
Abstract
Background
The detection and management of intracranial aneurysms (IAs) are vital to prevent life-threatening complications like subarachnoid hemorrhage (SAH). Artificial Intelligence (AI) can analyze medical images, like CTA or MRA, spotting nuances possibly overlooked by humans. Early detection facilitates timely interventions and improved outcomes. Moreover, AI algorithms offer quantitative data on aneurysm attributes, aiding in long-term monitoring and assessing rupture risks.
Methods
We screened four databases (PubMed, Web of Science, IEEE and Scopus) for studies using artificial intelligence algorithms to identify IA. Based on algorithmic methodologies, we categorized them into classification, segmentation, detection and combined, and then their merits and shortcomings are compared. Subsequently, we elucidate potential challenges that contemporary algorithms might encounter within real-world clinical diagnostic contexts. Then we outline prospective research trajectories and underscore key concerns in this evolving field.
Results
Forty-seven studies of IA recognition based on AI were included based on search and screening criteria. The retrospective results represent that current studies can identify IA in different modal images and predict their risk of rupture and blockage. In clinical diagnosis, AI can effectively improve the diagnostic accuracy of IA and reduce missed detection and false positives.
Conclusions
The AI algorithm can detect unobtrusive IA more accurately in communicating arteries and cavernous sinus arteries to avoid further expansion. In addition, analyzing aneurysm rupture and blockage before and after surgery can help doctors plan treatment and reduce the uncertainties in the treatment process.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Intracranial aneurysms (IAs) are widely recognized as both common and potentially lethal conditions [1, 2]. Ruptured intracranial aneurysms are the primary cause of spontaneous subarachnoid hemorrhage, which can result in severe consequences such as cerebral vasospasm, hydrocephalus and hyponatremia [3]. Therefore, early detection of intracranial aneurysms is particularly crucial. Medical imaging techniques play a significant role in the detection, risk assessment, treatment, and prognosis of intracranial aneurysms. Key imaging techniques used include computed tomography angiography (CTA) [4, 5], magnetic resonance angiography (MRA) [6, 7], digital subtraction angiography (DSA) [8, 9], and the examples are shown in Fig. 1.
CTA has high sensitivity and specificity in diagnosing intracranial aneurysms. However, due to the almost equal absorption effect of contrast agents and calcium on ionizing radiation, CTA is unsuitable for detecting small IAs near the skull [10]. MRA is a non-invasive examination that can accurately measure the size of aneurysms and their positional relationship with the parent artery. However, MRA has drawbacks, such as long imaging time and low resolution [11]. DSA has the advantages of high spatial resolution and has long been used as the gold standard for diagnosing intracranial aneurysms, but invasive procedures increase the risk of complications [12]. Consequently, the application of these imaging techniques generally depends on diverse circumstances and requirements of patients. Traditionally, these medical images are analyzed and interpreted by experienced radiologists, whose expertise is essential for accurate diagnosis [13]. Nevertheless, manually analyzing medical images can be a laborious process, prone to inaccuracies, and may vary depending on the observer.
Considering the exceptional efficacy of artificial intelligence (AI) in image-related tasks, methods utilizing traditional machine learning (ML) and deep learning (DL) have recently emerged for the recognition of intracranial aneurysms [14]. Artificial intelligence can provide precise analysis of the morphology, size, and location of intracranial aneurysms, offering clinicians more comprehensive information to better formulate diagnosis and treatment plans. Currently, AI-based classification, detection, segmentation, and composite models for intracranial aneurysms have been developed, aiding in the assessment of rupture risk and prognostic prediction for intracranial aneurysms [15, 16]. In general, AI models trained on extensively annotated data can effectively and automatically localize suspected IA regions within images, thereby enhancing diagnostic efficiency and accuracy.

Clinical Imaging Examples of IAs. a CTA Example; b MRA Example; c DSA Example
To date, little meta-analysis focuses specifically on the performance of image-based AI in the diagnosis of intracranial aneurysms. Our study aims to conduct a comprehensive review of AI-based IA recognition methods, and systematically evaluate their performance across various IA recognition tasks in medical imaging, providing a thorough overview of the current state of the field.
Methods
Search strategy
A systematic literature review of PubMed, Web of Science, IEEE and the Scopus Library was manually conducted from their establishment date until March 2024 to identify relevant reports. The databases were searched using the terms[(intracranial aneurysm classification), (intracranial aneurysm segmentation), (intracranial aneurysm detection) and (intracranial aneurysm recognition)]. The search strategies incorporated the Medical Subject Headings terms and keywords. References lists of the relevant articles were also screened.
Study selection
All collected studies were screened for eligibility by two independent reviewers. This review focuses on regional detection and localization recognition of IA. We have filtered out studies that do not align with the topic of this article, including aneurysm surgery and morphological analysis. Furthermore, we divide our research work into three types based on algorithmic forms: image segmentation, classification, and detection. Therefore, we screened the preliminary search results based on the following criteria: (1) original articles published until March 2024; (2) provide only English; (3) the research content includes aneurysm detection and recognition, and the method categories can be summarized into one of three types of algorithms; (4) only human subjects are involved. Any differences between the authors reviewers were resolved through consensus in the presence of a third reviewer.
