
Abstract
Background
Finding eligible studies for meta-analysis and systematic reviews relies on keyword-based searching as the gold standard, despite its inefficiency. Searching based on direct citations is not sufficiently comprehensive. We propose a novel strategy that ranks articles on their degree of co-citation with one or more “known” articles before reviewing their eligibility.
Method
In two independent studies, we aimed to reproduce the results of literature searches for sets of published meta-analyses (n = 10 and n = 42). For each meta-analysis, we extracted co-citations for the randomly selected ‘known’ articles from the Web of Science database, counted their frequencies and screened all articles with a score above a selection threshold. In the second study, we extended the method by retrieving direct citations for all selected articles.
Results
In the first study, we retrieved 82 % of the studies included in the meta-analyses while screening only 11 % as many articles as were screened for the original publications. Articles that we missed were published in non-English languages, published before 1975, published very recently, or available only as conference abstracts. In the second study, we retrieved 79 % of included studies while screening half the original number of articles.
Conclusions
Citation searching appears to be an efficient and reasonably accurate method for finding articles similar to one or more articles of interest for meta-analysis and reviews.
Similar content being viewed by others

Background
Meta-analysis is an increasingly popular statistical method for comparing and summarizing the results of multiple independent studies. First introduced to clinical research in the 1980s, meta-analysis is now a cornerstone of evidence-based medicine [1]. It has also become an important step in establishing the credibility of research findings, such as those from hypothesis-free discovery research studies [2]. The number of published meta-analyses indexed in PubMed is increasing by about 20 % per year (PubMed).
An ideal meta-analysis provides a complete representation of all relevant data, both published and unpublished. Finding eligible studies is often the most challenging and time-consuming phase in conducting a meta-analysis, especially when the terminology for key concepts, variables and outcomes differs among studies. The Cochrane Collaboration— internationally regarded for its rigorous approach to meta-analyses of clinical interventions—recommends searching multiple publication databases by using Boolean combinations of all possible keywords, including synonyms and related words that authors may have used to describe their studies, and complementing keyword-based searches with hand screening of references listed in the retrieved articles [3]. Casting a wide net often retrieves thousands of publications that must be screened to find a handful of eligible studies. Despite its inefficiency, this approach remains the gold standard.
Finding eligible studies by screening the references and subsequent citations of articles that are already known could be seen as a way to crowd-source expert knowledge of the published scientific literature. The network properties of scientific citations have been studied extensively since the 1950s, when they were used to create the Science Citation Index [4, 5]; they have been further exploited in the development of online research tools such as Web of Science, Scopus and Google Scholar. Some current research explores the use of computational algorithms to automate citation retrieval for systematic reviews [6].
Although it is intuitively appealing, backward and forward citation checking falls short as a way to identify eligible articles for meta-analysis. Searching these ‘direct’ citations could be an efficient strategy only if eligible studies consistently cited all relevant earlier work, thus creating a single citation network, but this is often not the case. For example, a review of 259 meta-analyses found that in fewer than half (46 %) were included articles connected in a single citation network; in the remainder, included articles were in either two (39 %) or three or more (15 %) disconnected citation networks [7]. Citation searching has thus gained only equivocal support, even as a complement to keyword searching [8, 9].
Searching based on direct citations is insensitive and inefficient because researchers tend to cite only some related earlier articles, not all. Although eligible studies may be only sparsely connected by direct citations, taking indirect connections into account can help identify additional studies. For example, two eligible studies that are not connected by direct citations might both be co-cited by the same newer article [10], or they may be coupled because they both cite the same earlier article [11]. These citing and cited articles may be commentaries, reviews or original research articles on related topics.
The principles of co-citation and bibliographic coupling are used extensively in bibliometrics and scientometrics to document and visualize similarity between articles, topics, authors and disciplines [12–15]; however, they have not been used specifically to find eligible studies for meta-analyses or systematic reviews. We propose a search method that ranks articles on their degree of co-citation with one or more known articles and demonstrate that other studies eligible for inclusion in the meta-analysis rank high on this list.
Methods
The method
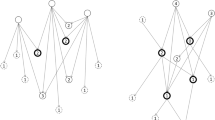
The search method assumes that one or more eligible studies are “known” at the start of the search (Fig. 1a, bold circles). In the event that researchers are unfamiliar with the topic, they can first perform a keyword-based search to find one or more studies that meet the inclusion criteria. When a known study is cited (Fig. 1a, squares), the reference list of the citing article contains articles co-cited with the known study (Fig. 1a, regular circles). If a known study is cited 50 times, for example, there will be 50 such reference lists. For each article on a reference list, we can count how frequently it appears on the other 49 lists. The higher the number, the more often the article was co-cited with the known study. Likewise, when two known articles are cited 50 times each, there are up to 100 reference lists. Articles that appear most frequently on these lists are the ones that were co-cited most often with one or both of the known articles. We hypothesized that limiting the screening of articles to those that were frequently cited together with one or more known articles might be an efficient method for finding other eligible studies.

