
Abstract
An electrocardiogram is a medical examination tool for measuring different patterns of heart blood flow circle either in the form of usual or non-invasive patterns. These patterns are useful for the identification of morbidity condition of the heart especially in certain conditions of heart abnormality and arrhythmia. Myocardial infarction (MI) is one of them that happened due to sudden blockage of blood by the cause of malfunction of heart. In electrocardiography (ECG) intensity of MI is highlighted on the basis of unusual patterns of T wave changes. Various studies have contributed for MI through T wave’s classification, but more to the point of T wave has always attracted the ECG researchers. Methodology. This Study is primarily designed for proposing the combination of latest methods that are worked for the solutions of pre-defined research questions. Such solutions are designed in the form of the systematic review process (SLR) by following the Kitchen ham guidance. The literature survey is a two phase’s process, at first phase collect the articles that were published in IEEE Xplore, Scopus, science direct and Springer from 2008 to 2023. It consist of steps; the first level is executed by filtrating the articles on the basis of keyword phase of title and abstract filter. Similarly, at two level the manuscripts are scanned through filter of eligibility criteria of articles selection. The last level belongs to the quality assessment of articles, in such level articles are rectified through evaluation of domain experts. Results. Finally, the selected articles are addressed with research questions and briefly discuss these selected state-of-the-art methods that are worked for the T wave classification. These address units behave as solutions to research problems that are highlighted in the form of research questions. Conclusion and future directions. During the survey process for these solutions, we got some critical observations in the form of gaps that reflected the other directions for researchers. In which feature engineering, different dependencies of ECG features and dimensional reduction of ECG for the better ECG analysis are reflection of future directions.
Similar content being viewed by others

