
Abstract
Objective
The identification of methodology for modelling cardiovascular disease (CVD) risk using longitudinal data and risk factor trajectories.
Methods
We screened MEDLINE-Ovid from inception until 3 June 2020. MeSH and text search terms covered three areas: data type, modelling type and disease area including search terms such as “longitudinal”, “trajector*” and “cardiovasc*” respectively. Studies were filtered to meet the following inclusion criteria: longitudinal individual patient data in adult patients with ≥3 time-points and a CVD or mortality outcome. Studies were screened and analyzed by one author. Any queries were discussed with the other authors. Comparisons were made between the methods identified looking at assumptions, flexibility and software availability.
Results
From the initial 2601 studies returned by the searches 80 studies were included. Four statistical approaches were identified for modelling the longitudinal data: 3 (4%) studies compared time points with simple statistical tests, 40 (50%) used single-stage approaches, such as including single time points or summary measures in survival models, 29 (36%) used two-stage approaches including an estimated longitudinal parameter in survival models, and 8 (10%) used joint models which modelled the longitudinal and survival data together. The proportion of CVD risk prediction models created using longitudinal data using two-stage and joint models increased over time.
Conclusions
Single stage models are still heavily utilized by many CVD risk prediction studies for modelling longitudinal data. Future studies should fully utilize available longitudinal data when analyzing CVD risk by employing two-stage and joint approaches which can often better utilize the available data.
Similar content being viewed by others

Background
Cardiovascular disease (CVD) is a leading cause of morbidity and mortality worldwide, accounting for 47 and 39% of deaths in females and males, respectively, in European Society of Cardiology member states [1]. Risk prediction models inform the understanding and management of CVD and have become an important part of clinical decision making. Many risk prediction models for CVD use one data point per patient (usually at baseline), such as the widely used Framingham Risk Score which predicts risk for coronary heart disease, [2] or QRISK3 which predicts risk of CVD in a subset of the UK population, and is widely used in CVD risk stratification in the UK [3]. These models use many variables at baseline including systolic blood pressure (SBP), total cholesterol, high-density lipoprotein cholesterol, or smoking status. As such, many cardiovascular risk prediction models do not account for measurement error or changes in risk factors over time [4, 5] which could lead to biased estimation. For example, SBP generally increases as people age, while diastolic blood pressure initially rises but starts decreasing after the age of 60 [6]. Further, as people age, they accumulate more risk factors. These complex and dynamic changes over time must be accounted for when modelling CVD risk to achieve the most robust possible risk prediction.
In risk prediction, longitudinal data permits the study of change in risk factors over time, accounting for within person-variance and usually provides an increase in power while reducing the number of patients needed [7]. However, analysis of longitudinal data adds complexity, such as dependence between observations, informatively censored or incomplete data and non-linear trajectories of longitudinal risk factors over time. Addressing these issues can add significant complexity and computational burden to the analysis.
The association between longitudinal measurements of blood pressure and risk of CVD has been studied using summaries such as time-averaged, cumulative, [8] trajectory patterns [9] and variability [10, 11]. However, less effort has been invested in modelling the complete record of longitudinal measurements, e.g. as time-varying covariates. Using summary measures in risk prediction models could be ineffective due to possible heterogeneity of variance for the summary measure. A review of risk prediction models covering the period 2009–2016 found that 46/117 (39.3%) studies considered longitudinal data, and only 9/117 (7.7%) studies included longitudinal data as time-varying covariates [12]. A more recent review of available methods adopted for harnessing longitudinal data in clinical risk prediction showed a further increase in the development of risk prediction models over the period 2009–2018 and identified seven different methodological frameworks [13].
The aim of this review was to conduct a comprehensive methodological evaluation of the estimation of risk for developing CVD in the general population, specifically targeting studies with a longitudinal design with three or more time-points, to allow for the trajectory of the longitudinal variable(s) to be modelled in predicting CVD risk.
Material and methods
Selection criteria
This review focused on risk prediction for CVD. Studies were included if they had a longitudinal design with data analyzed over at least three time points, where the outcome was a clinical diagnosis of a cardiovascular disease(s) or mortality. Cross-sectional, animal, and paediatric studies were excluded.
Search strategy
MEDLINE-Ovid was searched from inception until 3 June 2020 with no language restrictions. Search terms used for data type and modelling type were “longitudinal, repeat* measure*, hierarchical, multilevel model*” and “change, slope, trajector*, profile, growth curve” respectively in all text. For disease area, the following search terms were used: “cardiovasc*, cerebrovasc*, atrial fibrillation, coronary (and artery or disease), stroke” in title, “cardiovascular disease, brain ischemia, heart diseases” in MeSH with subheadings or “myocardial infarction, coronary disease, stroke, intracranial hemorrhages (without intracranial hemorrhage, traumatic)” in MeSH without subheadings. The standardized search filter, along with the search approach and search terms are listed in Fig. 1 and Supplementary Table 1. Studies needed at least one term for data type, modelling type and disease area. Further, the reference lists of included studies were reviewed to identify any additional relevant articles.

Summary of search strategy
Consideration of studies for inclusion followed a three-step process. First, titles were considered. Second, abstracts of potentially eligible studies were considered. Third, after abstract screening, the full-text articles were retrieved and assessed for eligibility. The first author (DS) completed the screening of studies and other authors were consulted to resolve any queries. Reasons for exclusion were recorded.
Data extraction
The following information were extracted from each study: first author, year of publication, model type, dataset region, time period for data collection, age range, proportion of males, length of follow-up, number of patients, number of longitudinal time points, longitudinal and survival outcome data types, covariates adjusted for in longitudinal and survival models, survival and longitudinal outcomes, and characteristics of the statistical and modelling approaches used including assumptions, handling of missing data, model selection, and software used. Data extraction was conducted by the first author (DS), with other authors consulted to resolve any queries.
Results
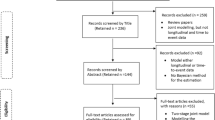
The searches returned 2601 studies with 12 duplicates (Fig. 2). Based on screening titles and abstracts, 2150 studies were excluded. The full texts were considered for 439 articles and a further 34 were excluded due to ≥1 of the following reasons: data not longitudinal, review article, data were summary measures rather than individual patient data, or non-CVD/mortality outcome. The number of repeated measures was assessed for 405 studies. A further 325 further studies were excluded due to having less than three repeated measures reported. Eighty studies were included in the review (Fig. 2) [14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93].

