
Abstract
Background
Like many developing countries, Thailand has experienced a rapid rise in obesity, accompanied by a rapid change in occupational structure. It is plausible that these two trends are related, with movement into sedentary occupations leading to increases in obesity. National health examination survey data contains information on obesity and socioeconomic conditions that can help untangle the relationship, but analysis is challenging because of small sample sizes.
Methods
This paper explores the relationship between occupation and obesity using data on 10,127 respondents aged 20–59 from the 2009 National Health Examination Survey. Obesity is measured using waist circumference. Modelling is carried out using an approach known as Multiple Regression with Post-Stratification (MRP). We use Bayesian hierarchical models to construct prevalence estimates disaggregated by age, sex, education, urban-rural residence, region, and occupation, and use census population weights to aggregate up. The Bayesian hierarchical model is designed to protect against overfitting and false discovery, which is particularly important in an exploratory study such as this one.
Results
There is no clear relationship between the overall sedentary nature of occupations and obesity. Instead, obesity appears to vary occupation by occupation. For instance, women in professional occupations, and men who are agricultural or fishery workers, have relatively low rates of obesity.
Conclusion
Bayesian hierarchical models plus post-stratification offers new possibilities for using surveys to learn about complex health issues.
Similar content being viewed by others


Background
Thailand has, in recent decades, experienced a rapid rise in obesity, with 42% of women and 33% of men having a BMI greater than 25 kg/m2 in 2014 [1]. This rise has coincided with a movement into sedentary occupations. Between 1990 and 2011, the proportion of workers employed in agriculture shrank from 63 to 41%, while the proportion employed in the services sector rose from 23 to 40% [2].
Work is an important component of overall physical activity, even if it is not the only one. A study in Barbados [3], for instance, found the work make up 57% of total physical activity energy expenditures. Evidence from high-income countries suggests that more sedentary occupations with less physical activity may be associated with higher obesity, though the relationship between occupation and obesity is confounded with socio-economic status especially education, and can differ between women and men [4,5,6,7,8,9,10,11,12,13,14,15].
Estimating how obesity rates vary across the Thai population is useful for understanding the recent changes, and for designing a policy response. Evidence on the relationship between occupation and obesity is, however, limited, in Thailand, and in middle-income countries more generally.
Constructing detailed estimates of Thai obesity rates is challenging. Thailand undertakes a National Health Examination Survey (NHES) every 5–10 years, which includes measures of obesity [16,17,18,19]. But once the sample has been disaggregated by occupation and by geographical and demographic variables, the number of observations in each cell is small, and direct estimates of prevalence are unreliable.
In this paper, we use Bayesian hierarchical models [20] to estimate obesity prevalence from data from the 2009 National Health Examination Survey. Our most detailed estimates are disaggregated by occupation, age, sex, education, region within Thailand, and urban-rural residence, though disaggregation to the level is driven partly by the need to account for the complex design of the Health Examination Survey. In our analyses, we work with population-weighted averages of the most detailed estimates. Findings from the analysis are of substantive interest, given that, internationally, there is limited information about the demographic and occupational profile of obesity within middle-income countries. The paper also illustrates how modern statistical methods can be used to obtain detailed prevalence estimates from household surveys. Our analysis is exploratory. We seek to understand the relationship between obesity and occupation, how this relationship varies with age, sex, and education level, and whether sedentary occupations have higher obesity than non-sedentary ones.
Methods
Data
Our main data source is the 2009 round of the Thai National Health Examination Survey (NHES). The survey uses a complex design, with stratification and clustering based on region and village or urban community. Interviews were conducted by local health personnel. The dataset we use in our analysis consists of records for 10,127 working-age (20–59 years) adults. Table 1 shows the unweighted sample classified by age, education, urban-rural residence, occupation, and obesity.
The classification of occupations in Table 1 is based on categories from the International Labour Organization classification ISCO-88 [21]. The survey asked the respondents’ current occupation, without distinguishing between permanent and temporary occupations. In our analyses, we divide occupations into two groups – sedentary and non-sedentary – based on the classification suggested by Choi et al. [22] as shown in Table 2. Choi et al. derive their classification from an analysis of detailed data from the Korean Working Conditions Survey. We assume that, particularly in industries other than agriculture, work conditions in Korea are broadly similar to those in Thailand.
