
Abstract
Background
This study aimed to establish and validate an easy-to-operate novel scoring system based on simple and readily available clinical indices for predicting the progression of chronic kidney disease (CKD).
Methods
We retrospectively evaluated 1045 eligible CKD patients from a publicly available database. Factors included in the model were determined by univariate and multiple Cox proportional hazard analyses based on the training set.
Results
Independent prognostic factors including etiology, hemoglobin level, creatinine level, proteinuria, and urinary protein/creatinine ratio were determined and contained in the model. The model showed good calibration and discrimination. The area under the curve (AUC) values generated to predict 1-, 2-, and 3-year progression-free survival in the training set were 0.947, 0.931, and 0.939, respectively. In the validation set, the model still revealed excellent calibration and discrimination, and the AUC values generated to predict 1-, 2-, and 3-year progression-free survival were 0.948, 0.933, and 0.915, respectively. In addition, decision curve analysis demonstrated that the model was clinically beneficial. Moreover, to visualize the prediction results, we established a web-based calculator (https://ncutool.shinyapps.io/CKDprogression/).
Conclusion
An easy-to-operate model based on five relevant factors was developed and validated as a conventional tool to assist doctors with clinical decision-making and personalized treatment.
Similar content being viewed by others


Introduction
Chronic kidney disease (CKD), a common kidney disease with a progressive decline in renal function, is increasingly recognized as a global public health problem [1]. It causes more than half a million patients to develop end-stage renal disease (ESRD) every year, and over 700,000 deaths [2]. CKD is multifactorial and is defined as glomerular filtration rate (GFR) < 60 mL/min per 1.73 m2 or abnormalities in kidney structure or function present for more than 3 months [3, 4]. Diabetic nephropathy is the leading cause of CKD, accounting for approximately 40% of patients with non-dialysis-dependent CKD and ESRD [5]. Other pathological processes for CKD include chronic glomerulonephritis, ureteral obstruction, and renal fibrosis [6,7,8]. As effective therapeutic strategies for ESRD are currently limited, it is important to identify treatments to delay the progression of CKD to ESRD. Rapid CKD progression leads to irreversible pathological changes and may be associated with unfavorable outcomes. Once a patient has developed ESRD, renal replacement therapy is needed to maintain their daily activities. Therefore, there is an urgent need for reliable and accurate progression prediction models for CKD.
Many definitions of CKD progression have been used over the years, such as doubling of serum creatinine level, decrease in estimated GFR (eGFR) to < 15 mL/min per 1.73 m2, and development of ESRD [9, 10]. Currently, there are no clinically robust biomarkers to predict progressive CKD. Rather, clinicians rely on multiple longitudinal kidney measurements, such as the eGFR, proteinuria, and urinary protein/creatinine ratio (UPCR) to identify progression [11]. The shortcomings of these traditional biomarkers are well recognized, and a single index has limited predictive capacity for progressive CKD [12]. However, the use of complex and potentially expensive detection strategies may prevent at risk patients from benefiting from preventative interventions, especially in settings where renal replacement therapy is not readily available. The use of risk models is an attractive and likely cost-effective method for large-scale CKD risk stratification and would allow the identification of populations that would benefit the most from CKD detection. There have been several attempts to create a risk model for predicting the progression of CKD. However, the prediction accuracy of these models has not been tested through widespread application in clinical practice [13,14,15,16].
In the present study, we aimed to establish a model using Cox regression analysis based on commonly used and readily available clinical characteristics to predict disease progression in CKD patients. We performed univariate and multivariate analyses to screen for independent risk factors. The visualization model was constructed by nomogram and web-based calculator, and prediction performance was measured by discrimination, calibration, and clinical utility. This novel simple-to-use model might predict the prognosis of patients with CKD with high accuracy.
Methods
Ethics statement
The study was conducted in accordance with the ethical standards and the Declaration of Helsinki and according to national and international guidelines. It was approved by the authors' institutional review board (No. 883).
