
Abstract
Background
Acute Myocardial Infarction (AMI) is the leading cause of death in Portugal and globally. The present investigation created a model based on machine learning for predictive analysis of mortality in patients with AMI upon admission, using different variables to analyse their impact on predictive models.
Methods
Three experiments were built for mortality in AMI in a Portuguese hospital between 2013 and 2015 using various machine learning techniques. The three experiments differed in the number and type of variables used. We used a discharged patients’ episodes database, including administrative data, laboratory data, and cardiac and physiologic test results, whose primary diagnosis was AMI.
Results
Results show that for Experiment 1, Stochastic Gradient Descent was more suitable than the other classification models, with a classification accuracy of 80%, a recall of 77%, and a discriminatory capacity with an AUC of 79%. Adding new variables to the models increased AUC in Experiment 2 to 81% for the Support Vector Machine method. In Experiment 3, we obtained an AUC, in Stochastic Gradient Descent, of 88% and a recall of 80%. These results were obtained when applying feature selection and the SMOTE technique to overcome imbalanced data.
Conclusions
Our results show that the introduction of new variables, namely laboratory data, impacts the performance of the methods, reinforcing the premise that no single approach is adapted to all situations regarding AMI mortality prediction. Instead, they must be selected, considering the context and the information available. Integrating Artificial Intelligence (AI) and machine learning with clinical decision-making can transform care, making clinical practice more efficient, faster, personalised, and effective. AI emerges as an alternative to traditional models since it has the potential to explore large amounts of information automatically and systematically.
Similar content being viewed by others


Background
Cardiovascular diseases are the leading cause of death in the European Union (EU) and the United States of America, representing approximately 30% of deaths [1,2,3]. In cardiovascular diseases, Acute Myocardial Infarction (AMI) is still the leading cause of death and hospitalisation in Portugal and globally [3], representing 3.3% of the total deaths in Portugal [4]. Moreover, the effects of COVID‐19 demonstrated the need to maintain access to high-quality acute care for AMI, as significant rises in AMI mortality rates were seen during this period [3, 5, 6]. In recent decades, introducing new technologies, optimising therapeutic means, and preventive policies, improving pre-hospital care, and creating guidelines have substantially impacted the mortality rate and length of hospital stay [3, 7].
However, the 30-day in-hospital AMI mortality rate that reflects the provision of care and clinical interventions [8, 9] significantly varies among EU countries. The lowest rates are found in The Netherlands, Sweden, Slovenia, Denmark, Poland and Ireland, with values below 5.0%. Portugal stands at 7.3%, above the average for EU countries, with an observed increase in 2020 [3].
But, many factors can influence AMI results. According to the European Society of Cardiology, AMI mortality is influenced by several risk factors with significant predictive power in the risk of death, such as age and sex, comorbidities, and high heart rate, but also changes in some laboratory findings [10, 11]. These factors can be managed during the medical emergency, where half of the deaths occur in the first hours after the onset of symptoms, and through early identification, which may help prevent or delay the condition and even prevent death [12,13,14].
In the digital health era, where we can access thousands of data, ML and data mining algorithms can contribute to clinical decision support [15]. Some examples are early screening and diagnosis, disease prevention that identifies risk factors [16], treatment management and monitoring with improved pharmacovigilance and patient safety, and improved outcomes and care provided [17]. Particularly in cardiovascular diseases [13, 18, 19].
Since cardiovascular diseases are complex and heterogeneous, resulting from genetic, environmental, and behavioural factors [10, 11], there is a growing need to analyse data from different sources of information, namely administrative, laboratory, and imaging, for interpretation, diagnosis, and decision-making. Furthermore, data analysis can reduce waste by optimising resources and installed capacity, improving the patient journey, and interacting with healthcare organisations [20,21,22] empowered by sophisticated technology.
In recent years, research on ML in AMI has mainly focused on predicting patient mortality [18, 23,24,25,26,27,28], prediction of patient readmission [29], or the occurrence of arrhythmia after acute myocardial infarction [25] and has already proved to be better predictors than the traditional statistical models [26,27,28]. Also, we found better performances of ML models than the traditional models, working on AMI mortality analysis in different settings and populations: Europe, the United States and Asia [18, 23,24,25,26,27,28], mainly predicting one year or 30 days survival after AMI.
In this study, we aim to build a model for predicting mortality in patients with AMI at hospital admission. We propose to measure the impact of introducing cardiac test results and physiological results in addition to administrative data based on machine learning (ML). We introduce in this work the capability of the model mortality prediction with the first data collected at hospital patient admission and during the stay.
We implemented three different approaches. In the first approach (experiment 1), we included only available variables at admission. Experiment 2 evaluates the impact of additional laboratory data, the number of comorbidities, and the performance of the surgical intervention. These other variables are possible to be collected during the hospital stay. In Experiment 3, we tested the inclusion of more specific pathology-related variables, such as body mass index, symptoms, suggestive time of onset of Acute Coronary Syndrome (ACS Time), heart rate, and the number of segments with injury.