We measure obesity using waist circumference. Waist circumference is generally a more sensitive measure of risks of cardiovascular disease and premature mortality than the Body Mass Index (BMI), in that it is less affected by individual variation in lean muscle mass [1, 16, 23,24,25]. In the NHES, the trained local health personnel measured each respondent’s waist circumference by placing a flexible plastic tape under the lower rib and 2 cm over the navel while respondents breathed normally. Two measurements were taken, and the average of the two was recorded. As with the BMI, nutritionists recommend using different thresholds to define obesity in different populations. International Diabetes Federation (IDF) [26] and Alberti et al. [27] recommend using a threshold of 90 cm for Asian men, 80 cm for Asian women, 102 cm for European men, and 88 cm for European women. We adopt the Asian standard, but as a sensitivity test we repeat our analyses using the European standard.
As can be seen in Table 1, the NHES dataset contains a small number of missing values. We impute these values using ‘k-nearest neighbour imputation’ as implemented in the function kNN in R package VIM [28]. This method searches the dataset for records that most closely resemble the ones with missing values, and borrows values from those.
We use the official One Percent Sample from Thailand’s 2010 Population and Housing Census to calculate population weights. The One Percent Sample is constructed by the National Statistical Office, using stratified random sampling. As with our obesity data, we calculate population weights for a classification defined by age, sex, education, urban-rural residence, region, and occupation.
Statistical models
We estimate obesity prevalence using a Bayesian hierarchical model [20]. The model allows us to obtain sensible estimates, including uncertainty measures, even for combinations of variables with few observations. It does this by ‘pooling strength’ across the entire dataset, and by smoothing estimates based on sample size.
Our model in effect assumes that, within each combination of variables, people in our sample are a simple random sample of people in the target population. To satisfy this assumption, our model includes all the variables that affect people’s probability of being selected into the sample, even when these variables are not of substantive interest in our study. However, rather than use these very detailed results, we use population weights derived from the population census to aggregate up to a classification containing only the variables of interest. Results for this more aggregate classification have less uncertainty than the original highly-disaggregated results. The general technique of fitting a very detailed hierarchical model to account for the complex survey design, and then using population weights to aggregate up is known as Multilevel Regression and Post-Stratification (MRP) [29, 30].
The first layer of our model states that the number of people with obesity in each cell within our classification by age, sex, education, occupation, urban-rural residence, and region can be treated as a draw from a binomial distribution,
Subscript i indexes cell within the classification: for instance, i might refer to 20–29 year old females with secondary or more education, with a “technicians and associated professional” occupation, living in an urban area in northern Thailand. The levels of all classifying variables are shown in Table 1. The quantity ni is the number of respondents in cell i; yi is the number of respondents in cell i who are obese; and πi is the probability that a randomly-chosen person in cell i is obese. We use πi as our measure of prevalence, and we seek to estimate it for all i. We include education in the model because we expect at least some of any bivariate relationship between occupation and obesity to reflect the influence of education, rather than of occupation itself.
Altogether, our classification includes 1760 cells. Once obesity counts yi are disaggregated to this degree, 56% of cells have value 0. The median count among non-zero cells is 2 and the mean is 4.7. The median count of respondents across all ni is 1 and the mean is 5.8. With such small numbers, modelling individual-level randomness in obesity outcomes, as we do with the binomial distribution, is essential.
The NHES is stratified by region and by urban-rural residence, implying that a person’s probability of being included in the survey varies according to the person’s region, and whether the person lives in an urban or rural area. By including region and urban-rural residence in our model, we allow for these differences in selection probabilities.
The NHES is also clustered, meaning that, to save collection costs, the survey selects communities at random within each stratum, and samples intensively within each community. We do not explicitly model the clustering process, as it would complicate the analysis considerably. If outcomes are correlated within communities even after controlling for background characteristics, then, by omitting these correlations, our model is understating uncertainty. However, because our model allows for variation by age, sex, occupation and education, and all combinations of these variables, it should do a good job of controlling for background characteristics, so the understatement of uncertainty due to clustering should be relatively small.
In the second layer of the model, we apply a logit transform to πi and treat the transformed value as a draw from a normal distribution.
Vector β includes main effects for age, sex, education, occupation, urban-rural residence, and region. It also includes all second-order interactions between age, sex, education, and occupation. The presence of the second-order interactions implies, for instance, that the age-profile for obesity is expected to be different for male and females, and that the occupational profile is expected to be different for people with and without secondary education. The vector xi is the i th row of the design matrix. It consists entirely of 1 s and 0 s, and is constructed so that each cell i receives the appropriate combination of main effects and interactions.
