
Abstract
Background
Palliative care trials have higher rates of attrition. The MORECare guidance recommends applying classifications of attrition to report attrition to help interpret trial results. The guidance separates attrition into three categories: attrition due to death, illness or at random. The aim of our study is to apply the MORECare classifications on reported attrition rates in trials.
Methods
A systematic review was conducted and attrition classifications retrospectively applied. Four databases, EMBASE; Medline, CINHAL and PsychINFO, were searched for randomised controlled trials of palliative care populations from 01.01.2010 to 08.10.2016. This systematic review is part of a larger review looking at recruitment to randomised controlled trials in palliative care, from January 1990 to early October 2016. We ran random-effect models with and without moderators and descriptive statistics to calculate rates of missing data.
Results
One hundred nineteen trials showed a total attrition of 29% (95% CI 28 to 30%). We applied the MORECare classifications of attrition to the 91 papers that contained sufficient information. The main reason for attrition was attrition due to death with a weighted mean of 31.6% (SD 27.4) of attrition cases. Attrition due to illness was cited as the reason for 17.6% (SD 24.5) of participants. In 50.8% (SD 26.5) of cases, the attrition was at random. We did not observe significant differences in missing data between total attrition in non-cancer patients (26%; 95% CI 18–34%) and cancer patients (24%; 95% CI 20–29%). There was significantly more missing data in outpatients (29%; 95% CI 22–36%) than inpatients (16%; 95% CI 10–23%). We noted increased attrition in trials with longer durations.
Conclusion
Reporting the cause of attrition is useful in helping to understand trial results. Prospective reporting using the MORECare classifications should improve our understanding of future trials.
Similar content being viewed by others

Background
Attrition is a major concern for accurate analysis of all trials and can influence the results of a study through potentially biasing the treatment effects and reducing the ability to detect differences [1,2,3]. Furthermore, conducting research with palliative care patients can be particularly challenging because of high levels of missing data and/or attrition due to high mortality rates and symptom burden [1, 4].
Authors report that the most important thing is to understand the reason for the missing data [5, 6]. Generally, missing data can be classified into three categories (Table 1): completely missing at random (CMAR), missing at random (MAR) and missing not at-random (MNAR), but in palliative care populations, missing data could mostly likely to be classified as MNAR because the patients being too unwell to complete a trial [1]. This is likely to be as a result of health deterioration, comorbidities and frailty [6], which are not random events [1, 7]. Recently, within the MORECare guidance, authors proposed three new categories to define the type of attrition in palliative care: attrition due to death (ADD), attrition due to illness (ADI) and attrition at random (AAR) [1]. Moreover, in 2013 the MORECare team developed guidance for conducting research with palliative care populations [8] and part of the checklist of conducting studies in palliative care, was how to deal with missing data and attrition [1, 8]. Consequently, the MORECare statements have been included in the EQUATOR Network website and database (http://www.equator-network.org/reporting-guidelines/morecare-statement/), to set clear standards on good practice in evaluating clinical studies in end of life care [9]. In fact, a barrier to the development of good practice in palliative care is the lack of quality research and evidence [8]. For this reason the MORECare guidance has been developed to identify research standards to aid future studies [8]. Furthermore, the inclusion of the MORECare guidance in the EQUATOR Network website could help to enhance the use of this guidance to improve the reliability of research in palliative care.
A crucial aspect of clinical trials is the proportion of missing data and how researchers approach this to avoid serious biases [10]. The proportion of missing data is directly related to the quality of statistical inferences that can be made. Standard trial guidance suggests that the levels of missing data should be between 5 and 20%, meanwhile previous palliative care research has shown levels of missing data up to 80% of the total results [11]. Hussain’s (2016) review of the amount of missing data in clinical trials relating to palliative care populations found missing data levels of over 20% in half of the studies with an overall rate of 23.1%. In a detailed investigation of missing data in cancer trials involving palliative care populations Hui et al. (2013) found an attrition rate of 26% for the primary endpoint and 44% for participants reaching the end of the study [12]. Hui et al. also concluded that some investigators struggled to attribute the cause of the missing data.
Once the possible reasons for missing data are determined, the next step is to decide how to deal with them [6]. The method used to estimate the missing data needs to be reported, since different methods of estimating missing data, based on different assumptions, could lead to different conclusions [7]. For this reason, some literature suggests using more than one method for analysis and to discuss the potential bias of missing data [7]. This is particularly important for trials conducted in the field of palliative care, where most of the missing data are MNAR that could be estimated and minimised through the study design and taken account of in the final analysis. Moreover, there are no specific statistical methods recommended to analyise missing data not at random [13].
General guidance on the management of missing data in palliative care studies stated that missing data and attrition should be expected in a palliative care population and low levels of missing data or attrition could lead you to question whether the population was infact a palliative care population [1]. Another issue in trial reporting is describing or even deciding who the total palliative care population is. Only by defining this group can all potential participants be screened for eligiblility. In many hospitals a large number of patients could be deemed eligible for a study but they are spread out across different departments and include both out and inpatients. It is unclear what the usual practice is for identifying and screening palliative care populations and whether, for example, this means screening patients from particular outpatient clinics or carrying out database searches of diagnoses or symptoms [6].
Overall when reporting trials including palliative care populations three main areas were seen as requiring more scrutiny: classification of attrition, levels of attrition and their accompanying imputation methods and descriptions of trial populations.
In this study we wanted to investigate whether the MORECare classifications on reporting attrition in trials can be retrospectively applied to data retrieved from a systematic review on attrition in palliative care and thus help to better understand the reported results.
Methods
Primary Aims:
-
To describe whether the MORECare attrition classifications could be retrospectively applied to palliative care randomised controlled trials.
-
To describe whether there were any statistical differences between cancer and non-cancer patients and between the enrolment settings.
Secondary Aims:
-
To describe any methods used to handle missing data.
-
To describe if there was any correlation between the length of the time to primary outcome measure and the total attrition rate.
We conducted a systematic review to identify randomised controlled trials (RCTs) conducted in the last 5 years in a palliative care field. This review followed the methods of a Cochrane review [14] . This systematic review is part of a larger review looking at recruitment to RCTs in palliative care which covers the period from January 1990 to early October 2016 [15]. From this larger review, we selected randomised controlled trials involving palliative care populations from the last 5 years as reporting was likely to be of a better standard.
Identification and selection of studies
In the primary review [16] Embase, Medline, psychINFO and CINAHL databases were searched from the 1st January 1990 until the 8th October 2016 (see Table 2 and Fig. 1). Consequently, randomised controlled trials from 01.01.2010 to 08.10.2016, were extracted. The search included the terms palliat*, hospice* and ‘terminal care’ as they are seen as a robust and valid strategy to identify and retrieve palliative care literature [17,18,19,20]. The search terms used within Medline via EBSCO were palliat* or hospice* or terminal care or palliative care/ or palliative medicine/ or terminal care/ (not exploded) and randomi*ed. controlled trial* or randomised controlled trial/ (publication and topic). The search strategy was modified as necessary for the other databases searched (Table 2 for further details of the search terms used). The reference lists of the included studies were also hand searched to identify additional papers specifically focusing on recruitment to palliative care RCTs.

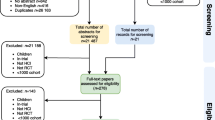
PRISMA study flow diagram
Study eligibility
Inclusion and exclusion criteria are listed in Table 3. AO and PS or LD screened the 3342 titles from the search. We used the WHO definition of palliative care which defines palliative care as an ‘approach which aims to improve the quality of life of patients and their families facing life threatening illness, through the prevention, assessment and treatment of pain and other problems, physical, psychosocial and spiritual’ [21] to identify palliative care populations.
