
Abstract
Objective
Breast cancer has become the most prevalent malignant tumor in women, and the occurrence of distant metastasis signifies a poor prognosis. Utilizing predictive models to forecast distant metastasis in breast cancer presents a novel approach. This study aims to utilize readily available clinical data and advanced machine learning algorithms to establish an accurate clinical prediction model. The overall objective is to provide effective decision support for clinicians.
Methods
Data from 239 patients from two centers were analyzed, focusing on clinical blood biomarkers (tumor markers, liver and kidney function, lipid profile, cardiovascular markers). Spearman correlation and the least absolute shrinkage and selection operator regression were employed for feature dimension reduction. A predictive model was built using LightGBM and validated in training, testing, and external validation cohorts. Feature importance correlation analysis was conducted on the clinical model and the comprehensive model, followed by univariate and multivariate regression analysis of these features.
Results
Through internal and external validation, we constructed a LightGBM model to predict de novo bone metastasis in newly diagnosed breast cancer patients. The area under the receiver operating characteristic curve values of this model in the training, internal validation test, and external validation test1 cohorts were 0.945, 0.892, and 0.908, respectively. Our validation results indicate that the model exhibits high sensitivity, specificity, and accuracy, making it the most accurate model for predicting bone metastasis in breast cancer patients. Carcinoembryonic Antigen, creatine kinase, albumin-globulin ratio, Apolipoprotein B, and Cancer Antigen 153 (CA153) play crucial roles in the model’s predictions. Lipoprotein a, CA153, gamma-glutamyl transferase, α-Hydroxybutyrate dehydrogenase, alkaline phosphatase, and creatine kinase are positively correlated with breast cancer bone metastasis, while white blood cell ratio and total cholesterol are negatively correlated.
Conclusion
This study successfully utilized clinical blood biomarkers to construct an artificial intelligence model for predicting distant metastasis in breast cancer, demonstrating high accuracy. This suggests potential clinical utility in predicting and identifying distant metastasis in breast cancer. These findings underscore the potential prospect of developing economically efficient and readily accessible predictive tools in clinical oncology.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Background
As the most common malignancy in women, breast cancer (BC) accounts for 30% of all cancers in females [1]. While its mortality rate ranks fourth, the number of new deaths is increasing most significantly [2]. This may be attributed to a continual decline in fertility rates and an increase in body weight [3]. In China, there are over 410,000 new cases of breast cancer and over 110,000 related deaths annually [4]. In recent years, the incidence of distant metastasis recurrence in BC patients remains high, serving as an adverse prognostic indicator.
For distant metastasis, the bone is the most common site, with over 60% of BC patients experiencing bone metastasis [5]. In Western countries, approximately 3.5–10% of all newly diagnosed breast cancer patients are diagnosed with distant metastasis [6]. For initially diagnosed metastatic breast cancer, this implies fewer treatment options and shorter survival times. Stage IV breast cancer is also a significant public health concern in many developed countries, exacerbated in resource-poor areas due to a lack of screening programs and early detection methods, resulting in many patients presenting with metastases at diagnosis [7]. Furthermore, while the 5-year overall survival rate for BC patients without metastasis exceeds 80% [8], distant metastasis significantly reduces this rate to only around 25% [9]. Notably, the 5-year overall survival rate for bone metastasis (BM) is even lower, at only about 22.8% [10]. Therefore, early identification of breast cancer bone metastasis has become a crucial issue that clinicians must address.
Currently, the identification and diagnosis of bone metastasis primarily rely on imaging techniques such as X-rays, bone scintigraphy, computed tomography, magnetic resonance imaging (MRI), and positron emission tomography-computed tomography. Among these, X-ray examination is the most widely used and cost-effective method in China. However, despite its high specificity, X-rays have low sensitivity, making it difficult to detect early metastatic lesions [11]. Moreover, other imaging tests suffer from unequal distribution of medical resources, equipment limitations, and high costs. Even in some developed regions, over-testing may occur without prior evaluation, leading to prolonged average hospital stays and increased hospital costs.
