
Abstract
Objective
To develop a mapping algorithm for generating the Short Form Six-Dimension (SF-6D) utility score based on the Functional Assessment of Cancer Therapy-Lung (FACT-L) of lung cancer patients.
Methods
Data were collected from 625 lung cancer patients in mainland China. The Spearman rank correlation coefficient and principal component analysis were used to evaluate the conceptual overlap between the FACT-L and SF-6D. Five model specifications and four statistical techniques were used to derive mapping algorithms, including ordinary least squares (OLS), Tobit and beta-mixture regression models, which were used to directly estimate health utility, and ordered probit regression was used to predict the response level. The prediction performance was evaluated using the correlations between the root mean square error (RMSE), mean absolute error (MAE), concordance correlation coefficient (CCC), Akaike information criterion (AIC) and Bayesian information criterion (BIC) and the observed and predicted SF-6D scores. A five-fold cross-validation method was used to test the universality of each model and select the best model.
Results
The average FACT-L score was 103.024. The average SF-6D score was 0.774. A strong correlation was found between FACT-L and SF-6D scores (ρ = 0.797). The ordered probit regression model with the total score of each dimension and its square term, as well as age and sex as covariates, was most suitable for mapping FACT-L to SF-6D scores (5-fold cross-validation: RMSE = 0.0854; MAE = 0.0655; CCC = 0.8197; AEs > 0.1 (%) = 53.44; AEs > 0.05 (%) = 21.76), followed by beta-mixture regression for direct mapping. The Bland‒Altman plots showed that the ordered probit regression M5 had the lowest proportion of prediction scores outside the 95% agreement limit (-0.166, 0.163) at 4.96%.
Conclusions
The algorithm reported in this paper enables lung cancer data from the FACT-L to be mapped to the utility of the SF-6D. The algorithm allows the calculation of quality-adjusted life years for cost-utility analyses of lung cancer.
Similar content being viewed by others
Background
Lung cancer is the second most common and deadly cancer in the world, with GLOBOCAN estimating 2.2 million new cases and 1.8 million deaths worldwide in 2020 [1]. According to statistics from the National Cancer Center of China, the incidence and mortality of lung cancer rank first among malignant tumors in China [2]. The treatment of lung cancer patients imposes a huge economic burden on the Chinese health care system [3]. It is expected that the total economic burden of lung cancer will increase to 40.4 billion USD and 53.4 billion USD in 2025 and 2030, accounting for 0.131% and 0.146% of China’s GDP, respectively [3].
To rationally allocate limited health care resources, health economic evaluations are very important. Currently, the most commonly used cost-utility analysis (CUA) in health economic evaluations entails the use of quality-adjusted life-years (QALYs), which combine health-related quality of life (HRQoL) and survival into a single metric [4]. The QALY parameter, which can assess the health benefits of interventions not only across treatment strategies but also across patient groups, is recommended by health technology assessment (HTA) agencies such as the UK’s National Institute for Health and Clinical Excellence (NICE) [5]. Preference-based HRQoL tools are commonly used for QALY calculations, such as the EuroQol Five Dimensions (EQ-5D) and Short Form Six-Dimension (SF-6D). Although preference-based health status values would ideally be determined prospectively in clinical studies, this is not always the case [6, 7]. In clinical research, non-preference-based disease-specific questionnaires are often used because they capture more disease-specific or disease-related aspects from clinical and patient perspectives [8]. At this point, “mapping” (or “crosswalking”) [7, 9] can be used to address such problems; that is, in the case of trials that include disease-specific nonpreference measures of HRQoL but not preference-based measures, algorithms that allow the “transfer” of scores from disease-specific measures to utility measures can be generated.
Mapping includes direct mapping and indirect mapping. A previous systematic review found that the most commonly used method for mapping was ordinary least squares (OLS) for direct mapping, followed by Tobit regression [10]. Meanwhile, OLS has achieved the best predictive performance in multiple previous studies [11, 12]. Recent studies have demonstrated the potential value of mixed models to better capture the multimodal distribution of HRQoL data and manage the complexity of the data [13, 14]. In addition, mixed models can also capture changes in the impact of covariates on HRQoL in the distribution of HRQoL, such as the adjusted limited dependent variable mixed model (ALDVMM) [15] and beta-mixture regression model (BETAMIX) [16]. The method of indirect mapping has become increasingly popular in applied work [13], and related alternatives have been proposed, such as ordered logit or probit and generalized ordered probit models.
Currently, only two mapping studies have used non-preference-based quality of life scales (QLQ-C30, FACT-G) for the SF-6D and selected multiple cancer types, including lung cancer [17, 18]. In addition, some mapping studies on SF-6D have been carried out in other cancers, such as breast cancer [11] and thyroid cancer [19]. On the basis of Functional Assessment of Cancer Therapy-General (FACT-G), the Functional Assessment of Cancer Therapy-Lung (FACT-L) has added a dedicated module for lung cancer to measure HRQoL [11]. Because FACT-L is specifically designed for lung cancer patients and uses aspects that are significant for this specific patient population, the FACT-L is often the first choice in clinical studies. To date, however, no suitable method to convert the FACT-L score into a utility score is available to calculate the health utility value of lung cancer, which would facilitate economic evaluations of current or future lung cancer interventions. To address this gap, this study aimed to develop an algorithm to map the lung cancer-specific FACT-L score to the SF-6D utility score in lung cancer patients to promote CUA in a Chinese lung cancer patient population.