Study selection
The first stage of the screening method involves evaluating the titles and abstracts of the identified papers, removing those unrelated to the research topic, and then eliminating duplicate papers. Subsequently, full texts of relevant articles are retrieved for final evaluation, followed by an assessment based on eligibility criteria. The remaining articles are then thoroughly reviewed to extract the required data. This screening process was conducted by two researchers (Z.Z and Y.J). In cases of disagreement, they consulted with a third researcher (H.Y) to discuss article selection, remove irrelevant/unqualified papers, and extract data. The collected articles were utilized to extract the following variables: first author, year of publication, study type, sampling method, annotation method, sample size, accuracy, sensitivity, and specificity.

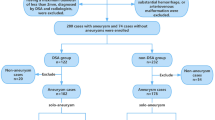
The flow of searching and selecting articles
Result
Study results
In the first stage of the search process, a total of 5168 papers were identified; 3772 were eliminated due to irrelevance. After removing duplicate entries, 1396 remained. Papers that did not meet eligibility criteria or align with the current research objectives were disqualified in the subsequent stage. Following the application of eligibility criteria, 80 articles were excluded. Finally, 47 articles were retained for analysis. The article selection process is described in detail as shown in Fig. 2.
Methodologies overview
Classification-based structure: As shown in Table 1, based on classification models, the recognition of IAs aims to determine whether IAs exist in the image or to assess the status of IAs (such as potential blockage or rupture), mainly divided into two categories:
(1) Based on morphological features [17,18,19,20,21]: by extracting morphological features of intracranial aneurysm images, such as size, shape and edges, and then using traditional machine learning methods or rule-based methods for classification. This method relies on manually designed feature extraction and classification algorithms, requires high demands on the morphological features of intracranial aneurysms, and may not capture subtle variations in the images.
(2) Based on imaging features [22,23,24, 4, 9, 25,26,27,28,29,30,31,32,33,34,35]: using deep learning techniques, such as convolutional neural networks (CNNs), to learn feature representations from intracranial aneurysm images and apply them to classification tasks. This method does not require manual feature extraction but learns feature representations from raw image data through end-to-end learning, which can better capture the complex features of intracranial aneurysms and improve classification performance.
Overall, classification methods based on morphological features rely heavily on the accuracy of upstream feature extraction, and the model’s performance is sensitive to changes in imaging quality and feature extraction thresholds. Samples with significant imaging differences often fail to exhibit robust inference performance. In contrast, classification methods based on imaging features can achieve end-to-end recognition of IA, and through training on large-scale datasets, they can robustly adapt to imaging variations. However, the automatically extracted image features lack a certain level of clinical interpretability.
Detection-based structure: As shown in Table 2 [36,37,38,39], object detection aims to identify the categories and bounding boxes of specific objects in images [40]. In the task of IA recognition, the purpose is to mark the area where IAs are located by bounding boxes, allowing doctors to quickly locate potential IA regions in the image. Specifically, the processing pipeline of object detection models includes feature extraction, region regression, and category prediction. In the feature extraction stage, the model extracts feature representations from the image, typically using CNNs to capture image features. Next, in the region regression stage, these features are utilized to predict the position and size of the bounding boxes, accurately locating the target objects. Finally, in the category prediction stage, these features are used to determine the category of each object within the bounding box, thereby completing the object detection task.
Compared to classification models, object detection not only provides more detailed information but also offers spatial location and category of objects. However, traditional object detection methods cannot segment the specific boundaries of IAs. It requires incorporating a segmentation module at the end of the model to segment the foreground mask of each object within the bounding box, known as instance segmentation. However, similar to segmentation methods, its prediction results also suffer from false positives/false negatives, necessitating further calibration by doctors to obtain the final diagnosis.
Segmentation-based structure: As shown in Table 3, [41,42,43,44,45,46,47,48,49,50,51,52], the goal of semantic segmentation is to classify each pixel in the image into a specific category to achieve pixel-level classification [53]. Segmentation-based IA recognition aims to accurately segment the specific boundaries of IAs in images. A common semantic segmentation model adopts a U-shaped architecture [54], which includes both an encoder and a decoder. Specifically, the encoder is responsible for extracting high-level semantic information from input images, typically composed of convolutional layers and pooling layers. This process gradually reduces the image size while increasing the depth of feature maps. In contrast, the decoder is tasked with mapping the features extracted by the encoder back to the original image size and generating pixel-level prediction results. Typically, the decoder consists of transposed convolutional layers and upsampling layers, which gradually restore the image size while preserving semantic information.
Additionally, segmentation methods offer greater interpretability compared to classification methods as they can clearly delineate the boundaries of IAs. However, since semantic segmentation identifies regions belonging to IAs as the same category when faced with the situation of multiple aneurysms adhering together, they will be recognized as a unified whole, making it unable to accurately distinguish the specific boundaries of different IA instances.
