
Abstract
The class of beta-generated distributions (Commun. Stat. Theory Methods 31:497–512, 2002; TEST 13:1–43, 2004) has received a lot of attention in the last years. In this paper, three new classes of bivariate beta-generated distributions are proposed. These classes are constructed using three different definitions of bivariate distributions with classical beta marginals and different covariance structures. We work with the bivariate beta distributions proposed in (J. Educ. Stat. 7:271–294, 1982; Metrika 54:215–231, 2001; Stat. Probability Lett. 62:407–412, 2003) for the first proposal, in (Stat. Methods Appl. 18: 465–481, 2009) for the second proposal and (J. Multivariate Anal. 102:1194–1202, 2011) for the third one. In each of these three classes, the main properties are studied. Some specific bivariate beta-generated distributions are studied. Finally, some empirical applications with well-being data are presented.
Mathematics Subject Classification (2000)
62E15; 60E05
Similar content being viewed by others

1 Introduction
In the recent statistical literature several methodologies of constructing bivariate and multivariate distributions based on marginal and conditional distributions have been proposed; see the works by Arnold et al. (1999; 2001), Kotz et al. (2000), Sarabia and Gómez-Déniz (2008) and Balakrishnan and Lai (2009) among others.
An important field of research focuses on the study of new classes of univariate distributions which contain the classical proposals, also allowing for more flexibility in fitting data. In this sense, the class of beta-generated (BG) distributions (Eugene et al. 2002; Jones 2004) has received an increasing amount of attention in recent years.
There are several reasons for studying classes of multivariate beta generated distributions. The two existing proposals of multivariate BG distributions present some drawbacks. The first proposal (Jones and Larsen 2004) is only valid for modeling data above the diagonal. The second proposal (Arnold et al. 2006) is defined in terms of the conditional distributions, and the corresponding marginal distributions do not follow, in general, beta generated distributions.
The three bivariate and multivariate models proposed in this paper present BG marginals, with high flexibility in the marginals and in the dependence structure. The marginal distributions of the first model share one of the shape parameters, and the structure of dependence satisfies TP2 condition (see Section 3). The marginals of the second model are free, and the different pairwise of marginals are associated (see Section 3). The third model is the more flexible, in the sense than all the marginals are free (they do not share any shape parameter) and the covariance structure admits correlations of any sign.
On the other hand, these classes of distributions present several fields of applicability. For example, bivariate beta generated distributions with classical beta marginals are natural choices to be used as prior distributions for the parameters of correlated binomial random variables (with any sign for the correlation) in Bayesian analysis (see Apostolakis and Moieni 1987; Arnold and Ng 2011).
In this work, three new classes of bivariate BG distributions are proposed. These classes are constructed using three alternative definitions of bivariate distributions with classical beta marginals and different covariance structures. We work with the bivariate beta distributions proposed by Libby and Novick (1982), Jones (2001) and Olkin and Liu (2003) for the first proposal, El-Bassiouny and Jones (2009) for the second proposal and Arnold and Ng (2011) for the third one. For each of these three classes, the main properties are obtained. Some specific bivariate BG distributions are studied. Finally, some empirical applications with well-being data are presented.
The contents of this paper are as follows. In Section 2 we present some basic properties of the class of the BG distributions and a brief review about two multivariate extensions of the BG distribution. Section 3 considers and studies the three classes of bivariate BG distributions and their main properties as well as to introduce three specific bivariate distributions. A number of applications of these distributions to fit well-being data are presented in Section 4. Finally, some conclusions and future research directions are given in Section 5.
2 Some univariate and multivariate beta-generated distributions
2.1 The univariate class of beta-generated distributions
In this section we present basic properties of the class of BG distributions. We begin with an initial baseline probability density function (PDF) f(x), where the corresponding cumulative distribution function (CDF) is represented by F(x). The class of BG distributions is defined in terms of the PDF by (a,b > 0),
where B(a,b) = Γ(a)Γ(b)/Γ(a + b) denotes the classical beta function. A random variable X with PDF (1) will be denoted by .
The CDF associated to (1) is,
where IF(x)(·,·) denotes the incomplete beta ratio.
If represents the classical beta distribution, a simple stochastic representation of (1) is,
This representation permits a direct simulation of the values of a random variable with PDF (1), which can be also used for generating multivariate versions of the BG distribution. The raw moments of a BG distribution can be obtained by,
An important number of new classes of distributions have been proposed using this methodology. Some representatives examples of BG distributions include the generalized beta of the first kind (GB1) proposed by McDonald (1984), the generalized beta of the second kind (GB2) proposed and studied by Venter (1983) and McDonald (1984), the logF distribution (Barndorff-Nielsen et al. 1982), the beta-normal distribution (Eugene et al. 2002), the beta-exponential distribution (Nadarajah and Kotz 2006) and the Skew-t distribution (Jones 2004).