Patients
This study used data from 1138 patients with CKD obtained via the Dryad Digital Repository (http://www.datadryad.org/), shared by Limori et al. [17]. According to Dryad's terms of service, researchers can use these data for secondary analysis without infringing on the author's rights. All eligible individuals who were not undergoing dialysis were diagnosed with stage G2–G5 CKD based on the Kidney Disease Improving Global Outcomes classification [18]. All participants were at least 20 years of age and visited nephrology centers for the first time between October 2010 and December 2011. Patients with malignancy that was diagnosed or treated within the previous 2 years, transplant recipients, and those with active gastrointestinal bleeding at enrollment were excluded. All eligible patients were randomly stratified into two groups in a 2:1 ratio (training set and validation set, respectively).
Data collection
We performed a secondary analysis based on data from the above database. Fifteen probable prediction variables were selected, including gender, age, etiology (diabetes, nephrosclerosis, glomerulonephritis, and others), hemoglobin level, serum albumin level, creatinine level, eGFR, proteinuria, urinary occult blood, UPCR, hypertension, history of cardiovascular disease, diabetes, use of RAAS inhibitor, use of calcium channel blocker, and use of diuretics. Moreover, the vital status and follow-up time of each CKD case were extracted.
Predictor selection and development of the prediction model
Depending on the training set, Cox proportion hazard regression models were used to screen potential prognostic factors and estimate their weights [19, 20]. Univariable Cox regression analysis was performed to explore the potential predictors [21]. The selected prognostic factors (p value below 0.05 in univariate analysis) were then included in a multivariate Cox regression analysis to obtain an integrated nomogram by a stepwise feature selection algorithm based on the AIC [22]. Moreover, to facilitate clinical application, we established a visualization tool by a web-based calculator.
Validation of the prediction model
The performance of our model to predict survival was quantified using AUC values from the ROC analysis and the C-index. The performance of the novel model was also evaluated by examining calibration in training and validation sets. In addition, DCA was carried out to assess the clinical utility of the model. These tests were all performed in both the training and validation sets.
Statistical analysis
Continuous variables following a normal distribution are presented as mean ± standard deviation and categorical variables are presented as percentages. Differences between the training and validation sets were analyzed using chi-square tests for the categorical variables and t-tests for the continuous variables. A p value < 0.05 was used as a cutoff for statistical significance. Statistical analysis was performed using SPSS software (version 24.0) and R software (version 3.6.2).
Results
Baseline characteristics
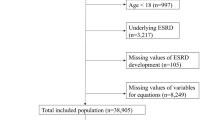
Figure 1 shows a flow diagram of the selection process. After excluding 93 patients with missing data, a total of 1,045 patients was included in the analysis. Patients were randomly divided at a ratio of 6:3 into training (N = 696) and validation sets (N = 349). The demographics and clinical characteristics of the whole, training, and validation sets are presented in Table 1. In the whole cohort, 69.9% of the participants were male, and the mean age was 67.31 ± 13.6 years. Most patients had positive proteinuria and history of hypertension. Across the entire study population, 260 patients had disease progression (CKD progression defined as > 50% eGFR loss or initiation of dialysis).

Flow diagram that shows the development and validation of the prediction model
Prognostic factors of CKD
Univariate Cox regression analysis showed that age, etiology, hemoglobin level, serum albumin level, creatinine level, eGFR, proteinuria, urinary occult blood, UPCR, hypertension, diabetes, use of renin–angiotensin–aldosterone-system (RAAS) inhibitor, use of calcium channel blocker, and use of diuretics were correlated with CKD progression. Multivariate Cox regression analysis identified etiology, hemoglobin level, creatinine level, proteinuria, and UPCR as independent prognostic factors of CKD patients (Table 2).
