaki D, Richards JB. A polygenic risk score to predict future adult short stature among children. J Clin Endocrinol Metab. 2021;106:1918–28.
Yengo L, Vedantam S, Marouli E, Sidorenko J, Bartell E, Sakaue S, Graff M, Eliasen AU, Jiang Y, Raghavan S. A saturated map of common genetic variants associated with human height. Nature. 2022;1–16:704.
Mars N, Lindbohm JV, della P BriottaParolo, Widén E, Kaprio J, Palotie A, Ripatti S. Systematic comparison of family history and polygenic risk across 24 common diseases. Am J Hum Genet. 2022;109:2152.
Yang J, Visscher PM, Wray NR. Sporadic cases are the norm for complex disease. Eur J Hum Genet. 2010;18:1039–43.
Ferrat LA, Vehik K, Sharp SA, Lernmark Å, Rewers MJ, She J-X, Ziegler A-G, Toppari J, Akolkar B, Krischer JP. A combined risk score enhances prediction of type 1 diabetes among susceptible children. Nat Med. 2020;26:1247–55.
Barnes DR, Rookus MA, McGuffog L, Leslie G, Mooij TM, Dennis J, Mavaddat N, Adlard J, Ahmed M, Aittomäki K. Polygenic risk scores and breast and epithelial ovarian cancer risks for carriers of BRCA1 and BRCA2 pathogenic variants. Genet Med. 2020;22:1653–66.
Fahed AC, Wang M, Homburger JR, Patel AP, Bick AG, Neben CL, Lai C, Brockman D, Philippakis A, Ellinor PT. Polygenic background modifies penetrance of monogenic variants for tier 1 genomic conditions. Nat Commun. 2020;11:3635.
Murray CJ, Aravkin AY, Zheng P, Abbafati C, Abbas KM, Abbasi-Kangevari M, Abd-Allah F, Abdelalim A, Abdollahi M, Abdollahpour I. Global burden of 87 risk factors in 204 countries and territories, 1990–2019: a systematic analysis for the global burden of disease study 2019. The lancet. 2020;396:1223–49.
Sun L, Pennells L, Kaptoge S, Nelson CP, Ritchie SC, Abraham G, Arnold M, Bell S, Bolton T, Burgess S. Polygenic risk scores in cardiovascular risk prediction: a cohort study and modelling analyses. Plos Med. 2021;18:e1003498.
Weale ME, Riveros-Mckay F, Selzam S, Seth P, Moore R, Tarran WA, Gradovich E, Giner-Delgado C, Palmer D, Wells D. Validation of an integrated risk tool, including polygenic risk score, for atherosclerotic cardiovascular disease in multiple ethnicities and ancestries. Am J Cardiol. 2021;148:157–64.
Neumann JT, Riaz M, Bakshi A, Polekhina G, Thao LT, Nelson MR, Woods RL, Abraham G, Inouye M, Reid CM. Prognostic Value of a polygenic risk score for coronary heart disease in individuals aged 70 years and older. Circ Genom Precis Med. 2022;15:e003429.
Vassy JL, Posner DC, Ho Y-L, Gagnon DR, Galloway A, Tanukonda V, Houghton SC, Madduri RK, McMahon BH, Tsao PS: Cardiovascular disease risk assessment using traditional risk factors and polygenic risk scores in the million veteran program. JAMA Cardiology 2023; 8:564-574.
He Y, Lakhani CM, Rasooly D, Manrai AK, Tzoulaki I, Patel CJ. Comparisons of polyexposure, polygenic, and clinical risk scores in risk prediction of type 2 diabetes. Diabetes Care. 2021;44:935–43.
Hodgson S, Huang QQ, Sallah N, Genes, Team HR, Griffiths CJ, Newman WG, Trembath RC, Wright J, Lumbers RT, Kuchenbaecker K. Integrating polygenic risk scores in the prediction of type 2 diabetes risk and subtypes in British Pakistanis and Bangladeshis: a population-based cohort study. Plos Med. 2022;19:e1003981.
Hurson AN, Pal Choudhury P, Gao C, Hüsing A, Eriksson M, Shi M, Jones ME, Evans DGR, Milne RL, Gaudet MM. Prospective evaluation of a breast-cancer risk model integrating classical risk factors and polygenic risk in 15 cohorts from six countries. Int J Epidemiol. 2021;50:1897–911.
Inouye M, Abraham G, Nelson CP, Wood AM, Sweeting MJ, Dudbridge F, Lai FY, Kaptoge S, Brozynska M, Wang T. Genomic risk prediction of coronary artery disease in 480,000 adults: implications for primary prevention. J Am Coll Cardiol. 2018;72:1883–93.
Abraham G, Malik R, Yonova-Doing E, Salim A, Wang T, Danesh J, Butterworth AS, Howson JM, Inouye M, Dichgans M. Genomic risk score offers predictive performance comparable to clinical risk factors for ischaemic stroke. Nat Commun. 2019;10:5819.
Choi SW. Mak TS-H, O’Reilly PF: Tutorial: a guide to performing polygenic risk score analyses. Nat Protoc. 2020;15:2759–72.
