
Abstract
Background
Given the significant role of immune-related genes in uterine corpus endometrial carcinoma (UCEC) and the long-term outcomes of patients, our objective was to develop a prognostic risk prediction model using immune-related genes to improve the accuracy of UCEC prognosis prediction.
Methods
The Limma, ESTIMATE, and CIBERSORT methods were used for cluster analysis, immune score calculation, and estimation of immune cell proportions. Univariate and multivariate analyses were utilized to develop a prognostic risk model for UCEC. Risk model scores and nomograms were used to evaluate the models. String constructs a protein-protein interaction (PPI) network of genes. The qRT-PCR, immunofluorescence, and immunohistochemistry (IHC) all confirmed the genes.
Results
Cluster analysis divided the immune-related genes into four subtypes. 33 immune-related genes were used to independently predict the prognosis of UCEC and construct the prognosis model and risk score. The analysis of the survival nomogram indicated that the model has excellent predictive ability and strong reliability for predicting the survival of patients with UCEC. The protein-protein interaction network analysis of key genes indicates that four genes play a pivotal role in interactions: GZMK, IL7, GIMAP, and UBD. The quantitative real-time polymerase chain reaction (qRT-PCR), immunofluorescence, and immunohistochemistry (IHC) all confirmed the expression of the aforementioned genes and their correlation with immune cell levels. This further revealed that GZMK, IL7, GIMAP, and UBD could potentially serve as biomarkers associated with immune levels in endometrial cancer.
Conclusion
The study identified genes related to immune response in UCEC, including GZMK, IL7, GIMAP, and UBD, which may serve as new biomarkers and therapeutic targets for evaluating immune levels in the future.
Similar content being viewed by others


Introduction
The probability of uterine corpus endometrial carcinoma (UCEC) is 4.4%, with a mortality rate second only to cervical and ovarian cancer [1]. The global incidence rate of UCEC is increasing, and patients affected by it are gradually becoming younger [2]. UCEC may be related to family heredity, menstrual history, reproductive history, exogenous estrogen, aging, and other factors. There are two types of pathogenesis: namely hormone-dependent and hormone-independent [3]. However, the pathogenesis of UCEC remains unclear. UCEC has no obvious clinical symptoms in the early stage, but develops with irregular vaginal bleeding, vaginal discharge, lower abdominal pain, and other symptoms [4]. Early diagnosis of UCEC is relatively straightforward. However, patients in late stages or experiencing recurrence have lower treatment efficacy and prognosis [5]. Therefore, it is extremely important to explore the prognostic genes related to UCEC diagnosis.
It was found that there were stromal sells of endometrial carcinoma, VEGF, IGF-I, and other related inflammatory factors. These immune cells and related inflammatory factors can stimulate the endogenous anti-tumor immune response [6]. The immune microenvironment of UCEC changes significantly, which affects the occurrence and progression of the endometrial cancer. To predict the survival of patients with UCEC and provide guidance for immunotherapy. The Immune-Related Risk Score Model (IRSM) is an independent predictor of adverse prognosis and reflects patient sensitivity to chemotherapy [7]. We aimed to analyze patient information to construct a risk prediction model based on the UCEC immune gene.
Materials and methods
Data source
The GDCRNA Tools package in R was utilized to acquire the following data from the TCGA database for UCEC: RNA-seq data, clinical information (such as age, sex, race, and tumor stage), and survival information. The dataset comprised 578 samples, including 520 primary cancer samples, 23 paired cancer tissue precancerous lesion samples, and 12 precancerous lesion samples.
The analysis dataset was randomly selected to includ 40% of the primary cancer samples, while the remaining samples were used as the validation set for the subsequent analysis. The ImmPort and InnateDB databases were used to download immune gene sets. There is only one mRNA dataset published by the UCEC, and there is no survival information available in the GSE database. mRNA expression data was downloaded from the TCGA database.
