
Abstract
Background
NorQ, a member of the MoxR-class of AAA+ ATPases, and NorD, a protein containing a Von Willebrand Factor Type A (VWA) domain, are essential for non-heme iron (FeB) cofactor insertion into cytochrome c-dependent nitric oxide reductase (cNOR). cNOR catalyzes NO reduction, a key step of bacterial denitrification. This work aimed at elucidating the specific mechanism of NorQD-catalyzed FeB insertion, and the general mechanism of the MoxR/VWA interacting protein families.
Results
We show that NorQ-catalyzed ATP hydrolysis, an intact VWA domain in NorD, and specific surface carboxylates on cNOR are all features required for cNOR activation. Supported by BN-PAGE, low-resolution cryo-EM structures of NorQ and the NorQD complex show that NorQ forms a circular hexamer with a monomer of NorD binding both to the side and to the central pore of the NorQ ring. Guided by AlphaFold predictions, we assign the density that “plugs” the NorQ ring pore to the VWA domain of NorD with a protruding “finger” inserting through the pore and suggest this binding mode to be general for MoxR/VWA couples.
Conclusions
Based on our results, we present a tentative model for the mechanism of NorQD-catalyzed cNOR remodeling and suggest many of its features to be applicable to the whole MoxR/VWA family.
Similar content being viewed by others

Background
Metalloproteins constitute at least 30% of all known proteins and are used for a multitude of important functions in the cell, such as oxygen binding and transport, catalysis, and electron-transfer chemistry. In many cases, the metal cofactors are inserted by dedicated chaperones during assembly of the metalloproteins [1]. The bacterial MoxR proteins are involved in a variety of such cofactor assembly/re-organization processes and their detailed mechanism of action is poorly understood. We recently showed that the MoxR protein NorQ from Paracoccus (P.) denitrificans is, together with NorD, its partner protein, essential for the insertion of the FeB cofactor into the nitric oxide reductase (NOR) protein [2]. Cytochrome (cyt.) c-dependent nitric oxide reductase (cNOR) is a two-subunit (NorCB) membrane protein complex, which catalyzes the reduction of toxic NO to N2O (2NO + 2e− + 2H+ ➔ N2O + H2O). This enzyme forms part of the bacterial denitrification chain, which involves the stepwise reduction of NO3− to N2. cNOR is related to the terminal oxidases of aerobic respiratory chains, including mitochondrial cytochrome c oxidase, as it belongs to the same superfamily of heme-copper oxidases (HCuOs) [3, 4], where cNORs form their own subfamily. The catalytic subunit NorB is an integral membrane protein that contains a low-spin heme b, a high-spin heme b3, and a non-heme iron FeB. Heme b3 and FeB form the binuclear active site and are spin-coupled via a μ-oxo bridge [5,6,7]. The NorC subunit, which is a c-cytochrome, is membrane-anchored by one helix and has a soluble domain in the periplasm. The cNOR structure also contains a calcium ion, bound at the interface of NorB and NorC [5]. Protons and electrons needed for NO reduction are taken up from the periplasm, which is why the reaction catalyzed by cNOR is non-electrogenic [8, 9], in contrast to the proton-pumping O2-reducing HCuOs.
A set of specific chaperones is needed for assembly of the O2-reducing HCuOs. This includes the insertion of heme groups and copper cofactors, e.g., copper insertion into the Rhodobacter (R.) sphaeroides aa3 oxidase (an A-type HCuO, for a description of subfamilies, see [10]) is facilitated by PCuAC, PrrC, and Cox11, and heme a3 insertion depends on Surf1p [11, 12]. In R. capsulatus, the insertion of CuB into cbb3 oxidase (a C-type HCuO) was shown to rely on similar copper-binding proteins [13]. However, only little is known about the assembly and cofactor insertion process of the NOR subfamily.
The nor operon of Paracoccus (P.) denitrificans comprises six genes (norCBQDEF) [14], but only norC and norB are coding for proteins present in the cNOR complex [5, 15, 16]. Mutational analysis supports the idea that norQ and norD are cooperatively involved in activation of cNOR on the protein level [14, 17, 18]. Recently, we reported that cNOR expressed in the absence of norQDEF forms a stable NorCB dimer that is fully hemylated but lacks the FeB cofactor and is therefore inactive. We further showed that the NorQ and NorD specifically act as chaperones involved in FeB insertion [2, 19]. In contrast, the homologous quinol-oxidizing qNOR, expressed from a single gene norZ, does not require any additional genes for FeB insertion and activity [17].
NorQ is a member of the large MoxR protein subfamily of bacterial AAA+ ATPases [20, 21]. AAA+ ATPases have diverse functions in the cell and are present in all three domains of life [22, 23]. AAA+ proteins are molecular motors that typically assemble as hexameric rings and share a function in remodeling and/or unfolding macromolecules. AAA+ proteins were classified into seven different clades based on evolutionary lineage and structural insertions (see [23, 24] for recent reviews), where the MoxR proteins belong to clade 7 which also contains, e.g., the dynein families and has the helix 2 insert (H2I). Recently though, this classification was challenged [24] since the cryo-EM “boom” in structural information shows that, e.g., the hexameric CbbQ, a clade 7 MoxR protein closely related to NorQ, structurally resembles the clade 6 McrB hexamer involved in DNA cleavage [25, 26] more than it resembles the hexameric assembly of the MoxR protein RavA [27]. The MoxR AAA+ proteins are among the least studied families of AAA+ proteins, but it has been speculated that they primarily act as molecular chaperones involved in metal cofactor insertion or other remodeling events [21].
NorQ (Fig. 1) consists of a single AAA+ module, which contains several conserved motifs, such as the Walker A and Walker B (WB) motif, which promote nucleotide binding and hydrolysis, respectively. The Walker A motif contains a critical lysine that stabilizes ATP binding, and the Walker B motif contains a conserved aspartate for binding of Mg2+ followed by a catalytic glutamate essential for ATP hydrolysis. In most AAA+ proteins, the ATP binding site is located at the interface between protomers with a conserved Arg finger acting in trans, making the AAA+ ATPase functional only in its multimeric state. The mechanistic sequence of AAA+ protein function is not fully understood but often involves an asymmetric organization of protomers in different nucleotide-bound states in the ring oligomer [28].

Schematic domain architecture of NorQ and NorD. NorQ is a single AAA+ ATPase module that consists of the large α/β subdomain (light blue) and the C-terminal all-α subdomain (dark blue). The conserved motifs of the AAA+ module are marked (purple): Walker A (WA), H2I (helix 2 insert), Walker B (WB), sensor I (SI), arginine finger (R), and sensor II (SII). NorD consists of a N-terminal domain (green) and a C-terminal Von Willebrand Factor A domain (VWA, yellow), connected via a disordered linker (see text). The conserved putative metal ion-dependent adhesion site (MIDAS) residues (red) are marked. For the predicted “finger”, see text
NorD (Fig. 1) is a 70-kDa protein that contains a 33-kDa C-terminal Von Willebrand Factor Type A (VWA) domain. VWA domains are believed to generally function by mediating metal ion-dependent protein-protein interactions [29]. Within the VWA domain, the MIDAS (metal ion-dependent adhesion site) motif (DxSxS-T-D) is involved in coordinating a divalent metal ion (often Mg2+). A sixth ligand of the coordination sphere is an acidic surface residue donated by the interacting target protein, thereby stabilizing the protein-protein interaction [29]. The protein sequence preceding the VWA domain in NorD shows no obvious homology to any other proteins in the databases. NorQ and NorD are most likely cytosolic proteins since they lack signal peptides.
Often, MoxR proteins genetically pair with VWA-carrying proteins (as for norQD), suggesting a functional relation [20]. MoxR AAA+/VWA interactions have been established for the RavA/ViaA couple interacting with fumarate reductase in E. coli [30] and the CbbQ/CbbO couple involved in RuBisCO activation in multiple bacteria [31], where ViaA and CbbO carry C-terminal VWA domains.
In this work, we established the expression and purification of the NorQ and the NorQD complex and investigated their functional and structural properties. We also identified the binding site for the NorQD complex on the surface of the cNOR target protein. Our data shed light on the FeB insertion mechanism for cNOR activation specifically and the structure-function relationships in the MoxR proteins and their binding to VWA-containing partner proteins in general.
Results
Expression and purification of the NorQ and NorD proteins
The wildtype 6-His-tagged NorQ protein was purified from E. coli (Fig. 2a) at a yield of ~40 mg/L culture. The Walker A (WA) variant of NorQ (K48A) was expressed but prone to precipitation and was not purified. The Walker B (WB) variant of NorQ (NorQWB, E109Q) expressed similarly to wildtype.

SDS-PAGE and Blue NativePAGE for NorQ and NorQWB. a SDS-PAGE of the purification process of NorQ. Lane 1: Cytosolic suspension. Lane 2: flow-through from Ni-NTA. Lane 3: Wash with 150–250 mM imidazole. Lane 4: Elution with a 250–500 mM imidazole gradient. b BN-PAGE of NorQ (14 μg) and NorQWB (18 μg), supplemented with 2 mM ATP and 20 mM MgCl2. The expected locations of several oligomeric states of NorQ are indicated. Original gel in Additional file 2
BN-PAGE and SEC analysis (Fig. 2b, Additional file 1: Fig. S1) showed that the NorQ protein forms multiple oligomeric states with sizes ranging from 30 kDa (monomer) to ~180 kDa (hexamer, more clearly observed in the NorQWB, Fig. 2b) with trimers, tetramers, and pentamers also clearly present. The addition of ATP to the BN-PAGE experiments showed a clear shifting of the oligomerization state to the hexamer (Fig. 2b) for the NorQWB, presumably linked to its loss of ATPase activity (see below).