Methods
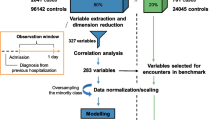
Figure 1 presents the proposed methodology with the following steps: (1) Database collection; (2) Feature Selection; (3) Modelling; and (4) Assessment of predictive capability, which are detailed in the following sections. The project was developed in Python using the following packages scikit-learn, pandas, numpy, imblearn.over_sampling and shap.

Process flow diagram of the proposed methodology
Study design and study population
This is a cross-sectional and analytical observational retrospective study. The study population included patients aged 18 years or older with an episode of hospital discharge, where the primary diagnosis was AMI. Episodes from patients transferred to another hospital were excluded. The International Classification of Diseases, Ninth Version, Clinical Modification (ICD-9-CM) codes were used to identify AMI 410 – Acute Myocardial Infarction episodes except for subsequent episodes representing a sample of 1,761 episodes.
From this set of episodes, we excluded all the patients with a nonspecific AMI type, as the database contained only deceased patients. From this, we obtained a final sample of 1,749 episodes, representing 7.18% of the total inpatient episodes discharged with circulatory system pathology (24,359 episodes).
Outcome
The outcome variable is in-hospital mortality, which assumes the value 0 for episodes whose outcome is “alive” and 1 for episodes whose outcome is “deceased”.
Data collection
We used discharge data from a National Health Service (NHS) large hospital in Portugal (~ 1,000 beds) from 2013 to 2015. The anonymised database includes administrative data, demographic data, discharge status (alive or deceased), length of stay, diagnoses and procedures (ICD-9-CM) of episodes whose primary diagnosis was AMI, laboratory data (LD), and cardiac and physiologic test results.
Feature selection and feature importance
Clinical discussions led to the removal of unnecessary features from the dataset. Then, we performed feature selection through Recursive Feature Elimination (RFE) to improve the performance of the machine learning models [30]. The primary idea behind RFE is to create a model using all features, then select and eliminate the weakest feature, and repeat the process for the remaining features until a specified number of features is reached. Later, we used the SHAP library to interpret the models on our dataset. The SHAP framework is a comprehensive tool that has been designed to interpret the predictions made by machine learning models [31]. It represents a novel approach for explaining a wide range of black-box models and has been proven to be highly effective in terms of its interpretability performance [32].
Pre-processing of data
The missing values for fields where the percentage of missing was very low (less than 5%) were filled with the average or the most common value according to the variable [33]. This is a common approach in data analysis, especially when the percentage of missing values is low. On our case, the features Type of AMI, Age had less than 1% of missing values.
Due to some algorithms’ requirement on data to be in the same numerical range, we used the Min–Max normalisation for quantitative variables. Additionally, we used the One-Hot method to process the multi-category variables.
Data imbalance
Skewed data is a challenging problem in clinical datasets, and it can adversely affect the performance of ML models. Therefore, we applied Synthetic Minority Oversampling Technique (SMOTE). SMOTE is a technique that creates synthetic data to oversample the minority classes in a dataset [33].
Experimental setting
Three distinct experiments were created, varying in the independent variables used, as shown in Table 1. The objective was to test if introducing cardiac test results and physiological results to administrative data improved the model performance and to test if different methods to determine which classification model performs better.
For experiments 1 and 2, a dataset with 1,749 episodes was used. Regarding experiment 3, the number of episodes with detailed information on cardiac test results and physiological results corresponds to 445 episodes (25.4% of the 1,749 episodes).
Experiment 1 includes variables existing at admission time, and experiment 2 has more variables (eight additional laboratory findings, the number of comorbidities, and the performance of surgical intervention). These other variables are possible to collect during the hospital stay. In experiment 3, we tested the inclusion of more specific pathology-related variables.
Administrative and laboratory data were selected as independent variables (see Table 1). We segregated the laboratory findings into below-normal, normal, and above-normal levels. The relevant comorbidities for AMI selected were Anaemia, Cancer, Cardiogenic Shock, Diabetes with complications, Diabetes without complications, Cardiac dysrhythmia, Cerebrovascular Disease, Pulmonary edema, Acute Kidney Failure, Chronic Kidney Failure, and Respiratory infection, and have been selected according to the literature [34, 35]. The number of comorbidities represents the sum of one or more secondary diagnoses unrelated to each episode’s principal diagnosis (see Table 3 for more details).
The laboratory data included in all three experiments were Albumin, Erythrocyte Distribution Range (RDW-CV), Calcium, Creatinine, Creatine kinase (CK), Eosinophils, Erythrocytes, Glucose, Hematocrit, Haemoglobin, Mean globular haemoglobin (HGM), International Normalised ratio (INR), Lactate Dehydrogenase (LDH), Lymphocytes, Neutrophils, Platelets, Potassium, C-reactive protein, Sodium, Activated Partial Thromboplastin Time (APTT), Prothrombin time, Glutamic-oxalacetic transaminase, Glutamic-pyruvic transaminase (SGPT), Troponin I and Urea.