Flow chart of study selection
General characteristics
Characteristics of the included studies are summarized in Table 1. Sixty (75%) studies reported analyses on large sample sizes (≥1000 patients). Exactly three longitudinal measurements were available in 27 (33.8%) studies, while 47 (58.8%) reported ≥3 data points with a mixture of median, mean or maximum number of longitudinal observations per patient; however, many studies did not utilize all available measurements. Follow-up lengths varied widely from 31 days [48] to 35 years, [50] with 29 (36.2%) reporting over a 10–20-year period. Patients were often followed up for survival after the last repeated measure, with 47 (58.8%) studies reporting a total follow-up of ≥10 years, while 31 (38.8%) reported a longitudinal outcome follow-up of ≥10 years. Over three-quarters (n = 65, 81.3%) were published after 2010, 15 studies (18.8%) were published prior to 2010. Data collection for many longitudinal datasets (n = 20, 25.0%) began in the 1980s, only 13 (16.2%) studies were from the 1990s, and about one-third were completed in the 2000s (n = 26, 32.5%).
Outcome data
Most (n = 63, 78.8%) studies reported disease outcomes as time-to-event or survival outcomes. Fewer studies examined disease outcomes as binary (n = 5, 6.2%), continuous (n = 8, 10.0%) or rates (n = 4, 5.0%). Most (n = 69, 86.2%) longitudinal outcomes were continuous; other longitudinal outcome types were binary (n = 3, 3.8%), categorical (n = 5, 6.2%), or ordinal (n = 3, 3.8%).
Adjusting for covariates
Sixty-one studies (76.2%) adjusted for age and 45 (56.2%) adjusted for sex as covariates in their survival analysis, while four (5.0%) stratified by age and three (3.8%) for sex. Nine (11.2%) studies analyzed data separately for each sex. Seventeen (21.2%) longitudinal analyses were adjusted for age, while 30 (37.5%) were not. Sex was adjusted for as a covariate in 9 (11.2%) longitudinal analyses. Four (5.0%) studies analyzed longitudinal data separately by sex, and 28 (35.0%) did not adjust for sex.
Statistical analysis
This review has identified a variety of statistical analysis methods that have been incorporated to analyze time-to-event and longitudinal outcome data. Three (3.8%) used a simple statistical test [14,15,16]. For example, Albani et al. [16] used the Wilcoxon signed rank test to compare two risk scores (the Framingham Risk Score and an atherosclerotic cardiovascular disease risk score) before treatment with pasireotide and 6 and 12 months after treatment. Other statistical approaches for modelling CVD risk using longitudinal data can be divided into three categories: 1) single-stage approaches including basic summary measures, 40 (50.0%), [17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56] 2) two-stage approaches using an estimated longitudinal parameter as a covariate in a survival outcome model, 29 (36.3%), [57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85] and 3) joint models fitting longitudinal and survival data simultaneously, 8 (10.0%) [86,87,88,89,90,91,92,93].
Characteristics of included studies
The characteristics of the included studies by different modelling approaches is shown in Table 2. Joint models have been fitted on smaller datasets with only one study using a joint model on a dataset of over 10,000 patients [87]. A larger proportion of two-stage or joint models had patients with a variable number of time points included compared to single-stage approaches (24/37 (64.9%) vs. 23/40 (57.5%), respectively). Five (6.3%) studies did not report the number of time points used in their analyses. Two-stage approaches were used on 10/16 (62.5%) datasets collected in Asia but only in 2/22 (9.1%) on European datasets. The longitudinal analysis in two-stage approaches rarely adjusted for age or sex, with adjustments made in 6/29 (20.7%) and 7/29 (24.1%), respectively. The frequency of studies using each model type over time is shown in Fig. 3. Since 2010, a substantial increase in the number of papers using two-stage approaches was observed with 26/65 (40.0%) using them after 2010 vs. 3/15 (20.0%) before. Use of joint models also commenced later that decade with only one study before 2015.

Stacked bar chart showing the frequency of the statistical model types by year
A complete case analysis was used in 65/80 (81.3%) studies, more often in smaller (< 1000, 16/18, 88.9%) and very large (> 10,000, 18/21, 85.7%) cohorts than medium-sized studies (1000–9999, 29/39, 74.4%) and those with a variable number of time-points (39/48, 81.3%) compared with exactly three time points (21/27, 77.8%). In addition, those with shorter follow-ups (< 10 years, 19/33, 57.6%) were more likely to use a complete case analysis. The methods used for handling missing data included multiple imputation (n = 6), single imputations (n = 3), last observation carried forward (n = 2) and indicators for missing variables (n = 2).
Single-stage approaches
A single-stage approach was used in 40 (50%) studies [17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56] (Table 3). The most common risk prediction model for single-stage models was the Cox proportional hazards (PH) model (n = 25, 62.5%) [94]. The model assumes a proportional effect on the hazard; the PH assumption should be checked, either by including time-varying coefficients or by a variety of graphical testing methods, such as Schoenfeld residual plots and log-log plots. Only 9/25 (62.5%) of articles utilizing Cox PH models as a single-stage approach stated that the PH assumption was checked [95].
The simplest method of utilizing the Cox PH model was used by including the values of the longitudinal outcome at baseline (Time 0) (n = 7, 17.5%) [18, 21, 24, 43, 50, 53, 54]. For example, Tanne et al. used baseline values of SBP to predict ischemic stroke mortality [53]. This model is easily interpretable clinically; it only uses data from a single time-point per patient and does not take into account all available data. Clustering and meta-analysis techniques were also incorporated through the Cox PH model. A study using impaired sleep as a CVD risk factor included patients in two separate baseline waves. Patients could appear in both waves and clustering was accounted for when fitting the Cox PH model [24]. A study examining the association between cholesterol and cardiovascular mortality fitted Cox PH models for each year of follow-up, and combined the coefficients from these models using meta-analysis techniques [50].
Three (7.5%) studies included the difference between the longitudinal predictor at baseline and a previous value as a covariate in the Cox model, [28, 35, 38] for example, risk of coronary heart disease was predicted by using the difference between a patient’s current Framingham Risk Score and their score 3 or 6 years ago [35]. This is a simple measure; however, it assumes that change is linear between two time-points. Further, three (7.5%) studies used a slope to predict CVD and the slope was calculated manually by dividing the difference by time duration [25, 29, 32]. Other summaries were included in the Cox PH models as covariates such as a mean, [36] mean change, [36] standard deviation, [19] summaries of changes between categories [20, 34, 41] and stability in categories [20, 34, 41].
Six studies (15.0%) included longitudinal predictors as time-dependent covariates in the Cox model [39, 42, 45, 47, 49, 51, 55] by splitting the timescale at each time point when predictors are updated. Reinikainen et al. included time-dependent summary measures as time-dependent covariates; updated mean values and the change between the current and previous time-points for SBP, total cholesterol and current smoking status [39].
