
Abstract
Background
It often takes more than 10 years and costs more than 1 billion dollars to develop a new drug for a particular disease and bring it to the market. Drug repositioning can significantly reduce costs and time in drug development. Recently, computational drug repositioning attracted a considerable amount of attention among researchers, and a plethora of computational drug repositioning methods have been proposed. This methodology has widely been used in order to address various medical challenges, including cancer treatment. The most common cancers are lung and breast cancers. Thus, suggesting FDA-approved drugs via drug repositioning for breast cancer would help us to circumvent the approval process and subsequently save money as well as time.
Methods
In this study, we propose a novel network-based method, named RepCOOL, for drug repositioning. RepCOOL integrates various heterogeneous biological networks to suggest new drug candidates for a given disease.
Results
The proposed method showed a promising performance on benchmark datasets via rigorous cross-validation. The final drug repositioning model has been built based on a random forest classifier after examining various machine learning algorithms. Finally, in a case study, four FDA approved drugs were suggested for breast cancer stage II.
Conclusion
Results show the potency of the proposed method in detecting true drug-disease relationships. RepCOOL suggested four new drugs for breast cancer stage II namely Doxorubicin, Paclitaxel, Trastuzumab, and Tamoxifen.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Background
Drug research and development is a complicated, time-consuming, and incredibly expensive process. Previous research reported that it often takes 10–15 years and approximately 1–3 billion dollars to develop a new drug and place it on the market [1,2,3]. Although such a huge amount of time and money is expending in this industry, the number of new Food and Drug Administration (FDA)-approved drugs reported annually remains low. So, in consideration of these challenges, discovering a new use for an existing drug, known as drug repositioning or drug repurposing, has been proposed as a solution for such a problem. The goal of drug repositioning is to identify new indications for drugs currently available in the market. Using such approaches can reduce the overall cost of commercialization and also bridge the gap between drug discovery and availability. In comparison to the traditional drug repositioning, which relies on clinical discoveries, computational drug repositioning methods can reduce the drug development timeline [4,5,6].
In recent years, different approaches are adopted for repurposing drugs, including network-based, text mining, machine learning, semantic inference-based methods. Recently, the network-based approach has attracted more attention and is widely used in computational drug repositioning due to the capability of using ever-increasing large-scale biological datasets such as genetic, pharmacogenomics, clinical and chemical data [7,8,9,10].
Networks are widely used in biology to comprehend and analyze the various connections in biological systems like protein–protein, gene–gene, and drug–target interactions. In such networks, nodes are representative of biological entities such as genes and proteins, while edges represent interactions between these components [11]. A variety of relationships can be introduced in a particular network at the same time. Moreover, quantitative information (weights) can be assigned to edges and nodes as well. Network-based drug repositioning methods can be divided into three classes regarding their main sources of biological data: (1) gene regulatory networks, (2) metabolic networks, and (3) drug interaction networks. Furthermore, a fourth category can be added to the above-mentioned classes, known as integrated approaches in which their data are provided simultaneously from multiple data sources. In gene regulatory networks, information about molecular perturbations, which occur because of drug administration or disease, can be captured via expression data. Metabolic networks give a different perspective. Nodes and edges in metabolic networks are representatives of the compounds and the metabolites. Drug–target interaction (DTI)-based prediction is one of the common repositioning methodologies. Indeed, many drugs frequently show additional targets than designed ones. For this reason, unintended novel usages can be shown through an effective and accurate prediction of drug targets. In addition to the previous strategies, there are other repositioning approaches based on several molecular networks. However, they show limited applicability [11,12,13].
In this study, we have proposed a network-based method for drug repositioning. Our method, RepCOOL, integrates various heterogeneous biological networks to obtain new drug-disease associations. The proposed method showed satisfactory performance in detecting drug-disease associations via stringent assessment procedures. Eventually, four new drugs were suggested for breast cancer.
Method
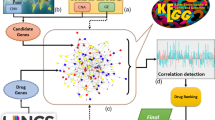
Figure 1 shows an illustration of the proposed drug repositioning method. Detailed descriptions for each step are provided in the following subsections.

Schematic flowchart of the proposed drug repositioning method
Data sources
We constructed nine different drug-disease association networks using six primary networks constructed based on the publicly available database (Table 1). These six networks were categorized into four different groups according to their types of nodes: drug–gene interaction network (DRGN), disease-gene interaction network (DIGN), protein–protein interaction network (PPIN) and gene co-expression network (GCN).
Drug–gene interaction network
DrugBank [14] database was used to construct the DRGN network. DrugBank provides comprehensive information about approved and investigational drugs, including UMLS-mapped, approved indications. This network consists of 3509 interactions between 1497 drugs and 673 genes.
