
Abstract
Background
Abnormalities in vocal expression during a depressed episode have frequently been reported in people with depression, but less is known about if these abnormalities only exist in special situations. In addition, the impacts of irrelevant demographic variables on voice were uncontrolled in previous studies. Therefore, this study compares the vocal differences between depressed and healthy people under various situations with irrelevant variables being regarded as covariates.
Methods
To examine whether the vocal abnormalities in people with depression only exist in special situations, this study compared the vocal differences between healthy people and patients with unipolar depression in 12 situations (speech scenarios). Positive, negative and neutral voice expressions between depressed and healthy people were compared in four tasks. Multiple analysis of covariance (MANCOVA) was used for evaluating the main effects of variable group (depressed vs. healthy) on acoustic features. The significances of acoustic features were evaluated by both statistical significance and magnitude of effect size.
Results
The results of multivariate analysis of covariance showed that significant differences between the two groups were observed in all 12 speech scenarios. Although significant acoustic features were not the same in different scenarios, we found that three acoustic features (loudness, MFCC5 and MFCC7) were consistently different between people with and without depression with large effect magnitude.
Conclusions
Vocal differences between depressed and healthy people exist in 12 scenarios. Acoustic features including loudness, MFCC5 and MFCC7 have potentials to be indicators for identifying depression via voice analysis. These findings support that depressed people’s voices include both situation-specific and cross-situational patterns of acoustic features.
Similar content being viewed by others


Background
Major depressive disorder (MDD) is one typical mood disorder that can be characterized by a core symptom of consecutive depressed mood. As an approach of emotional expression, voice was found to be linked with neurocognitive dysfunctions for patients with MDD [1]. The voice of a depressed person was summarized as slow, monotonous and disfluent on the basis of previous clinical research, which was quite different from that of healthy people [2]. Empirical studies also revealed that acoustic features have significant relationships with the rating of depression [3,4,5,6]. Additionally, they can be utilized for distinguishing depressed people from healthy ones [7,8,9,10]. Moreover, the differences of acoustic features between depressed and healthy people have shown relatively high stability over time [11].
It is expected that voice may provide objective clues to assist psychiatrists and clinicians in diagnosing MDD, as well as monitoring response to therapy [12], since it reflects the abnormal changes resulting from MDD and the changes are temporal stable. Nonetheless, a question remains: are the vocal differences in people with depression cross-situational, or can they only be detected in special situations? Answering this question will benefit the design of rational testing environments. If the vocal abnormalities in people with depression only exist in certain special situations, then the testing environment should be arranged to resemble these situations. If the abnormalities are cross-situational, then there are no special requirements on the testing environment. However, few studies [5, 13] have discussed the vocal abnormalities in people with depression in different situations (speech scenarios).
More than one variable has impacts on vocal expression. Therefore, to figure out whether the vocal differences between depressed and healthy people exist in multiple situations, these variables should be regarded as situational conditions when comparing the voices of the two groups.
The first variable is task. Different tasks usually have different demands of cognitive function. Cohen [13] compared vocal changes induced by different evocative stimuli like pictures and autobiographical memories. Results revealed that the recall of autobiographical memories could change vocal expression more significantly since it was more personally relevant. Alghowinem et al. [14] found that spontaneous speech caused more vocal variability than reading speech. They argued that acoustic features (e.g., loudness) probably are distinct during spontaneous speech and read speech [14]. In short, different tasks may affect differently on the values of the acoustic features.
The second variable is emotion. One study [10] investigated the vocal expression of depressed people in two emotional situations: conceal and non-conceal emotion. Their results indicated that vocal abnormalities in people with depression existed in both conceal and non-conceal conditions. Nevertheless, they did not focus on the vocal differences of depressed people experiencing different emotions. Different emotions have different patterns of vocal expression [15]. In addition, emotion induction (e.g., positive or negative) is a frequently used experimental design for studies of emotional expression of healthy people. In contrast, it was rarely considered in the study of emotional expression in depression. Accordingly, we think that our study, as a cross-situational study, should include emotion as one variable to set speech scenario.
Furthermore, vocal differences also have relationships with some demographic variables such as gender [16]. If these variables have not been excluded when recruiting participants or by being statistically controlled, it is hard to separate out the impact of depression on voice. Therefore, it is necessary to control these influential variables that are significantly discriminative between depressed and healthy people.