Data extraction and analysis
Data were extracted by two independent reviewers (AO & PS or LD). If no agreement could be reached about inclusion of data extraction, an arbitrator (NP) was consulted. If there was insufficient information to make a decision about data, authors were contacted via email. If information were not forthcoming then the paper was excluded.
Data were collected to analyse the primary aim of the study, which was the retrospective application of the MORECare classifications on attributing the cause of attrition. We used the same criteria as Hussein (2016) to identify attrition, namely the number of participants lost by the time of the evaluation of the primary end point or final assessment if the primary endpoint was not made. The primary outcome was chosen because it was the most important outcome. Moreover it should have been defined at the time the study was designed to reduce bias [22] . In addition, we included attrition cases which occured between consent and randomization where available. Reasons for attrition were determined retrospectively to one of the MORECare classifications of ADD, ADI or AAR based upon decriptions within the paper. We used weighted means to describe the proportion of missing data.
To describe whether there were any statistical differences between cancer and non-cancer patients and between enrollment setting, we ran random effect models with and without moderators, using the Metafor package [23]. We aggregated double arcsine transformed values computing a weighted mean (with inverse-variance weight). To ease interpretation, we back transformed averages to estimated true proportions with corresponding 95% confidence intervals using Miller’s formula [24].
We used descriptive analysis to describe which imputation methods were used. The mean length of the time to primary outcome was calculated to assess whether length of stay was correlated with increased attrition rate using the Pearson correlation. Because the heterogeneity of data, it was not possible to calculate any correlation with patients’ overall survival, primary outcome and attrition.
Quality assessment
The quality of the trial was not assessed as the focus of the review was on attrition rates as recorded in the study.
Results
Study selection
Of the 3342 titles and abstracts screened, full text articles of 202 studies were assessed for eligibility of which 136 were included in the final analysis, which included 17,472 participants (Table 4).
Study characteristics
We needed to decide which was the intervention and the control arm in 7 studies, because it was not specified by the authors. The median sample size was 75 (IQR 106). Among all the collected randomised controlled trials,few had a specific study design: 24 studies were feasibility/pilot studies, 3 were cluster trials, 2 were cross-over trials, one a fast-track trial. One study was designed to test the dose of a new drug. Four studies involved patients and their carers and one study patients and primary physicians. The median duration of studies to primary outcome measure was 7 weeks (IQR 11) with some studies having an intervention length of only a few hours or days. Thirteen studies did not mention the intervention duration.
In 5 studies participants were recruited from the hospice and in 28 from the hospital but it is unclear if these were inpatients and/or outpatients. The most common specific site mentioned in 47 studies was a ‘clinic’ which presumably meant outpatients. From the participants 25% were recruited from inpatient services, 30% from outpatient services and 16% recruited from both out patients and inpatients. For the remaining participants no indication was given as to whether they were inpatients or outpatients. Most patients had cancer (76%) with 20% having a non-cancer condition including heart failure, neurological conditions, respiratory, renal and liver disease or frail elderly populations. The remaining studies (4%) did not specify the patient’s condition.
Application of MORECare classifications
The attrition rate was not recorded in 17 trials leaving 119 trials with assessable total attrition data. We presented the data only with descriptive statistics because there were not sufficient data to calculate rates of attrition in the ADD, ADI and AAR groups (Table 5).
We applied the MORECare classifications of attrition to 91 out of 119 papers that contained sufficient information on the cause of missing data. This reflects the difficulty in attributing the cause of missing data based upon the authors’ descriptions in the published papers. Some authors reported withdrawal as a cause of attrition, without specifying if this was related to a specific cause such as adverse events.
We found the main reason for attrition was attrition due to death (ADD) and accounted for a weighted mean of 31.6% (SD 27.4) of attrition cases. Attrition due to illness (ADI) was cited as the reason for 17.6% (SD 24.5) of participants. For 7% of total participants they left due to adverse events. In 50.8% (SD 26.5) of cases, the attrition was at random (AAR) with reasons such as patients being no longer contactable.
The weighted average attrition across all studies was 29% (95% CI 28–30%). The statistical analysis including participants’ diagnosis as a covariate (cancer vs non-cancer), was possibile in 113 studies. We did not observe significant differences between groups (non-cancer patients, 26%; 95% CI 18–34%; cancer patients, 24%; 95% CI 20–29%).
We were able to calculate whether including the study setting, inpatients and non-inpatients, as a covariate in 68 studies. We found significant differences between the two groups (p = 0.01), with a higher attrition rate for outpatients (29%; 95% CI 22–36%) than inpatients (16%; 95% CI 10–23%). These estimated proportions apperared to be all heterogeneous (ps < 0.0001). In some studies, authors did not distinguish the amount of inpatients for the amount of outpatients, thus it was not possible to conduct any statistical analysis.
Twenty trials reported data about attrition between enrolment and randomisation. These pre-randomisation data were too heterogeneous to be analysed. Although only 20 trials reported these missing data it may have been true for other studies too but not mentioned. Moreover, some authors commented upon the level of missing data in their papers, whilst in others no comment was made but attrition data was calculated from the CONSORT flow-chart. Because the data were heterogeneous, it was not possible to calculate any statistical difference between the studies that commented upon attrition and those studies that did not.
Use of imputation methods for primary endpoint
According to primary endpoint, 74 of 136 studies (54%) commented that they used an imputation method for missing data but only 36 (26%) recorded how they managed their missing data (Table 6).
As previously described, imputation methods should be reported, since different methods of estimating missing data, based on different assumption, could lead to different conclusions [7]. For this reason, part of literature suggests using more than one method for analysis and to discuss the potential bias of missing data [7]. Despite these recommendations, authors used different multiple imputation methods in only 15 studies. These methods were not uniform and different among each study.
Among the feasibility studies, one considered missing data as a random effect, five used a single imputation method (Area Under the Curve analysis, last observation carried forward, intention to treat analysis, conservative statistic). Only in one study, authors did not impute missing data because the main intention of the study was the feasibility of the intervention and also to explore the nature of missing data.
In few other studies [14], authors used different non statistical methods to deal with missing data, for example adapting their protocol to reduce the number of missing data (i.e. adapting the time of follow up or a specific questionnaire).
Length of intervention
In 108 out of the 136 studies, it was possible to describe the length of the intervention. In the remaining studies this was not possible because it was not clearly reported by the authors. The median time to primary outcome measure was 7 weeks. There was a significant correlation (r = 0.37, p < 0.01) between the length of time to primary outcome measure and the total attrition rate, meaning that the longer the time to primary outcome the increased chance of attrition.
Discussion
In this review we found that the MOREcare classifications could be applied retrospectively in about 67% of studies. In the remaining papers this was not possible due to insufficient details in reporting the reasons for missing data. We could not calculate any analysis in relation to the reason for attrition using the MORECare classifications due to insufficient data. Vague phrases such as withdrawn do not inform the reader as it is still unclear what the the reasons for the withdrawal were, for example was it due to progression of the illness or side effects of a drug or another reason? Dumville et al. (2006) recommend reporting the causes of attrition clearly to help understand the findings of a study [161] and applying the MORECare classifications gives an indication of not only what has happened in a trial but also the characteristics of the population involved.
Our review emphasises the need to identify primary outcome measures which should be measured sooner than later given the large amount of missing data in longer studies. Given the median time to primary endpoint was only 7 weeks, this shows that we are looking at end points potentially shorter than this but obviously this depends upon the focus of the study.