Method
Study design and patients
This study followed the Mapping to Preference-Based Measures Reporting Standards (MAPS) checklist proposed for instrumental mapping [20, 21] and the International Society for Pharmacoeconomics and Outcomes Research (ISPOR) reporting standards on mapping [9], as well as the systematic review of mapping research in the annual report of the National Institute for Health and Care Excellence (NICE) [22].
This cross-sectional study was designed to develop a mapping model from the FACT-L to the SF-6D. The study was conducted from October 2020 to November 2021 at the Sichuan Cancer Hospital, the largest tertiary first-class tumour hospital in Southwest China. The annual volume of thoracic surgery exceeds 4,000, and lung cancer patients from all over the country are admitted. The inclusion criteria for research subjects were as follows: (1) lung cancer diagnosed by clinical examination or pathological diagnosis; (2) age ≥ 18 years; (3) clear cognition, a normal demeanour, and a certain ability to understand and communicate; and (4) willingness to participate in this study with signing of the “Informed Consent”. Exclusion criteria: other serious chronic diseases, such as cardiovascular and cerebrovascular diseases and mental illness. Recruitment and informed consent procedures were performed by the investigators, and patients received questionnaires during their hospital outpatient visits or inpatient care. The ethics committee of Sichuan Cancer Hospital approved the conduct of this study (reference number: SCCHEC-02-2020-042). Written informed consent was obtained from all study participants.
Research tool
FACT-L
The FACT-L (v.4.0) contains 36 questions in five dimensions, namely, 7 items for physical well-being (PWB), 7 items for social/family well-being (SWB), 6 items for emotional well-being (EWB), 7 items for functional well-being (FWB), and 9 additional items concerning lung cancer (LCS) (two of the nine were not included in the score) [23]. This system consists of a general scale (common module) FACT-G for measuring the common parts of the quality of life of cancer patients and an additional module for lung cancer. Among them, 27 items from the first 4 dimensions constitute FACT-G. Each item is scored between 0 and 4, and the total score of the scale is between 0 and 144, with higher scores indicating better quality of life. The Chinese version of the FACT-L (v4.0) has good reliability and validity [24].
SF-6D
The SF-6D is a preference-based general health tool derived from the SF-36, including six dimensions of physical functioning, role limitations, social functioning, pain, mental health and vitality [25]. All dimensions consist of 4∽6 levels, creating a total of 18,000 possible health states [26]. In the absence of a utility algorithm for mainland China, we use the Chinese version (Hong Kong) of the SF-6D utility scoring system [27]. The scoring system has been demonstrated to be effective, with utility scores ranging between 0.315 and 1.
Data collection
We asked participants to complete a combined questionnaire for both instruments. In addition to these two tools, we collected data on patient demographic and clinical characteristics. Data were collected by trained research team members. Before data collection, to ensure the quality of data collection, we also prepared a data collection manual.
Exploratory data analysis—concept overlap
In this study, medians were used to fill individual missing values. SF-6D and FACT-L scores were assessed to test normality, skewness, and kurtosis using the skewness/kurtosis test before investigating concept overlap. Since the FACT-L and SF-6D scores were not normally distributed, this study used the Spearman correlation coefficient to calculate the overlap between the source and target instruments. Spearman’s rank correlation coefficient, which was defined before the analysis and used to interpret the results, ranks the strength of correlation into five levels—very weak (0–0.19); weak (0.20–0.39); moderate (0.40–0.59); strong (0.60–0. 0.79); and very strong (0.80–1.00) [28].
This study also employed principal component analysis (PCA) to explore and compare the underlying dimensional structure of the FACT-L data and the SF-6D information evident in these datasets [29]. The eigenvalue in PCA represents the amount of variance of the original variable explained by each principal component, which determines the number of principal components [30]. In this study, only principal components with eigenvalues greater than 1 were considered for the exploratory PCA, and rotation was performed using the tilted Promax method [29].
Modelling methods and performance
We selected four models to map nonpreference-based health instruments onto general preference-based instruments: OLS, Tobit, ordinal probit regression (OPROBIT), and beta mixture regression (BETAMIX). Among them, OLS and Tobit regression are the two most widely used mapping methods [10, 20].
The utility score distribution obtained from general preference-based measures, such as the SF-6D, is usually not normally distributed and has a higher ceiling effect when the value is 1 and multiple peaks are present. Given that beta-mixture regression models have the advantage of addressing these issues [31], this study also used beta-mixture regression models to map the utility scores of the SF-6D. The beta-mixture regression model is a generalization of the truncated inflated beta regression model proposed by Botter Pereira [32]. Heterogeneity in the relationship between predictors and outcomes can be modelled by identifying clusters within the distribution, and mixture models provide a semiparametric and flexible approach to identifying these multimodalities [31, 33]. The beta-mixture regression model employed in this study specifies the gap between full health and the next feasible health state with a large number of observations at this cut-off point [34]. While the method could include probability mass at the lower bound of utility, we did not include this here because our sample did not contain any observations of the lower bound of utility for the SF-6D. We tried to use 1∽3 components to estimate the model, but some models may have convergence problems.
