
Abstract
Background
Mitochondrial dysfunction has been hypothesized to occur in Myalgic Encephalomyelitis/Chronic Fatigue Syndrome (ME/CFS), a disease characterized by fatigue, cognitive difficulties, pain, malaise, and exercise intolerance. We investigated whether haplogroup, single nucleotide polymorphisms (SNPs), or heteroplasmy of mitochondrial DNA (mtDNA) were associated with health status and/or symptoms.
Methods
Illumina sequencing of PCR-amplified mtDNA was performed to analyze sequence and extent of heteroplasmy of mtDNAs of 193 cases and 196 age- and gender-matched controls from DNA samples collected by the Chronic Fatigue Initiative. Association testing was carried out to examine possible correlations of mitochondrial sequences with case/control status and symptom constellation and severity as reported by subjects on Short Form-36 and DePaul Symptom Questionnaires.
Results
No ME/CFS subject exhibited known disease-causing mtDNA mutations. Extent of heteroplasmy was low in all subjects. Although no association between mtDNA SNPs and ME/CFS vs. healthy status was observed, haplogroups J, U and H as well as eight SNPs in ME/CFS cases were significantly associated with individual symptoms, symptom clusters, or symptom severity.
Conclusions
Analysis of mitochondrial genomes in ME/CFS cases indicates that individuals of a certain haplogroup or carrying specific SNPs are more likely to exhibit certain neurological, inflammatory, and/or gastrointestinal symptoms. No increase in susceptibility to ME/CFS of individuals carrying particular mitochondrial genomes or SNPs was observed.
Similar content being viewed by others

Background
The underlying cause of the disease known as Myalgic Encephalomyelitis (ME) or Chronic Fatigue Syndrome (CFS) is unknown, although a number of abnormalities have been detected in individuals with the illness. A substantial proportion of patients report becoming chronically ill after a flu-like illness, but others report a gradual onset. One favored hypothesis is that different types of insult result in the same outcome. As well as profound fatigue and post-exertional malaise, other symptoms that are common to many ME/CFS patients are neurological (difficulty concentrating, light sensitivity, sleep disturbances), inflammatory (such as flu-like symptoms, swollen lymph nodes, muscle pain) and gastrointestinal, sometimes including irritable bowel syndrome [1–4].
Mitochondrial dysfunction has been implicated in ME/CFS in multiple studies. One group has published three studies concerning ME/CFS that report impaired mitochondrial activity in neutrophils through an indirect assay of oxidative phosphorylation utilizing ATP measurement [5]. Interpretation of neutrophil studies is limited by the fact that they have fewer mitochondria than muscle cells or other types of blood cells. In contrast to the neutrophil analyses, two groups reported no detectable differences between the mitochondrial complex activities they assayed in peripheral blood mononuclear cells (PBMCs) of ME/CFS patients vs. controls [6, 7]. No ultrastructural abnormalities in mitochondria from CFS patients’ muscle were observed when an electron microscopic study was performed [8]. However, another group reported normal mitochondrial activity but decreased mitochondrial content in skeletal muscle of CFS patients [7]. Furthermore, two studies observed lower coenzyme Q content in blood cells or plasma of CFS patients [9, 10].
The literature on cardiac and/or skeletal muscle bioenergetic function analyzed by magnetic resonance spectroscopy in ME/CFS is also discordant, with some reports of abnormalities in CFS patients, while other reports indicate normal function [11–15]. It might be that only a fraction of cases exhibits abnormalities, which can hence go undetected when sample size is small. Either mitochondrial defects or problems in blood flow in muscles could result in anomalous findings in spectroscopic studies.
Little information is available concerning the mitochondrial genomes of individuals with ME/CFS. Particular variations in human mitochondrial genomes have been associated with different phenotypes such as climatic adaptation, high altitude tolerance and obesity, or increases or decreases in susceptibility or severity of medical problems such as diabetes, sepsis, stroke, Alzheimer’s and Parkinson’s disease, and hypertension, among others [16].
Human populations have inherited sets of polymorphisms representing different mitochondrial DNA (mtDNA) haplogroups. The effect of a nucleotide polymorphism may vary depending on the particular mitochondrial genome in which it arises. Haplogroup-level association testing is therefore valuable when analyzing the role of mtDNA polymorphisms in metabolic diseases. For example, such an approach was used to discover that mitochondrial haplogroup N9 confers resistance against type II diabetes in Asians [17]. Using individuals with European haplotypes, a recent study assessed whether or not two single nucleotide polymorphisms (SNPs) in a patient cohort were associated with symptoms and reported an association of one SNP with pain, chronic fatigue, and abnormal gastrointestinal motility [18]. Another study of mitochondrial genomes of 162 CFS cases carrying haplogroup H reported an association of disease status with a single SNP [19].
No reports have examined the degree of heteroplasmy (presence of more than one type of mitochondrial genome) in ME/CFS patients vs. controls. Somatic mutations in mitochondrial genomes can occur and are known to accumulate or to increase in effect during aging [16]. By obtaining the entire mitochondrial genome sequences from cells of ME/CFS patients and an age-matched cohort, it is possible to determine whether cases have accumulated more somatic mutations in mitochondrial DNA than expected. A recent examination of heteroplasmy in mitochondrial DNA from 1085 individuals found that 90 % carried at least one variant genome, and 20 % had sequence variants known to be pathogenic [20]. The frequency of pathogenic genomes in an individual can be examined through sequencing mitochondrial DNA at high depth, thus determining whether a threshold has been reached where disease has become manifest.