The following laboratory findings were used specifically for Experiments 2 and 3: Chlorine, Phosphokinase MM fraction (CK-MB), Arterial bicarbonate concentration (HCO3a), Mean corpuscular haemoglobin concentration (MCHC), Magnesium, Mean Platelet Volume (MPV), Blood oxygen (pO2) and Blood oxygen saturation (sO2).
Separation of data into training and test datasets
We used 70% of the dataset as training data, while 30% was allocated as testing to build the classifiers. We then used a tenfold cross-validation technique on the training set to avoid model overfitting and for hyperparameter tuning. The dataset was randomly divided into ten equal folds, each with approximately the same number of episodes; 10 validation experiments were performed, each used in turn as the validation set and the remaining nine used as the training set. We then used the 30% testing set to evaluate the model performance [36].
Predictive models
The dependent variable (hospital mortality) is categorical, which poses a classification problem. To mitigate this issue, we tested ten supervised learning methods, ranging from logistic regression to ensemble methods and neural networks.
-
Logistic Regression [37];
-
Decision Tree [38]
-
Random Forest (RF) [39]
-
Gradient Boosting [40]
-
Support Vector Machine (SVM) [41];
-
k-nearest neighbors (kNN) [42];
-
Gaussian Naive Bayes [43];
-
MLP Neural Network [41];
-
AdaBoost [44];
-
Stochastic Gradient Descent (SGD) [45].
A Grid Search method with a ten-fold CV was used to optimise the hyper-parameters of ML. Finally, the performance of each model was evaluated and compared in the test set. Table 2 presents the best hyperparameters used in this study for each method.
Models’ evaluation
Measuring the success of machine learning algorithms is essential in determining their suitability. Classification performance can be measured in many ways: absolute ability, performance relative to other factors, probability of success, and others [13]. This paper uses the area under the curve (AUC), Classification Accuracy (CA), F1-score, Precision, and Recall.
Results
Descriptive statistics study population
Table 3 presents the descriptive statistics of the study population regarding Experiments 1 and 2. Of the 1,749 episodes in the study, 218 correspond to patients that died, corresponding to a mortality rate of 12.5%. Most patients were male (65.4%) and 70 years or older (51.8%). However, a higher mortality rate was observed in females (15.0%).
Of the three types of AMI analysed, other ST-Elevation Myocardial Infarction (STEMI) presented the highest prevalence (44.9%) and mortality rate (15.7%). Although Non-ST-Elevation Myocardial Infarction (NSTEMI) gave the second higher prevalence (38.0%), it showed the lowest mortality rate (7.7%).
Regarding the number of comorbidities, 68% of the episodes had at least one comorbidity at admission. Patients without comorbidity (n = 560) registered a lower mortality rate (3.0%). Cardiac dysrhythmia was the most frequent comorbidity (27.5%) and presented a mortality rate of 21.2%, followed by diabetes without complications, observed in 395 patients (22.6%). Cardiogenic Shock was observed in 105 patients, accounting for the highest mortality rate (70.5%).
Most of the patients had a surgical intervention (61.6%). Patients with surgical intervention presented a lower mortality rate (8.6%) than those without surgical intervention (18.6%).
Table 4 presents the characterisation of the study population’s laboratory findings, which were divided into below-normal, normal, and above-normal levels. Most patients present above-level results for Troponin I (82.6%), Neutrophils (78.9%), Lymphocytes (77.4%), C-reactive protein (56.3%), Creatinine (55.8%), Lactate Dehydrogenase (LDH) (52.1%) and Eosinophils (51.8%).
Regarding mortality, the highest rate was prominent in patients with results of HCO3a below level (41.4%), erythrocytes above level (38.5%), activated partial thromboplastin time (APTT) below level (35.7%), blood oxygen saturation (sO2) below level (35.3%), sodium above level (34.4%) and International Normalized Ratio (INR) above level (33.1%).
For Experiment 3, which included 445 episodes, Table 5 presents the study population characterisation. Of the 445 episodes, 32 correspond to patients that died, with a mortality rate of 7.2%. Most patients were male (76.0%) and less than 70 years old (69.0%). However, it was observed a higher mortality rate in women (9.3%) when compared with men (6.5%) and in patients 70 years or older (18.1%).
Approximately 92% of the patients presented chest pain, with a mortality rate of 6.4%. A mortality rate of 100% for junctional rhythm was observed, and 66.7% for AVB 3rd degree.
Machine learning models
Experiment 1
As shown in Table 6, when applying feature selection and SMOTE, GNB and SGD were the methods that performed better in the test dataset (area under the ROC curve) when compared to the other classification methods, obtaining a an AUC value equal to 79%.
Regarding the remaining metrics: CA, precision, recall and F1-score, GNB obtained 82%, 37%, 75% and 49%, respectively. At the same time, SGD obtained 80%, 34%, 77% and 47%, respectively, on the test dataset.
