
Abstract
Background
Gene Ontology (GO) is a collaborative project that maintains and develops controlled vocabulary (or terms) to describe the molecular function, biological roles and cellular location of gene products in a hierarchical ontology. GO also provides GO annotations that associate genes with GO terms. GO consortium independently and collaboratively annotate terms to gene products, mainly from model organisms (or species) they are interested in. Due to experiment ethics, research interests of biologists and resources limitations, homologous genes from different species currently are annotated with different terms. These differences can be more attributed to incomplete annotations of genes than to functional difference between them.
Results
Semantic similarity between genes is derived from GO hierarchy and annotations of genes. It is positively correlated with the similarity derived from various types of biological data and has been applied to predict gene function. In this paper, we investigate whether it is possible to replenish annotations of incompletely annotated genes by using semantic similarity between genes from two species with homology. For this investigation, we utilize three representative semantic similarity metrics to compute similarity between genes from two species. Next, we determine the k nearest neighborhood genes from the two species based on the chosen metric and then use terms annotated to k neighbors of a gene to replenish annotations of that gene. We perform experiments on archived (from Jan-2014 to Jan-2016) GO annotations of four species (Human, Mouse, Danio rerio and Arabidopsis thaliana) to assess the contribution of semantic similarity between genes from different species. The experimental results demonstrate that: (1) semantic similarity between genes from homologous species contributes much more on the improved accuracy (by 53.22%) than genes from single species alone, and genes from two species with low homology; (2) GO annotations of genes from homologous species are complementary to each other.
Conclusions
Our study shows that semantic similarity based interspecies gene function annotation from homologous species is more prominent than traditional intraspecies approaches. This work can promote more research on semantic similarity based function prediction across species.
Similar content being viewed by others

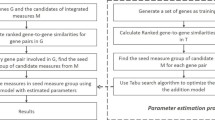
Background
Gene products, both proteins and RNAs, play crucial functions in many if not all, life processes, such as metabolism, signal transduction and hormonal regulation. Comprehensively annotating their biological functions is a crucial link in the development of drugs, vaccines, bio-chemicals and disease analysis [1–5]. However, rapidly accumulated genomic and proteomic data result in a continually expanding function-annotation gap for newly discovered genes and their products, since it is time consuming, expensive and low throughput to annotate them by wet-lab techniques. Furthermore, the experimental ethics involving human and animals, research interests of biologists and experimental techniques also bias the functional annotations of genes [6–9]. Therefore, automatically and efficiently annotating the functions of genes via computational techniques becomes one of the fundamental tasks in the post-genome era. To combat with this task, some approaches utilize amino acids and structure of proteins [10], some methods resort to protein-protein interactions [11], some other techniques take advantage of domains, motifs and pathways [12, 13]. More advanced techniques integrate multiple types of biological data or fuse predictions from multiple classifiers, which are trained on heterogeneous biological data sources [14–18].
Gene Ontology (GO) is a widely used golden standard for functional taxonomy in a species-neutral manner and it aims to unify the representation of gene products functions across different species [8, 19]. GO uses controlled vocabulary to describe terms (each term corresponds to a distinct function) and a direct acyclic graph (DAG) to capture the hierarchical relationship between ontological terms. For identification, each term is accompanied by an alphanumeric symbol (i.e., GO:0008150 (biological process)). If a gene is annotated with a term, then the gene is also annotated with its ancestor terms via any path in GO hierarchy. If a protein is not annotated with a term, the protein should also not be annotated with any of its descendant terms. This rule is recognized as true path rule [19, 20].
Gene function prediction can be viewed as a classification task with each function being viewed as a class label. In this way, various classification techniques have been applied to gene function prediction [2]. A protein engages with several different biological activities and carries out different functions. Recent techniques resort to multi-label learning [21] and correlations among functional labels for gene function prediction [13, 17, 18, 22]. Due to resources limitations, experimental protocols and priority of GO consortium, GO annotations of genes are incomplete [6–9, 23]. Given that, some approaches directly target at replenishing missing annotations of incompletely annotated genes [24–26].
Homologous species share a large portion of homologous genes and these genes have similar (or same) functional annotations. Due to research interests and particular types of experiments performed in different model organisms, homologous genes in different species are often annotated with different terms, and annotations of these genes are found to be complementary for each other [9]. Previous approaches often only use the homology information from deoxyribonucleic acid sequences, structure of proteins, pattern of interactions between genes/proteins, and domain composition to transfer annotations of annotated genes to un-annotated ones [27]. For example, Mitrofanova et al. [28] propose a Markov random field based approach to predict gene function that connects protein-protein interactions (PPI) networks of two (or more) different species by using inter-species sequence-homology information. This approach can only apply to a fixed number (≤32) of structured GO terms, and it only takes proteins annotated with these terms into account and exclude a lot of proteins not annotated with any of these terms. To overcome this issue, Benso et al. [29] firstly defined an integrated similarity between proteins using motifs and amino acids of proteins, and then used this similarity to filter out false positive interactions in PPI network. Next, they enriched the filtered PPI network by adding interactions with annotated proteins through sequence alignment, and assigned the most probable terms to a protein by the terms annotated to its interacting partners. However, it is difficult to specify a suitable threshold to filter out false positive interactions and to add uncovered interactions.