The NorD protein could not be expressed in the absence of NorQ, most likely due to low solubility of the protein. Co-expression of 6-His-tagged NorD and untagged NorQ led to purification of the NorQD via affinity chromatography (Fig. 3a). The identity of NorQ and NorD on SDS-PAGE was confirmed by mass spectrometry analysis of excised protein bands (see Additional file 1: Table S1).

SDS-PAGE and Blue NativePAGE for NorQD and NorQWBD. a SDS-PAGE of gradient-purified NorQD and NorQWBD (~2 μg protein per lane). Original gel in Additional file 3. b Blue NativePAGE of NorQWBD (~10 μg protein per lane). Original gel in Additional file 2. c Second dimension SDS-PAGE of individual bands of the Blue NativePAGE gel (panel b). The bands were visualized by silver staining and are labeled as identified by mass spectrometry (see Additional file 1: Table S1). Original gel in Additional file 3
The purified protein complex was prone to precipitate when concentrated, when kept at temperatures > 4 °C or with increasing number of freeze/thaw cycles. This is possibly related to the intrinsic property of NorQ to oligomerize and of the VWA domain in NorD to promote metal ion-dependent interactions. Proteins homologous to NorQ and NorD were also found prone to aggregate [31, 32]. The NorQWBD complex was generally better expressed and less prone to precipitation than the WT NorQD complex and band patterns on SDS-PAGE were very similar for both (Fig. 3a). BN-PAGE and SEC analysis (Fig. 3b, Additional file 1: Fig. S1b) showed that the NorQD proteins form multiple oligomeric states with sizes ranging from ~300 to ~30 kDa (presumably monomeric NorQ). Band size distribution shifted in the presence of ATP (Fig. 3b, Additional file 1: Fig. S1b).
A second dimension SDS-PAGE for bands excised from the BN-PAGE and mass-spec analysis (Fig. 3c, Additional file 1: Table S1) showed that the 310-kDa band in the NorQWBD preparation most clearly contained both NorD (70 kDa) and NorQ (30 kDa). This band size is consistent with a hexameric NorQ (6×30 kDa) bound to a monomer (or possibly dimer) of NorD (1×70 kDa). After addition of ATP, this band distributes to lower molecular weights (180–230 kDa) consistent with a trimer to hexamer of NorQ bound to a monomer of NorD (Fig. 3b).
Mutation of the conserved MIDAS residues in the VWA domain of NorD (T534V or D562N, see sequence alignment in Additional file 1: Fig. S2) still allowed co-purification of NorQ (Additional file 3: panel d), indicating that the NorQ-NorD interaction site does not involve this protein region.
Single particle cryo-EM
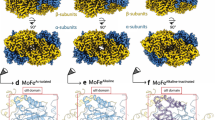
Because of the higher solubility of NorQWB, this variant was used for all cryo-EM work. 2D classification of NorQWB included about 42,000 particles (from a total number of about 130,000 picked particles) and showed various views (Additional file 1: Fig. S3). Initial models were calculated with and without 6-fold symmetry applied (Fig. 4a). The C1 ab initio models showed open ring and asymmetric ring assemblies of NorQWB. After 3D classification, refinement yielded two maps, one processed always in C1 and one processed in C6, but for which symmetry was relaxed to C1 at later stages (Fig. 4b). 3D maps processed in C6 tended to give a higher nominal resolution (~8 Å) compared with models without symmetry constraints (~11 Å) but not enough to justify the existence of a fully 6-fold symmetric assembly.

Ab initio models (a) and refined models (b) of NorQWB. a Two different ab initio models in C1 (blue models) and another two initial models in C6 (gray models) are shown. b A refined model processed in C1 is shown in blue. Another model which was refined using C6 constraints and then symmetry relaxed to C1 is shown in gray
Refinement of a C6 structure subpopulation of NorQWB (~30,000 particles) yielded a nominal resolution of ~8 Å (Fig. 5). A rigid body fit of the crystal structure of the homologous csoCbbQ from Halothiobacillus (H.) neapolitanus (PDB: 5C3C [33, 34], 49% sequence identity) as well as the recently solved structure of AfCbbQ2 from Acidithiobacillus ferrooxidans [25] with 53% sequence identity (PDB: 6L1Q ( [25, 35]) was found to match the 3D map of NorQWB (Fig. 5) relatively well. The AfCbbQ2 structure resolved for the first time the H2I region (residue 79-93 in the alignment in Additional file 1: Fig. S4a) of CbbQ, and this region is resolved also partially in our 8Å NorQ structure (Fig. 5b). The residues discussed in the text as well as the monomer/monomer interaction surface in the NorQ hexamer are highlighted in the NorQ homology model in Additional file 1: Fig. S4bc.

Refined 3D model of NorQWB. The cryo-EM map at ~8 Å (gray surface) and the rigid body fit of the NorQ homology model based on the AfCbbQ2 crystal structure (PDB: 6L1Q [25]) is shown. a Within the NorQ hexamer (blue) one protomer is highlighted in pink. b The H2Is from all subunits protruding at the convex side of the hexamer are shown in yellow
We further investigated the NorQWB in complex with NorD to gather additional information about the stoichiometry of the NorQWBD. 2D class averages from a subset of about 500,000 clean particles of NorQWBD were found to be consistent with a hexameric, ring-shaped oligomer. Most classes show an additional “comma-like” density in close proximity to the ring (Fig. 6a). Because of strong preferred particle orientation, while up to 3Å resolution was achievable in one direction, it was possible to determine an isotropic map only at 10Å. This low-resolution 3D map shows the presence of an asymmetric hexamer of NorQWB with density for NorD acting like a plug inserted in the middle of the hexameric ring (Fig. 6b). The “comma” to the side of the ring was not present in the refined model, presumably because of flexibility or conformational variability (see below and “Discussion”).

NorQWBD complex in cryo-EM. a Representative 2D class averages, with the “comma” visible to the side of the ring marked with arrows. b Refined cryo-EM 3D map at ~10 Å. Shown is also the modeled NorQ hexameric ring with the protomers labeled A–F (see text). Cryo-EM samples contained 1 mg/mL protein in 10 mM TRIS/HCl, pH 8, 150 mM NaCl, and 10% glycerol
Model building
In order to fit the extra unassigned cryo-EM density to NorD, we first predicted its structure using the recently developed tool AlphaFold [36] (AF), see Fig. 7a. The NorD prediction shows two well folded domains separated by a non-structured region, also predicted by conventional tools (see Additional file 1: Fig. S5) to be disordered. The prediction also shows a new feature not observed nor modeled previously in the VWA domain of NorD or in other VWA domain-containing proteins that partner with MoxR AAA+ proteins (Additional file 1: Fig. S6). This new feature is a “finger,” stabilized by a β-sheet, that sticks out of the VWA globular domain. We suggest this “finger” binds in the hexameric AAA+ central pore, which would position the MIDAS residues of the VWA domain “on top” of the ring (see below and “Discussion”).

Single-chain and multimer models of NorD and NorQ using AlphaFold. a Prediction of full-length NorD (Uniprot: Q51665) showing the N-terminal domain (gray), disordered region (yellow), and VWA domain (pink) with the MIDAS residues in red. b Multimer model of one NorD and one NorQ (blue, Uniprot: Q51663). Coloration of NorD is as in a). c Multimer model of one NorQ, the N-terminal domain of NorD (gray, residues 1-224) and the NorD VWA domain (pink, 336-638, MIDAS in red). d Multimer prediction with six chains of NorQ (alternating blue and cyan) and one NorD VWA domain (pink)
For predicting different versions of a complex between NorQ and NorD, we used AlphaFold-multimer [37]. We built a complete complex of 6 NorQ chains and one NorD chain. This complex consistently put the VWA domain of NorD in the center of a hexameric ring of NorQ (see Additional file 1: Fig. S7). The predicted TM score (pTM, see “Methods”) for this model is 0.41, indicating that it is of limited confidence (see Additional file 1: Table S2 for pTM scores for all models shown). We also modeled a complex of the 6 NorQ monomers (forming a hexamer) with only the VWA domain of NorD (Fig. 7d). The pTM for these models are 0.45–0.52, somewhat higher than for the full complex. To obtain a better picture of the interaction between NorD and NorQ, we also modeled a NorQ monomer-NorD monomer complex (Fig. 7b, pTM significantly higher at 0.7). We also modeled this complex without the disordered domain of NorD, i.e., the dimer was modeled as a trimer with the NorD N-terminal domain, the NorD (C-terminal) VWA domain, and the entire NorQ chain (Fig. 7c, pTM scores 0.63–0.74, similar to the full monomer-monomer complex). This model was then used for fitting into the EM density.
We generated a hexameric NorQ model to fit into the cryo-EM density (Fig. 6b) based on the hexameric asymmetric structure of the AAA+ protein ClpX (PDB:6SFW) [38, 39], by superimposing the AF NorQ monomer onto each of the ClpX protomers. The rationale behind is the rough placement of the NorQ protomers in the AAA+ ring with the seam subunit (protomer A) displaced (Fig. 6b). Even at this resolution, it is in fact clear that the NorQ ring is not perfectly symmetric similarly to many other AAA+ structures (see, e.g., also the McrBC complex (PDB: 6HZ4 and 6UT6) [26, 40,41,42]). We assume that the observed density plugged into the NorQ ring center is the VWA domain of NorD, based also on the observation of analogous low-resolution densities for the MoxR-VWA complex CbbQ-CbbO [25, 31] where the VWA domain was identified as the density bound to the pore of the ring. The NorQ-NorD AF model (Fig. 7c, omitting the N-terminal domain of NorD) was thus overlaid onto the NorQ ring protomer that would give the least of clashes, thus obtaining a full 6NorQ-NorD VWA domain model. This overall binding topology with the VWA domain of NorD inserted into the NorQ pore was also supported by the AF prediction shown in Fig. 7d. The 6NorQ-NorD model was flexibly fitted into the cryo-EM map using iMODFIT [43]. The resulting 6NorQ-NorD model (Fig. 8a–c and see Additional file 1: Fig. S8 for comparison to the NorQ6VWA model) is qualitatively consistent with the data. However, the model does not perfectly fit the density, especially at the convex side of the ring and there is “extra” density that could be the VWA domain “finger” or the NorQ H2I sitting in different positions (see Additional file 1: Fig. S9 and “Discussion”).