Experiment 2
In Experiment 2, the same variables from Experiment 1 were used, and eight laboratory findings were added, as well as the comorbidities number and the performance of the surgical intervention. Table 7 presents the performance obtained for the ten learning methods tested.
When applying feature selection and SMOTE, SVM was the method with the best performance in the test dataset regarding the AUC (81%), followed by the LR and GNB methods (78%).
Experiment 3
For Experiment 3, in addition to those used in the previous experiments, the set of new morbidity variables and test results were used. Table 8 presents the performance results.
When applying feature selection and SMOTE, SGD was the method with the best performance on the test dataset regarding the AUC metric (88%), followed by LR (86%). KNN and GNB obtained an AUC equal to or above 80%.
Feature importance in the experiments
To understand how variables impact the model’s output on each experiment proposed, we used SHAP on the best predictive model achieved for each experiment. Table 9 summarises the results of the experiments created with the best performances.
The top 10 risk factors were evaluated by their average absolute SHAP value and can be seen in Figs. 2A, 3A and 4A (for each experiment). Additionally, Figs. 2B, 3B and 4B displays the top 10 most important features for each experiment’s best model, with the y-axis indicating the importance of the predictive model and the x-axis representing the unified index that responds to the influence of a particular feature in the model. Each important feature row depicts the attribution of all patients to the outcome using dots of different colours, with red dots indicating high-risk values and blue dots representing low-risk values.

Experiment 1 model interpretation. A The importance ranking of the top 10 variables according to the mean (|SHAP value|); B The importance ranking of the top 10 risk factors with stability and interpretation using the optimal model

Experiment 2 model interpretation. A The importance ranking of the top 10 variables according to the mean (|SHAP value|); B The importance ranking of the top 10 risk factors with stability and interpretation using the optimal model

Experiment 3 model interpretation. A The importance ranking of the top 20 variables according to the mean (|SHAP value|); B The importance ranking of the top 10 risk factors with stability and interpretation using the optimal model
Regarding our first experiment, a higher value on urea, cardiogenic shock, older age, SGPT, prothrombin time and cancer were associated with higher predicted probability mortality. Furthermore, lower values of troponin I, eosinophils, neutrophils and albumin were found to be associated with a higher predicted probability of mortality.
For the second experiment, higher values of urea, cardiogenic shock, neutrophils, age and SGPT were found to be associated with a higher predicted probability of mortality, while lower values of eosinophils, troponin I, albumin and HCo3a also increased the risk of mortality.
Finally, for the third experiment, higher values on cardiac dysrhythmia, glucose, cardiogenic Shock, LDH, acute kidney failure, Urea, C-reactive protein, Nr of Segments with Injury 2, RDW-CV and prothrombin time were found to be associated with a higher predicted probability of mortality.
Discussion
In this study, we analysed the use of ten supervised machine learning methods to predict AMI in-hospital mortality. The aim was to build experiments with different approaches to determine which classification model performs better and whether introducing cardiac test results and physiological results to administrative data improve the model performance.
Regarding Experiment 1, SGD presented the best performance, with an AUC of 79% and recall of 77%, applying feature selection and oversampling, while in Experiment 2, SVM presented the best performance, with an AUC of 81% and recall of 75%, also applying feature selection and oversampling.
Regarding Experiment 3, KNN performed best on the test dataset, with an AUC of 89% and a recall of 90%, only applying oversampling but not feature selection. However, when using both oversampling and feature selection, SGD performed best, with an AUC of 88% and a recall of 80%.
Therefore, in the same conditions (feature selection and oversampling), the models’ performance was observed, suggesting the relevance of including more specific variables, such as cardiac test results and physiological results.
The number of publications on predicting the mortality of AMI using machine learning is still limited, most of which are based on scoring scales and Logistic Regression models that tend to have lower performances. Nevertheless, recent literature that used laboratory findings and symptoms presents better discriminative performance using an ML-based approach than traditional risk-scoring methods such as TIMI [26, 27].
Specifical, Aziz et al. [27] model performance using a complete and reduced variable produced an area under the receiver operating characteristic curve (AUC) from 0.73 to 0.90. Overall ML model performed better than TIMI for in-hospital, 30 days and 1-year AUC (0.88 vs 0.81, 0.90 vs 0.80, 0.84 vs 0.76). Aziz et al. [27] study is comparable with the results found in the present study for Experiment 3. As well as Khera et al. [46] results, whose AUC was 89.8% for the XGBoost method and 89.9% for the meta-classifier.
The study’s results suggest that including new variables, mainly cardiac test results and physiological results, and complex interactions between them can increase the performance of predictions in this context since they help identify patients at risk and reduce false positives and negatives.
Experiment 3 also includes vital signs, such as pain and heart rate, similar to TIMI and GRACE [47].