Some extensions of this family have been proposed by Alexander and Sarabia (2010), Alexander et al. (2012), Cordeiro and de Castro (2011) and Zografos (2011). Other alternative flexible families of distributions can be found in Alzaatreh et al. (2013, 2014) and Lee et al. (2013).
If a = i and b = n - i + 1 in (1), we obtain the PDF of the i-th order statistic from F (Jones 2004). Below, we highlight some representative values of a and b,
-
If a = b = 1, g F = f.
-
If a = n and b = 1, we obtain the distribution of the maximum.
-
If a = 1 and b = n, we obtain the distribution of the minimum.
-
If a ≠ b, we obtain a family of skew distributions.
Parameters a and b control the tailweight of the distribution. Specifically, the a parameter controls left-hand tailweight and the b parameter controls the right-hand tailweight of the distribution. On the other hand, a = b yields a symmetric sub-family, with a controlling tailweight. If a = b = 1 the BG family is always symmetric if the baseline function F(x) is symmetric. In this sense, the BG distribution accommodates several kind of tails. For example (see Jones 2004),
-
Potential tails: If f ∼ x-(α+1) and α > 0, when x→∞ g F ∼ x-bα-1,
-
Exponential tails: If f ∼ e-αx and β > 0, then g F ∼ e-bβx if x → ∞.
2.2 Two previous classes of multivariate extensions of beta-generated distributions
There are two proposals for multivariate extensions of BG distributions. The first proposal used the joint PDF of a subset of order statistics, and has been proposed by Jones and Larsen (2004). The second proposal used the so called Rosenblatt construction (Rosenblatt 1952), and has been proposed by Arnold et al. (2006). These two alternatives are not related with the multivariate BG distributions studied in this paper.
3 Three classes of bivariate beta-generated distributions
In this section we introduce three new classes of bivariate BG distributions. These three classes are constructed combining the basic stochastic representation (2) with three recent definitions of bivariate beta distributions proposed in the literature. The three definitions differ from each other in the marginal distributions and in the flexibility of the covariance structure. First, we need some previous notation. Let X be a random variable distributed as the classical gamma denoted by X ∼ G a , with PDF f(x) = [Γ(a)]-1xa-1e-x, with x ≥ 0 and a > 0. Then, if X1 ∼ G a and X2 ∼ G b are independent gamma random variables, the transformed random variable X = X1/(X1 + X2) is distributed as the classical beta distribution with parameters (a,b).
3.1 The first class of bivariate beta-generated distributions
The first class of bivariate beta-generated distribution is based on the following class of bivariate beta distribution.
Definition 1. Let , and G b be three independent gamma random variables with a1,a2,b > 0. The first class of bivariate beta distribution is defined by the stochastic representation,
This class was initially proposed by Libby and Novick (1982) and then studied by Jones (2001) and Olkin and Liu (2003).
Now, using (3) we define the following class of bivariate BG distributions.
Definition 2. Let , and G b be three independent gamma random variables with a1,a2,b > 0. The first class of bivariate BG distribution is defined by the stochastic representation,
where F1(·),F2(·) are genuine CDF.
3.1.1 Basic properties
In this section we study some basic properties of the bivariate BG distribution defined in (4). The marginal distributions of (4) are BG distributions,
Note that both marginals share the second shape parameter b. However, this fact does not make the model less flexible, since both baseline distributions F1 and F2 are different.
Using the joint PDF of the bivariate beta distribution (3) (See Appendix), we obtain the joint PDF of the first class of bivariate BG distribution given by,
where a1,a2,b > 0 and B(a1,a2,b) = Γ(a1)Γ(a2)Γ(b)/Γ(a1 + a2 + b). An alternative expression of (5) in terms of the PDF of the BG distribution is,
where g F (x;a,b) represents the PDF defined in (1). The joint PDF can be also written as an infinite mixture,
where and
The conditional distribution of X1 given X2 is,
and the regression function of X1 given X2 is,
In order to study the dependence between X1 and X2, we consider the local dependence function defined by (Holland and Wang 1987),
We use the definitions of total positivity of order 2 (T P2) functions and reverse rule of order 2 (R R2) functions, which are the following.
Definition 3. A joint PDF f(x,y) is said to be T P2 (R R2) if
for all x ≤ u and y ≤ v.