Wang Y, Zhu M, Ma H, Shen H. Polygenic risk scores: the future of cancer risk prediction, screening, and precision prevention. Medical Review. 2021;1:129–49.
Martin AR, Kanai M, Kamatani Y, Okada Y, Neale BM, Daly MJ. Clinical use of current polygenic risk scores may exacerbate health disparities. Nat Genet. 2019;51:584–91.
Dikilitas O, Schaid DJ, Tcheandjieu C, Clarke SL, Assimes TL, Kullo IJ. Use of polygenic risk scores for coronary heart disease in ancestrally diverse populations. Curr Cardiol Rep. 2022;24:1169–77.
Fritsche LG, Ma Y, Zhang D, Salvatore M, Lee S, Zhou X, Mukherjee B. On cross-ancestry cancer polygenic risk scores. Plos Genet. 2021;17:e1009670.
Chen F, Darst BF, Madduri RK, Rodriguez AA, Sheng X, Rentsch CT, Andrews C, Tang W, Kibel AS, Plym A. Validation of a multi-ancestry polygenic risk score and age-specific risks of prostate cancer: a meta-analysis within diverse populations. Elife. 2022;11:e78304.
Belbin GM, Cullina S, Wenric S, Soper ER, Glicksberg BS, Torre D, Moscati A, Wojcik GL, Shemirani R, Beckmann ND. Toward a fine-scale population health monitoring system. Cell. 2021;184(2068–2083): e2011.
Johnson R, Ding Y, Venkateswaran V, Bhattacharya A, Boulier K, Chiu A, Knyazev S, Schwarz T, Freund M, Zhan L. Leveraging genomic diversity for discovery in an electronic health record linked biobank: the UCLA ATLAS Community Health Initiative. Genome Med. 2022;14:1–23.
Chatterjee N, Shi J, García-Closas M. Developing and evaluating polygenic risk prediction models for stratified disease prevention. Nat Rev Genet. 2016;17:392–406.
Huang QQ, Sallah N, Dunca D, Trivedi B, Hunt KA, Hodgson S, Lambert SA, Arciero E, Wright J, Griffiths C. Transferability of genetic loci and polygenic scores for cardiometabolic traits in British Pakistani and Bangladeshi individuals. Nat Commun. 2022;13:4664.
Wang M, Menon R, Mishra S, Patel AP, Chaffin M, Tanneeru D, Deshmukh M, Mathew O, Apte S, Devanboo CS. Validation of a genome-wide polygenic score for coronary artery disease in South Asians. J Am Coll Cardiol. 2020;76:703–14.
Dikilitas O, Schaid DJ, Kosel ML, Carroll RJ, Chute CG, Denny JC, Fedotov A, Feng Q, Hakonarson H, Jarvik GP. Predictive utility of polygenic risk scores for coronary heart disease in three major racial and ethnic groups. Am J Hum Genet. 2020;106:707–16.
Cardiovascular disease: risk assessment and reduction, including lipid modification [https://www.nice.org.uk/guidance/indevelopment/gid-ng10178/documents].
Wray NR, Yang J, Goddard ME, Visscher PM. The genetic interpretation of area under the ROC curve in genomic profiling. Plos Genet. 2010;6:e1000864.
Mozaffarian D, Benjamin EJ, Go AS, Arnett DK, Blaha MJ, Cushman M, De Ferranti S, Després J-P, Fullerton HJ, Howard VJ. Heart disease and stroke statistics—2015 update: a report from the American Heart Association. Circulation. 2015;131:e29–322.
Isgut M, Sun J, Quyyumi AA, Gibson G. Highly elevated polygenic risk scores are better predictors of myocardial infarction risk early in life than later. Genome Med. 2021;13:1–16.
Jiang X, Holmes C, McVean G. The impact of age on genetic risk for common diseases. Plos Genet. 2021;17:e1009723.
Schaid DJ, Sinnwell JP, Batzler A, McDonnell SK. Polygenic risk for prostate cancer: decreasing relative risk with age but little impact on absolute risk. Am J Hum Genet. 2022;109:900–8.
Moorthie S, Hall A, Janus J, Brigden T, Villiers Babb de C, Blackburn L, Johnson E, Kroese M: Polygenic scores and clinical utility. PHG Foundation; The University of Cambridge; 2021.
Cross B, Turner R, Pirmohamed M. Polygenic risk scores: an overview from bench to bedside for personalised medicine. Front Genet. 2022;13:1000667.
Murray GK, Lin T, Austin J, McGrath JJ, Hickie IB, Wray NR. Could polygenic risk scores be useful in psychiatry?: a review. JAMA Psychiat. 2021;78:210–9.
Luckett AM, Weedon MN, Hawkes G, Leslie RD, Oram RA, Grant SF. Utility of genetic risk scores in type 1 diabetes. Diabetologia. 2023;66:1589–600.
Dixon P, Keeney E, Taylor JC, Wordsworth S, Martin RM. Can polygenic risk scores contribute to cost-effective cancer screening? A systematic review. Genet Med. 2022;24:1604.
Wong JZY, Chai JH, Yeoh YS, Mohamed Riza NK, Liu J, Teo Y-Y, Wee HL, Hartman M. Cost effectiveness analysis of a polygenic risk tailored breast cancer screening programme in Singapore. BMC Health Serv Res. 2021;21:379.
