
Abstract
Background
Sepsis, an acute and potentially fatal systemic response to infection, significantly impacts global health by affecting millions annually. Prompt identification of sepsis is vital, as treatment delays lead to increased fatalities through progressive organ dysfunction. While recent studies have delved into leveraging Machine Learning (ML) for predicting sepsis, focusing on aspects such as prognosis, diagnosis, and clinical application, there remains a notable deficiency in the discourse regarding feature engineering. Specifically, the role of feature selection and extraction in enhancing model accuracy has been underexplored.
Objectives
This scoping review aims to fulfill two primary objectives: To identify pivotal features for predicting sepsis across a variety of ML models, providing valuable insights for future model development, and To assess model efficacy through performance metrics including AUROC, sensitivity, and specificity.
Results
The analysis included 29 studies across diverse clinical settings such as Intensive Care Units (ICU), Emergency Departments, and others, encompassing 1,147,202 patients. The review highlighted the diversity in prediction strategies and timeframes. It was found that feature extraction techniques notably outperformed others in terms of sensitivity and AUROC values, thus indicating their critical role in improving sepsis prediction models.
Conclusion
Key dynamic indicators, including vital signs and critical laboratory values, are instrumental in the early detection of sepsis. Applying feature selection methods significantly boosts model precision, with models like Random Forest and XG Boost showing promising results. Furthermore, Deep Learning models (DL) reveal unique insights, spotlighting the pivotal role of feature engineering in sepsis prediction, which could greatly benefit clinical practice.
Similar content being viewed by others

Introduction
Sepsis, a severe and life-threatening condition triggered by an overwhelming immune response to infection, poses a significant global health challenge [1]. It is responsible for an estimated 31.5 million cases of sepsis and 19.4 million cases of severe sepsis annually, leading to approximately 5.3 million deaths worldwide [2]. The critical nature of timely sepsis identification in clinical practice is underscored by findings that even a brief delay in initiating treatment can substantially increase mortality rates, owing to irreversible organ damage[3]. This urgency has catalyzed research into advanced predictive methodologies, notably the application of Machine Learning (ML) techniques aimed at the early detection of sepsis[4]. Such research endeavors have largely concentrated on the development of ML models and tools with a focus on improving prognosis, diagnosis, and the integration of clinical workflows, thereby highlighting the potential for constructing sophisticated computerized decision support systems[5].
Despite these advancements, traditional sepsis prediction methodologies, including the Sequential Organ Failure Assessment (SOFA), Systemic Inflammatory Response Syndrome (SIRS), and quick SOFA (qSOFA), exhibit significant limitations[6]. These methods often rely heavily on clinical judgment and are subject to variability in interpretation across different levels of clinical expertise, which can lead to inconsistencies in early sepsis detection. Moreover, traditional approaches tend to identify sepsis at a more advanced stage, missing the crucial window for early intervention [6, 7]. Conversely, ML models offer a dynamic and continuous analysis of real-time patient data, enabling early detection and providing dynamic risk assessments. By harnessing data analysis and pattern recognition capabilities, ML models aim to enhance patient outcomes and alleviate the burden on healthcare systems[7].
Feature engineering emerges as a critical component in the optimization of ML models for sepsis prediction. This process entails the selection, transformation, and creation of relevant features from raw data, aiming to improve the predictive accuracy of models. While the significance of identifying and utilizing critical features in constructing robust and precise predictive models is well-recognized, the field continues to grapple with uncertainties surrounding the effectiveness of specific features and the methodologies for feature selection and extraction[8]. Variability in the approaches to feature engineering and their impact on model performance necessitates a comprehensive scoping review to evaluate the evidence and discern which strategies yield the most significant benefits in terms of prediction accuracy.
In the context of feature engineering for sepsis prediction, the current literature has focused on the importance of selecting and extracting the most relevant patient-related variables to enhance the model accuracy [9]. Though some studies have explored clinical and laboratory features to improve sepsis prediction models, such as vital signs (e.g., temperature, heart rate, respiration rate, blood pressure), laboratory values (e.g., white blood cell count, lactate levels), patient demographics, and clinical history to improve sepsis prediction models; but still there is uncertainty regarding the effectiveness of specific features and feature selection/extraction methods in sepsis prediction[10]. Our current study employed different approaches to feature engineering, and their impact on model performance varies. This variability highlights the need for a scoping review to comprehensively evaluate the available evidence and provide insights into which feature-engineering strategies offer the greatest benefits in terms of sepsis prediction accuracy.