Hybrid-based structure: As shown in Table 4, [16, 5, 55,56,57,58,59,60,61,62] The hybrid-based IA recognition model adopts a two-step approach to accurately identify and classify intracranial aneurysms. Firstly, a segmentation model is utilized to delineate the specific boundaries of IAs. This segmentation process enables precise localization of the aneurysm regions within the image. Subsequently, the segmented regions are input into a classification model, which determines the category of each IA, such as the risk of rupture or obstruction. By combining segmentation and classification techniques, hybrid-based models leverage the strengths of both approaches, allowing for comprehensive analysis and accurate diagnosis of IAs. This hybrid approach yields more detailed recognition results incrementally, but it also faces challenges similar to other domains’ hybrid models, such as high computational complexity and issues with error propagation.
Evaluation of IA recognition based on classification
A total of 21 studies implemented IA recognition based on classification models [4, 9, 17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35], as shown in Table 1. Combined with Tables 2, 3, and 4, it can be seen that classification is currently the predominant method for IA recognition. Classification studies report average accuracy, sensitivity, and specificity as outcome measures, with the patient cohort size ranging from 20 to 1897. Five studies [17,18,19,20,21] utilized pattern classification based on morphological features, focusing mainly on identifying aneurysm states such as rupture and obstruction risk prediction. These studies are primarily applied in postoperative follow-up, where aneurysm appearance parameters and patient clinical features are extracted to form feature vectors, which are then inputted into multilayer perceptron (MLP) to predict the aneurysm’s trend in status. The test group’s average accuracy ranges from 77.9% to 90.0%. Specifically, this morphology-based classification pattern can effectively infer the aneurysm’s status in postoperative follow-up diagnosis, providing valuable auxiliary diagnostic reference results.
In addition, 16 studies [22,23,24,25,26,27,28,29, 4, 30, 9, 31,32,33,34,35] utilized a pattern classification based on image features, aiming to extract deep semantic features from images using deep learning models and utilize these features for automatic classification and recognition of IAs. The test group’s average accuracy ranged from 74.5% to 98.8%, with average sensitivity ranging from 48.3% to 99.3% and average specificity ranging from 18.2% to 98.1%. Overall, DL models showed relatively consistent performance in IA image classification tasks in terms of accuracy, but there were significant differences in specificity and sensitivity performance, mainly influenced by factors such as training data size, imaging sampling, and the proportion of positive samples.
Evaluation of IA recognition based on object detection
Four studies [36,37,38,39] conducted IA recognition based on object detection, as shown in Table 2. Detection studies reported average sensitivity, specificity, and Mean Intersection over Union (MIoU) as outcome measures, with the patient cohort size ranging from 132 to 500. These detection models first locate and label the IA regions in the images, and then further classify and identify each region. The test group’s average sensitivity ranged from 82.9% to 94.3%, average specificity ranged from 83.0% to 96.0%, and MIoU ranged from 55.0% to 91.0%. However, compared to classification-based models, object detection models require more computational resources and time to process each image, thus may have some limitations in practical applications. Additionally, while the bounding boxes outputted by object detection models can locate the position and rough boundaries of IAs, they cannot be further utilized for calculating clinical parameters such as aneurysm area, maximum diameter ratio and roundness, unlike the boundary masks outputted by segmentation models. In real clinical diagnosis, object detection-based methods can assist doctors in locating suspected IA regions in images, but subsequent quantification and analysis of clinical parameters still rely on manual annotation by doctors and semi-automatic measurement tools. Therefore, it may be necessary to adapt it to the actual needs of clinical diagnosis by extending it into a model structure for instance segmentation.
Evaluation of IA recognition based on semantic segmentation
Twelve studies [41,42,43,44,45,46,47,48,49,50,51,52] conducted IA recognition based on semantic segmentation, as shown in Table 3. The detection studies reported average Pixel Accuracy (PA), Dice coefficient, and MIoU as outcome measures, with the patient group size ranging from 23 to 409. These segmentation models first extracted high-level semantic information from input images through an encoder. Then, through a decoder, they mapped the features extracted by the encoder back to the original image size, generating pixel-level prediction results. The test group’s average PA ranged from 77.2% to 99.9%, average Dice ranged from 22.6% to 95.5%, and MIoU ranged from 82.3% to 96.8%. From Table 3, it can be observed that while the models performed well in PA, the performance of Dice was relatively lower. This could be due to the overall low area of IAs in the images, allowing the model to achieve high PA even if it predicts all regions as negative areas. Conversely, Dice and MIoU simultaneously evaluate the overlap of foreground and background regions, thus better reflecting the model’s accuracy and coverage in IA boundary segmentation.