For clinicians, treating diseases requires individualization, advocating for precision medicine. Currently, precision medicine has evolved around four concepts: predictiveness, personalization, prevention, and participation [12]. Big data analysis techniques are becoming essential in clinical practice [13], indicating the need to utilize advanced technology to analyze vast amounts of medical data and provide recommendations for individualized treatment. Many studies have used machine learning techniques to investigate clinical risk factors associated with cancer metastasis to achieve early detection [14,15,16]. In recent years, several breast cancer bone metastasis (BCBM) prediction models have been developed using factors such as age, gender, race, treatment, and grade as predictive factors [17, 18]. However, these models still have specific areas for improvement in practicality and accuracy. This study aims to establish a more accurate clinical model, incorporating as many effective variables as possible.
Regarding model development, although nomograms are currently the most commonly used predictive models, machine learning is increasingly favored by medical professionals for its practicality, innovation, and accuracy. This study is based on common inpatient laboratory indicators in the real world, requiring no related pathological examination or imaging assessment, thus reducing the threshold for model establishment. Through horizontal comparison of multiple indicators, a reliable BCBM prediction model has been developed.
Ultimately, our goal is to stratify the risk of bone metastasis in breast cancer patients, assisting clinicians, especially primary breast specialists, in making decisions to alleviate unnecessary medical burdens on patients and greatly improve their quality of life.
Materials and methods
Patient population
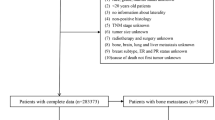
This retrospective study included data from two medical centers, approved by the institutional review boards of both centers. Inclusion criteria were as follows: (1) clear diagnosis of primary breast cancer with de novo bone metastasis; (2) completion of clinical blood biomarker testing before treatment (radiotherapy or chemotherapy) or surgical resection; (3) no history of hypertension, diabetes, or hyperlipidemia; (4) no history of abnormal blood indicators related to liver, kidney, or cardiovascular function; (5) no history of other diseases. Exclusion criteria were as follows: (1) occurrence of distant metastasis after treatment (surgical resection or chemotherapy); (2) incomplete clinical blood biomarker data, including tumor markers (Alpha-fetoprotein (AFP), Carcinoembryonic Antigen (CEA), Cancer Antigen 125 (CA125), Cancer Antigen 153 (CA153), and Cancer Antigen 199 (CA199)), liver function tests, kidney function tests, lipid profile, or cardiovascular function tests; (3) age less than 18 years old; (4) occurrence of metastasis in sites other than bones.
The study involved breast cancer cases from two research centers. One center included 176 cases, randomly divided at an 8:2 ratio into training (123 cases) and test (53 cases) cohorts. Another center provided 63 cases as an external validation cohort. The internal validation cohort (test cohort) consisted of data from the same medical center as the training cohort, characterized by similar clinical treatment processes and data collection standards, which facilitated the evaluation of the model’s robustness and performance in similar clinical environments. The external validation cohort came from a geographically proximate but different medical center, validating the model’s generalizability across different institutions and patient populations. The purpose of selecting these two validation cohorts was to comprehensively assess the reliability and applicability of the model under diverse conditions. The distribution details of the study are provided in Table 1. The workflow of the model in this study is illustrated in Fig. 1.

The workflow of LightGBM model in this study
Feature extraction and selection
The features included from clinical blood biomarkers comprised tumor markers (AFP; CEA; CA125; CA153; CA199), liver function indicators (total bilirubin, direct bilirubin, indirect bilirubin, total protein, albumin, globulin, albumin-globulin ratio, gamma-glutamyl transferase, prealbumin, aspartate transaminase (AST), alanine transaminase (ALT), AST/ALT ratio, alkaline phosphatase, cholinesterase, and total bile acid), kidney function indicators (urea, creatinine, uric acid, blood bicarbonate concentration, cystatin C, potassium ion, sodium ion, chloride ion, calcium ion, and inorganic phosphorus), lipid profile (total cholesterol, triglycerides, high-density lipoprotein cholesterol, low-density lipoprotein cholesterol, apolipoprotein A1, apolipoprotein B, A1/B ratio, and lipoprotein (a)), and cardiovascular function indicators (creatine kinase, creatine kinase isoenzyme MB (CK-MB), lactate dehydrogenase (LDH), and α-Hydroxybutyrate dehydrogenase (α-HBDH)).