The following result relates the local dependence function γ(x1,x2) with the T P2 and R R2 (see Theorem 7.1 in Holland and Wang 1987).
Theorem 1. Let f(x1,x2) be the joint PDF of (X1,X2) with support on a set S where the set S = S1 × S2. Then, f(x1,x2) is T P2 (R R2) if and only if γ(x1,x2) ≥ 0(≤ 0).
For the first class of BG distribution, it can be verified that
and then X1 and X2 are T P2. As a consequence, the linear correlation coefficient between X1 and X2 is always positive.
It can be proved (see Shaked 1977) that if the joint PDF f(x1,x2) is T P2 (R R2), then the conditional hazard rate of X1|X2 = x2 is decreasing (increasing) in x2. A similar property holds for the other conditional distribution X2|X1 = x1. As the PDF in (5) is T P2, this property shows the monotonicity properties of the hazard rate functions of the conditional distributions of X1|X2 = x2 as a function of x2 and the X2|X1 = x1 as a function of X1.
On the other hand, because X1 and X2 are increasing functions of independent random variables, X1 and X2 are associated random variables (Esary et al. 1967).
Expressions for the cross moments can be obtained from (5) or in terms of an infinite mixture from (6). On the other hand, if b > r, it can be shown that,
3.1.2 Extension to higher dimensions
The extension to higher dimensions is direct. The m-dimensional random vector is defined as,
The marginal distributions are , i = 1,2,…,m. The joint PDF of (7) is given by,
where c-1 = B(a1,…,a m ,b) = Γ(a1) ⋯ Γ(a m )Γ(b)/Γ(a1 + … + a m + b).
3.2 The second type of bivariate beta-generated distributions
The second type of bivariate BG distribution is motivated by the fact of having a bivariate distribution with arbitrary BG marginals. This second class is based on the following class of bivariate beta distribution, which was proposed by El-Bassiouny and Jones (2009).
Definition 4. Let , i = 1,2,3,4 be independent gamma random variables, where a i > 0, i = 1,2,3,4. The second class of bivariate beta distribution is defined by the stochastic representation,
Now, we define the second class of BG distributions.
Definition 5. Let , i = 1,2,3,4 be independent gamma random variables, where a i > 0, i = 1,2,3,4. The second class of bivariate BG distribution is defined by the stochastic representation,
where F1(·),F2(·) are genuine CDF.
3.2.1 Basic properties
The marginal distributions are BG distributions with arbitrary parameters,
Using the joint PDF (8) (see Appendix), the joint PDF of this second class of bivariate BG distributions is given by,
where k-1 = B(a1,a3)B(a2,a1 + a3 + a4), , a12(x1,x2) = H [F1(x1),F2(x2)] and
being 2F1[..;.;] the Gauss confluent hypergeometric function.
The conditional density function of X1|X2 = x2 is,
where and the conditional density function of X2|X1 = x1 is,
where .
The regression function of X1 given X2 is,
where and the regression function of X2 given X1 is,
being .
The cross-product moments can be obtained as,
where (Z1,Z2) is the bivariate random variable with joint PDF given by equation (23). Note that (10) can be computed easily by simulation from samples of the random variable (Z1,Z2). The local dependence function is given by,
The second term in (11) is long and will not be included here.
The random variables X1 and X2 are associated and then the linear correlation coefficient is always non-negative (see Definition I.11 and Proposition I.13 in Marshall and Olkin (2007)).
3.2.2 Multivariate extensions
A multivariate extension of (9) is also possible. We define,
where the marginal distributions are BG distributions with parameters,
3.3 The third type of bivariate beta-generated distributions
The next class of bivariate beta distribution is the more general class in the sense that the marginal distributions have arbitrary parameters and admits any sign for the linear correlation coefficient. The following definition was proposed by Arnold and Ng (2011).
Definition 6. The third class of bivariate beta distribution is defined by the stochastic representation,
where , i = 1,2,3,4,5 are independent gamma random variables, where a i > 0, i = 1,2,3,4,5.
Now, we define the third class of BG distributions.
Definition 7. Let , i = 1,2,3,4,5 be independent gamma random variables with a i > 0, i = 1,2,3,4,5. The third class of bivariate BG distribution is defined by the stochastic representation,
where F1(·),F2(·) are genuine CDF.
3.3.1 Basic properties
The marginal distributions of (12) are and .
The joint PDF of (12) is given by,
where fV,W(·,·) is defined in equation (24) in the Appendix.