Some advanced techniques exploit the hierarchical structure of GO and characteristics of GO annotations for gene function prediction. For example, Valentini [20], Barutcuoglu et al. [22] and Cesa-Bianchi et al. [17] firstly trained a classifier for each term in the hierarchy, and then made use of ontology structure to adjust the predictions for these terms. Lord et al. [30] directly employed the patterns of GO annotations of genes to predict gene function.
Some recent approaches directly exploit semantic similarity between genes from single species to predict gene function. Semantic similarity is computed based GO annotations of genes. It is found to be positively correlated with the similarity derived from various biological data and used to predict interactions between proteins [26, 31–33]. Tao et al. [24] and Yu et al. [26] firstly selected neighborhood genes of a gene using a predefined semantic similarity, and then used the annotations of these neighbors to predict missing annotations of the gene. Given these successful applications and complementary GO annotations of genes from homologous species, however, little work has been done to investigate semantic similarity for inter-species gene function prediction.
In this paper, we investigate whether it is possible to perform inter-species gene function prediction by directly using the semantic similarity between genes from two different species, which have homology to some extent. For this purpose, we utilize several representative semantic similarity metrics (i.e., term overlap (TO) [34], best match average (BMA) [35] and simGIC [36]) to measure the semantic similarity between genes, and make use of these metrics for semantic similarity based gene function prediction. We study these metrics’ contributions on improving the accuracy of gene function prediction for two homologous species (Human and Mouse). In addition, we also include another two species, Danio rerio and Arabidopsis thaliana, which have lower homology with Human and Mouse. Our investigation discloses that, interspecies gene function prediction using semantic similarity between genes from homologous species (Human and Mouse) outperforms the counterpart based on the semantic similarity between genes from single species alone, and it also performs better than using the semantic similarity between genes from two species with low homology.
Methods
Our work is motivated by the observation that GO annotations of genes are incomplete [7, 9] and genes from homologous species should have a large portion of similar GO annotations [8, 23]. However, because of experimental ethics and protocols, and research interests of biologists, homologous genes from different species currently are only annotated with some similar GO terms, these genes are also annotated with different terms. These different annotations provide complementary functional clue for genes from another high homology species. For example, as shown in Table S1 of Additional file 1, Human hMAP4K2 (Mitogen activated protein kinase kinase kinase kinases (MAP4K) are protein kinases that participate in the MAP kinase signal transduction cascade) shares 94% sequence identity with its ortholog Map4k2 in Mouse [9]. The overlapped GO annotations of these two proteins account for 81.19% of all the available annotations of these proteins by Jan-2014. hMAP4K3, a paralog of hMAP4K2, has 76.24% overlapped annotations with hMAP4K2. As more experimental evidences available, some terms only annotated to hMAP4K2 are also annotated to Map4k2, and vice versa. By Jan-2016, as more evidences accumulated in the past two years, the overlapped annotations between hMAP4K2 and MAP4K increases to 98.11%, and that between hMAP4K2 and hMAP4K3 rises to 86.79%. GO annotations of these three proteins by Jan-2014 and Jan-2016 are listed in Table S1 of Additional file 1. In addition, the evidence sources of new overlapped annotations from Jan-2014 to Jan-2016 are provided in Table S2 of Additional file 1. These observations indicate GO annotations of homologous genes from two species with high homology are complementary for each other.
Inspired by the aforementioned observation, we want to synthesize the semantic similarity between genes from single species and from two homologous species to predict additional annotations of genes. To better explain our main idea, we provide an illustrative example in Fig. 1. We can see from Fig. 1 that both a Human gene and a Mouse gene are annotated with a set of similar terms. Both of them also lack some annotations, respectively. The Human gene should be additionally annotated with ‘GO:f’ and ‘GO:h’, and the Mouse gene should be additionally annotated with ‘GO: e’, ‘GO:g’ and ‘GO: i’. By using the semantic similarity between these two genes from Human and Mouse, we can transfer available GO annotations of the Human gene to the Mouse gene, and thus to replenish the missing annotations of the latter one. Vice versa, we can transfer annotations of the Mouse gene to the Human gene. In this way, we can replenish missing annotations of respective genes by utilizing semantic similarity and complementary GO annotations of genes across species.

GO annotations of a human gene a and a mouse gene b. GO terms in white ellipses are the currently available annotations of the gene, and the terms in the gray ellipses are the missing annotations. The human gene should be annotated with ‘GO:f’ and mouse gene missing annotations of ‘GO:e’ and ‘GO:g’. Annotations of these two genes are different but also complementary for each other
Semantic similarity
Semantic similarity has been widely studied, and various methods have been proposed for quantifying the semantic similarity between genes [32, 33]. These methods fall into rough categories of term-based and entity-based. In general, term-based approaches depend on comparing and combining pairwise terms annotated to two respective genes, while entity-based approaches rely on comparing two sets of terms, each set is associated with a gene [32]. As a node in GO DAG, each term not only includes specific properties, but also connects with other terms by edges with different relationships (is a, part of and regulates). Therefore, there are two types of measures to calculate the similarity between terms in GO, node-based and edge-based. Node-based measures rely on the information of terms themselves, their ancestors, or their descendants. These measures mainly utilize the information content, which estimates a term’s specificity by its frequency annotated to genes [37–39]. Edge-based measures are mainly based on counting the number of edges in the GO DAG between two terms. For example, Pekar et al. [40] computed the proximity between two terms by the length of path from their lowest common ancestor to the root term. Wang et al. [41] suggested a hybrid measure that determines the proximity of two terms based on the locations of these terms in GO hierarchy and the relationships with their ancestor terms.
