
Abstract
Background
Advancements in cancer therapeutics have resulted in increases in cancer-related survival; however, there is a growing clinical dilemma. The current balancing of survival benefits and future cardiotoxic harms of oncotherapies has resulted in an increased burden of cardiovascular disease in breast cancer survivors. Risk stratification may help address this clinical dilemma. This study is the first to assess the association between a coronary artery disease-specific polygenic risk score and incident coronary artery events in female breast cancer survivors.
Methods
We utilized the Studies in Epidemiology and Research in Cancer Heredity prospective cohort involving 12,413 women with breast cancer with genotype information and without a baseline history of cardiovascular disease. Cause-specific hazard ratios for association of the polygenic risk score and incident coronary artery disease (CAD) were obtained using left-truncated Cox regression adjusting for age, genotype array, conventional risk factors such as smoking and body mass index, as well as other sociodemographic, lifestyle, and medical variables.
Results
Over a median follow-up of 10.3 years (IQR: 16.8) years, 750 incident fatal or non-fatal coronary artery events were recorded. A 1 standard deviation higher polygenic risk score was associated with an adjusted hazard ratio of 1.33 (95% CI 1.20, 1.47) for incident CAD.
Conclusions
This study provides evidence that a coronary artery disease-specific polygenic risk score can risk-stratify breast cancer survivors independently of other established cardiovascular risk factors.
Similar content being viewed by others

Introduction
There were approximately 2.1 million new cases of incident female breast cancer in 2018 globally, accounting for 25% of cancer cases in women [1]. Long-term survival has improved for women over the past 30 years as advances in cancer therapy have resulted in reduced cancer-specific mortality. Consequently, mortality from other causes has become more important [2], with cardiovascular disease (CVD) being the leading cause of death in older women who survive breast cancer [3]. This is partly due to the effect of cytotoxic chemotherapies and radiotherapy which are associated with an increase in cardiovascular morbidity and mortality [4,5,6,7]. In this paper, we focus on coronary artery disease (CAD), the most common type of CVD. Particularly for long-term survivors at higher CAD risk due to risk factors unrelated to their cancer and cancer therapy, adverse effects of therapy are likely to accumulate and thus become relatively more important. It seems likely that risk factors associated with CAD in the general population will also be associated with CAD in cancer survivors, but empirical evidence is needed, particularly in those treated with chemotherapy or radiotherapy. Multiple lifestyle and environmental risk factors have well-established CAD associations including smoking, body mass index (BMI), total cholesterol, type 1 and type 2 diabetes, and hypertension [8].
Inherited genetic variation is also known to affect risk: genome-wide association studies (GWAS) have identified many common genetic variants associated with CAD, and polygenic risk scores (PRS) have been shown to provide useful CAD risk discrimination [9,10,11]. Polygenic risk scores are an aggregation of genomic variant information and GWAS-derived weights reflecting magnitude of association for a condition of interest [12]. The motivation behind using a PRS is based on the common variant-common disease hypothesis, where much of the genetic risk for common adult-onset diseases can be attributed to the cumulative effect of many common variants with small effect sizes rather than rare variants with large effect sizes [13]. Within research assessing clinical utility of polygenic risk scores, most of the evidence appears to come from the study of CAD. While the consensus for the clinical utility of CAD PRS is still unclear [14,15,16,17], CAD PRS is potentially poised to add accuracy to clinical risk predictions, define populations who would most benefit from statin prescriptions, and estimate lifetime risk trajectories [18]. It still remains an open question as to whether existing CAD PRS can be as predictive in non-European populations, but there has been some research that has sought to validate existing PRS in a cohort of South Asian participants [19]. There are currently no studies quantifying the performance of CAD PRS for risk prediction in breast cancer survivors and, furthermore, whether polygenic risk scores interact with oncotherapy for breast cancer. Polygenic risk scores in combination with other risk factors may be useful in identifying women with breast cancer in whom the adverse effects of treatment may outweigh the benefits. The aim of this study was to evaluate the association of a published coronary artery disease polygenic risk score [10] and incident CAD outcomes in a cohort of women with breast cancer.
