
Abstract
Background
Polypharmacy is a key challenge in healthcare especially in older and multimorbid patients. The use of multiple medications increases the potential for drug interactions and for prescription of potentially inappropriate medications. eHealth solutions are increasingly recommended in healthcare, with big data analysis techniques as a major component. In the following we use the term analysis of big data as referring to the computational analysis of large data sets to find patterns, trends, and associations in large data sets collected from a wide range of sources in contrast to using classical statistics programs. It is hypothesized that big data analysis is able to reveal patterns in patient data that would not be identifiable using conventional methods of data analysis. The aim of this review was to evaluate whether there are existing big data analysis techniques that can help to identify patients consuming multiple drugs and to assist in the reduction of polypharmacy in patients.
Methods
A computerized search was conducted in February 2019 and updated in May 2020, using the PubMed, Web of Science and Cochrane Library databases. The search strategy was defined by the principles of a systematic search, using the PICO scheme. All studies evaluating big data analytics about patients consuming multiple drugs were considered. Two researchers assessed all search results independently to identify eligible studies. The data was then extracted into standardized tables.
Results
A total of 327 studies were identified through the database search. After title and abstract screening, 302 items were removed. Only three studies were identified as addressing big data analysis techniques in patients with polypharmacy. One study extracted antipsychotic polypharmacy data, the second introduced a decision support system to evaluate side-effects in patients with polypharmacy and the third evaluated a decision support system to identify polypharmacy-related problems in individuals.
Conclusions
There are few studies to date which have used big data analysis techniques for identification and management of polypharmacy. There may be a need to further explore interdisciplinary collaboration between computer scientists and healthcare professionals, to develop and evaluate big data analysis techniques that can be implemented to manage polypharmacy.
Similar content being viewed by others

Background
Polypharmacy is an essential challenge especially in older and multimorbid patients. The term polypharmacy was used over one and a half centuries ago to refer to issues related to the consumption of multiple drugs and excessive drug use [1]. Intake of five or more medications is a commonly used definition of polypharmacy. It has been shown that an intake of at least five medications significantly increases the risk of adverse events, such as falls, frailty, disability and mortality [2, 3]. Furthermore, drug-drug interactions are common with the use of multiple drugs and the prescription rate of potentially inappropriate medications raises. Neuropsychological problems like delirium, acute renal failure and hypotension are the most common unwanted side effects [2].. Furthermore, polypharmacy can lead to problems with medication adherence, especially in older adults if associated with visual or cognitive decline as well as aging, resulting in unwanted outcomes such as treatment failure or hospitalizations [4]. The prevalence of polypharmacy at hospital admission in various countries was reported to be between 20 and 60% [5,6,7] and it was recently reported that rehospitalization results in a significant increase in the number of drugs given to patients at discharge. Because of the reported risk of adverse drug reactions in patients receiving polypharmacy, optimal drug prescription is important for these individuals [8, 9]. EHealth, including the use of electronic devices and systems, should be integrated into healthcare because of their potential to improve the treatment of patients, especially multimorbid patients with polypharmacy [10, 11]. Big data analysis techniques as a part of eHealth were introduced in 1997 [12], and were defined by the “3Vs”: increasing volume of data, high velocity of data, and variety of data [13,14,15]. In the following we use the term analysis of big data as referring to the computational analysis of extremely large data sets to find patterns, trends, and associations in data collected from a wide range of sources in contrast to using classical statistics programs [12].
According to current recommendations the main advantage of big data analysis is the ability to identify new contexts and patterns in patient data that would go undetected using conventional methods of data analysis [16].
Data on drug prescription is frequently embedded in free-text fields in electronic health records [17, 18]. To extract free-text information, manual coding is necessary, which means that a human must read the free-text and assign codes to it manually using a defined set of coding rules [18]. This procedure is very time and labour intensive. Electronic health records texts have been analysed automatically using techniques such as natural language processing for a variety of purposes, e.g. the identification of drugs [19, 20]. However, attempts to develop and validate techniques for characterising meta-data such as polypharmacy have not been made [21].