Eeles RA, ni Raghallaigh H, Group BS: BARCODE 1: A pilot study investigating the use of genetic profiling to identify men in the general population with the highest risk of prostate cancer to invite for targeted screening. American Society of Clinical Oncology 2020;38:1505.
Kiflen M, Le A, Mao S, Lali R, Narula S, Xie F, Paré G. Cost-effectiveness of polygenic risk scores to guide statin therapy for cardiovascular disease prevention. Circ Genom Precis Med. 2022;15:e003423.
Riveros-Mckay F, Weale ME, Moore R, Selzam S, Krapohl E, Sivley RM, Tarran WA, Sørensen P, Lachapelle AS, Griffiths JA. Integrated polygenic tool substantially enhances coronary artery disease prediction. Circ Genom Precis Med. 2021;14:e003304.
Oni-Orisan A, Haldar T, Cayabyab MAS, Ranatunga DK, Hoffmann TJ, Iribarren C, Krauss RM, Risch N. Polygenic risk score and statin relative risk reduction for primary prevention of Myocardial infarction in a real-world population. Clin Pharmacol Ther. 2022;112:1070–8.
Marston NA, Kamanu FK, Nordio F, Gurmu Y, Roselli C, Sever PS, Pedersen TR, Keech AC, Wang H, Lira Pineda A. Predicting benefit from evolocumab therapy in patients with atherosclerotic disease using a genetic risk score: results from the FOURIER trial. Circulation. 2020;141:616–23.
Damask A, Steg PG, Schwartz GG, Szarek M, Hagström E, Badimon L, Chapman MJ, Boileau C, Tsimikas S, Ginsberg HN. Patients with high genome-wide polygenic risk scores for coronary artery disease may receive greater clinical benefit from alirocumab treatment in the ODYSSEY OUTCOMES trial. Circulation. 2020;141:624–36.
Shefer G, Silarova B, Usher-Smith J, Griffin S. The response to receiving phenotypic and genetic coronary heart disease risk scores and lifestyle advice–a qualitative study. BMC Public Health. 2016;16:1–11.
Widén E, Junna N, Ruotsalainen S, Surakka I, Mars N, Ripatti P, Partanen JJ, Aro J, Mustonen P, Tuomi T. How communicating polygenic and clinical risk for atherosclerotic cardiovascular disease impacts health behavior: an observational follow-up study. Circ Genom Precis Med. 2022;15:e003459.
Silarova B, Sharp S, Usher-Smith JA, Lucas J, Payne RA, Shefer G, Moore C, Girling C, Lawrence K, Tolkien Z. Effect of communicating phenotypic and genetic risk of coronary heart disease alongside web-based lifestyle advice: the INFORM randomised controlled trial. Heart. 2019;105:982–9.
Lee A, Mavaddat N, Wilcox AN, Cunningham AP, Carver T, Hartley S, de Babb Villiers C, Izquierdo A, Simard J, Schmidt MK. BOADICEA: a comprehensive breast cancer risk prediction model incorporating genetic and nongenetic risk factors. Genet Med. 2019;21:1708–18.
Lee A, Yang X, Tyrer J, Gentry-Maharaj A, Ryan A, Mavaddat N, Cunningham AP, Carver T, Archer S, Leslie G. Comprehensive epithelial tubo-ovarian cancer risk prediction model incorporating genetic and epidemiological risk factors. J Med Genet. 2022;59:632–43.
Lee A, Mavaddat N, Cunningham A, Carver T, Ficorella L, Archer S, Walter FM, Tischkowitz M, Roberts J, Usher-Smith J. Enhancing the BOADICEA cancer risk prediction model to incorporate new data on RAD51C, RAD51D, BARD1 updates to tumour pathology and cancer incidence. J Med Genet. 2022;59:1206–18.
Mavaddat N, Ficorella L, Carver T, Lee A, Cunningham AP, Lush M, Dennis J, Tischkowitz M, Downes K, Hu D. Incorporating alternative polygenic risk scores into the BOADICEA breast cancer risk prediction model. Cancer Epidemiol Biomarkers Prev. 2023;32:422–7.
Familial breast cancer: classification, care and managing breast cancer and related risks in people with a family history of breast cancer [https://www.nice.org.uk/guidance/cg164/chapter/Recommendations].
Austin-Tse CA, Jobanputra V, Perry DL, Bick D, Taft RJ, Venner E, Gibbs RA, Young T, Barnett S, Belmont JW. Best practices for the interpretation and reporting of clinical whole genome sequencing. NPJ Genom Med. 2022;7:27.
Lionel AC, Costain G, Monfared N, Walker S, Reuter MS, Hosseini SM, Thiruvahindrapuram B, Merico D, Jobling R, Nalpathamkalam T. Improved diagnostic yield compared with targeted gene sequencing panels suggests a role for whole-genome sequencing as a first-tier genetic test. Genet Med. 2018;20:435–43.