Palliative care populations are difficult to identify and these findings show a variation in where researchers looked for potential participants. Whilst we were able to make some comment upon where populations were identified from, this was difficult to extract as it was poorly recorded.
The level of missing data was higher than in other reviews (Hussain 2016; Hui 2013) which may reflect a broader definition of a palliative population. This is also reflected in the higher attrition rates noted in the non-cancer population and non-hospital populations. In the study by Hui (2013) the lower rates of attrition were in a cancer population based in one hospital. Modifications in trial design should be made for trials involving non-cancer, community based populations, as attrition rates were shown to be highest in these groups. Interestingly, we identified attrition even before randomisation. Perhaps this is something trial steering committees could monitor to assess the cause of attrition using the MORECare classifications, as it may help decide if attrition is due to the trial design or the population under study.
Only 26% of studies used any sort of imputation method for the primary outcome. All studies should comment upon missing data and notably report attrition following CONSORT guidelines not only for the primary outcome, but also for all the obtained results. Given all these studies were completed since 2010 you would expect this figure to be higher. With a rise in publishers asking for guidance in reporting of research to be followed hopefully this figure will increase. Moreover, according to the different type of missing data, different imputation methods can be used and it is recommended to use multiple imputation methods as a powerful tool for handling missing data with a sensitivity analysis [13].
One major concern about our review is that we relied upon our interpretation of descriptions of populations which we then decreed as palliative or not. Although the reviewers used the same definitions, their interpretation of the studies could have biased the reported results. Moreover, the causes of attrition have been interpreted according to the reasons given by the authors of the studies, which were not always clear. Hence some studies were excluded from this review because the causes of attrition were not clear. This may have changed the findings. As described, the high heterogeneity of collected data prevented further statistical analyses, such as calculation of the rates of attrition according to whether participants were in/outpatients, had cancer or not, or, according to type of attrition (ADD, ADI and AAR). The fact that most of the studies were about cancer patients limits the generalisability of our study in non-oncological settings. Moreover, most of the included studies were conducted in English-language nations.
This review included only randomised controlled trials, but more research is needed about the impact of missing data in other types of study design [162]. We assumed that from 2010, studies had a better standard of reporting and handling missing data. Further analysis about the correlation between the year of publication and the rate of missing data could have been assessed to analyse whether the reporting of missing data has improved over time.
Conclusion
The MORECare classifications provided a useful tool in highlighting attrition due to death in a readily accessible manner. In particular higher rates of attrition should be expected in longer trials, non-cancer andcommunity based palliative care populations. By applying the MORECare classifications we should be able to characterise trial populations more easily to enable a better understanding of the trials results. Moreover, the use of these classifications may help the readers to understand if authors described clearly the rate of missing data and if authors tried to take into account the rate of attrition in the interpretation of their results. The MoreCare guidelines could also help researchers to better design and conduct their studies in palliative care settings. In fact, the difficult we had in the collection of the data shows that more efforts should be done to report the results of the studies and to handle with missing information that could potentially bias the final results.
Availability of data and materials
Not applicable. The research strategy and the list of the included articles, are in the manuscript file.
Abbreviations
- ADD:
-
Attrition due to death
- ADI:
-
Attrition due to illness
- AO:
-
Anna Oriani
- ARR:
-
Attrition at random
- CI:
-
Interval of Confidence
- CMAR:
-
Completely missing at random
- IQR:
-
Interquartile Range
- LD:
-
Lesley Dunleavy
- MAR:
-
Missing at random
- MNAR:
-
Missing not at-random
- NP:
-
Nancy Preston
- PS:
-
Paul Sharples
- RTCs:
-
Randomised controlled trials
- SD:
-
Standard Deviation
References
Preston NJ, Fayers P, Walters SJ, Pilling M, Grande GE, Short V, et al. Recommendations for managing missing data, attrition and response shift in palliative and end-of-life care research: part of the MORECare research method guidance on statistical issues. Palliat Med. 2013;27:899–907.
Wood AM, White IR, Thompson SG. Are missing outcome data adequately handled? A review of published randomized controlled trials in major medical journals. Clinical Trials. 2004;1(4):368–76.
Zhang Y, Alyass A, Vanniyasingam T, Sadeghirad B, Florez ID, Pichika SC, et al. A systematic survey of the methods literature on the reporting quality and optimal methods of handling participants with missing outcome data for continuous outcomes in randomized controlled trials. J Clin Epidemiol. 2017;88:67–80.
Evans CJ, Benalia H, Preston NJ, Grande G, Gysels M, Short V, et al. The selection and use of outcome measures in palliative and end-of-life care research: the MORECare international consensus workshop. J Pain Symptom Manag. 2013;46(6):925–37.
Bruera E, Higginson I, von Gunten CF, Morita T. Textbook of palliative medicine and supportive care: CRC publisher; 2015.
Fielding S, Fayers PM, Loge JH, Jordhoy MS, Kaasa S. Methods for handling missing data in palliative care research. Palliat Med. 2006;20(8):791–8. https://doi.org/10.1177/0269216306072555.
Palmer JL. Analysis of missing data in palliative care studies. J Pain Symptom Manage. 2004;28:612–8.
Higginson IJ, Evans CJ, Grande G, Preston N, Morgan M, McCrone P, et al. Evaluating complex interventions in end of life care: the MORECare statement on good practice generated by a synthesis of transparent expert consultations and systematic reviews. BMC Med. 2013;11.
Equator Network. Enanching the Quality and Transparency in Health Care Research [Available from: http://www.equator-network.org/.
Schulz KF, Grimes DA. Sample size slippages in randomised trials: exclusions and the lost and wayward. Lancet. 2002:781–5.
Dong Y, Peng CY. Principled missing data methods for researchers. Springerplus. 2013;2(1):222.
Hui D, Glitza I, Chisholm G, Yennu S, Bruera E. Attrition rates, reasons, and predictive factors in supportive care and palliative oncology clinical trials. Cancer. 2013;119(5):1098–105.
Mallinckrodt CH, Kenward MG. Conceptual Considerations regarding Endpoints, Hypotheses, and Analyses for Incomplete Longitudinal Clinical Trial Data. Therapeutic Innovation & Regulatory Science. 2010:449–58.
Higgins JPT, Green S, Altman DG. Cochrane Handbook for Systematic Reviews of Interventions. Front Matter, in Cochrane Handbook for Systematic Reviews of Interventions: Cochrane Book Series; 2008.
Dunleavy L, Walshe C, Preston N. What Are the Barriers and Facilitators to Patient and Carer Recruitment to Randomised Controlled Trials in Palliative Care? A Systematic Review with Narrative Synthesis. Synthesis15th World Congress of the European Association for Palliative Care; 2017. p. 211.
Dunleavy L, Walshe C, Oriani A, Preston N. Using the ‘social marketing mix framework’ to explore recruitment barriers and facilitators in palliative care randomised controlled trials? A narrative synthesis review. Palliative Medicine. 2018.
Cochrane PaPaS. Palliative care search strategy Online: Cochrane Collaboration 2014 [Available from: http://papas.cochrane.org/papas-trials-register.
Sladek R, Tieman J, Fazekas BS, Abernethy AP, Currow DC. Development of a subject search filter to find information relevant to palliative care in the general medical literature. J Med Libr Assoc. 2006;94(4):394–401.
Tieman J, Sladek R, Currow D. Changes in the quantity and level of evidence of palliative and hospice care literature: the last century. J Clin Oncol. 2008;26:5679–83.
Sigurdardottir KR, Oldervoll L, Hjermstad MJ, Kaasa S, Knudsen AK, Lohre ET, et al. How are palliative care cancer populations characterized in randomized controlled trials? A literature review. J Pain Symptom Manage. 2014;47:906–14 e17.