Introduction and Background
Pattern recognition is a game changer in time series data. Differentiating between regular and irregular patterns is highly desirable in such cases that involve urgency and risk factors. In the context of these statements, data from MRI monitors the unusual behavior of the brain (brain tumor), data from CT SCAN relates to the broader picture of the human body, and data from ECG highlights the usual and non-invasive heart activities. The scope of this article deals with anomalous behaviors of the heart in terms of ECG analysis. Unusual activities of the heart are referred to as anomalous behavior that represents cardiovascular diseases (CVDs). Accurate and robust classification of these CVDs has especially attracted cardiologists and ECG researchers. Some of the CVDs are critical for diagnostic purposes like one of them is a myocardial infarction (MI). MI depends on the effects in the ST part and T wave and main focus is on changes of the T wave. The primary cause of myocardial infarction (MI) stems from anomalous T-wave episodes [1, 2]. Automated classification of T-wave episodes is a game changer for cardiologists and ECG researchers.
Accurate classification of T wave demonstrates the concept of different types of T wave episodes like flattened T wave, inversion T wave, and negative T wave. Identification of the exact characteristics of flattened T is an open research problem for ECG researchers. In operational investigations of literature for better classification of T-wave episodes, In one case, the identification of flattened T-wave characteristics involves assessing parameters such as time duration, peak value, and start and end times. Additionally, dependencies on various features related to T-wave episodes, such as the utilization of the R peak as a reference point for calculating the T-onset parameter [3], play a significant role in classifying diverse T-wave episodes. These calculations of dependency factors are crucial for achieving accurate and robust classification of different T-wave episodes, highlighting the importance of the literature problem definition. During the literature survey, numerous studies directly and indirectly related to T-wave classification were discovered, underscoring the relevance of this research. In several studies, one of them is a Manifold algorithm that works for anomaly detection in ECG data and gets the accuracy at 96% level. Such an algorithm works in three phases. In the first phase, segmentation, and feature extraction are performed. In the second phase, the manifold structure was discovered and mapped with findings. The last phase deals with the anomaly detection and recognition [2, 3]. Similarly, the Myocardial infraction detection algorithm MI detection algorithm surpasses the accuracy of traditional algorithms, achieving an impressive 98% accuracy rate [4]. It has been specifically designed for the detection of abnormalities in the ST segment and T-wave [5,6,7,8,9,10,11]. The MI detection algorithm is particularly focused on distinguishing between ST-segment elevation (STEMI) and non-ST segment elevation (NSTEMI) cases [12,13,14,15,16]. This study is intended to enhance the accuracy of state-of-the-art methods in classifying various T-wave episodes.
This article is designed for solutions to the defined problems through a literature survey. Such a solution belongs to the robust and accurate classification of different T wave episodes by using the hybrid approach. Concepts of behavior analytics are integrated with parametric analysis of the T wave for calculating the dependencies factor. This factor plays a critical role for another perspective in terms of classifying the T wave anomalies, such perspective reflects in terms of different neural models [17,18,19]. These three different perspectives are merged for a better and more accurate classification solution [20,21,22].For the conduction of this hybrid approach, the dependencies indicator of T wave parameters is a central theme of this approach like interconnectivity between T-onset, T-offset, T peak value, and T wave time duration [23,24,25,26,27,28,29].
By using our best knowledge this domain, so far, we are the first ones who proposed the best possible solution in terms of accurate and efficient classification of different T wave episodes based on nature. Such natural identification entirely relies on the parameters of T wave. In literature, a number of studies found that build a reasonable accuracy level in terms of classification of different T wave episodes, but due to these methods, the difference between flattened T wave and inversion T wave is still unclear [30,31,32,33,34]. Accurate and robust classification of different T wave episodes relies entirely on the identification of the values of T wave parameters especially in terms of T-onset and T-offset [35,36,37,38,39,40,41]. Such findings are further helpful for highlighting the intensity of MI in terms of ST-segment elevation and ST-segment depression [42,43,44,45,46].
This study delivers the good practice of Kitchenham guidelines [47]. Execution of this guideline in a systematic way like the first phase reflects the collection of 97 articles through four primary databases. These 97 studies were rectified by applying three different rectification levels and after these levels finally fetched the 26 articles. These 26 studies are the primary source for the execution of this review article. The core focus of this systematic study is to review the latest techniques of T wave anomaly classification and detection. A summary of our contributions is highlighted below.
-
1)
Execution of in-depth classification based on parametric analysis of different T-wave episodes.
-
2)
Introducing the discussion session of dependencies factors that work for robust and better classification.
-
3)
Proposed three-way perspectives with the help of selected articles. These three-way perspectives are designed for robust and accurate classification by using state-of-the-art terminologies like parametric analysis of T waves and classification of different T waves through neural models.
The rest of the paper is organized into different sections. Sect. " Selection Protocols" will deliver the complete methodology of research conduction. Section 3 covers the discussion portion of selected studies. Sect. " Methodological Comparison" delivers a short summary of relevant articles in the sense of results. Sects. " Taxonomical View:Three- Way Handshake" and 6 highlight the taxonomy and the future directions. Section 7 concludes the summary of this article.
Selection protocols
Healthcare systems give special consideration to scenarios involving risk factors, particularly in the context of cardiac process monitoring. Even minor details of heart activities cannot be overlooked in this process. Accurate and timely identification is crucial for diagnosing various cardiac conditions. In light of these considerations, providing specific attention to diagnostic purposes is essential when dealing with patients affected by myocardial infarction. In myocardial infarction, the most significant part is to identify the defective shape of the T wave. Classification is used to identify the abnormalities of T wave but identifying the abnormality of Flatten T wave is still a problem for researchers and cardiologists. This article delivers a way how to sort out the robust and accurate classification of the different T-wave episodes by manipulating the literature [48, 49].
Research questions
-
RQ1: how it is possible to classify the different anomalies of T wave through parameters of T wave?
-
RQ2: Which Parameters of T wave plays a vital role for identification the different T wave nature?
-
RQ3: how neural models are the best methods for identifying the feature dependencies of ECG?
-
RQ4: What are the main factors that play a critical role in the classification of different T-wave episodes?
Keywords for searching
The formation of SLR is built on the base of keywords, and such keywords are used in the query string for the collection of articles. Table 1 highlights the possible synonyms in this SLR. Table 2 reflects the possible acronyms.
Data source
Four primary databases that are highlighted in Table 3 are used for extraction articles.. This extraction process is executed by considering the last twenty years of articles
The following items are searched based on research questions and relevant literature. Proper classification of the various T wave anomalies based on nature is a hot issue for medical professionals especially flattened T wave. Accurate and robust classification of different T wave episodes is one of the primary purposes of this SLR. For this purpose, the first stage is to discuss all the possible interconnect dependencies of T wave parameters. This SLR is a joint alignment of different behaviors of different T wave episodes along with a discussion of T wave dependencies analysis. Finally, the usage of the above combination with neural models works for the achievement of robust and accurate classification of different T waves [50,51,52,53,54]. In the context of accurate and robust classification, the proposed idea is executed with the query string generation method. Such a method is stated below.
-
(1). “Behavior impact analysis” OR “Negative Behavior sequences” OR “Behavior Informatics.”
-
(2). “OnTo Behavioral Model” OR “Behavior Checkpoint”.
-
(3). “Neural networks” OR “Different methods of neural models for classification” OR “ECG classification through neural models.”
-
(4). “ECG morphology analysis” OR “ECG feature extraction” OR “ECG feature analysis.”
-
(5). “T wave behavior” OR “T wave start time” OR “T-onset.”
-
(6). “T wave behavior” OR “T wave end time” OR “T-offset.”
-
(7). “T wave behavior” OR “T wave peak value” OR ‘T wave amplitude” OR.
-
(8). “T wave behavior” OR “T wave time duration.”
These above search items are combined in the form of a string generator by using the Conjunction (AND) and Disjunction (OR) operators. The result of a search string for the collection of relevant literature is as follows:
(“Behavior impact analysis” OR “Negative Behavior sequences” OR “Behavior Informatics” OR” OnTo Behavioral Model” OR “Behavior Checkpoint”) AND (“Neural networks” OR “Different methods of Neural models for Classification” OR “ ECG classification through neural models”) AND (“ECG morphology analysis” OR “ECG feature extraction” OR “ECG feature analysis”) AND( “T wave behavior” OR “T wave start time” OR “T-onset”) AND( “T wave end time” OR “T-offset” OR “T wave behavior”) AND(“T wave behavior” OR” T wave peak value” OR ‘T wave amplitude”) AND (“T wave behavior” OR “T wave time duration”).
Inclusion and Exclusion Criteria
The above connection string is valuable for the selection of related articles. These articles passed through the other filtration process that is mentioned in Table 4. The formation of inclusion and exclusion checks in Table 4 is formated based on technical-oriented clinical research contributions which belongs to human participants for the collection of data and execution of experiments with ethical clearance.Footnote 1. The schema of inclusion and exclusion criteria relies on the above connection string. At the first phase, the inclusion of articles primarily depends on any novel approach or technique for the detection of anomalies of T wave. For understanding the different anomalous behaviors of the T wave in ECG, the induction of behavior analytics articles delivers the better knowledge of different dependencies concept. Conversely, articles excluded on the basis of unclear results and invalid techniques. Such type of articles is completely aborted. A few of the traditional techniques are also excluded due to their least effectiveness in percentage accuracy measurement..
Data extraction strategy
All the articles are selected after clearing the inclusion and exclusion stage. These research articles are assessed on the basis of parameters which are highlighted in Table 5. Specific information was extracted on the basis of predefined extraction items like Title, Publication venue,Publication Year,Approach (Feature analysis, Parametric discussion of T wave and classification of abnormalities in ECG through neural models),Research methods,Research questions addressed.
Above Table 5 displays the data extraction strategy in the form of first extracted identifier S1. Extraction policy is applied to all selected articles that captured unit information in tabularized form, and few samples are discussed in Appendix-A.
Literature quality assessment
The quality assessment activity is the third stage of study selection flow that is highlighted in Table 5. At first stage of screening, the combination of both schema’s inclusion and exclusion are worked with assessment criteria of literature for the identification of relative research articles.
Queries of Table 6 are implemented on those articles that are selected after first rectification process. Answer the queries of Tables 6 in the format of YES, NO and PARTIALLY that is the next step for further improvement of rectification process by the induction of five domain reviews (Rev). These reviews mark the score of the second stage selected articles according to the format of 0.5,0 and 1(represents the PARTIALLY, NO, and YES).
Selected Search Item
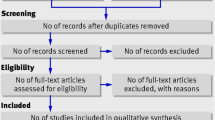
Execution of this systematic study relies on the rectification process, at first stage collection of 97 articles is done based on our best knowledge of the domain. In the next stage, another filter out of scope is worked on the basis of the title and abstract. After this stage, we get 60 articles out of 97 articles bank (excluded 28 articles on the basis of out of scope and 9 excluded on the basis of improper discussion towards problem). After exclusion of articles on such stage then again implement the next rectification process. At such point the articles based on the criteria for inclusion and exclusion that are highlighted in Table 4. In this rectification, we get 42 articles out of 60 articles (exclude 18 articles on the basis of another analysis discussion). Now after such processes again implement the second rectification process but this time consider such articles which are more in-depth discussion towards T wave anomalies, and also concern the quality parameters of literature that are mentioned in Table. The scoring range of 42 articles is displayed in appendix-B. Appendix-B displays the scoring calculator which works based on five reviewers (Rev). The selection of five reviewers on the bias of standard EASE 7 which covers the expertise, and potential computing interests of the reviewer considers the diversity and inclusion of reviewerFootnote 2 After selection. After the Selection of reviewers mark the score based on the literature quality assessment. The range of scoring is 0.5 to 1, in this range 0 represents false assessment, 0.5 shows partially, and 1 indicates accurate response towards quality assessment.The next step in this rectification process is to set the low threshold value that is equal to 3. Such a statement indicates that when your article scores equal to or higher than the threshold point, then the inclusion of the article is possible otherwise skip that particular article. After this rectification process, we fetched 26 articles out of 42 (excluding 16 articles based on the disappointing result in terms of quality assessment). Figure 4 is a pictorial representation of the whole selection process of articles.
Execution of the scoring table at a stage of 42 articles reveals the importance of different reviewer thinking, such a thoughtful process is highlighted in Fig. 1. According to Fig. 1, the maximum range of scoring is 4.5, and the minimum one is 0.