In summary, it is important to regard both task and emotion as two situational conditions of speech scenarios to investigate the cross-situational vocal differences between depressed and healthy people with irrelevant variables being regarded as covariates. Consequently, the first aim is to figure out whether the vocal differences between people with and without depression are exist in all situations we considered. To measure the vocal differences, acoustic features of depressed and healthy people were compared under different speech scenarios (situations). If any differences exist in all situations, some acoustic features probably are consistent to identify depression. Therefore, our second aim is to ferret out the potential acoustic features that could be used for identifying depression. If one acoustic feature is significant in all scenarios, it will be considered as an indicator of depression. Based on these aims, we designed various settings of speech scenarios that consisted of different tasks and emotions. We then compared 25 frequently used acoustic features between depressed and healthy people. These acoustic features will be described in the section about feature extraction.
Method
This experiment was a part of a clinical research project about the potential biological and behavioural indicators of MDD, approved by the ethical board of the Psychology of Institute, Chinese Academy of Science.
Participants
In this study, we recruited 47 patients who were already diagnosed with MDD from Beijing Anding Hospitals of Capital Medical University, which specializes in mental health. These patients were diagnosed based on DSM-IV criteria [17] by experienced psychologists or psychiatrists. Inclusion criteria included: a) diagnosed as MDD, b) no psychotropic medicines taken within past 2 weeks, c) without mobility difficulties, which could interfere with participation in the study, d) without current or historical DSM-IV diagnosis of any other mental diseases, and e) without current or historical DSM-IV diagnosis of alcohol or drug abuse.
In all, 57 people who matched gender and age with the depressed group and did not have depression (also screened based on DSM-IV by experts) were recruited via local advertisements to form a control group. No participants were diagnosed with other mental diseases.
Table 1 compares the demographic characteristics of depressed people with healthy people. The results denoted that the two groups did not have significant differences in age (t = 1.29, P = 0.2) and gender (χ2 = 0.04, P = 0.85). However, the control group has an obviously higher educational level than the depressive group (χ2 = 28.98, P < 0.001). Therefore, educational level will be regarded as a covariate in the data analysis.
Speech scenarios
To measure the vocal differences between depressed and healthy people and assess consistency of acoustic features under different situations, we need to design situations first. In our study, we regarded both task and emotion as two situational conditions to form diverse speech scenarios.
The studies about voice analysis of depression designed various tasks (details about the tasks are shown in Additional file 3), including: 1) interview, usually originating from interview [3, 7, 8, 18,19,20]; 2) natural speech, in general referring to daily talk or man-machine conversation [10, 21]; 3) describe or comment picture [1, 22]; and 4) reading, normally conducted by text [5, 6, 9, 10, 23]. In addition, video is a stimulus that is commonly utilized for evoking emotion [24, 25] and could be regarded as a task in our study. Thus, we used videos to form a speech task that asked participants to speak about the video they had watched.
Four tasks were designed based on the aforementioned studies, including “Video Watching” (VW), “Question Answering” (QA), “Text Reading” (TR), and “Picture Describing” (PD). Each task involved three emotional materials: positive (happy), negative (sadness) and neutral. All those materials were evaluated for validity before usage. Finally, we conducted a controlled laboratory experiment in 12 speech scenarios (4 tasks × 3 emotions).
After accepting informed consent, participants were seated 1 m away from a 21-in. computer. Information was presented on the computer monitor. The speeches of each participant were received by a professional condenser microphone (Neumann TLM102, Germany) and recorded by a voice recorder (RME Fireface UCX, Germany). The microphone was positioned 50 cm from the right side of the computer. The voice recorder was put at the right side of the computer on the same table. During the experiment, voices of videos, vocal questions and instructions were played via the speaker in the computer. All the recording of vocal questions and instructions were spoken in mandarin.
Participants were asked to complete VW, QA, TR and PD in order (but the order of emotion is random within every task). There are positive, neutral and negative emotional situations in each task, totaling 12 speech scenarios in our experiment.
In task VW, participants first watched a video clip. Then, they were asked to recall the video details based on this instruction “Which figure or scenario made the strongest impression on you in the last video?”. For the QA task, participants were asked to orally respond to nine questions (three questions per emotion) one by one (e.g., “Can you please share with us your most wonderful moment and describe it in detail?). In the task TR, participants were asked to read three text paragraphs after looking over the text. There are approximately 140 words and one emotion in each text. In the task PD, which included six images, participants were presented with facial expressions or scene images (e.g., a smiling female, a horse sculpture) one by one and asked to think about something associated with the presented image and then to speak about their thoughts. There was a 1-min break between two consecutive tasks.