This study also used ordinal probit regression, which is an indirect method known as “response mapping”. Four to six separate equations were used to estimate the probability for each level of the different health domains covered by the SF-6D. From these regressions, expected health utility scores were then derived based on the set of health utility values. This approach has an intuitive appeal compared to linear regression because it is more closely related to the actual data generation process for health utility [13].
The model included the five domains of the FACT-L scale as well as age and sex as potential variables to predict the utility of the EQ-5D-5 L while also considering the squared terms of the total score and domain scores [28, 29]. Five modelling methods were used in each of the four models, and a two-tailed p value less than 0.05 was considered statistically significant.
Model 1: FACT-H&N total score.
Model 2: FACT-H&N total score + the square term of the FACT-H&N total score.
Model 3: Scores for each domain of FACT-H&N.
Model 4: Scores for each domain of FACT-H&N + the square term of the scores for each domain of FACT-H&N.
Model 5: Model 4 + age + sex.
Four common prediction performance indicators were used to evaluate the ability of candidate models to accurately predict SF-6D values: the root mean square error (RMSE), mean absolute error (MAE), and mean error (ME). These indicators are used as simple fitting summary measures and can be used for cross-model comparisons. In addition, this study also calculated Lin’s concordance correlation coefficient (CCC) to evaluate the relationship between the predicted and observed values of the FACT-L and SF-6D [35]. A CCC value close to 1 implies good agreement between the predicted and observed measurements.
Since the penalized likelihood measures (Akaike information criterion and Bayesian information criterion) cannot be used for direct comparisons of direct and indirect mapping models, they were used to select the best model in each class [36]. A Bland‒Altman analysis was performed by plotting the distribution of the difference between the observed and predicted utility (y-axis) and the mean of the observed and predicted utility (x-axis) [37]. In the process of preliminary selection and final screening of the best model, this study carried out a comprehensive ranking according to the average rank of each index [38]. This study examined the predictive performance of the SF-6D continuum model, the best of the various models, using cumulative distribution values. This study also used a Bland–Altman plot. The width between the 95% empirical limits of agreement was determined, which was compared with the width of the 95% theoretical limits of agreement.
In each model, we preliminarily selected the 2 best models and then used 5-fold cross-validation to assess the overfitting of the models and finally select the best model. This in-sample cross-validation technique randomly divides the initial dataset into 5 subsamples of uniform size. Four of the subsamples are used for parameter estimation, and one subsample is used for validation. The process was repeated five times, each subsample was used for only one validation, and the results were averaged to assess the overall performance of the model.
All statistical analyses were performed using Stata® version 15.0 (StataCorp LP, College Station, Texas, USA), except that R4.1.1 was used for CCC determination and PCA was performed in SPSS 23.0 (IBM Corp., Armonk, NY, USA). The Stata command “betamix” was used to fit the mixed regression model for the dependent variable in the interval [16], and the Stata command “oprobit” was used to fit the ordered probit regression model.
Results
Descriptive statistics
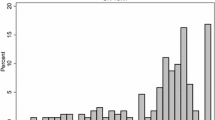
Data from 625 lung cancer patients were collected for analysis and modelling in this study. In the demographic data, FACT-L, and SF-6D scales of 625 lung cancer patients, missing data accounted for 0.062%. Data analysis was conducted after imputing the missing values. Table 1 shows the characteristics and utilities of the study sample. The mean (standard deviation, SD) age of the patients, 45.8% of whom were women, was 58.290 (9.872) years old. A good representation of disease severity, in terms of cancer TNM stage, was observed in the study sample. FACT-L scores ranged from 54 to 133, with a mean of 103.024 (SD = 15.554), and were nonnormally distributed (Pr(Skewness) = 0.0006, Pr(Kurtosis) = 0.7092, p = 0.000). Figure 1 shows the distribution of the SF-6D scores, which was skewed to the right. The utility values of the SF-6D ranged from 0.359 to 1, with a mean of 0.774 (SD = 0.359), and showed a significantly right-skewed distribution (Pr(Skewness) = 0.0000, Pr(Kurtosis) = 0.7092, p = 0.000).

The distribution of SF-6D utility scores in the sample
Overlap of concepts
Table 2 presents the Spearman rank correlation coefficients between the FACT-L and the total scores and domains of the SF-6D utility scores. Conceptually, the FACT-L score was positively correlated with the total SF-6D score (a higher FACT-L score is associated with a higher SF-6D utility score, indicating better health), the utility value of the SF-6D was positively correlated with the FACT-L total score and the scores for each dimension (higher FACT-L scores and higher SF-6D utility scores indicate better health), and SF-6D domain scores were negatively correlated with FACT-L total and domain scores (lower SF-6D domain scores correspond to higher FACT-L scores, indicating better health). Table 2 shows a strong correlation between the total scores of the SF-6D and FACT-L scales (ρ = 0.797); a negative correlation was found between each dimension, the correlation coefficient was − 0.217∽-0.758, and all correlation coefficients were statistically significant (p < 0.001). The correlation coefficient between the scores for each dimension of the FACT-L scale and the score for the SF-6D scale was highest in the PWB dimension and lowest in the SWB dimension.