In the third layer of the model, each main effect or interaction is treated as a draw from a normal distribution with mean 0 and standard deviation τ. For instance, the main effect for age is modelled using
Probabilistic sub-models like this are known within Bayesian statistics as prior distributions. Prior distributions can serve various purposes, but here they are acting as a soft constraint on the size of the main effects and interactions. The prior distributions pull the final estimates for the main effects and interactions towards zero. When an estimate is based on many observations, this pull is relatively unimportant, but when an estimate is based on only a few observations, the use of a prior distribution can have a strong moderating influence on the final estimate. This moderating influence, which is sometimes referred to as regularization or shrinkage, provides protection against over-fitting and false discovery [31].
The strength of the pull towards zero is governed by the standard deviation term τ. When a main effect or interaction has three levels or fewer (as with the sex effect, for instance), so that there is little scope for estimating τ, we set it equal to 1. When a main effect or interaction has four or more levels, we treat it as a draw from a half-normal distribution, that is, a normal distribution restricted to non-negative values,
The scale term A in the half-normal distributions is set equal to 1 for main effects and to 0.5 for interactions. Lower values for A tend to produce lower values for τ and hence generate a stronger pull towards 0 and more regularisation. Our choice of values for A is based on the assumption that main effects tend to be larger than interactions [32]. The standard deviation term σ is assumed to be drawn from a half-normal distribution with scale 1.
The outcome variable for our main model is obesity based on the Asian standard for waist circumference. However, as a sensitivity test, we also fit a model using obesity based on the European standard. We fit both models using function estimateModel in R package demest, available at github.com/statisticsnz/demest. All code for the analysis is available at [link to github repository.] The function estimateModel uses a set of techniques known as Markov chain Monte Carlo (MCMC) to generate its estimates [20].
The output from the modelling is a set of draws from the “posterior distribution” for the model parameters. If θ denotes a particular parameter in our model, then we obtain a sample θ(1), θ(2), …, θ(S) of draws for θ. To obtain a point estimate for θ we use the median of value for the θ(s); to obtain a 95% credible interval (the Bayesian analogue of a confidence interval), we use the 2.5 and 97.5% quantiles for θ(s).
To calculate a point estimate and credible interval for some function f of θ, we calculate f(θ(1)), f(θ(2)), …, f(θ(S)), and take the median and upper and lower quantiles of these values. The same principle extends to functions of multiple parameters. When calculating point estimates and credible intervals for population-weighted averages, for instance, we calculate weighted averages across each draw of the πi, and then calculate the medians and upper and lower quantiles of the weighted averages.
Results
The sample from the posterior distribution includes values for all 1760 prevalences πi, plus the parameters from the higher levels of the model. To illustrate, Fig. 1 shows point estimates and 95% credible intervals for πi for females in urban areas in the Northeast region of Thailand. The ‘x’ marks are direct estimates–that is, the estimates derived by dividing the observed number of obese respondents by the number of respondents, independently for each combination of the classifying variables.

Point estimates and 95% credible intervals for obesity prevalence, for females in urban areas in the Northeast region of Thailand, disaggregated by age, education, and occupation. Open black points denote sedentary occupations, and closed black points denote non-sedentary occupations. Lines denote 95% credible intervals. ‘x’ marks denote direct estimates
Some patterns are discernible in the point estimates: for instance, obesity seems to rise with age. The widths of the credible intervals vary from occupation to occupation. For example, the credible intervals for “legislators, senior officials, and managers”, for whom there are relatively few observations, are much wider than the credible intervals for “elementary occupations”. Overall, however, the level of uncertainty at this level of disaggregation is too great to form conclusions about any patterns in estimated prevalences. The model estimates are, however, less variable than the direct estimates, illustrating how Bayesian hierarchical models pull estimates towards central values. Note that we would not expect 95% of direct estimates to fall within the 95% credible intervals, as the credible intervals refer to the true, underlying prevalence, rather than the observed proportions, which, with small sample sizes, contain substantial random noise.
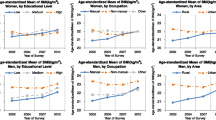
Figure 2 shows the result of taking population-weighted averages of the most disaggregated estimates. The figure presents obesity prevalence by age, education level, and occupation, for females. The prevalences average across region and urban-rural residence, and describe patterns at the national level. The figure shows separate results for each occupation, but also distinguishes sedentary occupations from non-sedentary ones.