In each speech scenario, participants were instructed to speak Mandarin as they normally speak. One experimenter controlled the beginning and ending of recording by clicking the button in the software developed by ourselves. Ambient noise was controlled under 50 dB during the experiment. Participants’ speeches were digitally recorded at a sampling frequency of 44.1 kHz and 24-bit sampling using a microphone.
Feature extraction
The openSMILE software [26] was used to extract acoustic features from the collected voices. In view of the related work, Table 2 shows the 25 acoustic features that were extracted. There are fundamental frequency (F0), loudness, F0 envelope, zero-crossing rate, voicing probability, 12 Mel-frequency cepstrum coefficients (MFCCs) and 8 Line Spectral Pairs (LSP).
Some acoustic features have already been investigated in the field of voice analysis of depression. F0 and loudness are the most frequently used features within such studies. Researchers identified a salient correlation between F0 and severity of depression [4, 5, 7, 27]. Loudness has an obvious negative relationship with the rating of depression [6, 21], and the loudness of depressed people is significantly lower than that of healthy people [1, 10]. Furthermore, some studies [28,29,30] showed that MFCCs can be used to identify depression.
Some acoustic features were rarely utilized in studies about depressed voice, but widely in the field of voice research and surveys. In our study, these features include F0 envelope, zero-crossing rate, voicing probability and Line Spectral Pairs. The F0 envelope is the envelope of the smoothed F0 contour, which is a common feature in affective computing [31]. Zero-crossing rate is the rate of sign-changes along a signal that contributed to detecting emotion from speech [32]. Voicing probability is an indicator of voice quality, and the durations of voiced sounds rely on it [33]. Line Spectral Pairs (LSP) are linear prediction coefficients for filter stability and representational efficiency, which are usually employed in studies of emotion recognition [34].
Data analysis
It is generally acknowledged that there is a great difference of educational level between depressed and healthy people. Therefore, the impact of educational level needs to be excluded as a covariate when analysing the vocal differences between groups. In this study, multiple analysis of covariance (MANCOVA) was used to compare the differences of acoustic features between groups. All tests are two-tailed, and the level of statistical significance was set at 0.001. The effects of group on 25 acoustic features were analysed by the main effect of MANCOVA. Wilks’ Lambda F, p-value and partial square of Eta (ηp2) [35] were reported in the analyses of main effect. When relevant, we reported the main effect of group on each acoustic feature and used ηp2 to provide insight into the magnitude of group differences. For ηp2, 0.01, 0.06, and 0.14 were considered small, moderate and large effect sizes, respectively [36]. We only regarded the acoustic features with large effect sizes as significant features, because “p < 0.001” was used as the evaluation criterion of significance in this study. The reason for setting this strict criterion (“p < 0.001″) is that multiple hypothesis testing was applied in this study and the impact of it should be controlled. The p-value of the significant features with large effect sizes (ηp2 ≥ 0.14) was found are all less than 0.001, so the criterion of p value was set at 0.001. This criterion is stricter than the criterion calculated by Bonferroni correction. Based on the formula of Bonferroni correction (adjusted p = p / n, n means the number of independent hypotheses which tested in a set of data), the adjusted p-value = 0.05 / 25 = 0.002 (there are 12 dependent multiple testing produced from 12 sets of vocal data. In each testing, there are 25 features conduct to 25 hypotheses).
Results
Multivariate analyses of covariance (MANCOVA) was calculated to test for main effects of group in each scenario, amounting to 12 separate MANCOVAs. As shown in Table 3, the main effects of group were salient in all scenarios, and its effect sizes were all large (to ηp2, 0.14 was considered large). Conversely, the main effects of educational level were not significant in 10 scenarios, except for negative VW and neutral QA. Although there were significant changes on some acoustic features, it indicated the negligible influence on features. In negative VW, educational level had significant impacts on four acoustic features loudness (ηp2 = 0.05), MFCC6 (ηp2 = 0.05), MFCC11 (ηp2 = 0.06) and F0 (ηp2 = 0.06). In neutral QA, educational level has significant influences on 3 acoustic features: loudness (ηp2 = 0.05), MFCC6 (ηp2 = 0.08) and F0 (ηp2 = 0.09).