World Health Organisation. Definition of palliative care. 2005.
Andrade C. The primary outcome measure and its importance in clinical trials. J Clin Psychiatry. 2015;76(10):e1320–3.
Viechtbauer W. Conducting meta-analyses in R with the metafor package. Journal of Statistical Software. 2010:1–48.
Miller JJ. The inverse of the Freeman–Tukey double arcsine transformation. The American Statistician 1978. p. 138.
Dumville JCTDJ, Hewitt CE. Research methods: reporting attrition in randomised controlled trials. BMJ: British Medical Journal. 2006:969.
Hoare S, Morris ZS, Kelly MP, Kuhn I, Barclay S. Do patients want to die at home? A systematic review of the UK literature, focused on missing preferences for place of death. PLoS One. 2015;10(11):e0142723.
Abernethy AP, McDonald CF, Frith PA, Clark K, Herndon IJE, Marcello J, et al. Effect of palliative oxygen versus room air in relief of breathlessness in patients with refractory dyspnoea: a double-blind, randomised controlled trial. Lancet. 2010;376(9743):784–93.
Abernethy AP, Currow DC, Shelby-James T, Rowett D, May F, Samsa GP, et al. Delivery strategies to optimize resource utilization and performance status for patients with advanced life-limiting illness: results from the "palliative care trial" [ISRCTN 81117481]. J Pain Symptom Manag. 2013;45(3):488–505.
Ahmedzai SH, Nauck F, Bar-Sela G, Bosse B, Leyendecker P, Hopp M. A randomized, double-blind, active-controlled, double-dummy, parallel-group study to determine the safety and efficacy of oxycodone/naloxone prolonged-release tablets in patients with moderate/severe, chronic cancer pain. Palliat Med. 2012;26(1):50–60.
Ando M, Morita T, Akechi T, Okamoto T. Efficacy of short-term life-review interviews on the spiritual well-being of terminally ill cancer patients. J Pain Symptom Manag. 2010;39(6):993–1002.
Aoun SM, O'Connor M, Breen LJ, Deas K, Skett K. Testing models of care for terminally ill people who live alone at home: is a randomised controlled trial the best approach? Health and Social Care in the Community. 2013;21(2):181–90.
Barton R, English A, Nabb S, Rigby AS, Johnson MJ. A randomised trial of high vs low intensity training in breathing techniques for breathless patients with malignant lung disease: a feasibility study. Lung Cancer (Amsterdam, Netherlands). 2010;70(3):313–9.
Bausewein C, Booth S, Gysels M, Kuhnbach R, Higginson IJ. Effectiveness of a hand-held fan for breathlessness: A randomised phase II trial. BMC Palliative Care. 2010;9(22).
Beijer S, Hupperets PS, Van Den Borne BEEM, Wijckmans NEG, Spreeuwenberg C, Van Den Brandt PA, et al. Randomized clinical trial on the effects of adenosine 5′-triphosphate infusions on quality of life, functional status, and fatigue in preterminal cancer patients. J Pain Symptom Manag. 2010;40(4):520–30.
Bennett MI, Johnson MI, Brown SR, Radford H, Brown JM, Searle RD. Feasibility study of transcutaneous electrical nerve stimulation (TENS) for Cancer bone pain. Journal of Pain. 2010;11(4):351–9.
Bhatnagar S, Joshi S, Rana SPS, Mishra S, Garg R, Ahmed SM. Bedside ultrasound-guided celiac plexus neurolysis in upper abdominal cancer patients: a randomized, prospective study for comparison of percutaneous bilateral paramedian vs. unilateral paramedian needle-insertion technique. Pain Practice: The Official Journal Of World Institute Of Pain. 2014;14(2):E63–E8.
Brannstrom M, Boman K. Effects of person-centred and integrated chronic heart failure and palliative home care. PREFER: a randomized controlled study. Eur J Heart Fail. 2014;16(10):1142–51.
Breitbart W, Rosenfeld B, Gibson C, Pessin H, Poppito S, Nelson C, et al. Meaning-centered group psychotherapy for patients with advanced cancer: a pilot randomized controlled trial. Psycho-Oncology. 2010;19(1):21–8.
Breitbart W, Poppito S, Rosenfeld B, Vickers AJ, Li Y, Abbey J, et al. Pilot randomized controlled trial of individual meaning-centered psychotherapy for patients with advanced cancer. J Clin Oncol Off J Am Soc Clin Oncol. 2012;30(12):1304–9.
Brisbois TD, de Kock IH, Watanabe SM, Mirhosseini M, Lamoureux DC, Chasen M, et al. Delta-9-tetrahydrocannabinol may palliate altered chemosensory perception in cancer patients: results of a randomized, double-blind, placebo-controlled pilot trial. Ann Oncol. 2011;22(9):2086–93.
Bruera E, Yennurajalingam S, Palmer JL, Perez-Cruz PE, Frisbee-Hume S, Allo JA, et al. Methylphenidate and/or a nursing telephone intervention for fatigue in patients with advanced cancer: a randomized, placebo-controlled, phase II trial. J Clin Oncol Off J Am Soc Clin Oncol. 2013;31(19):2421–7.
Bruera E, Hui D, Dalal S, Torres-Vigil I, Trumble J, Roosth J, et al. Parenteral hydration in patients with advanced cancer: a multicenter, double-blind, placebo-controlled randomized trial. J Clin Oncol Off J Am Soc Clin Oncol. 2013;31(1):111–8.
Chan CWH, Richardson A, Richardson J. Managing symptoms in patients with advanced lung cancer during radiotherapy: results of a psychoeducational randomized controlled trial. J Pain Symptom Manag. 2011;41(2):347–57.
Chen HW, Lin IH, Chen YJ, Chang KH, Wu MH, Su WH, et al. A novel infusible botanically-derived drug, PG2, for cancer-related fatigue: a phase II double-blind, randomized placebo-controlled study. Clinical and investigative medicine. Medecine clinique et experimentale. 2012;35(1):E1–11.
Cheville AL, Kollasch J, Vandenberg J, Shen T, Grothey A, Gamble G, et al. A home-based exercise program to improve function, fatigue, and sleep quality in patients with stage IV lung and colorectal cancer: a randomized controlled trial. J Pain Symptom Manag. 2013;45(5):811–21.
Chochinov HM, Kristjanson LJ, Breitbart W, McClement S, Hack TF, Hassard T, et al. Effect of dignity therapy on distress and end-of-life experience in terminally ill patients: a randomised controlled trial. The Lancet Oncology. 2011;12(8):753–62.
Chow E, van der Linden YM, Roos D, Hartsell WF, Hoskin P, Wu JSY, et al. Single versus multiple fractions of repeat radiation for painful bone metastases: a randomised, controlled, non-inferiority trial. The Lancet Oncology. 2014;15(2):164–71.
Cruciani RA, Revuelta M, Dvorkin E, Homel P, Lesage P, Esteban-Cruciani N. L-carnitine supplementation in patients with HIV/AIDS and fatigue: a double-blind, placebo-controlled pilot study. HIV/AIDS - Research and Palliative Care 2015;7:65-73.
De Raaf PJ, De Klerk C, Timman R, Busschbach JJV, Oldenmenger WH, Van Der Rijt CCD. Systematic monitoring and treatment of physical symptoms to alleviate fatigue in patients with advanced cancer: a randomized controlled trial. J Clin Oncol. 2013;31(6):716–23.