Heteroplasmic pathogenic mutations can also be transmitted through the germline, leading to mitochondrial disease if the proportion of mutant genomes becomes sufficiently high to impair function. For example, the m.3243A>G mutation can cause mitochondrial myopathy encephalopathy, lactic acidosis, and stroke (MELAS) when present at a frequency greater than 59 % [21].
We undertook a study of the mitochondrial genomes in a cohort of gender-and age-matched ME/CFS patients and controls of predominantly European origin. We performed next-generation sequencing to characterize the mtDNAs in the subjects with regard to haplotype, SNPs, and heteroplasmy. We carried out association testing to find whether any SNPs were significantly associated with ME/CFS status or with particular symptoms and their severity in the patient cohort.
Methods
Experimental design
Study population
CFI subjects were recruited at five different sites within the United States; Miami, Salt Lake City, Boston, New York City, and Sierra, Nevada and informed consent was obtained as described in Klimas et al. [22]. Cases were included in the study based on confirmed diagnosis by an expert clinician and based on either or both of the recognized ME/CFS case definitions, namely, the “1994 Fukuda criteria” and the “Canadian criteria”. The cohort was deliberately oversampled for patients with acute onset of the illness in the past 3 years. Gender, ethnicity, age (within 5 years)-matched healthy controls were specifically recruited for this study and were only included if they were both physically and mentally healthy. Time of sampling was also matched within 12 weeks from the sampling of cases and controls. Within a week of the questionnaire completion, blood was drawn, at which time the subjects underwent a full physical exam as well as filling out additional questionnaires to assess the severity of the illness on the day of sampling. All samples were processed similarly. Of the 405 subjects who participated in the CFI project, we received DNA from 193 patients with ME/CFS and 196 age and gender-matched healthy individuals from the CFI Biobank at the Duke Human Vaccine Institute (DHVI). DNA was prepared at DHVI from whole blood collected in Paxgene tubes (Qiagen, Germantown, MD).
Health questionnaires
In addition to demographic information, the Medical Outcomes Survey Short Form-36 (SF-36) and DePaul Symptom Questionnaire (DSQ) were administered to both cases and controls by the CFI physicians [22]. The SF-36 is a self-report general health survey of 36 items designed to compare the burden of disease on eight different aspects of well-being [23]. The DSQ is a self-report survey of the frequency and severity of 54 symptoms specifically associated with CFS, and covers various case definitions including the Fukuda et al. CFS criteria [24], Canadian Clinical criteria [25], and ME International Consensus criteria [26]. Only cases were surveyed by the DSQ. In the DSQ, frequency and severity of symptoms are scored from least to most on a scale from 0–4. An overall “distress” score is also calculated for each symptom on a scale from 0–16, by multiplying the frequency by severity scores [2, 27, 28]. In the CFI study, distress scores for the 54 symptoms were grouped into 10 functional clusters, and average cluster scores were calculated for each case [22].
DNA preparation and sequencing
Upon receipt from the Duke biobank, aliquots of the DNA samples were placed in 96-well plates before further processing. To avoid amplification of short nuclear mitochondrial copies, high-specificity long range PCR was performed, using NEB LongAmp® Hot Start Taq DNA polymerase (New England Biolabs®, http://www.neb.com). The 50 uL PCR reaction consisted of the following mixture: 10 uL 5X LongAmp Taq Reaction Buffer, 1.5 uL of dNTPs (1 mM), 4 uL of each primer pairs (10 uM each, see below for details), 2 uL of template DNA, 2 uL of LongAmp Hot Start Taq DNA polymerase (2500 U/mL) and 30.5 uL of nuclease-free water. Amplification was performed with a thermocycler PTC-100 (MJ Research Inc., Waltham, MA, USA), starting with 30 s at 94 °C, followed by 30 cycles consisting of denaturation (20 s at 94 °C), annealing (1 min at 55 °C) and extension (10 min at 65 °C) and a final extension at 65 °C for 10 min.
The 16,569 bp mitochondrial genome was amplified using two primer pairs (F402: ATCTTTTGGCGGTATGCACTTT; R11428: GGCTTCGACATGGGCTTT and F8940: CCCCATACTAGTTATTATCGAAACC; R2818: GCCCCAACCGAAATTTTTAAT, from Lyons et al. [29] leading to two PCR products of 11,026 bp and 10,447 bp respectively, overlapping by almost 2500 bp. The overlap was necessary to prevent loss of end sequence information due to the Mu technology used in the subsequent library preparation.
The success of the PCR amplification was confirmed by electrophoresis and 5 uL of post-PCR reaction product was treated to degrade unused primers and nucleotides using USB® HT ExoSAP-IT® High-Throughput PCR Product Cleanup (Affymetrix, http://www.affymetrix.com) according to the manufacturer’s instructions.
The treated PCR products were diluted with 50 uL of nuclease-free water before Quant-IT™ PicoGreen® dsDNA Assay Kit quantification (http://www.lifetechnologies.com) on a plate reader. The final mix of overlapping fragments was performed to obtain a final concentration of 0.2 ng/uL of each overlapping PCR product per sample before Illumina library preparation (http://www.illumina.com).