In the three experiments of this study, cardiogenic Shock and Urea were in the top 10 variables associated with a higher probability of mortality. These results align with the literature once cardiogenic shock was identified as the most common cause of death in patients hospitalised with AMI [48,49,50,51]. Regarding Urea, according to Zhu et al. [52], blood urea nitrogen was robustly associated with increased short-term mortality in patients with Cardiogenic Shock after AMI; Horiuchi et al. [53] also found that blood urea nitrogen is a predictor of in-hospital mortality in AMI patients.
The other risk factors identified are consistent with the literature, with advanced age, cancer, cardiac dysrhythmia, prothrombin time, and eosinophils already been highlighted and explained previously [30]. Tu et al. [54] identified diabetes, cancer, and renal failure as predictors of AMI. Thus, several of these comorbidities at admission influence the risk of death [54, 55].
Previous studies have also shown that the value of neutrophils is higher in patients with complications in AMI. Thus, it was considered a strong and independent predictor of in-hospital mortality in patients with AMI and ST-segment elevation [56].
Although the contributions of this study reinforce the importance of applying a machine learning system to predict AMI mortality, it presents several limitations. Specifically, the small sample size, particularly regarding Experiment 3; the data originating from a single hospital; and the data period that refers to 2013–2015, which could potentially be outdated.
In addition to those limitations, the implementation of a Machine Learning approach to support health care poses some challenges crucial to overcome, such as:
-
The time and cost associated with the collection and processing of data
-
The lack of data and systems interoperability;
-
The lack of trained professionals;
-
The lack of allocated and dedicated human resources.
Further studies should be conducted and consider the inclusion of more variables that may be relevant in predicting AMI mortality, such as socioeconomic factors, systolic blood pressure, heart rate, and electrocardiogram results. We also suggest creating mortality prediction models for other stages of care, such as at discharge, using different variables to analyse their influence on mortality, such as length of stay and length of stay in the intensive care unit.
We also consider that there is potential to extend this research to other pathologies with high mortality, such as other circulatory system diseases, malignant neoplasms, and respiratory system conditions.
Conclusions
Given the significant mortality rate of AMI, predicting its risk of death can assist healthcare organisations and their professionals in allocating the provision of care based on risk. Prediction models allow improved outcomes, based on more informed and accurate decision-making.
In conclusion, introducing new variables into the ML model impacts the performance of the methods, reinforcing the premise that no single approach is adapted to all situations but must be selected, taking into account the context and the information available.
All relevant variables identified in the different models are described in the literature as associated with a worse prognosis and a higher risk of death in AMI. Thus, similar to other studies in this area, this investigation demonstrates that the machine learning methods created could be valuable tools in clinical practice decision-making. Integrating machine learning can potentially transform care delivery and provide an increasingly accurate toolkit. When incorporated into information systems, they can make clinical practice more efficient, faster, personalised, and effective, reducing waste by optimising resources and installed capacity and improving the patient journey. In the era of Big Data, AI emerges as an alternative to traditional models since it can explore a large amount of information automatically and systematically with better performance, as proven in this study.
For such improvements to take place, there is a need to:
-
Continue research and development of improved mortality prediction models for the pathologies with the most significant morbidity and mortality rates;
-
Comprehend that optimal machine learning models only work if they have superior processes implemented around them;
-
Invest in technological infrastructure, implement standards that allow data and systems interoperability, and create a single repository with all types of available data;
-
Increase digital health literacy among professionals for a smooth digital transition in the healthcare industry;
Availability of data and materials
The data that supports the findings of this study is only available upon reasonable request to Teresa Magalhães (teresa.magalhaes@ensp.unl.pt) and with permission of Centro Hospitalar Universitário Lisboa Norte, E.P.E.
References s
Mansoor H, Elgendy IY, Segal R, Bavry AA, Bian J. Risk prediction model for in-hospital mortality in women with ST-elevation myocardial infarction: A machine learning approach. Heart Lung. 2017;46:405–11. https://doi.org/10.1016/J.HRTLNG.2017.09.003.
Roth GA, Huffman MD, Moran AE, Feigin V, Mensah GA, Naghavi M, et al. Measuring the Global Cardiovascular Disease Burden Global and Regional Patterns in Cardiovascular Mortality From 1990 to 2013 Global Burden of Cardiovascular Disease. 2015;132:1667–78. https://doi.org/10.1161/CIRCULATIONAHA.114.008720.
OECD/European Union. Health at a Glance: Europe 2022: State of Health in the EU Cycle. Paris; 2022. https://doi.org/10.1787/507433b0-en.
Instituto Nacional de Estatística. Causas de morte 2020 (Dados provisórios). 2021.
Pourasghari H, Tavolinejad H, Soleimanpour S, Abdi Z, Arabloo J, Bragazzi NL, et al. Hospitalization, major complications and mortality in acute myocardial infarction patients during the COVID-19 era: A systematic review and meta-analysis. IJC Hear Vasc. 2022;41:101058.