Maamari DJ, Brockman DG, Aragam K, Pelletier RC, Folkerts E, Neben CL, Okumura S, Hull LE, Philippakis AA, Natarajan P. Clinical implementation of combined monogenic and polygenic risk disclosure for coronary artery disease. JACC Advances. 2022;1:100068.
Lu T, Forgetta V, Richards JB, Greenwood CM. Polygenic risk score as a possible tool for identifying familial monogenic causes of complex diseases. Genet Med. 2022;24:1545.
Khera AV, Chaffin M, Aragam KG, Haas ME, Roselli C, Choi SH, Natarajan P, Lander ES, Lubitz SA, Ellinor PT. Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations. Nat Genet. 2018;50:1219–24.
Dornbos P, Koesterer R, Ruttenburg A, Nguyen T, Cole JB, Consortium A-TD-G, Leong A, Meigs JB, Florez JC, Rotter JI. A combined polygenic score of 21,293 rare and 22 common variants improves diabetes diagnosis based on hemoglobin A1C levels. Nat Genet. 2022;54:1–6.
Wang Z, Choi SW, Chami N, Boerwinkle E, Fornage M, Redline S, Bis JC, Brody JA, Psaty BM, Kim W. The value of rare genetic variation in the prediction of common obesity in European ancestry populations. Front Endocrinol (Lausanne). 2022;13:863893.
Lali R, Chong M, Omidi A, Mohammadi-Shemirani P, Le A, Cui E, Paré G. Calibrated rare variant genetic risk scores for complex disease prediction using large exome sequence repositories. Nat Commun. 2021;12:5852.
Chan AJ, Engchuan W, Reuter MS, Wang Z, Thiruvahindrapuram B, Trost B, Nalpathamkalam T, Negrijn C, Lamoureux S, Pellecchia G. Genome-wide rare variant score associates with morphological subtypes of autism spectrum disorder. Nat Commun. 2022;13:6463.
Shoaib M, Ye Q, IglayReger H, Tan MH, Boehnke M, Burant CF, Soleimanpour SA, GaglianoTaliun SA. Evaluation of polygenic risk scores to differentiate between type 1 and type 2 diabetes. Genet Epidemiol. 2023;47:303.
Li Z, Wu X, Leo PJ, De Guzman E, Akkoc N, Breban M, Macfarlane GJ, Mahmoudi M, Marzo-Ortega H, Anderson LK. Polygenic Risk Scores have high diagnostic capacity in ankylosing spondylitis. Ann Rheum Dis. 2021;80:1168–74.
Fahed AC, Philippakis AA, Khera AV. The potential of polygenic scores to improve cost and efficiency of clinical trials. Nat Commun. 2022;13:2922.
Chaudhury S, Brookes KJ, Patel T, Fallows A, Guetta-Baranes T, Turton JC, Guerreiro R, Bras J, Hardy J, Francis PT. Alzheimer’s disease polygenic risk score as a predictor of conversion from mild-cognitive impairment. Transl Psychiatry. 2019;9:154.
Jung S-H, Kim H-R, Chun MY, Jang H, Cho M, Kim B, Kim S, Jeong JH, Yoon SJ, Park KW. Transferability of Alzheimer disease polygenic risk score across populations and its association with Alzheimer disease-related phenotypes. JAMA Netw Open. 2022;5:e2247162–e2247162.
Natarajan P, Young R, Stitziel NO, Padmanabhan S, Baber U, Mehran R, Sartori S, Fuster V, Reilly DF, Butterworth A, et al. Polygenic risk score identifies subgroup with higher burden of atherosclerosis and greater relative benefit from statin therapy in the primary prevention setting. Circulation. 2017;135:2091–101.
Mega JL, Stitziel NO, Smith JG, Chasman DI, Caulfield M, Devlin JJ, Nordio F, Hyde C, Cannon CP, Sacks F, et al. Genetic risk, coronary heart disease events, and the clinical benefit of statin therapy: an analysis of primary and secondary prevention trials. Lancet. 2015;385:2264–71.
Gibson G. On the utilization of polygenic risk scores for therapeutic targeting. Plos Genet. 2019;15:e1008060.
Kogelman LJ, Esserlind A-L, Christensen AF, Awasthi S, Ripke S, Ingason A, Davidsson OB, Erikstrup C, Hjalgrim H, Ullum H. Migraine polygenic risk score associates with efficacy of migraine-specific drugs. Neurol Genet. 2019;5:364.
Jiang G, Luk AO, Tam CH, Lau ES, Ozaki R, Chow EY, Kong AP, Lim CK, Lee KF, Siu SC. Obesity, clinical, and genetic predictors for glycemic progression in Chinese patients with type 2 diabetes: a cohort study using the Hong Kong diabetes register and Hong Kong diabetes biobank. Plos Med. 2020;17:e1003209.
Lewis CM, Vassos E. Polygenic scores in psychiatry: On the road from discovery to implementation. Am J Psychiatry. 2022;179:800–6.
Loef D, Luykx J, Lin B, van Diermen L, Nuninga J, van Exel E, Oudega M, Rhebergen D, Schouws S, van Eijndhoven P. Interrogating associations between polygenic liabilities and electroconvulsive therapy effectiveness. Biol Psychiatry. 2022;91:S55.