Library preparation was implemented by the Cornell Biotechnology Resource Center (BRC, http://www.biotech.cornell.edu/biotechnology-resource-center-brc) following the manufacturer’s instructions for the Nextera® XT DNA Sample Preparation Kit (96 samples, FC-131-1096, http://www.illumina.com) and the Nextera XT Index Kits V2 Set A, B, C and D (FC-131-2001, FC-131-2002, FC-131-2003 and FC-131-2004, respectively, http://www.illumina.com) to be able to multiplex 384 samples during the sequencing reaction. After quality control for library size and amplification using Cornell BRC’s Fragment analyser, the Illumina MiSeq instrument generated paired-end reads (2 × 300 bp) with the MiSeq v3 kit. Three consecutive and identical runs were executed on the same library to increase coverage depth. Average mitochondrial DNA sequencing depth was 1497.3 ± 488.8 across patients and controls (Additional file 1: Figure S1).
Bioinformatics and statistical analysis
Read mapping
Sequencing reads were mapped to the entire human reference genome (GRCh37) using the BWA-MEM alignment algorithm [30]. A number of methods were applied to filter out variation due to sequencing artifacts and errors. After mapping, a custom bash function was used to remove reads with more than three mismatches compared to the mitochondrial DNA reference sequence; the revised Cambridge Reference Sequence (rCRS) [31]. Duplicate reads were identified and removed using the Mark Duplicates function in the Picard tools suite. To avoid including reads sequenced from regions of the nuclear genome sharing high similarity with mitochondrial DNA (NUMTs), reads that did not map uniquely to the mitochondrial genome were discarded using SAMtools [32, 33]. SAMtools was also used to remove reads not mapping in a proper mate-pair to the mitochondrial genome using the command “samtools view –f 3 [bam file] chrM:1-16,569”. Strand-specific sequence alignment files were used to generate corresponding forward and reverse-strand pileup files with the SAMtools “mpileup” function. While generating pileup files, reads and bases with a PHRED quality scores less than 30 (0.001 chance of sequencing error) were discarded from the dataset using the “–q 30” and “–Q 30” flags. Strand-specific pileup files were then used to identify mtDNA consensus sequences and heteroplasmies as described below.
Consensus sequence identification
In order to measure associations with mtDNA SNPs and haplogroups, mtDNA consensus sequences were identified for each individual. From the pileup files, the major allele at each mtDNA base-pair position was called as the allele in the consensus sequence. Positions which did not have at least 10× sequencing coverage on each strand were not included.
Haplogroup classification
Individuals were classified into mtDNA haplogroups using the online Haplogrep tool [34] which infers mtDNA haplogroups based on the Phylotree database of observed human mtDNA variation [35]. A custom python script was used to convert the consensus sequences into the HSD input file format used by Haplogrep. All positions where the consensus allele for an individual did not match the revised rCRS were included in the HSD file [31]. In cases where the set of mtDNA mutations for an individual matched multiple haplogroups, the individual was assigned to the haplogroup with the highest overall Haplogrep ranking.
Haplogroup associations
Individual clinical phenotypes were measured using regression models in PLINK [36]. Only the five haplogroups that reached a minimum 5 % frequency threshold within our study population were tested for associations. In the PLINK regression analysis, each haplogroup was represented as a separate binary covariate where a value of one indicated that the given individual belonged to that haplogroup and a value of zero indicated they did not. For phenotypes that had more than two values, a linear regression was applied, while a logistic regression was applied to those with only two. A dummy SNP was included in order to perform the PLINK analysis, but had no effect on the significance values of each haplogroup-phenotype association. Multiple-test correction was applied to results using the Benjamini-Hochberg approach to calculate q values and significance of associations was determined using a 5 % FDR [37]. P values were sorted in ascending order and each divided by its percentile rank to obtain an estimated FDR.
Single-Marker analysis
Single-marker association testing was used to measure the association between SNPs and ME/CFS case/control status, as well as all symptoms surveyed in the SF-36 and DSQ as well as symptom clusters. Association testing was performed using the PLINK whole genome analysis [36]. Allele information at each position was obtained from the consensus sequence described previously. Before testing, mtDNA SNPs were filtered based on missingness, if data were missing from more than 10 % of individuals (the “—geno 0.1”), and allele frequency, excluding SNPs with frequency less than 5 % were (“—maf 0.05”). The sex, collection site, and age of each individual were included as covariates in the analyses. Sex was included using the “—sex” flag. In a separate covariate file, each collection site was assigned a binary variable indicating whether an individual’s information had been collected at that site. Age was included as a single variable in the covariate file. A logistic regression model (–logistic) was used to measure associations between mtDNA SNPs and the binary case–control status, while a linear model (–linear) was used to measure associations with quantitative SF-36 and DSQ symptoms. False Discovery Rate (FDR) was used, following the method of Benjamini and Hochberg [37] to correct for multiple testing by using the “—adjust” flag.
Heteroplasmy calling
Mitochondrial heteroplasmies can be present at very low frequencies where they are difficult to distinguish from sequencing error. A multi-step approach, based on previous studies with experimental and simulated data, was used to improve the chance of identifying true heteroplasmies. After read-mapping and quality control steps were applied to the data, as described in the “Read Mapping” section, data in the strand-specific pileup files was used to detect heteroplasmies. Minor alleles had to be present at a frequency of 1 % on both sequencing strands, and only mtDNA positions with at least 500× coverage on each strand were included. After using SAMtools to generate strand-specific pileup files, a custom Python script was used to collect and parse coverage and allele data. Double-strand validation was also used to check that the heteroplasmic alleles were present on both DNA strands at a frequency of at least 1 % [20, 38].