Models of the NorQWBD complex with combined data from cryo-EM analysis and AlphaFold predictions. The NorQ hexamer is shown in blue and cyan, the NorD VWA domain in pink with MIDAS residues in red, and the N-terminal domain in gray (d). a Model of the NorQ hexamer bound to the NorD VWA domain based on the AF prediction shown in Fig. 7c and after flexible fitting into the cryo-EM map (Fig. 6b). b Cryo-EM map colored according to the fitted NorQD model shown in a and with the NorQ protomers labeled as in Fig. 6b. c Surface representation of the fitted NorQD model. d The NorD N-terminal domain was added to the fitted NorQD model preserving its relative position as predicted (Fig. 7c)
We further assume that the N-terminal of NorD is located to the side of the NorQ hexamer and is represented by the “comma” visible in the 2D classes (Fig. 6a) but is missing in the refined density. Figure 8d shows the tentative location for the NorD N-terminal using the NorQ-NorD AF prediction (Fig. 7c). The overall orientation of the NorD domains relative to each other and to the NorQ hexamer as modeled in Fig. 7b and c was supported by the AF prediction of the complex with the entire NorD protein (Additional file 1: Fig. S7).
ATPase activity of NorQ and the NorQD complex
The purified NorQ exhibited “uncoupled” ATP hydrolysis activity of ~100 nmol mg−1 min−1, measured with both the pyruvate kinase-coupled assay and the malachite green “end-point” assay (Table 1 and Additional file 1: Fig. S10). This corresponds to a kcat = 25/(min×hexameric complex), and the Km was measured to 0.16±0.02 mM ATP. This activity was lost in the NorQWB variant (Table 1, Additional file 1: Fig. S10).
In the wildtype NorQNorD (QD) complex, the ATPase activity was ~10% of that in NorQ alone, only slightly higher than in the QWBD preparation (Table 1), i.e., the “uncoupled” activity of NorQ alone is higher than in the presence of NorD (see “Discussion”). Because the residual activity of the NorQWBD preparation was higher than in the NorQWB alone, we engineered a double-tag (dt) construct (see “Methods”) in order to improve the purity of the preparation such that we could exclude contaminant activity. The data (Table 1) on the double-tag “ultrapure” NorQD complexes clearly show that ATPase activity is lost in the dt-NorQWBD construct and that the activity is higher in the wildtype NorQD. The wildtype NorQD complexes were more prone to aggregate under the measurement conditions such that the numbers for its activity could be somewhat underestimated (see “Methods”), but it is clear that the complexation with NorD inhibits NorQ activity significantly. Additions of the purified cNOR, either wildtype or the FeB-less variant, had no effect on the ATPase activity.
Binding of NorQD to NorB and insertion of the FeB
We investigated the putative involvement of specific cytoplasmic surface residues of NorB as an interaction surface for the VWA domain of NorD by mutagenesis. Here, aspartate and glutamate residues that are exposed to the bulk (as judged from the cNOR crystal structure, PDB: 3O0R [5]) and conserved in cNOR but not in qNOR were considered as likely candidates for such interactions (see alignment in Additional file 1: Fig. S11). This is because qNOR does not require homologs of NorQD for FeB insertion [17]. Among four candidate residues, only mutation of D220 or E222 abolished cNOR activity completely (Table 2). The non-heme iron content was substantially decreased in the D220A (to 28 ± 3 %) and E222A (to 24 ± 9 %) cNOR variants compared to wildtype. In contrast, a double mutation of E75 and E78 on the same protein surface produced active cNOR (~50 % of WT activity).
We further verified the functional importance of the WB-motif (E109) of NorQ and the MIDAS residues (T534 and D562) in NorD in the cNOR operon by the observation that exchanging them abolished the activity of the target protein cNOR (Table 2). His tags inserted at the N-terminus of NorD or NorQ were found not to interfere with NorQD function, as they caused only minor changes in cNOR activity (Table 2).
Re-activation experiments with crude cell extracts
After expression of the nor operon in E. coli, membrane fractions and soluble fractions were mixed in different combinations according to Additional file 1: Table S3 in order to test a possible re-activation effect on FeB-less cNOR (membrane bound) by NorQ and NorD proteins (soluble). NorE and NorF proteins have no effect on heterologous cNOR expression [2]. A drastic decrease in cNOR activity (to ~8%) and non-heme iron content (to ~10%) when NorQ and NorD were absent (norCB(ΔQDEF) samples) from both fractions is consistent with our earlier results [2]. When membranes that contained FeB-deficient cNOR were mixed with the soluble fraction of cells expressing the complete nor operon, purified cNOR showed a 2.5-fold increase in activity and a 2-fold increase in non-heme iron content (Additional file 1: Table S3). Mixing detergent solubilized FeB-deficient cNOR with the purified NorQD did not recover cNOR activity.
Discussion
NorQ is an AAA+ ATPase that forms hexameric rings
Purified NorQ forms several oligomeric states, but in the E109Q (NorQWB, Walker B motif) NorQ variant in the presence of ATP (Fig. 2), the hexameric state dominates. This behavior is similar to that found for other MoxR and AAA+ proteins [21, 23, 44].
The NorQ protein alone has an “uncoupled” (from target remodeling) ATPase activity of ~100 nmol mg−1min−1 (kcat ~ 25 min−1 for the hexamer). This is similar to the homologous A. ferrooxidans AfCbbQ2 and H. neapolitanus csoCbbQ proteins (activity ~30 nmol mg−1min−1) [31, 34], which both have a sequence identity of ~50% to NorQ (see alignment in Additional file 1: Fig. S6) but higher than that observed for the CoxD [32] MoxR protein. This activity was lost (~2 %) in the NorQWB variant, confirming the importance of the Walker B motif.
The NorQWB preparation was more homogenous than the wildtype NorQ, which led to better cryo-EM results. We could build a model for the NorQWB hexamer with a nominal resolution of 8 Å that is good agreement with the crystal structures of the homologous csoCbbQ [34] and AfCbbQ2 [25] (Fig. 5). In AfCbbQ2, density for the helix 2 insert (H2I), a flexible loop (residue 78-93) at the convex side was resolved, in contrast to the csoCbbQ crystal structure. Our NorQ structure has clear density in this region which is well modeled on the AfCbbQ2 structure [25]. Because we determined the NorQ structure by cryo-EM, this indicates that the H2I region has a largely defined structure also in solution and not only in tightly packed crystals. Interestingly, NorQ hexamers that were built without applying symmetry constraints show the existence of asymmetric rings (Fig. 4). Asymmetric ring conformations are observed for nearly all hexameric AAA+ protein structures determined to date, where each protomer often assumes a different conformation related to the status of the ATP-binding pocket being either ATP or ADP bound, in an intermediate state of ATP hydrolysis or nucleotide-free. It is common that one subunit of the ring is displaced, nucleotide-free and known as the “seam” protomer. Examples of such AAA+ proteins are ClpX, Vps4, LonA [45,46,47] or Hsp104 and ClpB for which opening of the ring is essential for function [48, 49]. Asymmetric ring conformations were also observed for the MoxR AAA+ protein RavA [50].
NorD forms a complex with the NorQ hexamer
Co-expressed NorQ co-purified with His-tagged NorD, showing that they interact (Fig. 3a). Expression of NorD was dependent on co-expression of NorQ, possibly because binding to NorQ makes NorD soluble and/or prevents its degradation. Similar observations were made for heterologous expression of the CbbQO proteins involved in RuBisCO activation [31, 34].
The NorQD complex was obtained in significantly better yield and less prone to aggregation with the NorQWB variant, presumably because of the loss of ATP hydrolysis activity. Our data (Figs. 3a and 6) shows that NorQWB forms primarily hexameric oligomers also within a NorQWBD complex. BN-PAGE for NorQWBD showed a predominant ~310 kDa band in the absence of ATP, which was verified (by mass-spec) to contain both NorQ and NorD and it is consistent with binding of one copy of NorD (70 kDa) to hexameric NorQ (6×30 kDa). The cryo-EM data (Fig. 6a) shows a “comma”-like attachment to the NorQWB hexameric ring, consistent with this stoichiometry.
The VWA domain of NorD is, as observed for other VWA domains [29], presumably involved in promoting metal ion-dependent protein-protein interactions via its conserved MIDAS motif (see Fig. 7a and conservation in other MoxR-associated VWA-containing proteins (e.g., from [51]) in Additional file 1: Fig. S2). Since exchanging residues in this motif (T534V or D562N) of NorD still allowed co-purification of NorQD but lead to inactivation of cNOR in the context of the full operon (Table 2), the MIDAS motif is likely to be involved in binding to the target cNOR, but not to binding NorQ.