Methods
Study cohort
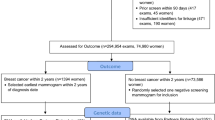
The Studies in Epidemiology and Research in Cancer Heredity (SEARCH) cohort is a population-based prospective study based in the Eastern Region of England, which was served by the East Anglian Cancer registry until 2002 and the Eastern Region Cancer Intelligence Unit from 2002 to 2016. Recruitment of patients was conducted from June 1996 to December 2016. Incident breast cancer cases were all cases diagnosed under the age of 70 years from July 1996 to December 2016. Patients completed a self-administered questionnaire upon recruitment, which included questions about personal information, reproductive history, and other medical history. Tumor characteristics were obtained from the national cancer registry. Follow-up was ascertained through death registration with the most recent update provided by Public Health England on May 31st, 2020. This provides the causes of death recorded on parts 1 and 2 of the death certificate. The SEARCH dataset was restricted to female breast cancer cases who had complete genotype information (n = 12413) for this study. The final analytic sample contained 8946 participants after removing those of non-European ancestries (n = 15) and those who experienced an event before diagnosis (n = 3452).
Linkage of the SEARCH cohort to hospital episodes statistics (HES) data was used to identify incident CAD events. HES data comprises a record for each finished consultant episode (FCE), which is a period of care for a patient under a single consultant at a single hospital [20]. Diagnoses coded for each FCE include all diagnoses noted in the clinical record. Variables of interest included the time (years) between diagnosis and hospital admission and the ICD-10 diagnosis code. The recorded episode time, admission time, or operation time elapsed since diagnosis with breast cancer in HES was considered the time of the event. For individuals with multiple records in which CAD was one of the clinical diagnoses, the earliest time to event was used as the analytical time to event. Prevalent disease at baseline was defined as an event occurring before diagnosis (encoded as negative time) and these times were excluded from the analysis.
Genotype data
A total of 12413 individuals from the SEARCH cohort were genotyped in two batches: batch I was genotyped on the Illumina Infinium iCOGS array (n = 8404) and batch II on the Illumina Infinium OncoArray (n = 4009). Both chips provide genome-wide coverage of common variants with 211115 SNPs on the iCOGS array [21] and 533631 SNPs on the OncoArray [22]. Genotyping QC was performed as previously described [21, 22]. Genotypes were then phased using SHAPEIT and imputed into the 1000 Genomes Project reference panel (version 3) using IMPUTE version 2 for iCOGS and OncoArray.
Calculating PRS and quality control
The polygenic risk score (PRS) used in this study was derived by Inouye et al. and is called metaGRS (henceforth referred to as PRS), which consists of approximately 1745180 variants (a detailed description of its derivation can be found in their Additional file) [10]. The set of SNPs and their corresponding weights for PRS were taken from the Polygenic Score Catalogue, which is an open database of published polygenic risk scores [23]. The PRS was calculated as a weighted sum of all the effect alleles carried using the imputed allele dosages and the published SNP effect sizes (log relative risk). Scores for each sample individual were generated using Plink 2.0 software [24]. SNPs with imputation quality scores of less than 0.3 and ambiguous strand SNPs (A/T and G/C pairs) were excluded. Multi-allelic SNPs with only two common alleles were treated as bi-allelic. All scores were standardized to zero-mean and unit variance.
CAD events
Incident coronary artery disease events were defined as a composite endpoint of unstable angina, myocardial infarction, or death due to complications following myocardial infarction according to the International Statistical Classification of Diseases and Related Health Problems 10th Revision (ICD-10) (Additional file 1: Table S1). This composite endpoint was chosen to maximize the number of incident cases, and no differential effects were observed between predictor variables and different definitions of incident CAD events (Additional file 1: Table S2).
Statistical analyses
All statistical analysis was performed using R 4.0.0 [25]. We investigated the association between PRS on the composite primary endpoint of the first incident coronary event using cause-specific Cox proportional hazards regression. We identified the presence of competing risks of non-CAD death (Additional file 1: Figure S1) and thus performed Cox regression treating competing events as censored [26]. Along the same vein, cumulative incidence curves are presented instead of Kaplan–Meier curves because Kaplan–Meier curves are known to represent upward-biased incidence estimates in the presence of competing risks [26]. Time zero was date of diagnosis with patients entering the at-risk cohort at date of study enrolment (left truncation). Participants were right censored on the date of first occurrence of a CAD event, death from a cause other than coronary artery disease or last follow-up. Schoenfeld residuals for variables used in modelling and time were assessed for any significant departure from the proportional hazards assumption using the “cox.zph” function in the survival package [27]. A Wald test was performed to assess whether failure events were independent of left truncation [28]. Regression models were sequentially adjusted, first using only continuous PRS as the main exposure variable adjusted for age at diagnosis (years, continuous), genotype assay (Oncoarray, iCOGs) and eight genetic principal components (PCs), and then including sequential adjustments for conventional risk factors: BMI (kg/m [2], continuous), smoking status (never, past, current); sociodemographic variables: drinking status (past, current), education level (below GSCE, GSCE, A-level, graduate), index of multiple deprivation (IMD) (continuous); medical variables: age at menarche (years, continuous), thyroid disease (binary), parity (ordinal), hormone replacement therapy (binary); and oncotherapy variables: chemotherapy (binary), radiotherapy (binary), and hormone therapy (binary). Note that we did not have available data on baseline measurement for blood pressure, cholesterol, lipid-lowering medications, diabetes, or familial history.