Fabbri C, Hagenaars SP, John C, Williams AT, Shrine N, Moles L, Hanscombe KB, Serretti A, Shepherd DJ, Free RC. Genetic and clinical characteristics of treatment-resistant depression using primary care records in two UK cohorts. Mol Psychiatry. 2021;26:3363–73.
Abu-El-Haija A, Reddi HV, Wand H, Rose NC, Mori M, Qian E, Murray MF. The clinical application of polygenic risk scores: A points to consider statement of the American College of Medical Genetics and Genomics (ACMG). Genet Med. 2023;25:100803.
Wilkinson MD, Dumontier M, Aalbersberg IJ, Appleton G, Axton M, Baak A, Blomberg N, Boiten J-W, da Silva Santos LB, Bourne PE. The FAIR guiding principles for scientific data management and stewardship. Sci Data. 2016;3:1–9.
Privé F, Arbel J, Aschard H, Vilhjálmsson BJ. Identifying and correcting for misspecifications in GWAS summary statistics and polygenic scores. Hum Genet Genomics Adv. 2022;3:100136.
Hayhurst J, Buniello A, Harris L, Mosaku A, Chang C, Gignoux CR, Hatzikotoulas K, Karim MA, Lambert SA, Lyon M. A community driven GWAS summary statistics standard. bioRxiv 2022:2022.2007. 2015.500230.
Lambert SA, Gil L, Jupp S, Ritchie SC, Xu Y, Buniello A, McMahon A, Abraham G, Chapman M, Parkinson H. The polygenic score catalog as an open database for reproducibility and systematic evaluation. Nat Genet. 2021;53:420–5.
Wand H, Lambert SA, Tamburro C, Iacocca MA, O’Sullivan JW, Sillari C, Kullo IJ, Rowley R, Dron JS, Brockman D. Improving reporting standards for polygenic scores in risk prediction studies. Nature. 2021;591:211–9.
Duncan L, Shen H, Gelaye B, Meijsen J, Ressler K, Feldman M, Peterson R, Domingue B. Analysis of polygenic risk score usage and performance in diverse human populations. Nat Commun. 2019;10:1–9.
Martin AR, Gignoux CR, Walters RK, Wojcik GL, Neale BM, Gravel S, Daly MJ, Bustamante CD, Kenny EE. Human demographic history impacts genetic risk prediction across diverse populations. Am J Hum Genet. 2017;100:635–49.
Mostafavi H, Harpak A, Agarwal I, Conley D, Pritchard JK, Przeworski M. Variable prediction accuracy of polygenic scores within an ancestry group. elife. 2020;9:48376.
Collins GS, Reitsma JB, Altman DG, Moons KG. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. Ann Intern Med. 2015;162:55–63.
Scutari M, Mackay I, Balding D. Using genetic distance to infer the accuracy of genomic prediction. Plos Genet. 2016;12:e1006288.
Ding Y, Hou K, Xu Z, Pimplaskar A, Petter E, Boulier K, Privé F, Vilhjálmsson BJ, Olde Loohuis LM, Pasaniuc B: Polygenic scoring accuracy varies across the genetic ancestry continuum. Nature. 2023;618:774–81.
Mills MC, Rahal C. The GWAS Diversity Monitor tracks diversity by disease in real time. Nat Genet. 2020;52:242–3.
Lewis AC, Perez EF, Prince AE, Flaxman HR, Gomez L, Brockman DG, Chandler PD, Kerman BJ, Lebo MS, Smoller JW. Patient and provider perspectives on polygenic risk scores: implications for clinical reporting and utilization. Genome Med. 2022;14:114.
Kamiza AB, Toure SM, Vujkovic M, Machipisa T, Soremekun OS, Kintu C, Corpas M, Pirie F, Young E, Gill D. Transferability of genetic risk scores in African populations. Nat Med. 2022;28:1163–6.
Novembre J, Stein C, Asgari S, Gonzaga-Jauregui C, Landstrom A, Lemke A, Li J, Mighton C, Taylor M, Tishkoff S. Addressing the challenges of polygenic scores in human genetic research. Am J Hum Genet. 2022;109:2095–100.
Hou K, Ding Y, Xu Z, Wu Y, Bhattacharya A, Mester R, Belbin GM, Buyske S, Conti DV, Darst BF. Causal effects on complex traits are similar for common variants across segments of different continental ancestries within admixed individuals. Nat Genet. 2023;55:1–10.
Graham SE, Clarke SL, Wu K-HH, Kanoni S, Zajac GJ, Ramdas S, Surakka I, Ntalla I, Vedantam S, Winkler TW. The power of genetic diversity in genome-wide association studies of lipids. Nature. 2021;600:675–9.
Wang Y, Namba S, Lopera E, Kerminen S, Tsuo K, Läll K, Kanai M, Zhou W, Wu K-H, Favé M-J. Global Biobank analyses provide lessons for developing polygenic risk scores across diverse cohorts. Cell Genomics. 2023;3:100241.
Ge T, Irvin MR, Patki A, Srinivasasainagendra V, Lin Y-F, Tiwari HK, Armstrong ND, Benoit B, Chen C-Y, Choi KW. Development and validation of a trans-ancestry polygenic risk score for type 2 diabetes in diverse populations. Genome Med. 2022;14:70.