Table 3 shows the PCA results, and the eight principal components explained 61.228% of the total variance. The first five principal components were the same as the SF-6D domains (“physical well-being”, “social/family well-being”, “emotional well-being”, “functional well-being”, and “LCS”), the sixth and seventh components can also be summarized into “physical well-being” and “LCS”, and the eighth component corresponds to “Sex/Weight”. Four SF-6D dimensions (“PF”, “RL”, “SF” and “PAIN”) were loaded to describe components related to the “physical well-being” dimension of the FACT-L. The other two SF-6D dimensions (“MH” and “VIT”) were loaded into “EWB”, “FWB” and “LCS”. None of the SF-6D dimensions were primarily loaded on the “SWB” component, which supports the poor correlation described above.
Model performance
Table 4 summarizes the performance of the models in the full sample (evaluated by seven goodness-of-fit indicators: the RMSE, MAE, CCC, AEs > 0.1 (%), AEs > 0.05 (%), AIC, and BIC) and sorts the best models according to the average rank of each indicator. Comparing the average ranks of different models in different mapping methods, Model 5 of OLS, Tobit, and ordered probit regression performed the best, followed by Model 4. Beta-mixture regression models without truncation performed better than those with truncation, and the average ranks of BETAMIX M4a and BETAMIX M4a were the lowest. Among all models, the RMSE of OLS M5 was the lowest (0.0838), the MAE of OLS M5 and BETAMIX M5a was the lowest (0.0653), the CCC of TOBIT M5 was the highest (0.8300), AEs > 0.1 (%) was lowest in TOBIT M5 and OPROBIT M5 (52.96%), and AEs > 0.05 (%) was lowest in TOBIT M3 (52.96%).
Table 5 shows the predicted values of the eight best candidate models. The OLS model best predicted the mean. The median predicted by the BETAMIX M4a model was closer to the observed value. Our best-fitting model overpredicted severe health states and underpredicted better health states.
One of the best models was selected from the four modelling techniques to draw a conditional distribution function graph (Fig. 2), which showed that the predicted data of the SF-6D were in good agreement with the observed data. A Bland‒Altman analysis was performed to understand the predictive performance at the individual level. Figure 3 shows that the average residuals of the 4 best models were − 0.004∽0.003, with the average residual of OLS Model 5 being the smallest, followed by ordered probit regression. Ordered probit regression M5 had the lowest proportion of prediction scores outside the 95% agreement limit (-0.166, 0.163) at 4.96%.
Through 5-fold cross-validation to test the predictive ability of the eight best candidate models, the indicators of various predictive performances obtained from the verification samples were identified and are shown in Table 6. The average rank demonstrated that ordered probit Model 5 had the best comprehensive ranking (RMSE = 0.0854, MAE = 0.0655, CCC = 0.8197, AEs > 0.05 = 53.44%, AEs > 0.05 = 21.76%), followed by beta-mixture regression Model 3a (RMSE = 0.0853, MAE = 0.0661, CCC = 0.8194, AEs > 0.05 = 54.24%, AEs > 0.05 = 20.8%). The CCC between the observed utility and the predicted utility of the SF-6D obtained in the validation sample was 0.8185∽0.8230, indicating good agreement.

Cumulative distribution functions of observed and predicted SF-6D scores

Bland–Altman plots of the observed and predicted SF-6D scores for a OLS M5, b TOBIT M5, c OPROBIT M5, d BETAMIX M3a
Regression results
The regression coefficients of the OLS and Tobit models are shown in Additional files 1–2 (see Additional files 1–2), and the regression coefficients of ordered probit Model 5 and beta-mixture regression Model 3 are shown in Tables 7 and 8. In the OLS and Tobit models, the FACT-L total score and the coefficient of the square term of the total score were both positive and statistically significant (p < 0.05). FWB and PWB were significant positive predictors of SF-6D scores in the OLS and Tobit models. In addition, the squared term of LCS was an important predictor of SF-6D scores in the OLS and Tobit models after adding the squared term of each domain of the FACT-L. In addition to FWB and PWB, the EWB domain score was also an important predictor in some domains of ordered probit models. Considering two sociodemographic variables, namely, age and sex, only sex was statistically significant in the Tobit model and the ordered probit model (p < 0.05), and a significant positive correlation was identified between male sex and the utility score of the SF-6D. This study also provides Excel calculators for the best fit direct mapping model and indirect mapping model (see Additional files 3–4), which allows users to easily calculate SF-6D from FACT-L scores.