This scoping review seeks to address these gaps by assessing the critical features that enhance sepsis prediction and by providing insights into identifying patterns that may lead to improved clinical outcomes. The primary objective of this review is twofold: firstly, to explore the feature engineering strategies utilized in ML models for sepsis prediction, thereby offering valuable insights for future research and model development; and secondly, to evaluate the performance of these models through a critical analysis of existing studies, focusing on metrics such as the Area Under the Receiver Operating Characteristic curve (AUROC), Sensitivity, and Specificity.
Through an exhaustive evaluation of 29 selected studies, this review aims to analyze and synthesize various feature engineering techniques applied in sepsis prediction models, assess their impact on model performance, and evaluate the overall effectiveness of ML models in predicting sepsis. By adopting a systematic approach, the review intends to provide a comprehensive understanding of the role of feature engineering in enhancing sepsis prediction models, ultimately contributing to more effective clinical decision-making and patient care.
Methods
Search strategy
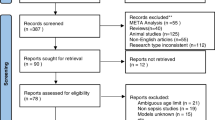
The search strategy for this scoping review was meticulously devised in alignment with the Preferred Reporting Items for Scoping Reviews (PRISMA) guidelines. PRISMA represents a rigorously developed framework, outlining a comprehensive set of standards for reporting scoping reviews. This methodology ensures transparency and reproducibility in the review process, as illustrated in Figure 1.[11]

Preferred Reporting Items for Scoping reviews and Meta-Analysis (PRISMA) flow diagram for the conducted study
On 13th March 2023, a comprehensive literature search was conducted across PubMed, Embase, and Scopus, targeting publications from the past five years (13 March 2018 to 13 March 2023). This search employed a detailed strategy, utilizing Boolean operators "AND" and "OR" to combine key phrases, specifically: "Machine Learning" and "Prediction" along with "Sepsis" and "Septic Shock". Each database was queried with these terms to ensure a thorough retrieval of relevant studies. Subsequently, the titles and abstracts of the retrieved studies were meticulously reviewed by an investigator (SB) to ascertain their suitability for inclusion in the review.
Inclusion and exclusion criteria
Inclusion criteria:
-
Research articles published in the English language.
-
Studies appearing in peer-reviewed journals.
-
Research focusing on the prediction of sepsis and associated outcomes.
-
Studies investigating ML (Machine Learning) models for sepsis prediction, emphasizing significant features for model optimization.
Exclusion criteria:
-
Conference abstracts and preliminary proof of concept studies.
-
Research studies exclusively predicting mortality related to sepsis.
-
Research studies published in the subscribed journals
These criteria ensured a comprehensive and focused review of the literature on ML models for sepsis prediction by excluding preliminary findings and studies that were not directly aligned with the core objectives of efficient prediction and feature analysis.
Data extraction and quality assessment
Data extraction was meticulously carried out by a primary reviewers (SB) and (JP), who cataloged essential details such as Title, Publication year, First author, Study objectives, Clinical setting, Patient cohort size, ML model utilized, Feature count, Sepsis classification, Observation period, Gender distribution, AUROC, Innovation, Model evaluation criteria,Training-test split, Data source, Sensitivity, and Specificity, in addition to the criteria used for sepsis diagnosis.
To ensure the accuracy and integrity of the data extraction process, two additional reviewers (ED and UU) collaboratively worked with the primary reviewer (SB) to scrutinize and validate the extracted information. Studies failing to align with the predetermined inclusion criteria were systematically excluded. Discrepancies encountered during the review process were resolved through comprehensive mutual discussion and further literature consultation, facilitating consensus among the reviewers.
Results
Characteristics of studies
The scoping review included 29 studies (See in Table 1), encompassing a total patient cohort of 1,147,202 (909,462 cases and 237,740 controls). The majority of the studies, numbering 20, (3,4,12,13,17,18,19,20,21,5,23,24,25,28,30,31,32,33,34,36) were conducted in Intensive Care Units (ICUs), while four were based in Emergency Departments (EDs) 16,26,29,35, and one was carried out in a general hospital setting[14]. These studies varied in patient demographics, prediction timeframes, and sepsis types, utilizing diverse database sources. For instance, the research by Meicheng Yang et al. [3]focused on hourly sepsis risk prediction in ICU settings with the EASP model, emphasizing interpretability. Maximiliano Mollura et al. [12] and Xin Zhao et al. [13] explored ICU data and PhysioNet/Clinic Challenge 2019 data, respectively, each applying distinct approaches to sepsis prediction and addressing specific challenges.
