
Abstract
Background
The internet has become a major source of health information, and obtaining appropriate information requires various abilities and skills, labeled as electronic health literacy (eHealth literacy). The existing instruments for measuring eHealth literacy are outdated because they were developed during the Web 1.0 era, or not sufficiently sensitive for people with a specific condition or disease because they were designed to assess eHealth literacy over a broad range for a general population. Approximately one in ten adults worldwide live with diabetes. Health professionals have a responsibility to identify patients with low eHealth literacy to prevent them from obtaining misleading internet diabetes information.
Aims
The aims were to develop a condition-specific eHealth literacy scale for diabetes and to evaluate its psychometric properties among people with type 2 diabetes.
Methods
An instrument development design was used. This study recruited 453 people diagnosed with type 2 diabetes at the outpatient clinics of hospitals in 2021. Psychometric properties (internal consistency, measurement invariance, and content, structural, convergent, and known-groups validities) were analyzed.
Results
An expert panel assessed content validity. Exploratory factor analysis, exploratory graph analysis, and confirmatory factor analysis (CFA) for structural validity yielded a two-factor solution (CFI = 0.977, SRMR = 0.029, RMSEA = 0.077). Cronbach’s alpha and omega values were excellent for each factor (0.87–0.94). Multigroup CFA yielded configural and metric measurement invariance across the gender, age, and glycemic control status groups. Convergent validity with a comparator instrument to measure health literacy was supported by a moderate correlation, and known-groups validity determined using groups with different internet-use frequencies was satisfied with a high effect size.
Conclusion
A new condition-specific eHealth literacy scale for people with type 2 diabetes was developed, comprising 10 items. The scale exhibited good psychometric properties; however, test–retest reliability must be determined for the stability of the scale and cross-cultural validity is required among different languages. The brief scale has the merits of being feasible to use in busy clinical practice and being less burdensome to respondents. The scale can be applied in clinical trials of internet-based diabetes interventions for assessing the eHealth literacy of respondents.
Similar content being viewed by others


Background
The internet has become a major source for obtaining information. There are currently 5.17 billion internet users worldwide, representing approximately 65.6% of the global population [1]. Based on world regions, North America has the highest internet usage rate of 93.9%, followed by Europe at 88.2% [1]. South Korea is the country with the highest internet penetration rate of 97% [2], and the rate of smartphone use among adults in the country was 95% [3]. With widespread access to the internet, individuals now use the internet for diverse purposes in their everyday lives. Using the internet to access health information is common, with one in two EU citizens (55%) aged 16–74 years looking for health information on the internet [4]. About 75.1% of adults in the US searched for health information on the internet each month, such as on diet/nutrition, exercises, medicines, and remedies [5].
Obtaining useful health information from the internet requires various abilities and skills, including not only the basic abilities of reading/writing and understanding health information, but also the skills of searching for and acquiring health information in the internet environment using digital devices. These abilities and skills were labeled together as electronic health literacy (eHealth literacy) in 2006, which was defined as “the ability to seek, find, understand, and appraise health information from electronic sources and apply the knowledge gained to address or solve a health problem” [6].
Several self-reporting instruments have been developed over the last 15 years to assess eHealth literacy. The eHealth Literacy Scale (eHEALS) was the first instrument developed [6], and has been psychometrically evaluated among 18 different languages and in 26 countries [7]. With the shift of information technology from Web 1.0 to Web 2.0, the pioneering instrument of the eHEALS developed in 2006 has not received sufficient attention regarding social media and mobile web skills [8, 9]. The need for an instrument that includes the attributes of skills required to use interactive communication technologies on the internet was reported by van der Vaart et al. [10].
With such a perspective, second-generation instruments were developed, including the e-Health Literacy Scale (e-HLS) [11], Digital Health Literacy Instrument (DHLI) [12], eHealth Literacy Assessment (eHLA) [13], eHealth Literacy Questionnaire (eHLQ) [14], and Transactional eHealth Literacy Instrument (TeHLI) [15]. However, the recent systematic review of measurement properties indicated that the second-generation instruments have considerable limitations [7]. Clearly defining the construct being measured is fundamental in developing a self-reporting instrument, but most of the second-generation instruments are not based on clear statements about what is being measured. This suggests the need for a new instrument in which the eHealth literacy definition being measured is clearly addressed. Further studies are also needed to increase the credibility of the psychometric evidence for these instruments, because the e-HLS and the TeHLI have insufficient low-quality evidence for convergent validity, the DHLI has sufficient low-quality evidence for structural validity, the eHLA has insufficient very-low-quality evidence for internal consistency, and the eHLQ has indeterminate low-quality evidence for measurement invariance [7].
When selecting a self-reporting instrument, the population in which the instrument is administered must be considered to determine whether to use a generic- or condition-specific instrument [16]. A generic instrument is designed to assess a construct (e.g., eHealth literacy) in a broad population, so that it can be applied to a healthy population, across healthy and disease populations, or across different disease populations. Its limitation is that it might not be sufficiently sensitive to assess the construct being measured in a population with a specific condition, because important attributes to the condition or disease are not fully covered. A condition-specific instrument focusing on the contents relevant to clinical conditions is recommended for use in a patient population [17].
The searching contents or abilities of people with a particular disease, which are associated with internet health information, were demonstrated to be different from other diseases. For example, Madrigal and Escoffery [5] found that people with a chronic disease were more likely to search for information on their medicines. The ability of patients with a particular chronic disease to process internet health information is different from those of patients with other diseases [18]. The condition-specific types of eHealth literacy instruments may therefore be a better fit for a patient population than generic types. The Transactional eHealth Literacy Instrument [15] is the only instrument developed in the specific populations of baby-boomer and older adults with chronic lung disease.
Diabetes is a global health problem, with approximately 537 million adults living with diabetes (1 in 10 adults), and about 90% of all diabetes cases being type 2 diabetes. [19]. It requires complex ongoing self-management in the daily lives of patients (e.g., dieting, physical exercise, monitoring blood glucose levels, administration of medications, foot care, and stress control). In the digital era, many people with diabetes obtain information on the disease and its self-management from the internet via digital devices, due to the reduced restriction from time and location [20]. Along with the shifting of diabetes information sources, eHealth literacy has emerged as an important determinant of enhancing diabetes self-management [21, 22]. In practice, many internet-based interventions for diabetes have been developed and serviced to empower patients to engage in self-management and control their glycemic levels [23,24,25]. It is essential for clinicians to assess the eHealth literacy levels of their patients when education or interventions are provided in the form of technology or digital services [26]. However, there is no condition-specific instrument that measures eHealth literacy specific to diabetes. The aims of this study were therefore to develop the Condition-Specific eHealth Literacy Scale for Diabetes (designated as the CeHLS-D) and to evaluate its psychometric properties.