Entity based semantic similarity metrics calculate similarity between genes by comparing two sets of terms annotated to two respective genes as a whole. Pesquita et al. [32] suggested to divide these metrics into two categories: pairwise and groupwise. Pairwise metrics integrate the proximity between pairwise terms using average [31], maximum combination and best match average (BMA) combination [42]. Groupwise metrics directly apply set, graph, or vector based measures to compute the similarity between two collections of terms. For example, Mistry and Pavlidis [34] introduced a set based metric called term overlap (TO), which takes the ratio between the number of shared annotations and minimum number of annotations of two genes. In graph-based metrics, terms annotated to a gene can be represented by a subgraph of GO DAG, and graph comparing techniques are used to measure the similarity between genes. For example, simUI takes the ratio between the number of common nodes of two subgraphs and the number of union nodes of these two subgraphs [42]. simGIC is similar to simUI, but it weights each term by information content of the term [42]. Vector-based metrics represent the associations between a gene and all terms as a vector, with each term corresponding to an entry, and then calculate similarity between genes using vector-based measures, i.e., cosine similarity.
Three representative semantic similarity metrics (TO [34], BMA and simGIC [42]) are adopted to investigate interspecies gene function prediction based on semantic similarity. BMA requires to specify the proximity between pairwise terms and simGIC needs to pre-compute the information content of a term. We choose Lin’s similarity [43] to measure the proximity of pairwise terms for its wide application and fixed scale (between 0 and 1). Lin’s similarity evaluates the proximity of two terms by the information of themselves and of their most specific common ancestor in GO hierarchy. Its formal definition is:
where t A is the most informative common ancestor of term t 1 and t 2. IC(t) is the information content of t and can be calculated as:
where p(t) is the frequency of t annotated to a gene. Tao et al. [24] and Teng et al. [44] suggested a ontology structure based manner to define the information content of t by the number of its descendants in GO hierarchy, instead of its frequency. The structure based information content IC s (t) is:
where |desct(t)| is the set of descendant GO terms of t and T is the total number of terms.
Given two genes i and j, their GO annotation sets are \(\mathcal {T}_{i}\) and \(\mathcal {T}_{j}\), respectively. BMA is given by the average proximity between each term in \(\mathcal {T}_{i}\) and its most similar term in \(\mathcal {T}_{j}\). BMA provides a good balance between the maximum and average approaches, since the latter two approaches are inherently influenced by the number of terms being combined [32]. The formal definition of BMA is:
where \(t_{1}\in {\mathcal {T}_{i}}, t_{2}\in {\mathcal {T}_{j}}\) and tsim(t 1,t 2) is the semantic similarity between t 1 and t 2. In this paper, we compute tsim(t 1,t 2) using Lin’s similarity with IC(t) defined by Eq. (2).
TO is a set-based metric [34], it is given by number of terms shared by \(\mathcal {T}_{i}\) and \(\mathcal {T}_{j}\) divided by the minimum cardinal of \(\mathcal {T}_{i}\) and \(\mathcal {T}_{j}\). Its formal definition is:
simGIC is a graph-based semantic similarity metric [25], it is given by the sum of IC(t) of each t in the intersection of \(\mathcal {T}_{i}\) and \(\mathcal {T}_{j}\), divided by the number of terms in the union of \(\mathcal {T}_{i}\) and \(\mathcal {T}_{j}\). Its formal definition is:
where IC(t) can be calculated by Eq. (3) or Eq. (4), To be different, we call simGIC based on IC s (t) in Eq. (4) as simGICs.
Gene function prediction using semantic similarity
Suppose there are two species, \(A^{s}=[{A_{1}^{s}}, {A_{2}^{s}},\cdots,A_{N_{s}}^{s}]\in \mathbb {R}^{{N_{s}}\times {T}}\)(s=1,2) be the gene-term association matrices for genes from these two species, respectively. These N s genes are annotated with T different terms. \({A_{i}^{s}}\in \mathbb {R}^{T}\) represents the associations between the i-th gene and T terms. \({A_{i}^{s}}(t)=1\) means the gene is annotated with term t, and \({A_{i}^{s}}(t)=0\) indicates that it is unknown whether the gene should be annotated with t or not.
The semantic similarity between genes is found to be positively correlated with the similarity derived from various types of genomic/proteomic data [31–33, 44, 45]. For example, amino acids sequences, gene expression profiles, protein-protein interactions. Tao et al. [24] and Yu et al. [26] computed the semantic similarity between pairwise genes from the same species and determined the k nearest neighborhood genes based on the semantic similarity, and then replenished novel annotations of a gene based on the terms annotated to its neighbors. The probability of term \(t \notin \mathcal {T}_{i}\) annotated to the i-th gene is voted as follow:
where \(\mathcal {N}_{k}(i)\) consists of k nearest neighbors of the i-th gene from the same species. From Eq. (7), we can replenish the missing annotation of the i-th gene if its neighbors, who are annotated with t. Because of resource limitations, priority of GO curators, experimental ethics and protocols, the GO annotations of its neighborhood genes from the same species may be shallow, incomplete and biased [6, 8, 9]. Equation (7) only accounts for GO annotations of genes from the same species, therefore it can only replenish some missing annotations. On the other hand, GO annotations of genes from homologous species may be annotated with more comprehensive and specific terms.