The models were fit to the same subsample of cohort participants with increasingly more complete covariates to allow for more consistent comparison of the impact of adjustments and reduce the potential for selection bias in the scenario of outset restriction to participants with the most complete information on adjustment covariates.
We additionally assessed possible variation of the association of PRS with CAD according to smoking status and BMI level based on interaction tests. We also assessed the incremental improvement in CAD risk prediction from the addition of PRS to models including combinations of age, BMI, smoking, and other baseline covariates.
We calculated the net reclassification improvement and incremental discrimination index using the ncirens package to explore the potential clinical utility of PRS in women with breast cancer. More details about these calculations can be found in the Additional file. All confidence intervals are shown at the 95% level. All p values are 2-tailed.
Results
Genotyped participant characteristics
The study cohort of women with breast cancer comprised 12413 participants who had complete genotype information. The mean age at diagnosis was 54.6, and almost all participants were of European ancestries. The median [5th, 95th percentiles] time from diagnosis to entry into the study was 1.8 years [0.4, 4.3], and the median follow-up time was 10.3 years [2.6, 19.4]. A total of 750 individuals experienced a CAD event during follow-up. Out of the genotyped participants, 9496 (77%) received adjuvant hormonal therapy, 8773 (71%) received radiotherapy, and 4735 (38%) received adjuvant chemotherapy. A summary of other lifestyle, medical treatment, breast cancer, and medical history characteristics is presented in Table 1. Summary information is provided for the full SEARCH cohort (n = 15,755) and participants who died from breast cancer in the Additional file 1: Table S3.
Association of PRS and incident CAD
Age-adjusted models were initially assessed to understand individual associations of each variable with incident CAD survival (Table 2). There was no evidence of a departure from the proportional hazards assumptions for any of the variables modelled, and left truncation was found to be independent (Additional file 1: Table S4). There was no association between PRS and breast cancer-specific survival (HR 1.02; 95% CI 0.96–1.08).
The sample size for the multivariate model was 8946 with a total of 432 events after including only participants who experienced an event after entry into the study and had European ancestry (Fig. 1). The hazard ratio for incident CAD per 1 SD higher PRS adjusted only for age at diagnosis, genotype array, and eight genetic PCs was 1.36 (95% CI 1.23–1.51). Adjusting for conventional risk factors of smoking status and BMI resulted in minimal attenuation (Table 3, HRmodel2 = 1.34; 95% CI 1.21–1.49). Adjusting for other sociodemographic, lifestyle, and medical variables did not substantially change the HR of PRS (HRmodel5 = 1.33; 95% CI 1.20–1.47). A similar magnitude HR was found for another polygenic risk score, GRS49K [9] (HRmodel5 = 1.31; 95% CI 1.19–1.44). Density distributions for both standardized PRS and GRS49K can be found in Figure S2 in Additional file 1. There was no evidence that—with the inclusion or PRS and other mediator variables—chemotherapy, radiotherapy, or hormone therapy was associated with incident CAD in this study. A sensitivity analysis for follow-up only after one year, assuming a lag time to account for treatment completion within one year of diagnosis, was performed. Using model 5, the association between PRS and CAD remained largely unchanged (HR = 1.33, 95% CI 1.20–1.48).

Flow diagram of selection of study cohort
Interaction of PRS and conventional risk factors
Interactions between PRS and established cardiovascular risk factors, log(BMI) and smoking, were added separately to a model containing genotype array, eight genetic PCs, log(BMI), smoking, education level, drinking, parity, hormone replacement therapy (Table 4). The baseline mediators were selected based on multivariate results (Table 3, Model 5). The interaction effect between PRS and log(BMI) scaled to the mean was not significant at the 95% confidence level. Addition of an interaction term between PRS and smoking status slightly attenuated the effect of PRS, and the interaction effect between being a past smoker and the PRS approached nominal significance (P = 0.069). The joint hazard ratios are presented in Table 5.