Discussion
This is the first study to produce a FACT-L to SF-6D mapping algorithm, and the availability of this algorithm means that researchers can obtain SF-6D health utility values for lung cancer patients simply by including the FACT-L even if the preference-based measurement tool itself is not included in the study. The final model included the total score for each dimension of the FACT-L, the squared term of the total score for the dimension, and sex. We found that models using subscales as independent variables outperformed models using total scores as independent variables [39]. All variables finally included were independent of the SWB dimension measured by the FACT-L, and similar results have been found in previous studies of other cancers [40]. On the one hand, this study found through correlation analysis that the correlation coefficient between the scores for each dimension of the FACT-L scale and the score for the SF-6D scale was the lowest in the SWB dimension. Conceptual differences between the source and target instruments may be another explanation, and exploratory factor analysis (EFA) is often used to examine the degree of conceptual overlap between the two, where PCA has been recommended as the preferred method for factor extraction [41]. From the PCA results of this study, none of the SF-6D dimensions were mainly loaded on the “SWB” component, which supports the result that the SWB dimension in the FACT-L scale cannot be entered into the mapping model.
Age and gender were considered important during the mapping process, and their inclusion was recommended where feasible [9]. Although previous mapping studies have added covariates such as the tumor stage [42] and Charlson comorbidity index [43], considering that other disease related variables may not be included in the study when using the algorithm of this study in the future, this study mainly considers age and gender in demographic variables. Among the four models in this study, age was not a statistically significant predictor of SF-6D scores, while sex was statistically significant in Tobit regression and ordered probit regression (p < 0.05). Male sex was significantly positively correlated with health utility scores [44]. The squared terms of LCS were significant predictors of SF-6D scores in both OLS and Tobit models after adding the squared terms in each domain of the FACT-L. The addition of the square term is beneficial to improve the performance of the model [44, 45].
This study adopted internal validation, passed five indicators [46], and found that ordered probit Model 5 was the best model for comprehensive ranking (RMSE = 0.0854, MAE = 0.0655, CCC = 0.8197, AEs > 0.1 = 53.44%, AEs > 0.05 = 21.76%), followed by beta-mixture regression Model 3a (RMSE = 0.0853, MAE = 0.0661, CCC = 0.8194, AEs > 0.1 = 54.24%, AEs > 0.05 = 20.8%), which is consistent with recent evidence indicating that indirect mapping and mixed models are better than linear regression. In this study, the difference between the SF-6D value obtained by all the best prediction models and the observed value was greater than 0.10 (absolute error percentage > 0.10) in less than 60% of the samples, which is lower than those in previous mapping studies [43].
In addition, good agreement was noted between the predicted value of the SF-6D and the measured value in this study because most of the observed values fell in the mean ± 1.96 SD difference area, and the Bland‒Altman plot showed that the predicted score of ordered probit M5 exceeds 95%. The consistency limit (-0.166, 0.163) had the lowest proportion (4.96%), and this result is similar to the results of previous mapping models [47]. The CCC (0.8185 ∽ 0.8230) between the observed and predicted utility of the SF-6D obtained in the validation sample was higher than 0.8, which is slightly higher than those in previous studies [48]; this is a good result and highlights the prediction. Good agreement was observed between the values and observations [49]. Past studies have shown that mapping is more likely to be successful if two tools overlap conceptually [50, 51]. Before mapping, this study explored the strong correlation between the total scores of the two scales through Spearman rank correlation analysis (ρ = 0.797), and all the correlation coefficients between the total score and the scores for each dimension were statistically significant (p < 0.001). In addition, the PCA results also suggest that the SF-6D dimension is loaded on the components of the FACT-L scale except for “SWB”.
Overall, the mapping function performed well in this study. While our best-fitting models overpredicted severe health states, they underpredicted better health states [8, 48]. For example, although the 10th percentile (0.5713) predicted by BETAMIX M4a for the SF-6D was closest to the observed value of 0.5340, it was above the observed value. Although the mapping model approaches used are not completely consistent, this finding is similar to previous research results [29]. Although the conditional distribution function plots show that the simulated SF-6D data from the best-fitting model are in good agreement with the observed data, these plots also confirm that these models generally underestimate the value of the SF-6D for mildly healthy states and overestimate the value of the SF-6D for healthier states [52]. At the same time, the Bland–Altman plot in this study also shows this difference between the observed and predicted values, which is similar to results in published literature related to mapping models [37]. This “mismatch” is a common problem in mapping studies and is mainly due to regression to the mean.
This study has some strengths. Given the lack of international studies and the absence of studies in China, this study developed a mapping algorithm to predict the SF-6D utility score in lung cancer patients. Second, this study utilized four regression models and five evaluation criteria to determine the best-performing algorithm while employing and comparing direct and indirect mapping methods.
Limitations of this study
Although the lung cancer patients in this study had different stages and pathological types, our sample size was limited to a single sample, and the results may not be representative of the entire lung cancer population in China. Future work could include data on lung cancer patients from more regions in China. Second, no other independent datasets with SF-6D and FACT-L observations were available to assess the external validity of the mapping algorithm reported in this study. Therefore, we did not use other datasets to evaluate the external validity of the mapping algorithm in this study, which may limit the generalizability of its application to some extent.