Figure 2's pie chart illustrates the data source distribution, revealing a nearly equal split between private (55%) and public databases (45%), such as MIMIC, indicating the varied origins of data in these studies. This comprehensive review underscored the array of strategies and methodologies employed to enhance sepsis prediction across different clinical environments, contributing to the ongoing advancement in the field.

Database sources used in the studies
Feature engineering techniques
Feature selection is a process of selecting feature subsets which are applied to the model construction. It is used in areas where there any many features and relatively few samples. On the other hand, feature extraction generates new features from the original features, which means that the new features after feature extraction is a mapping of the original features (See Figure 3). [35]

Classification of feature selection methods
Feature selection methods: Filter methods
Filter methods employ variable ranking techniques as their core criterion for feature selection, arranging variables based on their relevance. This relevance, termed feature relevance, measures a feature's utility in distinguishing between different classes within the data. Utilizing methods like Info Gain, GINI, and Relief, Jevier Enrique Camacho-Cogollo et al.[20] applied the filter approach to score and rank features according to their class label relevance, selecting features above a specified relevance threshold (0.0020). This process identified 31 medically relevant features and 88 statistical features, with Info Gain, GINI, and Relief methods selecting 75, 47, and 76 relevant features respectively. Similarly, Donghun Yang et al. [15] employed the filter method to narrow down from 1,738 initial features to the 50 most critical features, encompassing both laboratory data and drug interactions, thereby underscoring their significance in enhancing the accuracy of their predictive model.
Feature selection methods: Wrapper methods
Wrapper methods optimize feature selection by treating the prediction model as a “black box," utilizing the model's performance metrics as the objective function for evaluating subsets of variables. [2]This approach typically yields higher performance subsets than filter methods by leveraging actual modeling algorithms for evaluation.[38] Yash Veer Singh et al.[31] applied backward elimination, a wrapper method, effectively removing non-contributory features to identify 11 critical features, achieving a model accuracy of 0.96 with their Ensemble model. Meicheng Yang et al. employed forward feature selection, another wrapper strategy, categorizing their 168 selected features into raw features, information missingness, time series, and empiric categories, showcasing the adaptability of wrapper methods in refining feature sets for predictive modeling.
Feature selection methods: Embedded methods
Embedded methods integrate the feature selection process directly within the training phase of ML models, offering a nuanced approach that inculcates the complexity of model training with the simplicity of feature optimization. These methods, such as Lasso and Elastic Net, operate on the principle of regularization, which aims to minimize overfitting by penalizing the magnitude of feature coefficients, effectively shrinking some to zero. [38] This not only aids in identifying features that have little to no predictive value but also enhances model generalizability.
In the realm of sepsis prediction, embedded methods have shown considerable promise. For instance, the use of Random Forest importance as an embedded method highlights its capability to discern the relative value of each feature within a dataset. By analyzing feature importance, researchers can pinpoint which variables most significantly impact the model's predictions, particularly in the context of sepsis where timely and accurate prediction can save lives. Dong Wang et al.'s [5] application of this method led to the selection of a concise set of 20 features critical for sepsis prediction in ICU patients, underscoring the method's efficiency in distilling a dataset to its most informative components.
Further exploration by Cesario et al. [20]into Mean Decrease Accuracy and Mean Decrease GINI as embedded methods provides insights into the multifaceted nature of feature selection. These techniques evaluate the impact of each feature on the model's accuracy and the overall reduction in data impurity, respectively, offering a comprehensive view of feature significance. Such methodologies have elucidated the paramount importance of certain predictors, like age, which exhibited a profound influence on the model's predictive capabilities.
Rishikesan Kamaleswaran et al.'s [25] study stands out for its broad application of feature selection methods, spanning both embedded and wrapper techniques. By employing a wide array of methods, including parametric and non-parametric tests, Ridge, Lasso, and Recursive Feature Elimination (RFE), alongside Random Forest-based variable importance, the study showcases the depth of possible analysis when integrating feature selection with model development. The adoption of Recursive Feature Elimination, in particular, highlighted its effectiveness in isolating 22 highly predictive features, demonstrating the potential of embedded methods to refine and enhance model performance through targeted feature selection.
This comprehensive approach to feature selection, particularly within the scope of embedded methods, exemplifies the dynamic interplay between algorithmic complexity and model optimization. By embedding feature selection within the model training process, these methods provide a robust framework for developing highly accurate and generalizable predictive models, essential for advancing sepsis prediction and improving patient outcomes.
