
Abstract
Background:
We suggest that the need to account for systematic error may explain the apparent lack of agreement among studies of maternal dietary methylmercury exposure and neuropsychological testing outcomes in children, a topic of ongoing debate.
Methods:
These sensitivity analyses address the possible role of systematic error on reported associations between low-level prenatal exposure to methylmercury and neuropsychological test results in two well known, but apparently conflicting cohort studies: the Faroe Islands Study (FIS) and the Seychelles Child Development Study (SCDS). We estimated the potential impact of confounding, selection bias, and information bias on reported results in these studies using the Boston Naming Test (BNT) score as the outcome variable.
Results:
Our findings indicate that, assuming various degrees of bias (in either direction) the corrected regression coefficients largely overlap. Thus, the reported effects in the two studies are not necessarily different from each other.
Conclusion:
Based on our sensitivity analysis results, it is not possible to draw definitive conclusions about the presence or absence of neurodevelopmental effects due to in utero methylmercury exposure at levels reported in the FIS and SCDS.
Introduction
The potential effect of children's low-level exposure to methylmercury in the environment is a complex research issue that continues to receive considerable attention from researchers, government agencies, and the public [1]. The US Environmental Protection Agency (EPA) derived a reference dose for methylmercury in 2001, based on an analysis by the National Research Council (NRC) of the National Academy of Sciences [2]. The NRC performed benchmark dose analysis on a number of endpoints from three longitudinal prospective studies: the Seychelles Islands, the Faroe Islands, and the New Zealand studies [2]. Adverse effects were reported in the latter two studies [3–5], but not in the Seychelles study [6, 7].
This lack of consistency among studies and particularly the discrepancy between the Seychelles Child Development Study (SCDS) and the Faroe Islands Studies (FIS) was noted in several previous publications [8, 9]. However, most of these publications either focused on qualitative differences in the types of exposures, population characteristics and choice of endpoints between two studies [2, 10], or examined the impact of non-differential measurement error in exposure assessment [11, 12]. By contrast, the quantitative evaluation of systematic error in these studies does not appear to have received sufficient attention.
Current methodological literature emphasizes the importance of estimating, as opposed to merely acknowledging (or dismissing), the potential role of unaccounted systematic error in observational epidemiology [13–31] and in other fields of science [32–34]. Following these recommendations, we decided to build upon our previously published work on quantitative evaluation of potential bias in environmental epidemiologic studies [35, 36] and conduct a series of sensitivity analyses to evaluate the potential impact of systematic error on the reported associations between low-level maternal dietary exposure to methylmercury and children's neuropsychological testing results in the SCDS and FIS.
We used the score of the Boston Naming Test (BNT) as the outcome variable because it seems to have received substantial attention as an endpoint of interest (NRC 2000) and because both the SCDS and the FIS have used it in their analyses. The other cohort study, conducted in New Zealand [3, 5, 37], did not administer the BNT.
Methods
Our evaluation of the FIS and SCDS included two components: a qualitative review and comparison of the methods and results, and a quantitative analysis of selected sources of systematic error. The qualitative review evaluated the FIS and SCDS study methods with respect to their target population, selection of participants, exposure assessment, outcome ascertainment and data analyses. Particular attention was paid to identification of potential sources of systematic error, which were then evaluated in quantitative analyses.
The quantitative analyses presented in this article are conceptually similar to those described in our earlier publication [36] and involved calculating the impact of systematic error from three potential sources (confounding, selection bias, and information bias) on the observed relation between methylmercury exposure and a continuous neuropsychological outcome of interest.
In general terms, if a linear regression model Y = β0 + β1X + ε represents the relation between outcome (Y) and methylmercury exposure (X), or some transformation of these (e.g., Y could represent the logarithm of the dependent factor), then the least square estimate of the regression parameter β1 based on a sample of n observations (Xi, Yi) is:

For a systematic error of certain magnitude, it is possible to estimate the corrected linear regression coefficient by accounting for this error. The impact of systematic error can also be expressed as the difference between the observed and the corrected regression coefficients (bobs-b). It is important to keep in mind that the sensitivity analyses presented here do not address the impact of systematic error on the epidemiologic measure of association between methyl-mercury exposure and neuropsychological testing, but rather its impact on a regression coefficient in a given study. The actual measure of association can be further affected by the model assumptions, which are beyond the scope of this paper.
As mentioned previously, the BNT score was used as the outcome variable (Y) because both the SCDS and the FIS used it in their analyses. The BNT is a 60-item test that asks the examinee to provide the name of an object depicted in black-and-white line drawings. The response that is judged to be correct and the amount of time to respond are recorded. The test can be administered with or without cues. Semantic cues, if used, are provided if no response is made within 20 seconds. If the examinee is still unable to produce the name, a phonemic cue may be provided. The total score is then the number of items correctly named spontaneously or after cues. For the Seychelles study, a score of 43 was considered normal (standard deviation of 5) [7]. Scores on the BNT are a measure of word knowledge/vocabulary, verbal learning, word retrieval, and semantic language and have been associated with reading comprehension and written comprehension [38].
The possible effect of unadjusted confounding on FIS and SCDS results was assessed by measuring the impact of potentially important covariates not considered in these studies. To estimate the impact of selection bias, we calculated the difference in BNT results that would be observed in the FIS and SCDS assuming that the distributions of exposure and BNT scores among persons omitted from these studies were different than the analogous distributions among study participants. Finally, the potential role of information bias was quantified for a given range of outcome misclassification (in either direction) differentially affecting the low exposure and the high exposure groups in each study. The derivation of the corrected linear regression estimate (b) for each specific type of systematic error was conducted as follows.
Confounder Adjustment
Given the mathematical relationship between estimates of regression coefficients and correlation coefficients, one can use reported estimated correlation coefficients to calculate the potential impact of confounders. The correlation coefficient (r) for 2 variables, Z and Y, can be expressed as:

where b is the slope of the least square regression line, and s Z and s Y are the standard deviations of Z and Y, respectively. Let Y = b 0 + b Z represent the fitted linear regression model relating the outcome (Y) to confounder Z. If we assume that the same regression model applies to the exposed and non-exposed populations, then:

which becomes

where:
 Exp is the mean value of the outcome measure (e.g., BNT test score) among the exposed;
Exp is the mean value of the outcome measure (e.g., BNT test score) among the exposed;
Non-exp is the mean value of the outcome measure among the non-exposed;
s Y is the standard deviation of the outcome measure;
 Exp is the mean value of the potential confounder among the exposed;
Exp is the mean value of the potential confounder among the exposed;
Non-exp is the mean value of the potential confounder among the non-exposed;
s Z is the standard deviation of the potential confounder;
and
r(Z, Y) is the Pearson correlation coefficient for variables Z and Y.
Let a multiple linear regression model Y = β0 + β1X + β2Z + ε represent the relation between outcome (Y) and exposure (X) in the presence of an unaccounted confounder (Z). From the formula above, the regression parameter β1 corrected for unaccounted confounding can be estimated as:

where sX and sY are estimates of the standard deviations of X and Y, and r(XY), r(XZ) and r(ZY) represent estimates of the correlation coefficients between X and Y, X and Z, and Z and Y, respectively. If we use formula (1) to express bobs, that is the estimate of the regression parameter unadjusted for the effect of confounding, then the difference (bobs-bconf) in this case represents the impact of confounding by Z on the observed linear regression coefficient.
Selection bias
Selection bias may occur if the participants are systematically different from persons not included in the study with respect to their exposure and outcome levels. Thus, the regression slope derived from the data collected among the participants would differ from the estimate based on all eligible subjects. Let:
-
n represent the total number of all eligible subjects;
-
ns (ps) represent the number (proportion) of sampled subjects among the n eligible subjects;
-
nn (pn) represent the number (proportion) of non-sampled subjects among the n eligible subjects;
-
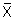 s and
s and 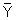 s represent the estimates of the mean exposure and outcome among the sampled subjects;
s represent the estimates of the mean exposure and outcome among the sampled subjects; -
n and n represent the estimates of the mean exposure and outcome among the non-sampled subjects;
-
sXs and sXn represent the estimates of the standard deviation of the exposure levels among the sampled and non-sampled subjects, respectively (we assumed, for simplicity, that sXn = sXs);
-
bs represent the estimate of the regression parameter derived using the data from the ns sampled subjects;
-
bn represent the estimate of the regression parameter for the nn non-sampled subjects, assumed here to be a multiple of bs, that is bn = νbs;
-
bsel represent the estimate of the corrected regression parameter based on all eligible subjects.
Then:
 , can be re-expressed as a function of the sums of squares, cross-products and means corresponding to the sampled and non-sampled subjects:
, can be re-expressed as a function of the sums of squares, cross-products and means corresponding to the sampled and non-sampled subjects:

where the estimates of ∑XsYs and ∑Xs
2 corresponding to the sampled subjects are easily derivable by substituting the estimates of ns, bs,  ,
, 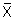 s and
s and 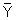 s available for the sampled subjects in standard computational formulas for the variance and linear regression parameter, to give:
s available for the sampled subjects in standard computational formulas for the variance and linear regression parameter, to give:

Similarly, the estimates of ∑XnYn and ∑Xn 2 corresponding to the non-sampled subjects:

can be estimated by substituting the hypothetical (assumed) estimates for the non-sampled subjects.
Thus (bobs-bsel) in this case represents the impact of selection bias on the observed linear regression slope.
Information bias
In this study we assessed the impact of one type of information bias (differential outcome misclassification), which may occur when the data about the outcome are obtained differently for subjects in different exposure categories. Thus, the reported (or "observed") outcome (Yobs) for a proportion of the subjects is different from the "true" outcome (Y). We assume that the absolute amount of over or underestimation in the observed outcome for a subject with exposure X is proportional to the difference between X and (the estimate of mean exposure).
Let:
-
p1 represent the proportion of subjects whose observed outcome is Yobs = Y + (X-
)a1, where a1 > 0. Then, p1 is the proportion of subjects whose bias in their observed outcome results in a positive bias in the observed slope; -
p2 represent the proportion of subjects whose observed outcome is Yobs = Y - (X-
)a2, where a2 > 0. Then, p2 is the proportion of subjects whose bias in their observed outcome results in a negative bias in the observed slope; -
bobs represent the estimate of β1 in the regression model defined in equation (1) above, derived using Yobs.
Thus, Ytrue = Yobs -a1(X-) for a subset (p1) of all subjects, and Ytrue = Yobs +a2(X-) for a subset (p2) of all subjects, while Ytrue = Yobs for the remaining subjects.
An estimate of the regression parameter (adjusted for information bias) binf is given by:

Substituting the expressions for Ytrue in the first term in the numerator of equation 7, we get:

where:




Similarly, substituting the expressions for Ytrue in the second term in the numerator of equation 7, we get:

Combining (8) and (9), the numerator of binf becomes:

If we assume that the exposure values (X) corresponding to the fractions p1 and p2 of subjects defined above are random subsamples of all X's, then, the second and third terms in equation (10) above become:
 , and
, and  , respectively. Thus, equation (7) becomes:
, respectively. Thus, equation (7) becomes:
 , which reduces to:
, which reduces to:
binf = bobs - p1a1 + p2a2 or bobs = binf + (p1)(a1) - (p2)(a2),
thus, (p1)(a1) - (p2)(a2), represents the magnitude of information bias (bobs-binf).
Monte Carlo simulations
To examine the aggregate uncertainty that results from a combination of random error and three types of systematic error (confounding, selection bias, and information bias), we used Monte Carlo simulations that included 50,000 randomly selected scenarios (Steenland and Greenland 2004). The observed distributions for FIS and SCDS were derived based on slope factors and corresponding confidence intervals reported in the original studies [7, 39]. The input parameters for each Monte Carlo simulation for FIS and SCDS are summarized in Tables 1 and 2, respectively. When the data were not available, we assumed a uniform distribution reflecting a range of plausible scenarios. The adjusted distributions were derived by combining the observed distributions of the data with the distribution of the combined bias. As described previously [17, 21], the events leading to the observed result could follow the following sequence: 1) effects of confounders generate population associations → 2) participants from a study are sampled from the underlying population in a manner that lead to selection bias → 3) the selected participants then become subject to differential outcome misclassification. As noted by Greenland, "this chronology suggests that we should correct misclassification first, then non-response, and then uncontrolled confounding" [17]. Adopting this approach, for each simulation iteration, the initial distribution of bobs after correcting for information bias served as the unadjusted distribution in the sensitivity analyses for selection bias, and the resulting slope distribution in turn was corrected for confounding producing the final adjusted distribution. All calculations were performed using Crystal Ball software (Standard Edition, 2000).
Results
Qualitative review of confounding
Despite rather lengthy lists of covariates that were considered in each study, the possibility remains of confounding due to unmeasured covariates or due to residual confounding. For example, no data were collected on nutritional factors (e.g., selenium, polyunsaturated fatty acids) in either study [7]. Although the authors of the FIS considered confounding to have had minimal impact due to the homogeneity of the community under study and the limited potential for other neurotoxic exposures [4], it is possible that the results of this study were affected by lack of information on home environment, such as that measured by the Caldwell-Bradley Home Observation for Measurement of the Environment (HOME) [40, 41]. HOME was administered to the Seychellois participants and was found to be associated with many neuropsychological tests including the Boston Naming Test [6, 7]. Other variables that were either not measured, or measured but not considered consistently in the analyses, include factors related to the test-taking environment (e.g., the child's anxiety level), which have been associated with performance on the WISC III Digit Spans subtest [41]; educational factors (e.g., quality of school/teachers); paternal intelligence; parental education; exposure to other chemicals that have been associated with neurobehavioral effects (e.g., lead, PCBs); as well as dietary components, such as selenium and omega-3 fatty acids, which are expected to have a beneficial effect on neurodevelopment [42].
Both studies assessed caregiver (SCDS) or maternal (FIS) intelligence by the Raven's Progressive Matrices test rather than using a comprehensive test, such as the Wechsler Adult Intelligence Scale (WAIS). Raven's Progressive Matrices measures nonverbal reasoning ability and is a useful test for those who do not speak English. Its correlation with other intelligence tests ranges from 0.5–0.8 [41].
Qualitative review of selection bias
Participants in the Faroe Islands study were recruited among 1,386 children from three hospitals in Torshavn, Klaksvik, and Suderoy between March 1, 1986 and December 31, 1987 [43]. Blood samples and questionnaire data were obtained from 1,023 infant-mother pairs, representing 75% of the eligible singleton births [4]. Reasons for non-participation were not described; however, it appears that patients born in two smaller hospitals were less likely to participate. It is also important to point out that the hospital with the lowest percent participation (33%) had the highest median blood mercury concentration [45].
Nine hundred seventeen of the 1,022 children returned for neuropsychological testing at approximately age seven [4]. Scores for the Boston Naming Test (no cues) were reported for 866 children, or 63% of the overall target population.
The 740 infant-mother pairs who remained in the cohort-for-analysis in the SCDS after exclusions represent approximately 50% of the target population [46]. The authors did not record specific reasons for non-participation, but indicate that some mothers were probably not informed of the study by the nurses in the hospital, some may have declined due to lack of sufficient information about the study or lack of interest, and some may have been afraid to participate in the study. Shamlaye et al. (1995) reported birth characteristics for SCDS participants and the target population and found small, non-significant differences in birth weight, gestational age, male:female ratio, and maternal age between the two groups [47]. Six hundred forty-three children completed the Boston Naming Test at age 108 months (9 years) in this study, which represents approximately 43% of the estimated target population.