Results
All subjects came from a large study supported by the Chronic Fatigue Initiative (CFI) [22, 39]. The subjects were diagnosed by physicians expert in ME/CFS and met either the Fukuda criteria [24] and/or the canadian consensus criteria [25] for diagnosis. Characteristics of subjects are shown in Table 1.
Causal mitochondrial disease variants
On average, there were 23.2 ± 11.3 SNPs in cases and 25.8 ± 12.4 in controls relative to the Cambridge reference sequence [31]. Polymorphisms observed in the consensus sequences of all individuals were cross-referenced with the MITOMAP database (http://www.mitomap.org/MITOMAP) of reported disease-associated mutations to determine whether any individuals harbored disease-causing mtDNA SNPs. Only one known mitochondrial-disease causing substitution was observed among the cases and controls. A T14484C substitution was found in a healthy control and is observed in individuals who develop Leber’s hereditary optic neuropathy (LHON) [40]. No other known disease-causing mtDNA variants were observed.
Rare variant association analysis
In order to assess the effect of whole-mtDNA variation including common and rare variants, we compared the cumulative pathogenicity between controls and ME/CFS individuals. For each mtDNA variant in an individual, a raw combined annotation dependent depletion (CADD) pathogenicity score was obtained from the freely available CADD database (http://cadd.gs.washington.edu) [41]. An average CADD score was calculated for each individual by dividing the individual’s cumulative CADD score by the number of their variant sites. The distribution of average CADD scores was compared between cases and controls using the Kolmogorov–Smirnov test as implemented in R. There was no significant difference in the distribution of average CADD scores between cases and controls.
Analysis of haplogroup with disease status
The vast majority of the individuals in the study (90.1 %) carried mtDNA haplogroups common to lineages of European descent, as expected because the cohort was >96 % white [22]. The most heavily represented haplogroups were H (39.1 %), U (15.4 %), T (10.6 %), K (9.1 %) and J (5.6 %). The remainder of the haplogroups represent lineages that spread through Asia and to the Americas (5.5 %) and those that are common to Africa (4.3 %).
The Fisher’s Exact Test was applied to compare the distributions of the haplogroups and showed no significant difference between cases and controls (Table 2). Additionally, we administered separate tests to each individual major haplogroup category. This revealed a nominally significant enrichment of haplogroup T (HgT) in controls versus cases that could suggest a potentially protective effect of HgT against CFS. However, the q-value (Benjamini and Hochberg corrected p value = 0.60) was not significant at a 5 % false discovery rate (FDR).
We also analyzed haplogroup distributions separately in males and females to account for sex-specific effects. We observed a nominally-significant enrichment of HgT among controls in females as above (Additional file 2: Table S1), but did not see any associations in males (Additional file 3: Table S2).
Analysis of haplogroup with symptoms
After observing no major association with disease, haplogroup association testing was then applied to 270 different symptom scores collected from the SF-36 and DSQ surveys. Because many of the symptoms are related or dependent on each other, we did not apply multiple-test correction over the combined body of association tests. Only European haplogroups were present at a high enough frequency to be included in this analysis and HgJ, HgU, and HgH all had significant associations using a 5 % FDR. Performing individual association-testing and Benjamani-Hochberg p value correction for the sampling of 70 SNPs, we found six significant associations between mitochondrial haplogroups and clinical phenotypes assessed by the DePaul Questionnaire (Table 3) [23]. All of the significant associations were with symptoms related to joint pain, bloating, or “feeling dead” after exercise. Haplogroup J showed a protective effect against all metrics of joint pain and individuals belonging to haplogroup U reported less severe bloating and had lower bloating distress scores compared to other haplogroups. On the other hand, ME/CFS individuals with haplogroup H tended to be more susceptible to “feeling dead” after exercise than other haplogroups.
Single-marker association analysis with disease
The majority of variable mtDNA sites (SNPs) in our dataset were singletons with only one individual carrying the variant alleles (Additional file 4: Figure S2), which were excluded from the association analysis. Seventy mtDNA SNPs met our minimum minor allele frequency threshold of 5 %, and were included in association tests with demographic and symptomatic variables associated with ME/CFS.
Single marker association testing was applied to measure SNP associations with the condition of individuals as either healthy controls or ME/CFS patients. Of the 70 SNPs, 10 reached nominal significance using an alpha threshold of 0.05, but none were significant with multiple test correction at a 5 % FDR (Additional file 5: Table S3). Within ME/CFS cases, we also measured SNP associations with acute or gradual onset of the disease and found no significant associations (Additional file 6: Table S4). In an effort to account for mtDNA genetic background and more accurately measure individual SNP effects, SNP associations were measured within the sub-group of individuals belonging to haplogroup H (HgH). Ideally, SNP associations would be measured within all haplogroups; however, given our sample size, HgH was the only haplogroup where analysis of association was feasible. Of the 151 HgH individuals in the study population for whom clinical data was available, none of the 18 SNPs meeting the 5 % frequency threshold had significant association with ME/CFS vs. healthy status.
The prevalence of CFS and fatigue-related syndromes has been observed to be higher in females than males. Additionally, because of the maternal inheritance pattern of mtDNA, mitochondrial variants are under sex-specific selective pressure that can lead to different fitness effects in males and females. To address possible sex differences, independent sex-stratified SNP association testing was performed, but revealed no associations (Additional file 7: Table S5 and Additional file 8: Table S6).