Overview of the search method. a Indirect citations (co-citations). Bold circles represent articles known at the beginning of the search. Squares represent citing articles; the articles on their reference lists (co-citing articles) are represented by circles. Numbers within circles indicate the number of times an article is co-cited (dashed circles represent articles co-cited only once). b. Direct citations. Bold circles represent articles known at the beginning of the search. Dashed squares represent citing articles; dashed circles represent articles on the known articles’ reference lists. Numbers within dashed squares and circles indicate the number of times an article cites or is cited by a known article
We investigated the method by using Web of Science to reproduce the set of studies included in two independently selected samples of recently published meta-analyses. First we conducted a pilot study (Study 1) that applied the method to ten meta-analyses. We investigated the performance of the method by comparing different selection thresholds and examined the types of studies that were not retrieved. In the second study (Study 2), we used results from the first study to fine-tune the selection threshold (see below) and augmented the search strategy with a second search based on direct citations, specifically to retrieve recent articles that had not been cited yet.
Study 1
Selection of meta-analyses
Meta-analyses were identified by two different PubMed searches: Eight meta-analyses by searching on a single title word (“meta-analysis”) and two by searching a specific journal name (“Cochrane Database Syst Rev”). Meta-analyses were selected consecutively and were eligible if they had reported the total number of articles that were retrieved by applying one or more search strategies to one or more databases. This number, which indicated the total number of articles that had been screened for eligibility in the meta-analysis, could be reported in a flowchart or in the text, but should have been reported separately from the number of full-text articles screened (we noticed that this distinction was ambiguous in many meta-analyses). All procedures and analyses described below were performed separately for each of the ten meta-analyses. A short description of the meta-analyses is provided in Additional file 1: Table S1.
Selection of “known” articles
From each meta-analysis, we randomly chose one or two included studies to start the search. After drawing citation networks (Additional file 1: Figure S1), we discovered that for two meta-analyses, we had chosen a study that would favor our results: the study of O’Keefe et al. in the meta-analysis of Frolkis et al. [16], which was part of a second citation network, and the study of Gallon et al. in the meta-analysis of Knoll et al. [17], which was not connected to any other study. We decided not to consider these studies “known” but to investigate whether they would be retrieved by searching from the one remaining study.
Obtaining citation networks
To illustrate the density of the citation networks, we obtained all direct citations between the studies included in the meta-analyses. Using Web of Science (Thomson Reuters, USA), we manually screened the reference lists of all published studies included in the meta-analysis and documented for each article which of the other included studies were cited. Citation networks were drawn manually (Additional file 1: Figure S1).
Data collection
The known articles (Fig. 1a, bold circles) were identified in the Web of Science database. Articles that cited a known article (which Web of Science calls “citing articles”; Fig. 1a, squares A, B, C) were saved to the “Marked list”. This list was downloaded with the full bibliographic details of each article, including the cited references (regular and dashed circles), and saved in a Microsoft Excel file. The list of citing articles naturally includes the published meta-analysis. We removed the meta-analysis itself and all articles with a more recent publication date from the list and excluded them from the rest of the analyses.
Web of Science provides the entire reference list for each citing article in a single cell. To obtain a full list of all co-cited articles, we extracted the references from all citing articles into a single datasheet. Any article that is cited by multiple citing articles appears more than once on the datasheet; the number of times it appears is its co-citation frequency or co-citation strength. The co-citation frequency has a minimum value of 1 and a maximum value equal to the number of citing articles. We counted and collapsed duplicate records, sorted the articles in descending order of co-citation frequency, and marked all articles that were included in the original meta-analysis.
Analyses
We quantified the performance of the search method using three different selection strategies to screen the co-citations: (1) those that were co-cited at least once (threshold ≥1, which was the entire dataset; Fig. 1a, regular circles); (2) those that were co-cited at least twice (threshold ≥2); and (3) those that were frequently co-cited with the known articles (varying the threshold among meta-analyses). We decided to examine frequently co-cited articles after exploring the distributions of co-citations; we learned that for each meta-analysis, about 80 % of the articles are co-cited once and only a limited number are co-cited frequently (Additional file 1: Figure S2). We chose a threshold for each meta-analysis such that the number of frequently co-cited articles was between 100 and 150, or closest to 100 when the nearest thresholds were both outside that range. The chosen threshold varied among meta-analyses, depending on the citation density (for highly-cited topics, the threshold could be set higher).