It is not yet known if analysis of big data is potentially useful in the identification of patients with polypharmacy and thus the reduction of the risk of adverse events caused by multiple medications. The aim of this review was to evaluate whether big data analysis techniques already exist that can help identify patients consuming multiple drugs and to assist in the reduction of polypharmacy in patients.
Methods
This review aimed to identify, appraise and summarize the current evidence on the use of big data analysis in identifying polypharmacy in patients. Established methodological frameworks for systematic evidence syntheses [22] and the preferred reporting items for Scoping Reviews [23] were used. No study protocol was registered.
Search methodology
The search strategy was defined by the principles of a systematic search, using the PICO scheme, and implied free-text keywords and Medical subject headings (Mesh terms) by two reviewers. A computerized search was conducted in February 2019 in the PubMed, Web of Science and Cochrane Library databases. A complex search strategy was developed in order to detect all areas of big data analysis. Major search terms for all databases are represented in Table 1. Relevant grey literature was located using a systematic search on Google Scholar. For this search the terms “big data” AND “polypharmacy” were used. Furthermore, we scrutinized reference lists of studies included and relevant reviews identified through the search. The results of the searches were imported into the web service Covidence (www.covidence.org) which was used for the entire review process. We updated the search in May 2020.
Study selection
All scientific articles evaluating big data analysis techniques to identify patients consuming more than five drugs were included, irrespective of study design and publication year. For inclusion, studies had to be in English or German. The University of Lübeck operates the “Center for Open Innovation in Connected Health (COPICOH)”, of which the authors of this review are members, working alongside computer scientists and researchers from other health care disciplines. Consensus meetings were held with other members of COPICOH in order to discuss articles if the authors were uncertain if an article should be included or excluded.
It was decided that studies that used standard statistical methods, for example large cohort studies that examined data from electronic health records, were not deemed eligible. Studies focusing on identifying new drug-drug interactions or new drug combinations were also excluded. Studies addressing big data analysis techniques to identify drug interactions or adverse drug events in patients on multiple medications were included. Although we originally determined that patients must be taking five medications or more to meet the criteria, we decided to include studies with patients taking three medications or more due to a lack of studies. Inclusion and exclusion criteria are shown in Table 2.
Two independent reviewers (DW, AH) assessed titles and abstracts from all search results to identify eligible studies. After selection of potentially relevant articles, full reports were obtained and assessed for inclusion and exclusion criteria. Any disagreement on the eligibility of studies was resolved through discussion to reach consensus or, if required, by involving a third experienced review author (JS). We used the details from the selection process in Covidence to complete the PRISMA flow diagram.
Data extraction
Data from each included study was extracted by one reviewer, with the accuracy of extraction being independently cross-checked by a second reviewer. In case of disagreements or discrepancies, a third review author was called upon to reach consensus. The validity of studies was evaluated based on the judgement of two independent researchers (DW, AH). The data was extracted into standardized tables, including publication year, country of origin, aim of the study, number of examined datasets, method of data analysis used and outcomes.
Results
Description of studies included
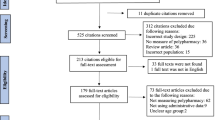
A total of 327 studies were identified through database searches. After removing duplicates, the final dataset consisted of 322 articles. Following title and abstract screening, 302 records were removed. 20 full texts were screened and finally three studies were included in the review. Main reasons for exclusion were not meeting the criterium of big data analysis (n = 10), polypharmacy (n = 6) and not being in English or German (n = 1). All included studies were published in English. Two studies were conducted in the US and one in the UK. For better traceability, the entire screening process is visualized using the PRISMA flow chart (Fig. 1). The results of the data extraction are summarized in Table 3.