Three studies (7.5%) used logistic regression to model a binary disease outcome [30, 31, 48]. One included the predictor at baseline, [31] another compared the predictive power at multiple time points to predict risk of myocardial infarction by including them in separate models, [30] while the third used summary measures (mean (SD), mean change from baseline, range and average daily risk range) of blood glucose to predict mortality in myocardial infarction patients [48].
Four (10.0%) studies used generalized estimating equations (GEE) to model a disease outcome. Two had binary outcomes, [17, 27] while two others modelled rates [22, 37]. Of the four studies, two used a logit link [17, 27] and two used a log link [22, 37]. All four included data from multiple time points. One of the studies used summaries of changes in socioeconomic status and lifestyle habit variables between categories such as stable, increasing (in the second or third time point), decreasing or unstable, to predict the Framingham Risk Score [22].
Two studies included baseline values of the longitudinal predictor in a Poisson regression model, [23, 26] a form of Generalized Linear Model (GLM) that can be used as a fully parametric alternative to the Cox PH model. Poisson regression for survival analysis involves splitting the follow-up time into intervals and assuming a constant baseline hazard in each interval [97].
Four (10.0%) studies modelled changes in risk scores over time using linear mixed effects (LME) models, [33, 44, 46] for example, predicting the trajectory of the Framingham Risk Score over four time-points [44]. Fixed effects linear regression was used by one study [52] to examine how change in body mass index (BMI) is correlated with the Framingham Risk Score.
Two-stage models
A two-stage modelling approach was used in 29 (36.3%) studies (Table 4) [57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85]. In a two-stage approach, the longitudinal data is first summarized with a longitudinal model(s). Parameters and/or estimates from this/these model(s) are then included as covariates in a survival model. The Cox PH model was used in most studies (n = 26, 89.7%) [57, 58, 60,61,62,63, 65,66,67,68,69,70,71,72,73, 75,76,77,78, 80,81,82,83,84,85, 88]. A weakness of the two-stage approach is that uncertainty in the longitudinal data summaries produced in the first stage is ignored.
Two methods were commonly used to generate summaries from longitudinal data to include in a Cox PH model as a covariate. The simplest method calculated summary measures such as a slope or the coefficient of variation (equivalent to residual variance) using a linear regression model for each patient in nine studies (31.0%) [57, 62, 63, 71, 78, 80, 82, 83, 85] Gao et al. used linear regression to estimate the intercept, slope, square of the slope and coefficient of variation for blood pressure that were then included in a Cox PH model to assess how variation and changes in blood pressure were associated with mortality [63].
The second most frequently used method (n = 17, 58.6%) was group-based trajectory models (GBTMs) to model the trajectory of the longitudinal variable [58, 60, 61, 65,66,67,68,69,70, 72, 73, 75,76,77, 81, 84, 88]. Wang et al. identified four separate trajectories of sleep duration and used these to predict risk of cardiovascular events or mortality [69]. Most models were fitted using the Proc Traj package from SAS [98] (n = 10, 58.8%), [60, 65,66,67,68,69,70, 73, 75, 81] although other software, including Stata (traj) [99] and R (lcmm) can be used [100]. Trajectory groups from GBTMs were also used in logistic regression (n = 1) [64] and Poisson regression (n = 1) [79] analyses of survival outcomes.
Desai et al. used weighted pooled logistic regression with inverse probability weights (IPWs) to examine the association between changes in serum uric acid and risk of incident diabetes, CVD and renal decline [59]. These models are complex, but the resulting hazard ratios can be interpreted as causal estimates assuming no unmeasured confounders [101].
Joint models
A joint modelling approach, where both the longitudinal variable and the survival model are fitted simultaneously, was used for eight studies (10.0%) [86, 87, 89, 91,92,93]; (Table 5). This approach makes full use of the available data and may be more statistically efficient than fitting a two-stage model; however, this increases the computational complexity.
.
Five studies (62.5%) [86, 87, 91,92,93] modelled the longitudinal outcome using an LME model and the survival outcome using a Cox PH model. One study used the model to analyze the association between blood pressure and coronary artery disease [92].
Batterham et al. used latent growth models, which is similar to LME models, to predict the slope and intercept of five different cognitive tests jointly with a Cox PH model to predict the risk of all-cause mortality and cause-specific mortality. The model is fitted using Mplus [89]. Ogata et al. used a GBTM jointly with a Cox PH model to predict risk of CVD using trajectories of fasting plasma glucose [88]. van den Hout et al. used a Bayesian approach to jointly model ordinal data from the Mini-Mental State Examination. Item response theory (IRT) models were used to model the ordinal data before using Gompertz survival models to model a multi-state outcome (e.g. healthy, history of strokes and death) [90].
Discussion
This review has identified a multitude of methods to analyze the risk of CVD using longitudinally repeated data. There has been an increase in the complexity of methodology used over the past two decades, with an increasing proportion of studies applying more efficient approaches such as two-stage and joint models over time. However, many studies only used simple analysis based on one time-point, even when more data were available.
When CVD risk was modelled in a two-stage model, two methods were commonly used: patient-level linear regression to account for longitudinal data, followed by the Cox PH model to estimate CVD risk, or GBTMs followed by the Cox PH model. On the other hand, in a joint model, the longitudinal and survival data are modelled simultaneously. Both models aimed to utilize a patient’s time-varying risk factors to predict CVD risk. These models can provide an important understanding of the association between changes in risk factors over time and CVD risk, which can be used to influence risk management decisions.
The characteristics and assumptions of a model need to be considered carefully when selecting and interpreting models. Although a time-dependent covariate Cox PH model provides an advantage by enabling risk estimates to be updated during follow-up for new individuals, the model assumes that values are constant between two time-points and are measured without error. Computationally, the model can quickly become unfeasible to fit if predictor values are updated at different time points for each individual. This model is also prone to greater overfitting as a time-dependent covariate forms a complex function over time which could lead to too much modelling; hence, this should be used with caution [102].
The disease risk is estimated as an odds ratio from logistic regression, and it should be interpreted appropriately (not as a risk ratio), especially when the outcome is not rare. Odds ratios cannot be compared between datasets or models with different independent variables because they reflect unobserved heterogeneity between observations which varies between datasets and models [103].