All extracted features underwent the following operations: first, Z-Score standardization (mean = 0, standard deviation = 1) was applied to normalize each feature, preprocessing the data to fit a standard normal distribution. Then, statistical analysis was conducted using Spearman rank correlation coefficient (ρ) to measure the correlation between two variables. ρ is a non-parametric statistical measure of the strength of a monotonic relationship between two variables. When ρ approaches 1 or -1, it indicates a strong correlation between the variables. We chose ρ > 0.9 as the threshold for high correlation. High correlation means that the variables exhibit very consistent trends, which can lead to multicollinearity issues. Highly correlated features can introduce redundant information, increase model complexity, and affect the stability and interpretability of the model. When the Spearman correlation coefficient between features was > 0.9, one of the features was retained, as keeping only one variable with a correlation coefficient greater than 0.9 helps reduce redundancy and improve the model’s generalizability.
Finally, feature dimension reduction was conducted using L1 regularization of the Least Absolute Shrinkage and Selection Operator (LASSO) regression. The LASSO method penalizes the absolute values of regression coefficients, thereby inducing some coefficients to be zero, facilitating feature selection and generating a sparse model. In LASSO regression, the choice of lambda (λ) is critical as it controls the strength of the penalty applied to regression coefficients. A higher lambda increases the penalty, leading more coefficients to shrink to zero, simplifying the model but posing a risk of underfitting. Conversely, a lower lambda reduces the penalty, potentially including more features but risking overfitting to the training data. Our 10-fold cross-validation process helped identify a lambda value that generalizes well to unseen data. We selected the lambda parameter by performing 10-fold cross-validation on the training set, choosing the value that minimized mean squared error. This approach ensures an optimal balance between model complexity and predictive performance, aiding in preventing overfitting.
Development and validation of models
In this study, the LightGBM machine learning algorithm was employed to construct models for breast cancer with and without bone metastasis as binary outcome variables, using the selected features for dimension reduction. Model construction was completed based on 5-fold cross-validation in the training set. After model construction, validation was conducted in both internal and external testing cohorts. Model performance was evaluated using metrics such as the area under the receiver operating characteristic curve (AUC), accuracy, sensitivity, specificity, positive predictive value, and negative predictive value. Subsequently, decision curve analysis (DCA) was performed to reflect the net benefit at different threshold probabilities in the training and internal and external validation cohorts, evaluating the clinical efficiency of the model.
Statistical analysis
Clinical baseline features were analyzed using t-tests, chi-square tests, or Fisher’s exact tests with SPSS software (version 25.0, IBM). The t-test was used for continuous variables with homogeneity of variance, represented as x ± s, while the chi-square test or Fisher’s exact test was used for categorical variables, represented as ratios. A two-tailed p-value < 0.05 indicated statistical significance. Spearman rank correlation tests, z-score normalization, univariate regression analysis, multivariate regression analysis, output of feature importance for LightGBM models, and LASSO regression analysis were performed using Python software (version 3.7.17; http://www.python.org). ROC curves and clinical decision curves were also plotted.
Results
Patient characteristics
This study involved a total of 239 female breast cancer patients from two research centers. One center contributed 123 cases to the training cohort, 53 cases to the testing cohort, and the other center provided 63 cases for the test1 cohort. In the baseline characteristic analysis of the study population, statistically significant differences were observed in one, two, or three cohorts for various blood biomarkers including CEA, CA153, total bilirubin, direct bilirubin, indirect bilirubin, albumin, globulin, albumin/globulin ratio, gamma-glutamyl transferase, total bile acid, prealbumin, aspartate transaminase, alanine transaminase, aspartate/alanine ratio, alkaline phosphatase, magnesium ion, creatine kinase, LDH, α-HBDH, total cholesterol, apolipoprotein A1, apolipoprotein B, and lipoprotein a. A summary of patient clinical blood biomarker features is presented in Table 1.
Feature selection
Feature data were normalized, and features with a Spearman correlation coefficient > 0.9 were retained. The heatmap illustrating the correlation analysis of features is shown in Supplementary Fig. 1. Dimension reduction was performed by eliminating features with zero coefficients using LASSO regression. The optimal λ value was determined based on the minimum mean squared error, and the Lasso regression model was fitted accordingly (Fig. 2a). After feature dimension reduction, 15 features were selected for each cohort (Fig. 2b).