Articles maps with a scoring range
In the scoring calculator, the 5 reviewers investigated each article and delivered the score with their best knowledge. The replica of the above statements is represented in the form of a showcase of reviewers’ trends in Fig. 2. The data mounted below showcase highlights the average, maximum, and minimum scoring rates. According to Fig. 2, the trend of the reviewer’s rating is displayed in such a manner that represents the article's rating in the form of 0. 0.5 and 1. Such a point indicates the selected 42 articles partially satisfied the pre-defined quality assessment, but with the help of this showcase, further rectification investigations are so simple.

Rating ratio of different reviewers
A further observation in terms of review analysis delivers a broad picture of selected articles that are mapped with a research problem. The expansion of the reviewer’s trend in the form of the reviewer’s analysis is represented in Fig. 3. Figure 3 represents the in-depth investigations that indicate the variations in the reviewing process. Such a process indicates the domain knowledge of these reviewers towards the defined problems. The above statements are executed in such a manner that reviewer 1(rev1) marks the article [2] as 1 based on the satisfaction of the quality parameters. The same reviewer (rev1) assesses the quality of the article [55] with parameters of quality assessment; such a reviewing process is applied to all selected articles. Figure 3 highlights the different behaviors of different reviewers towards the selected articles as the process is described in Fig. 4.

Reviewer analysis of selected articles

Selection Process of articles for composition of this systematic study
Discussion
Before highlighting the results from the analysis, the bibliometric data and overview of these studies are initially reported. Table 7 highlights the overview of all selected studies and bibliometric information.
The construction of the above table highlights the research questions addressed in different 26 rectified articles. Representation of the ✓ defines the research question address up to satisfied level. Similarly ✗ represents the unsatisfactory results that are not addressed to any research questions. The above construction represents that selected articles are in a range of years 2008 to 2023.However, taxonomical view some artciles consider from 1990 to 2007. Article [57] is the most cited article in the database of 26 research articles. This article addresses the three research questions except research question 3.. Figure 5 display the percentage level of conference, journal and book chapters [37]

Categorization of selected articles in the form of pie view
Methodological comparison
ECG researchers and cardiologists highly value the classification of various T-wave episodes with minimal ambiguity. In the context of this aim, such study is executed in the form of different operational investigations processes that represented the solutions to the defined problems [38, 39]. With the aim of this solutions, an increasing number of studies have found that relates the parametric importance of different ECG features [40]. According to literature, these parametric factors rely on external or internal variables, which can be referred to as feature dependencies [41, 43, 45]. Various state-of-the-art classification techniques for different T-wave patterns are sourced from the existing literature [58, 59]. In the construction of combo pack of solution for better classification of T wave anomalies, firstly designed or identified the best possible research questions after reviewing the literature [5, 50,51,52,53]. These research questions are analyzed in a systematic way and then report the solutions to these questions in a combo pack solution (better classification and visibility of T wave anomalies). Figure 6is a showcase categorization of research questions [60, 61].

Categorization of research questions address up for result generation
RQ1: Parametric analysis of T wave
Distinguishing typical and non-invasive patterns in T-waves is crucial for identifying the nature of myocardial infarction (MI). For achieving such fruitful results of classification by recognizing the keynotes. An increasing number of studies found during the process of literature review that different features of ECG are dependent upon their own parameters. By the help of these parameters’ the possibility of natural extraction of any feature is increased one. The importance of parametric solutions in the case of T wave is always on the high node. Literature displays the four critical parameters of T wave for the extraction of the nature of T wave during the classification. Identification of T wave parameters T-onset, T-offset, T-peak, and T-duration are helpful in own nature extraction and also fruitful for different analysis and techniques like beat-to-beat analysis, the myocardial infarction detection algorithm, and the T-wave alternans detection algorithm (TWA) are discussed in [11, 12, 22]. In beat-to-beat analysis, results are based on the QT interval, which is determined by the parameters Q-onset (start time) and T-offset (end time). Likewise, the myocardial infarction detection algorithm employs the window detector method to capture the peak value of the T-wave (T-peak). Finally, the TWA detection algorithm operates using the R peak as a fiducial point to calculate the T-onset. This algorithm mainly highlights the intensity of the T wave and also reflects the dependencies factor of features that indicate other research problems. [62,63,64,65] Such a research problem is a part of this SLR in RQ4. Below Fig. 7 is a showcase of four parameters of T wave [66, 67]

Parametric analysis of T wave in ECG
RQ2: T wave anomalies through a T-onset parameter
Identification of abnormalities in any time series in the dataset is highly desirable especially when you work out on any healthcare system [68,69,70]. Sometimes these systems deal with a risky situation like a case of MI in ECG. In connection with previous statements, accurate MI identification is essential for diagnostic purposes, as it addresses high-risk factors. In the diagnosis of MI, the primary focus is on recognizing sudden, non-invasive changes in the T-wave; this is a crucial initial step is to highlight the abnormal T-wave episodes [71, 72]. Better classification T wave anomalies depends on a parametric solution but primarily relied on T-onset parameters. An increased number of studies were found during the investigation of dependencies calculation of the T-onset parameter. T wave alterations detection (TWA) algorithm is one of them that is picked from the literature. This algorithm primarily functions to emphasize the energy intensity of the T-wave [73]. The TWA algorithm operates based on the R peak as a fiducial point and takes into account the RR intervals [22, 74]. A key component of the TWA algorithm is the RR interval, which is represented in the equation below. The presentation of this equation reflects the energy intensity of the T-wave, whether in a standard form or as anomalies, depending on the T-onset parameter of the T-wave [22].
4.3 RQ3: Classification through Neural Models. Detection of the irregularity in the sequences of data reveals the difference like the data. The classification process is commonly employed to identify irregular or unconventional patterns (novelty detection) in ECG data. This process differentiates between regular and irregular patterns. Traditionally, various ionic classification techniques are utilized to distinguish irregular responses, except for the predictive element. In cases of rapid and accurate classification commonly used methodologies are a neural network (NN) or artificial neural network (ANN) [75,76,77,78]. Figure 6 refers to the basic structure of NN with the inclusion of input, hidden, and output layers for classification.
Conducting operational investigations in any neural network methodology [79,80,81] involves a structured approach. The primary objective is to train the neural network by adjusting the weights of each unit to minimize the error between the desired output and the actual output. Error derivation of the outputs is a critical phase that shows changes in error as the weights are adjusted slightly, either increased or decreased [58]. The Back Propagation (BP) algorithm is commonly employed to assess and minimize error. The primary focus of this study is to classify anomalies in the T-wave of ECG signals using a feed-forward multi-layer neural network in conjunction with the backpropagation algorithm. In an ideal scenario, the neural network's target values closely approximate the expected output values. The Levenberg–Marquardt algorithm has been found to yield the best results in this context. The primary achievement of this algorithm is the accurate discrimination between two types of heartbeats, namely regular heartbeats and premature ventricular contractions (PVC). [32, 59].
Another success story of the artificial neural network (ANN) as in Fig. 8 is to detect the most significant part of the ECG waveform (QRS complex detection). In the scenario of accurate detection of the QRS complex, after the R peak detection by the formation of the feature vectors under usage the amplitude of the significant frequency components of the DFT frequency spectrum [58]. By using the knowledge from the literature, categorized the classification of different features of ECG through two different scenarios. One is a supervised scenario in which training samples are labeled as a standard or anomalous (abnormal) [82, 83]. The second one is unsupervised scenarios; this scenario works in such a manner that training samples are inducted in the neural network without any label [53, 54].