For each published meta-analysis, as a measure of the efficiency of the method, we counted the number of articles selected at each threshold and compared this with the number of articles screened by the authors of the meta-analysis. As a measure of the accuracy of the method, we also counted the number of studies that had been included in the meta-analysis and compared this with the total number of articles included in the meta-analysis at each selection threshold.
Study 2
Selection of meta-analyses
We searched PubMed using the title word “meta-analysis” to identify meta-analyses published between 1 January and 28 February 2015 in journals that were listed in the category of Core Clinical Journals. This search yielded 121 articles. We sorted the list on journal name and selected the first meta-analysis for each journal, which yielded 49 meta-analyses. Seven meta-analyses were excluded either because they had not performed a literature search (n = 4; e.g., genome-wide association studies), provided only one flowchart for multiple meta-analyses (n = 2), or reported a search for more recent articles to update a previously published meta-analysis (n = 1). A short description of the meta-analyses is provided in Additional file 1: Table S1.
Selection of “known” articles
For each meta-analysis, we used a standardized procedure to select two included studies. We surmised that researchers who consider performing a meta-analysis know of at least two studies and are more likely to be familiar with the studies that had larger sample sizes. We therefore assumed for this analysis that the two largest studies indexed in Web of Science were known and that literature searches were performed to find all the others. When the largest studies were not indexed (e.g., because they were published in journals that were not indexed, in theses or on websites; n = 11), we took the next largest. Choosing the largest study might seem to bias the results in our favor; however, the largest studies were often not the first, and were therefore not published in high-impact journals or were too recent to have been cited. Both of these conditions would tend to undermine the observed accracy of our method. On the other hand, when the largest studies were highly cited, choosing them would tend to reduce the method’s observed efficiency.
Data collection and analyses
The literature search in Study 2 consisted of two searches: first for co-citations and second for direct citations. The first search was identical to the procedure in Study 1, except that we applied a different selection threshold to improve efficiency in the case of highly-cited articles in dense citation networks. In this case, in addition to the simple count of the number of times an article was co-cited with the known articles, we calculated an index (the j-index) that represented the number of times the article was co-cited as percentage of the number of citing articles. We then selected for screening all articles that were co-cited more than once and co-cited in more than 1 % of the citing articles. Thus, the screening threshold was based on the number of citing articles: when the number of citing articles was less than 100, the threshold was based on the number of co-citations; when it was more than 100, it was based on the index.
For the second search, we extracted all backward and forward direct citations (Fig. 1b, dashed squares and circles, regular circles) for the two known articles and all articles that were retrieved in the first search (Fig. 1b, bold circles). We counted the frequency of each citation in the database and ranked the citations in descending order. All articles that had two or more direct citations were screened to find the articles that were included in the meta-analysis but not retrieved in the first search.
Results
Study 1
The meta-analyses included between 4 and 27 studies (median 10) for which the authors had screened from 784 to 17,500 articles (median 1,642; Table 1). The number of direct citations connecting the included studies ranged from 2 to 99 (median 15; Additional file 1: Figure S1) with a median of 2 citations between any two articles (data not shown). In three meta-analyses, all included studies were connected in a single citation network; the other meta-analyses included between one and seven disconnected studies, i.e., articles that did not cite and were not cited by any of the other articles in the direct citation network (Additional file 1: Figure S1). Among the 10 meta-analyses, the number of articles co-cited with the known articles ranged from 588 to 8,388 (median 997; Table 1), producing a much richer network of indirect connections than the sparse network of direct connections.
We evaluated three different selection criteria for screening co-citations. Screening all co-citations retrieved 75 to 100 % (median 94 %) of all studies included in the original meta-analyses (Table 1). This selection was more efficient than the original search, except when the known articles were highly cited (cited > 100 times). Screening only the articles that were co-cited more than once with known articles was more efficient than the original search for 9 of 10 meta-analyses (Table 1), retrieving a median of 82 % of included studies while screening a median of 11 % as many articles. Screening only the frequently co-cited articles (see definition in Methods and Additional file 1: Figure S2) reduced the number of screened articles to between 1 and 16 % (median 8 %) of the original number and retrieved 50 to 100 % (median 76 %) of the included studies.
We reviewed the titles of articles that ranked highest in co-citation frequency for each meta-analysis and found that they tended to refer to the same topic (see examples in Additional file 1: Table S2); also the articles that were not included or cited in the meta-analysis. Topics were more diverse among articles that were co-cited fewer times. This is most apparent in Additional file 1: Table S2D, where the titles of articles that were co-cited two or three times had little in common with the topic of the meta-analysis.
The types of articles that were not found by our method varied, as expected, according to the selection criteria. (Table 2). Most of the articles that were not co-cited or co-cited only once were either published in non-English languages, published before 1975, published very recently, or available only as abstracts.