In our cryo-EM map (Fig. 8), we assume that it is the VWA domain of NorD that “plugs” the center of the NorQ ring and we fitted the predicted structure of NorD (using the NorQD prediction, see Fig. 7c) into this density. This is done in analogy with the suggestion from data on the homologous CbbQ MoxR protein with its VWA domain-containing partner protein CbbO [25, 31], and for other reasons detailed below. In the predicted structure of NorD as well as of all other MoxR-associated VWA domains predicted in this study, there are “fingers” in the VWA domain (see Additional file 1: Fig. S6) that have not been observed in VWA domains experimentally (see, e.g., PDB ID: 6FPY [51], but note that the available high-resolution structural data does not include any MoxR-associated VWA domains). We suggest that the insertion of the VWA “finger” into the MoxR central pore is a general property also for other VWA domain-containing partner proteins to the MoxR AAA+ family members (e.g., CbbQ/O, RavA/ViaA), something that has to our knowledge not been observed or suggested before. We also suggest that this binding mode extends to eukaryotic AAA+ proteins in complex with VWA/MIDAS based on our predictions of the VWA domains of Rea1, ChlD, and VWA8 (Additional file 1: Fig. S12). In addition, we find it likely that the unassigned density (directly adjacent to a resolved VWA globular domain) observed in a cryo-EM structure of human Mdn1 [52] belongs to this VWA “finger” (see Additional file 1: Fig. S12c for the predicted fold of the Mdn homolog Rea 1 VWA domain). Binding of this region to the Mdn1 central pore was suggested previously, the “finger” residues, however, are only partly resolved and resemble more an unstructured loop in the crystal structure with Rea1 [53]. Interestingly, the “finger” is missing in the well-studied VWA domains of, e.g., integrins (see integrin-like ITI-HC1, PDB: 6FPY [51], Additional file 1: Fig. S12e) and they also do not interact with AAA+ motors.
This binding mode would also explain mutagenesis results for CbbQ, where exchanging residues in the H2I region was found to lead to “uncoupling” of the ATPase activity from the requirement for binding the CbbO partner [25], which we now can interpret in terms of the VWA “finger” (of CbbO)/H2I (of CbbQ) interaction.
Binding of the VWA “finger” to the center of the NorQ ring pore is also analogous to the McrC partner binding to the McrB AAA+ protein [26, 42], where the McrB hexamer ring structure shows high structural similarity to the NorQ/CbbQ MoxR proteins [24] although the sequence similarity is only ~20%. The McrC partner protein (see Additional file 1: Fig. S12f) has no sequence homology to the VWA domain proteins. This binding mode presumably also rules out direct “threading” of the target protein (cNOR) through the NorQ pore, as was also suggested for McrBC [42].
From the cryo-EM NorQWBD data (Fig. 6b), it is also clear that there is asymmetry in the NorQ hexamer and that this asymmetry has a defined relation to the binding of NorD, such that the “seam” NorQ subunit appears to be the protomer least tightly bound to the NorD VWA. We suggest that this is related to the binding of the VWA domain “finger” in the center of the NorQ ring, indicated also from the unassigned density (Additional file 1: Fig. S9) at the convex (bottom) side of the NorQ ring that could be due to displacement of the NorQ H2I region in the protomer(s) tightly interacting with the VWA “finger.” This asymmetry would then be linked to the propagation of the ATPase motor function to the VWA domain and onto the target cNOR, as the “finger” (at the bottom of the NorQ ring) is connected to the MIDAS residues (on the top) via a single β-strand (Additional file 1: Fig. S13).
The N-terminal domain (unresolved in the final cryo-EM map) of NorD presumably sits on the side of the ring, as indicated by the “comma” observed in the cryo-EM 2D classes (Fig. 6a) and the AlphaFold modeling (Fig. 8d, Additional file 1: Fig. S7). We suggest its role is primarily to mediate specificity towards the cNOR target, supported by the observation that the N-terminal domain is not conserved and shows high variation in length in VWA domain proteins associated with MoxR ATPases. Future higher-resolution structures resolving also the N-terminal domain of NorD should elucidate these issues.
Mechanism of NorQD-catalyzed cNOR maturation
Intact NorQ AAA+ and NorD VWA domains and NorQ ATP hydrolysis capability (Table 1), are all required for assembly of active cNOR (Table 2). These pieces of evidence all support an ATP hydrolysis-driven motor function of NorQD in order to remodel cNOR to allow Fe insertion. An intact NorD VWA MIDAS motif was also essential for expression of active cNOR (Table 2), but not for binding to NorQ (see above). These observations are consistent with how we have modeled the cryo-EM density (Fig. 8) and indicate that NorD uses its VWA MIDAS motif to bind cNOR.
VWA domains often use their MIDAS-coordinated metal ion to coordinate to an acidic surface residue or “patch” on the target protein (as the sixth metal ligand). We identified D220 and E222 on the NorB surface as good candidates for interacting with NorD, since their exchange yielded inactive cNOR, lacking FeB (Table 2). These effects are remarkable and highly unlikely to be caused by any direct effects on the FeB environment as both residues are positioned far from it (Fig. 9). Interestingly, the D220 and E222 residues are both located at the cytoplasmic end of TM helix VII which further up has two FeB-coordinating histidines (H253/H254, see Fig. 9). Conformational changes in this helix induced by the NorQD motor function could then affect accessibility to and/or affinity for iron in the FeB binding site.

Mutational analysis of exposed acidic residues on the cytoplasmic surface of NorB. Residues investigated by mutagenesis (green) and FeB-coordinating residues (orange) from TM helix VII (dark blue) are shown in stick representation. Picture is of the Ps. aeruginosa cNOR (PDB: 3O0R [5],) but amino acid numbering from the P. denitrificans cNOR sequence
We found that the NorQD complex has lower ATP hydrolysis activity (Table 1) than the “uncoupled” activity of NorQ alone. Thus, basal NorQ activity is inhibited when in complex with the NorD, which is different from the situation in CbbQO, where the CbbQ ATPase activity is stimulated by the presence of CbbO [31]. This difference is possibly exerted by the unrelated N-terminal domains of NorD/CbbO binding to the different final targets; for RuBisCO, the “after catalysis-inhibited protein” and for cNOR presumably an assembly intermediate (see below).
Our modeled insertion of the NorD VWA domain “finger” into the NorQ central pore explains in a straightforward way how the ATP hydrolysis activity of NorQ is affected by the interaction in analogy with the influence (in their case stimulatory) the McrC binding was shown to have on the McrB hexamer [26, 42] where there is direct influence on the active nucleotide hydrolysis site by the insertion of the McrC “finger.” The NorD inhibition of the “uncoupled” NorQ ATPase activity would then have to be relieved when NorD in turn binds to the “correct form” of the cNOR target, since we know the ATPase function is necessary for cNOR activation (Table 2).
As the expression of cNOR in the absence of NorQD yields folded and hemylated cNOR lacking the FeB cofactor [2], we considered the possibility that NorQD could remodel the fully formed cNOR complex in order to open up a cavity that allows uptake and binding of Fe. Our re-activation experiments in crude cell extracts (Additional file 1: Table S3) did lead to an increase in residual activity and non-heme Fe levels of FeB-less cNOR in membranes, but only 2–2.5-fold. This result together with the lack of effect on the NorQD ATPase activity in the presence of purified FeB-less cNOR suggests that the main target of the NorQD chaperone complex is a (temporarily formed) cNOR assembly intermediate and that they work inefficiently on the final cNOR product.
We previously showed that NorQD functions in non-heme FeB cofactor insertion into cNOR [2], but there was no biochemical data on the NorQD proteins. Based on the experimental data presented here, we can now suggest the following schematic mechanism for NorQD-catalyzed insertion of the FeB cofactor (Fig. 10): (1) The MIDAS motif of the NorD VWA domain binds to the surface residues D220/E222 on the TM helix VII of NorB in the apo-cNOR (without FeB bound). Presumably, also the N-terminal domain of NorD binds to cNOR in order to provide specificity and/or a “statoring” function. (2) Fueled by ATP hydrolysis in NorQ, conformational changes in the “finger” of VWA that extends through the central pore of the NorQ hexamer are propagated to the MIDAS surface residues and onto the cNOR surface opening/keeping open a channel/cavity around the TM helix VII that extends to the FeB binding site. Fe2+ (delivered from free Fe2+ in the cytosol or via iron chaperones/ferritin [54], but unlikely to involve the NorQD complex) can now access the FeB binding site. (3) When FeB is bound, conformational changes in the binding site could propagate back to the surface residues D220/E222 weakening the affinity for the MIDAS of the NorD VWA domain and the NorQD complex dissociates leaving the cNOR fully assembled and FeB-bound.

Proposed mechanism of cNOR activation by NorQD based on the presented data. a Structure models for the P. denitrificans cNOR based on PDB ID: 3O0R [5], overall arrangement of the NorQD complex based on our cryo-EM data, detailed structures of NorD and NorQ protein based on 6L1Q (CbbQ for NorQ) and the predicted structure of NorD (Fig. 7a), respectively. b Step 1: Hexameric NorQ (pink/magenta) uses one NorD (blue) as an adaptor protein in order to bind the apo-form of cNOR (gray, the suggested “immature” nature of this form indicated by the larger accessibility of the acidic patch). Interaction of NorQD with cNOR occurs via the MIDAS site on the NorD VWA domain binding to D220/E222 on NorB (light gray). Step 2: NorQ induces ATP hydrolysis-powered conformational changes in cNOR via the “finger” from the NorD VWA domain inserted into the hexamer pore. These conformational changes would then propagate from the NorD VWA via the NorB surface further up the TM helix VII, modulating accessibility and/or affinity of the Fe binding site. The inset (*) shows how the “finger”/H2I region in our model is structurally indirectly connected to the FeB site in cNOR. Step 3: Once cNOR has acquired the FeB cofactor and gained/restored functionality, the NorQD complex unbinds cNOR
Conclusions
In summary, this study provides the first and novel insight into the specific mechanism of action of the NorQD-catalyzed insertion of the FeB into cNOR. In doing so, it also sheds light on the properties and mechanisms for the AAA+ MoxR-VWA protein interactions and mechanisms in the general context of this understudied class of enzymes.