Single-marker association analysis with symptoms
Single-marker association testing was then applied to symptom scores as done above for the haplogroup association analysis. We found eight mtDNA SNPs to be associated with 16 symptom categories at a 5 % FDR (Table 4). The significant SNPs were at mtDNA positions 150, 930, 1719, 3010, 5147, 16093, 16223, and 16519. SNPs 930 and 5147 shared a single association while 3010, 16093, and 16223 were each associated with two different symptoms. Five symptoms were associated with 16519, 150 was associated with four, and 1719 was associated with seven. Examination of quantile–quantile plots (QQ-plots) generated for each of the 21 significantly associated symptoms indicated that most did not exhibit any inflation of p values (Additional file 9: Figure S3).
Allele 150T was associated with lower health scores in regards to emotional limitations, work ability, and accomplishments when surveyed across the ME/CFS patients using the SF-36 questionnaire. Both alleles 930G and 5147G were associated with greater difficulty performing work. The 1719A allele was associated with higher symptom scores in seven categories, all related to inflammation and neuroinflammation, as surveyed in ME/CFS patients using the DSQ. The two significant associations of 16223T with neuroinflammatory distress and frequency of sensitivity to bright lights overlapped with the same symptoms being associated with 1719A. Patients with 3010A suffered from higher frequency of and distress symptoms related to sleep disorder. Physical activities were more limited in patients with 16093T. The presence of 16519C was associated with more severe symptoms relating to gastrointestinal issues such as bloating and abdominal pain. Of the 24 total associations, there were four associations with cumulative distress clusters that had been calculated by grouping scores of functionally related DSQ symptoms [22] (Fig. 1 and Additional file 11: Figure S5).

Box plots of SF-36 or DSQ symptom scores associated with mtDNA alleles. The x-axis shows mtDNA position and alleles while the y-axis shows symptom scores and is labelled with descriptions. Scatter plots of the six other significant associations can be found in Additional file 11: Figure S5. Some symptom descriptions were shortened for this figure (less accomplishment: accomplished less than you would like; chemical sensitivity: some smells, foods, medications, or chemicals induce sickness; light sensitivity: sensitivity to bright lights; abdominal pain: abdomen/stomach pain; sleep disorder: sleep all day and stay awake all night)
Heteroplasmy analysis
A mitochondrial heteroplasmy occurs when an individual carries copies of mtDNA with different alleles. Heteroplasmies can occur through somatic mutation or maternal inheritance and can be present at very low frequencies within the mtDNA population or at high frequencies. Mitochondria are thought to undergo a germline bottleneck that reduces the frequency of heteroplasmies transmitted from mother to child. However, if heteroplasmies reach a critical frequency within a tissue or individual, they can potentially have pathogenic effects. The accumulation of heteroplasmies during aging may also contribute to the variable age of onset observed in various energetic diseases.
To investigate the role of heteroplasmy in CFS, we applied high coverage sequencing to identify and analyze heteroplasmies present in CFS patients. An average of 1.42 heteroplasmies per individual was observed in cases compared to only 1.28 in controls (Fig. 2). However, to account for the fact that the number of sites that met our criteria for calling heteroplasmies varied between samples, we calculated the number of heteroplasmies per usable site per individual (HPUI) and used that as metric for comparison. The Wilcoxon rank sum test with continuity correction was used to compare HPUI between cases and controls and showed no significant difference (p value = 0.93). The same test was used to compare the distribution of HPUI between patients who experienced acute onset of ME/CFS versus those who experienced onset, and no significant difference was observed (p value = 0.30, Additional file 10: Figure S4). Since cytokine profiles of ME/CFS patients have been observed to differ with the duration of the disease [39], HPUI was also compared between individuals who had experienced ME/CFS for 3 years or less and those who had endured it for more than 3 years. Again, the Wilcoxon rank sum test showed no significant difference in HPUI between groups (p value = 0.84, Additional file 12: Figure S6).

Heteroplasmy frequency spectrum within cohort. Heteroplasmy count (x-axis) refers to the number of heteroplasmies present in an individual. Frequency (y-axis) refers to the proportion of individuals with the given number of heteroplasmies in each case or control population
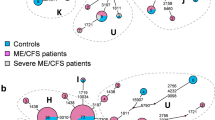
Comparison of the frequency of heteroplasmic alleles revealed very few heteroplasmies occurred in either cases or controls. Of the 406 different heteroplasmies observed between cases and controls, the average heteroplasmy was present in only 1.23 ± 0.85 individuals and 353 heteroplasmies were only found in single individuals (Fig. 3). The most common heteroplasmy was present in seven individuals.

Solarplot representing the location and frequency of heteroplasmies in the CFI cohort. The innermost ring represents the mtDNA sequence and each color coding corresponds to a different functional region. Each dot outside of the centermost ring represents a position where there is a heteroplasmy. The distance of the dot from the innermost ring indicates how many people in the dataset carry that heteroplasmy
Discussion
Our sequencing of the entire mitochondrial genome of patients revealed that no subjects who were included in this cohort have genetic mitochondrial disease due to known mtDNA mutations that was mis-identified as ME/CFS. Therefore, the expert physicians who selected the cases for inclusion did not erroneously include any individuals with a known mitochondrial disease.