Interaction of PRS and oncotherapy
The hazard ratios of the interaction terms between PRS and radiotherapy, PRS and chemotherapy, and PRS and anti-hormone therapy were 1.15 (0.92, 1.43), 0.93 (0.74, 1.16), and 1.15 (0.90, 1.46) respectively in a model containing genotype array, eight genetic PCs, log(BMI), smoking, education level, drinking, parity, and hormone replacement therapy (Additional file 1: Tables S6–S7).
Ability of PRS to risk-stratify incident CAD in breast cancer survivors
Figure 2 shows the cumulative risk of CAD by PRS quintile. Women in the lowest quintile of risk reached 5% cumulative incidence at 15.1 years compared to 8.9 years for women in the highest quintile of risk.

Cumulative risk of CAD by quintiles of metaGRS truncated at 20 years post-diagnosis
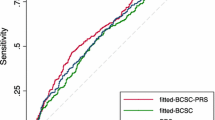
The discrimination of the PRS alone measured by the c-index was somewhat less than that of a model with BMI and smoking combined (0.73 vs. 0.74, P = 0.048) after adjusting for age, genotype array, and genetic PCs (Fig. 3). The addition of PRS made little practical improvement to a model including genotype array, eight genetic PCs, BMI, smoking status, education level, drinking, IMD, age at menarche, parity, hormone replacement therapy, and thyroid disease (0.757 vs. 0.764, P = 0.052). The total proportion of CAD and non-CAD cases that was reclassified was 22% and 11% respectively. The net proportion of CAD and non-CAD cases assigned to a higher risk category was 12% and 5.6% respectively for a 10-year CAD incidence risk (Additional file 1: Table S8).

Training C-indices for conventional risk factors and metaGRS
Discussion
Based on a large cohort of British women with breast cancer, we have provided evidence that a CAD polygenic risk score developed for the general population can be generalized to breast cancer patients, with an estimated 33% higher CAD risk per 1 SD higher PRS (HR = 1.33, 95% CI 1.20, 1.47), independent of established cardiovascular risk factors (age, smoking, BMI), oncotherapies and other variables associated with cardiovascular risk (education level) in a cohort of British women with breast cancer. Our results support previous evidence that the association of PRS and CAD risk may operate through molecular pathways that do not overlap with those of traditional risk factors such as smoking and BMI. This is consistent with the original PRS analysis which found only a modest attenuation for PRS when adjusting for BMI, smoking status, as well as diabetes, hypertension, family history of heart disease, and cholesterol levels (HR: 1.58 per SD; 95% CI 1.55–1.61 unadjusted; HR: 1.48 per SD; 95% CI 1.45–1.51 adjusted) [10]. Several other studies also found only modest attenuation of CAD polygenic risk scores when adjusting for variables such as lipid treatment at baseline, cholesterol, and systolic blood pressure [9, 19, 29].
However, we note that there was an almost significant interactive effect between being a past smoker and the PRS. Since PRS is known to be correlated to certain conventional CAD risk factors [10, 30], it is plausible that some fraction of incident CAD risk explained by PRS may be dependent on smoking status. While this paper is not expressly predictive in nature, we note that the addition of PRS may not have provided additional risk discrimination on top of BMI and smoking because by middle age, the genes that compose this risk score may have already exerted their influence, and thus the PRS would not be expected to add discriminatory ability.
The PRS improves risk discrimination in breast cancer survivors. For instance, we found an over twofold HR for CAD in a comparison of individuals in the top versus bottom one-fifth of the risk score distribution. Furthermore, when considering 10-year risk of incident CAD following breast cancer diagnosis, we found that 5.6% of lower risk participants who did not have a recorded CAD event were reclassified to a higher risk group with the addition of PRS to the baseline model (Additional file 1: Table S5). While the change is discrimination is small, this may result in meaningful risk reclassification in clinical decision-making between the harms and benefits of chemotherapy. Further work is required to evaluate whether such reclassification would justify the additional cost of genotyping.