The basic structure of the neural network, in input, hidden, and output layers are essential builder part
RQ4: Dependencies impact of the T wave
An anomalous pattern classifier is a valuable tool for cardiac specialists, particularly in high-risk situations such as the sudden onset of myocardial infarction (MI). The initial step in identifying these patterns, especially in the case of MI, is to pinpoint the underlying cause by analyzing T-wave changes [84, 85]. Understanding the root cause becomes feasible by highlighting the dependencies of the T-wave. Calculating these dependencies requires having access to all the parameters of the T-wave, including T-offset, T-wave duration, T-wave amplitude, and T-onset values, which are essential for accurately tagging T-wave anomalies All these parameters have equal importance that already discussed in the above address up part of RQ1, but T onset parameter has a unique concentration in case of extraction the nature of the anomalies. In the literature review session, Numerous studies have contributed to ECG feature analysis, and this analysis is often conducted using the advanced methodology known as Wavelet Transform Module Maxima (WTMM). The T-wave detection algorithm employs WTMM to identify T-waves, relying on various T-wave parameters, including a combination of T-wave amplitude and slope. In addition to this, another state-of-the-art approach, the Trapezium method, is utilized for T-wave detection, primarily through the T-peak amplitude parameter. These two state-of-the-art methods also indirectly aid in uncovering dependencies. In connection with such a statement, the same case is applied to different ECG features by using the above concept of dependencies. Highlighting the dependencies factors are quite hard without finding the exact nature of any ECG feature [86,87,88]. Similarly, in the specific case of two T-wave anomalies, T-wave inversion, and flattened T-waves, they are often grouped together, yet their behaviors in the context of MI differ significantly. To emphasize the distinctions between inverted and flattened T wave, we need some sort of novelty in our solution [89, 90]. For the achievement of this aim, we need particular checkpoints that are worked on the basis of the parametric solution, like behaviors identifier that worked in the Ontology behavior model (OntoB). The ontology behavior model is a composition of several factors which are briefly discussed in below Fig. 13 and the flow of these factors is highlighted [15, 30, 52].
Behavior descriptor: Behavior descriptor represents the core behavior properties or elements. Behavior Aggregation: Combination of behaviors hierarchical and hybrid These components are integrated to produce Semitics of TS through both intra-coupling and inter-coupling relationships within a set of behaviors [56]. The Behavior Constraint Indicator module formalizes natural language descriptions of behaviors into logical formulas. The Behavior Checker module serves as a checkpoint to verify the accuracy of the behavior constraints and properties claimed by the Behavior Constraint Indicator [51]. The Behavior Model Refiner module is used to make further refinements to the behavior model, addressing any identified issues. Finally, the Behavior Model Exporter exports a stable and desired behavior model as a result of the modeling process [91, 92]. Figure 9 higlighted the ontology behavior model.

Ontology Behavior model: Identification of intercouple and intracouple relationship in behaviors and behavior refiner
Efficient formation of the classifier is highly desirable for tagging the anomalies in ECG signals due to life care issues. We cannot afford any minor ambiguity in the monitoring process of the heart. ECG signals would be real-time patient’s heart data and risky if we missed any activity at any particular time that may cause the death of the patient. For the last decade, cardiologists and medical professionals are still searching for a way to highlight the intensity of myocardial infarction. This intensity is measured with the help of dependencies factors. In one scenario these dependent factors are measured with the help of changes in the T wave or anomalies of T wave [48]. For reduction of risky situations by integration the novel approach for determining the dependencies which are helpful for broad classification of different T wave episodes. Analysis of ECG is primarily dependent upon the classification result which represents the regularity and irregularity in ECG signals [29].
Considering the focus of this article, our primary concern is to find a way how it is possible to get robust and accurate results of diverse T wave classification. In the literature survey process, a lot of research found that worked in the form of, different methodologies and techniques for T wave classification. But efficient and accurate results have always attracted the researchers. In-depth analysis of literature, survey process creates a path for solution-oriented results. This idea works on the basis of three different perspectives, such are T wave parametric analysis, the combination of feature analysis of ECG and the behavior analytics techniques in the light of coupling concept of behavior analytics quire clears the concept of dependencies of T wave, finally add up the backpropagation and multi feed-forward algorithms of neural network in different models of neural network. Figure 14 is the pictorial representation of our proposed idea towards the robust and accurate classification of different T wave episodes. Figure 10 represnts the parametric classfication of different T-Wave anomalies.

Classification of T wave anomalies analysis
The most important part of this proposed study is our critical analysis that we get the knowledge after the literature survey session. According to our knowledge so far, we are the first ones who discussed the dependencies factor for the robotic classification of T wave anomalies. Such discussion will not be limited to robotic classification of T wave anomalies, but also creates a new room for researchers to crucially think about the different features of ECG in the light of dependencies factor. The inclusion of dependencies factor in feature analysis of ECG makes sense for depth analysis of different CVDs like myocardial infarction (MI), atrial fibrillation (AF), and premature ventricular contraction (PVC). Detection of these CVDs depends upon the different features of ECG [93, 94].
Taxonomical View:Three-Way Handshake
A joint venture of backpropagation approach of neural network (NN), parametric analysis of T wave, and novelty of behavior analytics plays an important role in the rapid and exact classification of T wave anomalies based on nature. Results of the above combination are already achieved as work on singleton, but our approach towards classification is robust and accurate. The methods of DWT for T wave detection, T wave detection algorithm, TRA approach, and wavelet analysis all are worked under the coverage of parametric analysis of T wave classification. Figure 11 indicates the addressing literature in a pictorial model [3, 49, 50].

Parametric Classification for T wave
The novelty of behavior analytics in this combination is playing the critical role for highlighting the dependences of T wave on the other features of ECG. In latest TWA algorithm, the same concept of features dependencies is reflected in the form of highlighting the T wave changes with the integration of R peak. The dependencies concept is further explained in behavior analytics in the reflection of the intercouple concept of behavioral theory. Below Fig. 12 highlights the concepts of behavior analytics with studied articles [50, 52].

Dependencies perspective of the T wave
In the perspective of a neural network using the combination of feedforward and backpropagation algorithms with the conventional techniques of neural network (pattern recognition and time clustering). Classification of T wave through neural models for the identification of dependencies is clearly highlighted. These dependencies are identified by some checkpoint; Fig. 13 capture the whole scenario [53, 54, 59].

Classification of T wave with NN
A complete package of three-way handshake process is highlighted in Fig. 14. The result of this combination is worked in such manner that the usage of different neural models in the first perspective is for validation and testing of our different results which we get from other two perspectives. In second dependences perspective, the OnToB model is worked on the basis of the output of neural models in a queued manner (first come first serve). This OnToB checks the indication of T wave in the light of coupling concepts of behavior analytics (intercouple and intracouple) that reflects the identification of dependencies factor [95]. This dependencies factor works as an input of the parametric perspective of T wave for the classification of the regular and anomalous T wave [96, 97]. One output of each regular and anomalous T wave is rebooted into the OnToB model and the second output of each regular and anomalous T wave are also rebooted in the combination of algorithms for further subclassification.