To evaluate the voice characteristics of depressed people, the 25 acoustic features of depressed and healthy people were compared by checking their statistical significances. The differences of 25 acoustic features between depressed and healthy people in three types of emotions in four tasks are shown in Tables 4, 5 and 6, respectively. Statistical significances of acoustic features were assessed by computing their effect size values, ηp2, which are also presented in Tables 4, 5 and 6 as well. For ηp2, 0.01, 0.06, and 0.14 were considered small, moderate, and large effect sizes, respectively [36]. Only acoustic features with large effect sizes were considered significant features.
It can easily be observed (see Tables 4, 5 and 6) that the significant acoustic features were distinguished in different speech scenarios. There were 5.75 significant acoustic features on average under neutral emotional scenarios. By contrast, the mean number of significant features was 4.5 in both positive and negative emotional scenarios. The comparison of the number of significant acoustic features among different tasks indicated that TR had the largest mean significant features (6.7), compared with VW (3.7), QA (5) and PD (4.3).
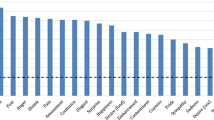
The number of significant acoustic features was calculated in each scenario. There were approximately five significant acoustic features on average. As shown in Fig.1, each scenario had acoustic features ranging from 3 to 8 that were statistically discriminative between depressed and healthy people.

The number of significant acoustic features in each scenario (Task: VW, video watching; QA, question answering; TR, text reading; PD, picture describing. Emotion: pos, positive; neu, neutral; neg, negative)
Tables 4, 5 and 6 show that the values of ηp2 revealed evident vocal differences in loudness, MFCC5 and MFCC7 between the groups, no matter which emotion or task the scenario was involved. The means of the three features of healthy people were all consistent and higher than those of depressed people in every scenario. That is to say, there were not only significant differences in acoustic features between groups, but the magnitude of these differences was large enough to be considered meaningful.
In addition, acoustic features F0 and MFCC3 had large effect sizes in some scenarios and moderate effect sizes in other scenarios.
Discussion
This study sought to help determine whether vocal differences between depressed and healthy people exist across various speech scenarios. We set up 3 (emotion) × 4 (task) speech scenarios to examine 25 acoustic features of 47 depressed people versus 57 healthy people. Notable strengths of the present study are, first, exclusion of the impact of covariate educational level; and second, use of statistical test and effect sizes to evaluate both statistical significance and effect magnitude. The results of MANCOVA in 12 speech scenarios showed 12 valid main effects of group with large effect sizes. There were five significant acoustic features on average between depressed and healthy people under 12 scenarios. Moreover, some acoustic features of depressed people were found to be consistently higher than those of healthy people.
One key finding in this study is that vocal differences between depressed and healthy people exist in all speech scenarios. The results of MANCOVA reported 12 valid main effects of group with large effect sizes, which means the vocal abnormalities in depressed people exist in various emotional or cognitive scenarios. Compared with the previous studies that usually compared among different tasks [5, 10, 14], we set up more multiple speech scenarios that included more diverse tasks (represented different cognitive demands) and added another influential variable emotion, while excluding the covariates. Therefore, our study provides more reliable evidence of the cross-situational vocal abnormalities in depressed people.
Although our study suggested that the voice abnormalities in depressed people exist in various situations, there were different significant discriminative acoustic features (the quantity range from 3 to 8) between people with and without depression in 12 different scenarios. This finding revealed that depressed voices include both cross-situational existence of abnormal acoustic features and situation-specific patterns of acoustic features.
Another key finding is that the acoustic features loudness, MFCC5 and MFCC7 are consistent (Additional file 4). They were statistically significant with large effect sizes across 12 speech scenarios. Loudness is defined as sound volume. In our study, the Loudness of healthy people was obviously louder than that of depressed people. This aligns with clinical observation [2] and a previous study [14] that supported that depression is associated with a decrease in loudness. MFCCs are coefficients of Mel-frequency cepstrum (MFC), which is a representation of the short-term power spectrum of a sound. MFCCs reflected vocal tract changes [37]. Taguchi et al. [30] found a distinguishable difference of MFCC2 between depressed and healthy people. In contrast, we have not found a difference of MFCC2, but found other differences in MFCC5 and MFCC7. The two coefficients of healthy people were visibly higher than those of depressed people. We speculate that these differences suggest depressed people have less vocal tract changes compared with healthy people, due to the symptom named psychomotor retardation that leads to a tight vocal tract. There is also a brain evidence to explain the differences of MFCCs between the two groups. The study of Keedwell [38] stated that the neural responses in inferior frontal gyrus (IFG) has a salient negative relationship with anhedonia in major depressive disorder. Furthermore, the left posterior IFG is a part of the motor syllable programs involved in phonological processing [39, 40]. That is to say, the decrease of MFCCs in depressed people possibly is an outcome derived from the reduction of neural responses in IFG, which results in less speech motor. The result that lower MFCCs in depressed people in our study is in accord with it, because lower MFCCs represents less vocal tract changes (equals to less vocal tract movements). Additionally, for those cross-situational significant features loudness, MFCC5 and MFCC7, we found that educational level has a mild influence on loudness in both negative VW and neutral QA, but not influence on MFCC5 and MFCC7. According to this result, we believe that MFCCs is a steadier type of acoustic feature to reflect the vocal difference between depressed and healthy people.