Disease-gene interaction network
We also used three databases for three different disease-gene interaction networks (Table 1): The Comparative Toxic genomics Database (CTD) [15], Online Mendelian Inheritance in Man (OMIM) [16] and DisGeNET [17]. CTD contains manually curated information about gene-disease relationships focusing on comprehending the effects of environmental chemicals on human health. It includes about 26 million gene-disease associations (GDAs), between 47,740 genes and 3158 diseases. OMIM (Online Mendelian Inheritance in Man) is a complete collection of human genes and genetic phenotypes that are updated on a daily basis. OMIM includes 6666 gene-phenotype associations between 6175 phenotypes and 4552 genes. The DisGeNET database integrates human gene-disease associations from various expert-curated databases and text-mining-derived associations including Mendelian, environmental and complex diseases [17]. This network includes 561,107 GDAs, between 17,068 genes and 20,371 diseases, disorders, traits, and clinical or abnormal human phenotypes.
Protein–protein interaction network
We extracted protein–protein interaction (PPI) information from IntAct database [18]. IntAct provides a freely available database system and analysis tools for molecular interaction data. This network has 16,523 proteins and 143,738 protein–protein interactions.
Gene co-expression network
We constructed a gene co-expression network (GCN) using the COXPRESdb database [19]. This database measured the similarity of gene expression patterns during several conditions, such as disease state tissue types. COXPRESdb includes co-expression relationships for multiple animal species and is freely available on http://coxpresdb.jp/. The obtained GCN includes 12,485 interactions and 24,442 genes.
Reconstructing new drug-disease networks via merging heterogeneous networks
We reconstructed nine new drug-disease networks using six primary networks. Figure 2 shows a schematic view of these networks. These nine networks have more than 9,400,000 drug-disease associations in total. Table 2 shows more details about these new drug-disease networks. One drug-disease interaction may be generated more than once in each network merging. So, the number of occurrences of a drug-disease interaction is considered as the weight of the interaction.

Schematic representation of reconstructing nine new drug-disease networks
Drug-disease association prediction
Encoding drug-disease networks as feature vectors
For each drug-disease pair, weights of its corresponding interaction in the reconstructed drug-disease networks were considered as features. Therefore, each drug-disease pair was encoded as a 9-dimensional feature vector. In addition, to prevent the occurrence of the duplication in weighing the networks, the limitation of the initial datasets must be considered.
Machine learning methods
We used five different classifiers, including naïve Bayes (NB), random forest (RF), logistic regression (LR), decision tree (DT) and support vector machine (SVM). The implementations of these classifiers in Weka [20] software package was used for drug-disease association prediction. Weka is a java-based machine learning workbench, developed for machine learning tasks. Also, we used tenfold cross-validation for evaluating the predicted drug-disease associations.
For evaluating the performance of RepCOOL, we adopted four different measures (Table 3). These measures are based on the following four basic terms:
-
True positive (TP): the number of drug-disease associations, which were correctly predicted.
-
True negative (TN): the number of drug-disease pairs, which were correctly predicted as non-associated.
-
False positive (FP): the number of unrelated drug-disease pairs, which were incorrectly predicted as associations.
-
False negative (FN): the number of drug-disease associations, which were incorrectly predicted as non-associations.
We also used the area under the ROC curve (AUC) as another measure for assessing the proposed method.
Benchmark dataset
We used PREDICT [21], which is a well-known benchmark dataset in drug repositioning, to assess the strength of the proposed drug repositioning method. PREDICT dataset includes 1834 interactions between 526 FDA approved drugs and 314 diseases.
Cytotoxicity assay
Human cell line BT474 was cultured in recommended media in the presence of 10% fetal bovine serum (FBS) and penicillin–streptomycin antibiotics. Cell viability was characterized using a standard colorimetric MTT reduction assay. Briefly, 6000 cells were plated in each well of the 96-well plates with 100 µL medium, which includes 10% serum. After 24-h incubation, the cell was treated with several concentrations of tamoxifen (0–100 µM). After 48 h, the MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) reagent (5 mg/mL in PBS) was added to each well, followed by incubation for 4 h at 37 °C with 5% CO2. After the incubation, the MTT crystals in each well were solubilized in 100 µL dimethyl sulfoxide (DMSO) incubation for 20 min at 25 °C, and the absorbance was read at 490 nm using a microplate spectrophotometer (µQuant, BioTek, USA).