Estimated obesity prevalence by age, sex, education level, and occupation, for females. Open black points denote sedentary occupations, and closed black points denote non-sedentary occupations. Lines denote 95% credible intervals. ‘x’ marks denote direct estimates
Most of the credible intervals in Fig. 2 are narrower than those of Fig. 1, since they are based on more data. The exception is credible intervals for combinations of variables that are rare even at the national level, such as women in the “legislators, officials, and managers” category. Obesity appears to rise with age, and to be less common among women with secondary education. However, although there is variation between occupations, there is no clear tendency for sedentary occupations to have higher obesity than non-sedentary group occupations. The results provide some evidence that, among women in sedentary occupations, women in “professional” occupations are less likely to be obese.
The modelled estimates and direct estimates in Fig. 2 are typically close to each other in categories with narrow credible intervals where there is substantial data, and further away in categories with wide credible intervals where there is limited data. When the modelled and direct estimates differ, the modelled ones are more conservative, in the sense that they lie closer to the mean value for each combination of age, sex, and education level. This is an example of the shrinkage or regularization discussed in the Statistical Models section above. In Fig. 2, and more generally, regularisation provides protection against misleadingly extreme estimates based on small samples.
Figure 3 is equivalent to Fig. 2, but refers to males rather than females. Obesity is less common among men than among women, though rates among men, like those among women, rise with age. There is once again no clear tendency for sedentary occupations as a whole to have higher obesity rates than non-sedentary occupations. The results do, however, suggest that obesity is relatively low among male “skilled agriculture and fishery workers”.

Estimated obesity prevalence by age, sex, education level, and occupation, for males. Open black points denote sedentary occupations, and closed black points denote non-sedentary occupations. Lines denote 95% credible intervals. ‘x’ marks denote direct estimates
Using the European standard (Figs. 4 and 5), rather than the Asian standard, to define obesity leads to lower estimated prevalences for both sexes, but particularly for males, as can be seen by comparing Figs. 4 and 5 with Figs. 2 and 3.

Estimated obesity prevalence using European rather than Asian standards for defining obesity: females. Open black points denote sedentary occupations, and closed black points denote non-sedentary occupations. Lines denote 95% credible intervals. ‘x’ marks denote direct estimates

Estimated obesity prevalence using European rather than Asian standards for defining obesity: males. Open black points denote sedentary occupations, and closed black points denote non-sedentary occupations. Lines denote 95% credible intervals. ‘x’ marks denote direct estimates
Roughly the same patterns appear with the European standard results as appear with the Asian standard results. Among women, there is no overall tendency for sedentary occupations to have higher obesity than non-sedentary occupations, as professional women have relatively low obesity rates. Among men, there is a tendency for agricultural and fishery workers to have low obesity, though the absolute differences in rates are tiny.
Discussion
Health surveys are a unique source of information about socio-economic differentials in health conditions. When analysing health surveys, however, researchers are constrained by sample size. To unlock the full potential of these surveys, it is necessary to use modern statistical methods that provide sensible estimates even when cell counts are small, such as Bayesian hierarchical models.
Applying Bayesian hierarchical models to 2009 Thai National Health Examination Survey data, in combination with post-stratification based on the 2010 census, we are able to shed light on the complicated relationship between age, sex, education, occupation, and obesity. With traditional statistical approaches, we would need to be concerned that any apparent findings were nothing more than statistical noise. Because of the regularisation build into our model, however, we are protected against such problems.
The results from our analysis suggest that in Thailand there is not a broad relationship, across all occupations, between the sedentary nature of the occupation and the degree of obesity. Instead, obesity varies from occupation to occupation. For instance, among women, professionals have a relatively low obesity rate, despite the relatively sedentary nature of professional work, and even after stratifying on education level. Among men, agricultural and fishery workers are distinctive for their low levels of obesity, even at higher ages.
In future work, we intend to extend our analysis to include more recent rounds of the National Health Examination Survey. This will allow us to see whether the patterns observed for 2009 have persisted. Combining data from multiple surveys will also boost sample sizes, allowing more precise estimates of parameters that are relatively constant over time.
Conclusions
Bayesian hierarchical models offer new possibilities for using survey data to study complex public health issues. An exploratory analysis of the Thai Health Examination Survey data suggests that there is no simple relationship between the sedentary nature of occupations and the level of obesity. Instead, obesity rates vary across specific occupations, and patterns are different for women and men.