Three different methods to model within-patient variation with a continuous outcome were encountered: GEEs, LME models and fixed effects regression. GEEs are an extension of GLMs that allows a correlation structure between observations [104, 105]. Similarly to GLMs, using different link functions or distributions, GEEs can be used to model continuous, binary, count or binomial outcomes. LME models are an alternative for continuous outcomes, which assumes that the residual error is normally distributed and models within-patient correlation with random effects which are also assumed to be normally distributed and independent of covariates. This allows LME models to make individual patient predictions rather than just the population-level predictions from a GEE [106]. Fixed effects regression relaxes the assumption that random effects are independent of covariates. The model is computationally easier to fit than an LME model and is more appropriate if unobserved heterogeneity is correlated with covariates [107].
GBTMs are a form of a finite mixture model that is an effective way of identifying a fixed number of groups of individuals who follow similar trajectories [108]. However, they are computationally difficult to fit. The results of this model may also be difficult to apply in clinical practice as it can be difficult to assign a patient to one trajectory group by hand accurately.
In a standard joint model, the longitudinal outcome is modelled by an LME model and the survival outcome by a Cox PH model. The two outcomes are linked via shared random effects to capture the time-dependent association between longitudinal measurements and the risk of an event [109]. This association can be defined in a variety of ways, but common approaches include a linear predictor (i.e. current value), a derivative (i.e. rate of change) or an integral (i.e. cumulative effect) of the linear predictor.
The reasons for the slow increase in the utilization of two-stage and joint models is multi-factorial. Computationally these models can be much harder to fit than single-stage models, with joint models in particular conveying significant computational burden. Also, there is poor awareness of inefficiency in simple methods. Many studies may not include a statistician as part of the research team and therefore, authors may not have the requisite experience of analyzing longitudinal data. However, as these methods become more common, and software to fit the models becomes more accessible and computationally more powerful, the utilization of more efficient methods should increase over time.
Different risk prediction models are appropriate for different settings. Models may be used for prediction in a clinical setting or used for studying the association between an exposure and an outcome. Many risk prediction models require computation to obtain a precise risk prediction which poses difficulties in a clinical setting. Existing risk prediction models such as QRISK3 use online calculators to predict risk using a complex model. Inputting all longitudinal data into an online calculator may not be possible in a clinical setting. Alternatives include either using single-stage models including summaries of the longitudinal data such as means, slopes or differences or integrating the risk prediction model into EHRs software. More complex models such as two-stage or joint models are very useful for explaining associations although interpretation can require more thought. Joint models especially need greater consideration when interpreting association structures such as random effect associations. Assigning and interpreting complex groups for GBTMs can be difficult for clinicians in practice although it is sometimes possible to assign clear descriptions to GBTM groups such as high, low, increasing or decreasing.
Reporting of the data in the included studies was highly variable. For example, the number of time-points used per patient in each study was disparate with studies choosing from a selection of mean, median, a range (e.g. 3–5), the maximum possible or frequency over the follow-up period; some studies, especially studies based on electronic health records, did not report the number of time-points, resulting in difficulties ascertaining exactly how many measurements were used. Follow-up length was also described as a date range, mean, median, maximum, dates of study waves etc. This resulted in a loss of clarity, especially when studies had a separate follow-up period for longitudinal data collection and for the survival outcome. Also, some studies did not report variables removed as part of variable selection.
Strengths and limitations
This review examined all available studies that have assessed the relationship between the trajectory of longitudinal risk factors and the risk of a cardiovascular event or mortality, and summarized the methods used in analyzing longitudinal risk factors for CVD risk. This review can be readily used to identify methods for future analysis of longitudinal trajectories and risk prediction in CVD. However, due to search terms having this specific focus, single-stage models underutilizing the data available are more likely to be underrepresented.
Queries over eligibility or the article content were thoroughly discussed among the authors of this review before reaching the final decision. However, articles were searched and screened by one author and there remains a possibility of bias or error. This review focused solely on a search of MEDLINE-Ovid providing a focused and consistent search, although inclusion of other bibliographic databases may have returned other studies.
This review was designed to highlight the strengths of statistical methods for summarizing longitudinal data to predict CVD risk. A deeper comparison of the methods using simulated data have been discussed in the literature numerous times as the methods were first developed or in their application [110,111,112]. A machine learning approach may also be worth considering when designing a study, although our search only identified one study using machine learning methods [113]. Machine learning algorithms have the potential to provide stronger predictions of risk using many variables; however, this incurs greater potential for overfitting and collinearity between variables. To avoid this, machine learning applies a greater focus on increased model validation, preferably external validation [114].
Conclusions
The use of two-stage and joint models is a critical part of understanding the relationship between the longitudinal risk factors and CVD. Many studies still employ single stage approaches which often underutilize available longitudinal data when modelling cardiovascular risk. Further studies should aim to optimize the use of longitudinal data by using two-stage and joint models whenever possible for a more accurate estimation of cardiovascular risk.
Availability of data and materials
The dataset(s) supporting the conclusions of this article is(are) included within the article (and its additional file(s)).
Abbreviations
- BMI:
-
body mass index
- CVD:
-
cardiovascular disease
- GBTM:
-
group based trajectory model
- GEE:
-
generalized estimating equations
- GLM:
-
generalized linear model
- IPW:
-
inverse probability weight
- IRT:
-
item response theory
- LME:
-
linear mixed effect
- PH:
-
proportional hazards
- SBP:
-
systolic blood pressure
References
Timmis A, Townsend N, Gale CP, Torbica A, Lettino M, Petersen SE, et al. European Society of Cardiology: cardiovascular disease statistics 2019. Eur Heart J. 2020;41(1):12–85.
D'Agostino RB Sr, Vasan RS, Pencina MJ, Wolf PA, Cobain M, Massaro JM, et al. General cardiovascular risk profile for use in primary care: the Framingham heart study. Circulation. 2008;117(6):743–53.
Hippisley-Cox J, Coupland C, Brindle P. Development and validation of QRISK3 risk prediction algorithms to estimate future risk of cardiovascular disease: prospective cohort study. BMJ. 2017;357:j2099.
Karp I, Abrahamowicz M, Bartlett G, Pilote L. Updated risk factor values and the ability of the multivariable risk score to predict coronary heart disease. Am J Epidemiol. 2004;160(7):707–16.
Zavaroni I, Ardigo D, Massironi P, Gasparini P, Barilli AL, Vetrugno E, et al. Do coronary heart disease risk factors change over time? Metabolism. 2002;51(8):1022–6.
Cheng S, Xanthakis V, Sullivan Lisa M, Vasan RS. Blood pressure tracking over the adult life course. Hypertension. 2012;60(6):1393–9.
Allison DB, Allison RL, Faith MS, Paultre F, Pi-Sunyer FX. Power and money: designing statistically powerful studies while minimizing financial costs. Psychol Methods. 1997;2(1):20–33.