Del Fabbro E, Garcia JM, Dev R, Hui D, Williams J, Engineer D, et al. Testosterone replacement for fatigue in hypogonadal ambulatory males with advanced cancer: a preliminary double-blind placebo-controlled trial. Support Care In Cancer. 2013;21(9):2599–607.
Donovan HS, Ward SE, Sereika SM, Knapp JE, Sherwood PR, Bender CM, et al. Web-based symptom management for women with recurrent ovarian cancer: a pilot randomized controlled trial of the WRITE symptoms intervention. J Pain Symptom Manag. 2014;47(2):218–30.
Edmonds P, Hart S, Wei G, Vivat B, Burman R, Silber E, et al. Palliative care for people severely affected by multiple sclerosis: evaluation of a novel palliative care service. Mult Scler. 2010;16(5):627–36.
El-Jawahri A, Podgurski LM, Eichler AF, Plotkin SR, Temel JS, Mitchell SL, et al. Use of video to facilitate end-of-life discussions with patients with cancer: a randomized controlled trial. J Clin Oncol. 2010;28(2):305–10.
Epstein AS, Volandes AE, Chen LY, Gary KA, Li Y, Agre P, et al. A randomized controlled trial of a cardiopulmonary resuscitation video in advance care planning for progressive pancreas and hepatobiliary cancer patients. J Palliat Med. 2013;16(6):623–31.
Farquhar MC, Prevost AT, McCrone P, Brafman-Price B, Bentley A, Higginson IJ, et al. Is a specialist breathlessness service more effective and cost-effective for patients with advanced cancer and their carers than standard care? Findings of a mixed-method randomised controlled trial. BMC Med. 2014;194.
Fischer SM, Cervantes L, Fink RM, Kutner JS. Apoyo con Carino: a pilot randomized controlled trial of a patient navigator intervention to improve palliative care outcomes for latinos with serious illness. J Pain Symptom Manag. 2015;49(4):657–65.
Galbraith S, Fagan P, Perkins P, Lynch A, Booth S. Does the use of a handheld fan improve chronic dyspnea? A randomized, controlled, crossover trial. J Pain Symptom Manag. 2010;39(5):831–8.
Galfin JM, Watkins ER, Harlow T. A brief guided self-help intervention for psychological distress in palliative care patients: a randomised controlled trial. Palliat Med. 2012;26(3):197–205.
Gebbia V, Lorusso V, Galetta D, Caruso MM, Palomba G, Riccardi F, et al. First-line cisplatin with docetaxel or vinorelbine in patients with advanced non-small-cell lung cancer: a quality of life directed phase II randomized trial of Gruppo Oncologico Italia Meridionale. Lung Cancer. 2010;69(2):218–24.
Greer JA, Traeger L, Bemis H, Solis J, Hendriksen ES, Park ER, et al. A pilot randomized controlled trial of brief cognitive-behavioral therapy for anxiety in patients with terminal cancer. Oncologist. 2012;17(10):1337–45.
Gutgsell KJ, Schluchter M, Margevicius S, Degolia PA, McLaughlin B, Harris M, et al. Music therapy reduces pain in palliative care patients: a randomized controlled trial. J Pain Symptom Manag. 2013;45(5):822–31.
Hardy J, Quinn S, Fazekas B, Plummer J, Eckermann S, Agar M, et al. Randomized, double-blind, placebo-controlled study to assess the efficacy and toxicity of subcutaneous ketamine in the management of cancer pain. J Clin Oncol Off J Am Soc Clin Oncol. 2012;30(29):3611–7.
Heisler M, Hamilton G, Abbott A, Chengalaram A, Koceja T, Gerkin R. Randomized double-blind trial of sublingual atropine vs. placebo for the Management of Death Rattle. J Pain Symptom Manag. 2013;45(1):14–22.
Henke CC, Cabri J, Fricke L, Pankow W, Kandilakis G, Feyer PC, et al. Strength and endurance training in the treatment of lung cancer patients in stages IIIA/IIIB/IV. Support Care Cancer. 2014;22(1):95–101.
Herr K, Titler M, Fine PG, Sanders S, Cavanaugh JE, Swegle J, et al. The effect of a translating research into practice (TRIP)-Cancer intervention on Cancer pain Management in Older Adults in hospice. Pain Medicine (United States). 2012;13(8):1004–17.
Homsi J, Walsh D, Lasheen W, Nelson KA, Rybicki LA, Bast J, et al. A comparative study of 2 sustained-release morphine preparations for pain in advanced cancer. Am J Hosp Palliat Medicine. 2010;27(2):99–105.
Hopkinson JB, Fenlon DR, Okamoto I, Wright DNM, Scott I, Addington-Hall JM, et al. The deliverability, acceptability, and perceived effect of the macmillan approach to weight loss and eating difficulties: a phase II, cluster-randomized, exploratory trial of a psychosocial intervention for weight- and eating-related distress in people with advanced cancer. J Pain Symptom Manag. 2010;40(5):684–95.
Hui D, Xu A, Frisbee-Hume S, Chisholm G, Morgado M, Reddy S, et al. Effects of prophylactic subcutaneous fentanyl on exercise-induced breakthrough dyspnea in cancer patients: a preliminary double-blind, randomized, controlled trial. J Pain Symptom Manag. 2014;47(2):209–17.
Hui D, Morgado M, Chisholm G, Withers L, Nguyen Q, Finch C, et al. High-flow oxygen and bilevel positive airway pressure for persistent dyspnea in patients with advanced cancer: a phase II randomized trial. J Pain Symptom Manag. 2013;46(4):463–73.
Ishiki H, Iwase S, Gyoda Y, Kanai Y, Ariyoshi K, Miyaji T, et al. Oral nutritional support can shorten the duration of parenteral hydration in end-of-life cancer patients: a randomized controlled trial. Nutr Cancer. 2015;67(1):105–11.
Israel FJ, Parker G, Charles M, Reymond L. Lack of benefit from paracetamol (acetaminophen) for palliative Cancer patients requiring high-dose Strong opioids: a randomized, double-blind, placebo-controlled, crossover trial. J Pain Symptom Manag. 2010;39(3):548–54.
Johnson JR, Burnell-Nugent M, Lossignol D, Ganae-Motan ED, Potts R, Fallon MT. Multicenter, double-blind, randomized, placebo-controlled, parallel-group study of the efficacy, safety, and tolerability of THC:CBD extract and THC extract in patients with intractable cancer-related pain. J Pain Symptom Manag. 2010;39(2):167–79.
Jones L, Harrington J, Barlow CA, Tookman A, Drake R, Barnes K, et al. Advance care planning in advanced cancer: can it be achieved? An exploratory randomized patient preference trial of a care planning discussion. Palliat Support Care. 2011;9(1):3–13.
Jones L, FitzGerald G, Leurent B, Round J, Eades J, Davis S, et al. Rehabilitation in advanced, progressive, recurrent cancer: a randomized controlled trial. J Pain Symptom Manag. 2013;46(3):315–25.
Juliao M, Barbosa A, Oliveira F. Efficacy of dignity therapy in psychological and existential distress of terminally-ill patients: randomized controlled trial. Palliat Med. 2012;26(4):440.
Kerr CW, Drake J, Milch RA, Brazeau DA, Skretny JA, Brazeau GA, et al. Effects of methylphenidate on fatigue and depression: a randomized, double-blind, placebo-controlled trial. J Pain Symptom Manag. 2012;43(1):68–77.
Kirste S, Treier M, Wehrle SJ, Becker G, Abdel-Tawab M, Gerbeth K, et al. Boswellia serrata acts on cerebral edema in patients irradiated for brain tumors: a prospective, randomized, placebo-controlled, double-blind pilot trial. Cancer. 2011;117(16):3788–95.