Co-citation searching identified 49 of 55 articles that were not connected with the known articles via direct citations (Table 3), including 15 of 19 articles that were completely disconnected from the entire single citation network surrounding the known articles (Additional file 1: Figure S1).
Study 2
We conducted a second study of 42 different meta-analyses, in which we applied a standardized strategy consisting of two consecutive searches. The first search was the same as in the Study 1, except that we screened all articles that were co-cited in more than 1 % of the citing articles. In the first search, we retrieved a median of 69 % of the included articles while screening only 29 % of the number of articles that the authors of the meta-analyses had screened (Table 4; Fig. 2). A higher number of citing articles increased the number of articles that needed to be screened (Fig. 3a) without markedly increasing the number of studies retrieved (Fig. 3b).

Articles screened and studies retrieved in Study 2. a. Number of articles screened for the published meta-analysis, compared with the number selected for screening by the new method (searches for indirect and direct citations combined). b Studies retrieved in Study 2 (searches for indirect and direct citations combined) as percent of the number of studies included in the published meta-analysis (numbered as in Fig. 2a)

Articles screened and studies retrieved in Study 2 (indirect citations), in relation to the number of citing articles. a Number of articles screened. b Studies retrieved (percent)
In the second search, we obtained the direct citations of all articles retrieved in the first search and screened those that cited or were cited by two or more of them. The second search retrieved an additional 10 % of the included studies, which brought the median to 79 % (Table 4; Fig. 2). The two searches combined required screening 50 % as many articles as had been screened by authors of the original meta-analyses.
Discussion
Before discussing the implications of our method, several methodological issues about the studies needs to be discussed. First, we evaluated the performance of our method conservatively by assuming that the original meta-analyses were comprehensive and complete. Thus, when we failed to retrieve a study, we considered it a shortcoming of our method, not of the published meta-analysis. Yet, in the meta-analysis of second surgery in Crohn’s disease, for example, we missed the only two pediatric studies [16], and we missed five articles that were published before 1975 (Table 2); these studies may be less comparable to others included in the meta-analysis. Furthermore, for all meta-analyses, we found original articles on the same topic that were more frequently co-cited than the articles that were included (see examples in Additional file 1: Table S2); however, we did not attempt to investigate whether they had been excluded after screening or perhaps should have been included in the meta-analyses.
Second, our method demonstrated lower efficiency and accuracy in the second study, which could be attributed to several factors. The second study included more highly cited topics, which tend to generate a higher number of co-citations, thus reducing efficiency. This study also included more meta-analyses for which the authors screened a relatively low number of articles. In the first study, none of the meta-analyses had screened fewer than 500 articles and only three (30 %) had screened fewer than 1,000 (Table 1); in contrast, of the 42 meta-analyses in the second study, 10 (24 %) had screened fewer than 500 articles and 20 (48 %) had screened fewer than 1,000 (Table 4).
The second study also included more meta-analyses on heterogeneous topics, which tended to reduce accuracy. For example, we retrieved only 10 % of the studies included in a meta-analysis on normalization of vitamin D levels in children of various ages and with various diseases [18]; 18 % of the studies on the use of simulation-based assessments for patient-related outcomes for a variety of tasks and skills in physicians, medical students, dentists and nurses [19]; and 38 % of the studies on the safety of intravenous iron preparations in patients with various disorders [20]. Clearly, the method does not work when the topic of the meta-analysis is heterogeneous and the studies of interest are unlikely to have cited each other. The second study also included several meta-analyses with very small sample sizes, including one in which half of the studies were case reports that had few or no references [21], as well as a meta-analysis for which the ‘known’ studies were cited only four times in total [22]. The percentage of retrieved studies jumped to 89 % when these five meta-analyses were excluded.
And third, we compared our method with literature searches of the published meta-analyses that often combined separate searches in multiple databases, supplemented with the screening of references lists, conference abstracts and grey literature, and the consultation of experts. These additional strategies may have yielded studies that were not indexed in databases like Web of Science or Medline, and contributed to underestimation of the accuracy. For example, we were unable to retrieve the two master theses that were included in a meta-analysis for which the authors searched the Dissertation Abstracts International database, [23] and missed many South-American and Asian studies of a meta-analysis for which the authors additionally searched the LILACS and KOREAMED databases [20]. Additional strategies like these can be used to complement our search method--either to find more eligible studies or to increase confidence in the results of the search method when no other studies are found.