Furthermore, most segmentation models adopted the UNet [54] design structure, incorporating skip connections between the encoder and decoder. This helps the model capture different levels of feature information more effectively and alleviates the issue of information loss. Skip connections allow the decoder to utilize lower-level feature information from the encoder, thereby better recovering image details and boundary information. The adoption of this structure contributes to improving the accuracy and robustness of the model in IA boundary delineation. Additionally, Guo et al. [51] introduced an encoder based on the Transformer structure, utilizing its self-attention mechanism to enhance the model’s ability to model global and local features, further improving performance. Overall, semantic segmentation-based models have made significant progress in IA recognition, providing important diagnostic information to clinicians through pixel-level prediction, and accurately delineating IA boundaries.
Evaluation of IA recognition based on hybrid model
Ten studies [16, 5, 55,56,57,58,59,60,61,62] employed hybrid models for IA recognition, as shown in Table 4. It is evident that these 10 studies all adopted a two-stage hybrid structure based on segmentation and classification. Consequently, the hybrid studies reported measurements for both segmentation and classification, including average accuracy, average specificity, and average sensitivity for classification, and Dice coefficient, MIoU, and F1-Score for segmentation. The patient cohort sizes ranged from 116 to 2272. The test groups showed average accuracy ranging from 79.2% to 94.4%, average sensitivity from 52.0% to 97.3%, average Dice coefficient from 74.0% to 94.4%, MIoU from 48.6% to 86.0%, and average F1-Score from 71.4% to 94.4%.
Moreover, a significant contribution introduced a 3D point cloud segmentation and classification dataset for IAs named IntrA dataset [56]. This dataset reconstructed 2D MRA scan images into 3D point cloud data format and meticulously annotated healthy vascular segments and aneurysmal segments. This innovative approach brought the IA recognition task into the realm of 3D point clouds, offering a fresh perspective for recognition. Subsequently, studies [44, 45, 52, 56, 58, 62] conducted model structure innovations and performance evaluations on this dataset, driving further advancements in IA recognition technology. It can be observed that while models based on hybrid structures may entail higher complexity, the two-stage models can balance both the accuracy and completeness of output results.
Discussion
Potential technical challenges and prospects
Our research indicates that AI is highly effective in the evaluation of IA, enabling the efficient analysis of extensive imaging datasets and fostering standardized assessments that reduce diagnostic discrepancies among clinicians. However, challenges persist, such as varying training sample sizes in different studies and the high computational demands of complex models. To achieve better clinical applications, further research could be conducted in the following aspects:
-
(1)
Reducing the latency of AI systems: Fully functional AI systems are often built on composite models, leading to delays in system recognitions, which are not conducive to real-time applications such as surgical treatments. Therefore, reducing the latency of AI system inference to meet clinical diagnostic needs is necessary. This could involve optimizing model structures to reduce computational complexity or introducing efficient inference algorithms to improve system response time.
-
(2)
Increasing the interpretability of reasoning: Current AI algorithms can detect subtle intracranial aneurysms in both arterial and venous sinuses, but lack interpretability in assessing postoperative recurrence risks or occlusion probabilities [63]. Comprehensive postoperative evaluations require consideration of patients’ medical histories and health records in addition to their imaging data. Therefore, AI models for postoperative assessment may need to incorporate patients’ electronic health records (EHR) and image features to provide interpretability for the reliability of diagnostic results while outputting auxiliary diagnostic outcomes.
-
(3)
Coordinating the diagnosis of multiple neurological disorders: In neurological disorders, IAs may coexist with other conditions such as atherosclerosis and thrombosis. In real clinical diagnostic scenarios, there is a greater need to consider multi-task, multi-modal situations. Therefore, comprehensive diagnosis of neurological disorders requires joint analysis of patients’ multi-modal images. Additionally, it may be necessary to establish links between different lesions through knowledge graph construction [64]. Consequently, designing artificial intelligence systems that cover a wide range of lesions with high sensitivity still faces many technical challenges and requires clinical validation.
-
(4)
Introducing large-language pretraining models: Influenced by the research trend of large-language models (LLM) [65], how to improve the recognition accuracy of specific tasks with the help of the prior weights of LLM is one of the current research hotspots. Due to the high cost of clinical data acquisition in IA, de novo training models tend to be less effective with limited datasets. Therefore, it is an idea worth exploring in the future to achieve accurate recognition within the model by leveraging the prior knowledge of the large model, even when confronted with limited IA data.
-
(5)
Promoting open data sharing: Currently, most studies rely on proprietary datasets, leading to inconsistencies in algorithm design and comparison. Additionally, there are few open-source datasets for IAs recognition, while high-quality public datasets are crucial as they enhance the credibility and replicability of research findings. For instance, the TCGA dataset [66] is utilized in pathological image analysis, and the CheXpert dataset [67] in lung X-ray studies. Moreover, integrating multiple datasets from various sources can facilitate cross-domain or multitask learning research, thereby enriching the scope and applicability of work in this field. Therefore, it is vital to expand the availability of open datasets for IA recognition and to establish clear performance evaluation criteria, which are key focuses for future research in this area.
Strengths
With the increasing popularity of AI and computer vision methods in medical image analysis and the auxiliary diagnosis of IAs, more and more studies have discussed the feasibility of automatic IA recognition. However, we have yet to find any reviews that provide a detailed methodological division and performance evaluation for IA recognition based on AI models.