Our study examined associations between mtDNA variation and demographic variables such as ME/CFS status, acute onset, and illness duration. We found a correlation between haplogroup and some symptoms related to joint pain, bloating and dead/heavy feeling after exercise. Most studies of mitochondrial DNA and disease pertain to the increased or decreased susceptibility to the disease depending on haplogroup or variant [42], rather than differences in type of symptoms or their severity. However, there are some diseases in which a haplogroup has been associated not with the chance of acquiring a disease, but instead the outcome once someone has been diagnosed. For example, haplogroup affects survival of severe sepsis [43] and progression of AIDS [44].
Measuring mtDNA SNP associations with ME/CFS case–control status did not reveal any associations significant at a 5 % FDR, though 10 SNPs reached nominal significance. Examination of these 10 SNPs revealed nine of them to be marker polymorphisms for HgT, and the tenth to be a marker for five other recognized sub-haplogroups within T. The finding is likely due to the fact that haplogroup association analysis found that more controls than ME/CFS subjects carried HgT in our cohort. A larger cohort will be needed to determine whether this haplotype is somewhat protective against ME/CFS. With regard to HgT, a molecular analysis of cybrid cells with identical nuclear backgrounds and different mtDNA populations indicated that HgT cybrids had a higher survival rate and were more tolerant of oxidative stress when compared to the more common European haplogroup H [45].
One previous study examined mitochondrial DNA SNPs at 3010 and 16519 in 162 CFS patients vs. controls. Boles et al. [18] found an enrichment of 16519T in CFS cases. However, in our study, we did not observe a significant association of 16519T or any other polymorphism to CFS vs. control status. Instead, among individuals with ME/CFS, we observed a significant association of 16519C with gastrointestinal symptoms. Furthermore, the alleles we found to be associated with more severe ME/CFS symptoms were 16519C and 3010A.
The variation in symptom constellation that occurs in ME/CFS could be due to genetic variation in individuals, rather than differences in underlying cause of the disease. Measurement of associations between haplogroups or mtDNA SNPs and symptom scores of ME/CFS patients collected through SF-36 and DSQ surveys revealed 24 significant associations at a 5 % FDR. Although we undertook this study because some of the major symptoms of ME/CFS could theoretically be due to mitochondrial dysfunction, we detected no mitochondrial DNA SNP associations with the major symptom clusters fatigue/post-exertional malaise, cognitive difficulties, autonomic dysfunction, endocrine abnormalities, and pain. Instead, we observed associations with neurological, inflammatory, and gastrointestinal symptoms and/or their severity, as well as correlations with the patients’ abilities to do work. It will be important to utilize a completely independent cohort to determine whether the correlations we have detected can be replicated.
Our study provides hints that at least some of the apparent sub-types in ME/CFS could be due to differences between DNA sequences in the patients, even though we have no evidence that particular mitochondrial genomes lead to increased susceptibility to the disease itself. Although a sample size of 389 is quite large in comparison to most ME/CFS studies, further analysis of the mitochondrial and nuclear genomes in a much larger population of patients will be needed to discover how genetic variation affects illness severity, progression, and symptom clusters.
Conclusions
We did not observe a significant association of mitochondrial DNA genome variation with either susceptibility or resistance to ME/CFS. We did not detect any significant difference in level of heteroplasmy between cases and controls. Using a cohort of 193 ME/CFS cases and 196 controls, at 5 % FDR we observed eight mtDNA SNPs to be associated with 16 symptom categories and three haplogroups associated with six symptom categories, suggesting that the mitochondrial genome of an individual with ME/CFS can affect the type and severity of particular symptoms.
References
Hutchinson CV, Maltby J, Badham SP, Jason LA. Vision-related symptoms as a clinical feature of chronic fatigue syndrome/myalgic encephalomyelitis? Evidence from the DePaul Symptom Questionnaire. Br J Ophthalmol. 2014;98(1):144–5. doi:10.1136/bjophthalmol-2013-304439.
Jason LA, Evans M, Porter N, Brown M, Brown A, Hunnell J, et al. The development of a revised Canadian myalgic encephalomyelitis-chronic fatigue syndrome case definition. Am J Biochem Biotechnol. 2010;6:120–35.
Aaron LA, Burke MM, Buchwald D. Overlapping conditions among patients with chronic fatigue syndrome, fibromyalgia, and temporomandibular disorder. Arch Int Med. 2000;160:221–7.
Komaroff AL, Buchwald D. Symptoms and signs of chronic fatigue syndrome. Rev Infect Dis. 1991;13(Suppl 1):S8–11.
Myhill S, Booth NE, McLaren-Howard J. Targeting mitochondrial dysfunction in the treatment of myalgic encephalomyelitis/chronic fatigue syndrome (ME/CFS)—a clinical audit. Int J Clin Exp Med. 2013;6(1):1–15.
Vermeulen RC, Kurk RM, Visser FC, Sluiter W, Scholte HR. Patients with chronic fatigue syndrome performed worse than controls in a controlled repeated exercise study despite a normal oxidative phosphorylation capacity. J Transl Med. 2010;8:93. doi:10.1186/1479-5876-8-93.
Smits B, van den Heuvel L, Knoop H, Kusters B, Janssen A, Borm G, et al. Mitochondrial enzymes discriminate between mitochondrial disorders and chronic fatigue syndrome. Mitochondrion. 2011;11(5):735–8. doi:10.1016/j.mito.2011.05.005.
Plioplys AV, Plioplys S. Electron-microscopic investigation of muscle mitochondria in chronic fatigue syndrome. Neuropsychobiology. 1995;32(4):175–81.