Ayala Solares JR, Canoy D, Raimondi FED, Zhu Y, Hassaine A, Salimi-Khorshidi G, et al. Long-term exposure to elevated systolic blood pressure in predicting incident cardiovascular disease: evidence from large-scale routine electronic health records. J Am Heart Assoc. 2019;8(12):e012129.
Tielemans S, Geleijnse JM, Laughlin GA, Boshuizen HC, Barrett-Connor E, Kromhout D. Blood pressure trajectories in relation to cardiovascular mortality: the rancho Bernardo study. J Hum Hypertens. 2017;31(8):515–9.
Nuotio J, Suvila K, Cheng S, Langén V, Niiranen T. Longitudinal blood pressure patterns and cardiovascular disease risk. Ann Med. 2020;52(3–4):43–54.
Barrett JK, Huille R, Parker R, Yano Y, Griswold M. Estimating the association between blood pressure variability and cardiovascular disease: an application using the ARIC study. Stat Med. 2019;38(10):1855–68.
Goldstein BA, Navar AM, Pencina MJ, Ioannidis JPA. Opportunities and challenges in developing risk prediction models with electronic health records data: a systematic review. J Am Med Inform Assoc. 2017;24(1):198–208.
Bull LM, Lunt M, Martin GP, Hyrich K, Sergeant JC. Harnessing repeated measurements of predictor variables for clinical risk prediction: a review of existing methods. Diagn Progn Res. 2020;4(1):9.
Fahs IM, Hallit S, Rahal MK, Malaeb DN. The community pharmacist's role in reducing cardiovascular risk factors in Lebanon: a longitudinal study. Med Princ Pract. 2018;27(6):508–14.
Ellsworth DL, O'Dowd SC, Salami B, Hochberg A, Vernalis MN, Marshall D, et al. Intensive lifestyle modification: impact on cardiovascular disease risk factors in subjects with and without clinical cardiovascular disease. Prev Cardiol. 2004;7(4):168–75.
Albani A, Ferrau F, Ciresi A, Pivonello R, Scaroni C, Iacuaniello D, et al. Pasireotide treatment reduces cardiometabolic risk in Cushing's disease patients: an Italian, multicenter study. Endocrine. 2018;61(1):118–24.
Odden MC, Rawlings AM, Arnold AM, Cushman M, Biggs ML, Psaty BM, et al. Patterns of cardiovascular risk factors in old age and survival and health status at 90. J Gerontol A Biol Sci Med Sci. 2020;75(11):2207–14.
Clouston SAP, Zhang Y, Smith DM. Pattern recognition to identify stroke in the cognitive profile: secondary analyses of a prospective cohort study. Cerebrovasc Dis Extra. 2019;9(3):114–22.
Elfassy T, Swift SL, Glymour MM, Calonico S, Jacobs DR Jr, Mayeda ER, et al. Associations of income volatility with incident cardiovascular disease and all-cause mortality in a US cohort. Circulation. 2019;139(7):850–9.
O'Neill D, Britton A, Hannah MK, Goldberg M, Kuh D, Khaw KT, et al. Association of longitudinal alcohol consumption trajectories with coronary heart disease: a meta-analysis of six cohort studies using individual participant data. BMC Med. 2018;16(1):124.
Li J, Wang H, Tian J, Chen B, Du F. Change in lipoprotein-associated phospholipase A2 and its association with cardiovascular outcomes in patients with acute coronary syndrome. Medicine (Baltimore). 2018;97(28):e11517.
Liao CM, Lin CM. Life course effects of socioeconomic and lifestyle factors on metabolic syndrome and 10-year risk of cardiovascular disease: A longitudinal study in Taiwan adults. Int J Environ Res Public Health. 2018;15(10).
Lind L, Sundstrom J, Arnlov J, Lampa E. Impact of aging on the strength of cardiovascular risk factors: A longitudinal study over 40 years. J Am Heart Assoc. 2018;7(1).
Clark AJ, Salo P, Lange T, Jennum P, Virtanen M, Pentti J, et al. Onset of impaired sleep and cardiovascular disease risk factors: a longitudinal study. Sleep. 2016;39(9):1709–18.
Hu WS, Hsieh MH, Lin CL. Comparisons of changes in the adapted diabetes complications severity index and CHA2DS2-VASc score for atrial fibrillation risk stratification in patients with type 2 diabetes mellitus: a nationwide cohort study. Int J Cardiol. 2018;269:122–5.
Glueck CJ, Kelley W, Wang P, Gartside PS, Black D, Tracy T. Risk factors for coronary heart disease among firefighters in Cincinnati. Am J Ind Med. 1996;30(3):331–40.
Infurna FJ, Mayer A, Anstey KJ. The effect of perceived control on self-reported cardiovascular disease incidence across adulthood and old age. Psychol Health. 2018;33(3):340–60.
Pokharel Y, Khariton Y, Tang Y, Nassif ME, Chan PS, Arnold SV, et al. Association of serial Kansas City cardiomyopathy questionnaire assessments with death and hospitalization in patients with heart failure with preserved and reduced ejection fraction: a secondary analysis of 2 randomized clinical trials. JAMA Cardiol. 2017;2(12):1315–21.
Iribarren C, Round AD, Lu M, Okin PM, McNulty EJ. Cohort study of ECG left ventricular hypertrophy trajectories: Ethnic disparities, associations with cardiovascular outcomes, and clinical utility. J Am Heart Assoc. 2017;6(10).
Gonzales TK, Yonker JA, Chang V, Roan CL, Herd P, Atwood CS. Myocardial infarction in the Wisconsin longitudinal study: the interaction among environmental, health, social, behavioural and genetic factors. BMJ Open. 2017;7(1):e011529.
Boehm JK, Soo J, Chen Y, Zevon ES, Hernandez R, Lloyd-Jones D, et al. Psychological well-being's link with cardiovascular health in older adults. Am J Prev Med. 2017;53(6):791–8.
Chan MY, Neely ML, Roe MT, Goodman SG, Erlinge D, Cornel JH, et al. Temporal biomarker profiling reveals longitudinal changes in risk of death or myocardial infarction in non-ST-segment elevation acute coronary syndrome. Clin Chem. 2017;63(7):1214–26.
Appiah D, Schreiner PJ, Durant RW, Kiefe CI, Loria C, Lewis CE, et al. Relation of longitudinal changes in body mass index with atherosclerotic cardiovascular disease risk scores in middle-aged black and white adults: the coronary artery risk development in young adults (CARDIA) study. Ann Epidemiol. 2016;26(8):521–6.