Methods
The CeHLS-D was developed and evaluated in four phases in this study: Conceptualization, Item generation, Content validation, and Field survey for quantitative psychometric tests.
Phase I: conceptualization
The initial step of developing the new scale was to conceptualize the construct being measured, which considered a target population for whom the developed scale is intended for use [16]. Since the first definition of eHealth literacy by Norman and Skinner in 2006, many definitions have been introduced, but without consensus. Griebel et al. [8] recently defined eHealth literacy as “a dynamic and context-specific set of individual and social factors as well as technology constraints in the use of digital technologies to search, acquire, comprehend, appraise, communicate, apply and create health information in all contexts of healthcare with the goal of maintaining or improving the quality of life throughout the lifespan” (p. 433), mostly based on the meta-definition proposed by Bautista [27], but with additional aspects from the definitions of others [28, 29].
The target population for the scale developed in the present study was adults diagnosed with type 2 diabetes. This group encounters or needs health information specific to their disease, treatment, and complex self-management to prevent the onset and progression of complications and to improve quality of life [30, 31]. Based on those perspectives, eHealth literacy was conceptualized in the present study as the abilities and skills to search, acquire, comprehend, appraise, communicate, apply, and create health information specific to diabetes, and its treatment and self-management in internet environments using digital devices, with the goals of improving or maintaining health and preventing complications to improve health-related quality of life. Internet environments in the present study not only refer to the read-only mode of the web but also to participative social media. The digital devices considered included personal computers, mobile phones, and tablets.
Phase II: item generation
For item generation during the development of the new scale, it was important to pool all attributes reflecting the construct being measured. A literature review and a semistructured interview were used as the sources of the attributes in this study. For the comprehensive literature review, a matrix table was constructed based on the above-mentioned eHealth literacy conceptualization. The top row of the matrix contained posited abilities and skills (search, acquire, comprehend, appraise, communicate, apply, and create). In the left column of the matrix, internet environments were posited: static searching portal (e.g., Google and NAVER), email/mobile text messengers (e.g., Gmail, NAVER Mail, KakaoTalk, and WhatsApp), and social network/media sharing (e.g., Facebook, Twitter, and YouTube). From the literature review, the cells of the matrix constructed by overlapping columns and rows were filled with the attributes regarding information on diabetes, and its treatment and self-management.
A semistructured interview was conducted by a trained interviewer (a nursing PhD candidate) in a small room at an outpatient clinic in June 2021. The inclusion criteria for the participants were being at least 19 years old, diagnosed with type 2 diabetes, and an internet user. The appropriate sample size in a qualitative interview is determined by data (attributes) saturation, referring to when collecting more data no longer yields any new data. In this study the interview initially included 20 participants, which is a commonly recommended sample size for research involving qualitative interviews [32]. Those who agreed to participate in the interview were asked to sign an informed-consent form. Each interview was conducted based on the above matrix table, and was recorded and transcribed verbatim. One researcher presented the eHealth literacy-related attributes by using the actual words said by the interviewees and filled in the matrix table. These processes were confirmed and discussed with another expert on eHealth and diabetes care.
Phase III: content validity
Expert panel
Content validity refers to the degree to which each item reflects the construct being measured [33]. A panel of five experts on eHealth literacy, measurement properties, and diabetes care were participated in the content validity. They were asked to respond on how much relevant each item was using a four-point Likert scale (1 = “not relevant,” 2 = “somewhat relevant,” 3 = “quite relevant,” and 4 = “very relevant”).
Analysis of content validity
Content validity was assessed using the item-level content validity index (I-CVI) [34]. The I-CVI was calculated as the proportion of experts who answered “quite relevant” or “very relevant.” If I-CVI > 0.78, the item was considered sufficiently relevant to the eHealth literacy construct. Open questions were also asked to the expert panel to ascertain comprehensiveness (if any of the key construct aspects were missed), comprehensibility (reading level, jargon, and ambiguity), an item response format with a five-point Likert scale ranging from 0 (“not at all”) to 4 (“very much”), and instructions on how to respond to items.
Phase IV: field survey
Study design
A cross-sectional survey was conducted to evaluate the internal consistency, measurement invariance, and structural, convergent, and known-groups validities of the CeHLS-D.
Sample and data collection
A convenience sample of 453 participants was recruited from outpatient clinics in multiple hospitals in South Korea from August to December in 2021. The inclusion criteria for the sample were being at least 19 years old, diagnosed with type 2 diabetes, experienced in using digital devices (personal computers, mobile phones, or tablets), and articulate in the Korean language. Trained research assistants met and provided the study information to potential participants at outpatient clinics. Those who agreed to participate in this study were asked to sign an informed-consent form and then to complete questionnaires. All participants were offered remuneration for participation.
Measures
For convergent validity, eHealth literacy was expected to be moderately correlated with health literacy, based on previous studies [35, 36]. The Diabetes Health Literacy Scale (DHLS) [30] was administered in this study as a comparator instrument to assess the convergent validity of the CeHLS-D. The DHLS was developed to measure diabetes-specific health literacy, and comprises 14 items scored on a 5-point Likert scale from 0 to 4. The scale score is the average of all items, with higher scores indicating better health literacy. The DHLS yielded good psychometric properties for content validity, structural validity (χ2/df = 2.41, RMSEA = 0.07, SRMR = 0.04, and CFI = 0.95), convergent validity, criterion validity, internal consistency (Cronbach’s alpha = 0.91), and test–retest reliability (intraclass correlation coefficient = 0.89). Cronbach’s alpha of the scale in the present study was 0.94. Cronbach’s alpha of the scale in the present study was 0.94.
The following question was asked about the frequency of internet use: “How often do you use the internet to seek health information?” There were four response options of “almost no use,” “approximately 1 day a week,” “several days a week,” and “almost every day.” This was administered to assess the known-groups validity of the CeHLS-D, because people who use the internet more frequently have a higher eHealth literacy than those who use it less [37]. If the mean CeHLS-D score increased with the frequency of internet use, the scale was considered to have satisfactory known-groups validity.
According to the systematic review of existing eHealth literacy instruments [7], a few measurement invariances were tested across groups, including demographic (gender and age), cultural, and physical activity frequency groups. Similarly, the measurement invariances in gender, age, and glycemic control status in the CeHLS-D were presented: male vs. female, ≥ 60 vs. < 60 years old, and glycated hemoglobin A1c (HbA1c) ≤ 6.5% vs. HbA1c > 6.5%. HbA1c values were collected from medical records from within the previous 3 months.