Using a citation-based search to identify articles for meta-analysis has several advantages. Perhaps most importantly, the quality of the search does not depend on keywords, which is particularly relevant for topics where there is no consistent terminology. In contrast to machine-learning algorithms, citation-based searching does not depend on the quality and selection of a training set. Co-citation searching was more efficient than keyword-based searching, retrieving a median of 76 % of eligible studies from a short list of around 100 of the most frequently co-cited articles (Table 1). Co-citation searching also retrieved articles published in journals that were not indexed in Web of Science, suggesting that the need to search other databases could be reduced. An interesting example is the meta-analysis of immunoglobulin treatment for severe acute respiratory infections such as SARS, avian influenza (H1N1), and the Spanish influenza of 1918 [24]. This meta-analysis included 16 studies published in 1919–1920, of which we were able to retrieve 13. These included publications in the Norsk Magazin för Laegevidenskapen, Boston Medical and Surgical Journal, La Presse Médicale, New York Medical Journal and Hygiea, which are all journals that no longer exist. These studies could be retrieved because they had been cited by studies of more recent outbreaks that were published in journals that were indexed in Web of Science.
The accuracy and efficiency of co-citation searching depends on characteristics of the underlying citation network. By design, our method misses the studies that the collective community of researchers apparently did not find worth citing. In our analysis, these included abstracts, articles in non-English languages, very old articles, and publications in semi-scientific journals, reports, websites, and theses. In addition, some newer and some very old articles were not cited often enough to rank high in our search. Some modifications of our method could help identify these articles; for example, as shown in Table 2, half of the missed articles were connected with retrieved articles through direct citations. Aggregating and ranking the direct citations among all articles that are retrieved by our search might be an efficient way to find them. Other modifications might be necessary when the method is applied to topics with very dense citation networks of highly-cited articles; in these situations the number of articles to be screened could be limited further, for example, by setting a higher citation threshold.
Conclusions
Reviewing published scientific findings requires evaluating unstructured data and text, for which human insight and judgment are crucial [25, 26]. Our method makes use of the collective knowledge of researchers in a given field by performing an initial ranking that can be fully automated. Researchers conducting meta-analyses must still identify and evaluate the eligible studies, but with the advantage of being able to screen only half of the number of articles compared to keyword-base literature search, and to screen the most similar articles first. Although we evaluated this method as it applies to meta-analysis, it could be used to find related articles for any type of study, as demonstrated in Additional file 1: Table S2. Screening a short list of frequently co-cited articles is an efficient strategy for finding key articles related to one or more “known” articles, even when a formal meta-analysis is not the goal. Going forward, this strategy has the potential to help strengthen connections among articles and improve and facilitate the process of evidence synthesis.
References
L’Abbe KA, Detsky AS, O’Rourke K. Meta-analysis in clinical research. Ann Intern Med. 1987;107(2):224–33.
Thompson PM, Stein JL, Medland SE, Hibar DP, Vasquez AA, Renteria ME, et al. The ENIGMA consortium: large-scale collaborative analyses of neuroimaging and genetic data. Brain Imaging Behav. 2014;8(2):153–82.
Higgins JPT, Green S, Cochrane Collaboration. Cochrane handbook for systematic reviews of interventions. Chichester, England ; Hoboken, NJ: Wiley-Blackwell; 2011.
Garfield E. Citation indexes for science; a new dimension in documentation through association of ideas. Science. 1955;122(3159):108–11.
Price DJ. Networks of scientific papers. Science. 1965;149(3683):510–5.
Choong MK, Galgani F, Dunn AG, Tsafnat G. Automatic evidence retrieval for systematic reviews. J Med Internet Res. 2014;16(10):e223.
Robinson KA, Dunn AG, Tsafnat G, Glasziou P. Citation networks of related trials are often disconnected: implications for bidirectional citation searches. J Clin Epidemiol. 2014;67(7):793–9.
Horsley T, Dingwall O, Sampson M. Checking reference lists to find additional studies for systematic reviews. Cochrane Database Syst Rev. 2011;8:MR000026.
Wright K, Golder S, Rodriguez-Lopez R. Citation searching: a systematic review case study of multiple risk behaviour interventions. BMC Med Res Methodol. 2014;14:73.
Small H. Co-citation in the Scientific Literature: a new measure of the relationship between two documents. J Am Soc Inf Sci. 1973;24(4):265–9.
Kessler MM. Bibliographic coupling between scientific papers. Am Doc. 1963;14(1):10–25.
Eto M. Evaluations of context-based co-citation searching. Scientometrics. 2013;94(2):651–73.
White HD, McCain KW. Visualizing a discipline: an author co-citation analysis of information science, 1972–1995. J Am Soc Inf Sci. 1998;49(4):327–55.
Jankovic MP, Kaufmann M, Kindler CH. Active research fields in anesthesia: a document co-citation analysis of the anesthetic literature. Anesth Analg. 2008;106(5):1524–33.
van Eck NJ, Waltman L. Appropriate similarity measures for author co-citation analysis. J Am Soc Inf Sci Technol. 2008;59:1653–61.