Three-way handshake structure for robust classification of different T wave episodes
Future research directions
In an ideal case highlighting the CVDs at early time delivers the in time treatment to patients. In Process of extraction of different features in ECG, at first, stage implemented the different noise filtration methods by setting the threshold value. From literature, we got different methodologies for feature extraction with different techniques. But after reviewing the articles, one issue is prevalent in every technique such issue is noise filtration. Reason for such issue is due to lack standard or state-of-the-art work on the threshold value. In case of T wave applied noise filtration, we need some sort of standard baseline value or threshold value (need a peak point and time duration of T wave) like the representation of Table 7 and reading parameters of ECG from Table 8.
Some essential research directions are highlighted in Fig. 15 after analyzing the selected studies.
-
1)
Analysis of dependencies factor of different CVDs, such analysis helps to provide the predictive information
-
2)
Calculation of dependencies factor through dimensional reduction techniques PCA, SAX on ECG signal
-
3)
Feature engineering embeds on ECG and works with the presence of noise in signal

Future direction for ECG analysis in terms of different anomalies analysis
Dependency analysis of different CVDs
Identification, the dependencies of each feature, is an ideal case for diagnostic purposes refering to Fig. 15. Such scenario will be implemented through the parameters of each feature as the above parametric discussion of T wave. Every CVDs depends on different features, and such features have some critical parameters. Highlight the dependencies between these parameters; such process will be performed by conducting the parametric analysis along with the coupling concepts of behavior analytics.
Calculation of dependencies through dimension reduction
Complexities reduction is the best way to proceed the data analysis in smooth and accurate manner. With concern of this ECG analysis, the dimensional reduction is highly demandable due to such reduction calculation of dependencies between different features will be simpler one. Such statement operates in ECG analysis by using the primary tacts of dimensional reduction. Most important part of the ECG is considered QRS complex. Reduction or segmentation of such part will be valuable for better analysis of R peak detection. PAC and SAX techniques will be used for segmentation of QRS complex and also cross-check the results of each technique. With the help of such segmentation, premature ventricular contraction (PVC) detection will be a more accurate job than previous work.
Feature engineering in ECG
Implementation of feature engineering reduces the noise involvement in ECG signal. In simple words, we will perform better ECG analysis with the presence of noise by embedding the feature engineering. In this engineering components of the system will be an enhancement and scalable for in-depth investigations.
Conclusion
Rapid and accurate classification of different T wave episodes is highly desirable in terms of identification of T wave anomalies. T wave anomalies is a crucial concern for the ECG researchers in the sense of analyzing the MI. This systematic study highlights the critical question which relates the behavior of T wave anomalies and dependencies between them. The purpose of this article is to find the solution of queries. Proceed this aim by a collection of 97 articles from four prime databases. In next phase set the rectification process for Pursuing a resolution for the specified issue by applying the filtration on 97 articles. Such filtration criteria set Based on the criteria for inclusion and exclusion, literature quality assessment and data extraction strategy. After these stages finally get the 26 refined articles that are the part of this systematic study. These articles included the parametric analysis of T wave, features analysis of ECG for understanding the dependencies of T wave parameters along with articles of behavior analytics for understanding the dependencies factors.
Few gaps are highlighted after the literature survey process, these gaps are related to the requirement of further qualitative improvement of noise filtration technique and feature detector window method. In the end portion of this study, we have used our best knowledge and skills by critically brainstorming activities. Such activities are worked under the coverage of selected articles for the best possible solution for rapid classification of T wave episodes. Our research is based on the joint version of three-way perspective. The proposed method is a three-way handshake that works by inclusion the neural models with their prime algorithms, and after then OnToB behavior model works under the light of coupling concepts of behavior analytics along with parameters of T wave. Such approach is a novelty theme-based solution and a perfect one for the rapid classification of the different T wave episodes.
Availability of data and materials
The extracted process of articles is mainly relying on four primary databases, and these are all available publicly.
References
Tafreshi R, Touma AA, Khan M. Detection of Cardiovascular Abnormalities through 5-lead System Algorithm. IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI). 2016. https://doi.org/10.1109/BHI.2016.7455884.
Hari MR, Anurag T, Shailja S. ECG signal processing for abnormalities detection using multi-resolution wavelet transform and Artificial Neural Network classifier. Measurement. 2013;46(9). https://doi.org/10.1016/j.measurement.2013.05.021.
Lobodzinski SS. ECG patch monitors for assessment of cardiac rhythm abnormalities. Progress in cardiovascular diseases. 2013;56(2):224–9. https://doi.org/10.1016/j.pcad.2013.08.006.
Chen C, Bian K, Huang A, Duan X, Gao H, Jiao B, Xie L, Wang S. WE-CARE: A Wearable Efficient Tele cardiology System Using Mobile 7-lead ECG Devices. IEEE International Conference on Communications (ICC). 2013. https://doi.org/10.1109/ICC.2013.6655252.
Zheng Q, Chen C, Li Z, Huang A, Jiao B, Duan X, Xie L. A Novel Multi-Resolution SVM (MR-SVM) Algorithm to Detect ECG Signal Anomaly in WE-CARE Project. IEEE Biosignals and Biorobotics Conference (BRC). 2015. https://doi.org/10.1109/BRC.2013.6487453.
Behbahani S, Dabanloo NJ. Detection of QRS complexes in the ECG signal using multiresolution wavelet and thresholding method. IEEE Computing in Cardiology. 2011. pp. 805–808.
Bulusu SC, Faezipour M, Ng V, Nourani M, Tamil LS, Banerjee S. Transient ST-segment episode detection for ECG beat classification. 2011 IEEE/NIH Life Science Systems and Applications Workshop (LiSSA) 2011. p. 121-124.