Analysis of differential immune genes and identification of immune subtypes in UCEC
Differential gene analysis was conducted between the sample dataset and the immune gene set using the limma method. The analysis was performed with the gdcDEA analysis function included in the GDCRNA Tools package. To enhance accuracy, the differential immune gene analysis data set was used to build a model, which was applied with the R package Consensus Cluster Plus (http://bioconductor.org/packages/release/bioc/html/ConsensusCluster Plus.html) for consistency cluster analysis. Set the parameters as follows: max K = 10 (maximum number of clusters to evaluate) and reps = 100 (number of subsamples). Select the most appropriate number of clusters and categorize the samples into distinct subtypes. PCA was used to verify the reliability of the classification.
Survival analysis and immune cell infiltration analysis of various immune subtypes
The ESTIMATE algorithm was used to score all cancer tissue samples, including the validation set, and to compare differences in immune scores. The CIBERSORT algorithm was used to assess the proportion of immune cells in all cancer tissue samples, including validation set samples. It was also used to analyze the correlation between clinical indicators, immune score, and the proportion of immune cells in each subtype.
Functional analysis of representative genes of each subtype
The rank-sum test was used to compare the expression of the identified differential genes in one subtype with that in all samples excluding this subtype. Significantly high expression is characteristic of the immune gene in this subtype, and the p-value of the differentially expressed gene was corrected by using the False Discovery Rate (Benjamini-Hochberg method). Genes identified by KEGG and GO (biological processes (BP), celluar components (CC), and molecular functions (MF)) analysis (FDR < 0.05) were selected from each subtype.
Construction of prognostic risk model and effect evaluation
A prognostic risk model of UCEC was developed and evaluated through univariate and multivariate analyses using the gene set specific to each subtype (p < 0.05) along with survival data. The study compared the differences in survival rates between the high- and low-risk groups and assessed the accuracy of the prediction model using the ROC curve. A nomogram and its calibration curve were used to evaluate the independent predictive ability of the model. Correlation analyses were conducted between the risk score and clinical indicators in the dataset.
Validation data set validation risk model
The survival disparities between the high- and low-risk samples of the validation dataset were compared. Nomograms and calibration curves were used to validate the prediction effect of the model. The correlation between the risk score and clinical indicators in the validation dataset was analyzed.
Patient sample collection and validation
This study was approved by the Ethics Committee of Yunnan Cancer Hospital (KYLX2023-008) and informed consent was obtained from patients. Collect endometrial cancerous tissue and adjacent normal tissue from patients undergoing surgery for UCEC at Yunnan Cancer Hospital (n = 10).
The qRT-PCR validation was performed using a kit (Thermo Fisher) to extract RNA, reverse transcribe it into cDNA, and then validate the expression levels using PCR (Takara). PCR primers (Table 1) were synthesized by Tsingke Biotechnology (Beijing). The expression levels of genes and key immune cell marker proteins in tissues were detected using immunofluorescence and immunohistochemistry kits (Abcam).
Results
Differential analysis of immune genes and identification of molecular subtypes
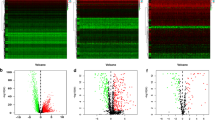
RNA-seq data (n = 578), clinical information, and survival data were retrieved from the TCGA database. The validation dataset was randomly obtained from the primary cancer samples (n = 208), while the remaining samples comprised the analysis set (n = 312). After analyzing the samples in the dataset and examining 2687 immune genes, 502 differentially expressed immune genes were identified. Among these, 213 were upregulated, and 289 were downregulated (Fig. 1A). Cluster analysis revealed that the number of clusters was determined to be four through consistent cluster analysis, and the samples were divided into four subtypes (Fig. 1B, C, D). The PCA results revealed that the contribution rate of the first principal component was 8.4%, the second principal component was 11.4%, and the cumulative contribution rate was 19.8%. There were significant differences among subtypes (p < 0.01), which were consistent with the results of the hot spot clustering analysis, confirming that the clustering was more reliable (Fig. 1E).