Availability of data and materials
The data that support the findings of this study are available from Health Systems Research Institute (HSRI) and National Statistical Office (NSO) but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of HSRI and NSO.
Abbreviations
- BMI:
-
Body Mass Index
- HSRI:
-
Health Systems Research Institute
- IDF:
-
Institutional Diabetes Federation
- MCMC :
-
Markov chain Monte Carlo
- MRP:
-
Multiple Regression with Post-Stratification
- NHES:
-
National Health Examination Survey
- NSO:
-
National Statistical Office
References
Aekplakorn W, Pakpeankitwatana V, Lee CM, Woodward M, Barzi F, Yamwong S, et al. Abdominal obesity and coronary heart disease in Thai men. Obesity. 2007;15:1036–42.
National Statistical Office. Working trend of Thai labour. 2017 [cited 2017 November 29]; Available from: http://service.nso.go.th/nso/nsopublish/citizen/news/news_lfsdirect.jsp.
Howitt C, Brage S, Hambleton IR, Westgate K, Samuels TA, Rose AMC, et al. A cross-sectional study of physical activity and sedentary behaviours in a Caribbean population: combining objective and questionnaire data to guide future interventions. BMC Public Health. 2016;16:1036. https://doi.org/10.1186/s12889-016-3689-2.
Cameron AJ, Welborn TA, Zimmet PZ, Dunstan DW, Owen N, Salmon J, et al. Overweight and obesity in Australia: the 1999–2000 Australian diabetes, obesity and lifestyle study (Ausdiab). MJA. 2003;178:427–32.
Allman-Farinelli MA, Chey T, Merom D, Bauman AE. Occupational risk of overweight and obesity: an analysis of the Australian health survey. J Occup Med Toxicol. 2010;5:1–9.
Meseguer CM, Galan I, Herruzo R, Rodríguez-Artalejo F. Trends in leisure time and occupational physical activity in the Madrid region, 1995–2008. Rev Esp Cardiol. 2011;64:21–7.
Church TS, Thomas DM, Tudor-Locke C, Katzmarzyk PT, Earnest CP, Rodarte RQ, et al. Trends over 5 decades in U.S. Occupation-related physical activity and their associations with obesity. PLoS ONE. 2011;6:e19657.
Monteiro CA, Conde WL, Popkin BM. What has happened in terms of some of the unique elements of shift in diet, activity, obesity, and other measures of morbidity and mortality within different regions of the world? Public Health Nutr. 2002;5:105–12.
Bonauto DK, Lu D, Fan ZJ. Obesity prevalence by occupation in Washington state, behavioral risk factor surveillance system. Prev Chronic Dis. 2014;11:130219.
Caban AJ, Lee DJ, Fleming LE, Gómez-Marín O, LeBlanc W, Pitman T. Obesity in us workers: the national health interview survey, 1986 to 2002. Am J Public Health. 2005;95:1614–22.
Gans KM, Salkeld J, Risica PM, Lenz E, Burton D, Mello J, et al. Occupation is related to weight and lifestyle factors among employees at worksites involved in a weight gain prevention study. J Occup Environ Med. 2015;57:e114–20. https://doi.org/10.1097/JOM.0000000000000543.
Kuntz B, Lampert T. Socioeconomic factors and obesity. Deutsches Arzteblatt international. 2010;107:517–22. https://doi.org/10.3238/arztebl.2010.0517.
Vernay M, Malon A, Oleko A, Salanave B, Roudier C, Szego E, et al. Association of socioeconomic status with overall overweight and central obesity in men and women: the French nutrition and health survey 2006. BMC Public Health. 2009;9:215. https://doi.org/10.1186/1471-2458-9-215.
Wardle J, Waller J, Jarvis MJ. Sex differences in the association of socioeconomic status with obesity. Am J Public Health. 2002;92:1299–304.
Dėdelė A, Miškinytė A, Andrušaitytė S, Bartkutė Ž. Perceived stress among different occupational groups and the interaction with sedentary behaviour. Int J Environ Res Public Health. 2019;16:4595. https://doi.org/10.3390/ijerph16234595.
Aekplakorn W, Kosulwat V, Suriyawongpaisal P. Obesity indices and cardiovascular risk factors in Thai adults. Int J Obes. 2005;30:1782–90.
Aekplakorn W, Hogan MC, Chongsuvivatwong V, Tatsanavivat P, Chariyalertsak S, Boonthum A, et al. Trends in obesity and associations with education and urban or rural residence in Thailand. Obesity. 2007;15:3113–21.