We acknowledge the limitation of how treatment (chemotherapy, radiotherapy, and anti-hormone therapy) was coded as dichotomous variable (whether or not a patient received treatment). The loss of information about other treatment aspects (e.g. dose, duration, type) may have contributed to measurement error that resulted in the associations reported in our paper. Furthermore, the association of the interaction of PRS and chemotherapy is likely explained by selection bias, where healthy patients are more likely to undergo chemotherapy. More granular data will be required to further assess these associations.
The role that PRS may play in breast cancer clinical care is currently unclear, but fundamentally, PRS may be used to help estimate the lifetime risk of cardiovascular disease in a breast cancer survivor. This may have two clinically useful benefits: (1) facilitate earlier detection of cardiovascular risk in breast cancer survivors to help them more effectively manage cardiovascular risk factors earlier to reduce future cardiovascular risk and (2) aid in treatment decision-making when considering the negative cardiotoxic effects of their treatment regiments.
This is especially important in breast cancer patients who face the unique challenge of needing to maximize gains from cancer treatment while also minimizing its cardiotoxic effects. More women are surviving breast cancer with an increase in 5-year survival for early stage breast cancer from 79% in 1990 to 88% in 2012 [31] (there were an estimated 3.4 million breast cancer survivors in the US in 2015 [32]), so cardiovascular mortality may become an increasingly important concern. Bradshaw et al. showed that there is nearly a twofold increase in the incidence of CVD for long-term breast cancer survivors around 7 years after diagnosis [4]. Several large randomized trials have provided evidence of the association between chemotherapy, radiotherapy, hormone therapy and increased risk of cardiovascular events [33, 34]. For instance, Darby et al. showed that the rate of CAD was proportional to the average dose of ionizing radiation during radiotherapy for breast cancer, with increases in rate continuing as long as 20 years post-exposure [35]. This is particularly important for women diagnosed at a relatively young age who begin treatment and may then have increased risk of CVD mortality. It suggests that breast cancer survivors may benefit from a PRS assessment and should be closely monitored for development of cardiovascular risk factors following diagnosis and subsequent treatment. In our study, cumulative incidence curves of incident CAD events did not appear to be substantially different when stratified by oncotherapy status (Additional file 1: Figure S3), which suggests that more granular data on treatment data, such as dosage, frequency, or duration, is needed to better assess the interplay between drug cardiotoxicity and genetic cardiovascular susceptibility. PRS may help clinicians and their patients make decisions about whether the benefits of adjuvant chemotherapy and other oncotherapies outweigh the risks.
Limitations
There are some limitations in interpreting the current findings. The association between PRS and incident CAD could not be adjusted for important risk factors such as diabetes, hyperlipidaemia, family history of cardiovascular disease, and hypertension because these data were not collected. It is worth noting; however, that the PRS used in this study has been shown in other cohorts to provide additional predictive benefit over standard cardiovascular risk prediction algorithms such as the Framingham risk score, which include such metabolic risk factors [9]. Treatment data were limited to whether the patient had received chemotherapy, radiotherapy, and anti-hormone therapy. Data on specific drugs or doses received were not available. Genotype data were available for predominantly participants of white European ancestry, which suggests the need for studies in people of other ancestries to maximize generalizability. Furthermore, the observational nature of these data limits any inference that might be drawn relating to the association between therapy and outcome.
Conclusion
Cardiovascular disease is an important long-term risk among women who survive breast cancer. This risk is increased by some breast cancer therapies. Comprehensive risk models for cardiovascular disease have the potential to help in the clinical management of this risk and may improve long-term outcomes for these women.
Availability of data and materials
The data are available from the authors on request. The HES data were supplied by PHE, and they will not give permission for the data to be shared.
References
Bray F, Ferlay J, Soerjomataram I, Siegel RL, Torre LA, Jemal A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2018;68(6):394–424.
Zamorano JL, Lancellotti P, Rodriguez Muñoz D, Aboyans V, Asteggiano R, Galderisi M, et al. 2016 ESC Position Paper on cancer treatments and cardiovascular toxicity developed under the auspices of the ESC Committee for Practice Guidelines: The Task Force for cancer treatments and cardiovascular toxicity of the European Society of Cardiology (ESC). Eur Heart J. 2016;37(36):2768–801.
Patnaik JL, Byers T, DiGuiseppi C, Dabelea D, Denberg TD. Cardiovascular disease competes with breast cancer as the leading cause of death for older females diagnosed with breast cancer: a retrospective cohort study. Breast Cancer Res BCR. 2011;13(3):R64.