The conditional density function of X1|X2 = x2 is,
where k′ = B(a2 + a4,a3 + a5) and the conditional density function of X2|X1 = x1 is,
where k′′ = B(a1 + a3,a4 + a5).
The regression function of X1 given X2 is,
where and the regression function of X2 given X1 is,
with .
The local dependence function can be written as,
where and , i = 1,2.
In a similar way, the cross-product moments can be obtained using formula (10), where now (Z1,Z2) is the bivariate random variable with joint PDF given by (24).
The covariance structure of (12) is flexible and the sign of the linear correlation coefficient can be positive or negative.
3.3.2 Multivariate extensions
The general multivariate version of the third class of BG distribution is based on the multivariate beta distribution proposed by Arnold and Ng (2011). Using this definition, the extension of (12) to dimensions higher than two is,
where , , i = 1,2,…,m and G c are independent gamma random variables.
3.4 Estimation
Here we derive the maximum likelihood (ML) estimator of the parameters of the BG family of the first type defined in (4). Let (x1i,x2i), i = 1,2,…,n be a random sample of size n from (5), where we assume that both baseline functions are F1(x1;τ1) and F2(x2;τ2), where τ i , i = 1,2 is a p i × 1, i = 1,2 vector of unknown parameters of the parent distributions. The log-likelihood function for θ = (τ1,τ2,a1,a2,b) may be written,
where we have used the notation , i = 1,2.
This expression may be maximized either directly, e.g. using the Mathematica software function FindMaximum (see Wolfram Research, Inc. 2010), the SAS procedure NLMIXED (SAS Institute, Inc. 2010), the R software functions nlm or optim (R Development Core Team 2011), or the MATLAB function fmincon (The Mathworks, Inc. 2011), among others, which provides numerical algorithms for nonlinear optimization), or by solving the nonlinear equations obtained by differentiating expression (13).
Initial estimates of the parameters a1, a2 and b can be inferred from estimates of τ1 and τ2, since if (X1,X2)⊤ is distributed as (4), then (F1(X1),F2(X2))⊤ is distributed as (3). If we define the random variables Y1 = F1(X1) and Y2 = F2(X2), we obtain the following expressions,
If m1, m2 and m12 are the sample versions of previous moments, solving Equations (14) to (16) for a1, a2 and b we have:
The components of the score vector U(θ) are given by,
where and are p j × 1 vectors, with j = 1,2 and ψ(s) = d logΓ(s)/d s is the digamma function.
For obtaining interval estimation and hypothesis testing on the model parameters, we need the observed information matrix. The (p1 + p2 + 3,p1 + p2 + 3) observed matrix J = J(θ) can be obtained by taking partial second derivatives in the score vector U(θ). Assuming conditions that are fulfilled for parameters in the interior of the parameter space (but not in the boundary), the distribution of is asymptotically normal , where I(θ) denotes the expected information matrix. As usual, we can substitute I(θ) by , that is, the observed information matrix evaluated at and then, the distribution can be used to construct approximate confidence intervals for the parameters.
The estimation of the other two models (9) and (12) requires a detailed study, which is beyond the scope of this paper and will be object of future research.
To finish this section, it should be mentioned that all the models proposed in this paper (4, 9 and 12) and their multivariate extensions can be enriched including location and scale parameters.
3.5 Some specific bivariate distributions
In this section we propose three specific bivariate BG models.
3.5.1 Bivariate Beta-Normal distributions
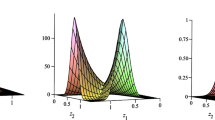
This model is a direct bivariate extension of the beta-normal distribution considered by Eugene et al. (2002). If F i (x i ) = Φ(z i ), where z i = (x i - μ i )/σ i , where and σ i > 0, i = 1,2 and Φ(z) is the CDF of a standard normal distribution, we obtain the bivariate joint PDF,
where a1,a2,b > 0.
3.5.2 Bivariate GB1 income distributions
If we take F(x) = xa in (1), we obtain the generalized beta distribution of the first kind (GB1) (see McDonald 1984), which will be denoted by X ∼ G B 1(p,q,a). Then, if , with i = 1,2 and using Equation (5) we obtain,
with 0 ≤ x1,x2 ≤ 1. The marginal distributions are X1 ∼ G B 1(p1,q,a1) and X2 ∼ G B 1(p2,q,a2). If we set a1 = a2 = 1 in (20), we obtain the bivariate beta proposed by Olkin and Liu (2003).