Conclusions
In conclusion, the FACT-L can be mapped to SF-6D utility with good prediction accuracy. Ordered probit regression models were best suited for mapping FACT-L scores to SF-6D scores, followed by beta-mixture regression for direct mapping. Our mapping algorithm can compute QALYs when no preference-based health utility measure is available for lung cancer patients. It can compare the cost-effectiveness of lung cancer-related interventions and help relevant decision-makers reach scientific decisions regarding the allocation of limited resources.
Data Availability
The datasets are available from the corresponding author on reasonable request.
Change history
27 February 2024
A Correction to this paper has been published: https://doi.org/10.1186/s12955-024-02237-y
Abbreviations
- AE:
-
Absolute error
- AIC:
-
Akaike Information Criterion
- ALDVMM:
-
Adjusted limited dependent variable mixed model
- BETAMIX:
-
Beta-mixture regression model
- BIC:
-
Bayesian information criterion
- CCC:
-
concordance correlation coefficient
- CUA:
-
Cost-utility analysis
- EFA:
-
Exploratory factor analysis
- EQ-5D:
-
EuroQol-5 dimension
- EWB:
-
Emotional well-being
- FACT-L:
-
Functional Assessment of Cancer Therapy- Lung
- FWB:
-
Functional well-being
- HRQoL:
-
Health-related quality of life
- HTA:
-
Health technology assessment
- ISPOR:
-
International Society for Pharmacoeconomics and Outcomes Research
- LCS:
-
Additional concerns about lung cancer
- MAE:
-
Mean absolute error
- MAPS:
-
Mapping onto Preference-Based Measures Reporting Standards
- NICE:
-
National Institute for Health and Clinical Excellence
- OLS:
-
Ordinary least-square
- OPROBIT:
-
Ordinal probit regression
- PCA:
-
Principal component analysis
- PWB:
-
Physical well-being
- QALYs:
-
Quality-adjusted life years
- RMSE:
-
Root mean squared error
- SF-6D:
-
Short Form Six-Dimension
- SWB:
-
social/family well-being
References
Sung H, Ferlay J, Siegel RL, Laversanne M, Soerjomataram I, Jemal A, et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2021;71(3):209–49.
Xia C, Dong X, Li H, Cao M, Sun D, He S, et al. Cancer statistics in China and United States, 2022: profiles, trends, and determinants. Chin Med J (Engl). 2022;135(5):584–90.
Liu C, Shi J, Wang H, Yan X, Wang L, Ren J, et al. Population-level economic burden of Lung cancer in China: Provisional prevalence-based estimations, 2017–2030. Chin J Cancer Res. 2021;33(1):79–92.
Kiadaliri A, Alava MH, Roos EM, Englund M, Mapping. EQ-5D-3L from the knee injury and osteoarthritis outcome score (KOOS). Qual Life Res. 2020;29(1):265–74.
NICE. (2013). Guide to the methods of technology appraisal 2013, National Institute for Health and Care Excellence, UK. https://www.nice.org.uk/process/pmg9/chapter/foreword.
Badia X, Trainer P, Biermasz NR, Tiemensma J, Carreño A, Roset M, et al. Mapping AcroQoL scores to EQ-5D to obtain utility values for patients with acromegaly. J Med Econ. 2018;21(4):382–89.
Brazier JE, Yang Y, Tsuchiya A, Rowen DL. A review of studies mapping (or cross walking) non-preference based measures of health to generic preference-based measures. Eur J Health Econ. 2010;11(2):215–25.
Sturkenboom R, Keszthelyi D, Brandts L, Weerts ZZRM, Snijkers JTW, Masclee AAM, et al. The estimation of a preference-based single index for the IBS-QoL by mapping to the EQ-5D-5L in patients with irritable bowel syndrome. Qual Life Res. 2022;31(4):1209–21.
Wailoo AJ, Hernandez-Alava M, Manca A, Mejia A, Ray J, Crawford B, et al. Mapping to estimate health-state utility from non–preference-based outcome measures: an ISPOR good practices for outcomes research task force report. Value Health. 2017;20(1):18–27.
Mukuria C, Rowen D, Harnan S, Rawdin A, Wong R, Ara R, et al. An updated systematic review of studies mapping (or cross-walking) measures of health-related quality of life to generic preference-based measures to generate utility values. Appl Health Econ Health Policy. 2019;17(3):295–313.
Nahvijou A, Safari H, Yousefi M, Rajabi M, Arab-Zozani M, Ameri H. Mapping the cancer-specific FACT-B onto the generic SF-6Dv2. Breast Cancer. 2021;28(1):130–6.
Yousefi M, Nahvijou A, Sari AA, Ameri H. Mapping QLQ-C30 onto EQ-5D-5L and SF-6D-V2 in patients with colorectal and Breast Cancer from a developing country. Value Health Reg Issues. 2021;24:57–66.
Hernández Alava M, Wailoo A, Wolfe F, Michaud K. A comparison of direct and indirect methods for the estimation of health utilities from clinical outcomes. Med Decis Making. 2014;34(7):919–30.