Kumar V, Laskar MA, Singh YS, Majumdar S, Sarkar SK. ANN Based Adaptive Detection of ECG Features from Respiratory, Pleythsmographic and ABP Signals. In: Proceedings of the 3rd International Conference on Frontiers of Intelligent Computing: Theory and Applications (FICTA). 2014. p. 359–365.
Sankari Z, Adeli H. Heartsaver: A mobile cardiac monitoring system for auto-detection of atrial fibrillation, myocardial infarction, and atrioventricular block. Comput Biol Med. 2011;41(4):211–20.
Hadjem M, Naït-Abdesselam F. An ECG T-wave anomalies Detection Using a Lightweight Classification Model for Wireless Body Sensors. Workshop on ICT-enabled services and technologies for eHealth and Ambient Assisted Living. IEEE ICC. 2015.
Sivaraks H, Ratanamahatana CA. Robust and Accurate Anomaly Detection in ECG Artifacts Using Time Series Motif Discovery. Computat Math Method Med. 2015;453214:20. https://doi.org/10.1155/2015/453214.
Blanco-Velasco M, Goya-Esteban R, Cruz-Roldán F, García-Alberola A, Rojo-Álvarez JL. Benchmarking of a T-wave alternans detection method based on empirical mode decomposition. Comput Method Prog Biomed. 2017;145:147–55.
Pala S, Mitrab M. Empirical mode decomposition based ECG enhancement and QRS detection. Comput Biol Med. 2012;42(1):83–92. https://doi.org/10.1016/j.compbiomed.2011.10.012.
Longbing Cao,University of Technology Sydney, Philip S. Yu, the University of Illinois at Chicago, Vipin Kumar, University of Minnesota. Non-occurring Behavior Analytics: A New Area. published in IEEE Intelligent Systems. 2015.
Cao L. Combined Mining: Analyzing Object and Pattern Relations for Discovering and Constructing Complex Yet Actionable Patterns. Wiley Interdisciplinary Rev: Data Mining and Knowledge Discovery. 2013;3(2):140–55.
Maria Riveiro, G¨oran Falkman. Interactive Visualization of Normal Behavioral Models and Expert Rules for Maritime Anomaly Detection. Sixth International Conference on Computer Graphics, Imaging, and Visualization. 2009.
Longbing Cao, University of Technology Sydney. Behavior Informatics and Analytics: Let Behavior Talk. IEEE International Conference on Data Mining Workshops. 2008.
Anuja Kelkar, Utkarsh Naiknaware, Sachin Sukhlecha, Ashish Sanadhya, Maitreya Natu, Vaishali Sadaphal. Analytics-Based Solutions for Improving Alert Management Service for Enterprise Systems. IEEE 13th International Conference on Data Mining Workshops. 2013.
Junn Min Pang, Vooi Voon Yap, Chit Siang Soh. Human Behavioral Analytics System for Video Surveillance. IEEE International Conference on Control System, Computing and Engineering, Penang Malaysia. 2014.
Christian Bauckhage, Anders Drachen, Member and Rafet Sifa. Clustering Game Behavior Data. IEEE Transactions on computational Intelligence and in games. 2015;7(3).
Stephen Haben, Colin Singleton, and Peter Grindrod. Analysis and Clustering of Residential Customers Energy Behavioral Demand Using Smart Meter Data. IEEE Transactions on smart grid. 2016;7(1).
XiangKui W, Kanghui Y, Dehan L, Yanjun Z. A combined algorithm for T-wave alternans qualitative detection and quantitative Measurement. J Cardiothora Surg. 2013. https://doi.org/10.1186/1749-8090-8-7.
Angelov P, Filev D, Kasabov N. Evolving Intelligent Systems – Methodology and Applications. New York: John Wiley & Sons; 2010.
Longbing Cao. In-depth behavior understanding and use: The behavior informatics approach. Information Sciences. 2010.
Diptangshu Pandit, Li Zhang, Nauman Aslam, Changyu Liu, Samiran Chattopadhyay. Improved Abnormality Detection from Raw ECG Signals using Feature Enhancement, 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD). 2016.
Yanting Shen, Yang Yang, Sarah Parish, Zhengming Chen, Robert Clarke, David A. Clifton. Risk prediction for cardiovascular disease using ECG data in the China kadoorie biobank” IEEE 38th Annual International Conference of the Engineering in Medicine and Biology Society (EMBC). 2016. https://doi.org/10.1109/EMBC.2016.7591218.
Tanveer A Bhuiyanl, Claus Graffl, J0rgen K Kanters, Jimmi Nielsen, Johannes J Struijk. Repolarization Effects of Sertindole Manifest as T -wave Flatness on the ECG. Comput Cardiol. 2014.
I Tasnova Tanzil Khan, Nadia Sultana, Rezwana Binte Reza and Raqibul Mostafa “ECG Feature Extraction in Temporal Domain and Detection of Various Heart Conditions” 2nd Int'l Conf. on Electrical Engineering and Information & Communication Technology (ICEEICT) 2015 Jahangirnagar University, Dhaka-I 342, Bangladesh, 21–23 May.
Kumar SU, Inbarani HH. Neighborhood rough set based ECG signal classification for diagnosis of cardiac diseases. Soft Comput. 2016.
Can Wang, Longbing Cao. Formalization, and Verification of Group Behavior Interactions. Ieee Transactions on Systems, Man, and Cybernetics: Systems, 2015;45(8).
Longbing C. Non-IIDness Learning in Behavioral and Social Data. Comput J. 2013. https://doi.org/10.1093/comjnl/bxt084.
Pranav R, Awni YH, Masoumeh H, Codie B, Andrew YNg. Cardiologist-Level Arrhythmia Detection with Convolutional Neural Networks. arXiv.org Computer Vision and Pattern Recognition. 2017.
Fahim Sufi and Ibrahim Khalil. Diagnosis of Cardiovascular Abnormalities From Compressed ECG: A Data Mining-Based Approach. IEEE Transactions on information technology in biomedicine. 2011;15(1).
Goutam Kumar sahoo , Samit Ari, Sarat Kumar Patra “ECG signal analysis for detection of Cardiovascular abnormalities and Ischemic episodes” IEEE Conference on information and communication technologies (ICT 2013).
Y.Dileep Kumar, Dr. A.M Prasad. ECG Abnormalities Detection using Doppler Shift Method” Fourth International Conference on Advanced Computing & Communication Technologies. 2014.
L.Salome Joysly, R.Tamilselvi. Abnormality Recognition during Drowsy State from ECG and EEG. 2nd International Conference on Innovations in Information Embedded and Communication Systems. ICIIECS’15. 2015.
Lei Chen and Iain Bate. Identifying Usage anomalies For ECG-based Sensor Nodes. IEEE 13th International Conference on Wearable and Implantable Body Sensor Networks (BSN). 2016. https://doi.org/10.1109/BSN.2016.7516236.
Adam Szczepański and Khalid Saeed. “Real-Time ECG Signal Feature Extraction for the Proposition of Abnormal Beat Detection – Periodical Signal Extraction” International Conference on Biometrics and Kansei Engineering. 2013.
DuyHoa Ngo, Bharadwaj Veeravalli. “Design of a Real-time Morphology-based Anomaly Detection Method from ECG Streams” IEEE International Conference on Bioinformatics and Biomedicine (BTBM). 2015.
Shubhajit Roy Chowdhury. Field Programmable Gate Array Based Fuzzy Neural Signal Processing System for Differential Diagnosis of QRS Complex Tachycardia and Tachyarrhythmia in Noisy ECG Signals. J Med Syst. 2012. https://doi.org/10.1007/s10916-010-9543-7.