Results and discussion
Performance evaluation of the proposed method
Figure 3 shows the performance of five classifiers on the PREDICT dataset in a tenfold cross-validation experiment. As it was evident, the decision tree is the most sensitive classifier in detecting true drug-disease associations, but random forests have the best performance in terms of ROC. For all the classifiers, recall (sensitivity) is in a satisfactory range, which shows the ability to detect true drug-disease associations. However, precision is relatively low for almost all classifiers, which can result from some true drug-disease associations that have not been discovered or reported yet.

Performance of different classifiers in a tenfold cross validation procedure in PRIDICT dataset. Classifiers include support vector machine (SVM), decision tree (DT), linear regression (LR), naïve Bayes (NB) and random forest (RF)
Comparison with the other methods
Nearly all of the previously published studies only reported their AUC. As it has been shown in Fig. 4, the highest AUC of the five classifiers is 0.83, which outperforms HGBI [22], LDB [23], TL-HGB [24] and Drug Net [23] methods on PREDICT dataset.

Performance comparison of RepCOOL with other methods in terms of AUC based on the obtained results in PREDICT dataset
New repurposed drugs for breast cancer
Information contained in RepoDB [25] was exploited to obtain a list of new repurposed drugs for breast cancer. RepoDB includes a gold standard set of drug repositioning which failed or succeeded. The RepoDB dataset contains 6677 approved, 2754 terminated, 483 suspended, and 648 withdrawn drug-disease interactions. Withdrawn and suspended drug-disease associations have an annotation phase between phase 0 and phase 3. Therefore, these two types of drug-disease pairs have more potential to suggest a valid new drug repositioning rather than a random pair. Considering this fact, we trained the five classifiers using the approved and terminated data. Figure 5 shows the training performance of the classifiers. Then, the best performing classifier, according to the approved and terminated data, was used to predict new drugs for breast cancer. The most sensitive classifier, random forest (it detected 2283 true drug-disease interactions out of 2292), was used to do this end.

Performance of different classifiers in a tenfold cross-validation procedure in repODB dataset. Classifiers include support vector machine (SVM), decision tree (DT), linear regression (LR), naïve Bayes (NB) and random forest (RF)
Using this classifier, four new drugs have been repurposed for breast cancer stage II. Table 4 shows the chemical structures of the drugs and their descriptions.
Analyzing the structural similarity between the three new repurposed drugs and previously FDA-approved drugs for breast cancer
We also carried out a structural similarity analysis among the repurposed drugs and 10 FDA-approved which were small molecule drugs for breast cancer including 5-FU, Abemaciclib (Verzeino), Taxotere (docetaxel), danazol, Pamidronate Disodium, Tamoxifen, Doxorubicin, Paclitaxel, Epirubicin, Capecitabine, Dutasteride, Olaparib, Afinitor. Also, Trastuzumab is a recombinant DNA-derived humanized monoclonal antibody which was eliminated from our repurposed drugs due to its large structure (145,531.5 Da). Figure 6 shows the results of the structural similarity analysis. Structural similarity was computed based on 3014 structural features which were extracted using Dragon tool [26]. Figure 6a compares the structures of the drugs via a distance matrix, and Fig. 6b represents the correlation matrix of the structures computed with Pearson correlation coefficient (PCC). Also, Fig. 6c depicts the dendrogram of 13 drugs based on the obtained distance matrix. According to this dendrogram, there are four distinct clusters: cluster1 = {Paclitaxel, Taxotere}, cluster2 = {Doxorubicin, Dutasteride, Epirubicin, Abemaciclib}, cluster3 = {Afinitor} and cluster4 = {Pamidronate Disodium, Capecitabine, Tamoxifen, Olaparib, 5FU, Verzeino}. As results indicate, Paclitaxel, Doxorubicin and Tamoxifen have the most structural similarity with Taxotere (PCC = 100), Dutasteride, Epirubicin (PCC = 100) and Capecitabine (PCC = 98), respectively.

Structural relationship between the repurposed (highlighted by rectangles) and FDA-approved drugs for the treatment of breast cancer. a Heat map of the merged repurposed and FDA-approved drugs based on the distance matrix. b Heat map of repurposed and FDA-approved drugs based on the correlation matrix. c Cluster dendrogram of repurposed and FDA-approved drugs based on the distance matrix. The highest and the lowest structural correlation are indicated in blue and red, respectively
Cell toxicity
An MTT assay was performed to assess the effectiveness of Tamoxifen from the repurposed drugs in this study on the growth of BT474, the breast cancer stage II, HER2 cell line. Based on the cell survival results, following the treatment with Tamoxifen in different concentrations, the inhibition effect on the cell growth increased with increasing amount of the drug in the culture medium. As it has been shown in Fig. 7, the half maximal inhibitory concentration (IC50) of Tamoxifen was 32.13 µM on BT474 cells. It should be noted that the toxic effect of two drugs including, Doxorubicin and Paclitaxel has been proved on MCF-7, SKBR-3 and MCF-7 cell lines, respectively, by other researchers [27,28,29,30]. Therefore, we can consider Tamoxifen and other repurposed molecules as effective drugs for breast cancer.