3.5.3 Bivariate GB2 income distributions
Now if we take F(x) = 1 - 1/(1 + xa) in (1), we obtain the generalized beta distribution of the second kind (GB2) (see McDonald 1984), which will be denoted by X ∼ G B 2(p,q,a). Then, if , with i = 1,2 and using formula (5) we have,
where the marginal distributions are X1 ∼ G B 2(p1,q,a1) and X2 ∼ G B 2(p2,q,a2).
4 Applications
To illustrate the methodology developed in this paper, we have fitted the bivariate BG model of the fist type defined in (4) to estimate the international distribution of well-being for the period 1980-2010. The estimation method is based on the formulation developed in Section 3.4. It should be worth noting that we have focused on three dimensions of well-being, namely income, health and education. Since these components present a positive correlation, the first type of BG distributions given by (4) is specially suitable in this case.
4.1 The data
We have used the most recent available data from International Human Development Indicators (UNDP 2012) on the HDI and its three components for the period 1980-2010 with five years intervals.
Note that we consider well-being as a multidimensional process which, in addition to economic variables, also involves social aspects such as health and education. In this context, the Human Development Index provides an excellent theoretical benchmark to make multidimensional assessments of well-being. Then, we have focused on three dimensions of quality of life: income, educational standards and health. In particular, we focus on the single-dimensional indices of the HDI, which are three normalized variables placed on scale 1-0. This structure of the data is specially representative in this case since we consider Beta and GB1 marginals for the BG models.
Income is represented by Gross National Income per capita measured in PPP 2005 US dollars, to make incomes comparable across countries and over time. The health component is represented by life expectancy at birth, which is considered an indicator of the health level.The education index is made up of two indicators, expected years of schooling and mean years of schooling, which are aggregated using the geometric mean. The first educational variable informs about the number of years that a child of school entrance age can expect to receive if prevailing patterns of age-specific enrollment rates persist throughout the child’s life (UNDP 2012). The second indicator reports the average number of years of education received by people aged 25 and older, converted from education attainment levels using official durations of each level (Barro and Lee, 2013).
Originally, our sample comprised only 105 countries, covering less than the 75 percent of global population. We had non-available data for 26 countries for one or more years before 1995. In order to offer comparable results across periods and to not restricting the sample considerably, missing values have been estimated. The estimation of these missing values has been based on two complementary methodologies which jointly offered feasible and consistent results according to the sample: piecewise cubic Hermite interpolating polynomial (PCHI) and the average rate of change, which was used when PCHI offered unfeasible estimations or out of range results. The interpolated values have been obtained using the command pchip of the R package Signal, which uses the methodology described by Fritsch and Carlson (1980). After this procedure, our data set includes 132 countries whose indicators of income, health and education are available for eight points of time (see Appendix for details). Consequently, the sample covers over 90 percent of the world population during the whole period.
4.2 Fitted models and results
The bivariate data consist of three pairs of variables (income,education), (income,health) and (education, health).
We have fitted the class of models given by Equation (4) with three specifications for the baseline CDFs:
-
F i (x i ) = x i , with 0 ≤ x i ≤ 1, i = 1,2 (classical beta marginals),
-
, with 0 ≤ x i ≤ 1, a i > 0, i = 1,2 (GB1 marginals) and
-
, with 0 ≤ x i ≤ 1, a i > 0, i = 1,2 (BG truncated exponential marginals).
The first model (with classical beta marginals) depends on 3 parameters, and the second and third models (with GB1 and BG truncated exponential marginals) are characterized by 5 parameters. The three models have been estimated by maximum likelihood using the equations given in Section 3.4. In total, we have fitted 7 × 3 × 3 = 63 different models. The initial estimates of the parameters have been obtained using Equations (17) to (19). In the case of the model with classical beta marginals, initial estimates are quite close to the ML estimators because they are based on sufficient statistics.
For the three pairs of variables, we have compared both models using the Akaike information criterion (AIC), defined by (Akaike 1974)
where is the log-likelihood of the model evaluated at the maximum likelihood estimates and d is the number of parameters. We chose the model with the smallest value of AIC statistic.
Tables 1, 2, 3, 4, 5 and 6 show the parameter estimates and their standard errors for the three alternative models considered: BG distribution with classical beta marginals (3 parameter model p1,p2,q) and with GB1 and BG truncated exponential marginals (5 parameter model p1,p2,q,a1,a2), which have been fitted to pairs of the variables: Education, Health and Income. In particular, Tables 1 and 4 show the results obtained for Education & Health, Tables 2 and 5 show the corresponding results for Education & Income, and Tables 3 and 6 for Income & Health. The estimations have been performed by maximum likelihood, focusing on quinquennial periods from 1980 to 2010. It can be seen that, assuming the asymptotic normality of the maximum likelihood estimates, most of the estimates are statistically significant at a 0.05 level of significance.