Differential analysis and molecular subtype identification of immune genes. A volcanic map of immune genes differentiable expressed in samples of the analysis set. B Delta Area Plot (K compared with k-1, the relative change of area under CDF curve (except k = 2)). C Matrix heat-map at k = 4. D Consistent cumulative distribution function (CDF) diagram. E PCA analysis. The coordinate axis represents the two components (PC1 and PC2) that can best reflect the difference of samples. The scale on the coordinate axis is the relative distance, and the percentage represents the contribution rate of components
Correlation analysis of immune cell infiltration and clinical data of different immune subtypes
Significant differences were found among four different subtypes. The survival prognosis of Cluster 1 was poor, whereas that of Clusters 2, 3, and 4 was relatively good (Fig. 2A). The immune infiltration estimate scores (estimate score, immune score, stromal score, and tumor purity) exhibited significant differences among the four subtypes (p < 0.05, Fig. 2B). The IBERSORT algorithm results illustrate significant differences among the proportions of immune cells of various subtypes (Fig. 2C), such as T cells regulatory (Tregs, p < 0.0001), Dendritic cells activated, macrophages M2, T cells CD4 memory activated, T cells CD4 naive (p < 0.001), dendritic cells resting and plasma cells (p < 0.01), mast cells resting, neutrophils, T cells CD4 memory resting (p < 0.05). The correlation between clinical indices of immune cell content varied among the four subtypes. The correlation between age and activated NK cells, macrophages M1, and activated mast cells was significant in Cluster 1. Additionally T cells CD4 memory cells and activated CD4 memory cells were significantly correlated survival time (Fig. 2D). Macrophage M2 survival time was significantly correlated with neutrophils with tumor stage in cluster 2 (Fig. 2E). Activated dendritic cells were significantly negatively correlated with patient age; CD4 memory activated T cells, regulatory T cells (Tregs), and resting NK cells were significantly correlated with tumor stage; CD4 memory activated T cells, Monocytes, and macrophages M1 were significantly correlated with death in Cluster3 (Fig. 2F). No immune cells showed a significant correlation in cluster 4.

Survival analysis of different immune subtypes, analysis of immune cell infiltration, and function analysis of representative genes of each subtype. A Survival analysis of KM in different immune subtypes. B Box plot of score and purity of each subtype. C all cancer tissues have a box plot of the proportion of immune cells in the sample. D, E, F, scatter diagram of correlation analysis between clinical indexes and immune cell content of samples in each subtype. *, p < 0.05, * *, p < 0.01, * * *, p < 0.001, * * * *, p < 0.0001
The construction and inspection of the risk model
The genes of each subtype sample and corresponding survival information were selected (p < 0.05). A total of 423 genes were identified through Cox univariate analysis, and 111 were found to be significantly associated with Cox multivariate analysis. These genes were utilized to develop the prognostic risk model of UCEC. 33 genes significantly related to prognosis were obtained from the prognosis model: BACH2, TRAIP, CD22, TYMP, CP, IL16, TRIM22, TNFRSF9, ESRRG, BCL2A1, CD300LF, UBD, GIMAP6, TEK, P2RY1, GZMK, CXCL14. The risk coefficients for these genes are negative. Additionally, ITGA7, APOBEC3G, GIMAP7, PLAUR, CLEC10A, IRF8, PIK3CG, IL7, SLAMF8, IL32, PIGR, IL20RA, ENTPD3, RORA, TCF4, and BMP4 have positive risk coefficients.These genes were used to construct the prognostic model, and the risk score was calculated. There was a significant difference in survival information (p < 0.01) and the expression of model genes between the high- and low-risk groups (Fig. 3A, B). The AUC values for neutron patients in the ROC curve at 1, 3, and 5 years were 0.701, 0.710, and 0.710, respectively. These values indicate that the model has excellent predictive ability for the survival of patients with UCEC (Fig. 3C).