Chowdhury SR. High-resolution detection of sustained ventricular and supraventricular tachycardia through FPGA-based fuzzy processing of ECG signal. Medical & Biological Engineering & Computing. 2015;53(10):1037–47.
Dengao LWM, Jumin Z. A Novel J wave Detection Method Based on Massive ECG Data and MapReduce. Chapter: Big Data Computing and Communications Volume 9784 of the series. Lecture Notes in Computer Science. 2016. p. 399–408.
Alireza M, Niloofar S, Hossein R, Mohaddeseh B. Posterior ECG: Producing a New Electrocardiogram Signal from Vectorcardiogram Using Partial Linear Transformation. IEEE 12th International Conference on Bioinformatics & Bioengineering (BIBE), Larnaca, Cyprus. 2012. p. 11–13.
Zimarino M, Montebello E, Radico F. ST segment/heart rate hysteresis improves the diagnostic accuracy of ECG stress test for coronary artery disease in patients with left ventricular hypertrophy. European Journal of preventive cardiology. 2016;23(15):1632–9.
Kanakapriya K, Mandali A, Manivannan M. ECG simulation for Myocardial Infarction diagnosis in high fidelity mannequins. Annual IEEE India Conference (INDICON). 2011.
Kanakapriya K, Mandali A, Manivannan M. Statistical approach for lightweight detection of anomalies in ECG. IEEE 38th Annual International Conference of the Engineering of Medicine and Biology Society (EMBC). 2016. https://doi.org/10.1109/EMBC.2016.7590674.
Harmon KG, Zigman M, Drezner JA. The effectiveness of screening history, physical exam, and ECG to detect potentially lethal cardiac disorders in athletes: A systematic review/meta-analysis. Journal of Electro cardiology. 2015;48(3):329–38. https://doi.org/10.1016/j.jelectrocard.2015.02.001.
Mateo J, Sánchez-Morla EM, Santos JL. A new method for removal of power line interference in ECG and EEG recordings. Comput Electric Engr. 2015;45:235–248. https://doi.org/10.1016/j.compeleceng.2014.12.006.
Medina Hadjem, Farid Naït-Abdesselam1, Ashfaq Khokhar“ ST-segment and T-wave anamolies Prediction in an ECG Data Using RUSBoost” IEEE 18th International Conference on e-Health Networking, Applications and Services (Healthcom), 2016. https://doi.org/10.1109/HealthCom.2016.7749493
Michael Bloem, Nicholas Bambos “Ground Delay Program Analytics with Behavioral Cloning and Inverse Reinforcement Learning” Journal of aerospace information systems. 2015;12(3).
Zhigang Zheng, Yanchang Zhao, Ziye Zuo, and Longbing Cao “An Efficient GA-Based Algorithm for Mining Negative Sequential Patterns” Advances in Knowledge Discovery and Data Mining Volume 6118 of the series Lecture Notes in Computer Science pp 262–273, 2010.
Longbing Cao, Xiangjun Dong, Zhigang Zheng “e-NSP: Efficient Negative Sequential Pattern Mining” Artificial Intelligence, 2016.
Sahar H. El-Khafif, Mohamed A. El-Brawny. Artificial Neural Network-Based Automated ECG Signal Classifier. Biomedical Engineering, 2013.
Kan L, Jianqing L, Zhigang W, Alfred C. Patient-specific deep architectural model for ECG classification. J Healthc Engr. 2017.
Price DE, McWilliams A, Irfan M, Price DE, McWilliams A, Asif IM, Martin A, Elliott SD, Dulin M, Drezner JA. Electrocardiography-inclusive screening strategies for detection of cardiovascular abnormalities in high school athletes. Heart Rhythm. 2014;11(3):442–9. https://doi.org/10.1016/j.hrthm.2013.12.002.
Shakibfar S, Graff C, Kanters JK, Nielsen J, Schmidt S, Struijk JJ. Minimal T‐wave representation and its use in the assessment of drug arrhythmogenicity. Ann Noninvasive Electrocardiol. 2016.
Saritha C, Sukanya V, Narasimha Murthy Y. ECG Signal Analysis Using Wavelet Transforms. Bulgarian J Phys. 2008.
Morteza Zabihi, Ali Bahrami Rad, Serkan Kiranyaz, Moncef Gabbouj, Aggelos K Katsaggelos “ Heart Sound Anomaly and Quality Detection using Ensemble of Neural Networks without Segmentation” Computing in Cardiology Conference (CinC), 2016.
Ali Bahrami Rad, Trygve Eftestøl, Kjersti Engan, Unai Irusta, Jan Terje Kvaløy, Jo Kramer-Johansen, Lars Wik, Aggelos K. Katsaggelos. ECG-Based Classification of Resuscitation Cardiac Rhythms for Retrospective Data Analysis. IEEE transactions on biomedical engineering. 2017.
Emir Z, Almir D, Dusanka B. Web-based and mobile system for training and improving in the field of electrocardiogram (ECG). 5th Mediterranean Conference on Embedded Computing (MECO). 2016. https://doi.org/10.1109/MECO.2016.7525688.
Lei C, Iain B. Identifying usage anomalies for ECG-based sensor nodes. IEEE 13th International Conference on Wearable and Implantable Body Sensor Networks (BSN). 2016. https://doi.org/10.1109/BSN.2016.7516236.
Hrusca A, Rachisan AL, Gach P, Pico H, Sorensen C, Bonello B, Ovaert C, Petit P, Fouilloux V, Mace L, Gorincour G. Detection of pulmonary and coronary artery anomalies in tetralogy of Fallot using non-ECG-gated CT angiography. Diagn Interv Imaging. 2016;97(5):543–8.
Zheng D, Li F, Zhao T. Self-adaptive statistical process control for anomaly detection in time series. Expert Systems With Applications. 2016;57:324–36.
Chandra BS, Sastry CS, Jana S. Reliable resource-constrained telecardiology via compressive detection of anomalous ECG signals. Computers in Biology and Medicine. 2015;66:144–53.
Bollepalli SC, Challa SS, Soumya J. A comparative study of supervised learning techniques for ECG T-wave anomalies detection in a WBS context. International Conference on Protocol Engineering (ICPE) and International Conference on New Technologies of Distributed Systems (NTDS). 2015. https://doi.org/10.1109/NOTERE.2015.7293505.
Amruta Mhatre, Sadhana Pai “Temporal Analysis and Remote Monitoring of ECG Signal” International Conference on Nascent Technologies in the Engineering Field (ICNTE). 2015.
Vishwanath RH1, Vaishnavi R, Srikantaiah K C, and Venugopal KR. IATSJ: Identification of anomalies in time series data using similarity join processing” International Conference on Computer and Communication Technology (ICCCT). 2014. https://doi.org/10.1109/ICCCT.2014.7001461.
Lei Chen, Iain Bate “ Identifying usage anomalies for ECG-based sensor nodes” IEEE 13th International Conference on Wearable and Implantable Body Sensor Networks (BSN), 2016. https://doi.org/10.1109/BSN.2016.7516236
Carr MJ, O’Shea, JT, Hinfey PB. Identification of the stemi-equivalent de winterelectrocardiogram pattern after ventricular fibrillation cardiac arrest: a case report. The Journal of Emergency Medicine. 2016;50(6):875–80.
Hesham R. Omar, Devanand Mangar, Enrico M. Camporesi. A woman with recurrent chest pain and ST-segment elevation. Eur J Inter Med. 2016.
Brandão RM, Samesima N, Pastore CA, Staniak HL, Lotufo PA, Bensenor IM, Alessandra C. Goulart, Itamar S. Santos. ST-segment abnormalities are associated with long-term prognosis in non-ST-segment elevation acute coronary syndromes: The ERICO-ECG study. J Electrocardiol. 2016.