Frolkis AD, Lipton DS, Fiest KM, Negron ME, Dykeman J, deBruyn J, et al. Cumulative incidence of second intestinal resection in Crohn’s disease: a systematic review and meta-analysis of population-based studies. Am J Gastroenterol. 2014;109(11):1739–48.
Knoll GA, Kokolo MB, Mallick R, Beck A, Buenaventura CD, Ducharme R, et al. Effect of sirolimus on malignancy and survival after kidney transplantation: systematic review and meta-analysis of individual patient data. BMJ. 2014;349:g6679.
McNally JD, Iliriani K, Pojsupap S, Sampson M, O’Hearn K, McIntyre L, et al. Rapid normalization of vitamin D levels: a meta-analysis. Pediatrics. 2015;135(1):e152–166.
Brydges R, Hatala R, Zendejas B, Erwin PJ, Cook DA. Linking simulation-based educational assessments and patient-related outcomes: a systematic review and meta-analysis. Acad Med. 2015;90(2):246–56.
Avni T, Bieber A, Grossman A, Green H, Leibovici L, Gafter-Gvili A. The safety of intravenous iron preparations: systematic review and meta-analysis. Mayo Clin Proc. 2015;90(1):12–23.
Kumar AR, Guilleminault C, Certal V, Li D, Capasso R, Camacho M. Nasopharyngeal airway stenting devices for obstructive sleep apnoea: a systematic review and meta-analysis. J Laryngol Otol. 2015;129(1):2–10.
Fazeli MS, Lin Y, Nikoo N, Jaggumantri S, Collet JP, Afshar K. Biofeedback for nonneuropathic daytime voiding disorders in children: a systematic review and meta-analysis of randomized controlled trials. J Urol. 2015;193(1):274–9.
Williams R, Murray A. Prevalence of depression after spinal cord injury: a meta-analysis. Arch Phys Med Rehabil. 2015;96(1):133–40.
Mair-Jenkins J, Saavedra-Campos M, Baillie JK, Cleary P, Khaw FM, Lim WS, et al. The effectiveness of convalescent plasma and hyperimmune immunoglobulin for the treatment of severe acute respiratory infections of viral etiology: a systematic review and exploratory meta-analysis. J Infect Dis. 2015;211(1):80–90.
Elliott JH, Mavergames C, Becker L, Meerpohl J, Thomas J, Gruen R, et al. The efficient production of high quality evidence reviews is important for the public good. BMJ. 2013;346:f846.
Greenhalgh T, Peacock R. Effectiveness and efficiency of search methods in systematic reviews of complex evidence: audit of primary sources. BMJ. 2005;331(7524):1064–5.
Boothe VL, Boehmer TK, Wendel AM, Yip FY. Residential traffic exposure and childhood leukemia: a systematic review and meta-analysis. Am J Prev Med. 2014;46(4):413–22.
Oliver-Williams CT, Heydon EE, Smith GC, Wood AM. Miscarriage and future maternal cardiovascular disease: a systematic review and meta-analysis. Heart. 2013;99(22):1636–44.
Stevanovic A, Rossaint R, Fritz HG, Froeba G, Heine J, Puehringer FK, et al. Airway reactions and emergence times in general laryngeal mask airway anaesthesia: a meta-analysis. Eur J Anaesthesiol. 2015;32(2):106–16.
de Vries FM, Kolthof J, Postma MJ, Denig P, Hak E. Efficacy of standard and intensive statin treatment for the secondary prevention of cardiovascular and cerebrovascular events in diabetes patients: a meta-analysis. PLoS One. 2014;9(11):e111247.
Crider KS, Cordero AM, Qi YP, Mulinare J, Dowling NF, Berry RJ. Prenatal folic acid and risk of asthma in children: a systematic review and meta-analysis. Am J Clin Nutr. 2013;98(5):1272–81.
Herretes S, Wang X, Reyes JM. Topical corticosteroids as adjunctive therapy for bacterial keratitis. Cochrane Database Syst Rev. 2014;10:CD005430.
Gharaibeh A, Savage HI, Scherer RW, Goldberg MF, Lindsley K. Medical interventions for traumatic hyphema. Cochrane Database Systematic Rev. 2013;12:CD005431.
Gu XL, Wu GN, Yao YW, Shi DH, Song Y. Is high-frequency oscillatory ventilation more effective and safer than conventional protective ventilation in adult acute respiratory distress syndrome patients? A meta-analysis of randomized controlled trials. Crit Care. 2014;18(3):R111.
Mehrabi A, Hafezi M, Arvin J, Esmaeilzadeh M, Garoussi C, Emami G, et al. A systematic review and meta-analysis of laparoscopic versus open distal pancreatectomy for benign and malignant lesions of the pancreas: it’s time to randomize. Surgery. 2015;157(1):45–55.