Illustrates the process of feature selection using the least absolute shrinkage and selection operator (LASSO) regression model. (a) LASSO coefficients for different λ values, where vertical dashed lines indicate the number of features corresponding to the optimal λ value. (b) After feature selection using LASSO regression, the nonzero coefficient features are showed
Model construction and validation
The LightGBM machine learning algorithm was utilized to construct predictive models for breast cancer bone metastasis using the selected features. The ROC curve results of the LightGBM model are shown in Fig. 3a. The ROC of the LightGBM model in the training, test, and test1 cohorts were 0.945 (95% CI 0.910–0.981), 0.892 (95% CI 0.813–0.971), and 0.908 (95% CI 0.836–0.980), respectively. The ROC of the combined model in the training, test, and test1 cohorts were 0.955 (95% CI 0.934–0.976), 0.835 (95% CI 0.739–0.931), and 0.918 (95% CI 0.856–0.981), respectively. Other performance parameters are presented in Table 2.

Evaluation of Receiver Operating Characteristic curves for the LightGBM models constructed in both the training (a), test (b) and test1 (c) cohorts were presented
The DCA curves of the LightGBM model in the training, test, and test1 cohorts are shown in Fig. 4. The results indicate that the LightGBM model demonstrates good net benefits in identifying breast cancer bone metastasis across all three cohorts.

Clinical decision curves analysis (DCA) for the LightGBM models constructed in the training (a), test (b), and test1 (c) cohorts were demonstrated
Feature importance analysis and logistic regression analysis
To identify features crucial for predicting bone metastasis in the LightGBM model, feature importance analysis was conducted, as shown in Fig. 5a. The top 5 features with relatively high impact on the labels in the LightGBM model were CEA, creatine kinase, albumin/globulin ratio, apolipoprotein B, and CA153. Univariate and multivariate regression analyses were performed on the features involved in the model, with odds ratios and p-values displayed in Fig. 5b and c. In the univariate regression analysis, p-values of albumin-globulin ratio, total cholesterol, lipoprotein a, CA153, gamma-glutamyl transferase, α-HBDH, alkaline phosphatase, and creatine kinase were < 0.05, suggesting potential associations with breast cancer metastasis. Among these, lipoprotein a, CA153, gamma-glutamyl transferase, α-HBDH, alkaline phosphatase, and creatine kinase were positively correlated, while white blood cell count and total cholesterol were negatively correlated.

Feature importance analysis of LightGBM model (a) and univariate (b) and multivariate (c) logistic regression analysis of variables (features) involved in LightGBM model
In the multivariate analysis, albumin-globulin ratio and total cholesterol had p-values < 0.05 and were negatively correlated. CK-MB, CA153, and alkaline phosphatase were positively correlated.
Discussion
In this study, we utilized the LightGBM algorithm to construct a predictive model for identifying breast cancer patients with bone metastasis based on relatively easily accessible clinical blood biomarker features. The model demonstrated favorable performance in both internal and external testing cohorts. Our predictive model effectively distinguished breast cancer patients with bone metastasis from those without, providing clinicians with additional evidence to facilitate more efficient triage management in breast cancer diagnosis and treatment.
Most previous studies on predicting breast cancer distant metastasis have focused on assessing the risk of metastasis occurrence. Delpech et al. developed and validated nomograms for predicting bone metastasis in early-stage breast cancer patients based on clinical and pathological variables, with C-indexes of 0.69 and 0.73 in the training and validation cohorts, respectively [19]. Similarly, Xu et al. constructed nomograms for predicting bone metastasis in breast cancer patients based on clinical and pathological variables, with C-indexes of 0.714 and 0.705 in the training and validation cohorts, respectively [20]. Zhang et al. incorporated MRI and ultrasound features into prognostic nomograms for predicting distant metastasis in breast cancer, achieving C-indexes of 0.882 and 0.812 in the training and validation cohorts, respectively [21]. Additionally, Wang et al. utilized gene expression data from the National Center for Biotechnology Information Gene Expression Omnibus to construct prognostic nomograms for predicting lung metastasis risk in breast cancer, achieving C-indexes of 0.862 and 0.772 in the training and validation cohorts, respectively [22].