Castro-Marrero J, Cordero MD, Saez-Francas N, Jimenez-Gutierrez C, Aguilar-Montilla FJ, Aliste L, et al. Could mitochondrial dysfunction be a differentiating marker between chronic fatigue syndrome and fibromyalgia? Antiox. Redox Sig. 2013;19(15):1855–60. doi:10.1089/ars.2013.5346.
Maes M, Mihaylova I, Kubera M, Uytterhoeven M, Vrydags N, Bosmans E. Coenzyme Q10 deficiency in myalgic encephalomyelitis/chronic fatigue syndrome (ME/CFS) is related to fatigue, autonomic and neurocognitive symptoms and is another risk factor explaining the early mortality in ME/CFS due to cardiovascular disorder. Neuro endocrinol Lett. 2009;30(4):470–6.
Hollingsworth KG, Jones DE, Taylor R, Blamire AM, Newton JL. Impaired cardiovascular response to standing in chronic fatigue syndrome. Eur J Clin Invest. 2010;40(7):608–15. doi:10.1111/j.1365-2362.2010.02310.x.
Lane RJ, Barrett MC, Taylor DJ, Kemp GJ, Lodi R. Heterogeneity in chronic fatigue syndrome: evidence from magnetic resonance spectroscopy of muscle. Neuromuscul Dis. 1998;8(3–4):204–9.
Wong R, Lopaschuk G, Zhu G, Walker D, Catellier D, Burton D, et al. Skeletal muscle metabolism in the chronic fatigue syndrome. In vivo assessment by 31P nuclear magnetic resonance spectroscopy. Chest. 1992;102(6):1716–22.
McCully KK, Smith S, Rajaei S, Leigh JS Jr, Natelson BH. Blood flow and muscle metabolism in chronic fatigue syndrome. Clin Sci. 2003;104(6):641–7. doi:10.1042/CS20020279.
McCully KK, Smith S, Rajaei S, Leigh JS Jr, Natelson BH. Muscle metabolism with blood flow restriction in chronic fatigue syndrome. J Appl Phys. 2004;96(3):871–8. doi:10.1152/japplphysiol.00141.2003.
Wallace DC. Mitochondrial DNA mutations in disease and aging. Environ Mol Mutagen. 2010;51(5):440–50. doi:10.1002/em.20586.
Fuku N, Park KS, Yamada Y, Nishigaki Y, Cho YM, Matsuo H, et al. Mitochondrial haplogroup N9a confers resistance against type 2 diabetes in Asians. Am J Hum Genet. 2007;80(3):407–15. doi:10.1086/512202.
Boles RG, Hornung HA, Moody AE, Ortiz TB, Wong SA, Eggington JM, et al. Hurt, tired and queasy: specific variants in the ATPase domain of the TRAP1 mitochondrial chaperone are associated with common, chronic “functional” symptomatology including pain, fatigue and gastrointestinal dysmotility. Mitochondrion. 2015;23:64–70. doi:10.1016/j.mito.2015.05.002.
Boles RG, Zaki EA, Kerr JR, Das K, Biswas S, Gardner A. Increased prevalence of two mitochondrial DNA polymorphisms in functional disease: are we describing different parts of an energy-depleted elephant? Mitochondrion. 2015;23:1–6.
Ye K, Lu J, Ma F, Keinan A, Gu Z. Extensive pathogenicity of mitochondrial heteroplasmy in healthy human individuals. Proc Natl Acad Sci USA. 2014;111(29):10654–9. doi:10.1073/pnas.1403521111.
de Laat P, Koene S, van den Heuvel LP, Rodenburg RJ, Janssen MC, Smeitink JA. Clinical features and heteroplasmy in blood, urine and saliva in 34 Dutch families carrying the m.3243A>G mutation. J Inherit Metab Dis. 2012;35(6):1059–69. doi:10.1007/s10545-012-9465-2.
Klimas NG, Ironson G, Carter A, Balbin E, Bateman L, Felsenstein D, et al. Findings from a clinical and laboratory database developed for discovery of pathogenic mechanisms in myalgic encephalomyelitis/chronic fatigue syndrome. Fatigue. 2015;3:75–96. doi:10.1080/21641846.2015.1023652.
Ware JE Jr, Kosinski M, Bayliss MS, McHorney CA, Rogers WH, Raczek A. Comparison of methods for the scoring and statistical analysis of SF-36 health profile and summary measures: summary of results from the medical outcomes study. Med Care. 1995;33(4 Suppl):AS264–79.
Fukuda K, Straus SE, Hickie I, Sharpe MC, Dobbins JG, Komaroff A. The chronic fatigue syndrome: a comprehensive approach to its definition and study. International Chronic Fatigue Syndrome Study Group. Ann Intern Med. 1994;121(12):953–9.
Carruthers BM, Jain AK, DeMeirleir KL, Peterson DL, Klimas NG, Lerner AM, et al. Myalgic encephalomyelitis/chronic fatigue syndrome: clinical working case definition, diagnostic and treatments protocols. J Chronic Fatigue Synd. 2003;11:7–115.
Carruthers BM, van de Sande MI, De Meirleir KL, Klimas NG, Broderick G, Mitchell T, et al. Myalgic encephalomyelitis: international Consensus Criteria. J Int Med. 2011;270(4):327–38. doi:10.1111/j.1365-2796.2011.02428.x.
Jason LA, So S, Brown AA, Sunnquist M, Evans ME. Test–retest reliability of the DePaul symptom questionnaire. Fatigue. 2015;3:16–32. doi:10.1080/21641846.2014.978110.