Construction of prognostic risk model of representative genes of each subtype. A there were differences in survival between high and low-risk groups. B Heat map of differential gene expression in high and low-risk samples. C ROC curve. D Survival nomogram. E, F, and G are nomogram calibration curves for 1-, 3- and 5-years respectively
Risk model score and clinical phenotype: The predictive effect of the prognostic model was assessed through univariate and multivariate analyses. The nomogram and calibration curve indicate that the predicted survival probability aligns with the actual survival probability, demonstrating high discrimination and consistency in the model (Fig. 3D, E, F, G).
The survival of patients in the high- and low-risk groups was significantly different (p < 0.05, Fig. 4A), and the expression of model genes in the validation set was consistent with the data expression in the analysis set (Fig. 4B); In the ROC curve, the AUC values for UCEC patients in the next 1, 3, and 5 years were 0.684, 0.694, and 0.628, respectively. These values indicate that the prognosis model has excellent prediction accuracy, with the best prediction effect observed for the 5-year prognosis (Fig. 4C). Univariate and multivariate analyses were conducted on the prognostic model gene by examining the risk score and clinical phenotype. The results showed a significant between the tumor stage, risk score, and prognosis (p < 0.05). The nomogram and calibration curve showed that the relationship between the predicted survival probability and the actual survival probability was the same, and the prediction effect of 5 years was the best (Fig. 4D, E, F, G).

Validation of the prediction effect of a risk model. A there were differences in survival between high and low-risk groups. B Heat map of differentially expressed genes in high and low-risk samples. C ROC curve of 1-, 3- and 5-years. D Survival nomogram. E, F, and G represent 1-, 3- and 5-year nomograph calibration curves. H, Gene interaction network diagram
Risk score and immune function analysis of risk model gene in the analysis set
There were significant differences in the scores and immune infiltration scores between the high-risk and low-risk groups (p < 0.05), but there were no significant differences in stromal cell scores, immune and stromal comprehensive scores, and tumor sample purity (p < 0.01, Fig. 5A). Macrophages M1 (p < 0.0001), naïve B cells, eosinophils, resting NK cells, T cells CD4 memory resting, macrophages M1 (p < 0.05), and macrophages M2, mast cells activated, and Plasma cells (p < 0.01) showed significant differences, while the other immune cells did not exhibit any variation (Fig. 5B).

Correlation Analysis of risk model gene, risk score, and clinical phenotype. A Box chart of high and low-risk group scores. B Box diagram of the proportion of immune cells in high and low-risk groups. *p < 0.05, * *, p < 0.01, * * *, p < 0.001, * * * *, p < 0.0001
Functional analysis of representative genes of each subtype
The results of GO analysis indicated that the interacting genes were involved in 662 GO classifications of model genes. The results of different subtypes GO analysis showed that 237 pathways were enriched in cluster 1, including 204 biological processes (BP), 8 celluar components (CC), and 25 molecular function (MF)-related pathways; 437 pathways were enriched in cluster 2, including 415 BP, 4 CC, and 18 MF-related pathways; and 754 pathways were enriched in cluster 3, including 714 BP, 4 CC, and 36 MF-related processes. 49 pathways were enriched in cluster 4, including 46 BP and three MF-related processes.
KEGG analysis illustrated that 27, 48, 67, and 9 pathways were significantly enriched in clusters 1, 2, 3, and 4, respectively. Among them, the cytokine receptor interaction, MAPK signaling pathway, NF-κB signaling pathway, and PI3K/Akt signaling pathway contained the most differentially expressed genes (Fig. 6A, B, C, D).

KEGG bubble diagrams of representative genes and protein-protein interaction networks of key genes. A-D represents KEGG bubble diagrams of representative genes in Cluster 1(A), cluster 2(B), Cluster 3(C), and Cluster 4(D)respectively; E Analysis of protein-protein interaction networks of key genes. The lines represent the interactions between them, on the left are genes that interact in the database, and on the right are off genes that have interactions in the database. The colors represent their degree values, from blue to yellow, the blue color the more in the core position, and the more the color the smaller the degree value
Analysis of protein-protein interaction networks of key genes
The results of the protein-protein interaction network analysis of key genes indicated that the top four pivotal genes for interactions were GZMK, IL7, GIMAP, and UBD in 33 key genes. The databases with strong interactions with key genes were CD4, IL2, CTNNB1, PTPRC, and CXCL9 (Fig. 6E).