Development of an individualized prediction model
Based on Akaike information criterion (AIC) results, five factors (etiology, hemoglobin, creatinine, proteinuria, and UPCR) were selected to establish the predictive nomogram, which is an intuitive visualization of the model (Fig. 2A). According to the constructed model, the risk score of each sample was calculated according to the model coefficients combined with the corresponding value of the five chosen factors. CKD patients were divided into high- (N = 348) and low-risk (N = 348) groups based on their median risk score. Risk score distribution is shown in Fig. 2B. The Kaplan–Meier survival curve of low- and high-risk groups in the training set is shown in Fig. 2C (p < 0.001). The CKD progression status and follow-up time of each individual is shown in Fig. 2D.

The model to predict the probability of progression in chronic kidney disease (CKD) patients from the training cohort. A The nomogram based on the five variables identified by the Cox hazards analysis. B Distribution of the risk scores calculated by the nomogram scoring system. C Progression-free survival curves stratified by the low- and high-score groups. D Patient distribution in the low- and high-score groups based on progression status
Establishment of a web-based calculator
For convenient clinical use and visualization of the prognostic model, we developed an easy-to-operate web-based model (https://ncutool.shinyapps.io/CKDprogression/) to predict the progression of CKD based on the established nomogram (Fig. 3). Estimated disease progression probabilities can be obtained by drawing a perpendicular line from the total point axis to the outcome axis.

Establishing an easy-to-operate web-based calculator for predicting the progression of chronic kidney disease (https://ncutool.shinyapps.io/CKDprogression/). A Web progression-free survival rate calculator. B 95% confidence interval of the web progression-free survival rate
Model performance in the training set
In the training set, the model was evaluated using time-dependent receiver operating characteristic (ROC) curve analysis over 1-, 2-, and 3-years, along with the concordance index (C-index). The area under the ROC curve (AUC) values for the 1-, 2-, and 3-year survival probabilities were 0.947, 0.931, and 0.939, respectively (Fig. 4A). The C-index for the prediction of progression-free survival was 0.912. The calibration curves of the model showed good probability consistencies between the predicted and observed values (Fig. 4B). These results might confirm that our model was reliable in predicting the prognosis of CKD. Furthermore, a decision curve analysis (DCA) confirmed our expectations, as the analysis revealed that the net benefit in 1-, 2- and 3-year predictions was the highest in the combined nomogram model compared to the single variable (Fig. 4C). Hence, we chose the combined model for clinical use.

Model discrimination and performance in the training set. A Receiver operating characteristic curves for model-based progression-free survival prediction. B Calibration plot examining estimation accuracy. C Decision curve analysis assessing clinical utility
Model performance in the validation set
In the validation set, CKD patients were divided into high- (N = 174) and low-risk (N = 175) cohorts based on their median risk score. The risk score distribution is shown in Fig. 5A. The CKD progression status and follow-up time of all individuals are shown in Fig. 5B. The Kaplan–Meier survival curve of the low- and high-risk groups is shown in Fig. 5C (p < 0.001). The time-dependent ROC curve analysis validated prediction accuracy of this model over other features (Fig. 5C).

Validation of the nomogram in the validation set. A Distribution of the risk scores calculated by the nomogram scoring system. B Patient distribution in the low- and high-score groups based on progression status. C Progression-free survival curves stratified by the low- and high-score groups. D Time-dependent ROC curves for nomogram vs. other single parameters included in the model
In addition, we performed calibration plot analysis in the validation set. The calibration curves of the model showed good probability consistencies between the predicted and observed values (Fig. 6A). DCA analysis revealed that the net benefit in the 1-, 2- and 3-year predictions was the highest in the combined nomogram model compared to the single variable (Fig. 6B).

Assessment of the model in the validation set. A Calibration plot examining estimation accuracy. B Decision curve analysis assessing clinical utility
Discussion
Predicting the CKD outcome in individual patients is beneficial for identifying those who need an aggressive therapeutic regimen. This study showed that etiology, together with proteinuria, serum creatinine, and UPCR, was a better predictor of the risk of progression in patients with CKD when compared to a single indicator. Furthermore, a novel nomogram and corresponding web-based calculator were built as a reference for clinicians to help with clinical decision-making. The risk score identified the highest risk patients accurately, and therefore can identify patients who may benefit most from management by nephrologists without referring the entire population with CKD to them.