Bradshaw PT, Stevens J, Khankari N, Teitelbaum SL, Neugut AI, Gammon MD. Cardiovascular disease mortality among breast cancer survivors. Epidemiol Camb Mass. 2016;27(1):6–13.
Hamood R, Hamood H, Merhasin I, Keinan-Boker L. Risk of cardiovascular disease after radiotherapy in survivors of breast cancer: a case-cohort study. J Cardiol. 2019;73(4):280–91.
Okwuosa TM, Anzevino S, Rao R. Cardiovascular disease in cancer survivors. Postgrad Med J. 2017;93(1096):82–90.
Sharma AV, Reddin G, Forrestal B, Barac A. Cardiovascular Disease Risk in Survivors of Breast Cancer. Curr Treat Options Cardiovasc Med. 2019;21(12):79.
Hippisley-Cox J, Coupland C, Brindle P. Development and validation of QRISK3 risk prediction algorithms to estimate future risk of cardiovascular disease: prospective cohort study. BMJ [Internet]. 2017;357. Available from: https://www.bmj.com/content/357/bmj.j2099
Abraham G, Havulinna AS, Bhalala OG, Byars SG, De Livera AM, Yetukuri L, et al. Genomic prediction of coronary heart disease. Eur Heart J. 2016;37(43):3267–78.
Inouye M, Abraham G, Nelson CP, Wood AM, Sweeting MJ, Dudbridge F, et al. Genomic risk prediction of coronary artery disease in 480,000 adults: implications for primary prevention. J Am Coll Cardiol. 2018;72(16):1883–93.
Khera AV, Chaffin M, Aragam KG, Haas ME, Roselli C, Choi SH, et al. Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations. Nat Genet. 2018;50(9):1219–24.
Sugrue LP, Desikan RS. What are polygenic scores and why are they important? JAMA. 2019;321(18):1820–1.
Becker KG. The common variants/multiple disease hypothesis of common complex genetic disorders. Med Hypotheses. 2004;62(2):309–17.
Rotter JI, Lin HJ. An outbreak of polygenic scores for coronary artery disease. J Am Coll Cardiol. 2020;75(22):2781–4.
Khan SS, Cooper R, Greenland P. Do polygenic risk scores improve patient selection for prevention of coronary artery disease? JAMA. 2020;323(7):614–5.
Mosley JD, Gupta DK, Tan J, Yao J, Wells QS, Shaffer CM, et al. Predictive accuracy of a polygenic risk score compared with a clinical risk score for incident coronary heart disease. JAMA. 2020;323(7):627–35.
Elliott J, Bodinier B, Bond TA, Chadeau-Hyam M, Evangelou E, Moons KGM, et al. Predictive accuracy of a polygenic risk score-enhanced prediction model vs a clinical risk score for coronary artery disease. JAMA. 2020;323(7):636–45.
Lambert SA, Abraham G, Inouye M. Towards clinical utility of polygenic risk scores. Hum Mol Genet. 2019;28(R2):R133–42.
Wang M, Menon R, Mishra S, Patel AP, Chaffin M, Tanneeru D, et al. Validation of a genome-wide polygenic score for coronary artery disease in South Asians. J Am Coll Cardiol. 2020;76(6):703–14.
Office of National Statistics. Hospital Admitted Patient Care Activity 2018–19. [cited 2020 Jul 17]; Available from: https://digital.nhs.uk/data-and-information/publications/statistical/hospital-admitted-patient-care-activity/2018-19
Michailidou K, Hall P, Gonzalez-Neira A, Ghoussaini M, Dennis J, Milne RL, et al. Large-scale genotyping identifies 41 new loci associated with breast cancer risk. Nat Genet. 2013;45(4):353–61.
Michailidou K, Lindström S, Dennis J, Beesley J, Hui S, Kar S, et al. Association analysis identifies 65 new breast cancer risk loci. Nature. 2017;551(7678):92–4.
Lambert SA, Gil L, Jupp S, Ritchie SC, Xu Y, Buniello A, et al. The Polygenic Score Catalog: an open database for reproducibility and systematic evaluation. medRxiv. 2020;2020.05.20.20108217.
Chang CC, Chow CC, Tellier LC, Vattikuti S, Purcell SM, Lee JJ. Second-generation PLINK: rising to the challenge of larger and richer datasets. GigaScience. 2015;4:7.