Tshiaba PT, Ratman DK, Sun JM, Tunstall TS, Levy B, Shah PS, Weitzel JN, Rabinowitz M, Kumar A, Im KM. Integration of a cross-ancestry polygenic model with clinical risk factors improves breast cancer risk stratification. CO Precis Oncol. 2023;7:e2200447.
Fatumo S, Inouye M. African genomes hold the key to accurate genetic risk prediction. Nat Hum Behav. 2023;7:1–2.
Chikowore T, Ekoru K, Vujkovi M, Gill D, Pirie F, Young E, Sandhu MS, McCarthy M, Rotimi C, Adeyemo A. Polygenic prediction of type 2 diabetes in Africa. Diabetes Care. 2022;45:717–23.
Galinsky KJ, Reshef YA, Finucane HK, Loh PR, Zaitlen N, Patterson NJ, Brown BC, Price AL. Estimating cross-population genetic correlations of causal effect sizes. Genet Epidemiol. 2019;43:180–8.
Giannakopoulou O, Lin K, Meng X, Su M-H, Kuo P-H, Peterson RE, Awasthi S, Moscati A, Coleman JR, Bass N. The genetic architecture of depression in individuals of East Asian ancestry: a genome-wide association study. JAMA Psychiat. 2021;78:1258–69.
Ikeda M, Takahashi A, Kamatani Y, Momozawa Y, Saito T, Kondo K, Shimasaki A, Kawase K, Sakusabe T, Iwayama Y. Genome-wide association study detected novel susceptibility genes for schizophrenia and shared trans-populations/diseases genetic effect. Schizophr Bull. 2019;45:824–34.
Ruan Y, Lin Y-F, Feng Y-CA, Chen C-Y, Lam M, Guo Z, He L, Sawa A, Martin AR. Improving polygenic prediction in ancestrally diverse populations. Nat Genet. 2022;54:573–80.
Zhang H, Zhan J, Jin J, Zhang J, Lu W, Zhao R, Ahearn TU, Yu Z, O’Connell J, Jiang Y. A new method for multiancestry polygenic prediction improves performance across diverse populations. Nat Genet. 2023;55:1–12.
Marnetto D, Pärna K, Läll K, Molinaro L, Montinaro F, Haller T, Metspalu M, Mägi R, Fischer K, Pagani L. Ancestry deconvolution and partial polygenic score can improve susceptibility predictions in recently admixed individuals. Nat Commun. 2020;11:1628.
Wang Y, Guo J, Ni G, Yang J, Visscher PM, Yengo L. Theoretical and empirical quantification of the accuracy of polygenic scores in ancestry divergent populations. Nat Commun. 2020;11:3865.
Weissbrod O, Hormozdiari F, Benner C, Cui R, Ulirsch J, Gazal S, Schoech AP, Van De Geijn B, Reshef Y, Márquez-Luna C. Functionally informed fine-mapping and polygenic localization of complex trait heritability. Nat Genet. 2020;52:1355–63.
Márquez-Luna C, Gazal S, Loh P-R, Kim SS, Furlotte N, Auton A, Price AL. Incorporating functional priors improves polygenic prediction accuracy in UK Biobank and 23andMe data sets. Nat Commun. 2021;12:1–11.
Weissbrod O, Kanai M, Shi H, Gazal S, Peyrot WJ, Khera AV, Okada Y, Martin AR, Finucane HK, Price AL. Leveraging fine-mapping and multipopulation training data to improve cross-population polygenic risk scores. Nat Genet. 2022;54:450–8.
MacLeod I, Bowman P, Vander Jagt C, Haile-Mariam M, Kemper K, Chamberlain A, Schrooten C, Hayes B, Goddard M. Exploiting biological priors and sequence variants enhances QTL discovery and genomic prediction of complex traits. BMC Genomics. 2016;17:1–21.
Ishigaki K, Sakaue S, Terao C, Luo Y, Sonehara K, Yamaguchi K, Amariuta T, Too CL, Laufer VA, Scott IC. Multi-ancestry genome-wide association analyses identify novel genetic mechanisms in rheumatoid arthritis. Nat Genet. 2022;54:1–12.
Miao J, Guo H, Song G, Zhao Z, Hou L, Lu Q. Quantifying portable genetic effects and improving cross-ancestry genetic prediction with GWAS summary statistics. Nat Commun. 2023;14:832.
Majara L, Kalungi A, Koen N, Tsuo K, Wang Y, Gupta R, Nkambule LL, Zar H, Stein DJ, Kinyanda E: Low and differential polygenic score generalizability among African populations due largely to genetic diversity. Hum Genet Genomics Adv. 2023;4:100184.
Favé M-J, Lamaze FC, Soave D, Hodgkinson A, Gauvin H, Bruat V, Grenier J-C, Gbeha E, Skead K, Smargiassi A. Gene-by-environment interactions in urban populations modulate risk phenotypes. Nat Commun. 2018;9:827.