Brown AA, Jason LA. Validating a measure of myalgic encephalomyelitis/chronic fatigue syndrome symptomatology. Fatigue. 2014;2:132–52.
Lyons EA, Scheible MK, Sturk-Andreaggi K, Irwin JA, Just RS. A high-throughput Sanger strategy for human mitochondrial genome sequencing. BMC Genomics. 2013;14:881. doi:10.1186/1471-2164-14-881.
Li H, Durbin R. Inference of human population history from individual whole-genome sequences. Nature. 2011;475(7357):493–6. doi:10.1038/nature10231.
Bandelt HJ, Kloss-Brandstatter A, Richards MB, Yao YG, Logan I. The case for the continuing use of the revised cambridge reference sequence (rCRS) and the standardization of notation in human mitochondrial DNA studies. J Hum Genet. 2014;59:66–77.
Dayama G, Emery SB, Kidd JM, Mills RE. The genomic landscape of polymorphic human nuclear mitochondrial insertions. Nuc Acids Res. 2014;42(20):12640–9. doi:10.1093/nar/gku1038.
Li H, Handsaker B, Wysoker A, Fennell T, Ruan J, Homer N, et al. The sequence alignment/map format and SAMtools. Bioinformatics. 2009;25(16):2078–9. doi:10.1093/bioinformatics/btp352.
Kloss-Brandstatter A, Pacher D, Schonherr S, Weissensteiner H, Binna R, Specht G, et al. HaploGrep: a fast and reliable algorithm for automatic classification of mitochondrial DNA haplogroups. Hum Mutat. 2011;32:25–32. doi:10.1002/humu.21382.
van Oven M, Kayser M. Updated comprehensive phylogenetic tree of global human mitochondrial DNA variation. Hum Mutat. 2009;30(2):E386–94.
Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MA, Bender D, et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Human Genet. 2007;81:559–75. doi:10.1086/519795.
Benjamini Y, Hochberg Y. Controlling the false discovery rate—a practical and powerful approach to multiple testing. J Roy Stat Soc B Met. 1995;57:289–300.
Goto H, Dickins B, Afgan E, Paul IM, Taylor J, Makova KD, et al. Dynamics of mitochondrial heteroplasmy in three families investigated via a repeatable re-sequencing study. Genome Biol. 2011;12:R59. doi:10.1186/gb-2011-12-6-r59.
Hornig M, Montoya JG, Klimas NG, Levine S, Felsenstein D, Bateman L, et al. Distinct plasma immune signatures in ME/CFS are present early in the course of illness. Sci Adv. 2015;1:e1400121. doi:10.1126/sciadv.1400121.
Chinnery PF, Brown DT, Andrews RM, Singh-Kler R, Riordan-Eva P, Lindley J, et al. The mitochondrial ND6 gene is a hot spot for mutations that cause Leber’s hereditary optic neuropathy. Brain. 2001;124(Pt 1):209–18.
Kircher M, Witten DM, Jain P, O’Roak BJ, Cooper GM, Shendure J. A general framework for estimating the relative pathogenicity of human genetic variants. Nature Genet. 2014;46(3):310–5. doi:10.1038/ng.2892.
Urzúa-Traslaviña CG, Moreno-Treviño MG, Martínez-Treviño DA, Barrera-Saldaña HA, León-Cachón RBR. Relationship of mitochondrial DNA haplogroups with complex diseases. J Genet Genome Res. 2014;1:2.
Baudouin SV, Saunders D, Tiangyou W, Elson JL, Poynter J, Pyle A, et al. Mitochondrial DNA and survival after sepsis: a prospective study. Lancet. 2005;366(9503):2118–21.
Hart AB, Samuels DC, Hulgan T. The other genome: a systematic review of studies of mitochondrial DNA haplogroups and outcomes of HIV infection and antiretroviral therapy. AIDS Rev. 2013;15(4):213–20.
Mueller EE, Brunner SM, Mayr JA, Stanger O, Sperl W, Kofler B. Functional differences between mitochondrial haplogroup T and haplogroup H in HEK293 cybrid cells. PLoS One. 2012;7:e52367.
Authors’ contributions
PBR and KY analyzed the data. AG designed and performed the experiments. AK, ZG, and MRH conceived and designed the experiments. All authors participated in writing of the manuscript and approved the final manuscript. All authors read and approved the final manuscript.
Acknowledgements
We thank the CFI physicians for selecting subjects, obtaining blood samples, and administering survey forms as part of the CFI study, and the subjects for their participation. We thank the Chronic Fatigue Initiative and the Hutchins Family Foundation for funding for this project, and Yiqin Wang for verification of some of the computational analysis. P.B-R was also supported by a National Science Foundation predoctoral fellowship. KY was also supported by NIH grant R01 HG006849 to AK.
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Additional information
Paul Billing-Ross and Arnaud Germain contributed equally to this work
Additional files
12967_2016_771_MOESM12_ESM.docx
Additional file 12: Figure S6. Comparison of HPUI distribution between individuals who have experienced ME/CFS for less than 3 years and more than 3 years.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Billing-Ross, P., Germain, A., Ye, K. et al. Mitochondrial DNA variants correlate with symptoms in myalgic encephalomyelitis/chronic fatigue syndrome. J Transl Med 14, 19 (2016). https://doi.org/10.1186/s12967-016-0771-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12967-016-0771-6