Lee C, Vather R, O'Callaghan A, Robinson J, McLeod B, Findlay M, et al. Validation of the phase ii feasibility study in a palliative care setting: Gastrografin in malignant bowel obstruction. Am J Hosp Palliat Med. 2013;30(8):752–8.
Liao J, Yang YF, Cohen L, Zhao YC, Xu Y. Effects of Chinese medicine five-element music on the quality of life for advanced cancer patients: a randomized controlled trial. Chin J Integr Med. 2013;19(10):736–40.
Lim JT, Wong ET, Aung SK. Is there a role for acupuncture in the symptom management of patients receiving palliative care for cancer? A pilot study of 20 patients comparing acupuncture with nurse-led supportive care. Acupunct Med. 2011;29(3):173–9.
Lloyd-Williams M, Cobb M, O'Connor C, Dunn L, Shiels C. A pilot randomised controlled trial to reduce suffering and emotional distress in patients with advanced cancer. J Affect Disord. 2013;148(1):141–5.
López-Sendín N, Alburquerque-Sendín F, Cleland JA, Fernández-de-las-Peñas C. Effects of physical therapy on pain and mood in patients with terminal cancer: a pilot randomized clinical trial. J Altern Complement Med (New York, NY). 2012;18(5):480–6.
Lundholm K, Gunnebo L, Korner U, Iresjo BM, Engstrom C, Hyltander A, et al. Effects by daily long term provision of ghrelin to unselected weight-losing cancer patients: a randomized double-blind study. Cancer. 2010;116(8):2044–52.
McLean LM, Walton T, Rodin G, Esplen MJ, Jones JM. A couple-based intervention for patients and caregivers facing end-stage cancer: outcomes of a randomized controlled trial. Psycho-Oncology. 2013;22(1):28–38.
Mok E, Lau KP, Lai T, Ching S. The meaning of life intervention for patients with advanced-stage cancer: development and pilot study. Oncol Nurs Forum. 2012;39(6):E480–E8.
Ng CG, Boks MPM, Roes KCB, Zainal NZ, Sulaiman AH, Tan SB, et al. Rapid response to methylphenidate as an add-on therapy to mirtazapine in the treatment of major depressive disorder in terminally ill cancer patients: a four-week, randomized, double-blinded, placebo-controlled study. Eur Neuropsychopharmacol. 2014;24(4):491–8.
Oldervoll LM, Loge JH, Lydersen S, Paltiel H, Asp MB, Nygaard UV, et al. Physical exercise for cancer patients with advanced disease: a randomized controlled trial. Oncologist. 2011;16(11):1649–57.
Oxberry SG, Torgerson DJ, Bland JM, Clark AL, Cleland JGF, Johnson MJ. Short-term opioids for breathlessness in stable chronic heart failure: a randomized controlled trial. Eur J Heart Fail. 2011;13(9):1006–12.
Pantilat SZ, O'Riordan DL, Dibble SL, Landefeld CS. Hospital-based palliative medicine consultation: a randomized controlled trial. Arch Intern Med. 2010;170(22):2038–40.
Pelayo-Alvarez M, Perez-Hoyos S, Agra-Varela Y. Clinical effectiveness of online training in palliative care of primary care physicians. J Palliat Med. 2013;16(10):1188–96.
Popa-Velea O, Cernat B, Tambu A. Influence of personalized therapeutic approach on quality of life and psychiatric comorbidity in patients with advanced colonic cancer requiring palliative care. J Medicine Life. 2010;3(3):343–7.
Portenoy RK, Ganae-Motan ED, Allende S, Yanagihara R, Shaiova L, Weinstein S, et al. Nabiximols for opioid-treated cancer patients with poorly-controlled chronic pain: a randomized, placebo-controlled, graded-dose trial. J Pain. 2012;13(5):438–49.
Rhondali W, Perez-Cruz P, Hui D, Chisholm GB, Dalal S, Baile W, et al. Patient-physician communication about code status preferences: a randomized controlled trial. Cancer. 2013;119(11):2067–73.
Ringash J, Au HJ, Siu LL, Shapiro JD, Jonker DJ, Zalcberg JR, et al. Quality of life in patients with K-RAS wild-type colorectal cancer: the CO.20 phase 3 randomized trial. Cancer. 2014;120(2):181–9.
Salas S, Frasca M, Planchet-Barraud B, Burucoa B, Pascal M, Lapiana JM, et al. Ketamine analgesic effect by continuous intravenous infusion in refractory cancer pain: considerations about the clinical research in palliative care. J Palliat Med. 2012;15(3):287–93.
Schofield P, Ugalde A, Gough K, Reece J, Krishnasamy M, Carey M, et al. A tailored, supportive care intervention using systematic assessment designed for people with inoperable lung cancer: a randomised controlled trial. Psycho-Oncology. 2013;22(11):2445–53.
Sidebottom AC, Jorgenson A, Richards H, Kirven J, Sillah A. Inpatient palliative care for patients with acute heart failure: outcomes from a randomized trial. J Palliat Med. 2015;18(2):134–42.
Stein RA, Sharpe L, Bell ML, Boyle FM, Dunn SM, Clarke SJ. Randomized controlled trial of a structured intervention to facilitate end-of-life decision making in patients with advanced cancer. J Clin Oncol. 2013;31(27):3403–10.
Sternberg CN, Molina A, North S, Mainwaring P, Fizazi K, Hao Y, et al. Effect of abiraterone acetate on fatigue in patients with metastatic castration-resistant prostate cancer after docetaxel chemotherapy. Ann Oncol. 2013;24(4):1017–25.
Suh SY, Choi YS, Oh SC, Kim YS, Cho K, Bae WK, et al. Caffeine as an adjuvant therapy to opioids in cancer pain: a randomized, double-blind, placebo-controlled trial. J Pain Symptom Manag. 2013;46(4):474–82.
Temel JS, Greer JA, Muzikansky A, Gallagher ER, Admane S, Jackson VA, et al. Early palliative care for patients with metastatic non-small-cell lung cancer. N Engl J Med. 2010;363(8):733–42.
Uitdehaag MJ, van der Velden LA, de Boer MF, Spaander MCW, Steyerberg EW, Kuipers EJ, et al. Recordings of consultations are beneficial in the transition from curative to palliative cancer care: a pilot-study in patients with oesophageal or head and neck cancer. Eur J Oncol Nurs. 2012;16(2):109–14.
Uitdehaag MJ, Van Putten PG, Van Eijck CHJ, Verschuur EML, Van Der Gaast A, Pek CJ, et al. Nurse-led follow-up at home vs. conventional medical outpatient clinic follow-up in patients with incurable upper gastrointestinal cancer: a randomized study. J Pain Symptom Manag. 2014;47(3):518–30.
Vogel RI, Petzel SV, Cragg J, McClellan M, Chan D, Dickson E, et al. Development and pilot of an advance care planning website for women with ovarian cancer: a randomized controlled trial. Gynecol Oncol. 2013;131(2):430–6.
Volandes AE, Paasche-Orlow MK, Mitchell SL, El-Jawahri A, Davis AD, Barry MJ, et al. Randomized controlled trial of a video decision support tool for cardiopulmonary resuscitation decision making in advanced cancer. J Clin Oncol Off J Am Soc Clin Oncol. 2013;31(3):380–6.
Wallen GR, Baker K, Stolar M, Miller-Davis C, Ames N, Yates J, et al. Palliative care outcomes in surgical oncology patients with advanced malignancies: a mixed methods approach. Qual Life Res. 2012;21(3):405–15.