Validation of hub genes expression in UCEC patients
qRT-PCR detection revealed that the level of UBD in cancer tissue was significantly higher than that in adjacent tissues, while the levels of GZMK, GIMAP7, and IL-17 in cancer tissue were significantly lower than those in adjacent tissues (Fig. 7A, B, C, D). The IHC detection results of UBD, GZMK, and GIMAP7 are consistent with qRT-PCR results, indicating that UBD may promote poor prognosis in UCEC, high expression levels of GZMK, GIMAP7, and IL-17 is an indicator of a favorable prognosis in patients.

Clinical sample validation of hub genes. A-D, qRT-PCR was used to detect the expression of four hub genes in cancer and adjacent tissues of UCEC patients; E, IHC detection of UBD, GZMK, and GIMAP7 expression. *p < 0.05, * *, p < 0.01, * * *, p < 0.001, * * *, p < 0.001
The results of immune cell analysis indicate that Macrophages M1 and activated mast cells are immune cells with significant differences. Our immunofluorescence test results indicate that the surface marker protein CD80 of Macrophages M1 is highly expressed in cancer tissue, and Macrophages M1 is associated with the development of UCEC (Fig. 8A). However, the surface marker protein FCER1A, activated by mast cells, is expressed at low levels in cancer tissue and high levels in adjacent tissues (Fig. 8B). This suggests that mast cell activated by FCER1A may enhance the body’s immunity.

Clinical sample validation related to immune cell surface marker levels. A Immunofluorescence detection of CD80 expression; B Immunofluorescence detection of FCER1A levels. *p < 0.05, * *, p < 0.01, * * *, p < 0.001, * * *, p < 0.001
Discussion
The high mortality rate of UCEC is largely due to untimely diagnosis and poor treatment outcomes. In recent years, changes in the management of UCEC have highlighted the significant role of biological and genetic patterns in the treatment of the disease [8]. More and more researchers aim to enhance the quality of treatment for UCEC. Our aspiration for the future is to develop the most effective treatment methods tailored to each patient [9]. Immune score was used to score and predict the overall survival of patients with colorectal cancer, Subsequently, it was also applied in the treatment of diffuse large B-cell lymphoma (DLBCL), melanoma, and other types of tumors [10, 11]. At present, the immune scoring system serves as a tumor prognostic factor that has been integrated into the traditional tumor staging system. It has become a crucial component of routine tumor diagnosis and prognosis evaluation. In our study, we analyzed the relationship between immune genes and patients with UCEC using various database systems. The results indicated significant differences in survival and immune function, which showed varying correlations with clinical indicators. This is consistent with previous research [12].
Previous studies have demonstrated that the tumor’s tolerance to the stressful environment determines its malignancy and response to treatment [13]. Additionally, the MAPK pathway is closely related to the growth of UCEC cells. Some studies have found that MAPK is overexpressed in UCEC, which is closely related to the growth, proliferation, and migration of UCEC cells [14]. In this study, the KEGG analysis also indicated that the abnormally expressed genes in endometrial carcinoma were significantly enriched in the MAPK signaling pathway. In addition, it is significantly enriched in cytokine receptor interaction, the NF-κB signaling pathway, and the PI3K-Akt signaling pathway [15].