R Core Team. R: A Language and Environment for Statistical Computing [Internet]. Vienna, Austria: R Foundation for Statistical Computing; 2020. Available from: https://www.R-project.org/
Austin PC, Lee DS, Fine JP. Introduction to the analysis of survival data in the presence of competing risks. Circulation. 2016;133(6):601–9.
Grambsch PM, Therneau TM. Proportional hazards tests and diagnostics based on weighted residuals. Biometrika. 1994;81(3):515–26.
Tsai W-Y. Testing the assumption of independence of truncation time and failure time. Biometrika. 1990;77(1):169–77.
Natarajan P, Young R, Stitziel NO, Padmanabhan S, Baber U, Mehran R, et al. Polygenic risk score identifies subgroup with higher burden of atherosclerosis and greater relative benefit from statin therapy in the primary prevention setting. Circulation. 2017;135(22):2091–101.
Isgut M, Sun J, Quyyumi AA, Gibson G. Highly elevated polygenic risk scores are better predictors of myocardial infarction risk early in life than later. Genome Med. 2021;13(1):13.
Curigliano G, Cardinale D, Dent S, Criscitiello C, Aseyev O, Lenihan D, et al. Cardiotoxicity of anticancer treatments: Epidemiology, detection, and management. CA Cancer J Clin. 2016;66(4):309–25.
Bodai BI, Tuso P. Breast cancer survivorship: a comprehensive review of long-term medical issues and lifestyle recommendations. Perm J. 2015;19(2):48–79.
Early Breast Cancer Trialists’ Collaborative Group (EBCTCG). Comparisons between different polychemotherapy regimens for early breast cancer: meta-analyses of long-term outcome among 100,000 women in 123 randomised trials. The Lancet. 2012;379(9814):432–44.
Early Breast Cancer Trialists’ Collaborative Group (EBCTCG). Effects of chemotherapy and hormonal therapy for early breast cancer on recurrence and 15-year survival: an overview of the randomised trials. The Lancet. 2005;365(9472):1687–717.
Darby SC, Ewertz M, McGale P, Bennet AM, Blom-Goldman U, Brønnum D, et al. Risk of ischemic heart disease in women after radiotherapy for breast cancer. N Engl J Med. 2013;368(11):987–98.
Acknowledgements
We thank all the study participants who contributed to this study and all the researchers, clinicians and technical and administrative staff who have made possible this work. This work was supported by core funding from the: UK Medical Research Council (MR/L003120/1), British Heart Foundation (RG/13/13/30194; RG/18/13/33946) and NIHR Cambridge Biomedical Research Centre (BRC-1215-20014) [*]. This work was also supported by Health Data Research UK, which is funded by the UK Medical Research Council, Engineering and Physical Sciences Research Council, Economic and Social Research Council, Department of Health and Social Care (England), Chief Scientist Office of the Scottish Government Health and Social Care Directorates, Health and Social Care Research and Development Division (Welsh Government), Public Health Agency (Northern Ireland), British Heart Foundation and Wellcome. *The views expressed are those of the author(s) and not necessarily those of the NIHR or the Department of Health and Social Care.
Funding
SEARCH is supported by the Cambridge Cancer Centre, the NIHR Biomedical Research Centre at the University of Cambridge and Cancer Research UK (C490/A16561). The University of Cambridge receives salary support for PDPP the from the NHS in the East of England through the Clinical Academic Reserve. Stephen Kaptoge is funded by a BHF Chair award (CH/12/2/29428). Mike Inouye is supported by the Munz Chair of Cardiovascular Prediction and Prevention and the NIHR Cambridge Biomedical Research Centre (BRC-1215-20014) [*].
Author information
Authors and Affiliations
Contributions
LL analyzed and interpreted the data and wrote the manuscript. PDPP and DE conceptualized the study. PDPP, SK, and MI were major contributors in writing and revising the manuscript. JD, MT, and JS queried and performed quality control of the data and assisted with polygenic risk score calculation. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics and consent
SEARCH is approved by the NRES Committee East of England—Cambridge South.
Consent for publication
Consent for publication was received.
Competing interests
The authors have no competing interests to declare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1
. Supplementary appendix containing additional description of methods and tables and figures for sensitivity analyses described in the main text.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Liou, L., Kaptoge, S., Dennis, J. et al. Genomic risk prediction of coronary artery disease in women with breast cancer: a prospective cohort study. Breast Cancer Res 23, 94 (2021). https://doi.org/10.1186/s13058-021-01465-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13058-021-01465-0