Qualitative review of information bias
Approximately half of all FIS participants underwent testing in the morning and half underwent testing in the afternoon. Most (but not all) children were examined in Torshavn. If the time of testing or the need to travel before testing were related to exposure, this could have introduced additional bias due to diurnal variation and/or fatigue. According to the Faroese transportation guide, long-distance bus service combined with the ferry services, links virtually every corner of the country. However, it appears that a trip to Torshavn may take up to several hours [48]. Some of the FIS participants were examined in local hospitals close to their homes. Although this may have alleviated the potential bias associated with travel, it may have introduced additional bias due to differences in testing environment.
The methods description does not indicate whether or not investigators administering the test were blinded with respect to the participants' exposure status. According to the study authors, the participation rate in the capital was lower and the participants' geometric mean mercury concentration was about 28% higher (~23 μg/L vs. ~18 μg/L) than that of non-participants. This may indicate that residence was related to both exposure level and the need to travel, as well as to the AM/PM testing status.
A re-analysis of the FIS data showed that, after controlling for residence (town vs. country), the linear regression slope for BNT without cues changed from -1.77 (p < 0.001) to -1.51 (p = 0.003), whereas the slope for BNT with cues changed from -1.91 (p < 0.001) to -1.60 (p = 0.001) [2]. However, this adjustment would only partially address the above problems. There may still be substantial room for residual misclassification because the analysis did not take into consideration distance from Torshavn or duration of travel.
Similar concerns, although to a lesser extent, apply to the SCDS results. The testing was performed "mostly in the morning." This does not exclude the potential impact of diurnal variation on the results; however, this impact would have been probably lower than that in the FIS, where the AM/PM testing ratio was 1:1.
All testing for SCDS was performed on Mahe. Some families apparently had to travel to the testing site. Similarly to the FIS, it is possible that children who had to travel were more tired prior to testing. However, one of the criteria for inclusion into the main study was Mahe residence and prolonged travel does not appear likely as Mahe extends 27 km north to south and 11 km east to west [49]. The SCDS authors state that none of the families and none of the investigators administering the test were aware of the participants' methylmercury exposure status.
Quantitative analysis results
The results of the sensitivity analyses evaluating the potential impact of systematic error on the association between measures of methylmercury exposure and BNT scores are presented in Tables 3 through 5.
When evaluating the possible role of unmeasured confounders in the FIS and SCDS analyses, we assumed that the correlation coefficient between confounder and exposure ranged from -0.5 to +0.5 and the correlation coefficient between confounder and outcome (BNT score) ranged from 0.2 to 0.8. The results are presented in Table 3. Based on these assumptions, the corrected regression coefficient for the FIS would become as extreme as -0.136 (Scenario 8), assuming a moderately positive correlation (r = 0.5) between the confounder and exposure and a strong correlation (r = 0.8) between the same confounder and the BNT results. On the other hand, a moderate negative correlation with exposure (r = -0.5) and a strong correlation (r = 0.8) with the outcome would reverse the direction of the association from bobs = -0.019 to bconf = +0.085 (Scenario 7). In the SCDS analyses, the same range of correlation coefficients would produce a corresponding range of corrected linear regression slopes between -0.58 (Scenario 8) and 0.55 (Scenario 7).
Table 4 illustrates the potential impact of selection bias on study results. Assuming that the differences between the mean exposures and outcomes of eligible persons who were excluded from the study and the mean exposures and outcomes of those who were included ranged between -10% and +10%, and regression slope among persons excluded from the study ranged between 0 and -0.038 (bobs × 2), the corrected slope for FIS may range between -0.027 (Scenario 4) and -0.009 (Scenario 7). The same selection bias scenarios in the SCDS would result in a change of direction from -0.012 to +0.017 (Scenario 7) or in a stronger than observed association, with a regression slope of -0.037 (Scenario 6).
The analyses of information bias demonstrated the effect on study results with a relatively small proportion of misclassified participants (e.g., 10%) and the relatively modest magnitude of misclassification (a1 and a2 between 0.1 and 0.4). For the eight scenarios presented in Table 5, the corrected regression slopes ranged from -0.069 (Scenario 1) to 0.071 (Scenario 2) for FIS; and from -0.062 (Scenario 1) to 0.078 (Scenario 2) for SCDS.
Figures 1 and 2 illustrate the change in the distribution of the linear regression slopes assuming various degrees of combined bias (in either direction) for FIS and SCDS using the same level of random error as reported in the original studies. As shown in Figure 1, the observed distributions of FIS and SCDS results demonstrate apparently conflicting findings. However, if the FIS and SCDS study results for BNT were subject to mild-to-moderate bias from all three sources, the adjusted linear regression distributions are no longer inconsistent and the overall uncertainty makes the results of the two studies more similar.