Data analysis
The data were analyzed using SPSS for Windows (version 25), AMOS software (version 25), and the R statistical environment [38]. Missing data were replaced using regression imputation. Mean and standard-deviation values of the items were computed using descriptive statistics. An interitem correlation matrix of all items was conducted, and weakly correlated (r < .30) or redundant (r > .80) items were removed [39].
For the cross-validation of structural validity, the total sample was split into two subsamples using the SPSS random assignment function. Subsample 1 (n = 231) was used for exploratory factor analysis (EFA) and exploratory graph analysis (EGA), and subsample 2 (n = 222) was used for confirmatory factor analysis (CFA). The sample size of each subsample satisfied 7 times the number of items for EFA and at least 200 cases for CFA [40, 41].
To determine whether the application of EFA to the subsample 1 data was available, the Kaiser-Meyer-Olkin (KMO) test and Bartlett’s test of sphericity were conducted [42]. EFA with varimax rotation was conducted to reduce the number of items and determine their underlying structure. Factors with eigenvalue > 1 were retained, and the results was satisfactory when at least 50–60% of the variance was explained by the factors [39]. Factor loadings higher than 0.70 were considered significant to capture the essence of a factor [16]. The dimensionality and patterns of items clustered together in the EFA were further assessed using EGA, which is a new approach for identifying the dimensions of constructs based on network psychometrics [43]. The EGA involves depicting a network as nodes (test items) that are connected by edges (links) representing the internode strengths (i.e., partial correlations). The EGA was conducted using a graphical least absolute shrinkage and selection operator from the EGAnet package.
CFA was performed on subsample 2 using maximum-likelihood estimation. The CFA model fit was determined using multiple indices: normed χ2 (χ2/df < 3), comparative fit index (CFI) > 0.95, standardized root-mean-square residual (SRMR) < 0.08, and root-mean-square error of approximation (RMSEA) < 0.08 [44]. Supplementary to the CFA, the heterotrait-monotrait ratio of correlations (HTMT) was calculated to determine whether a pair of factors (subscales) derived by CFA was distinctively different from another [45]. An HTMT of < 0.85 suggested that the pair of factors was discriminant [46].
For internal consistency analysis, traditional Cronbach’s alpha was assessed, with acceptable values ranging from 0.70 to 0.95 [47]. In a more robust manner, McDonald’s omega (ω) was computed with the criterion value of > 0.70 [48].
Measurement invariance across the gender, age, and glycemic control status groups were analyzed using multigroup CFA (MGCFA). Sample sizes of at least 100 in each of the gender, age, and glycemic control status groups were satisfied for the MGCFA [46]. The MGCFA was tested in the following successive phases using AMOS software [49]: configural invariance model (a baseline model for comparing subsequent invariance tests), metric invariance model (all factor loadings were constrained equally, which is called the measurement weights model), structural covariances model (factor loadings, factor variances, and covariances were constrained equally), and measurement residuals model (factor loadings, factor variances, factor covariances, and error variances were constrained equally). The first two models were given the most attention in practice since the others were considered excessively stringent tests that often are not satisfactory [50]. Configural and metric invariance models were therefore tested in the present study. A CFI change (\(\varDelta\)CFI) of <–0.010, supplemented by either an RMSEA change (\(\varDelta\)RMSEA) of < 0.015 or an SRMR change (\(\varDelta\)SRMR) of < 0.030, indicated invariance on the metric invariance model test [51]. A χ2 difference test is a traditional method for measurement invariance decisions on criteria, but has the limitation of being sensitive to a large sample [49], and was therefore not used in this study.
Convergent validity was analyzed using Pearson’s correlation coefficient. Known-groups validity was tested using one-way analysis of variance (ANOVA). The magnitude of known-groups validity was assessed using the effect size of an eta-squared value (η2), with values of 0.01, 0.06, and 0.14 indicating small, moderate, and large effects, respectively [52].
The floor and ceiling effects of the potential scores were explored using descriptive statistics, and interpreted if 15% or more of the respondents achieved the lowest and highest scores on the instrument [53].
Results
Items derived
The literature review extracted an initial pool of 28 attributes that filled the cells of the matrix table constructed in this study (more than one attribute was allowed in a cell). Each semistructured interview lasted about 30 min. Attributes saturation occurred at the 14th participant in this study. This is consistent with a recent systematic review finding that saturation occurred after 9–17 interviews in qualitative research [54]. General characteristics are listed in Table S1 in the Supplementary Material. From the semistructured interview, the following four additional attributes were added to the initial pool of attributes: thinking of appropriate search words, blocking out spammers, distinguishing whether a text message (e.g., information for visiting a clinic or receiving a medical examination) is for someone or anyone, and protecting personal information. Each attribute on the matrix table was then converted into the content of each item.
Content validity
Of the derived items, 29 achieved I-CVI > 0.78, and the remaining items not satisfying the criterion value were deleted. As suggested by the expert panel, some phrases of five items were slightly modified to increase comprehensibility, but no new items were added. The five-point Likert scale was unchanged. The instructions on how to respond to items was maintained in which the asking recall period was “at the present time.” The content-validated items were then checked by a professional who majored in the Korean language, and seven items were semantically polished into plain language.
Field survey
General characteristics
Among the 453 participants, more than a half were male (64.7%), employed (66.2%), and had graduated from high school (87.9%). They were aged 56.8 (SD = 10.8) years. Approximately two-thirds of the participants were taking an oral hypoglycemic agent (78.1%), and their diabetes duration was 8.9 (SD = 7.3) years (Table S2 in the Supplementary Material).
Interitem correlation matrix
The interitem correlation coefficients of all items ranged from 0.42 to 0.89 (p < .05). Ten item pairs were strongly correlated (coefficient > 0.80). One item from each strongly correlated pair was removed because they indicated item redundancy, leading to a multicollinearity problem [39].
Structural validity
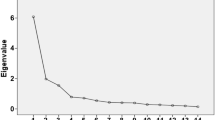
EFA was conducted on subsample 1 (Table 1) Bartlett’s test was significant (χ2 = 4242.46, p\(<\)0.001) and KMO = 0.95, implying that the data had very good factorability. EFA with varimax rotation extracted a two-factor solution (eigenvalue > 1), and the amount of variance explained by the two factors was 70.00%. A total of 12 items were meaningfully loaded onto one of the 2 factors. Factors 1 and 2 were loaded with eight and four items, respectively. If Cronbach’s alpha was > 0.95, some items in the factor might be redundant [47]. Cronbach’s alpha of factor 1 was > 0.95. Item 10 was also very strongly correlated with the total score of factor 1 (a corrected item-total correlation of r = .91) implying the existence of a redundant item [39], and so it was deleted. The second EFA was then performed with 11 items, and extracted a 2-factor solution explaining 75.55% of the variance (Table 1). Factors 1 and 2 were named “cognitive actions for internet diabetes information” and “abilities of digital communication,” respectively. The EGA also demonstrated two dimensions, as depicted in Fig. 1. The patterns of items clustered together were consistent with the EFA results, and the partial correlation between items 16 and 17 was the strongest.