It is recognized that homologous genes from different species conserve a large portion of similar annotations [8, 9, 46]. Motivated by this fact, we resort to semantic similarity between genes from two species and to predict missing annotations of genes by transferring annotations of genes from two species, instead from single species they belonging to. In this way, if a gene has a small semantic similarity with genes from its own species, it still can have high semantic similarity with genes from another species, and these genes may be just annotated with the missing terms of that gene. Given that, we integrate GO annotations of two species and predict missing annotations of the i-th gene as below:
where \(\mathcal {N}_{k_{1}}^{1}(i)\) denotes the k 1 nearest neighborhood genes of the i-th gene from its own species, \(N_{k_{2}}^{2}(i)\) denotes the k 2 nearest neighborhood genes from another species. k 1>0, k 2>0 and k 1+k 2=k, this setting ensures neighborhood genes from two species instead from single species, and is consistent with Eq. (7). Our following experimental study shows that synergy the semantic similarity between genes from two homologous species can more accurately predict gene function than that from single species alone.
Results and discussion
Datasets and experimental setup
To comparatively study the contribution of integrating semantic similarity between genes and GO annotations of genes from two species, we conduct experiment on annotations of genes from Human and Mouse. We downloaded recent GO file [47] (access date: 2016-01-04) that contains hierarchical relationships between GO terms. These terms are organized in three sub-ontology, namely biological process (BP), cellular component (CC) and molecular functions (MF), the terms in each ontology form a DAG. We downloaded historical GO annotation (GOA) file [48] (archived date: 2014-01-20) for each species. GOA file specifies which GO terms are annotated to a given gene products, it follows a convention to annotate a gene with appropriate and as well as specific terms. These annotations are called direct annotations. We applied true path rule to annotate all the ancestor terms of direct annotations of a gene to the same gene. We then made use of these annotations to predict GO annotations of genes. Next, we updated the annotations of these genes using recent GOA files (archived date: 2016-01-04) and utilized updated annotations to assess the quality of prediction. To avoid circular prediction, annotations with evidence code ‘IEA’ (Inferred from Electronic Annotation), ‘NR’ (Not Recorded), ‘ND’ (No biological Data available), or ‘IC’ (Inferred by Curator) were excluded. Myers et al. [49] suggested that terms annotated to too few genes are hard to be validated by wet-lab experiments and of no interests to biologists. Follow this suggestion, we excluded terms annotated to no more than 3 genes in each species.
To investigate whether GO annotations from any species contribute the same for interspecies gene function prediction, we also downloaded GOA files of another two species (Danio rerio and Arabidopsis thaliana) (archived date: 2014-01-20), and processed available GO annotations of these species in the same way as Human and Mouse. The processed annotations of these four species are revealed in Table 1. From the table, we can find that a number of new annotations have been appended to genes from each species since 2014, and each gene on average is annotated with at least 4 terms.
To assess whether the semantic similarity defined by annotations of genes from two homologous species can improve the accuracy of gene function prediction than that from single species alone, we firstly compute the semantic similarity between genes from single species by a specific metric (i.e., TO, simGIC, BMA), and then employ Eq. (7) to predict functions of genes from the same species. Similarly, we also compute the semantic similarity between genes from two species using the same metric and then employ Eq. (8) to predict functions of genes from two species. To balance the contribution of genes from the same species and from another species, we set k 1=250, k 2=250 and k=500 for all the following experiments.
Evaluation metrics
Various evaluation metrics are used to assess the quality of gene function prediction [2, 25]. Since a gene is often annotated with more than one terms, we adopt three representative multi-label learning evaluation metrics [21]: MacroAvgF1, MicroAvgF1, RankLoss, and two additional metrics Fmax [2] and RAccuracy [50]. The formal definitions of these widely used metrics are detailed in Additional file 1.
To maintain consistency with other evaluation metrics, we report 1-RankLoss. Thus, similar to other metrics, the larger the value of 1-RankLoss, the better the performance is. We would like to remark that these metrics evaluate the quality of function prediction from different aspects. It is difficult for a method always performing better than another one across all these metrics.
Prediction on archived GO annotations
In this section, we conduct experiments to comparatively and quantitatively study the contribution of semantic similarity between genes from single species, from two species with high (or low) homology. Particularly, we perform intraspecies gene function prediction by computing semantic similarity between genes from Human at first. Then, we utilize annotations of k nearest neighborhood Human genes of a Human gene to replenish missing annotations of the gene as Eq. (7). Next, we use updated annotations in the recent GOA file of Human to validate the predictions. We label the intraspecies approach as H →H. For brevity, hereinafter, H is short for Human species, M is short for Mouse, D is short for Danio rerio and A is short for Arabidopsis thaliana. Similarly, we perform interspecies gene function prediction by using the same semantic similarity metric between genes from Human and another species. Then, we use the annotations of k1 nearest neighborhood genes from Human and k 2 nearest neighborhood genes from another species to predict missing annotations of a Human gene, and validate the predictions by annotations in recent GOA file of Human. We tag these interspecies approaches as M+H →H, D+H →H and A+H →H, respectively. In addition, we also direct use the GO annotations of k nearest neighborhood Mouse (Danio rerio or Arabidopsis thaliana) genes of a Human to predict the missing annotations of the Human gene. We tag this kind of approaches as M →H (D →H or A →H). Following the same protocols, we conduct similar experiments on Mouse for intraspecies and interspecies gene function prediction. The recorded experimental results under different semantic similarity metrics are reported in Table 2 (BMA) and Table 3 (TO). The results with other semantic similarities (simGIC and simGICs) are included in Table S3 and Table S4 of Additional file 1.