In this comprehensive review, we systematically categorize existing studies on IAs recognition facilitated by AI, dividing them into four methodological groups: classification, detection, segmentation, and hybrid approaches. This structured classification aids readers and researchers in discerning the methodological distinctions across studies. Our review draws from an extensive selection of studies found in leading scientific databases encompassing both the technical and healthcare fields. To mitigate selection bias, we implemented a robust study selection process managed independently by two reviewers and verified by a third reviewer. We thoroughly assess the results and identify potential technical challenges faced by AI models in IA recognition tasks. To the best of our knowledge, this is the first review that not only methodologically categorizes but also evaluates the performance of AI models specifically for IA recognition tasks. It integrates the latest trends in AI and medical image analysis, shedding light on technological advancements in the field. Our review summarizes the potential applications of AI in the medical imaging evaluation of intracranial aneurysms, highlighting its valuable role in assisting clinicians with diagnosis and treatment. Furthermore, this review offers researchers and readers insights into the challenges and prospects of developing advanced methods for IA analysis.
Limitations
The articles selected for this review exhibit varied characteristics such as retrospective methodologies, constrained sample sizes, diverse artificial intelligence algorithms, assorted performance metrics, and distinct methods of outcome measurement. These factors complicate direct comparisons across different models. Furthermore, the limited sample sizes and the absence of standardized metrics have somewhat hindered the broader application and dissemination of these AI models in clinical settings. Despite exhaustive efforts to include research published up to March 2024, we acknowledge the possibility that certain emergent or evolving AI models might not have been captured in this review. Additionally, this analysis is limited to studies published in English, potentially omitting relevant research conducted in other languages.
Conclusion
This paper aims to conduct a systematic review to understand the current research progress of applying artificial intelligence techniques in intracranial aneurysm recognition. Current studies have achieved good results in IA recognition. But the field still needs more common test benchmarks and public datasets. In addition, the model structure designed by the corresponding research institute is still relatively limited and needs to be improved and enhanced in combination with actual clinical scenarios. In summary, with further improvements, AI methods show favorable prospects in identifying intracranial aneurysms and predicting their potential for rupture and blockage.
Availability of data and materials
The data used in this study are available on request from the corresponding author.
Abbreviations
- IA:
-
Intracranial aneurysm
- AI:
-
Artificial intelligence
- SAH:
-
Subarachnoid hemorrhage
- CTA:
-
Computed tomography angiograph
- MRA:
-
Magnetic resonance angiograph
- DSA:
-
Digital subtraction angiograph
- ML:
-
Machine learning
- DL:
-
Deep learning
- CNN:
-
Convolutional neural network
- MLP:
-
Multilayer perceptron
- SIF:
-
Spatial information fusion
- SR:
-
Sparse representation
- PCC:
-
Point cloud classification
- PCS:
-
Point cloud segmentation
- LSTM:
-
Long short-term memory network
- SCTR:
-
Staged cluster transformer
- MIoU:
-
Mean intersection over union
- PA:
-
Pixel accuracy
- Sen:
-
Sensitivity
- Spe:
-
Specificity
- Acc:
-
Accuracy
- MIoU:
-
Mean Intersection over Union
- IoU:
-
Intersection over Union
- EHR:
-
Electronic health record
- LLM:
-
Large-language model
- AUC:
-
Area Under Curve
References
Brown R, Broderick J. Unruptured intracranial aneurysms: epidemiology, natural history, management options, and familial screening. Lancet Neurol. 2014;13(4):393–404.
Rikhtegar R, Mosimann P, Rothaupt J, Mirza-Aghazadeh-Attari M, Hallaj S, Yousefi M, et al. Non-coding RNAs role in intracranial aneurysm: General principles with focus on inflammation. Life Sci. 2021;278:119617–31.
Claassen J, Park S. Spontaneous subarachnoid haemorrhage. Lancet. 2022;400(10355):846–62.
Xie Y, Liu S, Lin H, Wu M, Shi F, Pan F, et al. Automatic risk prediction of intracranial aneurysm on CTA image with convolutional neural networks and radiomics analysis. Front Neurol. 2023;14:1126949–65.
You W, Sun Y, Feng J, et al. Protocol and Preliminary Results of the Establishment of Intracranial Aneurysm Database for Artificial Intelligence Application Based on CTA Images. Front Neurol. 2022;13:932933–55.
Acar T, Karakas A, Ozer M, Koc A, Govsa F. Building Three-Dimensional Intracranial Aneurysm Models from 3D-TOF MRA: a Validation Study. J Digit Imaging. 2019;32(6):963–70.
Kim Y, Choi J, Lim Y, Song J, Park J, Jung W. Usefulness of Silent MRA for Evaluation of Aneurysm after Stent-Assisted Coil Embolization. Korean J Radiol. 2022;23(2):246–55.
Marbacher S, Gruter B, Wanderer S, Andereggen L, Cattaneo M, Trost P, et al. Risk of intracranial aneurysm recurrence after microsurgical clipping based on 3D digital subtraction angiography. J Neurosurg. 2022;138(3):717–23.