Construction of a protein-protein interaction network revealed that the immune genes GZMK (Granzyme K), IL7 (Interleukin-7), GIMAP (GTPases of immunity-associated proteins), and UBD (Ubiquitin D) may be the central genes regulated by the network. The GZMK gene product is a member of a group of serine proteases found in cytoplasmic granules of cytotoxic lymphocytes. Related to serine-type endopeptidase activity and serine-type peptidase activity. GZMK is a crucial gene involved in the regulating of cytotoxic T cells in colorectal cancer [16]. However, no study has yet shown its immunomodulatory function in endometrial carcinoma. IL7 encodes a protein that is crucial for the development of B and T cells. Studies have indicated that IL7 is involved in the AKT2 signaling pathway, which is consistent with the pathway enriched in our KEGG analysis [17]. GIMAP is under-expressed in a variety of cancers, correlates with a favorable patient prognosis and immune-related pathways, and positively correlates with the abundance of CD8 + and CD4 + T cells [18]. Significant differences in CD4 + T cells were also found between the high- and low-risk groups in this study. GIMAP plays a crucial role in the development of breast cancer and lung cancer and is closely linked to immune cell infiltration and the expression of immune components. This association is expected to serve as a marker and offer guidance for targeted therapies [19, 20]. UBD is highly expressed in multiple cancers, promotes colorectal cancer cell growth, and enhances chemotherapy resistance in breast cancer [21, 22]. In addition, CD22 is ubiquitous in normal B cells and B-cell malignancies and is regulated through downstream NF-κB pathways [23]. PIK3CG regulates the PI3K-Akt/PKB pathway and affects rectal cancer progression. Thus, PIK3CG may be a potential therapeutic target for prostate cancer [24, 25]. This study suggests that PIK3CG may regulate the progression of UCEC by controlling the PI3K-Akt signaling pathway. Studies have shown that Adriamycin (ADR) can treat endometrial cancer [26], and that TEK promotes the metastatic effects of ADR on breast cancer cells [27], suggesting that TEK may promote the effectiveness of ADR in treating endometrial cancer.
Many disease studies have found that predicting tumors and cancer can be realized through a risk prediction model, such as for prostate cancer [28]. The use of nomograms provides individualized prognostic risk assessment, which provides a reference for individual clinical decision-making. It has been used in pancreatic cancer, breast cancer, cervical cancer, and other diseases [29,30,31]. The model constructed in this study was verified using a nomogram and calibration curve, and it was found to have excellent prediction accuracy. Previous studies have constructed an mRNA-miRNA-lncRNA network and indicated that the pyroptosis-related genes GPX8 and TIRAP are also involved in regulating the number and function of CD8 + cells [32]. Prognostic models of UCEC based on hypoxia molecules [33] and metabolism-related genes have also been constructed using the TCGA database. All of these models indicate a correlation between immune infiltrating cells and immune functions [34, 35]. The risk model we constructed also plays a role in patient prognosis, although the genes exported from the model have not yet been validated experimentally and clinically validated.
Conclusion
Using the prognostic model developed in this study, we can enhance predictions for patients with endometrial cancer based on the key genes GZMK, IL7, GIMAP, and UBD. It is essential to clearly understand the patient’s disease status as it can help improve the patient’s quality of life and guide the selection of more suitable treatment methods.
Availability of data and materials
Analyzed during the current study are available in the GEO and TCGA repository, [GEO: https://www.ncbi.nlm.nih.gov/geo/, TCGA: https://www.cancer.gov/ccg/research/genome-sequencing/tcga].
References
Zhang X, Ye Z, Xiao G, et al. Prognostic signature construction and immunotherapy response analysis for uterine corpus endometrial carcinoma based on cuproptosis-related lncRNAs[J]. Comput Biol Med (in eng). 2023;159:106905.
Yao Y, Liu K, Wu Y, et al. Comprehensive landscape of the functions and prognostic value of RNA binding proteins in uterine corpus endometrial carcinoma[J]. Front Mol Biosci (in eng). 2022;9:962412.
Llauradó M, Ruiz A, Majem B, et al. Molecular bases of endometrial cancer: new roles for new actors in the diagnosis and the therapy of the disease[J]. Mol Cell Endocrinol (in eng). 2012;358(2):244–55.