From these tables, we can observe that M+H →H always gets better results than H →H and M →H, irrespective of the semantic similarity metrics (TO, BMA, simGIC and simGICs). Taking evaluation metric RAccuracy in Table 2 for example, M+H →H on average improves H →H by 53.22% and M →H by 62.38%. M+H →H utilizes GO annotations of Human and Mouse to compute the semantic similarity between genes by a chosen metric, and then uses the annotations of k nearest neighborhood genes (including k 1 Human genes and k 2 Mouse genes) of a Human gene to predict annotations of the gene. In contrast, H →H only employs semantic similarity between genes from Human species, and the annotations of k nearest neighborhood Human genes of a gene to predict GO annotations of the target Human gene. M →H only utilizes the annotations of k nearest neighborhood Mouse genes of a Human gene to predict GO annotations of the target Human gene. D+H →H always outperforms D →H and A+H →H outperforms A →H. From this observation, we can say GO annotations of genes from two different species should work together for interspecies gene function prediction.
D+H →H and A+H →H follow the same procedures as M+H →H to predict GO annotations of genes from Human, except they synergy GO annotations of Danio rerio (or Arabidopsis thaliana) with those of Human. These two approaches to M+H →H. D →H and A →H follow the same protocols as M →H to predict GO annotations of genes from Human, and they are outperformed by M →H and sometimes by H →H. In actual fact, Tao et al. [24] and Yu et al. [26] also adopt similar techniques as H →H (or M →M) for intraspecies gene function prediction. From these results, we can say that interspecies gene function prediction based on semantic similarity from two species with high homology is more prominent than traditional intraspecies approaches. Compared with Mouse, Danio rerio has lower homology (about 85%) with Human, and Arabidopsis thaliana has even lower homology with Human. Given that, M+H →H performs better than D+H →H, and it performs even more better than A+H →H. D+H →H also produces better results than A+H →H. These results show that synergy GO annotations of two species with high homology contributes much more for interspecies gene function prediction than synergy GO annotations of two species with low homology.
From these tables, we can find A+H →H often produces similar (or lower) results as H →H. The cause is that Arabidopsis thaliana has the lowest homology with Human among these species. The results on Mouse give the similar observations and lead to the same conclusions. From these comparisons, we can conclude that GO annotations of two species with high homology are more complementary for each other than two species without such high homology.
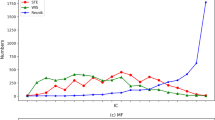
The largest improvement on RAccuracy is CC sub-ontology, followed with MF sub-ontology and then BP sub-ontology. The reason is that the number of involved GO terms and annotations in CC, MF and BP increases one by one, so the complementary effect of GO annotations across species in CC is more prominent than that in MF and BP. Another interesting observation is that, irrespective of TO, BMA, simGIC and simGICs, M+H →H obtains relatively close values for each evaluation metric under every fixed setting. This observation strengthens that our conclusions are independent of the adopted semantic similarity.
To check the difference between M+H →H and H →H, D+H →H and A+H →H based on the results in Tables 2–3 and Tables S3-S4, we use Wilcoxon signed rank test [51, 52] and find that M+H →H significantly performs better than them with p value smaller than 10−10. We perform the same test to check the difference between H+M →M, M →M, D+H →M and A+H →M. We also find H+M →M works significantly better than them with p<10−9.
To investigate the effect of GO annotations across sub-ontology, we further combine GO annotations in CC, MF and BP together for function annotation prediction using genes from single species (Human or Mouse) or from two species, and then follow the same protocol as in previous experiments to evaluate the predictions on Human (or Mouse) genes for each sub-ontology. The recorded results using semantic similarity BMA are reported in Table 4. The results using the semantic similarity TO are included in Table S4 of the Additional file 1.
From the these tables, we can find an interesting observation is that H →H in Table 4 (and Table S4) has larger values on these evaluation metrics than its counterpart in Tables 2–3 and Tables S3–S4. This observation suggests that shared GO annotations in one sub-ontology give clues of shared GO annotations in another sub-ontology. That is because the molecular function, biological roles and cellular location of gene products have some correlations. For this reason, the improvement between M+H →H and H →H is smaller than that in Tables 2–3. One exceptional observation is that MacroAvgF1 is significantly reduced in CC and MF sub-ontology in Table 4. The reason is that BP sub-ontology have more general terms than that other sub-ontology. These general BP terms are annotated to much more genes than specific (or sparse) terms, so they often rank ahead of the terms in CC and MF sub-ontology, and are more likely being predicted as missing annotations of a gene by Eq. (7) or (Eq. (8)).
Overall, M+H →H significantly outperforms H →H and M →H, and H+M →M works much better than M →M and H →M, by Wilcoxon signed rank test with p<10−10. These superior results again corroborate the effectiveness of semantic similarity based interspecies gene function prediction by synergy GO annotations of genes from homologous species.