Methods
Cloning, expression and purification
cNOR was over-expressed in Escherichia (E.) coli from plasmids containing the complete nor operon (pNOREX-His) or in absence of the nor accessory genes (pNOREX-HisΔQDEF) [2, 55]. For heterologous co-expression of NorQ and NorD an expression vector (pET-QhD) was constructed by cloning the P. denitrificans norQ and norD genes into a pET21a backbone. For both genes, the native ribosome binding site (RBS) was exchanged for the T7 RBS (sequence: aaggag) and for NorD an N-terminal 6-His tag was introduced. We also expressed NorQ with an N-terminal 6-His tag in absence of NorD from a plasmid pET-hQ based on a pET21a backbone. The “ultrapure” NorQD complexes were produced from a modified pETDuet-1 (Novagen) co-expression vector containing two multiple cloning sites (MCS). The original C-terminal S-tag located 3′ to the second MCS was exchanged for the Strep-tag II sequence. The NorD sequence was inserted into the first MCS and 3′ to the existing His tag sequence and NorQ was cloned into the second MCS and 5′ to the Strep-tag II sequence via conventional restriction/ligation. This allowed for over- and co-expression of NorD with a N-terminal 6xHis tag and of NorQ with a C-terminal Strep-tag II. For site-directed mutagenesis a modified version of the QuickChange™ method and conventional cloning techniques were used. Correct assembly of pET-QhD and pET-hQ and site-directed mutagenesis was confirmed by sequencing (Eurofins Genomics).
For cNOR expression, pNOREX constructs were co-transformed together with pEC86 (encoding cytochrome c maturation factors [56]) into E. coli JM109 as described in [55]. The growth procedure and His tag-based purification of cNOR is essentially described in [57, 58] with modifications of the purification protocol [2]. For co- and over-expression of NorQ and NorD and individual expression of NorQ corresponding plasmids (pET-QhD respectively pET-hQ) were transformed into E. coli BL21 (DE3) and all growth media were supplemented with 100 mg/L ampicillin. LB medium (800 mL) was inoculated with 8 mL of pre-culture and shaken at 180 rpm and 37 °C.
NorQ was grown at 30°C and shaken at 180 rpm overnight, without IPTG induction. NorQWB was induced with 1 mM IPTG and grown at 30°C and shaken at 180 rpm overnight. The cells were harvested by centrifugation and all the subsequent steps were performed on ice or at 4°C. NorQ cell pellets were suspended and diluted 4× in 100 mM HEPES, pH 7.6, 600 mM NaCl, 1 mM PMSF. NorQWB was suspended and diluted 4× in 100 mM HEPES, pH 7.6, 1 mM PMSF. Dilution was followed by cell disruption at 22 kpsi (Emulsiflex C3 Homogenizer) and centrifugation. Imidazole (20 mM) was added to the supernatant, and the proteins were purified on a Hitrap HP column (5 mL GE/Cytiva), eluted with an imidazole gradient (50 mM to 500 mM) in 20 mM HEPES, pH 7.6, 300 mM NaCl, 5% (v/v) glycerol. The sample was dialyzed (12 kDa cut-off) against 20 mM HEPES, pH 7.6, 150 mM NaCl, 5% (v/v) glycerol. Concentration was determined using A280.
NorQD was grown at 25°C and shaken at 180 rpm overnight, without IPTG induction. NorQWBD was induced with 0.1 mM IPTG, grown at 16°C and shaken at 180 rpm for 40 h. The purification proceeded as for NorQ and NorQWB with some changes: after harvest, the cells were diluted in 4× 50 mM TRIS, pH 8, 50 mM NaCl, supplemented with one pill cOmplete, EDTA-free Protease Inhibitor Cocktail. The purification buffer contained 20 mM TRIS/HCl, pH 8, 300 mM NaCl, 10% (v/v) glycerol, and imidazole concentration ranging from 50 to 500 mM. The sample was dialyzed against 10 mM TRIS, pH 8, 150 mM NaCl, and 10% (v/v) glycerol.
Double-tagged (Q-Strep, D-His) NorQD and NorQWBD were grown and purified as described above with an additional purification step on Strep-Tactin superflow column (iba). The sample was eluted with 2.5 mM desthiobiotin, followed by His tag purification as before.
For SDS-PAGE, protein samples were diluted in NuPAGE™ LDS sample buffer (Invitrogen). After incubation for 10 min at 95 °C, the sample was loaded and run on NuPAGE™ 4–12% Bis-Tris gels (constant 100 V, room temperature) and stained with Coomassie Brilliant Blue or silver staining. Identification of individual protein bands was supported by mass spectrometry analysis performed by the SciLifeLab Mass Spectrometry Facility at Uppsala University using nano-LC-MS/MS.
Blue native (BN) PAGE was performed with pre-cast NativePAGE™ 4–16% Bis-Tris (Invitrogen) gels according to the manufacturer’s instruction. The gels were run at 4 °C in two stages: (1) 60 min at 150 V, (2) 45 min at 250 V. The gels were stained with Coomassie Brilliant Blue.
NorQWB for Cryo-EM was produced as described above, with some exceptions. The cells were harvested 6 h after induction and diluted 4× in 100 mM HEPES, pH 7.6, 20 mM β-mercaptoethanol. After cell disruption and centrifugation, 20 mM imidazole and 10% (v/v) Ni-NTA agarose resin was added to the supernatant and the mixture was incubated under rotation for 2 h. The resin was added to a gravity-controlled column and washed with 5 CV (column volumes) of purification buffer (20 mM HEPES, pH 7.6, 300 mM NaCl, 5 % (v/v) glycerol, 20 mM β-mercaptoethanol) containing 20 mM imidazole. The protein was eluted with 2 CV of purification buffer containing 250 mM imidazole. The sample was dialyzed (12 kDa cut-off) against 20 mM HEPES, pH 7.6, 150 mM NaCl, 2 mM DTT overnight. Finally, all protein samples were concentrated with centrifugal filters (10 kDa cut-off) and concentrations were determined using the Pierce™ BCA Protein Assay Kit.
Purified protein samples were analyzed with size exclusion chromatography (SEC). Approximately 500 μg protein was run on a Superdex 200 10/300 GL-column (Cytiva) at 0.3 mL/min in 20 mM TRIS/HCl pH 8, 300 mM NaCl, 10% (v/v) glycerol. Detergent solubilized membranes were prepared by using the same cNOR expression system described above. Mutants of NorB, NorQ, or NorD were produced by genetic modification of pNOREX-His. After induction with 1 mM IPTG, the cells were grown in 25 mL TB (containing 100 mg/L ampicillin, 30 mg/L chloramphenicol) overnight at 30 °C, 180 rpm. Cells were pelleted by centrifugation and suspended in 1 mL of 100 mM TRIS/HCl, pH 7.5, 50 mM NaCl, 1 mM EDTA. The cells were sonicated for 2 min (30s on/30s off cycle) in an ice bath followed by addition of 1% DDM. Insoluble cell debris was removed by centrifugation (20,000g, 10 min) and cNOR concentrations in the supernatant were determined spectrophotometrically (ɛ550 reduced-oxidized = 28 mM−1 cm−1). cNOR is the only enzyme with appreciable NO reduction activity as well as the only c-heme containing protein in the membranes, making normalization to cNOR content straightforward.
ATPase activity measurements
ATPase activity was measured using the pyruvate kinase-coupled assay [59]. The reaction mixture contained 50 mM TRIS/HCl, pH 8.0, 150 mM NaCl, 15 mM MgCl2, 2.5 mM ATP, 1 mM phosphoenolpyruvate, 0.3 mM NADH, 12 U/mL pyruvate kinase, and 12 U/mL lactate dehydrogenase. After addition of 0.15 mg/mL protein, the ATPase activity was measured by following NADH consumption photometrically (ε340 = 6.22 mM−1 cm−1) at 22 °C. Because of the tendency of the NorQ and NorQD complex to aggregate at higher concentrations, the sample was centrifuged, the protein concentration determined right before the activity measurements, and the stock solutions kept at 0.5–1mg/ml or lower.
In order to avoid potential artifacts in the optical assay from competing aggregation reactions of the samples, ATPase activity was also measured using the malachite green end-point assay [60]. The initial reaction mixture contained 50 mM TRIS/HCl, pH 8, 150 mM NaCl, 10% (v/v) glycerol, 20 mM MgCl2, and 2 mM ATP. One minute after addition of 0.03 or 0.05 mg/mL protein, 109 μL color reagent (0.034% malachite green oxalate, 1% ammonium molybdate tetrahydrate, 0.04% Triton-X) was added to 27.3 μL of the initial reaction mixture, and the sample was vortexed. After 1 min, 13.5 μL 34% citrate solution was added and the sample was vortexed. After 5 min, the absorption at 620 nm was measured and the phosphate concentration determined using a standard curve. The experiment was repeated at regular time points after addition of protein, and the ATPase activity determined as the increase of phosphate concentration over time. Measurements were performed for at least two different protein concentrations in order to avoid artifacts from aggregation reactions, the rate of which should increase with protein concentrations.
NO multiple turnover measurements
NO reduction activity was measured for detergent solubilized membranes and for purified cNOR (see above). NO reduction measurements were performed as described in [61] with the following modifications: 25 nM cNOR was added already before deoxygenating the buffer solution. The reaction was started by addition of 10 μM horse heart cyt. c, 0.5 mM TMPD and 3 mM ascorbate after injection of NO. The measurements were performed at 22 °C.