In addition, we found depressed F0 and MFCC3 were pronounced and significantly lower than in healthy people in some speech scenarios. It was consistent with several previous studies that demonstrated that F0 has a dramatic negative relationship with depression severity [41] and increased after positive treatment [5]. It was reported that F0 had a positive relationship with the overall muscle tension of the speaker [42], which possibly symbolized a weak voice in depressed people. A lower MFCC3 in depressed people again indicated that depressed people have less vocal tract changes than healthy people because of their tight vocal tracts. Additionally, as a high-risk factor of depression, suicidal behaviours have significant relationships with some acoustic features [43]. F0 and MFCCs are distinctly different between suicidal and non-suicidal groups.
An additional interesting finding is that the acoustic features loudness, F0, MFCC3, MFCC5 and MFCC7 were smaller in people with depression than in healthy people in all scenarios. These vocal differences indicate that the depressed voice is untoned, low-pitched and weak. This finding provides powerful evidences for supporting the theory of emotion context insensitivity [44] which claimed that the emotional response of depression is generally flatter than normal emotional reaction, regardless of emotional type.
Gender difference also need to be mentioned. The result (Additional file 1 and Additional file 2) shows that the differences of MFCC3 between depressed and healthy people are significant only in males. This finding accords with a previous study [45] which found that MFCC features are help for gender detection.
Several limitations of this study should be mentioned. First, the small sample size limited the generalizability of our findings. Second, educational level of health group is high in this study because we adopted convenience sampling in an area surrounded by many research institutes. It is another limitation which might impact the generalizability of this study. In general, MDD patients have lower education degrees than their health controls [46, 47]. Furthermore, the impact of educational level was controlled as a covariate during data analysis. Therefore, the influence of educational difference should be reasonably controlled. Even so, we should be cautious about the generalizability of this result while considering the indirect correlation between education and depression. That is, low education degree probably leads to low income, while low income is a risk factor of depression [48]. In addition, our sample focuses on major depressive disorder. Thus, the conclusion of this study should not simply be generalized to other kinds of depression.
For future research, the experimental paradigm of this study should be repeated in a larger sample with a stricter sampling strategy. Besides, these are three themes could be considered for the further investigation. One theme is about the vocal differences among different depression severities which might have different quantities or types of abnormal acoustic features. One theme is to compare the vocal differences between different time by adding follow-up data. For example, comparing the vocal differences between the time before and after treatment for evaluating the response to therapy. Future studies also should investigate whether the vocal features are steady across languages. Although Pitch (F0) was found remarkably similar across languages and cultures [49], other features have not been proved significant across languages. So the language we used might limit the generalizability to other languages, considering Mandarin is very different from other common-used languages like English, Germany.
Conclusion
In our study, the voices of 47 depressed people were compared with the voices of 57 healthy people throughout 12 speech scenarios. Our results pointed out that the vocal differences between depressed and healthy people follow both cross-situational and situation-specific patterns, and loudness, MFCC5 and MFCC7 are effective indicators that could be utilized for identifying depression. These findings supported that there are no special requirements on testing environment while identifying depression via voice analysis, but it is better to utilize loudness, MFCC5 and MFCC7 for modelling.
Availability of data and materials
Data of this study are not publicity available as being a part of a broader project, which data are still analyzing, but are available from the corresponding author on reasonable request.