Yeo YH, Wang M, He X, Lv F, Zhang Y, Zu J, et al. Excess risk for acute myocardial infarction mortality during the COVID-19 pandemic. J Med Virol. 2023;95:e28187. https://doi.org/10.1002/JMV.28187.
Virani SS, Alonso A, Benjamin EJ, Bittencourt MS, Callaway CW, Carson AP, et al. Heart Disease and Stroke Statistics—2020 Update: A Report From the American Heart Association. Circulation. 2020;141:E139-596. https://doi.org/10.1161/CIR.0000000000000757.
30-Day Acute Myocardial Infarction In-Hospital Mortality | CIHI. https://www.cihi.ca/en/indicators/30-day-acute-myocardial-infarction-in-hospital-mortality. Accessed 26 Feb 2023.
Moledina SM, Shoaib A, Sun LY, Myint PK, Kotronias RA, Shah BN, et al. Impact of the admitting ward on care quality and outcomes in non-ST-segment elevation myocardial infarction: insights from a national registry. Eur Hear J Qual Care Clin Outcomes. 2022;8:681–91. https://doi.org/10.1093/EHJQCCO/QCAB062.
Ibanez B, James S, Agewall S, Antunes MJ, Bucciarelli-Ducci C, Bueno H, et al. 2017 ESC Guidelines for the management of acute myocardial infarction in patients presenting with ST-segment elevation: The Task Force for the management of acute myocardial infarction in patients presenting with ST-segment elevation of the European Socie. Eur Heart J. 2018;39:119–77. https://doi.org/10.1093/EURHEARTJ/EHX393.
Collet JP, Thiele H, Barbato E, Bauersachs J, Dendale P, Edvardsen T, et al. 2020 ESC Guidelines for the management of acute coronary syndromes in patients presenting without persistent ST-segment elevation. Eur Heart J. 2021;42:1289–367. https://doi.org/10.1093/EURHEARTJ/EHAA575.
Tsien CL, Fraser HSF, Long WJ, Kennedy RL. Using classification tree and logistic regression methods to diagnose myocardial infarction. Stud Health Technol Inform. 1998;52(Pt 1):493–7. https://doi.org/10.3233/978-1-60750-896-0-493.
Jiang F, Jiang Y, Zhi H, Dong Y, Li H, Ma S, et al. Artificial intelligence in healthcare: past, present and future. Stroke Vasc Neurol. 2017;2:230–43. https://doi.org/10.1136/SVN-2017-000101.
Krittanawong C, Zhang HJ, Wang Z, Aydar M, Kitai T. Artificial Intelligence in Precision Cardiovascular Medicine. J Am Coll Cardiol. 2017;69:2657–64. https://doi.org/10.1016/J.JACC.2017.03.571.
Pina A, Macedo MP, Henriques R. Clustering Clinical Data in R. In: Matthiesen R, editor. Mass Spectrometry Data Analysis in Proteomics. 2019. p. 309–43.
Pina AF, Meneses MJ, Sousa-Lima I, Henriques R, Raposo JF, Macedo MP. Big data and machine learning to tackle diabetes management. Eur J Clin Invest. 2023;53:e13890. https://doi.org/10.1111/ECI.13890.
Pina A, Helgadottir S, Mancina RM, Pavanello C, Pirazzi C, Montalcini T, et al. Virtual genetic diagnosis for familial hypercholesterolemia powered by machine learning. Eur J Prev Cardiol. 2020;27:1639–46. https://doi.org/10.1177/2047487319898951.
Barrett LA, Payrovnaziri SN, Bian J, He Z. Building Computational Models to Predict One-Year Mortality in ICU Patients with Acute Myocardial Infarction and Post Myocardial Infarction Syndrome. AMIA Summits Transl Sci Proc. 2019;2019:407 (/pmc/articles/PMC6568079/. Accessed 13 Mar 2022).
Wallert J, Tomasoni M, Madison G, Held C. Predicting two-year survival versus non-survival after first myocardial infarction using machine learning and Swedish national register data. BMC Med Inform Decis Mak. 2017;17:99. https://doi.org/10.1186/S12911-017-0500-Y.
Shilo S, Rossman H, Segal E. Axes of a revolution: challenges and promises of big data in healthcare. Nat Med. 2020;26:29–38. https://doi.org/10.1038/S41591-019-0727-5.
Mehta N, Pandit A, Shukla S. Transforming healthcare with big data analytics and artificial intelligence: A systematic mapping study. J Biomed Inform. 2019;100:103311. https://doi.org/10.1016/J.JBI.2019.103311.
Galetsi P, Katsaliaki K, Kumar S. Values, challenges and future directions of big data analytics in healthcare: A systematic review. Soc Sci Med. 2019;241:112533. https://doi.org/10.1016/J.SOCSCIMED.2019.112533.
Payrovnaziri SN, Barrett LA, Bis D, Bian J, He Z. Enhancing Prediction Models for One-Year Mortality in Patients with Acute Myocardial Infarction and Post Myocardial Infarction Syndrome. Stud Health Technol Inform. 2019;264:273. https://doi.org/10.3233/SHTI190226.