Re-activation experiments
The nor operon proteins were expressed as described above from pNOREX-His and pNOREX-HisΔQDEF plasmids. After cell lysis and subsequent centrifugation, the membrane fraction and soluble fraction was saved. In order to assess a possible re-activation effect of soluble NorQ and NorD proteins on membrane bound, FeB-lacking cNOR, the membrane fraction and supernatant were re-united according to the scheme in Additional file 1: Table S3. The samples were homogenized and incubated for 1.5 h at room temperature followed by sedimentation of the membrane fraction by centrifugation. cNOR was then purified from membranes as described above. Protein concentrations were determined spectrophotometrically (ɛ410 = 311 mM−1 cm−1 [62]) followed by NOR activity measurements and non-heme iron determinations.
Non-heme iron determinations
The non-heme iron content was measured using the ferene method [63, 64]. To 60 μL protein solution (8 μM), 6 μL of 37% HCl was added. The sample was incubated for 5 min and precipitated protein was removed by centrifugation (20,000g, 15 min), followed by addition of 100 μL of 3 M sodium acetate and 10 μL of 1 M ascorbic acid (pH 5–6). Ten microliters of 3 mM ferene was added, and after 5 min, the non-heme Fe concentration was measured photometrically (ɛ593 = 35.5 mM−1 cm−1). The signal was corrected for the background of contaminating Fe dissolved in the buffer as well as for background absorbance in the sample before ferene addition.
Cryo-EM
For NorQ alone, samples contained 1 mg/mL protein in 20 mM HEPES, pH 7.6, 150 mM NaCl, and 2 mM DTT. 3.5 μL of the sample was blotted on CF-2/2-3Cu-T-50 grids (glow discharge for 40 s, blotting for 3 s, blotting chamber at 4 °C, 100% humidity).
For co-purified NorQWBD, cryo-EM samples contained 1 mg/mL protein in 50 mM TRIS/HCl, pH 8.0, 150 mM NaCl, and 10% glycerol.
The dataset of NorQ without NorD was collected on a Talos Arctica (Thermo Fisher Scientific) using a Falcon3 detector (Thermo Fisher Scientific) in counting mode. The exposure time was 80 s, and the movie frames 42 with 1.24 e−/Å2 per frame. The data were collected at a magnification of 150k giving a pixel size of 0.99 Å. On-the-fly data processing was performed as for the NorQD complex and further image processing using Relion 3 [65] integrated into the Scipion frame.
Around 130,000 particles were picked automatically on-the-fly using the Xmipp pattern matching approach protocol [66]. Upon 2D classification, particles belonging to good 2D classes both representing end and side views were selected in a dataset of around 50,000 particles. Two 3D initial models were generated using the ab initio stochastic gradient descent method implemented in Relion3. The two models looked virtually identical and one of the two was used as reference for 3D classification into two classes. The 3D classification allowed to further clean the dataset and 90% of the particles contributed to a good 3D class while the rest segregated into a “junk” 3D. The 42,000 particles belonging to the good 3D class were refined using C6 symmetry into an 8Å map and, with no-symmetry applied, into a 11Å map. The C6 map was used for 3D classification while relaxing the symmetry.
Data acquisition of NorQD was performed on a Titan Krios G3i (Thermo Fisher Scientific) microscope using a K3 detector (Gatan, Ametek) in super-resolution hard-binned mode, using a dose rate of 12 e−/px/s and a pixel size of 0.8464 Å. The total dose was 40 e− and the movie frames 40. On-the-fly data processing was performed using the cryoSPARC Live suite [67], and subsequent image processing was continued in cryoSPARCv 3.0. From 23018 micrographs, ~14 million particles were blob-picked on-the-fly, but only ~500,000 were selected using 2D classification and three ab initio models were created with and without C6 symmetry applied. The asymmetric models all contained extra density inserted in the NorQ ring and a lateral “comma-like” protrusion later assigned to NorD. The dataset was subjected to extensive 3D classification and using the sixfold symmetric model helped in angle assignment. This was due to substantial preferential orientation of the available views so that an isotropic map was only obtainable to a nominal resolution of 5Å using non-uniform refinement in cryoSPARC. By inspection, the map is more consistent with a 10Å resolution where AAA+ subdomains are easily recognizable as well as the VWA domain. While the “comma” density was present in the ab initio models, it was lost in the further refinement. Based on other evidence, we interpret the “comma” as the N-terminus of NorD and it is most likely flexible. More isotropic data is required to be able to determine a high-resolution structure and to distinguish different conformations.
Sequence alignments, disorder predictions, and homology models
Sequence alignments were made using T-Coffee [68, 69], Clustal Omega [69], EMBOSS Needle [70], and ESPript 3.0 [71]. The homology model for the P. denitrificans NorQ was made based on the crystal structure of AfCbbQ from A. ferrooxidans (PDB ID: 6L1Q) using SWISS-MODEL [72]. Disordered regions (for NorD) were predicted using the PrDOS server [73].
Prediction of single-chain NorD and NorQD complexes using AlphaFold
The AlphaFold prediction [36] of the structure of NorD alone (and related proteins, Additional file 1: Figs. S6 and S12) was made using the Colabfold web resource at https://colab.research.google.com/github/deepmind/alphafold/blob/main/notebooks/AlphaFold.ipynb.
Note that the single-chain predictions can now be found via their UniProt identifiers [74]. All models of multimeric complexes shown in “Results” were built using AlphaFold-multimer original or updated versions [37] with default settings. Here four multiple sequence alignments (MSAs) are created by searching Uniref90 v.2020_01 [75], Uniprot v.2021_04 [76], and MGnify v.2018_12 [77] with jackHMMER [78] and using Hhblits [79] to search the Big Fantastic Database [80] and uniclust30_2018_08 [81]. Only proteins from UniProt are paired by using species information as described in Evans et al. [37]. All of the created MSAs (one paired and three block-diagonalized) are used to predict the structure of a protein complex. Models are evaluated using the predicted template/model (pTM) score [82].
We also used the FoldDock protocol [83] to build complexes, however, for the resulting models only one out of five had the NorD in the center of the NorQ hexamer, and was thus considered not consistent with experimental data.
Availability of data and materials
The cryo-EM density maps were deposited in the Electron Microscopy Data Bank [84] under accession codes EMD-16656 (NorQ) [85] and EMD-16655 (NorQD complex) [86]. All other datasets generated during and/or analyzed during the current study are either included in the manuscript or supporting information files.
Abbreviations
- cNOR:
-
Cytochrome c-dependent nitric oxide reductase
- MIDAS:
-
Metal ion-dependent adhesion site
- VWA:
-
von Willebrand factor Type A
- qNOR:
-
Quinol-dependent nitric oxide reductase
- HCuO:
-
Heme-copper oxidase
- TM:
-
Transmembrane (helix)
- WT:
-
Wildtype cNOR
- TMPD:
-
N,N,N′,N′-Tetramethyl-p-phenylene-diamine
- RBS:
-
Ribosome binding site
- DDM:
-
n-Dodecyl β-D-maltoside
- cyt. c :
-
Cytochrome c
- WB:
-
Walker B (motif)
References
Waldron KJ, Robinson NJ. How do bacterial cells ensure that metalloproteins get the correct metal? Nat Rev Microbiol. 2009;7(1):25–35.
Kahle M, ter Beek J, Hosler JP, Ädelroth P. The insertion of the non-heme FeB cofactor into nitric oxide reductase from P. denitrificans depends on NorQ and NorD accessory proteins. Biochim Biophys Acta. 2018;1859:1051–8.
Hemp J, Gennis RB. Diversity of the heme-copper superfamily in archaea: insights from genomics and structural modeling. Results Probl Cell Differ. 2008;45:1–31.
Sousa FL, Alves RJ, Ribeiro MA, Pereira-Leal JB, Teixeira M, Pereira MM. The superfamily of heme-copper oxygen reductases: types and evolutionary considerations. Biochim Biophys Acta. 2012;1817(4):629–37.
Hino T, Matsumoto Y, Nagano S, Sugimoto H, Fukumori Y, Murata T, et al. Structural basis of biological N2O generation by bacterial nitric oxide reductase. Science. 2010;330(6011):1666–70.
Moënne-Loccoz P, Richter OMH, Huang HW, Wasser IM, Ghiladi RA, Karlin KD, et al. Nitric oxide reductase from Paracoccus denitrificans contains an oxo-bridged heme/non-heme diiron center. J Am Chem Soc. 2000;122(38):9344–5.
Pinakoulaki E, Gemeinhardt S, Saraste M, Varotsis C, Nitric-oxide reductase. Structure and properties of the catalytic site from resonance Raman scattering. J Biol Chem. 2002;277(26):23407–13.
Hendriks JH, Jasaitis A, Saraste M, Verkhovsky MI. Proton and electron pathways in the bacterial nitric oxide reductase. Biochemistry. 2002;41(7):2331–40.
Reimann J, Flock U, Lepp H, Honigmann A, Ädelroth P. A pathway for protons in nitric oxide reductase from Paracoccus denitrificans. Biochim Biophys Acta. 2007;1767(5):362–73.
Sousa FL, Alves RJ, Pereira-Leal JB, Teixeira M, Pereira MM. A bioinformatics classifier and database for heme-copper oxygen reductases. PLoS One. 2011;6(4):e19117.
Thompson AK, Gray J, Liu A, Hosler JP. The roles of Rhodobacter sphaeroides copper chaperones PCu(A)C and Sco (PrrC) in the assembly of the copper centers of the aa(3)-type and the cbb(3)-type cytochrome c oxidases. Biochim Biophys Acta. 2012;1817(6):955–64.
Smith D, Gray J, Mitchell L, Antholine WE, Hosler JP. Assembly of cytochrome-c oxidase in the absence of assembly protein Surf1p leads to loss of the active site heme. J Biol Chem. 2005;280(18):17652–6.