Feature extraction methods
Zhengling He et al. [19] and colleagues explored the potential of LSTM (Long Short-Term Memory networks) for deriving features from sequential data, employing an ablation study to gauge the impact of individual features. Their findings highlight the ICU Length Of Stay (LOS) as a pivotal predictor, alongside other significant LSTM-derived features like the pseudo SOFA score and body temperature. These insights underscore the value of deep learning in identifying nuanced indicators for sepsis onset prediction.
Further innovation in feature engineering was demonstrated through the development of second-order derived features and aggregate features [17], capturing complex relationships and condensing data into insightful metrics. This approach yielded a comprehensive set of 672 features, with 192 identified as unique, revealing the synergistic effect of body temperature and heart rate, among others, on sepsis prediction accuracy and lead time.
Table 2 consolidates various feature selection and extraction methods, ranging from wrapper and embedded methods to unsupervised techniques, highlighting their effectiveness in distilling critical predictors from a broad spectrum of clinical and demographic data. This table illustrates the evolution from initial feature identification to the final selection, emphasizing the top ten features across studies, and showcasing the diversity and impact of feature selection and extraction strategies on enhancing model performance.
The analysis of the top 10 features, as depicted in Figure 4, highlights the most critical physiological markers for sepsis prediction. These indicators are crucial for recognizing the onset of sepsis, emphasizing the necessity of vigilant monitoring of such parameters. The graphical representation serves to underline the significant role these features play in the early detection and prediction of sepsis, pointing to the potential changes in these parameters as early signs of sepsis. This insight is vital for the development of effective early diagnosis and intervention strategies in sepsis management, illustrating the clinical importance of these markers.

Frequency of features identified in studies
To comprehensively assess the influence of various feature selection and extraction methodologies on the predictive accuracy of sepsis models, a meticulous analysis was carried out. This scrutiny was confined to investigations leveraging publicly accessible databases, namely MIMIC and PhysioNet, to ensure an unbiased comparison across diverse studies. By filtering through an expansive array of research, significant contributions from each category—Filter, Wrapper, Embedded, and Feature Extraction—were identified and their optimal results meticulously synthesized.
The graphical representation, depicted in Figure 5, elucidates the differential efficacy of these methodologies, with a particular spotlight on the Feature Extraction technique. This method emerged as notably superior, showcasing enhanced sensitivity and AUROC metrics, thereby suggesting its unparalleled effectiveness in sepsis prediction. Such findings are instrumental, indicating that feature extraction methods when specifically adapted for the nuances of sepsis prediction, are capable of significantly elevating the predictive precision of models. This detailed comparative analysis not only highlights the distinct advantages of tailored feature extraction techniques but also serves as a critical resource, offering insights into the optimization of sepsis prediction models through strategic feature selection and extraction.

Performance analysis of different feature selection and extraction methods across open database
Model performance
Table 3 synthesizes outcomes from a spectrum of studies dedicated to sepsis prediction, encapsulating the application of Machine Learning (ML) and Deep Learning (DL) strategies. It meticulously outlines the top-performing models, highlighting their Area Under the Receiver Operating Characteristic Curve (AUROC) values, Sensitivity, Specificity, and the Distribution of data for training, testing, and validation phases. The compilation reveals a broad array of algorithmic approaches, underscoring the dynamic potential of different ML models in accurately predicting sepsis. For instance, Kim et al.'s [30] bespoke model showcases exemplary performance metrics, whereas Yang et al.'s [13] study presents a contrasting scenario with their Random Forest model. This diversity in model efficacy and algorithmic application illustrates the ongoing evolution and complexity in the quest for improved sepsis prediction methodologies, aiming to significantly uplift patient care standards through enhanced diagnostic accuracy.
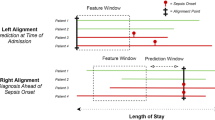
Impact of prediction time window on model performance
The prediction time window is crucial as it plays an important role in clinical intervention, resource allocation, treatment planning, false positive rates, clinical workflow, and model evaluation. Figure 6 depicts the impact of the different prediction time windows on the model performance.

Predicting the performance of multi-time window
Some studies including [18, 21, 34] showed that the ML model gave dependable results (higher AUROC while minimizing false positive and false negative rates) when predicting sepsis at different time intervals 12, 24 and 48 h. These results have clinical significance as they demonstrate that the model’s predictive power remains consistent across the crucial time windows. It’s also worth noting that some studies [12,13,14, 32,33,34, 36] have shown consistent results across early time points (1 to 6 h) which indicates that they can identify septic cases in their early stages.