Hu T, Yang H, Ni W. A framework for intracranial aneurysm detection and rupture analysis on DSA. J Clin Neurosci. 2023;115:101–7.
White P, Wardlaw J, Easton V. Can noninvasive imaging accurately depict intracranial aneurysms? A systematic review Radiology. 2000;217(2):361–70.
Zhu C, Liu R, Ye Y, Li Z, Li W, Zhang X, et al. Review Article Imaging Evaluation for the Size of Saccular Intracranial Aneurysm. World Neurosurg. 2024;183:172–9.
Alakbarzade V, Pereira A. Cerebral catheter angiography and its complications. World Neurosurg. 2018;18(5):393–8.
van Asch C, Velthuis B, Rinkel G. Diagnostic yield and accuracy of CT angiography, MR angiography, and digital subtraction angiography for detection of macrovascular causes of intracerebral haemorrhage: prospective, multicentre cohort study. Br Med J. 2015;9:351–64.
Dai X, Huang L, Qian Y, Xia S, Chong W, Liu J, et al. Artificial Intelligence Applications in Intracranial Aneurysm: Achievements. Challenges and Opportunities Acad Radiol. 2022;3:201–14.
O A, X L, M X, P H. Deep learning for automated cerebral aneurysm detection on computed tomography images. Int J Comput Assist Radiol Surg. 2020;15(4):715–23.
Shi Z, Miao C, Schoepf U, et al. A clinically applicable deep-learning model for detecting intracranial aneurysm in computed tomography angiography images. Nat Commun. 2020;11(1):6090–106.
Paliwal N, Jaiswal P, Tutino V, Shallwani H, Davies J, Siddiqui A, et al. Outcome prediction of intracranial aneurysm treatment by flow diverters using machine learning. Neurosurg Focus. 2019;45(5):7–22.
Chen G, Lu M, Shi Z, Xia S, Ren Y, Liu Z, et al. Development and validation of machine learning prediction model based on computed tomography angiography-derived hemodynamics for rupture status of intracranial aneurysms: a Chinese multicenter study. Eur Radiol. 2020;30(9):5170–82.
Detmer F, Luckehe D, Mut F, Slawski M, Hirsch S, Bijlenga P, et al. Comparison of statistical learning approaches for cerebral aneurysm rupture assessment. Int J Comput Assist Radiol Surg. 2020;15(1):141–50.
Bhurwani M, Waqas M, Waqas M, et al. Feasibility study for use of angiographic parametric imaging and deep neural networks for intracranial aneurysm occlusion prediction. J NeuroInterventional Surg. 2020;12(7):714–9.
Detmer F, Luckehe D, Mut F, Slawski M, Hirsch S, Bijlenga P, et al. Stability Assessment of Intracranial Aneurysms Using Machine Learning Based on Clinical and Morphological Features. Transl Stroke Res. 2020;11(6):1287–95.
Park A, Chute C, Rajpurkar P. Deep Learning-Assisted Diagnosis of Cerebral Aneurysms Using the HeadXNet Model. Open Access Med Res. 2019;5(5):6–18.
Ueda D, Yamamoto A, Nishimori M, Shimono T, Doishita S, Shimazaki A, et al. Deep Learning for MR Angiography: Automated Detection of Cerebral Aneurysms. Radiology. 2019;290(1):187–94.
Joo B, Ahn S, Yoon P, Bae S, Sohn B, Lee Y, et al. A deep learning algorithm may automate intracranial aneurysm detection on MR angiography with high diagnostic performance. Eur Radiol. 2019;30(11):5785–93.
Zeng Y, Liu X, Xiao N, Li Y, Jiang Y, Feng J, et al. Automatic Diagnosis Based on Spatial Information Fusion Feature for Intracranial Aneurysm. IEEE Trans Med Imaging. 2020;39(5):1448–58.
Yang J, Xie M, Hu C, Alwalid O, Xu Y, Liu J, et al. Deep Learning for Detecting Cerebral Aneurysms with CT Angiography. Radiology. 2021;298(1):155–63.
Joo B, Choi H, Ahn S, Cha J, Won S, Sohn B, et al. A Deep Learning Model with High Standalone Performance for Diagnosis of Unruptured Intracranial Aneurysm. Yonsei Med J. 2021;62(11):1052–61.
Wei X, Jiang J, Cao W, Yu H, Deng H, Chen J, et al. Artificial intelligence assistance improves the accuracy and efficiency of intracranial aneurysm detection with CT angiography. Eur J Radiol. 2022;149:110169–84.
Li P, Liu Y, Zhou J, Tu S, Zhao B, Wan J, et al. A deep-learning method for the end-to-end prediction of intracranial aneurysm rupture risk. Patterns. 2023;21(4):100709–22.
Niemann A, Behme D, Larsen N, Preim B, Saalfeld S. Deep learning-based semantic vessel graph extraction for intracranial aneurysm rupture risk management. Int J Comput Assist Radiol Surg. 2023;18(3):517–25.