Abbreviations
- F0:
-
Fundamental frequency
- LSP:
-
Line spectral pair
- MANCOVA:
-
Multiple analysis of covariance
- MDD:
-
Major depressive disorder
- MFCC:
-
Mel-frequency cepstrum coefficient
- PD:
-
Picture describing
- QA:
-
Question answering
- TR:
-
Text reading
- vp:
-
Voicing probability
- VW:
-
Video watching
- zcr:
-
Zero-crossing rate
References
Cohen AS, Kim Y, Najolia GM. Psychiatric symptom versus neurocognitive correlates of diminished expressivity in schizophrenia and mood disorders. Schizophr Res. 2013;146:249–53. https://doi.org/10.1016/j.schres.2013.02.002.
American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders (DSM-5®). Washington D.C: American Psychiatric Pub; 2013.
Cannizzaro M, Harel B, Reilly N, Chappell P, Snyder PJ. Voice acoustical measurement of the severity of major depression. Brain Cogn. 2004;56:30–5. https://doi.org/10.1016/j.bandc.2004.05.003.
Kuny S, Stassen HH. Speaking behavior and voice sound characteristics in depressive patients during recovery. J Psychiatr Res. 1993;27:289–307. https://doi.org/10.1016/0022-3956(93)90040-9.
Mundt JC, Vogel AP, Feltner DE, Lenderking WR. Vocal acoustic biomarkers of depression severity and treatment response. Biol Psychiatry. 2012;72:580–7. https://doi.org/10.1016/j.biopsych.2012.03.015.
Stassen HH, Kuny S, Hell D. The speech analysis approach to determining onset of improvement under antidepressants. Eur Neuropsychopharmacol. 1998;8:303–10. https://doi.org/10.1016/S0924-977X(97)00090-4.
Cohn JF, Kruez TS, Matthews I, Yang Y, Nguyen MH, Padilla MT, et al. Detecting depression from facial actions and vocal prosody. In: 2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops; 2009. p. 1–7.
Ee Brian Ooi K, Lech M, Brian Allen N. Prediction of major depression in adolescents using an optimized multi-channel weighted speech classification system. Biomed Signal Process Control. 2014;14(Supplement C):228–39. https://doi.org/10.1016/j.bspc.2014.08.006.
Moore E II, Clements MA, Peifer JW, Weisser L. Critical analysis of the impact of glottal features in the classification of clinical depression in speech. IEEE Trans Biomed Eng. 2008;55:96–107.
Solomon C, Valstar MF, Morriss RK, Crowe J. Objective methods for reliable detection of concealed depression. Hum-Media Interact. 2015;2:5. https://doi.org/10.3389/fict.2015.00005.
Cohen AS, Elvevåg B. Automated computerized analysis of speech in psychiatric disorders. Curr Opin Psychiatry. 2014;27:203–9. https://doi.org/10.1097/YCO.0000000000000056.
Cohen AS, Najolia GM, Kim Y, Dinzeo TJ. On the boundaries of blunt affect/alogia across severe mental illness: implications for research domain criteria. Schizophr Res. 2012;140:41–5. https://doi.org/10.1016/j.schres.2012.07.001.
Cohen AS, Lee Hong S, Guevara A. Understanding emotional expression using prosodic analysis of natural speech: refining the methodology. J Behav Ther Exp Psychiatry. 2010;41:150–7. https://doi.org/10.1016/j.jbtep.2009.11.008.
Alghowinem S, Goecke R, Wagner M, Epps J, Breakspear M, Parker G. Detecting depression: A comparison between spontaneous and read speech. In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing; 2013. p. 7547–51.
Laukka P, Juslin P, Bresin R. A dimensional approach to vocal expression of emotion. Cogn Emot. 2005;19:633–53. https://doi.org/10.1080/02699930441000445.
Fu Q-J, Chinchilla S, Galvin JJ. The role of spectral and temporal cues in voice gender discrimination by Normal-hearing listeners and Cochlear implant users. J Assoc Res Otolaryngol. 2004;5:253–60. https://doi.org/10.1007/s10162-004-4046-1.
Frances A. Diagnostic and statistical manual of mental disorders: DSM-IV. Washington D.C: American Psychiatric Association; 1994.
Dibeklioglu H, Hammal Z, Cohn JF. Dynamic Multimodal Measurement of Depression Severity Using Deep Autoencoding. IEEE J Biomed Health Inform. 2017;22:1–1.
Ellgring H, Scherer PKR. Vocal indicators of mood change in depression. J Nonverbal Behav. 1996;20:83–110. https://doi.org/10.1007/BF02253071.