To further study that GO annotations of genes from two species with high homology are more complementary for each other than two species without such high homology, we conduct additional experiments on annotations of Yeast, Fly and Human using the similar protocol as in previous experiments. The results under different semantic similarity metrics are include in Tables S10(TO) and Table S11(BMA) of Additional file 1. From these tables, we can observe that F+Y →Y and Y+F →F always achieve better result than H+F →F and H+Y →Y, since Fly and Yeast share larger homology than that between Human. In summary, these comparative studies further confirm that it is more prominent to perform semantic similarity based interspecies gene function prediction across species with high homology than that with low homology.
Prediction on simulated missing annotations
In this section, we perform simulated experiments by randomly masking a fixed number (q=1, 2, 3) annotations of a gene, and take these masked annotations as missing annotations of the gene. Next, we follow the similar procedure as in the previous experiments to replenish these missing annotations. From Fig. 1, we can see the terms annotated to a gene form a hierarchy by themselves. In the masking process, any leaf term in the hierarchy can be masked (or removed), once the descendant terms of a non-leaf term are all masked, then itself can also be masked. All these masked terms are viewed as simulated missing annotations of the gene. To avoid random effect of masked GO annotations, we repeat the experiments 10 times for each setting of q. The results (average of 10 independent repetitions and the standard deviation) are reported in Table 5 using semantic similarity BMA in CC sub-ontology and Table 6 in MF sub-ontology. Additional results with respect to other semantic similarities between genes are included in Tables S5–S9 of the Additional file 1. In these tables, the results in bold font are statistically better than their counterparts, according to pairwise t-test at 95% significance level.
From these tables, we can see M+H →H also achieves better results than H →H, and H+M →M outperforms M →M, irrespective of the sub-ontology, the setting value of q and the adopted semantic similarity. These results again support our motivation to synergy GO annotations and semantic similarity between genes from two homologous species, instead from single species. The improvement of M+H →H to H →H is more obvious than that on archived GO annotations as reported in the previous section. The cause is that the actual missing annotations of a gene often correspond to descents of several (or only one) terms annotated to the gene, instead of all the terms [26]. In contrast, our simulated experiment equally masks all leaf terms in the self-formed hierarchy of the gene. From the self-formed hierarchy of a gene and true path rule, we can see the masked terms of a gene are corresponding to specific terms, which are annotated to fewer genes than their ancestor terms. MacroAvgF1 is biased toward specific terms, MicroAvgF1 is biased toward non-specific terms, so the improvement of MicroAvgF1 is more significant than that of MacroAvgF1 in the simulated experiments.
In the end, we have to remark that GO annotations of gene products in recent GOA files are still not complete, all the reported results are conservative, since a predicted annotation not appear in the GOA file should not simply be taken as a false positive prediction. This predicted annotation may be lack of experimental evidences, or not curated by GO consortium, and thus it is not included into the GOA file by now. We also want to note that the studied semantic similarity based interspecies gene function prediction can only apply to genes with some annotations. Similar to other techniques, interspecies gene function prediction may result in over-annotated terms to genes. One possible way to mitigate this issue is to integrate with more biological data and work together with other techniques [53–55]. Synergy multiple types of biological data from different species, ontology hierarchy and semantic similarity to further boost the performance of interspecies gene function prediction is an interesting future pursue. We believe our work can prompt more work on semantic similarity based gene function prediction across species, especially for the species with high homology.
Conclusions
In this paper, we investigate the possibility of predicting GO annotations of gene products across species using semantic similarity between genes. For this purpose, we adopt three widely used semantic similarity metrics and collect GO annotations of four species (Human, Mouse, Danio rerio and Arabidopsis thaliana). Our extensive experimental results show that interspecies gene function prediction using GO annotations of two highly homologous species is more prominent than that of two species without such high homology. Our investigation shows GO annotations of two homologous species are complementary for each other. However, for two species with low homology, it is not helpful to synergy their GO annotations for interspecies gene function prediction.
There are several avenues for future work. Adaptive setting k 1 and k 2 can further improve the accuracy of interspecies gene function prediction. Synergy the semantic similarity with other biological data can enhance functional association coherency between genes and thus to boost the prediction accuracy. Designing more advanced semantic similarity metric that takes into account incomplete and shallow annotations of genes is another interesting future pursue.
References
Roberts RJ. Identifying protein function-a call for community action. PLoS Biol. 2004; 2(3):293–4.
Radivojac P, Clark WT, Oron TR, Schnoes AM, Wittkop T, Sokolov A, Graim K, Funk C, Verspoor K, Ben-Hur A. A large-scale evaluation of computational protein function prediction. Nat Methods. 2013; 10(3):221–7.
Zou Q, Li J, Hong Q, Lin Z, Wu Y, Shi H, Ying J. Prediction of microrna-disease associations based on social network analysis methods. Biomed Res Int. 2014; 2015(10):1–9.
Zou Q, Li J, Wang C, Zeng X. Approaches for recognizing disease genes based on network. Biomed Res Int. 2014; 2014(5013):416323–16323.
Zeng X, Zhang X, Zou Q. Integrative approaches for predicting microrna function and prioritizing disease-related microrna using biological interaction networks. Brief Bioinform. 2015; 17(2):193–203.
Alexandra MS, David CR, Alexander WT, Patricia CB, Iddo F. Biases in the experimental annotations of protein function and their effect on our understanding of protein function space. PLoS Comput Biol. 2013; 9(5):1003063.