Exploratory graph analysis (EGA) of the number of factors
Blue and red nodes indicate factors 1 and 2, respectively. Items are numbered as in Table 1. Line thicknesses indicate the strength of partial correlations.
Based on the EFA/EGA results, CFA was performed on subsample 2 using the two-factor model. As presented in Table 2, the initial two-factor model provided a marginal fit to the data. The possibility of model misspecification was therefore explored: the modification index value was the highest between the error terms of items 16 and 17 (46.07) in factor 2. The two error terms of the items had their covariance presented with two-headed curved arrows, and CFA was again performed. This modification (modified model 1) markedly improved the fit (\(\varDelta\)χ2 [1] = 82.05, p < .05, \(\varDelta\)CFI = 0.035), and the values of the model-fit indices were satisfied (Table 2). However, the standardized error covariance parameter estimate between items 16 and 17 was somewhat high (0.745). This implies overlap in the content of the items, although they were worded differently but asked the same question [49]. Both items 16 and 17 related to “the skills about text messages.” After eliminating item 17, modified model 2 represented a meaningful improvement over the initial model (\(\varDelta\)CFI = 0.032) and yielded a good fit across all indices (Table 2). All of the loaded items were significant in their designated factors (critical ratio value > 1.96), and standardized factor loading values ranged from 0.766 to 0.887. The standardized factor covariance parameter estimate (\(\phi\)) was 0.778 (Fig. 2). HTMT was 0.76 (the criterion value was < 0.85), hence satisfying that the discriminant structure of the two factors.

Findings of confirmatory factor analysis for the CeHLS-D
Factor 1, cognitive actions for internet diabetes information; Factor 2, abilities of digital communication; e, measurement error. Items are numbered as in Table 1.
Internal consistency
For the total sample, Cronbach’s alpha values of factors 1 and 2 were 0.92 and 0.89, respectively. The \(\omega\) values of factors 1 and 2 were 0.94 and 0.87, respectively. The CeHLS-D therefore demonstrated excellent internal consistency.
Measurement invariance
Table 3 presents the nested tests of measurement invariance for the CeHLS-D across the gender, age, and glycemic control status groups. All of the configural invariance models exhibited a satisfactory fit to the data. All of the metric invariance models displayed satisfactory fit to the data, and the \(\varDelta\)CFA, \(\varDelta\)SRMR, and \(\varDelta\)RMSEA values satisfied their invariance criteria. The measurement invariance of the CeHLS-D was therefore supported.
Convergent and known-groups validities
The CeHLS-D had a moderate correlation with the DHLS (r = .57, p < .001), suggesting that convergent validity was satisfied. One-way ANOVA revealed statistically significant differences in the mean scores of the CeHLS-D among the four response groups of internet use frequency (F = 35.50, p < .001) (Table 4). The effect size of the mean differences between the four groups was large (\(\eta\)2 = 0.19). A post-hoc test for group comparisons found that the mean scores on the CeHLS-D of the almost-every-day use group was significantly higher than those of the approximately-1-day-a-week and almost-no-use groups, and the CeHLS-D mean score of the several-days-a-week use group was significantly higher than that of the almost-no-use group. These findings indicate that the CeHLS-D had satisfactory known-groups validity.
Floor and ceiling effects
Regarding the final CeHLS-D, participants achieved the lowest and highest scores for item 19 (Mean = 2.06, SD = 1.48) and item 16 (Mean = 3.20, SD = 1.09), respectively. The average scores for the total scale, factor 1, and factor 2 were 2.39 (SD = 1.04), 2.37 (SD = 1.04), and 2.58 (SD = 1.22), respectively (Table 5). The lowest floor effects of the participants for total score, factor 1, and factor 2 were 4.6%, 5.5%, and 3.8%, respectively; the corresponding ceiling effects were 2.6%, 4.6%, and 21.4%.
Discussion
This study developed the CeHLS-D under a comprehensive definition of eHealth literacy, which encompassed the attributes required for the social-media nature of the current digital environment. The CeHLS-D is the first condition-specific instrument for measuring eHealth literacy specifically in the context of diabetes. The Transactional eHealth Literacy Instrument [15] was developed in a population with chronic lung disease; however, there were no contents particularly relevant to the disease. So, the instrument was closer to a generic than to a condition-specific instrument.
Structural validity is defined as “the extent to which the structure of a multi-item instrument adequately reflects the hypothesized dimensionality of the construct being measured” [16]. Many psychometric studies of eHealth literacy instruments have only analyzed structural validity using EFA [6, 12, 55,56,57,58,59,60,61,62,63,64,65]. EFA was applied to reduce the numbers of items or to hypothesize the number of dimensions (factors) that the instrument had and which items were loaded on the factors. EFA was therefore considered to be not sufficiently adequate for structural validity [66]. A strength regarding the structural validity of the CeHLS-D was the application of a cross-validation approach. EFA yielded a two-factor solution for the CeHLS-D, and EGA under a network psychometric perspective supported that solution. CFA was then performed to verify whether the empirically hypothesized two-factor structure was fit for the actual data.
The CFA in this study yielded a correlation value of 0.778 between the two factors, which was considered a moderately strong correlation, and further exploration of the discriminant is required. Traditionally, the Fornell-Lacker criterion developed for marketing in 1981 (the average extracted variance of each construct > shared variance2) has been frequently applied to assess whether two latent variables (factors) in a measurement model of CFA are discriminant [67]. However, that criterion is criticized as lacking in discriminant detection [45]. In the present study, a recently recommended HTMT value was calculated, which confirmed the discriminant nature of the two-factor solution.
Cronbach’s alpha values may be higher when more items are included in an instrument [66]. The CeHLS-D is a relatively short instrument, and yet it achieved excellent Cronbach’s alpha values of 0.92 and 0.89 for factors 1 and 2, respectively. These values were similar or higher than those of other instruments with more items: 0.87–0.92 for the Transactional eHealth Literacy Instrument subscales [15], 0.77–0.86 for the eHealth Literacy Questionnaire subscales [14], 0.57–0.89 for the Digital Health Literacy Instrument subscales [12], and 0.52–0.81 for the eHealth Literacy Scale-Extended subscales [68]. Cronbach’s alpha has continually served as a dominant indicator of internal consistency. It is currently recommended that shifting to using ω would be a better alternative [69]. The ω values of the CeHLS-D subscales also demonstrated good internal consistency.