Tolkmitt F, Helfrich H, Standke R, Scherer KR. Vocal indicators of psychiatric treatment effects in depressives and schizophrenics. J Commun Disord. 1982;15:209–22. https://doi.org/10.1016/0021-9924(82)90034-X.
Alpert M, Pouget ER, Silva RR. Reflections of depression in acoustic measures of the patient’s speech. J Affect Disord. 2001;66:59–69. https://doi.org/10.1016/S0165-0327(00)00335-9.
Mandal MK, Srivastava P, Singh SK. Paralinguistic characteristics of speech in schizophrenics and depressives. J Psychiatr Res. 1990;24:191–6. https://doi.org/10.1016/0022-3956(90)90059-Y.
Naarding P, Broek WW van den, Wielaert S, Harskamp F van. Aprosodia in major depression. J Neurolinguistics. 2003;16:37–41. doi: 10.1016/S0911-6044(01)00043-4.
Kohler CG, Martin EA, Milonova M, Wang P, Verma R, Brensinger CM, et al. Dynamic evoked facial expressions of emotions in schizophrenia. Schizophr Res. 2008;105:30–9. https://doi.org/10.1016/j.schres.2008.05.030.
Renneberg B, Heyn K, Gebhard R, Bachmann S. Facial expression of emotions in borderline personality disorder and depression. J Behav Ther Exp Psychiatry. 2005;36:183–96. https://doi.org/10.1016/j.jbtep.2005.05.002.
Eyben F, Weninger F, Gross F, Schuller B. Recent developments in openSMILE, the Munich open-source multimedia feature extractor. In: Proceedings of the 21st ACM international conference on multimedia. New York: ACM; 2013. p. 835–8. https://doi.org/10.1145/2502081.2502224.
Mundt JC, Snyder PJ, Cannizzaro MS, Chappie K, Geralts DS. Voice acoustic measures of depression severity and treatment response collected via interactive voice response (IVR) technology. J Neurolinguistics. 2007;20:50–64. https://doi.org/10.1016/j.jneuroling.2006.04.001.
Cummins N, Epps J, Breakspear M, Goecke R. An investigation of depressed speech detection: features and normalization; 2011. p. 2997–3000.
Gupta R, Malandrakis N, Xiao B, Guha T, Van Segbroeck M, Black M, et al. Multimodal prediction of affective dimensions and depression in human-computer interactions. In: Proceedings of the 4th international workshop on audio/visual emotion challenge. New York: ACM; 2014. p. 33–40. https://doi.org/10.1145/2661806.2661810.
Taguchi T, Tachikawa H, Nemoto K, Suzuki M, Nagano T, Tachibana R, et al. Major depressive disorder discrimination using vocal acoustic features. J Affect Disord. 2018;225(Supplement C):214–20. https://doi.org/10.1016/j.jad.2017.08.038.
Schuller B, Steidl S, Batliner A, Burkhardt F, Devillers L, Müller C, et al. The INTERSPEECH 2010 paralinguistic challenge. In: In Proc. Interspeech; 2010.
Chiou BC, Chen CP. Feature space dimension reduction in speech emotion recognition using support vector machine. In: 2013 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference; 2013. p. 1–6.
Schuller B, Villar RJ, Rigoll G, Lang M. Meta-Classifiers in Acoustic and Linguistic Feature Fusion-Based Affect Recognition. In: Proceedings. (ICASSP ‘05). IEEE International Conference on Acoustics, Speech, and Signal Processing, 2005; 2005. p. 325–8.
Dhall A, Goecke R, Joshi J, Wagner M, Gedeon T. Emotion recognition in the wild challenge 2013. In: Proceedings of the 15th ACM on international conference on multimodal interaction. New York: ACM; 2013. p. 509–16. https://doi.org/10.1145/2522848.2531739.
Tabachnick BG, Fidell LS. Multivariate analysis of variance and covariance. In: Using multivariate statistics. New York: Pearson; 2007. p. 402–7.
Cohen J. Statistical power analyses for the behavioral sciences. 2nd ed. Hillsdale: Lawrence Erlbaum Associates; 1988.
Zhu Y, Kim YC, Proctor MI, Narayanan SS, Nayak KS. Dynamic 3-D visualization of vocal tract shaping during speech. IEEE Trans Med Imaging. 2013;32:838–48.
Keedwell PA, Andrew C, Williams SCR, Brammer MJ, Phillips ML. The neural correlates of anhedonia in major depressive disorder. Biol Psychiatry. 2005;58:843–53. https://doi.org/10.1016/j.biopsych.2005.05.019.