Aekplakorn W, Inthawong R, Kessomboon P, Sangthong R, Chariyalertsak S, Putwatana P, et al. Prevalence and trends of obesity and association with socioeconomic status in Thai adults: National health examination surveys, 1991–2009. J Obes. 2014. https://doi.org/10.1155/2014/410259.
Angkurawaranon C, Wisetborisut A, Rerkasem K, Seubsman SA, Sleigh A, Doyle P, et al. Early life urban exposure as a risk factor for developing obesity and impaired fasting glucose in later adulthood: Results from two cohorts in Thailand. BMC Public Health. 2015;15:1–10.
Gelman A, Carlin J, Stern H, Dunson DB, Vehtari A, Rubin D. Bayesian data analysis. 3rd ed. Boca Raton: Chapman & Hall/CRC; 2014.
International Labour Organization. International Standard Classification of Occupations (ISCO-88). In: International Standard Classification of Occupations; 2016. http://www.ilo.org/public/english/bureau/stat/isco/isco08/index.htm. Accessed 29 Sep 2016.
Choi SB, Yoon JH, Lee W. The modified international standard classification of occupations defined by the clustering of occupational characteristics in the Korean working conditions survey. Ind Health. 2020;58:132–41.
Snijder M, van Dam R, Visser M, Seidell J. What aspects of body fat are particularly hazardous and how do we measure them? Int J Epidemiol. 2006;35:83–92.
Bhurosy T, Jeewon R. Overweight and Obesity Epidemic in Developing Countries: A Problem with Diet, Physical Activity, or Socioeconomic Status? Sci World J. 2014;(2014)964236:7. https://doi.org/10.1155/2014/964236.
Visscher TL, Seidell JC. Time trends (1993–1997) and seasonal variation in body mass index and waist circumference in the Netherlands. Int J Obes Relat Metab Disord. 2004;28:1309–16.
(IDF) IDF. The IDF consensus worldwide definition of the metabolic syndrome. Brussels: International Diabetes Federation (IDF); 2006.
Alberti KG, Zimmet P, Shaw J. Metabolic syndrome–a new world-wide definition. A consensus statement from the international diabetes federation. Diabet Med. 2006;23:469–80.
Kowarik A, Templ M. Imputation with the r package vim. J Stat Softw. 2016;74:1–16.
Ghitza Y, Gelman A. Deep interactions with MRP: election turnout and voting patterns among small electoral subgroups. Am J Polit Sci. 2013;57:762–76.
Downes M, Gurrin LC, English DR, Pirkis J, Currier D, Spittal MJ, et al. Multilevel regression and post stratification: a modeling approach to estimating population quantities from highly selected survey samples. Am J Epidemiol. 2018;187:1780–90.
Gelman A, Hill J, Yajima M. Why we (usually) don’t have to worry about multiple comparisons. J Res Educ Effective. 2012;5:189–211.
Gelman A, Jakulin A, Pittau MG, Su Y-S. A weakly informative default prior distribution for logistic and other regression models. Ann Appl Stat. 2008;4:1360–83.
Acknowledgements
Appreciation to National Health Examination Survey Office, Heath System Research Institute and National Statistical Office of Thailand and for the data used in this study.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
JR, JB, WA, AP and MS designed research, provided suggestions and approved the submitted manuscript. JR conducted review, edited and interpreted the data regarding the relationship between obesity and occupations and a major contributor in writing the manuscript. JB analyzed data and provided statistical consultation. WA provided consultation on the dataset. The author(s) read and approved the final manuscript.
Authors’ information
JR (Ph.D. in Demography) is an assistant professor at Institute for Population and Social Research (IPSR), Mahidol University. JB (Ph.D. in Demography) is a director at Bayesian Demography Limited and an adjunct professor at IPSR. WA (MD., Ph.D.) works at Department of Community Medicine, Ramathobodi Hospital, Mahidol University. AP (Ph.D. in Demography) is an adjunct professor at IPSR. MS (Ph.D. in Demography) is an assistant professor at IPSR.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This research has been approved by Institute for Population and Social Research-Institutional Review Board (COE. No. 2018/08–225).
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Rittirong, J., Bryant, J., Aekplakorn, W. et al. Obesity and occupation in Thailand: using a Bayesian hierarchical model to obtain prevalence estimates from the National Health Examination Survey. BMC Public Health 21, 914 (2021). https://doi.org/10.1186/s12889-021-10944-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12889-021-10944-0