PRISMA flow chart
Analysis of big data for patients with polypharmacy
Kadra et al. 2015 [25] extracted antipsychotic data (APP) from two big healthcare providers in Europe, containing structured as well as free-text labels. This data was supplemented by pharmacy records to estimate both the prevalence of APP and prescription patterns.
All patients with a diagnosis of schizophrenia, schizoaffective disorders or bipolar disorders who received care between January and June 2012 were included and prescription schemes for a period of six months were considered. Because antipsychotic medication data contained free-text labels, an NLP (natural language processing) information extraction application software was developed using General Architecture for Text Engineering (GATE) [25, 27]. Case records were screened for whether two or more antipsychotic drugs were prescribed within a period of six weeks between January and June 2012, defined as baseline polypharmacy (t0). Kadra et al. 2015 [25] defined long-term APP as the use of two or more antipsychotics for six or more months and therefore all patients with baseline polypharmacy were screened again six months later (t1). To guarantee generalizability, the APP algorithm was verified following an iterative validation process. Because the NLP application combined with the APP algorithm showed significant results, it can be assumed that patients were correctly identified as being prescribed APP. This approach is an effective combination of natural language processing and a bespoke algorithm for extracting APP data. It was possible to identify polypharmacy from electronic mental health records using this approach. Furthermore, the extracted data can be used to characterize patterns of polypharmacy over time, including different drug combinations, trends in polypharmacy prescription, predictors of polypharmacy prescription and the impact of polypharmacy on patient outcomes (e.g. mortality or physical health consequences) [25].
A decision support system to evaluate side effects in patients with polypharmacy was introduced by Duke et al. 2010 [26]. After selecting 250 commonly used medications, Structured Product Labels (SPL’s) were developed. By using and combining manual and natural language processing techniques, it was possible to extract the side effects for each SPL [28]. In a second step, a scoring system to identify the relationship between each drug and associated adverse events was developed. For this purpose, single numeric values were used and 39 different algorithms were needed. In total, 16,340 medications and adverse events were extracted and the most common side effects of each drug was presented by bar graphs (with the bar length proportional to the calculated score for each side effect). It was also possible to filter the results for specific side effects that were of interest [26, 28]. The developed scoring system was evaluated in a pilot study involving 24 physicians. For evaluating speed and accuracy of the developed tool, two sample clinical tasks including a patient description, a medication list and four hypothetical side effects were presented. Physicians were then asked one of the following two questions: which of the patient’s drugs are known to cause this reaction; or which one drug is most likely to cause this reaction. Time and answer were recorded and finally the results were compared with the results from tool developed. Results showed that using the application is 60% faster in searching adverse events compared to traditional drug information resources. Furthermore, physicians were very satisfied with the developed tool and rated its usability as very high [28].
Another decision support system was evaluated by Keine et al. 2019 [24]. The aim of this system was to identify problems of polypharmacy in individuals, such as drug-drug interactions (DDIs), drug-genome interactions (DGIs), and drug-diet interactions. The clinical decision support system using machine-learning algorithms created recommendations to help physicians with medication management in order to improve clinical decision making and patient safety. The algorithms are capable of parsing interactions, rating them based on input from opensource databases, and recording all interactions in the treatment plan. This enables physicians to review a patient’s medication plan in an easy way. The decision support system was evaluated using 295 individuals aged 65 and older. Of the 295 individuals, 97.59% were on at least one medication, with an overall mean of 11.5 medications per person, with 83.66% of them on five or more medications. Additionally, many interactions were identified [24].
Discussion
The aim of this review was to evaluate whether there are existing big data analysis techniques that can help identify patients consuming multiple drugs and assist in reducing polypharmacy in patients. We identified only three articles using this approach to identify cases of polypharmacy and to avoid the side-effects of multiple medications. Although polypharmacy is defined as taking five or more medications, this review includes studies with patients taking at least three medications. The number of studies addressing the use of big data analysis in patients with polypharmacy is very small so we have no indication that the redefinition of the inclusion criteria was likely to have a negative impact on the results or would have changed our conclusions.