However, fewer predictive models have been developed specifically for diagnosing breast cancer distant metastasis. Wen-Cai et al. developed a web-based predictor using the XGBoost model to forecast the risk of bone metastasis in breast invasive ductal carcinoma patients based on factors such as diagnostic age, race, gender, grade, T/N staging, breast subtype, and marital status. The XGBoost model exhibited the best predictive performance among six different machine learning algorithms, with an AUC of 0.888, accuracy of 0.803, sensitivity of 0.801, and specificity of 0.837 [23]. Similarly, based on the Surveillance, Epidemiology, and End Results database, Xuguang et al. constructed diagnostic and prognostic models for breast cancer bone metastasis using the XGBoost algorithm, which achieved the highest accuracy (diagnostic model AUC = 0.98; prognostic model AUC = 0.88) [24]. However, these models often lack commonly available clinical indicators such as blood routine and biochemical parameters, which may limit their real-world applicability and require further validation.
This study represents the first attempt to construct a diagnostic predictive model for breast cancer bone metastasis using relatively easily accessible clinical blood biomarkers reflecting heart, liver, and kidney function. These biomarkers are typically part of routine admission tests for patients, providing real-time physiological information and offering cost-effective and easy-to-operate advantages compared to pathological examinations, imaging studies, or genetic tests. Additionally, our model underwent external validation at another research center and demonstrated satisfactory performance, with an AUC of 0.908. This external validation not only enhanced the credibility of our research findings but also demonstrated the model’s robustness and generalizability across different datasets.
In contrast to the relatively high-performing XGBoost model [25], this study employed the LightGBM machine learning algorithm. LightGBM exhibited greater flexibility and efficiency in feature processing and model construction, capable of handling complex nonlinear relationships better, thereby enhancing the model’s predictive accuracy and generalization capability. Despite achieving an AUC of over 0.9 in predicting breast cancer bone metastasis in our study, direct comparison of these AUC values with those of other models is not appropriate due to differences in variables and machine learning algorithms used. This diagnostic predictive model based on clinical blood biomarkers offers a novel and cost-effective approach for early detection of breast cancer bone metastasis. It not only contributes to improving personalized treatment management for breast cancer patients but also enhances the accuracy and efficiency of early intervention in clinical practice. Future research could further expand sample sizes and conduct multicenter validations to further verify the model’s robustness and broad applicability, thereby advancing its clinical implementation.
CK-MB was identified as one of the most important features in the LightGBM model prediction. As a creatine kinase isoenzyme, CK-MB exists mainly in the myocardium and skeletal muscle and has been found to be elevated in the serum of late-stage cancer patients compared to early-stage patients [26]. Previous studies have shown that serum CK-MB activity is significantly higher in patients with metastatic tumors compared to primary tumors [27]. However, further research is needed to elucidate why CK-MB elevation occurs in breast cancer patients with distant metastasis [26] and whether the elevated CK-MB originates from tumors or other sources [28]. α-HBDH, another important feature in our model, is an LDH isoenzyme that has been associated with prognosis in various malignant tumors [29,30,31]. In early breast cancer diagnosis, α-HBDH, CEA, and CA125 have been shown to have certain value when used in combination [32]. CA153, a common tumor marker, has predictive capabilities for breast cancer distant metastasis and was also identified as an important feature in our model [33].
Although we successfully constructed a predictive model for breast cancer bone metastasis using clinical blood biomarkers and demonstrated good predictive performance and external validation results, we still face several potential limitations and challenges. Firstly, we only focused on the most common type of breast cancer distant metastasis—bone metastasis. Thus, we did not consider other types of distant metastasis such as brain metastasis and post-treatment breast cancer metastasis [34]. Secondly, although our external validation set originates from different medical centers within the same geographical region, these data still have limitations. Similar patient demographics and treatment protocols may restrict the model’s generalizability globally. Future research should incorporate more extensive multi-center, geographically diverse external validation sets to further validate the model’s performance across diverse populations and enhance its generalizability and reliability. Additionally, while we selected relatively accessible clinical blood biomarkers as input variables for the predictive model, the specificity and sensitivity of these biomarkers may not fully cover all complex scenarios of breast cancer bone metastasis. In clinical practice, it may be necessary to combine more biomarkers or other clinical features to further optimize the model’s predictive ability. Furthermore, although the LightGBM algorithm performs well in handling complex nonlinear relationships, its sensitivity to data quality and feature selection needs attention. The quality of data, standardization, and feature selection significantly impact model performance. Future research needs to further optimize these aspects to enhance the stability and reliability of the model. Lastly, with advances in technology and medical research, new biomarkers and technologies continue to emerge, which may pose new challenges and opportunities for the construction and application of existing models. Therefore, continuous technological innovation and data updates are crucial for the ongoing optimization and widespread application of the model.