Wang J, Ti L, Sun X, Yang R, Zhang N, Sun K. DSA Image Analysis of Clinical Features and Nursing Care of Cerebral Aneurysm Patients Based on the Deep Learning Algorithm. J Clin Neurosci. 2023;8485651:1–7.
Timmins K, Schaaf I, Vos I, Ruigrok Y, Velthuis B, Kuijf H. Geometric Deep Learning Using Vascular Surface Meshes for Modality-Independent Unruptured Intracranial Aneurysm Detection. IEEE Trans Med Imaging. 2023;42(11):3451–60.
Noto T, Marie G, Tourbier S, Alemán-Gómez Y, Esteban O, Saliou G, et al. Towards Automated Brain Aneurysm Detection in TOF-MRA: Open Data, Weak Labels, and Anatomical Knowledge. Neuroinformatics. 2023;21(1):21–34.
Peng Y, Wang Y, Wen Z, Xiang H, Guo L, Su L, et al. Deep learning and machine learning predictive models for neurological function after interventional embolization of intracranial aneurysms. Front Neurol. 2024;115:1321923–38.
Cao H, Zeng H, Lv L, Wang Q, Ouyang H, Gui L, et al. Assessment of intracranial aneurysm rupture risk using a point cloud-based deep learning model. Front Physiol. 2024;15:1293380–94.
Dai X, Huang L, Qian Y, Xia S, Chong W, Liu J, et al. Deep learning for automated cerebral aneurysm detection on computed tomography images. Int J Comput Assist Radiol Surg. 2019;15(4):715–23.
Liao J, Duan H, Dai H, Huang Y, Liu L, Chen L, et al. Automatic detection of intracranial aneurysm from digital subtraction angiography with cascade networks. In: Proceeding in 2019 13nd International Conference on Artificial Intelligence and Pattern Recognition (ICAIPR). Beijing; 2019. p. 18–23.
Duan H, Huang Y, Liu L, Dai H, Chen L, Zhou L. Automatic detection on intracranial aneurysm from digital subtraction angiography with cascade convolutional neural networks. Biomed Eng OnLine. 2019;18(1):110–24.
Assis Y, Liao L, Pierre F, Anxionnat R, Kerrien E. Aneurysm pose estimation with deep learning. In: Proceeding in 2024 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). Vancouver; 2023. p. 543–553.
Zhao Z, Zheng P, Xu S, Wu X. Object Detection With Deep Learning: A Review. IEEE Trans Neural Netw Learn Syst. 2019;30(11):3212–32.
Podgorsak A, Rava R, Shiraz Bhurwani M, Chandra A, Davies J, Siddiqui A, et al. Automatic radiomic feature extraction using deep learning for angiographic parametric imaging of intracranial aneurysms. J NeuroInterventional Surg. 2020;12(4):417–21.
Jin H, Geng J, Yin Y, Hu M, Yang G, Xiang S, et al. Fully automated intracranial aneurysm detection and segmentation from digital subtraction angiography series using an end-to-end spatiotemporal deep neural network. J NeuroInterventional Surg. 2020;12(10):1023–7.
Yuan W, Peng Y, Guo Y, Ren Y, Xue Q. DCAU-Net: dense convolutional attention U-Net for segmentation of intracranial aneurysm images. Vis Comput Ind Biomed Art. 2022;5(1):9–22.
Liu Y, Liu J, Yuan Y. Edge-oriented point-Cloud transformer for 3D intracranial aneurysm segmentation. In: Proceeding in 2022 25th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). Singapore; 2022. p. 97–106.
Liu Y, Li W, Liu J, Chen H, Yuan Y. GRAB-Net: Graph-Based Boundary-Aware Network for Medical Point Cloud Segmentation. IEEE Trans Med Imaging. 2023;42(9):2776–86.
Claux F, Baudouin M, Bogey C, Rouchaud A. Dense, deep learning-based intracranial aneurysm detection on TOF MRI using two-stage regularized U-Net. J Neuroradiol. 2023;50(1):9–15.
Ham S, Seo J, Yun J, Bae Y, Kim T, Sunwoo L, et al. Automated detection of intracranial aneurysms using skeleton-based 3D patches, semantic segmentation, and auxiliary classification for overcoming data imbalance in brain TOF-MRA. J Neuroradiol. 2023;13(1):12018–32.
Mu N, Lyu Z, Rezaeitaleshmahalleh M, Tang J, Jiang J. An attention residual u-net with differential preprocessing and geometric postprocessing: Learning how to segment vasculature including intracranial aneurysms. Med Image Anal. 2023;84:102697–714.
Zhang J, Zhao Y, Liu X, Jiang J, Li Y. FSTIF-UNet: A Deep Learning-Based Method Towards Automatic Segmentation of Intracranial Aneurysms in Un-Reconstructed 3D-RA. IEEE J Biomed Health Inform. 2023;27(8):4028–39.
Abdullah A, Javed A, Malik K, Malik G. DeepInfusion: a dynamic infusion based-neuro-symbolic AI model for segmentation of intracranial aneurysms. IEEE J Biomed Health Inform. 2023;551:126510–24.