In this study, the measurement invariance of the CeHLS-D was satisfied across the gender, age, and glycemic control status groups. This means that the participants in the different groups recognized that not only the number of factors and patterns were the same, but also were the items loaded to the factors. The CeHLS-D can therefore be used in practice for people with type 2 diabetes regardless of gender, age, and glycemic control status.
Convergent validity is a test of the hypothesized relationship of scores on a focal instrument under study, with scores on a comparator measuring a similar construct. Here, the instrument used as a comparator was likely to be psychometrically satisfied. Regarding the convergent validity of existing eHealth literacy instruments, the measurement properties of their comparator instruments have not been reported for about 44% of studies, degrading the quality of convergent validity [7]. In the present study, the CeHLS-D exhibited satisfactory convergent validity with a moderate correlation using the psychometrically satisfied comparator of the DHLS to measure health literacy [30]. This was consistent with a study on the correlation between eHealth literacy measured using the eHealth Literacy Scale and health literacy measured using the Health Literacy Questionnaire subscales (r = .38–0.56) [35]. The CeHLS-D also had satisfactory known-groups validity. This was consistent with a study on a patient group that used the internet more frequently, which had had higher eHealth literacy than the other patient groups who used the internet several times a week or less [70].
There was a ceiling effect on the CeHLS-D subscale of the “abilities of digital communications.” This might attributable to the item of “text messaging (e.g., KakaoTalk, WhatsApp)”, which achieved the highest mean score among the items. In South Korea, 95% of the population owns a smartphone, 92% of those older than 13 years used a mobile messenger during the previous year, and around 99.1% of all mobile messenger users are utilizing KakaoTalk (a free mobile instant text messaging app) [71, 72]. Mobile text messaging, particularly using KakaoTalk, seems to be an essential communication method for South Koreans. Considering that, the item of “text messaging” might be a relatively easy skill for the participants of this study. It is therefore recommended to make that item more difficult or complicated in future studies. It also needs to be determined whether the ceiling effect was due to the cultural aspect of living in a society that is highly centered around digital communication.
All existing eHealth literacy instruments other than the eHealth Literacy Scale [6] were criticized for the instructions provided on how to respond to items not specifying the recall period, which may induce bias in the response items [7]. The instructions of the CeHLS-D classified the recall period as “at present.”
The CeHLS-D comprised 10 items with responses on a 5-point Likert-type scale. The number of items was much smaller than in the eHealth Literacy Scale-Extended (eHEALS-E) (20 items) [68], e-HLS (19 items) [11], DHLI (21 items) [12], eHLA (44 items) [13], eHLQ (35 items) [14], and TeHLI (18 items) [15]; but was larger than for the eHEALS (8 items) [6]. The CeHLS-D may therefore be feasible for use in practice and less burdensome to respondents.
Limitations
This study had some limitations. First, the study design was cross-sectional, and the test–retest reliability—referring to the temporal stability for the same individuals on at least two occasions—of the CeHLS-D was therefore not assessed. Previous studies on the test–retest reliability of eHealth literacy instruments had several methodological limitations: insufficient sample sizes, no information on administration intervals, and/or using an inadequate reliability statistic [6, 55, 56, 73, 74]. It is therefore recommended to consider the limitations for further reliability tests of the CeHLS-D. Second, the criterion validity of the CeHLS-D was not tested because the patient-reported outcome measures (self-reporting instruments) almost always lack a gold standard, except when developing a short-version instrument using its corresponding long version as a gold standard for the criterion validity test [66]. In contrast, others insist that an expert opinion, physiological indicator, or clinical measure can be used as a gold standard for criterion validity [34]. If this is correct, it is recommended that further tests use an actual performance skill related to eHealth literacy as a criterion for the CeHLS-D. Third, the CeHLS-D was only psychometrically tested on Korean adults with type 2 diabetes, and so cross-cultural validation testing of the instrument is still needed.
Implications for practice and research
With the rapid development of internet technology, individuals such as those with type 2 diabetes have come to seek health information on the internet and use the obtained information to make medical decisions [75]. However, these individuals have not equal abilities in evaluating whether information from the internet is effective or useful. In practice, health professionals have a responsibility to instruct patients about how to avoid obtaining conflicting or misleading internet diabetes information. To do so, they must identify patients with low eHealth literacy, and provide patients vulnerable to misleading or conflicting eHealth literacy information with methods and sources for trustworthy diabetes information in the internet. In such a situation, the CeHLS-D can be used for people with type 2 diabetes.
Diabetes self-management education is well known as an intervention that impacts self-management and glycemic control. The traditional delivery method of face-to-face diabetes education has recently been shifting to an internet- or app-based digital method. During the coronavirus disease 2019 pandemic, the importance of the digital delivery method came to the fore in clinical practice as a method for remote care and communication between health providers and patients. This suggests that internet- or app-based diabetes interventions or care should be tailored to eHealth literacy levels. The CeHLS-D can be used to assess eHealth literacy levels to develop tailored applications of internet-based diabetes interventions.
Even though the CeHLS-D is a population-specific instrument for type 2 diabetes, it may be applicable to patients with other chronic disease (e.g., hypertension), if some item phrases are adopted. For example, the phrase “information of diabetes and self-management” could be changed to “information of hypertension and self-management,” and the phrase “diabetes-related numeric medical examination values (e.g., HbA1c and fasting glucose)” changed to “hypertension-related numeric medical examination values (e.g., blood pressure and cholesterol).” To do so, a psychometric study on the adopted instrument (provisionally named CeHLS-hypertension) should be conducted on individuals diagnosed with hypertension.
Conclusion
This study developed a new condition-specific eHealth literacy instrument for people with type 2 diabetes, designated as the CeHLS-D. The CeHLS-D comprises 10 items scored on a 5-point Likert scale; this brief instrument therefore has the strengths of being feasible for use in practice and being less burdensome to respondents. The CeHLS-D exhibited good psychometric properties of internal consistency, and content, structural, convergent, and known-groups validities. Its measurement invariance was also satisfied across gender, age, and glycemic control groups. The CeHLS-D can therefore be applied in research and practice to assess the eHealth literacy of people with type 2 diabetes. However, its test–retest reliability still needs to be evaluated, and a cross-cultural validity study is required among different languages and countries.
Data Availability
The dataset used and/or analyzed during this study can be provided from the corresponding author on reasonable request.