Kent S, Gray A, Schlackow I, Jenkinson C, McIntosh E. Mapping from the Parkinson’s Disease questionnaire PDQ-39 to the generic EuroQol EQ-5D-3L: the value of mixture models. Med Decis Making. 2015;35(7):902–11.
Ara R, Rowen D, Mukuria C. The use of mapping to estimate health state utility values. PharmacoEconomics. 2017;35(Suppl 1):57–66.
Gray L, A AMH. A command for fitting mixture regression models for bounded dependent variables using the beta distribution. The Stata J. 2018;18(1):51–75.
Kontodimopoulos N. The potential for a generally applicable mapping model between QLQ-C30 and SF-6D in patients with different cancers: a comparison of regression-based methods. Qual Life Res. 2015;24(6):1535–44.
Teckle P, McTaggart-Cowan H, Van der Hoek K, Chia S, Melosky B, Gelmon K, et al. Mapping the FACT-G cancer-specific quality of life instrument to the EQ-5D and SF-6D. Health Qual Life Outcomes. 2013;11:203.
Yang Q, Huang D, Jiang L, Tang Y, Zeng D, Obtaining. SF-6D utilities from FACT-H&N in thyroid carcinoma patients: development and results from a mapping study. Front Endocrinol (Lausanne). 2023;14:1160882.
Dakin H, Abel L, Burns R, Yang Y. Review and critical appraisal of studies mapping from quality of life or clinical measures to EQ-5D: an online database and application of the MAPS statement. Health Qual Life Outcomes. 2018;16(1):31.
Petrou S, Rivero-Arias O, Dakin H, Longworth L, Oppe M, Froud R, et al. The MAPS reporting statement for studies mapping onto generic preference-based outcome measures: explanation and elaboration. PharmacoEconomics. 2015;33(10):993–1011.
Longworth L, Yang Y, Young T, Mulhern B, Hernández Alava M, Mukuria C, et al. Use of generic and condition-specific measures of health-related quality of life in NICE decision-making: a systematic review, statistical modelling and survey. Health Technol Assess. 2014;18(9):1–224.
Cella DF, Bonomi AE, Lloyd SR, Tulsky DS, Kaplan E, Bonomi P. Reliability and validity of the Functional Assessment of Cancer Therapy-Lung (FACT-L) quality of life instrument. Lung Cancer. 1995;12(3):199–220.
Wan C, Zhang C, Cai L, Tu X, Feng C, Luo J, et al. Psychometric properties of the Chinese version of the FACT-L for measuring quality of life in patients with Lung cancer. Lung Cancer. 2007;56(3):415–21.
Brazier J, Usherwood T, Harper R, Thomas K. Deriving a preference-based single index from the UK SF-36 Health Survey. J Clin Epidemiol. 1998;51(11):1115–28.
Ameri H, Safari H, Poder T. Exploring the consistency of the SF-6Dv2 in a Breast cancer population. Expert Rev Pharmacoecon Outcomes Res. 2021;21(5):1017–24.
McGhee SM, Brazier J, Lam CL, Wong LC, Chau J, Cheung A, et al. Quality-adjusted life years: population-specific measurement of the quality component. Hong Kong Med J. 2011;17(6):17–21.
Vilsbøll AW, Kragh N, Hahn-Pedersen J, Jensen CE. Mapping Dermatology Life Quality Index (DLQI) scores to EQ-5D utility scores using data of patients with atopic dermatitis from the National Health and Wellness Study. Qual Life Res. 2020;29(9):2529–39.
Lamu AN, Chen G, Gamst-Klaussen T, Olsen JA. Do country-specific preference weights matter in the choice of mapping algorithms? The case of mapping the Diabetes-39 onto eight country-specific EQ-5D-5L value sets. Qual Life Res. 2018;27(7):1801–14.
Oppe M, Devlin N, Black N. Comparison of the underlying constructs of the EQ-5D and Oxford Hip score: implications for mapping. Value Health. 2011;14(6):884–91.
Hernández Alava M, Wailoo AJ, Ara R. Tails from the peak district: adjusted limited dependent variable mixture models of EQ-5D questionnaire health state utility values. Value Health. 2012;15(3):550–61.
Pereira GHA, Botter DA, Sandoval MC. The truncated inflated beta distribution. Commun Statistics-Theory Method. 2012;41(5):907–19.
Lamont AE, Vermunt JK, Van Horn ML. Regression mixture models: does modeling the covariance between Independent variables and latent classes improve the results? Multivar Behav Res. 2016;51(1):35–52.
Gray LA, Hernández Alava M, Wailoo AJ. Development of methods for the mapping of utilities using mixture models: mapping the AQLQ-S to the EQ-5D-5L and the HUI3 in patients with Asthma. Value Health. 2018;21(6):748–57.
Barnhart HX, Haber M, Song J. Overall concordance correlation coefficient for evaluating agreement among multiple observers. Biometrics. 2002;58(4):1020–7.
Gray LA, Hernandez Alava M, Wailoo AJ. Mapping the EORTC QLQ-C30 to EQ-5D-3L in patients with Breast cancer. BMC Cancer. 2021;21(1):1237.