Burton MW. The role of inferior frontal cortex in phonological processing. Cogn Sci. 2001;25:695–709.
Paulesu E, Goldacre B, Scifo P, Cappa SF, Gilardi MC, Castiglioni I, et al. Functional heterogeneity of left inferior frontal cortex as revealed by fMRI. NeuroRep. 1997;8:2011 https://journals.lww.com/neuroreport/Abstract/1997/05260/Functional_heterogeneity_of_left_inferior_frontal.42.aspx. Accessed 2 Aug 2018.
Yang Y, Fairbairn C, Cohn JF. Detecting depression severity from vocal prosody. IEEE Trans Affect Comput. 2013;4:142–50.
Scherer KR. Voice, Stress, and Emotion. In: Dynamics of Stress. Boston: Springer; 1986. p. 157–79. https://doi.org/10.1007/978-1-4684-5122-1_9.
Cummins N, Scherer S, Krajewski J, Schnieder S, Epps J, Quatieri TF. A review of depression and suicide risk assessment using speech analysis. Speech Commun. 2015;71:10–49. https://doi.org/10.1016/j.specom.2015.03.004.
Rottenberg J, Gross JJ, Gotlib IH. Emotion context insensitivity in major depressive disorder. J Abnorm Psychol. 2005;114:627–39.
Vogt T, Andre E. Improving automatic emotion recognition from speech via gender differentiation. LREC. 2006. p. 1123–6.
Kendler KS, Gardner CO, Prescott CA. Toward a comprehensive developmental model for major depression in men. Am J Psychiatry. 2006;163:115–24. https://doi.org/10.1176/appi.ajp.163.1.115.
Kendler KS, Gardner CO, Prescott CA. Toward a comprehensive developmental model for major depression in women. FOCUS. 2005;3:83–97. https://doi.org/10.1176/foc.3.1.83.
Zimmerman FJ, Katon W. Socioeconomic status, depression disparities, and financial strain: what lies behind the income-depression relationship? Health Econ. 2005;14:1197–215.
Ohala JJ. Cross-language use of pitch: an ethological view. Phonetica. 1983;40:1–18. https://doi.org/10.1159/000261678.
Acknowledgements
The authors would like to thank the Ministry of Science and Technology of the People’s Republic of China who funded the study. They are also very grateful to all psychiatrists for their work in assessing patients for this program; Professor Yiwen Chen for his statistical consultation; Mr. Krittipat Chuen for his consultation of writing; the members of the experiment collaboration who assisted with recruitment and the participants who contributed their time and experiences.
Funding
The cost of is study was funded by the Major State Basic Research Development Program of China (973 Program for short, No. 2014CB744603) and partially supported by the Key Research Program of the Chinese Academy of Sciences (No. ZDRW-XH-2019-4). The design of the study and the data collection was inspired and partially supported by the 973 Program. The funders of the projects took no part in the data analysis, interpretation of the data or the writing of the manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed to designing and conducting the study. JW analysed and interpreted data and wrote the draft of the manuscript. LZ extracted acoustic features and revised the manuscript. TL rechecked results and revised the manuscript. WP contributed to acquisition of data. BH revised the manuscript. TZ revised the manuscript. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
All patients provided informed written consents for their participation in this study after the procedure had been fully explained to them, and the study protocol was approved by the ethical board of the Institute of Psychology, Chinese Academy of Science (H15010).
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1: Table S1.
Positive emotion: the different acoustic features between depressed and healthy people under different tasks (female). Table S2. Neutral emotion: the different acoustic features between depressed and healthy people under different tasks (female). Table S3. Negative emotion: the different acoustic features between depressed and healthy people under different tasks (female).
Additional file 2: Table S1.
Positive emotion: the different acoustic features between depressed and healthy people under different tasks (male). Table S2. Neutral emotion: the different acoustic features between depressed and healthy people under different tasks (male). Table S3. Negative emotion: the different acoustic features between depressed and healthy people under different tasks (male).
Additional file 3.
Stimuli in the tasks.
Additional file 4.
Box-whisker plots of loudness, MFCC5, and MFCC7 in each emotion.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Wang, J., Zhang, L., Liu, T. et al. Acoustic differences between healthy and depressed people: a cross-situation study. BMC Psychiatry 19, 300 (2019). https://doi.org/10.1186/s12888-019-2300-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12888-019-2300-7