The etiology of CKD is multifactorial and diverse. The main causes included diabetes, nephrosclerosis, and glomerulonephritis. In the present study, we found that the highest risk of progression is diabetic kidney disease (DKD). Type 2 diabetes is the most common cause of severe kidney disease worldwide, and DKD is associated with premature death [23]. Although, the fundamental mechanism responsible for the development of DKD to ESRD is poorly understood [24], it is now believed that vessel disease and inflammation are the main pathological mechanisms of CKD [25]. Approximately 40% of diabetic patients develop DKD, and the resultant kidney damage often leads to kidney failure, ultimately requiring dialysis or kidney transplant [26]. Our results suggest that measures should be taken to delay the progression of CKD, especially in cases of DKD.
Proteinuria generally precedes the loss of renal function in kidney disease [27]. For instance, a population-based cohort study in China found that elevated albuminuria was a key predictor of progression to CKD or ESRD and indicated a higher risk of cardiovascular disease and mortality [28]. However, an increasing number of studies have cast doubt on this classic paradigm. In several recent studies, eGFR reduced to 20–39% resulted in normal albuminuria levels [29,30,31]. In some clinical trials, improvement in proteinuria did not translate to an increased GFR or a reduction in end points such as the need for dialysis or death [32, 33]. The critical role of proteinuria as a single predictor of CKD prognosis requires further study. In the current study, incorporation of several factors including proteinuria might increase model accuracy.
Anemia is a common feature at any stage of CKD, especially in patients with advanced stages of CKD. Anemia in CKD is mainly attributable to the relative decrease in erythropoietin production by the kidneys, absolute or functional iron deficiency, and shortened red blood cell survival. The severity of anemia increases with CKD progression and affects nearly all patients with ESRD [34, 35]. The development of erythropoietic stimulatory agents, such as recombinant human erythropoietin and darbepoetin alpha, has resulted in substantial health benefits for patients with end-stage renal failure, including improved quality of life, reduced blood transfusion requirements, decreased left ventricular mass, diminished sleep disturbance, and enhanced exercise capacity [36, 37]. It is generally believed that low levels of hemoglobin are associated with worse outcomes in patients with CKD [38]. These results are in agreement with the findings of our model.
Previous studies have tried to establish models for progression of CKD to kidney failure [13, 14, 39, 40]. Although the estimations produced by previous models were moderately accurate, the results were somewhat complex because many predictors were involved, each with precise classification levels. We identified five easily accessible and simple demographic and clinical characteristics to include in our novel model, which demonstrated that these traditional factors are important in patients with CKD. Our model showed good calibration and discrimination, and the AUC values generated to predict 1-, 2-, and 3-year progression-free survival in the training set were 0.947, 0.931, and 0.939, respectively. In the validation set, the model revealed excellent calibration and discrimination, and the AUC values generated to predict 1-, 2-, and 3-year progression-free survival were 0.948, 0.933, and 0.915, respectively. These results showed that our model can perfectly predict patient survival in CKD. Moreover, we developed an easy-to-operate calculator that allows the public to freely predict local cases and diagnose the adaptability of the model.
Admittedly, there are some shortcomings in our research. First, the model was developed based on the five variables. However, these factors were unstable throughout the follow-up period, which might have partly influenced the precision of the model. Second, although the performance of the model was good in both the training and validation sets, multicenter clinical application is needed to evaluate the external utility of this model. Third, as the main outcome measure was the progression status of CKD, other outcomes such as survival time should be evaluated in future studies.
In conclusion, we constructed and validated a model incorporating five clinical characteristics (etiology, proteinuria, hemoglobin, creatinine, and UPCR) to predict disease progression in CKD patients. This model could serve as a reliable tool for determining CKD treatment strategies and potential outcomes.