Li YM, Jiang LC, He JJ, Jia KY, Peng Y, Chen M. Machine Learning to Predict the 1-Year Mortality Rate After Acute Anterior Myocardial Infarction in Chinese Patients. Ther Clin Risk Manag. 2020;16:1–6. https://doi.org/10.2147/TCRM.S236498.
Wang S, Li J, Sun L, Cai J, Wang S, Zeng L, et al. Application of machine learning to predict the occurrence of arrhythmia after acute myocardial infarction. BMC Med Inform Decis Mak. 2021;21:301. https://doi.org/10.1186/S12911-021-01667-8.
Lee W, Lee J, Woo SIl, Choi SH, Bae JW, Jung S, et al. Machine learning enhances the performance of short and long-term mortality prediction model in non-ST-segment elevation myocardial infarction. Sci Rep. 2021;11:12886.
Aziz F, Malek S, Ibrahim KS, Shariff RER, Wan Ahmad WA, Ali RM, et al. Short- and long-term mortality prediction after an acute ST-elevation myocardial infarction (STEMI) in Asians: A machine learning approach. PLoS ONE. 2021;16:e0254894. https://doi.org/10.1371/JOURNAL.PONE.0254894.
Kasim S, Malek S, Cheen S, Safiruz MS, Ahmad WAW, Ibrahim KS, et al. In-hospital risk stratification algorithm of Asian elderly patients. Sci Reports. 2022;12:1–17. https://doi.org/10.1038/s41598-022-18839-9.
Zhang Z, Qiu H, Li W, Chen Y. A stacking-based model for predicting 30-day all-cause hospital readmissions of patients with acute myocardial infarction. BMC Med Inform Decis Mak. 2020;20:1–13. https://doi.org/10.1186/S12911-020-01358-W/TABLES/5.
Lazaros K, Tasoulis S, Vrahatis A, Plagianakos V. Feature Selection For High Dimensional Data Using Supervised Machine Learning Techniques. 2023. p. 3891–4.
Lundberg SM, Allen PG, Lee S-I. A Unified Approach to Interpreting Model Predictions. Adv Neural Inf Process Syst. 2017;30. https://github.com/slundberg/shap. Accessed 4 Mar 2023.
Ning Y, Ong MEH, Chakraborty B, Goldstein BA, Ting DSW, Vaughan R, et al. Shapley variable importance cloud for interpretable machine learning. Patterns. 2022;3:100452.
Elreedy D, Atiya AF. A Comprehensive Analysis of Synthetic Minority Oversampling Technique (SMOTE) for handling class imbalance. Inf Sci (Ny). 2019;505:32–64.
Magalhães T, Lopes S, Gomes J, Seixo F. The Predictive Factors on Extended Hospital Length of Stay in Patients with AMI: Laboratory and Administrative Data. J Med Syst. 2016;40:1–7.
Than MP, Pickering JW, Sandoval Y, Shah ASV, Tsanas A, Apple FS, et al. Machine Learning to Predict the Likelihood of Acute Myocardial Infarction. Circulation. 2019;140:899–909. https://doi.org/10.1161/CIRCULATIONAHA.119.041980.
Steyerberg EW. Validation in prediction research: the waste by data splitting. J Clin Epidemiol. 2018;103:131–3.
Tripepi G, Jager KJ, Dekker FW, Zoccali C. Linear and logistic regression analysis. Kidney Int. 2008;73:806–10. https://doi.org/10.1038/sj.ki.5002787.
Kingsford C, Salzberg SL. What are decision trees? Nat Biotechnol. 2008;26:1011. https://doi.org/10.1038/NBT0908-1011.
Breiman L. Random forests. Mach Learn. 2001;45:5–32. https://doi.org/10.1023/A:1010933404324/METRICS.
Natekin A, Knoll A. Gradient boosting machines, a tutorial. Front Neurorobot. 2013;7:21. https://doi.org/10.3389/FNBOT.2013.00021.
Burges CJC. A tutorial on support vector machines for pattern recognition. Data Min Knowl Discov. 1998;2:121–67. https://doi.org/10.1023/A:1009715923555/METRICS.
Zhang Z. Introduction to machine learning: k-nearest neighbors. Ann Transl Med. 2016;4:218–218. https://doi.org/10.21037/ATM.2016.03.37.
Ruppert D. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. https://doi.org/10.1198/jasa2004.s339. 2011;99:567–567. https://doi.org/10.1198/JASA.2004.S339.
Hatwell J, Gaber MM, Atif Azad RM. Ada-WHIPS: Explaining AdaBoost classification with applications in the health sciences. BMC Med Inform Decis Mak. 2020;20:1–25. https://doi.org/10.1186/S12911-020-01201-2/TABLES/24.