In order to illustrate the interval estimation of the parameters in Section 3.4, we have included the asymptotic confidence intervals at 95 percent for the models with beta and GB1 marginals (Tables 7, 8 and 9).
Tables 10 and 11 show the values of the AIC statistic (Equation (21)) obtained for both candidate models fitted to three pairs of variables: Education & Health, Education & Income and Income & Health. Our estimates point out that the values of AIC statistic for the BG model with GB1 marginals are lower than those observed for the BG distribution with classical beta marginals, except in the case of Education & Health and Education & Income for the year 2010. For the Education & Health data the best model is the model with GB1 marginals (except in 2000). In the case of Education & Income data the model with BG truncated exponential marginals outperforms the other two models. Finally, for Income & Health data, the model with GB1 marginals outperforms the BG truncated exponential marginals model in 1980, 1985 and 1995 while in the other four years the BG truncated exponential marginals is the model that provides the best fit. These results imply that, in general terms, the accuracy of the estimates is higher for the models with 5 parameters.As an illustration, Figures 1, 2, 3, 4, 5 and 6 present the contour plots for the BG distributions with classical beta marginals and GB1 marginals fitted to the pairs of variables: Education & Health, Education & Income and Income & Health for every five years during the period 1980-2010. The shape of this graphics supports the existence of a positive correlation among the variables considered, thus pointing out the suitability of the first type of BG model. The contour plots also reveal that the proposed models represent the geography of the bivariate data adequately, being more accurate in the case of the BG distribution with GB1 marginals, as concluded from the results of the Akaike information criteria.

Contour plots for the BG model with beta marginals fitted to the variables Education & Health.

Contour plots for the BG model with GB1 marginals fitted to the variables Education & Health.

Contour plots for the BG model with beta marginals fitted to the variables Education & Income.

Contour plots for the BG model with GB1 marginals fitted to the variables Education & Income.

Contour plots for the BG model with beta marginals fitted to the variables Income & Health.

Contour plots for the BG model with GB1 marginals fitted to the variables Income & Health.
5 Conclusions
The main conclusions of this paper are the following. Three different classes of bivariate BG distributions have been presented. These classes have been constructed using three different definitions of bivariate beta distributions, proposed by Libby and Novick (1982), Jones (2001) and Olkin and Liu (2003) for the first proposal, El-Bassiouny and Jones (2009) for the second proposal and Arnold and Ng (2011) for the third proposal. The main properties of these three classes have been studied. Three specific bivariate BG distributions have been obtained. Finally, an empirical application with well-being data has been presented.
The future research about bivariate BG distributions moves in three directions. The first line research is to propose specific models for their practical use in statistical modeling. The study of these possible models in any dimension could be an interesting field of research. Secondly, we propose to study statistical inference methodologies for bivariate (and, more generally, multivariate) BG distributions in (9) and (12). Finally, we propose to establish a model competition between BG distributions in (4), (9) and (12) for different choices of F1 and F2.
Appendix
The joint PDF of the different classes of bivariate beta distribution
The joint PDF of the bivariate random variable in (3) is (see Libby and Novick (1982), Jones (2001) and Olkin and Liu (2003)),
where B(a1,a2,b) = Γ(a1)Γ(a2)Γ(b)/Γ(a1 + a2 + b) and the marginal distributions are and . Note that (22) belongs to the three-parametric exponential family, where sufficient statistics for (a1,a2,b) are given by,
For n = 1, the distributions of the sufficient statistics are:
and
where denotes beta distribution of the second kind.
The log-moments of (22) are:
The joint PDF of the bivariate beta density (8) is givenby (see El-Bassiouny and Jones (2009)),
where A = a1 + a2 + a3 + a4, k-1 = B(a1,a3)B(a2,a1 + a3 + a4) and 2F1[..;.;] denote the Gauss hypergeometric function.
The expression for the fV,W(v,w) function is given by (see Arnold and Ng 2011),
where
where u4/w - u5 < u3 < (u4 + u5)v, u4,u5,v,w > 0.