In the course of this investigation in a study [4], a novel Smart Sepsis Predictor (SSP) model was meticulously developed, employing a Recurrent Neural Network (RNN) architecture. The SSP model was thoughtfully designed to operate in two distinct modes, each harnessing crucial inputs encompassing a spectrum of patient data, including vital signs, demographics, and laboratory values. What sets this model apart is its remarkable proficiency in achieving higher Area Under the Curve (AUC) scores when applied to a 12-h prediction window. This capability arises from its unique capacity to discern intricate and nuanced relationships within vital sign data, thereby facilitating timely alerts to healthcare practitioners. It is noteworthy that the findings reported herein align consistently with the outcomes observed in prior studies, specifically references [34] and [36].
This study [31] introduced a novel early warning model known as the Double Fusion Sepsis Predictor (DFSP), which stands as a hybrid deep-learning framework amalgamating deep features with meticulously engineered attributes encompassing statistical metrics and clinical scores. The outcomes of this investigation present compelling evidence for the superior performance of DFSP when juxtaposed with a pure deep learning model. Specifically, DFSP demonstrates a substantial enhancement in the Area Under the Receiver Operating Characteristic (AUROC) curve across 6, 12, and 24-h prediction horizons. This improvement is attributed to the utilization of fusion strategies, which not only enhance predictive capabilities but also significantly elevate the AUROC scores.
In this study [19], an advanced Sepsis Early Risk Assessment (SERA) algorithm was devised, incorporating both structured and unstructured clinical notes. Through data mining techniques, the SERA algorithm demonstrated enhanced predictive accuracy compared to utilizing solely clinical metrics. The Receiver Operating Characteristic (ROC) analysis of the SERA algorithm consistently surpassed predictions made by physicians across all examined time intervals, exhibiting notably high Area Under the ROC Curve (AUROC) scores even up to 48, 24, 12, 6, and 4 h preceding the onset of sepsis.
Discussion
From the list of 29 included studies, almost all of them, ICU-based studies (68%) and ED-based studies (13%), were conducted in critical care settings in the hospitals, thus showing the significance of ML in critical care data analytics. Early diagnosis and treatment play an important role in reducing the mortality due to sepsis, but advanced and accurate detection of sepsis is still a challenge in the clinical domain. When we discuss the electronic monitoring of sepsis patients for predicting and detecting early symptoms of complications, that's where the ML algorithms come in and play their role by identifying patterns and relationships from vast / big patients' datasets to solve this complex problem [37]. While reviewing the related literature, we found several studies using ML models and algorithms for sepsis prediction as mentioned in the above results section. Linked with the subject of our current study, we found three important scoping reviews / meta-analysis that focused on the potentials of ML for sepsis prediction [2, 38,39]. The review from Deng et al. included 21 studies focusing on early sepsis detection, prediction and mortality. It concluded that no model could be adopted widely yet in general due to the lack of unified validation standards / procedures and the heterogeneity in patients’ cohort, though it referred Deep Neural Networks (DNNs) as more suitable tool as compared to the other traditional tools for high-dimensional and highly heterogeneous patients' sepsis data. Interestingly, it recommended using ML as a feature engineering tool, which reflects the need for and importance of our conducted study in this field; and suggested AUROC as evaluation standard for model performance as in our results. The review and meta-analysis from Fleuren et al. [38] showed ML models prediction for Sepsis ahead of time using retrospective data by examining 28 included studies out of which 24 reported AUROC as their performance metric in critical care settings. and focused on AUROC to analyze model performance whereas we looked at the other metrics like sensitivity and specificity in addition to AUROC. Though the results of this review showed that individual models outperformed the traditional scoring tools, the authors suggested the need of development of reporting guidelines for ML models in critical/intensive care settings and their implementation with diverse patient populations to see the clinical impact. Similarly, another meta-analysis study from Islam et al. [39] included seven observational studies to quantify the performance of ML models for Sepsis prediction. The outcomes showed that.