Wu Z, Jin C, Vaidya A, Jin W, Huang Z, Wu S, et al. Longitudinal patterns of blood pressure, incident cardiovascular events, and all-cause mortality in normotensive diabetic people. Hypertension. 2016;68(1):71–7.
Mainous AG 3rd, Everett CJ, Player MS, King DE, Diaz VA. Importance of a patient's personal health history on assessments of future risk of coronary heart disease. J Am Board Fam Med. 2008;21(5):408–13.
Janszky I, Romundstad P, Laugsand LE, Vatten LJ, Mukamal KJ, Morkedal B. Weight and weight change and risk of acute myocardial infarction and heart failure - the HUNT study. J Intern Med. 2016;280(3):312–22.
Stenholm S, Kivimaki M, Jylha M, Kawachi I, Westerlund H, Pentti J, et al. Trajectories of self-rated health in the last 15 years of life by cause of death. Eur J Epidemiol. 2016;31(2):177–85.
Kamijo-Ikemori A, Hashimoto N, Sugaya T, Matsui K, Hisamichi M, Shibagaki Y, et al. Elevation of urinary liver-type fatty acid binding protein after cardiac catheterization related to cardiovascular events. Int J Nephrol Renovasc Dis. 2015;8:91–9.
Reinikainen J, Laatikainen T, Karvanen J, Tolonen H. Lifetime cumulative risk factors predict cardiovascular disease mortality in a 50-year follow-up study in Finland. Int J Epidemiol. 2015;44(1):108–16.
Juanola-Falgarona M, Salas-Salvado J, Martinez-Gonzalez MA, Corella D, Estruch R, Ros E, et al. Dietary intake of vitamin K is inversely associated with mortality risk. J Nutr. 2014;144(5):743–50.
Hulsegge G, Smit HA, van der Schouw YT, Daviglus ML, Verschuren WM. Quantifying the benefits of achieving or maintaining long-term low risk profile for cardiovascular disease: the Doetinchem cohort study. Eur J Prev Cardiol. 2015;22(10):1307–16.
Araujo AB, Chiu GR, Christian JB, Kim HY, Evans WJ, Clark RV. Longitudinal changes in high-density lipoprotein cholesterol and cardiovascular events in older adults. Clin Endocrinol. 2014;80(5):662–70.
Little J, Phillips L, Russell L, Griffiths A, Russell GI, Davies SJ. Longitudinal lipid profiles on CAPD: their relationship to weight gain, comorbidity, and dialysis factors. J Am Soc Nephrol. 1998;9(10):1931–9.
Elbaz A, Shipley MJ, Nabi H, Brunner EJ, Kivimaki M, Singh-Manoux A. Trajectories of the Framingham general cardiovascular risk profile in midlife and poor motor function later in life: the Whitehall II study. Int J Cardiol. 2014;172(1):96–102.
Gerber Y, Myers V, Goldbourt U, Benyamini Y, Scheinowitz M, Drory Y. Long-term trajectory of leisure time physical activity and survival after first myocardial infarction: a population-based cohort study. Eur J Epidemiol. 2011;26(2):109–16.
Karp I, Abrahamowicz M, Fortin PR, Pilote L, Neville C, Pineau CA, et al. Longitudinal evolution of risk of coronary heart disease in systemic lupus erythematosus. J Rheumatol. 2012;39(5):968–73.
Nuesch R, Wang Q, Elzi L, Bernasconi E, Weber R, Cavassini M, et al. Risk of cardiovascular events and blood pressure control in hypertensive HIV-infected patients: Swiss HIV cohort study (SHCS). J Acquir Immune Defic Syndr. 2013;62(4):396–404.
Lipska KJ, Venkitachalam L, Gosch K, Kovatchev B, Van den Berghe G, Meyfroidt G, et al. Glucose variability and mortality in patients hospitalized with acute myocardial infarction. Circ Cardiovasc Qual Outcomes. 2012;5(4):550–7.
Strasak AM, Kelleher CC, Klenk J, Brant LJ, Ruttmann E, Rapp K, et al. Longitudinal change in serum gamma-glutamyltransferase and cardiovascular disease mortality: a prospective population-based study in 76,113 Austrian adults. Arterioscler Thromb Vasc Biol. 2008;28(10):1857–65.
Menotti A, Lanti M. The duration of the association between serum cholesterol and coronary mortality: a 35-year experience. J Cardiovasc Risk. 2001;8(2):109–17.
Kalantar-Zadeh K, Kilpatrick RD, Kuwae N, McAllister CJ, Alcorn H Jr, Kopple JD, et al. Revisiting mortality predictability of serum albumin in the dialysis population: time dependency, longitudinal changes and population-attributable fraction. Nephrol Dial Transplant. 2005;20(9):1880–8.
Wilsgaard T, Arnesen E. Body mass index and coronary heart disease risk score: the Tromso study, 1979 to 2001. Ann Epidemiol. 2007;17(2):100–5.
Tanne D, Yaari S, Goldbourt U. Risk profile and prediction of long-term ischemic stroke mortality: a 21-year follow-up in the Israeli ischemic heart disease (IIHD) project. Circulation. 1998;98(14):1365–71.
Bos AJ, Brant LJ, Morrell CH, Fleg JL. The relationship of obesity and the development of coronary heart disease to longitudinal changes in systolic blood pressure. Coll Antropol. 1998;22(2):333–44.
Wolinsky FD, Gurney JG, Wan GJ, Bentley DW. The sequelae of hospitalization for ischemic stroke among older adults. J Am Geriatr Soc. 1998;46(5):577–82.
Galanis DJ, Harris T, Sharp DS, Petrovitch H. Relative weight, weight change, and risk of coronary heart disease in the Honolulu heart program. Am J Epidemiol. 1998;147(4):379–86.
Ronaldson A, Kidd T, Poole L, Leigh E, Jahangiri M, Steptoe A. Diurnal cortisol rhythm is associated with adverse cardiac events and mortality in coronary artery bypass patients. J Clin Endocrinol Metab. 2015;100(10):3676–82.
Zeng S, Yan LF, Luo YW, Liu XL, Liu JX, Guo ZZ, et al. Trajectories of circulating monocyte subsets after ST-elevation myocardial infarction during hospitalization: latent class growth modeling for high-risk patient identification. J Cardiovasc Transl Res. 2018;11(1):22–32.
Desai RJ, Franklin JM, Spoendlin-Allen J, Solomon DH, Danaei G, Kim SC. An evaluation of longitudinal changes in serum uric acid levels and associated risk of cardio-metabolic events and renal function decline in gout. PLoS One. 2018;13(2):e0193622.