Description of the data set
The list of countries used in the analysis are the following:
Afghanistan, Guatemala, Pakistan, Albania, Guyana, Panama, Algeria, Haiti, Papua New Guinea, Argentina, Honduras, Paraguay, Armenia, Hong Kong, China (SAR), Peru, Australia, Hungary, Philippines, Austria, Iceland, Poland, Bahrain, India, Portugal, Bangladesh, Indonesia, Qatar, Belgium, Iran (Islamic Republic of), Romania, Belize, Ireland, Russian Federation, Benin, Israel, Rwanda, Bolivia (Plurinational State of), Italy, Saudi Arabia, Botswana, Jamaica, Senegal, Brazil, Japan, Sierra Leone, Brunei Darussalam, Jordan, Slovakia, Bulgaria, Kenya, Slovenia, Burundi, Korea (Republic of), South Africa, Cameroon, Kuwait, Spain, Canada, Lao PDR, Sri Lanka, Central African Republic, Latvia, Sudan, Chile, Lesotho, Swaziland, China, Liberia, Sweden, Colombia, Lithuania, Switzerland, Congo, Luxembourg, Syrian Arab Republic, Congo (Democratic Republic of), Malawi, Tajikistan, Costa Rica, Malaysia, Tanzania (United Republic of), Cote D’ivoire, Mali, Thailand, Cuba, Malta, Togo, Cyprus, Mauritania, Tonga, Denmark, Mauritius, Trinidad and Tobago, Dominican Republic, Mexico, Tunisia, Ecuador, Moldova (Republic of), Turkey, Egypt, Mongolia, Uganda, El Salvador, Morocco, Ukraine, Estonia, Mozambique, United Arab Emirates, Fiji, Myanmar, United Kingdom, Finland, Namibia, United States, France, Nepal, Uruguay, Gabon, Netherlands, Venezuela (Bolivarian R.), Gambia, New Zealand, VietNam, Germany, Nicaragua, Yemen, Ghana, Niger, Zambia, Greece, Norway, Zimbabwe.
Data on the health index can be retrieved from https://data.undp.org/dataset/Health-index/9v27-i7ic, data on the education index can be drawn from https://data.undp.org/dataset/Expected-Years-of-Schooling-of-children-years-/qnam-f624 for the variable expected years of schooling and https://data.undp.org/dataset/Mean-years-of-schooling-of-adults-years-/m67k-vi5c for the mean years of schooling. Finally, income data come from https://data.undp.org/dataset/Income-index/qt4g-yea9.
References
Alexander C, Cordeiro GM, Ortega EMM, Sarabia JM: Generalized beta-generated distributions. Comput. Stat. Data Anal 2012, 56: 1880–1897. 10.1016/j.csda.2011.11.015
Alexander C, Sarabia JM: Generalized Beta-Generated Distributions, ICMA Centre Discussion Papers in Finance DP2010–09, ICMA Centre. The University of Reading, Witheknights, PO Box 242, Reading RG6 6BA, UK; 2010.
Alzaatreh A, Lee C, Famoye F: A new method for generating families of continuous distributions. Metron 2013, 71: 63–79. 10.1007/s40300-013-0007-y
Alzaatreh A, Lee C, Famoye F: The gamma-normal distribution: properties and applications. Comput. Stat. Data Anal 2014, 69: 67–80.
Akaike H: A new look at the statistical model identification. IEEE Trans. Automatic Control 1974, 19: 716–723. 10.1109/TAC.1974.1100705
Apostolakis FJ, Moieni P: The foundations of models of dependence in probabilistic safety assessment. Reliability Eng 1987, 18: 177–195. 10.1016/0143-8174(87)90097-7
Arnold BC, Ng HKT: Flexible bivariate beta distributions. J. Multivariate Anal 2011, 102: 1194–1202. 10.1016/j.jmva.2011.04.001
Arnold BC, Castillo E, Sarabia JM: Conditional Specification of Statistical Models, Springer Series in Statistics. Springer Verlag, New York; 1999.
Arnold BC, Castillo E, Sarabia JM: Conditionally specified distributions: an introduction (with discussion). Stat. Sci 2001, 16: 249–274. 10.1214/ss/1009213728
Arnold BC, Castillo E, Sarabia JM: Families of multivariate distributions involving the Rosenblatt construction. J. Am. Stat. Assoc 2006, 101: 1652–1662. 10.1198/016214506000000159
Balakrishnan N, Lai C-D: Continuous Bivariate Distributions. Springer, New York; 2009.
Barndorff-Nielsen O, Kent J, Sorensen M, mixtures Normalvariance-mean, z distributions Int: Stat. Rev. 1982, 50: 145–159. 10.2307/1402598
Barro RJ, Lee JW: A new data set of educational attainment in the world, 1950–2010. J. Dev. Econ 2013, 104: 184–198.