ML prediction models performed well as compared to existing sepsis scoring systems, such as SIRS, MEWS, SOFA, and qSOFA for identification and prediction of sepsis patients; and suggested for more multi-centered studies with more precise clinical variables for sepsis prediction in the future. In contrast to these review / meta-analysis studies, our review dedicatedly focused on different critical features and feature extraction methods. The results of our study showed the key dynamic features that are pivotal in early sepsis prediction; demonstrated the critical role of feature selection methods in enhancing the efficacy of predictive models in sepsis; and proved the effectiveness of feature extraction models—Random Forest and XG Boost with high sensitivity and AUROC in facilitating the sepsis prediction, and DL showing excellent AUROC values for different predicting time windows (12–48 h.). Concisely, the increased accuracy of sepsis prediction using these ML models can lead to minimizing the hospital mortality rate, reducing the LOS, improving the patient safety, and at the same time saving millions of dollars of investment in large clinical settings, hence proving the potentials and importance of these models in this domain.
This scoping review has several strengths. It followed a comprehensive and systematic approach to assess the landscape of sepsis prediction using ML techniques. It offered a thorough compilation of feature selection and extraction techniques used in the sepsis prediction and identified the top features for sepsis prediction across all studies. Additionally, by categorizing the studies based on features, prediction time and model performance, this study provided a clear comparison of different approaches that can support researchers and healthcare professionals in informed decision making.
There were certain limitations related to features. Firstly, the feature variability, the studies examined in this review utilize a wide array of features reflecting the diversity of clinical data sources and methodologies. However, the variability in selected features across studies can hinder direct comparisons and the identification of universally impactful features. Secondly, the features that prove influential in one clinical context may not necessarily generalize to other healthcare settings or patient populations. Thirdly, many studies identified critical features, but not all provided in-depth insights into the clinical significance or mechanistic explanations of these features. Lastly, this review was constrained by the availability of data in the studies analyzed, as incomplete or restricted datasets can lead to incomplete representation of potentially critical features.
We hope that this review will help clarify which features and methods are most promising for improving the accuracy of sepsis prediction models for future research studies. Ultimately, the findings from this review will be valuable not only for researchers but also for healthcare professionals, as they seek to enhance early sepsis detection and patient care.
Conclusion
To our best knowledge, this is the first study of its kind that reviewed critical features and feature extraction methods for sepsis prediction. Spanning diverse studies, it encompassed over 18,841 features and explored techniques like wrapper, filter, and embedded extraction to assess their impact on sepsis prediction models. The findings of this study highlighted the pivotal role of dynamic features, notably encompassing vital signs, such as Temperature, Heart Rate, and Blood Pressure, alongside critical laboratory parameters including White Blood Cell count (WBC), Creatinine, Bilirubin, Platelet count, and Lactate levels in sepsis prediction. These dynamic features have shown consistent and substantial prominence in prognosticating the onset of sepsis, exhibiting remarkable discriminatory power and pivotal utility in the early detection of septic conditions. In contrast, the demographic variables have evinced comparatively diminished influence in effectively predicting sepsis. For enhancing the predictive efficacy of sepsis models, the strategic implementation of feature selection methodologies has emerged as a crucial factor. The judicious identification and integration of key predictors via Filter, Wrapper, and Feature extraction techniques, these methodologies have effectively mitigated data dimensionality issues and conferred enhanced model stability, thereby facilitating the development of accurate and refined predictive models. In terms of model efficacy, the Random Forest and XG Boost models have exhibited superior performance, with commendable AUROC, sensitivity, and specificity scores. Additionally, Deep Learning models have demonstrated consistent and profound insights into the correlation between features and model predictions, an aspect that conventional Machine Learning models have not been able to fully elucidate yet. These Deep Learning models have demonstrated remarkable AUROC values across different prediction time windows, ranging from 12 to 48 h.
We recommend standardization of feature engineering methods used in sepsis prediction models which will facilitate comparison across studies and will foster consistency. Also, researchers should provide detailed description of the feature engineering process in their publication, including the rationale behind selecting methods and detailed data preprocessing steps.
In summary, this study reaffirmed the crucial role of features in sepsis prediction. The careful choice of feature extraction methods can significantly impact the model’s performance and provide clinicians with valuable insights into complex interrelationships.
Availability of data and materials
Data supporting the findings of this study are available from the corresponding author, upon reasonable request.
References
DeShon B, Dummitt B, Allen J, Yount B. Prediction of sepsis onset in hospital admissions using survival analysis. J Clin Monit Comput. 2022;36(6):1611–9.
Deng H-F, Sun M-W, Wang Y, Zeng J, Yuan T, Li T, et al. Evaluating machine learning models for sepsis prediction: A systematic review of methodologies. Iscience. 2022;25(1):103651.