Rhee SY, Wood V, Dolinski K, Draghici S. Use and misuse of the gene ontology annotations. Nat Rev Genet. 2008; 9(7):509–15.
Consortium GO. The gene ontology’s reference genome project: A unified framework for functional annotation across species. PLoS Comput Biol. 2009; 5(7):1000431.
Thomas PD, Wood V, Mungall CJ, Lewis SE, Blake JA, Consortium GO. On the use of gene ontology annotations to assess functional similarity among orthologs and paralogs: A short report. PLoS Comput Biol. 2012; 8(2):1454–1459.
Lee D, Redfern O, Orengo C. Predicting protein function from sequence and structure. Nat Rev Mol Cell Biol. 2007; 8(12):995–1005.
Sharan R, Igor U, Shamir R. Network-based prediction of protein function. Molecular Systems Biology. 2007; 3(1):88.
Cao M, Pietras CM, Feng X, Doroschak KJ, Schaffner T, Park J, Zhang H, Cowen LJ, Hescott BJ. New directions for diffusion-based network prediction of protein function: incorporating pathways with confidence. Bioinformatics. 2014; 30(12):219–27.
Wu J, Huang SJ, Zhou Z. Genome-wide protein function prediction through multi-instance multi-label learning. IEEE/ACM Trans Comput Biol Bioinforma. 2014; 11(5):891–902.
Mostafavi S, Morris Q. Fast integration of heterogeneous data sources for predicting gene function with limited annotation. Bioinformatics. 2010; 26(14):1759–1765.
Yu G, Zhu H, Domeniconi C, Guo M. Integrating multiple networks for protein function prediction. BMC Syst Biol. 2015; 9(1):3.
Yu G, Rangwala H, Domeniconi C, Zhang G, Zhang Z. Predicting protein function using multiple kernels. IEEE/ACM Trans Comput Biol Bioinforma. 2015; 12(1):219–33.
Cesa-Bianchi N, Re M, Valentini G. Synergy of multi-label hierarchical ensembles, data fusion, and cost-sensitive methods for gene functional inference. Mach Learn. 2012; 88(1):209–41.
Yu G, Rangwala H, Domeniconi C, Zhang G, Yu Z. Protein function prediction using multilabel ensemble classification. IEEE/ACM Trans Comput Biol Bioinforma. 2013; 10(1):1045–1057.
Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, Davis AP, Dolinski K, Dwight SS, Eppig JT, et al. Gene ontology: tool for the unification of biology. Nat Genet. 2000; 25(1):25–9.
Valentini G. True path rule hierarchical ensembles for genome-wide gene function prediction. IEEE/ACM Trans Comput Biol Bioinforma. 2011; 8(3):832–47.
Zhang ML, Zhou ZH. A review on multi-label learning algorithms. IEEE Trans Knowl Data Eng. 2014; 26(8):1819–1837.
Barutcuoglu Z, Schapire RE, Troyanskaya OG. Hierarchical multi-label prediction of gene function. Bioinformatics. 2006; 22(7):830–6.
Legrain P, Aebersold R, Archakov A, Bairoch A, Bala K, Beretta L, Bergeron J, Borchers C, Corthals GL, Costello CE. The human proteome project: Current state and future direction. Mol Cell Proteome. 2011; 10(7):111–009993.
Tao Y, Sam L, Li J, Friedman C, Lussier YA. Information theory applied to the sparse gene ontology annotation network to predict novel gene function. Bioinformatics. 2007; 23(13):529–38.
Yu G, Zhu H, Domeniconi C. Predicting protein functions using incomplete hierarchical labels. BMC Bioinforma. 2015; 16(16):1.
Yu G, Zhu H, Domeniconi C, Liu J. Predicting protein function via downward random walks on a gene ontology. BMC Bioinforma. 2015; 16(1):217.
Loewenstein Y, Raimondo D, Redfern OC, Watson J, Frishman D, Linial M, Orengo C, Thornton J, Tramontano A. Protein function annotation by homology-based inference. Genome Biol. 2009; 10(2):207.
Mitrofanova A, Pavlovic V, Mishra B. Prediction of protein functions with gene ontology and interspecies protein homology data. IEEE/ACM Trans Comput Biol Bioinforma. 2011; 8(3):775–84.
Benso A, Carlo SD, Rehman HU, Politano G, Savino A, Suravajhala P. A combined approach for genome wide protein function annotation/prediction. Proteome Sci. 2013; 11(1):1.
King OD, Foulger RE, Dwight SS, White JV, Roth FP. Predicting gene function from patterns of annotation. Genome Res. 2003; 13(5):896–904.
Lord PW, Stevens RD, Brass A, Goble CA. Investigating semantic similarity measures across the gene ontology: the relationship between sequence and annotation. Bioinformatics. 2003; 19(10):1275–1283.
Pesquita C, Faria D, Falcao AO, Lord P, Couto FM. Semantic similarity in biomedical ontologies. PLoS Comput Biol. 2009; 5(7):1000443.
Guzzi PH, Mina M, Guerra C, Cannataro M. Semantic similarity analysis of protein data: assessment with biological features and issues. Brief Bioinforma. 2012; 13(5):569–85.
Mistry M, Pavlidis P. Gene ontology term overlap as a measure of gene functional similarity. BMC Bioinforma. 2008; 9(15):327.
Schlicker A, Domingues FS, Rahnenfuhrer J, Lengauer T. A new measure for functional similarity of gene products based on gene ontology. BMC Bioinforma. 2006; 7(1):302.