Conclusions
In conclusion, this study successfully developed and validated artificial intelligence clinical models and comprehensive models for predicting breast cancer bone metastasis based on clinical blood biomarkers. Particularly, the LightGBM model exhibited high accuracy and potential clinical utility in predicting and identifying breast cancer bone metastasis. In China’s healthcare system, patients with advanced cancer stages are often referred to economically developed regions for treatment, while underdeveloped regions may experience delayed diagnosis due to a lack of early cancer screening. Therefore, the model has the potential to mitigate disease misdiagnosis caused by a lack of imaging technology in underdeveloped regions and improve the clinical decision-making skills of primary care physicians, thereby providing patients with more timely treatment. Similarly, in developed regions, the model can reduce the demand for expensive or invasive imaging techniques. This study highlights the prospect of using easily accessible clinical blood biomarkers for developing artificial intelligence predictive tools.
Data availability
All datasets generated for this study are included in the article/Supplementary Material.
References
Siegel RL, Miller KD, Fuchs HE, Jemal A. Cancer statistics, 2021. CA Cancer J Clin. 2021;71(1):7–33. https://doi.org/10.3322/caac.21654.
Sung H, Ferlay J, Siegel RL, Laversanne M, Soerjomataram I, Jemal A, Bray F. Global Cancer statistics 2020: GLOBOCAN estimates of incidence and Mortality Worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2021;71(3):209–49. https://doi.org/10.3322/caac.21660.
Pfeiffer RM, Webb-Vargas Y, Wheeler W, Gail MH. Proportion of U.S. Trends in breast Cancer incidence attributable to long-term changes in risk factor distributions. Cancer Epidemiol Biomarkers Prev. 2018;27(10):1214–22. https://doi.org/10.1158/1055-9965.Epi-18-0098.
Cao W, Chen H-D, Yu Y-W, Li N, Chen W-Q. Changing profiles of cancer burden worldwide and in China: a secondary analysis of the global cancer statistics 2020. Chin Med J (Engl). 2021;134(7):783–91. https://doi.org/10.1097/cm9.0000000000001474.
Kennecke H, Yerushalmi R, Woods R, Cheang MCU, Voduc D, Speers CH, Nielsen TO, Gelmon K. Metastatic behavior of breast cancer subtypes. J Clin Oncol. 2010;28(20):3271–7. https://doi.org/10.1200/jco.2009.25.9820.
Gennari R, Audisio RA. Surgical removal of the breast primary for patients presenting with metastases - where to go? Cancer Treat Rev. 2009;35(5):391–6. https://doi.org/10.1016/j.ctrv.2009.03.003.
Smith RA, Caleffi M, Albert U-S, Chen THH, Duffy SW, Franceschi D, Nyström L, Detection GSE, Panel AC. Breast cancer in limited-resource countries: early detection and access to care. Breast J. 2006;12(s1):S16–26. https://doi.org/10.1111/j.1075-122X.2006.00200.x.
Allemani C, Matsuda T, Di Carlo V, Harewood R, Matz M, Nikšić M, Bonaventure A, Valkov M, Johnson CJ, Estève J, et al. Global surveillance of trends in cancer survival 2000-14 (CONCORD-3): analysis of individual records for 37 513 025 patients diagnosed with one of 18 cancers from 322 population-based registries in 71 countries. Lancet. 2018;391(10125):1023–75. https://doi.org/10.1016/s0140-6736(17)33326-3.
Valastyan S, Weinberg RA. Tumor metastasis: molecular insights and evolving paradigms. Cell. 2011;147(2):275–92. https://doi.org/10.1016/j.cell.2011.09.024.
Xiong Z, Deng G, Huang X, Li X, Xie X, Wang J, Shuang Z, Wang X. Bone metastasis pattern in initial metastatic breast cancer: a population-based study. CMAR. 2018;10:287–95. https://doi.org/10.2147/cmar.S155524.
Hamaoka T, Madewell JE, Podoloff DA, Hortobagyi GN, Ueno NT. Bone imaging in metastatic breast cancer. JCO. 2004;22(14):2942–53. https://doi.org/10.1200/jco.2004.08.181.
Alonso-Betanzos A, Bolón-Canedo V. Big-Data Analysis, cluster analysis, and machine-learning approaches. Adv Exp Med Biol. 2018;1065:607–26. https://doi.org/10.1007/978-3-319-77932-4_37.