Availability of data and materials
All the data were obtained from the Dryad Digital Repository (http://www.datadryad.org/).
Abbreviations
- CKD:
-
Chronic kidney disease
- AUC:
-
Area under the curve
- ESRD:
-
End-stage renal disease
- GFR:
-
Glomerular filtration rate
- eGFR:
-
Estimated glomerular filtration rate
- UPCR:
-
Urinary protein/creatinine ratio
- RAAS:
-
Renin–angiotensin–aldosterone-system
- AIC:
-
Akaike information criterion
- ROC:
-
Receiver operating characteristic
- DCA:
-
Decision curve analysis; C-index, concordance index
References
Bikbov B, Purcell CA, Levey AS, Smith M, Abdoli A, Abebe M, Adebayo OM, Afarideh M, Agarwal SK, Agudelo-Botero M, Ahmadian E. Global, regional, and national burden of chronic kidney disease, 1990–2017: a systematic analysis for the Global Burden of Disease Study 2017. Lancet. 2020;395:709–33.
Lozano R, Naghavi M, Foreman K, Lim S, Shibuya K, Aboyans V, Abraham J, Adair T, Aggarwal R, Ahn SY, Alvarado M, Anderson HR, Anderson LM, Andrews KG, Atkinson C, Baddour LM, Barker-Collo S, Bartels DH, Bell ML, Benjamin EJ, Bennett D, Bhalla K, Bikbov B, Bin Abdulhak A, Birbeck G, Blyth F, Bolliger I, Boufous S, Bucello C, Burch M, Burney P, Carapetis J, Chen H, Chou D, Chugh SS, Coffeng LE, Colan SD, Colquhoun S, Colson KE, Condon J, Connor MD, Cooper LT, Corriere M, Cortinovis M, de Vaccaro KC, Couser W, Cowie BC, Criqui MH, Cross M, Dabhadkar KC, Dahodwala N, De Leo D, Degenhardt L, Delossantos A, Denenberg J, Des Jarlais DC, Dharmaratne SD, Dorsey ER, Driscoll T, Duber H, Ebel B, Erwin PJ, Espindola P, Ezzati M, Feigin V, Flaxman AD, Forouzanfar MH, Fowkes FG, Franklin R, Fransen M, Freeman MK, Gabriel SE, Gakidou E, Gaspari F, Gillum RF, Gonzalez-Medina D, Halasa YA, Haring D, Harrison JE, Havmoeller R, Hay RJ, Hoen B, Hotez PJ, Hoy D, Jacobsen KH, James SL, Jasrasaria R, Jayaraman S, Johns N, Karthikeyan G, Kassebaum N, Keren A, Khoo JP, Knowlton LM, Kobusingye O, Koranteng A, Krishnamurthi R, Lipnick M, Lipshultz SE, Ohno SL, Mabweijano J, MacIntyre MF, Mallinger L, March L, Marks GB, Marks R, Matsumori A, Matzopoulos R, Mayosi BM, McAnulty JH, McDermott MM, McGrath J, Mensah GA, Merriman TR, Michaud C, Miller M, Miller TR, Mock C, Mocumbi AO, Mokdad AA, Moran A, Mulholland K, Nair MN, Naldi L, Narayan KM, Nasseri K, Norman P, O’Donnell M, Omer SB, Ortblad K, Osborne R, Ozgediz D, Pahari B, Pandian JD, Rivero AP, Padilla RP, Perez-Ruiz F, Perico N, Phillips D, Pierce K, Pope CA 3rd, Porrini E, Pourmalek F, Raju M, Ranganathan D, Rehm JT, Rein DB, Remuzzi G, Rivara FP, Roberts T, De León FR, Rosenfeld LC, Rushton L, Sacco RL, Salomon JA, Sampson U, Sanman E, Schwebel DC, Segui-Gomez M, Shepard DS, Singh D, Singleton J, Sliwa K, Smith E, Steer A, Taylor JA, Thomas B, Tleyjeh IM, Towbin JA, Truelsen T, Undurraga EA, Venketasubramanian N, Vijayakumar L, Vos T, Wagner GR, Wang M, Wang W, Watt K, Weinstock MA, Weintraub R, Wilkinson JD, Woolf AD, Wulf S, Yeh PH, Yip P, Zabetian A, Zheng ZJ, Lopez AD, Murray CJ, AlMazroa MA, Memish ZA. Global and regional mortality from 235 causes of death for 20 age groups in 1990 and 2010: a systematic analysis for the Global Burden of Disease Study 2010. Lancet. 2012;380:2095–128.