The inhibitory effect of different concentrations of Tamoxifen on the growth of BT474 cells. The results were presented as a percentage relative to the control and graph was plotted using GraphPad Prism 6.01 software
Conclusion
In this study, a network-based method has been employed for drug repositioning using heterogeneous biological and chemical information. Results show the strength of the proposed method for detecting true drug-disease relationships. RepCOOL suggests four new drugs for breast cancer stage II including Doxorubicin, Paclitaxel, Trastuzumab and Tamoxifen. Structural analysis shows the high structural similarity of these four drugs to the current FDA-approved drugs for breast cancer stage II.
Availability of data and materials
No applicable.
Abbreviations
- FDA:
-
Food and Drug Administration
- DRGN:
-
Drug–gene interaction network
- DIGN:
-
Disease-gene interaction network
- PPIN:
-
Protein–protein interaction network
- GCN:
-
Gene co-expression network
- CTD:
-
Comparative Toxic genomics Database
- OMIM:
-
Online Mendelian Inheritance in Man
- GDAs:
-
Gene–disease associations
- NB:
-
Naïve Bayes
- RF:
-
Random forest
- LR:
-
Logistic regression
- DT:
-
Decision tree
- SVM:
-
Support vector machine
- TP:
-
True positive
- TN:
-
True negative
- FP:
-
False positive
- FN:
-
False negative
- ROC:
-
Receiver operator characteristics
- AUC:
-
Area under the curve
- PCC:
-
Pearson correlation coefficient
- MTT:
-
Methyl thiazolyl tetrazolium
- FBS:
-
Fetal bovine serum
- DMSO:
-
Dimethyl sulfoxide
- IC50 :
-
Half-maximal inhibitory concentration
References
Zeng X, Zhu S, Liu X, Zhou Y, Nussinov R, Cheng F. deepDR: a network-based deep learning approach to in silico drug repositioning. Bioinformatics. 2019;35(24):5191–8. https://doi.org/10.1093/bioinformatics/btz418.
Luo H, Li M, Yang M, Wu F-X, Li Y, Wang J. Biomedical data and computational models for drug repositioning: a comprehensive review. Brief Bioinform. 2020. https://doi.org/10.1093/bib/bbz176.
Xue H, Li J, Xie H, Wang Y. Review of drug repositioning approaches and resources. Int J Biol Sci. 2018;14(10):1232.
Sadeghi SS, Keyvanpour MR. An analytical review of computational drug repurposing. IEEE/ACM Trans Comput Biol Bioinform. 2019. https://doi.org/10.1109/TCBB.2019.2933825.
Karaman B, Sippl W. Computational drug repurposing: current trends. Curr Med Chem. 2019;26(28):5389–409.
Romano JD, Tatonetti NP. Informatics and computational methods in natural product drug discovery: a review and perspectives. Front Genet. 2019;10:368.
Li J, Zheng S, Chen B, Butte AJ, Swamidass SJ, Lu Z. A survey of current trends in computational drug repositioning. Brief Bioinform. 2016;17(1):2–12.
Ferrero E, Dunham I, Sanseau P. In silico prediction of novel therapeutic targets using gene–disease association data. J Transl Med. 2017;15(1):182.
Bisgin H, Liu Z, Fang H, Kelly R, Xu X, Tong W. A phenome-guided drug repositioning through a latent variable model. BMC Bioinform. 2014;15(1):267.
Jiang H-J, You Z-H, Huang Y-A. Predicting drug–disease associations via sigmoid kernel-based convolutional neural networks. J Transl Med. 2019;17(1):382.
Lotfi Shahreza M, Ghadiri N, Mousavi SR, Varshosaz J, Green JR. A review of network-based approaches to drug repositioning. Brief Bioinform. 2018;19(5):878–92.
Alaimo S, Pulvirenti A. Network-based drug repositioning: approaches, resources, and research directions. In: Vanhaelen Q, editor. Computational methods for drug repurposing. Berlin: Springer; 2019. p. 97–113.
Chen H-R, Sherr DH, Hu Z, DeLisi C. A network based approach to drug repositioning identifies plausible candidates for breast cancer and prostate cancer. BMC Med Genomics. 2016;9(1):1–11.