Reddi HV, Wand H, Funke B, Zimmermann MT, Lebo MS, Qian E, Shirts BH, Zou YS, Zhang BM, Rose NC. Laboratory perspectives in the development of polygenic risk scores for disease: A points to consider statement of the American College of Medical Genetics and Genomics (ACMG). Genet Med. 2023;25:100804.
Chen S-F, Dias R, Evans D, Salfati EL, Liu S, Wineinger NE, Torkamani A. Genotype imputation and variability in polygenic risk score estimation. Genome Med. 2020;12:1–13.
Nguyen DT, Tran TT, Tran MH, Tran K, Pham D, Duong NT, Nguyen Q, Vo NS. A comprehensive evaluation of polygenic score and genotype imputation performances of human SNP arrays in diverse populations. Sci Rep. 2022;12:17556.
Weiner DJ, Nadig A, Jagadeesh KA, Dey KK, Neale BM, Robinson EB, Karczewski KJ, O’Connor LJ. Polygenic architecture of rare coding variation across 394,783 exomes. Nature. 2023;614:492–9.
Si Y, Vanderwerff B, Zöllner S. Why are rare variants hard to impute? Coalescent models reveal theoretical limits in existing algorithms. Genetics. 2021;217:iyab011.
Li JH, Mazur CA, Berisa T, Pickrell JK. Low-pass sequencing increases the power of GWAS and decreases measurement error of polygenic risk scores compared to genotyping arrays. Genome Res. 2021;31:529–37.
Kim S, Shin J-Y, Kwon N-J, Kim C-U, Kim C, Lee CS, Seo J-S. Evaluation of low-pass genome sequencing in polygenic risk score calculation for Parkinson’s disease. Hum Genomics. 2021;15:58.
Homburger JR, Neben CL, Mishne G, Zhou AY, Kathiresan S, Khera AV. Low coverage whole genome sequencing enables accurate assessment of common variants and calculation of genome-wide polygenic scores. Genome Med. 2019;11:1–12.
Reisberg S, Iljasenko T, Läll K, Fischer K, Vilo J. Comparing distributions of polygenic risk scores of type 2 diabetes and coronary heart disease within different populations. Plos One. 2017;12:e0179238.
Khera AV, Chaffin M, Zekavat SM, Collins RL, Roselli C, Natarajan P, Lichtman JH, D’onofrio G, Mattera J, Dreyer R. Whole-genome sequencing to characterize monogenic and polygenic contributions in patients hospitalized with early-onset myocardial infarction. Circulation. 2019;139:1593–602.
Khan A, Turchin MC, Patki A, Srinivasasainagendra V, Shang N, Nadukuru R, Jones AC, Malolepsza E, Dikilitas O, Kullo IJ. Genome-wide polygenic score to predict chronic kidney disease across ancestries. Nat Med. 2022;28:1412–20.
Wand H, Kalia SS, Helm BM, Suckiel SA, Brockman D, Vriesen N, Goudar RK, Austin J, Yanes T. Clinical genetic counseling and translation considerations for polygenic scores in personalized risk assessments: a practice resource from the national society of genetic counselors. J Genet Couns. 2023;32:558.
Lewis AC, Green RC, Vassy JL. Polygenic risk scores in the clinic: translating risk into action. Hum Genet Genomics Adv. 2021;2:100047.
Brockman DG, Petronio L, Dron JS, Kwon BC, Vosburg T, Nip L, Tang A, O’Reilly M, Lennon N, Wong B. Design and user experience testing of a polygenic score report: a qualitative study of prospective users. BMC Med Genomics. 2021;14:1–20.
Alliance PRSTFotICD. Responsible use of polygenic risk scores in the clinic: potential benefits, risks and gaps. Nat Med. 2021;27:1876–84.
National Academies of Sciences E, Medicine: using population descriptors in genetics and genomics research: a new framework for an evolving field. Washington (DC): National Academies Press (US); 2023.
Kerminen S, Martin AR, Koskela J, Ruotsalainen SE, Havulinna AS, Surakka I, Palotie A, Perola M, Salomaa V, Daly MJ. Geographic variation and bias in the polygenic scores of complex diseases and traits in Finland. Am J Hum Genet. 2019;104:1169–81.
Sakaue S, Hirata J, Kanai M, Suzuki K, Akiyama M, Lai Too C, Arayssi T, Hammoudeh M, Al Emadi S, Masri BK. Dimensionality reduction reveals fine-scale structure in the Japanese population with consequences for polygenic risk prediction. Nat Commun. 2020;11:1569.
Atkinson EG, Dalvie S, Pichkar Y, Kalungi A, Majara L, Stevenson A, Abebe T, Akena D, Alemayehu M, Ashaba FK. Genetic structure correlates with ethnolinguistic diversity in eastern and southern Africa. Am J Hum Genet. 2022;109:1667–79.
James JE, Riddle L, Koenig BA, Joseph G. The limits of personalization in precision medicine: polygenic risk scores and racial categorization in a precision breast cancer screening trial. Plos One. 2021;16:e0258571.
Knevel R, le Cessie S, Terao CC, Slowikowski K, Cui J, Huizinga TW, Costenbader KH, Liao KP, Karlson EW, Raychaudhuri S. Using genetics to prioritize diagnoses for rheumatology outpatients with inflammatory arthritis. Sci Transl Med. 2020;12:eaay1548.