Sevilla JL, Segura V, Podhorski A, Guruceaga E, Mato JM, Martinezcruz LA, Corrales FJ, Rubio A. Correlation between gene expression and go semantic similarity. IEEE/ACM Trans Comput Biol Bioinforma. 2005; 2(4):330–8.
Jiang JJ, Conrath DW. Semantic similarity based on corpus statistics and lexical taxonomy. In: Proceedings of International Conference on Research in Computational Linguistics. Taiwan: 1997. p. 11512–11520.
Rada R, Mili H, Bicknell E, Blettner M. Development and application of a metric on semantic nets. IEEE Trans Syst Man Cybern. 1989; 19(1):17–30.
Wu Z, Palmer M. Verb semantics and lexical selection. In: Proceedings of Annual Meeting on Association for Computational Linguistics. New Mexico: Las Cruces: 1994. p. 133–8.
Pekar V, Staab S. Taxonomy learning: factoring the structure of a taxonomy into a semantic classification decision. In: International Conference on Computational Linguistics. Taiwan: 2002.
Wang JZ, Du Z, Payattakool R, Philip SY, Chen CF. A new method to measure the semantic similarity of go terms. Bioinformatics. 2007; 23(10):1274–1281.
Pesquita C, Faria D, Bastos H, Ferreira AE, Falcao AO, Couto FM. Metrics for go based protein semantic similarity: a systematic evaluation. BMC Bioinforma. 2008; 9(S5):4.
Lin D. An information-theoretic definition of similarity. In: In Proceedings of 15th International Conference on Machine Learning. Madison: 1998. p. 296–304.
Teng Z, Guo M, Liu X, Dai Q, Wang C, Xuan P. Measuring gene functional similarity based on group-wise comparison of go terms. Bioinformatics. 2013; 29(11):1424–1432.
Yang H, Nepusz T, Paccanaro A. Improving go semantic similarity measures by exploring the ontology beneath the terms and modelling uncertainty. Bioinformatics. 2012; 28(10):1383–1389.
Hahn MW. Distinguishing among evolutionary models for the maintenance of gene duplicates. J Hered. 2009; 100(5):605–17.
The gene ontology database. http://geneontology.org/page/download-ontology. Accessed 4 Jan 2016.
The gene ontology annotation files. http://geneontology.org/page/download-annotations. Accessed 20 Jan 2014.
Myers CL, Barrett DR, Hibbs MA, Huttenhower C, Troyanskaya OG. Finding function: evaluation methods for functional genomic data. BMC Genomics. 2006; 7(10):187.
Yu G, Domeniconi C, Rangwala H, Zhang G. Protein function prediction using dependence maximization. In: European Conference on Machine Learning and Knowledge Discovery in Databases: 2013. p. 574–89.
Wilcoxon L. Individual comparison by ranking methods. Biometrics. 1945; 1(6):80–3.
Demsar J. Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res. 2006; 7(1):1–30.
Holzinger A, Schantl J, Schroettner M, Seifert S, Verspoor K. Biomedical text mining: state-of-the-art, open problems and future challenges. In: Interactive Knowledge Discovery and Data Mining in Biomedical Informatics. Berlin: Springer: 2014. p. 271–300.
Couto FM, Silva MJ, Lee V, Dimmer E, Camon E, Apweiler R, Harald K, Dietrich RS. Goannotator: linking protein go annotations to evidence text. J Biomed Discov Collab. 2006; 1(19):1–6.
Good BM, Clarke EL, Alfaro LD, Su AI. The gene wiki in 2011: Community intelligence applied to human gene annotation. Nucleic Acids Res. 2011; 40(1):1255–1261.
Acknowledgements
We appreciate the comments from anonymous reviewers for improving our work. This work is supported by Natural Science Foundation of China (61402378), Natural Science Foundation of CQ CSTC (cstc2014jcyjA40031 and cstc2016jcyjA0351), Fundamental Research Funds for the Central Universities of China (2362015XK07, XDJK2016B009 and XDJK2016D021) and Chongqing Graduate Student Research Innovation Project (CYS16070).
Declarations
Publication costs for this article was funded by the corresponding author. This article has been published as part of BMC Systems Biology Volume 10 Supplement 4, 2016: Proceedings of the 27th International Conference on Genome Informatics: systems biology. The full contents of the supplement are available online at http://bmcsystbiol.biomedcentral.com/articles/supplements/volume-10-supplement-4.
Authors’ contributions
GY proposed the idea, conceived the whole process, drafted and finalized the manuscript, WL and GF performed the experiments, JW participated in results analysis and revised the manuscript. All the authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Additional information
From The 27th International Conference on Genome Informatics Shanghai, China. 3-5 October 2016
Additional file
Additional file 1
Supplementary file of ‘Interspecies gene function prediction using semantic similarity’. This PDF file includes achieved GO annotations of hMAP4K2, hMAP4K2 and Map4k2 from Jan-2014 to Jan-2016, definition of evaluation metrics, and additional experimental results mentioned in the main text.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver(http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Yu, G., Luo, W., Fu, G. et al. Interspecies gene function prediction using semantic similarity. BMC Syst Biol 10 (Suppl 4), 121 (2016). https://doi.org/10.1186/s12918-016-0361-5
Published:
DOI: https://doi.org/10.1186/s12918-016-0361-5