Wishart DS, et al. DrugBank: a comprehensive resource for in silico drug discovery and exploration. Nucleic Acids Res. 2006;34(suppl_1):D668–72.
Mattingly CJ, Colby GT, Forrest JN, Boyer JL. The comparative toxicogenomics database (CTD). Environ Health Perspect. 2003;111(6):793.
Hamosh A, Scott AF, Amberger JS, Bocchini CA, McKusick VA. Online Mendelian Inheritance in Man (OMIM), a knowledgebase of human genes and genetic disorders. Nucleic Acids Res. 2005;33(suppl_1):D514–7.
Piñero J, et al. DisGeNET: a discovery platform for the dynamical exploration of human diseases and their genes. Database. 2015. https://doi.org/10.1093/database/bav028.
Kerrien S, et al. The IntAct molecular interaction database in 2012. Nucleic Acids Res. 2011;40(D1):D841–6.
Obayashi T, Hayashi S, Shibaoka M, Saeki M, Ohta H, Kinoshita K. COXPRESdb: a database of coexpressed gene networks in mammals. Nucleic Acids Res. 2007;36(suppl_1):D77–82.
Hall M, Frank E, Holmes G, Pfahringer B, Reutemann P, Witten IH. The WEKA data mining software: an update. ACM SIGKDD Explor Newsl. 2009;11(1):10–8.
Gottlieb A, Stein GY, Ruppin E, Sharan R. PREDICT: a method for inferring novel drug indications with application to personalized medicine. Mol Syst Biol. 2011;7(496):496. https://doi.org/10.1038/msb.2011.26.
Wang W, Yang S, Li J. Drug target predictions based on heterogeneous graph inference. In: Biocomputing 2013. World Scientific; 2013. pp. 53–64.
Martínez V, Navarro C, Cano C, Fajardo W, Blanco A. DrugNet: network-based drug–disease prioritization by integrating heterogeneous data. Artif Intell Med. 2015;63(1):41–9.
Wang W, Yang S, Zhang X, Li J. Drug repositioning by integrating target information through a heterogeneous network model. Bioinformatics. 2014;30(20):2923–30.
Brown AS, Patel CJ. A standard database for drug repositioning. Sci Data. 2017;4:170029.
Mauri A, Consonni V, Pavan M, Todeschini R. Dragon software: an easy approach to molecular descriptor calculations. Match. 2006;56(2):237–48.
Jenie RI, et al. The cytotoxic and antimigratory activity of brazilin-doxorubicin on MCF-7/HER2 cells. Adv Pharm Bull. 2018;8(3):507–16. https://doi.org/10.15171/apb.2018.059.
Nurhayati IP, Khumaira A, Pradani G, Ilmawati N, Meiyanto E, Hermawan A. Cytotoxic and antimetastatic activity of hesperetin and doxorubicin combination toward Her2 expressing breast cancer cells. Asian Pac J Cancer Prev. 2020;21:1259–67. https://doi.org/10.31557/apjcp.2020.21.5.1259.
Zajdel A, Wilczok A, Jelonek K, Musiał-kulik M, Fory A. Cytotoxic effect of paclitaxel and lapatinib co-delivered in polylactide-co-poly (ethylene glycol) micelles on HER-2-negative breast cancer cells. Pharmaceutics. 2019. https://doi.org/10.3390/pharmaceutics11040169.
Peng J, et al. Biomaterials Herceptin-conjugated paclitaxel loaded PCL-PEG worm-like nanocrystal micelles for the combinatorial treatment of HER2-positive breast cancer. Biomaterials. 2019;222(August):119420. https://doi.org/10.1016/j.biomaterials.2019.119420.
Acknowledgements
The authors would like to thank Mohammad Hossein Afsharinia for his help with preparing figures, and Saber Mohammadi and Sayeh Emadi for their help with the editing the manuscript. Also, we would like to thank Dr. Ahmad Mani for his help with structural similarity analysis. Last but not least, the authors would like to express their sincere gratitude to the anonymous reviewers for their critical review.
Funding
No applicable.
Author information
Authors and Affiliations
Contributions
JZ, SSA and RHS conceived the idea. GF and JZ did the analysis. JZ, RHS and SSA interpreted the results. GF and JZ wrote the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Fahimian, G., Zahiri, J., Arab, S.S. et al. RepCOOL: computational drug repositioning via integrating heterogeneous biological networks. J Transl Med 18, 375 (2020). https://doi.org/10.1186/s12967-020-02541-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12967-020-02541-3