Abbreviations
- CeHLS-D:
-
Condition-specific eHealth literacy scale for diabetes
- CFA:
-
Confirmatory factor analysis
- CFI:
-
Comparative fit index
- DHLI:
-
Digital health literacy instrument
- EFA:
-
Exploratory factor analysis
- EGA:
-
Exploratory graph analysis
- eHealth literacy:
-
Electronic health literacy
- eHEALS:
-
eHealth literacy scale
- eHLQ:
-
eHealth literacy questionnaire
- e-HLS:
-
e-Health literacy scale
- HTMT:
-
Heterotrait-monotrait ratio of correlation
- I-CVI:
-
Item-level content validity index
- MGCFA:
-
Multigroup confirmatory factor analysis
- RMSEA:
-
Root-mean-square error of approximation
- SRMR:
-
Standardized root-mean-square residual
- TeHLI:
-
Transactional eHealth literacy instrument
References
Internet World Stats. World internet usage and population statistics 2021 year-Q1 estimates. 2021. https://www.internetworldstats.com/stats.htm. Accessed 25 Jan 2022.
DataRepotal. Digital 2021: South Korea. 2021. https://datareportal.com/reports/digital-2021-south-korea. Accessed 03 Feb 2022.
Pew Research Center. Smartphone ownership is growing rapidly around the world, but not always equally. 2019. https://www.pewresearch.org/global/2019/02/05/smartphone-ownership-is-growing-rapidly-around-the-world-but-not-always-equally. Accessed 03 Feb 2022.
Eurostat. One in two EU citizens look for health info. 2021. https://ec.europa.eu/eurostat/web/products-eurostat-news/-/edn-20210406-1. Accessed 22 Nov 2021.
Madrigal L, Escoffery C. Electronic health behaviors among US adults with chronic disease: cross-sectional survey. J Med Internet Res. 2019;21(3):e11240. https://doi.org/10.2196/11240.
Norman CD, Skinner HA. eHEALS: The eHealth Literacy Scale. J Med Internet Res Nov. 2006;8:e27. https://doi.org/10.2196/jmir.8.4.e27.
Lee J, Lee E-H, Chae D. eHealth literacy instruments: systematic review of measurement properties. J Med Internet Res. 2021;23(11):e30644. https://doi.org/10.2196/30644.
Griebel L, Enwald H, Gilstad H, Pohl A-L, Morekand J, Sedlmayr M. eHealth literacy research-Quo Vadis? Inf Health Soc Care. 2018;43(4):427–42. https://doi.org/10.1080/17538157.2017.1364247.
Norman C. eHealth literacy 2.0: problems and opportunities with an evolving concept. J Med Internet Res. 2011;13(4):e125. https://doi.org/10.2196/jmir.2035.
van der Vaart R, Drossaert CH, de Heus M, Taal E, van de Laar MA. Measuring actual eHealth literacy among patients with rheumatic diseases: a qualitative analysis of problems encountered using Health 1.0 and Health 2.0 applications. J Med Internet Res. 2013;15(2):e27. https://doi.org/10.2196/jmir.2428.
Seckin G, Yeatts D, Hughes S, Hudson C, Bell V. Being an informed consumer of health information and assessment of electronic health literacy in a national sample of internet users: validity and reliability of the e-HLS instrument. J Med Internet Res. 2016;18(7):e161. https://doi.org/10.2196/jmir.5496.
van der Vaart R, Drossaert C. Development of the Digital Health Literacy Instrument: measuring a broad spectrum of Health 1.0 and Health 2.0 skills. J Med Internet Res. 2017;19(1):e27. https://doi.org/10.2196/jmir.6709.
Karnoe A, Furstrand D, Christensen KB, Norgaard O, Kayser L. Assessing competencies needed to engage with digital health services: development of the eHealth literacy assessment toolkit. J Med Internet Res. 2018;20(5):e178. https://doi.org/10.2196/jmir.8347.
Kayser L, Karnoe A, Furstrand D, Batterham R, Christensen KB, Elsworth G, et al. A multidimensional tool based on the eHealth literacy framework: development and initial validity testing of the eHealth Literacy Questionnaire (eHLQ). J Med Internet Res. 2018;20(2):e36. https://doi.org/10.2196/jmir.8371.
Paige SR, Stellefson M, Krieger JL, Miller MD, Cheong J, Anderson-Lewis C. Transactional eHealth literacy: developing and testing a multi-dimensional instrument. J Health Commun. 2019;24(10):737–48. https://doi.org/10.1080/10810730.2019.1666940.
Polit DF, Yang FM. Measurement and the Measurement of Change. Philadelphia: Wolters Kluwer; 2016.
Dehghani A, Keshavarzi A. Development and validation of a multidimensional health literacy questionnaire for multiple sclerosis patients. Mult Scler Relat Disord. 2018;25:156–62. https://doi.org/10.1016/j.msard.2018.07.018.
El Benny M, Kabakian-Khasholian T, El-Jardali F, Bardus M. Application of the eHealth literacy model in digital health interventions: scoping review. J Med Internet Res. 2021;23(6):e23473. https://doi.org/10.2196/23473.
International Diabetes Federation. Diabetes Atlas 2021 (10th ed.): Diabetes facts and Fig. 2021. https://www.idf.org/aboutdiabetes/what-is-diabetes/facts-figures.html. Accessed 21 Jan 2022.
Horigan G, Davies M, Findlay-White F, Coates CV. Reasons why patients referred to diabetes education programs choose not to attend: a systematic review. Diabet Med. 2017;34(1):14–26. https://doi.org/10.1111/dme.13120.
Dao J, Spooner C, Lo W, Harris MF. Factors influencing self-management in patients with type 2 diabetes in general practice: a qualitative study. Aust J Prim Health. 2019;25:176–84. https://doi.org/10.1071/PY18095.
Guo SH-M, Hsing H-C, Lin J-L, Lee C-C. Relationships between mobile eHealth literacy, diabetes self-care, and glycemic outcomes in Taiwanese patients with type 2 diabetes: cross-sectional study. JMIR MHealth and UHealth. 2021;9(2):e18404. https://doi.org/10.2196/18404.
Kebede M, Christianson L, Khan Z, Heise T, Pischke CR. Effectiveness of behavioral change techniques employed in eHealth interventions designed to improve glycemic control in persons with poorly controlled type 2 diabetes: a systematic review and meta-analysis protocol. Syst Rev. 2017;6:211. https://doi.org/10.1186/s13643-017-0609-1.
Pal K, Dack C, Ross J, Michie S, May C, Stevenson F, et al. Digital health interventions for adults with type 2 diabetes: Qualitative study of patient perspectives on diabetes self-management education and support. J Med Internet Res. 2018;20(2):e40. https://doi.org/10.2196/jmir.8439.