Stevens PE, Levin A. Evaluation and management of chronic kidney disease: synopsis of the kidney disease: improving global outcomes 2012 clinical practice guideline. Ann Intern Med. 2013;158:825–30.
Petreski T, Piko N, Ekart R, Hojs R, Bevc S. Review on inflammation markers in chronic kidney disease. Biomedicines. 2021;9:182.
Rhee CM, Kovesdy CP, Ravel VA, Streja E, Brunelli SM, Soohoo M, Sumida K, Molnar MZ, Brent GA, Nguyen DV, Kalantar-Zadeh K. Association of glycemic status during progression of chronic kidney disease with early dialysis mortality in patients with diabetes. Diabetes Care. 2017;40:1050–7.
Ligtenberg G. Regulation of blood pressure in chronic renal failure: determinants of hypertension and dialysis-related hypotension. Neth J Med. 1999;55:13–8.
Pyram R, Kansara A, Banerji MA, Loney-Hutchinson L. Chronic kidney disease and diabetes. Maturitas. 2012;71:94–103.
Genovese F, Manresa AA, Leeming DJ, Karsdal MA, Boor P. The extracellular matrix in the kidney: a source of novel non-invasive biomarkers of kidney fibrosis? Fibrogenesis Tissue Repair. 2014;7:4.
Bakris GL, Sarafidis PA, Weir MR, Dahlöf B, Pitt B, Jamerson K, Velazquez EJ, Staikos-Byrne L, Kelly RY, Shi V, Chiang YT, Weber MA. Renal outcomes with different fixed-dose combination therapies in patients with hypertension at high risk for cardiovascular events (ACCOMPLISH): a prespecified secondary analysis of a randomised controlled trial. Lancet. 2010;375:1173–81.
Marks A, Fluck N, Prescott GJ, Robertson LM, Simpson WG, Smith WC, Black C. Definitions of progression in chronic kidney disease–predictors and relationship to renal replacement therapy in a population cohort with a 6 year follow-up. Nephrol Dial Transplant. 2014;29:333–41.
Floege J, Barbour SJ, Cattran DC, Hogan JJ, Nachman PH, Tang SCW, Wetzels JFM, Cheung M, Wheeler DC, Winkelmayer WC, Rovin BH. Management and treatment of glomerular diseases (part 1): conclusions from a Kidney Disease: Improving Global Outcomes (KDIGO) Controversies Conference. Kidney Int. 2019;95:268–80.
Echouffo-Tcheugui JB, Kengne AP. Risk models to predict chronic kidney disease and its progression: a systematic review. PLoS Med. 2012;9:e1001344.
Tangri N, Stevens LA, Griffith J, Tighiouart H, Djurdjev O, Naimark D, Levin A, Levey AS. A predictive model for progression of chronic kidney disease to kidney failure. JAMA. 2011;305:1553–9.
Desai AS, Toto R, Jarolim P, Uno H, Eckardt KU, Kewalramani R, Levey AS, Lewis EF, McMurray JJ, Parving HH, Solomon SD, Pfeffer MA. Association between cardiac biomarkers and the development of ESRD in patients with type 2 diabetes mellitus, anemia, and CKD. Am J Kidney Dis. 2011;58:717–28.