Koga M, Kawamura Y, Ito D , Iseki H, Yuji Ikari3. A case of ST segment-elevated myocardial infarction with less common forms of single coronary artery. Cardiovasc Interv Ther. 2016. https://doi.org/10.1007/s12928-015-0357-x.
Dorothée C. van Trier, Ilse Feenstra, Petra Bot, Nicole de Leeuw , Jos M.Th. Draaisma” Cardiac anomalies in individuals with the 18q deletion syndrome; report of a child with Ebstein anomaly and review of the literature” European Journal of Medical Genetics, 2013.
Bollepalli S. Chandra, Challa S. Sastry, Soumya Jana “Telecardiology: Hurst Exponent based Anomaly Detection in Compressively Sampled ECG Signals” IEEE 15th International Conference on e-Health Networking, Applications, and Services (Healthcom ), 2013.
Rupendra Nath Mitra; Sayak Pramanik; Sucharita Mitra; Bidyut B Chaudhuri “Pattern classification of time plane features of ECG wave from cell-phone photography for machine-aided cardiac disease diagnosis” 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 2014 https://doi.org/10.1109/EMBC.2014.6944699.
Ralph Laite , Nataliya Portman, Karthik Sankaranarayanan “Behavioral analysis of agent-based service channel design using neural networks” Winter Simulation Conference (WSC), 2016 https://doi.org/10.1109/WSC.2016.7822404.
Frank Jiang, Jin Gan, Yuanyuan Xu, Guandong Xu “Coupled Behavioral Analysis for User Preference-based Email Spamming” International Conference on Behavioral, Economic and Socio-cultural Computing (BESC), 2016. https://doi.org/10.1109/BESC.2016.7804482
Mehran Goli, Jannis Stoppe, Rolf Drechsle “AIBA: an Automated Intra-Cycle Behavioral Analysis for System C-based Design Exploration” IEEE 34th International Conference on Computer Design (ICCD), 2016. https://doi.org/10.1109/ICCD.2016.7753303.
Medha Sagar, Arushi Gupta, Rishabh Kaushal “Performance Prediction and Behavioral Analysis of Student Programming Ability” International Conference on Advances in Computing, Communications, and Informatics (ICACCI), 2016 https://doi.org/10.1109/ICACCI.2016.7732181 .
Jiangpeng Dai, Bo Chai, Hongbin Qiu, Bo Zhang , Wei Jiang “Probabilistic Graphical Model-Based Residential Energy Behavioral Analysis on Hybrid Computing Platform” China International Conference on Electricity Distribution (CICED), Xi’an, 10–13 Aug 2016 https://doi.org/10.1109/CICED.2016.7576328.
K.Narasimma Mallikarjunan, S.Prabavathy, K.Sundarakantham, S.Mercy Shalinie “Model for Cyber Attacker Behavioral Analysis” IEEE Workshop on Computational Intelligence: Theories, Applications and Future Directions (WCI), 2015 https://doi.org/10.1109/WCI.2015.7495520.
Seppe K. L. M. vanden Broucke, Jochen De Weerdt, Jan Vanthienen, and Bart Baesens “Determining Process Model Precision and Generalization with Weighted Artificial Negative Events” IEEE transactions on knowledge and data engineering. 2014;26(8).
Kiran L. N. Eranki, Kannan M. Moudgalya “Evaluation of Web-Based Behavioral Interventions using Spoken Tutorials” IEEE Fourth International Conference on Technology for Education, 2012.
Agatonovic-Kustrin S, Beresford R. Basic concepts of the artificial neural network (ANN) modeling and its application in pharmaceutical research. J Pharm Biomed Anal. 2000;22(5):717–27. https://doi.org/10.1016/S0731-7085(99)00272-1.
Tomasz Arod, Marcin Kurdziel, Erik O.D. Sevreb, David A. Yuenb “ Pattern recognition techniques for automatic detection of suspicious-looking anomalies in mammograms “Computer Methods and Programs in Biomedicine. Volume 79, Issue 2, Pages 135–149, 2005 https://doi.org/10.1016/j.cmpb.2005.03.009
Christian Bauckhage, Anders Drachen, “The Age of Analytics” IEEE transactions on computational intelligence and ai in games. 2015;7(3).
Shu Ming Wang “Module-Based Learning Analytics System for Facebook Supported Collaborative Creativity Learning” IEEE 14th International Conference on Advanced Learning Technologies, 2014.
Yanchang Zhao, Huaifeng Zhang, Longbing Cao, Chengqi Zhang, and Hans Bohlscheid “Mining Both Positive and Negative Impact-Oriented Sequential Rules from Transactional Data” Machine Learning and Knowledge Discovery in Databases, 2009
Fooa SY, Stuartb G, Harveya B. Anke Meyer-Baese Neural network-based EKG pattern recognition. Eng Appl Artif Intell. 2002;15(3–4):253–60. https://doi.org/10.1016/S0952-1976(02)00041-6.
S.S. Mehta, N.S. Lingayat “ SVM-based algorithm for recognition of QRS complexes in electrocardiogram” IRBM, 2008.
Tang, Jingtian, Qing Zou, Yan Tang, Bin Liu, and Xiao-kai Zhang. "Hilbert-Huang transform for ECG de-noising." In 2007 1st international conference on bioinformatics and biomedical engineering, pp. 664–667. IEEE, 2007.
Giurcăneanu CD, Tăbuş I, Mereuţă Ş. Using contexts and R-R interval estimation in lossless ECG compression. Comput Methods Programs Biomed. 2002;67(3):177–86.
CH Salvador, MP Carrasco, MA Gonzalez De Mingo, A Muñoz Carrero, J Marquez Montes, L Sosa Martin, MA. Cavero, I Fernández Lozano, JL Monteagudo. Airmed-cardio: a GSM and Internet services-based system for out-of-hospital follow-up of cardiac patients. IEEE Trans inf technol Biomed. 2005;9(1): 73–85.
Anna Magdalena Kosek “Contextual anomaly detection for cyber-physical security in Smart Grids based on an artificial neural network model” Joint Workshop on Cyber-Physical Security and Resilience in Smart Grids (CPSR-SG), 2016 https://doi.org/10.1109/CPSRSG.2016.7684103
Oshin Misra, Ajit Singh “An Approach to Face Detection and Alignment Using Hough Transformation with Convolution Neural Network” 2nd International Conference on Advances in Computing, Communication, & Automation (ICACCA) (Fall), 2016 https://doi.org/10.1109/ICACCAF.2016.7748996
Arzeno NM, Deng Z-D, Poon C-S. Analysis of first-derivative based QRS detection algorithms. IEEE Trans Biomed Eng. 2008;55(2):478–84.
Park H-J, Jeong D-U, Park K-S. Automated detection and elimination of periodic ECG artifacts in EEG using the energy interval histogram method. IEEE Trans Biomed Eng. 2002;49(12):1526–33.
Acknowledgements
This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-RP23034)
Funding
This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU−RP23034).
Author information
Authors and Affiliations
Contributions
Uzair Iqbal and M. Usman works on the design of protocols of this research work. Riyad Almakki and Abdullah Altameem work on the collection of clinical studies and funded this work. Mubarak Albathan and Abdul Khader Jilani validate the conducted research work.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Research ethical committee of FAST institute approved for conduction of this research.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Iqbal, U., Almakki, R., Usman, M. et al. Methodological identification of anomalies episodes in ECG streams: a systematic mapping study. BMC Med Res Methodol 24, 127 (2024). https://doi.org/10.1186/s12874-024-02251-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-024-02251-0