Kadra et al. 2015 [25] presented an effective combination of natural language processing and a bespoke algorithm for extracting APP data. They were able to not only identify polypharmacy using electronic mental health records but also different drug combinations, trends in polypharmacy prescription, predictors of polypharmacy prescription and the impact of polypharmacy on patient outcomes [25]. This approach has to be examined over a longer period of time and further validated, including a broader variety of medications.
Two studies [24, 26] were identified as focusing on uncovering drug-drug interactions in patients on multiple medications. The developed scoring system from Duke et al. 2010 [26] was evaluated in a pilot study and the results showed that using the application is 60% faster in searching for adverse events compared to traditional drug information resources. Furthermore, physicians were very satisfied with the tool developed and rated its usability as very high [29]. This approach has also to be validated further and evaluated in the clinical setting.
The third study [24] included in this review also addresses interactions in medication plans. The results of the evaluation showed that older populations have a high medication burden and therefore medication management for polypharmacy is a challenging task. The system developed was able to identify a multitude of polypharmacy problems that individuals are currently facing [24].
Although the results are promising overall, the identified approaches have to be examined and validated further. In addition, a clear definition of big data is missing from all studies. Similar results have been shown in another recently published review aiming to evaluate big data analysis for multimorbid patients [30]. Based on the results of our review and the results from other studies, there is a lack of big data analysis integration in health care [30,31,32,33]. Through our screening process, we identified two other studies [34, 35] aiming to develop big data analysis to identify new drug-drug interactions or effective drug combinations in cancer therapy, but it did not address patients with polypharmacy. Thus, a lack of big data analysis implementation in health care for addressing polypharmacy was also identified.
None of the other identified reviews on big data analysis included a definition of big data [24, 29, 30]. There is an assumption that big data analysis represents a big opportunity for healthcare. The use of big data analysis techniques is growing quickly, both in clinical medicine as well as health care administration. The analysis of health care data has the potential to reduce treatment costs, avoid preventable diseases and improve the quality of care [12]. In terms of polypharmacy, this would mean a reduction of multiple medications in patients, prevention of drug-drug interactions and improving quality of life.
This review has clearly shown that there is a need to further develop and evaluate big data analysis techniques and algorithms in health care and to implement them in the clinical setting.
Limitations
Strengths and limitations
To the best to our knowledge, this is the first review addressing analysing big data in the treatment of patients with polypharmacy. To minimize bias, the whole screening and data extraction process was conducted by two independent researchers. There may be a risk of publication bias because researchers working in the field of big data analysis may be publishing their results in journals other than those used by health professionals. We conducted an additional search on Google Scholar in order to identify articles that might not be indexed in PubMed. A limitation of this review is that only a very small number of studies (n = 3) are included. A further limitation is that we did not contact study authors and experts in the field and did not ask about unpublished or ongoing studies.
Conclusion
We identified only one study that used a big data approach to identify patients with polypharmacy and two studies that used big data approaches to avoid side effects in patients with multiple medications. A clear definition for big data analysis was missing from all studies. Big data analysis techniques and algorithms currently exist in other contexts, but they are rarely used in healthcare. One possible way to improve implementation of big data analysis may be to further develop interdisciplinary research environments involving computer sciences and health care professionals. This could allow for development and evaluation of big data analysis techniques in clinical settings, for example in the management of polypharmacy.
Availability of data and materials
The complete search strategy is available on request.
Abbreviations
- NLP:
-
Natural language processing
- GATE:
-
General Architecture for Text Engineering
- APP:
-
Antipsychotic data
- SPL:
-
Structured Product Label
- DDI:
-
Drug-drug interaction
- DGI:
-
Drug-genome interaction
References
Masnoon N, Shakib S, Kalisch-Ellett L, Caughey GE. What is polypharmacy? A systematic review of definitions. BMC Geriatr. 2017;17(1):230.