Pathak R, Pandit A, Karmacharya P, Aryal MR, Ghimire S, Poudel DR, et al. Meta-analysis on risk of bleeding with apixaban in patients with renal impairment. Am J Cardiol. 2015;115(3):323–7.
Viswanathan M, Kahwati LC, Golin CE, Blalock SJ, Coker-Schwimmer E, Posey R, et al. Medication therapy management interventions in outpatient settings: a systematic review and meta-analysis. JAMA Int Med. 2015;175(1):76–87.
Vrablik ME, Snead GR, Minnigan HJ, Kirschner JM, Emmett TW, Seupaul RA. The diagnostic accuracy of bedside ocular ultrasonography for the diagnosis of retinal detachment: a systematic review and meta-analysis. Ann Emerg Med. 2015;65(2):199–203. e191.
van Wely BJ, de Wilt JH, Francissen C, Teerenstra S, Strobbe LJ. Meta-analysis of ultrasound-guided biopsy of suspicious axillary lymph nodes in the selection of patients with extensive axillary tumour burden in breast cancer. Br J Surg. 2015;102(3):159–68.
Schuit E, Stock S, Rode L, Rouse DJ, Lim AC, Norman JE, et al. Effectiveness of progestogens to improve perinatal outcome in twin pregnancies: an individual participant data meta-analysis. BJOG. 2015;122(1):27–37.
Deng JL, Wu YX, Liu J. Efficacy of implantable cardioconverter defibrillator or cardiac resynchronization therapy compared with combined therapy in survival of patients with heart failure: a meta-analysis. Medicine (Baltimore). 2015;94(5):e418.
Nwachuku EL, Balzer JR, Yabes JG, Habeych ME, Crammond DJ, Thirumala PD. Diagnostic value of somatosensory evoked potential changes during carotid endarterectomy: a systematic review and meta-analysis. JAMA Neurol. 2015;72(1):73–80.
Gu WJ, Wang F, Liu JC. Effect of lung-protective ventilation with lower tidal volumes on clinical outcomes among patients undergoing surgery: a meta-analysis of randomized controlled trials. CMAJ. 2015;187(3):E101–109.
Sanlorenzo M, Wehner MR, Linos E, Kornak J, Kainz W, Posch C, et al. The risk of melanoma in airline pilots and cabin crew: a meta-analysis. JAMA Dermatol. 2015;151(1):51–8.
Al-Wassia H, Shah PS. Efficacy and safety of umbilical cord milking at birth: a systematic review and meta-analysis. JAMA Pediatr. 2015;169(1):18–25.
Elshaer M, Gravante G, Thomas K, Sorge R, Al-Hamali S, Ebdewi H. Subtotal cholecystectomy for “difficult gallbladders”: systematic review and meta-analysis. JAMA Surg. 2015;150(2):159–68.
Mumme K, Stonehouse W. Effects of medium-chain triglycerides on weight loss and body composition: a meta-analysis of randomized controlled trials. J Acad Nutr Diet. 2015;115(2):249–63.
Hazlewood GS, Rezaie A, Borman M, Panaccione R, Ghosh S, Seow CH, et al. Comparative effectiveness of immunosuppressants and biologics for inducing and maintaining remission in Crohn’s disease: a network meta-analysis. Gastroenterology. 2015;148(2):344–54. e345; quiz e314-345.
Sheyin O, Davies O, Duan W, Perez X. The prognostic significance of troponin elevation in patients with sepsis: a meta-analysis. Heart Lung. 2015;44(1):75–81.
Yuan Q, Wu X, Sun Y, Yu J, Li Z, Du Z, et al. Impact of intracranial pressure monitoring on mortality in patients with traumatic brain injury: a systematic review and meta-analysis. J Neurosurg. 2015;122(3):574–87.
Elmariah S, Mauri L, Doros G, Galper BZ, O’Neill KE, Steg PG, et al. Extended duration dual antiplatelet therapy and mortality: a systematic review and meta-analysis. Lancet. 2015;385(9970):792–8.
Cheelo M, Lodge CJ, Dharmage SC, Simpson JA, Matheson M, Heinrich J, et al. Paracetamol exposure in pregnancy and early childhood and development of childhood asthma: a systematic review and meta-analysis. Arch Dis Child. 2015;100(1):81–9.
Gu WJ, Wang F, Tang L, Liu JC. Single-dose etomidate does not increase mortality in patients with sepsis: a systematic review and meta-analysis of randomized controlled trials and observational studies. Chest. 2015;147(2):335–46.
Saleh A, Khanna A, Chagin KM, Klika AK, Johnston D, Barsoum WK. Glycopeptides versus beta-lactams for the prevention of surgical site infections in cardiovascular and orthopedic surgery: a meta-analysis. Ann Surg. 2015;261(1):72–80.