Choi RY, Coyner AS, Kalpathy-Cramer J, Chiang MF, Campbell JP. Introduction to machine learning, neural networks, and Deep Learning. Transl Vis Sci Technol. 2020;9(2):14. https://doi.org/10.1167/tvst.9.2.14.
Li W, Hong T, Liu W, Dong S, Wang H, Tang Z-R, Li W, Wang B, Hu Z, Liu Q, et al. Development of a machine learning-based predictive model for lung metastasis in patients with Ewing Sarcoma. Front Med. 2022;9807382. https://doi.org/10.3389/fmed.2022.807382.
Li W, Liu W, Hussain Memon F, Wang B, Xu C, Dong S, Wang H, Hu Z, Quan X, Deng Y et al. An external-validated prediction model to predict lung metastasis among osteosarcoma: a multicenter analysis based on machine learning. Computational Intelligence and Neuroscience 2022; 2022:2220527;https://doi.org/10.1155/2022/2220527.
Li W, Liu Y, Liu W, Tang Z-R, Dong S, Li W, Zhang K, Xu C, Hu Z, Wang H, et al. Machine learning-based prediction of Lymph Node Metastasis among Osteosarcoma patients. Front Oncol. 2022;12:797103. https://doi.org/10.3389/fonc.2022.797103.
Yao Y-B, Zheng X-E, Luo X-B, Wu A-M. Incidence, prognosis and nomograms of breast cancer with bone metastases at initial diagnosis: a large population-based study. Am J Transl Res. 2021;13(9):10248–61.
Liu D, Wu J, Lin C, Andriani L, Ding S, Shen K, Zhu L. Breast subtypes and prognosis of breast Cancer patients with initial bone metastasis: a Population-based study. Front Oncol. 2020;10:580112. https://doi.org/10.3389/fonc.2020.580112.
Delpech Y, Bashour SI, Lousquy R, Rouzier R, Hess K, Coutant C, Barranger E, Esteva FJ, Ueno NT, Pusztai L, et al. Clinical nomogram to predict bone-only metastasis in patients with early breast carcinoma. Br J Cancer. 2015;113(7):1003–9. https://doi.org/10.1038/bjc.2015.308.
Xu Y, Wu H, Xu G, Yin Z, Wang X, Chekhonin V, Peltzer K, Li S, Li H-y, Zhang J, et al. Survival estimation, prognostic factors evaluation, and Prognostic Prediction Nomogram construction of breast Cancer patients with bone metastasis in the Department of bone and soft tissue tumor: a single Center experience of 8 years in Tianjin, China. Breast J. 2022;2022:1–14. https://doi.org/10.1155/2022/7140884.
Zhang C, Qi L, Cai J, Wu H, Xu Y, Lin Y, Li Z, Chekhonin VP, Peltzer K, Cao M, et al. Clinicomics-guided distant metastasis prediction in breast cancer via artificial intelligence. BMC Cancer. 2023;23(1):239. https://doi.org/10.1186/s12885-023-10704-w.
Wang L, Wang W, Zeng S, Zheng H, Lu Q. Construction and validation of a 6-gene nomogram discriminating lung metastasis risk of breast cancer patients. PLoS ONE. 2020;15(12):e0244693. https://doi.org/10.1371/journal.pone.0244693.
Liu W-C, Li M-X, Wu S-N, Tong W-L, Li A-A, Sun B-L, Liu Z-L, Liu J-M. Using machine learning methods to predict bone metastases in breast infiltrating Ductal Carcinoma patients. Front Public Health. 2022;10:922510. https://doi.org/10.3389/fpubh.2022.922510.
Zhong X, Lin Y, Zhang W, Bi Q. Predicting diagnosis and survival of bone metastasis in breast cancer using machine learning. Sci Rep. 2023;13(1):18301. https://doi.org/10.1038/s41598-023-45438-z.
Xing L, Zhang X, Guo Y, Bai D, Xu H. XGBoost-aided prediction of lip prominence based on hard-tissue measurements and demographic characteristics in an Asian population. Am J Orthod Dentofacial Orthop. 2023;164(3):357–67. https://doi.org/10.1016/j.ajodo.2023.01.017.