Cordeiro GM, de Castro M: A new family of generalized distributions. J. Stat. Comput. Simul 2011, 81: 883–893. 10.1080/00949650903530745
El-Bassiouny AH, Jones MC: A bivariate F distribution with marginals on arbitrary numerator and denominator degrees of freedom, and related bivariate beta and t distributions. Stat. Methods Appl 2009, 18: 465–481. 10.1007/s10260-008-0103-y
Esary JD, Proschan F, Walkup DW: Association of random variables, with applications. Ann. Math. Stat 1967, 38: 1466–1474. 10.1214/aoms/1177698701
Eugene N, Lee C, Famoye F: The beta-normal distribution and its applications. Commun. Stat. Theory Methods 2002, 31: 497–512. 10.1081/STA-120003130
Fritsch FN, Carlson RE: Monotone piecewise cubic interpolation. SIAM J. Numerical Anal 1980, 17: 238–246. 10.1137/0717021
Holland PW, Wang YJ: Dependence function for continuous bivariate densities. Commun. Stat. Theory Methods 1987, 16: 863–876. 10.1080/03610928708829408
Jones MC: Multivariate t and beta distributions associated with the multivariate F distribution. Metrika 2001, 54: 215–231.
Jones MC: Families of distributions arising from distributions of order statistics. Test 2004, 13: 1–43. 10.1007/BF02602999
Jones MC, Larsen PV: Multivariate distributions with support above the diagonal. Biometrika 2004, 91: 975–986. 10.1093/biomet/91.4.975
Kotz S, Balakrishnan N: Johnson, N L. John Wiley and Sons, New York; 2000.
Lee C, Famoye F, Alzaatreh A: Methods for generating families of continuous distribution in the recent decades. Wiley. Interdiscip. Rev.: Comput. Stat 2013, 5: 219–238. 10.1002/wics.1255
Libby DL, Novick MR: Multivariate generalized beta distributions with applications to utility assessment. J. Educ. Stat 1982, 7: 271–294.
Marshall AW, Olkin I: Life Distributions. Structure of Nonparametrics, Semiparametric and Parametric Families. Springer, New York; 2007.
McDonald JB: Some generalized functions for the size distribution of income. Econometrica 1984, 52: 647–663. 10.2307/1913469
Nadarajah S, Kotz S: The beta exponential distribution. Reliability Eng. Syst. Safety 2006, 91: 689–697. 10.1016/j.ress.2005.05.008
Olkin I, Liu R: A bivariate beta distribution. Stat. Probability Lett 2003, 62: 407–412. 10.1016/S0167-7152(03)00048-8
R Development Core Team: R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria; 2011. http://www.R-project.org/
Rosenblatt M: Remarks on a multivariate transformation. Ann. Math. Stat 1952, 23: 470–472. 10.1214/aoms/1177729394
Sarabia JM, Gómez-Déniz E: Construction of multivariate distributions: a review of some recent results (with discussion), SORT. Stat. Oper. Res. Trans 2008, 32: 3–36.
SAS Institute Inc.: SAS/STAT, version 9.2. Cary, NC, USA; 2010.
Shaked M: A family of concepts of dependence for bivariate distributions. J. Am. Stat. Assoc 1977, 72: 642–650. 10.1080/01621459.1977.10480628
The Mathworks Inc. Matlab, release 2011, Novi, MI, USA; 2011.
UNDP: International Human Development Indicators. 2012.http://hdr.undp.org/en/statistics/ Retrieved from . Last Accessed 10 Nov 2012
Venter G: Transformed beta and gamma distributions and aggregate losses. Proc. Casualty Actuarial Soc 1983, LXX: 156–193.
Wolfram Research Inc.: Mathematica, version 8.0. Champaign, IL, USA; 2010.
Zografos K: Generalized beta generated-II distributions. In Modern Mathematical Tools and Techniques in Capturing Complexity. Edited by: Pardo L, Balakrishnan N, Angeles Gil M. Berlin: Springer; 2011.
Acknowledgements
The authors thank to Ministerio de Economía y Competitividad (project ECO2010-15455) for partial support of this work. The authors thank also the comments by the attendants of the first ICOSDA meeting celebrated at Mount Pleasant, MI USA. We are grateful to the Editors-in-Chief and the reviewers for careful reading and for their comments and suggestions which greatly improved the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
All the authors have contributed equally. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0), which permits use, duplication, adaptation, distribution, and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Sarabia, J.M., Prieto, F. & Jordá, V. Bivariate beta-generated distributions with applications to well-being data. J Stat Distrib App 1, 15 (2014). https://doi.org/10.1186/2195-5832-1-15
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/2195-5832-1-15