Monte Carlo simulation of the observed and adjusted linear regression coefficients for FIS assuming various degrees of systematic error from confounding, selection bias and information bias (unit of exposure: 1 μg/L of cord blood).

Monte Carlo simulation of the observed and adjusted linear regression coefficients for SCDS assuming various degrees of systematic error from confounding, selection bias and information bias (unit of exposure: 1 μg/g maternal hair)
Discussion
A comparison of the two studies included in our analysis revealed a number of similarities. Both were prospective evaluations of neuropsychological endpoints in children whose prenatal methylmercury exposure status was ascertained at birth. Both used objective biomarker-based measures of exposure. Both conducted multivariate analyses in an attempt to separate the effects of methylmercury from other factors that influence neuropsychological function.
Yet, despite similarities, the results and conclusions of these two studies were inconsistent. For example, testing of the language function showed a statistically significant improvement with increasing methylmercury exposure among Seychellois children at about 51/2 years of age when measured by the Preschool Language Scale and no significant association at nine years of age when measured by BNT. In contrast, the Faroese study group displayed a statistically significant decline in BNT scores with increasing methylmercury exposure at the age of seven. Other discrepancies between the two sets of results were present in the domains of the visual-spatial function, memory, learning achievement, and sustained attention. Only in one domain (motor function) did both studies report statistically significant inverse associations between test scores and methylmercury exposure, but those associations were not consistent. In the SCDS, the association was for the "non-dominant" hand grooved pegboard test among males only, whereas the FIS reported the association for the "preferred" hand finger tapping.
The proposed interpretations of the observed disagreement between the two studies have been based primarily on the assumption that the differences in results have an underlying biological explanation. Recent reviews paid substantial attention to the fact that the two studies reported their main findings using different measures of methylmercury exposure: cord blood versus maternal hair [2, 10]. As cord blood concentrations measure recent exposures, the National Academy of Sciences review on methylmercury toxicity suggested that the FIS results may reflect a more recent (and presumably more relevant) period of exposure [2]. Another proposed explanation is the difference in the source and rate of methylmercury exposure: daily consumption of fish in the Seychelles as opposed to episodic consumption of whale in the Faroes.
Prior to the publication of the most recent SCDS update, it appeared plausible that the differences between the two study results could also be explained by the lack of comparability in the neuropsychological test batteries. However, the last testing of the SCDS participants included many of the same tests previously used by the FIS investigators – specifically, those with significant findings – and the above explanation no longer appears likely.
Our analyses indicate that each of the potential sources of systematic error under certain conditions is capable of changing the results from significant to non-significant and vice versa. Moreover, under some scenarios even the direction of the observed associations can be reversed. Although the scenarios in our sensitivity analyses cover a wide range of assumptions, they are not entirely hypothetical. The differences in exposure levels between participants and non-participants in the FIS have been reported [4, 45] and, in fact, exceed the differences assumed in our selection bias simulation. The low (just over 40%) participation rate in the SCDS also falls within the proposed scenarios. We demonstrated the potential effect of confounding by home environment and the need for a comprehensive parental IQ evaluation in our earlier publication [36]. The correlation coefficients between potential confounders and exposure are similar to those reported in the FIS. The potential misclassification due to fatigue, timing and sequencing of testing and lack of adequate blinding also finds support in the literature [38, 41].
For all of the above reasons, the uncertainty around the FIS and the SCDS regression slope estimates is probably larger than is suggested by the reported 95% confidence intervals. The discrepant results of the two studies may, in fact, fall within an expected range and departures from null in either direction can be explained by a combination of random and systematic error.