Wang XM, Fang A, Peng YC, et al. PHF6 promotes the progression of endometrial carcinoma by increasing cancer cells growth and decreasing T-cell infiltration[J]. J Cell Mol Med. 2023;27(5):609–21.
Brooks RA, Fleming GF, Lastra RR, et al. Current recommendations and recent progress in endometrial cancer[J]. CA Cancer J Clin (in eng). 2019;69(4):258–79.
Rodriguez-Garcia A, Minutolo NG, Robinson JM, et al. T-cell target antigens across major gynecologic cancers[J]. Gynecol Oncol (in eng). 2017;145(3):426–35.
Wei W, Ye B, Huang ZT et al. Prediction of prognosis, immunotherapy and chemotherapy with an immune-related risk score model for endometrial cancer[J]. Cancers. 2023;15(14):3673.
D’Oria O, Giannini A, Besharat AR et al. Management of endometrial cancer: molecular identikit and tailored therapeutic approach[J]. Clin Exp Obstet Gynecol. 2023;50(10):210.
Di Donato V, Giannini A, Bogani G. Recent advances in endometrial cancer management[J]. J Clin Med. 2023;12(6):2241.
Xiong D, Li M, Zeng C. Construction and validation of a risk scoring model for diffuse large B-cell lymphoma based on ferroptosis-related genes and its association with immune infiltration[J]. Transl Oncol (in eng). 2022;16:101314.
Sheng Y, Tong L, Geyu L. An immune risk score with potential implications in prognosis and immunotherapy of metastatic melanoma[J]. Int Immunopharmacol (in eng). 2020;88:106921.
Galon J, Fridman WH, Pagès F. The adaptive immunologic microenvironment in colorectal cancer: a novel perspective[J]. Cancer Res (in eng). 2007;67(5):1883–6.
Ziech D, Franco R, Pappa A, et al. Reactive oxygen species (ROS)--induced genetic and epigenetic alterations in human carcinogenesis[J]. Mutat Res (in eng). 2011;711(1–2):167–73.
Lu Y, Jiang S, Zhang J, et al. Estradiol activates MAPK signaling pathway by estrogen induced VEGF and bFGF in endometrial cancer cells[J]. Zhonghua Fu Chan Ke Za Zhi (in chi). 2014;49(12):925–31.
Zhou HY, Zhang CF, Li HR et al. A novel risk score system of immune genes associated with prognosis in endometrial cancer[J]. Cancer Cell Int. 2020;20(1):240.
Masuda K, Kornberg A, Miller J et al. Multiplexed single-cell analysis reveals prognostic and nonprognostic T cell types in human colorectal cancer[J]. JCI Insight (in eng). 2022;7(7):e154646.
Chang YS, Huang HD, Yeh KT, et al. Genetic alterations in endometrial cancer by targeted next-generation sequencing[J]. Exp Mol Pathol (in eng). 2016;100(1):8–12.
Qin Y, Liu H, Huang X, et al. GIMAP7 as a potential predictive marker for pan-cancer prognosis and immunotherapy efficacy[J]. J Inflamm Res (in eng). 2022;15:1047–61.
Huo X, Shen G, Li J, et al. Identification of the GTPase IMAP family as an immune-related prognostic biomarker in the breast cancer tumor microenvironment[J]. Gene (in eng). 2022;812:146094.
Chen SY, Tian D, Petersen L et al. Prognostic value of GIMAP4 and its role in promoting immune cell infiltration into tumor microenvironment of lung adenocarcinoma[J]. Biomed Res Int. 2022: 7440189. https://doi.org/10.1155/2022/7440189.
Su H, Qin M, Liu Q, et al. Ubiquitin-like protein UBD promotes cell proliferation in Colorectal Cancer by facilitating p53 Degradation[J]. Front Oncol (in eng). 2021;11:691347.
Han T, Liu Z, Li H, et al. High expression of UBD correlates with epirubicin resistance and indicates poor prognosis in triple-negative breast cancer[J]. Onco Targets Ther. 2015;8:1643–9.