Li Y, Chen Y, Shao B, Liu J, Hu R, Zhao F, Cui X, Zhao X, Wang Y. Evaluation of creatine kinase (CK)-MB to total CK ratio as a diagnostic biomarker for primary tumors and metastasis screening. Practical Lab Med. 2023;37:e00336. https://doi.org/10.1016/j.plabm.2023.e00336.
Chang CC, Liou CB, Su MJ, Lee YC, Liang CT, Ho JL, Tsai HW, Yen TH, Chu FY. Creatine kinase (CK)-MB-to-Total-CK ratio: a Laboratory Indicator for Primary Cancer Screening. Asian Pac J cancer Prevention: APJCP. 2015;16(15):6599–603. https://doi.org/10.7314/apjcp.2015.16.15.6599.
Lee BI, Bach PM, Horton JD, Hickey TM, Davis WA. Elevated CK-MB and CK-BB in serum and tumor homogenate of a patient with lung cancer. Clin Cardiol. 1985;8(4):233–6. https://doi.org/10.1002/clc.4960080409.
Yuan ZM, Wang LH, Chen C. Prognostic value of serum α-HBDH levels in patients with lung cancer. World J Surg Oncol. 2023;21(1):78. https://doi.org/10.1186/s12957-023-02965-3.
Bai Y, Zhu B, Zhu Y, Ma Y, Zhang J. Exploration on the application value of the expression level of alpha-hydroxybutyrate dehydrogenase in the diagnosis of ovarian cancer. Chin J Lab Med. 2019;42(7):529–34.
Spector I, McFarland W, Trujillo NP, Ticktin HE. Bone marrow lactic dehydrogenase in hematologic and neoplastic disease. Enzymologia Biologica et Clin. 1966;7(1):78–88. https://doi.org/10.1159/000457206.
Zhan CH, Liu GJ. Diagnostic value of a combined serum α-Hydroxybutyrate dehydrogenase, Carcinoembryonic Antigen and Glycoantigen 125 test for early-stage breast Cancer. Breast cancer (Dove Med Press). 2023;15:617–23. https://doi.org/10.2147/bctt.S410500.
Zhang J, Wei Q, Dong D, Ren L. The role of TPS, CA125, CA15-3 and CEA in prediction of distant metastasis of breast cancer. Clin Chim Acta. 2021;523:19–25. https://doi.org/10.1016/j.cca.2021.08.027.
Gennari A, André F, Barrios CH, Cortés J, de Azambuja E, DeMichele A, Dent R, Fenlon D, Gligorov J, Hurvitz SA, et al. ESMO Clinical Practice Guideline for the diagnosis, staging and treatment of patients with metastatic breast cancer. Annals Oncology: Official J Eur Soc Med Oncol. 2021;32(12):1475–95. https://doi.org/10.1016/j.annonc.2021.09.019.
Funding
This work was supported by the National Natural Science Foundation of China (NSFC; Grant No. 82160481), the Natural Science Foundation of Guangxi, China (Grant No. 2021GXNSFBA196015, 2021GXNSFAA196013, 2024GXNSFAA010058).
Author information
Authors and Affiliations
Contributions
Y.Tan and W.H. Zhang contributed equally as co-first authors to the study’s conceptualization, formal analysis, visualization, and the writing of the original draft. W.H. Zhang, Z. Huang, Y.M. Zhang and Q.X. Tan were involved in data curation and validation. Y. Tan and W.H. Zhang conducted the investigation and were responsible for resource acquisition and software utilization. C.Y. Wei was pivotal in funding acquisition, project administration, methodology development, and supervision. C.Y. Wei was instrumental in reviewing and editing the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study has obtained ethical approval from the Medical Ethics Committee of the First Affiliated Hospital of Guangxi Medical University (Reference Number: 2023-E749-01) and the Medical Ethics Committee of Guangxi Medical University Cancer Hospital (Reference Number: KY2023868). Due to the retrospective nature of the study, the requirement for informed consent has been waived by the Medical Ethics Committee of the First Affiliated Hospital of Guangxi Medical University and the Medical Ethics Committee of Guangxi Medical University Cancer Hospital.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Zhang, Wh., Tan, Y., Huang, Z. et al. Development and validation of an artificial intelligence model for predicting de novo distant bone metastasis in breast cancer: a dual-center study. BMC Women's Health 24, 442 (2024). https://doi.org/10.1186/s12905-024-03264-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12905-024-03264-z