Emdin CA, Rahimi K, Neal B, Callender T, Perkovic V, Patel A. Blood pressure lowering in type 2 diabetes: a systematic review and meta-analysis. JAMA. 2015;313(6):603–15.
Sayegh ET, Strauch RJ. Does nonsurgical treatment improve longitudinal outcomes of lateral epicondylitis over no treatment? A meta-analysis. Clin Orthop Relat Res. 2015;473(3):1093–107.
Kamper SJ, Apeldoorn AT, Chiarotto A, Smeets RJ, Ostelo RW, Guzman J, et al. Multidisciplinary biopsychosocial rehabilitation for chronic low back pain: cochrane systematic review and meta-analysis. BMJ. 2015;350:h444.
Taioli E, Wolf AS, Flores RM. Meta-analysis of survival after pleurectomy decortication versus extrapleural pneumonectomy in mesothelioma. Ann Thorac Surg. 2015;99(2):472–80.
Sharpe RA, Bearman N, Thornton CR, Husk K, Osborne NJ. Indoor fungal diversity and asthma: a meta-analysis and systematic review of risk factors. J Allergy Clin Immunol. 2015;135(1):110–22.
Zhang D, Lv S, Song X, Yuan F, Xu F, Zhang M, et al. Fractional flow reserve versus angiography for guiding percutaneous coronary intervention: a meta-analysis. Heart. 2015;101(6):455–62.
Siddiqui NY, Grimes CL, Casiano ER, Abed HT, Jeppson PC, Olivera CK, et al. Mesh sacrocolpopexy compared with native tissue vaginal repair: a systematic review and meta-analysis. Obstet Gynecol. 2015;125(1):44–55.
Bonitsis NG, Luong Nguyen LB, LaValley MP, Papoutsis N, Altenburg A, Kotter I, et al. Gender-specific differences in Adamantiades-Behcet’s disease manifestations: an analysis of the German registry and meta-analysis of data from the literature. Rheumatology (Oxford). 2015;54(1):121–33.
Souto A, Salgado E, Maneiro JR, Mera A, Carmona L, Gomez-Reino JJ. Lipid profile changes in patients with chronic inflammatory arthritis treated with biologic agents and tofacitinib in randomized clinical trials: a systematic review and meta-analysis. Arthritis Rheumatol. 2015;67(1):117–27.
Zhen C, Xia Z, Ya Jun Z, Long L, Jian S, Gui Ju C, et al. Accuracy of infrared tympanic thermometry used in the diagnosis of Fever in children: a systematic review and meta-analysis. Clin Pediatr (Phila). 2015;54(2):114–26.
Shan L, Shan B, Suzuki A, Nouh F, Saxena A. Intermediate and long-term quality of life after total knee replacement: a systematic review and meta-analysis. J Bone Joint Surg Am. 2015;97(2):156–68.
Marcuzzi A, Dean CM, Wrigley PJ, Hush JM. Early changes in somatosensory function in spinal pain: a systematic review and meta-analysis. Pain. 2015;156(2):203–14.
Lipinski MJ, Baker NC, Escarcega RO, Torguson R, Chen F, Aldous SJ, et al. Comparison of conventional and high-sensitivity troponin in patients with chest pain: a collaborative meta-analysis. Am Heart J. 2015;169(1):6–16. e16.
Stevens AJ, Woodman RJ, Owen H. The effect of ondansetron on the efficacy of postoperative tramadol: a systematic review and meta-analysis of a drug interaction. Anaesthesia. 2015;70(2):209–18.
Bernstein RS, Meurer LN, Plumb EJ, Jackson JL. Diabetes and hypertension prevalence in homeless adults in the United States: a systematic review and meta-analysis. Am J Public Health. 2015;105(2):e46–60.
Acknowledgements
A.C.J.W. Janssens acknowledges financial support by the European Research Council (ERC) Consolidator Grant GENOMICMEDICINE. All the data reported in this manuscript are presented in the main paper and in the supplementary materials. The raw data can be obtained from the corresponding author.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
ACJWJ has filed a patent application for the method described in this article. MG declares that she has no competing interests.
Authors’ contributions
ACJWJ developed the method, designed the study and carried out the analyses. MG critically reviewed the method, the study design and results. Both authors contributed to the writing of the manuscript and approved the final version.
An erratum to this article is available at http://dx.doi.org/10.1186/s12874-015-0093-z.
Additional file
Additional file 1:
(DOCX 975 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Janssens, A.C.J.W., Gwinn, M. Novel citation-based search method for scientific literature: application to meta-analyses. BMC Med Res Methodol 15, 84 (2015). https://doi.org/10.1186/s12874-015-0077-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-015-0077-z