Hachisuga T, Fukuda K, Nakamura S, et al. Local immune response in endometrial carcinomas[J]. Br J Obstet Gynaecol (in eng). 1997;104(1):110–4.
Chang JHL, Liu Y, Erratum. Targeting PIK3CG in combination with paclitaxel as a potential therapeutic regimen in claudin-low breast cancer [Corrigendum][J]. Cancer Manag Res (in eng). 2020;12:3331–2.
Chung WC, Zhou X, Atfi A, et al. PIK3CG is a potential therapeutic target in androgen receptor-indifferent metastatic prostate Cancer[J]. Am J Pathol. 2020;190(11):2194–202.
Okada H, Yamamoto T. Therapy of advanced endometrial cancer[J]. Gan Kagaku Ryoho (in jpn). 1990;17(9):1848–55.
Yang F, Hu Y, Shao L, et al. SIRT7 interacts with TEK (TIE2) to promote adriamycin induced metastasis in breast cancer[J]. Cell Oncol (Dordr). 2021;44(6):1405–24.
Foley RW, Gorman L, Sharifi N, et al. Improving multivariable prostate cancer risk assessment using the prostate Health Index[J]. BJU Int. 2016;117(3):409–17.
Zou W, Wu D, Wu Y, et al. Nomogram predicts risk of perineural invasion based on serum biomarkers for pancreatic cancer[J]. BMC Gastroenterol. 2023;23(1):315.
Zong Q, Deng J, Ge W, et al. Establishment of simple nomograms for predicting axillary lymph node involvement in early breast cancer[J]. Cancer Manag Res. 2020;12:2025–35.
Zuo J, Huang Y, An J, et al. Nomograms based on HPV load for predicting survival in cervical squamous cell carcinoma: an observational study with a long-term follow-up[J]. Chin J Cancer Res. 2019;31(2):389–99.
Liu ZS, Jing CL. A novel risk prediction model of pyroptosis-related genes for the prognosis and immunotherapy response of endometrial cancer[J]. Eur Rev Med Pharmacol Sci. 2022;26(7):2259–78.
Jiao Y, Geng R, Zhong ZH, et al. A hypoxia molecular signature-based prognostic model for endometrial cancer patients[J]. Int J Mol Sci. 2023;24(2):1675.
Huang H, Cai X, Lin J, et al. A novel five-gene metabolism-related risk signature for predicting prognosis and immune infiltration in endometrial cancer: a TCGA data mining[J]. Comput Biol Med. 2023;155:106632.
Wang Y, Zhang J, Zhou Y, et al. Construction of a microenvironment immune gene model for predicting the prognosis of endometrial cancer[J]. BMC Cancer. 2021;21(1):1203.
Acknowledgements
We thank all those who contributed to this study.
Funding
Special fund project for training high-level health technical personnel in Yunnan Province (D-2018053).
Author information
Authors and Affiliations
Contributions
LL Y, Q S, and CY D were provided experimental ideas. LL Y, LF Z, RL X, and H L obtained and analyzed data, Q S, H Z, CY D, and YF Z were involved in manuscript writing, LL Y, and Y Q modified and checked the manuscripts. LL Y was involved in the majority of experiments, data statistics and analysis, and drafting and revising of the manuscript. CY D was involved in experiment supervision and management, data analysis, and revision of the manuscript. LL Y, FL Z, RL X, and H L performed bioinformatics analysis of the RNA sequencing data and performed differential expression analysis. H Z, CY D, and YF Z were involved in the acquisition of human samples, data capture, and analysis of clinical data.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study was performed in line with the principles of the Declaration of Helsinki. This study was approved by the Ethics Committee of Yunnan Cancer Hospital (KYLX2023-008).
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sang, Q., Yang, L., Zhao, H. et al. Risk prediction model of uterine corpus endometrial carcinoma based on immune-related genes. BMC Women's Health 24, 429 (2024). https://doi.org/10.1186/s12905-024-03237-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12905-024-03237-2