Rollo ME, Aguiar EJ, Williams RL, Wynne K, Kriss M, Callister R, et al. eHealth technologies to support nutrition and physical activities behaviors in diabetes self-management. Diabetes Metab Syndr Obes: Targets Ther. 2016;9:381–90. https://doi.org/10.2147/DMSO.S95247.
Karnoe A, Kayser L. How is eHealth literacy measured and what do the measurements tell us? A systematic review. Knowl Manag E-Learn. 2015;7(4):576–600. https://doi.org/j.kmel.2015.07.038.
Bautista JR. From solving a health problem to archiving quality of life: redefining eHealth literacy. J Lit Technol. 2015;16(2):33–54. https://doi.org/10.2196/jmir.8439.
Kayser L, Kushniruk A, Osborne RH, Norgaad O, Turner P. Enhancing the effectiveness of consumer-focused health information technology systems through systems eHealth literacy: a framework for understanding user’s needs. JMIR Hum Factors. 2015;2(1):e9. https://doi.org/10.2196/humanfactors.3696.
Klecun E, Lichtner V, Cornford T. e-Literacy in health care. Stud Health Technol Inform. 2014;205:843–47. https://doi.org/10.3233/978-1-61499-432-9-843.
Lee E-H, Lee YW, Lee K-W, Nam M, Kim SH. A new comprehensive diabetes health literacy scale: development and psychometric evaluation. Int J Nurs Stud. 2018;88:1–8. https://doi.org/10.1016/j.ijnurstu.2018.08.002.
Saisho Y. Use of diabetes treatment satisfaction questionnaire in diabetes care: importance of patient-reported outcomes. Int J Environ Res Public Health. 2018;15(5):947. https://doi.org/10.3390/ijerph15050947.
Mason M. Sample size and saturation in PhD studies using qualitative interviews. Forum Qual Soc Res. 2010;11(3). https://doi.org/10.17169/fqs-11.3.1428.
Mokkink LB, Terwee CB, Patrick DL, Alonso J, Stratford PW, Knol DL, et al. The COSMIN study reached international consensus on taxonomy, terminology, and definitions of measurement properties for health-related patient reported outcomes. J Clin Epidemiol. 2010;63(7):737–45. https://doi.org/10.1016/j.jclinepi.2010.02.006.
Polit DF, Beck CT, Owen S. Is the CVI an acceptable indicator of content validity? Appraisal and recommendations. Res Nurs Health. 2007;30(4):459–67. https://doi.org/10.1002/nur.20199.
Brørs C, Wentzel-Larsen T, Dalen H, Hansen TB, Norman CD, Wahl A, et al. Psychometric properties of the Norwegian version of the Electronic Health Literacy Scale (eHEALS) among patients after percutaneous coronary intervention: Cross-sectional validation study. J Med Internet Res. 2020;22(7):e17312. https://doi.org/10.2196/17312.
Efthymiou A, Middleton N, Charalambous A, Papastavrou E. Health literacy and eHealth literacy and their association with other caring concepts among carers of people with dementia: a descriptive correlational study. Health Soc Care Community. 2021;00:1–11. https://doi.org/10.1111/hsc.13341.
Chang A, Schulz PJ. The measurements and an elaborated understanding of Chinese eHealth literacy (C-eHEALS) in chronic Patients in China. Int J Environ Res Public Health. 2018;15(7):1553. https://doi.org/10.3390/ijerph15071553.
R core team. R: a language and environment for statistical computing. Vienna. Austria: R Foundation for Statistical Computing; 2020. https://www.R-project.org.
Pett MA, Lackey NR, Sullivan JJ. Making Sense of Factor Analysis. Thousand Oaks: Sage; 2003.
Mokkink LB, de Vet HCW, Prinsen CAC, Patrick DL, Alonso J, Bouter LM, Terwee CB. COSMIN Risk of Bias checklist for systematic reviews of patient-reported outcome measures. Qual Life Res. 2018;27(5):1171–79. https://doi.org/10.1007/s11136-017-1765-4.
Cappelleri JC, Zou KH, Bushmakin AG, Alvi JMJ, Alemayehu D, Symonds T. Patient-reported outcomes: measurement, implementation, and interpretation. Florida: CRC Press; 2014.
Tabachnick BG, Fidell LS. Using multivariate statistics. 6th edition. Boston: Pearson; 2013. p. 681–785.
Golino H, Shi D, Christensen AP, Garrido LE, Nieto MD, Sadana R, et al. Investigating the performance of exploratory graph analysis and traditional techniques to identify the number of latent factors: a simulation and tutorial. Psychol Methods. 2020;25(3):292–320. https://doi.org/10.1037/met0000255.
Hu LT, Bentler PM. Cutoff criteria for fit indexes in covariance structure analysis: conventional criteria versus new alternatives. Struct Equ Modeling. 1999;6:1–55. https://doi.org/10.1080/10705519909540118.
Henseler J, Christian M, Mario S. A new criterion for assessing discriminant validity in variance-based structural equation modeling. J Acad Mark Sci. 2015;43(1):115–35. https://doi.org/10.1007/s11747-014-0403-8.
Kline RB. Principles and practice of structural equation modeling. 4th edition. New York: Guilford Press; 2016.
Tavakol M, Dennick R. Making sense of Cronbach’s alpha. Int J Med Educ. 2011;2:53–5. https://doi.org/10.5116/ijme.4dfb.8dfd.
McDonald RP. Test theory: a unified treatment. Mahwah: Lawrence Erlbaum; 1999.
Byrne BM. Structural equation modeling with AMOS: basic concepts, applications, and programming. 3rd edition. New York: Routedge; 2016.
Chen Y-J, Tang TL-P. Attitude toward and propensity to engage in unethical behavior: measurement invariance across major among university students. J Bus Ethics. 2006;69:77–93. https://doi.org/10.1007/s10551-006-9069-6.
Chen F-F. Sensitivity of goodness of fit indexed to lack of measurement invariance. Struct Equ Modeling. 2007;12:464–504. https://doi.org/10.1080/10705510701301834.
Fayers PM, Machin D. Quality of life: the assessment, analysis, and interpretation of patient-related outcomes. 2nd edition. West Sussex; 2007.
McHorney CA, Tarlov AR. Individual-patient monitoring in clinical practice: are available health status survey adequate? Qual Life Res. 1995;4:293–307. https://doi.org/10.1007/BF01593882.