Hallan SI, Ritz E, Lydersen S, Romundstad S, Kvenild K, Orth SR. Combining GFR and albuminuria to classify CKD improves prediction of ESRD. J Am Soc Nephrol. 2009;20:1069–77.
Kent DM, Jafar TH, Hayward RA, Tighiouart H, Landa M, de Jong P, de Zeeuw D, Remuzzi G, Kamper AL, Levey AS. Progression risk, urinary protein excretion, and treatment effects of angiotensin-converting enzyme inhibitors in nondiabetic kidney disease. J Am Soc Nephrol. 2007;18:1959–65.
Iimori S, Naito S, Noda Y, Sato H, Nomura N, Sohara E, Okado T, Sasaki S, Uchida S, Rai T. Prognosis of chronic kidney disease with normal-range proteinuria: The CKD-ROUTE study. PLoS One. 2018;13:e0190493.
Cheung AK, Chang TI, Cushman WC, Furth SL, Hou FF, Ix JH, Knoll GA, Muntner P, Pecoits-Filho R, Sarnak MJ, Tobe SW, Tomson CRV, Lytvyn L, Craig JC, Tunnicliffe DJ, Howell M, Tonelli M, Cheung M, Earley A, Mann JFE. Executive summary of the KDIGO 2021 Clinical Practice Guideline for the Management of Blood Pressure in Chronic Kidney Disease. Kidney Int. 2021;99:559–69.
Tang Y, Jiang Y, Qing C, Wang J, Zeng Z. Systematic construction and validation of an epithelial-mesenchymal transition risk model to predict prognosis of lung adenocarcinoma. Aging (Albany NY). 2020;13:794–812.
Tang Y, Hu Y, Wang J, Zeng Z. A novel risk score based on a combined signature of 10 immune system genes to predict bladder cancer prognosis. Int Immunopharmacol. 2020;87:106851.
Wang J, He L, Tang Y, Li D, Yang Y, Zeng Z. Development and validation of a nomogram with an epigenetic signature for predicting survival in patients with lung adenocarcinoma. Aging. 2020;12:23200–16.
Tang Y, Wang J, Chen G, Ye W, Yan N, Feng Z. A simple-to-use web-based calculator for survival prediction in Parkinson’s disease. Aging. 2021;13:5238–49.
Ramanathan K, Padmanabhan G. Soluble neprilysin: A versatile biomarker for heart failure, cardiovascular diseases and diabetic complications-A systematic review. Indian Heart J. 2020;72:14–9.
Tang YL, Dong XY, Zeng ZG, Feng Z. Gene expression-based analysis identified NTNG1 and HGF as biomarkers for diabetic kidney disease. Medicine (Baltimore). 2020;99:e18596.
Barrett EJ, Liu Z, Khamaisi M, King GL, Klein R, Klein BEK, Hughes TM, Craft S, Freedman BI, Bowden DW, Vinik AI, Casellini CM. Diabetic microvascular disease: an Endocrine Society Scientific Statement. J Clin Endocrinol Metab. 2017;102:4343–410.
Li Y, Hu Q, Li C, Liang K, Xiang Y, Hsiao H, Nguyen TK, Park PK, Egranov SD, Ambati CR, Putluri N, Hawke DH, Han L, Hung MC, Danesh FR, Yang L, Lin C. PTEN-induced partial epithelial-mesenchymal transition drives diabetic kidney disease. J Clin Invest. 2019;129:1129–51.
Fernandez-Fernandez B, Ortiz A, Gomez-Guerrero C, Egido J. Therapeutic approaches to diabetic nephropathy–beyond the RAS. Nat Rev Nephrol. 2014;10:325–46.
Liao LN, Liu CS, Li CI, Lin WY, Lin CH, Li TC, Lin CC. Three-year incidence of elevated albuminuria and associated factors in a population-based cohort: The Taichung Community Health Study. Eur J Prev Cardiol. 2015;22:788–97.