Varghese D, Haseer Koya H. Polypharmacy. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2018. Available from: https://www.ncbi.nlm.nih.gov/books/NBK532953/. [Updated 2018 Dec 2].
Hajjar ER, Cafiero AC, Hanlon JT. Polypharmacy in elderly patients. Am J Geriatr Pharmacother. 2007;5:345–51.
von Buedingen F, Hammer MS, Meid AD, Müller WE, Gerlach FM, Muth C. Changes in prescribed medicines in older patients with multimorbidity and polypharmacy in general practice. BMC Fam Pract. 2018;19(1):131.
Wawruch M, Zikavska M, Wsolova L, et al. Polypharmacy in elderly hospitalized patients in Slovakia. Pharm World Sci. 2008;30:235–42.
Corsonello A, Pedone C, Corica F, Incalzi RA. Polypharmacy in elderly patients at discharge from the acute care hospital. Ther Clin Risk Manag. 2007;3:197–203.
Mizokami F, Koide Y, Noro T, Furuta K. Polypharmacy with common diseases in hospitalized elderly patients. Am J Geriatr Pharmacother. 2012;10:123–8.
Marcum ZA, Amuan ME, Hanlon JT, et al. Prevalence of unplanned hospitalizations caused by adverse drug reactions in older veterans. J Am Geriatr Soc. 2012;60:34–41.
Kojima T, Akishita M, Kameyama Y, et al. High risk of adverse drug reactions in elderly patients taking six or more drugs: analysis of inpatient database. Geriatr Gerontol Int. 2012;12:761–2.
Rijken M, Struckmann V, van der Heide I, et al. (on behalf of the ICARE4EU consortium). How to improve care for people with multimorbidity in Europe? Policy Brief 23. European Observatory on Health Policies and Systems. Denmark 2017. http://www.euro.who.int/en/about-us/partners/observatory/publications/policy-briefs-and-summaries/how-to-improve-carefor-people-with-multimorbidity-in-europe. (accessed 27 Jun 2018).
Martin CM, Vogel C, Grady D, et al. Implementation of complex adaptive chronic care: the patient journey record system (PaJR). J Eval Clin Pract. 2012;18(6):1226–34.
Garapati SL, Garapati S. Application of big data analytics: an innovation in health care. Comput Intell. 2018;14(1):15–27.
McAfee A, Brynjolfsson E. Big data: the management revolution. Harv Bus Rev. 2012;90(10):60–6 68, 128.
Laney D. 3D data management: controlling data volume, velocity and variety. http://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf. (accessed 4 Mar 2019).
Langkafel P. Intro Big Data for Healthcare? In: Langkafel P, editor. Big Data in Medicine und Health Economics. Diagnosis, Therapy, Side effects. Heidelberg: medhochzwei Verlag GmbH; 2014. p. 12.
Roski J, Bo-Linn GW, Andrews TA. Creating value in health care through bog data: opportunities and policy implications. Health Aff (Millwood). 2014;33:1115–22.
Karystianis G, Sheppard T, Dixon WG, et al. Modelling and extraction of variability in free-text medication prescriptions from an anonymised primary care electronic medical record research database. BMC Med Inform Decis Mak. 2015;16:18. https://doi.org/10.1186/s12911-016-0255-x.
Levin MA, Krol M, Doshi AM, Reich DL. Extraction and mapping of drug names from free text to a standardized nomenclature. AMMIA Annual Symposia Proceedings Arch. 2007:438–42.
Su YP, Chang CK, Hayes RD, Harrson S, Lee W, Broadbent M, Taylor D, Stewart R. Retrospective chart review on exposure to psychotropic medications associated with neuroleptic malignant syndrome. Acta Psychiatr Scand. 2014;130(1):65–9.
Meystre SM, Savova GK, Hurdle JF. Extracting information from textual documents in the electronic health record: a review of recent research. IMIA Yearb Med Informatics. 2008;1:28–44.