Hennink M, Kaiser BN. Sample sizes for saturation in qualitative research: a systematic review of empirical tests. Soc Sci & Med. 2022;292:114523. https://doi.org/10.1016/j.socscimed.2021.114523.
Bazm S, Mirzaei M, Fallahzadeh H, Bazm R. Validity and reliability of the Iranian version of eHealth Literacy Scale. J Community Health Res. 2016;5(2):121–30.
Chung S, Park BK, Nahm E-S. The Korean eHealth Literacy Scale (K-eHEALS): reliability and validity testing in younger adults recruited online. J Med Internet Res. 2018;20(4):e138. https://doi.org/10.2196/jmir.8759.
Dale JG, Lüthi A, Skaraas BF, Rundereim T, Dale B. Testing measurement properties of the Norwegian version of electronic Health Literacy Scale (eHEALS) in a group of day surgery patients. J Multidiscip Healthc. 2020;13:241–47. https://doi.org/10.2147/JMDH.S242985.
Del Giudice P, Bravo G, Poletto M, De Odorico A, Conte A, Brunelli L, et al. Correlation between eHealth literacy and health literacy using the eHealth Literacy Scale and real-life experiences in the health sector as a proxy measure of functional health literacy: cross-sectional web-based survey. J Med Internet Res. 2018;20(10):e281. https://doi.org/10.2196/jmir.9401.
Duplaga M, Sobecka K, Wójcik S. The reliability and validity of the telephone-based and online Polish eHealth Literacy Scale based on two nationally representative samples. Int J Environ Res Public Health. 2019;16(17):3216. https://doi.org/10.3390/ijerph16173216.
Efthymiou A, Middleton N, Charalambous A, Papastavrou E. Adapting the eHealth Literacy Scale for carers of people with chronic diseases (eHeals-Carer) in a sample of Greek and Cypriot carers of people with dementia: reliability and validation study. J Med Internet Res. 2019;21(11):e12504. https://doi.org/10.2196/12504.
Holch P, Marwood JR. EHealth literacy in UK teenagers and young adults: exploration of predictors and factor structure of the eHealth Literacy Scale (eHEALS). JMIR Form Res. 2020;4(9):e14450. https://doi.org/10.2196/14450.
Koo M, Norman CD, Hsiao-Mei C. Psychometric evaluation of a Chinese version of the eHealth Literacy Scale (eHEALS) in school age children. Int Electron J Health Educ. 2012;15(1):29–36.
Tomás C, Queirós P, Ferreira T. Analysis of the psychometric properties of the Portuguese version of an eHealth literacy assessment tool. Revista de Enfermagem Referéncia. 2014;4(2):19–28. https://doi.org/10.12707/RIV14004.
van der Vaart R, van Deursen AJ, Drossaert CH, Taal E, van Dijk JA, van de Laar MA. Does the eHealth Literacy Scale (eHEALS) measure what it intends to measure? Validation of a Dutch version of the eHEALS in two adult populations. J Med Internet Res. 2011;13(4):e86. https://doi.org/10.2196/jmir.1840.
Wångdahl J, Jaensson M, Dahlberg K, Nilsson U. The Swedish version of the electronic Health Literacy Scale: prospective psychometric evaluation study including thresholds levels. JMIR Mhealth Uhealth. 2020;8(2):e16316. https://doi.org/10.2196/16316.
de Vet HCW, Terwee CB, Mokkink LB, Knol DL. Measurement in medicine: a practical guide. New York: Cambridge University Press; 2011.
Fornell C, Larcker DF. Evaluating structural equation models with unobservable variables and measurement error. J Mark Res. 1981;18:39–50. https://doi.org/10.2307/3151312.
Petrič G, Atanasova S, Kamin T. Ill literates or illiterates? Investigating the eHealth literacy of users of online health communities. J Med Internet Res. 2017;19(10):e331. https://doi.org/10.2196/jmir.7372.
Taylor JM. Coefficient omega. J Nurs Educ. 2021;60(8):429–30. https://doi.org/10.3928/01484834-20210722-02.
Wong DK-K, Cheung M-K. Online health information seeking and eHealth literacy among patients attending a primary care clinic in Hong Kong: a cross-sectional survey. J Med Internet Res. 2019;21(3):e10831. https://doi.org/10.2196/10831.
Digital Business Lap. South Korea insight: social media landscape overview. 2020. https://digital-business-lab.com/2020/04/south-korea-insight-social-media-landscape-overview. Accessed 30 Jan 2022.
Gallup Korea. Market 70 2021 (2) Media, contents, social network services. 2021. https://www.gallup.co.kr/gallupdb/reportContent.asp?seqNo=1205. Accessed 06 Feb 2022.
Chung S-Y, Nahm E-S. Testing reliability and validity of the eHealth Literacy Scale (eHEALS) for older adults recruited online. Comput Inf Nurs. 2015;33(4):150–56. https://doi.org/10.1097/CIN.0000000000000146.
Wijaya MC, Kloping YP. Validity and reliability testing of the Indonesian version of the eHealth Literacy Scale during the COVID-19 pandemic. Health Inf J. 2021;27(1):1460458220975466. https://doi.org/10.1177/1460458220975466.
Shen Y, Wang F, Zhang X, Zhu X, Sun Q, Fisher E, et al. Effectiveness of internet-based interventions on glycemic control in patient with type 2 diabetes: meta-analysis of randomized controlled trials. J Med Internet Res. 2018;20(5):e172. https://doi.org/10.2196/jmir.9133.
Acknowledgements
We thank all those who participated in this study.
Funding
This research was supported by a grant from the National Research Foundation of Korea (NRF) funded by the government of the Republic of Korea (NRF-2021R1A2B5B01001603). The funder did not play any role in the conduct or publication of the study.
Author information
Authors and Affiliations
Contributions
Study conception and design: E.-H.L. Data collection: Y.W.L, K.-W.L., H.J.K., S.H., S.H.K., and E.-H.K. Data analysis: E.-H.L., Y.W.L, and E.-H.K. Drafting the articles: E.-H.L., and Y.W.L. All authors have read and approved the final submitted version of the manuscript.
Corresponding author
Ethics declarations
Ethical approval and consent to participate
This study was approved by the institutional review boards of the participating hospitals (approval numbers AJIRB-MED-SUR-21-179 and INHAUH 2021-07-022). Written informed consent was obtained from all participants. All methods were performed in accordance with the relevant guidelines and regulations.
Consent for publication
No applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Lee, EH., Lee, Y.W., Lee, KW. et al. Development and psychometric evaluation of a new brief scale to measure eHealth literacy in people with type 2 diabetes. BMC Nurs 21, 297 (2022). https://doi.org/10.1186/s12912-022-01062-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12912-022-01062-2