The interpretation of sensitivity analyses presented here, just like the interpretation of any epidemiological analyses, requires careful consideration of caveats and underlying assumptions. Many sensitivity analyses, including ours, are limited by insufficient information (e.g., lack of data on the correlation between confounder and exposure) and have to rely on hypothetical distributions of the parameters of interest. When no data were available, we assumed a uniform distribution in the Monte Carlo analyses. We recognize that the uniform distribution may not accurately reflect the uncertainty since all values within the range are given equal probabilities. In the future, alternative approaches such as the use of triangular or beta distributions, which give more weight to the more "probable" values, may need to be explored. The assumptions of normal distribution and independence of various sources of bias also need to be considered and alternative analytical methods for circumstances that do not fit these assumptions may need to be developed. For example, our adjustment for unmeasured confounders does not condition on the variables for which adjustment was made. It is important to point out that adjusting for the measured covariates may reduce the residual confounding attributable to the unmeasured confounder. All of the above considerations may affect the results of sensitivity analyses; however, in the absence of sensitivity analyses, one implicitly assumes that systematic error had no effect on study results, an assumption that may be even more difficult to defend.
In summary, despite caveats, we feel that our analyses served their purpose of illustrating the proposed methodology. We conclude that sensitivity analyses serve as an important tool in understanding the sources of such disagreement as long as the underlying assumptions are clearly stated. It is important to recognize that disagreement across studies is one of the unavoidable features of observational epidemiology.
References
Stern AH Gochfeld, M.: Effects of methylmercury exposure on neurodevelopment. JAMA 1999, 281(10):896–897.
NRC NRC: Toxicological Effects of Methylmercury. Washington, DC , National Academies Press 2000.
Crump KS Kjellstrom T, Shipp AM, Silvers A, Stewart A.: Influence of prenatal mercury exposure upon scholastic and psychological test performance: Benchmark analysis of a New Zealand cohort. Risk Analysis 1998,18(6):701–713.
Grandjean P Weihe P, White RF, Debes F, Araki S, Yokoyama K, Murata K, Sorensen N, Dahl R, and Jorgensen PJ.: Cognitive deficit in 7-year-old children with prenatal exposure to methylmercury. Neurotoxicol Teratol 1997,19(6):417–428.
Kjellstrom T Kennedy P, Wallis S, Stewart A, Friberg L, Lind B, Wutherspoon, and Mantell C.: Physical and Mental Development of Children with Prenatal Exposure to Mercury from Fish. Stage 2: Interviews and Psychological Tests at Age 6. Solna, National Swedish Environmental Protection Board 1989.
Davidson PW Myers, GJ, Cox C, Axtell C, Shamlaye C, Sloane-Reeves J, Cernichiari E, Neddham L, Choi A, Wang Y, Berlin M, and Clarkson TW.: Effects of prenatal and postnatal methylmercury exposure from fish consumption on neurodevelopment: Outcomes at 66 months of age in the Seychelles Child Development Study. JAMA 1998,280(8):701–707.
Myers GJ Davidson, PW, Cox C, Shamlaye CF, Palumbo D, Cernichiari E, Sloane-Reeves J, Wilding GE, Kost J, Huang LS, Clarkson TW.: Prenatal methylmercury exposure from ocean fish consumption in the Seychelles Child Development Study. Lancet 2003,361(9370):1686–1692.
Dourson ML, Wullenweber AE, Poirier KA: Uncertainties in the reference dose for methylmercury. Neurotoxicology 2001,22(5):677–689.
Jacobson JL: Contending with contradictory data in a risk assessment context: The case of methylmercury. Neurotoxicology 2001,22(5):667–675.
Myers GJ Davidson, PW, Cox, C, Shamlaye, C, Cernichiari, E, Clarkson, TW.: Twenty-seven years studying the human neurotoxicity of methylmercury exposure. Environ Res 2000,83(3):275–285.
Budtz-Jorgensen E, Keiding N, Grandjean P, Weihe P, White RF: Consequences of exposure measurement error for confounder identification in environmental epidemiology. Stat Med 2003,22(19):3089–3100.
Keiding N, Budtz-Jorgensen E, Grandjean P: Prenatal methylmercury exposure in the Seychelles. Lancet 2003,362(9384):664–665.
Greenland S: Basic methods for sensitivity analysis of biases. Int J Epidemiol 1996,25(6):1107–1116.
Greenland S: Basic methods for sensitivity analysis and external adjustment. Modern Epidemiology (Edited by: Rothman KJGS). Philadelphia, PA 1998, 343--357.
Greenland S: Sensitivity analysis, Monte Carlo risk analysis, and Bayesian uncertainty assessment. Risk Anal 2001,21(4):579–583.
Greenland S: The impact of prior distributions for uncontrolled confounding and response bias: a case study of the relation of wire codes and magnetic fields to childhood leukemia. Journal of the American Statistical Association 2003, 98:47–54.
Greenland S: Multiple-bias modeling for analysis of observational data. J R Statist Soc A 2005,168(2):267–306.
Gustafson P: Measurement Error and Misclassification in Statistics and Epidemiology. New York , Chapman and Hall 2003.
Lash TL Fink, AK.: Semi-automated sensitivity analysis to assess systematic errors in observational data. Epidemiology 2003,14(4):451–458.
Lash TL, Silliman RA: A sensitivity analysis to separate bias due to confounding from bias due to predicting misclassification by a variable that does both. Epidemiology 2000,11(5):544–549.