Uzuner O, Solti I, Cadag E. Extracting medication information from clinical text. J Am Inform Assoc. 2010;17(5):514–8.
Higgins JPT, Green S (editors). Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0. The Cochrane Collaboration, 2011. Available at www.cochrane-handbook.org. [updated March 2011].
Tricco AC, Lillie E, Zarin W, et al. PRISMA extension for scoping reviews (PRISMA-ScR): checklist and explanation. Ann Intern Med 2018;169(7):467–473. doi: https://doi.org/10.7326/M18-0850. Epub 2018 Sep 4.
Keine D, Zelek M, Walker JQ, Sabbagh MN. Polypharmacy in an elderly population: enhancing medication management through the use of clinical decision support software platforms. Neurol Ther. 2019;8:79–94.
Kadra G, Stewart R, Shetty H, Jackson RG, Greenwood MA, Roberts A, Chang CK, MacCabe JH, Hayes RD. Extracting antipsychotic polypharmacy data from electronic health records: developing and evaluating a novel process. BMC psychiatry. 2015;15:166.
Duke JD, Li X, Grannis S. Data visualization speeds review of potential adverse drug events in patients on multiple medications. J Biomed Inform. 2010;43(2):326–31.
Cunningham H, Tablan V, Roberts A, Bontcheva K. Getting more out of biomedical documents with GATE’s full lifecycle open source text analytics. PLoS Comput Biol. 2013;9(2):e1002854.
DailyMed: About DailyMed. Available at http://dailymed.nlm.nih.gov/dailymed/about.cfm.
Calibe A, Burger HU, Knoerzer D, Kieser M. Big Data in der klinischen Forschung: Vieles ist noch Wunschdenken.Dtsch Arztebl 2019; 116(35–36): A-1534 / B-1266 / C-1246.
Waschkau A, Wilfling D, Steinhäuser J. Are big data analytics helpful in caring for multimorbid patients in general practice? A Scoping review. BMC Family Practice. 2019;20:37.
Zhang R, Simon G, Yu F. Advancing Alzheimer’s research: a review of big data promises. Int J Med Inform. 2017;106:48–56. https://doi.org/10.1016/j.ijmedinf.2017.07.002 Epub 2017 Jul 24.
Mehta N, Pandit A. Concurrence of big data analytics and healthcare: a systematic review. Int J Med Inform. 2018;114:57–65. https://doi.org/10.1016/j.ijmedinf.2018.03.013 Epub 2018 Mar 26.
Kruse CS, Goswamy R, Raval Y, et al. Challenges and opportunities of big data in health care: a systematic review. JMIR Med Inform. 2016;4(4):e38.
Sharma A, Rani R. An integrated framework for identification of effective and synergistic anti-cancer drug combinations. J Bioinforma Comput Biol. https://doi.org/10.1142/S0219720018500178.
Sridhar D, Fakhraei S, Getoor L. A Probabilistic Approach for Collective Similarity-based Drug-Drug Interaction Prediction. Bioinformatics. 2016;32(20):3175–82.
Acknowledgements
Not applicable.
Funding
All authors are members of the Center for Open Innovation in Connected Health (COPICOH) at the University of Lübeck, which is co-funded by Cisco Systems. The funding body was not involved in the design of the study, nor the collection, analysis, and interpretation of the data, nor the writing of the manuscript. The funding body approved the final manuscript. Open Access funding provided by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
DW conducted the database search, screened the search results, extracted the data, and drafted the manuscript. AH conducted the database search and screened the search results. JS had the idea for the study and was the senior coordinator for all steps of the study. All authors revised the manuscript and read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1.
Full electronic search strategy in PubMed.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Wilfling, D., Hinz, A. & Steinhäuser, J. Big data analysis techniques to address polypharmacy in patients – a scoping review. BMC Fam Pract 21, 180 (2020). https://doi.org/10.1186/s12875-020-01247-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12875-020-01247-1