Yang M, Liu C, Wang X, Li Y, Gao H, Liu X, Li J. An explainable artificial intelligence predictor for early detection of sepsis. Crit Care Med. 2020;48(11):e1091–6.
Rafiei A, Rezaee A, Hajati F, Gheisari S, Golzan M. SSP: early prediction of sepsis using fully connected LSTM-CNN model. Comput Biol Med. 2021;128: 104110.
Wang D, Li J, Sun Y, Ding X, Zhang X, Liu S, et al. A machine learning model for accurate prediction of sepsis in ICU patients. Front Public Health. 2021;9: 754348.
Sakib N, Ahamed SI, Khan RA, Griffin PM, Haque MM. Unpacking prevalence and dichotomy in quick sequential organ failure assessment and systemic inflammatory response syndrome parameters: Observational data–driven approach backed by sepsis pathophysiology. JMIR Med Inform. 2020;8(12): e18352.
Qureshi KN, Din S, Jeon G, Piccialli F. An accurate and dynamic predictive model for a smart M-Health system using machine learning. Inf Sci. 2020;538:486–502.
Tran T, Luo W, Phung D, Gupta S, Rana S, Kennedy RL, et al. A framework for feature extraction from hospital medical data with applications in risk prediction. BMC Bioinformatics. 2014;15(1):1–9.
Zhang Y, Hu J, Hua T, Zhang J, Zhang Z, Yang M. Development of a machine learning-based prediction model for sepsis-associated delirium in the intensive care unit. Sci Rep. 2023;13(1):12697.
Elkin ME, Zhu X. Predictive modeling of clinical trial terminations using feature engineering and embedding learning. Sci Rep. 2021;11(1):3446.
Kutiame S, Millham R, Adebayor FA, Tettey M, Weyori BA, Appiahene P. Application of machine learning algorithms in coronary heart disease: a systematic literature review and meta-analysis. Int J Adv Comput Sci Appl. 2022. https://doi.org/10.14569/IJACSA.2022.0130620.
Mollura M, Lehman L-WH, Mark RG, Barbieri R. A novel artificial intelligence based intensive care unit monitoring system: using physiological waveforms to identify sepsis. Philos Trans R Soc A. 2021;379(2212):20200252.
Zhao X, Shen W, Wang G. Early prediction of sepsis based on machine learning algorithm. Comput Intell Neurosci. 2021;2021:1–13.
Misra D, Avula V, Wolk DM, Farag HA, Li J, Mehta YB, et al. Early detection of septic shock onset using interpretable machine learners. J Clin Med. 2021;10(2):301.
Yang D, Kim J, Yoo J, Cha WC, Paik H. Identifying the risk of sepsis in patients with cancer using digital health care records: machine learning-based approach. JMIR Med Inform. 2022;10(6): e37689.
Wardi G, Carlile M, Holder A, Shashikumar S, Hayden SR, Nemati S. Predicting progression to septic shock in the emergency department using an externally generalizable machine-learning algorithm. Ann Emerg Med. 2021;77(4):395–406.
Rangan ES, Pathinarupothi RK, Anand KJ, Snyder MP. Performance effectiveness of vital parameter combinations for early warning of sepsis—an exhaustive study using machine learning. JAMIA open. 2022;5(4):ooac080.
Bai Y, Xia J, Huang X, Chen S, Zhan Q. Using machine learning for the early prediction of sepsis-associated ARDS in the ICU and identification of clinical phenotypes with differential responses to treatment. Front Physiol. 2022;13:2591.
He Z, Du L, Zhang P, Zhao R, Chen X, Fang Z. Early sepsis prediction using ensemble learning with deep features and artificial features extracted from clinical electronic health records. Crit Care Med. 2020;48(12):e1337–42.
Cesario EO, Gumiel YB, Martins MCM, Dias VMdCH, Moro C, Carvalho DR. Early Identification of Patients at Risk of Sepsis in a Hospital Environment. Brazil Arch Biol Technol. 2021. https://doi.org/10.1590/1678-4324-75years-2021210142.
Goh KH, Wang L, Yeow AYK, Poh H, Li K, Yeow JJL, Tan GYH. Artificial intelligence in sepsis early prediction and diagnosis using unstructured data in healthcare. Nat Commun. 2021;12(1):711.
Camacho-Cogollo JE, Bonet I, Gil B, Iadanza E. Machine learning models for early prediction of sepsis on large healthcare datasets. Electronics. 2022;11(9):1507.