Bottou L, Large-scale machine learning with stochastic gradient descent. Proc COMPSTAT 2010 - 19th Int Conf Comput Stat Keynote. Invit Contrib Pap. 2010;177–86. https://doi.org/10.1007/978-3-7908-2604-3_16/COVER.
Khera R, Haimovich J, Hurley NC, McNamara R, Spertus JA, Desai N, et al. Use of Machine Learning Models to Predict Death After Acute Myocardial Infarction. JAMA Cardiol. 2021;6:1. https://doi.org/10.1001/JAMACARDIO.2021.0122.
Churpek MM, Yuen TC, Park SY, Meltzer DO, Hall JB, Edelson DP. Derivation of a cardiac arrest prediction model using ward vital signs*. Crit Care Med. 2012;40:2102–8. https://doi.org/10.1097/CCM.0B013E318250AA5A.
Hochman JS, Buller CE, Sleeper LA, Boland J, Dzavik V, Sanborn TA, et al. Cardiogenic shock complicating acute myocardial infarction—etiologies, management and outcome: a report from the SHOCK Trial Registry. J Am Coll Cardiol. 2000;36:1063–70.
Webb JG, Sanborn TA, Sleeper LA, Carere RG, Buller CE, Slater JN, et al. Percutaneous coronary intervention for cardiogenic shock in the SHOCK Trial Registry. Am Heart J. 2001;141:964–70. https://doi.org/10.1067/MHJ.2001.115294.
Holmes DR, Bates ER, Kleiman NS, Sadowski Z, Horgan JHS, Morris DC, et al. Contemporary reperfusion therapy for cardiogenic shock: The GUSTO-I trial experience. J Am Coll Cardiol. 1995;26:668–74. https://doi.org/10.1016/0735-1097(95)00215-P.
Hashmi KA, Abbas K, Hashmi AA, Irfan M, Edhi MM, Ali N, et al. In-hospital mortality of patients with cardiogenic shock after acute myocardial infarction; Impact of early revascularization. BMC Res Notes. 2018;11:1–5. https://doi.org/10.1186/S13104-018-3830-7/TABLES/3.
Zhu Y, Sasmita BR, Hu X, Xue Y, Gan H, Xiang Z, et al. Blood Urea Nitrogen for Short-Term Prognosis in Patients with Cardiogenic Shock Complicating Acute Myocardial Infarction. Int J Clin Pract. 2022;2022:9396088. https://doi.org/10.1155/2022/9396088.
Horiuchi Y, Aoki J, Tanabe K, Nakao K, Ozaki Y, Kimura K, et al. A High Level of Blood Urea Nitrogen Is a Significant Predictor for In-hospital Mortality in Patients with Acute Myocardial Infarction. Int Heart J. 2018;59:263–71. https://doi.org/10.1536/IHJ.17-009.
Tu JV, Austin PC, Walld R, Roos L, Agras J, McDonald KM. Development and validation of the Ontario acute myocardial infarction mortality prediction rules. J Am Coll Cardiol. 2001;37:992–7. https://doi.org/10.1016/S0735-1097(01)01109-3.
Luepker RV, Caralis DG, Voigt GC, Burns RF, Murphy LW, Richard WJ. Detection of pulmonary edema in acute myocardial infarction. Am J Cardiol. 1977;39:146–52. https://doi.org/10.1016/S0002-9149(77)80183-5.
Gazi E, Bayram B, Gazi S, Temiz A, Kirilmaz B, Altun B, et al. Prognostic Value of the Neutrophil-Lymphocyte Ratio in Patients With ST-Elevated Acute Myocardial Infarction. Clin Appl Thromb Hemost. 2015;21:155–9. https://doi.org/10.1177/1076029613492011.
Acknowledgements
Not applicable.
Funding
The present publication was funded by Fundação Ciência e Tecnologia, IP national support through CHRC (UIDP/04923/2020). The funding body did not played any roles in the design of the study and collection, analysis, and interpretation of data and in writing the manuscript.
Author information
Authors and Affiliations
Contributions
Conceptualization, R.H. and T.M.; methodology, R.H. and T.M.; software, M.O.; validation, T.M., R.H. and F.P.; formal analysis, R.H. and T.M.; investigation, M.O.; data curation, M.O. and T.M.; writing—original draft preparation, M.O. and J.S.; writing—review and editing, T.M., R.H. and F.P.; supervision, T.M., R.H. and F.P. The author(s) read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The study/ project was performed in accordance with the Declaration of Helsinki, and it was approved by the Ethics Committee of Centro Academico de Medicina de Lisboa, code DSCI2022. Due to the retrospective nature of the study, the Ethics Committee of Centro Academico de Medicina de Lisboa has waived informed consent for the study.
Consent to publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Oliveira, M., Seringa, J., Pinto, F.J. et al. Machine learning prediction of mortality in Acute Myocardial Infarction. BMC Med Inform Decis Mak 23, 70 (2023). https://doi.org/10.1186/s12911-023-02168-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12911-023-02168-6