Guo L, Liang Y, Guo R, Cao Z, Ye J, Lai X. Staged cluster transformers for intracranial aneurysmssegmentation from structure fused 3D MRA. Int J Imaging Syst Technol. 2024;34(2):23039–53.
Estrella-Ibarra L, León-Cuevas A, Tovar-Arriaga S. Nested Contrastive Boundary Learning: Point Transformer Self-Attention Regularization for 3D Intracranial Aneurysm Segmentation. Technologies. 2024;12(3):28–42.
Qureshi I, Yan J, Abbas Q, Shaheed K, Riaz A, Wahid A, et al. Medical image segmentation using deep semantic-based methods: A review of techniques, applications and emerging trends. Inf Fusion. 2023;90:316–52.
Ronneberger O, Fischer P. Brox T. U-Net: Convolutional networks for biomedical image segmentation. In: Proceeding in 2015 18th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). Munich; 2015. p. 234–41.
Wu K, Gu D, Qi P, Cao X, Wu D, Chen L, et al. Evaluation of an automated intracranial aneurysm detection and rupture analysis approach using cascade detection and classification networks. Comput Med Imaging Graph. 2020;102:126–40.
Yang X, Xia D, Kin T, Igarashi T. IntrA: 3D intracranial aneurysm dataset for deep learning. In: Proceeding in 2022 33 th IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR). New Orleans; 2020. p. 963–970.
Timmins K, Schaaf I, Bennink E, et al. Comparing methods of detecting and segmenting unruptured intracranial aneurysms on TOF-MRAS: The ADAM challenge. NeuroImage. 2021;238:118216–32.
Shao D, Lu X, Liu X. 3D Intracranial Aneurysm Classification and Segmentation via Unsupervised Dual-Branch Learning. IEEE J Biomed Health Inform. IEEE J Biol Health Inform. 2023;27(4):1770–9.
Ou C, Qian Y, Chong W, Hou X, Zhang M, Zhang X, et al. A deep learning-based automatic system for intracranial aneurysms diagnosis on three-dimensional digital subtraction angiographic images. Med Phys. 2022;49(11):7038–53.
Irfan M, Malik K, Ahmad J, Malik G. StrokeNet: an automated approach for segmentation and rupture risk prediction of intracranial aneurysm. Comput Med Imaging Graph. 2023;108:102271–87.
Nageler G, Gergel I, Fangerau M, Breckwoldt M, Seker F, Bendszus M, et al. Deep Learning-based Assessment of Internal Carotid Artery Anatomy to Predict Difficult Intracranial Access in Endovascular Recanalization of Acute Ischemic Stroke. Clin Neuroradiol. 2023;33(3):783–92.
Cao R, Zhang D, Wei P, Ding Y, Zheng C, Tan D, et al. PMMNet: A dual branch fusion network of point cloud and multi-View for intracranial aneurysm classification and segmentation. IEEE J Biomed Health Inform. 2024;Early Access:1–12.
Linardatos P, Papastefanopoulos V, Kotsiantis S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy. 2021;23(1):18–35.
Kermany D, Goldbaum M, Cai W. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell. 2018;172(5):1122–31.
Singhal K, Azizi S, Tu T. Large language models encode clinical knowledge. Nature. 2023;620(7972):172–80.
Weinstein J, Collisson E, Mills G, Shaw K, Ozenberger B, Ellrott K, et al. The Cancer Genome Atlas Pan-Cancer analysis project. Nature. 2013;45(10):1113–20.
Luo L, Yu L, Chen H, Liu Q, Wang X, Xu J, et al. Deep mining external imperfect data for chest X-ray disease screening. Nature. 2020;39(11):3583–94.
Acknowledgements
None to declare.
Funding
The present study is supported by the Teaching Reform Engineering Project of Undergraduate Universities in Guangdong Province (2022) (grant no. SJZLGC202211).
Author information
Authors and Affiliations
Contributions
Conceptualization: Z.Z. and Y.J.; Methodology: Z.Z. and Y.J. and H.Y.; Software: H.Y., Z.Z. and Y.J.; Validation: H.Y.; Formal analysis: Z.Z. and Y.J.; Investigation: Z.Z. and Y.J.; Resources: J.L., X.Z. and W.Z.; Data curation: J.L. and X.Z.; Writing—original draft preparation: H.Y., Z.Z. and Y.J. ; Writing—review and editing: H.Y., Z.Z. and W.Z.; Visualization: Y.J.; Supervision:J.L.,X.Z. and W.Z.; Project administration: J.L. and W.Z.; The author(s) read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Since this was a review study, ethical approval was not necessary. However, this study included investigations that took ethical policy into account.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Zhou, Z., Jin, Y., Ye, H. et al. Classification, detection, and segmentation performance of image-based AI in intracranial aneurysm: a systematic review. BMC Med Imaging 24, 164 (2024). https://doi.org/10.1186/s12880-024-01347-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12880-024-01347-9