Wentlandt K, Burman D, Swami N, Hales S, Rydall A, Rodin G, et al. Preparation for the end of life in patients with advanced cancer and association with communication with professional caregivers. Psycho-Oncology. 2012;21(8):868–76.
Wyatt GSA, Rahbar MH, Victorson D, You M. Health-related quality-of-life outcomes: a reflexology trial with patients with advanced-stage breast Cancer. Oncol Nurs Forum. 2012;39(6):568–77.
Zaghloul MS, Boutrus R, El-Hossieny H, Kader YA, El-Attar I, Nazmy M. A prospective, randomized, placebo-controlled trial of zoledronic acid in bony metastatic bladder cancer. Int J Clin Oncol. 2010;15(4):382–9.
Zimmermann C, Swami N, Krzyzanowska M, Hannon B, Leighl N, Oza A, et al. Early palliative care for patients with advanced cancer: a cluster-randomised controlled trial. Lancet. 2014;383(9930):1721–30.
Laltanpui C, Singh YI, Phom YW. Comparison between two different fractionation radiation dose schedules for palliation of advanced solid tumours. Journal of Medical Society. 2016;30(1):24–6.
Litterini AJ, Fieler VK, Cavanaugh JT, Lee JQ. Differential effects of cardiovascular and resistance exercise on functional mobility in individuals with advanced cancer: a randomized trial. Arch Phys Med Rehabil. 2013;94(12):2329–35.
Mariani P, Blumberg J, Landau A, Lebrun-Jezekova D, Botton E, Beatrix O, et al. Symptomatic treatment with lanreotide microparticles in inoperable bowel obstruction resulting from peritoneal carcinomatosis: a randomized, double-blind, placebo-controlled phase III study: editorial comment. Obstet Gynecol Surv. 2013;68(6):437–8.
Ng CG, Lai KT, Tan SB, Sulaiman AH, Zainal NZ. The effect of 5 minutes of mindful breathing to the perception of distress and physiological responses in palliative care Cancer patients: a randomized controlled study. J Palliat Med. 2016;19(9):917–24.
Strong RA, Georges JM, Connelly CD. Pilot evaluation of auricular acupressure in end-stage lung Cancer patients. J Palliat Med. 2016;19(5):556–8.
Vermandere M, Warmenhoven F, Van Severen E, De Lepeleire J, Aertgeerts B. Spiritual history-taking in palliative home care: a cluster randomized controlled trial. Palliat Med. 2014;28(6):639.
Agarwal KK, Singla S, Arora G, Bal C. <sup>177</sup>Lu-EDTMP for palliation of pain from bone metastases in patients with prostate and breast cancer: a phase II study. Eur J Nucl Med Mol Imaging. 2015;42(1):79–88.
Ahmed N, Hughes P, Winslow M, Bath PA, Collins K, Noble B. A pilot randomized controlled trial of a holistic needs assessment questionnaire in a supportive and palliative care service. J Pain Symptom Manag. 2015;50(5):587–98.
Anter AH. Single fraction versus multiple fraction radiotherapy for treatment of painful bone metastases: a prospective study. Mansoura experience Forum of Clinical Oncology. 2015;6(2):8–13.
Badr H, Smith CB, Goldstein NE, Gomez JE, Redd WH. Dyadic psychosocial intervention for advanced lung cancer patients and their family caregivers: results of a randomized pilot trial. Cancer. 2015;121(1):150–8.
Bajwah S, Ross JR, Wells AU, Mohammed K, Oyebode C, Birring SS, et al. Palliative care for patients with advanced fibrotic lung disease: a randomised controlled phase II and feasibility trial of a community case conference. Thorax. 2015;23.
Bakitas MA, Tosteson TD, Li Z, Lyons KD, Hull JG, Li Z, et al. Early versus delayed initiation of concurrent palliative oncology care: patient outcomes in the ENABLE III randomized controlled trial. J Clin Oncol Off J Am Soc Clin Oncol. 2015;33(13):1438–45.
Berwouts D, De Wolf K, De Neve W, Olteanu LA, Lambert B, Speleers B, et al. Variations in target volume definition and dose to normal tissue using anatomic versus biological imaging (<sup>18</sup>F-FDG-PET) in the treatment of bone metastases: results from a 3-arm randomized phase II trial. Journal of Medical Imaging and Radiation Oncology. 2016.
Buckingham S, Kendall M, Ferguson S, Macnee W, Sheikh A, White P, et al. NPJ Primary Care Respiratory Medicine. 2015;25(15020).
Chan KY, Yip T, Yap DYH, Sham MK, Wong YC, Lau VWK, et al. Enhanced psychosocial support for caregiver burden for patients with chronic kidney failure choosing not to be treated by Dialysis or transplantation: a pilot randomized controlled trial. Am J Kid Dis. 2016;67(4):585–92.
Currow DC, Quinn S, Agar M, Fazekas B, Hardy J, McCaffrey N, et al. Double-blind, placebo-controlled, randomized trial of octreotide in malignant bowel obstruction. J Pain Symptom Manag. 2015;49(5):814–21.
Davies HE, Mishra EK, Kahan BC, Wrightson JM, Stanton AE, Guhan A, et al. Effect of an indwelling pleural catheter vs chest tube and talc pleurodesis for relieving dyspnea in patients with malignant pleural effusion: the TIME2 randomized controlled trial. JAMA. 2012;307(22):2383–9.
Eguchi K, Honda M, Kataoka T, Mukouyama T, Tsuneto S, Sakamoto J, et al. Efficacy of corticosteroids for cancer-related fatigue: a pilot randomized placebo-controlled trial of advanced cancer patients. Palliat Support Care. 2015;13(5):1301–8.
Eldeeb NA, Bela AM, Eganady AA, Radwan AS. Comparative study of two radiotherapy regimens for palliation of symptomatic advanced non-small cell lung cancer. Egyptian Journal of Chest Diseases and Tuberculosis. 2014;63(2):423–34.
Fallon M, Hoskin PJ, Colvin LA, Fleetwood-Walker SM, Adamson D, Byrne A, et al. Randomized double-blind trial of pregabalin versus placebo in conjunction with palliative radiotherapy for cancer-induced bone pain. J Clin Oncol. 2016;34(6):550–6.
Hardy J, Randall C, Pinkerton E, Flatley C, Gibbons K, Allan S. A randomised, double-blind controlled trial of intranasal midazolam for the palliation of dyspnoea in patients with life-limiting disease. Support Care Cancer. 2016;24(7):3069–76.
Higginson IJ, Bausewein C, Reilly CC, Gao W, Gysels M, Dzingina M, et al. An integrated palliative and respiratory care service for patients with advanced disease and refractory breathlessness: a randomised controlled trial. Lancet Respir Med. 2014;2(12):979–87.
Higginson IJ, Costantini M, Silber E, Burman R, Edmonds P. Evaluation of a new model of short-term palliative care for people severely affected with multiple sclerosis: a randomised fast-track trial to test timing of referral and how long the effect is maintained. Postgrad Med J. 2011;87(1033):769–75.
Hopp FP, Zalenski RJ, Waselewsky D, Burn J, Camp J, Welch RD, et al. Results of a hospital-based palliative care intervention for patients with an acute exacerbation of chronic heart failure. J Card Fail. 2016;15.
Ibrahim IM, Dokhan AL, El-Sessy AA, Eltaweel MF. Povidone-iodine pleurodesis versus talc pleurodesis in preventing recurrence of malignant pleural effusion. J Cardiothorac Surg. 2015;10:64.