Leonenko G, Baker E, Stevenson-Hoare J, Sierksma A, Fiers M, Williams J, de Strooper B, Escott-Price V. Identifying individuals with high risk of Alzheimer’s disease using polygenic risk scores. Nat Commun. 2021;12:4506.
Turley P, Meyer MN, Wang N, Cesarini D, Hammonds E, Martin AR, Neale BM, Rehm HL, Wilkins-Haug L, Benjamin DJ. Problems with using polygenic scores to select embryos. New Engl J Med. 2021;385:78–86.
Forzano F, Antonova O, Clarke A, de Wert G, Hentze S, Jamshidi Y, Moreau Y, Perola M, Prokopenko I, Read A. The use of polygenic risk scores in pre-implantation genetic testing: an unproven, unethical practice. Eur J Hum Genet. 2022;30:493–5.
Polyakov A, Amor DJ, Savulescu J, Gyngell C, Georgiou EX, Ross V, Mizrachi Y, Rozen G. Polygenic risk score for embryo selection—not ready for prime time. Hum Reprod. 2022;37:2229–36.
Rossello X, Dorresteijn JA, Janssen A, Lambrinou E, Scherrenberg M, Bonnefoy-Cudraz E, Cobain M, Piepoli MF, Visseren FL, Dendale P, et al. Risk prediction tools in cardiovascular disease prevention: a report from the ESC Prevention of CVD Programme led by the European Association of Preventive Cardiology (EAPC) in collaboration with the Acute Cardiovascular Care Association (ACCA) and the Association of Cardiovascular Nursing and Allied Professions (ACNAP). Eur J Prev Cardiol. 2019;26:1534–44.
Zhou W, Kanai M, Wu K-HH, Rasheed H, Tsuo K, Hirbo JB, Wang Y, Bhattacharya A, Zhao H, Namba S. Global biobank meta-analysis initiative: powering genetic discovery across human disease. Cell Genomics. 2022;2:100192.
Fatumo S, Chikowore T, Choudhury A, Ayub M, Martin AR, Kuchenbaecker K. A roadmap to increase diversity in genomic studies. Nat Med. 2022;28:243–50.
Claw KG, Anderson MZ, Begay RL, Tsosie KS, Fox K, Garrison NA. A framework for enhancing ethical genomic research with Indigenous communities. Nat Commun. 2018;9:2957.
Ju D, Hui D, Hammond DA, Wonkam A, Tishkoff SA. Importance of including non-European populations in large human genetic studies to enhance precision medicine. Annu Rev Biomed Data Sci. 2022;5:321–39.
AJHG. Advancing diverse participation in research with special consideration for vulnerable populations. Am J Hum Genet. 2020;107:379–80.
Fox K. The illusion of inclusion—The “All of Us” research program and indigenous peoples’ DNA. New Engl J Med. 2020;383:411–3.
Caliebe A, Tekola-Ayele F, Darst BF, Wang X, Song YE, Gui J, Sebro RA, Balding DJ, Saad M, Dubé MP. Including diverse and admixed populations in genetic epidemiology research. Genet Epidemiol. 2022;46:347–71.
Acknowledgements
We acknowledge Professor Peter Kraft for insightful past conversations and Twitter threads on the subject of PGS and baseline risks.
Funding
This work was supported by core funding from the British Heart Foundation [RG/18/13/33946], National Human Genome Research Institute of the National Institutes of Health grant [1U24HG012542-01 to H.P. M.I.], NIHR Cambridge Biomedical Research Centre [BRC-1215–20014], Cambridge BHF Centre of Research Excellence (RE/18/1/34212) and BHF Chair Award (CH/12/2/29428) as well as by Health Data Research UK, which is funded by the UK Medical Research Council, Engineering and Physical Sciences Research Council, Economic and Social Research Council, Department of Health and Social Care (England), Chief Scientist Office of the Scottish Government Health and Social Care Directorates, Health and Social Care Research and Development Division (Welsh Government), Public Health Agency (Northern Ireland), British Heart Foundation and Wellcome.
M.I. is supported by the Munz Chair of Cardiovascular Prediction and Prevention and the UK Economic and Social Research 878 Council (ES/T013192/1). H.P. is supported by European Molecular Biology Laboratory Core Funds.
Y.X. was supported by the UK Economic and Social Research Council (ES/T013192/1).
Author information
Authors and Affiliations
Contributions
S.A.L. and M.I. conceived of the manuscript structure. R.X., S.A.L., K.L., Y.X., M.I., L.W.H, and H.P. drafted and revised the manuscript. All authors read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
M.I.: Trustee of the Public Health Genomics (PHG) Foundation; Scientific Advisory Board of Open Targets; Research collaborations with AstraZeneca, Nightingale Health, and Pfizer. The remaining authors declare that they do not have any competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Xiang, R., Kelemen, M., Xu, Y. et al. Recent advances in polygenic scores: translation, equitability, methods and FAIR tools. Genome Med 16, 33 (2024). https://doi.org/10.1186/s13073-024-01304-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13073-024-01304-9