Khalfaoui-Hassani B, Verissimo AF, Koch HG, Daldal F. Uncovering the transmembrane metal binding site of the novel bacterial major facilitator superfamily-type copper importer CcoA. mBio. 2016;7(1):e01981–15.
de Boer AP, van der Oost J, Reijnders WN, Westerhoff HV, Stouthamer AH, van Spanning RJ. Mutational analysis of the nor gene cluster which encodes nitric-oxide reductase from Paracoccus denitrificans. Eur J Biochem. 1996;242(3):592–600.
Hendriks J, Gohlke U, Saraste M. From NO to OO: nitric oxide and dioxygen in bacterial respiration. J Bioenerg Biomembr. 1998;30(1):15–24.
Girsch P, deVries S. Purification and initial kinetic and spectroscopic characterization of NO reductase from Paracoccus denitrificans. Biochim Biophys Acta. 1997;1318(1-2):202–16.
Zumft WG. Nitric oxide reductases of prokaryotes with emphasis on the respiratory, heme-copper oxidase type. J Inorg Biochem. 2005;99(1):194–215.
Jüngst A, Zumft WG. Interdependence of respiratory NO reduction and nitrite reduction revealed by mutagenesis of nirQ, a novel gene in the denitrification gene cluster of Pseudomonas stutzeri. FEBS Lett. 1992;314(3):308–14.
Kahle M, Blomberg MRA, Jareck S, Ädelroth P. Insights into the mechanism of nitric oxide reductase from a FeB-depleted variant. FEBS Lett. 2019;593(12):1351–9.
Snider J, Houry WA. MoxR AAA+ ATPases: a novel family of molecular chaperones? J Struct Biol. 2006;156(1):200–9.
Wong KS, Houry WA. Novel structural and functional insights into the MoxR family of AAA+ ATPases. J Struct Biol. 2012;179(2):211–21.
Snider J, Thibault G, Houry WA. The AAA+ superfamily of functionally diverse proteins. Genome Biol. 2008;9(4):216.
Puchades C, Sandate CR, Lander GC. The molecular principles governing the activity and functional diversity of AAA+ proteins. Nat Rev Mol Cell Biol. 2020;21(1):43–58.
Jessop M, Felix J, Gutsche I. AAA+ ATPases: structural insertions under the magnifying glass. Curr Opin Struct Biol. 2021;66:119–28.
Tsai YC, Ye F, Liew L, Liu D, Bhushan S, Gao YG, et al. Insights into the mechanism and regulation of the CbbQO-type Rubisco activase, a MoxR AAA+ ATPase. Proc Natl Acad Sci U S A. 2020;117(1):381–7.
Nirwan N, Itoh Y, Singh P, Bandyopadhyay S, Vinothkumar KR, Amunts A, et al. Structure-based mechanism for activation of the AAA+ GTPase McrB by the endonuclease McrC. Nat Commun. 2019;10(1):3058.
El Bakkouri M, Gutsche I, Kanjee U, Zhao B, Yu M, Goret G, et al. Structure of RavA MoxR AAA+ protein reveals the design principles of a molecular cage modulating the inducible lysine decarboxylase activity. Proc Natl Acad Sci U S A. 2010;107(52):22499–504.
Sysoeva TA. Assessing heterogeneity in oligomeric AAA+ machines. Cell Mol Life Sci. 2017;74(6):1001–18.
Whittaker CA, Hynes RO. Distribution and evolution of von Willebrand/integrin A domains: widely dispersed domains with roles in cell adhesion and elsewhere. Mol Biol Cell. 2002;13(10):3369–87.
Wong KS, Bhandari V, Janga SC, Houry WA. The RavA-ViaA chaperone-like system interacts with and modulates the activity of the fumarate reductase respiratory complex. J Mol Biol. 2017;429(2):324–44.
Tsai YC, Lapina MC, Bhushan S, Mueller-Cajar O. Identification and characterization of multiple rubisco activases in chemoautotrophic bacteria. Nat Commun. 2015;6:8883.
Maisel T, Joseph S, Mielke T, Bürger J, Schwarzinger S, Meyer O. The CoxD protein, a novel AAA+ ATPase involved in metal cluster assembly: hydrolysis of nucleotide-triphosphates and oligomerization. PLoS One. 2012;7(10):e47424.
Sutter M, Kerfeld CA. Structural characterization of a newly identified component of alpha-carboxysomes: The AAA+ domain Protein cso-CbbQ: Protein Data Bank; 2015. https://doi.org/10.2210/pdb5c3c/pdb.
Sutter M, Roberts EW, Gonzalez RC, Bates C, Dawoud S, Landry K, et al. Structural characterization of a newly identified component of alpha-carboxysomes: the AAA+ domain protein CsoCbbQ. Sci Rep. 2015;5:16243.
Ye FZ, Tsai YCC, Mueller-Cajar O, Gao YG. Crystal structure of AfCbbQ2, a MoxR AAA+-ATPase and CbbQO-type Rubisco activase from Acidithiobacillus ferrooxidans: Protein Data Bank; 2019. https://doi.org/10.2210/pdb6l1q/pdb.
Jumper J, Evans R, Pritzel A, Green T, Figurnov M, Ronneberger O, et al. Highly accurate protein structure prediction with AlphaFold. Nature. 2021;596(7873):583–9.
Evans R, O’Neill M, Pritzel A, Antropova N, Senior A, Green T, et al. Protein complex prediction with AlphaFold-Multimer. bioRxiv. 2021. https://doi.org/10.1101/2021.10.04.463034v1.
Gatsogiannis C, Merino F, Raunser S. Cryo-EM Structure of the ClpX component of the ClpXP1/2 degradation machinery: Protein Data Bank; 2019. https://doi.org/10.2210/pdb6sfw/pdb.
Gatsogiannis C, Balogh D, Merino F, Sieber SA, Raunser S. Cryo-EM structure of the ClpXP protein degradation machinery. Nat Struct Mol Biol. 2019;26(10):946–54.
Itoh Y, Nirwan N, Saikrishnan K, Amunts A. Structure of McrBC without DNA binding domains (one half of the full complex): Protein Data Bank; 2019. https://doi.org/10.2210/pdb6hz4/pdb.
Niu Y, Suzuki H, Hosford CJ, Chappie JS, Walz T. Cryo-EM structure of the Thermococcus gammatolerans McrBC complex: Protein Data Bank; 2020. https://doi.org/10.2210/pdb6ut5/pdb.
Niu Y, Suzuki H, Hosford CJ, Walz T, Chappie JS. Structural asymmetry governs the assembly and GTPase activity of McrBC restriction complexes. Nat Commun. 2020;11(1):5907.
Lopéz-Blanco JR, Chacón P. iMODFIT: Efficient and robust flexible fitting based on vibrational analysis in internal coordinates. J Struct Biol. 2013;184(2):261–70.
Lupas AN, Martin J. AAA proteins. Curr Opin Struct Biol. 2002;12(6):746–53.
Glynn SE, Martin A, Nager AR, Baker TA, Sauer RT. Structures of asymmetric ClpX hexamers reveal nucleotide-dependent motions in a AAA+ protein-unfolding machine. Cell. 2009;139(4):744–56.
Caillat C, Macheboeuf P, Wu Y, McCarthy AA, Boeri-Erba E, Effantin G, et al. Asymmetric ring structure of Vps4 required for ESCRT-III disassembly. Nat Commun. 2015;6:8781.
Lin CC, Su SC, Su MY, Liang PH, Feng CC, Wu SH, et al. Structural insights into the allosteric operation of the Lon AAA+ Protease. Structure. 2016;24(5):667–75.
Lee S, Roh SH, Lee J, Sung N, Liu J, Tsai FTF. Cryo-EM structures of the Hsp104 protein disaggregase captured in the ATP conformation. Cell Rep. 2019;26(1):29–36.e3.
Yu H, Lupoli TJ, Kovach A, Meng X, Zhao G, Nathan CF, et al. ATP hydrolysis-coupled peptide translocation mechanism of Mycobacterium tuberculosis ClpB. Proc Natl Acad Sci U S A. 2018;115(41):E9560–E9.
Jessop M, Arragain B, Miras R, Fraudeau A, Huard K, Bacia-Verloop M, et al. Structural insights into ATP hydrolysis by the MoxR ATPase RavA and the LdcI-RavA cage-like complex. Commun Biol. 2020;3(1):46.
Briggs DC, Langford-Smith AWW, Birchenough HL, Jowitt TA, Kielty CM, Enghild JJ, et al. Inter-alpha-inhibitor heavy chain-1 has an integrin-like 3D structure mediating immune regulatory activities and matrix stabilization during ovulation. J Biol Chem. 2020;295(16):5278–91.
Chen Z, Suzuki H, Kobayashi Y, Wang AC, DiMaio F, Kawashima SA, et al. Structural insights into Mdn1, an essential AAA protein required for ribosome biogenesis. Cell. 2018;175(3):822–34 e18.
Ahmed YL, Thoms M, Mitterer V, Sinning I, Hurt E. Crystal structures of Rea1-MIDAS bound to its ribosome assembly factor ligands resembling integrin-ligand-type complexes. Nat Commun. 2019;10(1):3050.
Andrews S, Norton I, Salunkhe AS, Goodluck H, Aly WSM, Mourad-Agha H, et al. Control of iron metabolism in bacteria. In: Banci L, editor. Metallomics and the Cell. Dordrecht: Springer Netherlands; 2013. p. 203–39.
Butland G, Spiro S, Watmough NJ, Richardson DJ. Two conserved glutamates in the bacterial nitric oxide reductase are essential for activity but not assembly of the enzyme. J Bacteriol. 2001;183(1):189–99.