Matlock DD, Keech TA, McKenzie MB, Bronsert MR, Nowels CT, Kutner JS. Feasibility and acceptability of a decision aid designed for people facing advanced or terminal illness: a pilot randomized trial. Health Expect. 2014;17(1):49–59.
Jensen W, Baumann FT, Stein A, Bloch W, Bokemeyer C, De Wit M, et al. Exercise training in patients with advanced gastrointestinal cancer undergoing palliative chemotherapy: a pilot study. Support Care Cancer. 2014;22(7):1797–806.
Jacobs C, Kuchuk I, Bouganim N, Smith S, Mazzarello S, Vandermeer L, et al. A randomized, double-blind, phase II, exploratory trial evaluating the palliative benefit of either continuing pamidronate or switching to zoledronic acid in patients with high-risk bone metastases from breast cancer. Breast Cancer Res Treat. 2016;155(1):77–84.
Jatoi A, Nieva JJ, Qin R, Loprinzi CL, Wos EJ, Novotny PJ, et al. A pilot study of long-acting octreotide for symptomatic malignant ascites. Oncology (Switzerland). 2012;82(6):315–20.
Kwekkeboom KL, Abbott-Anderson K, Cherwin C, Roiland R, Serlin RC, Ward SE. Pilot randomized controlled trial of a patient-controlled cognitive-behavioral intervention for the pain, fatigue, and sleep disturbance symptom cluster in cancer. J Pain Symptom Manag. 2012;44(6):810–22.
Li F, Wang W, Li L, Chang Y, Su D, Guo G, et al. An effective therapy to painful bone metastases: Cryoablation combined with Zoledronic acid. Pathol Oncol Res. 2014;20(4):885–91.
Lund Rasmussen C, Klee Olsen M, Thit Johnsen A, Aagaard Petersen M, Lindholm H, Andersen L, et al. Effects of melatonin on physical fatigue and other symptoms in patients with advanced cancer receiving palliative care: a double-blind placebo-controlled crossover trial. Cancer. 2015;121(20):3727–36.
Maddocks M, Halliday V, Chauhan A, Taylor V, Nelson A, Sampson C, et al. Neuromuscular electrical stimulation of the quadriceps in patients with non-small cell lung cancer receiving palliative chemotherapy: A randomized phase II study. PLoS ONE. 2013;8(12, e86059).
Maltoni M, Scarpi E, Dall'Agata M, Zagonel V, Berte R, Ferrari D, et al. Systematic versus on-demand early palliative care: results from a multicentre, randomised clinical trial. Eur J Cancer. 2016;65:61–8.
McMillan SC, Small BJ, Haley WE. Improving hospice outcomes through systematic assessment: a clinical trial. Cancer Nurs. 2011;34(2):89–97.
Nava S, Ferrer M, Esquinas A, Scala R, Groff P, Cosentini R, et al. Palliative use of non-invasive ventilation in end-of-life patients with solid tumours: a randomised feasibility trial. Lancet Oncol. 2013;14(3):219–27.
Nilsson S, Strang P, Aksnes AK, Franzn L, Olivier P, Pecking A, et al. A randomized, dose-response, multicenter phase II study of radium-223 chloride for the palliation of painful bone metastases in patients with castration-resistant prostate cancer. Eur J Cancer. 2012;48(5):678–86.
Okur E, Baysungur V, Tezel C, Ergene G, Okur HK, Halezeroglu S. Streptokinase for malignant pleural effusions: a randomized controlled study. Asian Cardiovasc Thorac Ann. 2011;19(3–4):238–43.
Ozkul S, Turna A, Demirkaya A, Aksoy B, Kaynak K. Rapid pleurodesis is an outpatient alternative in patients with malignant pleural effusions: a prospective randomized controlled trial. J Thorac Dis. 2014;6(12):1731–5.
Rief H, Welzel T, Omlor G, Akbar M, Bruckner T, Rieken S, et al. Pain response of resistance training of the paravertebral musculature under radiotherapy in patients with spinal bone metastases - a randomized trial. BMC Cancer. 2014;14(1):485.
Saha A, Chattopadhyay S, Azam M, Sur P. The role of honey in healing of bedsores in cancer patients. South Asian J Cancer. 2012;1(2):66–71.
Sau S, Dutta P, Gayen G, Banerjee S, Basu A. A comparative study of different dose fractionations schedule of thoracic radiotherapy for pain palliation and health-related quality of life in metastatic NSCLC. Lung India. 2014;31(4):348–53.
Steel JL, Geller DA, Kim KH, Butterfield LH, Spring M, Grady J, et al. Web-based collaborative care intervention to manage cancer-related symptoms in the palliative care setting. Cancer. 2016;122(8):1270–82.
Wadhwa D, Burman D, Swami N, Rodin G, Lo C, Zimmermann C. Quality of life and mental health in caregivers of outpatients with advanced cancer. Psycho-Oncology. 2013;22(2):403–10.
Warth M, Kesler J, Hillecke TK, Bardenheuer HJ. Music therapy in palliative care: results of a randomized, controlled trial on psychophysiological indicators of relaxation and well-being. Oncology Research and Treatment. 2016;39:128–9.
Warth M, Kessler J, Hillecke TK, Bardenheuer HJ. Trajectories of terminally ill Patients' cardiovascular response to receptive music therapy in palliative care. J Pain Symptom Manag. 2016;52(2):196–204.
Xue D, Han S, Jiang S, Sun H, Chen Y, Li Y, et al. Comprehensive geriatric assessment and traditional Chinese medicine intervention benefit symptom control in elderly patients with advanced non-small cell lung cancer. Med Oncol. 2015;32(4):1–7.
Yousef AAAM, El-Mashad NM. Pre-emptive value of methylprednisolone intravenous infusion in patients with vertebral metastases. A double-blind randomized study. J Pain Symptom Manag. 2014;48(5):762–9.
Tarumi Y, Wilson MP, Szafran O, Spooner GR. Randomized, double-blind, placebo-controlled trial of oral docusate in the management of constipation in hospice patients. J Pain Symptom Manag. 2013;45(1):2–13.
McCorkle R, Jeon S, Ercolano E, Lazenby M, Reid A, Davies M, et al. An advanced practice nurse coordinated multidisciplinary intervention for patients with late-stage Cancer: a cluster randomized trial. J Palliat Med. 2015;18(11):962–9.
Allen RS, Harris GM, Burgio LD, Azuero CB, Miller LA, Shin HJ, et al. Can senior volunteers deliver reminiscence and creative activity interventions? Results of the legacy intervention family enactment randomized controlled trial. J Pain Symptom Manag. 2014;48(4):590–601.
Wong FKY, Ng AYM, Lee PH, Lam PT, Ng JSC, Ng NHY, et al. Effects of a transitional palliative care model on patients with end-stage heart failure: a randomised controlled trial. Heart. 2016;102(14):1100–8.
Acknowledgements
Not applicable.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
AO made a substantial contribution to the concept and design of the work; acquisition, analysis and interpretation of data; DL made a substantial contribution to the acquisition, analysis and interpretation of data; SP made a substantial contribution to the acquisition, analysis and interpretation of data; PAG made a substantial contribution to the statistical analysis and interpretation of data; NP drafted the article and revised it critically for important intellectual content. Approved the version to be published. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
Nancy Preston is a member of the editorial board (Associate Editor) of BMC Palliative Care. She had no role in the editorial process of this article.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Oriani, A., Dunleavy, L., Sharples, P. et al. Are the MORECare guidelines on reporting of attrition in palliative care research populations appropriate? A systematic review and meta-analysis of randomised controlled trials. BMC Palliat Care 19, 6 (2020). https://doi.org/10.1186/s12904-019-0506-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12904-019-0506-6