Jin C, Chen S, Vaidya A, Wu Y, Wu Z, Hu FB, et al. Longitudinal change in fasting blood glucose and myocardial infarction risk in a population without diabetes. Diabetes Care. 2017;40(11):1565–72.
Inoue H, Shimizu S, Watanabe K, Kamiyama Y, Shima H, Nakase A, et al. Impact of trajectories of abdominal aortic calcification over 2 years on subsequent mortality: a 10-year longitudinal study. Nephrol Dial Transplant. 2018;33(4):676–83.
Sanders JL, Guo W, O'Meara ES, Kaplan RC, Pollak MN, Bartz TM, et al. Trajectories of IGF-I predict mortality in older adults: the cardiovascular health study. J Gerontol A Biol Sci Med Sci. 2018;73(7):953–9.
Gao S, Hendrie HC, Wang C, Stump TE, Stewart JC, Kesterson J, et al. Redefined blood pressure variability measure and its association with mortality in elderly primary care patients. Hypertension. 2014;64(1):45–52.
Deschenes SS, Burns RJ, Schmitz N. Trajectories of anxiety symptoms and associations with incident cardiovascular disease in adults with type 2 diabetes. J Psychosom Res. 2018;104:95–100.
Li Y, Huang Z, Jin C, Xing A, Liu Y, Huangfu C, et al. Longitudinal change of perceived salt intake and stroke risk in a Chinese population. Stroke. 2018;49(6):1332–9.
Rahman F, Yin X, Larson MG, Ellinor PT, Lubitz SA, Vasan RS, et al. Trajectories of risk factors and risk of new-onset atrial fibrillation in the Framingham heart study. Hypertension. 2016;68(3):597–605.
Li W, Jin C, Vaidya A, Wu Y, Rexrode K, Zheng X, et al. Blood pressure trajectories and the risk of intracerebral hemorrhage and cerebral infarction: a prospective study. Hypertension. 2017;70(3):508–14.
Duncan MS, Vasan RS, Xanthakis V. Trajectories of blood lipid concentrations over the adult life course and risk of cardiovascular disease and all-cause mortality: observations from the Framingham study over 35 years. J Am Heart Assoc. 2019;8(11):e011433.
Wang YH, Wang J, Chen SH, Li JQ, Lu QD, Vitiello MV, et al. Association of longitudinal patterns of habitual sleep duration with risk of cardiovascular events and all-cause mortality. JAMA Netw Open. 2020;3(5):e205246.
Niiranen TJ, Enserro DM, Larson MG, Vasan RS. Multisystem trajectories over the adult life course and relations to cardiovascular disease and death. J Gerontol A Biol Sci Med Sci. 2019;74(11):1778–85.
Suchy-Dicey AM, Wallace ER, Mitchell SV, Aguilar M, Gottesman RF, Rice K, et al. Blood pressure variability and the risk of all-cause mortality, incident myocardial infarction, and incident stroke in the cardiovascular health study. Am J Hypertens. 2013;26(10):1210–7.
Shackleton N, Darlington-Pollock F, Norman P, Jackson R, Exeter DJ. Longitudinal deprivation trajectories and risk of cardiovascular disease in New Zealand. Health Place. 2018;53:34–42.
Johnson-Lawrence V, Kaplan G, Galea S. Socioeconomic mobility in adulthood and cardiovascular disease mortality. Ann Epidemiol. 2013;23(4):167–71.
Smitson CC, Scherzer R, Shlipak MG, Psaty BM, Newman AB, Sarnak MJ, et al. Association of blood pressure trajectory with mortality, incident cardiovascular disease, and heart failure in the cardiovascular health study. Am J Hypertens. 2017;30(6):587–93.
Sharashova E, Wilsgaard T, Lochen ML, Mathiesen EB, Njolstad I, Brenn T. Resting heart rate trajectories and myocardial infarction, atrial fibrillation, ischaemic stroke and death in the general population: the Tromso study. Eur J Prev Cardiol. 2017;24(7):748–59.
Dayimu A, Wang C, Li J, Fan B, Ji X, Zhang T, et al. Trajectories of lipids profile and incident cardiovascular disease risk: a longitudinal cohort study. J Am Heart Assoc. 2019;8(21):e013479.
Dayimu A, Qian W, Fan B, Wang C, Li J, Wang S, et al. Trajectories of haemoglobin and incident stroke risk: a longitudinal cohort study. BMC Public Health. 2019;19(1):1395.
Grove JS, Reed DM, Yano K, Hwang L-J. Variability in systolic blood pressure—a risk factor for coronary heart disease? Am J Epidemiol. 1997;145(9):771–6.
Petruski-Ivleva N, Viera AJ, Shimbo D, Muntner P, Avery CL, Schneider AL, et al. Longitudinal patterns of change in systolic blood pressure and incidence of cardiovascular disease: the atherosclerosis risk in communities study. Hypertension. 2016;67(6):1150–6.
Shimizu Y, Kato H, LIN CH, Kodama K, Peterson A, Prentice R. Relationship between longitudinal changes in blood pressure and stroke incidence. Stroke. 1984;15:839–46.
Maddox TM, Ross C, Tavel HM, Lyons EE, Tillquist M, Ho PM, et al. Blood pressure trajectories and associations with treatment intensification, medication adherence, and outcomes among newly diagnosed coronary artery disease patients. Circ Cardiovasc Qual Outcomes. 2010;3(4):347–57.
Cappola AR, O'Meara ES, Guo W, Bartz TM, Fried LP, Newman AB. Trajectories of dehydroepiandrosterone sulfate predict mortality in older adults: the cardiovascular health study. J Gerontol A Biol Sci Med Sci. 2009;64(12):1268–74.
Arnold AM, Newman AB, Cushman M, Ding J, Kritchevsky S. Body weight dynamics and their association with physical function and mortality in older adults: the cardiovascular health study. J Gerontol A Biol Sci Med Sci. 2010;65(1):63–70.
Yuan Z, Yang Y, Wang C, Liu J, Sun X, Liu Y, et al. Trajectories of long-term normal fasting plasma glucose and risk of coronary heart disease: A prospective cohort study. J Am Heart Assoc. 2018;7(4).
Haring R, Teng Z, Xanthakis V, Coviello A, Sullivan L, Bhasin S, et al. Association of sex steroids, gonadotrophins, and their trajectories with clinical cardiovascular disease and all-cause mortality in elderly men from the Framingham heart study. Clin Endocrinol. 2013;78(4):629–34.
Hughes MF, Ojeda F, Saarela O, Jorgensen T, Zeller T, Palosaari T, et al. Association of repeatedly measured high-sensitivity-assayed troponin I with cardiovascular disease events in a general population from the MORGAM/BiomarCaRE study. Clin Chem. 2017;63(1):334–42.