Maclure M, Schneeweiss S: Causation of bias: the episcope. Epidemiology 2001,12(1):114–122.
Maldonado G: Informal evaluation of bias may be inadequate (abstract). American Journal of Epidemiology 1998, 147:S82.
Maldonado G Delzell, E, Tyl RW, Sever LE.: Occupational exposure to glycol ethers and human congenital malformations. Int Arch Occup Environ Health 2003,76(6):405–423.
Maldonado G: Quantifying the impact of study imperfections on study results (abstract). American Journal of Epidemiology 2005, 161:S100.
Maldonado G, Delzell E, Poole C: A unified approach to conducting and interpreting occupational studies of congenital malformations (abstract). American Journal of Epidemiology 1999, 149::S59.
Maldonado G, Greenland S: Estimating causal effects. Int J Epidemiol 2002,31(2):422–429.
Marais ML Wecker, WE: Correcting for omitted-variables and measurement-error bias in regression with an application to the effect of lead on IQ. J Am Stat Assoc 1998,93(442):494–517.
Phillips CV: Quantifying and reporting uncertainty from systematic errors. Epidemiology 2003,14(4):459–466.
Phillips CV, G M: Using Monte Carlo methods to quantify the multiple sources of error in studies (abstract). American Journal of Epidemiology 1999, 149:S17.
Phillips CV, LaPole LM: Quantifying errors without random sampling. BMC Med Res Methodol 2003, 3:9.
Steenland K, Greenland S: Monte Carlo sensitivity analysis and Bayesian analysis of smoking as an unmeasured confounder in a study of silica and lung cancer. Am J Epidemiol 2004,160(4):384–392.
Leamer EE: Sensitivity analyses would help. Am Econ Rev 1985, 75:308–313.
Morgan MG, Henrion M: Uncertainty. A Guide to Dealing With Uncertainty in Quantitative Risk and Policy Analysis. New York , Cambridge University Press 1990.
Vose D: Risk Analysis. A Quantitative Guide. 2nd Edition New York , John Wiley & Sons 2000.
Goodman M Kelsh M, Ebi K, Iannuzzi J, Langholz B.: Evaluation of potential confounders in planning a study of occupational magnetic field exposure and female breast cancer. Epidemiology 2002,13(1):50–58.
Mink PJ, Goodman M, Barraj LM, Imrey H, Kelsh MA, Yager J: Evaluation of uncontrolled confounding in studies of environmental exposures and neurobehavioral testing in children. Epidemiology 2004,15(4):385–393.
Kjellstrom T Kennedy P, Wallis S, and Mantell C.: Physical and Mental Development of Children with Prenatal Exposure to Mercury from Fish. Stage 1: Preliminary Tests at Age 4. Solna , National Swedish Environmental Protection Board 1986.
Baron IS: Neuropsychological Evaluation of the Child. New York , Oxford University Press 2004.
Budtz-Jorgensen E, Debes F, Weihe P, Grandjean P: Adverse Mercury Effects in 7 Year-Old Children as Expressed as Loss in “IQ”. Final report to the EPA. Odense , University of Southern Denmark 2005.,2005(December 16 ):
Bradley RH Caldwell BM: The relation of infants' home environments to achievement test performance in first grade: A follow-up study. Child Dev 1984,55(3):803–809.
Sattler JM: Assessment of Children: Cognitive Applications. 4th Edition San Diego , Jerome M. Sattler, Publisher, Inc. 2001.
Steuerwald U, Weihe P, Jorgensen PJ, Bjerve K, Brock J, Heinzow B, Budtz-Jorgensen E, Grandjean P: Maternal seafood diet, methylmercury exposure, and neonatal neurologic function. J Pediatr 2000,136(5):599–605.
Grandjean P Weihe P, Jorgensen PJ, Clarkson T, Cernichiari E, Videro T.: Impact of maternal seafood diet on fetal exposure to mercury, selenium, and lead. Arch Environ Health 1992,47(3):185–195.
Dahl R, White RF, Weihe P, Sorensen N, Letz R, Hudnell HK, Otto DA, Grandjean P: Feasibility and validity of three computer-assisted neurobehavioral tests in 7-year-old children. Neurotoxicol Teratol 1996,18(4):413–419.
Grandjean P, Weihe P: Neurobehavioral effects of intrauterine mercury exposure: potential sources of bias. Environ Res 1993,61(1):176–183.
Marsh DO Clarkson TW, Myers GJ, Davidson PW, Cox C, Cernichiari E, Tanner MA, Lednar W, Shamlaye C, Choisy O, Hoareau C, Berlin M: The Seychelles study of fetal methylmercury exposure and child development: Introduction. Neurotoxicology 1995,16(4):583–596.
Shamlaye CF Marsh, DO, Myers GJ, Cox C, Davidson PW, Choisy O, Cernichiari E, Choi A, Tanner MA, Clarkson TW.: The Seychelles child development study on neurodevelopmental outcomes in children following in utero exposure to methylmercury from a maternal fish diet: background and demographics. Neurotoxicology 1995,16(4):597–612.
Strandfaraskip Landsins: Ferdaælanin, http://www.ssl.fo. [http://www.ssl.fo]
Africa Guide: Seychelles http://www.africaguide.com/country/seychel. [http://www.africaguide.com/country/seychel]
Acknowledgements
This research was funded by the Electric Power Research Institute (EPRI), a private, independent, non-profit center for public interest energy and environmental research.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Goodman, M., Barraj, L.M., Mink, P.J. et al. Estimating uncertainty in observational studies of associations between continuous variables: example of methylmercury and neuropsychological testing in children. Epidemiol Perspect Innov 4, 9 (2007). https://doi.org/10.1186/1742-5573-4-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1742-5573-4-9