Ameri H, Yousefi M, Yaseri M, Nahvijou A, Arab M, Akbari Sari A. Mapping the cancer-specific QLQ-C30 onto the generic EQ-5D-5L and SF-6D in Colorectal cancer patients. Expert Rev Pharmacoecon Outcomes Res. 2019;19(1):89–96.
Lim J, Choi SE, Bae E, Kang D, Lim EA, Shin GS. Mapping analysis to estimate EQ-5D utility values using the COPD assessment test in Korea. Health Qual Life Outcomes. 2019;17(1):97.
Gray LA, Wailoo AJ, Hernandez Alava M. Mapping the FACT-B instrument to EQ-5D-3L in patients with Breast cancer using adjusted limited dependent variable mixture models versus response mapping. Value Health. 2018;21(12):1399–405.
Hagiwara Y, Shiroiwa T, Taira N, Kawahara T, Konomura K, Noto S, et al. Mapping EORTC QLQ-C30 and FACT-G onto EQ-5D-5L index for patients with cancer. Health Qual Life Outcomes. 2020;18(1):354.
Lamu AN, Olsen JA. Testing alternative regression models to predict utilities: mapping the QLQ-C30 onto the EQ-5D-5L and the SF-6D. Qual Life Res. 2018;27(11):2823–39.
Wong CK, Lam CL, Rowen D, McGhee SM, Ma KP, Law WL, et al. Mapping the Functional Assessment of Cancer Therapy-general or -colorectal to SF-6D in Chinese patients with colorectal Neoplasm. Value Health. 2012;15(3):495–503.
Peiris CL, Taylor NF, Watts JJ, Shields N, Brusco NK, Mortimer D. Mapping the functional independence measure to a multi-attribute utility instrument for economic evaluations in rehabilitation: a secondary analysis of randomized controlled trial data. Disabil Rehabil. 2020;42(21):3024–32.
Abdin E, Chong SA, Seow E, Tan KB, Subramaniam M. Mapping the PHQ-8 to EQ-5D, HUI3 and SF6D in patients with depression. BMC Psychiatry. 2021;21(1):451.
Bilbao A, Martín-Fernández J, García-Pérez L, Arenaza JC, Ariza-Cardiel G, Ramallo-Fariña Y, et al. Mapping WOMAC onto the EQ-5D-5L utility index in patients with hip or knee osteoarthritis. Value Health. 2020;23(3):379–87.
Liu T, Li S, Wang M, Sun Q, Chen G. Mapping the Chinese version of the EORTC QLQ-BR53 onto the EQ-5D-5L and SF-6D utility scores. Patient. 2020;13(5):537–55.
Panchagnula S, Sun X, Montejo JD, Nouri A, Kolb L, Virojanapa J, et al. Validating the transformation of PROMIS-GH to EQ-5D in adult spine patients. J Clin Med. 2019;8(10):1506.
Xu RH, Dong D, Luo N, Wong EL, Yang R, Liu J, et al. Mapping the Haem-A-QoL to the EQ-5D-5L in patients with hemophilia. Qual Life Res. 2022;31(5):1533–44.
Martín-Fernández J, Morey-Montalvo M, Tomás-García N, Martín-Ramos E, Muñoz-García JC, Polentinos-Castro E, et al. Mapping analysis to predict EQ-5D-5 L utility values based on the Oxford hip score (OHS) and Oxford knee score (OKS) questionnaires in the Spanish population suffering from lower limb osteoarthritis. Health Qual Life Outcomes. 2020;18(1):184.
Round J, Hawton A. Statistical alchemy: conceptual validity and mapping to generate health state utility values. Pharmacoecon Open. 2017;1(4):233–9.
Erim DO, Bennett AV, Gaynes BN, Basak RS, Usinger D, Chen RC. Mapping the memorial anxiety scale for Prostate cancer to the SF-6D. Qual Life Res. 2021;30(10):2919–28.
Boland MR, van Boven JF, Kocks JW, van der Molen T, Goossens LM, Chavannes NH, et al. Mapping the clinical Chronic Obstructive Pulmonary Disease questionnaire onto generic preference-based EQ-5D values. Value Health. 2015;18(2):299–307.
Acknowledgements
Not applicable.
Funding
Foundation of Department of Science and Technology of Sichuan Province, China, Grant Number: 2020YFS0397.
Author information
Authors and Affiliations
Contributions
All authors have contributed to design of the study, the acquisition of data, and the interpretation of the results. QY and LLJ analyzed the data and involved in drafting the manuscript; YHL and DYH were involved in revising the manuscript critically for important intellectual content. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethical approval and consent to participate
The study obtained the approval by the Ethics Committee of Sichuan Cancer Hospital (reference no. SCCHEC-02-2020-042). Signed informed consent and permission to use personal health information were obtained from all participating patients.
Consent for publication
Not applicable. All results are reported as aggregated data.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Yang, Q., Jiang, L.L., Li, Y.F. et al. Prediction of the SF-6D utility score from Lung cancer FACT-L: a mapping study in China. Health Qual Life Outcomes 21, 122 (2023). https://doi.org/10.1186/s12955-023-02209-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12955-023-02209-8