Posch F, Ay C, Stoger H, Kreutz R, Beyer-Westendorf J. Longitudinal kidney function trajectories predict major bleeding, hospitalization and death in patients with atrial fibrillation and chronic kidney disease. Int J Cardiol. 2019;282:47–52.
Ogata S, Watanabe M, Kokubo Y, Higashiyama A, Nakao YM, Takegami M, et al. Longitudinal trajectories of fasting plasma glucose and risks of cardiovascular diseases in middle age to elderly people within the general Japanese population: the Suita study. J Am Heart Assoc. 2019;8(3):e010628.
Batterham PJ, Mackinnon AJ, Christensen H. The association between change in cognitive ability and cause-specific mortality in a community sample of older adults. Psychol Aging. 2012;27(1):229–36.
van den Hout A, Fox JP, Klein Entink RH. Bayesian inference for an illness-death model for stroke with cognition as a latent time-dependent risk factor. Stat Methods Med Res. 2015;24(6):769–87.
de Kat AC, Verschuren WM, Eijkemans MJ, Broekmans FJ, van der Schouw YT. Anti-mullerian hormone trajectories are associated with cardiovascular disease in women: results from the Doetinchem cohort study. Circulation. 2017;135(6):556–65.
Yang L, Yu M, Gao S. Prediction of coronary artery disease risk based on multiple longitudinal biomarkers. Stat Med. 2016;35(8):1299–314.
Wolk R, Bertolet M, Singh P, Brooks MM, Pratley RE, Frye RL, et al. Prognostic value of adipokines in predicting cardiovascular outcome: explaining the obesity paradox. Mayo Clin Proc. 2016;91(7):858–66.
Cox DR. Regression models and life-tables. J R Stat Soc Series B Stat Methodol. 1972;34(2):187–220.
Persson I, Khamis HJ, editors. A comparison of graphical methods for assessing the proportional hazards assumptions in the Cox model2007.
Boehm JK, Chen Y, Qureshi F, Soo J, Umukoro P, Hernandez R, et al. Positive emotions and favorable cardiovascular health: a 20-year longitudinal study. Prev Med. 2020;136:106103.
Crowther MJ, Riley RD, Staessen JA, Wang J, Gueyffier F, Lambert PC. Individual patient data meta-analysis of survival data using Poisson regression models. BMC Med Res Methodol. 2012;12(1):34.
Jones BL, Nagin DS, Roeder K. A SAS procedure based on mixture models for estimating developmental trajectories. Sociol Methods Res. 2001;29(3):374–93.
Jones BL, Nagin DS. A note on a Stata plugin for estimating group-based trajectory models. Sociol Methods Res. 2013;42(4):608–13.
Proust-Lima C, Philipps V, Liquet B. Estimation of extended mixed models using latent classes and latent processes: The R package lcmm. J Stat Softw. 2017;78(2).
Cole SR, Hernán MA. Constructing inverse probability weights for marginal structural models. Am J Epidemiol. 2008;168(6):656–64.
Fisher LD, Lin DY. Time-dependent covariates in the Cox proportional-hazards regression model. Annu Rev of Public Health. 1999;20(1):145–57.
Mood C. Logistic regression: why we cannot do what we think we can do, and what we can do about it. Eur Sociol Rev. 2010;26(1):67–82.
Liang K-Y, Zeger SL. Longitudinal data analysis using generalized linear models. Biometrika. 1986;73(1):13–22.
Ballinger GA. Using generalized estimating equations for longitudinal data analysis. Organ Res Methods. 2004;7(2):127–50.
Laird NM, Ware JH. Random-effects models for longitudinal data. Biometrics. 1982;38(4):963–74.
Gardiner JC, Luo Z, Roman LA. Fixed effects, random effects and GEE: what are the differences? Stat Med. 2009;28(2):221–39.
Nagin DS, Jones BL, Passos VL, Tremblay RE. Group-based multi-trajectory modeling. Stat Methods Med Res. 2016;27(7):2015–23.
Ibrahim JG, Chu H, Chen LM. Basic concepts and methods for joint models of longitudinal and survival data. J Clin Oncol. 2010;28(16):2796–801.
Sayers A, Heron J, Smith A, Macdonald-Wallis C, Gilthorpe MS, Steele F, et al. Joint modelling compared with two stage methods for analysing longitudinal data and prospective outcomes: a simulation study of childhood growth and BP. Stat Methods Med Res. 2014;26(1):437–52.
Ibrahim JG, Chu H, Chen LM. Basic concepts and methods for joint models of longitudinal and survival data. Journal of Clinical Oncology : Official Journal of the American Society of Clinical Oncology. 2010;28(16):2796–801.
Henderson R, Diggle P, Dobson A. Joint modelling of longitudinal measurements and event time data. Biostatistics. 2000;1(4):465–80.
Pebesma J, Martinez-Millana A, Sacchi L, Fernandez-Llatas C, De Cata P, Chiovato L, et al. Clustering cardiovascular risk trajectories of patients with type 2 diabetes using process mining. Annu Int Conf IEEE Eng Med Biol Soc. 2019;2019:341–4.
Obermeyer Z, Emanuel EJ. Predicting the future - big data, machine learning, and clinical medicine. N Engl J Med. 2016;375(13):1216–9.
Author information
Authors and Affiliations
Contributions
DS, DAL, SLH, RKD: have made substantial contributions to conception or design of the work, or the acquisition, analysis, or interpretation of data for the work. DS, DAL, SLH, RKD: drafted the initial work and had full access to data. DS, DAL, SLH, GYHL, RKD: revised it critically for important intellectual content. DS, DAL, SLH, GYHL, RKD: final approval of the version to be published. DS, DAL, SLH, GYHL, RKD: agreed to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
DS and RKD: None declared.
DAL: Received investigator-initiated educational grants from Bristol-Myers Squibb (BMS), has been a speaker for Boehringer Ingeheim, and BMS/Pfizer and has consulted for BMS/Pfizer, Bayer, Boehringer Ingelheim, and Daiichi-Sankyo.
SLH: Received investigator-initiated funding from Bristol-Myers Squibb.
GYHL: Consultant and speaker for BMS/Pfizer, Boehringer Ingelheim and Daiichi-Sankyo. No fees are received personally.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Stevens, D., Lane, D.A., Harrison, S.L. et al. Modelling of longitudinal data to predict cardiovascular disease risk: a methodological review. BMC Med Res Methodol 21, 283 (2021). https://doi.org/10.1186/s12874-021-01472-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-021-01472-x