Al-Mualemi BY, Lu L. A deep learning-based sepsis estimation scheme. Ieee Access. 2020;9:5442–52.
Rosnati M, Fortuin V. MGP-AttTCN: an interpretable machine learning model for the prediction of sepsis. PLoS ONE. 2021;16(5): e0251248.
Kamaleswaran R, Sataphaty SK, Mas VR, Eason JD, Maluf DG. Artificial intelligence may predict early sepsis after liver transplantation. Front Physiol. 2021;12: 692667.
Lin P-C, Chen K-T, Chen H-C, Islam M, Lin M-C. Machine learning model to identify sepsis patients in the emergency department: Algorithm development and validation. J Personal Med. 2021;11(11):1055.
Shashikumar SP, Wardi G, Malhotra A, Nemati S. Artificial intelligence sepsis prediction algorithm learns to say “I don’t know.” NPJ Dig Med. 2021;4(1):134.
Calvert J, Saber N, Hoffman J, Das R. Machine-learning-based laboratory developed test for the diagnosis of sepsis in high-risk patients. Diagnostics. 2019;9(1):20.
Greco M, Caruso PF, Spano S, Citterio G, Desai A, Molteni A, et al. Machine learning for early outcome prediction in septic patients in the emergency department. Algorithms. 2023;16(2):76.
Yuan K-C, Tsai L-W, Lee K-H, Cheng Y-W, Hsu S-C, Lo Y-S, Chen R-J. The development an artificial intelligence algorithm for early sepsis diagnosis in the intensive care unit. Int J Med Informatics. 2020;141: 104176.
Singh YV, Singh P, Khan S, Singh RS. A machine learning model for early prediction and detection of sepsis in intensive care unit patients. J Healthc Eng. 2022;2022:1–11.
Kim JK, Ahn W, Park S, Lee S-H, Kim L. Early prediction of sepsis onset using neural architecture search based on genetic algorithms. Int J Environ Res Public Health. 2022;19(4):2349.
Duan Y, Huo J, Chen M, Hou F, Yan G, Li S, Wang H. Early prediction of sepsis using double fusion of deep features and handcrafted features. Appl Intell. 2023;53(14):17903–19.
Lauritsen SM, Kalør ME, Kongsgaard EL, Lauritsen KM, Jørgensen MJ, Lange J, Thiesson B. Early detection of sepsis utilizing deep learning on electronic health record event sequences. Artif Intell Med. 2020;104: 101820.
Giannini H, Ginestra J, Chivers C. A machine learning algorithm to predict severe sepsis and septic shock. Development, implementation, and impact on clinical practice. Crit Care Med. 2019;47(11):1485–92.
Scherpf M, Gräßer F, Malberg H, Zaunseder S. Predicting sepsis with a recurrent neural network using the MIMIC III database. Comput Biol Med. 2019;113: 103395.
Alanazi A, Aldakhil L, Aldhoayan M, Aldosari B. Machine Learning for Early Prediction of Sepsis in Intensive Care Unit (ICU) Patients. Medicina (Kaunas). 2023;59(7):1276.
Fleuren LM, Klausch TLT, Zwager CL, Schoonmade LJ, Guo T, Roggeveen LF, et al. Machine learning for the prediction of sepsis: a systematic review and meta-analysis of diagnostic test accuracy. Intensive Care Med. 2020;46(3):383–400.
Islam MM, Nasrin T, Walther BA, Wu CC, Yang HC, Li YC. Prediction of sepsis patients using machine learning approach: a meta-analysis. Comput Methods Programs Biomed. 2019;170:1–9.
Acknowledgements
Not Applicable.
Funding
Not Applicable.
Author information
Authors and Affiliations
Contributions
Each Author contributed equally according to their work. SSA, SCH, SB designed the study conception and design. SB and JP did the collection of fetching information from studies. UU and ED verified the information fetched. SB, JP, UU, and MK analyzed the studies. SB, MU wrote the first manuscript draft of the article. SSA, MK, and UU did the proofreading and editing of the manuscript. SSA, SB, JP, UU, SCH, and ED did the final reading and approved the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not Applicable.
Consent for publication
Not Applicable.
Competing interests
There is no competing interest declared by all authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Bomrah, S., Uddin, M., Upadhyay, U. et al. A scoping review of machine learning for sepsis prediction- feature engineering strategies and model performance: a step towards explainability. Crit Care 28, 180 (2024). https://doi.org/10.1186/s13054-024-04948-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13054-024-04948-6