Arslan E, Schulz H, Zufferey R, Künzler P, Thöny-Meyer L. Overproduction of the Bradyrhizobium japonicum c-type cytochrome subunits of the cbb3 oxidase in Escherichia coli. Biochem Biophys Res Commun. 1998;251(3):744–7.
Flock U, Thorndycroft FH, Matorin AD, Richardson DJ, Watmough NJ, Ädelroth P. Defining the proton entry point in the bacterial respiratory nitric-oxide reductase. J Biol Chem. 2008;283(7):3839–45.
Flock U. Nitric Oxide Reductase from Paracoccus denitrificans-A proton transfer pathway from the 'wrong' side. Stockholm: Ph D thesis, Stockholm University; 2008.
Norby JG. Coupled assay of Na+,K+-ATPase activity. Methods Enzymol. 1988;156:116–9.
Lanzetta PA, Alvarez LJ, Reinach PS, Candia OA. An improved assay for nanomole amounts of inorganic phosphate. Anal Biochem. 1979;100(1):95–7.
ter Beek J, Krause N, Reimann J, Lachmann P, Ädelroth P. The nitric-oxide reductase from Paracoccus denitrificans uses a single specific proton pathway. J Biol Chem. 2013;288(42):30626–35.
Field SJ, Thorndycroft FH, Matorin AD, Richardson DJ, Watmough NJ. The respiratory nitric oxide reductase (NorBC) from Paracoccus denitrificans. Methods Enzymol. 2008;437:79–101.
Hennessy DJ, Reid GR, Smith FE, Thompson SL. Ferene - a new spectrophotometric reagent for iron. Can J Chem. 1984;62(4):721–4.
Pierik AJ, Wolbert RBG, Mutsaers PHA, Hagen WR, Veeger C. Purification and biochemical characterization of a putative [6Fe-6S] prismane-cluster-containing protein from Desulfovibrio vulgaris (Hildenborough). Eur J Biochem. 1992;206(3):697–704.
Zivanov J, Nakane T, Forsberg BO, Kimanius D, Hagen WJH, Lindahl E, et al. New tools for automated high-resolution cryo-EM structure determination in RELION-3. eLife. 2018;7:e42166.
Zaldívar-Peraza A, Sorzano COS, Otón J, Vargas J, Carazo JM, de la Rosa-Trevín JM, et al. A pattern matching approach to the automatic selection of particles from low-contrast electron micrographs. Bioinformatics. 2013;29(19):2460–8.
Punjani A, Rubinstein JL, Fleet DJ, Brubaker MA. cryoSPARC: algorithms for rapid unsupervised cryo-EM structure determination. Nat Methods. 2017;14(3):290–6.
Notredame C, Higgins DG, Heringa J. T-Coffee: a novel method for fast and accurate multiple sequence alignment. J Mol Biol. 2000;302(1):205–17.
Madeira F, Ym P, Lee J, Buso N, Gur T, Madhusoodanan N, et al. The EMBL-EBI search and sequence analysis tools APIs in 2019. Nucleic Acids Res. 2019;47(W1):W636–W41.
Madeira F, Pearce M, Tivey ARN, Basutkar P, Lee J, Edbali O, et al. Search and sequence analysis tools services from EMBL-EBI in 2022. Nucleic Acids Res. 2022;50(W1):W276–W9.
Robert X, Gouet P. Deciphering key features in protein structures with the new ENDscript server. Nucleic Acids Res. 2014;42(W1):W320–W4.
Waterhouse A, Bertoni M, Bienert S, Studer G, Tauriello G, Gumienny R, et al. SWISS-MODEL: homology modelling of protein structures and complexes. Nucleic Acids Res. 2018;46(W1):W296–303.
Ishida T, Kinoshita K. PrDOS: prediction of disordered protein regions from amino acid sequence. Nucleic Acids Res. 2007;35:W460–W4.
The UniProt C. UniProt: the Universal Protein Knowledgebase in 2023. Nucleic Acids Res. 2023;51(D1):D523–D31.
Suzek BE, Huang H, McGarvey P, Mazumder R, Wu CH. UniRef: comprehensive and non-redundant UniProt reference clusters. Bioinformatics. 2007;23(10):1282–8.
UniProt C. UniProt: the universal protein knowledgebase in 2021. Nucleic Acids Res. 2021;49(D1):D480–D9.
Mitchell AL, Almeida A, Beracochea M, Boland M, Burgin J, Cochrane G, et al. MGnify: the microbiome analysis resource in 2020. Nucleic Acids Res. 2020;48(D1):D570–D8.
Eddy SR. Accelerated Profile HMM Searches. PLoS Comput Biol. 2011;7(10):e1002195.
Steinegger M, Meier M, Mirdita M, Vohringer H, Haunsberger SJ, Soding J. HH-suite3 for fast remote homology detection and deep protein annotation. BMC Bioinformatics. 2019;20(1):473.
Steinegger M, Mirdita M, Soding J. Protein-level assembly increases protein sequence recovery from metagenomic samples manyfold. Nat Methods. 2019;16(7):603–6.
Mirdita M, von den Driesch L, Galiez C, Martin MJ, Soding J, Steinegger M. Uniclust databases of clustered and deeply annotated protein sequences and alignments. Nucleic Acids Res. 2017;45(D1):D170–D6.
Zhang Y, Skolnick J. TM-align: a protein structure alignment algorithm based on the TM-score. Nucleic Acids Res. 2005;33(7):2302–9.
Bryant P, Pozzati G, Elofsson A. Improved prediction of protein-protein interactions using AlphaFold2. Nat Commun. 2022;13(1):1265.
Lawson CL, Patwardhan A, Baker ML, Hryc C, Garcia ES, Hudson BP, et al. EMDataBank unified data resource for 3DEM. Nucleic Acids Res. 2016;44(D1):D396–403.
Adelroth P, Carroni M, Kahle M, Elofsson A, Appelgren S. Low-resolution structure of the NorQ chaperone from Paracoccus denitrificans: EMDB (Electron Microscopy Data Bank); 2023. https://www.emdataresource.org/EMD-16656. Accessed 23 Feb 2023.
Adelroth P, Carroni M, Kahle M, Elofsson A, Appelgren S. Low-resolution cryo-EM structure of the NorQD chaperone complex from Paracoccus denitrificans: EMDB (Electron Microscopy Data Bank); 2023. https://www.emdataresource.org/EMD-16655. Accessed 23 Feb 2023.
Acknowledgements
We are grateful to Patrick Bryant and Gabriele Pozzati for help with implementing the use of AlphaFold-multimer. The mass spectrometry analysis was supported by the Science for Life Laboratory Mass Spectrometry Based Proteomics Facility in Uppsala. The pETDuet vectors for double-tagged NorQD were constructed in the lab of Petra Wendler (University of Potsdam).
Funding
Open access funding provided by Stockholm University. This work was supported by grants from the Swedish Research Council (VR- 2015-04512 and 2019-04124) to PÄ. The Cryo-EM data was collected at the Cryo-EM Swedish National Facility funded by the Knut and Alice Wallenberg, Family Erling Persson and Kempe Foundations, SciLifeLab, Stockholm University. The AlphaFold-multimer computations were supported by the Swedish Research Council for Natural Science (VR-2016-06301 to AE), the Swedish E-science Research Centre, and the Knut and Alice Wallenberg foundation and the computational resources are supported by the Swedish National Infrastructure for Computing, grants: SNIC 2021/5-297, SNIC 2021/6-197 and Berzelius-2021-29.
Author information
Authors and Affiliations
Contributions
MK and PÄ conceived the study. MK, SA, MC, and PÄ designed the experiments. MK, SA, and MC performed the experiments. MK, SA, MC, and PÄ analyzed the data. AE performed the AlphaFold-multimer predictions and evaluated the models. MK and PÄ drafted the manuscript with parts contributed by SA, MC, and AE. All authors revised and commented on the draft and on the final manuscript. All author(s) read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1: Fig S1.
SEC profiles. Fig S2. Comparison of VWA domains and the MIDAS region from different organisms. Fig S3. 2D class averages of NorQ in cryo-EM experiments. Fig S4. Sequence alignment, characteristics and homology model of NorQ. Fig S5. Prediction of disordered regions and overall architecture for full-length NorD from P. denitrificans. Fig S6. Finger-like protrusions predicted for several MoxR-associated VWA domains and pairwise alignments. Fig S7. AlphaFold-multimer model of the full-length NorD in complex with the NorQ hexamer. Fig S8. Superposition of the NorQ-VWA AlphaFold prediction and the fitted cryo-EM-model. Fig S9. Extra densities in the NorQWBD cryo-EM map. Fig S10. ATPase activity measurements. Fig S11. Sequence alignment of the NorB subunit of cNOR with NorZ (qNOR) from various organisms. Fig S12. Predicted VWA domain of NorD in comparison to several eukaryotic VWA domains. Fig S13. Structural connection between the “finger” and the MIDAS site in the NorD VWA domain. Table S1. Mass spectrometry analysis. Table S2. AlphaFold-multimer prediction datasets. Table S3. Re-activation experiments with cNOR using crude cell extracts. Table S4. Primers used in this study.
Additional file 3.
Original SDS-PAGE gels.
Additional file 5.
AlphaFold-multimer models related to Additional file 1: Table S2.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Kahle, M., Appelgren, S., Elofsson, A. et al. Insights into the structure-function relationship of the NorQ/NorD chaperones from Paracoccus denitrificans reveal shared principles of interacting MoxR AAA+/VWA domain proteins. BMC Biol 21, 47 (2023). https://doi.org/10.1186/s12915-023-01546-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12915-023-01546-w