Kramer HJ, Nguyen QD, Curhan G, Hsu CY. Renal insufficiency in the absence of albuminuria and retinopathy among adults with type 2 diabetes mellitus. JAMA. 2003;289:3273–7.
Retnakaran R, Cull CA, Thorne KI, Adler AI, Holman RR. Risk factors for renal dysfunction in type 2 diabetes: U.K. Prospective Diabetes Study 74. Diabetes. 2006;55:1832–9.
Garg AX, Kiberd BA, Clark WF, Haynes RB, Clase CM. Albuminuria and renal insufficiency prevalence guides population screening: results from the NHANES III. Kidney Int. 2002;61:2165–75.
Haller H, Ito S, Izzo JL Jr, Januszewicz A, Katayama S, Menne J, Mimran A, Rabelink TJ, Ritz E, Ruilope LM, Rump LC, Viberti G. Olmesartan for the delay or prevention of microalbuminuria in type 2 diabetes. N Engl J Med. 2011;364:907–17.
Mann JF, Schmieder RE, McQueen M, Dyal L, Schumacher H, Pogue J, Wang X, Maggioni A, Budaj A, Chaithiraphan S, Dickstein K, Keltai M, Metsärinne K, Oto A, Parkhomenko A, Piegas LS, Svendsen TL, Teo KK, Yusuf S. Renal outcomes with telmisartan, ramipril, or both, in people at high vascular risk (the ONTARGET study): a multicentre, randomised, double-blind, controlled trial. Lancet. 2008;372:547–53.
George C, Matsha TE, Erasmus RT and Kengne AP. Haematological profile of chronic kidney disease in a mixed-ancestry South African population: a cross-sectional study. BMJ Open 2018; 8: e025694.
Choi HY, Kim TY, Lee M, Kim SH, Jhee JH, Lee YK, Kim HJ, Park HC. Kidney mesenchymal stem cell-derived extracellular vesicles engineered to express erythropoietin improve renal anemia in mice with chronic kidney disease. Stem Cell Rev Rep. 2021. https://doi.org/10.1007/s12015-021-10141-x.
Valderrábano F. Erythropoietin in chronic renal failure. Kidney Int. 1996;50:1373–91.
Benz RL, Pressman MR, Hovick ET, Peterson DD. A preliminary study of the effects of correction of anemia with recombinant human erythropoietin therapy on sleep, sleep disorders, and daytime sleepiness in hemodialysis patients (The SLEEPO study). Am J Kidney Dis. 1999;34:1089–95.
Levin A, Stevens PE. Summary of KDIGO 2012 CKD Guideline: behind the scenes, need for guidance, and a framework for moving forward. Kidney Int. 2014;85:49–61.
Wakai K, Kawamura T, Endoh M, Kojima M, Tomino Y, Tamakoshi A, Ohno Y, Inaba Y, Sakai H. A scoring system to predict renal outcome in IgA nephropathy: from a nationwide prospective study. Nephrol Dial Trans. 2006;21:2800–8.
Johnson ES, Thorp ML, Platt RW, Smith DH. Predicting the risk of dialysis and transplant among patients with CKD: a retrospective cohort study. Am J Kidney Dis. 2008;52:653–60.
Acknowledgements
We would like to thank the investigators of Tokyo Medical and Dental University Hospital and its affiliated hospitals for sharing their data.
Funding
This work was supported by the National Natural Science Foundation of China (No. 82060043).
Author information
Authors and Affiliations
Contributions
QX, YW and YF collected and analyzed the data; FF and CC analyzed and interpreted the data; YJ conceived the study. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The present study was approved by the Ethics Committee and Institutional Review Board of affiliated Cancer Hospital & Institute of Guangzhou Medical University.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Xu, Q., Wang, Y., Fang, Y. et al. An easy-to-operate web-based calculator for predicting the progression of chronic kidney disease. J Transl Med 19, 288 (2021). https://doi.org/10.1186/s12967-021-02942-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12967-021-02942-y